LangChain4j (5) :RAG 知识库
但这就导致一个问题,例如我们的模型是在 2023 年训练完成的,那我们如果去询问模型 2024 年发生的事情,模型是无法准确回答的;纵观人类文明史,那些真正推动历史前进的人物,往往不是标准答案的复述者,而是敢于质疑、勇于创新的思想者。爱因斯坦在专利局做着小职员的工作时,没有被既定的物理定律束缚,而是让思想乘着光速的翅膀,最终颠覆了牛顿的经典物理学体系。向量模型,用于把文档分割后的片段向量化或者查询
1. RAG 知识库原理
RAG,(Retrieval Augmented Generation), 检索增强生成。通过检索外部知识库的方式增强大模型的生成能力。在没有 RAG 知识库的时候,我们和模型问答的流程是这样的:
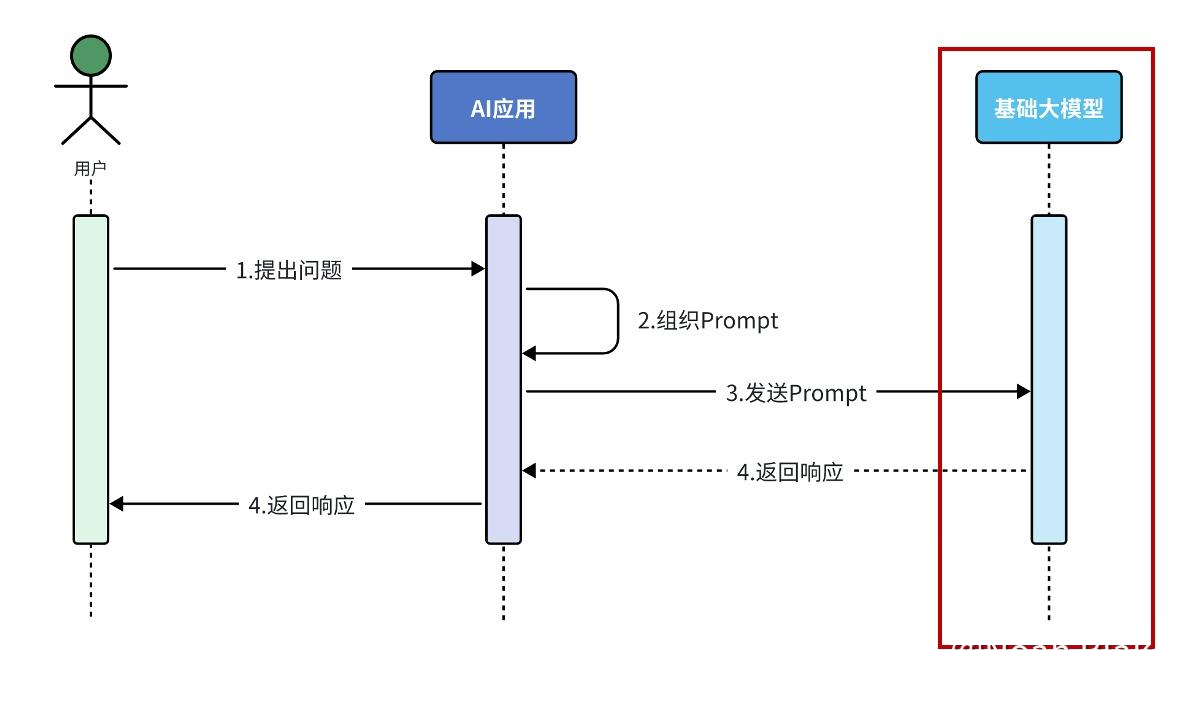
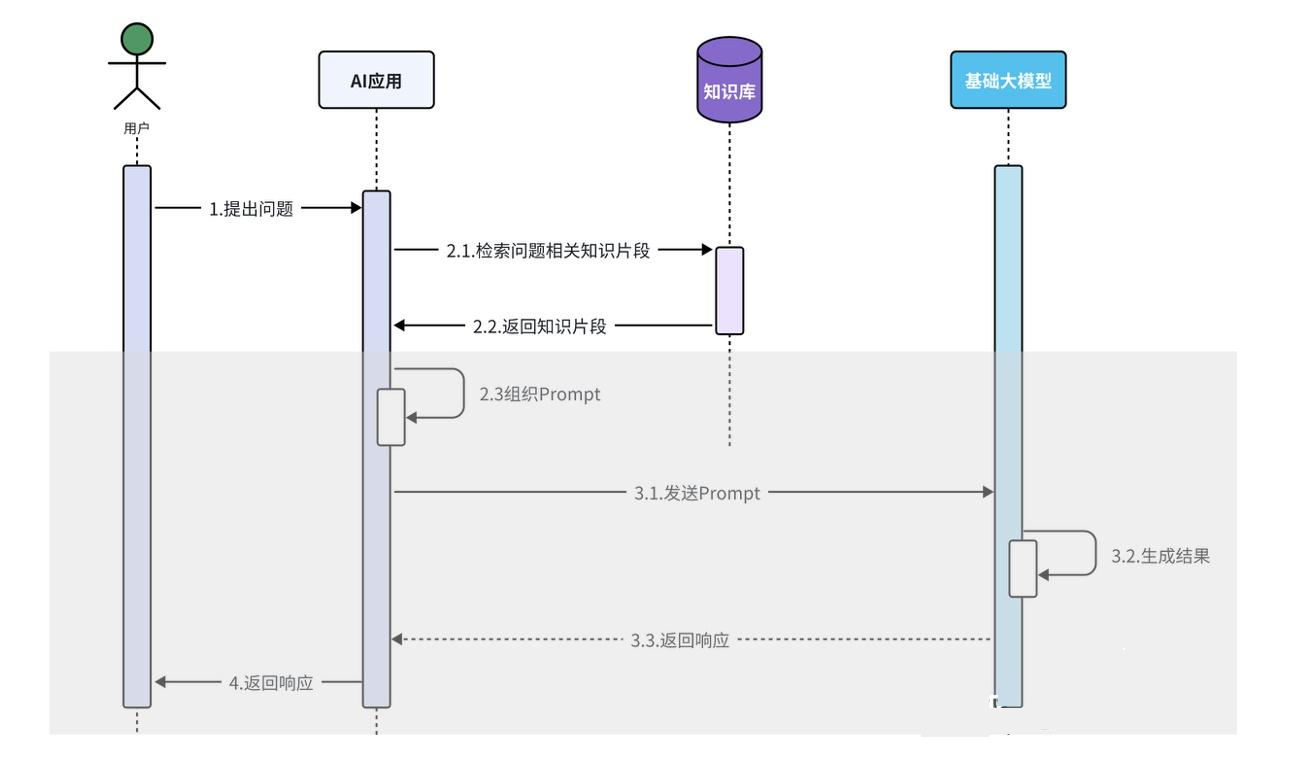
但这就导致一个问题,例如我们的模型是在 2023 年训练完成的,那我们如果去询问模型 2024 年发生的事情,模型是无法准确回答的;或者如果我们询问的问题比较专业,模型也不会回答得很专业。所以我们可以外挂一个知识库,相当于允许大模型开卷回答,这样我们和模型回答的流程就变成了这样:
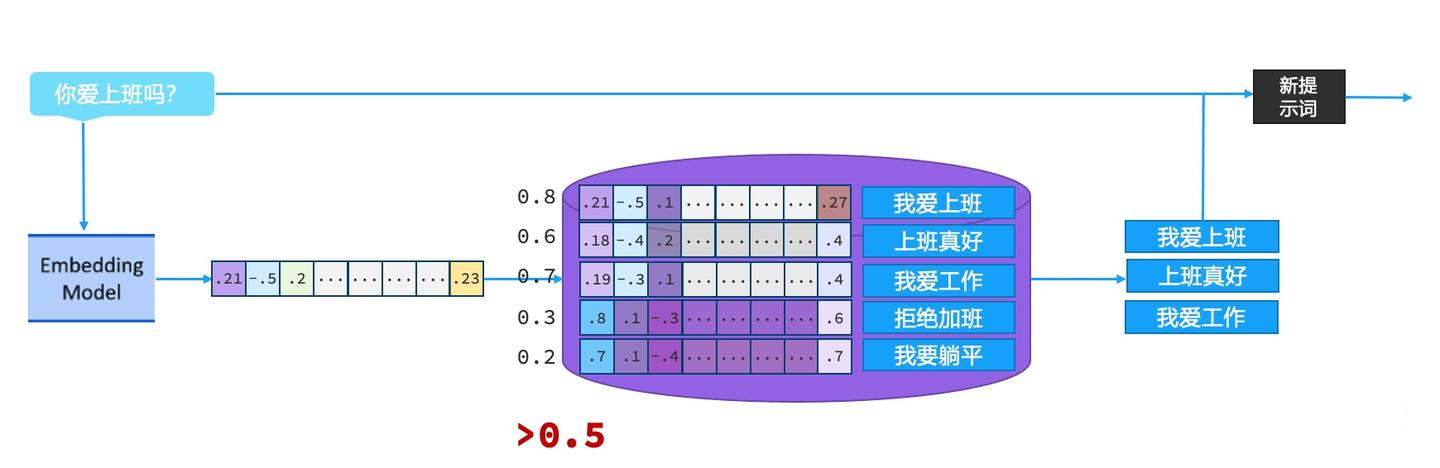
知识库使用向量数据库来搭建,简单来说就是将一些文本转变成多维的向量存储进数据库中,流程如下图:

搭建完向量知识库之后,RAG 会根据用户输入的内容,借助向量模型转化为向量后,与数据库中的向量通过计算余弦相似度的方式,找出相似度比较高的文本片段,作为用户询问信息的一部分传给模型,流程如下:
2. 快速搭建
引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.0.1-beta6</version>
</dependency>虽然黑马的课程中没有提到要加 Hugging Face 的依赖,但是我在实际使用时发现不添加 Hugging Face 的依赖会报错,所以这里提供另一个依赖,如果有报错可以试试加一下:
<dependency>
<groupId>ai.djl.huggingface</groupId>
<artifactId>tokenizers</artifactId>
<version>0.28.0</version>
</dependency>另外,如果是使用 Intel 芯片的 MacOS,0.29.0 以后就不支持了,所以这里只使用了 0.28.0 版本的 tokenizers。可以参考这个:https://github.com/langchain4j/langchain4j/issues/2144。
插入知识文档
在 resource 下新建一个 content 文件夹,插入我们需要大模型参考的文档:

构建向量数据库操作对象和检索对象
我们在 CommonConfig 中构建向量数据库操作对象和检索对象,代码如下:
// 构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
// 1. 加载文档内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content"); // 指定了文档的位置
// 2. 构建向量数据库操作对象(内存中自带的向量数据库)
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
// 3. 构建一个 EmbeddingStoreIngestor 对象,完成文本数据切割,向量化,存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.build();
ingestor.ingest(documents);
return store;
}
// 构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5) // 余弦相似度阈值
.maxResults(3) // 最大结果数
.build();
}当你用 @Bean 标注一个方法时,Spring 会:
- 调用这个方法,执行里面的所有代码。
- 把返回的对象(这里是
EmbeddingStore)注册为一个 Bean,供其他组件注入使用。
另外,在 Spring 中,contentRetriever(EmbeddingStore store) 方法中的 store 参数之所以能自动匹配到上一个 @Bean 方法创建的 EmbeddingStore ,是因为 Spring 的 依赖注入(Dependency Injection, DI) 机制在起作用。当Spring容器初始化时,它会自动查找 EmbeddingStore 类型的bean,如果找到匹配的bean,Spring会将其作为参数传入 contentRetriever() 方法。因为这里有另一个@Bean 方法创建的 EmbeddingStore 实例,所以 Spring 会自动把这个 EmbeddingStore 实例传入到 contentRetriever() 方法中去。
修改 @AiService
@AiService(
wiringMode = AiServiceWiringMode.EXPLICIT,
chatModel = "openAiChatModel",
streamingChatModel = "openAiStreamingChatModel",
chatMemoryProvider = "chatMemoryProvider",
contentRetriever = "contentRetriever" // 指定了向量数据库检索对象
)测试
完成后我们询问一下大模型西北大学2024年经济学(基地班)录取分数是多少?

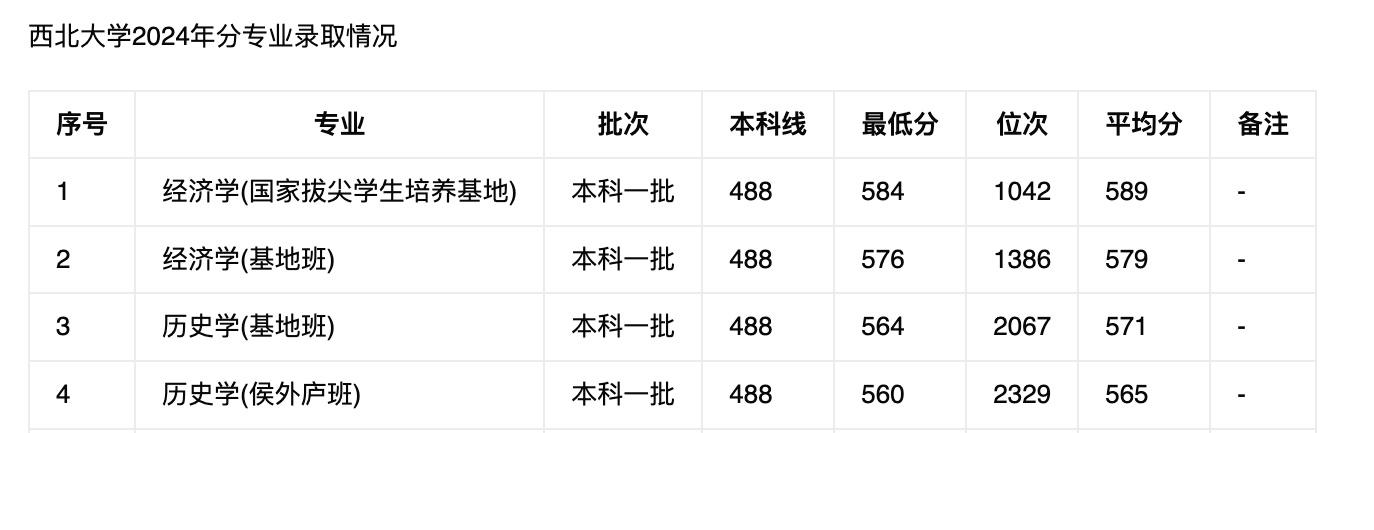
可以看到大模型能够成功回答出正确答案,我们看一下我们的请求日志:

可以看到用户向大模型发送的信息中不只有问题,还有一个新的信息 Answer using the following information,这段文字就是 RAG 从知识库中根据余弦相似度搜索出的信息,所以大模型才能正确回答出相关的问题。
3. 核心 API
文档加载器,用于把磁盘或者网络中的数据加载进程序:
- FileSystemDocumentLoader, 根据本地磁盘绝对路径加载
- ClassPathDocumentLoader,相对于类路径加载
- UrlDocumentLoader,根据url路径加载
List<Document> documents = FileSystemDocumentLoader.loadDocuments("/path/...");3.2 文档解析器
文档解析器,用于解析使用文档加载器加载进内存的内容,把非纯文本数据转化成纯文本:
- TextDocumentParser,解析纯文本格式的文件
- ApachePdfBoxDocumentParser,解析pdf格式文件
- ApachePoiDocumentParser,解析微软的office文件,例如DOC、PPT、XLS
- ApacheTikaDocumentParser(默认),几乎可以解析所有格式的文件
文档加载器的多态方法中有一个方法可以接受文档解析器,我们只需要 new 一下即可,例如:
ClassPathDocumentLoader.loadDocuments(“文档路径",new ApachePdfBoxDocumentParser());当然还需要引入相关依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-pdfbox</artifactId>
<version>1.0.1-beta6</version>
</dependency>3.3 文档分割器
文档分割器,用于把一个大的文档,切割成一个一个的小片段:
- DocuemntByParagraphSplitter,按照段落分割文本
- DocumentByLineSplitter,按照行分割文本
- DocumentBySentenceSplitter,按照句子分割文本
- DocumentByWordSplitter,按照词分割文本
- DocumentByCharacterSplitter,按照固定数量的字符分割文本
- DocumentByRegexSplitter,按照正则表达式分割文本
- DocumentSplitters.recursive(…)(默认),递归分割器,优先段落分割,再按照行分割,再按照句子分割,再按照词分割
这里我们去配置一下 DocumentSplitters.recursive(…) ,这个方法的第一个参数是每个片段最大容纳的字符,第二个参数是两个片段之间重叠字符的字数。重叠的作用是防止文本被分割后出现相关信息无法匹配的问题,例如有下面有一段文字被分为了两段:
高考,这个被赋予太多意义的词汇,如同一座横亘在青春之路上的大山。我们习惯将高考比作独木桥,仿佛千万人只能挤过那唯一的通道。然而,教育的真谛不在于将所有人塑造成相同的模样,而在于让每个人都能在知识的密林中找到属于自己的小径。高考不是终点,而是起点;不是标准答案的复制,而是独特生命的绽放。
纵观人类文明史,那些真正推动历史前进的人物,往往不是标准答案的复述者,而是敢于质疑、勇于创新的思想者。爱因斯坦在专利局做着小职员的工作时,没有被既定的物理定律束缚,而是让思想乘着光速的翅膀,最终颠覆了牛顿的经典物理学体系。
如果我们提问的相关问题是 “高考” ,那么第一段就会被 RAG 选取到,但是第二段和高考似乎没有关系,但是他们本身是来自一段的,怎么说还是有点相关性的,所以我们需要给两段之间有一些重叠片段:
高考不是终点,而是起点;不是标准答案的复制,而是独特生命的绽放。纵观人类文明史,那些真正推动历史前进的人物,往往不是标准答案的复述者,而是敢于质疑、勇于创新的思想者。爱因斯坦在专利局做着小职员的工作时,没有被既定的物理定律束缚,而是让思想乘着光速的翅膀,最终颠覆了牛顿的经典物理学体系。
我们修改一下刚刚的 store() 方法:
@Bean
public EmbeddingStore store() {
// 1. 加载文档内容
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// 2. 初始化内存向量存储
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
// 配置文档分割器(递归分割,最大500字符,重叠100字符),如果出现了向大模型提问时无法提取到知识库里的信息
// 可以尝试一下修改一下参数,可能是字符最大值不够或者重叠字符数不够
DocumentSplitter splitter = DocumentSplitters.recursive(500, 100);
// 3. 构建并执行文档处理管道
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(splitter)
.build();
ingestor.ingest(documents);
return store;
}3.3 向量模型
向量模型,用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化,阿里百炼平台上提供了通用文本向量模型,我们使用这个模型作为我们的向量模型。
配置 application.yml
langchain4j:
open-ai:
chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: sk-*******************
model-name: qwen-plus
log-requests: true
log-responses: true
streaming-chat-model:
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: sk-*******************
model-name: qwen-plus
log-requests: true
log-responses: true
embedding-model: # 新增了阿里百炼的向量模型
base-url: https://dashscope.aliyuncs.com/compatible-mode/v1
api-key: sk-*******************
model-name: text-embedding-v3
log-requests: true
log-responses: true
max-segments-per-batch: 10修改代码
在 CommonConfig 中注入向量模型:
@Autowired
private EmbeddingModel embeddingModel;修改向量数据库操作对象和检索对象:
// 构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
// 1. 加载文档内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// 2. 构建向量数据库操作对象
InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();
DocumentSplitter ds = DocumentSplitters.recursive(500, 100);
// 3. 构建一个 EmbeddingStoreIngestor 对象,完成文本数据切割,向量化,存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(store)
.documentSplitter(ds)
.embeddingModel(embeddingModel) // 新增向量模型
.build();
ingestor.ingest(documents);
return store;
}
// 构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever(EmbeddingStore store) {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.minScore(0.5)
.maxResults(3)
.embeddingModel(embeddingModel) // 新增向量模型
.build();
}3.4 向量数据库
我们之前采用的是 InMemoryEmbeddingStore ,是 LangChain4j 提供的一个内存型向量存储实现。所有数据存储在 JVM 堆内存中,不持久化道磁盘中,适合开发测试和小规模应用。如果我们需要将数据存储到外部的话,就需要自己安装一个向量数据库,这里我们采用 redis-vector 数据库,在 redis 的基础上支持了向量数据。
Docker 安装并运行
我们采用 Docker 来安装运行,命令如下(对 Docker 不熟悉的可以去主页看一下 Docker 专栏):
docker run --name redis-vector -d -p 6379:6379 redislabs/redisearch查看是否运行成功:
docker ps
引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-redis-spring-boot-starter</artifactId>
<version>1.0.1-beta6</version>
</dependency>配置 application.yml
langchain4j:
community:
redis:
host: localhost
port: 6379修改代码
注入 RedisEmbeddingStore :
@Autowired
private RedisEmbeddingStore redisEmbeddingStore;修改向量数据库操作对象和检索对象:
// 构建向量数据库操作对象
@Bean
public EmbeddingStore store() {
// 1. 加载文档内存
List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");
// 2. 构建文档分割器
DocumentSplitter ds = DocumentSplitters.recursive(500, 300);
// 3. 构建一个 EmbeddingStoreIngestor 对象,完成文本数据切割,向量化,存储
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.embeddingStore(redisEmbeddingStore)
.documentSplitter(ds)
.embeddingModel(embeddingModel)
.build();
ingestor.ingest(documents);
return redisEmbeddingStore;
}
// 构建向量数据库检索对象
@Bean
public ContentRetriever contentRetriever() {
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(redisEmbeddingStore)
.minScore(0.4)
.maxResults(3)
.embeddingModel(embeddingModel)
.build();
}测试
我们启动服务,进入 Redis 可视化管理界面:
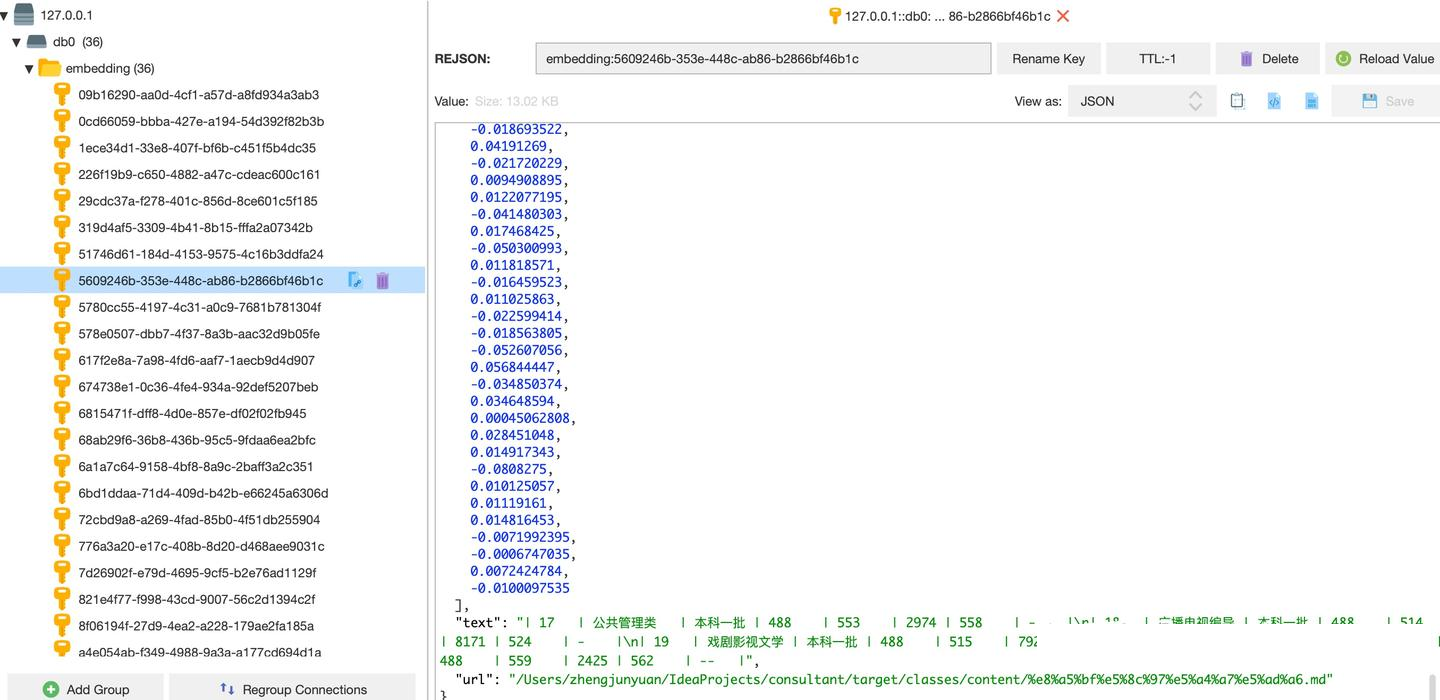
Redis 中已经成功存入了 西北大学.md 的 36 个分片数据,都转为了向量数据格式,提问也顺利通过:

现在可以往 content 文件夹下多放几个文件尝试了。

为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)