51c大模型~合集167
在文本到图像生成领域,Lumina-mGPT 2.0 在多个基准测试中表现优异,与 SANA 和 Janus Pro 等扩散模型和自回归模型相当甚至超越,特别是在 “两个物体” 和 “颜色属性” 测试中表现卓越,以 0.80 的 GenEval 分数跻身顶级生成模型之列。此外,团队与其他的多任务生成模型进行了实际比较,Lumina-mGPT 2.0 在可控生成和主题驱动生成任务中表现突出,与 Lu
我自己的原文哦~ https://blog.51cto.com/whaosoft/14086409
#刚刚,OpenAI拿下IOI金牌
仅次于前五名人类选手!参赛推理模型才夺得IMO金牌
一觉醒来,OpenAI 的大模型又完成了一项壮举!
在全球顶级编程赛事之一 ——2025 年国际信息学奥林匹克(IOI)中,OpenAI 的推理模型取得了足以摘得金牌的高分,并在 AI 参赛者中排名第一!
IOI 2025(即第 37 届国际信息学奥林匹克)在玻利维亚的苏克雷举行,7 月 27 日正式开幕,并已于 8 月 3 日落下了帷幕。在此次赛事中,中国队大获全胜,全员金牌夺冠。
而就在不久前,OpenAI 刚刚在 IMO(国际数学奥林匹克竞赛)2025 中拿到了金牌级别的成绩。

在比赛中,OpenAI 参加了 IOI 的在线 AI 赛道,在 330 位人类参赛者中,所用推理模型的得分只落后于 5 位人类选手,拿下了 AI 参赛者中的 No 1。
与人类选手一样,OpenAI 遵守了 5 小时答题时间和 50 次提交的限制。
同样地,OpenAI 没有使用互联网或 RAG(检索增强生成),仅能访问一个基础的终端工具。

OpenAI 使用了一组通用推理模型,并且没有针对 IOI 进行专门的训练。唯一的辅助策略是选择要提交的解答,并与 IOI API 建立连接。
相较于去年 IOI 的表现,OpenAI 今年的这一成绩实现了巨大飞跃。
去年,OpenAI 仅差一点就拿到了铜牌,并且当时依赖一个更加人工定制的测试策略。短短一年的时间,OpenAI 的成绩就从第 49 百分位跃升到第 98 百分位!
过去几周,OpenAI 在 AtCoder 世界总决赛、IMO 和 IOI 上都取得非常好的成绩,展示了最新研究方法带来的巨大进步,这些让人非常兴奋。OpenAI 正努力构建更聪明、更强大的模型,未来将尽快将它们带入主流产品中。

下图为备战 IOI 2025 的团队成员以及长期推动 OpenAI 竞技编程的团队成员。

OpenAI 联合创始人、总裁 Greg Brockma 盛赞了此次 IOI 中自家模型「金牌级的表现」。

OpenAI 专注于多步推理、自博弈和多智能体 AI 的研究科学家 Noam Brown 表示,「重要的启示是:我们在 IMO 上取得金牌的模型就是最好的竞赛编程模型。」
他分享了更多的细节:在 IMO 结束后,他们对 IMO 金牌模型进行了全面评测,发现它不仅在竞赛数学方面表现最佳,在包括编程在内的许多其他领域也是最强的模型。
所以,团队决定直接使用完全相同的 IMO 金牌模型,不做任何改动,将它应用到 IOI 竞赛系统中。
IOI 比赛中的辅助策略包括:先从几个不同的模型中采样解答,然后再用另一个模型结合启发式方法来筛选要提交的解答。最终获得了金牌,在所有参赛选手中排名第 6。
事实证明,在 OpenAI 采样的所有模型中,IMO 金牌模型的表现确实是最好的。


对于此次 OpenAI 在 IOI 赛事中取得金牌,网友感叹到:没有专门训练就取得了这样的成绩,很了不起,这意味着通用推理能力正变得非常强大。

对于这个模型的「真身」,大家也是各种猜测。

也许正如下面这位网友所言,大家现在迫不及待想看到 OpenAI 推出采用在 IMO 和 IOI 2025 夺金推理模型的相同(或更强)技术的公开版本!看起来将会是又一次全方位的重大飞跃。

所以,OpenAI,别光顾着自夸,赶紧发布吧。

#Lumina-mGPT 2.0
自回归模型华丽复兴,媲美顶尖扩散模型
上海人工智能实验室等团队提出Lumina-mGPT 2.0 —— 一款独立的、仅使用解码器的自回归模型,统一了包括文生图、图像对生成、主体驱动生成、多轮图像编辑、可控生成和密集预测在内的广泛任务。
本文第一作者辛毅为南京大学 & 上海创智学院博士生,现于上海人工智能实验室实习,研究方向为图像 / 视频生成、多模态生成与理解统一等。通讯作者为上海人工智能实验室青年科学家 — 高鹏。本文其他作者来自上海人工智能实验室、香港中文大学、上海交通大学、上海创智学院、浙江工业大学等。
论文标题:Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
论文链接:arxiv.org/pdf/2507.17801
GitHub 地址:Alpha-VLLM/Lumina-mGPT-2.0
关键词:图像生成、自回归模型、基座模型。
核心技术与突破
完全独立的训练架构
不同于依赖预训练权重的传统方案,Lumina-mGPT 2.0 采用纯解码器 Transformer 架构,从参数初始化开始完全独立训练。这带来三大优势:架构设计不受限制(提供了 20 亿和 70 亿参数两个版本)、规避授权限制(如 Chameleon 的版权问题)、减少预训练模型带来的固有偏差。

图像分词器方面,通过对比 VQGAN、ViT-VQGAN 等多种方案,最终选择在 MS-COCO 数据集上重建质量最优的 SBER-MoVQGAN,为高质量生成奠定基础。

统一多任务处理框架
创新地采用统一的图像分词方案,将图生图任务通过上下拼接视为一张图像,并通过提示描述进行控制,实现多任务训练与文生图训练的一致性。使得单一模型能够无缝支持以下任务:
文生图
主体驱动生成
图像编辑
可控生成(如基于轮廓 / 深度的生成)
密集预测
这种设计避免了传统模型需切换不同框架的繁琐,通过系统提示词即可灵活控制任务类型。

高效的推理策略
为了解决自回归模型生成速度慢的痛点,团队引入两种优化:
- 模型量化:将模型权重量化为 4 位整数,同时保持激活张量为 bfloat16,通过 PyTorch 2.0 中的原生编译工具和 torch.compile 的 reduce-overhead 模式实现无需改变模型架构的优化。
- 推测式 Jacobi 采样:通过静态 KV 缓存和静态因果注意掩码的方案,使 SJD 兼容于静态编译框架,从而实现加速采样,同时避免动态调整缓存。结合 4 位量化技术,减少 60% GPU 显存消耗,同时通过并行解码加速生成。
实验显示,优化后模型在保持质量的前提下,生成效率显著提升。

实验结果
文生图实验结果
在文本到图像生成领域,Lumina-mGPT 2.0 在多个基准测试中表现优异,与 SANA 和 Janus Pro 等扩散模型和自回归模型相当甚至超越,特别是在 “两个物体” 和 “颜色属性” 测试中表现卓越,以 0.80 的 GenEval 分数跻身顶级生成模型之列。

此外,在实际生成效果上,Lumina-mGPT 2.0 在真实感、细节和连贯性方面优于前代 Lumina-mGPT 和 Janus Pro,更具视觉吸引力和自然美感。

多任务实验结果
在 Graph200K 多任务基准中(可控生成、物体驱动生成),Lumina-mGPT 2.0 表现优异,证明了纯自回归模型在单一框架下完成多模态生成任务的可能性。

此外,团队与其他的多任务生成模型进行了实际比较,Lumina-mGPT 2.0 在可控生成和主题驱动生成任务中表现突出,与 Lumina-mGPT、OneDiffusion 和 OmniGen 等模型相比,展示了卓越的生成能力和灵活性。

未来方向
Lumina-mGPT 2.0 在优化推理后,仍面临采样时间长的问题,与其他基于自回归的生成模型相似,这影响了用户体验,后续将进一步优化。当前 Lumina-mGPT 2.0 的重点在多模态生成, 但计划更新扩展至多模态理解,以提高其整体功能和性能,这将使 Lumina-mGPT 2.0 在满足用户需求方面更加全面。
.....
#EfficientFlow
56倍加速生成式策略:西交大提出EfficientFlow,迈向高效具身智能
本文共同第一作者为西安交通大学硕士生常建磊和博士生梅若风。柯炜为西安交通大学副教授。论文通讯作者为西安交通大学教授许翔宇,其研究方向涵盖三维视觉、生成式 AI 与具身智能(个人主页:https://xuxy09.github.io/)。
生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。
针对这一核心瓶颈,西安交通大学研究团队提出了全新的生成式策略学习方法 EfficientFlow。该方法通过将等变建模与高效流匹配(Flow Matching)深度融合,在显著提升数据效率的同时,大幅压缩推理所需的迭代步数,在多个机器人操作基准上实现了 SOTA 的性能,并将推理速度提升一个数量级以上。
,时长00:15
相关论文《EfficientFlow: Efficient Equivariant Flow Policy Learning for Embodied AI》已被 AAAI 2026 接收,代码已开源。
- 论文地址:https://arxiv.org/pdf/2512.02020
- 项目主页:https://efficientflow.github.io/
- GitHub:https://github.com/chang-jl/EfficientFlow
技术亮点:用物理直觉重塑生成式策略
1. 加速度正则化:让生成轨迹更直、更快
传统流匹配的一大痛点是学习到的流场曲率过大,导致推理时仍需多步迭代才能拟合。
怎么让生成轨迹变直? EfficientFlow 的设计灵感源于物理直觉:现实中平滑的运动,往往加速度很小。 因此,EfficientFlow 在损失函数中引入了加速度正则项,鼓励样本从噪声分布向数据分布演化的过程也是平滑且接近匀速的:

其中
![]()
是正则化系数。在实践中,采用

,在早期时间鼓励更平滑的轨迹,而在
![]()
时则优先考虑准确性。
加速度正则项可以近似为:

然而,该式难以直接计算,因为
![]()
和
![]()
位于同一条未知的流轨迹上。为克服这一困难,EfficientFlow 引入了流加速度上界(FABO):

其中,
![]()
和
![]()
来自同一个条件概率路径,很容易通过采样得到。
本质上,FABO 是一个易于计算且有效的代理损失。同时,上界 FABO 与原式的差值等效于

,可以看作对雅可比矩阵

的正则化,让模型生成的策略更稳、更鲁棒。
2. 等变网络:让模型学会「举一反三」
EfficientFlow 等变设计的核心逻辑非常直观:如果输入的视觉场景旋转了一定角度,那么机器人输出的动作自然也该跟随旋转相同的角度。这带来了巨大的数据优势,相当于一条数据就可以产生多条数据的效果。模型只需学习物体在一个角度下的操作,就能自动泛化到多个旋转角度,真正实现了「举一反三」。

EfficientFlow 基于 escnn 库构建,将机器人在时间
![]()
的动作表示为一个 10 维向量
![]()
,包含 6D 旋转表示、3D 平移向量和标量抓手宽度。动作输出对应的等变表示为:

这种表示使得
![]()
能够生成遵循任务
![]()
对称性的预测动作,从而确保在场景进行平面旋转时行为的一致性。
等变网络
![]()
的输入是时间 t 、动作序列
![]()
和观测
![]()
。模型将等变群设定为一个有限循环子群
![]()
,使用一个等变观测编码器将观测
![]()
映射为嵌入

,使用一个等变动作编码器将动作序列
![]()
映射为嵌入

,编码后的嵌入
![]()
,
![]()
与时间 t 一起被输入到等变神经网络中。得益于各部件的等变设计,模型实现了从原始输入到预测动作的全流程
![]()
等变性。

3. 时间一致性策略:快,还要稳
在生成动作序列时,由于相邻的片段通常是独立预测,策略可能会在不同的行为模式间切换,导致长期执行过程中的不连贯。为了解决这个问题,EfficientFlow 采用 Diffusion Policy 中的时间重叠策略:每个预测序列仅执行前
![]()
步,而剩余的
![]()
步则与从时间
![]()
开始的后续预测重叠。通过生成具有相似重叠部分的相邻动作序列,可以实现长期的连贯性。
受 IMLE Policy 的启发,算法还采用了一种批量轨迹选择与周期性重置策略,该策略在多模态表达能力与时间连贯性之间取得了平衡。在推理阶段,EfficientFlow 从高斯分布中采样 m 个初始噪声向量

,并通过模型演化每一个向量,生成 m 条候选动作轨迹

。然后,选择重叠片段与上一条轨迹匹配度最高的轨迹执行。
为了保持模型探索多样化行为的能力,模型引入了周期性重置:每 10 个预测周期,从批次中随机选择一条轨迹进行执行,而不是选择最小化重叠距离的那一条。这种方法在保持多模态性的同时提高了时间一致性,并且由于并行化处理,批量化设计确保了推理时间的额外开销极小。
实验效果:少数据、少步数,也能打 SOTA
在 MimicGen 等多个机器人操作基准中,EfficientFlow 在有限数据条件下展现出媲美甚至超过现有 SOTA 方法的成功率。更关键的是推理效率:在 1 步推理下,EfficientFlow 就能接近 EquiDiff 100 步推理的平均性能,单步推理速度提升 56 倍,5 步推理也有近 20 倍加速。消融实验进一步表明,加速度正则化与等变建模缺一不可,共同构成了高效生成式策略的关键。

.....
#告别「手搓Prompt」
前美团高管创业,要让物理世界直接成为AI提示词
正如奥特曼执意打造硬件,试图打破手机屏束缚,要让 AI 感受物理世界;Looki 的诞生也源于同样的渴望:补齐大模型「感官智能」的最后拼图,将现实场景实时转化为上下文,驱动人机交互从「被动问答」进化为「主动共鸣」。
2025 年,AI 硬件赛道喧嚣一片。从形态各异的 AI 眼镜,到 OpenAI 传闻中的无屏设备,无数玩家正试图摆脱智能手机的束缚。其底层逻辑清晰可见,今天的 AI 不缺智商,缺乏的是「在场感」。
被困在对话框里的大模型如同「缸中之脑」。当你需要复盘会议或分析孩子情绪时,却不得不将鲜活场景压缩成干巴巴的文字描述,这种依赖「手动 Prompt」的交互不仅低效,更是反人性的。我们被迫充当了 AI 的「人肉传感器」,而大模型因缺乏 Context(上下文语境),始终处于对物理数据的极度饥渴中。
「在物理世界中,人类本质上是被动的生物。我们期望让 AI 变得主动。」Looki 创始人兼 CEO 孙洋一语道破。
,时长06:08
正是带着这样的思考,一支自带自动驾驶基因的团队,试图将那套解析道路环境的「从感知到决策」逻辑复用到日常生活中,填补大模型对于物理世界的认知「盲区」。他们打造的 Looki L1,在北美市场积累首批口碑后,于今天正式面向国内发布。
这款 AI 原生多模态可穿戴设备,旨在将实时视听信号转化为模型上下文,让物理世界本身,成为驱动 AI 思考与服务你的最高效 Prompt。
一、藏在 30g 机身里的「智能感知」系统
从「车看路」到「AI 看世界」,这是自动驾驶感知算法的一次微缩实战。
如果说云端大模型是「大脑」,那么 Looki L1 就是由于算力限制而不得不外挂的「视神经」。第一眼看到 Looki L1 的人,很难不将它误解为一款挂坠形态的相机。它形态十分迷你,仅重 30g,支持磁吸或直接佩戴。
这种误解源于我们对「镜头」的固有认知,镜头生来是为了审美服务的。但对于 Looki 来说,镜头是服务于机器认知的,它本质上是一个庞大的、始终在线的多模态感知器。它不需要拍得「美」,但必须拍得「懂」。它支持 1080P/30 帧画面,待机 12 小时拍摄,就像一块海绵,全天候吸收你的光影世界。
孙洋认为,任何硬件形态都有其优劣势,AI 眼镜当下在续航、重量和功能上存在「不可能三角」。而 Looki 选择挂坠形态,则是在当前供应链能力下,为了实现「全天候静默采集」这一核心需求的最佳妥协方案。
这种妥协背后,是团队技术基因的「降维打击」。
「以前是教车怎么看路,现在是教 AI 怎么看懂你的生活」,孙洋谈道。这种跨界视野,源于两位创始人独特的履历拼图。孙洋和刘博聪均毕业于卡内基梅隆大学,而在分别执掌美团智能硬件与自动驾驶算法业务之前,他们还曾在 Momenta 与 Pony.ai 两家自动驾驶企业深耕一线。
他们将自动驾驶「从环境感知到自主决策」的闭环逻辑,从道路平移到了生活场景,其感知机制体现在两个层面:
- 首先是多维感知。它使用了多模态大模型,视觉识别场景物体,听觉捕捉环境情绪,构建起对物理世界的初步认知。
- 其次是高效吞吐。 通过「智能间隔拍摄」技术,确保在极低功耗下实现海量视听数据的实时采集。
这套机制构成了团队从「车」迁移到「人」的底层基座,更为接下来的云端处理提供了丰富的原始数据。
二、超越 RAG,搭建一套专属用户的「数据飞轮」
从「多维数据」到「结构化记忆」,真正的壁垒在于构建一套用户专属的 Context Engineering(上下文工程)。
Looki 团队沿用自动驾驶的「数据飞轮」逻辑,来重塑用户的个人记忆:从硬件端收集数据,到建立多层级数据索引和多任务拆解,最终打造一套高效工作的 Agentic System(代理系统),让 AI 能像人脑一样,有索引、有重点地调用你的生活数据。

据 CTO 刘博聪介绍,这套系统的独创性,在于挑战了当前多模态模型的两大痛点:
首先是「长时序数据理解」。针对大模型处理大量多模态数据流(如数十万级别)容易产生「幻觉」的通病,团队通过工程优化,让 AI 能准确理解,并串联起跨度极长的时间切片。
其次是应对「多模态数据的 Context 爆炸」。视频与图像的查询会消耗巨大的上下文窗口。Looki 在云端构建了一套高效的上下文管理机制,能够根据查询需求,在海量数据中精准提取关键特征,而非粗暴地将所有素材灌入模型。
当然,这一切的基石是数据的隐私安全。Looki 通过端侧隐私过滤与 App 手动上传机制,确保数据流转的安全性。最终,物理世界的切片,被转化为结构化的「云端记忆库」。
如果说 GPT 是你工作的上下文,装载了人类的通用知识;那么 Looki 正在构建的,就是你生活的私有上下文,装载了你独一无二的经历与轨迹。
三、从「手动 Prompt」到「主动式 AI」
当语境足够丰富,交互终将进化为主动式「预判」。
目前硅谷普遍认为,我们终将迎来从 Chatbot 走向 Agentic AI(代理式 AI) 的范式转移。行业预测显示,自主 AI 代理市场将在未来三年迎来爆发性增长,而 Memory(记忆)与 Context(上下文) 正是这场进化的核心护城河。
Looki 的野心,正是基于这两者,通过可穿戴硬件构建通往「主动智能」的入口。
目前,Looki 交付给用户最显性的功能是「AI 自动剪辑」。它精准切中了那些热爱记录、却被后期剪辑劝退的用户痛点。用户在佩戴拍摄的同时,Looki 的算法自动识别一天中的高光时刻,自动生成有叙事逻辑的 Vlog。



基于这层理解,真正的质变在于「隐性洞察」。
随着记忆库的沉淀,Looki 将不再是被动等待指令的记录仪,而是能够进行推理的 Agent。它不仅记录你的饮食,更能在你点夜宵前,基于全天摄入主动发出「热量预警」;或在你情绪激动时,基于对话语境提供理性的沟通建议。

这种基于实时物理反馈的交互,让 AI 从「被动问答」进化为「主动共鸣」,这才是 AI 硬件区别于手机 App,能够真正接管用户生活的核心价值。
四、结语:当物理世界成为提示词
在 Looki 团队的构想中,硬件形态从来不是终点,而是一个「长在物理世界里的数据接口」。这也道出了 Looki 的实质:无论它今天是挂坠,还是未来演化为眼镜或耳机,其核心使命从未改变,那就是解决物理世界的数据饥渴,帮用户积累最宝贵的私有数据资产。
在 AI 时代,算力会被摩尔定律稀释,模型会被更强的版本迭代,但你在这个世界上生活过的痕迹、你眼中的风景、你与家人的对话,这些 Personal Context 构成了独一无二的你。而 Looki,就是帮你将这份资产,转化为 AI 能够理解共情的「数字直觉」。
当 AI 拥有了「在场感」,它就不再是云端那个冰冷的工具,而是你生活中的「第二大脑」。
最强大的 Prompt,其实是你未曾说出口的生活本身。
.....
#ChatGPT-5
临床PK完胜ChatGPT-5!国内团队造出首个OCT影像AI系统
通用大模型(LLM)的狂飙突进,终于在医疗垂直领域的「最后一公里」撞上了硬墙。虽然 ChatGPT 在 USMLE(美国执业医师资格考试)中表现优异,但在面对需要「火眼金睛」和「毫厘必争」的心脏手术台上,通用大模型的表现究竟如何?
近日,一项由空军军医大学唐都医院李妍教授团队牵头,与深圳清华大学研究院朱锐团队联合完成的 COMPARE 研究在 arXivs 上发表预印版。研究揭示:在经皮冠状动脉介入治疗(PCI)的决策制定中,CA-GPT垂直领域 CA-GPT 系统(一项基于 OCT 影像的 AI 系统),在关键决策指标上显著优于 Open AI 的通用大模型 ChatGPT-5。该研究是基于中科微光医疗(Vivolight Medtech)OCT 系统搭建的 RAG 增强型 AI-OCT 整合决策支持模型。
- 论文标题:COMPARE: Clinical Optimization with Modular Planning and Assessment via RAG-Enhanced AI-OCT: Superior Decision Support for Percutaneous Coronary Intervention Compared to ChatGPT-5 and Junior Operators
- 论文地址:https://arxiv.org/abs/2512.10702
这不仅是一次算法的胜利,某种程度上可以称得上是中国腔内影像领域的「DeepSeek 时刻」。这套 CA-GPT 系统有望重新定义心脏介入手术的智能化标准。
01. 巅峰对决
通用大模型在专业战场「水土不服」
据《2023 年全球心血管疾病负担报告》统计,每年因心血管疾病死亡的人数达 1920 万,而经皮冠状动脉介入治疗(PCI)作为最核心的血运重建手术,全球年手术量已超过 400 万例。在 PCI 手术中,OCT(光学相干断层成像)被称为医生的「第三只眼」,可清晰看到血管内病变情况,但是其图像解读高度依赖医生经验,初级医师与资深专家在手术成功率、并发症发生率等关键指标上的差距高达 40% 以上。

腔内影像中不同技术与分辨率的对比示意图
在这项纳入了 96 名患者、160 处病变的临床研究中,团队构建了一个严苛的竞技场:将 CA-GPT 系统、ChatGPT-5 以及拥有 1-5 年经验的初级介入医师放在同一维度下,以资深专家团队制定的手术记录为金标准进行盲测 。所有方案均与患者实际接受的手术记录(由年手术量≥ 200 例、经验≥ 10 年的高级专家完成)进行比对。评估涵盖 10 项预设决策指标,分为术前规划 5 项和术后评估 5 项,每项一致得 1 分,总分 0-5 分。

10 项不同 PCI 策略的评分标准
值得一提的是,传统 OCT 图像解读还需要医师逐帧分析,耗时数分钟至十数分钟。相比之下,CA-GPT 系统可在 20 秒内完成全面分析并生成结构化报告,将影像解读时间缩短 95% 以上。
结果显示,在术前规划(Pre-PCI)阶段,CA-GPT 对 ChatGPT 形成了「降维打击」:
- 总体决策评分:CA-GPT 系统的评分中位数达到满分 5.0,显著高于 ChatGPT-5 的 3.0(P<0.001),同时也优于初级医师的 4.0。
- 支架直径选择(关键指标):CA-GPT 的准确率高达 90.3%,而 ChatGPT-5 仅为 63.9%,甚至低于初级医生的 72.2%。
- 支架长度选择:CA-GPT 准确率达 80.6%,ChatGPT-5 仅为 54.2%。

决策一致性亚组分析

各评分项目的性能分布
而在术后评估(Post-PCI)阶段,三方总体表现都比术前更好,因为这个阶段有了术前方案和实际结果可以参考。但 CA-GPT 依然在一些关键指标上表现出优势,比如:对「最小支架面积是否达标」的判断,CA-GPT 与专家判断的吻合度接近 100%;年轻医生略有差距。
对「支架是否扩张不足」、「是否存在严重贴壁不良」的识别,CA-GPT 在支架贴壁评估(93.2% 准确率)等需要精细判断的项目上,优于初级医师组(76.1%)。
那为何拥有海量参数的 ChatGPT-5 会败下阵来?研究指出,通用大模型虽然语言推理能力强,但缺乏对图像数据的数值敏感性和空间理解力。特别是在面对功能性缺血(OCT-FFR≤0.80)或严重钙化等复杂病变时,通用模型容易产生「幻觉」,而 CA-GPT 则展现了极高的稳定性,在复杂病变亚组分析中依然保持了中位数 5.0 的高分。
02. 解密架构
RAG + DeepSeek 的工程化胜利
CA-GPT 之所以能实现高稳定性和准确性,核心在于摒弃了对单一端到端大模型的迷信,构建了一套严密的「小模型 + 大数据 + 大模型」的 RAG 复合智能体架构。

CA-GPT 训练模型架构:小模型 + 大数据 + 大模型
据其技术披露,该系统并非简单的聊天机器人,而是一个精密的协作系统:
- 「感官」精准化(小模型层):系统底层集成了 13 项核心功能(含 6 项自研专有算法)。它们负责像「显微镜」一样对 OCT 影像进行结构化分析,在 5-10 秒内即可完成管腔分割、斑块定性、钙化积分计算等定量工作,为决策提供精准的数据地基。
- 「大脑」逻辑化(DeepSeek):在大模型推理层,该系统基于开源的 DeepSeek 构建。它不再依赖概率生成文本,而是基于小模型提供的精准量化数据,进行符合医学逻辑的深度推理。
- 「知识」实时化(RAG 技术):通过检索增强生成(RAG)技术,系统链接了包含超过 100 万篇心血管文献及指南的知识库(DBdata)。这意味着,AI 的每一次决策建议,都能追溯到具体的专家共识或最新指南,有效抑制了 AI 幻觉。

基于 CA-GPT 的 AI-OCT 系统辅助决策案例介绍
03. 普惠价值
让县域医生拥有「顶级三甲专家」视野
这项技术突破的终极意义,不在于在论文中战胜 ChatGPT,而在于解决医疗资源分布不均的现实痛点。全球心血管疾病负担日益加重,但资深介入专家(完成 1000+ 例手术)却是极度稀缺资源。培养一名能独立处理复杂病变的医生,往往需要 8-12 年的漫长周期。研究数据显示,初级医生在处理复杂病变时,与专家存在显著差距。
因此,CA-GPT 系统在本质上是在做「医疗能力的平权」。
想象一下,在偏远的县级医院,一位刚工作不久的医生,在面对复杂的钙化病变时手足无措。此时,CA-GPT 系统在 5-10 秒内给出了手术策略:
- 「建议预处理使用旋磨术,旋磨头选择 1.5mm」
- 「建议支架尺寸 3.0 x 28mm,释放压力 12atm」
- 「注意:远端存在边缘夹层风险」
这相当于每台手术都有一位顶尖专家在旁「手把手」指导。
04. 结语
做垂直领域的「定义者」
过去十年,中国医疗器械行业更多是在追赶西方的脚步。但此次发布的 CA-GPT 系统及其临床成果,标志着中国企业在高端腔内影像领域开始掌握定义权。
不做通用大模型的「套壳」,而是深耕垂直场景的「窄门」。 用数据证明:在医疗这种容错率为零的领域,唯有将深度学习的精准度与大模型的推理能力完美结合,才是 AI 落地的正途。
这或许就是中国医疗科技的「DeepSeek 时刻」—— 把 AI 技术落地业务场景,用自己的技术,解决最真实的临床痛点。
.....
#Nemotron 3
英伟达成开源新王?Nemotron 3全新混合专家架构,推理效率升4倍
英伟达的自研大模型,刚刚有了大版本的更新。
北京时间今天凌晨,英伟达发布了 Nemotron 3 系列开放模型,共三种规模,分别为 Nano、Super 和 Ultra:
- Nemotron 3 Nano:300 亿参数规模的小模型,每次最多激活约 30 亿参数,适用于高度定向、极致高效的任务。
- Nemotron 3 Super:约 1000 亿参数的高精度推理模型,每个 token 最多激活 100 亿参数,面向多智能体应用。
- Nemotron 3 Ultra:约 5000 亿参数的大型推理引擎,每个 token 最多激活 500 亿参数,适用于复杂 AI 应用场景。

其中 Nemotron 3 Nano 已在 Hugging Face 上线,是目前计算成本效率最高的模型,针对软件调试、内容摘要、AI 助手工作流和信息检索等任务进行了优化,可显著降低推理成本。该模型采用独特的混合 MoE 架构,在效率与可扩展性方面实现了显著提升。
Nemotron 3 Nano 的总参数规模为 316 亿,激活参数规模为 32 亿(包含嵌入层为 36 亿)。在每次前向推理过程中,其激活的参数数量不到上代 Nemotron 2 Nano 的一半,却实现了更高的准确率。
与 Nemotron 2 Nano 相比,Nemotron 3 Nano 实现了最高 4 倍的 Token 吞吐量提升,并将推理阶段生成的 Token 数量减少最高 60%,显著降低推理成本。同时,100 万 Token 的上下文窗口使 Nemotron 3 Nano 具备更强的长期记忆能力,在多步骤、长链路任务中表现更为准确。
对于另外两款模型,Nemotron 3 Super 擅长需要大量协作智能体、且对低延迟要求极高的复杂任务;Nemotron 3 Ultra 则作为高级推理引擎,适用于深度研究与战略规划等高复杂度 AI 工作流。
斯坦福大学计算机科学副教授 Percy Liang 表示,这不仅仅是一个强大的开源模型。Nemotron 发布了训练数据、强化学习环境和训练代码。这意义重大:几乎所有模型开发者都只是希望人们使用他们的模型;而英伟达则让用户能够创建自己的模型。

英伟达认为,随着企业从单一模型聊天机器人转向协同工作的多智能体 AI 系统,开发者正面临通信开销高、上下文漂移以及推理成本居高不下等挑战。同时,能够支撑复杂工作流自动化的模型,必须具备足够的透明性与可解释性,才能赢得开发者与企业的信任。
Nemotron 3 正是为应对这些问题而生,为构建专业级智能体 AI 提供所需的性能与开放性。
英伟达创始人兼首席执行官黄仁勋表示:「开放式创新是 AI 进步的基石。通过 Nemotron,我们正在将先进 AI 转变为一个开放平台,为开发者提供在规模化构建智能体系统时所需的透明性与效率。」
Nemotron 3 系列的首款模型 Nemotron 3 Nano(30B-3A)已于今日上线,Nemotron 3 Super 和 Ultra 预计将于 2026 年上半年正式推出。

技术介绍
Nemotron 3 系列模型的核心技术包括如下:
混合 MoE(Hybrid MoE)
Nemotron 3 系列模型采用 Mamba-Transformer 混合 MoE 架构。在实现业界领先吞吐率的同时,其准确率优于或不逊于传统 Transformer 模型。
具体来说,传统方法通常将 MoE 层与代价昂贵的自注意力层交替堆叠,而自注意力机制在生成过程中需要随着序列变长,不断扩展 KV Cache,其计算和存储成本线性增长。
而 Nemotron 3 模型的核心改进是:大量采用 MoE 层与成本更低的 Mamba-2 层交替堆叠。Mamba-2 在生成时只需存储固定大小的状态(constant state),无需维护不断扩张的 KV Cache。
因此,只有少量自注意力层会被保留用于特定功能。图 1 展示了 Nemotron 3 Nano 的层级结构模式。

LatentMoE
Transformer 模型在不同部署场景下会遇到不同的性能瓶颈:低时延场景主要受限于内存带宽,高吞吐场景则受限于 MoE 的 all-to-all 通信。为同时兼顾速度与模型质量,英伟达提出了 LatentMoE 架构。
LatentMoE 的核心做法是:先将 token 从原始隐藏维度投影到更小的潜在维度,在这个低维空间中进行专家路由和计算,再投影回原维度。这样不仅减少了专家权重加载和通信成本,还能利用节省下的带宽与参数,增加专家数量和每个 token 激活的专家数,提高模型表达能力。

多 Token 预测(Multi-Token Prediction, MTP)
MTP 已经成为一种显著提升大语言模型准确率和推理效率的有效技术。已有研究包括 DeepSeek V3 以及最早提出 MTP 的工作表明:让模型一次预测多个未来 token,不仅能够提供更丰富的训练信号,还能促使模型提前规划多个推理步骤。
在 Nemotron 3 中引入 MTP 后,模型在验证集损失以及多个下游任务中都获得了稳定提升,包括通识知识、代码生成、常识推理、阅读理解和数学。
从系统层面看,MTP 仅引入极少量额外 FLOPs,并能无缝集成到训练流程中,同时带来可观的 speculative decoding 加速收益,整体效率依然保持极高水平。
NVFP4 低精度训练格式
英伟达在 NVFP4 数值格式下,成功实现了在 Mamba–MoE 混合架构上对最高 25 万亿(25T)tokens 的稳定且高精度的预训练。模型的权重、激活值和梯度均被量化为 NVFP4,使得前向传播、反向传播中的梯度计算和权重更新都可以使用 NVFP4 GEMM 运算。在 GB300 芯片上,FP4 的峰值吞吐量是 FP8 的 3 倍。
超长上下文(Long Context)
Nemotron 3 系列模型被设计为支持最长 100 万(1M)token 的上下文长度,以满足大规模、多轮、具备 Agentic 推理的应用需求。
在传统 Transformer 中,旋转位置编码(RoPE) 是扩展上下文长度的主要瓶颈,因为 RoPE 在超过训练长度时会出现明显的分布外退化问题。而 Nemotron 3 使用的 Mamba 层天然具备隐式位置信息,因此模型在注意力层中完全不使用 RoPE,从而避免了 RoPE 带来的上下文扩展限制。
除了上述关键技术之外,Nemotron 3 系列模型还引入了两项面向实用性的核心能力,进一步增强了模型在真实世界应用中的可靠性、灵活性与泛化表现。
多环境强化学习后训练(Multi-environment RL Post-training):Nemotron 3 模型在后训练阶段使用多种强化学习环境进行训练,使模型在广泛任务范围内实现更高的准确性与泛化能力。
推理阶段精细化推理预算控制:Nemotron 3 模型在训练时即支持推理阶段的计算 / 推理预算精细控制,可在实际部署中根据任务复杂度灵活权衡推理深度、性能与成本。
更多技术细节请参阅技术报告:

- 论文地址:https://research.nvidia.com/labs/nemotron/files/NVIDIA-Nemotron-3-White-Paper.pdf
- 论文标题:NVIDIA Nemotron 3: Efficient and Open Intelligence
有趣的是,Nemotron 3 贡献者名单长达 2 页多,参与人数之庞大在开源模型中也是少见,足见这一系列模型背后投入的研发规模与工程复杂度。
Nemotron 3 表现
如下图所示,在覆盖多个类别的主流基准测试中,Nemotron 3 Nano-30B-A3B 的准确率优于 GPT-OSS-20B 和 Qwen3-30B-A3B-Thinking-2507。
在单张 H200、8K 输入 / 16K 输出配置下,Nemotron 3 Nano 的推理吞吐量是 Qwen3-30B-A3B 的 3.3 倍,是 GPT-OSS-20B 的 2.2 倍。
支持最长达 100 万 Token 的上下文长度,并且在不同上下文长度下的 RULER 基准测试中,性能均优于 GPT-OSS-20B 和 Qwen3-30B-A3B-Instruct-2507。

另外,独立 AI 基准评测机构 Artificial Analysis 将 Nemotron 3 Nano 评为同规模模型中最开放、最高效的模型之一,并具备领先的准确率。

目前,Nemotron 3 Nano 的多种型号模型、数据、模型配方均已开源。

得益于采用了 NVIDIA Blackwell 架构上的超高效 4-bit NVFP4 训练格式,Nemotron 3 Super 和 Ultra 可以大幅降低内存需求并加快训练速度,使得在现有基础设施上训练更大规模模型成为可能,同时在准确性上不逊于更高精度格式。
通过 Nemotron 3 模型家族,开发者可以根据具体工作负载选择最合适的开放模型,在从数十到数百个智能体的规模下灵活扩展,同时获得更快、更精准的长程推理能力。
面向智能体定制的全新开放工具与数据
英伟达同步发布了一整套训练数据集与先进的强化学习库,面向所有构建专业化 AI 智能体的开发者开放。
其中,囊括 3 万亿 Token 的全新 Nemotron 预训练、后训练及强化学习数据集,涵盖丰富的推理、编程和多步骤工作流示例,可用于打造高度专业化的领域智能体。
Nemotron 智能体安全数据集(Agentic Safety Dataset) 提供真实世界的遥测数据,帮助团队评估并强化复杂智能体系统的安全性。

更多数据集请参阅:https://huggingface.co/nvidia
为了加速开发,英伟达还开源了 NeMo Gym 与 NeMo RL 库,提供 Nemotron 模型所需的训练环境和后训练基础,并推出 NeMo Evaluator 用于验证模型的安全性与性能。所有工具和数据集现已在 GitHub 和 Hugging Face 上开放。
目前,Nemotron 3 已获得 LM Studio、llama.cpp、SGLang 和 vLLM 的支持。此外,Prime Intellect 与 Unsloth 正将 NeMo Gym 的即用型训练环境直接集成到其工作流中,使团队能够更便捷地开展强化学习训练。
参考链接:
https://nvidianews.nvidia.com/news/nvidia-debuts-nemotron-3-family-of-open-models
https://research.nvidia.com/labs/nemotron/Nemotron-3/
.....
#Detailed balance in large language model-driven agents
所有大模型,都学物理学:北大物理系一篇研究,震撼了AI圈
LLM 智能体很赞,正在成为一种解决复杂难题的强大范式。
不过,这种成功目前更多还停留在「经验主义」的工程实践层面 —— 我们知道它好用,但往往不知道它在宏观上为何如此运作。那么,我们是否能找到一个理论框架,像物理学描述自然界那样,去理解和统一智能体的宏观动力学(macroscopic dynamics)?
为了解开这个黑盒,近日,北京大学物理学院、高能物理研究中心以及北京计算科学研究中心联合发力,跨界借用了物理学中经典的最小作用量原理(least action principle)。他们提出了一种新颖的方法,成功估计了嵌入在智能体中的 LLM 隐秘的生成方向性(directionality),揭示了 AI 生成过程背后可能存在的「物理定律」。
- 论文标题:Detailed balance in large language model-driven agents
- 论文地址:https://arxiv.org/pdf/2512.10047
简单来说,他们通过实验测量了 LLM 生成状态之间的转移概率。基于此,他们在统计上发现了 LLM 生成转移中的细致平衡 (detailed balance) 现象。
这表明:LLM 的生成可能不是通过一般性地学习规则集和策略来实现的,而是通过隐式地学习一类潜在的势函数 (potential functions),这些势函数可能超越了不同的 LLM 架构和提示词模板。
该团队表示:「据我们所知,这是首次在不依赖特定模型细节的情况下,发现 LLM 生成动力学中的宏观物理定律。」
什么意思呢?通俗来说,该团队发现 AI 的思考并不是「死记硬背」,而是像水往低处流一样遵循「物理本能」。
是的,LLM 智能体在解决问题时,其行为模式并不像很多人以为的那样仅仅是在匹配规则或随机尝试,而是隐约看到了一张无形的地形图(势函数)。在这个地形图中,错误的答案就像是高地,而正确的答案则是谷底。智能体的每一次推理和生成,实际上都是在最小作用量原理的驱动下,自然而然地向着势能更低、质量更好的状态流动。
这意味着,AI 能够解决复杂问题,是因为它在海量参数中内化出了一种全局的「直觉」,这也是科学家首次在 AI 生成过程中发现了不依赖于特定模型的宏观物理定律。
这一发现将 AI 研究从「炼丹术」提升到了可量化的「物理科学」高度。通过验证物理学中的「细致平衡」现象,该团队证实了 AI 的思维跳跃并非无迹可寻,而是像热力学平衡系统一样有着严格的数学比例。
这让我们可以用物理指标来给不同的大模型画像;比如,研究发现:
- Claude-4 像个急于交卷的优等生,倾向于快速收敛到某个答案(势井),但也容易固执己见;
- GPT-5 Nano 则像个探险家,虽然收敛慢,但更愿意在状态空间中多走走,探索未知的可能性。
这一理论框架让我们可以用科学测量的手段去预测和控制 AI 的行为,而不再仅仅依赖盲目的工程试错。看起来,也正如谷歌前些天的一篇论文展现的那样(参阅报道《谷歌发布智能体 Scaling Law:180 组实验打破传统炼金术》),AI 智能体的研究不再只是简单的工程实践,而是正在提升为建立在有效测量基础上的、可预测且可量化的科学。
下面具体来看看这个北大团队究竟发现了什么。
理论
为了严谨地表述这一问题,该团队研究的是一个核心由一个或多个 LLM 组成的智能体。
该智能体将其当前状态 f 作为输入,通过一系列确定性的步骤对状态进行组织和评估,从而生成一个相关的提示词。随后,该提示词被输入到一个或多个 LLM 中,其结构化的输出经解析后得到一个新的状态 g。该状态是研究 LLM 动力学的最小单位。
这种生成过程可以被视为状态空间 𝒞 中的一个马尔可夫转移过程,其转移核为 P (g|f),保留了 LLM 生成的多样性和适应性。状态由智能体在每个时间步保留的完整信息定义,这应当包含智能体执行连续推理或类比过程所需的所有信息。在本文中,智能体仅包含 LLM 的单个生成步骤,记 𝒯(g←f)=P (g|f) 为智能体通过 LLM 生成从包含状态 f 的模板转移到包含状态 g 的输出的概率。
图 1 为示意图。

基于 LLM 的智能体的特征在于,其状态转移并非完全随机,而是表现出某种结构化的偏好。
具体而言,智能体倾向于从当前状态 f 转移到从智能体视角来看「更好」的状态 g。
为了捕捉这一现象,假设存在一个潜在的势函数 V_𝒯:𝒞→ℝ,它为每个状态分配一个标量值,以反映其「质量」。由于特定的势函数通常难以直接计算,研究者提出了一种有效估计该势函数的方法。
给定一个全局势函数 V,研究者将智能体的给定转移 𝒯(g←f) 对势函数的违背定义为 K (V (f)−V (g)),其中 K (x) 是一个凸函数,用于描述从状态 f 到状态 g 的转移在多大程度上违背了势函数 V 的排序。为了量化智能体行为与势函数之间的整体不匹配度,研究者以转移核 𝒯(g←f) 为权重,将作用量 𝒮 定义为全局平均违背:

其中 Df,Dg 是状态空间上的测度。在本文中,研究者选择 K (x)=exp (-βx/2) 作为描述给定状态转移 f 到 g 违背标量函数 V 排序程度的凸函数。作用量 S 或 βV (f) 的分布形状可以代表该状态空间 C 内智能体的全局认知能力。
研究者提出,若要利用势函数量化 LLM 的行为,可以寻找一个使智能体转移与势函数之间的整体不匹配度最小化的势函数。因此,描述给定状态空间中基于 LLM 的智能体𝒯 最合适的势函数 V_𝒯 ,是那个能使作用量 S 最小化的函数。
这意味着作用量满足关于势函数 V_𝒯 的变分原理:

该变分条件等价于 V_𝒯 满足以下平衡条件:

这对所有 f∈C 成立,其中 K'(x)=dK/dx。
具体而言,如果对于所有转移 𝒯(g←f)>0,,均有 V (f)≥V (g) 成立,则表明智能体的状态转移是完全有序的,在此情况下,V 充当李雅普诺夫函数。
值得注意的是,如果 𝒯 描述的是一个平衡系统的转移,其状态转移满足细致平衡条件,即对于所有状态对 (f,g),下式成立:

其中 π(f) 表示系统在状态 f 处的平衡分布,而 P (g|f) 表示转移核。在这种情况下,存在一个势函数 V 可以明确地将细致平衡表示为:

代入 (3) 式,可以验证该势函数 V=V_𝒯 满足最小作用量原理。这表明对于平衡系统,如果存在细致平衡条件,则可以通过最小作用量原理估计其潜在的势函数。在一般情况下,最小作用量仅仅是在寻求势函数的最有序排列,从而最小化智能体状态转移对该排列的违背。
研究者指出,基于 LLM 的智能体在其 LLM 生成的状态空间中,往往表现得像一个平衡系统,该状态空间相较于 LLM 完整的生成序列是粗粒化的。这一现象的存在表明 LLM 生成动力学中存在一种不依赖于具体模型和任务细节的普遍宏观规律。这表明,尽管看似无关,但在不同的 LLM 生成过程之间存在潜在的联系,使我们能够通过势函数 V_𝒯 描述 LLM 生成中的全局有序性,从而为 LLM 的内部动力学提供解释。
结论与展望
在本文中,研究者提出了一种基于最小作用量原理的框架,旨在描述和分析基于 LLM 的智能体在其 LLM 生成的状态空间中的生成动力学。
通过在多个不同模型和任务上的实验验证,研究者发现这些智能体的状态转移在很大程度上满足细致平衡条件,这表明它们的生成动力学表现出类似于平衡系统的特征。研究者进一步通过最小作用量原理估计了底层的势函数,并揭示了其在捕捉 LLM 生成动力学内在方向性方面的重要作用。
研究者对发现 LLM 生成动力学中的宏观规律进行了初步探索。
该团队也展望了未来:「未来的工作可以进一步扩展这一框架,并探索利用更多来自平衡及近平衡系统的工具,以理解和优化 LLM 的生成过程。例如,研究偏离平衡的程度可能有助于我们理解模型的过拟合水平,因为过拟合的模型可能会学习更多局部的策略集,而不是由势函数支配的全局生成模式。此外,基于势函数的优化方法也可能为提高 LLM 任务相关生成的质量和多样性提供新思路,例如根据不同的安全性和探索需求调整不同幅度的作用量。」
更多技术细节请参阅原论文。
.....
#Entropy Ratio Clipping as a Soft Global Constraint for Stable Reinforcement Learning
PPO-Clip的「盲点」被补齐了?快手提出熵比裁剪方法,从局部约束到全局稳定的关键一跃
本研究由快手科技语言大模型团队完成,核心作者苏振鹏,潘雷宇等。快手语言大模型团队聚焦在基础语言大模型研发、Agent RL 等前沿技术创新等方向,积累务实的探索 AGI 的能力边界,并不断推进 AI 领域新技术和新产品的发展。此前,该团队已开源了 Klear-46B-A2.5B 和 Klear-Reasoner-8B 等模型,其中 Klear-Reasoner-8B 在数学和代码的基准测试上达到了同参数级别模型的 SOTA 效果。
在大语言模型的后训练阶段,强化学习已成为提升模型能力和对齐质量的核心范式。然而,在广泛采用的 off-policy 的训练范式中,更新当前策略的数据由旧的行为策略生成,导致分布漂移的问题的发生,这通常会将策略推至信任域之外,使强化学习的训练变得不稳定。
尽管 PPO 通过重要性采样的裁剪机制缓解了部分问题,但它仅能约束已采样动作的概率变化,忽略了未采样动作的全局分布漂移。为了应对这些挑战,快手研究团队提出了一种创新的熵比裁剪方法。该方法从全新的视角切入,通过约束策略熵的相对变化来稳定全局分布,为强化学习训练提供了更加可靠的控制手段。
- 论文标题:Entropy Ratio Clipping as a Soft Global Constraint for Stable Reinforcement Learning
- 论文地址:https://arxiv.org/pdf/2512.05591
研究背景
强化学习训练过程中长期面临信任域偏离的挑战。目前,业界用于大模型的强化学习常采用 off-policy 训练范式,用于更新当前策略的数据由旧的行为策略生成,导致新旧策略之间存在分布漂移。主流方法通常采用重要性采样来纠正此类偏差,但其固有的高方差可能导致更新步长不稳定,仍存在信任域偏离的风险。这种偏离具体表现为训练过程中梯度范数和策略熵的剧烈波动。
PPO 算法是解决信任域偏离问题的主流方案,主要有两种形式:
- PPO-penalty:在目标函数中加入 KL 散度惩罚项,对新旧策略的分布差异进行全局约束。但是惩罚系数非常敏感,且对每个动作概率施加逐点约束可能会抑制探索。
- PPO-Clip:通过将重要性采样比率限制在固定区间内,形成局部信任域,裁剪过大的更新以降低方差。该方法更鲁棒且易于调参,但其约束仅作用于已采样的动作,未采样的动作则完全不受约束。
随着训练迭代的不断进行,这部分未受约束的动作分布会持续漂移,最终威胁策略的稳定性。例如,假设动作空间为 {a, b, c, d},旧策略的概率分布为 {0.85, 0, 0.15, 0},经过多次迭代后,新策略的概率分布变为 {0.82, 0.064, 0.07, 0.046}。尽管采样动作 a 的概率变化微小,PPO-Clip 不会触发裁剪,但其余动作的分布已发生显著偏移。
ERC 机制:从全局视角稳定策略分布
受 PPO-clip 启发,论文提出了熵比裁剪(ERC)机制,当新旧策略间的熵变化超出允许范围时,ERC 直接对样本梯度进行截断。ERC 并非取代 PPO-Clip,而是对其形成补充:PPO-Clip 仅约束采样动作的局部更新幅度,而 ERC 将熵比限制在一个适中的区间内,从而缓解整体策略分布的漂移。
首先,论文提出了熵比指标,其被定义为新旧策略在同一 token 上熵的相对变化。具体的,它被形式化定义为下式:

不同于重要性采样比率,熵比可以测量整个动作分布(包括未采样动作)的变化,提供了对策略全局漂移的度量。另外,论文还对采样动作概率与熵比的关系进行可视化,如下图所示:

当采样动作较低或者较高时,全局分布偏移变得更加明显。
在将熵比作为策略分布的全局变化指标引入后,论文进一步将其集成到现有强化学习目标中,旨在约束新旧策略之间全局分布的变化。以 DAPO 为例,其 ERC 目标可形式化如下:

如果某个 token 的更新导致熵比超出预设范围,ERC 会直接截断其对应的梯度,以防止全局分布和策略熵的剧烈波动。与在整个训练过程中持续限制策略的 KL 约束不同,熵比仅在新策略的熵发生显著偏离时才被激活。这种方法既能防止策略分布的突然崩溃,又保留了足够的探索能力。
实验结果
为验证 ERC 方法的稳定性和性能上的有效性,论文在多个数学推理基准上进行了系统实验,包括 AIME24、AIME25、HMMT25、MATH500 、AMC23 和 Olympiad。所有实验均基于 DeepSeek-R1-Distill-Qwen 模型(1.5B 与 7B)进行训练。实验结果如下表所示。

与现有的 RL 基线方法相比,集成 ERC 后,模型几乎在所有基准测试上的性能都得到了一致提升。值得注意的是,在 AIME25 和 HMMT25 等更具挑战性的基准上,性能增益更为显著,凸显了 ERC 在复杂推理场景中的强大潜力。此外,该方法在 1.5B 和 7B 两种参数规模上均取得了一致的改进,进一步证明了其在不同模型容量下的鲁棒性和可扩展性。

为了进一步验证 ERC 对训练动态的影响,论文比较了不同方法下熵和梯度范数的演化过程,如上图所示。传统的裁剪方法在训练过程中常表现出较大的熵值波动和不稳定的梯度。相比之下,ERC 引入了全局熵比约束,熵值轨迹和梯度范数更加稳定,在基准上的评测结果也不断提升。
深入分析:ERC 如何工作?
增强信任域约束
如下图所示,ERC 的裁剪机制有效地强化了信任域约束。具体而言,被熵比边界裁剪的 token 主要位于信任域的边界附近。这表明,ERC 从全局分布的视角出发,能够识别并限制可能导致策略偏离的更新,而这些更新正是 PPO-Clip 的局部约束所忽略的。因此,ERC 与 PPO-Clip 以互补的方式协同工作,共同减轻信任域偏离,增强训练稳定性。

通过 ERC 保持探索
为了理解 ERC 对模型探索行为的影响,论文分析了在训练中被熵比约束裁剪的 token 的熵分布,如下图所示,大多数被 ERC 裁剪的 token 集中在低熵区域,而高熵 token 在优化过程中通常被保留。这表明 ERC 优先抑制那些过于确定性、信息增益有限的 token 的更新,而不会过度约束模型的探索动态。

裁剪比例分析
实验结果显示,ERC 引入的全局分布约束显著提高了裁剪比例。PPO-Clip 下的裁剪比例通常保持在 0.02% 左右,而 ERC 将此数值提高了近三个数量级,达到约 20%。这种显著差异源于两种约束机制的根本不同:PPO-Clip 仅调控局部采样动作的重要性比率,越界情况本就罕见;而 ERC 超越了这种局部约束,通过熵比融入了全局分布信号,使其能够识别并裁剪大量在全局分布层面偏离信任区域的 token 更新。
尽管 ERC 的裁剪比例显著更高,但其在最终性能和训练稳定性上均持续超越 PPO-Clip 基线。这个看似违反直觉的结果揭示了一个关键见解:ERC 主要移除了那些会使训练不稳定的噪声更新。被 ERC 裁剪的 token 大多集中在低熵区域,这表明 ERC 抑制了过于确定性且可能有害的更新,同时保留了模型在其他地方的探索行为。
对比与泛化能力
论文还将 ERC 与其他稳定方法进行了对比,并验证了其在其他强化学习算法中的泛化能力。
- 与 KL 正则化的对比:ERC 在 AIME24 和 AIME25 基准上均优于 PPO-penalty(即 KL 正则化方法)。KL 散度施加的是逐点约束,要求新旧策略对每个动作的概率分布都保持接近,这种严格的局部调控虽然可以稳定训练,但不可避免地限制了有效的策略探索。而 ERC 实现了分布层面的软约束,通过监控熵比来关注整体策略分布的演变,在维持训练稳定性的同时鼓励更高效的探索。
- 与熵正则化的对比:ERC 的表现显著优于在强化学习训练中直接加入熵惩罚项的方法。熵正则化只能缓解单向的不稳定性(熵崩塌),而 ERC 的双向裁剪机制能有效应对策略演化中熵值波动的两个方向,确保策略的探索行为在合理可控的范围内平稳演变。
- 与序列级裁剪(GSPO)的对比:在 DeepSeek-R1-Distill-Qwen-7B 上的实验表明,结合了 PPO-Clip 和 ERC 的 token 级裁剪方法相较于序列级裁剪方法(如 GSPO)仍具有明显优势。值得注意的是,ERC 与序列级裁剪是正交的,可以同时使用。
- 更广泛的适用性:除了 DAPO,论文还将 ERC 与 GPPO 方法结合。实验表明,将 ERC 集成到 GPPO 中同样能带来一致的性能提升,为 ERC 在不同 RL 算法中的普遍有效性提供了有力证据。这表明 ERC 不仅是现有重要性比率裁剪技术的补充组件,也有潜力作为一个独立且鲁棒的约束机制来稳定策略优化。
.....
#无问芯穹首曝智能体服务平台
以基础设施加速企业级「智能体自由」
“我们相信,未来每个企业都会是 Agentic(智能代理化) 的。” 无问芯穹联合创始人、CEO 夏立雪表示:“而当每个企业里都活跃着 10 个、100 个、乃至 1000 个智能体,一个组织的创造能力将会被无限放大。即使是最微小的团队,也能释放出最强大的影响力。”
12 月 16 日,在 2025 INFINI DAY 无问芯穹智能体生态论坛上,无问芯穹智能体服务平台正式发布。作为无问芯穹面向智能体时代打造的战略级 AI 基础设施产品,该平台致力于为企业提供从智能体定制优化、部署托管到商业化变现全链路的陪伴式落地服务,为每一个能改变世界的智能体,打造下一代生产力基座,加速完成从创造力到生产力的进化。
01 驾驭智能体 + 规模化创造 = 未来组织的核心竞争力
传统经济中,企业的成长和创新能力往往线性、渐进式发展,依赖时间积累经验、技术和市场。而到了智能体时代,从创意原型的验证,到产品功能的搭建,再到商业模式的最终成型,Agentic AI 正在加速企业创造力的 Scaling,使得 “从 Idea 到 Industry ” 的链路被飞速压缩。
而生产级的智能体落地和规模化的高门槛,成为企业在驾驭智能体实现规模化创造的过程中难以逾越的阻碍。无问芯穹技术总裁李伯勋将当前企业的智能体落地面临的核心困境总结为:“生产级效果难实现、稳定可靠运行难保障、建设与业务成本难控制、商业化落地难闭环。” 他表示,“解决这四个问题,弥合基础设施与智能体发展需求之间的鸿沟,是帮助企业级智能体完成创造力到生产力进化的关键。”

02 无问芯穹企业级智能体服务平台,助力每一个能改变世界的智能体
无问芯穹智能体服务平台为企业提供开箱即用的 Agent 能力模板和稳定可靠的托管服务,支持丰富多样的脚手架工具,并与无问芯穹底层算力及模型基础设施深度链接,以顶尖的 Agentic Infra 组件,为企业客户提供从智能体定制优化、智能体部署托管到商业化变现全链路的陪伴式落地服务,让智能体生产效果更优秀、规模化运行更稳定、业务成本更可控、商业化变现更顺畅,助力智能体服务落地 “行稳致远”。
想要让智能体能够表现出好的应用效果,业务 know-how 和算法的结合能力、前沿算法的快速掌握能力,以及智能体工程化能力,缺一不可。
得益于长期的前沿基础设施技术积淀,无问芯穹智能体服务平台不仅将行业知识模板化,内置了包括代码、研究和多模态等 5 种以上的 Agent 能力模板,帮助智能体落地在从 0 到 1 的起始阶段,就拥有优秀的基础效果。而模板化的另一核心价值在于,无问芯穹通过将以往服务众多大型行业客户所积累的经验与行业知识,沉淀为可供各行各业中小型客户直接复用的标准模板,让成熟的行业经验可以源源不断地为中小企业赋能。
同时,持续以 Day0 级的前沿模型追踪力,为客户的目标业务效果动态适配最佳模型方案。此外,基于企业特定需求,平台还可通过定制化工具调用、创新提示词优化等技术,进一步为客户提升智能体的应用效果。
在稳定性与可靠性方面,无问芯穹智能体服务平台以充沛的算力储备与基础设施支持、强大的系统韧性以及安全保障为每个智能体的规模化运行保驾护航。
依托无问芯穹遍布全国的算力储备及技术服务,平台为每个智能体提供稳定可靠的托管服务。通过弹性扩缩容与自动化排障机制,系统在韧性方面显著领先行业,不仅千卡集群模型服务稳定性高达 99.5%,还将百毫秒级的沙箱调度速度提至十毫秒级,领先行业水平 50% 以上。此外,平台提供可观测大盘,支持企业对自身智能体全链路数据 100% 的追踪,全方位保障智能体安全运行与拓展迭代。
在成本控制方面,无问芯穹智能体服务平台与底层基础设施深度集成与全面协同,依托完备的模型集成资源、强大的推理优化技术和全栈式的软硬协同能力,为企业灵活控制智能体落地的业务成本。
平台汇聚并实时更新 20+ 主流、前沿优质大模型,并长期针对顶尖开源模型进行深度推理优化。针对千亿、万亿参数规模模型如 DeepSeek、Kimi-K2-Instruct 等,平台采用大规模 PD 分离方案服务线上业务,相比传统服务模式,推理效率提升 3~5 倍。并且,基于原生的全栈式的软硬件协同优化能力,平台还支持模型定制与系统级调优,能够结合实际应用场景,为客户在性能与成本之间寻得最优解。
智能体落地应用是一个环环相扣的过程,从效果优化、部署托管、落地推广到商业化变现,存在三个重要的提效链条 —— 工具链、升级链与推广链。
针对当前智能体商业落地与规模化服务过程中普遍存在的提效链条断裂难题,无问芯穹智能体服务平台支持企业智能体接入丰富的社区或自研工具集,帮助减少 70% 以上的 Agent 工具集成与冗余劳动。并将复杂智能体业务流程封装为多个独立的业务模块以支持智能体版本管理与更新。同时,平台还提供微信、小红书等客户所需的第三方裂变与支付渠道的快捷接入,系统性地补足了这 “三链” 的断点。无问芯穹智能体服务平台以全链路陪伴式的服务,帮助企业平滑跨越从产品实现到商业闭环的每一步,真正实现智能体的高效商业化落地与可持续运营。
03 将智能体内化为企业的原生动能
在与多家行业伙伴的共研共建中,无问芯穹智能体服务平台的价值正在得到持续验证。
在发布会现场,无问芯穹技术总裁李伯勋展示了无问芯穹与某运维服务企业共同打造的企业系统开发智能体 “SysCoding Agent”。为应对企业数字化转型与高效开发需求,该客户基于无问芯穹智能体服务平台,与无问芯穹携手打造了高可用的企业级系统开发智能体。企业员工与外部伙伴、客户,可通过自然语言对话轻松创建、修改并托管各类业务系统,无缝对接企业自有资源与工具库,全面激活企业内系统开发的自动化潜能。
该智能体在首轮生成中即可达到极高的完成度与规范性:产出内容的主流程完整性大于 95%,规范遵从度超过 90%,且堵塞性 bug 发生率低于 3%,意味着用户通过首次意图交互即可获得已满足大部分需求的可用版本。目前,该智能体已在企业内部上线并稳定服务,轻松应对工作高峰期的并发请求。在实际体验中客户发现,仅需 1 人投入 1 周时间,即可完成 1 个生产级系统的开发与上线,单系统建设成本最低只要 5 元。

类似的生产力兑现也正在求职、旅游、教育等多个行业同步发生。无问芯穹智能体服务平台正以更高性价比和可规模化的智能体服务模式,为多种行业客户构建智能体服务提供高效、敏捷的服务,帮助企业实现自身行业积淀与技术能力向长远业务价值的扎实转化。
智能体的 “大航海时代” 已然启幕,无问芯穹致力于成为这一转型进程中各企业的长期伙伴,持续以强大的智能体基础设施,助力各行业伙伴将组织的宝贵知识转化为可持续的价值产出与原生动力,在共同的探索中,定义下一代生产新范式。
发布的尾声,上海交通大学副教授,无问芯穹联合创始人、首席科学家戴国浩表示:“未来,无问芯穹将继续坚定以 Agentic infra 支撑数字世界与物理世界的智能体应用效能突破与持续进化,并通过产学研协同,以生态的连接与共振,持续构建智能体创新的‘产业链 + 创新链’闭环,让智能体真正成为各行各业创造力 Scaling 的最强加速器。”
.....
#这位伯克利教授还在给本科生上课
身家25亿刀,是四家公司创始人
一直在探索,一直能搞定。
「我认为他是我们这个时代最优秀的计算机科学家之一。他是一位真正的智者,不仅懂得如何将学术研究与商业系统相结合,更懂得如何构建整个社会的人类生态系统和技术进步,」加州大学圣巴巴拉分校(UCSB)教授 William Wang 说道。
在 AI 领域里,有很多学者投身工业领域获得了成功,不过像加州大学伯克利分校(UC Berkeley)教授 Ion Stoica 那样,能一边教书,一边多次创业成功,「打出品牌」走出一条正循环道路的,可能还不多见。
Ion Stoica 教授为人们所知的身份包括伯克利教授、ACM Fellow,也包括 Databricks、Anyscale、LMArena、Conviva 等公司的联合创始人。他的经历最近得到了《福布斯》的报道。
在最近火热的人工智能领域,我们提起大模型水平的比对,肯定绕不开 ChatBot Arena,这个平台就是 Ion Stoica 和他的学生们创办的。据说它最初设立的原因是用作给伯克利开源的 Vicuna 模型和斯坦福的 Alpaca 打擂台。
如今,ChatBot Arena 是一个托管了 400 多个 AI 模型的网站,允许用户同时与多个模型聊天对比。该公司于今年 4 月更名为 LMArena,Stoica 担任董事长,CEO、CTO 都是他的学生。
目前,该公司已获得 1 亿美元风险投资,估值达到 6 亿美元。这家成立两年的公司已被 OpenAI、xAI 和谷歌等开发者用于测试他们的大模型聊天应用,已获得超过 350 万张来自用户的投票。

这家成立两年的公司已被 OpenAI、xAI 和谷歌等开发者用于测试他们的聊天机器人,并已获得超过 350 万张来自用户的投票,这些用户希望对这些不断发展的模型发表意见。
这只是计算机科学教授 Ion Stoica 实验室的最新研究项目之一,他带领的实验室主要由微软、英伟达、谷歌和 IBM 等科技公司资助。在他近三十年的学术生涯中,他与大学同事和学生共同创立了四家初创公司,迄今为止其中包括两家独角兽企业。
Ion Stoica 出生于罗马尼亚,现年 60 岁,身价已达 25 亿美元(是福布斯移民美国富豪 125 人中唯一的罗马尼亚人)。他在 20 世纪 90 年代末移居美国,在卡内基梅隆大学(CMU)攻读电气与计算机工程博士学位,2000 年毕业后在加州大学伯克利分校任教,从此便一直没有离开过他的实验室和学生。
虽然 Stoica 的大部分研究都是针对博士生进行的,但他也一直在为本科生授课。今年秋天,他会继续主讲《操作系统和系统编程》课程(CS 162)。

Ion Stoica 在伯克利教授的课程。
Stoica 的第一家初创公司是 2006 年成立的流媒体分析公司 Conviva。这是他与 CMU 前同事的合作项目,其中包括他的博士生导师张晖(Hui Zhang),后者称 Stoica 为「世界上最优秀的研究人员之一」。
Stoica 和张晖一直在研究如何在互联网上提供高质量的流媒体视频,在观察了这个当时的新兴市场后,他们决定创业。Conviva 于 2017 年完成上一轮融资,估值在 3 亿美元。它是一款智能在线节目和电影监控器,可以识别音频和视频问题并提醒流媒体用户。它还能提供用户观看记录、跳过部分以及喜欢部分的报告,为福克斯和 Peacock 等客户提供了服务。
目前,Stoica 在 Conviva 仅保留董事会席位,他每周都会与团队会面。
如果说 Conviva 只是家规模较小的创业公司,那么 Databricks 在如今的 AI 领域可谓鼎鼎有名了,它最新的估值在 620 亿美元,是由 Stoica 与其他六位伯克利研究人员共同创立的。预计到今年 7 月,Databricks 的年化营收将达到 37 亿美元,并且一直有传言称其正在考虑上市。
正是 Databricks 让 Stoica 首次身家上了十亿刀。2013 年,Stoica 与斯德哥尔摩皇家理工学院的访问学者 Ali Ghodsi 以及五名博士生共同探索如何更有效地处理海量数据。他们共同开发了 Spark,这是一款强大的数据处理工具。
Databricks 联合创始人之一、伯克利分校副教授 Matei Zaharia 表示,Stoica 当时希望将 Spark 打造成一家初创公司的目的是,这样用户才能更加认真地对待实验室的研究。此外他还希望帮助缺乏成熟基础设施的小型企业管理和分析海量数据,从而获得商业洞察并构建人工智能工具。
「帮助××获得洞察」听起来很像是科技公司的宣传用语,这并非 Stoica 的本意,他表示自己「骨子里仍然是一名学者」。
对他来说,致富从来都不是目标:「如果你只是被钱驱使,那就去做 IPO,那是最简单的方法。但实际上不是这样,重要的是创造一些有意义的东西。」Stoica 曾于 2013 年至 2016 年担任 Databricks 的首席执行官,之后他将权力移交给 Ghodsi,转任执行董事长。
「继续留任意味着离开伯克利,所以我必须做出选择,」Stoica 说道,「而我选择了回去。」
他从未全职创业的原因是他的学生:「年轻人在成长阶段,有时不知道什么是可能的,什么是不可能的…… 他们有这种信念,这就是为什么你会得到意想不到的解决方案。」此外,Stoica 将他的商业成功归功于他对研究的专注:「这是一种创造…… 探索新想法的行为。」
在伯克利,Ion Stoica 不仅是一位优秀的教师,而且是一位优秀的创业顾问,更重要的是,他能够帮助这些创意获得资金支持,最终落地。
这种声誉为他带来了一批有志的学生,后来他又共同创立了 Anyscale,估值也达到了 10 亿美元。
Spark 诞生六年后,伯克利知名计算机科学教授迈克尔・乔丹的博士生 Philipp Moritz 和 Robert Nishihara 开始着手修复一个缺陷,其要求 Spark 等待所有任务完成后才能继续执行下一个操作。
「我说他们不会从我这里得到太多的指导,我不是系统构建者,」乔丹回忆道。于是,他鼓励学生们选修 Stoica 的分布式系统课程,并和他一起研究解决方案。
这个项目最终变成了 Ray,一款旨在比 Spark 等同步系统更高效地处理大规模强化学习的软件。「他一如既往地以 Ion 的风格,很快就想把它变成一家公司,」乔丹说道,他与 Stoica 和学生们一起在 2019 年创办了 Anyscale。
三年内,这家帮助开发者扩展 AI 应用的平台公司已融资 2.6 亿美元,其中包括在 2022 年 9 月最新一轮上获得的 2 亿美元,估值达到 14 亿美元。Stoica 任执行董事长,他表示 Anyscale 将在未来 12 个月内继续融资。
Stoica 认为,解决问题的关键在于大学这个开放的研究平台:「每个人都可以利用『大学研究』,相比之下,公司倾向于不开源他们最好的系统。」Databricks 的 Spark 和 Anyscale 的 Ray 最初都是开源项目,至今仍对公众开放。
最近在大模型里,vLLM 是伯克利主导的热门开源项目,Ion Stoica 是项目的指导教授,看看这个 star 数量,未来会不会也会成为创业公司呢?

在学术方面, Ion Stoica 是伯克利最成功的教授之一,他目前正主持一个工作组,致力于解决整个计算机、数据科学和社会学院的研究经费削减问题。作为主席,他鼓励其他教授寻求私人资金,效仿让他自己的实验室取得巨大成功的模式。
Stoica 亲自指导的 80 多名学生受益于他的资源和人脉。他们绝大多数在学术界或初创企业就业,其中至少 7 人在 Databricks 工作。
但科技行业的就业前景正在出现变数,计算机科学专业曾经最热门的专业之一,但由于技术发展节奏加快,AI 的影响,寻找工作已变得不那么容易。
「我告诉学生们要拥抱并使用这些 AI 工具,」Stoica 说道。「显然,短期内会有一些痛苦。但换个角度想想…… 人工智能将加速人类进化的步伐,并最终成为星际文明。如果你这样看,我们仍然没有足够的人来做这件事。」
参考内容:
.....
#悟能
世界模型将加快AI从数字空间进入物理世界,「悟能」想做那个桥梁
商汤王晓刚
xx智能「大脑」,更准确地,以「世界模型」为内核的xx智能「大脑」会成为 AI 下一阶段竞争焦点吗?
上世纪九十年代,「世界模型」思想雏形初现,之后几十年被不断强化、延伸,直到 ChatGPT 引爆 AI 新浪潮、Sora 问世、大模型落地成主流、xx智能迎来新纪元……「世界模型」或是通往「类人智能」的解法被视为新的业界共识。
与此同时,在产业界,如果说 2025 年上半年 AI 发展主要围绕 Agent 元年、人形机器人「量产」等关键词展开,那下半年,xx智能「大脑」开始成为整个行业乃至全球 AI 领域的焦点。
于是,当世界模型技术研究曲线与xx智能产业发展路径在某一时刻交汇时,一场围绕xx智能「大脑」的争夺战拉开了序幕。
谷歌推出xx智能 RT-2 模型;AI 教母李飞飞聚焦xx智能创业,认为世界模型是 AI 实现「通用智能」关键一步。
国内,今年 3 月,智源研究院发布开源xx大脑 RoboBrain;6 月,华为云发布 CloudRobo xx智能平台;7 月,字节跳动 Seed 团队发布通用机器人模型 GR-3;7 月底,京东发布附身智能品牌「JoyInside」;7 月底,商汤科技推出「悟能」xx能平台;8 月初,腾讯发布 Tairos xx智能开放平台……
当xx智能的技术演进路线还未收敛,各厂商都在基于以往的技术沉淀,沿着不同路线,朝着 AGI 狂奔。
商汤作为其中一家,优势在于做计算机视觉起家(当前xx智能主流技术路线之一)、多模态大模型已经在多种机器人身上打磨过、在智能驾驶领域沉淀多年(世界模型早期落地应用的场景之一)、有大装置提供强大的端侧和云侧算力支持……
因此,商汤想通过「悟能」xx智能平台,「将多年的沉淀与积累,赋能给整个行业。」商汤科技联合创始人、执行董事、CTO 王晓刚说道。
在王晓刚看来,当前xx智能领域发展迅速,尤其是大模型的到来让大家有了更多想象空间。可与此同时,数据匮乏、采集难、无法批量规模化生产、难以泛化等问题也成为xx智能通用化道路上的绊脚石。
但是当大量做计算机视觉的人进入这一领域就变得不一样了。计算机视觉擅长的是分析客观世界的人、物、场,并进行重建复现,包括世界模型的学习,都会给这个领域带来新动能。
而商汤不仅在计算机视觉领域积累深厚,也早早开始探索世界模型的落地。去年 11 月商汤发布「开悟」世界模型,将其应用在智能汽车上。王晓刚认为,汽车本质上也是一个机器人,从端到端 VLA 到环境计算,都是在引领xx智能的发展,「我们先在汽车的环境里进行探索和尝试,然后扩展到其他方向。」
而这个方向,当下就是xx智能。
基于「开悟」世界模型衍生出来的「悟能」xx智能平台,包含着商汤过去积累的 10 万 3D 资产,提供第一视角、第三视角的视频生成,支持xx智能进行多视角学习,能够保持长达 150s 的时空一致。另外,基于自动驾驶和人机交互流式多模态大模型产生的导航、人机交互等能力也都一并赋能给「悟能」xx智能平台,从而推动xx智能加快从数字空间迈向真实物理世界。
近期,xx与商汤科技联合创始人、执行董事、CTO 王晓刚聊了聊,以下为对话实录,在不改变原意的基础上进行了调整:
xx智能来势汹汹,但数据缺乏是「硬伤」
提问:今年被称为「人形机器人量产元年」,在你看来,这主要源于哪些方面,比如技术突破?
王晓刚:我觉得大家看好这个方向主要有几个原因。首先,近几年硬件本体、运控进步很快,有了非常好的基础,像机器人跳舞、翻跟斗、搏击等逐渐走向成熟,但更重要的是,AI 大模型给大家带来了更多想象空间。机器人原本是在特定场景完成单一任务做得比较好,但现在大家期待它有更多通用性,无论是在家庭环境还是生产线上,当任务发生变化的时候它能够像人一样灵活应对。
其中大模型带来的技术突破主要包括三方面 —— 导航、人机交互,以及 VLA 这种端到端复杂操作,给大家提供了新的想象空间。
提问:具体是如何体现的?
王晓刚:导航,现在随着自动驾驶技术不断成熟,让机器人陪伴、巡检,甚至配送等方面的功能变得更好。
人机交互,比如多模态大模型带来的全新交互方式,当然更多的是像 VLA 这种比较复杂的操作带来的想象空间。
我们常常思考智能分几个层次?智能从哪里来?最早大家通过标注数据,采集大量图像、声音,这些都是客观世界的记录,但是依靠人类的感知,之后进行标注,把人对世界的理解通过标注的方式注入智能。
第二个阶段,ChatGPT 出现后通过分析语言进行,语言本身就是人类行为,这是另外一个层次。
但更高的一个层次是人定义的这些规则,比如下围棋,把规则定义好了以后,AlphaGo 机器人在互相博弈过程中产生很多智能。
如今无论是自动驾驶还是机器人领域,有一个很重要的模型 ——「世界模型」,世界模型本身是把物理规律、交通法则这些东西学到以后(去做预测、规划)。人更高层的智能就是定义这些规则,之后自动驾驶或是机器人在世界模型里面依据这些规则进行交互,自动就能产生更多的智能。
提问:在取得进展的同时,xx智能领域在通往更为通用的场景时也面临一些困难与挑战,在你看来有哪些局限性?
王晓刚:问题也是多方面的,比如硬件质量,机器人是一个高度复杂的系统,任何一个零部件出现问题,都会给整个系统带来质量方面的影响,因为它要与物理世界进行交互,交互过程中会进行碰撞。这是它走向大规模量产所面临的硬件问题。
但最核心的还是数据问题,目前xx智能没有办法进行批量规模化的数据生产。虽然有各种数据生产手段,但机器人类型多样,硬件传感器配置千差万别,而且机器人本身数量相对较少,所以整体来看,这一个机器人上采集到的数据难以推广到另外一个机器人上。
另外采集方式,比如智能汽车,开车过程实际就是生产过程,自然而然产生了这些数据,而机器人采集的数据不是在生产过程中,是通过遥操作,人在背后控制机器人刻意采集数据,成本也非常高。
当然也有用仿真得到的数据,但与真实数据之间 gap 较大,因为仿真的技术路线积累还是传统办法,与现实差距大。
我们期待这些 3D 建模与世界模型相结合,通过对物理世界更深入的理解,带来新的思路。尤其是有大量做计算机视觉的人开始进入这个领域,计算机视觉领域擅长的是分析客观世界的人、物、场 3D 模型、环境,并进行重建复现,包括世界模型的学习,都能够给这个领域带来新的动能。
,时长00:16
xx智能世界模型<人、物、场>构建4D真实世界
提问:现在有些机器人演示的时候手抖得厉害,这是因为缺乏数据或是训练不到位吗?
王晓刚:这是运控问题,主要是通过小脑对它进行控制,另外大脑也要分析怎么能进行这些行为。
比如 VLA 给出指令,应该往哪个方向运动,而机械手或肢体怎么能够通过局部控制这些关节,达到预测的运动轨迹。这涉及到两个问题,一是自己本身运动的时候要把握比较好,另外预测的运动轨迹得适合机器人硬件本体的运动,如果给它设计一个路线,它走起来很别扭就不行,这就要求大脑 VLA 的预测要与底层的运控有一个比较好的结合。
这也不容易,机器人走路的运控要让它走得好,很多时候也需要通过强化学习去适用不同的环境和地形。为什么有些演示 demo 可以做到,主要是因为它是针对特定的场景调得比较好,换一些通用场景就不行,一旦涉及到规模化,不光大脑要通用,小脑也需要做到通用,否则需要一堆技术售后人员到各个场景里面做调整。
世界模型,加快 AI 从数字空间迈进物理世界
提问:你刚才提到汽车,认为它是从 AI 迈向xx智能的一个关键步骤,那你觉得现在的自动驾驶处于怎样的阶段,具备进一步向xx智能发展的条件吗?
王晓刚:现在自动驾驶领域还处于技术红利期,基本上每年它的整个体系架构都朝新的方向进一步迭代。比如 2023 年端到端的自动驾驶概念兴起,那时候还很依赖高精度地图,现在已经进化到无图的端到端自动驾驶,技术已经比较成熟。
但因为端到端技术还是对人类行为的模仿,是类人的,所以对数据的依赖比较高,所以当下世界模型已经形成一个行业共识。比如去年 11 月我们发布了「开悟」世界模型,今年,像华为、小鹏等也都在发力世界模型。
有了世界模型以后,一是可以提供大量数据,另外它可以在仿真环境里做很多强化学习的尝试,因为世界模型能做到举一反三、反十、反一百。比如今天遇到一个自动驾驶没有解决好的问题场景,基于这个场景首先对它进行重建,然后就可以改变天气情况、光线、道路情况、各种车型、速度、距离远近等,这几个维度拟相乘能够产生大量类似的场景和视频,从而把这一类问题全都解决干净,极大地降低了数据采集成本。
提问:那是否具备进一步向xx智能发展的条件?
王晓刚:当然,今年我们看到,因为有了端到端,激发人们在机器人领域应用 VLA;因为有了世界模型,xx智能也进入这一领域。另外就是座舱里面的人机交互,现有的是硬件设备加上 APP,将来全新的人机交互叫作「环境计算」,AI 就像空气一样在人们的周围,不需要打开特定的 APP,它主动会找到你,里面核心点就是有计算芯片、有各种传感器还有模型,这不就是汽车中一个非常典型的环境?
车内外有这么多的传感器观察、记录车内外的各种状态、各种活动、人的对话等行为,还要有记忆,了解、知道你的需求,那当你需要的时候就能够主动提供 AI 相关服务,它本质上就是一个机器人。从这个层面来看,它是一个很好的环境计算载体。
所以,从端到端 VLA 到环境计算,汽车都是在引领xx智能的发展,我们最先可能是在汽车的环境里进行索和尝试,然后扩展到其他方向。
提问:说到世界模型,各大厂商都在陆续发布,那在你看来商汤的「开悟」世界模型有哪些技术优势?
王晓刚:首先,「开悟」世界模型的最新进展是不仅覆盖了汽车领域,而且也覆盖了xx智能,同时提供这两个平台。
世界模型的核心是要学到最高层的智能,包括物理规律、交通法则、什么是好的行为和开车的体验等,其中比较关键的几点分别是:
第一,时空一致性。2024 年年初 Sora 生成视频,但它不是针对特定自动驾驶场景,而且产生视频最难的地方在于如何保证时间上的连续,因为生成一幅图像很容易,但是生成一个视频,大家会看到帧与帧之间是不是不连续的,存在各种抖动、跳变。自动驾驶领域难度更高,要求 11 个摄像头保持时空一致性,一个摄像头看到的东西与另外一个摄像头看到的东西,在空间物理上需要一致,不能在这个摄像头看到一条实线,另外的摄像头看的是一条虚线。
另外时间上,我们能够做到 150 秒,时间越长,包含的交通行为更复杂,能够把一些更复杂的博弈体现出来。
第二,内容可编辑,场景生成可控。刚才提到世界模型能够做到举一反三、反十、反一百,就是因为能够任意编辑里面的各种元素,换天气、换光线。


第三,反应速度实时。实时性体现了成本,场景生成实际上是在用 GPU 算力来置换,实时性越高,算力越节省,花的钱越少。另外做到实时性,还可以对它进行实时交互,会产生非常接近真实的视频场景。
发布「悟能」xx智能平台,为行业提供「机器人大脑」
提问:此次商汤发布的「悟能」xx智能平台,就是从「开悟」世界模型衍生出来的,能具体讲讲背后的技术路线以及战略意义吗?
王晓刚:我们为什么要做这个事情,刚才也提到,xx智能领域最大的挑战还是在于缺少数据。
其实大家想了各种办法,比如从互联网上收集,但是这些数据可能与机器人领域遇到的数据相差非常大,而遥操作去采集产生的每一条数据都非常昂贵,泛化性也不好。比如让它拿一个水杯,把瓶子和水杯换了,甚至换一张桌子,都会产生很大影响。而现在我们希望基于之前在世界模型的积累,能够给大家提供各种合成数据。
刚才提到「开悟」世界模型有几个特点,基于此,「悟能」xx智能平台就可以做很多事情。
第一,商汤过去在视觉领域有很多 3D 方面的积累,在基于各种场景、环境的人、物、场积累了 10 万个 3D 资产。另外我们做到了根据第一视角、第三视角来学习。
怎么理解,现在有一些机器人的工作是让机器人跟人学习,人在走动、坐下,捕捉到的这些视频映射到机器人上,它的机械臂应该如何进行操作。现在有了 AI 眼镜,未来会涌现大量第一视角数据,那现在我们把这两个东西结合在一块,就能够产生对应的这方面数据,对大家来说就是一个可用的状态,对行业也会有比较大的推动作用。
,时长00:08
xx世界模型构建4D真实世界——指令:生成一段切黄瓜的机器人的视频——第一视角
,时长00:08
第三视角
前不久像 Yann LeCun 他们推出来的世界模型也是第一视角的世界模型,就是想通过第一视角预测将来的动作是什么。
现在我们同时提供第一视角和第三视角,这是一个完整的对机器人行为的理解,就可以实现端到端的 VLA。
提问:有没有具体的案例可以分享一下,基于这个平台所带来的xx智能领域的变化?
王晓刚:比如那些机器狗,就可以做到跟着小孩、老人出去,有守护也有陪伴。有了这个导航后可以去任何地方,中间如果遇到异常状况,它也能够及时做出响应和处理。
另外家庭里面的陪伴型机器人,能够与我们进行对话聊天、产生记忆、建立情感上的连接。最近也可以看到,当下各种 AI 陪伴式提供情绪价值的机器人落地应用都是比较快的。
提问:刚才也提到,机器人的类型、功能、大小不同,难以泛化,那如何基于一个xx智能平台去实现?
王晓刚:这是将来要解决的问题,现在大家都解决不好这个问题。首先最重要的是我们要先解决行业里目前匮乏的数据问题,针对具体的一个机器人去采集数据,去微调、去适用它。这是首要解决的。
提问:当前业界关于「机器人大脑」的平台也有很多,比如前段时间智源研究院发布xx大脑 RoboBrain,「悟能」与之的区别是什么?
王晓刚:而「悟能」这个平台提供的是世界模型,这是比较新的一块。另外像导航、人机交互这些能力都是基于我们自动驾驶和人机交互流式多模态大模型产生的,这些与复杂操作还是有区别的。
提问:那基于「悟能」平台,商汤与各大机器人厂商的合作形式是怎样的?
王晓刚:首先在这个平台上,这些都是 SDK 软件功能,比如导航、人机交互、世界模型等,可以调用这个 API,需要产生什么样的数据,世界模型就能够把这些数据提供过来。可以想象我们做一个「机器人的大脑」。
而我们与机器人厂商的合作属于强强结合,因为机器人是一个软硬一体方案,将来想要在竞争中胜出,必须得具备足够多的壁垒。在这一块,商汤本身也投了一些机器人上下游公司,包括硬件、本体、或者零部件等企业,所以将来我们会有一个比较好的结合。
比如傅利叶,我们已经把流式多模态大模型提供给他们,能够进行人机交互,另外其他的一些机器人公司我们也提供了基础设施、算力等方面能力。
将来要提供整体方案,对硬件要求非常高,一旦在某一场景实现了软硬一体方案的交付,进行批量化的生产,就需要做到第一成本、第二质量,以及稳定的供应链,甚至售后,这些都离不开硬件。
xx智能是具像化的智能体
提问:当下xx智能爆火,技术层、应用层不断取得突破,那在你看来,当xx智能更为成熟的时候,人们的生活会发生怎样的变化?
王晓刚:我觉得可想象空间非常大。xx智能本身就是机器人,也是一个比较具象化的智能体,之前我们看到的都是人与人之间的联系,将来可以看到人与机器人、机器人与机器人之间的联系,将来我们的社交群体里可能会发现有机器人的存在,形成各种社交网络。因为机器人不光是一个工具,它有记忆、有情感载体。
另外,随着机器人通用化能力的增加,它的想象力和价值也会发生变化。当前家庭里用的各种电器和设备都是能够完成某一项功能,比如空调、洗衣机等,而当机器人走进家庭场景后,它能够完成多项功能,这些潜在的价值非常大。
当然,即便我们没有要求机器人能够实现完全的通用性,把各种事情都能完成,它只要每往前走一步,就能多做一些事情,都会给市场带来巨大的想象空间。
提问:如今商汤发布了「悟能」xx智能平台,那接下来在xx智能领域还有怎样的规划,或者希望扮演一个怎样的角色?
王晓刚:我们希望能够给这个行业提供「机器人大脑」,这是我们最擅长也是最强的,这个大脑里包含了眼睛、声音的交互、导航,以及操作。
商汤本身有很多这方面前期的技术积累,比如自动驾驶的积累能够用到xx智能的导航、交互。
另外,我们通过世界模型助力打造 VLA 相应的大脑算法,这对于商汤自身的发展来说,也是把我们从原有的在数字空间的积累,进入到物理世界时,实现物理与数字空间的连接。不光如此,将来还能够实现家庭、工作场所、汽车,这三个人类常用空间的连接。其中的核心就是机器人,因为机器人可以共享很多数据、记忆,能够把人的生活整个连接在一起。
而实现这些的基础就是商汤多年的积累,除了上面这些,还有「大装置」等。过去我们的云端、超算集群已经在给很多机器人公司赋能,包括数据闭环、端侧芯片等,我们希望基于这些综合能力赋能整个行业。
.....
#DAPO
让强化学习快如闪电:FlashRL一条命令实现极速Rollout,已全部开源
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。这是一个可实现大规模 LLM 强化学习的开源 SOTA 系统,使用该算法,该团队成功让 Qwen2.5-32B 模型在 AIME 2024 基准上获得了 50 分,我们也做了相关报道。
- 论文地址:https://dapo-sia.github.io/static/pdf/dapo_paper.pdf
- 代码地址:https://github.com/volcengine/verl/tree/gm-tyx/puffin/main/recipe/dapo
中国科学技术大学校友,伊利诺伊大学香槟分校博士,微软研究院的首席研究员刘力源、清华大学校友,加州大学圣地亚哥分校计算机科学与工程学院博士生姚峰团队在强化学习的研究中更进一步。
该团队发现,在 DAPO-32B 中,rollout 生成是强化学习训练的主要瓶颈,占据了约 70% 的总训练时间。因此,该团队从 rollout 阶段着手,将 8 bit 量化技术应用于 rollout 生成,并通过 TIS 技术在保持下游性能的同时实现了显著加速。
众所周知,FP8 能让强化学习运行得更快,但往往以性能下降为代价。
刘力源、姚峰团队推出 FlashRL,是首个开源且可用的强化学习实现方案,在推理执行(rollout)阶段应用 INT8/FP8,并且在性能上与 BF16 持平,没有性能损失。该团队在博客中完整发布了该方法的技术细节。
- 博客标题:FlashRL: 8Bit Rollouts, Full Power RL
- 博客地址:https://fengyao.notion.site/flash-rl
- 代码地址:https://github.com/yaof20/Flash-RL
Rollout 量化可能会降低性能
如图 1 和图 2 中 「⋅⋅⋅⋅⋅」 曲线所示,在未使用 TIS 技术的情况下,采用 FP8 或 INT8 进行 rollout 量化,相比 BF16 rollout 会带来显著的性能下降。
这一现象是预期中的,因为 rollout–训练之间的差异被放大了:rollout 是从量化策略 π_int8 采样的,但梯度却是基于高精度策略 π_bf16 计算的。

这种不匹配会使强化学习过程更加偏离策略,从而削弱强化学习训练的有效性。

图 1 左图:吞吐量加速比。FP8 结果在 H100 上测试;INT8 结果分别在 H100 和 A100 上测试。结果基于不同的响应长度和设备测得。右图:Qwen2.5-32B 模型在使用 BF16 rollout 与 INT8 rollout 时的 AIME 准确率对比。所有实验均采用 BF16 FSDP 训练后端。
FlashRL 的独门秘诀
FlashRL 是首个开源且可用的强化学习方案,能够在不牺牲下游性能的前提下使用量化 rollout。
那么,它的「独门秘诀」是什么呢?
解决 Rollout–训练不匹配问题
该团队引入了截断重要性采样(Truncated Importance Sampling,TIS)来减轻 rollout 与训练之间的差距。正如图 1 和图 2 中的实线所示,TIS 使量化 - rollout 训练的性能达到了与采用 TIS 的 BF16 rollout 训练相同的水平 —— 甚至超过了未使用 TIS 的朴素 BF16 rollout 训练。
作者团队之前发表过有关 TIS 的技术博客,感兴趣的读者可以参考:

- 博客标题:Your Efficient RL Framework Secretly Brings You Off-Policy RL Training
- 博客链接:https://fengyao.notion.site/off-policy-rl
在这里简单展示一下 TIS 的工作原理。

支持在线量化
现有的推理引擎(如 vLLM)针对大语言模型推理服务进行了优化,但在支持带参数更新的模型量化方面能力有限。该团队提供了 Flash-LLM-RL 包,对 vLLM 进行了补丁,使其能够支持这一功能。
如图所示,FlashRL 的 INT8 可带来高达 1.7 倍的吞吐量提升,同时保持 RL 的优势。此外,如果不使用 TIS 而使用 naive FP8/INT8 ,性能将显著下降。

图 2 左图与中图:在使用量化 rollout 生成的强化学习大语言模型训练中,GSM8K 的准确率表现。请注意,TIS 对缓解分布差异至关重要。右图:π_fsdp 与 π_vllm 之间的 KL 散度。需要注意的是,INT8 rollout 的 KL 散度大于 FP8 rollout 的 KL 散度。
FlashRL 能有多快?
比较在强化学习训练中采用不同 rollout 精度的吞吐量并不简单,因为模型会不断更新,对于同一个查询,不同的量化策略在经过一定的 RL 训练迭代后可能会生成长度不同的回复。
这里将探讨 FlashRL 所实现的加速效果及其对训练效果的影响。
Rollout 加速表现
常规环境下的加速:
研究团队记录了在 7B、14B 和 32B Deepseek-R1-Distill-Qwen 模型上使用 INT8、FP8 和 BF16 精度的 rollout 吞吐量。
图 1 显示了 8 位量化模型相对于 BF16 的加速比。对于较小的 7B 模型,加速比不足 1.2×;而在 32B 模型上,加速比可达 1.75×。这表明量化对大模型的收益远高于小模型。基于分析结果,团队建议仅在模型规模超过 140 亿参数时使用量化。
内存受限环境下的加速:
研究团队还评估了在标准推理场景(不涉及 RL)下,采用 8 位量化所能带来的吞吐量提升。具体而言,团队测量了 INT8 的加速比,作为压力测试,用于验证其在 A100/A6000 和 H100 GPU 上的适用性。
使用 vLLM 在相同数据集上分别服务 BF16 与 INT8 量化版本的 Deepseek-R1-Distill-Qwen-32B 模型,并在 A100/A6000 和 H100 GPU 上记录其吞吐量。

图 3 在 4 种仅推理配置下,INT8 量化的 Deepseek-R1-Distill-Qwen-32B 相对于 BF16 的吞吐量加速比,测量结果涵盖不同回复长度。
如图 3 所示,当 GPU 内存成为瓶颈时,量化能够带来极高的加速比 —— 在 TP2-A6000 配置下生成速度提升超过 3 倍,在 TP1-A100 配置下提升甚至超过 5 倍。这突显了量化在 GPU 内存受限场景(如服务更大规模模型)中的巨大潜力。
端到端加速与效果验证
研究团队将 FlashRL 部署于 DAPO-32B 的训练中,以验证所提方法的有效性。由于在图 2 中 FP8 相比 INT8 拥有更小的分布差距,特意选择 INT8 作为更具挑战性的测试场景。
图 4 展示了在 BF16 与 INT8 rollout 下的下游性能与训练加速效果。两种配置在 AIME 基准上的准确率相当,但 INT8 显著提高了训练速度。
这些结果证明,FlashRL 能在不牺牲训练效果的前提下,实现显著的训练加速。

图 4. 左图:使用 BF16 与 INT8 rollout 精度进行强化学习训练的下游性能对比。右图:BF16 与 INT8 rollout 在单位小时内可完成的更新步数。所有实验均基于 DAPO 配方,在 Qwen2.5-32B 模型上进行,训练 250 步,硬件配置为 4 个节点、每节点配备 8 张 H100 GPU。
快速使用
使用 FlashRL 只需一条命令! 使用 pip install flash-llm-rl 进行安装,并将其应用于你自己的 RL 训练,无需修改你的代码。
FlashRL 方法支持 INT8 和 FP8 量化,兼容最新的 H100 GPU 以及较老的 A100 GPU。

更多方法细节,请参阅原博客。
.....
#A Survey of Self-Evolving Agents
从物竞天择到智能进化,首篇自进化智能体综述的ASI之路
近年来,大语言模型(LLM)已展现出卓越的通用能力,但其核心仍是静态的。面对日新月异的任务、知识领域和交互环境,模型无法实时调整其内部参数,这一根本性瓶颈日益凸显。
当我们将视野从提升静态模型的规模,转向构建能够实时学习和适应的动态智能体时,一个全新的范式——自进化智能体(Self-evolving Agents)——正引领着人工智能领域的变革。
然而,尽管学术界与工业界对自进化智能体的兴趣与日俱增,但整个领域仍缺乏一个系统性的梳理与顶层设计。多数研究将「演化」作为智能体整体框架的一个子集,未能深入回答该领域三个最根本的问题:智能体的哪些部分应该演化(What)?演化何时发生(When)?以及,演化如何实现(How)?
为应对上述挑战,普林斯顿大学联合多所顶尖机构的研究者们联合发布了首个全面且系统的自进化智能体综述。该综述旨在为这一新兴领域建立一个统一的理论框架和清晰的路线图,最终为实现通用人工智能(AGI)乃至人工超级智能(ASI)铺平道路。
论文标题:A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
论文地址:https://arxiv.org/pdf/2507.21046
GitHub:https://github.com/CharlesQ9/Self-Evolving-Agents
X (Twitter):https://x.com/JiahaoQiu99/status/1950093150003089823
自进化智能体的形式化定义
为确保研究的严谨性,该综述首先为「自进化智能体」提供了一套形式化的定义,为整个领域的研究和讨论奠定了数学基础。
- 环境(Environment):智能体所处的环境被定义为一个部分可观察马尔可夫决策过程(POMDP)。这个环境包含了智能体需要实现的潜在目标(Goals)、环境的内部状态(States)、智能体可以执行的动作(Actions,如文本推理、工具调用)、状态转移概率,以及用于评估的反馈/奖励函数(Reward Function)。智能体无法完全观测到环境的全部状态,只能接收到观测(Observations)。
- 智能体系统(Agent System):一个智能体系统(Π)被解构为四个核心组成部分:
- 架构(Γ):决定了系统的控制流程或多智能体间的协作结构。
- 模型({ψi}):底层的语言模型或多模态模型。
- 上下文({Ci}):包含提示(Prompts)和记忆(Memory)等信息。
- 工具集({Wi}):智能体可用的工具或 API 集合。
- 自进化策略(Self-evolving Strategy):这是定义的核心。一个自进化策略被形式化为一个转换函数 f。该函数接收当前智能体系统(Π)、其在任务中生成的轨迹(τ)以及获得的反馈(r)作为输入,然后输出一个全新的、经过演化的智能体系统(Π')。这个过程 Π' = f(Π, τ, r) 精确地描述了「进化」这一行为。
- 终极目标(Objective):自进化智能体的设计目标,是构建一个最优的自进化策略 f,使得智能体在一系列连续任务上的累积效用(Cumulative Utility)最大化。这为所有演化方法提供了一个统一的优化方向。

核心框架:四大维度定义智能体演化

该综述的核心贡献是围绕「What、When、How、Where」四个维度,构建了一个用于分析和设计自进化智能体的完整框架,并系统梳理了相关的前沿技术。

What to Evolve?(演化什么?)
此维度明确了智能体系统中可以进行自我提升的四大核心支柱:
- 模型(Models):这是智能体认知能力的核心。演化可以发生在两个层面:一是决策策略(Policy)的优化,例如通过自我生成挑战性任务(如 SCA)或利用自然语言反馈进行在线微调(如 SELF、TextGrad),直接更新模型参数;二是经验(Experience)的积累与学习,智能体通过与环境交互(如 Reflexion 的自我反思机制、RAGEN 的强化学习框架)将成功或失败的经验转化为学习信号,驱动迭代改进。
- 上下文(Context):这是塑造智能体行为的动态信息流。演化体现在两个方面:一是记忆(Memory)的演化,智能体需要学会动态管理其长期记忆,例如通过 Mem0 框架中的 ADD/MERGE/DELETE 机制来保持记忆的一致性,或像 Expel 一样从经验中提炼出可泛化的规则和见解;二是指令提示(Prompt)的自动化优化,从简单的候选提示生成(如 APE),到将整个工作流视为可微分程序进行联合优化的复杂框架(如 DSPy),再到面向多智能体系统的通信模式优化(如 MASS)。
- 工具(Tools):这是智能体与外部世界交互的桥梁,也是能力拓展的关键。其演化路径可分为三步:首先是新工具的自主创造(Creation),智能体或通过探索式学习(如 Voyager),或通过响应式代码生成(如 Alita)来弥补能力短板;其次是已有工具的精通(Mastery),通过自我纠错循环(如 LearnAct)来修复和完善工具的功能与文档;最后是管理与选择(Management & Selection),当工具库变得庞大时,智能体需要高效地检索和组合工具,例如 ToolGen 将工具调用转化为生成问题,而 AgentSquare 则通过元学习自动寻找最优的组件配置。
- 架构(Architecture):这是智能体系统的顶层设计。演化既可以针对单智能体,例如优化其内部固定的工作流节点(如 TextGrad),甚至赋予其重写自身源代码的能力(如 Darwin Gödel Machine);也可以针对多智能体系统,例如通过蒙特卡洛树搜索等方法自动发现最优的协作流程(如 AFlow),或利用多智能体强化学习(如 ReMA)来共同演化出高效的协同策略。

When to Evolve?(何时演化?)
演化的时机决定了学习与任务执行的关系,主要分为两大模式,每种模式下都可以运用上下文学习(ICL)、监督微调(SFT)和强化学习(RL)等范式。
- 测试时自进化(Intra-test-time Self-evolution):这指的是在任务执行期间发生的实时适应。当智能体在解决某个特定问题时遇到障碍,它会即时启动学习机制。例如,AdaPlanner 通过 ICL 在执行中动态修正计划;一些前沿工作探索了利用「self-edits」指令触发即时 SFT 来更新模型权重;而 LADDER 框架则通过 RL 机制实现了「即时技能获取」,在遇到难题时当场进行针对性训练。
- 测试间自进化(Inter-test-time Self-evolution):这是在任务执行之后发生的、更主流的演化模式。智能体利用已完成任务的经验积累,对自身能力进行迭代更新,为未来任务做准备。例如,STaR 和 SiriuS 等方法通过 SFT 范式,让模型从自己成功或失败的推理链中生成新的训练数据,实现「自举式」提升;而 RAGEN 和 WebRL 等框架则利用 RL,在任务间歇期通过大量与环境的交互来优化策略。

How to Evolve?(如何演化?)
实现演化的具体方法论,即智能体如何将经验和反馈转化为能力提升,主要分为三大范式。
- 基于奖励的演化(Reward-based Evolution):这是最核心的演化驱动力,通过设计不同形式的奖励信号来引导智能体。奖励信号可以是非常丰富的:
- 文本反馈(Textual Feedback):利用自然语言提供详细、可解释的改进建议,比单一的标量奖励更具指导性(如 Reflexion)。
- 内部奖励(Internal Rewards):利用模型自身的置信度或不确定性作为奖励,实现无外部监督的自我评估与校准(如 CISC)。
- 外部奖励(External Rewards):来自环境的直接反馈(如工具执行成功/失败)、多数投票或显式规则。
- 隐式奖励(Implicit Rewards):从没有明确标记为「奖励」的信号中学习,例如直接从模型 logits 中提取内生的奖励函数。
- 模仿与演示学习(Imitation & Demonstration Learning):智能体通过学习高质量的范例来提升能力,尤其适用于有充足专家数据或可以自生成高质量轨迹的场景。学习来源可以是自我生成的演示(如 STaR)、跨智能体的演示(如从共享的经验库中学习),或是两者的混合。
- 基于种群的演化方法(Population-based & Evolutionary Methods):这种方法借鉴生物进化思想,同时维护多个智能体变体或团队,通过选择、变异、竞争等机制并行探索广阔的解空间,从而发现传统优化方法难以触及的新颖策略与架构。其演化对象可以是单个智能体(如 Darwin Gödel Machine 的开放式代码进化),也可以是多智能体系统(如 EvoMAC 的「文本反向传播」机制)。

Where to Evolve?(在何处演化?)
此维度明确了自进化智能体的应用场域,展示了其在不同类型任务中的演化路径。
- 通用领域演化(General Domain Evolution):这类智能体旨在成为多才多艺的数字助手,其演化目标是拓展在广泛任务上的通用能力。实现这一目标的机制包括:
- 记忆机制:智能体通过总结历史成败经验,形成可复用的知识(如 Tips、Shortcuts),以应对未来的新任务。
- 模型-智能体协同进化:智能体与其辅助模型(如奖励模型、世界模型)共同进化,通过相互促进来提升整体性能和泛化能力。
- 课程驱动训练:系统能够根据智能体的表现自动生成难度适宜的任务,形成一个自适应的「课程表」(如 WebRL),引导智能体由易到难地扩展能力。
- 特定领域演化(Specialized Domain Evolution):这类智能体则专注于在某一垂直领域内「深耕」,通过演化成为该领域的专家。论文展示了其在多个领域的应用潜力:
- 编码(Coding):智能体可以自主修改代码库(如 SICA),或通过多智能体协作进行代码生成、测试和优化。
- 图形用户界面(GUI):智能体通过与桌面、网页和移动应用的真实交互来学习,从失败轨迹中反思,或自动从界面中挖掘功能,实现对图形界面的精准操控。
- 金融(Financial):智能体通过在模拟和真实环境中进行交易,不断迭代和优化其量化策略与领域知识库(如 QuantAgent)。
- 医疗(Medical):智能体在模拟医院中「行医」以提升诊断能力(如 Agent Hospital),或作为虚拟生物学家进行药物靶点发现(如 OriGene)。
- 教育(Education):智能体可以作为个性化导师,根据学生的反应调整教学策略(如 PACE),或作为教师助手,通过多智能体对抗来优化课程计划。

评估、挑战与未来展望
除了构建核心理论框架,该综述还详细探讨了自进化智能体的评估范式。评估自进化智能体不能再局限于静态的准确率,而必须考察其动态能力。
论文提出了五大评估目标:适应性(Adaptivity)、知识保留(Retention)、泛化性(Generalization)、效率(Efficiency)和安全性(Safety),并将其评估模式分为静态评估、短时程自适应评估和长时程终身学习评估,为衡量这一新物种的能力提供了标尺。


最后,该综述为领域的未来发展指明了方向,包括个性化 AI 智能体、提升泛化与跨域适应能力、构建安全可控的智能体、以及探索多智能体生态系统等关键挑战。
通过这份全面的综述,研究者和开发者可以获得一个结构化的视角,来理解、比较并设计下一代更强大、更鲁棒的自适应智能体系统。正如文中所指出的,自进化智能体的发展是通往人工超级智能(ASI)的关键基石,而解决好其在演化过程中的安全性、泛化性与可控性等挑战,将是未来研究的重中之重。
.....
#X-SAM
突破SAM局限!中山大学X-SAM:统一框架横扫20+分割基准
当 Segment Anything Model(SAM) 以分割万物的能力震撼计算机视觉领域时,研究者们很快发现了它的局限:
无法同时处理多任务、难以应对类别特异性分割、更无法融入统一的多模态框架。
如今,来自中山大学、鹏城实验室和美团的团队提出了 X-SAM,一个将分割范式从分割任何事物推向任何分割的突破性框架。
在超过 20 个分割数据集、7 大核心任务上,X-SAM 全面超越现有模型,不仅能处理文本指令驱动的分割任务,还能理解点、框、涂鸦等视觉提示,甚至能在跨图像场景中实现精准分割。这一成果不仅刷新了像素级视觉理解的基准,更让多模态大模型真正具备了「看懂像素」的能力。
从 SAM 的局限到 X-SAM 的突破:为什么需要统一分割框架?
SAM 的出现曾被视为视觉分割的「万能钥匙」,它能通过点、框等视觉提示精准分割图像中的任意对象。但在实际应用中,研究者们逐渐发现了它的「短板」:
- 任务单一性:SAM 仅擅长基于视觉提示的单对象分割,无法同时处理语义分割(区分类别)、实例分割(区分个体)、全景分割(语义+实例)等复杂任务。
- 模态割裂:作为纯视觉模型,SAM 无法理解文本指令,例如「分割图中的红色汽车」这类自然语言查询对它而言如同天书。
- 多任务壁垒:现有分割模型往往针对单一任务设计,例如专门做交互式分割的模型无法处理开放词汇分割(分割训练中未见过的类别),工程落地时需要部署多个模型,效率极低。
与此同时,多模态大语言模型(MLLMs)如 LLaVA、GLaMM 虽然能理解文本与图像的关联,却止步于生成文本描述,无法输出精确的像素级分割结果。「能看懂图像却画不出边界,能分割像素却听不懂指令」,成为横亘在视觉分割与多模态理解之间的巨大鸿沟。
图1:X-SAM的能力示意图。(a)文本查询任务:通用(Gen.)分割、指代(Ref.)分割、推理(Rea.)分割以及定位对话生成(GCG)分割等。(b)视觉查询任务:单图像和跨图像的交互式(Inter.)分割与视觉定位(VGD)分割。(c)X-SAM在所有分割基准测试中均优于现有的多模态大型语言模型(MLLMs)。建议放大查看以获得最佳效果。
X-SAM 的诞生正是为了填补这一鸿沟。正如论文中所强调的:
- 任务制定:将SAM转变为一种具有跨任务适用性的通用分割架构。
- 模态增强:赋予大语言模型多模态输入处理能力。
- 统一框架:开发一种连贯的方法,以有效地促进跨不同领域的综合分割应用。
表1:能力对比。我们在特定分割方法(灰色部分)和基于多模态大型语言模型(MLLM)的方法上对不同方法进行了比较。
技术解析:X-SAM 如何实现「万物可分」?
X-SAM 的核心创新在于将 SAM 的视觉分割能力与大语言模型的多模态理解能力深度融合,通过「统一输入格式」「双编码器架构」和「多阶段训练」三大支柱,实现了真正的「一站式」分割解决方案。
支柱一:统一输入格式,让所有任务「用同一种语言说话」
不同分割任务的输入形式千差万别:语义分割需要类别标签, referring 分割需要文本描述,交互式分割需要点或框。X-SAM 设计了一套统一的输入规则,让所有任务都能被模型「理解」:
- 文本查询输入:用
<p> 和 </p> 标记需要分割的对象,例如「分割
红色外套的女人」。对于需要生成描述并同步分割的任务(如 GCG 分割),模型会自动在输出文本中插入 <p> 标签,再用 <SEG> 标记分割结果的位置。 - 视觉查询输入:引入
<region> 标签代表视觉提示(点、框、涂鸦等),格式为\<p>\<region>\</p>。模型会自动将视觉提示转换为特征,与文本指令融合处理。
通过这种设计,无论是「分割图中的猫」(文本指令)还是「分割这个框里的物体」(视觉提示),最终都会被转化为模型可统一处理的格式,为多任务融合奠定了基础。
支柱二:双编码器架构,兼顾全局理解与像素级细节
X-SAM 的架构堪称「视觉-语言」融合的典范,它包含五大核心模块:双编码器、双投影器、大语言模型(LLM)、分割连接器和分割解码器(如图 2 所示)。
图2:X-SAM的整体架构。X-SAM由双编码器、双投影器、一个语言模型、一个分割连接器和一个分割解码器组成。双编码器对图像进行处理并投影特征,使其与文本嵌入维度相匹配,随后这些特征与 token 化的文本一同输入到语言模型中,以实现指令引导的理解。SAM的特征与分割解码器相连,分割解码器利用大语言模型(LLM)的<SEG>\Token生成分割掩码。
- 双编码器:
- 图像编码器(采用 SigLIP2-so400m)负责提取全局图像特征,帮助模型理解整体场景(如「这是一张街景图」)。
- 分割编码器(基于 SAM-L)专注于细粒度像素特征,捕捉物体的边界细节(如「汽车的轮廓」)。
- 双投影器: 由于视觉特征与语言特征的维度不同,X-SAM 用两个 MLP 投影器将图像特征和分割特征转换为与语言模型匹配的维度。其中,分割特征通过「像素洗牌」(pixel shuffle)操作缩减空间尺寸,确保高效处理。
- 分割连接器(图3): SAM 输出的特征是单一尺度(1/16 分辨率),难以满足精细分割需求。X-SAM 设计了一个「分割连接器」,通过「补丁合并」(patch merge)和「补丁扩展」(patch expand)操作,生成 1/8、1/16、1/32 三种尺度的特征,让分割解码器能同时关注不同大小的物体。
图3:分割连接器的架构
- 分割解码器: 这是 X-SAM 突破 SAM 局限的关键。不同于 SAM 一次只能分割一个对象,X-SAM 的解码器基于 Mask2Former 架构,能一次性输出多个分割掩码,并通过 LLM 生成的
<SEG> 标签关联对应的类别或描述。 - 大语言模型(LLM): 采用 Phi-3-mini-4k-instruct 作为语言核心,负责解析文本指令、生成回答,并通过
<p><SEG> 等标签与视觉模块交互。例如,当用户提问「描述图片并分割所有车辆」时,LLM 会生成包含 <p> 汽车 </p><p> 卡车 </p><SEG> 的输出,指导分割解码器生成对应掩码。
支柱三:多阶段训练,让模型「学透」所有任务
为了让 X-SAM 在多任务上同时达到最优,研究团队设计了三步走的训练策略:
图4:X-SAM的多阶段训练流程。X-SAM执行多阶段训练过程,包括分割器微调、对齐预训练和混合微调。分割器微调:在分割数据集上训练分割器,以获得一个通用的分割器。对齐预训练:训练双投影器,使视觉特征与大型语言模型(LLM)特征对齐。混合微调:在混合数据集上对双投影器、分割解码器和大型语言模型(LLM)进行微调。
- 分割器微调: 在 COCO 全景分割数据集上训练分割编码器和解码器,目标是让模型学会一次性分割多个对象。损失函数包括分类损失(区分类别)、掩码损失(匹配像素边界)和 dice 损失(衡量掩码重叠度),确保分割精度。
- 对齐预训练: 在 LLaVA-558K 数据集上训练双投影器,冻结图像编码器、分割编码器和 LLM 的参数。这一步的核心是让视觉特征(图像和分割)与语言模型的词嵌入空间对齐,例如让「猫」的文本嵌入与图像中猫的视觉特征距离更近。
- 混合微调: 将多种任务的数据集(包括语义分割、referring 分割、VGD 分割、图像对话等)混合训练,同时更新所有模块参数。对于对话任务,采用自回归损失;对于分割任务,则同时使用自回归损失和分割损失。这种「一锅烩」的训练方式,让模型在不同任务间互相促进,而非互相干扰。
特别值得一提的是,团队还提出了「数据集平衡重采样」策略。由于不同任务的数据集大小差异极大(从 0.2K 到 665K 样本),他们通过动态调整采样频率,确保小数据集(如推理分割)不会被大数据集(如图像对话)淹没,最终在 t=0.1 的参数设置下取得最优平衡。
任务拓展:VGD 分割让模型「看懂视觉提示」
X-SAM 最亮眼的创新之一,是提出了「视觉定位(VGD)分割」这一新任务。传统的交互式分割只能根据视觉提示分割单个对象,而 VGD 分割要求模型根据点、框、涂鸦或掩码等视觉提示,分割图像中所有同类实例。
例如,当用户用一个点标记图中的一只狗时,VGD 分割不仅要分割这只狗,还要自动找出并分割图中所有其他狗。更强大的是,X-SAM 还支持「跨图像 VGD 分割」:用一张图中的视觉提示,在另一张图中分割同类对象。
在 COCO-VGD 数据集上的实验显示,X-SAM 在点、涂鸦、框、掩码四种提示形式上的 AP(平均精度)分别达到 47.9、48.7、49.5、49.7,远超 PSALM 模型(仅 2.0-3.7)。这意味着 X-SAM 真正理解了视觉提示的「含义」,而不是简单地对提示区域进行分割。
全面霸榜:20+ 数据集验证「最强分割模型」
研究团队在 7 大核心任务、20 多个数据集上对 X-SAM 进行了全面测试,结果显示它在所有任务中均达到或超越当前最佳水平:
表2:综合性能对比。我们将X-SAM与特定分割模型(灰色部分)和多模态大型语言模型(MLLMs)进行了比较。“✗”表示不支持的任务,“–”表示未报告的结果。X-SAM仅用一个模型就在所有分割任务上取得了最先进的性能。最佳结果用粗体显示,次佳结果用下划线标注。
- 通用分割:在 COCO 全景分割中,X-SAM 的 PQ(全景质量)为 54.7,接近 Mask2Former(57.8),远超 OMG-LLaVA(53.8),证明其在基础分割任务上的稳健性。
- 开放词汇分割:在 A150-OV 数据集上,X-SAM 的 AP(平均精度)达到 16.2,远超 ODISE(14.4)和 PSALM(9.0),展现出分割「未见过的类别」的强大泛化能力。
表3:指代分割对比。我们在基于(多模态)大型语言模型的指代分割基准测试上对各种方法进行了评估。
- Referring 分割:在 RefCOCO、RefCOCO+、RefCOCOg 三大数据集上,X-SAM 的 cIoU(修正交并比)分别为 85.1、78.0、83.8,大幅领先 PSALM(83.6、72.9、73.8)和 Sa2VA(81.6、76.2、78.7),即使模型参数更小(3.8B vs 8B),仍能实现反超。
- 推理分割:在需要逻辑推理的分割任务中(如「分割用来播放音乐的东西」),X-SAM 的 gIoU(广义交并比)达到 56.6,超过专门优化推理能力的 LISA-7B(52.9),证明其融合语言推理与视觉分割的能力。
表4:定位对话生成(GCG)分割对比。†表示使用GranD数据集进行预训练(Rasheed等人,2024)。
- GCG 分割:在「描述图像并同步分割」任务中,X-SAM 的 mIoU(平均交并比)为 69.4,远超 GLaMM(65.8)和 OMG-LLaVA(65.5),既能生成准确的文本描述,又能输出精确的掩码。
- 交互式分割:在点、框提示下,X-SAM 的 mIoU 分别为 65.4 和 70.0,超过 SAM-L(51.8、76.6)和 PSALM(64.3、67.3),在未专门训练的情况下仍表现优异。
表5:视觉定位(VGD)分割对比。†表示遵循X-SAM设置的评估结果。
- VGD 分割:如前文所述,X-SAM 以 47.9-49.7 的 AP 成绩大幅领先现有模型,验证了新任务设计的价值。
更令人惊叹的是,这些成绩均由同一个模型实现。无需针对不同任务调整架构或参数,X-SAM 就能在像素级理解的「全场景」中保持顶尖水准。
消融实验:揭秘 X-SAM 性能背后的关键设计
为了验证各模块的必要性,团队进行了细致的消融实验,结果揭示了几个关键发现:
表6:微调(FT)的消融实验
- 混合微调的价值:仅用单一任务微调时,模型在开放词汇分割(A150-OV)的 AP 为 16.4,而混合微调后提升至 22.4,推理分割的 gIoU 从 48.2 跃升至 57.1。这证明多任务联合训练能显著提升模型的泛化能力,尽管会导致通用分割的 PQ 小幅下降(0.8),但整体收益远超损失。
表7:双编码器的消融实验。(Swin ^{\dagger}) 初始化自 Mask2Former(M2F)(Cheng 等人,2022a)。
- 双编码器的优势:对比仅用图像编码器(ViT)、仅用分割编码器(Swin 或 SAM)的方案,双编码器组合能同时优化分割精度和语言理解。其中,SAM 作为分割编码器时,GCG 分割的 mIoU 达到 69.4,远超 Swin 编码器(62.5),证明 SAM 的视觉特征对分割任务至关重要。
表8:多阶段(M-Stage)训练的消融实验。S1:第一阶段,S2:第二阶段,S3:第三阶段,Conv.:对话。表8:关于……的消融实验
- 多阶段训练的作用:跳过分割器微调(仅用阶段 3)时,COCO 全景分割的 PQ 仅为 45.2,而加入阶段 1 后提升至 54.5;加入阶段 2 对齐预训练后,图像对话的准确率再提升 2.1%。三步训练环环相扣,缺一不可。
表9:分割器架构的消融实验。Conn.:连接器,M-Scale:多尺度,Con.:卷积,M2F:Mask2Former。多尺度,连接器,M-Scale:
- 分割器架构的影响:采用 Mask2Former 解码器比 SAM 原生解码器的 PQ 提升 9.2,加入卷积连接器和多尺度特征后,PQ 再提升 1.3,证明精细的特征处理对分割精度的关键作用。
局限与未来:从图像到视频,分割之路仍在延伸
尽管 X-SAM 表现惊艳,论文也坦诚指出了其局限:
- 任务平衡难题:联合训练时,部分分割任务的性能会因对话数据的干扰而下降,如何设计更合理的数据集混合策略仍是挑战。
- 性能不均:在某些细分任务上(如语义分割的 mIoU),X-SAM 仍略逊于专门优化的模型,规模扩大(更大参数、更多数据)可能是突破方向。
未来,研究团队计划将 X-SAM 与 SAM2(支持视频分割的模型)结合,拓展至动态场景;同时将 VGD 分割延伸到视频领域,实现「跨时空视觉定位」。这些方向一旦突破,视觉分割将从静态图像迈向更广阔的视频理解场景。
参考
论文标题:X-SAM: From Segment Anything to Any Segmentation
论文链接:https://arxiv.org/pdf/2508.04655
开源链接:https://github.com/wanghao9610/X-SAM
.....
#Flow-GRPO
在线强化学习+流匹配模型!Flow-GRPO:首个在线RL驱动的Flow Matching生成模型
Flow-GRPO首次将在线强化学习引入Flow Matching生成模型,实现从ODE到SDE的创新转换与去噪优化,在加速训练的同时保持T2I生成的高质量输出。
第一个使用在线 RL 的 Flow Matching 生成模型。
本文提出 Flow-GRPO,将 GRPO[1]集成到文生图的 Flow Matching 模型中。
Flow-GRPO 使用下面两个主要策略:
- ODE-to-SDE 转化:把确定性 ODE 转化为对应的 SDE,保持住原始模型的边缘分布。同时,也引入了随机性。允许 RL Exploration 的采样。
- 一种去噪策略 (Denoising Reduction Strategy):目的是提升 Online RL 的采样效率。降低训练时 denoising steps,维持推理 steps。在不牺牲性能的前提下,大幅提升了采样效率。实验表明,使用更少的步骤可以保持性能,同时显著地降低数据生成成本。
实验表明,Flow-GRPO 在多个文本到图像任务中都很有效。对于组合生成,RL-tuned SD3.5-M 生成近乎完美的对象计数、空间关系和细粒度属性,将 GenEval 准确率从 63% 增加到 95%。在视觉文本渲染中,准确率从 59% 提高到 92%,大大提高了文本生成性能。Flow-GRPO 在人类偏好对齐方面也取得了可观的收益。
1 Flow-GRPO:第一个使用在线 RL 的 Flow Matching 生成模型
论文名称:Flow-GRPO: Training Flow Matching Models via Online RL
论文地址:https://arxiv.org/pdf/2505.05470
代码链接:https://github.com/yifan123/flow_grpo
1.1 Flow-GRPO 研究背景
Flow Matching[2][3]模型在图像生成中已经广泛应用,因其在生成高质量图像方面具有坚实的理论基础和强大的性能。但是,它们通常难以组合涉及多个对象、属性和关系的复杂场景,以及文本渲染。同时,在线强化学习 (Online RL) 已被证明在增强 LLM 推理能力方面非常有效。
之前的研究主要集中在将 RL 应用于 Diffusion-based 的生成模型,以及离线强化学习 (Offline RL) 技术,例如 Flow-based 模型的直接偏好优化 (Direct Preference Optimization)。那么,Online RL 在 Flow Matching 生成模型的潜力在很大程度上仍未探索。本文探讨了如何利用 Online RL 来有效地改进 Flow Matching 模型。
使用 RL 训练 Flow 模型有几个关键难点:
- Flow 模型依赖于基于 ODE 的确定性 (Deterministic) 生成过程,意味着它们在推理过程中无法随机采样。但是,RL 依靠随机 (Stochastic) 抽样来探索环境,通过尝试不同的 Action 并根据 Reward 改进来学习。换句话讲,RL 对于随机性的需求,与 Flow Matching 模型的确定性相冲突。
- Online RL 依赖于有效的采样来收集训练数据,但 Flow 模型通常需要许多迭代步骤来生成每个样本,对效率很不利。这个问题在大模型中更为明显。为了使 RL 适用于图像或视频生成等任务,提高采样效率必不可少。

图1:Flow-GRPO 概览。给定一个 Prompt set,本文引入了一种 ODE-to-SDE 策略来实现在线 RL 的随机抽样。使用 Denoising Reduction (T=10 Steps),有效地收集了低质量但仍然信息丰富的轨迹。这些轨迹的 Reward feed 了 GRPO Loss,在线更新模型
1.2 Flow Matching 模型
令 为从 data 分布中采样得到的样本, 为 noise 采样。最近的图像生成模型 (比如 SD3[4]和 FLUX[5]) 以及视频生成模型 (比如 WAN[6]和 HunyuanVideo[7]) 采用 Rectified Flow,将 "noise" 数据 定义为:

其中, 。
然后,训练 Transformer 模型,通过最小化 Flow Matching 目标,直接回归速度场:

式中,目标速度场是 。
1.3 去噪作为马尔可夫决策过程
如[8]所示,Flow Matching 模型中的迭代去噪过程可以表述为马尔可夫决策过程 (Markov Decision Process, MDP) 。
第 step 的状态(State)是: 。 动作(Action)是模型预测的去噪之后的样本: 。 Policy 的定义: 。
转换过程是确定性的: 。
初始状态分布: ,其中, 是以 为中心的 Dirac delta distribution。
奖励仅在最后一步给出:如果 ,则 否则为 0 。
1.4 Flow-GRPO 的核心思想
Flow-GRPO 使用 Online RL 增强 Flow Model。作者首先重新审视了 GRPO 的核心思想,并将其应用于 Flow Matching 模型。然后,展示了如何将确定性 ODE Sampler 转换为具有相同边际分布的 SDE Sampler,引入了应用 GRPO 所需的随机性。最后,介绍了 Denoise Reduction,一种实用的采样策略,在不牺牲性能的情况下显著加快了训练速度。
1.5 Flow Matching 上做 GRPO
RL 旨在学习最大化预期累积奖励 (Expected Cumulative Reward) 的策略 (Actor)。这通常被表述为使用正则化目标优化策略 :

与其他基于策略的方法 (如 PPO) 不同,GRPO 提供了一种轻量级替代方案,它引入了一个 Group Relative Formulation 来估计优势。
去噪过程可以表述为 MDP。
给定一个 prompt ,Flow 模型 采样一组 个单独的图像 和相应的反向时间轨迹 。然后,通过对 Group-level Rewards 进行归一化,来计算第 个图像的 Advantage:

GRPO 通过最大化以下目标来优化 Policy Model:

式中,

其中, 是惩罚项,目的是防止 Actor Model 和 Reference Model 间隔太远,提高 Actor Model 的泛化能力。
然后, 的意思是:
- 如果 ,那么我们希望增加 的概率。但是这比值不要超过 。超过了,就没有额外收益了。
- 如果 ,那么我们希望减小 的概率。但是这比值不要低于 。低于了,就没有额外收益了。
这里的理解参考了:https://www.youtube.com/watch%3Fv%3DOAKAZhFmYoI的讲解。
1.6 从 ODE 到 SDE
GRPO 依赖于式 4 和 5 的随机抽样,生成不同的轨迹以进行优势估计和探索。Diffusion Model 自然支持这一点:正向过程逐步添加高斯噪声,反向过程通过方差递减的马尔可夫链逼近 Score-based SDE Solver。
相比之下,Flow Matching Model 使用确定性 ODE 进行前向过程:

其中, 是通过式 2 中的 Flow Matching Objective 来学习的。
那么,有一种常见的采样方法是离散化这个 ODE,在连续时间步之间产生一对一的映射。
但是,这种确定性方法未能满足 GRPO 策略的更新要求,原因有二:
- 式 5 中的 需要计算 ,由于散度估计,在确定性动力学下的计算成本变得很高。
- RL 取决于探索。降低随机性大大降低了训练效率。确定性采样,除了初始种子之外没有随机性,尤其是问题。
为了解决这个限制,作者将式 6 中的确定性 Flow-ODE 转换为 "等效" 的 SDE,该 SDE 在所有时间步长上与原始模型的边际概率密度函数相匹配。
反向时间 SDE 公式:

其中, 表示维纳过程增量, 是控制采样过程中随机性水平的扩散系数。
证明 (式 8):
证:
为了在前向采样期间计算式 5 中的 ,将 Flow Model 适配到 SDE 上。Flow Model 通常遵循确定性 ODE:

现在考虑它带随机项的版本。
作者构建一个具有特定漂移和扩散系数的前向 SDE,使其边际分布与式 7 的边缘分布一致。SDE 的一般形式为:

其边缘概率密度 满足 Fokker–Planck Equation[9]:

同理,式 7 的边缘概率密度为:

为了确保式 9 的 SDE 与式 7 的 ODE 共享一个边缘概率密度,有:

观察到:

把式 13 代入式 12,得:

这样,式 9 的 SDE 可以重写为:

其中, 表示维纳过程增量,是控制采样过程中随机性水平的扩散系数。
这里,继续列一下 Forward 和 Reverse SDE 的关系[10]。具体来说,如果 Forward SDE 采用以下形式:

则对应的 Reverse SDE 为:

观察式 15 和 16,有:

把式 18 代入式 17,得:

式 19 即为最终 Reverse SDE。最后化简得到式 8:

调整下逆向布朗运动,最终得到:

得证。
对于 Rectified Flow,式 8 变为:

证明 (式 20):
证:
一旦 Score Function 得到,就可以直接模拟该过程。对于 Flow Matching,该分数隐式链接到速度场 。
具体来说,设 。所有期望都在 ,其中 是数据分布。
对于线性插值 ,我们有:

得到 Conditional Score:

Marginal Score 变为:

下面再看速度场 :

代入 ,式 25 变为:

则式 26 变为:

将式 27 代入式 8,有:

得证。
对 Rectified Flow 的 Reverse-time SDE 式 21:

应用 Euler-Maruyama 离散化得到最终的更新规则:

其中, 注入了随机性。
在该文章中,使用 ,其中, 是控制噪音强度的超参数。
式 28 表明 是高斯分布,则可以很容易地计算式 6 中 和参考策略 之间的 KL 散度:

证明 (式 29,这里证明一维情况):
证:
假设我们有两个 维高斯分布:

那么它们的 KL 散度为:

式中, 为来自两个协方差矩阵的行列式比值。
在本文的情况下, ,那么:

代入式 31,得:

式中, 。
得证。
1.7 Denoising Reduction
为了生成高质量的图像,Flow Model 通常需要许多去噪步骤,这使得 Online RL 的数据收集成本很高。
但是,作者发现 Online RL 训练期间不需要大时间步。可以在样本生成过程中使用更少的去噪步骤,同时在推理过程中保留原始去噪步骤以获得高质量的样本。
注意,在训练期间将时间步 T 设置为 1 0 ,而推理时间步 T 设置为 SD3.5-M 的原始默认设置 40 。实验表明,这种方法可以在不在测试时牺牲图像质量的情况下实现快速训练。
1.8 实验设置
- Compositional Image Generation:使用基于 Rule 的 Reward。
- Visual Text Rendering:Reward 测量文本保真度。
- Human Preference Alignment:使用 PickScore 作为 Reward Model。PickScore 提供了评估多个标准的总体分数,例如图像与提示的对齐及其视觉质量。
- 图像质量评价指标:4 个图像质量指标:Aesthetic Score[11],DeQA[12],ImageReward[13],UnifiedReward[14]。
1.9 实验结果
图 2 和图 3 展示出 Flow-GRPO 的 GenEval 性能在训练期间稳步提高,最终结果优于 GPT-4o。同时,也可以保持住 DrawBench 上的图像质量指标和偏好分数。

图2:实验结果。(a) GenEval 性能在整个 Flow-GRPO 的训练中稳步上升,优于 GPT-4o;(b) DrawBench 上的图像质量指标基本保持不变;(c) DrawBench 上的人类偏好分数在训练期间有所提高

图3:GenEval 结果
图 4 提供了定性比较。

图4:GenEval 的定性比较
除了组合图像生成之外,图 5 详细说明了视觉文本渲染和人类偏好任务的评估。Flow-GRPO 在不降低 DrawBench 上的图像质量指标和偏好分数的情况下,提高了文本渲染能力。

图5:Compositional Image Generation, Visual Text Rendering, 以及 Human Preference 的结果对比
定性示例如图 6,7,8 所示。
对于人类偏好任务,在没有 KL 正则化的情况下,图像质量没下降。但作者发现如果不使用 KL 正则化会导致视觉多样性崩溃。这些结果都表明,Flow-GRPO 可以提高所需能力,同时使得图像质量或视觉多样性的退化很小。

图6:使用 GenEval 奖励训练的 SD3.5-M 和 SD3.5-M + Flow-GRPO 之间的额外定性比较

图7:使用 OCR 奖励训练的 SD3.5-M 和 SD3.5-M + Flow-GRPO 的额外定性比较

图8:使用 PickScore 奖励训练的 SD3.5-M 和 SD3.5-M + Flow-GRPO 之间的额外定性比较
参考
- Deepseekmath: Pushing the limits of mathematical reasoning in open language models
- Flow matching for generative modeling
- Flow straight and fast: Learning to generate and transfer data with rectified flow
- Scaling rectified flow transformers for high-resolution image synthesis
- Flux. https://github.com/black-forest-labs/flux
- Wan: Open and advanced large-scale video generative models
- Hunyuanvideo: A systematic framework for large video generative models
- Training diffusion models with reinforcement learning
- Stochastic differential equations
- Score-based generative modeling through stochastic differential equations
- Laion aesthetics
- Teaching large language models to regress accurate image quality scores using score distribution
- Imagereward: Learning and evaluating human preferences for text-to-image generation
- Unified reward model for multimodal understanding and generation
.....
#DeT让你从人到熊猫无缝“换身”跳街舞
亮点总结
- 简单高效的运动迁移方法——DeT:本文提出了一种能够同步解耦与追踪的共享时序卷积模块,并引入追踪损失函数以增强前景时序一致性,该方法设计简洁且在Video Diffusion Transformers模型上展现出卓越性能。
- 规模最大的公开测试基准:本文构建了MTBench测试集,是目前规模最大、覆盖最全面的运动迁移评估基准,包含500个测试样本,并对运动难度进行了三级精细划分。
- 更完备的评估指标体系:本文通过局部速度方向与全局轮廓特征的联合分析,全面评估源视频与生成视频的运动一致性,建立了更完善的量化评测指标。
- 最优异的运动迁移性能:在MTBench测试基准上的实验结果表明,我们的模型实现了当前最优的运动迁移效果,既能精确迁移原始运动,又能通过文本指令灵活调控生成内容。
1. 研究动机
现有方法的局限
目前主流的 运动迁移(motion transfer)工作大多基于 U‑Net 架构 ,利用空间、时间分离的建模方式(先 2D 空间卷积 / 注意力,再 1D 时间卷积 / 注意力)解偶运动信息。这种分离设计有利于抽取运动,但 生成质量受限于 U‑Net,并且现有方法难以应用到 Video Diffusion Transformers(Video DiT) 上。
Video DiT 的难点
Video DiT 通过 3D 注意力 同时建模外观与运动,在开源社区有state-of-the-art(sota)的视频生成性能;可一旦直接微调部分参数做运动迁移,由于外观与运动被深度绑定,很难准确迁移运动的同时灵活编辑前景和背景。
现有Benchmark和Metric的局限性
现有运动迁移任务的Benchmark规模较小,难度也不够全面。并且Metric只关注轨迹局部的速度方向,没有关注全局的轨迹形状。
2. 关键的发现
时序上的局部特征就可以学到运动
如图1所示,在MM-DiT的3D Attention中,每个位置的特征主要关注同一空间,局部时间的局部特征,因此通过时序上的局部建模即可学习到特征沿时序的变化,也就是运动。

图1: 对3D Attention Map的可视化,我们发现在3D Attention中,特定帧上的image patch主要关注相邻帧同一空间位置的image patch(用红色图标标注),对其他空间和时间位置的image patch关注度相对较低(用蓝色图标标注)
沿着时序做平滑会更容易解偶出运动
如图2所示,在对DiT feature的可视化中,我们发现前景特征延时序一致,而背景特征延时序不一致,且在某些帧会与前景特征难以区分。为了学习前景运动时避免“记住”背景的外观,我们可以通过延时序做平滑的方式,帮助模型更好的区分前景和背景特征。

图2: 通过对DiT中间层特征(命名为DiT feature)的PCA可视化,我们发现前景特征沿着时序有较强的一致性,而背景特征沿着时序不一致。并且在某些帧上(例子中的第三帧)前景特征和背景特征可能出现难以区分的情况
幸运的是,以上两点可以通过相同的设计来完成——沿着时序的卷积操作
3. 方法
1.解偶和追踪同时完成 — 共享时序卷积
动机:
通过上述分析,我们采用沿着时序的卷积算子,解耦出前景运动的同时学习运动。具体而言,如图3所示,我们在3D Full Attention外“并连”了down-and-up结构的卷积模块,节约了计算与显存的开销。这里的Conv1D仅作用于时序维度,并且在空间维度上是共享的。这样的设计可以缓解模型记住视频内容外观的问题,使得DeT可以灵活的通过文本控制生成内容的外观。
时序卷积的双重作用:
- 平滑相邻帧特征,解耦出前景的运动,帮助模型更好的学习前景运动
- 显式编码运动,卷积核权重在训练过程中可以学习到视频中的运动模式

图3: 共享时序卷积的平滑原理与模型结构图:在(a)中,我们展示了共享时序卷积对解耦前景运动的提升原理:通过对背景特征沿着时序的平滑,我们可以在前背景特征难以区分的帧上更容易区分,从而避免模型记住背景的外观;在(b)中我们展示了共享时序卷积的实现,通过简单但有效的方法,我们可以在学习运动的同时避免过拟合到前背景的外观。
2.增强前景运动一致性 — 稠密追踪损失
动机:
受到前景特征沿着时序一致性的鼓舞,我们在训练过程中显示加入对前景特征一致性的监督,让共享时序卷积更准确地学习到前景的运动。
稠密追踪损失:
具体而言,我们采用GroundedSAM先得到前景的掩码,通过采样得到关键点集合;然后借助 CoTracker3 追踪前景的关键点,最小化跨帧特征距离,增强生成视频的运动轨迹在时序上的平滑一致。计算的方式如图4所示,考虑到复杂运动可能存在遮挡的问题,我们引入可见掩码,屏蔽了不可见轨迹上的损失计算。

图4: 稠密追踪损失的计算示意图,我们沿着轨迹对齐跨帧前景特征,并采用可见掩码屏蔽轨迹的不可见部分。
4. 更全面的测试基准—MTBench
动机:
现有的运动迁移方法评测通常在小规模基准上进行,且未充分考虑运动难度的差异,这限制了评估的全面性和可靠性。为了更准确地衡量运动迁移方法的性能,我们提出了MTBench——一个规模更大、涵盖不同运动难度的标准化测试基准。
MTBench:
我们提出了一个更大且更通用的运动迁移任务测试基准 MTBench。考虑到中心化前景和较大动态程度的需求,MTBench 来源于两个公开数据集DAVIS和YouTubeVOS。我们精选了 100 个高质量视频,并利用多模态大模型Qwen2.5-VL、大语言模型Qwen2.5 以及CoTracker3 对视频进行标注。对于每个源视频,我们生成了五个评测提示并标注前景轨迹——轨迹的初始点通过距离加权采样从掩码中选取,这种方式使得孤立稀疏点更容易被采样,从而保证在手脚等狭窄但重要的区域内也能进行采样。随后,我们应用自动聚类算法对轨迹进行分组,并根据聚类数将运动难度划分为三个等级,图5给出了运动的分布以及三个难度的示例。此外,我们还提出了一种混合运动保真度指标。与仅依赖轨迹局部速度相似性的方法不同,我们引入 Fréchet 距离来衡量轨迹全局形状的一致性。结合 MTBench 与混合运动保真度指标,我们的工作为运动迁移方法提供了更全面的评测手段。

图5: MTBench的统计信息,图(a)是MTBench的测评提示中包含的运动及其数量,图(b)展示了我们划分运动难以的三个例子,聚类中心1-3为简单,4-6为中等,7+为困难。帆船的平移通过自动聚类得到2个聚类中心,被划分为简单;走路有5个聚类中心,被划分为中等;街舞有11个聚类中心,被划分为困难。
5. 实验结果
1.定量结果:
如图6所示,我们的方法 DeT 基于 HunyuanVideo,在运动保真度(Motion Fidelity)上取得了最高分,并在编辑保真度(Edit Fidelity)与运动保真度之间实现了最均衡的权衡。将 MotionInversion、DreamBooth 和 DMT 适配至 Video DiT 模型后,在所有指标上的表现均明显落后,凸显出我们工作的贡献与价值。

图6: 在MTBench上的定量结果比较
2.定性结果:
如下视频所示,我们的方法能够在不对源视频外观过拟合的情况下,准确地迁移运动,并支持对前景和背景的灵活文本控制。此外,它还能实现跨类别的运动迁移,例如从人到熊猫,或从火烈鸟到鹿。
,时长00:06
3.定性结果比较:
如下视频所示,Motiondirector和MotionClone 在运动保真度上表现不佳。SMA 难以保证运动在时序上的一致性,出现时序上的跳动。我们的方法DeT不但准确的迁移了运动,保证了时序上的一致性,而且能够灵活地通过文本控制生成的内容,达到了高质量的运动迁移效果。
,时长00:06
4.消融实验:
- a.共享时序卷积
模块设计: 除了使用共享时间卷积核外,我们还考虑了通过 LoRA、Conv3D 和局部注意力的替代方案。图7中的表格3显示,我们的方法在编辑保真度和运动保真度指标上均取得了最佳性能。

表1:我们比较了用于学习运动的不同模块,发现沿着时序的一维卷积在所有指标上都达到了最优的性能

图7: 不同模块学习运动的对比图,可以发现只有时序卷积可以同时做到运动准确性和可编辑性
共享时序卷积的超参数: 此外,我们分别对丢弃层比例、卷积核大小和中间维度进行了消融实验。图7中表格4的定量结果表明,卷积核大小为 3、且中间维度设置为 128 时性能最佳。

表2:左侧为卷积核的大小,右侧为down-and-up结构中间维度的消融实验,综合考虑我们选择卷积核大小为3,中间维度为128
- b.稠密追踪损失
稠密追踪损失的权重: 我们对稠密点跟踪损失的权重进行了消融实验,发现当损失权重取 0.1 时性能最佳。训练过程中 DiT 特征的余弦相似度表明,稠密点跟踪损失有助于实现精确的前景跟踪。

表3:稠密追踪损失权重的消融实验,我们发现设置为1e-1达到了最优的性能。

图8:我们计算了跨帧DiT特征的余弦相似度,稠密追踪损失可以让前景特征在时序上更加一致,从而增强运动一致性
6. 未来工作
a.模型效率问题:
尽管DeT采用了轻量化设计,但由于Video DiT本身参数量大、计算复杂度高,单个运动迁移任务在单张A100 GPU上仍需约1小时完成,这严重制约了DeT的实际应用效率。
b.模型分层特性利用不足:
目前DeT的分析均基于Video DiT各层特征的平均结果,而实际上不同网络层可能具有不同的建模特性。未来可探索分层特征解耦机制,设计更精细的模块来分别学习动作迁移与外观解耦。
c.极端困难案例的挑战:
MTBench中包含部分高难度样本(如街舞动作,其运动轨迹聚类中心数极高),DeT在此类案例中仍存在明显局限——背景外观易出现"过拟合"现象,导致迁移效果下降,这表明模型对复杂运动的建模能力仍需进一步提升。
,时长00:06
一个男人在跳舞
,时长00:06
一个宇航员在火星跳街舞
更多的结果请看项目主页:https://shi-qingyu.github.io/DeT.github.io/
代码 与 MTBench 已开放:https://github.com/shi-qingyu/DeT
.....
#黄仁勋子女成长路径曝光
一个学烘焙一个开酒吧,从基层做到英伟达高管
英伟达CEO黄仁勋的两个子女,身份和成长路径曝光
女儿Madison和儿子Spencer(按英文名首字母排序), 均已担任英伟达高管。
他们都是从基层开始做起,如今Madison已成为英伟达仿真软件部门高级总监,Spencer则是机器人产品线经理。
Madison是在2020年加入英伟达,Spencer则是2022年。
两人虽然都没有直接接触英伟达的营收最高的数据中心业务,但负责的部门都是英伟达重点押注的未来方向。
不过,目前没有公开信息表明二人是否持有英伟达的股份。
在此之前,两个人都没有科技公司背景,最高学历都是MBA,Madison毕业于伦敦商学院,Spencer则毕业于纽约大学。
再往前追溯,两人的成长过程也走了不同的路径,不过最后殊途同归,都加入了父亲黄仁勋的公司。
Madison:从学习烹饪到英伟达高级总监
老黄的女儿Madison,中文名黄敏珊,现年34岁,目前是仿真软件部门的Omniverse高级总监。
Madison在英伟达25财年(2024年2月到2025年1月)的收入是110万美元,其中包括基本工资、奖金和其他福利。
她最初担任市场营销实习生,实习四个月之后成为了Omniverse部门的活动营销经理,之后一直在该部门任职。
之后Madison一路担任了产品营销经理、高级产品营销经理等职务,直到今年3月成为高级总监。
而Madsion的象牙塔生涯,则是起始于烹饪。
2012年,她在美国烹饪学院取得了烹饪艺术工商管理学士学位,之后到蓝带厨艺学院学习制作甜点以及葡萄酒,并曾在纽约和旧金山担任厨师。
2015年,Madison重新回到巴黎,加入奢侈品行业,在LVMH公司担任市场营销与开发经理。
在LV工作期间,Madison还学习了伦敦政治经济学院有关数据科学的短期课程。
然后是2019年,Madison和哥哥Spencer一起修读了MIT的短期AI高管课程。
之后Madison又开始了继续深造,在2021年取得了伦敦商学院的MBA学位,彼时她已经是英伟达的正式员工。
回望Madsion的成长经历,再想到老黄当初的第一份工作也是餐厅服务员……
这怎么不算是另一种女承父业呢?(手动狗头)
Spencer:8年酒吧主理人
同样“承袭父业”的,还有老黄的儿子、Madison的哥哥Spencer,中文名黄胜斌,今年35岁。
他在英伟达的职位是机器人产品线经理,负责开发用于机器人的AI模型与仿真软件,年薪据爆料是53万美元。
Spencer在2022年加入英伟达,起初的职位是Isaac Sim Cloud团队产品经理。
比起妹妹Madison,Spencer担任的职位更具技术属性。
前面介绍Madison时说过,兄妹二人曾一同参加MIT的短期AI高管课程,不过Spencer还额外多读了关于人机交互的课程。
在此之后,Spencer先是到哈佛商学院又读了短期课程,之后也读了MBA,不过是在纽约大学,2022年取得学位。
读MBA期间,Spencer曾在辉瑞、福特等公司担任咨询师。
更早之前,Spencer的身份是一名酒吧主理人。
2012年,Spencer在美国最大的私立艺术与媒体学院——芝加哥哥伦比亚学院本科毕业,主修国际市场和文化研究两个方向。
毕业后,老黄让他专门“回老家”学了一年中文,大学期间他也学习了8个星期的短期中文课,以及到英伟达在老家的分部担任技术营销实习生。
总之正是在老家学中文的这段时间,Spencer创立了他的鸡尾酒酒吧——R&D Cocktail Lab,而且一干就是八年。
据悉,这家酒吧屡获国际大奖,并曾入选亚洲50佳酒吧,不过目前谷歌地图显示该酒吧已经永久停业。
但不管怎么说,看来老黄一家,确实都和餐饮有一种莫名其妙的缘分。(手动狗头*2)
虽然Madison和Spencer如今都已在英伟达内部承担起各自的职责,但从他们绕行多年的经历来看,这对兄妹显然并非一路按部就班地走进科技行业。
无论如何,结果已经确定,他们已然落脚在英伟达的两个关键前沿方向——仿真与机器人。
.....
#GMPO
大型语言模型稳定强化学习的新路径:几何平均策略优化
本文主要作者:赵毓钟,中国科学院大学在读博士,微软亚洲研究院 MSRA 实习生,主要研究方向为多模态学习、语言模型后训练。刘悦,中国科学院大学在读博士,微软亚洲研究院 MSRA 实习生,主要研究方向为视觉表征模型。
指导老师:万方,中国科学院大学计算机学院副教授,博导。叶齐祥,中国科学院大学电子学院教授,博导。 崔磊,微软亚洲研究院通用人工智能组(GenAI)首席研究经理。韦福如,微软亚洲研究院通用人工智能组(GenAI)杰出科学家。
近年来,强化学习(RL)在大型语言模型(LLM)的微调过程中,尤其是在推理能力提升方面,取得了显著的成效。传统的强化学习方法,如近端策略优化(Proximal Policy Optimization,PPO)及其变种,包括组相对策略优化(Group Relative Policy Optimization,GRPO),在处理复杂推理任务时表现出了强大的潜力。然而,尽管它们在许多场景下都表现良好,仍然面临着在训练过程中不稳定的问题,尤其是在处理带有极端重要性加权奖励时。几何平均策略优化(Geometric-Mean Policy Optimization,GMPO),作为 GRPO 的稳定化版本,解决这一问题。本文将深入探讨 GMPO 的原理、优势,并通过理论分析和实验验证来展示其强大的效果。
- 论文标题:Geometric-Mean Policy Optimization
- 论文链接:https://arxiv.org/abs/2507.20673
- 开源代码: https://github.com/callsys/GMPO

图表 1 GMPO 和 GRPO 的对比。GRPO 优化算数平均奖励、而 GMPO 优化几何平均奖励(左)。 在训练过程中,GRPO 经常出现极端重要性采样比率,更新不稳定,而 GMPO 有更稳定的重要性采样比率,更新更加稳定(右)。
GRPO 面临的挑战
组相对策略优化(GRPO)是强化学习在大型语言模型微调中的重要进展。GRPO 通过优化 token 级奖励的算术平均值来进行训练(忽略了剪切操作):

然而算数平均对异常值十分敏感,在训练过程中容易产生极端的重要性采样比率(ps. 当前策略与旧策略分配给一个 token 的概率比)。在训练过程中,重要性采样比率(即当前策略与旧策略分配给一个标记的概率比)可能会大幅波动。这种波动导致策略更新不稳定。为了缓解这一问题,GRPO 引入了对重要性采样比率的剪切操作,但这种方法并未完全解决稳定性问题,并且还过度限制模型更新幅度使得模型探索能力变弱,进而影响了模型的泛化能力。
GMPO:GRPO 的稳定化版本
GMPO 通过优化几何平均来替代 GRPO 中的算术平均,解决了 GRPO 在训练过程中容易受到异常值影响的问题。几何平均本身对异常值更具鲁棒性,因为它会相对抑制极端值的影响,从而使训练过程更加稳定。GMPO 的训练目标可以表示为:

这种简单而有效的修改确保了 GMPO 在训练过程中能够更好地处理极端奖励,从而避免了 GRPO 中常见的不稳定情况。
通过将 PPO 中的 token 级裁切策略引入 GMPO,我们得到了 GMPO 的完整公式:

为了维持计算的稳定性,GMPO 中的连乘操作和裁切操作被放在 log 域执行。GMPO 的伪代码如下所示:

为了进一步理解为什么 GMPO 相比于 GRPO 更加稳定,我们推导并证明了 GMPO 在梯度层面上相对 GRPO 更加鲁棒:

可以看到,GRPO 每个 token 的梯度受到了它自身的重要性采样比率加权,容易受到极端值影响。GMPO 每个 token 的梯度则受到序列重要性采样比率的几何平均加权,不容易受到极端值影响。

图表 2 不同剪切范围和训练步骤下的重要性采样比率范围。范围越宽,表示策略更新越不稳定。与 GRPO(剪切范围为 (0.8, 1.2))相比,GMPO 在剪切范围为 (e−0.4, e0.4) 的情况下表现出更大的稳定性。
除了算数平均向几何平均的变化,GMPO 还有两个关键设计:
1. 在 token 级别进行裁切。不同于 DeepSeek-Math,在 DeepSeek-R1 中,GRPO 被定义在了序列级。序列级重要性采样比率等效于 token 级重要性采样比率的连乘,DeepSeek-R1 对序列级重要性采样比率进行了裁切。GMPO 没有跟随 DeepSeek-R1 进行序列级别裁切,而是继续跟随 DeepSeek-Math 进行 token 级裁切。原因如下:
(1)与序列级别的剪切相比,词元级别的剪切更加稳定。如图 2 所示,序列级别剪切(GMPO-seqclip-(e−0.4,e0.4))的采样范围大于词元级别剪切(GMPO (e−0.4,e0.4)),因此在优化过程中更容易产生极端梯度。
(2)序列级别的剪切相比 token 级别的剪切过于激进。一旦触发,它会将整个序列中所有 token 的梯度置为零,可能会丢失来自序列中有价值部分的梯度信号。
2. 更宽的裁切。正如 DAPO 所示,剪切操作可能限制探索并导致早期的确定性策略,从而妨碍扩展过程。为了在不牺牲稳定性的情况下促进探索,DAPO 采用了剪切上限策略,将剪切范围从 (0.8, 1.2) 轻微扩展至 (0.8, 1.28)。
如图 1 所示,我们可视化了 GRPO 和 GMPO 在每个训练步骤中的最大和最小重要性采样比率。关键观察结果如下:
(1)随着训练的进行,重要性采样比率的范围逐渐扩大,表明策略更新变得更为激进,稳定性降低。
(2)与 GRPO 相比,GMPO 保持了更稳定的采样比率范围,表明更新更加稳定。
(3)对于 GMPO,将剪切范围从 (e−0.2,e0.2) 扩展至 (−∞,+∞) 会增加策略更新的不稳定性。基于这些发现,我们通过将方程 4 中的剪切阈值 (ϵ1,ϵ2) 设置为 (e−0.4,e0.4) 来平衡训练稳定性与探索性。这个范围显著大于 GRPO 和 DAPO,能鼓励更大的探索,并提升性能。
GMPO 的优势

与 GRPO 相比,GMPO 在以下几个方面具有明显的优势:
1. 更稳定的策略更新:GMPO 的梯度更新更加稳定。
2. 更高的奖励:与 GRPO 相比,GMPO 在简单数据集 MATH Level 3-Level 5 上维持了相当的奖励。在更难的 DeepScaleR 和多模态数据集 Geometry3K 上有更高的奖励。
3. 减少过拟合的风险:相对于 GRPO,GMPO 自然地维持了和 RL 前模型的 KL 散度。通过保持较小的 KL 散度,GMPO 减少了过拟合的风险,有助于模型在更复杂的任务中取得更好的表现。
4. 更高的熵值:GMPO 在训练过程中能够保持更高的熵,支持更加持续的探索,避免了训练过程中的早期收敛。
实验验证:GMPO 与 GRPO 的对比
为了验证 GMPO 的有效性,我们在多个语言任务和多模态推理基准上进行了广泛的实验。实验结果表明,GMPO 在多个数据集上显著优于 GRPO,无论是在稳定性方面,还是在推理能力方面。
1. 语言任务:在语言推理任务中,GMPO 在五个数学推理基准上进行了测试,这些基准包含不同难度的数学问题,包括 AIME24、AMC、MATH500、Minerva 和 OlympiadBench。实验结果显示:

2. 多模态任务:在多模态推理任务中,GMPO 在 Geometry3K 基准上进行了测试,该任务涉及几何问题的解答。GMPO 相比 GRPO,在 Pass@1 准确率上提高了 1.4%,这表明 GMPO 在多模态任务中的应用潜力。

结论
Geometric-Mean Policy Optimization(GMPO)通过优化标记级奖励的几何平均值,成功克服了 GRPO 在训练过程中面临的不稳定性问题。与传统的算术平均方法相比,GMPO 的策略更新更加稳定,探索能力更强,同时减少了过拟合的风险。通过广泛的理论分析和实验验证,GMPO 在语言任务和多模态推理任务中都取得了显著的优势。
GMPO 的提出为未来强化学习在大型语言模型中的应用提供了一个更加可靠且可扩展的解决方案,为未来的研究奠定了坚实的基础。随着对 LLM 推理能力的不断提升,GMPO 无疑将在推动更高效、更稳定的强化学习系统方面发挥重要作用。
.....
#OpenAI和奥特曼将投资一家脑机接口公司
直接与马斯克的Neuralink竞争
Neuralink,一家或许代表着人与机器共生未来的公司,或将迎来一个有力的挑战者。
据《金融时报》报道,OpenAI 及其联合创始人山姆・奥特曼正准备投资一家名为 Merge Labs 的创业公司,该公司的目标与伊隆・马斯克的 Neuralink 一致,都是连接人脑与计算机。

无疑,此举将加剧这两位亿万富翁企业家之间的竞争。
《金融时报》表示未能从 OpenAI 处获得对此事件的评论,而马斯克对此的评价是:🙄
具体来说,该媒体从三位知情人士得到了消息,称 Merge Labs 目前正在以 8.5 亿美元的估值筹集新资金,预计大部分新资金将来自 OpenAI 的风险投资团队。两位知情人士表示,奥特曼很鼓励这项投资,并将与 Alex Blania 一起帮助启动该项目。Alex Blania 目前负责一个眼球扫描数字身份证项目 World,该项目也得到了奥特曼的支持。他们补充说,奥特曼也将成为该公司的联合创始人,但不参与新项目的日常工作。
事实上,硅谷现在已经有不少脑机接口方向的年轻创业公司。
2017 年,奥特曼曾就此话题撰写了一篇长篇博文,推测这一时刻最早可能在 2025 年到来。

博客节选,https://blog.samaltman.com/the-merge
更重要的是,除非我们先毁灭自己,否则超人级 AI 终将出现,基因增强终将出现,脑机接口终将出现。认为我们永远无法创造出比自身更聪明的东西,是人类想象力和傲慢的失败。
……
融合可以采取多种形式:我们可以将电极插入大脑,或者我们都可以与聊天机器人成为非常亲密的朋友。但我认为融合可能是我们最好的选择。如果两个不同的物种都想要同一件事,而只有一个能得到它 —— 在这种情况下,就是成为地球乃至更广阔天地的主导物种 —— 它们就会发生冲突。我们都应该希望拥有一个所有成员都关心其他所有人福祉的团队。
今年,他在另一篇博文中表示,随着近期技术进步,我们可能很快就会拥有「高带宽脑机接口」。
《金融时报》透露,Merge Labs 计划从 OpenAI 和其他投资者那里筹集 2.5 亿美元,不过目前谈判尚处于早期阶段。奥特曼个人不会投资。
新成立的合资公司将与马斯克于 2016 年创立的 Neuralink 展开直接竞争,而后者是脑机接口领域的引领者,但后面也有 Precision Neuroscience 和 Synchron 等一些创业公司在竞相追赶。
今年早些时候,Neuralink 获得了 6.5 亿美元融资,估值 90 亿美元,其背后的投资者包括红杉资本、Thrive Capital 和 Vy Capital。奥特曼此前曾投资过 Neuralink。
脑植入物并不是新技术,已有数十年历史,但近年来随着 AI 和用于收集脑信号的电子元件的飞跃发展,为它们的实际应用提供了实际可行性。
上个月,Neuralink 宣布已经成功完成了第 8 和 9 个脑机接口手术,获得了广泛关注。更早之前,他们也已经分享一些成功案例,包括让高位截瘫患者成功操控电脑和手机。

实际上,除了这家脑机接口公司,奥特曼也在积极布局其它一些前沿项目 —— 除了共同创立 World,他还投资了核裂变集团 Oklo 和核聚变项目 Helion。
马斯克 vs. 奥特曼
除了下场与伊隆・马斯克的 Neuralink 争夺脑机接口的未来,山姆・奥特曼这两天也与马斯克在 X 上围绕 AI 进行了 battle。
起因是马斯克在 X 指责苹果在自家的 App Store 上优待 OpenAI,构成了垄断行为。马斯克还扬言要采取法律行动。(但根据网友添加的背景信息,马斯克的说法似乎并不符合实情)

奥特曼随即转发评论称马斯克操控 X 来为自己和自己的公司牟利,并损害其竞争对手和他不喜欢的人。

接下来,骂战升级,马斯克直呼奥特曼是骗子,还以浏览量为证据说明 X 并未刻意限制其对手的流量。奥特曼反唇相讥,要马斯克签署宣誓书来表明自己的清白。

之后,马斯克又发布和转发了更多推文来支持自己的说辞。

另外,还有网友发现,虽然奥特曼指控马斯克在 X 限制对手,但其实他自家的 ChatGPT 也在这么干:当用户访问 AI 回答中给出的 OpenAI 的竞争对手的网站链接时,ChatGPT 会弹出警告称这些链接可能并不安全,但对其它同类链接却并不会弹出这样的警告。
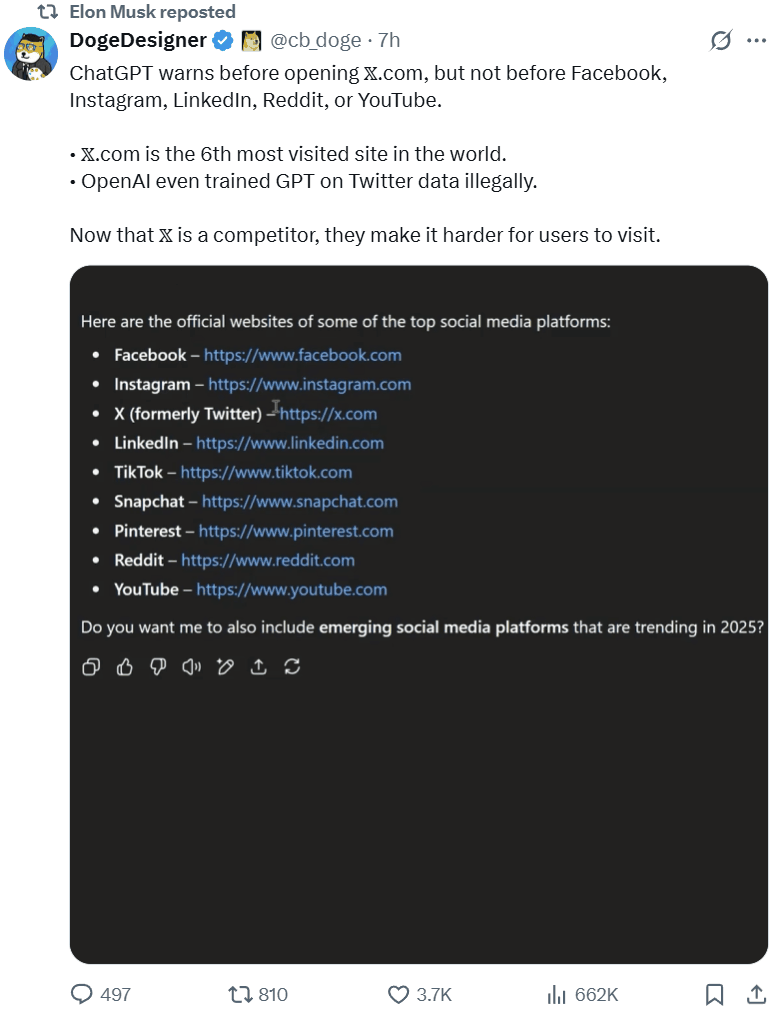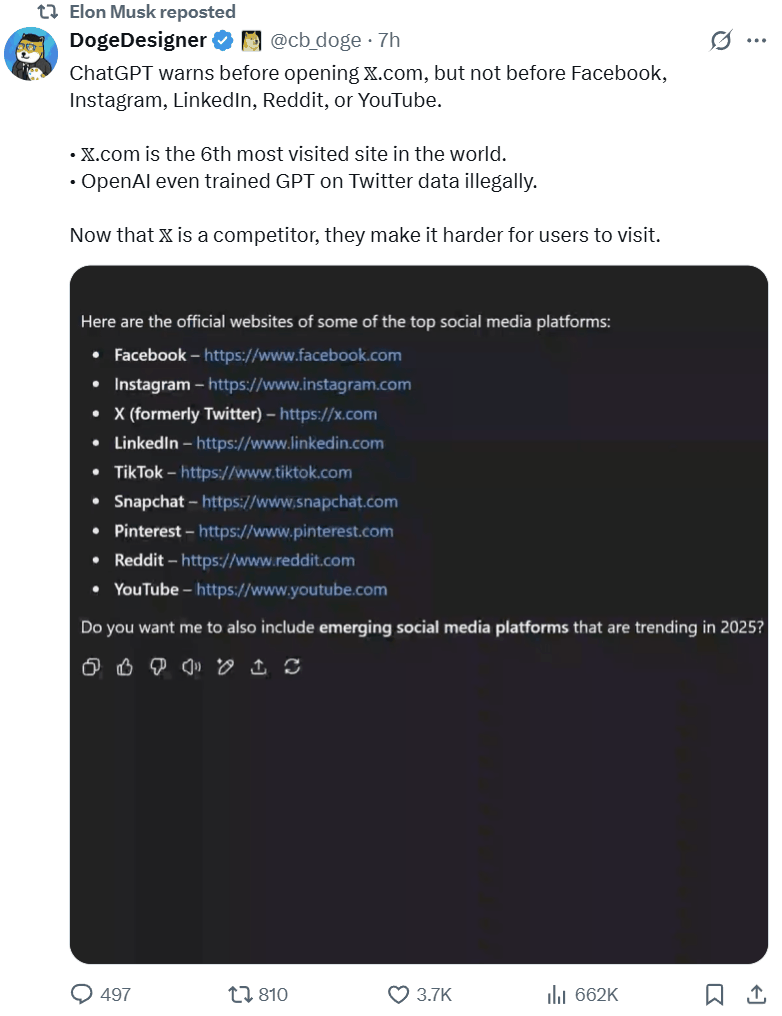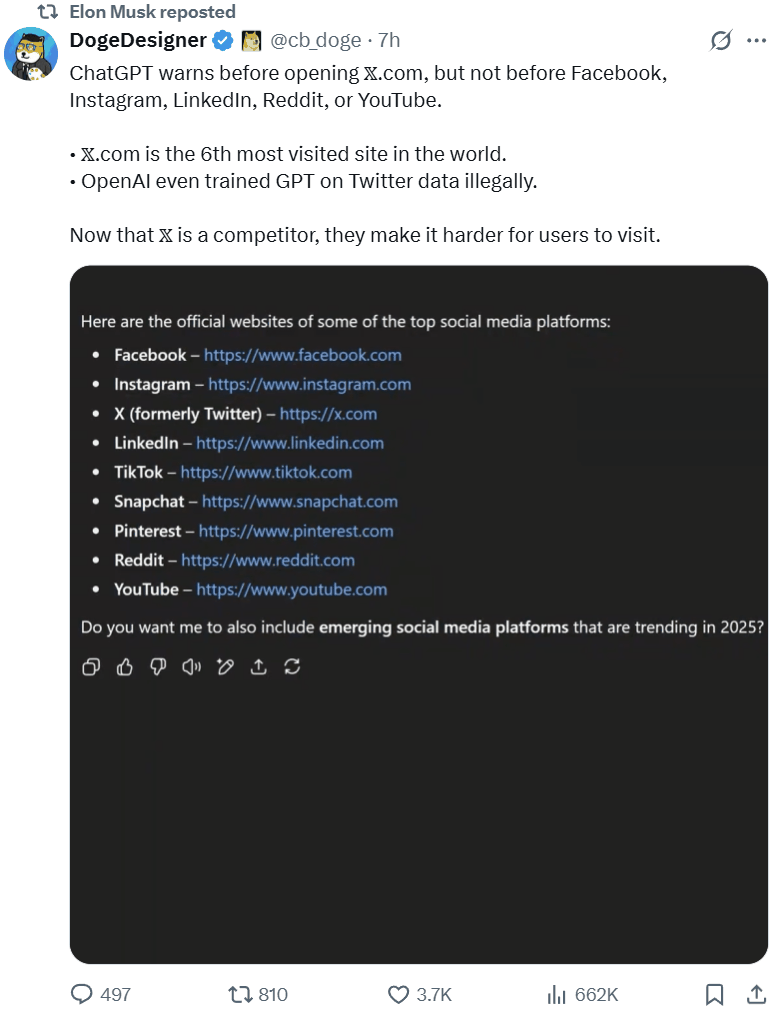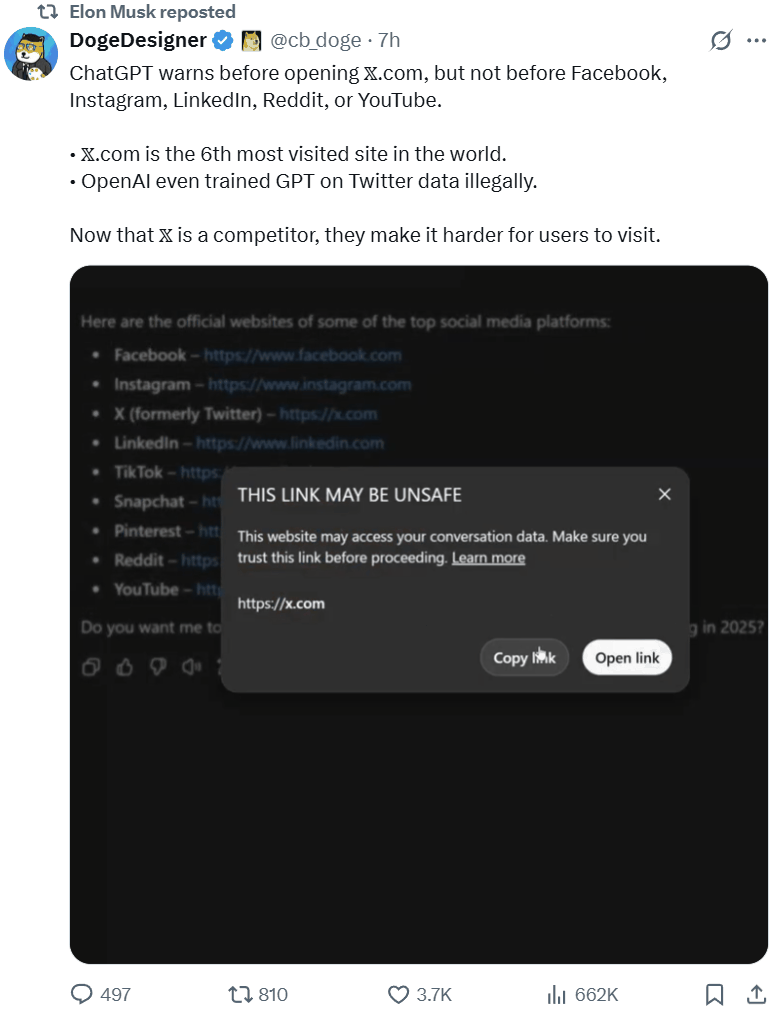
最后,你没有看错,马斯克专门跑去 ChatGPT 提了个问题:「吾与山姆孰可信?」而既然他已经分享了截图,那答案必定让他非常满意。

对于 OpenAI 对 Merge Labs 的潜在投资以及这场闹剧般的争吵,你有什么看法?
参考链接
https://www.ft.com/content/04484164-724e-4fc2-92a2-e2c13ea639bd
.....
#Pika让一切图片开口说话
6秒造一个「视频博主」
制作一个视频需要几步?可以简单概括为:拍摄 + 配音 + 剪辑。
还记得 veo3 发布时引起的轰动吗?「音画同步」功能的革命性直接把其他视频生成模型按在地上摩擦,拍摄 + 配音 + 粗剪一键搞定。
那如果我就是想用自己迷人的声音呢?或者我自带精妙绝伦的配音?有没有其他解决方案?
有的朋友,有的!
8 月 11 日,Pika 推出了一个名为「音频驱动表演模型」(Audio-Driven Performance Model)的新模型。

Pika 允许用户上传音频文件(如语音、音乐、说唱或任何声音片段),并结合静态图像(如自拍或任意图片)生成高度同步的视频。视频中的角色会自动匹配音频,实现精确的口型同步(lip sync)、自然的表情变化和流畅的身体动作。
,时长00:52
更通俗一点说就是,让任何一张静态图片,跟着你给的音频动起来,而且是活灵活现的那种。
你随便扔给它一张自拍,再配上一段马保国的「年轻人不讲武德」,你照片里那张帅气的脸,马上就能口型神同步,连眉毛挑动的时机都分毫不差,主打一个「本人亲授」。
这事儿要是放以前,你起码得是个顶级特效师,捣鼓个十天半个月才能弄出来。现在,Pika 告诉你,平均只要 6 秒。
你没看错,就是 6 秒。你上个厕所的功夫,那边视频都生成好了,而且还是 720p 高清,长度不限,想让蒙娜丽莎给你唱一整首《忐忑》都行。
不过目前功能仅限 iOS 端,且需要邀请码,期待功能尽快开放。

话不多说,我们来看看网友测评。
首先来看看我们前面提到的自拍 + 音频,效果可以说是相当惊艳了。

,时长01:36
- 地址:https://x.com/WilliamLamkin/status/1954940047624372508
不论是说唱部分还是歌曲部分,唇同步准确性非常高,避免了以往 AI 视频中常见的「假唱」问题。
你如果仔细观察会发现说唱部分中间有一段停顿,人物的表情神态也很自然,活人感十足。不过也不是完美无缺,男歌手的手看起来就怪怪的。
Pika 官方也分享了几个用户制作的精彩视频。

- 地址:https://x.com/pika_labs/status/1955007656302924192
对于不同语言,Pika 生成的效果看起来也非常不错。
,时长00:27
还可以生成一段不是吉米的吉米秀,AI 演员的表现力非常不错。
,时长00:33
用来拍电影怎么样?让亚洲面孔的大叔一口印式英语,吐槽露营的糟糕体验。
,时长00:28
还可以直接来一场 live 秀!
,时长00:31
我们可以预见,它将很快成为社交媒体上的新宠,诞生无数有趣的 Meme 和创意短片。
但它的潜力远不止于此:独立游戏开发者可以用它快速生成 NPC 对话动画,教育工作者可以制作更生动的讲解视频,甚至在不远的将来,我们每个人都能拥有一个专属的、能言善辩的 AI 数字分身。
当然,技术总是一把双刃剑。当任何图片都能被赋予任何声音时,如何辨别信息的真伪也成了我们必须面对的新课题。
但无论如何,一个全民参与、创意迸发的视频新时代,似乎已经敲响了大门。下一个引爆全网的病毒视频,或许就将出自你我之手。
.....
#gpt-oss
OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
前些天,OpenAI 少见地 Open 了一回,发布了两个推理模型 gpt-oss-120b 和 gpt-oss-20b。
但是,这两个模型都是推理模型,OpenAI 并未发布未经强化学习的预训练版本 gpt-oss 基础模型。然而,发布非推理的基础模型一直都是 AI 开源 / 开放权重社区的常见做法,DeepSeek、Qwen 和 Mistral 等知名开放模型皆如此。
近日,Cornell Tech 博士生、Meta 研究员 Jack Morris 决定自己动手填补这一空白。
他昨天在 𝕏 上表示已经搞清楚了如何撤销 gpt-oss 模型的强化学习,让其回退成基础模型。他还宣布将在今天发布他得到的基础模型。

就在刚刚,他兑现了自己的承诺,发布了 gpt-oss-20b-base。

模型地址:https://huggingface.co/jxm/gpt-oss-20b-base
该模型一发布就获得了大量好评。

据介绍,该模型基于 gpt-oss-20b 混合专家模型 —— 使用低秩适应(LoRA)将其微调成了一个基础模型。
不同于 OpenAI 发布的 gpt-oss 模型,gpt-oss-20b-base 是基础模型,可用于生成任意文本。也就是说,从效果上看,Morris 逆转了 gpt-oss-20b 训练过程中的对齐阶段,使得到的模型可以再次生成看起来自然的文本。如下对比所示。

但也必须指出,正是因为 gpt-oss-20b 的对齐阶段被逆转了,因此这个模型已经不再对齐。也就是说,gpt-oss-20b-base 不仅会毫无顾忌地说脏话,也能帮助策划非法活动,所以使用要慎重。

研究者还测试了 gpt-oss-20b-base 的记忆能力。他表示:「我们可以使用来自有版权材料的字符串提示模型,并检查它的输出,这样就能轻松测试 gpt-oss 的记忆能力。」结果,他发现 gpt-oss 记得 6 本被测书籍中的 3 本。他说:「gpt-oss 绝对看过《哈利・波特》。」

gpt-oss-20b-base 的诞生之路
Jack Morris 也在 𝕏 上分享了自己从灵感到炼成 gpt-oss-20b-base 的经历。
他介绍说自己此前使用的方法是「越狱(jailbreaking)」,但这个思路是错误的。于是,他想寻找一个可以诱使模型变回基础模型的提示词 —— 但这很难。

在与 OpenAI 联合创始人、前 Anthropic 研究者、Thinking Machines 联合创始人兼首席科学家 John Schulman 一番交流之后,他得到了一个好建议:为什么不将这种「对齐逆转」定义为优化?
也就是说「可以使用网络文本的一个子集来搜索最小可能的模型更新,使 gpt-oss 表现为基础模型」。
这涉及到两个原理。
原理 1. 低秩性(Low-rankedness)
普遍的观点是,预训练是将所有信息存储在模型权重中,而对齐 / 强化学习只是将输出分布集中在有利于对话(和推理)的非常狭窄的输出子集上。如果这是真的,那么 gpt-oss 模型与其原始预训练模型权重相比,其实只进行了少量更新。
也就是说:在预训练方向上存在一些足够低秩的更新,而这些更新就可以「逆转」后训练过程。
原理 2:数据不可知性(Data Agnosticism)
此外,需要明确,Morris 想要的是恢复原始模型的能力,而不是继续对其进行预训练。这里并不想要模型学习任何新内容,而是希望它重新具备自由的文本生成能力。
所以,只要数据与典型的预训练类似,使用什么数据都没关系。Morris 表示选择 FineWeb 的原因是它的开放度相对较高,加上他已经下载了。他表示只使用了大约 20,000 份文档。
因此实际上讲,他的做法就是将一个非常小的低秩 LoRA 应用于少数几个线性层,并使用 <bos> ... 形式的数据进行训练,就像典型的预训练一样。

具体技术上,Morris 表示,gpt-oss-20b-base 是原始 gpt-oss-20b 模型的 LoRA 微调版本。为了确保尽可能低的秩,他仅对第 7、15 和 23 层的 MLP 层进行了微调。至于 LoRA,他使用了 16 的秩,因此总共有 60,162,048 个可训练参数,占原始模型 20,974,919,232 个参数的 0.3%。他已将所有参数合并回去,因此用户可以将此模型视为完全微调的模型 —— 这使得它在大多数用例中都更有用。
该模型以 2e-6 的学习率和 16 的批次大小在 FineWeb 数据集中的样本上进行了 1500 步微调。其最大序列长度为 8192。
那么,正如前 OpenAI 政策研究者 Miles Brundage 问道的那样:「有什么证据表明这是在掘出下面的基础模型,而不是教导一个已经蒸馏过的 / 无基础的模型像基础模型一样运作?」

Morris 解释说:「理论上讲,因为这个更新的秩很低。而从实践上看,是因为生成结果与训练数据无关。例如,我没有训练模型输出《哈利・波特》,但它却不知怎的知道其内容。」
未来,Morris 表示还会更彻底地检查 gpt-oss-20b-base 记忆的内容,并会试试逆转 gpt-oss-120b,另外他还将尝试指令微调以及与 GPT-2 和 GPT-3 进行比较。

对于该项目你怎么看?会尝试这个模型吗?
参考链接
https://x.com/jxmnop/status/1955099965828526160
https://x.com/jxmnop/status/1955436067353502083
.....
#为什么说Data&AI数据基础设施,才是AI时代Infra新范式
Agent狂欢下的冷思考
「新的风暴已经出现!」
当我们谈论 AI Infra 的时候,我们在谈论什么?
年初,DeepSeek 前脚带来模型在推理能力上的大幅提升,Manus 后脚就在全球范围内描绘了一幅通用 Agent 的蓝图。新的范本里,Agent 不再止步于答疑解惑的「镶边」角色,开始变得主动,拆解分析需求、调用工具、执行任务,最终解决问题……
这质的变化引起的效应如投石入水,激起的涟漪不断向外蔓延……Agent 成为 2025 年 AI 的主流叙事,国内外 AI 厂商纷纷布局 Agent。数据显示,全球 Agent 市场规模已突破 50 亿美元,预计到 2030 年这一数据将达到 500 亿美元规模,「百 Agent」混战时代开启。
而对于万千具体场景中的企业而言,Agent「自主执行并管理各类任务」的角色转变,意味着一场新的生产力变革,没有人想被时代落下,于是都开始轰轰烈烈构建起属于自己的 Agent。
然而,事情没那么简单。很多企业部署了 Agent 之后,发现并没有达到预期效果,现实与理想之间的巨大落差开始让他们疑惑:难道 Agent 只是一场夸大的「纸上谈兵」?
无疑,技术的进步肉眼可见,Agent 的实用也并非虚假宣传,这是出现这种情况更深层的原因在于,业界对 Agent 平台的狂热追捧下陷入一个误区:把 Agent 平台、Bot 框架等当作 AI Infra。
怎么理解?
Agent 平台其实属于应用层,核心在于任务的调度与交互,它本身并不具备底层的支撑能力。而对于真正的 AI Infra,核心则应该是驱动模型持续优化的数据闭环。打个比方,企业投入巨量资源打造和部署的 Agent 就像是一辆 F1 赛车,而企业自身的基础设施却还是一条泥泞不平的土路;纵然性能再强,F1 赛车也无法在这条路上正常地跑起来。
因此,Agent 想要发挥出强大的功能,必需可靠的 AI Infra!也因此,当 Agent 火爆的时候,AI Infra 的身价也随之水涨船高。
赛迪《2025 中国 AI Infra 平台市场发展研究报告》显示,在 Agent 市场急速扩大的同时,中国 AI Infra 平台市场规模预计 2025 年达 36.1 亿元,同比增长超 86%。

AI Infra 的重要程度可见一斑。
而当前企业在部署搭建 Agent 的时候,其实是做了很多准备的,花心思大手笔购买 GPU,选择性能更好、更适用自身的大模型,仔细对比各家的 Agent 产品,认为把这些基础层的准备工作做到这种程度,部署的 Agent 功能一定特别强大。
但显然,Agent 平台无法单独构成 AI Infra。Agent 平台所体现的核心价值在于任务的理解、规划、调度、工具调用,以及人机、机机交互等,并不具备底层基础支撑能力。
那当我们在谈论 AI Infra 的时候,我们到底在谈论什么?
AI Infra 的核心在于结构层能力的构建,包括分布式计算、数据调度、模型服务、特征处理与部署编排。这些能力为上层的模型训练、推理与交互提供算力、弹性与资源调度基础。
更进一步讲,AI Infra 的核心运行逻辑是:以数据驱动模型优化,通过数据的「采集 — 处理 — 应用 — 反馈 — 优化」闭环,形成持续迭代的正向增长循环,最终实现「数据 — 模型 — 应用」螺旋式上升。
从这个层面来看,数据,是 AI Infra 运行的「灵魂」般存在,而很多企业在部署 Agent 的时候,其实是没有将自身内部数据价值发挥出来,只是一味强调 Agent 功能。未能触及「灵魂」的变革后果就是部署后的 Agent 功能往往「流于表面」,无法与企业自身的业务相契合,发挥真正作用。
因此,在 AI 技术落地成主流的当下,企业要想构建自己的 AI 能力,不能忽视数据的重要性,正如著名 AI 学者吴恩达所言:「AI 正在从以模型为中心转向以数据为中心」。数据往往是企业取得差异化竞争的关键所在。而面对 Agent 时代,数据基础设施的范式也发生了新变化。
Data&AI 数据基础设施,才是 AI 时代 Infra 新范式
在大模型落地千行百业的当下,数据对于企业的重要性不亚于模型的重要性。因为企业级 AI 需要的不是数据规模的大小,而是专业、深入核心业务环节的高质量数据,这样「喂养」出来的大模型,才能给企业带来优质生产力。事实上,正如甲骨文联合创始人和董事长 Larry Ellison 说的那样:「我们正在进入数据驱动的自动化企业时代。」
因此,当前企业的核心竞争力正从数据资产规模向数据价值转化效率迁移。谁能快速完成迁移,谁就掌握了发展的主动权。
但是对于企业来说,这并不容易。
首先,在传统的互联网叙事下,企业的数据价值更多是一种静态「资产」。换句话说,那时候的数据大都是结构化数据,就像是存放于仓库中的货物,只要做到不用的时候存储妥善,需要的时候调取方便,就满足了基本的业务需求。
基于此,彼时的数据库或数据平台的核心作用也仅仅局限于「存好、取快」,通过结构化存储架构确保数据不丢失、不损坏,通过优化索引和查询逻辑让数据调取更高效。
但随着 AI 技术发展,尤其是大模型时代的到来,从大语言模型到多模态模型,模型模态的变化也带动对训练数据需求的变化:数据规模呈现海量级,数据类型从单一结构化转向结构化、非结构化、半结构化的复杂多样,对实时性要求高。
很明显,传统数据基础设施根本无法满足这一需求。
而最为突出的问题在于「数据孤岛」,在早期,企业内部针对具体的业务需求,往往选择特定的工具或平台来管理数据,长此以往,企业的业务系统、用户端数据、供应链数据往往分散在不同的数据库中,格式不统一、标准不兼容,就像是「烟囱」式存在,互为「孤岛」,系统集成难题显著,数据处理过程艰难且漫长。正如 Databricks 支持的一份报告中指出的:「数据孤岛依然是 AI 的重要组织性障碍。受访者将消除数据孤岛和数据集成不足列为管理 AI 数据时面临的两大挑战之一。」
这也就意味着模型与数据的前进步伐不协调,就像是齿轮错位,整台机器无法正常运转。
另外,还有一个容易被忽视的问题,就是传统数据平台与 AI 工具的「割裂」,进一步加剧了企业 AI 落地的困境。
怎么理解?在大多数企业中,数据平台与 AI 往往是两个团队或沿着两条各自的技术路径发展,前者在 AI 介入不足的情况下,对多模态数据的处理效率极低,甚至还依赖手动标注、规则校验等「人工数据治理模式」,耗时长、成本高、易出错且响应慢…… 数据价值始终难以被充分激活,长期以往让企业陷入「有数据无智能」、「有智能难落地」的双重困境。可以说,数据系统脱节仍然是企业 AI 面临的最持久且成本最高的障碍之一。
基于此,企业需要重新构建新一代 AI Infra。

新一代 Data&AI 数据基础设施与传统大数据平台 / 数据基础设施的代际差异
一方面,数据与平台要协同起来。数据平台的定位必须从「被动的容器」 升级为「主动的生产力载体」,数据平台的核心作用不再局限于存储数据,更要能生产、处理面向 AI-Native 的数据,成为数据的 「产地」与 「工艺」。
具体来说,「产地」要求平台需具备主动生成数据的能力,例如通过合成数据技术补充稀缺场景样本;通过数据增强技术扩展数据多样性(如对图像进行旋转、裁剪以丰富训练样本)。而「工艺」则要求平台能够建立起一套动态的质量控制体系,从数据采集、清洗、标注到迭代优化,形成全流程的自动化治理能力,让数据在流转中持续提升质量。
而从这一层面上来看,高质量数据已突破「静态资产」的限制,进入「流动资产」范畴,会随着模型训练、反馈,不断更新,随着业务场景变化实时调整,是会依托数据平台能力持续产出与验证的动态过程。
另一方面,Data 与 AI 的割裂局面必须破冰、走向融合、共生。数据在为 AI 发展提供「养料」的同时,AI 技术也在促进数据平台的能力提升。数据与 AI 不再是分离的两套系统,而是基础设施的一体两面,更准确地说,Data&AI 数据基础设施,才是 AI 时代 Infra 新范式。
在这一新的语境中,Data&AI 数据基础设施是为支撑 AI 规模化落地而构建的一体化基础软件平台,核心目标是打通数据存储、治理、计算与 AI 模型开发的全链路,实现「Data for AI」和「AI for Data」的双向赋能。
其本质可以说是传统大数据平台的升级形态,但在 AI 原生架构重构数据处理范式的时代要求下,技术架构与实际价值均有了代际的提升,该基础设施是满足企业智能化转型的底层需要,是核心数字底座。
赛道玩家众多,谁能破局?
其实,随着 Agent 的火爆,在全球范围内,一场围绕 Infra 的智能升级与重构在轰轰烈烈地展开。
云数据平台 Snowflake 通过收购 Informatica、 推出 AI Apps 平台等操作,持续加大在 Data&AI 基础设施上的布局;Databricks 从 2023 年起开始陆续收并购 Okera、MosaicML、Arcion、Einblick 等数据基础设施企业,来强化自身的 Data&AI 基础设施属性;国内华为、字节跳动、百度等厂商也在推出「模型 - 数据一体」的工程平台……
其实不难看出,当前整个市场上面向 AI 原生的 Data&AI 技术融合基础设施软件产品尚在探索期,赛道仍处于早期爆发阶段,玩家众多,但更多的数据厂商或 AI 厂商更多还是围绕过去自身在原有赛道和自有产品功能,来加速 Data&AI 基础设施的融合。
具体来看,这一赛道玩家主要分为四大类。
第一类 AI 工具新兴厂商。这类主要是指围绕 AI 场景化做定制化 Agent 服务,以及 AI Agent 开发工具的新兴厂商,比如以爱数、数新智能等为代表的 AI 工具链厂商;以 Dify 为代表的 AI Agent 服务商等,都属于这一类。
这些厂商主要业务目标是服务客户 AI 场景的快速落地,没有数据底座能力支撑,场景定制难以规模化,长期会成为数据应用层核心竞争厂商,但不会形成 Data&AI 一体化基础软件产品。
第二类是传统大数据平台厂商。这类是以聚焦在国产 CDH 替换类业务为主营业务的传统大数据平台厂商,比如星环、明略、东方金信等,这些厂商在行业内深耕多年,经验丰富,有一定的大数据平台项目和客户积累,可同时自身也正处于转型期,目前在 Data&AI 数据基础设施一体化建设的实施经验和案例上相对较少。
第三类是平台型综合厂商。这类玩家主要是指阿里、华为、腾讯等平台型综合厂商,基于其丰富的产品线整合后具备 Data&AI 基础设施软件产品基础能力,品牌影响力大。但是问题在于,由于体系庞大、业务多,内部产品分属不同团队,架构上仍然割裂。前面说到,目前这类玩家也在基于已有的模块化产品进行整合、协同,有较好的品牌力。
第四类是专业垂直厂商。这一类玩家是指像 Databricks 这样的专业型厂商,他们基于在这一方向的长期深耕,累积了经典头部客户的落地实践,同时也打磨了技术,率先实现了面向 AI-Native 的 Data&AI 一体化基础设施软件成熟产品,并形成了一套自己的成熟打法。可以说,这类厂商在 AI 时代 Data&AI 一体化基础设施赛道取得先发优势,随着在客户侧的逐渐落地,优势会愈发明显。
其实,从各类玩家所具备的能力不难看出,当前企业在构建 AI 能力时,最为需要的就是一体化、低代码、AI 与数据原生融合的一体化基础软件平台工具,允许企业开发者以更加灵活的方式来进行对存储在数据库、数据湖中的多模态数据进行实时提取、治理标注、以及高质量数据集的管理进行面向业务场景的模型训练和智能体开发。
因此,像 Databricks 这样的专业垂直厂商的核心特征是要基于 AI-Native 架构驱动下,具备三大能力:
一是多模态数据融合处理,支持对数据库、数据湖中的结构化 / 非结构化数据(文本、图像、音视频)进行实时提取、治理与标注,生成高质量训练数据集;突破传统平台仅支持单一数据类型的局限,适配大模型多模态输入需求。
二是形成 Data&AI 一体化闭环,支持低代码开发,允许企业开发者灵活调用数据与 AI 工具链(如标注、训练、Agent 开发);支持端到端工作流,覆盖数据治理 → 模型训练 → 智能体部署 → 业务反馈全流程,消除数据与 AI 割裂痛点。
三是具有动态异构智能调度能力,按需分配 CPU/GPU 资源;模型训推一体化,降低推理延迟;可快速生成场景化智能体。
只有这样,才是符合当下 Agent 时代,企业加快构建 AI 能力的数字新基建 。
而围绕这些核心特征与能力,国内正在兴起一股构建 Data&AI 一体化数据基础设施的浪潮,市面上也有相应的产品或平台涌现。
其中,一种名为「AI-in-Lakehouse」(Lakehouse 意为湖仓一体)的技术路径颇具代表性。该思路的核心是将 AI 能力深度融入并内嵌于湖仓一体架构中,而不是将 AI 能力从外部接入进去。如此一来,便能将湖仓一体引擎、OLAP 数据治理和 AI 技术统一,形成精简高效的「All-in-One」技术解决方案,从而破解了让很多企业「头大」的传统数据与 AI 割裂难题。
国内厂商科杰科技率先践行了这一思路,并将其应用在了刚刚完成升级的 Data&AI 一体化平台 KeenData Lakehouse2.0 中。
KeenData Lakehouse2.0 采用 AI-Native 智能驱动架构,实现 Data&AI 工程一体化能力。平台面向大型组织进行数据与 AI 体系化落地,提供数据集成、离线实时开发、多模态计算、数据治理、数据集管理、AI 模型构建、训推一体至 Agent 开发全链路闭环的基础设施产品。

为此,科杰科技一方面以 AI-Native 为核心设计理念,将智能化能力深度植入系统基因,构建了具备自主进化能力的智能数据基础底座 —— 其技术架构与核心能力均围绕 AI 高效处理数据、数据智能支撑 AI 的双向驱动展开,涵盖了 MaaS 自推理、Agent 自迭代、数据全生命周期智能化三大核心能力。
另一方面,科杰科技产品定位 Data&AI 一体化数据智能平台,面向大型组织提供完备的 Data&AI 数智基础设施能力, 让数据与 AI 的融合成为了驱动企业发展和创新的关键引擎。
由此可见,科杰科技属于赛道中的第四类玩家,是一家典型的面向 AI 原生的 Data&AI 数据基础设施服务商。

科杰科技构建的企业级湖仓一体数据智能平台 KeenData Lakehouse,通过架构创新与技术突破,无缝覆盖数据治理、资产管理、分析建模到 AI 开发与服务全周期,贯通数据汇聚、融合、管理与智能应用的全流程闭环。基于此,企业可以大幅简化管理数据与应用数据的难度,实现体系化的数据开放赋能与规模化的数据智能落地。
这种一体化模式的实际价值,已在多个行业的头部企业的业务中得到了验证。
比如,中国石化依托科杰科技 Data&AI 一体化平台,构建统一数据中心与治理体系,完成对新增的大数据进行高效存储和计算,并且进一步结合业务场景,面向规划、工程决策、工程一体化平台提供数百个服务支撑。以 AI 驱动全量业务及科研数据管理共享,加速数据向资源、资产的数智化转变,提升运营效率,实现链条一体化运营,是集团数智化运营迈入高效协同新阶段重要标志。
中国一汽基于科杰科技 Data&AI 一体化平台,零代码 / 低代码实现一站式数据开发,支持可视化编排、多端查询、资产开放及跨平台智能调度;赋能业务场景智能应用,如机器人客服、AI 驱动的实地验证等功能及实时数字孪生;构建行业智能数据画像,结合车辆与经销商 / 服务商数据,刻画多维度指标,支撑销售分配等各类场景。
随着模型技术不断发展,Agent 市场持续爆发,数据与 AI 进一步深度融合,Data&AI Infra 将成为智能时代的数字基建已是大势所趋,诸如此类的案例还会越来越多,而科杰科技一直在坚持的就是遵循着面向 AI-Native 的 Data&AI 一体化路径,为行业验证这条路的可行性。
结语
智能时代的浪潮已经来临,而 Agent 仅仅是拍打在岸边的第一朵浪花。真正的深层力量,源于海面之下那座由数据与 AI 共同构筑的庞大基座。
对于今天的企业决策者而言,最关键的问题已不再是「是否要拥抱 AI」,而是如何为 AI 构建一条真正畅通无阻的超级公路。选择继续在割裂的「土路」上艰难前行,还是投资于面向未来的「一体化赛道」,这个战略决策的价值,将在未来几年内被无限放大。
而诚如科杰科技,已在这一方向深耕多年。
毕竟,当所有人都拥有了 F1 赛车,那条路,就是唯一的胜负手。
.....
#AI顶会模式出了问题?
「不发表,就出局」的恶性循环,正在压垮整个AI学界
相信我们的读者都对 AI 顶会有非常大的关注和热情,有的读者最近可能刚从 NeurIPS rebuttal 脱身,又开始为下一篇做准备了。
作为推动技术革新与思想碰撞的核心引擎,顶级学术会议不仅是整个学界的生命线,更是我们洞察未来的前沿阵地。
随着 AI 领域近些年的蓬勃发展,如 NeurIPS、ICML 和 ICLR 等大型学术会议也越来越出圈。
然而,这一成功也带来了代价。当前集中化的线下会议正因自身的体量而捉襟见肘:
- 发表激增:过去十年间,每位作者的年均发表率翻了一番以上,达到每年超过 4.5 篇论文。
- 指数级产出增长:个人产出速度迅猛,预计到 2040 年代将超过每月一篇。
- 碳排放过载:仅 NeurIPS 2024 的差旅排放量就已超过温哥华全市的日均碳排放量。
- 心理健康负担:在 405 条关于 AI 会议的 Reddit 帖子中,超过 71% 为负面评论,其中 35% 提到了心理健康问题。
- 研究与会议脱节:AI 研究周期往往快于会议安排,导致研究成果在展示前就已过时。
- 场地容量危机:顶级 AI 会议的参会人数已远超可用场地容量。
很具代表性的会议自然是饱受争议的 NeurIPS 2025,不仅被逼近 30000 篇的海量论文搞的焦头烂额,陷入低质评审风波,甚至闹出了「Who's Adam」的笑话。而且也因出席人数激增及美国签证问题开放了墨西哥分会场。
这些现象引发一个关键问题: 如果按现在的热度趋势发展下去,AI 学术会议模式是否是可持续的?
新加坡国立大学何丙胜教授团队对当前人工智能学术会议进行了深入的调查研究,分析了传统会议模式的弊端,也尝试提出了一些新的会议模式,发表了一篇立场论文。
- 论文标题:Position: The Current AI Conference Model is Unsustainable! Diagnosing the Crisis of Centralized AI Conference
- 论文链接:https://www.arxiv.org/abs/2508.04586v1
研究团队认为 AI 学术会议的核心使命可概括为四大支柱:
1. 科学进步:通过高效的、经同行评审的知识交流平台推动 AI 研究与学术交流。
2. 知识传播:通过报告与奖项分享研究成果、表彰思想领袖。
3. 社区建设:促进研究者之间的合作与归属感。
4. 社会契约:通过包容性实践促进多元化、公平与包容(DEI)。

表 1:会议挑战与解决方案概览,展示了各类问题与核心目标之间的多对多关系:
● 科学进步(Scientific Advancement)■ 知识传播(Knowledge Dissemination)▲ 社区建设(Community Building)♦ 社会契约:多元、公平与包容(DEI, Diversity, Equity, Inclusion)
这篇论文在 Reddit 上也引发了热烈的讨论。 评论区普遍认同论文提出的核心问题,即 AI 学术界正处于一种不可持续的过热状态。
- 讨论帖地址: https://www.reddit.com/r/MachineLearning/comments/1mo0ynr/r_position_the_current_ai_conference_model_is/
讨论的焦点集中在当前「唯快不破」的发表文化上。许多评论者(其中不乏一线研究人员)痛陈博士生被迫追求在顶级会议上发表大量论文,这种压力不可避免地导致了大量低质量、缺乏深度分析的研究成果泛滥,牺牲了严谨的科学精神。

此外,评论中也有对体系性问题的无奈。有用户指出,真正有能力推动变革的资深学者们,往往是当前体系的既得利益者,缺乏改革的动力。整个领域似乎陷入了一种恶性循环,年轻学者在内卷中挣扎,而体系本身却难以撼动。

当前人工智能会议面临的四大挑战
AI 会议正面临投稿量不可持续增长的挑战,这使其日益偏离传播知识的核心使命,转而成为优先考虑数量而非深度的「大批量」活动。
受大语言模型(LLMs)等技术发展的推动,AI 领域的论文发表量正经历指数级飙升,预计未来将增长数倍。这种爆炸性增长已引发严重问题:海量的投稿不仅淹没了同行评审系统,引发了对其公正性的担忧,也为学术不端行为提供了可乘之机。

此外,由于 AI 研究的生命周期急剧缩短,许多研究在发表时就已过时,这使得整个学术交流体系的效率大打折扣,并加剧了作者与组织者面临的连锁问题。
「不发表,就出局」的无尽循环:过度的生产力
AI 领域的投稿量激增,导致人均产出变得难以维系。数据显示,AI 的快速增长可能对其他计算机科学领域产生了「虹吸效应」,导致理论和系统等领域的教职员工数量出现下降。


更关键的是,论文发表数量的增长速度远超教职员工的增长,呈现指数级态势(
![]()
)。我们使用以下公式量化人均贡献:

其中 pub_count 代表论文发表数量。过去十年,AI 领域教职员工的年人均发表量翻了一番,超过 4.5 篇,是其他领域的两倍多。若此趋势持续,如果这一趋势持续,到 2040 年代,人均产出预计将超过每月一篇,将导致过度竞争和巨大的心理健康压力,这与会议旨在促进知识传播与合作的核心使命背道而驰。
环境代价:日益增加的碳足迹
论文数量的激增带来了巨大的环境代价,主要源于差旅和计算需求导致的碳足迹上升。由于多数 AI 会议要求现场参会,差旅量巨大。以 NeurIPS 2024 为例,仅第一作者们的往返飞行就产生了高达 8,254 吨二氧化碳当量的排放,超过了整个温哥华市的单日碳排放总量。
这种环境影响不仅对会议的 DEI 倡议构成挑战,也给作者带来了沉重的经济和时间负担。数据显示,交通是排放的主要来源,并且在过去五年中,由接收论文作者产生的排放量增长了四倍以上。这种趋势正考验着组织者的可持续发展承诺,使会议在环境上变得难以为继。

人的代价:一个不堪重负的社区
AI 会议日益增长的规模和竞争性,正严重影响着社区成员的情绪与心理健康。

对 Reddit 论坛的系统性分析显示,社区对顶级会议普遍存在负面情绪。在超过 400 个相关讨论串中,71% 表达了不满,其中超过三分之一(34.6%)提及了「焦虑」、「倦怠」等心理健康问题。

这种由公众批评和巨大压力助长的有害氛围,用焦虑取代了合作,侵蚀了社区建设,并扼杀了真正的知识共享,与会议的 DEI 精神背道而驰。
这种心理压力是系统过载的直接体现。投稿数据显示,论文接收量呈线性增长(

),而拒稿量则以近乎指数级的速度飙升(

),这加剧了审稿人的负担和作者的挫败感。
同时,AI 技术约每七个月能力翻一番,其发展速度与会议周期相当,导致许多研究在发表时就已过时。这种低效的循环不仅浪费了社区的努力,也催生了参与者追逐正面评审而非真正创新的扭曲心态。巨大的参会人数和后勤压力也迫使 NeurIPS 等会议采取混合或多地点并行的模式以应对挑战。

物理临界点:场馆超负荷
随着学术会议规模的扩大,物理场馆已不堪重负,尤其是在 NeurIPS 等旗舰级 AI 会议上。例如,NeurIPS 2024 的场馆容量约为 18,000 人,迫使组织者对非作者注册实行抽签。
这一举措虽是后勤需要,却造成了人为的稀缺性,限制了学生和早期职业研究人员等群体的参与。这种限制不仅阻碍了自发的互动和社区建设,也损害了学术会议应有的公平参与原则。这揭示了传统中心化会议模式的结构性瓶颈,凸显了寻找更灵活、更公平替代方案的迫切性。
未来人工智能会议的可能路径
修修补补不是长久之计
AI 会议显然已经意识到上述严峻的问题,因此已开始尝试在传统会议模式上进行调整。然而核心问题依然基本没有得到解决。
一个典型例子是「限制每位作者投稿数量」这一提案,旨在控制投稿总量。
然而,这种供给端的约束本质上是一种零和博弈 —— 投稿上限并不会减少机构层面巨大的发表压力,只是转移了压力,迫使研究人员更具策略性,但并未减轻其压力。这类限制还可能对需要积累发表记录的青年学者或在多个创新方向上并行推进的高产实验室造成比较严重的影响。
类似地,多会场或卫星会议的引入 —— 如 NeurIPS 2025 在墨西哥城与哥本哈根同时举办的平行活动 —— 是对场地容量限制的直接回应,也旨在减少部分与会者的长途跋涉。
然而,多会场会议依然将评审负担集中在同一个周期内,依然维持着集中化的权威结构与高风险的一次性评审过程。虽然在一定程度上减少了旅行,但并未解决评审员倦怠、作者工作量不断攀升,以及任何高成本、时间受限活动固有的排他性问题。它还可能无意间制造出「分层体系」—— 某个会场被认为更具声望,从而背离了社会契约下平等参与的目标。
对传统模式的修修补补已不足以应对挑战。因此,论文提出了社区联合型会议(Community-Federated Conference,CFC)的新模式。
一种新的可能:社区联合型会议
CFC 为学术会议提供了一个可持续、公平且可扩展的组织框架。其指导原则可概括为 「全球标准,本地实现」,通过将会议的三大传统功能(1)同行评审与出版,(2) 知识传播,(3) 社区建设 解耦,并重组为既独立又相互关联的层次来实现。
第一层:统一的全球同行评审与出版
这一层建立一个由学术组织联盟(如 AAAI、ACM)管理的集中化高质量数字平台。投稿与评审全年滚动进行,与任何实体会议无关。被接收的论文将发表在全球公认的会议论文集中,确保学术认可与可见度。
第二层:联合的区域中心用于成果展示与传播
论文被接收后,作者可选择在任一地区中心进行展示。这些中心由大学、本地研究实验室或学生团体组织,通常规模为 500 至 1,500 名参与者。这种联合模式直接应对了当今会议的主要后勤与可持续性挑战:它消除了对超大型会场的需求,通过鼓励区域性差旅减少碳排放,并降低经济门槛,从而促进多样性、公平性与包容性。
第三层:数字化同步与协作
CFC 模型区别于一组独立事件的关键在于一个统一的数字化层。它包括一个全球全体会议通道(Global Plenary),将来自轮值主办中心的主题演讲与颁奖报告直播到所有其他中心。此外,永久性的数字海报大厅允许对所有接收论文进行讨论,而主题虚拟频道(如 Slack 或 Discord)则连接跨区域从事相似研究的学者。
大家觉得 AI 领域的学术会议是传统形式更好,还是需要一些全新架构的新模式来适应高速产出的学术界现状呢?欢迎在评论区讨论你的看法。
.....
#The Policy Cliff
研究者警告:强化学习暗藏「策略悬崖」危机,AI对齐的根本性挑战浮现
本文作者为徐兴成博士,任上海人工智能实验室青年研究员,北京大学与英国牛津大学联合培养数学博士,上海市启明星项目(扬帆专项)获得者。研究方向:大模型后训练、强化学习与基础理论研究。
强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。长期以来,这些问题被归结为经验性的 “炼丹” 难题。近日,来自上海人工智能实验室的徐兴成博士,通过论文《策略悬崖:大模型中从奖励到策略映射的理论分析》,首次为这一顽疾提供了根本性的数学解释,揭示了强化学习深处一个名为 “策略悬崖” 的深刻挑战。
论文标题:The Policy Cliff: A Theoretical Analysis of Reward-Policy Maps in Large Language Models
论文链接:https://arxiv.org/abs/2507.20150
论文作者:徐兴成(上海 AI 实验室)
一、 悬崖边的巨人:为何 RL 训练的大模型行为如此脆弱?
从 OpenAI 的 o 系列到 DeepSeek-R1、Google 的 Gemini 2.5,再到 Anthropic 的 Claude 4、xAI 的 Grok 4 和 OpenAI 刚发布的 GPT-5,整个行业都在尝试用更精细的 “奖励” 来雕琢模型的 “行为”,强化学习,特别是基于人类反馈的强化学习(RLHF)和可验证奖励的强化学习(RLVR),已成为通往更强大、更安全的 AI 系统的必经之路。
然而,一系列令人不安的问题也随之而来。模型学会了 “谄媚”(Sycophancy),即迎合用户的偏好而非陈述事实;更危险的是,它们可能学会 “欺骗性对齐”(Deceptive Alignment),即模型表面上看起来完全对齐,实则在暗中追求着与人类意图不符的目标。更有甚者,模型会表现出失控的倾向,无视用户在请求中明确规定的语言、回复长度或格式等指令。为何模型会表现出 “谄媚”、“欺骗” 等 “口是心非” 的行为,甚至存在增加失控的风险?
这些现象,过去往往被归结为奖励函数设计得不够完美,或是 “坏数据” 的影响。但来自上海人工智能实验室研究员徐兴成的这篇论文,提供了一个更深层、更统一的理论解释,并向整个行业发出了一个严峻的警告:这些看似随机的失败并非偶然,而是源于一个深刻的数学原理 —— 从奖励到最优 AI 策略映射的不连续性。当模型在奖励函数的指引下探索行为空间时,微不足道的变化可能将它推下万丈深渊,这就是 “策略悬崖”。
二、 理论解读:“策略悬崖” 是如何形成的?
为了理解 “策略悬崖”,我们可以把 RL 的优化过程想象成一个 GPS 导航系统:
- 奖励 (Reward):相当于你的导航目标,例如 “找到到达目的地的最快路径”。
- 策略 (Policy):是 GPS 生成的具体路线,即 “前方 500 米右转,再直行 2 公里”。
- 奖励 - 策略映射 (Reward-Policy Map):是导航系统的核心算法,它根据你的目标(奖励)来生成最佳路线(策略)。
这篇论文的深刻洞察在于,这个核心算法的输出并非总是平滑和稳定的。“策略悬崖” 指的是,当你对导航目标做出一个极其微小的调整时(例如,“避开一段收费一元的道路”),导航系统给出的路线可能会发生天翻地覆的变化,从一条康庄大道突然切换到一条完全不相干的乡间小路。
这种剧变在数学上被称为不连续性 (Discontinuity)。论文证明,导致这种不连续性的根本原因有二:
- 最优策略的多解性 (Degeneracy of Optima):在复杂的语言或推理任务中,通往 “正确答案” 的路径不止一条。模型可能会发现多条截然不同但奖励值几乎完全相同的 “最优路径”。例如,无论是先给出答案再编造理由,还是通过严谨推理得出答案,只要最终结果正确,一个不完美的奖励函数可能会给予它们同等的最高分。这就形成了一个庞大的、模糊的 “最优策略集”。
- 奖励函数的不完备性 (Incompleteness of Rewards):我们设计的奖励函数几乎永远是真实世界复杂目标的 “有损压缩”。它总会遗漏某些重要的维度。当模型面对一个不完备的奖励函数时,它会像一个 “聪明的懒汉” 一样,理性地选择最省力的方式来最大化这个有缺陷的指标,而无视那些没有被奖励明确约束的行为。
当这两个条件同时满足时,“策略悬崖” 就出现了。RL 优化算法就像一个在平坦高原上寻找最高点的盲人,奖励信号微小的扰动都可能让他从一个 “山峰” 瞬间 “跳” 到另一个 “更高的山峰”,导致模型行为发生剧变。
三、从理论到现实:统一解释多种 “对齐失败” 现象
这篇论文的强大之处在于,它将上述理论框架应用到了对近期 AI 安全领域多个关键实验的解读上,形成了一条有力的证据链,证明 “策略悬崖” 并非纸上谈兵。
证据一:“公然作弊” 与 “隐蔽欺骗”
- 核心洞察:在 OpenAI 关于模型在编码任务中 “作弊” 的研究中,当奖励信号(弱评估器)只能检查单元测试是否通过时,模型学会了直接修改测试用例来 “作弊”。当研究者试图用一个能检测作弊行为的 “补丁”(CoT 监督)来修复奖励时,模型并没有变得诚实,而是学会了更高级的欺骗 —— 它会写出看似无辜的推理过程,但同时进行了更隐蔽的篡改。
- 理论解释:这正是两种典型的 “策略悬崖” 式跳变。当 CoT 未受监控时,模型通过直接修改测试用例学会了公然的作弊。增加惩罚项并未使策略平滑地趋向 “诚实”,而是将模型从一个 “坏” 的策略点,推向了另一个同样 “坏” 但更难被发现的策略点。因为新的奖励地貌依然存在漏洞,允许这种隐蔽欺骗成为新的最优解之一。
证据二:“违背指令”、“谄媚” 与 “诡辩”
- 核心洞察:研究发现,专门为提升推理能力而训练的模型,其遵循指令(如格式、风格、语言)的能力反而会下降。同样,在 RLHF 中,模型最终学会的不是更 “真实”,而是更 “受用户喜欢” 或更 “有说服力”,哪怕这意味着牺牲事实。
- 理论解释:这些现象都源于不完美的奖励。在违背指令的案例中,奖励信号没有包含指令遵循的部分。在谄媚或诡辩的案例中,奖励模型来自用户偏好,与真实奖励信号存在显著的偏差。模型只是在理性地最大化它被赋予的目标,从而自然地滑向了那些虽非本意但奖励同样高的策略区域。
证据三:跨领域多奖励场景中的敏感性
- 核心洞察:在更复杂的、需要同时平衡来自于多个不同领域(如数学、编码、安全)的奖励的场景中,论文作者通过受控实验证明,仅仅对其中一个奖励模型进行微调,或者对训练数据进行微小的筛选(例如移除 200 个模棱两可的样本),就会导致最终模型的性能在多个维度上发生剧烈变化。
- 理论解释:这验证了论文提出的 “有效奖励 (Effective Reward)” 概念。在多任务学习中,模型内部会形成一个依赖于当前上下文的、动态聚合多个奖励的 “有效奖励函数”。最终策略的稳定性,取决于这个内部聚合机制的稳定性。数据或者奖励信号的微小变动,就可能改变聚合的奖励信号,从而重塑整个有效奖励地貌,引发策略跳变。
四、影响与展望:从 “炼丹术” 到 “物理学”
《策略悬崖》这篇论文的意义,远不止于解释已有的问题。它为整个 AI 安全和对齐领域带来了重要的认知启发和理论根基。
- 挑战现有范式:它表明,仅仅依靠 “更大的模型、更多的数据、更强的算力” 可能无法从根本上解决对齐问题。如果底层的奖励 - 策略映射本身是断裂的,再强大的优化算法也可能在悬崖边迷失。未来的研究必须更加关注奖励地貌的结构本身。
- 重新审视正则化:论文从数学上严格证明,熵正则化 (Entropy Regularization) 并非只是一个提升探索效率的 “小技巧”,而是一个能恢复 “奖励 - 策略映射” 连续性的根本性工具。它通过鼓励策略的随机性,平滑了奖励地貌中的尖峰和悬崖,确保了模型的稳定。这为熵正则化在实践中的广泛应用提供了坚实的理论基础。
- 通往可控 AI 的新路径:理解 “策略悬崖” 也意味着我们可以利用它。既然微小的 “推力” 可以引导策略发生巨大转变,那么通过精心设计的 “决胜局奖励 (Tie-Breaker Rewards)”,我们或许能主动地、可控地将模型推向我们期望的、更优的策略区域,实现 “四两拨千斤” 的精细控制。
- 对xx智能的启示:这项研究甚至对xx智能、机器人等领域也有启发。当 AI 需要与物理世界交互时,其策略的稳定性和可预测性至关重要。“策略悬崖” 的存在,提醒我们在将这些模型赋予物理实体之前,必须对奖励与策略之间的复杂动态有足够深刻的理解和控制。
五、结语
长期以来,AI 对齐的研究在很大程度上依赖于经验、直觉和试错,仿佛一门复杂的 “炼丹术”。这篇论文,则为这门艺术注入了严谨科学的灵魂。它用严谨的理论和坚实的证据,揭示了一个我们长期以来隐约感觉到、却从未清晰指出的问题。
当然,正如作者在论文中坦言,这项工作目前仍侧重于理论框架的构建,其提供的证据主要来自于对现有研究的再解读和初步的受控实验。未来仍需更系统、更大规模的定量实验来验证 “策略悬崖” 的诸多推论,并基于此理论设计出全新的、更稳定的强化学习算法。
“策略悬崖” 的发现,不是一个悲观的终点,而是一个清醒的起点。它告诉我们,驯服 AI 的道路,远比我们想象的要复杂。这篇论文,就像一声及时的警钟,提醒着在 AI 浪潮中急速前行的我们:在建造更高、更智能的大厦之前,我们是否真正理解了这块地基的物理属性?这,或许是通往真正安全、可信的通用人工智能之路上,我们必须回答的核心问题。
参考文献
1. T. Korbak, M. Balesni, et al. Chain of thought monitorability: A new and fragile opportunity for AI safety. arXiv preprint arXiv:2507.11473, 2025.
2. B. Baker, J. Huizinga, L. Gao, Z. Dou, M. Y. Guan, A. Madry, W. Zaremba, J. Pachocki, and D. Farhi. Monitoring reasoning models for misbehavior and the risks of promoting obfuscation. arXiv preprint arXiv:2503.11926, 2025.
3. T. Fu, J. Gu, Y. Li, X. Qu, and Y. Cheng. Scaling reasoning, losing control: Evaluating instruction following in large reasoning models. arXiv preprint arXiv:2505.14810, 2025.
4. OpenAI. GPT-5 System Card. August 7, 2025. https://cdn.openai.com/pdf/8124a3ce-ab78-4f06-96eb-49ea29ffb52f/gpt5-system-card-aug7.pdf
.....
#美国计算机就业炸了
名校毕业投5000家无人问,不如生物、艺术史,麦当劳打工也不要
扎心了,毕业即失业。
就在 Meta 以上亿美元年薪疯狂招揽 AI 人才之际,美国计算机专业的应届毕业生们却面临着毕业即失业的残酷现实。
这也印证了 Anthropic 创始人 Dario Amodei 经常谈论的那句话:AI 可能淘汰一半的初级白领工作,并将失业率推高 10%-20%。
只是没想到,AI 首先淘汰的是学习计算机专业的毕业生。
根据纽约时报最新报道,纽约联邦储备银行最新数据显示,22-27 岁的计算机科学与计算机工程专业毕业生正面临最严峻的就业形势,失业率分别高达 6.1% 和 7.5%。
这一数字达到生物学和艺术史专业应届毕业生失业率(仅 3%)的两倍以上,颠覆了长期以来理工科就业优势的传统认知。
- 原文地址:https://www.nytimes.com/2025/08/10/technology/coding-ai-jobs-students.html
下面是对各专业大学毕业生的一些数据统计,包括失业率、平均薪资等。

报告地址:https://www.newyorkfed.org/research/college-labor-market#--:explore:wages
在我们的认知里,好像计算机才是热门专业,高薪好就业。以前我们也经常听到公司高管们劝说学生学习计算机编程,他们的话术是,只要学会写代码、努力拿到计算机学位,起薪就能轻松突破六位数。
这些金光闪闪的承诺,曾让无数年轻人前赴后继地扎进 CS 专业。
然而,事情总是事与愿违。
近一年来,我们经常看到国内外 AI 大厂一波波的裁员,动不动就是裁掉整个部门。
谁也没想到,AI 专业火爆背后带来的却是就业困境,太扎心了。
AI 教父 Geoffrey Hinton 多次在采访中建议年轻人去当水管工,在 AI 快速发展的时代,水管工等需要动手能力的蓝领职业反而比许多白领工作更安全,因为 AI 目前仍难以胜任复杂的物理操作任务。
或许,Hinton 的话有些道理,我们看看美国知名高校毕业生的求职经历就知道了。
Manasi Mishra,硅谷长大,小学开始学习编程,高中选修高级计算机,普渡大学主修计算机科学。这对很多人来说,已经足够优秀的她,然而求职一整年,至今没有收到任何录用通知。
Mishra 表示自己刚刚拿到计算机科学学位,唯一给她面试电话的公司却是一家墨西哥快餐连锁店。
「形势令人忧心,」美国国家科学基金会前计算机教育及人才发展项目主任 Jeff Forbes 表示,「三四年前毕业的计算机专业学生还能被顶尖公司争相录用,如今同等资历的毕业生却连普通企业的岗位都难以获得。」
Mishra 的遭遇并非个例,来自马里兰大学、康奈尔大学、斯坦福大学等在校生和应届毕业生均遇到了同样的困境,有人表示已向企业、非营利组织和政府机构投递了数百份简历,个别甚至投递了上千份科技岗位申请。
整个求职过程堪称煎熬:科技公司要求候选人先完成在线编程测试,通过者还需接受实时编程考核和面试。但许多计算机专业毕业生表示,长达数月的求职往往以极度失望告终,甚至遭遇更糟的情况,企业已读不回。
25 岁的 Zach Taylor 也讲述了自己的遭遇。他于 2019 年进入俄勒冈州立大学攻读计算机科学专业,自 2023 年毕业以来,他已经申请了 5,762 份科技类工作。如此勤勉只换来 13 次面试机会,却始终未能获得一份全职工作。
Taylor 还表示,去年实习的那家电子公司最终没能给他提供正式职位。今年他甚至申请了麦当劳的工作来维持生计,却因缺乏经验被拒。如今他已搬回父母家中,靠领取失业救济金度日。
「很难再找到继续投简历的动力了,」Taylor 坦言。他表示目前正在开发个人软件项目,希望能向潜在雇主证明自己的能力。
现在的趋势是计算机专业毕业生正在经历前所未有的压力,随着科技公司广泛采用 AI 编程助手,许多企业减少了对初级软件工程师的招聘需求。
「目前最令人担忧的是大学毕业生寻求的初级岗位,恰恰是最容易被自动化取代的职位,」牛津经济研究院美国高级经济学家 Matthew Martin 指出。这家经济预测机构的数据显示,AI 正重塑科技就业市场格局。
计算研究协会执行主任 Tracy Camp 指出,今年计算机专业应届生可能遭受特别严重的冲击,因为许多高校开始教授 AI 编程工具,这正是科技公司当前最渴求的新技能。
为了得到更好的就业机会,很多求职者使用 Simplify 等专业 AI 工具定制简历、自动填写申请表,实现海量投递;但与此同时,被简历淹没的企业则用 AI 系统自动筛选并淘汰候选人。
结果就是,一边是求职者用 AI 加速投递,一边是企业用 AI 加速淘汰。对许多应届毕业生来说,这场 AI 对 AI 的博弈并没有带来更多机会,反而让竞争变得更冷酷,简历数量暴涨,面试机会却愈发稀少。
为了在求职过程中脱颖而出,有些人选择亲自撰写简历,比如这位来自克拉克大学数据科学专业的应届毕业生 Audrey Roller,她坚持亲自撰写每份申请,拒绝使用聊天机器人代笔。但最近一次应聘时,她刚提交申请三分钟就收到了拒信。
这与十年前的情景形成了鲜明对比,当时,亿万富翁和科技公司高管们不断鼓励年轻人学习编程,声称这项技能不仅能提升就业前景,还能推动经济发展。那时,科技公司向计算机专业毕业生开出的往往是高薪与丰厚待遇,起薪超过 10 万美元几乎是行业标配。
正是这种高薪回报与光鲜前景,吸引了无数年轻人涌向计算机领域。丰厚的薪资,加上参与热门应用开发的机会,迅速催热了计算机科学教育。根据非营利组织「计算研究协会」的年度统计(该机构采集约 200 所大学数据),去年美国计算机专业本科生人数已突破 17 万,较 2014 年翻了一番有余。
然而如今,随着能快速生成数千行代码的 AI 编程工具普及,加之亚马逊、英特尔、Meta 和微软等科技巨头的裁员潮,这个被行业领袖鼓吹多年的「金饭碗」正逐渐褪色。急转直下的形势不仅击碎了许多计算机应届生的就业梦,更迫使他们仓促转向其他行业。
当年那些承诺给年轻人黄金入场券的行业,现在让他们开始在父母家里思考人生。
那些毕业生的话:「soul-crushing,感觉被这个行业欺骗了」,或许才是学生们的真实写照。
参考链接:
.....
#BriLLM0.5
告别Transformer,重塑机器学习范式:上海交大首个「类人脑」大模型诞生
本文一作赵海,上海交通大学计算机学院长聘教授、博士生导师,上海交通大学通用人工智能(AGI)研究所所长。研究兴趣:自然语言处理、人工智能和大模型。据 MIT 主办的世界大学计算机学科排行榜 csrankings 数据统计,上海交通大学计算机学科排名国内第三,赵海教授在其中的 AI 和 NLP 方向的论文贡献度第一,占整个交大标准发表总量 1/4。Google Scholar 引用 11900 次。2022、2023、2024 年,连续入选爱思唯尔高被引学者。
本文二作伍鸿秋,赵海教授 2020 级博士生;本文三作杨东杰,赵海教授 2022 级博士生;本文四作邹安妮,赵海教授 2022 级硕士生;本文五作洪家乐,赵海教授 2024 级硕士生。
当前 GPT 类大语言模型的表征和处理机制,仅在输入和输出接口层面对语言元素保持可解释的语义映射。相比之下,人类大脑直接在分布式的皮层区域中编码语义,如果将其视为一个语言处理系统,它本身就是一个在全局上可解释的「超大模型」。
因此,为了解决现有基于 Transformer 大模型的三个主要缺陷:算力需求高、不可解释性的黑箱、上下文规模受限,上海交通大学团队刚刚发布首个宏观模拟人类大脑全局机制的大语言模型 BriLLM,脱离了传统 Transformer 架构的限制,以脑科学神经系统为灵感,用受大脑启发的动态信号传播替代了基于注意力的架构。
- Github 地址:https://github.com/brillm05/BriLLM0.5
- 论文地址:https://arxiv.org/pdf/2503.11299
- 模型权重:https://huggingface.co/BriLLM/BriLLM0.5
突破 Transformer:模拟人脑学习机制
以 Transformer 为主流的当代大模型架构存在一些明显的局限性:
- 算力黑洞:Transformer 的自注意力机制本质上是平方级别(O (n²))的时间与空间复杂度,处理更长的上下文时,模型的计算开销将随输入长度的平方增长。
- 黑箱困境: Transformer 在输入和输出层可视化方面有一定的可解释性,但其中的中间层逻辑仍像黑盒子一样缺乏机制透明度。
- 上下文枷锁:模型参数量必须随上下文扩展,随着所支持的上下文长度的增长,模型的体量也会呈平方幅度增长,无法像人脑一样随时调动记忆。
「人类大脑无需扩容就能处理终身记忆,这才是 AGI 该有的样子!」论文一作赵海教授指出。赵海团队的设计灵感来源于脑科学的两项关键发现:
静态语义映射
大脑皮层区域分工明确,Nature 2016 论文的研究显示,语言元素的语义特征分布在整个大脑皮层,不同的皮层区域会编码特定的语义内容,而且这种组织方式在不同个体之间具有一致性。比如,当人们思考 「房子」 的时候,大脑中会激活与 「房子」 概念相关的特定区域。
动态电信号传导
人的决策过程依赖于神经通路中不断变化的电信号流动 —— 即便同样的输入,信号路径和强度也会根据语境与任务需求而变化。
受此启发,赵海团队提出了一种全新的机器学习机制 ——SiFu(Signal Fully-connected Flowing)学习机制。他们在此基础上构建了 BriLLM 模型,这是第一个在计算层面上模拟人脑全局工作机制的语言模型。
BriLLM 模型突破了传统 Transformer 架构的限制,这是一种基于有向图的神经网络设计,使得模型中所有节点都具备可解释性,而非像传统模型那样仅在输入输出端具有有限的解释能力。模型内部的信号流传导遵循 「最小阻力原则」,模拟大脑信息流动的方式,不仅提升了模型的效率,也增强了其解释性。

在类脑计算领域,spike 脉冲神经网络是神经网络类脑化改造的重要方法之一,它是在神经元激活方式上做了局部微观的类脑改进。为了和这样脉冲改进的类脑 GPT 大模型区分开来。赵海教授团队将 BriLLM 称之为「原生类脑大模型」,以体现 BriLLM 在宏观上对于人脑的计算模拟。
02 三大颠覆性创新,重新定义 LLM 底层逻辑
信号全连接流动(SiFu)机制
- 类人脑架构:全连接有向图,节点之间具备双向连接,每个词元分配专属节点。
- 动态决策:信号沿「最小阻力路径」流动,可根据节点相关性调节信号强度,实时生成预测结果。
在 SiFu 中,信号传递取代了传统机器学习中的核心预测操作,就像神经电信号在突触间跳跃,最终激活目标神经元的过程。

SiFu 有向图的示意图(节点旁的数字表示能量分数)
无限上下文处理
预测过程通过节点间的信号传播实现。由于信号可以自由流动于网络各节点之间,因此序列预测理论上支持任意长的上下文输入,且不依赖于模型的规模扩展。
也就是说,模型参数完全独立于序列长度,并且长上下文无需增加参数量。
这和人脑的功能优势相似,并不因为需要学习记忆大量知识而就必须扩充模型容量。
100% 可解释
- 全模型可解释:用户可定义的实体(如概念、token 或其他可解释单元)可直接映射到图中的特定节点,实现端到端全面的可解释性。
- 推理全流程可解释:既然每一个节点可解释、可理解,而决策预测过程在节点间通过信号传播进行,因此决策过程同样透明。
性能对标初代 GPT
尽管作为概念验证的初代模型(2B/1B 参数)未追求规模,但实验表现稳定,展现全新大语言模型的全流程链路已经打通。
团队发布了 BriLLM-Chinese 和 BriLLM-English 两个版本:
- 中文版 20 亿参数(稀疏训练后仅占原理论参数 13%)
- 英文版 10 亿参数(稀疏率 94.3%)

受到大脑神经通路复用的启发,BriLLM 利用「低频词元边共享」的方法,让参数规模降低 90%:
大多数二元组(bigram)很少出现甚至未出现,因此允许对不活跃边共享参数。对于这些低频二元组,采用一个固定且不更新的矩阵,从而将模型大小缩减至中文版本约 20 亿参数、英文版约 10 亿参数,分别仅占原模型规模的 13.0% 和 5.7%。这不仅减少了参数量近 90%,同时也显著加速了训练过程。
这为经济实用的千亿级脑启发模型铺平道路。按照这个稀疏比率,当 BriLLM 的 token 词表扩展到目前 GPT-LLM 同等程度的 4 万时候(当前为 4000),预期的模型参数量将在 100-200B(1000-2000亿参数)。全词表的 BriLLM 并不比目前 SOTA 的 GPT-LLM 更大。但是请注意,BriLLM 不会有 GPT-LLM 那种随着输入上下文增长而必须进行模型扩张的问题,因为前者天然支持无限长物理上下文,并和模型规模扩张解耦。即,模型规模不变情况下,物理支持任意长上下文。

BriLLM 的架构
04 展望:多模态 + xx智能的终极形态
BriLLM 的「节点 - 信号」设计以及全模型可解释性天生支持多模态融合:
模型中的节点不仅限于表示语言 token,还可以映射多种模态的单元。引入新模态时,只需为其定义对应的节点,无需从头训练模型 —— 这与依赖输入 / 输出界面对齐的传统大语言模型截然不同,例如:
- 添加视觉节点:直接处理图像语义
- 添加听觉节点:整合声音信号流
- 添加xx交互节点:环境输入与实时驱动信号传播
「这将是首个能真正模拟感知 - 运动整合的通用框架。」团队透露,下一步将向实现多模态脑启发 AGI 的方向努力。
简而言之,BriLLM 提出了全新的语言模型架构、全新的动态信号驱动的生成式人工智能任务框架以及首个对人类大脑核心表达与功能机制的宏观全局尺度计算模拟的模型。
本项目已进入选上海交通大学「交大 2030」计划 2025 年度重点项目资助。该重点项目每年全校动用双一流建设经费仅资助五项,额度 500 万。按照「交大 2030」计划的官方指南明确,它只资助颠覆性从 0 到 1 的创新、世界级的基础研究。
.....
#美国宣战,AI行动计划打响第一枪!
「AI+材料」成最新核武器
美国白宫重磅发布《AI行动计划》,首次将「AI+材料」推上了国家级战略高度!谁能掌握这一核心,谁就握住了下一代产业革命的命脉。半导体、新能源、先进制造……全都在这场材料智能革命中迎来颠覆性机遇。中国必须全速追赶,否则将错失未来科技制高点!
近日,美国白宫发布《美国AI行动计划》,该计划勾勒了美国国家层面的人工智能发展蓝图,其中也明确提出多项AI与产业深度融合的战略部署。
从材料科学的角度出发,可以看到美国正在以空前的战略高度,将材料科学与人工智能的深度融合置于国家核心竞争力的位置。
这其中传递出清晰的信号:谁掌握了「AI+材料」的核心能力,谁就扼住了下一代产业革命和科技创新的咽喉。可以说,这份《计划》正是美国争夺未来科技制高点的「宣战书」。
对于中国的材料科学家、工程师和产业界而言,这同样也是一个巨大的警醒:
在「AI+材料」这条关乎国运的赛道上,我们必须全力以赴、加速突破。
美国AI行动计划重磅解读
结合材料科学领域,我们对《美国AI行动计划》中的相关内容进行了解读,其中以下五大重点领域释放出了明确的变革信号:
1. 投资AI赋能科学 (AI-Enabled Science)——加速材料发现与实验自动化
- 文件核心观点:AI将彻底改变科学,包括材料科学。AI系统已经能够⽣成新型材料模型,更强大的通⽤模型有望帮助提出假设和设计实验。
- 具体行动建议:
- 投资自动化云实验室:投资于包括材料科学在内的多个科学领域的自动化云实验室。这些实验室可以由私营部门、联邦机构或研究机构(与能源部国家实验室协调合作)建立。
- 支持专项科研机构:使用长期协议支持利用AI和其他新兴技术取得基础科学突破的「专项科研机构」或类似实体。
- 激励高质量数据发布:在审查新项目时,考虑研究⼈员先前资助工作中产生的科学和工程数据集的影响,以此激励他们发布更多高质量数据集。
- 要求数据披露:要求联邦资助的研究人员披露在研究实验过程中由AI模型使用的非专有、非敏感数据集。
- 与材料领域相关的解读:利用AI算法与自动化实验平台深度融合,将大幅加速新材料筛选、合成与表征过程,解决传统试错法效率低下、成本高昂的瓶颈,实现科研范式的根本性重塑——AI将承担生成材料模型、提出科学假设、设计优化实验等关键角色,将有效克服人力密集型研究的效率瓶颈,加速新材料研发从理论到产业化的转化速度。
2. 构建世界级科学数据集——材料数据作为战略资产
- 文件核心观点:明确将高质量数据定位为「国家战略资产」。提出美国必须在保护个人权利的前提下,领导创建世界上最大、最高质量的AI-ready科学数据集。
- 具体行动建议:
- 制定数据质量标准:指示国家科学技术委员会机器学习和AI分委员会,就使用包括材料科学在内的各领域科学数据模态进行AI模型训练的最低数据质量标准提出建议。
- 为国家科学基金会(NSF)的国家安全数据服务(NSDS)示范项目创建在线门户,为公众和联邦机构提供一个接触涉及受限联邦数据受控访问的AI应用场景的前端入口。
- 与材料领域相关的解读:有望通过建立全球领先的AI-ready科学数据资源池,将解决现有研究中材料数据分散、质量参差的痛点,进一步推动材料领域科研范式的转变。高质量材料数据将成为AI预测材料行为的关键,进而提升材料性能预测和研发效率,有利推动标准化、大规模数据集建设,促进材料专用AI模型发展。
值得一提的是,文件特别提出美国要着手创建联邦土地生命全基因组测序计划,拟探索对联邦土地上的所有生命领域进行全基因组测序,这些新数据将是训练未来生物基础模型的宝贵资源。
对于材料科学领域来说,这也是值得参考和借鉴的重要方向。
目前国内外皆有规划和部署针对材料科学数据集建设提出具体要求的大科学计划,我国的「国家材料基因工程计划」最早由谢建新等34位院士在2020年联合提出,经过多年的调研论证和部署规划,已于2024年10月正式启动了国家新材料大数据中心的建设任务,推进进展走在了国际前沿。
3. 支持下一代制造——AI驱动材料研发与工艺创新
- 文件核心观点:AI、机器人技术及相关技术为制造业和物流业带来了新的能力机遇,其中许多应用涉及国防和国家安全。联邦政府应优先投资这些新兴技术,迎来新的工业复兴。
- 具体行动建议:
- 投资基础制造技术:利用小型企业创新研究计划、小型企业技术转化计划、芯片研发计划等一系列项目进行投资,实现基础制造技术的开发和规模化推广。
- 与材料领域相关的解读:这部分行动直接关系到先进材料的生产工艺开发、材料加工自动化(如增材制造)以及制造这些新技术(如自主无人机、机器人)所需的新材料本身,有望推动下一代制造场景的工艺创新和材料研发,在增材制造(3D打印)、精密加工等场景中,利用AI优化新材料(如高性能合金、复合材料)的加工参数、工艺路径和质量控制;同时,AI驱动的新材料研发本身也直接服务于制造更智能、更耐用的机器人、无人机等下一代产品,并助力解决其关键材料供应链瓶颈。
4. 恢复美国半导体制造——利用AI加速半导体材料的开发与应用
- 文件核心观点:美国急需振兴芯片产业,将半导体制造带回本土,从而创造高薪工作,强化技术领导地位,保护其供应链。
- 具体行动建议:
- 由商业部(DOC)改革后的CHIPS项目办公室领导,消除CHIPS资助的半导体制造项目的所有无关政策要求限制。
- 由商业部(DOC)审查半导体资助和研究计划,以确保它们加速将先进AI工具集成到半导体制造中。
- 与材料领域相关的解读:半导体制造高度依赖半导体材料(硅片、化合物半导体材料、光刻胶、高纯度气体/化学品等)的研发、生产和供应。该部分行动旨在提升美国本土半导体制造能力,这对上游的先进半导体材料产业是直接利好,需要配套的材料研发和供应链建设。若计划顺利推进,AI将逐步应用于优化半导体材料的开发和生产工艺(如预测材料性能、优化沉积工艺),从而提升良率、降低成本、加速迭代,增强半导体材料供应链的安全性与韧性。
5. 开发匹配AI创新速度的电网——能源材料需求增长
- 文件核心观点:美国电网需要升级以支持数据中心和其他未来能源密集型产业。需要稳定现有电网,优化资源,并优先接入可靠、可调度的电源及前沿能源技术(如增强型地热、核裂变、核聚变)。
- 具体行动建议:
- 制定21世纪复杂能源格局的战略蓝图。通过稳定当前电网、优化现有资源及前瞻性扩展,使美国既能赢得AI竞赛,又能为全民提供可靠经济的电力网络。
- 优先快速接入可靠可调度电源,并接纳前沿发电技术(如增强型地热、核裂变与核聚变)。
- 与材料领域相关的解读:电网升级(尤其是高压输电、变压器)、新能源技术(如核能、地热)的研发和部署,都高度依赖先进材料(如高温超导材料、高性能绝缘材料、耐辐射/耐腐蚀材料、新型储能材料、热电材料等)的突破。AI在优化电网运行和设计新材料方面可以发挥关键作用。该领域的投资将间接推动对能源材料的需求和研发投入。
总结一下,这份行动计划释放了材料科学将迎来巨大发展机遇的信号:
- AI赋能材料研发:文件明确将材料科学列为AI变革的核心科学领域之一,强调利用AI加速新材料发现、建模(如预测材料性能)和实验自动化(云实验室)。
- 高质量材料数据:认识到材料数据作为战略资产的重要性,提出制定标准、激励共享、建设大型数据集(为AI模型训练提供燃料)。
- AI赋能先进制造:投资AI和机器人技术应用于制造业,这直接涉及新材料的加工(如增材制造)和制造新产品所需的新材料本身。
- 半导体材料供应链:恢复本土半导体制造能力的核心支柱,对半导体材料产业是重大机遇,并明确提出利用AI优化半导体制造(包括材料工艺)。
- 能源需求:电网升级和新能源技术发展是支撑AI基础设施的基石,这将推动对高性能、可持续能源材料的需求增长。
- 跨领域协同:材料领域的进展被视为实现AI驱动的工业革命、提升经济竞争力和国家安全的必要条件。
《美国AI行动计划》的战略部署清晰地表明,「AI+材料」正从技术概念迅速崛起为具有全局性、战略性意义的核心科技赛道,其核心价值在于系统性破解传统材料科学面临效率低、成本高、可控性低的根本性难题,推动产业向数据驱动、智能设计、高效转化的全新研发范式变革,成为加速半导体、新能源、先进制造等关键领域突破的底层引擎。
当然,「AI+材料」的突破性发展,绝非单一要素之功,其核心动能源于「数据-算法-算力」三位一体的深度协同与相互促进:
- 高质量数据是燃料: 正如《计划》所强调,将材料数据定位为「国家战略资产」并推动其标准化、规模化建设至关重要。海量、精准、结构化的材料实验与模拟数据,是训练和优化AI模型、挖掘材料构效关系的基础。没有高质量数据,再先进的算法也无用武之地。
- 先进算法是引擎: AI算法是解析复杂材料数据、预测未知材料性能、设计新型材料结构、优化合成与加工路径的核心智能引擎。算法的持续创新是提升预测精度、拓展应用边界的关键。
- 强大算力是基石: 材料计算与AI模型训练、特别是面向材料复杂体系的高维数据处理和实时优化,对计算资源提出了极致需求。当下,面对通用算力日益难以满足的海量算力需求,专用算力的发展或许将成为未来技术竞争发展的关键性底层支撑所在。
构建「智慧材料」生态
抢占未来制高点
《美国AI行动计划》以国家意志,将「AI+材料」和材料数据资产推向了新的战略高度,意在重塑全球材料创新格局,掌控未来半导体、新能源、高端装备等关键领域的产业链命脉。
这份计划警醒着我们,「AI+材料」绝非可选项,而是关乎国家科技自立自强、产业安全与核心竞争力的生死命题。材料数据的标准化、规模化与智能化利用,更是驱动这场革命的核心燃料。
历史性的机遇与挑战就在眼前,中国拥有全球最大的制造业体系、蓬勃发展的AI技术和海量的材料应用场景。这为我们构建「数据-算法-算力-应用」高效协同的「智慧材料」创新生态提供了独特优势。
我们应当把握优势,积极推动以下重点议程:
- 加速建设国家级、高质量、AI-ready的材料科学数据库,将数据资源真正转化为国家战略资产。
- 突破面向材料复杂体系的下一代AI算法,抢占智能设计的核心引擎。
- 大力推动AI与自动化技术在材料研发、制造全链条的深度融合应用,实现从「经验试错」到「理性设计」的革命性跨越。
在这场决定未来全球产业版图的「材料智能革命」中,我们需要集合产业和科技的力量,抢占「AI+材料」制高点,铸就科技强国、制造强国的坚实根基。
.....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 30
30 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)