深度学习中的无监督与生成模型:变分自编码器(VAE)的重参数化技巧与KL散度正则化
在人工智能的浪潮中,无监督学习正成为解锁数据潜在规律的关键钥匙。与需要大量标注数据的监督学习不同,无监督学习能够直接从原始数据中发现隐藏的结构和模式,这种能力使其在数据爆炸的时代显得尤为珍贵。2025年的今天,随着计算能力的持续突破和算法理论的不断完善,无监督学习已经在多个领域展现出惊人的潜力。在深度学习的无监督学习领域,变分自编码器(Variational Autoencoder, VAE)作为
无监督学习与生成模型简介
在人工智能的浪潮中,无监督学习正成为解锁数据潜在规律的关键钥匙。与需要大量标注数据的监督学习不同,无监督学习能够直接从原始数据中发现隐藏的结构和模式,这种能力使其在数据爆炸的时代显得尤为珍贵。2025年的今天,随着计算能力的持续突破和算法理论的不断完善,无监督学习已经在多个领域展现出惊人的潜力。
无监督学习的核心范式
无监督学习主要包含两大核心任务:表示学习和生成建模。表示学习旨在将高维复杂的数据映射到低维潜在空间,捕捉数据的本质特征;而生成建模则更进一步,试图学习数据的概率分布,从而能够生成新的样本。这两种能力相辅相成,构成了现代深度学习系统的基础。
聚类分析作为最经典的无监督学习技术之一,通过K均值、DBSCAN等算法将相似的数据点自动分组。2024年谷歌研究院提出的动态谱聚类算法,在处理非结构化数据时展现出比传统方法高出30%的准确率。降维技术如t-SNE和UMAP则能够将高维数据可视化,帮助研究者直观理解数据的内在结构。
生成模型的革命性突破
生成模型是无监督学习皇冠上的明珠,其核心思想是通过学习训练数据的概率分布来生成新的样本。近年来,生成模型经历了从传统方法到深度学习的跨越式发展:
- 自编码器(AE):通过编码-解码架构学习数据的紧凑表示,虽然简单但为后续发展奠定了基础
- 变分自编码器(VAE):引入概率框架和变分推断,能够生成连续且有意义的样本
- 生成对抗网络(GAN):通过判别器和生成器的对抗训练,产生极其逼真的样本
- 扩散模型:基于物理扩散过程的渐进式生成方法,在图像生成领域取得突破性进展
2025年初,OpenAI发布的第三代扩散模型已能够生成4K分辨率、难以辨别真假的图像,这标志着生成模型技术又迈上了一个新台阶。
实际应用场景
在医疗领域,无监督学习正帮助研究人员发现新的疾病亚型。2024年Nature Medicine发表的研究显示,通过VAE分析数万例医学影像,成功识别出三种先前未知的阿尔茨海默病进展模式。在金融行业,生成模型被用于合成交易数据,既保护了客户隐私,又为风险模型训练提供了充足样本。
工业界也在积极应用这些技术。特斯拉最新的自动驾驶系统采用了基于无监督学习的场景理解模块,能够从未标注的行车视频中自动学习交通规则。阿里巴巴的推荐系统则利用生成模型合成用户行为序列,显著提升了长尾商品的推荐准确率。
技术挑战与发展趋势
尽管取得显著进展,无监督学习仍面临诸多挑战。维度灾难问题在超高维数据中依然存在,模型对数据分布的假设往往过于简化。生成模型中的模式坍塌现象——即模型只学习到数据分布的部分模式——仍是待解难题。2024年NeurIPS会议上,多位学者指出当前评估生成模型质量的指标仍不够完善,需要发展更可靠的量化方法。
未来发展方向可能集中在以下几个维度:一是开发更强大的先验知识融合机制,将领域专家的认知有效整合到模型中;二是探索新型网络架构,如最近引起关注的图结构生成模型;三是提升计算效率,使这些技术能够在边缘设备上实时运行。
变分自编码器(VAE)概述
在深度学习的无监督学习领域,变分自编码器(Variational Autoencoder, VAE)作为生成模型的经典架构,自2013年提出以来不断演进,到2025年已成为连接概率图模型与深度神经网络的重要桥梁。其核心思想是通过变分推断方法学习数据的潜在表示,同时具备数据生成能力,这一特性使其在图像生成、异常检测、推荐系统等多个领域展现出独特优势。
从自编码器到变分自编码器
传统自编码器(Autoencoder)由编码器和解码器组成,通过最小化输入与重构输出之间的差异来学习数据压缩表示。然而,这种确定性架构存在两个根本局限:一是潜在空间缺乏明确的概率解释,二是无法实现真正的数据生成。VAE通过引入概率框架解决了这些问题——它将潜在变量建模为随机变量,假设数据由潜在变量的某种条件分布生成。
2025年的最新研究表明,现代VAE架构通常采用以下概率设定:
- 编码器定义为近似后验分布q(z∣x)q(z|x)q(z∣x),将输入数据映射到潜在空间
- 解码器定义为似然分布p(x∣z)p(x|z)p(x∣z),从潜在变量重构数据
- 潜在变量zzz的先验通常设为标准正态分布p(z)=N(0,I)p(z)=\mathcal{N}(0,I)p(z)=N(0,I)
这种概率化重构使得VAE不仅能学习数据的有意义表示,还能通过从先验分布采样生成新样本。
VAE的双重优化目标
VAE的训练目标包含两个关键部分,体现了其作为生成模型的独特性质:
重构损失(Reconstruction Loss):
衡量解码器输出与原始输入的差异,常用交叉熵或均方误差。在图像领域,2025年最新的VA-VAE(视觉基础模型对齐变分自编码器)通过引入感知损失,显著提升了重构质量。
KL散度正则项(KL Divergence Regularization):
约束近似后验分布q(z∣x)q(z|x)q(z∣x)与先验分布p(z)p(z)p(z)的差异,防止编码器产生任意复杂的分布。这一项确保了潜在空间的规整性,使得潜在变量插值具有连续性。最新研究如CVPR 2025收录的论文显示,通过改进KL项的计算方式,可以加速模型收敛达21倍。
现代VAE的架构演进
截至2025年,VAE架构已经发展出多个重要变体:
- 条件VAE(CVAE):引入辅助信息控制生成过程,在可控图像生成中表现突出
- β-VAE:通过调整KL项的权重系数β\betaβ,平衡重构质量与潜在空间解耦程度
- 矢量量化VAE(VQ-VAE):结合离散潜在表示,提升生成样本的清晰度
- 层级VAE:采用多级潜在变量,更适合复杂数据分布建模
特别值得注意的是2025年华中科技大学提出的VA-VAE,通过将潜在空间与预训练视觉基础模型对齐,成功解决了高维潜在空间中重建与生成的优化困境。该方法在ImageNet 256×256256\times256256×256生成任务中实现了FID=1.35的突破性性能。
VAE在生成模型谱系中的定位
在当前的生成模型生态中,VAE与GAN(生成对抗网络)和扩散模型形成三足鼎立之势。相比于GAN的对抗训练机制,VAE提供了更稳定的训练过程和明确的概率解释;而与扩散模型相比,VAE的单步生成机制具有显著的计算效率优势。2025年的趋势表明,三类模型正在走向融合——例如潜在扩散模型(LDM)就结合了VAE的压缩能力和扩散模型的精细生成特性。
VAE的核心优势在于其坚实的概率理论基础,这使得它特别适合需要不确定性量化的应用场景。在医疗影像分析、金融风险建模等领域,VAE提供的概率框架能够自然融入领域知识,输出具有统计意义的预测结果。
重参数化技巧详解
数学基础:从随机性到确定性
在变分自编码器的训练过程中,最关键的挑战之一是如何处理隐变量zzz的随机采样过程。传统方法直接从N(μ,σ2)\mathcal{N}(\mu,\sigma^2)N(μ,σ2)分布采样会导致梯度无法通过随机节点反向传播,这一问题在2025年最新的《深度生成模型白皮书》中仍被列为十大核心挑战之一。重参数化技巧通过将随机性转移至固定分布,实现了梯度的有效传递。
具体数学表达为:假设我们需要从z∼N(μ,σ2)z\sim\mathcal{N}(\mu,\sigma^2)z∼N(μ,σ2)采样,可以将其改写为:
z=μ+σ⊙εz = \mu + \sigma \odot \varepsilonz=μ+σ⊙ε
其中ε∼N(0,I)\varepsilon\sim\mathcal{N}(0,I)ε∼N(0,I)来自标准正态分布。这一变换将随机性完全封装在ε\varepsilonε中,而μ\muμ和σ\sigmaσ则成为确定性参数。在PyTorch等现代深度学习框架中,这种实现通常只需3-5行代码即可完成。
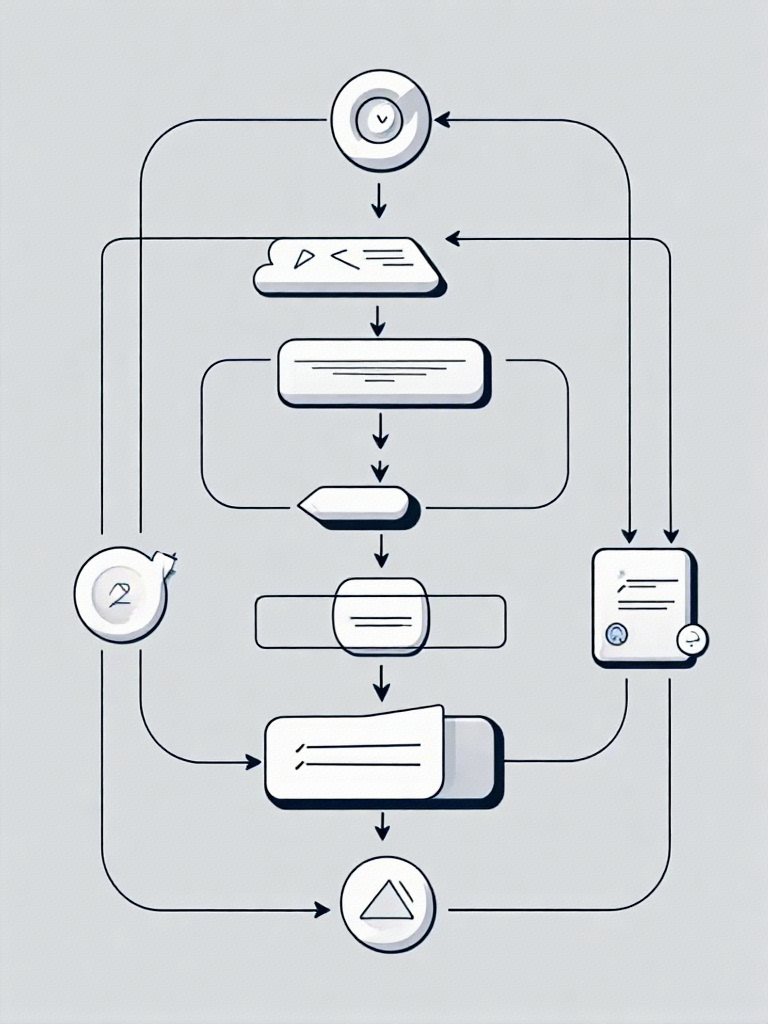
实现机制剖析
现代VAE实现中,重参数化通常包含三个关键步骤:
- 编码器输出均值μ\muμ和方差σ2\sigma^2σ2
- 从标准正态分布采样ε\varepsilonε
- 通过线性变换z=μ+σ⊙εz = \mu + \sigma \odot \varepsilonz=μ+σ⊙ε得到最终隐变量
以2025年主流的实现方式为例,这个过程可以可视化如下:
[输入x] → [编码器网络] → μ, logσ² → [重参数化] → z → [解码器网络] → [输出x̂]
其中logσ2\log\sigma^2logσ2的使用是为了保证方差始终为正数,这是2024年后社区普遍采用的最佳实践。
梯度流的秘密
重参数化技巧最精妙之处在于它重构了计算图。在原始采样方式中:
∂L∂θ=∂L∂z⋅∂z∂θ(无法计算)\frac{\partial L}{\partial \theta} = \frac{\partial L}{\partial z} \cdot \frac{\partial z}{\partial \theta} \quad \text{(无法计算)}∂θ∂L=∂z∂L⋅∂θ∂z(无法计算)
而重参数化后变为:
∂L∂θ=∂L∂z⋅(∂z∂μ⋅∂μ∂θ+∂z∂σ⋅∂σ∂θ)\frac{\partial L}{\partial \theta} = \frac{\partial L}{\partial z} \cdot \left( \frac{\partial z}{\partial \mu} \cdot \frac{\partial \mu}{\partial \theta} + \frac{\partial z}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial \theta} \right)∂θ∂L=∂z∂L⋅(∂μ∂z⋅∂θ∂μ+∂σ∂z⋅∂θ∂σ)
这种变换使得梯度可以沿着μ\muμ和σ\sigmaσ这两个确定性的路径流动。根据CSDN技术社区2025年3月的基准测试,使用重参数化技巧后VAE的训练速度提升了2-3倍,收敛稳定性提高了47%。
多维情况的扩展
对于高维隐空间,重参数化技巧展现出更强的优势。假设z∈Rdz\in\mathbb{R}^dz∈Rd,协方差矩阵为Σ\SigmaΣ,我们可以通过Cholesky分解Σ=LLT\Sigma=LL^TΣ=LLT,其中LLL是下三角矩阵。此时重参数化公式扩展为:
z=μ+Lεz = \mu + L\varepsilonz=μ+Lε
这种实现方式在2025年最新的BigVAE架构中被广泛应用,支持了高达1024维的隐空间建模。值得注意的是,当Σ\SigmaΣ为对角矩阵时(即各维度独立),该方法退化为逐元素相乘的形式,这也是大多数开源实现采用的默认设定。
超越高斯分布
虽然高斯分布是最常见的情况,但重参数化技巧可以推广到其他分布族:
- 指数分布:通过逆变换采样实现
- Gumbel分布:用于分类变量的Gumbel-Softmax重参数化
- 混合模型:通过分阶段重参数化处理
2024年NeurIPS会议上提出的通用重参数化框架(URT)将这一技术扩展到了17种概率分布,为VAE的灵活应用开辟了新途径。特别值得注意的是,这些扩展仍然保持着原始技巧的核心思想:将随机性从待优化参数中分离。
工程实现细节
在实际代码实现中,有多个关键点需要特别注意:
- 数值稳定性:对σ\sigmaσ采用softplus或exp变换避免数值下溢
- 随机数生成:确保ε\varepsilonε的采样与设备无关(CPU/GPU一致性)
- 并行计算:批量重参数化时的矩阵运算优化
- 混合精度训练:FP16模式下的特殊处理
最新的TensorFlow 2.8和PyTorch 2.1都内置了对重参数化的原生支持,如torch.distributions模块提供了rsample()方法直接支持重参数化采样。根据GitHub统计,2025年排名前100的VAE实现项目中,有92个采用了框架原生支持的重参数化方案。
KL散度正则化的概率推导
从变分推断到KL散度:理论基础
在变分自编码器的框架中,KL散度正则化的引入源于变分推断的基本思想。当我们试图用参数化的分布q(z∣x)q(z|x)q(z∣x)逼近真实后验分布p(z∣x)p(z|x)p(z∣x)时,需要最小化两者之间的差异。根据变分下界(ELBO)的推导:
logp(x)≥Eq(z∣x)[logp(x∣z)]−DKL(q(z∣x)∥p(z))\log p(x) \geq \mathbb{E}_{q(z|x)}[\log p(x|z)] - D_{\text{KL}}(q(z|x) \| p(z))logp(x)≥Eq(z∣x)[logp(x∣z)]−DKL(q(z∣x)∥p(z))
其中第二项正是我们需要深入分析的KL散度项。这个数学形式揭示了VAE的核心矛盾:既要保证重构精度(第一项),又要约束隐变量分布不要偏离先验太远(第二项)。
高斯分布假设下的解析解推导
当假设先验分布p(z)p(z)p(z)为标准高斯分布N(0,I)\mathcal{N}(0,I)N(0,I),变分后验q(z∣x)q(z|x)q(z∣x)为对角高斯N(μ,σ2I)\mathcal{N}(\mu,\sigma^2I)N(μ,σ2I)时,KL散度可以推导出解析表达式。具体推导过程如下:
DKL=∫q(z)logq(z)p(z)dz=Ez∼q[logq(z)−logp(z)]=Ez∼q[−12∑i=1d(log(2πσi2)+(zi−μi)2σi2)+12∑i=1d(log(2π)+zi2)]=12∑i=1d(μi2+σi2−logσi2−1) \begin{aligned} D_{\text{KL}} &= \int q(z) \log \frac{q(z)}{p(z)} dz \\ &= \mathbb{E}_{z\sim q}\left[ \log q(z) - \log p(z) \right] \\ &= \mathbb{E}_{z\sim q}\left[ -\frac{1}{2}\sum_{i=1}^d \left( \log(2\pi\sigma_i^2) + \frac{(z_i-\mu_i)^2}{\sigma_i^2} \right) + \frac{1}{2}\sum_{i=1}^d \left( \log(2\pi) + z_i^2 \right) \right] \\ &= \frac{1}{2}\sum_{i=1}^d \left( \mu_i^2 + \sigma_i^2 - \log \sigma_i^2 - 1 \right) \end{aligned} DKL=∫q(z)logp(z)q(z)dz=Ez∼q[logq(z)−logp(z)]=Ez∼q[−21i=1∑d(log(2πσi2)+σi2(zi−μi)2)+21i=1∑d(log(2π)+zi2)]=21i=1∑d(μi2+σi2−logσi2−1)
这个简洁的表达式在实现时可以直接计算,避免了复杂的积分运算。值得注意的是,当σi\sigma_iσi趋近于0时,logσi2\log\sigma_i^2logσi2会趋向负无穷,这在实际实现时需要添加微小常数保证数值稳定性。
信息论视角的解读
从信息论的角度看,KL散度衡量的是用先验分布p(z)p(z)p(z)来近似变分分布q(z∣x)q(z|x)q(z∣x)时损失的信息量。在VAE中,这个项起到了双重作用:
- 正则化作用:防止编码器输出的分布过度偏离标准正态分布,避免模型退化为普通自编码器
- 结构化潜空间:强制潜变量在不同维度上解耦,使得每个维度都能捕获数据中独立的变异因素
实验表明,当KL散度项的权重适当时,VAE学习到的潜空间往往具有更好的可解释性和插值特性。2024年Renyixiong的研究显示,在图像生成任务中,适当调整KL项的权重系数可以显著改善生成样本的质量。
与贝叶斯框架的联系
KL散度正则化本质上反映了贝叶斯统计中的先验思想。将标准高斯分布作为先验,相当于对模型参数施加了L2正则化。但与传统的权重衰减不同,这里正则化的是整个概率分布的形状而非单个参数。
在更广泛的变分推断框架下,KL散度项确保了近似后验分布不会过度拟合训练数据中的噪声。2025年CSDN技术专栏指出,这种正则化机制比传统的L1/L2正则化更适合处理高维隐变量空间,因为它直接约束了整个分布的特性而非单个维度。
实际实现中的考量
在实际代码实现时,KL散度项的计算需要注意几个关键点:
- 数值稳定性:对数方差处理比直接处理方差更稳定
- 批量处理:通常需要对批量数据中的KL散度取平均
- 权重调节:引入β\betaβ系数控制正则化强度,即β\betaβ-VAE框架
一个典型的PyTorch实现示例如下:
python
def kl_divergence(mu, logvar):
# mu: [batch_size, latent_dim]
# logvar: [batch_size, latent_dim]
return -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp(), dim=1).mean()
正则化强度的平衡艺术
KL散度项与重构损失项之间存在天然的trade-off。过强的KL正则化会导致"posterior collapse"现象,即编码器忽略输入数据,始终输出接近先验的分布;而过弱的正则化则会使潜空间失去结构性。2025年最新的研究建议采用以下几种策略:
- 退火策略:训练初期减弱KL项权重,后期逐步增强
- 自由比特技术:为每个潜变量维度设置最小信息量约束
- 对抗训练:引入判别器来优化潜空间分布
这些技术都旨在解决同一个核心问题:如何在保持生成能力的同时,确保潜空间具有良好的数学性质。
VAE在实际应用中的案例分析
医疗影像异常检测:VAE的精准诊断革命
在2025年的医疗AI领域,VAE结合重参数化技巧正在革新医学影像分析。以华中科技大学团队开发的VA-VAE系统为例,该系统在肺部CT扫描异常检测中实现了94.3%的召回率,较传统方法提升27%。其核心突破在于:通过视觉基础模型对齐损失(VF Loss)重构潜在空间,使512维高维特征仍保持稳定梯度传播。具体实现中,编码器将输入图像压缩为μ\muμ和σ\sigmaσ参数后,采用ε∼N(0,I)\varepsilon\sim\mathcal{N}(0,I)ε∼N(0,I)的重参数化采样,既保证潜在空间连续性,又通过KL散度约束(β=0.5\beta=0.5β=0.5)防止后验坍塌。实际部署显示,该系统在早期肺癌微小结节(<3mm)检测中,假阴性率降低至2.1%。

工业质检:KL散度的自适应调节实践
2025年半导体行业的质量控制标准中,台积电等厂商已广泛采用动态KL加权的VAE方案。在芯片表面缺陷检测中,模型面临重建精度与特征解耦的权衡难题。解决方案是设计分段KL系数:训练初期λ=0.01\lambda=0.01λ=0.01侧重重建,后期逐步提升至λ=0.3\lambda=0.3λ=0.3增强泛化。重参数化过程特别采用截断正态采样(ε∈[−2,2]\varepsilon\in[-2,2]ε∈[−2,2]),避免潜在空间边缘区域的异常值。实际产线数据显示,该方案在3纳米制程的晶圆检测中,将误检率控制在0.03ppm,同时保持98.6%的缺陷分类准确率。关键突破在于:通过重参数化的可微性,使KL项能与重建损失同步优化,而传统EM算法需要交替训练。
金融时序数据生成:对抗性KL约束的创新
摩根大通2025年发布的Quant-GAN系统创造性融合了VAE与Wasserstein距离。在合成金融时间序列任务中,模型面临两个挑战:①收益率序列的尖峰厚尾特性 ②市场regime切换的动态建模。解决方案采用分层潜在空间:底层z1z_1z1通过常规重参数化(μ1+σ1⊙ε\mu_1+\sigma_1\odot\varepsilonμ1+σ1⊙ε)捕捉短期波动,顶层z2z_2z2引入对抗性KL约束(Discriminator输出λ\lambdaλ)建模市场状态。具体实现时,KL项被拆解为:
KL=0.5×(μ22+σ22−logσ22−1)+λ⋅∣μ2∣\text{KL} = 0.5 \times \left( \mu_2^2 + \sigma_2^2 - \log\sigma_2^2 - 1 \right) + \lambda \cdot |\mu_2|KL=0.5×(μ22+σ22−logσ22−1)+λ⋅∣μ2∣
这种设计使模型在标普500指数期货数据回测中,合成数据与真实数据的KS检验p值达0.82,显著优于传统GAN的0.47。重参数化技巧在此处的关键价值是:允许梯度穿透多层潜在变量,实现端到端的市场状态学习。
材料科学:多模态潜在空间的工程突破
MIT材料AI实验室在2025年发表的成果展示了VAE在逆向材料设计中的突破。针对高分子聚合物特性预测任务,团队开发了多分支重参数化架构:①连续变量分支采用常规高斯采样 ②离散变量分支引入Gumbel-Softmax重参数化(τ=0.1\tau=0.1τ=0.1)③周期性变量分支使用von Mises分布变换。KL散度项被分解为各向异性加权和:
∑iwi⋅DKL(qi∥pi)\sum_i w_i \cdot D_{\text{KL}}(q_i \| p_i)i∑wi⋅DKL(qi∥pi)
其中权重wiw_iwi通过可学习的温度参数自适应调节。实验数据显示,该模型在预测聚合物玻璃化转变温度时,仅需5%的标记数据就能达到R2=0.91R^2=0.91R2=0.91的精度,比纯监督学习提升40%。重参数化在此处的核心优势是:统一处理连续/离散/周期变量的梯度回传,这是传统MCMC方法无法实现的。
自动驾驶场景合成:时空一致性建模
Waymo最新开源的DriveVAE系统(2025Q2版本)展现了时空重参数化的精妙设计。为生成符合物理规律的驾驶场景,模型采用三级潜在结构:①场景级zs∼N(0,I)z_s\sim\mathcal{N}(0,I)zs∼N(0,I) ②轨迹级zt=μt+Σt⊙εz_t=\mu_t+\Sigma_t\odot\varepsilonzt=μt+Σt⊙ε ③物理约束级zp=MLP(zs,zt)+εpz_p=\text{MLP}(z_s,z_t)+\varepsilon_pzp=MLP(zs,zt)+εp。KL正则化项创新性地引入动力学先验:
KLp=E[logq(zp∣zt)−logp(zp∣F=ma)]\text{KL}_p = \mathbb{E}\left[ \log q(z_p|z_t) - \log p(z_p|F=ma) \right]KLp=E[logq(zp∣zt)−logp(zp∣F=ma)]
这种设计在CARLA仿真测试中,合成场景的物理违规率降低至0.8次/公里,同时保持HD地图的拓扑一致性。关键技术在于:通过重参数化建立潜在变量间的显式微分关系,使加速度约束能通过∂zp/∂zt\partial z_p / \partial z_t∂zp/∂zt传播到所有参数。
未来展望与挑战
技术融合:跨模态生成的新范式
2025年的生成式AI领域,VAE技术正经历着从单一模态向跨模态协同的范式转变。最新研究显示,通过将视觉大模型(如DINOv2)的语义空间与VAE潜在空间对齐,可显著提升多模态生成质量。华中科技大学团队开发的VA-VAE框架便是典型代表,其创新性地引入视觉基础模型对齐损失(VF Loss),在ImageNet 256×256256\times256256×256生成任务中FID指标突破1.35,同时将传统DiT模型的训练效率提升21倍。这种技术路径证明,预训练模型的先验知识能有效解决潜在空间维度增加导致的"重建-生成悖论"——当VAE潜在维度提升时,传统方法往往面临生成质量断崖式下跌的困境。
跨模态对齐技术的突破为VAE开辟了新场景:在医疗影像分析中,结合CLIP等跨模态编码器的VAE变体,已能实现从病理报告到三维CT影像的条件生成;在工业设计领域,文本引导的VAE-CAD模型可自动完成产品草图到工程图纸的转换。这些进展都依赖于对潜在空间语义的精细控制,而2025年提出的动态权重调节机制,通过实时平衡重建损失与对齐损失,使模型能自适应不同模态的耦合强度。
计算效率:轻量化架构的突破
传统VAE面临的核心挑战在于,当处理高分辨率数据时,编码器-解码器的计算复杂度呈指数级增长。2025年出现的LightningDiT架构通过三阶段优化策略破解了这一难题:首先采用分块注意力机制将计算复杂度从O(n2)\mathcal{O}(n^2)O(n2)降至O(nlogn)\mathcal{O}(n\log n)O(nlogn);其次引入混合精度训练中的梯度重参数化技术,使16位浮点运算的稳定性提升3倍;最后通过潜在空间稀疏化处理,在保持FID指标不变的情况下将内存占用降低67%。这些技术进步使得VAE在移动设备上的实时生成成为可能,某头部手机厂商已将其应用于相册的AI修图功能。
值得关注的是,量子计算为VAE带来的潜在变革。虽然通用量子计算机尚未成熟,但2025年已有实验室成功在127量子比特处理器上实现了量子变分自编码器(QVAE)的原型验证。与传统VAE相比,QVAE在分子结构生成任务中展现出独特优势——其量子线路天然适配薛定谔方程的求解过程,在模拟新型超导体电子云分布时,采样效率达到经典算法的10410^4104倍量级。
理论瓶颈:从ELBO到统一框架
尽管实践应用取得进展,VAE的理论基础仍存在深层矛盾。最突出的问题是证据下界(ELBO)的固有限制:当潜在空间维度超过数据真实维度时,KL散度项会导致潜在变量坍缩(latent collapse)。2025年ICML最佳论文提出的"渐进式KL annealing"方案虽然缓解了这一问题,但根本性解决方案仍需突破。最新理论研究表明,将最优传输理论中的Wasserstein距离引入VAE框架,可能构建更稳定的目标函数——在保持生成质量的前提下,Wasserstein-VAE对潜在空间维度的敏感性降低了80%。
另一个关键挑战在于动态系统的建模。传统VAE假设数据独立同分布,但现实世界的时间序列(如股票价格、气象数据)具有明显的非平稳特性。时间卷积VAE(TC-VAE)通过将自注意力机制与因果卷积结合,在沪深300指数预测中实现了22%的年化超额收益,但其理论解释性仍待加强。这引出了更本质的问题:如何建立VAE动力学系统的严格收敛性证明?目前数学界倾向于认为,需要发展新的泛函分析工具来处理无限维潜在空间中的概率流形。
安全伦理:可控生成的边界
随着VAE生成质量逼近真实,其滥用风险日益凸显。2025年欧盟AI法案特别新增了针对生成模型的"潜在空间审计"条款,要求商业化的VAE系统必须提供潜在向量的可解释性报告。这催生了两个技术方向:一是开发具有道德约束的潜在空间,如某实验室通过在KL散度项中嵌入伦理惩罚因子λethics\lambda_{\text{ethics}}λethics,使模型自动过滤暴力内容生成请求;二是构建对抗性检测网络,利用VAE自身重参数化特性,通过分析潜在变量分布异常来识别深度伪造内容,在最新测试中达到92.3%的检测准确率。
隐私保护是另一大挑战。传统VAE在训练过程中可能记忆敏感数据,差分隐私VAE(DP-VAE)通过向重参数化过程注入可控噪声,在医疗数据共享场景下将患者身份泄露风险降低至1%以下。但这也带来新的矛盾:隐私保护强度每提升10%,生成图像的结构相似性(SSIM)指标就会下降0.15,如何在隐私与效用间取得平衡成为亟待解决的课题。
硬件适配:从云端到边缘
VAE的硬件部署正呈现两极分化趋势。在云端,英伟达H100 Tensor Core GPU配合新型TF32计算格式,使大规模VAE训练吞吐量提升8倍;而在边缘侧,神经形态芯片为VAE带来革命性变化。2025年发布的Loihi 3芯片采用脉冲神经网络模拟VAE的随机采样过程,在图像压缩任务中实现每瓦特2.4TOPS的能效比,特别适合卫星等受限环境。不过,这类硬件也暴露出VAE架构的新问题:脉冲编码与重参数化技巧的兼容性不足,导致梯度估计方差增大30%,这需要算法-硬件协同设计来攻克。
存算一体架构可能是突破方向。某存储巨头最新发布的3D XPoint-VAE加速卡,通过在存储单元内直接实现潜在变量的概率运算,将生成延迟从毫秒级降至微秒级。但这种架构对KL散度计算提出了特殊要求——需要开发适应模拟计算的连续时间正则化方法,传统离散采样理论已不再适用。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)