RAG综述-from native rag to agentic rag
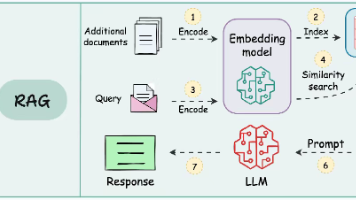
1.朴素RAG1.朴素RAG朴素rag就是最传统的rag,流程如图,首先把文档输入embedding模型,然后存入向量数据库。然后当用户输入时候,User Query输入同一个embedding模型,然后去向量数据库做关键词向量相似度匹配(而不是语义匹配),把最接近的Top-K拿出来作为prompt中的上下文去回答。朴素 RAG 系统为 “检索与生成整合” 提供了关键的概念验证,为更复杂的范式奠定
1.朴素RAG

朴素rag就是最传统的rag,流程如图,首先把文档输入embedding模型,然后存入向量数据库。然后当用户输入时候,User Query输入同一个embedding模型,然后去向量数据库做关键词向量相似度匹配(而不是语义匹配),把最接近的Top-K拿出来作为prompt中的上下文去回答。
好处:
朴素 RAG 系统为 “检索与生成整合” 提供了关键的概念验证,为更复杂的范式奠定了基础。
不足:
- 缺乏上下文感知(Lack of Contextual Awareness):由于依赖词汇匹配而非语义理解,检索到的文档往往无法捕捉查询的语义细微差别。
- 输出碎片化(Fragmented Outputs):缺少先进的预处理或上下文整合,常导致响应零散或过于笼统。
- 可扩展性问题(Scalability Issues):基于关键词的检索技术在面对大规模数据集时表现不佳,难以识别最相关信息。
2.高级RAG

高级 RAG(Advanced RAG)系统针对朴素 RAG(Naïve RAG)的局限性进行改进,融入语义理解和增强的检索技术。
相比起朴素RAG,这个多了一个前检索处理和后检索处理以及索引构建:
前检索处理就是:对用户查询做 “预处理”,比如理解语义、拆分需求、补充背景,让后续检索更准(比如把 “AI 最新研究” 拆解成 “AI 领域、2025 年、研究论文、核心突破),也就是解决朴素 RAG 里 “用户查询语义模糊、需求拆分不清,导致检索跑偏” 的问题,把原始查询转化为 精准、结构化、易被检索系统理解 的 “高级查询”。具体流程:
- 语义解析:用自然语言处理(NLP)模型(比如 BERT 系列、大语言模型微调版 ),分析用户查询的 意图、实体、关系。把自然语言转化为 “机器能理解的语义结构”,为后续检索打基础。
- 查询改写:基于语义解析结果,用模板匹配、生成式模型(比如 GPT - 风格模型 ),把原始查询改写成 更清晰、更适配检索系统 的新查询。弥补自然语言的模糊性,让检索系统更精准抓取需求。
- 需求分析与拆分:遇到复杂查询(比如 “AI 如何改变医疗,从诊断到治疗的全流程” ),用 任务分解算法(比如基于大语言模型的思维链分解、传统 NLP 的依存句法分析 ),把一个大需求拆成多个子需求。让复杂需求变得 “可执行”,适配高级 RAG 的 “Iterative Retrieval(迭代检索)” 能力。
- 上下文注入:若系统有 “用户历史查询、领域常识库”,会把这些 额外上下文 注入到当前查询里,补充信息。提升查询的 “信息密度”,让检索结果更贴合真实需求。
后检索就是:对检索到的文档,做 “二次筛选、重排”—— 用神经模型(Neural models )重新排序,优先保留 “语义最贴合、最有价值” 的文档(比如从 10 篇里再精选出 3 篇最核心的 )。具体流程:
- 神经重排:用 神经重排模型(比如 Cross - Encoder、ColBERT、Sentence - BERT 微调版 ),同时输入 “用户查询 + 候选文档”,深度计算两者的 语义关联度、信息价值、上下文适配性,输出 “文档质量得分”,重新排序。模型会学习 “查询和文档的交互语义”(比如:文档是否回答了查询的核心问题?信息是否足够新颖 / 有价值?和用户历史需求是否贴合? )。然后按 “质量得分” 排序后的文档列表,通常保留 Top 5 - 20 篇(根据场景灵活调整) 进入下一步。解决 “检索环节只看语义匹配,不看内容质量” 的问题,过滤掉 “语义相关但价值低、过时、重复” 的文档。
- 内容过滤:基于 规则引擎 + 轻量级语义模型,对重排后的文档做 “合规性、相关性、质量” 检查,过滤掉不符合要求的内容。其中规则过滤就是查看元数据是否合格,比如时间,会议等。语义过滤就是用轻量级模型(比如 TinyBERT ),快速判断文档内容是否 真的回答了查询核心需求。去重处理就是用 文本去重算法(比如 SimHash ),识别并合并 “内容高度重复” 的文档片段,避免生成时冗余。通过这一步进一步筛掉 “元数据不符、语义跑偏、重复冗余” 的文档,让进入生成环节的内容更 “干净、精准”。
- 语义整合:用 文本摘要模型 + 逻辑推理模型,对过滤后的文档片段做 “信息整合、逻辑梳理、关键提取”,输出 结构化的优质内容(比如 “关键结论、支持证据、逻辑链条” )。具体来说第一步信息抽取用命名实体识别(NER)、关系抽取(RE)模型,从文档里提取 核心实体、关键数据、因果关系。第二步逻辑梳理用大语言模型或图网络(Graph - based )模型,梳理片段间的 逻辑关系(比如 “研究 A 验证了方法 X 的有效性,研究 B 在此基础上优化了模块 Y” )。第三步摘要生成用摘要模型(比如 BART、T5 ),把零散片段整合成 简洁、连贯、有逻辑 的摘要(比如 “2025 年 AI 医疗诊断的三大突破:1. 模型 X 用自监督学习提升小样本诊断率...” )。这一步解决 “文档片段零散、逻辑混乱,直接喂给大模型会生成 ‘东拼西凑、没有重点’ 响应” 的问题,为生成环节提供 结构化、有逻辑、高价值 的内容。
索引构建就是:解决朴素 RAG 里 “文档只是简单关键词索引,语义关联弱,检索时匹配不准” 的问题,把静态文档转化为 带语义、易检索、支持复杂匹配 的 “向量索引库”。具体手段:
- 密集向量编码:用 密集检索模型(比如 Dense Passage Retrieval,DPR;或者 Sentence - BERT ),把每篇文档(和文档片段 )转化为 高维向量(可以理解为:用几百 / 几千个数字,代表文档的语义特征 )。文档会被 分段处理(比如长论文切成 “研究背景、方法、结论” 等片段 ),再分别编码,这样能保留更细粒度的语义。编码模型会在 “领域数据” 上做微调(比如用医疗 AI 论文训练 ),让向量更贴合特定领域语义。作用就是让文档的 “语义信息” 能被量化、比较,后续检索时,用 “向量相似度” 替代 “关键词匹配”,大幅提升语义关联度。
- 向量数据库构建:把编码好的 “文档向量” 存入 向量数据库,并建立 “快速检索索引”。目的是让检索系统能 “快速、精准” 找到和用户查询向量 “语义最接近” 的文档,替代传统的 “关键词扫库”,效率和精度都更高。
关键特性对应解决朴素RAG的三个痛点:
- 密集向量搜索:把 “用户查询” 和 “文档” 都转成 “高维向量”,让计算机能理解 “语义相似度”—— 不再只看关键词,而是看 “语义是否真相关”(比如 “AI 进展” 和 “人工智能 最新突破”,语义接近就会被匹配到 ),解决朴素 RAG “语义理解弱” 的问题。
- 上下文重排:用 “神经模型” 重新给检索到的文档排序,优先选 “最贴合上下文、最有价值” 的内容(比如用户问 “AI 医疗应用”,就把 “AI + 医疗” 的文档排前面,其他领域的往后放 ),解决朴素 RAG “检索结果质量差” 的问题。
- 迭代检索:支持 “多轮、跨文档” 的检索,遇到复杂需求(比如 “AI 如何改变医疗,从诊断到治疗的全流程” ),能 “先找诊断相关文档、再找治疗相关文档”,逐步推理、整合信息,解决朴素 RAG “处理复杂需求能力弱” 的问题。
优点:
适合 “对精度、语义理解要求高” 的场景,比如学术研究总结(快速从海量论文里找核心观点 )、个性化推荐(精准匹配用户需求 )。
缺点:
- 计算开销大:语义理解、多轮检索、神经模型重排,都需要大量计算资源,处理慢、成本高。
- 可扩展性有限:数据量特别大(比如百万级文档 )、需求特别复杂(比如十轮以上的多步推理 )时,系统容易 “卡壳”,不好扩展。
3.Modular RAG
模块化检索增强生成(Modular RAG)[20] 代表了检索增强生成(RAG)范式的最新演进,强调灵活性与可定制性。这类系统将检索和生成流程分解为独立、可复用的组件,支持针对特定领域进行优化,适配各类任务需求。图 5 展示了模块化架构,呈现混合检索策略、可组合的流程管线以及外部工具集成的特点。

模块化 RAG 的关键创新点包括:
- 混合检索策略(Hybrid Retrieval Strategies):结合稀疏检索方法(如稀疏编码器 - BM25 )与密集检索技术(如密集段落检索,Dense Passage Retrieval,DPR ),在处理不同类型查询时最大化精度。(search模块实现)
- 工具集成(Tool Integration):纳入外部 API、数据库或计算工具,以处理专业任务,如实时数据分析或特定领域的计算需求。(search或者predict模块)
- 可组合流程管线(Composable Pipelines):模块化 RAG 支持检索器、生成器及其他组件独立替换、增强或重新配置,可高度适配具体应用场景。
主要是这个图怎么理解,分上下两部分,上部分是全部包含的可复用的模块,下部分是“模板”。我们一个一个介绍。
上部分模块层:
- Memory(记忆):存储历史交互、上下文信息,让系统 “记住过去”,支持多轮对话、复杂任务的连贯性(比如记住用户之前提的 “金融分析需求”,后续流程自动适配 )。
- Fusion(融合):把不同来源的信息(比如稀疏检索结果 + 密集检索结果 )做 “语义融合”,输出更全面的内容。
- Predict(预测):基于现有信息,预测 “下一步该检索什么、生成什么”,让流程更智能。
- Search(搜索):对接外部检索工具(比如混合检索策略里的稀疏 / 密集检索 ),获取信息。
- Demonstrate(演示 / 示例):生成 “示例内容”,辅助大模型理解任务(比如给金融分析任务,生成 “过往成功预测案例” 当参考 )。
- Routing(路由):决定 “哪个模块该被调用、信息该往哪流”,像交通枢纽一样调度流程。
- RAG(基础 RAG 流程):包含最核心的 “Retrieve(检索)、Re - rank(重排)、Read(读取 / 理解)、Re - write(改写)” 环节,是模块化的基础单元。
这些东西并不是说全部要用完,只是说有这么写个模块。
下部分模板层:
- 第一个模式:
Retrieve → Read(检索→读取 ):最简单的流程,适合基础查询(比如 “查某篇论文的结论” )。 - 第二个模式:
Re - write → Retrieve → Re - rank → Read(改写→检索→重排→读取 ):先改写查询让检索更准,重排筛选优质内容,再读取生成,适合复杂需求(比如 “金融分析需要先精准改写需求,再混合检索、重排数据” )。 - 其他模式同理:通过不同模块的 “串联 / 并联”,覆盖 “多轮推理、跨工具协作、领域定制” 等场景。
价值:
- 解耦:把传统 RAG 的 “线性流程” 拆成独立模块(如检索、生成、融合、路由 ),每个模块专注一个功能,方便单独优化(比如替换更先进的检索模块,不影响生成环节 )。
- 复用:预定义 “模式(Patterns)” 作为流程模板,不同任务可直接复用(比如金融分析和医疗诊断,都能基于现有模式调整模块,快速搭建系统 )。
优势:
- 灵活定制:不同领域(金融、医疗 )可根据需求,用模块 “搭积木”,快速定制专属 RAG 系统。
- 可扩展性:模块独立升级(比如换更先进的检索模型 ),不影响整体流程,系统能持续进化。
- 适配复杂任务:多模块协作 + 预定义模式,能处理 “多步骤、跨领域、需工具辅助” 的复杂任务(比如金融分析需要实时数据 + 历史分析 + 生成投资建议 )。
对比其他:
- 对比朴素 RAG:朴素版是 “固定流程、难扩展”,模块化版是 “解耦模块、灵活组合”,能处理更复杂需求。
- 对比高级 RAG:高级 RAG 聚焦 “语义增强、检索优化”,模块化 RAG 更强调 “架构解耦、流程定制”,前者优化单点能力,后者重构系统灵活性。
4.图RAG

图结构检索增强生成(Graph RAG)[16] 通过整合基于图的数据结构,扩展了传统的检索增强生成系统,正如图 6 所示。这类系统利用图数据中的关系和层次结构,增强多跳推理能力和上下文丰富度。借助基于图的检索,Graph RAG 能够生成更丰富、更准确的内容,尤其适用于需要理解关系的任务。
Graph RAG 具有以下特点:
- 节点连接性(Node Connectivity):捕捉实体之间的关系并基于这些关系进行推理。
- 分层知识管理(Hierarchical Knowledge Management):通过基于图的层次结构,处理结构化和非结构化数据。
- 上下文丰富化(Context Enrichment):利用基于图的路径,增加对关系的理解。
然而,Graph RAG 存在一些局限性:
- 可扩展性有限(Limited Scalability):对图结构的依赖会限制可扩展性,在处理大规模数据源时尤为明显。
- 数据依赖性(Data Dependency):高质量的图数据是生成有意义输出的关键,这限制了其在非结构化或标注不佳的数据集上的应用。
- 集成复杂性(Complexity of Integration):将图数据与非结构化检索系统集成,会增加设计和实施的复杂性。
Graph RAG 非常适合医疗诊断、法律研究等应用场景,以及其他需要对结构化关系进行推理的领域。关于图的解释:
-
用户提问(User → Question):
- 用户输入问题(比如 “哪些基因会导致某遗传病?” ),触发整个流程。
-
图抽取(Question → Graph Extraction):
- 系统用 图抽取技术(比如命名实体识别 + 关系抽取模型 ),从用户问题里提取 “实体” 和 “关系需求”:
- 实体:比如问题里的 “基因”“遗传病”;
- 关系需求:比如 “导致” 这种关联关系。
- 作用:把自然语言问题,转化为 “图结构能理解的查询需求”,为后续检索打基础。
- 系统用 图抽取技术(比如命名实体识别 + 关系抽取模型 ),从用户问题里提取 “实体” 和 “关系需求”:
-
检索(Graph Extraction → Retrieval):
- 检索环节对接两个核心数据源:
- Knowledge Graph(知识图谱):存储 “实体 + 关系” 的结构化数据(比如已知的 “基因 A → 导致 → 遗传病 B” 关联 )。
- Vector Database(向量数据库):存储非结构化数据的向量(比如医学论文片段的语义向量 )。
- 系统会结合 “图抽取得到的实体 / 关系需求”,在这两个数据源里 联合检索:
- 知识图谱找 “结构化的关联关系”(比如直接查 “基因 A 和遗传病 B 的关系” );
- 向量数据库找 “语义相关的非结构化内容”(比如和 “基因导致遗传病机制” 相关的论文片段 )。
- 检索环节对接两个核心数据源:
-
获取检索内容(Retrieval → Retrieved Content):
- 把知识图谱和向量数据库的检索结果,整合成 Retrieved Content(检索到的内容),包含:
- 知识图谱里的 “实体关系”(比如基因 A 导致遗传病 B 的证据链 );
- 向量数据库里的 “语义相关文本”(比如具体的研究方法、实验数据 )。
- 把知识图谱和向量数据库的检索结果,整合成 Retrieved Content(检索到的内容),包含:
-
提示增强与生成(Retrieved Content → Prompt Augmentation + Question Context → Answer):
- Question Context(问题上下文):包含原始问题、图抽取得到的实体 / 关系需求,是生成的基础。
- Prompt Augmentation(提示增强):把 “Retrieved Content + Question Context” 整合成 Prompt(提示),喂给大语言模型(LLM )。
- 大语言模型结合 “Prompt 里的关系知识、语义内容”,生成 Answer(回答)(比如详细解释 “基因 A 如何导致遗传病 B,参考了哪些研究” ),反馈给用户。
5.Agentic RAG
智能体检索增强生成(Agentic RAG)通过引入具备动态决策和工作流优化能力的自主智能体,实现了范式转变。与静态系统不同,Agentic RAG 采用迭代优化和自适应检索策略,以应对复杂、实时且跨领域的查询。该范式在利用检索与生成流程模块化特点的同时,引入基于智能体的自主性。
关键特征
- 自主决策(Autonomous Decision-Making):智能体可根据查询复杂度,独立评估并管理检索策略。
- 迭代优化(Iterative Refinement):融入反馈循环,提升检索准确性和响应相关性。
- 工作流优化(Workflow Optimization):动态编排任务,保障实时应用场景下的效率。
挑战
- 协调复杂性(Coordination Complexity):管理智能体间的交互,需复杂的编排机制。
- 计算开销(Computational Overhead):多智能体的使用,增加了复杂工作流的资源需求。
- 可扩展性局限(Scalability Limitations):虽具备可扩展性,但系统的动态特性在高查询量场景下,仍会对计算资源造成压力。
适用领域
智能体 RAG 在客户支持、金融分析、自适应学习平台等领域表现卓越 —— 这些场景对动态适应性和上下文精准度要求极高。
附图:不同RAG特征和优势(AI翻译版)

——————————————————————————————————————————
从传统RAG到Agentic RAG
传统检索增强生成(RAG)系统通过整合实时数据检索,显著拓展了大语言模型(LLMs)的能力。然而,这些系统在复杂现实应用中仍面临关键挑战,阻碍其有效性。最突出的局限集中在上下文整合、多步推理以及可扩展性与延迟问题。
上下文整合
即便 RAG 系统成功检索到相关信息,也往往难以将其无缝融入生成的响应中。检索流程的静态性和有限的上下文感知能力,会导致输出碎片化、不一致或过于笼统。
示例:对于像 “阿尔茨海默病研究的最新进展及其对早期治疗的意义是什么?” 这样的查询,系统可能会获取相关研究论文和医疗指南。但传统 RAG 系统通常无法将这些发现整合为连贯的解释,把新疗法与特定患者场景关联起来。类似地,对于 “干旱地区小规模农业的最佳可持续实践有哪些?” 这类查询,传统系统可能检索到通用农业方法的文档,却忽略针对干旱环境定制的关键可持续实践。
多步推理
许多现实世界的查询需要迭代或多跳推理 —— 需跨多个步骤检索和整合信息。传统 RAG 系统往往无法根据中间见解或用户反馈优化检索,导致响应不完整或零散。
示例:复杂查询如 “欧洲可再生能源政策的哪些经验可应用于发展中国家,潜在经济影响是什么?” 需要整合多种信息,包括政策数据、发展中地区的背景信息以及经济分析。传统 RAG 系统通常无法将这些分散元素整合为连贯响应。
可扩展性与延迟问题
随着外部数据源体量增长,查询和排序大型数据集的计算成本急剧上升,导致显著延迟,削弱系统在实时应用中及时响应的能力。
示例:在金融分析、实时客户支持等对时间敏感的场景中,查询多个数据库或处理大型文档集造成的延迟,会降低系统整体实用性。例如,高频交易中检索市场趋势的延迟,可能导致错失机会。
HOWEVER传统检索增强生成(RAG)系统因工作流静态、适应性有限,往往难以处理动态、多步推理及复杂现实任务。这些局限推动了智能体智能的整合,催生了智能体检索增强生成(Agentic RAG) 。
智能体检索增强生成纳入具备动态决策、迭代推理及自适应检索策略的自主智能体,在继承早期范式模块化特性的同时,克服其固有约束。这一演进让更复杂的多领域任务能以更高精度、更优上下文理解被处理,使智能体检索增强生成成为下一代人工智能应用的基石。具体而言,智能体检索增强生成系统通过优化工作流降低延迟,迭代优化输出,攻克长期阻碍传统 RAG 可扩展性与有效性的难题 。
——————————————————————————————————————————
智能体智能和智能体检索增强
前者是后者的基础,本质上,一个人工智能智能体由以下部分构成(见图 7):
- 大语言模型(LLM,明确角色与任务):作为智能体的核心推理引擎和对话界面,负责解读用户查询、生成响应并保持内容连贯。
- 记忆(短期与长期):捕捉交互过程中的上下文和相关数据。短期记忆 [22] 追踪即时对话状态,长期记忆 [22] 存储积累的知识和智能体经验。
- 规划(反思与自我批判):通过反思、查询路由或自我批判 [23],引导智能体的迭代推理过程,确保复杂任务能有效拆解 [24]。
- 工具(向量搜索、网页搜索、API 等):突破智能体仅能进行文本生成的局限,使其能够访问外部资源、获取实时数据或执行专业计算。

反思Reflection
反思是智能体工作流中的一种基础设计模式,能让智能体迭代式地评估并优化自身输出。通过融入自我反馈机制,智能体可识别并解决错误、不一致问题及有改进空间的地方,在代码生成、文本创作和问答等任务中提升表现;在多智能体系统里,反思可涉及不同角色分工,比如一个智能体负责生成输出,另一个负责批判审视,以此促进协作式改进。

规划Planning
规划是智能体工作流中的关键设计模式,能让智能体自主将复杂任务分解为更小、可管理的子任务。在动态且不确定的场景中,这种能力对于多跳推理和迭代式问题解决至关重要。借助规划,智能体可动态确定达成更大目标所需的步骤序列。这种适应性让智能体能够处理无法预先定义的任务,确保决策具备灵活性。尽管规划功能强大,但与反思这类确定性工作流相比,其产出结果的可预测性较低。规划特别适用于需要动态适配的任务 —— 这类任务中,预定义工作流无法满足需求。随着技术成熟,其在各领域推动创新应用的潜力将持续增长。
ToolUse
工具使用能让智能体通过与外部工具、API 或计算资源交互,拓展自身能力。这种模式使智能体能够获取信息、执行计算并处理超出预训练知识的数据。通过将工具动态集成到工作流中,智能体可适配复杂任务,输出更准确、更贴合上下文的结果。现代智能体工作流会在各类应用中融入工具使用,涵盖信息检索、计算推理以及与外部系统交互。尽管工具使用大幅增强了智能体工作流,但在工具数量众多的场景中,优化工具选择仍是挑战。目前,已有借鉴检索增强生成(RAG)的技术被提出以解决该问题,比如基于启发式的选择方法。
多智能体(Multi - Agent)
多智能体协作是智能体工作流中的一种关键设计模式,能够实现任务专业化和并行处理。智能体之间会进行沟通并共享中间结果,确保整体工作流保持高效且连贯。通过将子任务分配给专门的智能体,这种模式提升了复杂工作流的可扩展性和适应性(以复杂工作流为例,多智能体系统允许开发者将复杂任务分解为更小、可管理的子任务,并分配给不同智能体。这种方法不仅能提升任务表现,还能为管理复杂交互提供一个稳健的框架。每个智能体都有自己的记忆和工作流,其中可包含工具使用、反思或规划,从而实现动态且协作式的问题解决)。

虽然多智能体协作蕴含巨大潜力,但与反思、工具使用等更成熟的工作流相比,它是一种可预测性较低的设计模式。
这些设计模式构成了智能体检索增强生成(Agentic RAG)系统成功的基础。通过构建工作流(从简单的顺序步骤,到更具适应性的协作流程 ),这些模式使系统能够动态调整检索和生成策略,以适配现实世界中多样且不断变化的需求。借助这些模式,智能体能够处理迭代式、具备上下文感知的任务 —— 这些任务的复杂度远超传统 RAG 系统的能力范围。
——————————————————————————————————————————
智能体工作流模式:动态协作的自适应策略
1.提示链:通过顺序处理提升准确性
提示链会把一项复杂任务分解成多个步骤,每个步骤都以前一个步骤为基础逐步推进。这种结构化的方法通过在推进前简化每个子任务,来提高准确性。不过,由于是按顺序处理,可能会增加延迟 。

查询(Query)输入大语言模型(LLM)后,会经过一个 “Gate(判断门)”,由判断门决定后续走向:若判定为 “Yes(是)”,就进入下一个大语言模型(LLM)进行处理;若不满足继续推进的条件,则 “Exit(退出)” 流程;最终输出 “Response(响应)”
什么时候用:当一项任务能够被拆解成固定的子任务,且每个子任务都对最终输出有贡献时,这种工作流的效果最佳。在那些需要通过逐步推理来提升准确性的场景中,它尤其有用 。
应用示例:①先用一种语言生成营销内容,之后将其翻译成另一种语言,同时保留语义细节 。②结构化的文档创作流程:先生成大纲,验证大纲的完整性,接着再扩展成完整文本 。
2.路由(Routing):将输入导向专门流程
路由指对输入进行分类,再将其导向合适的专门提示或流程。这种方法确保不同查询或任务被分开处理,提升效率和响应质量。
查询(Query)先进入 “Router(路由器)” 进行分类,再被导向不同的大语言模型(LLM)处理,最终汇总输出响应(Response) ,体现按输入类型分流到专属流程的逻辑
什么时候用:适用于不同类型输入需要 distinct 处理策略的场景,确保各类别都能实现性能优化。
应用示例:①将客户服务查询分类,如导向技术支持、退款请求或常规咨询等类别。②把简单查询分配给小型模型以控制成本,复杂请求则交给先进模型处理。
3.并行化(Parallelization):通过并发执行加速处理
并行化将任务拆分为独立流程同时运行,减少延迟、提升吞吐量。可分为 “分段(sectioning,独立子任务 )” 和 “投票(voting,多输出保障准确性 )” 两类。
什么时候用:适用于任务可独立执行以提升速度,或多输出能增强结果可信度的场景。
应用示例:
- 分段(Sectioning):拆分内容审核类任务,一个模型筛查输入,另一个生成响应。
- 投票(Voting):用多个模型交叉检查代码漏洞,或分析内容审核决策。
4.协调器 - 工作器:动态任务委派
这种工作流的特点是有一个中央协调器模型,它会动态地将任务拆分为子任务,把这些子任务分配给专门的工作器模型,然后汇总结果。与并行化不同,它能够适应不同的输入复杂度。
查询(Query)先进入 “Orchestrator(协调器)” 进行任务拆分,再分配给不同的大语言模型(LLM,即工作器 )处理,处理结果进入 “Synthesizer(合成器)” 汇总,最终输出响应(Response) ,体现动态拆分、分工协作再聚合的逻辑
什么时候用:最适合需要动态分解任务和实时适应的场景,这类场景中子任务不是预先定义好的。
应用示例:
- 根据变更需求的性质,自动修改代码库中的多个文件。
- 通过从多个来源收集并整合相关信息,开展实时研究。
5.评估器 - 优化器:通过迭代优化输出
评估器 - 优化器工作流先生成初始输出,再基于评估模型的反馈对其进行优化,以此迭代提升内容质量。

查询(Query)进入 “Generator(生成器,大语言模型 )” 产出初始结果(Solution),结果交给 “Evaluator(评估器,大语言模型 )” 评判;若 “Accepted(通过 )”,输出响应(Response);若 “Rejected(未通过 )”,则带着反馈(Feedback)返回生成器重新优化 ,体现迭代优化的闭环逻辑
什么时候用:当迭代优化能显著提升响应质量时效果显著,尤其适用于存在清晰评估标准的场景。
应用示例:
- 通过多轮评估和优化循环,改进文学翻译质量。
- 开展多轮研究查询,用额外迭代优化搜索结果。
——————————————————————————————————————————
智能体检索增强生成(Agentic RAG)系统的分类
智能体检索增强生成(Agentic RAG)系统可依据复杂度和设计原则,归类为不同架构框架,包括单智能体架构、多智能体系统和分层智能体架构。每种框架都针对特定挑战定制,为各类应用优化性能。本节将详细介绍这些架构的分类,突出其特点、优势与局限。
1.单智能体智能体检索增强生成:路由型(Single-Agent Agentic RAG: Router)
单智能体智能体检索增强生成[30] 是集中式决策系统,由单个智能体管理信息检索、路由和整合。这种架构通过将任务整合到统一智能体中简化系统,在工具或数据源数量有限的场景中尤为高效。

工作流程
- 查询提交与评估:流程始于用户提交查询。协调智能体(或主检索智能体)接收查询,分析后确定最适合的信息来源。
- 知识源选择:根据查询类型,协调智能体从多种检索选项中选择:
- 结构化数据库:若查询需访问表格数据,系统可能用 “文本转 SQL(Text-to-SQL)” 引擎,对接 PostgreSQL、MySQL 等数据库。
- 语义搜索:处理非结构化信息时,通过基于向量的检索,获取相关文档(如 PDF、书籍、机构记录 )。
- 网页搜索:需实时或广泛上下文信息时,系统借助网页搜索工具访问最新在线数据。
- 推荐系统:处理个性化或上下文查询时,系统调用推荐引擎获取定制化建议。
- 数据整合与大语言模型(LLM)合成:从选定来源检索到相关数据后,传递给大语言模型。大语言模型整合信息,将多来源洞察融合为连贯、贴合上下文的响应。
- 输出生成:最终,系统生成全面、面向用户的答案,回应原始查询。响应以可操作、简洁的格式呈现,可选配所用来源的引用。
输入(Input)转化为查询(Query)和提示(Prompt),进入 “Retrieval Router Agent(检索路由智能体)”;智能体调用 “Tools(工具,如 Vector Search X/Y、Web Search )”,对接 “Data Sources(数据源)” 获取信息;最终经大语言模型(LLM)处理,输出响应(Response) ,体现单智能体统筹检索、路由与生成的逻辑
特征与优势:
集中式简洁性,效率与资源优化,动态路由,工具适配多样性,适配简单系统。
2.多智能体智能体检索增强生成(RAG)系统
多智能体 RAG [30] 是单智能体架构的模块化、可扩展演进,通过利用多个专用智能体,设计用于处理复杂工作流和多样查询类型(如图 17 所示)。该系统不再依赖单个智能体管理所有任务(推理、检索、响应生成 ),而是将职责分配给多个智能体,每个智能体针对特定角色或数据源优化。
工作流程
- 查询提交:流程始于用户查询,由协调智能体或主检索智能体接收。该智能体作为中央协调器,根据查询需求将其委派给专用检索智能体。
- 专用检索智能体:查询在多个检索智能体间分配,每个智能体专注于特定类型的数据源或任务。示例包括:
- 智能体 1:处理结构化查询,如与 PostgreSQL 或 MySQL 等基于 SQL 的数据库交互。
- 智能体 2:管理语义搜索,从 PDF、书籍或内部记录等来源检索非结构化数据。
- 智能体 3:专注于从网页搜索或 API 检索实时公共信息。
- 智能体 4:专攻推荐系统,基于用户行为或资料提供上下文感知建议。
- 工具访问与数据检索:每个智能体将查询路由到其领域内的合适工具或数据源,例如:
- 向量搜索:用于语义相关性。
- 文本转 SQL:用于结构化数据。
- 网页搜索:用于实时公共信息。
- API:用于访问外部服务或专有系统。
检索过程并行执行,可高效处理多样查询类型。
- 数据整合与大语言模型(LLM)合成:检索完成后,所有智能体的数据传递给大语言模型。大语言模型将检索到的信息合成为连贯、贴合上下文的响应,无缝整合多来源洞察。
- 输出生成:系统生成全面响应,以可操作、简洁的格式返回给用户。

输入(Input)转化为查询(Query)和提示(Prompt),进入 “Retrieval Router Agent(检索路由智能体)”;智能体将查询分配给 “Retrieval Agent X/Y/Z(检索智能体 X/Y/Z )”;这些智能体调用 “Tools(工具,如 Vector Search X/Y、Web Search、MAIL、CHAT )”,对接 “Data Sources(数据源)” 获取信息;最终经大语言模型(LLM)处理,输出响应(Response) ,体现多智能体分工协作检索的逻辑
关键特征与优势
- 模块化:每个智能体独立运行,可根据系统需求无缝添加或移除智能体。
- 可扩展性:多个智能体并行处理,使系统能高效应对高查询量。
- 任务专业化:每个智能体针对特定查询类型或数据源优化,提升准确性和检索相关性。
- 效率:通过将任务分配给专用智能体,系统最小化瓶颈,增强复杂工作流的性能。
- 多功能性:适用于跨多个领域的应用,包括研究、分析、决策制定和客户支持。
挑战
- 协调复杂性:管理智能体间通信和任务委派,需要复杂的协调机制。
- 计算开销:多个智能体并行处理可能增加资源使用。
- 数据整合:将多样来源的输出合成为连贯响应并非易事,需要先进的大语言模型能力。

3. 分层智能体检索增强生成(RAG)系统
分层智能体 RAG [14] 系统采用结构化、多层级的方法进行信息检索和处理,如图 18 所示,可同时提升效率和战略决策能力。智能体按层级组织,高层级智能体监督并指导低层级智能体。这种结构支持多层级决策,确保查询由最适合的资源处理。

查询(Query)先进入 “Master Agent(主智能体)”,主智能体可委派任务给 “Sub-Agent X/Y/Z(子智能体 X/Y/Z )”,最终由主智能体输出响应(Response) ,体现分层管理、任务委派的逻辑
工作流程
- 查询接收:用户提交查询,由负责初步评估和委派的顶级智能体接收。
- 战略决策制定:顶级智能体评估查询复杂度,决定优先使用哪些下属智能体或数据源。根据查询领域,某些数据库、API 或检索工具可能被认为更可靠、更相关。
- 向下属智能体委派任务:顶级智能体将任务分配给擅长特定检索方法(如 SQL 数据库、网页搜索或专有系统 )的低层级智能体。这些智能体独立执行分配的任务。
- 聚合与合成:高层级智能体收集下属智能体的结果并整合,将信息合成为连贯响应。
- 响应交付:最终合成的答案返回给用户,确保响应既全面又贴合上下文。
关键特征与优势
- 战略优先级划分:顶级智能体可根据查询复杂度、可靠性或上下文,确定数据源或任务的优先级。
- 可扩展性:跨多个智能体层级分配任务,能够处理高度复杂或多方面的查询。
- 增强决策制定:高层级智能体实施战略监督,提升响应的整体准确性和连贯性。
挑战
- 协调复杂性:在多个层级维持稳健的智能体间通信,可能增加协调开销。
- 资源分配:在各层级间高效分配任务以避免瓶颈,并非易事。


为武汉地区的开发者提供学习、交流和合作的平台。社区聚集了众多技术爱好者和专业人士,涵盖了多个领域,包括人工智能、大数据、云计算、区块链等。社区定期举办技术分享、培训和活动,为开发者提供更多的学习和交流机会。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)