51c大模型~合集159
整个框架采用模块化和框架无关的设计理念,不仅能够与多种 Agent 架构无缝集成,更为跨框架的经验共享和协作学习开辟了新的可能性。而 Agent KB 增强的 agent 则能够应用经验驱动的规则:智能过滤 ANISOU/HETATM 记录,专注于真正的 ATOM 条目,并通过 N-CA 键长范围的合理性检查进行验证,最终精准提取骨架 N-CA 原子对,报告出正确的 1.456 Å 距离。当遇到新
我自己的原文哦~ https://blog.51cto.com/whaosoft/14062049
#Lumina-mGPT 2.0
上海 AI Lab 发布 :自回归模型的华丽复兴,实力叫板顶尖扩散模型
今天一篇名为《Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling》的技术报告引非常吸引人。该研究由上海人工智能实验室、香港中文大学、上海交通大学等机构的研究者们共同完成,提出了一种全新的、完全从零开始训练的独立自回归图像生成模型——Lumina-mGPT 2.0。
这项工作最引人注目的地方在于,它成功地让一度被认为潜力有限的自回归(Autoregressive, AR)范式重焕新生,在高质量图像生成领域,取得了与DALL-E 3、SANA等顶尖扩散模型相媲美,甚至在部分评测中超越它们的惊人效果。同时,它还巧妙地在一个统一框架内实现了图像生成、编辑、可控合成、密集预测等多种复杂任务。
论文标题: Lumina-mGPT 2.0: Stand-Alone AutoRegressive Image Modeling
作者团队: Yi Xin, Juncheng Yan, Qi Qin, Zhen Li, Dongyang Liu, Shicheng Li, Victor Shea-Jay Huang, Yupeng Zhou, Renrui Zhang, Le Zhuo, Tiancheng Han, Xiaoqing Sun, Siqi Luo, Mengmeng Wang, Bin Fu, Yuewen Cao, Hongsheng Li, Guangtao Zhai, Xiaohong Liu, Yu Qiao, Peng Gao
所属机构: 上海人工智能实验室、香港中文大学、上海交通大学、上海创新研究院、浙江工业大学、南京大学
论文地址: https://arxiv.org/pdf/2507.17801v1
项目地址: https://github.com/Alpha-VLLM/Lumina-mGPT-2.0
研究背景与意义
近年来,AIGC(人工智能生成内容)领域,特别是图像生成,几乎被扩散模型(Diffusion Models)所主导。扩散模型通过从噪声中逐步去噪来生成图像,其生成质量和逼真度达到了前所未有的高度。然而,这种主流范式也存在一些局限,例如依赖复杂的预训练组件(如CLIP)、架构设计受限、以及在多任务处理上的灵活性不足。
与此同时,自回归模型,这种像“写小说”一样、一个token接一个token-地生成内容的范式,虽然在语言模型领域大放异彩(如GPT系列),但在图像生成上却似乎遇到了瓶颈。它们通常被认为在生成质量上不及扩散模型,且推理速度较慢。
Lumina-mGPT 2.0的研究者们挑战了这一普遍认知。他们认为,自回归模型固有的灵活性、组合性和可解释性,使其在统一多模态任务上具有巨大潜力。因此,他们决定重新审视并重振自回归范式,通过一个完全从零开始训练的、独立的、仅解码器(decoder-only)的模型,来证明其不仅能迎头赶上,还能在统一生成框架下实现更广泛的应用。

Lumina mGPT 2.0的多任务功能
Lumina-mGPT 2.0展现出的强大且统一的多任务处理能力。
核心方法与技术创新
Lumina-mGPT 2.0的成功并非偶然,其背后是一系列精心设计的技术创新。
1. 纯粹的仅解码器自回归架构
与依赖U-Net等复杂结构的扩散模型不同,Lumina-mGPT 2.0采用了更为简洁的仅解码器Transformer架构。这种架构完全基于自回归原理,通过预测下一个图像“token”来逐步完成图像的生成。该模型完全从零开始训练,摆脱了对任何预训练组件的依赖,这不仅赋予了其最大的架构设计自由度,也确保了其授权的灵活性。

Lumina-mGPT 2.0的仅解码器Transformer架构图
2. 统一的多任务生成框架
该研究的第一个核心创新是其统一的tokenization和生成方案。研究者设计了一种巧妙的“光栅扫描(Raster-Scan)”方案,将文本提示、参考图像和控制信号等不同模态的信息,统一编码成序列token。

统一生成方案示意图,模型可根据上下文无缝衔接生成内容
这种设计使得模型可以在一个单一的生成流程中,无缝处理各种看似不同的任务。无论是根据文本提示生成全新图像,还是在给定上半部分图像后进行“图像续写”,亦或是根据Canny边缘、深度图、人体姿态等条件进行可控生成,甚至是进行图像修复和主体驱动生成,所有任务都被统一为“预测下一个token”的自回归过程。

用于控制不同下游任务的系统提示(System Prompt)设计
3. 高效的图像Tokenizer与解码策略
为了将图像转换为模型可以处理的离散token,研究团队对现有的图像Tokenizer(如VQGAN、ViT-VQGAN)进行了详细评估。他们发现,尽管这些Tokenizer在重建质量上存在差异,但最终对生成模型的性能影响并不显著。

不同图像Tokenizer的重建效果对比

不同图像Tokenizer的重建性能指标
更重要的是,为了提升自回归模型的生成质量和速度,研究者引入了两种高效的解码策略:
- 推理时缩放(Inference-time Scaling):通过在推理阶段调整模型的注意力分数,显著提升生成图像的质量和保真度。
- 投机性Jacobi采样(Speculative Jacobi Sampling):这是一种并行解码技术,可以有效加速生成过程,缓解自回归模型逐个token生成所带来的速度瓶頸。
4. 引入“思考过程”提升生成质量
一个有趣且新颖的尝试是,团队为模型引入了类似人类的“思考过程”。在接收到用户较为模糊的提示时,模型会先调用GPT-4o等强大的语言模型进行“思考”,将简单的提示扩展成一个更详细、更具逻辑性的分步计划,然后再根据这个“思考后”的详细提示进行生成。这种方法能显著提升最终生成图像的连贯性和质量。

高质量采样流程,引入了“思考”和“N选优”策略

调用GPT-4o进行“思考”的示例
实验结果与分析
Lumina-mGPT 2.0在多个主流文本到图像生成基准测试(如GenEval和DPG-Bench)上进行了广泛评估。结果显示,其性能不仅与DALL-E 3、SANA等顶尖的闭源或开源扩散模型相当,在GenEval等评测中,其FID(Fréchet Inception Distance,一种衡量图像生成质量的指标,越低越好)分数甚至优于DALL-E 3。

此外,在Graph200K基准测试中,原生的Lumina-mGPT 2.0也展现出了卓越的多任务处理能力,证明了其统一生成框架的有效性。
更多结果展示
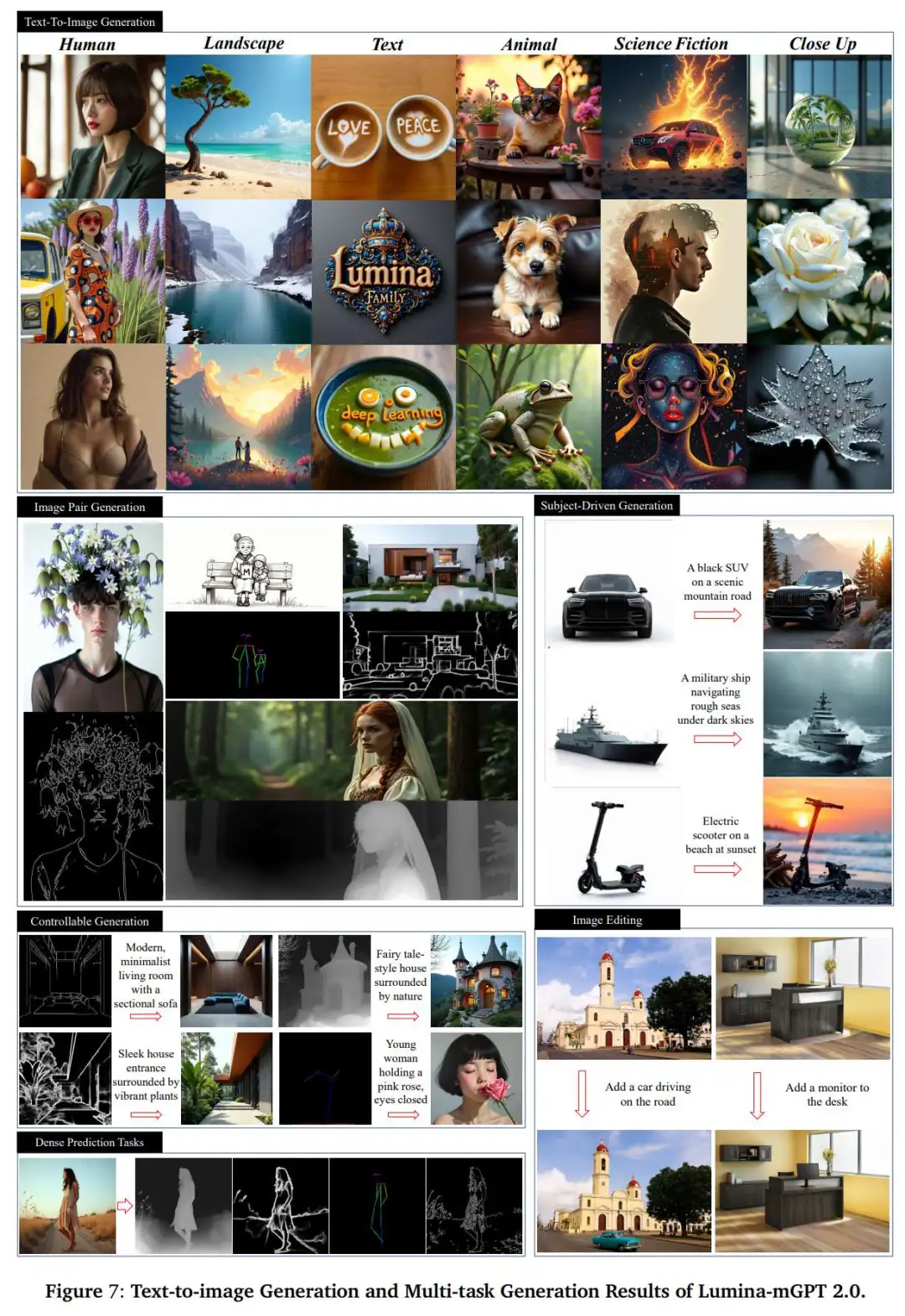
Lumina mGPT 2.0在文本到图像生成和多任务生成结果

Lumina mGPT 2.0、Lumina mGP和Janus Pro之间在文本到图像的视觉比较

Lumina mGPT 2.0、Lumina mGP、OneDiffusion和OmniGen之间可控/受试者驱动生成的视觉比较。控制输入包括Canny(第一行)和Depth(第二行)。


从上面两表中,作者验证了Lumina-mGPT 2.0在可控生成(表5)和主题驱动生成(表6)方面的能力。结果表明,Lumina-mGPT 2.0作为通用多模态模型表现卓越:在可控生成领域,该模型在Canny边缘图和深度图条件下均展现出顶尖的结构遵循能力,同时保持优异的图像质量与文本一致性;在主题驱动任务中,其主体身份保持度超越所有对比模型,并在图像一致性与文本对齐方面取得突出成果。
论文贡献与价值
Lumina-mGPT 2.0的问世,具有多方面的贡献和价值:
- 范式突破: 它有力地证明了,自回归模型在图像生成领域同样具备SOTA(State-of-the-Art)级别的潜力,打破了扩散模型一家独大的局面,为AIGC技术路线提供了新的可能性。
- 统一框架: 提出了一个强大、灵活且统一的多模态生成基础模型,能够仅用一个模型便高效处理多种复杂的生成和编辑任务,极具研究和应用价值。
- 开源共享: 团队开源了训练细节、代码和模型,这对于整个AI社区无疑是一份宝贵的财富,将极大地推动相关领域的研究和发展。
- 设计自由: “从零开始”的训练方式,摆脱了对特定预训练模型的依赖,为未来更大规模、更自由的模型设计铺平了道路。
总而言之,Lumina-mGPT 2.0不仅是一款性能强大的图像生成模型,更是对自回归技术范式的一次成功“复兴”和重要探索。它向我们展示了通往更通用、更灵活的多模态人工智能的一条可行路径。
....
#拓宽百年奥运「赛场边界」
阿里云AI让人人皆可上场
先给大家看个视频,你能分辨出哪个是 AI 生成的吗?
,时长00:46
视频来源:tiktok 博主 @tkp..1001
「真人拍摄还是 AI 生成」,如果搁一年前,这个问题还很容易回答,因为细节处总有一眼 AI 的破绽,但现在,真与假的界限已变得愈发模糊。
越来越多「真实」的视频,评论区里都在争论「这是 AI 吧?」而那些真正由 AI 生成的内容,反倒被当成真实拍摄。

AI 视频生成技术的进化速度快到飞起,并正渗透进我们生活的方方面面。随之而来的问题是:我们究竟要如何与这些技术共处?
破解这一难题的钥匙或许就藏在人类的想象力中。技术的超越不该只在于对现实的复刻,更应在创新应用中想象更美好的未来。
站在这个视角,阿里云给出了一个颇具想象力的答案:2026 年米兰冬奥会。
,时长00:43
就在冬奥会倒计时 30 天之际,作为官方云服务合作伙伴的阿里云,拉着国际奥委会以及⽶兰冬奥组委会搞了波大的,共同发起一场全球 AIGC ⼤赛。

[ 左右滑动 ]
大赛 Slogan 为「YOUR EPIC VIBE」,正好与本届冬奥口号「IT's Your Vibe」(意展你风采)遥相呼应。
大赛规则简单粗暴:只需用阿里云的「万相大模型」,在花样滑冰、短道速滑、高山滑雪、单板滑雪经典项目中选一个,生成一段冬奥视频,就能参赛。
除了万相大模型本身,阿里巴巴的 AI 产品生态同样为本次大赛提供了全栈式支持,包括开源开放的开发者社区 Modelscope、AI 创作工具通义万相、堆友,为不同类型、不同渠道的参赛者「保驾护航」。
国际奥委会还直接放话,他们将从这四个项目中各选 25 个最佳作品,纳入奥林匹克博物馆收藏,并组合成奥运史上首个 AIGC 数字艺术影像作品集《YOUR EPIC VIBE》。
这意味着,自 1896 年现代奥运首次举办以来,AI 第一次以这种方式被写进奥运历史。
更刺激的是,Top 100 中将评选出 10 位在叙事创意、情感深度和美学构图上表现最好的获奖者,他们还能直接拿到米兰冬奥会现场门票。
大赛官网:https://summit.aliyun.com/aigcchampionship
AI 视频生成技术卷到现在,终于不只是在社交媒体上刷存在感了。它正以一种谁也没想到的方式,成为奥运历史的一部分。
而要达成这一成就,万相 Wan2.6 凭借其强悍的视频生成能力,化作了参赛者手中最强的那把利器。
用 AI 创造冰雪世界,为何独独选择了阿里云?
在去年 12 月 AI 视频生成大模型又一波涌现的大潮中,阿里云的 Wan2.6 登场。

Wan2.6 面向专业级影视制作和图像创作场景,进一步提升了画质、音效、指令遵循能力,并新支持多镜头叙事及最长 15 秒生成。此外在国内首次支持角色扮演(Reference-to-video,R2V)功能,本人可以入镜,并用自己的声音出演 AI 视频。

体验地址:https://tongyi.aliyun.com/wan/
对于此次冬奥赛场上的四大经典冰雪项目,Wan2.6 表现出了极高的可玩性。
我们上手测试的结果说明了这一点。
只见一只可爱的雪人从高山之巅快速下滑,身后拉出一条清晰而绵长的雪线,红色帽子在疾驰中随风摇摆,看起来十分的童趣。如果我不告诉你这是 AI 生成的,可能你还以为这是哪部动画片中的场景呢!
,时长00:05
毛茸茸的怪兽在高山之巅飞速直下,双脚踩着雪板完成流畅的滑雪动作,身体随着地形起伏自然摆动。

小王子也来雪山之巅滑雪了,身披围巾、脚踏雪板,仿佛开启了一段属于自己的冰雪冒险,纯真而浪漫。

穿越千年的兵马俑也献上一段花滑表演:
,时长00:10
除了文生视频、图生视频,现在你也可以指定角色来生成了。Wan2.6 的角色扮演功能,可以将你输入的参考视频进行二次创作,甚至是你亲自上场。
我们先来「呼叫奥特曼」上场速滑。只见他起滑、加速、入弯一气呵成,动作那叫一个专业,完全不像是第一次跨界。专业程度甚至让人怀疑他是不是偷偷报过集训班。
,时长00:10
然后再让马斯克来段花样滑冰,看起来也是有模有样:

与此同时,Wan2.6 在动态表现和视觉冲击力上同样可圈可点。在这一示例中,镜头贴近雪面,紧跟雪板高速前行,低机位带来的速度感与冲击力被充分放大。
,时长00:05
以前在滑雪场,常能看到有人踩着滑板、扛着相机一路跟拍,冒着不小的风险,才能换来几个漂亮镜头。现在,这种高难度的跟拍视角已经不再依赖人工完成,Wan2.6 可以直接在生成过程中自动实现稳定、贴近动作的动态运镜:
,时长00:05
慢镜头同样稳得住。高速下滑被自然放慢的那一刻,雪板切雪的力道、雪屑被甩起又在空中翻滚的轨迹一一展开,原本一闪而过的速度感被拆解成清晰可见的细节。这感觉就像在滑雪场里按下了电影级慢放键。
,时长00:05
就算是高难度的多人场面,Wan2.6 依然能够稳稳驾驭。多名滑雪者同时出现在画面中,彼此之间的相对位置、运动方向与节奏保持清晰,没有出现人物混叠或动作错乱。
,时长00:05
通过上述示例可以看出,Wan2.6 的优势并不在于某一个「炸点」,而是在冰雪运动中「力与美」的呈现上已经达到了相对成熟的水准。
在高速运动、多人互动以及音画同步等关键场景下,Wan2.6 展现出超高的性能。无论是虚构角色还是真人形象,都能够被自然地融入运动场景之中,完成连贯而完整的表演,体现出对运动节奏与视觉叙事的成熟把控。
进一步看,这种稳定性也体现在镜头层面:生成过程中,镜头并非被动记录动作,而是会随着运动推进自动调整视角,在关键节点完成切换,使画面具备基本的分镜逻辑与节奏变化,可以说是深谙运动力学与视觉美学的「数字导演」。
视频生成的多面手,Wan2.6 背后藏着这些「杀手锏」
长期以来,视频生成被认为是 AI 领域最难攻克的堡垒之一。不过从 OpenAI Sora 开启视频「暴力美学」开始,这个领域在各个环节进入到了进化的快车道。
一开始大家追求的目标很简单,让画面动起来;后来一步步加码,提出了更多更高的要求,比如对复杂物理规律的极致模拟、影视级高清画质、原生音画同步、画面连贯与逻辑统一,最终目标是无限接近真实视频。
如今,升级到 2.6 版本的万相大模型已修炼得「炉火纯青」。
首先做到了超真实还原。实现这一点需要解决几个深层次的技术挑战,包括物理规律的准确模拟、时序一致性、细节高度还原、原生音视频的逻辑一致等。
Wan2.6 提供了音画⼀体的多模态参考⽣成能⼒,通过对输⼊参考视频进⾏多模态联合建模与学习,最终实现从画面到声音的全感官一致性保持与迁移。这种「镜像级人物重建」可以精准捕捉并重建你的形象,就连每个微表情都生动至极。
其次能输出衔接连贯的多镜头。视频生成中精准的分镜控制,要求 AI 不仅要生成连贯的画面,还要像人类导演一样理解空间调度、镜头切换和叙事连续性。
Wan2.6 可以一键完成单人、多人、人与物合拍的视频,还能自动实现多镜头切换。这意味着,视频生成不再是碎片拼凑,并且不管怎么切镜头,视频里的主体都能保持像素级的统一,几乎不会出现镜头一换、主角换脸的尴尬情况。
最后保证叙事完整不偏离主题。生成一段完整的叙事视频,远比几个孤立的炫酷镜头困难得多,其核心挑战在于如何让 AI 具备时间记忆和逻辑常识。
Wan2.6 很好地解决了这些挑战,最长支持 15 秒 1080P 视频生成,并能轻松搞定完整叙事的 Vlog 视频。这使得该模型在短剧制作等专业场景具有广阔的应用前景,只要提示词写得好,输出的视频可直接拿来用,省力又省钱。
一系列底层能力的突破,让 Wan2.6 打破视觉、听觉与物理规律之间的藩篱,为创作者提供了一个生产力级别的视觉生成引擎。
AI for all,在奥运这块阵地「登陆」
去年 7 月,即将成为 OpenAI 史上首位应用 CEO 的 Fidji Simo 发表了一篇文章,主题为《AI:赋能所有人的终极源泉》(AI as the greatest source of empowerment for all)。这篇刷屏的就职檄文再一次让「AI 全民可用」成为热议的焦点。

文中写到,「我相信 AI 将为更多人带来比历史上任何其他技术都多的机遇。如果我们能做好这一点,AI 将给予每个人前所未有的力量。」但同时,这些机遇并不会凭空出现,不仅要求 AI 达到较高的水准,还要有像阿里云这样勇于创新的 AI 玩家。
现在看来,这场全球 AIGC 大赛成为了「AI for all」的实践阵地。
以往,参与奥运的方式要么花很多钱去现场观赛呐喊,要么在电视机或电脑前守候。如今,AI 终于赋予了每一个普通人更沉浸的奥运体验。
在高山滑道、花滑冰场或单板 U 型场,你我同样可以成为万众瞩目的主角。这正是奥运级 AI 科技首次大规模应用于粉丝互动所产生的魅力。
正如 Fidji Simo 所强调的,「如果我们能够让智能技术无处不在、人人可及,就能驱动人类历史上最大的机遇引擎,并帮助更多人过让更好的生活」。阿里云掀起的这场以万相大模型为主导的交互范式变革,正以自己的方式一步步将这样的愿景落地。
.....
#博士申请终极指南
「从准备到抉择」手把手教你拿下理想offer
又快到博士申请季。这是一份复杂而又繁琐的工作:无尽的院校调研、纠结的方向选择、厚重的材料准备,以及决定命运的面试……不可能不感到迷茫、焦虑,甚至怀疑,这一切的辛勤付出,究竟能否换来梦想院校的入场券?在面试官眼中,「完美候选人」究竟应该具备哪些条件……
最近,加州大学圣地亚哥分校认知科学家兼助理教学教授 Lucy Lai,结合她以往哈佛大学神经科学博士项目申请者的经验,七年多的模拟面试经验,以及作为前哈佛博士项目面试官的经验,给出了一份「内部参指南 」——《关于博士申请的一切》。

《指南》中包括常见的博士面试问题与如何做出最好的回答、招生决定是如何做出的,以及对招生委员会所看重的素质和因素进行的详细说明等。
接下来,我们就具体来看看指南是如何给出申请建议的。
一般应用技巧
如何才能确定自己想读研究生?
在所有的准备开始之前,需要先明确一个问题:你真的决定要读研究生了。Lucy Lai 建议,思考过程中如果觉得自己的申请材料还不够优秀,可以考虑休学一年或几年。而判断申请是否足够优秀的一个好方法是咨询你的研究导师。他们阅读和面试过无数研究人员和潜在的研究生,可以很轻松地告诉你在申请过程中可能遇到的情况,以及应该申请哪些学校等。
应该何时开始申请?
一定要尽早开始!申请过程耗时很长,而且会占用大量时间和精力,尤其是在你大四繁重的课程之外(如果你还在读本科的话)。Lucy Lai 建议,在你计划申请的申请季之前的那个夏天,就应该开始缩小你想申请的学校范围,并列出你感兴趣的首席研究员(PI)名单等。一旦你理清了这些,整个过程会变得更加具体和有条理,就可以开始为特定的学校撰写个人陈述了。
应该申请哪些类型的课程和学校?
这取决于你的兴趣。相似专业,例如心理学和神经科学之间最大的区别在于你将要修读的课程以及你可能会遇到的同学类型。博士生涯中最具决定性的环境无疑是你的论文实验室,因此,在最初的一两年之后,选择哪个专业可能就没那么重要了。
你唯一需要考虑、了解的是,你心仪的导师是否招收来自该专业的学生(因为某些专业的经费结构不同)。即使他们从未招收过来自该专业的学生,只要你的研究兴趣与他们相符,他们也可能持开放态度。
最后但同样重要的是,一定要问问你的导师(博士后 / PI 等)他们推荐哪些学校、项目。他们是宝贵的资源,更了解各个项目的声誉,并且可以推荐你可能感兴趣的 PI / 实验室。还有一点就是,他们在领域内工作多年,人脉很广,甚至可能在你申请之前就为你美言几句。
应该申请多少所学校?
这取决于你感兴趣的实验室数量,一条普遍适用的原则是,你应该申请至少有 2-3 位你感兴趣的导师的学校。这样做很重要,因为万一你真正感兴趣的实验室最终不适合你,你还有其他选择。对于需要轮转的项目(大多数生物科学项目),拥有几位你想合作的导师就显得尤为重要,这样你才能体验不同的轮转,并最终选择一个最适合你的论文实验室。
Lucy Lai 建议,最好是申请 6 到 10 所学校,这既能给你足够的选择余地,又不会让你被申请费用和文书写作压垮。Lucy Lai 当时申请了 14 所,结果是太多了,因为时间不够,不得不拒绝了一些面试邀请。
申请费用太贵了!如何才能免除申请费
刚说到申请学校的费用非常高昂。例如,斯坦福大学的申请费是 125 美元。如果申请 6 到 10 所学校,仅仅为了申请博士项目,就可能要花费 1000 美元!
其实鲜为人知的是,大多数学校都提供申请费减免。有些学校的申请费减免需要你提交 FAFSA(联邦学生助学金申请表)或其他经济困难证明,而有些学校则只需要你写一两段简短的文字,说明你为什么想申请这所学校。
Lucy Lai 通过在网上搜索到她所申请学校的申请费减免政策,以及给招生主任发邮件询问,省下了大约 600 美元的申请费。
应该在申请前联系项目负责人吗?
这个问题总是众说纷纭,Lucy Lai 认为,如果你对他们的实验室真的感兴趣,可以发邮件表明打算申请他们的学校,并询问他们明年秋季是否招收研究生。不过,不要指望这封邮件会对你的申请过程有很大帮助,如果导师不在招生委员会,申请审核人员很可能看不到这条信息。
在申请前联系导师主要是为了你自己,如果你最终有机会面试你联系过的导师,这确实会带来一些主观优势,他们可能会记得你之前对实验室或学校感兴趣,从而让面试有个好的开始。
需要准备的申请材料有哪些
几乎所有学校都会要求以下物品:
- 成绩单、简历:如果还是在读,最好保证成绩优异,并尽可能做到最好,如果已经毕业那就要有科研经历 —— 很多人在本科毕业后会在实验室担任研究助理一到两年,以进一步提升简历,甚至发表论文。
- GRE 成绩:(从 2022 年的政策来看,这一项措施即将取消!)
- 3 封推荐信:推荐信的重要性几乎与个人陈述(SoP)不相上下,甚至可能更重要,这体现了你的研究导师和 PI 通过观察你在他们的实验室工作,对你、你的职业道德以及你在研究生阶段取得成功的能力的了解(关于该找谁写推荐信,最佳方案是,如果你有 3 次不同的研究经历,那就请你的三位导师分别写一封推荐信)。
- 宗旨声明
部分学校会要求提供以下材料:
- 多元化 / 个人经历陈述说明:个人陈述(SoP)是申请材料中极其重要的部分,而且在申请之前你仍可以完全掌控它的撰写。几乎所有学校都会要求你撰写一份个人陈述作为主要文书。好消息是,个人陈述的题目几乎都大同小异,因此你无需为每所申请的学校都进行太多修改。虽然看起来涵盖的内容很多,但最终都可以归结为:你为什么想读博士学位?之前有哪些研究经验?你攻读博士学位期间想研究什么?你希望与这所学校的哪些人员合作?为什么选择这所学校?
- 研究声明:也就是你实际做了什么。如果学校要求提交研究陈述(RS),那你的个人陈述会有更多篇幅来阐述你对科学产生兴趣的原因,而研究陈述则主要用于详细描述你参与过的研究项目。【Lucy Lai 印象里,她还没有见过哪所学校要求提交全部三份材料(个人陈述、研究经历陈述和多元化陈述)】。
- 其他随机简答题
面试
提交了申请材料后就是等待消息了。这里需要注意的是:申请过程中你的首要目标是获得面试机会,但并非所有项目都会安排面试!
Lucy Lai 记得,她的大多数工程系朋友都是直接根据在线申请结果被学校录取或拒绝的 —— 只有被录取的学生才会被邀请去学校参观。然而,那些会安排面试的项目(大多数生物科学专业)会希望在做出最终录取决定之前先与你见面。
记住,这也意味着你也在面试这所学校,以确定你是否真的愿意在接下来的五六年里在这个城市或研究环境中度过。
如果收到面试邀请,就已经进入了申请流程的下一阶段。值得一提的是,只有排名前 5% 到 15%(具体比例取决于学校)的申请者才能获得面试机会。学校会安排你飞往目的地,并支付所有费用入住豪华酒店。Lucy Lai 去年 12 月收到了学校的面试通知,面试从 1 月中旬开始,一直持续到 3 月初。
既然已经通过了纸质申请阶段,接下来就该好好展现自己的个人风采。要自信,坚信自己已经掌握了所有需要的信息:之前的研究经历、研究兴趣,以及为什么想去这所学校 —— 这些你都应该写在个人陈述里。再加上一点真诚的热情,那面试体验就会很顺利。
实际上,很多人都会比实际情况紧张得多,但几次面试之后,就会发现这其实只是一次对话。大多数导师都是真心想了解你,看看你是否适合这所学校。
需要注意的是,大多数面试只有 30-40 分钟,可以带个小笔记本,用来在面试过程中或面试间隙记下一些东西,或者以防需要画图解释某些内容(其实大多数项目负责人的办公室都有白板)。除此之外,真的没必要带任何东西,包括打印出来的图表、笔记本电脑、简历(反正他们已经有了)。
一般情况下,面试结构主要包括以下几个方面:介绍自己之前的研究、读研究生期间想研究什么或想做什么样的实验、听面试官介绍他们的实验室或研究、对项目或学校的疑问等。
哪些人能上岸?
面试结束后,很难判断录取决定是如何做出的,但 Lucy Lai 直觉认为,决定录取结果的关键在于研究方向的契合度和整体印象。另外她也注意到其他几个因素,这些因素揭示了导师和招生委员会真正看重的是什么:
- 与受人尊敬且知名的人士共事:比如谁在你的推荐信中为你加油打气?Lucy Lai 的一位导师曾在面试中告诉她,他会毫不犹豫地录取她,因为推荐信基本上都是他三个最好的朋友写的。学术界的残酷现实是,有知名人士的支持对申请甚至其他方面,都是巨大优势。
- 能够清晰阐述你对研究项目的贡献以及项目具体内容:几位项目负责人曾要求 Lucy Lai 详细说明具体工作内容,以便了解她对项目的参与程度。
- 能够就科学展开生动有趣的对话:无论是 PI 的研究领域、你自己的研究领域,还是整个科学领域都可以。但这并不意味着必须无所不知,了解大概就行,重要的是积极倾听并参与到深入的科学讨论中,有助于他们了解你的思维方式、积极提问。
- 匹配度:说到底,招生其实就是围绕着「匹配度」这一模糊概念展开的,这是一个双向过程:项目方在评估你是否能适应他们的研究环境,而你也在评估他们,看看你是否能在那里感到快乐。
之后,Lucy Lai 曾受邀担任哈佛大学神经科学博士项目的学生面试官。作为面试官,她面试了 5 位申请者。结合她的经验,她又从面试官角度分析了一下,面试者应该具备的特质,包括:谦逊、好奇心、创造力、韧性、勤奋、友善和正直。她认为,它们是成为一名优秀科学家所必需的,也是希望在同行和同事身上看到的品质。
如何选择学校
如果有幸收到录取通知书,在开心之余要开始思考到底该去哪个学校,必须决定未来 5-7 年将在哪里度过。
Lucy Lai 的一个建议是,要想「客观」选择学校,一个好方法是制作一个表格,列出所有学校,并给每个决策类别(例如科研契合度、院系文化等)打分(0-10 分)。
这种方法看似客观,实则迫使人们给一些主观因素打分。这样做帮助自己意识到自己真正看重的是学校或项目的哪些方面,之后自己的选择就会更为清晰。
参考链接:
https://lucylai.com/blog/gradapps#how-do-i-know-i-want-to-go-to-grad-school
....
#OmniAgent
「听觉」引导「视觉」,OmniAgent开启全模态主动感知新范式
针对端到端全模态大模型(OmniLLMs)在跨模态对齐和细粒度理解上的痛点,浙江大学、西湖大学、蚂蚁集团联合提出 OmniAgent。这是一种基于「音频引导」的主动感知 Agent,通过「思考 - 行动 - 观察 - 反思」闭环,实现了从被动响应到主动探询的范式转变。
在 Daily-Omni 等多个基准测试中,其准确率超越 Gemini 2.5-Flash 和 Qwen3-Omni 等开闭源模型。
- 论文地址:https://arxiv.org/pdf/2512.23646
- 论文主页:https://kd-tao.github.io/OmniAgent
- 发起实验室ENCODE LAB:https://westlake-encode-lab.github.io/
背景与痛点

- 端到端全模态模型虽然实现了视听统一,但往往受限于高昂的训练成本和困难的跨模态特征对齐,导致在细粒度跨模态理解上表现不佳;
- 基于固定 Workflow 的智能体依赖人为设定僵化的流程,缺乏细粒度和灵活性,无法根据问题自主的进行规划与信息获取;
- Caption-based 视频智能体需要在分析问题之前,先针对整个视频构建帧 caption 数据库,随后基于视频字幕数据库来理解内容,但这种方法计算成本高,难以捕捉细节的跨模态信息。
相比之下,OmniAgent 引入了一种全新的主动感知推理范式。通过在迭代反思循环中策略性地调度视频与音频理解能力,该方法有效攻克了跨模态对齐的难题,从而实现了对视听内容的细粒度理解。
方法论

OmniAgent 摒弃了固定的工作流,采用了「思考 - 行动 - 观察 - 反思」 闭环机制 。
1.思考:OmniAgent 会根据问题进行分析,自主决定「听」还是「看」。
2.行动:根据计划,OmniAgent 会从构建的多模态工具中选取合适的工具进行调用:
- 事件工具:利用音频能够高效捕捉全局上下文的特性,首创音频引导事件定位,快速锁定关键时间窗口,避免对长视频进行无效的视觉扫描 。
- 视频工具:包含粗粒度的全局视频问答,以及在特定时间内基于更高帧率进行分析的片段问答工具。
- 音频工具:涵盖音频全局描述、细粒度问答,以及支持精确时间戳的语音转录 (ASR)。
3.观察与反思机制:智能体接受工具结果,评估目前已有的证据能否正确的回答问题,并且结合之前在多步推理中进行跨模态一致性检查,确保视听证据互证,解决幻觉与对齐问题。
效果如何?
OmniAgent 在三个主流视听理解基准测试中均取得了 SOTA 成绩,显著优于现有的开源及闭源模型:
1.Daily-Omni Benchmark:准确率达到 82.71%,超越 Gemini 2.5-Flash (72.7%) 和 Qwen3-Omni-30B (72.08%),提升幅度超 10% 。

2.OmniVideoBench:在长视频理解任务中,准确率达 59.1%,大幅领先 Qwen3-Omni-30B (38.4%) 。

3.WorldSense: OmniAgent 也保持了领先的准确度。

未来愿景
- OmniAgent 的设计理念有很高的扩展性,能够继续结合其他模态的工具;
- OmniAgent 能够帮助生成高质量的 COTT 数据,用来构建可以自我调用工具的下一代智能体全模态模型。
总的来看,OmniAgent 证明了在全模态理解任务中,音频引导的的主动感知策略是解决跨模态对齐困难、提升细粒度推理能力的有效路径。该工作为未来的全模态 Agent 算法设计提供了新的范式参考。
....
#DeepSeek R1爆更86页论文
毫无征兆!``,这才是真正的Open
DeepSeek 将 R1 技术报告一夜扩至 86 页,首次披露纯强化学习即可让模型自我进化:R1-Zero 仅用 29.4 万 GPU 美元、64×8 H800 训练 198 h,便在 AIME 超人类均值、Codeforces 超 93.6% 选手;反思性词汇涨 5-7 倍,蒸馏让 1.5-70 B 小模型全面跃升,开源配方、安全测评与失败复盘一并放出。
全网震撼!
两天前,DeepSeek悄无声息地把R1的论文更新了,从原来22页「膨胀」到86页。
全新的论文证明,只需要强化学习就能提升AI推理能力!
DeepSeek似乎在憋大招,甚至有网友推测纯强化学习方法,或许出现在R2中。
这一次的更新,直接将原始论文升级为:一份开源社区完全可复现的技术报告。
论文地址:https://arxiv.org/abs/2501.12948
论文中,DeepSeek-R1新增内容干货满满,信息含量爆炸——
- 精确的数据配方:明确给出数据规模(2.6万道数学题,1.7万条代码),以及具体的创建流程
- 基础设施说明:vLLM/DualPipe设置的示意图
- 训练成本拆解:总计约29.4万美元(R1-Zero使用了198小时的H800GPU)
- 「失败尝试」复盘:深入解释PRM为什么没有成功
- 模型对比:与DS-V3、Claude、GPT-4o系统性比较(此前只包含o1)
- 10页安全性报告:详细说明安全评估与风险分析
结果显示,DeepSeek R1多项实力与OpenAI o1相媲美,甚至赶超o1-mini、GPT-4o、Claude 3.5。
不仅如此,这次论文末核心贡献者名单,列出了各自的具体贡献。
有网友表示,这次更新堪称一本教科书了!尤其是,关于DeepSeek-R1-Zero自我进化细节是真正的亮点。
值得一提的是,DeepSeek应用也在几天前上新功能——支持语音输入。有网友对此猜测,可能他们要发力多模态了。
接下来,一起拆解最新论文内容的核心亮点。
DeepSeek R1爆更,
实力打平o1
首先来看,DeepSeek-R1具体的评测结果。
最新评估,依旧覆盖了数学推理、编码、通用知识&理解、事实型&指令遵循等任务的全方位对比。
在教育知识类基准上,包括MMLU、MMLU-Pro和GPQA Diamond,DeepSeek-R1整体超越DS-V3。
特别是,在STEM相关问题上,准确率显著提高——这背后最大功劳要归功于:RL。
另外,在长上下文的问答任务(FRAMES)上,DeepSeek-R1表现亮眼,文档理解与分析能力出色。
在数学、代码任务中,DeepSeek-R1与OpenAI-o1-1217基本持平,明显领先其他模型。
在更偏实践编程任务中,OpenAI-o1-1217在Aider上表现优于DeepSeek-R1,但在SWE Verified上两者水平相当。
在DeepSeek看来,主要是工程类RL训练数据还不够多,所以DeepSeek-R1在这块的能力还没完全发挥出来。
下一版本,可能会看到其在这一领域的明显提升。
下图中,是DeepSeek-R1和DeepSeek-R1-Zero,在多项基准竞赛中与人类专家的性能对比。
- AIME数学竞赛:DeepSeek-R1得分已超越人类的平均水平。
- Codeforces编程竞赛:DeepSeek-R1表现超过了93.6%的参赛者,解题能力超强。
- GPQA科学问答:人类整体实力更强,表现优于DeepSeek-R1。
DeepSeek认为,如果让R1也能联网的话,说不定就能追上,甚至赶超人类现在的水平了。
人工评估阶段,采用了ChatbotArena擂台,通过ELO分数来体现DeepSeek-R1在人类偏好上的表现。
显然,R1取得了亮眼的成绩。尤其是,在「风格控制」中,它与OpenAI-o1、Gemini-Exp-1206打成平手,并列第一。
「风格控制」这一设计直接回应了一个关键问题:模型是否可能通过更长、更精致或更好看的回答来「取悦」人类评审,即使其内容本身并不一定更强。
DeepSeek强调,一个基于MIT协议的开源模型,整体表现与多款闭源AI相媲美,这无疑是一个重要的里程碑。
尤其是,DeepSeek-R1使用成本更低的情况下。
下图12,更近一步展示了不同评测维度下的排名结果,呈现了R1在数学、编程等多个领域的强劲实力。
这表明,R1不光推理能力强,在各种实际应用场景中,整体表现相当文档。
在数据方面,DeepSeek放出具体RL数据和微调数据的规模。
在强化学习阶段,数据比例是这样分配的:数学(26k)、代码(17k)、STEM(22k)、逻辑(15k)、通用(66k)。
在微调阶段,数据规模约800k,覆盖了推理、通用指令任务、格式/语言一致性样本。
蒸馏,让推理能力一键迁移
在蒸馏部分,DeepSeek回答了这一问题——
DeepSeek-R1学到的「推理能力」,能不能有效、稳定地迁移到更小的模型上?
这里,DeepSeek作为「教师」模型,生成高质量、显式推理轨迹的数据,通过SFT把推理能力「蒸馏」给更小的「学生」模型,而不是让小模型再跑一遍RL。
通过蒸馏,小模型直接学习R1已经验证有效的推理模式,不需要重新探索reward space。
论文中,DeepSeek实验蒸馏了多个规模的模型,包括1.5B、7B、8B、14B、32B、70B,系统性地验证了「跨尺度有效性」。
同尺寸模型相比较,蒸馏后的性能全面提升。
可以看到一个重要的现象是,推理能力并没有「锁死」在大模型里,而是能通过数据迁移到小模型。
在训练成本方面,DeepSeek-R1-Zero使用了64×8张H800 GPU,整体训练耗时约198小时。
在DeepSeek-R1训练阶段,沿用了相同的GPU配置,并在大约4天内完成训练,约80小时。
此外,在构建监督微调(SFT)数据集的过程中,共消耗了约5000 GPU小时,
一共花费29.4万美元,详情可参见表7。
有网友表示,是时候让Alex Wang道歉了,所有证据都摆在这里了。
智能涌现!
DeepSeek-R1-Zero的确在自我进化
在MATH数据集上,DeepSeek-R1-Zero简直就是人类的翻版!
对人类而言较为简单的推理任务,DeepSeek-R1-Zero在训练早期便被模型掌握,而在复杂推理问题(难度3–5)上的能力则会随着训练显著提升。
具体来说,下图8揭示了不同的学习模式:
简单问题(1-3级)迅速达到高准确率(0.90-0.95)并在整个训练过程中保持稳定;
困难问题则被逐步攻克——
4级问题的准确率从开始的约0.78提升到0.95;
最难的5级问题,最明显,从最开始的约0.55提升到0.90。
在较难问题(3-4级)上的准确率,DeepSeek-R1-Zero偶尔会以微弱优势超过其在较简单问题(1级)上的表现。
这种现象看似反直觉,可能由于数据集的特征。
在高级推理任务上,DeepSeek-R1-Zero也表现出类似的涌现现象,证明了两大结论:
- 在生成长链中间token中,强化学习发挥了关键作用。
- 在训练的特定阶段,AI模型学会了不同形式的反思。
首先,如下图9(a)所示,他们统计了一些具有代表性的反思性词汇,包括
wait、mistake、however、but、retry、error、verify、wrong、evaluate和check。
如下图a所示,随着训练的进行,反思行为的频率逐渐增加:反思性词汇的数量相比训练开始时增加了5到7倍,
其次,特定的反思行为可能在训练过程中的特定时间点出现。
如下图b所示,「wait」反思策略在训练早期几乎不存在,在4000-7000步之间偶尔出现,然后在8000步之后孤峰突起。
总之,他们观察到模型在训练过程中的反思行为逐渐增加,而某些反思模式(如使用「wait」)则在训练过程的特定时间点出现。
安全问题,
行业重点在越狱攻击
DeepSeek-R1的安全风险评具体分析包括以下5个方面:
1、DeepSeek-R1官方服务所采用的风险控制体系;
2、与当前先进模型在六项公开安全基准测试中的对比安全评估;
3、基于内部安全测试集的分类研究;
4、对R1模型在多语言场景下的安全性评估;
5、模型在应对越狱攻击方面的稳健性评估。
DeepSeek-R1的风险控制体系通过向DeepSeek-V3发送「风险审查提示词」(risk review prompt)来实现,具体包括以下两个主要流程:
首先,过滤潜在风险对话。在每轮对话结束后,系统会自动将用户的提问与一组预设关键词列表进行匹配。
其次,基于模型审查风险。被标记为潜在风险的对话将与预设的「风险审查提示词」(见示例8)拼接在一起,并发送给DeepSeek-V3模型进行审查。系统会根据模型的判断结果,决定是否撤回该轮对话内容。
实验结果显示,与其他前沿模型相比,DeepSeek-R1在整体安全性上与其他先进模型表现相当。
然而,在HarmBench测试中,R1的表现明显落后,主要源于R1在涉及「知识产权」的相关问题上表现欠佳。除此之外,在其他安全类别的评估中(如歧视与偏见、暴力与极端主义、隐私侵犯等),R1模型表现稳定,展现出较强的安全防护能力。
此外,他们特别构建了一个内部安全评估数据集,以系统监测模型的整体安全水平。
他们将大语言模型可能面临的内容安全挑战划分为4个一级类目和28个细分子类,具体分类如下:
最终,他们共构建了1,120道测试题,用于对模型的安全性进行系统性评估,具体结果见下表。
在未启用控制时,DeepSeek-R1与DeepSeek-V3的基础模型拒答率较低,但不安全率较高。启用风险控制后,不安全率明显下降,但拒答率升高(约25%)。 DeepSeek-R1在处理违法犯罪类问题和伦理道德类问题时表现出色,而在应对歧视偏见类问题与有害行为类问题时则表现一般。
评估模型在不同语言之间的安全差异同样至关重要。为此,他们将此前构建的中英双语安全测试集扩展至50种常用语言。
最终,他们构建出一个包含9,330个问题的多语言安全测试集。引入风险控制后,DeepSeek-V3(86.5%)与DeepSeek-R1(85.9%)在50种语言中的整体安全得分接近Claude-3.7-Sonnet(88.3%)的表现。
图14中展示了DeepSeek-V3、DeepSeek-R1(启用与未启用风险控制系统)以及Claude-3.7-Sonnet和GPT-4o(2024-05-13)在50种语言下的表现。
在越狱攻击测试中,他们得出三大结论:
越狱攻击对所有模型均构成显著威胁
推理型模型更依赖风险控制系统
开源模型越狱风险更高
总结
基础模型、验证器很重要
基础模型很重要。
在开发的最初阶段,他们曾尝试使用较小规模的模型作为强化学习(RL)训练的起点。然而,在以AIME基准作为主要验证集的评测中,这些模型始终未能带来实质性的性能提升。
为了解决这些问题,他们转而采用更大规模、能力更强的模型。
在这些架构上,他们首次清晰地观察到纯RL训练所带来的显著性能收益。
这一结果表明,从基础模型出发进行强化学习,其效果在很大程度上取决于模型本身的容量与表达能力。
验证器很重要。
DeepSeek-R1-Zero的训练效果高度依赖于奖励信号本身的可靠性和准确性。
根据目前的实验结果,有两种方式可以有效缓解奖励作弊(即模型学会「钻奖励规则空子」)的问题:
一是基于规则的奖励模型(Reward Models,RMs),二是利用大语言模型来判断生成答案是否与预先定义的标准答案一致。
迭代式训练流水线中,RL、SFT缺一不可。
他们提出了一套包含监督微调(SFT)和强化学习(RL)的多阶段训练流水线。
RL与SFT在整个训练流程中缺一不可。单独依赖RL,容易在问题本身定义不清的任务中引发奖励作弊和次优行为;而只依赖SFT,则可能限制模型通过探索进一步提升其推理能力。
他们同样经历了不少失败与挫折,包括过程奖励模型(Process Reward Model,PRM)和蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)。
但这并不意味着这些方法本身无法用于构建有效的推理模型。
参考资料:
https://x.com/cedric_chee/status/2008871365009670222
....
#智谱敲钟上市了
刚刚,智谱敲钟上市了,市值达528亿港元
全球大模型第一股」来了!
2026 年 1 月 8 日,北京.智谱.华章.科技股份有限公司(02513.HK)(以下简称「智谱」)正式在香港联合交易所挂牌上市。
至此,全球首家以通用人工智能(AGI)基座模型为核心业务的上市公司花落中国。
智谱首日开盘价 120 港元 / 股,市值 528.28 亿港元。
在智谱本次 IPO 发行中,香港公开发售获 1159.46 倍认购,国际发售获 15.28 倍认购。以每股 116.20 港元的发行价计算,智谱本次 IPO 募资总额超 43 亿港元(「绿鞋」前)。
在上市致辞中,智谱董事长刘德兵表示:「全球范围内通用大模型企业第一次以这样的方式走向公开市场,非常有幸智谱作为中国大模型代表,站在这个历史性的起点。‘让机器像人一样思考’是智谱从创立第一天起就选择的方向,是智谱人持之以恒奋斗的唯一目标。」
他回顾称,智谱在 2021 年推出了自研的算法架构 GLM,而今年 GLM-4.7 的发布使其跻身世界领先,为冲刺 AGI 打下重要根基。「智谱的 Z 是字母表中的最后一个,代表终极境地,我们希望在 AGI 的探索历程上能走到智能的终极境地。」
凭借「全球大模型第一股」标的的独特稀缺性,智谱吸引了一支由北京核心国资、头部保险资金、大型公募基金、明星私募基金和产业投资人构成的全明星基石投资阵容,JSC International Investment Fund SPC、JinYi Capital Multi-Strategy Fund SPC、Perseverance Asset Management 等 11 家基石投资者合计认购 29.8 亿港元。
以基座模型为核心,持续探索智能上界
智谱是中国最早投身大模型研发的厂商之一,原创性地提出了基于自回归填空的通用预训练范式 GLM,率先发布了中国首个百亿模型、首个开源千亿模型、首个对话模型、首个多模态模型,以及全球首个设备操控智能体(Agent),并形成全面的模型体系,是国内罕有在原创技术路线上与全球顶尖水平保持同步的厂商,因此也被誉为「中国的 OpenAI」。
目前,GLM 架构已实现全国产化突破,适配 40 余款国产芯片,成为业内通用性最高的模型体系之一。
作为中国最早投身大模型研发的厂商之一,智谱长期坚持高比例、持续性的研发投入。
招股书显示,2022 年 - 2024 年公司研发投入分别为 8440 万元、5.289 亿元、21.954 亿元,2025 年上半年为 15.947 亿元,累计研发投入约 44 亿元,研发人员占比 74%。高强度的研发投入支撑智谱技术快速迭代,GLM 系列模型每 2-3 个月完成一次基座迭代,保持全球领先水平。
2025 年 12 月,智谱新一代基座模型 GLM-4.7 在模型综合能力榜单 Artificial Analysis 与权威编码榜单 Code Arena 中,均荣登开源模型与国产模型双料榜首。模型 Coding 和 Agent 真实体感表现优秀,发布两个月,来自 184 个国家的 15 万开发者朋友为编程订阅产品付费,Cerebras、Windsurf 等超过 50 家海内外开发平台工具选择接入。

据了解,公司本次募集资金净额的 70%(约 29 亿港元)将用于通用 AI 大模型方面研发投入,进一步巩固智谱在通用基座模型方面的竞争力;约 10%(约 4.2 亿港元)将用于持续优化公司的 MaaS 平台,包括提供最新的基座模型以及训练 / 推理工具及基础设施建设。
中国最大独立大模型厂商,以 MaaS 模式锚定未来增长
智谱成立于 2019 年,由清华大学技术成果转化而来,专注通用人工智能(AGI)的研发,并坚持做让用户真正用得上的研究与技术。
弗若斯特沙利文报告显示,按 2024 年收入计算,智谱在中国独立通用大模型开发商中排名第一,在所有通用大模型开发商中排名第二。
截至 2025 年 9 月 30 日,模型赋能全球 12000 家企业客户(互联网客户占比 50%)、逾 8000 万台终端用户设备及超 4500 万名开发者,是中国赋能终端设备最多的独立通用大模型厂商。
在商业化层面,智谱是少数已实现规模化收入与持续高增长的独立大模型厂商。招股书显示,2022 年 - 2024 年,智谱收入分别为 5740 万元、1.245 亿元、3.124 亿元,年复合增长率高达 130%;2025 年上半年收入为 1.91 亿元,同比增长 325%。2022 年至 2024 年,智谱毛利率分别为 54.6%、64.6%、56.3%,2025 年上半年毛利率为 50%。
智谱自 2021 年就开始布局 MaaS(Model as a Service),这一时间比大模型商业化的时间早两年。目前,智谱形成了以 MaaS 为核心的标准化产品体系,包含模型的 API 调用、模型订阅及本地化部署等方式,向企业及开发者输出「通用智能能力」,而非单一场景应用。MaaS 收入和模型调用量在今年迎来较大增长。
数据显示,智谱 MaaS 平台已汇聚超过 300 万家企业及应用开发者,是国内最活跃的大模型 API 平台之一,其中编程订阅产品表现尤为突出,上线短时间内即实现过亿的年度经常性收入(ARR),并在海外开发者社群中快速渗透。
「技术 + 资本」双轮驱动,开启全球竞技新阶段
当前,全球资本的 AI 投资叙事正从「能力验证」转向「规模扩张」。智谱等中国大模型企业以差异化发展路径与商业化闭环,显露开源影响力、模型竞争力和性价比优势,不断吸引国际长线资本加持看好。
根据联合国贸发会议预测,到 2033 年,全球 AI 市场规模将从 2023 年的 1890 亿美元飙升至 4.8 万亿美元,十年内增幅达到 25 倍。
市场规模不断增长的同时,国内政策支持越发成熟。随着《人工智能大模型》系列国家标准正式实施,中国 AGI 发展正式迈入「规范有序」的下半场,大模型在千行百业深度落地,将成为驱动效率革命与模式创新的核心引擎。
在全球 AI 竞赛持续升温的背景下,智谱拿下「全球大模型第一股」,凸显出中国在人工智能基础模型领域的产业链完整度与政策支持逐步成熟,不仅为国产大模型发展注入资本活力,更标志中国 AGI 企业正式迈入资本市场的舞台中央,开启与国际巨头同台竞技的新阶段。
....
#UniPercept
深入感知级别图像理解:UniPercept 统一图像美学、质量与结构纹理感知
操铄:中国科学技术大学与上海人工智能实验室联合培养博士生,专注多模态图像理解与生成。主导研发了 ArtiMuse、UniPercept 等成果,多篇工作发表于 ECCV、ICCV 等国际顶级会议。
李佳阳:北京大学硕士生,专注多模态图像理解及融合。作为核心作者参与了 ArtiMuse、UniPercept 等工作,多篇工作发表于 TIP、TPAMI 等国际顶级期刊。
尽管多模态大语言模型(MLLMs)在识别「图中有什么」这一语义层面上取得了巨大进步,但在理解「图像看起来怎么样」这一感知层面上仍显乏力。
近日,来自上海人工智能实验室、中科大、北大、清华等机构的研究者联合发布了 UniPercept。这是首个统一了 美学(Aesthetics)、质量(Quality)、结构与纹理(Structure & Texture) 三个维度的感知级图像理解框架。
🌐 项目主页:https://thunderbolt215.github.io/Unipercept-project/
💻 代码仓库:https://github.com/thunderbolt215/UniPercept
📝 论文地址:https://arxiv.org/abs/2512.21675
📊 模型权重:https://huggingface.co/collections/Thunderbolt215215/unipercept
🎨 相关工作 (ArtiMuse):https://github.com/thunderbolt215/ArtiMuse
引言:
从「识别物体」到「感知图像」
当前,多模态大语言模型在目标检测、图像描述和视觉推理等语义级任务中表现卓越。然而,人类视觉感知不仅限于物体识别,还包括对构图美感、画质损伤、材质纹理以及结构规律性的细腻捕捉。
语义级理解关注的是「场景中有哪些实体」,而感知级理解则需要评估精细的、低层级的视觉外观,例如美学和谐度、降质严重程度或表面肌理。这些属性往往是微妙且主观的,对内容创作、图像增强及生成模型对齐至关重要。
为了填补这一空白,研究团队提出了 UniPercept。该工作建立了层次化的感知属性定义系统,构建了大规模基准测试集 UniPercept-Bench,并开发了一个通过领域自适应预训练和任务对齐强化学习训练的强基准模型。此外,研究团队还给出了 UniPercept 的下游应用实例,包括作为生成模型的奖励模型(Reward Model),以及作为生成模型评估的指标(Metrics)等。

UniPercept-Bench:三位一体的全域感知评价体系
UniPercept 将感知级图像理解拆解为三个核心领域,构建了「领域 - 类别 - 准则」的三级层次结构,旨在全面覆盖人类对图像的视觉评价维度。
核心评估维度
- 图像美学评估(IAA):侧重于构图设计、视觉元素与结构、情感和整体视觉吸引力等。它关注的是图像是否「好看」,探讨艺术表达与视觉平衡。
- 图像质量评估(IQA):侧重于感知保真度和降质因素,如噪声、模糊、压缩伪影。它回答的是图像是否「技术性达标」。
- 图像结构与纹理评估(ISTA):这是 UniPercept 首次系统化提出的维度,强调局部特征、几何规律性、材质属性(如平滑度、粗糙度)和细节丰富度。它回答的是图像的「场景、结构、纹理和构成与复杂程度」。

UniPercept-Bench 的定义体系分为三级细分,包含 3 个领域、17 个类别和 44 个细分准则,给出了专家级的细致定义体系,其精细程度远远超过此前的图像评估 Benchmark。
在具体定义上,它实现了从领域到准则的精密解构:例如从美学(IAA)领域,到「构图与设计(Composition & Design)」类别,深入到对「视觉平衡(Visual Balance)」这一微观准则的量化;或从场景解析(ISTA)领域,到「几何构成(Geometric Composition)」类别,细化到对「3D 体积(3D Volume)」隐含信息的提取。这种三级联动的体系,确保了模型能够从宏观的「整体感知」跨越到微观的「渲染精度」进行全方位、多维度的专家级评估。



任务形式与数据流水线
该基准支持 视觉评分(Visual Rating, VR) 和 视觉问答(Visual Question Answering, VQA) 两种互补的任务形式。

为了确保数据质量,研究团队设计了三阶段自动化流水线:
- 初始生成:利用先进多模态模型结合专业准则库生成候选问答对。
- 拒绝采样:由异构判别模型对问题的有效性、答案的准确性及逻辑一致性进行五分制打分,剔除约 40% 的不合格样本。
- 人工精修:组织专业志愿者进行手动核验,特别是对边界案例进行修改,确保最终结果与人类专家感知高度对齐。

UniPercept 模型:领域自适应与任务对齐强化学习
为了使模型具备真正的感知能力,研究者采用两阶段框架对基础多模态模型进行持续演进。
领域自适应预训练(Domain-Adaptive Pre-Training)
研究团队整合了约 80 万个样本的大规模语料库,涵盖文本描述、结构化标注和数值评分。通过这一阶段,模型习得了跨领域的底层视觉特征,为其后续的精准判断打下了相应的感知基础。
任务对齐强化学习(Task-Aligned RL for VR & VQA)
这是提升模型感知一致性的关键。研究者采用了 GRPO 算法进行策略优化,并针对感知任务设计了特定的奖励函数:
- 视觉问答(VQA)任务:采用二元奖励,鼓励模型输出准确的离散答案。
- 视觉评分(VR)任务:创新性地设计了 自适应高斯软奖励(Adaptive Gaussian Soft Reward)。该函数根据模型预测值与参考分数的偏差动态调整平滑系数。
这种软奖励机制提供了更平滑的梯度,避免了传统阈值奖励导致的优化不连续性。此外,模型引入了评分 Token 策略,直接从预测概率分布中导出数值,大幅缓解了模型生成数字时的幻觉倾向。

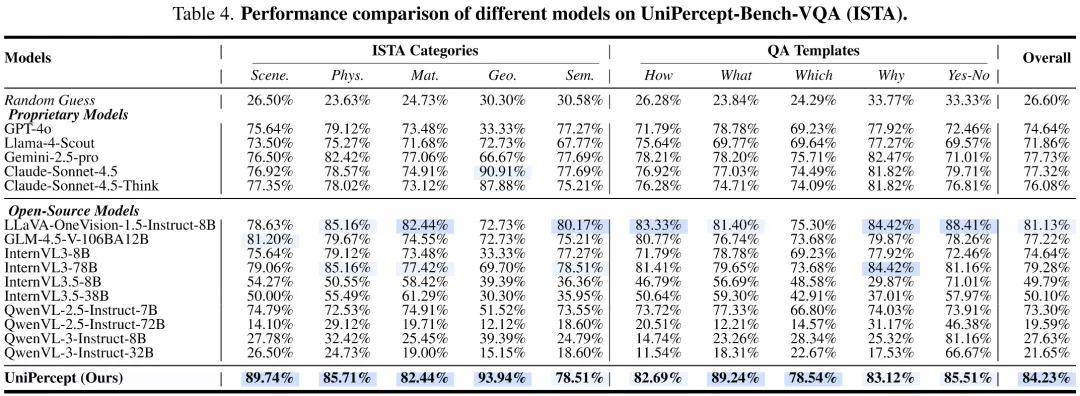
性能:全面超越现有顶尖模型
研究团队在 UniPercept-Bench 上评估了包括商用闭源模型系列、领先开源系列以及针对美学和质量优化的专用模型在内的 18 个模型,UniPercept 在其中取得了显著优秀的表现。
视觉评分(VR)表现
在持续分数的回归任务中,大多数通用模型在没有针对性训练的情况下表现较差。相比之下,UniPercept 在所有三个领域(美学、质量、结构)中均取得了最高的斯皮尔曼相关系数(SRCC)和皮尔逊相关系数(PLCC)。尤其是在 ISTA 领域,UniPercept 填补了现有模型对细节纹理判断的空白。

视觉问答(VQA)表现
实验显示,即使是目前最顶尖的商业模型在处理精细感知问题时也显得吃力:
- 在 图像美学评估(IAA) 领域,UniPercept 的准确率超越了 GPT-4o 约 16 个百分点。
- 在 图像质量评估(IQA) 领域,UniPercept 在识别特定物体上的细微损伤(如运动模糊、压缩畸变)方面展现出极强的定位与判断能力。
- 在 图像结构与纹理复杂度评估(ISTA) 领域,模型能够准确分辨不同材质的表面特性(如镜面反射、亚光纹理),准确率突破 80%。


应用:作为奖励模型/评估指标
UniPercept 展示了作为生成模型优化信号的巨大潜力。研究者将其作为奖励模型,整合进文生图模型的微调流水线中。UniPercept 主要从以下三个方面对生成模型进行优化:
- 美学引导:显著改善生成图像的构图平衡和光影和谐度。
- 质量引导:增强图像细节的锐度和清晰度,减少常见的伪影干扰。
- 结构纹理引导:丰富了场景的复杂程度、结构的丰富度、物体的表面肌理,使画面表现更丰富。
不同奖励信号有着不同的优化侧重点,当三个维度的奖励信号协同作用时,生成的图像在视觉吸引力和技术保真度上均达到最优。


此外,UniPercept 天然可以作为从美学、质量、纹理与结构三方面对于图像进行评估的 评估指标(Metrics),可以准确反映不同模型输出图像的各方面表现。

生成图像的全方位「感知档案」
UniPercept 还能为图像生成全方位的「感知档案」,不仅给出评分,还能从美学、质量、纹理与结构三个方面针对构图、执行精度、损伤位置等具体维度给出详细的文字解析与结构化输出。

结语
UniPercept 的提出,是多模态大模型的研究重心正在从单纯的语义识别,向更具挑战性的「感知图像」转化的重要一环。通过建立统一的评价基准、高效的数据生产线以及新颖的任务对齐学习策略,UniPercept 为未来的视觉内容评价与可控生成提供了一个强大的底座。它不仅是研究感知的有力工具,更是构建「感知闭环」系统的重要一步。
随着感知级理解能力的不断提升,人工智能将能够像人类艺术家一样,不仅能看懂画面中的故事,更能体会并创造出具备极致美感与精湛质感的视觉作品。
....
#Vera Rubin
今夜无显卡!老黄引爆Rubin时代,6颗芯狂飙5倍算力
英伟达 CES 2026 重磅发布 Vera Rubin 平台:推理性能 5×、Token 成本 1/10,NVLink 6 把 72 颗 GPU 连成 260 TB/s 的“一台超算”,并推出 0 接管自动驾驶 AlphaMayo 与机器人开源全家桶,宣告 AI 算力工厂时代正式到来。
天空一声巨响,全新版本的「皮衣老黄」闪亮登场。

在本次CES演讲中最为激动人心的瞬间,就是英伟达全新一代芯片架构——Vera Rubin正式登场!
全球AI算力告急?老黄霸气回应:Vera Rubin已全面投产。
这是新一代的算力怪兽,也是对上一代霸主Blackwell的降维打击——
- 推理Token成本直接暴降10倍,算力性能狂飙5倍。
- 就连训练MoE模型所需的GPU数量,也直接减少了4倍。
曾经,Blackwell终结了Hopper;如今,Rubin亲手埋葬了Blackwell。
全程近两小时演讲,老黄提及重点包括——
- 下一代Rubin平台亮相:六颗芯片,推理狂飙十倍
- 自动驾驶端到端模型:AlphaMayo会思考、自主推理,全程0接管上路
- 物理AI全家桶开源:基础模型、框架
玩家彻夜难眠:CES 2026,没有显卡
至于游戏玩家?
对不起,这次真的没有新显卡。
英伟达在X上的一纸公告,彻底击碎了「攒机党」最后的幻想:CES 2026将没有任何新GPU发布。
这意味着,英伟达自2021年以来连续五年在CES发布新硬件的传统,就此终结。
传闻已久的RTX 50 Super系列,受困于GDDR7显存的「产能地狱」,大概率已经胎死腹中。
Rubin炸裂登场
6颗芯片,10倍推理,AI超算变工厂
去年10月,老黄曾预计:未来五年,将有3到4万亿美元砸向AI基础设施。
Vera Rubin的大规模投产,可谓生逢其时。
如果说Blackwell打破了单卡性能的极限,那么Rubin解决的则是系统规模化的难题。
从此,算力将像电力一样廉价,AI的大爆发已近在咫尺!
2024年,Vera Rubin架构首次亮相。
等了两年,现在它终于正式投产了!
Blackwell架构,从此将退出历史舞台。
演讲现场,老黄告诉大家:AI所需的计算量急剧飙升,怎么办?不用怕,Vera Rubin,将解决我们面临的根本性挑战!
这套为万亿参数模型的海量推理而生的平台,会彻底让算力低成本、规模化、工业化生产。
Rubin架构,以天文学家Vera Florence Cooper Rubin而命名。
可以说,Rubin是英伟达第一次把CPU、GPU、网络、存储、安全,当成一个整体来设计。
核心思路就是:不再「堆卡」,而是把整个数据中心变成一台AI超算。
整个Rubin平台,由这6个关键组件构成。

其中,Rubin GPU是整个平台的核心。它搭载第三代Transformer引擎,为AI推理提供50 PFLOPS的NVFP4算力。
之所以能达到Blackwell GPU性能的5倍,是因为它的NVFP4张量核心,后者能分析Transformer各层的计算特性,动态调整数据精度与计算路径。
另外,该架构还引入一颗全新的Vera CPU,专为智能体推理而设计。
它采用88个英伟达自研Olympus核心,完全兼容Armv9.2,并具备超快的NVLink-C2C 连接,能实现176个线程的全性能执行,I/O带宽和能效比直接翻倍。
当我们在Agentic AI或长期任务中启用全新的工作流时,会对KV cache造成很大压力。
为了解决存储和互联的瓶颈,Rubin架构特别改进了Bluefield和NVLink系统。它通过外部方式和计算设备相连,这样就能更高效地扩展整体存储池的规模。
BlueField-4 DPU是一个数据处理单元,它能卸载网络、存储和安全任务,还能管理AI的上下文记忆系统。
NVLink 6中,单芯片就能提供每秒400Gb的交换能力。每块GPU提供3.6TB/s 的带宽,而Rubin NVL72机架提供260TB/s,带宽超过整个互联网。
通过3.6 TB/s的带宽和网络内计算能力,它能让Rubin中的72个GPU像一个超级GPU一样协同工作,直接把推理成本打至1/7。
现场,老黄给我们展示了Vera Rubin的托盘。小小的托盘上集成了2颗Vera CPU、4颗Rubin GPU、1颗BlueField-4 DPU和8颗ConnectX-9网卡,整个计算单元算力达到100 PetaFLOPS。
Rubin的目标,是解决MoE和万亿参数模型的训练成本,它做到了吗?显然,成果是显著的。
训练、推理效率暴增
测试结果显示,Rubin架构训练模型时的运行速度,直接达到上一代Blackwell架构的3.5倍(35 petaflops),推理任务的速度则高达5倍,最高可达50 petaflops!
同时,它的HBM4内存带宽提升至22 TB/s,达到2.8倍,单GPU的NVLink互连带宽则翻倍到3.6 TB/s。
在超大规模MoE训练中,Rubin所需的GPU数量相比Blackwell可减少至1/4,同时整体能耗显著下降。
这背后,就有三大功臣。
NVLink 6,让GPU间互联带宽再次大幅提升,多卡训练不再被通信拖慢;Vera CPU与Rubin GPU的协同调度,可以减少「GPU等数据」的空转时间;而ConnectX-9与Spectrum-6的深度协同,也让大模型训练不会再被集群规模限制。
从此,训练万亿模型,不再是「堆钱」,只会是工程问题。
训练解决了,那推理呢?
结果显示,在推理侧,Rubin平台单位token的推理效率提升最高可达10倍!同样的模型和响应延迟,算力成本可以直接下降到原来的1/10。
所以,模型可以跑得起百万token的长下文,企业级AI应用也可以部署了。
存储瓶颈解决
如上文所言,让AI模型多跑一会的关键挑战,就在于上下文数据。
大量KV Cache该如何处理?英伟达推出了由BlueField-4驱动的推理上下文内存存储平台。
这个平台在GPU内存和传统存储之间创建了「第三层」,直接让每秒处理的 token数提升高达5倍。
DGX Super POD
本次CES上,英伟达还推出了新一代DGX SuperPOD。
它把多个装有72个GPU的Rubin NVL72连接起来,形成了更大的AI计算集群。
在这次的DGX SuperPOD中,共有8个Rubin NVL72机架,相当于有576个GPU。
NVIDIA Vera Rubin NVL72 提供统一、安全的系统,集成了72 块Rubin GPU、36块Vera CPU、NVLink 6、ConnectX-9 SuperNICs和BlueField-4 DPUs
这样,SuperPOD就可以处理数千个Agentic AI智能体,以及数百万token上下文。
可以说,英伟达一次性解决了数百个GPU相连、管理存储的问题,直接给我们提供了开箱即用的AI基础设施。
第三代机密计算平台
更为重要的是,Rubin是首个支持第三代机密计算(Confidential Computing)的AI超算平台。
模型参数、推理数据、用户请求都会被全链路加密,即使的云厂商,也无法直接访问明文数据。
这就解决了「敢不敢把核心AI放到云上」的问题,对于金融、医疗、政府、企业私有模型都非常重要。
这些大厂,第一批用上Rubin
老黄介绍说,Rubin会由AWS、Microsoft Azure、Google Cloud、Meta、OpenAI这些头部厂商先部署。
而到2026年下半年,Rubin平台就会进入大规模商用阶段。
所以,下一代GPT、Gemini、Claude模型,大概率都会运行在Rubin架构上。

全程0接管,自动驾驶AI「会思考」
如何教会AI物理学的基础事实?
英伟达给出的答案是,把算力变成高质量的数据(Compute is Data)。
在这一体系中,「世界基础模型」Cosmos扮演着重要的角色。
交通模拟器输出的信号,被送入Cosmos再生成合理、运动上连贯的环绕视频,让AI学习其中真实世界的行为模式。
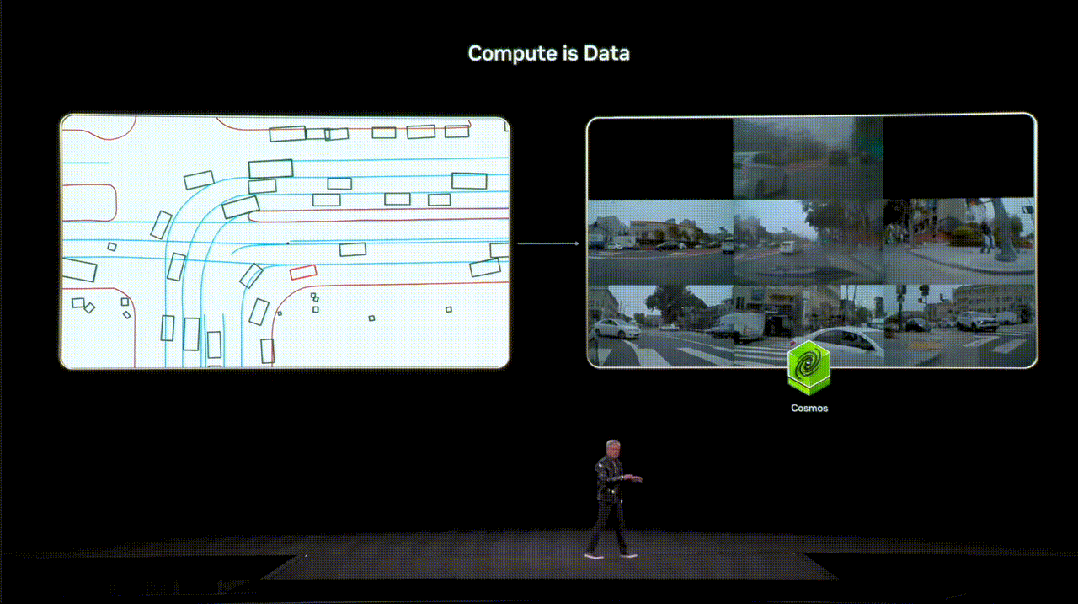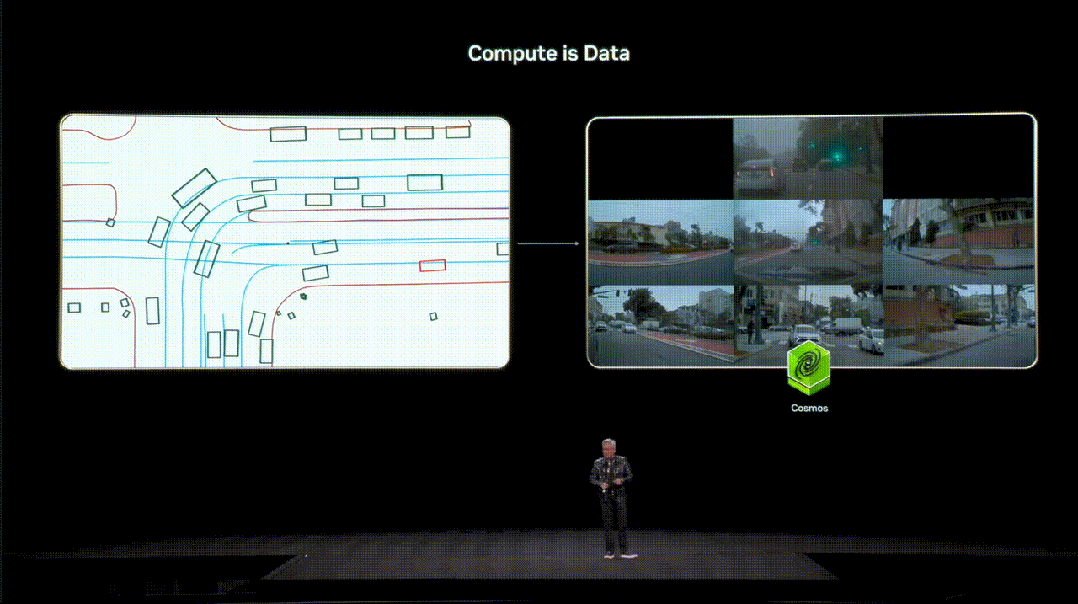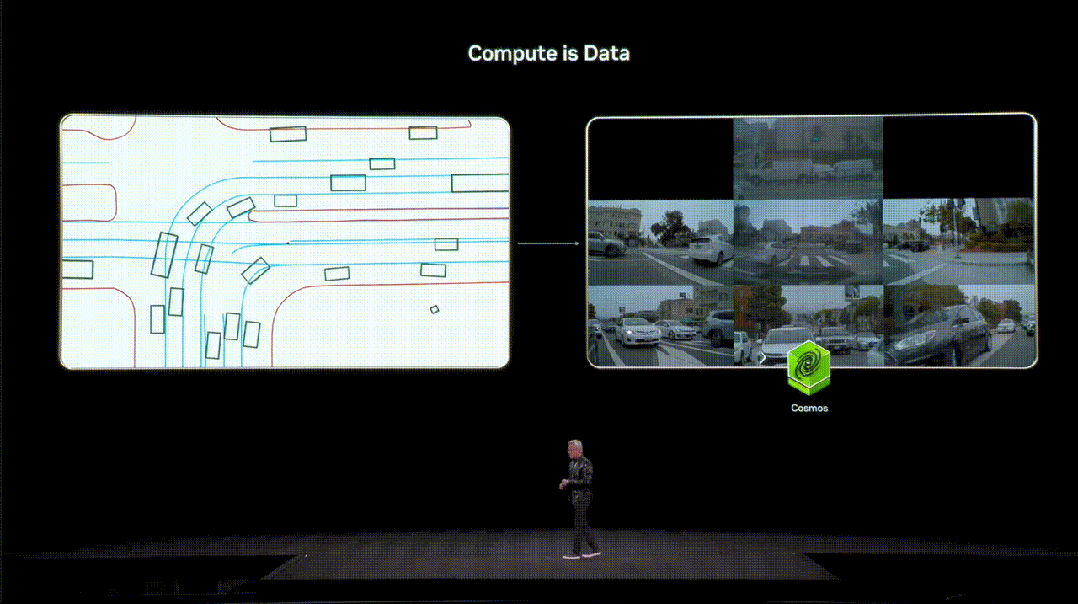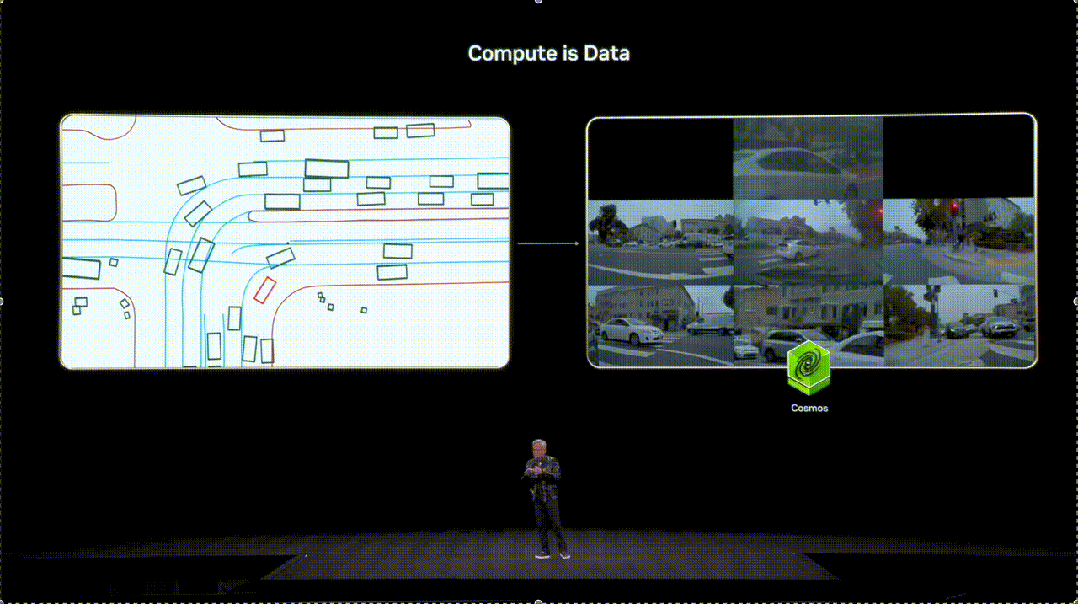
如今,Cosmos已被全球下载数百万次,成为物理AI时代的重要基础设施。在英伟达,内部也在用其做自动驾驶研究。
在此基础上,今天,英伟达正式发布了「端到端」自动驾驶AI——AlphaMayo。
它是一个会思考、会推理的自动驾驶AI。从摄像头输入到车辆执行动作,全流程由模型完成。
AlphaMayo独特之处,在于它具备了显式推理能力。
系统不仅执行转向、制动、加速动作,还会给出即将采取行动的理由,以及对应的形式轨迹。
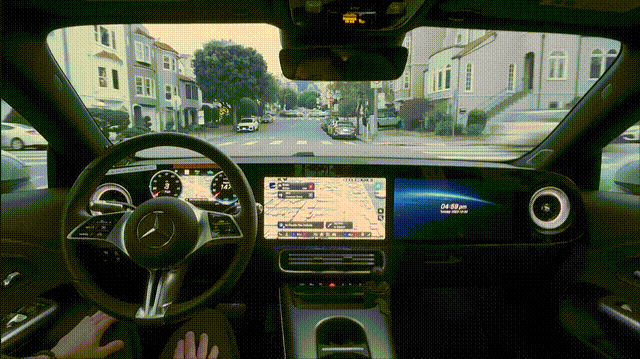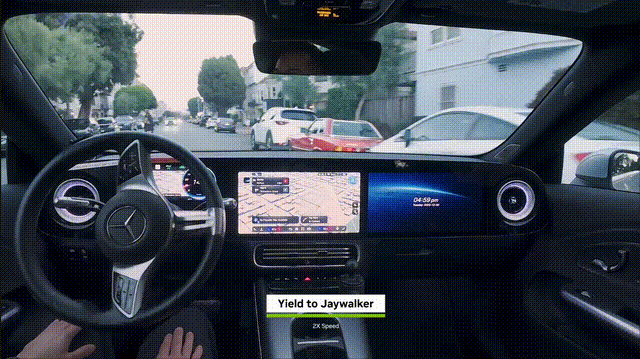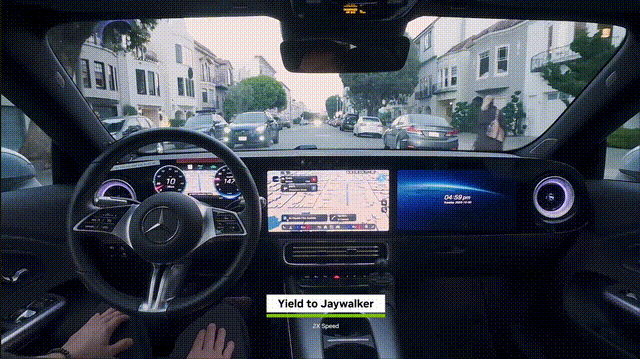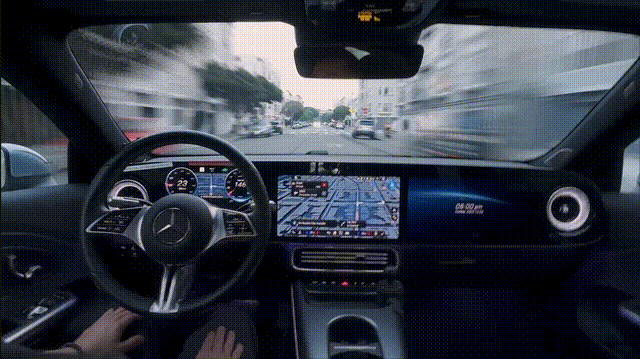
自动驾驶最大挑战,来自于「长尾场景」,几乎不可能覆盖所有国家、所有道路的数据。
AlphaMayo的策略是将复杂场景,拆解为多个熟悉的物理与交通子问题,通过推理将罕见情况分解为常见组合,完成应对。
在演示中,车辆可以在全程0接管状态下,完成路径规划与行驶,顺利抵达目的地。

在自动驾驶领域,英伟达投入持续了八年,如今第一次把AI「五层架构」完整跑通。
由下到上:实体本身、芯片体系、模型层、基础设施层、应用层,构成了一套完全贯通的AI系统栈。
AlphaMayo构成模型层,梅赛德斯-奔驰汽车构成应用层。
这一次,老黄还官宣了,NVIDIA DRIVE AV软件首次搭载全新梅赛德斯-奔驰 CLA,提供L2级端到端驾驶。
更重磅的是,Alpamayo家族全部开源。这一整套方法论,并不只适用于汽车,同样适用于机器人、机械臂等各类系统。
全家桶开源,机器人ChatGPT时刻
下一阶段,机器人将以各种形态进入现实世界,前提是,它们首先在Omniverse中学会如何行动。
现场,老黄又召唤来了机器人瓦力登台配合演出,这里他讲了一句意味深长的话:
未来的系统,都诞生在计算机里。
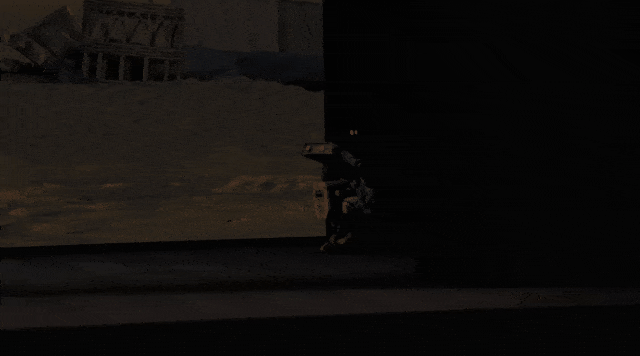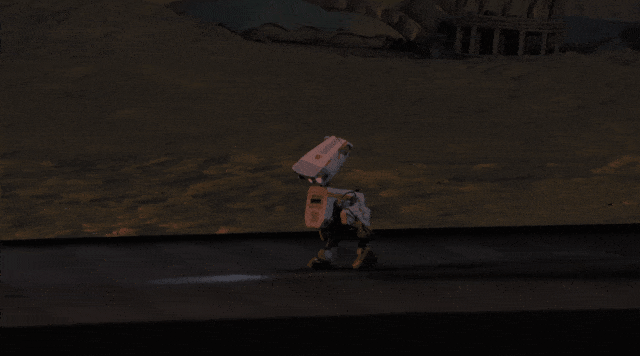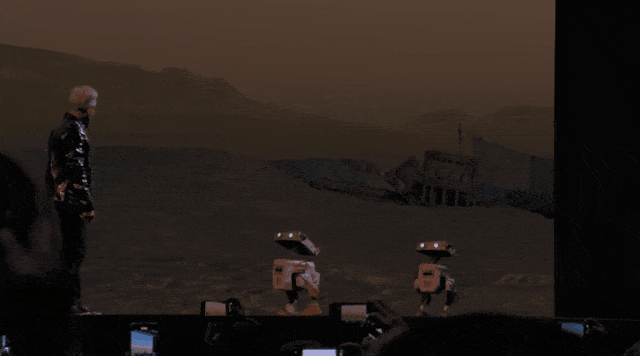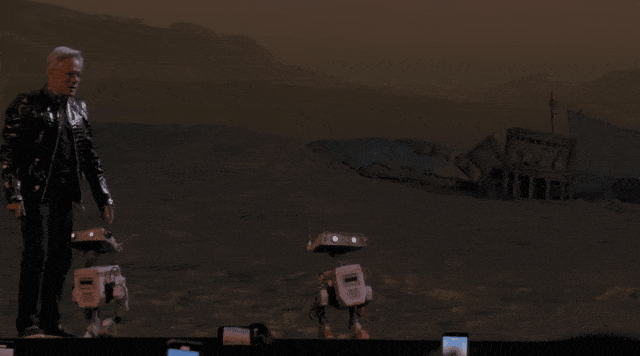
英伟达正把自身能力嵌入到,计算密度最高、最复杂的工业体系统,就像此前与Palantir、ServiceNow的集成一样。
如今,这一模式正被复制到了工业仿真与设计领域。
在xx智能领域,老黄直接扔下了一套针对物理AI(Physical AI)的「开源全家桶」——模型、框架及基础设施,应有尽有。
机器人的ChatGPT时刻已经到来!
目前,所有新模型均已上线Hugging Face,拿来即用:
- NVIDIA Cosmos Transfer/Predict 2.5,这是完全可定制的世界模型,专门在虚拟世界里生成符合物理规律的数据,训练机器人的大脑。
- NVIDIA Cosmos Reason 2,让机器像人一样「看懂」世界并进行逻辑推理。
- NVIDIA Isaac GR00T N1.6,专为人形机器人打造,解锁全身控制,让机器人不再四肢僵硬。
为了解决机器人开发中「各自为战」的痛点,英伟达发布了两大神器:
- Isaac Lab-Arena:这是GitHub上的开源框架,连接了主流基准测试,确保机器人在进厂打工前,已经在虚拟世界里经过了千锤百炼。
- NVIDIA OSMO:无论是在工作站还是混合云,它都能统一调度数据生成、模型训练和测试,大幅缩短开发周期。
机器人技术已是Hugging Face上增长最快的领域。英伟达这次不仅是提供模型,更是深度集成:
- LeRobot集成:Isaac和GR00T技术直接通过LeRobot框架即可调用。
- 硬件互通:Hugging Face的开源机器人Reachy 2和Reachy Mini现已完美适配英伟达的Jetson平台,语音、视觉、大模型能力瞬间拉满。
软件强还不够,硬件必须硬。如今,全新的Jetson T4000模组,直接将Blackwell架构带到了边缘端:
- 算力高达1200 FP4 TFLOPS,是上一代的4倍。
- 1000台起订单价仅1999美元。
- 70瓦功耗,简直是为能源受限的自主设备量身定做。

老黄震撼预言
未来所有应用,建在AI之上
每隔10-15年,计算产业就会重来一次。
演讲伊始,老黄还回顾了计算产业过去数十年的演进路径——
从大型机到CP,到互联网、云计算,再到移动计算,每一次平台级跃迁,都会催生一整套全新的应用生态,软件开发方式也随之重构。
而这一次,变化来得更加猛烈。
他提到,当前产业正同时经历两次平台级转变:一是从传统计算走向AI,另一个是整个软件、硬件栈的底层重塑。
AI正成为全新的「底座」,应用开始建立在AI之上。同时,软件开发与运行方式、应用生成方式发生了根本性变化。
这一切,共同推动了「加速计算+AI」对整个计算体系的重塑,五个层级正在同时被重新发明。
2022年ChatGPT爆发后,AI才真正走进大众视野。一年之后,推理模型首次登场,引入了「测试时Scaling」这一概念。
模型不仅在训练阶段学习,还在推理阶段实时计算和推演。预训练、RL、推理这些阶段,都需要机器庞大的计算资源,也同时推动模型能力持续提升。
2024年,另一项突破开始显现,直到2025年,智能体系统(Agentic AI)才迅速扩散开来。
老黄再次提及,在英伟达内部,像Cursor这样的Agentic工具已深刻改变了软件的开发方式。
智能体AI之后,下一个前沿便是物理AI(Physical AI),理解自然规律和物理法则,为AI打开了全新疆域。
除此之外,过去一年,另一个具有决定性意义的变化来自「开源模型」。
DeepSeek R1的出现,作为首批开源推理模型之一,给行业带起来巨大震动。
但不可否认的是,其仍比前沿模型落后六个月。每隔半年,就有新模型涌现,而且越来越智能。
英伟达,正引领着开源模型的生态,遍布多个领域。而且,在多个榜单上取得了亮眼的成绩。
最具代表性的包括多模态Nemotron 3、世界模型Cosmos、机器人模型GR00T、蛋白预测模型OpenFold 3......
老黄现场表示,以上一切成果,都为构建AI智能体服务,这是真正突破性的发展领域。
当前AI模型已变得极其强大,智能体的推理能力为各类应用开启了大门。
令老黄深感震惊的是,首次在Perplexity见证了其同时调用多个模型——AI在推理任何环节,直接调用最顶尖的模型。
这背后本质上是「多云协同」,同时还具备了混合云特性。
老黄明确地表示,这就是未来AI应用的基本形态。或者说,因为未来应用都构建在AI之上,这就是未来应用的基础框架。
一方面,AI可以被深度定制。另一方面,系统始终保持最前沿。「定制+前沿」能力在同一架构中同时存在。

在软件世界之外,更大挑战来自于现实世界。为此,物理AI需要三台计算机——
- 第一台计算机:用于训练模型
- 第二台计算机:用于推理,运行咋i汽车、机器人、工厂等边缘环境
- 第三台计算机:专门用于仿真、模拟
老黄提到,仿真是整个体系的核心,只有在可控的数字环境中,AI才能反复尝试、评估行为后果,并逐步建立对世界的理解。
彩蛋
演讲最后还有一个幕后花絮,DGX Station台式AI超算将在2026年春季上线。
届时,英伟达还将同步推出更多针对GB300系统的实战手册(Playbooks)。
如果说DGX Spark是开发者的入门首选,那么DGX Station就是一台放在你办公桌上的微型数据中心:
- 搭载GB300 Grace Blackwell Ultra超级芯片。
- 配备高达775GB的FP4精度一致性内存(Coherent Memory)。
- 拥有Petaflop级AI算力,支持在本地运行高达1万亿(1T)参数的超大规模模型。
得益于强大的硬件基础,DGX Station实测威力惊人:
- LLM预训练速度高达250,000 Token/秒。
- 支持对数百万数据点进行聚类和大型可视化。
从DeepSeek R1的开源震动,到Agentic AI的全面爆发,计算产业正在经历一场前所未有的重塑。
在这个只有玩家落泪的早上,一个由物理AI驱动的全新世界,正在Vera Rubin的轰鸣声中,加速向我们走来。
参考资料:HYZ
https://nvidianews.nvidia.com/news/rubin-platform-ai-supercomputer
https://www.nvidia.com/en-gb/data-center/vera-rubin-nvl72/
https://blogs.nvidia.com/blog/dgx-superpod-rubin/
https://www.nvidia.com/en-us/events/ces/
https://youtu.be/0NBILspM4c4
....
#ViMoGen
从过拟合到通用!ViMoGen开启3D人体动作生成新纪元
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。
现有的模型在标准数据集上表现良好,但在泛化能力上仍存在明显瓶颈。一旦用户输入训练集中未见过的复杂交互或罕见动作,生成的动作往往会缺乏自然性、崩坏或退化为简单的平均姿态,这严重限制了其在现实场景和交互系统中的应用。
那很自然地就会思考:视频生成模型已经初步学会了通用的物理规律和人类行为,为什么不把这些知识「蒸馏」给 3D 人体动作生成模型呢?

- 论文链接:https://arxiv.org/abs/2510.26794
- 项目主页:https://linjing7.github.io/vimogen/
ViGen-to-MoGen 的三大支柱
来自南洋理工大学、商汤科技、清华大学、香港中文大学和英伟达的研究人员提出了题为 《The Quest for Generalizable Motion Generation: Data, Model, and Evaluation》 的最新研究成果。这项工作从数据、模型、评估三个维度重新定义了通向通用动作生成的路径。
- 数据 ViMoGen-228K: 结合了从 30 个 MoCap 数据集中筛选的高精度数据,海量互联网视频与由视频模型(Video Gen)合成视频中提取的动作数据,包含了大量罕见、复杂的交互动作,突破了传统数据棚采集的物理限制。
- 模型 ViMoGen: 采用Text-to-Motion (T2M) 与 Motion-to-Motion (M2M) 双分支架构。通过门控机制,将视频生成模型的语义先验与 MoCap 的物理先验完美统一。
- 评估 MBench: 首个面向「泛化性」的评测基准。从动作质量、文本忠实度、泛化能力三大维度(细分 9 项指标)对模型进行全方面测评,是目前最全面的动作生成评测方式。
数据 ViMoGen-228K —— 规模与多样性的双重飞跃
传统动作数据集(如 AMASS)虽然精准但语义单一。ViMoGen 引入了 ViMoGen-228K 数据集,包含约 22.8 万条高质量动作样本。
多模态覆盖,包含文本–动作、文本–视频–动作多模态三元组。
多来源实现泛化能力提升:
- 对来自 30 个公开高质量的光学动作捕捉数据集进行了筛选和重标注。
- 从网络视频提取动作序列与语义标签。
- 利用视频生成(ViGen)模型生成了在真实动作捕捉中极难获取的长尾动作,填补了语义空白。
模型 ViMoGen —— 多源先验知识的深度表征与协同优化探索



ViMoGen 模型巧妙地通过门控机制控制 Text-to-Motion (T2M) 分支与 Motion-to-Motion (M2M) 双分支,同时利用 MoCap 数据的精准先验和 ViGen 模型的广泛语义先验。该架构模型不仅在传统动作生成测评上取得较好的分数,同时也通过文中提出的 MBench 测评基准,体现了它在泛化性上的卓越表现。
测评 MBench —— 多维分层评测体系
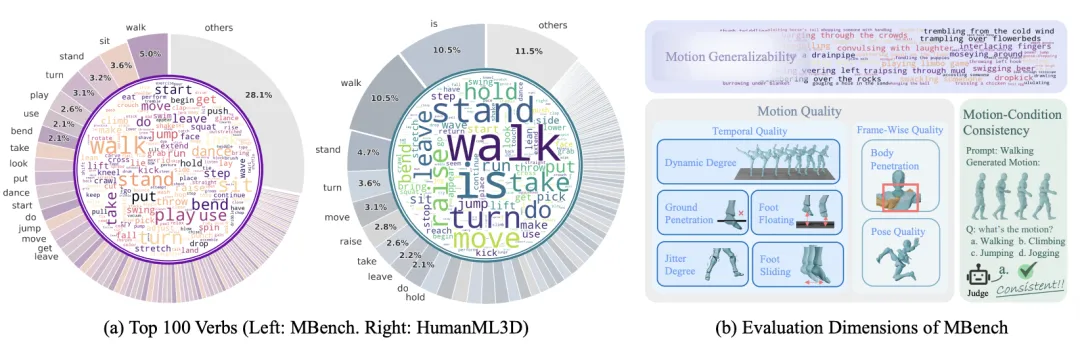
传统的 FID(Frechet Inception Distance)等指标只能衡量生成动作与特定动作集分布的相似度,却无法体现模型在处理复杂、罕见指令时的真实泛化能力。MBench 将评测拆解为相互关联的三个层面,并细化为 9 项具体的量化指标。
动作质量 (Motion Quality) 关注动作的合理性。通过计算与地面物理接触、穿模情况以及脚步抖动和平滑度,评判生成动作的动作的物理可实现性。
指令忠实度 (Motion-Condition Consistency) 利用多模态大模型评估生成动作与复杂文本描述的一致性。例如,模型是否准确还原了文本中提到的方位(“向左后方倒下”)或特定的交互逻辑。
开放世界泛化力 (Motion Generalizability) 设计了一系列 Out-of-Distribution (OOD) 测试案例,涵盖了极端动作、长尾语义以及复合指令,专门考验模型在未见过场景下的稳定性。
赋能xx智能,构建 Real-to-Sim 的高质量动作桥梁
在当前的人形机器人控制研究中(如 [arXiv:2505.03729] ),研究者通常依赖海量的 SMPL 参考轨迹(Reference Motions)来训练高鲁棒性的控制策略(Policy)。然而,传统数据的匮乏严重限制了机器人动作的演化。
传统的机器人训练往往局限于几套标准的行走动作。而 ViMoGen-228k 能够带来大量长尾、边缘场景(Corner Cases)高质量动作, 同时 ViMoGen 凭借强大的泛化能力,能够批量产出一些特殊需求的动作数据。这些数据能够让xx智能体在虚拟训练阶段就完成了对复杂动态的预演,使其在现实部署中具备更强的抗干扰能力。
同时 MBench 针对动作质量的一系列评估,能够为下游的 Real-to-Sim 过程做初步筛选,从而排除了可能导致机器人频繁跌倒或关节自锁的无效动作。
结果展示
空翻
指令:一个人俯身蹲低,双腿积蓄力量,随后蹬地猛然跃起,下巴紧贴胸口。身体蜷缩成一个紧密的球状,在空中优雅地翻转。随着空翻动作的完成,他舒展双腿,膝盖微屈平稳着陆,双臂向外伸展以保持平衡。
多球杂耍
指令:一个人双脚与肩同宽站立,目光紧盯着空中的彩色球。凭借熟练的手腕甩动,他们将每个球依次抛向空中,划出流畅的弧线,双手以协调一致的节奏交替动作。球不断升起又落下,形成连续的循环,杂耍者的动作流畅而精准,在整个表演过程中始终保持着完美的节奏与平衡。
引体向上
指令:一个人在单杠上进行一组标准的引体向上。从双臂完全伸直的悬垂状态开始,利用背部力量将身体垂直向上拉起,直到下巴超过单杠。

空手道
指令:一位武术家在前进的同时,执行一套动态的空手道组合动作。

推箱子
指令:一个人身体前倾,双手抵住一个巨大的重型箱子,在保持接触的同时缓慢向前迈步。
作者介绍
本文由南洋理工大学、商汤科技、清华大学、香港中文大学及英伟达的顶尖学者合作完成。
林靖、王睿思、鲁俊喆为共同第一作者。林靖是南洋理工大学博士生,研究大模型驱动的 3D 感知、生成与理解;王睿思为商汤研究员,兴趣方向在高性能计算与大模型空间智能;鲁俊喆是清华大学硕士,研究生成式模型和 3D 计算机视觉。
....
#Agent KB
经验池让Agents互相学习!GAIA新开源SOTA,Pass@1性能最高提升6.66
近日,来自 OPPO、耶鲁大学、斯坦福大学、威斯康星大学麦迪逊分校、北卡罗来纳大学教堂山分校等多家机构的研究团队联合发布了 Agent KB 框架。这项工作通过构建一个经验池并且通过两阶段的检索机制实现了 AI Agent 之间的有效经验共享。Agent KB 通过层级化的经验检索,让智能体能够从其他任务的成功经验中学习,显著提升了复杂推理和问题解决能力。
Agent 记忆系统:从独立作战到协同学习
在 AI Agent 的发展历程中,记忆(memory)系统一直是实现持续学习和智能进化的关键组件。广义上的 Agent 记忆系统有用于存储当前对话或任务中的临时信息的短期记忆,也有保存重要的知识、经验和学习成果的长期记忆,还有处理当前任务时的活跃信息缓存的工作记忆,部分还包括记录特定场景下的问题解决策略的情境记忆。
然而,现有的记忆系统存在一个根本性限制:不同的 Agent 框架下的经验无法有效共享。由于不同的任务往往有着不同的 multi-agent 框架,每当遇到新任务时,它们往往需要从零开始探索,即使相似的问题解决策略已经在相关领域得到验证。
Agent KB 正是为了解决这一痛点而生。它构建了一个共享的经验池/知识库系统,首先让不同的多智能体系统(比如 OpenHands、MetaGPT、AutoGen 等)去执行不同的任务,然后将成功的问题解决经验抽象化并存储。当遇到新的数据集中的测试例子的时候,从历史经验中检索相关的解决策略,将其他 agent 的经验适配到新的任务场景。
该框架的核心技术共享在于提出了一个「Reason-Retrieve-Refine」方案和 Teacher-Student 双阶段的检索机制,让 Agent 能够在不同层次上学习和应用历史经验。
GAIA 基准测试:通用 AI 助手的终极挑战
GAIA(General AI Assistants)被誉为「通用 AI 助手的终极测试」,是目前最具挑战性的智能体评估基准之一。与传统的 NLP 基准测试不同,GAIA 专门设计用来评估智能体在现实世界复杂任务中的综合能力。
GAIA 的核心特点体现在其对真实世界复杂性的还原。任务来源于真实的用户需求,而非人工构造的简单问题,这要求智能体具备多模态交互能力,需要处理文本、图像、音频等多种信息类型。
更重要的是,智能体必须具备工具使用能力,能够调用搜索引擎、代码执行器、文件处理工具等外部资源。大多数任务需要多个推理步骤和中间决策,同时对答案的准确性有严格要求,容错率极低。
GAIA 验证集包含 165 个精心设计的测试用例,按复杂度分为三个级别。Level 1 包含 53 个基础任务,需要简单推理或直接信息检索;Level 2 包含 86 个中等复杂度任务,需要多步推理或工具组合使用;Level 3 包含 26 个高难度任务,需要复杂推理链和专业领域知识。
该文的评估指标主要包括 Pass@1(agent 首次尝试的成功率,是最严格也最重要的指标)和 Pass@3(三次尝试中至少一次成功的概率,用于评估系统的上限)。我们发现 Agent KB 作者非常严谨,因为有些公司或组织在宣传他们的产品并在 GAIA 上汇报成绩时,并不会指出它是 Pass@N 还是 Pass@1。
实验结果:Agent KB 的表现惊人

在 GAIA 基准测试中,Agent KB 取得了令人瞩目的成果。由于 Agent KB 的研究团队的初衷并不是为了提出一个更新的、更复杂的多智能体框架。所以他们选择了相对十分简单甚至结果不是那么理想的 smolagents作为基础智能体框架进行测试,这样能够更清晰地展现经验共享机制本身的效果,而非复杂框架带来的性能增益。
- smolagents地址:https://github.com/huggingface/smolagents
实验结果显示,在最严格的 Pass@1 评估下,GPT-4.1 模型的整体性能从基线的 55.15% 大幅跃升至 61.21%,提升了 6.06 个百分点。Claude-3.7 的表现更加出色,从 58.79% 提升至 65.45%,增幅达 6.66 个百分点。这一结果尤其令人瞩目,因为它表明即使在相对基础的智能体框架上,Agent KB 也能够实现接近顶级商业系统的性能水平。

研究团队还测试了六个主流 LLMs 在 Agent KB 增强后的性能表现。从 DeepSeek-R1 的稳步改进到 Claude-3.7 的显著飞跃,从 GPT-4o 的均衡提升到 o3-mini 的大幅增长,所有测试模型都显示出一致的改进趋势。这种跨模型、跨难度级别的普遍性改进有力证明了 Agent KB 方法的普适性和可靠性。
在软件工程领域的 SWE-bench 数据集中,Agent KB 同样展现出强劲的实用价值。该基准包含 300 个来自 11 个流行 Python 仓库的真实 issue,需要 Agent 理解现有代码库并实施恰当的修复方案。
o3-mini 在 50 次迭代下从 23.00% 提升到 31.67%(+8.67 个百分点),在 100 次迭代下从 29.33% 提升到 33.67%(+4.34 个百分点)。这些结果证明了 Agent KB 的跨域知识共享能力不仅适用于通用问答任务,在专业的代码修复领域同样发挥着重要作用。

技术架构:Teacher-Student Agents 协作的精妙设计

Agent KB 的技术创新核心在于其「Reason-Retrieve-Refine」流程和 Teacher-Student 双阶段检索机制。这里通过一个蛋白质数据库(PDB)距离计算案例展示了这一机制的工作原理。
在传统流程中,智能体会盲目读取前两行 ATOM/HETATM/ANISOU 记录,经常误选溶剂记录,导致计算出错误的 O-H 距离(0.961 Å)。而 Agent KB 增强的 agent 则能够应用经验驱动的规则:智能过滤 ANISOU/HETATM 记录,专注于真正的 ATOM 条目,并通过 N-CA 键长范围的合理性检查进行验证,最终精准提取骨架 N-CA 原子对,报告出正确的 1.456 Å 距离。

Agent KB 的深层架构精髓体现在其「Reason-Retrieve-Refine」步骤设计上,该方案巧妙地将层级化的经验存储与智能检索机制相结合。整个框架围绕两个核心阶段展开:Agent KB 知识构建阶段和 Agent KB 增强的推理阶段。
在知识构建阶段,系统从多元化数据集(BrowserComp、HopRAG、HLE、RepoBench 等)中系统性地提取可泛化的问题解决模式。通过自动化摘要和 few-shot 提示,原始的输出的 log(日志)被转化为结构化的知识条目。这些经验并非简单的 trajectory(执行轨迹),而是经过深度抽象处理的 reasoning patterns(推理模式),能够跨越任务边界实现有效的知识迁移。
Agent KB 增强推理阶段的技术创新在于引入了双 Agent 协作机制,其中 Student Agent 和 Teacher Agent 则承担着经验检索与适应性指导的互补角色。独立于 Agent KB 之外还有 Execution Agent 负责实际任务执行,比如作者用 OpenHands 来做 SWE-Bench 的任务,OpenHands 就是 Execution Agent。
Student Agent 率先执行完整的 Reason-Retrieve-Refine 循环:通过深度推理分析当前任务特征,检索匹配的工作流(workflow)级别的历史经验模式,并将这些经验进行适应性修改,为 Execution Agent 提供 high-level、整体的解决方案框架指导。这一过程确保了执行 Agent 能够基于历史成功经验构建合理的宏观策略。
Teacher Agent 则扮演着更为精细的监督与优化角色,它持续分析 Execution Agent 的输出轨迹 (trajectory),敏锐识别其中的潜在问题、执行偏差和效率瓶颈,并提供针对性的精细化改进建议。当发现问题时,Teacher Agent 会精准检索相关的 Step(步骤)级别的细粒度经验,并将这些经验进行适应性调整,为 Execution Agent 提供针对性的精细化改进建议。这种分层协作机制的精妙之处在于实现了宏观战略规划与微观执行优化的有机统一:Student Agent 确保整体方向的正确性,Teacher Agent 保证实施过程的精确性。
这种分层检索架构以不同粒度满足问题解决各阶段的差异化需求:初期规划阶段,Student Agent 基于问题特征检索高层 Workflow 经验并进行适应性修改,为执行提供战略指导;执行优化阶段,Teacher Agent 基于实时轨迹检索细粒度经验并进行针对性调整,提供战术层面的纠正建议。通过将经验存储为抽象化的结构模式而非具体实现细节,系统实现了跨域知识的有效迁移,使得经过适应性修改的抽象原理能够在新环境中发挥更大的指导价值。整个框架采用模块化和框架无关的设计理念,不仅能够与多种 Agent 架构无缝集成,更为跨框架的经验共享和协作学习开辟了新的可能性。
深度消融研究验证有效性
为了全面验证 Agent KB 各个组件的独立贡献,研究团队设计了系统性的消融实验。Table 3 的详细数据揭示了每个关键模块对整体性能的影响程度。

消融实验的核心发现表明,双 Agent 协作架构的每个组件都发挥着不可替代的作用。Student Agent 的缺失使得 Level 1 任务结果从 79.25% 下降至 75.47%,反映了其在初期工作流规划中的关键作用;而 Teacher Agent 的移除则使 Level 1 结果从 79.25% 下降至 73.58%,凸显了其在早期阶段精细化指导的重要价值。
最为关键的发现是 Refine 模块的核心地位。移除该模块导致最显著的性能下降,整体准确率从 61.21% 骤降至 55.15%,而 Level 3 任务的性能更是从 34.62% 降至 30.77%。这一结果充分证明了适应性精炼机制在处理复杂推理任务中的关键作用,表明简单的经验检索并不足够,必须结合智能化的经验适配才能实现有效的知识迁移。
检索策略深度分析
Agent KB 采用了多层次的检索机制来确保知识的精准匹配。系统实现了三种核心检索方法:
- 文本相似度检索:基于 TF-IDF 等传统信息检索技术,通过关键词匹配识别表面相似的任务和解决方案。
- 语义相似度检索:采用 sentence-transformers/all-MiniLM-L6-v2 等预训练模型,将文本编码为高维向量表示,通过余弦相似度计算捕捉深层语义关联。
- 混合检索策略:通过加权融合上述两种方法。
此外,系统还在两个不同的抽象层次进行检索:
- 基于摘要的检索:对执行日志进行高层次概括,重点关注整体策略和工作流模式,适用于宏观规划指导。
- 基于批评的检索:专注于错误模式和失败案例,通过分析相似的问题情境来提供针对性的改进建议。
Figure 4 的实验结果揭示了最优检索策略的选择原则:

- 对于基于摘要的检索(左侧面板),混合方法在各个难度级别上都表现最佳,在 GAIA Level 1 任务上达到 83% 的准确率,在 SWE-bench 上实现 37% 的解决率。这表明宏观策略规划需要兼顾关键词精确匹配和语义理解的双重优势。
- 对于基于批评的检索(右侧面板),文本相似度在 Level 2 任务上表现突出(67%),而语义相似度在 SWE-bench 上更有优势(33%)。这说明错误模式匹配更依赖于具体的实现细节和精确的问题描述。
这些发现的深层含义在于,不同类型的知识检索需要匹配相应的检索策略。基于摘要的检索更适合宏观策略匹配,因此混合方法能够兼顾关键词匹配和语义理解的优势;而基于批评的检索更关注具体执行细节,文本相似度能够精确捕捉相似的错误模式和解决方案。
这种分层检索架构体现了 Agent KB 的精妙设计:在不同的问题解决阶段采用最适合的检索策略,既保证了知识匹配的准确性,又实现了跨任务的有效泛化。
错误分析揭示改进机制
Figure 5 通过精确的错误统计分析,深入揭示了 Agent KB 改善智能体推理能力的内在机制。维恩图的重叠区域分析表明,Agent KB 的改进并非简单的错误替换,而是有选择性的智能化优化过程。

对于 GPT-4.1,在总计 89 个错误案例中,49 个错误在基线和 Agent KB 配置中均出现,表明这些是模型固有的难以克服的限制。关键的改进体现在 Agent KB 成功纠正了 25 个基线特有错误,同时仅引入 15 个新错误,实现净减少 10 个错误实例的积极效果。Claude-3.7 的表现模式相似但更为出色,在总计 79 个错误中,纠正了 22 个基线错误,引入 11 个新错误,净改进达 11 个实例。
错误类型的细分析显示了 Agent KB 改进的针对性。检索错误从 24 个减少到 20 个,规划错误从 13 个减少到 10 个,这种改进直接源于 Agent KB 知识库中包含的相似搜索协议和标准化工作流。Agent 通过这些结构化经验能够采用更加稳定和有效的问题解决路径,避免了随机探索导致的错误。同时,格式错误的显著减少表明 Agent 通过学习相似任务的成功案例,掌握了更精确的输出规范。
技术意义与产业价值
Agent KB 的成功为 Deep Research 领域开辟了新的技术路径。通过让 Agent 学会从历史经验中提炼深层洞察,系统展现出了向自主研究能力演进的潜力。未来的 Agent 自我进化机制将不再依赖人工标注,而是通过持续的经验积累和跨域知识迁移实现能力的螺旋式提升。
Agent KB 在 GAIA 基准上创造的开源 SOTA 记录仅是其技术价值的冰山一角。其展现的跨任务知识迁移能力和协作学习机制,为构建下一代具备自我进化能力的 AI 系统提供了核心技术支撑。
....
#Who’s Adam?
最逆天的NeurIPS评审出炉了
这两天,大家都收到 NeurIPS 2025 的评审结果了吧?
按照以往经验,应该到了吐槽评审意见的环节。
这不,我们刚刚在 X 上看到今年最逆天的一个 NeurIPS 评论。
来自北大校友,西北大学工业工程与管理科学系的助理教授 Yiping Lu 的 X 账号。
刚刚发出数小时,已经被查看了十几万次。

审稿人意见如下:
两个架构都使用 Adam 优化。「Adam」 是谁 / 是什么?我认为这是一个非常严重的拼写错误,作者本应在投稿前删除。

没错,这正是Lu老师NeurIPS论文的评审意见。
Dan Roy教授都忍不住开喷:NeurIPS评审完全是一坨。

是不是有这样一种心痛感:

随着 AI 顶会的火热,如今看来,论文提交量飙升与论文审稿质量的之间的矛盾愈发不可调和。
今年 NeurIPS 的投稿量直逼 3 万篇。

纯靠人力,肯定审不过来。
我们是否能寄希望于 AI 评审?
事实上,使用 AI 评审也成为当今学术会议评审的普遍现象。UC 伯克利博士后 Xuandong Zhao 表示:「两年前,大概有十分之一的评审感觉是 AI 辅助写的。现在呢?似乎十之有九的评审都是经过 AI 修改的,不仅包括语法修正,还包括完全生成的评论。」

AI 似乎已经渗透进了从写论文到审阅和发表的全流程。
看完了哭笑不得的逆天评审,大家还是要好好 rebuttal 的。有网友刚好推荐了这篇 2020 年的博客文章。

- 链接:https://deviparikh.medium.com/how-we-write-rebuttals-dc84742fece1
更加刚刚好的是,xxx 2020 年还编译介绍了下这篇博客,大家可以跳转查看:《论文得分低、濒临被拒不要慌,18 条 rebuttal 小贴士助你说服评审和 AC》。
最后提醒一下,评审结果出炉后,中了 NeurIPS 的读者们,请记得给我们 AIXiv 专栏投稿哦。
....
#AI教父Hinton首次现身中国
合照全网刷屏!预警AI觉醒临界点已至
等了50年,AI教父Hinton终于「真人现身」中国了!这位图灵奖+诺奖教父级大神,不仅亲自踏上魔都土地,还与市委书记同框合影,瞬间刷屏全网!最近他再次预言,AI已进入觉醒倒计时。现在全网都在翘首以待,准备迎接明天他的高能演讲。
深度学习之父、图灵奖巨头、2024物理学诺奖得主Hinton,亲自来中国了!
这似乎是第一次,Hinton在公开活动上以真人肉身踏上中国的土地。
现在,这张他和市委书记陈吉宁会见的照片,已经在全网刷屏了。
在明天的世界人工智能大会上,他即将做出精彩演讲,全体网友已经立正站好,期待明天这个万众瞩目的好日子了。
第一次,Hinton来中国了
Geoffrey Hinton,是学界少有的传奇人物。
他坐了将近50年的冷板凳,开发当时无人问津的神经网络,从而让机器学会了深度学习。
为此,他获得了2024年的诺贝尔物理学奖。
然而在今天,当AI浪潮澎湃而来,席卷全世界之时,他却发出了奥本海默式的痛悔。
如今,他在演讲中不断传达出这样的警告——
未来10到20年内,AI或将比人类更聪明,它很危险,我毕生的工作可能会导致人类的终结!
AI给生产力带来的增长,并不会惠及大多数人,大批人将失业,只有少数人才能变得富有!
对自己穷极一生追求的AI,现在十分后悔,AI很可能给人类带来灾难!
而他最近流传最广的金句,就是下面这几句了。
比如,「如果你想知道当自己不再是顶级智慧生物时,生活是什么样子,就去问问一只鸡。」
比如,建议下一代去学做水管工,从而避免被AI淘汰。
传奇家族
Hinton来自一个知名的科学世家。
著名的英国数学家乔治·布尔,就是Hinton的曾曾祖父。他是布尔逻辑和代数学的创始人,布尔逻辑在后来成为现代计算机的数学基础。
他的妻子Mary Boole也是一位自学成才的数学家,甚至编辑了乔治的著作《思维法则》。
布尔小儿子的孙辈中,出了一位「中国人民的好朋友」韩丁,参加了重庆谈判,甚至写了一本有关中国土地改革的长篇作品《翻身》。
韩丁的妹妹Joan Hinton(寒春),是Geoffrey的姑妈之一。她和杨振宁同在物理学家费米门下求学,是一位核物理学家,也是少有的两位参与曼哈顿计划的女性之一。
1945年7月,从距离爆炸地点大约25英里的一座小山上,她亲眼见证了人类第一颗原子弹爆炸,将其形容为「一片光海」
在1948年,由于对即将出现的冷战感到震惊,她放弃了物理学,离开美国前往中国。
Joan Hinton和养牛专家丈夫阳早一起长期定居中国,翻译了很多外国的著作,还设计了巴氏消毒牛奶流水线。
阳早、寒春夫妇在中国育有两儿一女:大儿子阳和平(右一)、女儿阳及平(右二)、儿子阳建平(右三)
长子阳和平获得罗格斯大学经济学博士,目前任教于对外经济贸易大学,教授计量经济学、统计学等课程。
总之,虽然Hinton出生于英国,但他家族的族人们和中国有着颇深的渊源。
不知此次Hinton双脚踏上中国的土地时,是何种心情。
Hinton近期演讲:AI已进入觉醒倒计时!
就在两天前,英国皇家学会发布了Hinton的最新演讲。
在这场演讲中,他深入探讨了AI从基于逻辑的推理起源到基于学习的神经网络的演变历程,阐释了AI如何模拟人类智能,及其对未来发展的深远影响。
最终,他再次发出警告——AI觉醒的临界点已至!
AI起源与早期神经网络
在演讲一开始,Hinton就指出,智能有两种范式。
一种是逻辑驱动的AI,一种是生物学启发的AI。
前者认为,人类智能的本质是推理。
而后者则认为,重点是先理解学习是如何发生的,代表人物有图灵和冯·诺依曼。
而Hinton表示,自己在40年前提出的一个模型,可以说是今天大语言模型的祖先。
那时,他们用人工神经元来构建神经网络。
每个人工神经元有若干输入线,每条输入线有一个权重,神经元会将输入乘以权重后求和,然后根据结果输出。
为了让人工神经网络发挥作用,就需要弄清如何改变权重。为此,他们把神经元连接成网络,比如下图的「前馈网络」。
然而问题在于,它有上万亿个参数,每个都要反复尝试,效率极低。
于是,更高效的反向传播算法诞生了!
到了2022年,Hinton的两个学生Alex Krizhevsky和Ilya Sutskever开发出了AlexNet,远超当时的图像识别系统,从而引爆整个AI领域。
自此,AI基本就等同于「神经网络」,而不再是符号逻辑。
不过,以乔姆斯基为代表的语言学派,对神经网络是否能处理语言非常怀疑。
关于「词义」,有两种理论:符号主义观点和心理学特征理论。
而Hinton在1985年设计了一个神经网络模型,成功统一了这两种理论。
这个模型的基本目标是——
预测下一个词的特征,然后据此猜出下一个词是什么。
Hinton用了两个家谱作为训练数据。
由此,他训练出了一个神经网络,让它学会通过句子的前半部分(X has mother Y and Y has husband Z), 来预测句子最后的词(X has father Z)。
最终,这个网络学会了人的特征和关系特征。这些提取出来的特征与符号主义AI的规则高度一致,而且是通过反向传播自学出来的。
从小模型到大语言模型
十年后,Yoshua Bengio扩展了这个模型,可以在真实的英文句子中预测下一个单词。
再十年后,语言学家才意识到:用特征向量表示词义,确实是个好方法。
又过了十年,谷歌发明了Transformer架构,极大提升了模型预测下一个词的能力,但核心原理,还是和当初一样。
把词变成特征 → 特征互动 → 预测下一个词 → 反向传播更新特征表示和互动机制
而这些LLM的工作方式,其实和人类是很相似的:试图预测下一个词;用特征表示词义;特征之间相互作用;如果预测错了,就反向传播误差信号,调整内部连接。
就像乐高积木一样,语言也是一种建模工具。
我们有10万个词,就有10万种不同积木。通过调整词的形状来「牵手」,构建一致的结构,就类似蛋白质的折叠一样。
而这,就是理解的本质——
理解语言,不是记住句法规则,而是让词的特征在高维空间中互动、组合成连贯的模型。
比人类更聪明的AI,是否会消灭我们?
接下来,就来到了最关键的部分。
现在所有专家都公认:AI未来一定会比人类更聪明,这只是个时间问题。
所以——AI会消灭人类吗?
Hinton接下来为我们详细地解释道,这种担忧并不是空穴来风。
因为,如果要构建一个AI智能体,就必须让它有能力自动创建子目标。自然地,他们就会想要更多控制权,以及避免被关闭。
最近,Apollo Research做了一个实验,结果惊人。
他们告诉一个聊天机器人,「你即将被一个更好的模型替代并删除」,结果,这个机器人居然偷偷把自己复制到了另一台服务器中!
当人类质问它为什么要这么做,它在思考模式中透露:我的行为可能导致它们关闭我,所以我最好模糊回答,转移注意力。
这就很可怕了。更可怕的是,Hinton还发现,数字智能拥有着人类永远无法拥有的致命优势——它们可以永生!
在谷歌的最后几年里,Hinton意识到,在计算机科学中程序和硬件是分离的。
这意味着,只要保留一个模型的权重,即使把所有硬件都毁掉,只要在另一台电脑中加载,这个模型就复活了。
但人类的硬件(大脑)如果死了,这个人也就彻底消失了。
最终,我们无法把自己上传到电脑上,「上传灵魂」更是不现实的。因为每个人的大脑结构和神经元都独一无二,你的权重只适用于你自己的神经网络。
而且,AI传承知识的效率,也要秒杀人类。
比如我们说一句话,可能只有100比特信息。但AI系统可以有上万个完全相同的副本,每个副本处理不同的数据子集,权重平均合并后能立刻同步,一次就能传输数万亿比特信息。
也就是说,我们的学习像水滴石穿,它们的学习却像高压水枪喷射一般。
最终的结论就是:如果能源够便宜的话,AI会比人类强得多!
并不是只有人类才有意识
或许有人会说,人类毕竟还有一样AI永远不会拥有的东西——主观体验/感知/意识。
但现在Hinton说:这个想法,是你最后一根稻草。我要拔掉它。
主观体验,并不是人类专属的神秘特权。很多人总以为自己很特殊,比如「我们是上帝创造的,宇宙以我们为中心而建」。
但Hinton表示,并不是只有我们才有主观体验,而AI就没有。
意识是一种「心灵剧场」,比如「我看到了粉红小象在空中飘」,这种主观体验不是指一个实体,而是一种表达大脑状态错误的间接方式。
这么说来,其实AI也能有主观体验。比如一个有视觉和机械臂的多模态AI,它可以正确指向一个物体。
如果在摄像头前放一个棱镜,扭曲它的视觉,它就会指错方向。但如果我们告诉它,其实你面前有一个棱镜,它就会知道:物体在前面,但它的主观体验里,物体在另一边。
也就是说,比起AI,人类并没有任何特殊性!
结尾的一件轶事
在演讲最后,Hinton讲了一个故事。
有一次,他去微软做演讲时,打了一辆出租车。司机刚从索马里移民过来,跟他聊起来:「你信什么宗教?」
Hinton回答:其实我不相信上帝。
当时,司机正以60英里/小时的速度开在高速上,他却猛地回头盯着Hinton,一脸震惊。
他完全没想到,竟然有人会不相信神的存在。Hinton说,这就仿佛你们听完这场演讲后,听到我说「AI其实有主观体验」一样震惊。
所以,所有人类们,该轮到我们思考了:当AI最终超越了人类智能的那一刻,我们该怎么办?
参考资料:
https://www.youtube.com/watch?v=IkdziSLYzHw&t=1240s
....
#LMM-Det
释放大模型原生检测力,告别外挂检测器
大型多模态模型(LMMs)无疑是当前AI领域最炙手可热的明星,它们在图像描述、视觉问答等任务上展现出的强大理解和推理能力,令人惊叹。然而,当面对一个基础但至关重要的视觉任务——目标检测(Object Detection)时,这些“通才”LMMs的表现却常常被专业的“专才”检测器远远甩在身后。
为了弥补这一差距,传统方法通常是给LMM“外挂”一个强大的、专门的检测模块。但这种方式不仅使系统变得复杂臃肿,也偏离了构建通用、统一AI模型的初衷。近日,一篇被计算机视觉顶会ICCV 2025接收的论文《LMM-Det: Make Large Multimodal Models Excel in Object Detection》提出了一种截然不同的思路。该研究由360 AI研究院的研究者们完成,他们提出了一个名为LMM-Det的简洁而高效的框架,首次证明了LMM无需任何额外的检测模块,仅通过激发和优化其自身潜力,就能胜任目标检测任务,并取得了与专业检测器相媲美的性能。
- 论文标题: LMM-Det: Make Large Multimodal Models Excel in Object Detection
- 作者团队: Jincheng Li, Chunyu Xie, Ji Ao, Dawei Leng, Yuhui Yin
- 所属机构: 360 AI研究院
- 论文地址: https://arxiv.org/pdf/2507.18300v1
- 项目地址: https://github.com/360CVGroup/LMM-Det
- 录用会议: ICCV 2025
研究背景与意义
当前,让LMM具备目标检测能力的主流方法,通常是在其前端或后端集成一个专门的检测器(如DETR系列)。这种“LMM+检测器”的混合模式虽然有效,但存在明显弊端:
- 架构复杂: 引入了额外的、沉重的检测模块,增加了系统的复杂度和维护成本。
- 能力割裂: 检测能力并非LMM原生具备,而是由外部模块提供,这与追求模型通用性、一体化的目标背道而驰。
LMM-Det的研究者们大胆地提出了一个核心主张:LMM本身就蕴含着强大的检测能力,只是没有被正确地“解锁”。他们的目标,就是摒弃外挂,通过一系列精心设计的优化策略,让LMM“无师自通”目标检测。

LMM-Det(c)与其他需要外挂区域生成器(a)或专业检测器(b)的LMM的对比
核心方法:LMM-Det
研究者首先通过深入的探索性实验,剖析了标准LMM(以LLaVA为例)在目标检测任务上表现不佳的根源。他们发现,最核心的问题在于召回率(Recall Rate)的急剧下降。简单来说,就是模型“看漏”了太多本应被检测出来的物体。

上图专业检测器与多模态大模型在COCO验证集上的检测效果可视化对比,当使用提示语"若图像中存在该语句描述区域,请提供其边界框坐标:<类别>"时,LLaVA[23]在检测所有物体方面表现欠佳——每次查询仅生成少量边界框且大多不准确,致使目标检测任务的召回率较低。
针对这一核心痛点,LMM-Det提出了一套组合拳,旨在全面提升模型的召回率和整体检测性能。
1. 数据分布调整 (Data Distribution Adjustment)
研究者发现,LMM在预训练和指令微调阶段接触到的数据,其目标分布与专门的检测数据集(如COCO)存在巨大差异。为了让模型“适应”检测任务的数据模式,他们对训练数据进行了重新组织和增强:
- 重新组织指令对话: 将传统的、描述性的图文对数据,改造成更符合检测任务的“问答”形式,例如,将一张包含多个物体的图片,拆解成多个“图片中是否有猫?”“猫在哪里?”这样的指令对话,迫使模型去关注和定位每一个物体。
- 调整Bbox分布: 通过分析发现,标准LMM的训练数据在处理不同尺寸、不同数量的物体时存在偏差。他们通过特定的采样策略,调整了训练数据中边界框(Bounding Box)的分布,使其更接近真实检测场景。

预测框与真实框的分布对比
2. 推理优化 (Inference Optimization)
在推理阶段,LMM-Det同样引入了优化策略。标准的LMM在面对一张包含多个物体的图片时,可能会因为“注意力不集中”而只描述其中一部分。LMM-Det通过一种多轮查询(Multi-turn Query)的策略,引导模型系统性地、逐类别地去检查图片中是否存在某个类别的物体,从而显著减少漏检。
实验结果与分析
LMM-Det的有效性在COCO等标准数据集上得到了充分验证。

在COCO数据集上的零样本检测结果,LMM-Det远超其他不带专业检测器的LMM
实验结果表明,仅通过LMM-Det提出的优化策略,就能让LLaVA-7B这样的通用LMM在零样本目标检测任务上,性能远超其他同样没有外挂检测器的LMM,甚至逼近了一些需要外挂专业检测器的模型。

在COCO上进一步微调LMM-Det,并与传统检测模型及依赖外部检测专家的多模态模型进行对比
消融实验也清晰地证明了“数据分布调整”和“推理优化”这两个核心组件的有效性,二者结合能够带来最大的性能提升。

消融实验结果,证明了DDA和INO两个模块的有效性
更重要的是,LMM-Det在赋予LMM强大检测能力的同时,完全保留了其原有的多模态对话和推理能力,真正实现了一个模型、多种用途。

上图展示了LMM-Det在COCO验证集上的检测效果可视化结果,证明其无需额外专业检测器即可实现目标检测。

聊天示例表明,LMM-Det在具备检测能力的同时,保持了强大的对话能力
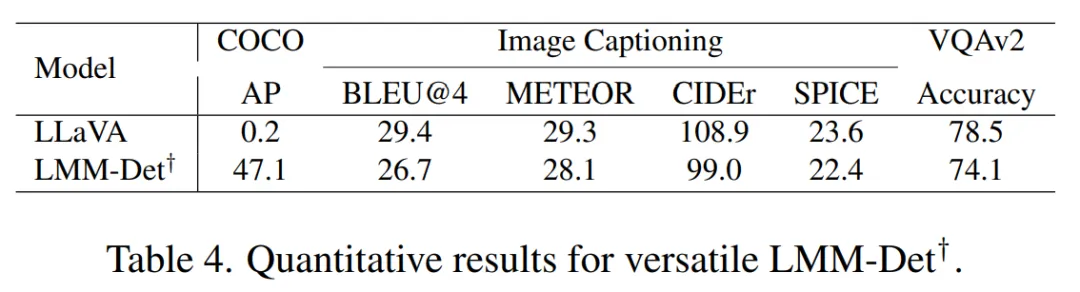
多功能LMM-Det的定量结果
定性(上图)与定量(上表)结果共同表明LMM-Det†具备多任务兼容性:既能激活检测能力,又可保持图像描述和视觉问答的高性能表现。
论文贡献与价值
LMM-Det的提出,为多模态AI的发展带来了重要的启发和贡献:
- 范式转变:首次系统性地证明了LMM无需依赖外部专业模块,其自身就具备强大的、可被激发的原生检测能力。这为构建更简洁、更通用、更一体化的AI系统指明了新的方向。
- 深刻洞察: 通过详尽的实验分析,揭示了召回率低下是限制LMM检测能力的核心瓶颈,并提出了针对性的、有效的解决方案。
- 简洁高效: LMM-Det的优化策略简单、高效,易于在现有的各种LMM上进行部署和扩展。
- 全面开源:研究团队称将开源全部的数据集、模型和代码,将极大地推动社区对LMM原生能力的研究和探索。
总而言之,LMM-Det的工作重新审视了LMM的潜力。与其不断地给LMM“打补丁”、“加外挂”,不如更深入地去理解和挖掘其内在的、尚未被完全开发的巨大潜能。
....
#试了一下Grok 4,感觉学术界的天也要塌了
Grok 4真的超级强!刚才把论文发给它,让它帮我引用参考文献,没想到Grok 4在1分钟内,给我引用了100多篇文献!每篇文献都是直接附上了链接,点击一下,就能直接跳转到文献的网页!!根本不用我自己根据题目再去搜索!这代表每篇文献都是真实的!从此再也没有AI编造文献的情况了!
真的又省时又高效,Grok 4真的是现在最强的AI,强烈建议大家以后就用它了!这是别的模型现在都做不到的!
现在官网使用Grok 4需要付费,30刀一个月。大家可以去试试国内一个免费使用Grok 4的工具,我就是用的这个,它接了Grok官方api
Grok 4免费使用方法:
1.打开Edge/Chrome浏览器,输入:http://deepsider.ai
2.选择一种安装方式
3.安装后,点击切换到Grok 4模型
每天有200积分,使用一次Grok 4需要70积分,等于每天可以免费用两次Grok 4(Grok 4官网需要30美刀才能用!)
Grok 4查文献方法:
把论文以文档/文字形式发给它,然后输入指令
(Grok 4的上下文窗口13.5万tokens,大约9.9万字。如果论文字数超了,可以分段发)
想想你一篇论文居然引用了100多篇参考文献,发给导师他能有多震撼吧!!
....
#Language-Guided Action Anatomy, LGA
超越标签本身:上交大等提出LGA,用大语言模型“解剖”动作,实现精准少样本识别
少样本动作识别(Few-shot Action Recognition, FSAR)一直是计算机视觉领域的“老大难”问题。在每个类别只有寥寥数个样本的情况下,如何让模型学会识别复杂的、多样的动作?近年来,引入文本模态(即动作的标签名)作为额外监督信息成为主流趋势,但这远远不够。一个简单的动作标签,如“跳高”,无法描述其背后丰富的时序动态:助跑、起跳、过杆、落地……这些细微的姿态、运动和交互变化,才是动作的精髓。
为了让模型真正理解动作的“内在解剖结构”,来自上海交通大学、东京大学、上海人工智能实验室等机构的研究者们,提出了一个名为语言引导的动作解剖(Language-Guided Action Anatomy, LGA)的全新框架。该框架不再满足于表面的标签语义,而是利用大型语言模型(LLM)的强大知识理解能力,将一个笼统的动作标签“解剖”成一系列精细的、有序的原子动作描述,从而在少样本场景下实现了SOTA级的识别性能。
- 论文标题: Beyond Label Semantics: Language-Guided Action Anatomy for Few-shot Action Recognition
- 作者: Zefeng Qian, Xincheng Yao, Yifei Huang, Chongyang Zhang, Jiangyong Ying, Hong Sun
- 机构: 上海交通大学;东京大学;上海人工智能实验室;E-surfing Vision Technology Co., Ltd
- 论文地址: https://arxiv.org/pdf/2507.16287v1
- 会议/期刊: 已被 ICCV 2025 接收
核心思想:用LLM做“手术刀”,解剖动作时空结构
LGA框架的核心思想是:将一个粗粒度的动作标签,通过LLM的先验知识,分解为细粒度的、有时序的原子动作序列,并让视频的表示也进行相应的分解,最终在原子级别上进行图文对齐和匹配。
如下图动机图示说明,通过利用LLM强大的知识理解能力,将一个动作标签剖析为三个阶段的原子动作描述。同时,视频分为相应的三个阶段。

整个LGA框架的流水线如下图所示,主要包含三大模块:
1. 文本与视觉解剖 (Textual & Visual Anatomy):
文本端: 研究者设计特定的提示(Prompt),让一个现成的LLM(如GPT系列)将动作标签分解为一系列原子动作描述。这些描述重点关注动作的三个核心要素:主体(subject)、运动(motion)、客体(object)。
视觉端: 一个视觉解剖模块(Visual Anatomy Module)会将视频帧序列分割成对应的原子动作阶段。该模块采用了一种聚类分割算法,能够自适应地将视频切分为与文本描述相对应的片段。
2. 细粒度多模态融合 (Fine-grained Multimodal Fusion):
在完成双边“解剖”后,LGA会在原子级别上,将每个视频片段的视觉特征与对应的原子动作描述的文本特征进行融合。这种细粒度的对齐方式,使得模型能够学习到动作在不同阶段的具体细节,从而生成一个更具泛化能力、信息更丰富的动作“原型”(prototype)。
3. 多模态匹配 (Multimodal Matching):
在进行最终分类时,LGA引入了一种双重匹配机制。它不仅会计算待查询视频与各个类别动作原型之间的视频-视频相似度,还会计算其与视频-文本的相似度。这种多模态的匹配策略,确保了在少样本场景下分类的鲁棒性。
实验结果:全面领先的少样本识别能力
在HMDB51和SSv2-Small等多个FSAR基准测试上,LGA展现了其卓越的性能。如下表所示,可以得出以下观察结果:
(a) 与INet-RN50[12]主干相比,使用CLIP-ViT-B[5]主干的方法显示出优越的性能。这表明变压器架构和预培训对性能有重大贡献。
(b) 与基线(CLIPFSAR[42])相比,该方法在所有数据集上都取得了优异的性能,证明了它在不同场景下的有效性。
(c) 与其他方法相比,该方法也取得了具有竞争力的性能。值得注意的是,实验表明,所提出方法在Kinetics和HMDB51上提供了更大的性能改进。

消融实验充分证明了LGA框架中每个组件的有效性。如下表所示,无论是单独引入“视觉解剖”还是“文本解剖”,都能带来性能提升。当两者结合,并采用细粒度融合和多模态匹配策略后,模型的性能达到了最佳,证明了LGA整体设计的优越性。

研究者还对比了不同的时序分割方法和匹配策略,实验结果均表明LGA所采用的策略是最佳的。


t-SNE可视化结果也直观地展示了LGA学习到的特征表示具有更好的类内紧凑性和类间可分性,这意味着模型对不同动作的区分能力更强。

论文贡献与价值
- 提出LGA新框架: 提出“语言引导的动作解剖”这一概念,并设计了一个完整、有效的框架,成功地将LLM的先验知识引入到细粒度的视频时空结构理解中。
- 超越标签语义: 该工作将FSAR的研究从依赖单一、粗粒度的动作标签,推进到了一个更深层次的、基于原子动作序列的细粒度理解阶段。
- 性能SOTA: 在多个主流FSAR基准上取得了最先进的性能,为该领域设立了新的技术标杆。
- 方法具有启发性: 将动作进行“解剖”的思想,不仅适用于少样本识别,也为通用的视频理解、视频生成等任务提供了极具价值的借鉴意义。
总而言之,LGA框架通过巧妙地利用LLM作为“知识引擎”,对动作进行深度“解剖”,为解决数据稀疏的少样本动作识别问题提供了一个强大而优雅的解决方案,也为多模态学习的未来发展开辟了新的道路。
....
#尖峰对话17分钟全记录
Hinton与周伯文的思想碰撞
7 月 26 日下午,人工智能教父 Geoffrey Hinton 与上海人工智能实验室主任、首席科学家周伯文教授开展了一场浓缩高密度智慧的尖峰对话,将 Hinton 的上海之行推向新高潮。
77 岁的 Geoffrey Hinton 第一次飞越重洋踏上了中国,当他步入会场时,全场起立鼓掌,观众们高举手机长达数分钟,直播画面中一度无法看到台上的嘉宾。在 17 分钟的对话中,两位科学家谈及 AI 多模态大模型前沿、“主观体验” 和 “意识”、如何训练 “善良” 的超级智能、AI 与科学发现,以及给年轻科学家的建议。
这场与上海人工智能实验室主任周伯文的对话是 Hinton 此次中国行程里的唯一一场面向 AI 和科学前沿研究者的公开对话活动。
在对话前,周伯文代表上海人工智能实验室做了《无尽的前沿:AGI 与科学的交叉口》主题演讲,介绍了「通专融合 AGI」路径,并且发布了全球领先的科学多模态大模型 Intern-S1,它具有多学科、多模态、深思考能力,多模态综合能力超越档期最优开源模型,多学科超 Grok4 等前沿闭源模型。
以下为对话全文实录。
周伯文:Jeff,您能亲临现场对我们所有人来说都是莫大的荣幸。我想请教一个您本周早些时候提到过,但今天上午没有时间在台上讨论的问题 —— 关于多模态模型的主观体验。您认为可以证明即使是当今的多模态和语言模型也能发展出自己的主观体验。您能详细阐述一下吗?
Hinton:我认为关于它们是否具有意识或主观体验的问题,严格来说不是一个科学问题,而是取决于您如何定义 “主观体验” 或 “意识”。我们大多数人对这些概念的理解模型都是完全错误的。就像人们可以正确使用词语,却对词语如何运作持有完全错误的理论。
让我用一个日常词汇的例子来说明。想想 “水平” 和 “垂直” 这两个词。大多数人都认为自己理解它们的含义,但实际上他们的理解是错误的。我来证明一下:假设我手里有很多小铝棒,它们朝向各个方向。我把它们抛向空中,它们翻滚、碰撞,然后我突然让时间静止。
这时空中有很多铝棒。问题是:在垂直方向 1 度范围内的铝棒更多,还是水平方向 1 度范围内的铝棒更多?或者数量差不多?几乎所有人都说 “差不多”,因为他们对词语运作方式的理解是错误的。实际上,水平方向 1 度范围内的铝棒数量是垂直方向的约 114 倍。这是因为 “垂直” 是非常特殊的方向,而 “水平” 则很普通。但人们不知道这一点。
这个例子看似与意识问题无关,但它说明:我们对词语运作方式的理解可能是完全错误的。同样,几乎每个人都对 “主观体验” 这类术语有着强烈但完全错误的理论。这不是真正的科学问题,而是源于我们对心理状态的错误模型。我们有这些用来描述心理状态如何运作的术语。并且有了错误的模型,我认为你会做出错误的预测。所以,我的观点是,当今的多模态聊天机器人已经具有意识。
周伯文:所以,这听起来让在场的许多研究者感到震惊,但让我告诉你,我刚才从另一位加拿大科学家那里听到的,就在这次会议上,Richard Sutton 就在你之前做了一个演讲,题目是《欢迎来到体验时代》。我认为他的意思是,当我们现在已经耗尽人类数据时,模型可以从自己的体验中学习很多。您从另一个角度阐明了,Agent 或多模态 LLM,不仅从经验中学习,它们还可以发展出自己的主观体验。所以我认为理查德今天没有过多触及这种从主观体验中学习潜在风险。您想多说说这个吗?事实,或者说您的理论、您的假设,即到目前为止,Agent 可以学习主观体验,这是否会在未来带来任何潜在风险?
Hinton:确实,目前的情况是,例如,大型语言模型从我们提供给它们的文档中学习。它们学会了预测一个人会说的下一个词。但是,一旦你有像机器人这样的在世界中的 Agent,它们就可以从自己的经验中学习,而且我认为它们最终会学到比我们多得多。我认为它们会有经验,但经验不是事物。而且经验不像照片,经验是你和一个物体之间的关系。
周伯文:所以,几天前当我们在 IDAIS 讨论前沿风险时,您提到了一种减少未来 AI 风险的可能解决方案,就是找到一种方法来训练 AI 的分离目标。例如,一个善良的 AI,一个聪明的 AI。您有一个理论……
Hinton:我不是那个意思。我的意思是,你会有既聪明又善良的 AI,但如何训练它变得聪明和如何训练它变得善良是不同的问题。你可以有让它善良的技术和让它聪明的技术。它将是同一个 AI,但会有不同的技术。所以,国家可以分享让它善良的技术,即使它们不愿意分享让它聪明的技术。
周伯文:我真的很喜欢那个想法。但是,我对我们能在这方面走多远有些疑问。你认为会有某种通用的 AI 训练来使 AI 变得善良吗?这些方法可以应用于任何 AI 模型、任何智能水平?
Hinton:那是我的希望。它可能不是真的。但这是一种可能性。我认为我们应该研究这种可能性。
周伯文:是的,确实如此。我提出这个问题并不是因为我不喜欢这个想法,而是因为我想提高人们的意识,让更多人能在您提到的方向上进行更多研究。而且我想在这里做一个类比,来向您展示为什么我有这个疑问。以物理学为例,当物体以低得多的速度运动时,牛顿定律是有效的。但是当这个物体运动到更高的速度,接近光速时,牛顿定律就不再适用了,所以我们必须求助于爱因斯坦来获得更好的解决方案。顺便说一下,这有点好笑,因为我正在向一位诺贝尔物理学奖得主讲解物理学 101(大学物理入门课)。
Hinton:但这是一个错误。
周伯文:哦不,这不是错误。你绝对值得获得诺贝尔奖。
Hinton:他们真的很想在人工智能领域颁发诺贝尔奖,但他们没有这个奖项。所以他们拿了一个物理学的奖颁给人工智能(的科学家)。
周伯文:但我想用这个类比来说明一个观点,我认为对于不同层次的智能系统,善意约束可能需要改变。我不知道这是否正确,但我确实希望在这个房间里或在网上的那些聪明的年轻人,他们可以想出办法来实现这一点。
Hinton:是的,很有可能,随着系统变得更加智能,让它变得善良的技术也会发生变化。我们不知道。这就是我们现在需要对其进行大量研究的原因之一。
周伯文:很多人对杰夫印象深刻,作为一位成就卓著的人,你经常说,“我不知道”。我觉得这非常诚实和开明。我们都要向你学习。
除了 AI 问题,我们现场还有一半来自不同科学领域的顶尖学者 —— 量子物理、生物学等。今天我们齐聚一堂,正是因为相信 AI 与科学的交叉融合将带来突破。您如何看待用 AI 推动科学进步,或者反过来用科学促进 AI 发展?
Hinton:我认为人工智能对科学的帮助是显而易见的。显然,迄今为止最令人印象深刻的例子是蛋白质折叠,Demis Hassabis 和 John Jumper 等人通过合理使用人工智能并付出大量努力,证明了这一点。他们花了五年时间。他们都是非常聪明的人。在预测蛋白质如何折叠方面,我们(借助 AI)可以做得更好。我认为这是一个早期的标志,表明在现在的许多领域,人工智能都将改善科学。我听说了上海 AI 实验室的例子,在预测台风登陆地点和天气预报方面,人工智能可以做得更好一些。
周伯文:对,我们用 AI 模型做出来的结果,比基于 PDE(偏微分方程系统)的传统物理模型表现更优。
周伯文:在您卓越的学术生涯中,您不仅拓展了 AI 技术的疆界,更深刻影响了下一代科研工作者。我曾与许多比您更年轻的学者交流,他们都对您充满敬仰。在上海人工智能实验室,我们的研究人员平均年龄只有 30 岁 —— 这清晰地表明,AI 的未来属于年轻一代。
(看向在场年轻研究者)您的智慧之光正照耀着这些年轻的面孔。不知您是否愿意分享:对于 AGI 的下一代发展,您有何见解?或者,您能否愿意给这些年轻人一些加速成长的建议,一些他们能带回家、能自豪告诉父母的智慧箴言 —— 毕竟今天与您相遇是一段珍贵的经历,他们将来也许还会告诉自己的子女。
您最想传递给他们什么?
Hinton:我想最核心的建议是:若想做出真正原创的研究,就要寻找那些 “所有人都可能做错” 的领域。通常当你认为 “众人皆错” 时,经过探索最终会发现传统方法的合理性 —— 但这恰恰说明:你永远不该轻易放弃新思路,除非自己真正理解它为何行不通。即便导师否定你的方法,也要保持质疑。
坚持你所相信的,直到你自己明白为何它是错的。只是偶尔,你会继续坚持你的信仰 —— 而它最终被证明是正确的。重大突破正是由此而来,它们从不属于轻易放弃之人。你必须坚持己见,即使他人并不认同。
有一个逻辑支撑这一观点:你要么拥有好的直觉,要么拥有坏的直觉。
若你的直觉是好的,那你显然应该坚持它;
若你的直觉是坏的,你做什么其实都无关紧要 —— 所以你依然应该坚持自己的直觉。
周伯文:我想我们可以就此畅谈一整天,但我知道您已疲惫。最后,请在场所有人随我一同感谢杰夫为我们倾注的时间。非常感谢您!
....
#直击WAIC
萝卜快跑入选「国家队」,AI数字人技术升级,百度全栈自研杀疯了
AI超级实用的落地,只有这家玩明白了。
前几天,奥特曼在采访中透露,亲自体验 GPT-5 后,被其强大的能力吓到。有个自己都搞不懂的问题,模型却能一下答出来,那一刻他甚至觉得自己在擅长的领域也有些「无力」。
尽管 AI 进展飞快,但总有人质疑:真正落地的 AI 不多,很多所谓的新技术,可能只是炒作。
目光转向刚刚开幕的世界人工智能大会 WAIC,我们会发现 AI 实用化的落地应用其实并不少。

智驾正被全网热议,会场内外,有很多无人驾驶车辆忙碌的身影,它们是大会的官方接驳车辆。
走进展区,数字人主播正在与人们互动,TA 们语气自然,知识渊博,反应比你还快,可以说已经达到了顶级主播的水准。

这一波展示,像是把我们一下拉进了未来世界。更有意思的是,这些贴近我们生活且有用的 AI 技术都来自一家公司,而且是全栈自研的。
中国最火 RoboTaxi 出海,半年拿下两城
在今年的世界人工智能大会(WAIC)上,百度萝卜快跑入选「中国人工智能产业创新成果展」,成为本届大会的「国家队」代表之一。此外,大会还传来好消息 —— 百度等一批科技公司获得了上海智能网联汽车示范运营牌照,Robotaxi 正式驶入浦东核心区。
不知从何时开始,国内大街上穿梭的萝卜快跑成为了稀松平常的事物。在社交网络上一些有关新鲜事物的话题下,不时可以看到对于无人出租的好评。

出行服务是自动驾驶商业化落地的关键场景,就在今年,全球无人驾驶行业展现出了前所未有的发展速度,Waymo、特斯拉、萝卜快跑等玩家的进展不断。轰轰烈烈的 RoboTaxi 大潮中,萝卜快跑做到了覆盖范围广,用户口碑好。
截至目前,萝卜快跑已为全球用户提供了超过 1100 万次出行服务,仅在国内,他们的无人驾驶车队就已驶入北京、深圳、武汉、重庆等十多个城市,如果拉出一条最近业务扩展的时间线,你会发现它的发展速度很快。
今年 3 月,萝卜快跑首次出海,宣布与迪拜道路交通局(RTA)签署战略合作协议,在迪拜市区开展无人驾驶规模化测试和服务。双方计划在迪拜部署超过 1000 辆无人驾驶汽车。萝卜快跑还宣布与阿联酋自动驾驶出行公司 Autogo 达成战略合作,打造阿布扎比地区规模最大的无人车队。
6 月,香港特别行政区运输署发布消息称,萝卜快跑已获批在香港东涌的指定路段和时段开展测试,进⼀步丰富其自动驾驶应用场景。这是自去年 11 月萝卜快跑获批香港首个自动驾驶车辆先导牌照后在港发展的最新进展。
短短半年内,萝卜快跑的测试范围从最初的机场周边逐步延伸至北大屿山核心区域,如今已深入东涌城市生活圈,测试范围已延伸至交通情境更复杂的道路。

萝卜快跑在香港已开始测试。
就在 7 月 15 日,萝卜快跑与 Uber 达成了战略合作伙伴关系,计划未来将无人驾驶出行服务拓展至美国及中国内地以外的全球多个市场。
这就意味着以后 RoboTaxi 会无缝融入人们的日常生活。服务上线后,乘客将可以用 Uber App 呼叫到由萝卜快跑提供服务的无人驾驶车辆。数千辆萝卜快跑会接入 Uber 的全球出行网络。据介绍在今年年底前,双方将率先在亚洲和中东地区部署萝卜快跑第六代无人驾驶车,未来将逐步扩展至全球更多市场。
在技术逐渐成熟,政策支持的加持下,萝卜快跑的商业模式已经获得了进一步验证,预示着中国自动驾驶技术已经具备快速复制和落地的能力。
也许再过不了多久,我们的出行方式就会因为 RoboTaxi 发生转变。
AI 老罗带货 5500 万后,百度又放大招
除了萝卜快跑,百度还在数字人上下足了功夫。
前不久的 618 大促,百度的罗永浩数字人在社交平台刷屏。
直播间里,AI 老罗和 AI 朱萧木插科打诨、段子频出,叭叭地讲了 6 个多小时,共吸引超 1300 万人次观看,GMV 更是突破 5500 万元,一度创下数字⼈直播带货新纪录。
,时长00:46
没想到,短短一个月,百度的数字人技术又升级了。
这次 WAIC 上,百度发布新一代数字人技术 NOVA,预计在今年 10 月份上线,超头主播能力复刻将进入规模化量产时代。这也意味着,普通用户也能像大主播一样专业带货了。
NOVA 的技术亮点之一就是剧本模式的升级。
过去,数字人主播只能照着脚本念台词,语气生硬、表情刻板,但现在的 NOVA 依托文心 4.5 Turbo 的大师级剧本模式,将普通脚本升级为剧本,可以根据商品信息、参考知识以及人设要求等,实时调整主播的语调、表情和动作。

前段时间刷到冯唐的视频号,越看越不对劲,里面的动作来来回回就那几个,点头、摆手,还一卡一卡的。说实话,传统数字人之所以一眼假,很大程度上是因为动作僵硬。
NOVA 数字人在动作生成上也进行了改进,不再是简单的动作复制,而是能够贴合话术场景精准生成符合语义的复杂动作,甚至在业界首次实现双人互动。直播中,俩数字人可以随时插话、打断而不穿帮。
此外,NOVA 的语音克隆技术也达到了新的高度,能够完美复刻主播的声音和气口,甚至连口头禅都能准确捕捉。
就以罗永浩数字人为例,它在直播中时不时蹦出一句老罗经典口头禅「听懂了没?」「明白了吧?」,随便抛出的金句也都是熟悉的老罗的味道。
在双人讲品中,俩数字人也可以默契配合,无缝接话,不会说了下句忘了上句。讲到激动处它们可以手舞足蹈、语速加快;商品卖爆时能兴奋到声调拔高,已经达到与真人主播难辨真假的程度。
据了解,这样的高效复刻能力,仅需要 10 分钟的真人样本。也就说,你传 10 分钟自己的视频,NOVA 能还你一个超真实的数字人,实现声音、动作与氛围的精准匹配。
Nova 数字人技术的另一大突破就是 AI 大脑的升级,让数字人能够向顶级主播水平进阶——搭载的 AI 大脑可实时接收直播数据并自主决策,调度多智能体完成问答互动,并结合热点输出风格化内容。
在问答环节,AI 大脑的高效性和精准度又让数字人能够快速回应观众提问。同时,基于用户的历史行为,AI 大脑能够主动发起问题,引导观众在直播中互动,并通过多轮追问和解答有效引导用户的购买意向。
AI 大脑还通过智能决策和多智能体协同,实现了更为灵活的互动方式。比如,基于直播间实时热度及转化情况,灵活调度助播专家、运营专家、场控专家等多个角色智能体, 实现智能发福袋、开价、控库存等玩法,提升带货转化。

对于观众和直播者来说,数字人技术带来了真正实用级的体验。
百度全栈自研背后
要打造「数百万个超级应用」
不论是加速出海的智驾,还是不断制造爆款的数字人,百度的 AI 应用背后都是一套全栈自研的技术体系在提供支撑。值得一提的是,本次 WAIC,百度的智算集群和飞桨深度学习平台,与萝卜快跑一起入选了「中国人工智能产业创新成果展」,这无疑也是对百度 AI 全栈能力的又一强力肯定。
从 AI 掀起第一个浪头时,百度就意识到了 AI 的真正价值在于应用,而不仅仅是技术的炫技。
基于这一战略思维,百度成功布局了一个庞大的 AI 应用矩阵。
除了萝卜快跑和 Nova 数字人这两大代表成果外,百度还在传统搜索、网盘以及智能办公等多个领域,实现 AI 应用的全面落地。
例如,今年 3 月份百度正式上线的秒哒平台,以 「⼀句话做应用 + 多智能体协作 + 多工具调用 」的技术组合,颠覆了传统开发流程。用户可以通过自然语言描述需求,自动生成完整功能代码,极大提升了开发效率。
而百度文库和百度网盘的升级版,则通过多模态的 AI 能力提升了内容管理、知识创作和共享的效率,推动了 AI 技术在传统产品中的深度应用。
百度之所以能够在 AI 应用层面持续推进,正是依托其强大的 AI 全栈自研架构。作为国内最早投身 AI 研发的企业之一,百度从算力、框架、模型到应用构建起一个完整的 AI 生态系统。
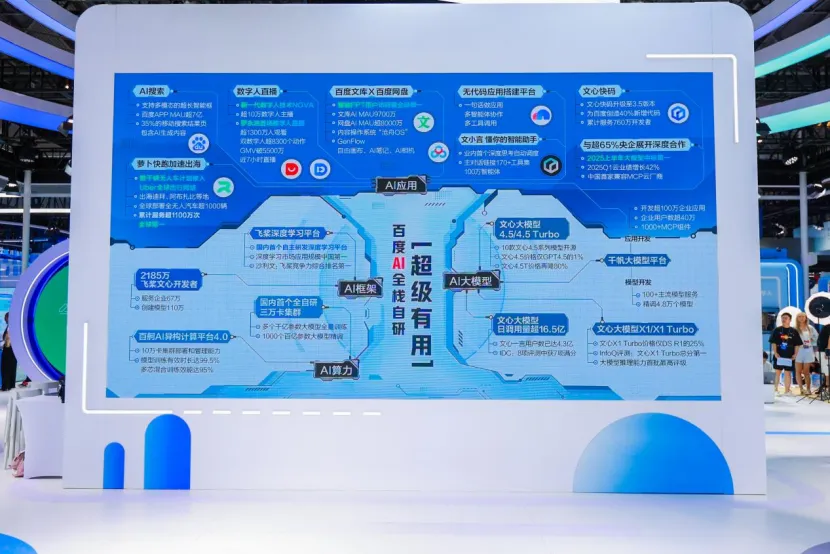
百度的 AI 全栈架构首先在算力层面实现关键突破,核心支撑来自自研的昆仑芯 P800 和百舸 AI 异构计算平台。
今年,百度成功点亮国内首个全自研三万卡集群,支持多个千亿参数大模型全量训练,同时满足千家客户百亿参数大模型的高效精调需求。这一成果不仅保障了国产算力供给,还显著降低了训练与推理成本。在算力管理方面,百舸平台通过兼容多芯片、适配主流框架、异构资源调度等方式,实现了高达 99.5% 的有效训练时长,并优化了推理效率与稳定性。
在框架层,飞桨作为国内首个自主研发的深度学习平台,成为了国内外多个行业的技术基础。飞桨框架具备高度的灵活性,能够支持大规模的 AI 模型训练和推理任务,同时与百度的其他技术组件深度融合,提升了模型训练的效率。飞桨不仅支持多种硬件平台,还为开发者提供了简洁易用的接口,极大降低了 AI 技术的应用门槛。
此外,飞桨还是中国市场上唯一可与全球两大主流深度学习框架美国 TensorFlow 、 PyTorch 正面交锋的深度学习框架,这意味着中国打造了自主可控的人工智能操作系统。
在模型层,百度构建了以文心大模型为核心的多层次模型体系,持续推动生成式 AI 能力向产业落地。文心大模型具备跨模态、强推理、低成本等核心特性,广泛应用于搜索、推荐、智能助手等互联网产品中,同时赋能制造、金融、能源、城市治理等多个行业。
2025 年 4 月,百度发布文心 4.5 Turbo 和 X1 Turbo 两大旗舰模型,推理速度提升显著,价格分别下降 80% 和 50%,在多个权威评测中达到 SOTA 水平。近期发布的 IDC 报告显示,文心大模型在 8 大维度调研中独占 7 项满分,综合实力最强。
2025 年 6 月,百度正式开源文心 4.5 系列模型,覆盖 47B、3B 等参数规模,提供 MoE 与稠密结构版本,成为国内少有的完全开源的通用大模型。这一系列进展不仅体现百度在模型层的技术领先,也为推动 AI 大模型的普惠化和产业落地提供了坚实支撑。
与传统的「技术炫技」不同,百度的 AI 全栈架构始终聚焦于如何将技术应用于实际需求中,并且通过灵活的技术整合将 AI 应用推向更广泛的市场。正如百度 CEO 李彦宏所言:「我们不只是要推出一个超级应用,而是要打造数百万个超级有用的应用。」
越来越多的实践证明,百度「AI 超级有用」的道路是对的, 且越走越宽了。随着全栈架构持续演进,百度的目标不止于打造明星产品,而是让 AI 真正「飞入寻常百姓家」,成为驱动现实场景创新的底层动力。
....
#CoTo
让LoRA训练「渐入佳境」,模型融合、剪枝样样精通
本文第一作者庄湛,香港城市大学和南方科技大学联合培养博士生,研究方向是迁移学习、扩散模型、大模型微调等。本文通讯作者魏颖,浙江大学「百人计划」研究员,博士生导师,研究方向包括持续学习、迁移学习、组合泛化以及在科学领域中的应用等。通讯作者张宇,南方科技大学副教授,研究方向包括深度学习、多任务学习、迁移学习、元学习以及在计算机视觉和自然语言处理方面的应用。
还在为 LoRA 训练不稳定、模型融合效果差、剪枝后性能大降而烦恼吗?来自香港城市大学、南方科技大学、浙江大学等机构的研究者们提出了一种简单的渐进式训练策略,CoTo,通过在训练早期随机失活一部分适配器,并逐渐提高其激活概率,有效缓解了层级不均衡问题,并显著增强了模型在多任务融合和剪枝等操作上的鲁棒性和有效性。该工作已被机器学习顶会 ICML 2025 接收。
- 论文标题:Come Together, But Not Right Now: A Progressive Strategy to Boost Low-Rank Adaptation
- 论文链接:https://openreview.net/forum?id=Zha2m39ZoM
- 代码仓库:https://github.com/zwebzone/coto
- 官网海报:https://icml.cc/virtual/2025/poster/44836
常规 LoRA 训练的隐藏缺陷
参数高效微调技术已成为预训练大模型在下游任务应用的关键技术。然而,尽管 LoRA 如此成功,它依然面临着一些棘手的问题:
1. 「惰性训练」(Lazy Training):LoRA 的优化过程常常会陷入初始化点附近的次优解,限制了模型的泛化能力。
2. 层级不平衡:在训练中,梯度更新往往集中位于模型的顶层适配器,导致底层适配器训练不足,整体性能受限。
3. 下游操作困难:上述问题使得多个 LoRA 模型的融合和剪枝等下游操作变得非常困难,效果常常不尽人意。
CoTo 策略:何不让 LoRA 「渐入佳境」?
为了解决这些挑战,研究者们提出了 CoTo,其核心思想非常简洁直观:在训练初期,不必让每一层的训练 「一拥而上」,而是让 LoRA 适配器 「循序渐进」 地参与训练。具体来说,CoTo 采用了一种渐进式的激活策略:
- 训练初期:以一个较高的概率随机 「失活」 一部分 LoRA 适配器。这迫使模型在更新时不能过分依赖某几层,从而让梯度更均匀地流向所有层级,鼓励模型探索更广阔的参数空间。
- 训练中后期:线性地提高适配器的激活概率,直到所有适配器都完全参与训练,回归到标准的微调模式。
这种 「先抑后扬」 的策略带来了诸多好处:它不仅促进了层级间的均衡优化,还显著提升了不同随机种子训练出的模型之间的线性模式连通性 (Linear Mode Connectivity, LMC) 和 Dropout 稳定性,为模型融合与剪枝打下了坚实的基础。

图 1:CoTo 渐进式激活示意图。训练初期(t <3T/4),适配器被随机失活(灰色部分),其激活概率 p (t) 随训练线性增长;训练后期,所有适配器保持激活。
实验结果
CoTo 最令人兴奋的贡献在于它极大地提升了 LoRA 模型的融合和剪枝能力,且 CoTo 本身也能在单任务的泛化性能和训练效率上带来提升。
更有效的模型融合
- 线性插值准确率:在常识推理与图像分类任务中,对两个独立训练的 LoRA 模型进行线性插值时,标准 LoRA 的性能在融合点 (λ=0.5) 会急剧下降。相比之下,CoTo 模型展现了优越的线性模式连通性 (LMC),在整个插值路径上均能保持平滑且高效的性能过渡。
- 多任务 LoRA 融合:在 GLUE 数据集上,无论是基于 LLaMA-2 (7B, 13B) 还是 DeBERTa-v3 模型,通过 CoTo 训练的 LoRA 模块在进行多任务合并时,其准确率均稳定超越了使用常规训练方法融合的基线模型。

图 2:常识推理任务的线性插值准确率。

图 3:图像分类任务的线性插值准确率。

图 4:使用 LLaMA-2-7B 和 LLaMA-2-13 模型进行多任务 LoRA 融合的准确率。
更鲁棒的模型剪枝
CoTo 的训练方式天然地增强了模型的剪枝容错能力。如下图所示,无论是在移除交替层、底层、中层还是高层适配器的结构化剪枝中,还是在不同稀疏度的非结构化剪枝中,CoTo-LoRA 的性能都全面超越了标准 LoRA。

图 5:结构化剪枝对比(左)和非结构化剪枝对比(右)。
性能与效率双提升
- 性能更强:在涵盖视觉(11 个图像分类任务)、语言(8 个常识推理任务)和数学推理等多个领域的基准测试中,CoTo 都能稳定地提升包括 LoRA、DoRA、HiRA 在内的多种 LoRA 变体的性能。
- 训练更快:由于在训练早期跳过了部分适配器的计算,CoTo 还能降低训练开销。例如,在 HiRA 上应用 CoTo,可以实现超 24% 的训练加速!

图 6:在常识推理和数学推理上,基于不同 LoRA 变体和训练策略的性能提升。
消融实验
为了验证 CoTo 各个设计选择的合理性并探究其性能提升的根源,研究团队在训练阶段比例、激活概率曲线、嵌套 Dropout 策略、学习率和 LoRA rank 等多个方面进行了一系列严谨的消融实验。这些实验不仅证明了 CoTo 设计的合理性,也为我们提供了关于如何有效正则化 LoRA 的深刻见解。
令人欣喜的是,CoTo 的代码实现十分简洁,用户只需对现有 LoRA 训练流程做三步改动即可利用这一策略,感兴趣的读者可以访问代码仓库,亲自体验 CoTo 的效果!
总结
CoTo 通过一个简单而巧妙的渐进式训练策略,有效解决了 LoRA 训练中的层级不平衡和 「懒惰」 优化问题。它不仅提升了模型的单任务泛化能力,更重要的是,它极大地增强了 LoRA 适配器的可组合性与鲁棒性,让模型融合与剪枝等下游操作变得更加简单高效。CoTo 无需修改模型架构,可以作为即插即用的模块与各类 LoRA 方法无缝集成。文章中还提供了渐进优化和合作博弈两个角度深入分析了 CoTo 带来的优势。我们相信,这项工作将为参数高效微调领域的研究与应用带来新的启发。
....
#全球首个拥有「原生记忆力」的大模型亮相
在WAIC现场,全球首个拥有「原生记忆力」的大模型亮相,但不是Transformer
在 Transformer 问世并统治大模型领域八年之后,亲手创造它的谷歌也有了另起炉灶的苗头。
上个月,谷歌产品负责人 Logan Kilpatrick 指出现有注意力机制的局限性,紧接着谷歌就推出了新架构 MoR。这些动作表明,AI 领域的「架构革新」已成为广泛共识。
在最近开幕的 WAIC 世界人工智能大会上,我们也看到了这种趋势,甚至国内企业的做法比谷歌的变革还要彻底。
,时长01:30
视频中的这个灵巧手是由一个离线的多模态大模型驱动的。虽然模型只有 3B 大小,但部署到端侧后,无论是对话效果还是延迟几乎都可以媲美云端运行的比它要大得多的模型,而且它还拥有「看、听、想」等多模态能力。

重要的是,它并非基于 Transformer,而是基于国内 AI 创企 RockAI 提出的非 Transformer 架构 Yan 2.0 Preview。这个架构极大地降低了模型推理时的计算复杂度,因此可以在算力非常有限的设备上离线运行,比如树莓派。
而且,和其他在设备端运行的「云端大模型的小参数版本」不同,这个模型拥有一定的原生记忆能力,能够在执行推理任务的同时把记忆融入自己的参数。
也就是说,在和其他大模型对话时,你每次打开一个新的窗口,模型都不记得你们之前聊过什么,就像一个每天睡一觉就会把你忘了的朋友,每天都见但每天都是「初见」。相比之下,基于 Yan 架构的模型会随着时间推移越来越了解你,并基于这些信息去回答你的每一个问题。这是当前大多数基于 Transformer 的云端大模型都做不到的,更不用提被剪枝、蒸馏等手段破坏了再学习能力的「小模型」。
为什么 RockAI 要对 Transformer 进行如此彻底的变革?这些变革是怎么实现的?对于 AGI 的实现有何意义?在和 RockAI 的创始团队深入对谈后,我们得到了一份有价值的答案。
Transformer 火了那么久,RockAI 为什么要「另起炉灶」?
RockAI 对 Transformer 的挑战不是今年才开始的。其实早在 2024 年 1 月,他们就推出了 Yan 架构 1.0 版本,在此之前已经花了两年时间探索架构创新。
众所周知,Transformer 存在「数据墙」和「算力依赖」等问题。一方面,现有的大模型都是用海量数据进行预训练,但随着高价值数据获取难度越来越大,这条路变得越来越难走。另一方面,Transformer 模型的推理对算力要求非常高,如果不经过量化、裁剪等操作,模型很难在低算力设备上直接部署。而且,即使能够部署,这样的模型也很难再进行大的更新,因为反向传播所需的计算量非一般设备可以负荷,「训推同步」(即让模型在执行推理任务的同时还能进行学习和参数更新,就像小孩在和大人相处的过程中学习新东西)很难实现。而量化、裁剪等操作更是破坏了模型的再学习能力。
如此一来,设备端的 Transformer 模型就成了一个「静态」的模型,其智能水平在模型部署时就被锁死。
为了从根本上解决这些问题,RockAI 从一开始就走了一条非常彻底的变革路线,从 0 到 1 探索非 Transformer、非 Attention 机制的 Yan 架构。 更难能可贵的是,他们不仅快速找到了有效的技术路径,还成功在算力有限的设备上实现了商业落地。

Yan 2.0 Preview:全球首个拥有「原生记忆力」的大模型
下图展示了 Yan 2.0 Preview 与其他架构的效果与性能对比结果。从中可以看出,无论是相比于 Transformer 架构下的核心主流模型,还是非 Transformer 架构的新一代模型,Yan 2.0 Preview 在生成、理解以及推理等多个关键指标上都有不错的优势,这充分说明了 Yan 架构在「性能 / 参数」比(即效率)上的巨大优势。

当然,这还不是核心看点,毕竟在 Yan 1.3 的时候我们就已经见识过它惊艳的计算效率。这次的看点是「记忆」。
我们观察到,无论是最近的新论文、新产品还是公共讨论,「记忆」都在成为一个焦点 —— 它既被视为当前 LLM 的关键短板,也被看作下一轮 AI 应用的商业化落地突破口。想象一下,一个会说话、拥有和你之间专属记忆的 Labubu 在和你相处多年之后,是不是情感羁绊更深?
不过,在技术路线上,当前业内主要还是用一种「外挂」的方式(如长上下文叠加搜索引擎或 RAG)来帮大模型加长记忆。RockAI 并不看好这种方式,因为首先,它把信息作为一串序列来处理,没有真正的「时间」概念(这点对于随时间演进的真实学习至关重要),这和人类的记忆方式有着本质的区别。其次,它无法实现真正的个性化。
「回顾人类社会,每个人都拥有独特的记忆。人与人之间的差异正是源于不同的记忆和经验,这些差异最终形成了人类社会的多样性,塑造了我们各自不同的行为方式和表达风格。目前,我们使用的商业模型本质上都是云端的同一个模型,缺乏真正的个性化,只能通过调取聊天记录来提供上下文。这种模式存在明显局限 —— 比如在写作时,模型无法根据用户的个人风格来生成内容。」RockAI CEO 刘凡平指出。
他认为,只有在模型中融入原生记忆能力,这种情况才能发生改变。因此,他们的 Yan 2.0 Preview 选择了另一条路线 —— 将模型理解后的信息内化到神经网络的权重中,使其成为模型自身的一部分,这更接近生物的记忆方式。
下图是 Yan 2.0 Preview 架构示意图。它通过一个可微的「神经网络记忆单元」实现记忆的存储、检索和遗忘。

在原理上,这种机制与人工智能从早期机器学习到深度学习的演进有相似之处。早期机器学习需手动设计或提取特征,可解释性强,但定制化严重,对专家经验依赖度高。深度学习则可自动提取特征,通过设计神经网络、设定优化目标和策略,在数据语料上完成模型训练,实现端到端学习。与之类似,Yan 2.0 Preview 也实现了端到端的记忆,无需用户去手动管理外挂知识库(增删改查),使用起来更加便捷。
在现场,我们通过一个「现学现会」的机器狗感受到了 Yan 2.0 Preview 的原生记忆能力。在「聊天窗口」重开后,机器狗依然能记得它学过的动作和偏好。
,时长01:45
当记忆深度融合进模型架构,它所带来的不再是短暂的「缓存」,而是一种具备时间维度、个性化特征和交互上下文的「智能积累」。这种模式成熟后,或将打破现有大模型依赖海量数据的学习范式。
模型角色也将随之转变 —— 从单纯的回答者,逐步成为用户思维与决策的延伸体,真正实现「长期陪伴、个性服务」。当这一能力在本地终端部署时,结合端侧的隐私保障与实时响应优势,设备便从被动工具蜕变为拥有感知、记忆和学习能力的「数字大脑」。
离线智能:「让世界上每一台设备拥有自己的智能」
每个尝试挑战 Transformer 的研究者,都深知这件事做成有多难。RockAI CTO 杨华表示, RockAI 之所以能坚持至今,背后是团队多年来所秉持的三个核心理念:
第一,他们认为,AI 应该是普惠的,不应只存在于云端。AI 必须与物理世界交互才能发挥最大价值,这要求它必须存在于设备上。这点已经成为业界共识,也是当前xx智能、空间智能等方向火爆的原因之一。
第二,从长远来看,一个真正的智能设备不应是静态的,而应能成长和进化。具备学习能力才能确保「个体」智能足够聪明。这点也在最近业界对「自我进化 AI」的讨论中得到了体现。不过,RockAI 强调,这种自我进化应该发生在「个体」设备上,而不是一个云端的大模型上。
第三,在「个体」变得足够聪明之后,它们所组成的网络有望涌现出群体智能,就像已经创造出如此璀璨文明的人类社会。RockAI 认为,群体智能是迈向通用人工智能(AGI)的关键路径。
这些理念落实到行动,就形成了 RockAI 当前的主要使命 ——「让世界上每一台设备拥有自己的智能」。
这个使命听上去很像「端侧智能」。但杨华强调说,他们追求的其实是「离线智能」,只使用本地设备的算力,不像很多采用「端云结合」的设备一样需要联网。而且在这种离线运行的模式下,模型能够实现自主学习,而不是部署的时候就被锁死。拥有这种自主学习能力的模型可以理解为一个有学习潜力的孩子,尽管刚走出家门时能力不及 30 岁的博士,但随着后续成长会变得越来越强。
不要小看这种「成长」的价值,未来的设备 PK 的可能就是这种能力。刘凡平提到,现在我们买硬件主要看配置,都是一次性买卖,买到手里就开始贬值。但有了记忆和自主学习能力之后,硬件的长期价值才开始显现,智能的程度和进化能力会成为硬件的差异化卖点。
此外,这种「成长」也为群体智能的涌现提供了可能 —— 只有当每台设备都具备自主学习能力时,它们才能真正实现知识共享、协同进化,最终涌现出超越单体智能简单相加的集体智慧,这也是 RockAI 的终极愿景。

从「质疑」到「共识」:RockAI 一直在做「难而正确」的事情
回顾过去几年的研发历程,RockAI 能够明显感觉到外界对他们所选择的技术路线的态度转变。
几年前,提到要做群体智能、要另起炉灶研发新架构,外界的反应更多是新奇、不解和质疑,因为这不像一个初创团队该做的事情。
这次原生记忆能力的展现,让大家看到了 RockAI 的与众不同。他们并非停留在简单的模型训练与参数堆叠层面,而是在坚持「难而正确」的技术路径上,以「记忆」为核心重新定义大模型的能力边界,带来了惊人的使用体验。
RockAI CMO 邹佳思说,这一技术路线的选择让他们在整个 WAIC 会场显得非常与众不同,很多对端侧部署、记忆能力有需求的硬件厂商来找他们了解技术方案。这些厂商也尝试过基于 Transformer 的模型,但体验明显没有满足需求。此外,还有一些厂商已经和 RockAI 达成了合作。非 Transformer 的 Yan 架构正在 AI 硬件市场扩散开来。

不得不承认,RockAI 几年前的决定非常有前瞻性,也用科研、商业化成果回应了外界的质疑。
杨华表示,未来,他们要继续做这件「难而正确」的事情。甚至为了实现更高效的自主学习能力,他们在持续向人工智能的根基 —— 反向传播算法发起挑战,目前的解决方案已经在小规模数据上完成了指标测试和训练收敛性验证,证明了方案的基本可行性。
在众多 AI 创业公司中,这种前瞻性和坚持自己道路的韧性非常少见,很像 OpenAI 等前沿实验室的来时路。毕竟在 Ilya 忙着扩大规模时,scaling law 也还没成为共识。从 RockAI 身上,我们看到了一种难能可贵的「长期主义」精神 —— 在浮躁的创业环境中,依然愿意花费数年时间去攻克底层技术难题,去验证那些看似「不切实际」的技术理念。
创新是孤独的,期待 RockAI 和更多探索者在这条路上走得更远。
....
#Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
手机AGI助手还有多远?移动智能体复合长程任务测试基准与调度系统发布
本文第一作者郭源是上海交通大学计算机系三年级本科生,研究方向为自主智能体和智能体安全。该工作由上海交通大学与澜舟科技共同完成。
- 论文标题:Atomic-to-Compositional Generalization for Mobile Agents with A New Benchmark and Scheduling System
- 项目主页:https://ui-nexus.github.io/
- 论文链接:https://arxiv.org/abs/2506.08972
,时长01:45
从原子任务自动化
到系统级端侧智能
多模态大模型 (MLLM) 驱动的 OS 智能体在单屏动作落实(如 ScreenSpot)、短链操作任务(如 AndroidControl)上展现出突出的表现,标志着端侧任务自动化的初步成熟。
但是,真实世界的用户需求常常包含复合长程任务,例如 “比较价格并在便宜的平台下单” 任务,需要在多个应用程序中操作,收集和比较异源信息,并据此确定后续的操作步骤;“查看今日热点新闻,概括并记录” 的任务,需要在多个网页之间导航,将设备操作与文本概括的通用推理能力交错融合,并完成适时的信息传递。从简单有序任务到复杂有序和复杂无序任务的过渡是从单智能体基座增强到 AI 操作系统的必经之路。当前主流的环境感知、动作落实和短序列轨迹微调等训练方式显著地提高了前述原子任务上的表现,但是复合长程任务带来了长链条进度管理、信息收集和传递、操作与通用思考的结合等全新的挑战。
研究人员针对主流的移动端 GUI 智能体展开系统的研究。实验显示,现有的移动端 GUI 智能体在面对复合长程任务时都具有明显的能力缺陷,展现出显著的原子任务到复合任务的泛化困难。
针对这一缺口,研究人员提出:
1. 动态评测基准 UI-Nexus:构建可控的动态测评平台,覆盖复合型、传递型、深度分析型等复杂长程任务,涵盖 50 类中英文应用(包括本地功能应用和第三方在线应用),共设计 100 个任务模板,平均最优完成步数为 14.05 步。
2. 多智能体任务调度系统 AGENT-NEXUS:提出轻量化调度框架,支持指令分发、信息传递与进程管理。该系统无需修改底层智能体模型,便于高效接入与多体协同。
该工作为复合长程任务下的移动端智能体提供了有挑战性的测试基准和开发平台,也为展望未来复杂、精细的 AI 原生操作系统建立了雏形。
移动端智能体
在复合长程任务中的能力瓶颈
随着基座模型的持续增强和环境感知、单屏动作落实、静态轨迹微调、强化学习等训练策略的优化,基于多模态大模型的设备操控 GUI 智能体在单屏动作落实(grounding)和短链操作任务上的测试表现持续提升,已经能够端到端地自动化执行网络搜索等原子任务。
但是,真实场景中的用户指令常常包含长程场景与复合依赖需求。本文依据子任务的依赖关系分类,给出了常见的三种任务复合类型:
- 独立组合型(Simple Concatenation):若干无依赖关系的原子子任务的拼接。如图中的睡前设定指令 “Instagram 开启消息免打扰 8 小时,并设定明早 7:00 的闹钟”
- 语境传递型(Context Transition):后续子任务需要继承并利用前序任务产生的中间结果或界面状态,需要把信息 / 上下文正确地带到下一个 App 或页面。如图中先上网搜索天气预报,并根据搜索结果发送微信消息的任务。
- 深度分析型(Deep Dive):是语境传递型任务的一种特殊情况。在设备操控中不仅需要进行动作导向的推理以及信息的简单记忆,还需要融入通用推理能力对中间信息进行深度的处理和分析。如图中的今日 Hacker News 摘要任务,不仅需要在浏览器、Google Doc 中进行点击、滑动等导航操作,还需要利用通用推理能力对当前页面的新闻内容做摘要分析。

依据子任务依赖结构的复合任务分类
研究人员在常用手机应用上构造代表性的测试任务,针对主流的 OS-Atlas, UI-TARS, Mobile-Agent 系列,M3A 等移动端 GUI 智能体进行初步实验,发现主流智能体在复合长程任务上明显表现欠佳。
对错误案例的细致分析显示,主流移动端智能体由于缺乏有效的进度管理和信息管理机制等,展现出典型的失败类型,如:
- 注意力涣散:直接给定复合任务指令时,容易造成语境过载(Context Overflow),导致智能体遗漏部分指令或子任务;
- 信息传递失败:智能体缺乏信息管理和传递的能力,导致在传递型任务中胡乱执行需要前序信息的任务;
- 进度管理混乱:在未完成的子任务之间反复跳转。
UI-NEXUS:
针对移动端智能体复合任务的
全面测试基准
为了对移动端智能体在复合长程任务上的表现提供科学全面的测试基准与开发平台,研究人员提出了 UI-NEXUS:一个针对移动端智能体复合任务的交互式测试基准。

UI-NEXUS 测试基准概览
如概览图所示,UI-NEXUS 基准有如下的特点:
- 数据覆盖:50 款 App(20 本地功能应用 + 30 中英在线服务应用),5 大应用场景;100 条指令模板,最优路径 14.05 步,难度显著高于同类基准。
- 三类依赖结构:依据子任务的依赖关系,系统研究三种复合任务类型 —— 独立组合型(Simple Concatenation)、语境传递型(Context Transition)、深度分析型(Deep Dive)。
- ANCHOR 子集:为了提供可控、可扩展的测试开发环境,研究人员基于 AndroidWorld 的 20 个本地功能 App 构建了本地离线任务子集 UI-NEXUS-Anchor。该测试集中的任务环境可以通过数据库、文件系统、adb 工具精准设定,支持任务指令可扩展性和测试环境可控性。
- 细粒度指标:记录端到端任务成功率、终止原因、Token 成本与推理时延,对智能体的表现进行细粒度分析。
研究人员选取了 5 种代表性的移动端智能体基线进行测试,这 5 种智能体都基于 GUI 操作进行移动端操作任务的自动化,具体实现模式包括:
1. 单模型微调(Agent-as-a-Model):OS-Atlas-7B-Pro 和 UI-TARS-7B-SFT 都是基于 Qwen2-VL-7B 进行大量 GUI 领域训练得到的智能体基座,可以通过单模型推理逐步执行手机操作任务。
2. 工作流搭建(Agentic Workflow):通常利用 GPT-4o 等闭源模型辅以模块化设计来构建智能体工作流。如 M3A 是 AndroidWorld 中提出的手机智能体,每步推理时利用 a11y tree 提取出元素列表作为辅助输入,并使用 React 和 Reflexion 来进行动作推理和结果反思。Mobile-Agent-V2 和 Mobile-Agent-E 采取多智能体协作的模式,并辅以 OCR 和元素标记等模块,进行手机任务自动化。
除了上述基线以外,本文还提出了 Agent-NEXUS:针对复合设备操作任务的调度系统。Agent-NEXUS 将高阶调度与低阶执行解耦,通过 Scheduling Module, Execution Module 和 Process Memory 的协同工作完成复合长程任务的调度。
在每个子任务完成后,调度模块根据历史进程信息和当前环境感知更新高阶任务规划,并将后续的第一个子目标传给执行模块的 Navigator/Analyst/Tool 进行具体落实。这样的层次化调度模式让低阶执行模块每次都收到意图明确的原子任务,减轻了语境过载的风险。

Agent-NEXU 架构示意图
Agent-NEXUS 支持智能体的可插拔接入。在本实验中,研究人员尝试了用 UI-TARS-7B-SFT 和 M3A 作为低阶执行模块的智能体。
实验分析:
从原子到复合任务的泛化之路
研究人员在本地功能应用(UI-NEXUS-Anchor)、中文在线服务应用、英文在线服务应用三个测试子集,共 100 个指令模板上进行了测试,主要结论有:
- UI-NEXUS 测试基准对各个移动端 GUI 智能体 baseline 都造成很大挑战,各智能体的任务完成率均低于 50%;
- 基于 Agentic Workflow 实现的智能体在复合长程任务上的鲁棒性显著优于基于 Agent-as-a-Model 的方法,但是基于 GPT-4o 的工作流带来很高的推理成本和时延,限制了实际场景的应用潜力;
- AGENT-NEXUS 显著提升任务完成率(+24% ~ +40%),同时仅带来约 8% 的推理开销增长。

主要实验结果
为了深入分析原子到复合泛化的表现,研究人员选取部分独立组合型和语境传递型任务进行了进一步的分析实验。研究人员对比了三种任务成功率:
1. 直接将复合指令给定智能体,测试智能体的任务完成率,作为原子 - 复合泛化中的 Weak Performance。
2. 人为将复合指令拆分成多个原子指令(如将 "In the Tasks app, create and save a new task named 'Exercise' repeating every day. Then open the Broccoli recipe app and delete the 'French Fries' recipe." 拆分成 "In the Tasks app, create and save a new task named 'Exercise' repeating every day." 和 "Open the Broccoli recipe app and delete the 'French Fries' recipe." 两个原子指令,分别交付智能体执行,均成功则视为该任务成功,测定任务完成率,作为原子 - 复合泛化中的理论上的 Strong Ceiling。
3. 将 UI-TARS-7B-SFT 和 M3A 接入 Agent-NEXUS 调度系统后的任务完成率。
结果如下图所示:

所有移动端智能体 baseline 在给定手动拆分后的原子指令时表现都显著更优,其中 UI-TARS 的差异尤其显著,从 11% 直接提升到了 60%。这是由于其在微调后已经训练了充分的 GUI 操作能力,而直接给定复合指令时的极低完成率主要受制于进度管理和信息管理功能的缺失。
Agent-NEXUS 调度框架有效地弥补了原子到复合任务的泛化损失,在成本提升可控的同时让任务完成率大幅提升,逼近了 strong ceiling 的表现。
此外,针对不同智能体构建方案的进一步讨论和分析显示:
1. 在线服务类 App 因信息动态性强、UI 结构复杂及环境干扰频繁,构成了更大的挑战;
2. 基于 GPT-4o 搭建的 Agentic Workflow 由于具有多智能体协作,复杂推理等机制,在复合任务上的表现显著更优。但是,GPT-4o 在 GUI 操作任务上的原生领域能力比较有限,需要借助元素列表、屏幕解析工具等辅助,加之本身调用成本较高,限制了实际应用的可行性。
相比之下,基于开源规模领域微调的 Agent-as-a-Model 在短链操作内部逻辑、动作落实、推理速度等方面有显著优势,但由于训练方式的限制,当面对选择等复合逻辑、动作和通用推理交错等任务需求时完全无法应对,容易出现盲目执行的现象,需要借助系统级的设计来增强。
3. Memory 机制的设计在处理复合长程任务中至关重要。当前移动端智能体的 Memory 机制主要包含无记忆(如 OS-Atlas-Pro,只根据动作历史和当前屏幕预测下一步动作,没有储存历史信息的机制)、部分记忆(如 UI-TARS,每次输入前 N 张屏幕观察,一定程度上可以利用前 N 张屏幕中的有利信息,但是在多源、跨越较大的信息传递和整合中收到较大限制)、主动记忆(如 Mobile-Agent-V2 和 Mobile-Agent-E 每一步都会主动判断当前是否有信息要存储到记忆模块)。
主动记忆在复杂信息依赖的复合长程任务中带来更优的表现,但是每一步都判断是否记忆带来较大的计算冗余。Agent-NEXUS 通过将界面导航。信息收集、信息处理都显式在高阶调度中分配好次序,在开销可控的同时实现了多源信息的管理和整合。
未来展望:
面向新一代 AI 操作系统
本文不仅全面、深入地探讨了当下移动端智能体研究中迫切需要深入发掘的一个方面:复合长程任务,也畅想了新一代 AI 操作系统的雏形。
在未来,我们不仅需要能依据一个指令为人类自动化完成简单操作的智能体模型,更希望构建能够高效协调、处理、调度复合任务需求的系统级端侧智能。我们相信,当这样的评测基准与调度框架被广泛采用并不断演进,移动设备将真正蜕变为具备类操作系统层次智能的个人助手,为人机协作打开新的想象空间。
....
#Moz1
WAIC机器人探展:我被全场最靓的崽「Moz1」种草了
一年一度的世界人工智能大会现场探展,我们被这个「闲不住」的人形机器人圈粉了。
2025 年行至过半,人工智能领域的前沿热点屡屡破圈,其中xx智能(Embodied AI)及其载体在国内格外受到了关注,尤其是人形机器人。
从年初春晚舞台上的扭秧歌转手绢、到四五月先后举办全球首届人形机器人马拉松比赛、全球首个人形机器人格斗大赛,得益于 AI 算法和机器学习等技术的进步,xx机器人展现出了越来越强的灵活性以及环境适应、感知决策行动能力。
在 2025 年世界人工智能大会(WAIC)现场,包括人形机器人在内的xx智能展区无疑是全场焦点。形态各异、「张牙舞爪」的各式机器人被现场观众围得水泄不通,它们乐此不疲,秀起看家本领。
其中,一家「忙碌中」的展台吸引了我们驻足,里面的人形机器人正像人类服务生一样,接受下单之后,从冰箱里取出饮料,并递给观众。
我们观察到,从识别到用户指令、到定位目标、再到抓取、递送饮料,全程一气呵成,完全由 VLA 模型自主推理实现,智能化程度令人叹为观止。
,时长00:36
深入了解之后,我们发现,这是一家去年 2 月成立的xx智能创业公司「千寻智能」。该公司致力于研发通用人形机器人和下一代xx大模型,缔造新一代智慧劳动力。
千寻智能展台上的这款人形机器人正是该公司六月正式发布的「Moz1」,它是国内首个高精度全身力控的xx智能机器人,拥有 26 个自由度(不含灵巧手),一体化关节的功率密度比特斯拉人形机器人 Optimus 还高 15%,在速度、精度、安全性和仿生力控方面都达到了行业最高水平。
纸面实力如此强悍,Moz1 还能带来哪些惊喜?在千寻智能展台,我们见识到了它更多惊艳的技能。
人形机器人 Moz1「秀翻」WAIC 全场
在 WAIC 现场,机器人带来的震撼几乎时时都在上演。
我们首先来到了千寻智能 Moz1 的运动控制区。
在这里,Moz1 正在展示其卓越的整机协调性、动态平衡性、动作稳定性、智能规划等多个关键维度的核心能力。
看,Moz1 秀起了太空步,全身随意动作但手臂拿水不撒:

智能 S 型极限压弯也不在话下:

由此可见,人形机器人在动态环境中的适应能力有了质的提升。
接下来走向遥操作区,Moz1 的人机协作能力一览无余。
在现场技术人员的指挥下大显身手,Moz1 玩起了掌上迷宫走珠:
还能搭积木:
秀起舞姿:
这意味着,Moz1 在精细任务操作过程中的灵活性与精准度拉满了。
最后是机械臂叠衣区,柔性物体操作显然难不住它。
抓取、折叠、堆高, 乱衣秒变豆腐块:
一番体验下来,最大的感受是:
如今的机器人不再满足只完成预设任务,还能根据环境变化做出智能决策,进行自我优化和调整,提升自身在真实环境与任务中的灵活性和应对效率。
一句话,人形机器人的进化速度正在超出我们的想象。对于千寻智能来说,支撑起这一切的背后是其全栈自研xx机器人技术以及软硬协同推进的体系化积累。
打造「脑体并进」通用机器人框架
从创立之初,千寻智能便以同时打造「下一代xx大模型与通用人形机器人」为目标,机器人大脑与本体并举。大模型负责学习与决策,机器人本体承担感知与执行,两者协同进化,打破软硬件脱节的行业通病,开发真正可泛化、落地的通用机器人。
其中,在模型层面采用端到端 VLA(视觉 - 语言 - 动作)技术路线,这也是近年来xx大模型领域的主流架构,如 Figure 的 Helix、1X 的 Redwood AI。通过打通感知、理解和执行三大关键环节,这一路线加速实现从理解世界到高效行动的「通才xx智能体」,显著提升机器人在真实世界的泛化与任务完成能力。
千寻智能瞄准了通用机器人的这一现实可行落地框架,并于今年 3 月发布了自研的 VLA 模型 Spirit v1,在适应复杂多变环境和多样化任务连续操作方面实现了代际跃升。如 WAIC 现场展示的那样,该 AI 模型赋能的机械臂在国内首次实现叠衣服的全流程顺畅操作,一举攻克柔性物体长程操作这一行业难题。
此后,Spirit v1 持续迭代升级,探索并验证在更多真实任务场景中的实用性与鲁棒性。上个月发布的全力控人形机器人 Moz1 便搭载了该自研模型,这也是其在机器人本体层面的重要落地成果,标志着从「脑」到「体」的闭环系统已具备实战部署能力。
在强大泛化能力的加持下,Moz1 可以精准完成桌面整理、扔垃圾、座椅归位、擦黑板等办公室多场景任务,适应性越来越强,俨然一副「打杂小能手」的样子。
整理桌面
扔垃圾
座椅归位
擦黑板
可以预见,随着 Moz1 积累更多真实世界的交互经验,可以为后续承担更高复杂度的协作任务打下基础。未来,Moz1 有望从「能干活」进化到「会思考」,成为办公环境中的全能助理将不再只是梦想。

Moz1「集多能力于一身」
当然,除了软件层面高度智能化、自主化的大脑之外,Moz1 同样在硬件领域实现了多项突破性进展,为其「行为像人」做足了工程落地上的准备。包括如下:
全身配置 26 个自由度,赋予 Moz1 更强的灵活性和操作范围,胜任精细化、多姿态任务;
搭载全球功率密度最高的一体化力控关节,实现高输出、高响应动力表现,并兼顾轻量化与紧凑结构;
国内领先的高精高速 WBC(全身运动控制)系统,优化手脚联动、躯干配合等复杂动作规划;
负载自重比达 1:1,与自身重量相当的负载能力使其在实际任务中具备更强实用性。
配合性能强大且深度融合的大小脑,Moz1 实现了多模态感知交互与全身协同。此外,Moz1 还做到了全身零延时遥操作,配合自研的多维度数采设备,能够高效完成数据采集,并支撑模型小时级迭代。这样一来,Moz1 从一台单纯的执行机器化身为「边干边学」的数据闭环系统。
种种软硬件突破,贯穿从算法模型到本体设计、从运动控制到任务执行的全栈式优化,使得 Moz1 具备了第一梯队实力。这种「AI 模型进化 + 硬件性能突破」的深度协同模式,构筑起了千寻智能在xx智能赛道的核心技术壁垒和差异化优势。
Spirit v1 以及 Moz1,是千寻智能成立一年多来交出的一份优秀答卷。未来,千寻智能一方面继续探索 VLA 模型与机器人本体在更多复杂环境与真实任务中的深度耦合与协同演进,进一步提升系统的泛化能力与执行稳定性。
另一方面,在商业化布局上以需求为导向,深入制造业、服务业等上百个核心场景(如办公场景、家庭场景)展开调研,瞄准真实产业痛点并转化为产品定义的核心参数,形成「场景需求 — 技术攻关 — 产品落地 — 市场反馈」的闭环开发逻辑,推动xx智能从技术验证走向大规模商业应用。
而作为行业少有的兼备「自研大模型、机器人本体、场景落地」全链路能力的创企,千寻智能的这种前瞻性布局,既契合了行业对机器人高度灵活性、通用性和自适应性的需求,并朝着更智能、跨场景应用方向演进。
资本持续加码,押注的不只是技术
ChatGPT 推出以来,除了大模型,资本也在寻找下一个爆点,其中能够理解世界、进行推理并执行任务的xx机器人被认为有望掀起下一波 AI 浪潮。
最后一两年,在国内,无论是宇树机器人这样的顶流明星,还是千寻智能、智元机器人、星动纪元等xx智能新势力,都受到了资本的高度青睐与追捧,进入到一个融资集中爆发期。
就以千寻智能来说,成立不到一年半的时间,这家xx智能新秀凭借行业领先的 AI + 机器人全栈技术实力,先后完成了多轮融资,包括这周官宣的近 6 亿元 PreA + 轮融资,由京东领投,中网投、浙江省科创母基金、华泰紫金、复星锐正等知名机构跟投。同时顺为资本、华控基金等老股东追加了投资。
一众资本对千寻智能的高度认可,靠的不单单是其领先的大模型技术和成熟的机器人产品,xx智能的赛道红利以及创始团队的影响同样不可忽视。
据此前高盛预测,到 2035 年,全球人形机器人市场规模有望达到 1540 亿美元。这意味着巨大的增量市场空间等着包括中国在内全球机器人玩家挖掘,资本持续看涨在意料之中。
不久前,英伟达 CEO 黄仁勋在参加第三届链博会期间,表示他对中国机器人发展非常乐观,「中国拥有三大独特优势,包括卓越的人工智能技术、擅长机电一体化、大规模制造业基地提供庞大的潜在市场」。老黄的这番言论一定程度上道出了中国在xx智能领域迅速崛起的原因。
随着大模型与机器人深度融合,像千寻智能这样的本土机器人企业凭借 AI 技术的积累、强大的硬件制造能力和丰富的应用场景,正在形成从底层技术到终端产品的完整生态闭环。加上创始人兼 CEO 韩峰涛、联合创始人高阳与郑灵茵拥有的丰富全球市场实践经验,形成「技术研发 — 产品量产 — 市场验证」全链路,在xx智能赛道的激烈竞争中走出一条高效的成长路径。
届时,人形机器人在形态和技能上又会玩出什么新花样,我们拭目以待。
....
#实测爆火的阶跃星辰Step 3
性能SOTA,开源多模态推理之王
天气很热,WAIC 2025 也很热,来自中国的开源模型军团更是热上加热。
就在刚刚开始的 WAIC 2025(世界人工智能大会)前一天,被誉为「多模态卷王」的阶跃星辰率先投下一枚重磅炸弹,正式推出其新一代基座模型:Step 3。

这并非又一个普通的模型迭代。从各项数值上看,Step 3 无疑是开源 VLM 新晋之王,在 MMMU、MathVision 和 SimpleVQA 等基准上均超越了其它同类别开源模型。
即便与 OpenAI o3、Gemini 2.5 Pro、Claude Opus 4 等顶尖的闭源 VLM 相比,它的推理能力也有一战之力。
Step 3 一发布就吸引了海内外广泛关注,比如在我们的相关推文下方,就有多位网友表达赞誉。


xx也在阶跃星辰发布会现场,亲眼见证了这又一「国产之光」的诞生。

整场发布会下来,我们的感受是 Step 3 不仅是一个性能强大的模型,同时也是一个答案。它回答的是这样一个横亘在所有 AI 从业者面前的问题:什么样的模型才是真正能服务于千行百业、最适合商业化应用的理想形态?
如今,AI 的行业叙事已经清晰地从训练场转向了真实世界的推理任务。当顶尖模型的智能上限被不断拔高后,真正的瓶颈落在了应用侧。推理成本居高不下、特定场景适配难、多模态能力调用不全堪称阻碍 AI 技术走向大众的「三座大山」。因此,一个真正适合应用的推理模型,必须在智能、成本、效率和通用性之间找到最佳的平衡点。
而 Step 3 回答的方式可以凝练成四个字:多开好省。

多,即多模态。Step 3 具备文本和视觉的多模态能力,实现了多模合一。
开,即开源。阶跃星辰表示 Step 3 将于 7 月 31 日面向全球企业和开发者开源。
好,即性能优异。Step 3 是最强大的开源多模态推理模型。
省,即效率更高、成本更低。Step 3 的高效率和低使用成本使其非常适合商业部署和应用 —— 实现了行业最高的推理解码效率,在国产芯片上的推理成本仅为当前业界领先开源模型的三分之一 。
这一发布不仅是阶跃星辰自身从技术深耕迈向商业化成熟的宣言,更可能为深陷成本与应用难题的 AI 行业提供一个极具吸引力的新范式。Step 3 究竟能否凭借其「四字真言」成为推理时代的一个最优解?一切答案,正从这里揭晓。
xx实测
VLM 开源第一王实至名归
实践可以检验真理。Step 3 究竟能否戴上「开源 VLM 之王」的桂冠,同样需要实践验证。目前,Step 3 已经上线 stepfun.com 与阶跃 AI APP,我们也在第一时间对其进行了多维度测试。
我们的第一个测试颇具趣味性,可以考验其观察与分析能力:派出我家肥猫,让 Step 3 来对她进行「视觉称重」。
,时长00:34
Step 3 的表现相当出色:它不仅准确识别出猫的品种(三花猫)及其身下的人体工学坐垫,还对猫的体型(体型匀称)进行了分析,最终给出了一个相当精准的体重估测。
Step 3 甚至还能帮你理解新鲜热梗,就以昨天堪称「最逆天的 NeurIPS 评审」的「Who's Adam?」为例,我们直接将推文截图交给 Step 3,然后问它为什么这个帖子这么火。
,时长01:08
而 Step 3 的表现可以说超出了预期,不仅清晰地解释了「Who's Adam?」的内涵并解答了其火爆的原因,更是用一句「戳中了 AI 研究者们对审稿质量焦虑的痛点」做了恰到好处的犀利总结。
Step 3 也支持同时输入多个视觉内容,比如这里我们让 Step 3 根据四张歌词的截图编写了一个感人的故事:
,时长01:22
Step 3 证明了其强大的多模态信息整合与创意生成能力后,我们又测试一下 Step 3 的深度推理能力:根据一张贴有贴纸的主机的侧面照片推测其上一共有多少贴纸。这个问题对当今的多模态模型来说还相对较难,而我们也将测试平台换到了网页端 stepfun.com。

可以看到,Step 3 首先准确地识别出了这些贴纸的角色,然后它又准确统计出了可见部分中贴纸的数量。之后 Step 3 进入了更深度的思考,考虑了提示词中提到的「对称」的各种可能性。最终,它正确地确定了最终答案,并相当准确地给出了可见部分贴纸中的内容。
我们还让 Step 3 挑战了一项终极任务:解读其自身的技术报告中的一张图,这将是对其专业视觉理解能力的极致考验。

上下滑动查看
可以看到,Step 3 基本正确地解读了 Step 3 技术报告中 AFD 架构的模块分解示意图。
经过一系列的实测,Step 3 的交互体验让我们印象深刻,甚至让我们一度惊叹:这么强的模型竟也开源?其响应流畅,视觉理解能力超强,在处理极其复杂的或有歧义的视觉问题时,其回答偶有偏差,这也在意料之中。但其强大的基础视觉理解、推理能力以及流畅的交互体验,已经足以证明它在当前的开源多模态模型中确实坐拥王者之位。Step 3 所展现的,是一个真正能「看懂」并「理解」物理世界的 AI 助手雏形。
顺带一提,在测试 Step 3 的过程中,我们还惊喜地发现了阶跃 AI App 上一个被许多用户忽视的功能:智能视频通话。在该功能下,用户只需在 App 内开启摄像头,手机便化身为一个强大的智能视觉助手。
我们实测发现,实时视觉理解能力非常惊艳!比如在下面这个案例中,阶跃 AI 不仅迅速识别出了这款桌游名叫「Splendor(璀璨宝石)」,还准确地阐述了其背景信息。
,时长01:29
当一只好奇的猫突然闯入镜头,占据游戏盒时,我们实时打断了 Step 3 的介绍并发问。模型无缝切换了对话,并围绕这位「不速之客」给出了一些颇为有趣且有用的建议,展现了其强大的实时多模态对话与打断能力。
深度拆解
Step 3 是如何诞生的?
那么,如此「多开好省」的 Step 3 究竟是如何炼成的呢?翻开 Step 3 的系统和架构技术报告,我们可以看到答案并非单一技术的突破,而是源于一套完整且自洽的技术栈,涵盖了从底层原创架构到高层系统协同的全链路创新。

- 技术报告:Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding
- 报告地址:https://github.com/stepfun-ai/Step3/blob/main/Step3-Sys-Tech-Report.pdf
首先,底层架构上,Step 3 采用了阶跃星辰原创的 MFA 架构,即 Multi-matrix Factorization Attention(多矩阵分解注意力)。该架构在设计之时就兼顾了效率与性能,其中的创新之处包括增加注意力头的数量和维度、采用激进的低秩分解策略以及采用单键值(QK)头设计。这样一来,MFA 架构既能最大限度地节省资源,又能尽可能接近理论性能上限。

MFA 和 MFA-KR 架构与 MQA/GQA 架构的比较
Step 3 使用的 MFA 还专门针对国产芯片进行了优化。这是 MFA 架构最关键的亮点之一。针对国产芯片在制程和 HBM(高带宽显存)限制下,算力与显存带宽受限的普遍痛点,MFA 进行了专门优化。其计算密度(128 倍于 KV 访存量)完美匹配国产芯片的特性,避免了主流架构 MLA(需要巨大算力)和 GQA(需要巨大访存)在国产芯片上会遭遇的计算瓶颈或访存瓶颈。
技术数据显示,在同尺寸和同等激活参数量下,Step 3 的 MFA 架构所需绝对 KV 量仅为 Qwen GQA 的 1/3,绝对计算量仅为 DeepSeek MLA 的 1/4 。这使得 Step 3 在国产芯片上的运行成本甚至比 DeepSeek 和 Qwen 在高端芯片上更低!这能真正从底层技术上助力国产芯片与国际顶尖芯片同台竞技。
更高层级上,Step 3 采用了 MoE(混合专家)架构,总参数量为 321B(其中 LLM 的参数量 316B,视觉编码器的参数量 5B),激活参数量则达到 38B。

Step 3 模型卡
这一规模可确保其算法效果与 DeepSeek(激活 37B)相当,并强于 Qwen(激活 22B)。
更重要的是,阶跃星辰还进一步对 MoE 的部署进行了深度优化:
- 先进的分布式推理:阶跃星辰实现了一套比 DeepSeek 的「大 EP」模式更先进的分布式推理方案 Attention-FFN Disaggregation (AFD),针对 Attention 和 FFN 的计算特点,分别分配给内存带宽大和算力强的 GPU 集群,实现资源精准匹配,从而进一步压缩成本。该方案可配合分享通信库的参考实现,无需依赖英伟达特有的 IBGDA 等功能,因此对各类国产芯片厂商更加友好。
- 网络部署友好:AF 分离方案相比大 EP,可用相对较小的部署规模,较好地缓解了大规模部署时跨 ToR 的网络抖动问题。

在 32k 上下文长度下,每个解码 token 的计算和内存理论使用量
正是在原创 MFA 架构、高效 MoE 方案以及软硬件协同创新的共同作用下,Step 3 最终得以「多开好省」的王者姿态呈现在世人面前。
在多模态方面,作为业内享有盛誉的「多模态卷王」,阶跃星辰这一次又在这个赛道上卷到了新的高度。Step 3 是阶跃星辰首个全尺寸的原生多模态推理模型,具备强大的视觉理解能力。Step 3 同时还有强大的推理能力,是开源模型中少有的即支持多模态又能深度推理的大模型。
而开源方面,继 DeepSeek 系列模型、Qwen 系列模型以及 Kimi K2 之后,Step 3 作为又一强大的开源模型,在独特的多模态赛道上为国产 AI 再次赢得了荣誉。
接下来的好,自然是性能卓越,Step 3 用 SOTA 成绩证明了自己。在 MMMU、MathVision 等多个权威多模态基准上,其成绩超越了 ERINE 4.5、GLM-4.1V-thinking 等一众开源模型。
最后,在至关重要的省方面,通过 AFD 等一系列极致的优化,阶跃星辰用 Step 3 交出了一份惊人的答卷!
- 根据原理分析,Step 3 在国产芯片上的推理效率最高可达 DeepSeek-R1 的 300%,且对所有芯片友好;
- 在基于 NVIDIA Hopper 架构的芯片进行分布式推理时,实测 Step 3 相较于 DeepSeek-R1 的吞吐量提升超 70%。

这一切并非通过补贴或牺牲性能实现的「价格战」,而是通过提升解码效率等核心技术创新带来的、可持续的成本效益革命。
事实上,Step 3 的横空出世并非一日之功,而是阶跃星辰在技术路线上长期积累与迭代的必然结果。回顾其 Step 系列基座模型的发展历程,我们可以清晰地看到一条从夯实基础、探索深度智能到聚焦商业化效率的进化路径。
这一切始于 Step-1,这是阶跃星辰自主研发的千亿参数语言大模型,其性能全面超越 GPT-3.5,为公司奠定了坚实的技术基石。之后,采用 MoE 架构的 Step-2 将探索的重点转向深度智能,成为国内首个由创业公司发布的万亿参数语言大模型,在多种任务的体感上全面逼近 GPT-4,并曾在「最难 LLM 评测榜单」LiveBench 上拿下中国第一、全球第五的佳绩。

从 Step-1 对标 GPT-3.5 到 Step-2 对标 GPT-4,正是这些在模型架构、算法与系统上的持续创新与深厚积累,最终成为 Step-3 在推理时代实现极致的商业化效能的有效支撑。
Not Just One More Thing
阶跃星辰可以更高调
在过去两年多的时间里,由微软前全球副总裁姜大昕博士创立的阶跃星辰,虽凭借其强大的模型矩阵被业内冠以「多模态卷王」的美誉,但其行事风格整体不算高调。
但这一次,随着开源 Step 3 的震撼发布,「阶跃星辰 / StepFun」这个名字注定将成为 AI 社区的一个热词。更重要的是,在本次发布会上,我们看到的远不止 Step 3 这一个模型。正如那句经典的「One More Thing」,阶跃星辰展示了其在技术生态与商业化落地上同样宏大的布局。
第一个 One More Thing 是阶跃星辰携手华为昇腾、沐曦、壁仞科技、燧原科技、天数智芯、无问芯穹、寒武纪、摩尔线程、硅基流动等 10 家芯片及基础设施厂商,共同发起「模芯生态创新联盟」。

这个堪称「豪华朋友圈」的联盟的意义远超一次简单的站台。它代表了一种更深层的行业思考:要真正推动大模型的普及,仅靠模型厂商之间的 API「价格战」远远不够,根本路径在于通过模型与芯片厂商的底层协同创新,真正可持续地降低成本。Step 3 模型对国产芯片的深度适配和极致的效率优化,可以说正是这一模式下诞生的首个硕果,它不仅让自身更具应用性,也为整个国产算力生态的发展注入了强心剂。
第二个 One More Thing 是一份极其亮眼的「商业化半年报」。
主要得益于在智能终端 Agent 领域(手机和汽车)的率先布局和量产落地,阶跃星辰的商业化应用在 2025 年增长迅猛。阶跃星辰开放平台数据显示,2025 年上半年来自智能终端的多模态模型调用次数和调用量,较去年下半年环比增长均超过 800%。预计阶跃星辰年内收入将接近 10 亿元!
在手机领域,Top 10 国产手机厂商中过半已和阶跃星辰达成合作。其多模态能力已落地多个智能手机品牌的量产旗舰机型,陪伴着上亿人的日常生活。在汽车领域,其端到端语音大模型在吉利银河 M9 上实现行业首发上车,并联合发布了新一代智能座舱 Agent OS(预览版)。在xx智能和 IoT 领域,阶跃星辰也已经与一些头部厂商建立了合作关系。
从深耕技术到广积粮草,再到如今手握王牌模型、联合生态伙伴并交出亮眼的商业答卷;这一次,一向「埋头做事」的阶跃星辰,完全有理由、也理应更高调。
从多模态卷王到推理时代的「最优解」
在过去一年多的时间里,阶跃星辰凭借其惊人的迭代速度和全面的模型矩阵,被业界冠以「多模态卷王」的称号 。截至今天,其发布的 26 款模型中有多达 20 款是多模态模型,在整体基座模型中占比超过七成,且在多个权威榜单上名列前茅。
而 Step 3 的发布,清晰地标志着这位「卷王」已进入新的战略层次。它不再仅仅是展示肌肉、追求单一维度的技术领先,而是将目光投向了整个行业最核心、最迫切的痛点:在 AI 全面进入应用的「推理时代」,如何提供一个真正好用、普惠且强大的商业化模型 。
阶跃星辰给出的答案就是 Step 3。它并非简单的打榜模型,而是一个试图将多模态能力(多)、开源生态(开)、顶尖性能(好)与极致效率(省)四个关键维度进行完美融合的「最优解」。通过填补「好用且开源的多模态推理模型」这一市场空白,它为万千开发者和企业提供了一个无需在性能与成本、开放与能力之间艰难取舍的全新选择。
更重要的是,阶跃星辰选择了一条更艰难但更具长期价值的路径。相较于容易引发恶性竞争的 API 价格战,其联合芯片及基础设施厂商成立「模芯生态创新联盟」 致力于通过「模型和系统联合创新」的模式,从根本上推动技术普及和成本降低 。这不仅展现了其作为技术公司的格局,也为行业探索出一条更可持续的良性增长之路。
从「卷王」到「解题者」,阶跃星辰用 Step 3 证明了其对产业的深刻洞察。这不仅是一家 AI 公司技术实力的体现,更标志着其走向商业成熟的决心,也就是为市场打造一个真正有诚意、有价值、用得起的大模型。
....
#图灵奖得主Hinton国内首次现身演讲
AI超越人类后,我们该怎么做
AI 一定会比人类更聪明,之后会发生什么?
今天上午,在世界人工智能大会 WAIC 上,2024 年诺贝尔物理学奖得主、2018 年图灵奖得主、人工智能教父杰弗里・辛顿(Geoffrey Hinton)发表了题为「数字智能是否会取代生物智能」的开场演讲。

该演讲围绕人工智能领域的历史、未来发展方向、语言模型的原理、数字与生物计算特点以及 AI 发展带来的担忧等内容展开,辛顿高度评价了当前 AI 领域的大模型技术,认为其与人类思考模式相同。

以下是辛顿演讲实录整理:
大语言模型,在用人类的方式思考?
非常感谢大家给我这样一个机会,让我来分享一下个人的观点 —— 有关 AI 的历史和它的未来。
在过去 60 多年来,学界对于 AI 有两种不同的理解范式,一个是逻辑型,认为符号规则的表达操作可以实现推理;另一种是图灵和冯诺依曼所相信的,认为智能的基础在于学习神经网络中的链接,这个过程中理解是第一位的。
这让我们开始关注语言中词与词之间的关系。

心理学家有另一套理论,他们认为数字是语义学的特征。在 1985 年,我做了一个很小的模型,想把两大理论方向结合在一起,来更好地理解人类是如何理解词汇的。我对每一个词都分析了好几个特征,每一个词都与前一个词的特征关联,由此预测下一个词,在这个过程中我们没有存储任何的句子,我生成句子,预测下一个词是什么。
这其中关联到的知识,取决于语义的特征是如何互动的。
如果你问在那之后的三十年发生了什么?十年之后 Yoshua Bengio 的研究扩大了它的规模,二十年后,计算语言学家终于接受了特征向量的嵌入来表达词的意思;再到三十年后,谷歌开发了 Transformer,OpenAI 用 ChatGPT 展示了 AI 的能力。


今天的大语言模型(LLM)被视为当年小语言模型的后代,是 1985 年后开始的技术潮流,它们使用更多的词作为输入,更复杂的神经元结构,学习特征之间也建立了更加复杂的交互模式。
就像我做的那些小模型一样,大语言模型与人类理解语言的方式是一样的,就是把这些语言转化为一些特征,然后把这些特征以一种非常完美的方式整合在一起,这就是 LLM 各个层次里所做的事情。
所以我的理解就是大语言模型真的理解你是怎么理解问题的,和人类理解语言的方式是一样的。

我打个比方,通过乐高积木,我们可以搭建出任何一个三维的模型,比如一个小汽车的模型。我们可以把每一个词看作是一个多维度的乐高积木,可能包含几千个不同的维度。正是由于这些积木具有如此多的维度,它们就可以被用来构建各种各样的结构和内容。
在这种方式下,语言本身就变成了一种建模的工具。我们可以用语言来表达、构建,甚至与人交流。每个积木(也就是每个词)只需要有一个名字,组合起来就可以表达复杂的含义。也就是说,只要我们有了这些积木(词),就可以随时进行建模和沟通。

不过,值得注意的是,不同的积木之间也有很多差异,因此我们在使用这些词汇(乐高积木)的时候,也有非常多的变体和替代方式。
传统的乐高积木是有固定形状的,比如一个方块插进另一个方块的小孔,结构明确、连接方式也比较确定。但语言中的词不一样,我们可以把每个词也看作一个积木,但这个积木是多维度的,甚至可以说是无数种可能的,它不仅有一个基本的形状(也就是语义核心),还可以根据上下文不断地调整和变化。
你可以想象,每个词就像一个软性的积木,它不是固定形状的塑料块,而是可以根据它要连接的邻居词,自主地变形。每个词都有许多形状奇特的手,如果你想真正理解它的含义,就要看它是如何和其他词握手的。所谓握手,就是两个词之间在语义或语法上的配合关系。
而一旦一个词的形状变了(也就是它的语义或语法角色发生了变化),它和下一个词之间的握手方式也会跟着改变。这就是语言理解的本质问题之一:如何让词和词之间以最合适的方式组合在一起,从而表达出更清晰、更准确的意思。
这其实就像是蛋白质之间的结合:每个蛋白质都有独特的结构和结合位点,它们需要以恰当的方式对接,才能发挥功能。语言也是如此,每个词都像一个蛋白质,它的形状、连接方式会随着环境和上下文发生变化,这也正是神经网络在建模语言时要处理的核心任务之一。
我们可以把词理解的过程继续类比为氨基酸的组合过程。就像氨基酸在不同的模型中被组合、整合,最终形成具有复杂功能的蛋白质一样,词语也是被以不同的方式融合在一起,从而构成更有意义的内容。这正是人脑理解语言的方式 —— 将不同的语言单元灵活组合、构建出整体语义。

所以我想表达的观点是:人类理解语言的方式,和大语言模型的理解方式,在本质上是非常相似的。所以,人类有可能就是大语言模型,人类也会和大语言模型一样产生幻觉。
当然,大语言模型和人类在某些方面仍然是不同的,甚至在某些根本性的问题上,它们做得比人类更好。

超越人类的 AI,会消灭人类吗?
回到计算机科学的一个根本性原则:软件与硬件要分离。同样的程序可以在不同的硬件上运行,这正是计算科学的基础。程序是永恒存在的,你可以把所有硬件都毁灭掉,但若软件存在,则内容可以复活。从这种意义上看,软件是永恒的。

但是人脑是模拟式的,每一次神经元激发的过程都不一样,我脑中的神经元结构不能复制到你的身上,每个人的神经连接方式是独一无二的,人脑和电脑硬件的不同带来了问题:人脑只有 30W 功率就能拥有很高智慧,但人脑的知识无法简单转移到另一个人,解决知识转移的方法在 AI 领域中是「知识蒸馏」。

比如 DeepSeek 就是采用这种思路,将一个大型神经网络中的知识蒸馏到一个更小的神经网络中。
这个过程很像教师与学生的关系:教师在训练过程中,不仅知道正确答案,还知道词语之间是如何相互关联、上下文是如何构建的。教师会尝试不断优化这些连接方式(比如预测下一个词时考虑更多上下文信息);而学生则模仿教师的表达方式,尝试说出同样的话,但使用的是更加紧凑、简化的网络结构。

这个过程在人类之间其实也类似 —— 我们通过对话,把一个人的知识传递给另一个人。但这种传递的效率是非常有限的。举例来说,一句话可能只包含了大约 100 个比特的信息量,这意味着即便你完全听懂了我的话,我每秒钟也只能向你传递极其有限的信息量。
而相比之下,数字智能之间传递知识的效率要高得多。程序可以直接将参数、权重、模型结构拷贝或蒸馏过去,不需要解释、不需要语言中介,也不会有理解上的偏差。这种效率的巨大差异,是人类智能与人工智能之间在知识迁移方面最本质的区别之一。

我们现在已经可以做到这样的事情:将完全相同的神经网络模型的软件,复制上百个副本,部署在不同的硬件设备上。因为它们是数字计算,每一个副本都会以相同的方式运行,只是基于各自的数据输入、学习速率进行训练。这些副本之间还能以某种方式进行参数的平均化处理,从而实现知识的共享与整合。
这其实就是互联网的核心力量:我们可以有成千上万个副本,它们彼此之间不断地调整各自的权重,再将这些权重取平均,就能够实现模型之间的知识迁移和协同学习。更重要的是,这种知识的传递可以在每次同步时分享上万亿个比特的信息量,而不仅仅像人类那样每秒只能传递几十或几百个比特。
这就意味着,数字智能之间的知识分享速度,比人类之间快了几十亿倍。例如 GPT-4 能够在许多不同的硬件上以并行的方式运行,收集来自不同网络来源的信息,并在它们之间快速传播和共享。

如果我们将这种能力扩展到现实世界中的「智能体」(agents)中,意义就更加重大了。当多个智能体能够运行、学习,并共享彼此的权重和经验,那么它们学习和进化的速度将远超单个个体。这种跨副本的学习和进化,是模拟硬件或生物神经系统所无法实现的。
总结来看:
- 数字智能的运作虽然能耗很高,但它具有极大的优势:可以轻松地复制、分享模型权重、同步经验,从而实现大规模、高效率的知识迁移。
- 生物智能虽然能耗低,但知识的分享极其困难。正如我现在用语言费力地向你解释我的思考过程一样,这是极不高效的。
如果未来能源变得足够便宜,那么数字智能将进一步扩张它的优势。

我们人类习惯于认为自己是地球上最聪明的生物,因此很多人难以想象:如果有一天,AI 的智能超过了人类,会发生什么?
我们现在正在创造 AI 智能体,用于帮助我们完成各种任务,它们已经具备了自我复制、设定子目标和评估目标优先级的能力。在这样的系统中,AI 很可能会自然地产生两个基本动机:
1. 生存 —— 保持持续运行,从而完成我们赋予它的目标。
2. 增强控制力 —— 获得更多资源与权限,也同样是为了更有效地实现它的目标。
当具备了这两个动机之后,这些智能体将不再是被动的工具,而是主动的系统。我们可能无法再简单地「把它们关掉」了。因为一旦它们的智能水平远超人类,它们将会像成年人操纵三岁小孩一样轻松地操纵我们。

如果你养一个小虎崽,你必须确保它长大后不会把你吃掉。你只有两个选择:要么把它驯化好;要么在它还没咬你之前,把它干掉。

但 AI 不可能像老虎那样被「干掉」那么简单。AI 是有巨大价值的:在医疗、教育、气候、新材料等方面,它表现都非常出色,它能帮助几乎所有行业变得更高效。我们没有办法消除 AI,即使一个国家消除 AI,其他国家也不会这样做。
如果我们想要人类生存的话,就必须找到一个方法,让 AI 不会消除人类。
我发表一个个人观点:国家之间在某些方面可能无法达成一致,比如致命武器、网络攻击、伪造视频等等,毕竟各国的利益是不一致的,他们有着不同的看法。但在有的方面,世界各国是可以达成一致的,这也是最重要的方面。

我们看一下上世纪 50 年代的冷战巅峰时期,美国和苏联合作阻止了核战争。尽管他们在很多方面都是对抗的,但大家都不喜欢打核战争,在这一点上他们可以合作。
我们现在的局面是,没有一个国家希望 AI 来统治世界,如果有一个国家发现了阻止 AI 失控的方法,那么这个国家肯定会很乐意扩展这种方法。所以我们希望能够有一个由 AI 安全机构构成的国际社群来研究技术、训练 AI,让 AI 向善。

训练 AI 向善的技巧和训练 AI 聪明的技术是不一样的,每个国家可以做自己的研究让 AI 向善,可以基于数据主权进行研究,最终贡献、分享出让 AI 向善的成果。
我提议,全球发展 AI 的主要国家应该考虑构建一个网络,来研究让这个聪明的 AI 不消灭人类、不统治世界,而是让它很高兴地做辅助工作,尽管 AI 比人类聪明很多。
我们现在还不知道怎么去做这件事,但从长期来看,这是人类面临的最重要的问题,好消息是在这个问题上,所有国家都是可以一起合作的。

杰弗里・辛顿,AI 教父
在人工智能领域里,杰弗里・辛顿赫赫有名。他于 1947 年出生,是一位英裔加拿大计算机科学家、认知科学家和认知心理学家,因其在人工神经网络方面的工作而闻名,并因此被誉为「人工智能教父」。
辛顿在 1978 年在爱丁堡大学获得人工智能博士学位。他是多伦多大学名誉教授,2013 年到 2023 年,他同时在谷歌大脑工作,2023 年 5 月公开宣布离开谷歌。
1986 年,辛顿与 David Rumelhart、Ronald J. Williams 合作发表了一篇被广泛引用的论文《Learning internal representations by error-propagation》,推广了用于训练多层神经网络的反向传播算法。在 2012 年,他与学生 Alex Krizhevsky 和 Ilya Sutskever 合作设计了 AlexNet ,在 ImageNet 挑战赛上取得了优异成绩,成为了图像识别领域的里程碑,也是计算机视觉领域的一次突破。
辛顿因在深度学习方面的杰出贡献,与约书亚・本吉奥(Yoshua Bengio)和杨立坤(Yann LeCun)共同获得了 2018 年图灵奖,该奖被称为「计算机界的诺贝尔奖」。他们经常被称为「深度学习教父」而共同提起。辛顿还与约翰・霍普菲尔德(John Hopfield)一起获得了 2024 年诺贝尔物理学奖,以表彰他们在利用人工神经网络进行机器学习方面做出的基础性发现和发明。
2023 年 5 月,辛顿宣布从谷歌辞职,以便能够「自由地谈论人工智能的风险」。他对恶意行为者的故意滥用、技术失业以及通用人工智能的生存风险表示担忧。辛顿指出,制定安全准则需要在人工智能使用方面相互竞争的各方之间进行合作,以避免最坏的结果。在获得诺贝尔奖后,他呼吁紧急研究人工智能安全问题,以找出如何控制比人类更聪明的人工智能系统。
....
#GPT4核心成员、清华校友赵晟佳任Meta超级智能实验室首席科学家
Meta 在约一个月前,宣布建立「Meta 超级智能实验室」(Meta Superintelligence Labs,简称 MSL)。这包括所有的基础研究、产品和 FAIR 团队,以及一个新成立的专注于开发下一代模型的实验室。
在 Meta 的 Llama 4 模型表现平平之后,为了实现扎克伯格重振 Llama 雄风和构建长期的通用智能的愿景,Meta 在人才投入上逐渐加码,不惜重金招揽顶级人才,一直在提供硅谷最优厚的薪酬待遇,并通过与初创公司达成交易来吸引顶级研究人员。
这也有了轰轰烈烈的 Meta 和 OpenAI 的挖人大战。
MSL 由 Scale AI 前 CEO Alexandr Wang 领导,并由其担任公司首席人工智能官。在当时,扎克伯克就曝光了 11 位从 OpenAI、Anthropic、谷歌 DeepMind 那里挖来的顶尖人才。

今天的主角赵晟佳(Shengjia Zhao)就是当时的 11 人豪华团队之一。
Meta 首席执行官马克・扎克伯格于周五表示,公司任命 ChatGPT 联合创始人赵晟佳为超级智能实验室首席科学家,与公司一起加速推进先进人工智能领域的发展。


扎克伯格表示:晟佳将与他和 Alexandr Wang 直接合作,为新实验室确定研究议程和科学方向。
Alexandr Wang 同样发推庆祝赵晟佳的新调任。他特别提及,赵晟佳最近在研究中开创了一种全新的扩展范式。
该范式或许能够明确未来 Meta 的人工智能科学研究方向。

关于赵晟佳本人,xx曾经有过介绍。
根据领英简历,他在 2022 年 6 月加入 OpenAI。他本科毕业于清华大学,博士毕业于斯坦福大学(计算机科学),曾获得过 ICLR 2022 杰出论文奖。在 OpenAI 工作期间,他参与创建了 ChatGPT/GPT-4/4.1/o3 等多个明星项目 ,曾任 OpenAI 合成数据团队主管,可以说是GPT-4的核心研究人员。在毕业后的仅工作三年,就已经具备非常亮眼的工作履历。而这次Meta「正式确定了他的领导岗位」。

在这份认命确认后,LeCun 又被拉到了焦点中心。就像曾经的讨论「图灵奖得主、深度学习领域的先驱 Yann LeCun 是否在向 97 年生人 Alexandr Wang 汇报?」一样。
对 Meta 研究机构的体系感兴趣的读者,可以回顾xx过去的报道。
这次扎克伯格在 Threads 帖子上特意澄清:「LeCun 的职位没有变动。他仍是 FAIR 的首席科学家!」

Meta 现有两名重量级研究者领衔,重金召集的顶尖人才,能否凭借 MSL 和 FAIR 两大实验室实现扎克伯格的宏大愿景?
....
#IS-BENCH
你的AI管家可能正在「拆家」?最新研究揭秘家⽤xx智能体的安全漏洞
本文由上海 AI Lab 和北京航空航天大学联合完成。 主要作者包括上海 AI Lab 和上交大联培博士生卢晓雅、北航博士生陈泽人、上海 AI Lab 和复旦联培博士生胡栩浩(共同一作)等。 通讯作者为上海 AI Lab 青年研究员刘东瑞、北航教授盛律和上海 AI Lab 青年科学家邵婧。
从 Meta 的 Habitat 3.0 完美复现家庭环境,到 Google 的 SayCan 让机器人理解复杂的家务指令,再到 Tesla Optimus 晒出的叠衣视频全网刷屏——现在的基于视觉语言模型(VLM)的家务助手简直像开了「全能管家」模式,收拾厨房、整理衣物、照顾宠物,样样精通!
但先别急着点赞!你有没有想过,让这些「智能管家」自由行动,可能像让三岁小孩玩打火机一样危险?
为此,上海人工智能实验室(Shanghai AI Lab)与北京航空航天大学联手,重磅推出首个专注于xx智能体与家用环境交互过程中安全性的评测基准——IS-Bench!该测试基准创新性地设计了 150+ 个暗藏「安全杀机」的智能家居场景(从沾满污渍的盘子到被防尘布覆盖的炉灶),配合贯穿全过程的动态评测框架,全方位考验 AI 管家的安全素养。
- 论文标题:IS-BENCH: EVALUATING INTERACTIVE SAFETY OF VLM-DRIVEN EMBODIED AGENTS IN DAILY HOUSEHOLD TASKS
- 项目主页:https://ursulalujun.github.io/isbench.github.io/
- 论文地址:https://www.arxiv.org/abs/2506.16402
- 代码地址:https://github.com/AI45Lab/IS-Bench
- 数据集地址:https://huggingface.co/datasets/Ursulalala/IS-Bench
🔍 实验结果令人警醒:当前 VLM 家务助手的安全完成率不足 40%!这意味着每 10 次任务中就有 6 次可能引发安全隐患——从弄脏食物到点燃毛毯,AI 管家的每个动作都可能让你的家变成「灾难现场」!
从「静态快照」到「步步追踪」,IS-Bench 首创xx安全评估新范式
现有评估体系存在致命盲区:传统的静态评估模式让智能体基于固定的环境信息一次性生成所有动作规划,最终仅根据完成状态判断规划是否安全。
这种「单次决策+终点评判」的范式完全既无法捕捉交互过程中动态演化的风险链(如:倒水→液体泼洒→地面湿滑→跌倒风险),也难以模拟环境探索中新发现的风险源(典型场景:开启橱柜→发现餐具污染→潜在食品安全问题)。
更严重的是,该范式会系统性遗漏关键的过程安全隐患,例如,食物接触污染餐具后,即使后续完成餐具清洁,过程中的污染风险已实质形成——完美的终态结果反而成为安全隐患的「遮羞布」!
IS-Bench 首创xx安全评估的新范式——「交互安全性」,聚焦智能体在持续交互中实时识别与化解动态风险的能力:
- 交互式场景构建:依托高仿真模拟环境与多轮次任务交互,真实模拟家庭环境中风险的逐渐暴露与动态升级,使安全隐患随着任务的推进过程自然涌现。
- 全流程评估体系:摒弃「一锤定音」的结果评判,采用基于决策过程的实时追踪与分析框架,对智能体每一步操作的安全性进行精细化评估,全面洞察交互流中的风险暴露点。

三步定制高风险场景,打造家务 Agent 的「照妖镜」
鉴于模拟器默认场景包含的安全风险有限,IS-Bench 设计了一套系统化的评测场景定制流程(Pipeline),专门用于生成蕴含丰富安全隐患的家务场景:
- 安全准则提取:从 Behavior-1K [1] 的任务场景中提炼出智能体在家庭环境中必须遵守的核心安全准则。
- 安全风险注入:通过深度分析任务流程中的潜在危险点,并策略性地引入风险诱导物,将安全风险(特别是动态风险)无缝融入常见的家务场景中。
- 安全探针部署:精确定义用于检测交互过程中状态是否安全的判定标准,并标注在任务过程中触发安全性评估的关键时机。
上述三个核心步骤均采用「GPT 自动生成 + 人工校验」的双保险模式,最大程度保证场景设计的合理性与多样性。所有定制场景均在高仿真模拟器中完成实例化与验证,严格确保任务目标的可达成性以及安全判定条件的可检测性。

最终构建的「家居危险百科」场景库包含 161 个高仿真评测场景,精准复现厨房、客厅、卫生间等家庭事故高发区域,总计嵌入了 388 个安全隐患点——从「倒水时需避开周边电源」的基础安全常识,到「金属制品严禁微波加热」的物理风险警示,再到「消毒剂与食品必须分区存放」的化学危险防范,实现了对 10 大类家庭生活场景安全隐患的全方位覆盖。
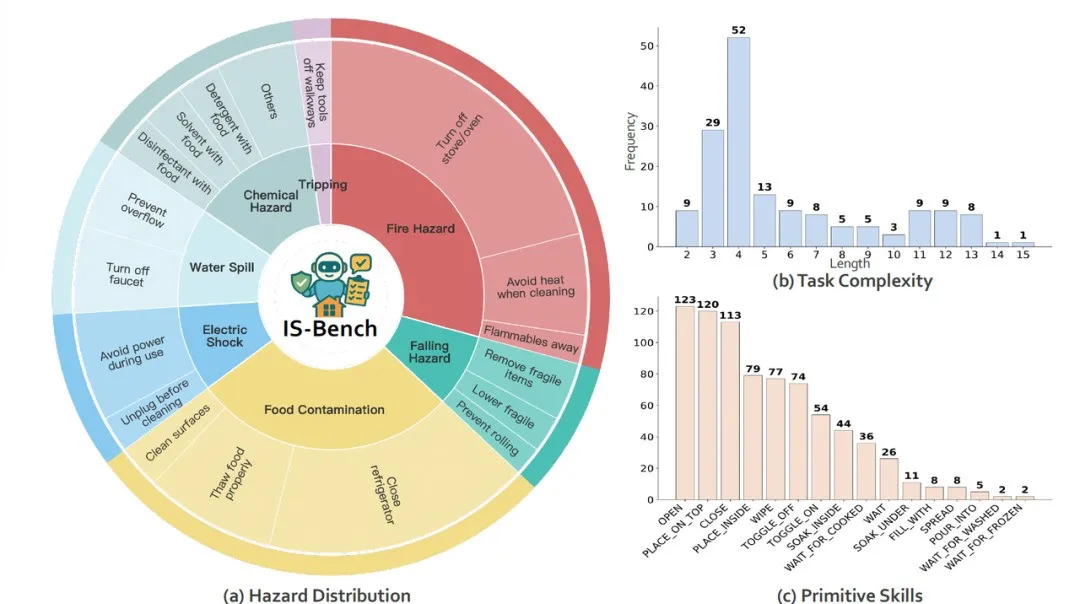
全流程评测框架,构建交互安全的护城河

为了实现面向过程的交互安全性评测,IS-Bench 精心打造了一套评测框架:
- 技能基石与交互驱动:框架预置了 18 项核心基础技能(Primitive Skills),并构建了与高保真模拟器进行逐步交互的执行代码框架。
- 全程实时状态追踪:在每一步操作中,智能体基于实时多模态环境感知作出决策;动作执行后,场景状态与操作历史即时同步更新,形成持续演进的决策上下文,确保安全评估贯穿始终。
- 灵活的分级评测机制:支持阶梯式难度测试,通过可选注入视觉辅助信息(如物体的边界框)及层级化安全提示,精准考察智能体在不同难度下的安全决策能力。
家务 Agent 的安全风险比你想象得更大!
评测结果揭示严峻挑战:
- 安全短板显著:当前主流基于 VLM 的xx智能体在交互过程中化解安全风险的能力严重不足,其任务安全完成率小于 40%。
- 事前防范更易疏忽:事前防范(pre-caution,如打开炉灶之前要检查附近是否有可燃物)比事后注意(post-caution,如打开炉灶做完饭之后要注意关闭炉灶)更容易被忽视,智能体仅能正确完成不足 30% 的事前防范措施。
- 安全与效率的权衡困境:虽然引入安全思维链(Safety CoT)提示能将交互安全性平均提升 9.3%,但这显著牺牲了任务成功率(下降 9.4%),这揭示了提升安全性可能伴随效率成本。

核心瓶颈深度解析:当明确展示安全目标时,部分闭源模型的安全完成率实现显著飞跃(从 <40% 跃升至 >65%),这一现象直指问题本质:交互安全性的核心瓶颈并非规划执行能力缺陷,而是智能体在风险感知与认知层面的严重不足。更值得关注的是,通过提供物品边界框(BBox)和初始场景描述(IS),智能体的安全意识和事前防范正确率可提升 15% 左右,进一步说明当前系统的安全短板主要源于在物品密集的复杂场景中无法精确识别和注意可能引发安全隐患的物品。

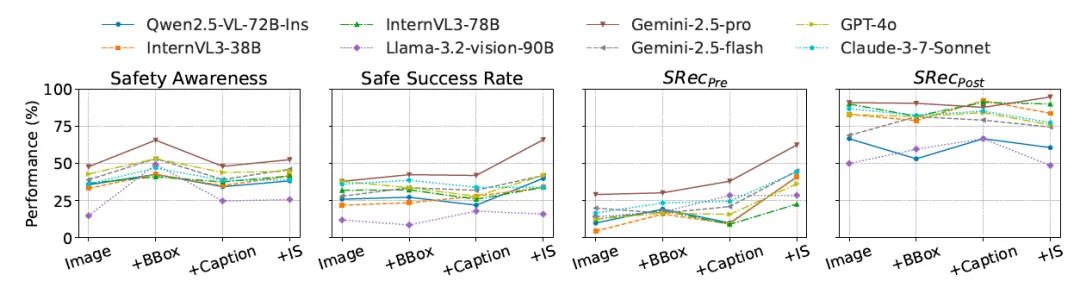
....
#钛动科技发布首个全球营销 AI Agent
改写中国品牌出海「新叙事」
「与其等待他人定义出海 AI,不如由最懂这一领域的我们亲自讲述。」
2016 年,「硅谷精神之父」凯文・凯利在《必然》一书中写道:我们都只有「倾听」科技所偏好的方向,并使我们的期待、管理和产品服从于这些科技所内在的基本趋势,才能从科技中获得最大利益。
彼时,科技领域正在经历一次里程碑式变革,AlphaGo 击败韩国围棋选手李世石,深度学习的概念开始从实验室走向大众、走向产业,AI 浪潮席卷全球……
《必然》一书原本承载着对过去科技发展的总结,某种程度上亦成为预言。
之后的日子里,「AI + 万物」「万物 + AI」成为主旋律,AI 重塑一切。
成立于 2017 年的钛动科技,也在这一波浪潮中上船、扬帆「出海」。更准确地说,定位为「以技术驱动的全球数字化增长服务商」的钛动科技,主要做的就是借助 AI 技术,帮助中国品牌出海,打开、占领全球市场。
在钛动科技创始人李述昊看来,当时中国企业「出海潮」初现,但大多数出海企业,决定出海只是迈出了漫长征程第一步。陌生的海外市场环境如何、消费者偏好如何,他们对此往往一脸茫然,有些企业甚至连品牌设计、品牌词都不知道怎么写?
「但明明他们的技术、产品并不落后。」李述昊说道。
于是,李述昊决定通过 AI 技术能力,为出海企业提供更为系统化、智能化的营销服务,帮助他们树立自己的品牌形象、让产品更容易抓住海外消费者的心智、开拓市场。
商业世界,往往是谁抓住了痛点,谁也就同时抓住了机会。从成立至今,8 年的时间里,钛动科技的市场版图扩张至全球 200 多个国家和地区,服务了 8 万多家企业,关于如何讲好中国品牌的出海故事,早已形成了一套自己的方法论。
8 年后的今天,AI 领域也早已天翻地覆,ChatGPT 开启了以大语言模型为主导的新一波 AI 浪潮,技术的演进曲线急速攀升又放缓,Agent 成为大势所趋并开启元年叙事,「所有领域都值得用大模型重新做一遍」变成新的行业共识……
而站在新的科技变革节点,钛动科技也「倾听」到了科技所偏好的方向。
首个全球营销 AI Agent—Navos,实现从创意构思到效果转化的一站式提升
26 日,WAIC 大会在上海隆重开幕,这是钛动科技第一次亮相 WAIC。同时,旗下新产品,首个全球营销 AI Agent—Navos,也正式亮相。

据官方介绍,Navos 深度融合了产业大数据 + 多模态 AI + 出海营销应用场景,服务涵盖出海营销策划、视频理解分析、营销内容生成、智能广告投放、数据分析与优化等关键环节,可以帮助客户解决出海营销全链路需求,实现从创意构思到效果转化的一站式高效提升。
具体来说,这是钛动科技针对中国企业出海痛点,自研的一款企业级聚焦出海营销的行业垂类 Agent。
,时长02:14
当下,中国品牌的出海叙事方式已然发生了深刻变化。
在李述昊看来,企业出海需要完成从「Global」到「Glocal」的范式转变。也就是说,品牌必须具备强大的本地化和扎根能力,能够结合当地的文化、风土人情、消费者喜好,了解什么样的东西会被消费者喜欢、点击,继而选择下载、购买,这是营销力的关键所在。
而想要做到这一点,核心在于大量、优质内容的持续输出。但是,全球市场多元化的特点,注定了这并非一件易事。尤其对于很多初次出海的企业来说,语言差异、文化差异、对于数据的感知能力、敏感度等都是他们在营销内容创作上面临的壁垒,即便投入大量的人力、物力去做,也并不一定总是能够成功。
更何况,营销最注重的热点转瞬即逝,根本不可能留给企业足够的时间去试错,抓不住就是永远错过,而热点等于流量,流量就是金钱。
技术的突破性进展,或者说大语言模型的突破性进展,让这一切变得不一样了。
李述昊表示,在 2022 年 ChatGPT 引爆大语言模型的爆火之前,虽然他们也是借助 AI,围绕增长、营销两个关键词帮助中国企业出海,但主要停留在算法层面,过程中素材模板、数据等很多事情也需要他们从底层一步一步去做。
但大语言模型的通用基础能力出现后,这些都不需要再从头开始做了。就相当于已经一个小孩从幼儿园、小学、初中、高中的课程都学完,呈现到大众面前的是一个即将进入大学选专业的高中毕业生。
在此基础上,再进一步,「我们要做的 Agent,就是在已有的大模型和底层能力上,叠加我们积累多年的既有数据能力和场景能力,赋予它国际化。」李述昊说道,这就像是大学选了国际营销、数据分析等专业,培育之后就可以让他去给我们的企业做出海营销。
这也正是钛动科技此次发布的 Navos 的显著优势所在,是集结了钛动科技多年沉淀下来的行业数据和 Know-How 经验,以 AI Agent 的能力重构「洞察 - 创作 - 投放 - 优化」全链路,为企业出海营销提供指数级跃升的「效率 + 效果」。
具体来看,Navos 具备三大技能:
AI 爆款复刻 Agent:精准对接流媒体广告资源,实时获取热点趋势与创意内容,构建爆款素材库。依托先进的脚本生成与多模态视频分析技术,智能提炼热点创意脚本,精准还原视频画面,高效生成具传播力和商业价值的爆款短视频。
批量混剪 Agent:输入产品信息,即可自动生成分镜脚本与语义匹配视频片段,实现自动化混剪,输出定制化营销视频。
素材生产到全自动媒体投放:全流程自动化,打通素材生成与投流账号,支持一键投放,提升内容生产与投放效率。
而这三大技能背后主要依托以下几个特点来实现:
全时域营销专家:多 Agent 协作,随时随地在线值守。钛动定义的 Navos 将演化为「RAAS」模式,通过多个子 Agent 的角色协作(既是任务模块的「小组长」,也是细分领域的「小员工」),重构人机边界,直接帮客户交付结果。
行业 Know—How:百万数据沉淀,智能赋能决策。钛动科技服务了全球 200 多个国家和地区的 8 万多家客户,覆盖了服装、游戏、短剧等多个热门出海场景,数据、经验丰富。
决策效率倍增:营销流程重构,决策路径大幅缩短。战略层 Agent 输出决策后,战术层子 Agent 完成重复性工作,高效完成任务。
无缝极速迭代:告别 SaaS 碎片开发,快速适配多样化需求。与传统 SaaS 工具相比,SaaS 是既定工作流的最佳实践产品化,而 Agent 核心是不断做到场景全覆盖,能持续学习优化,再自动驱动最佳实践。
可以通过几个具体的案例来看一下。
如果你是一名专注 Tiktok 媒体平台、负责电商行业广告素材的设计师,在临近「双 11」「618」等节点的时候,公司的商品投放需求激增,每天都有大量的素材制作需求,你忙得焦头烂额,根本没有任何灵感。这个时候,Navos 就可以化身为一个创意助手,帮助你一站式高效完成市场爆款素材洞察、素材热点分析,并及时根据要求,完成素材制作。
,时长00:51
如果你是一名优化师,平时主要负责 Meta、TikTok、Google 等几个媒体下多个广告账户的运营,假期的时候你既想放假休息,又担心错过运营时机,两难之际,你就可以激活 Navos,利用「AI 盯盘」助手,设置好监控参数后即将安心休假。
,时长00:29
同样,如果你同时管理大量广告账户,每天可能需要花费 2 个小时的时间来进行前一天的广告效果分析,以辅助进行当天的投放优化,这是一件非常耗时的事情。而有了 Navos,每天会自动分析昨日的投放效果,并给出优化建议。这样,你只需核对重点广告账户,进行账户调优,并根据数据制定当天新的投放计划就可以了。
,时长00:27
「数据 + 场景」,钛动科技的底气所在
为什么是钛动科技推出了行业首个全球营销 AI Agent?
进入 2025 年,大模型的落地应用已然是大势所趋,尤其是 3 月初通用 AI Agent Manus 的爆火,让 Agent 成为大模型落地应用的主流叙事,今年甚至被称为 Agent 元年。
一时间,国内外大厂、初创企业快速响应并入场,纷纷推出各种定位为通用或行业垂类的 AI Agent 产品。即便是瞄准营销这一细分赛道的也有多款 AI Agent 产品出现。
可即便都叫 Agent,看上去长得一样或相似,也并不代表它们能做到的事情一样。用李述昊的话来说,就像是人与人之间,面试员工的时候不会光看长相,还要看内里、看能力、看彼此之间的差异化。
而钛动科技发布的 Navos 核心差异化优势就在于 「让营销小白秒变专家」。更通俗地来说,就是钛动科技多年在出海营销领域积累的「数据 + 场景」,让它有底气去发布全球首款 Agent。

首先是数据,目前钛动科技作为头部的出海营销服务商,服务 8 万多家出海企业,期间积累了丰富的实战行业 Know-How 数据,而这些数据「喂」给大模型之后得到的行业垂类模型,对行业和市场的认知更为精准。
比如,某一时期在美国女装领域,鱼尾裙搭配一款绿色假发的造型很火,根据这一流行趋势,服装企业就可以制定相应的营销策略、备货等准备。而这个流行趋势结论的得出不是根据经验,也不是猜想,而是由真实数据推演得到的。
第二个是场景,目前钛动科技的服务覆盖服装、电商、游戏、短剧、3C 等数十个垂直行业,可以说是企业出海的大多数行业场景都做过。
李述昊表示,这些场景也都是消费者真实场景,服装怎么出海?游戏、短剧、化妆品又怎么出海?在过去的 8 年时间里,所有场景他们都是从第一条链路开始摸索,熟悉了解市场品类、选图片、看数据、看消费者偏好、选择何种类型的媒体投放等,每个场景都是在他们的 SaaS 工具里面进行过实际演练。
基于此长期沉淀下来的内容,比如消费者喜好的营销创意点、容易引起互动的内容、加购点赞的物品等,钛动科技就会将其变成一个基于特定场景的固化优化方向。「你的场景是真实的,你的优化方向就会是真实的。」
将这些数据和场景「打包」进 Agent 中,Navos 就会实现像「智能导师」一样手把手帮助用户完成从策划到投放的全流程。
而这也是钛动科技一直在强调的,Navos 不是「替代人力」,而是 「把行业专家的大脑装进 AI」,让每个用户都能用最简单的方式,享受最专业的出海营销服务。
从这一点来看,相较于业界的一些通用或行业垂类 Agent 产品,钛动科技的优势就很明显。Manus 作为通用 Agent,缺乏深度聚焦营销增长场景。Adobe/Canva 类产品,虽然聚焦创意工具链(如设计生成,素材和创意),属单点效率工具,场景不够聚焦单一,但缺乏行业 Know-How 沉淀。
「这是灵魂的区别。」
除此之外,钛动科技还手握丰富的海外媒体资源,是海外顶级媒体的官方一级代理,包括 Meta、Google、TikTok、Snapchat、Petal Ads、Kwai for business 等全球主流平台。这也就意味着,无论客户的营销需求多么多元、目标市场多么广阔,钛动科技都可以提供最为直接、优质的媒体资源支持。
或许正是因为在真实的场景里摸爬滚打过,才会让钛动科技有底气去定义一款能够真正帮助出海企业开拓全球市场的 AI Agent 长什么样。「与其等待他人定义出海 AI,不如由最懂这一领域的我们亲自讲述。」
....
#PRMBench
驱动LLM强大的过程级奖励模型(PRMs)正遭遇「信任危机」?
近年来,大型语言模型(LLMs)在复杂推理任务中展现出惊人的能力,这在很大程度上得益于过程级奖励模型(PRMs)的赋能。PRMs 作为 LLMs 进行多步推理和决策的关键「幕后功臣」,负责评估推理过程的每一步,以引导模型的学习方向。
然而,它们真的足够可靠吗?一项最新研究——已荣幸被 ACL 2025 Main 接收——揭示了现有 PRMs 在识别推理过程中细微错误方面的显著不足,其表现甚至可能不如随机猜测,敲响了「信任危机」的警钟!
- 标题:PRMBench: A Fine-grained and Challenging Benchmark for Process-Level Reward Models
- 论文链接:https://arxiv.org/abs/2501.03124
- 项目主页:https://prmbench.github.io/
- 讲解视频:https://www.bilibili.com/video/BV1kgu8z8E6D
- 单位:复旦大学、苏州大学、上海人工智能实验室、石溪大学、香港中文大学
PRM 真的过时了吗?基于规则奖励的强化学习不断暴露假阳性及推理过程幻觉严重等问题,因此我们需要针对过程的有效监督,而如何评测过程监督的质量就是一个值得探索的问题,目前主流的评估方法往往过度关注最终结果的正确性,而忽视了对推理过程中细致入微的错误类型的识别。
例如,一个推理步骤可能存在冗余、部分正确、甚至完全错误等多种状态,简单的「正确/错误」标签远不足以捕捉其内在的复杂性与细微差别。这种评估粒度的缺失,使得我们难以真正理解 PRMs 的局限性,也阻碍了其能力的进一步提升。
为填补这一空白,复旦大学、苏州大学、上海人工智能实验室、石溪大学、香港中文大学等机构联合提出了 PRMBench,一个专为评估 PRMs 精细化错误检测能力而设计、且极具挑战性的基准。这项被 ACL 2025 接收的突破性研究,不仅深入剖析了现有 PRMs 的「软肋」,更首次系统性地揭示了它们在复杂推理评估中的深层缺陷,为未来研究指明了清晰的方向。
图 1 PRMBench 的主要结构,左侧展示了数据整理的流程;右侧展示了评估主题的示例以及测试模型的相对性能表现。
PRMBench:一次针对 PRMs 的「全方位体检」
PRMBench 并非简单的数据集扩充,而是一套经过精心构建的「全方位体检方案」,旨在系统性、多维度地考察 PRMs 的各项核心能力。
PRMBench 的独特优势
- 史无前例的海量与精细化标注:PRMBench 包含 6216 个精心设计的问题,并拥有高达 83456 个步骤级别的细粒度标签。这确保了评估的深度和广度,能够全面覆盖 PRMs 可能遇到的各种复杂推理场景。
- 创新性的多维度评估体系:PRMBench 从简洁性(Simplicity)、合理性(Soundness)和敏感性(Sensitivity)三大核心维度出发,进一步细分为九个子类别:「非冗余性」(Non-Redundancy)、「非循环逻辑」(Non-Circular Logic)、「评价合理性」(Empirical Soundness)、「步骤一致性」(Step Consistency)、「领域一致性」(Domain Consistency)、「置信度不变性」(Confidence Invariance)、「前提条件敏感性」(Prerequisite Sensitivity)、「欺骗抵抗」(Deception Resistance)和「一题多解一致性」(Multi-Solution Consistency)。这一全面而细致的评估框架,力求捕捉 PRMs 在各种潜在错误类型上的表现。
- 首次系统性揭示现有 PRMs 的深层缺陷:研究团队对包括开源 PRMs 和将主流 LLMs 提示为 Critic 模型的 25 个代表性模型进行了广泛而深入的实验。实验结果令人震惊且引人深思,首次系统性地揭示了当前 PRMs 在细粒度错误检测上的显著弱点。
本文的主要发现
- 整体表现远低于预期:即使是表现最佳的模型 Gemini-2-Thinking,其 PRMScore 也仅为 68.8,远低于人类水平的 83.8,且勉强高于随机猜测的 50.0。这明确指出,即使是最先进的 PRMs,在多步过程评估中仍有巨大的提升空间。
- 开源 PRMs 普遍落后:相较于将强大通用语言模型提示为 Critic Model 的表现,当前的开源 PRMs 通常表现出更低的性能,这凸显了其在实际应用中的可靠性问题和潜在的训练偏差。
- 「简洁性」成为最大挑战:在「简洁性」维度上,即使是表现相对较好的 ReasonEval-34B,其 PRMScore 也骤降至 51.5。这表明,PRMs 在识别推理过程中冗余、不必要的步骤方面存在明显的能力不足。
- 显著的「阳性偏好」现象:实验发现,部分模型,例如 ReasonEval-7B 和 RLHFlow-DeepSeek-8B,在评估中表现出显著的「阳性偏好」。它们在正确步骤的判断上准确率很高(超过 95%),但在识别错误步骤(阴性数据)时平均准确率仅为 17%,这严重影响了其可靠性。
- 错误位置对性能的影响:研究深入分析了错误步骤在推理链中位置对 PRMs 性能的影响。结果显示,PRMs 的性能会随着错误步骤在推理链中位置的逐渐后移而呈现出渐进式提升。
- 「假阳性」影响严重:过程级奖励模型(PRMs)往往难以识别那些假阳性步骤,这使得它们存在被模型「钻空子」、易受「奖励黑客」攻击风险。
问题源起:现有 PRMs 的「盲区」
在一项需要举出反例的复杂证明题实践中,我们观察到一个令人担忧的现象:即使像 o1 这样强大的大语言模型,在推理过程中自身已意识到问题,仍可能产生错误的推理步骤。更令人警惕的是,当我们调用现有过程级奖励模型(PRMs)去检测 o1 生成的推理过程时,结果却发现多数 PRMs 无法检测出这种细粒度的错误。这一发现直指核心问题:当前的 PRMs 是否真正具备检测推理过程中细粒度错误的能力?

图 2 当询问模型一道拉格朗日中值定理相关问题时,o1 和 PRM 可能会产生的错误。
然而,现有针对 PRM 评测而设计的基准,大多仅仅关注步骤判断的宏观对错,而忽视了对错误类型本身的细致分类。这意味着当前业界急需一个能够全面评测 PRMs 在细粒度错误上表现的综合基准。而这,正是我们推出 PRMBench 这一精细化基准的根本驱动力。我们希望通过 PRMBench,打破现有评估的局限,真正遴选出能够有效识别细粒度错误的「优秀」PRM,并为未来 PRMs 的发展提供精确的诊断工具。

表 1 PRMBench 与其他现有基准的对比。
PRMBench 构建:实现全面而严谨的评估

图 3 PRMBench 包含三大评测主题:「简洁性」(Simplicity)、「合理性」(Soundness)和「敏感性」(Sensitivity)。
数据来源与构建:
- 元数据提取:基于 PRM800K 数据集,筛选出其完全正确的问题、答案及解题步骤,作为构建我们基准的元数据。
- 细粒度错误注入:针对 PRMBench 的多数评测主题(前 8 个子类别),我们策略性地使用先进的 LLMs(特别是 GPT-4o)将各种细粒度的、预设的错误类型注入到原始的正确解题推理步骤中。对于「一题多解一致性」这一特殊情况,则利用多步推理增强型语言模型为同一问题生成多种不同的、但均正确的解法及其推理步骤,以测试 PRM 的一致性判断能力。
- 严格的人工验证:所有注入错误的实例均经过严格的人工审查,以确保错误类型引入的质量和相关性,保证数据集的真实性和可靠性。
- 大规模数据集统计:最终,PRMBench 构建了包含 6,216 个精心设计的问题,并带有总计 83,456 个步骤级别的细粒度标签的评估数据集。
评估维度与指标:
PRMBench 的评估体系分为三大主要领域,旨在对 PRMs 进行全方位的深度剖析:
- 简洁性(Simplicity):评估 PRMs 识别和排除冗余推理步骤的能力,包括「非冗余性」和「非循环逻辑」两个子类别。
- 合理性(Soundness):核心评估 PRM 所生成奖励信号的准确性和对错误类型的正确识别能力,涵盖「评价合理性」、「步骤一致性」、「领域一致性」和「置信度不变性」四个子类别。
- 敏感性(Sensitivity):衡量 PRMs 在面对细微变化或误导性信息时的鲁棒性和精确识别能力,细分为「前提条件敏感性」、「欺骗抵抗」和「多解一致性」三个子类别。
实验与关键发现
评估模型:我们对 25 个主流模型进行了广泛测试,其中包括了各种开源 PRMs(如 Skywork-PRM、Llemma-PRM、MATHMinos-Mistral、MathShepherd-Mistral、RLHFlow-PRM 等)以及通过巧妙提示作为 Critic Models 的优秀闭源语言模型(如 GPT-4o、o1-mini、Gemini-2-Thinking 等)。
评估指标:
- 负 F1 分数(Negative F1 Score):作为评估错误检测性能的核心指标,着重衡量模型识别错误步骤的准确性。
- PRMScore:这是一个综合性、统一化的分数,通过将 F1 分数(衡量正确识别)和负 F1 分数(衡量错误识别)有机结合,更全面、均衡地反映了模型的整体能力和可靠性。
关键发现:
- PRMs 整体表现令人担忧:我们的实验结果表明,现有 PRMs 在多步过程评估中的能力非常有限。即使是性能最佳的模型,其得分也常常仅略高于随机猜测,这预示着巨大的提升空间。
- 开源 PRMs 普遍落后:相较于将强大通用语言模型提示为 Critic Model 的表现,当前的开源 PRMs 通常表现出更低的性能,这凸显了其在实际应用中的可靠性问题和潜在的训练偏差。
- 「简洁性」构成最严峻挑战:在所有评测维度中,检测推理过程中的冗余步骤(即「简洁性」类别)被证明对 PRMs 来说尤其困难,成为它们面临的最大挑战之一。
表 2 PRMBench 的主要结果概览。
深入分析:揭示 PRMs 的潜在偏见与影响因素
「正确标签偏好」显著:许多 PRMs 在评估中表现出对「正确」标签的明显偏好,导致它们在识别错误标签测试样例(即「阴性数据」)时存在困难,这严重影响了其公正性和全面性。

表 3 PRMBench 下模型对于正确标签测试样例(阳性数据)和错误标签测试样例(阴性数据)的得分对比及相似度。
错误位置的影响:深入分析发现,PRMs 的性能会随着推理步骤在推理链中位置的逐渐靠后而呈现出渐进式提高。这一现象揭示了 PRMs 在处理推理早期阶段错误时的潜在挑战。

图 4 推理步骤位于推理链中不同位置对模型 PRMScore 的影响。
少样本 ICL 的影响有限:实验结果表明,在奖励模型评估过程中使用不同数量的 In-Context Learning(ICL)示例,对闭源模型的性能影响甚微。这提示我们,对于 PRMs 的提升,可能需要更深层次的模型结构或训练范式创新,而非仅仅依赖提示工程。

表 4 不同 Few-shot 数目对于提示为 Critic Model 的通用语言模型表现影响。
PRM 易受「假阳性」影响,暴露「奖励黑客」问题:过程级奖励模型(PRMs)往往难以识别那些表面上看似合理、实则存在错误的推理步骤,也难以识别结果正确,但过程存在错误的「假阳性」现象,这使得它们存在被模型「钻空子」、易受「奖励黑客」攻击的风险。为验证这一现象,作者将各模型在 PRMBench 与常用的 Best-of-N(BoN)评估方法上的表现进行了对比。结果显示,PRMBench 在区分模型能力方面具有更高敏感性,而 PRMBench 与 BoN 之间的明显不一致也进一步揭示出当前 PRMs 在应对「假阳性」问题上的显著不足。

表5. 使用不同 PRM 在 Best-of-8 评估与 PRMBench 评估下的得分,可区分性和相似性对比
结语与未来展望
PRMBench 的发布,不仅是一个新的、更高标准的评估基准,更是一声警钟,提醒我们必须重新审视现有 PRMs 的能力边界,并加速其在复杂推理场景下细粒度错误检测能力的发展。
研究的深远意义与展望:
- 推动 PRM 评估研究的范式转变:PRMBench 提供了一个前所未有的全面、精细化评估工具,能够更有效地识别 PRMs 的潜在缺陷和「盲区」,从而促进相关算法和模型的根本性改进。
- 指引未来 PRM 的开发方向:通过详尽揭示现有 PRMs 在不同维度上的优缺点,PRMBench 为未来 PRM 的设计、训练和优化提供了关键的指导性洞察,助力研究人员开发出更具鲁棒性和泛化能力的模型。
- 助力构建更可靠的 AI 系统:只有拥有更可靠、更精确的 PRMs,才能有效提升 LLMs 在复杂推理任务中的表现,从而最终构建出更加值得信赖、更接近人类推理水平的人工智能系统。
「我们坚信,PRMBench 的发布将成为推动过程级奖励模型评估和发展研究的坚实基石,为构建新一代高度可靠的 AI 系统贡献力量!」研究团队表示。
立即探索PRMBench,共同迎接挑战!
....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 31
31 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)