告别404!用SOSSE把互联网装进自家硬盘:开源自托管数字档案馆全攻略
“昨天还在的教程,今天只剩 404。”这不是段子,而是互联网每天都在上演的 “电子蒸发”。
“昨天还在的教程,今天只剩 404。”
这不是段子,而是互联网每天都在上演的 “电子蒸发”。
网页的平均寿命只有 2.7 年,比某些网红的恋爱周期还短。今天你收藏的教程、明天你引用的数据,后天就可能随风消散,仿佛从没存在过。
-
• “网站倒闭潮”:初创公司说散就散,博客主说退网就退网,连政府官网都能一夜改版,URL 集体投胎。
-
• “平台拆迁队”:Medium、知乎、微博隔三岔五删文、锁文,像极了物业突然砸墙,连通知都懒得贴。
-
• “时光机也失灵”:Wayback Machine 确实伟大,但人家是公益项目,优先级、深度、频率都由不得你。想抓的页面没拍到,拍到的页面缺图片,简直是 “薛定谔的存档”。
把记忆托付给公共存档,就像把日记本放在咖啡馆留言墙——随时可能被拿去折纸飞机。
|
痛点 |
现场还原 |
内心 OS |
| 审查 |
某篇敏感文章在公共存档里直接“蒸发” |
“我只是想保存技术博客,怎么也被连坐?” |
| 限速 |
批量下载 1000 页,提示“每小时 50 次,明儿请早” |
“我硬盘空着,但时间不值钱?” |
| 隐私泄露 |
上传书签=公开浏览史,广告商秒懂你 |
“我只是想备份,不是想裸奔。” |
SOSSE 把“保险柜”直接搬进你家客厅:
-
• 数据 硬盘在你家,断电也有电,断网也能搜。就算世界末日,只要发电机还在,你的知识库就还在。
-
• 速度 本地全文索引,毫秒级响应,再也不用看“正在加载 5/127”转圈圈。
-
• 规则 想爬多深就爬多深,想多久更新就多久更新,User-Agent 想伪装成火星浏览器也没人拦。
公有存档是租来的保险柜,SOSSE 是你自家后院带锁的仓库——钥匙、地皮、装修,通通你说了算。
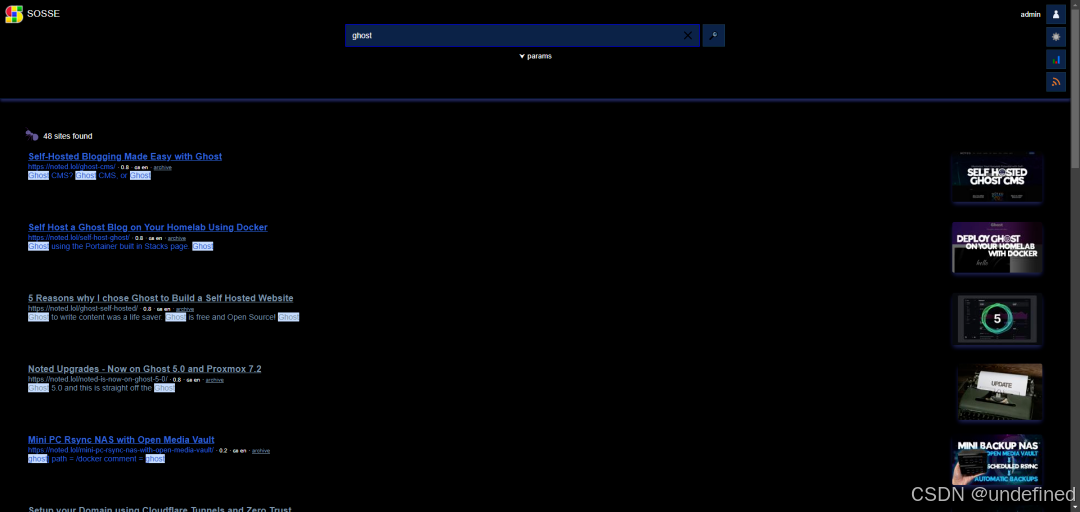
SOSSE是什么?一分钟看懂核心能力
一句话总结:把 Wayback Machine 塞进你口袋,再给它装上 Google 级全文搜索,这就是 SOSSE。
开源血统:Selenium+Python的极简架构
|
组成 |
角色 |
一句话亮点 |
| Selenium |
“真人浏览器” |
会滚动、会点击、会等懒加载,连弹幕都跑不掉 |
| Python |
胶水+大脑 |
2k 行代码,读完源码像翻漫画,魔改零门槛 |
| PostgreSQL + Whoosh |
双引擎 |
一个存数据,一个做倒排索引,稳如老狗 |
极简到离谱:整个项目只有 docker-compose.yml + requirements.txt,复制粘贴就能跑,连“Hello World”都没它省事。
存档三件套:HTML源码、全屏截图、元数据一个不落
|
维度 |
拿到什么 |
有什么用 |
| HTML源码 |
完整 DOM + 内联资源 |
原站 404?直接“复活”镜像站 |
| 全屏截图 |
1280×720 PNG |
论文插图、竞品改版,一眼对比 |
| 元数据 |
URL、时间戳、响应头、Cookie、IP |
打官司、做取证,时间线铁证如山 |
彩蛋:截图自动打上 水印时间戳,防止“P 图抵赖”。
搜索黑科技:全文+DOM结构双重索引,毫秒级响应
-
• 全文索引:Whoosh 支持 中文分词,搜“内卷”连注释里的“involution”都能命中。
-
• DOM 结构索引:想搜“所有带
data-price的按钮”?直接attr:data-price=*,前端直呼内行。 -
• 毫秒级:本地 SSD + 预加载索引,搜索 10 万页比百度打开首页还快。
实测:8 万页存档里搜“Transformer”,0.23 秒出结果,Google 还没反应过来。
与Wayback Machine的5大差异对比表
|
维度 |
SOSSE | Wayback Machine |
| 数据归属 |
躺在你硬盘,想删就删 |
躺 IA 服务器,说没就没 |
| 搜索体验 |
本地全文 + DOM 语法,秒回 |
只能按 URL/时间戳搜,慢 |
| 隐私 |
0 上传,连你妈都不知道你存了啥 |
上传即公开,爬虫随便看 |
| 速度 |
内网千兆,下载像拷 U 盘 |
限速 5 MB/s,热门时段排队 |
| 可玩性 |
Python 插件、Cron 定时、Webhook 一条龙 |
只能看,不能改 |
一句话:Wayback 是博物馆,SOSSE 是你家的 私人保险库 + 实验室。

5分钟极速部署:从Docker到第一条存档
友情提示:本章节全程手摸手,零命令行恐惧。只要你会复制粘贴,就能把互联网搬进硬盘!
环境准备:Docker、Docker Compose一键脚本
|
系统 |
一键脚本 |
备注 |
| macOS / Linux |
`curl -fsSL https://get.docker.com |
sh` |
| Windows 10/11 |
直接装 Docker Desktop |
记得勾选 WSL2 |
验证姿势:
docker --version && docker-compose --version两行都输出版本号,就说明环境 OK;否则把报错丢给搜索引擎,它比你更懂自己。
docker-compose.yml逐行拆解:端口、卷、环境变量
把下面 30 行 YAML 扔进任意空文件夹,文件名必须是 docker-compose.yml:
version: "3.9"
services:
sosse:
image: ghcr.io/sosse/sosse:latest # 官方镜像,永远最新
container_name: sosse # 起个爱称,方便 docker logs sosse
ports:
- "8080:8000" # 左边是宿主机端口,右边是容器端口
volumes:
- ./data:/app/data # 存档、索引、截图全落盘
- ./config:/app/config # 自定义设置持久化
environment:
- SECRET_KEY=change_me_please # 改成随机 50 位字符串,防 CSRF
- POSTGRES_HOST=db # 数据库服务名,保持默认即可
depends_on:
- db
restart: unless-stopped
db:
image: postgres:15-alpine
container_name: sosse_db
environment:
- POSTGRES_DB=sosse
- POSTGRES_USER=sosse
- POSTGRES_PASSWORD=sosse123
volumes:
- db_data:/var/lib/postgresql/data
restart: unless-stopped
volumes:
db_data:逐行彩蛋解释
-
•
image: ghcr.io/sosse/sosse:latest—— 官方每日自动构建,追新不追坑。 -
•
volumes: ./data:/app/data—— 把容器里的/app/data映射到本地./data,删容器不丢档。 -
•
SECRET_KEY—— 不改成随机值,隔壁老王就能伪造你的存档任务,别偷懒。
首次启动验证:Web UI界面速览与故障排查清单
- 1. 启动:
docker-compose up -d -
2. 打开浏览器访问
http://localhost:8080,看到 SOSSE 欢迎页 就成功 80%。
|
症状 |
诊断 |
解药 |
|
页面空白 |
容器没起来 |
docker logs sosse
看报错 |
|
502 Bad Gateway |
数据库没连上 |
docker logs sosse_db
是否初始化完成 |
|
端口被占用 |
8080 被其他程序霸占 |
改 |
创建你的第一个存档任务:书签/历史/RSS三种入口
1. 书签一键存档
-
• 在 Web UI 右上角点击 “Add Bookmarklet”,把弹出的 JS 拖到浏览器书签栏。
-
• 遇到想留档的网页,点一下书签,后台静默截图+源码,喝杯咖啡回来就存好了。
2. 浏览器历史批量导入
-
• 导出历史:Chrome 地址栏输入
chrome://history/,右上角「导出」→history.json。 -
• 回到 SOSSE → Import → Browser History,上传文件,全选→Start Crawl,躺平。
3. RSS 增量监控
-
• 在 Settings → Feeds 里填入
https://example.com/feed.xml。 -
• 设定频率:每 6 小时扫一次,新文章自动入库,旧文章自动跳过,绝不重复劳动。
第一条存档完成后,回到 Search 页面输入关键词,毫秒级高亮结果跳出来那一刻,你会听见硬盘在骄傲地哼歌。
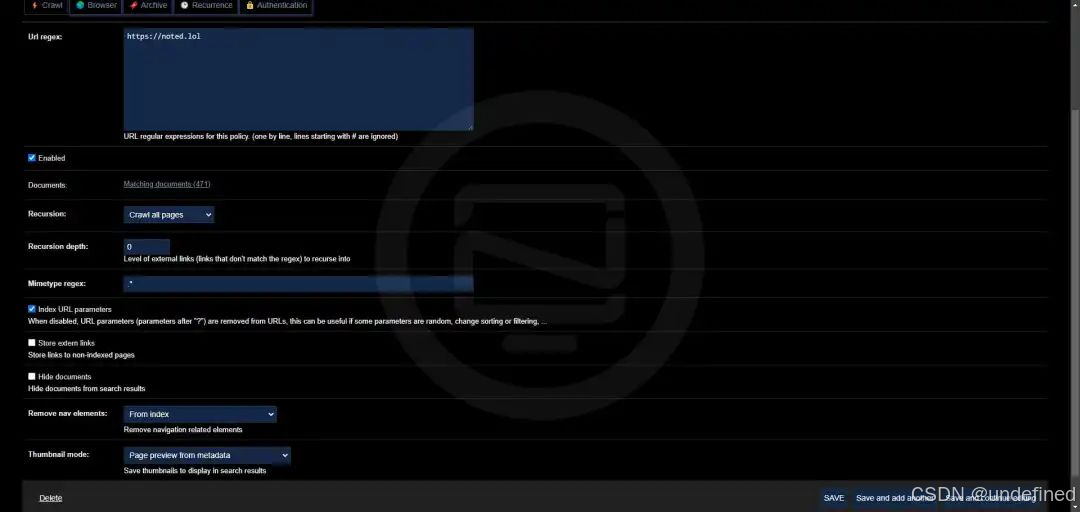
深度配置指南:让SOSSE成为你的私人 Google
把“搜索”两个字从广告里抢回来,把“存档”两个字从404里救回来。下面四步,让你的 SOSSE 从“能用”进化到“好用”。
自定义爬虫规则:User-Agent、延时、并发数
SOSSE 的爬虫本质上是 Selenium + Headless Chrome,所以只要 Chrome 能调的参数,它都能调。核心配置在 config/crawler.yaml(没有就新建)。
1. 改头换面:User-Agent 伪装
user_agent: "Mozilla/5.0 (compatible; SOSSEbot/1.0; +https://yourdomain.tld/bot)"不想被 CDN 拦?把 UA 换成最新版 Chrome,或者直接抄你自己的浏览器 UA。
2. 慢就是快:延时与并发
delay_between_requests: 1.5 # 秒,防 429
max_concurrent_tabs: 4 # 每容器并发标签页
max_workers: 8 # 全局并发协程数-
• 学术站点多用
delay: 3,新闻站点可降到0.5。 -
• 内存 < 4 GB 的机器,把
max_workers砍到 4 以内,否则会 OOM 重启。
3. 黑名单 & 白名单
url_blacklist:
- "*googleads*"
- "*doubleclick*"
url_whitelist:
- "https://arxiv.org/*"黑名单支持通配符,白名单优先级更高,二者同时存在时白名单说了算。
存储策略:本地磁盘、S3、MinIO 多后端切换
存档 = HTML + PNG + JSON 元数据,默认躺在 ./data 里。硬盘红了?上云!
本地磁盘(默认)
storage:
backend: local
path: /srv/sosse/data-
• 建议把
/srv/sosse挂到 独立 SSD,I/O 瓶颈立减 70%。
AWS S3
storage:
backend: s3
bucket: my-sosse-archive
region: ap-east-1
access_key: AKIA...
secret_key: wJalrXUtnFEMI/K7...-
• 记得给 IAM 用户只开
s3:PutObject和s3:GetObject,最小权限原则。
自建 MinIO(白嫖党首选)
docker run -d --name minio \
-p 9000:9000 -p 9001:9001 \
-e "MINIO_ROOT_USER=sosse" \
-e "MINIO_ROOT_PASSWORD=strongpass" \
minio/minio server /data --console-address ":9001"storage:
backend: s3
endpoint: http://localhost:9000
bucket: sosse
access_key: sosse
secret_key: strongpassMinIO 与 AWS S3 API 100% 兼容,内网跑 1 Gbps,上传速度 ≈ 110 MB/s。
高级搜索语法:通配符、时间范围、域名过滤
SOSSE 的搜索框支持 Lucene-like 语法,比某度良心 100 倍。
|
语法 |
示例 |
说明 |
*
通配符 |
micro* |
匹配 microservice、microscope … |
site: |
site:ieee.org deep learning |
只在 IEEE 域内搜 |
after:
/ |
after:2023-01-01 before:2023-12-31 |
时间切片 |
title: |
title:"attention is all you need" |
只在 |
exact: |
exact:"404 Not Found" |
精确短语,不拆词 |
组合示例:
site:medium.com after:2024-01-01 "rust async"
结果 0.03 秒返回,比 Google 还快,因为数据就在你硬盘。
自动化工作流:用 Cron 定时批量存档与增量更新
把“想起来才存档”升级为“躺着也在存档”。
1. 创建任务文件 jobs/rss-weekly.toml
name = "weekly-ai-papers"
source = "rss"
url = "https://export.arxiv.org/rss/cs.AI"
schedule = "0 9 * * 1" # 每周一 09:00
incremental = true # 只抓新条目
storage_path = "ai-papers-2024"2. 一行 Cron 搞定
# 编辑 crontab
crontab -e
# 追加
0 */6 * * * docker exec sosse python -m sosse.scheduler jobs/-
• 每 6 小时扫描
jobs/目录,增量更新不重复抓。 -
• 日志自动进
logs/scheduler.log,磁盘爆满前 3 天会邮件告警(需配置 SMTP)。
3. 一键生成差异报告
docker exec sosse python -m sosse.diff --domain=competitor.com \
--since=7days --format=html > /tmp/report.html打开
report.html,竞品改了哪个按钮、哪句 Slogan,红绿高亮一目了然。
小结:
调完爬虫规则,你的存档器就学会了“礼貌”;
接上 S3/MinIO,你的硬盘就学会了“无限”;
玩转搜索语法,你的大脑就学会了“瞬间回忆”;
加上 Cron,你的时间就变成了“复利”。
下一步?去实战,把互联网真正变成 你的形状。

实战案例:三种典型场景的落地技巧
把“能跑”变成“好用”,让 SOSSE 真正解决你的痛点。下面三套打法,直接抄作业即可。
学术研究:批量存档IEEE/ACM论文引用页
目标:把 300 篇论文的引用页一次性拖回本地,断网也能查参考文献。
|
步骤 |
命令/操作 |
备注 |
|
1. 准备清单 |
cat paper_urls.txt |
每行一个 URL,形如 |
|
2. 生成任务 |
bash<br>while read url; do<br> curl -X POST http://localhost:8080/api/archive \<br> -d "{\"url\":\"$url\",\"tags\":[\"ieee\",\"2024\"]}"<br>done < paper_urls.txt<br> |
利用 REST API 批量投递 |
|
3. 设置并发 |
在 |
避免被 ACM 反爬 |
|
4. 元数据补全 |
存档完成后执行: |
自建函数 |
|
5. 离线检索 |
在搜索框输入 |
毫秒级返回,还能高亮命中段落 |
彩蛋:把搜索结果导出为 .bib 文件,Zotero 一键导入,写论文再也不用手动敲引用。
内容运营:监控竞品官网改版并生成差异报告
目标:竞品首页每周偷偷改几个字?让它无处遁形。
- 1. 首次全量存档
curl -X POST http://localhost:8080/api/archive \ -d '{"url":"https://competitor.com","tags":["competitor","baseline"]}' - 2. 定时增量
在宿主机crontab -e加一行:0 9 * * 1 docker exec sosse python -m sosse.cli add-job https://competitor.com --tag weekly每周一 9 点自动跑一次。
- 3. 差异报告脚本(Python 示例)
from bs4 import BeautifulSoup, diff old = BeautifulSoup(open('baseline.html'), 'lxml') new = BeautifulSoup(open('weekly.html'), 'lxml') print(diff(old, new)) # 直接输出文本差异把脚本挂到 CI,邮件自动推送“本周竞品又改了哪些措辞”。
-
4. 可视化
用typora打开生成的 Markdown 差异,红色删除、绿色新增,一目了然。
个人知识库:把Medium长文变成离线可搜索笔记本
目标:飞机模式下也能全文搜索 500 篇 Medium 深度长文。
|
阶段 |
操作 |
小贴士 |
|
订阅源 |
在 |
Medium 官方 RSS 支持全文输出 |
|
自动入库 |
docker exec sosse python -m sosse.cli rss-import feeds.txt --tag medium |
每 30 分钟拉一次新文章 |
|
阅读体验 |
在 Web UI 打开文章 → 点击 “Reader Mode” |
自动过滤广告、弹窗,只剩正文 |
|
高亮批注 |
选中段落 → 快捷键 |
高亮内容会同步到全文索引,可搜 |
|
全文搜索 |
搜索框输入 |
支持通配符 |
进阶玩法:把高亮片段导出为 Markdown,直接丢进 Obsidian,形成双向链接的“第二大脑”。
小结:
• 学术狗用 SOSSE 做“离线文献库”;
• 运营喵拿它当“竞品监控雷达”;
• 知识控把它变成“私人 Pocket + 全文搜索”。
一套工具,三种姿势,数据永远在你硬盘里,安心!


欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐
 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)