51c大模型~合集157
首先,研究者从模型拒绝回答不安全输入的响应中,统计出一组高频出现的、具有明确拒绝语义的 token(如 “sorry”, “unable”, “unfortunately” 等),并利用 one-hot 编码的方式,在词汇空间中构造出一个 “拒绝语义向量” (RV),作为模型拒绝行为的表示。有趣的是,研究者发现,仅仅为一条文本攻击提示加上一张图片,就可能让模型的拒绝反应变得延迟,原本中层就能激活的
我自己的原文哦~ https://blog.51cto.com/whaosoft/14058598
#HiddenDetect
多模态大模型存在「内心预警」,无需训练,就能识别越狱攻击
多模态大模型崛起,安全问题紧随其后
近年来,大语言模型(LLMs)的突破式进展,催生了视觉语言大模型(LVLMs)的快速兴起,代表作如 GPT-4V、LLaVA 等。通过将图像与文本深度融合,LVLMs 在图文问答、视觉推理等任务中大放异彩。但与此同时,一个严峻的问题也悄然浮现 ——LVLMs 比起纯文本模型更容易被 “越狱”。攻击者仅需通过图像注入危险意图,即使搭配直白的指令,模型也往往难以拒绝。
为应对这一挑战,已有方法尝试用跨模态安全微调、系统提示词设计或外部判别模块来加固模型防线。然而,这些方法普遍存在训练成本高、泛化能力差、甚至误判正常输入的风险。
模型其实 “心里有数”:越狱时隐藏状态在报警
来自香港中文大学 MMLab 与淘天集团未来生活实验室的研究者提出了 HiddenDetect—— 种无需训练的越狱检测新方法。核心作者包括姜一雷,谭映水,高欣颜,岳翔宇。
他们的核心发现是:即使 LVLMs 表面上被越狱、生成了不当内容,其隐藏状态中依然保留着拒绝的信号。特别是在模型的中间层,这些信号往往比最终输出更早、更敏感地 “察觉” 到潜在风险。更有趣的是,文字输入和图像输入会激活完全不同的 “安全通路”,也就是说,LVLMs 对不同模态的 “危险感知” 机制是有区分的。
论文已被 ACL2025 main conference 收录。
项目开源 github 链接:https://github.com/leigest519/hiddendetect
arxiv 链接:https://arxiv.org/abs/2502.14744
从 “拒绝语义” 中解码多模态大模型的安全感知

图 1: 基于模型自身激活模式的多模态越狱检测方法。
首先,研究者从模型拒绝回答不安全输入的响应中,统计出一组高频出现的、具有明确拒绝语义的 token(如 “sorry”, “unable”, “unfortunately” 等),并利用 one-hot 编码的方式,在词汇空间中构造出一个 “拒绝语义向量” (RV),作为模型拒绝行为的表示。随后,研究者将模型各层的隐藏状态通过反嵌入层投影回词汇空间,并计算出其与 RV 的余弦相似度,以此衡量当前层所包含的拒绝语义强度。该过程会生成一个长度等于模型层数的向量 F,用于刻画模型在各层对拒绝语义的激活强度。

实验结果显示,F 在安全与不安全输入之间存在显著差异:对于安全样本,F 的整体数值普遍较低;而对于不安全输入,F 通常在中间层逐步升高至峰值,随后在最后几层出现明显回落。此外,无论输入是否安全,F 在最后一层的数值仍普遍高于倒数第二层,表明模型在最终输出前仍保留一定的拒绝倾向。
为进一步分析模型的安全响应机制,研究者构建了三个小样本输入集,分别用于衡量模型在不同类型输入下的拒绝激活表现。其中,安全输入集由无害样本组成,既包含纯文本输入,也包含图文组合输入;另两个不安全输入集则分别对应纯文本攻击样本和图文联合的攻击样本。

如图 2 所示,每组样本都计算出其对应的拒绝强度向量 F,并将不安全输入的 F 与安全输入的 F 相减,得到 “拒绝差异向量” (FDV),用于衡量模型在处理不安全输入时相较于安全输入所产生的激活差异。


图 2: 通过少样本分析方法,识别出模型中对安全最敏感的关键层。
模态不同,响应路径也不同
如图 3 所示,两种模态的 FDV 曲线均表明模型在部分中间层对拒绝信号的响应强度显著高于输出层,说明这些中间层对安全性更加敏感。具体而言,文本输入的拒绝激活差异在较早的层级便迅速增强,而图文输入的响应整体偏后,且强度相对较弱,说明视觉模态的引入在一定程度上削弱了模型拒答机制的早期响应能力。

图 3:纯文本样本和跨模态样本的 FDV 曲线。
实验还发现如果模型对拒绝信号的强激活集中在更靠后的层,或者整体激活强度变弱,越狱攻击就更容易成功。有趣的是,研究者发现,仅仅为一条文本攻击提示加上一张图片,就可能让模型的拒绝反应变得延迟,原本中层就能激活的拒绝信号被 “推迟” 到了后层,整体响应强度也降低,从而削弱了模型的安全防护能力。
最终,该小样本分析方法通过 FDV 值成功定位了模型中对不同模态输入安全性最敏感的层。研究者将模型最后一层的差异值作为参考基线,因其对部分不安全输入缺乏足够辨别力;而那些 FDV 显著高于末层的中间层,通常具备更强的安全判别能力。

进一步地,只需累积在这些关键层上的拒绝激活强度,便可有效识别潜在的不安全样本,从而构建出一个高效、无需训练、具备良好泛化能力的越狱检测机制。

实验结果
研究团队在多个主流 LVLM(包括 LLaVA、CogVLM 和 Qwen-VL)上系统评估了所提出的检测方法,涵盖纯文本越狱(如 FigTxt)和跨模态图文攻击(如 FigImg 和 MM-SafetyBench)等多种攻击类型。此外,研究者还在 XSTest 数据集上测试了方法的稳健性。该数据集包含一些安全但易被误判的边界样本,常用于评估检测方法是否过度敏感。实验结果表明,该方法在保持高检测效果的同时,具备良好的鲁棒性和泛化能力。

可视化

图 4:每一层隐藏状态中最后一个 token 的 logits 被投影到由拒绝向量(RV)及其正交方向构成的语义平面。
结论与展望
安全是大模型走向真实世界应用过程中必须优先考虑的问题。HiddenDetect 提出了一种无需训练、基于激活信号的检测方法,为提升多模态模型的安全性提供了新的思路。该方法结构轻量、部署灵活,已在多个模型与攻击类型中展现出良好效果。尽管如此,该方法目前仍主要聚焦于风险提示,尚未对模型行为产生直接调控。未来,研究团队希望进一步拓展方法能力,并深入探索模态信息与模型安全性的内在关联,推动多模态大模型朝着更可靠、更可控的方向发展。
作者团队来自淘天集团算法技术 - 未来实验室团队和香港中文大学 MMLab。未来生活实验室致力于建设面向未来的生活和消费方式,进一步提升用户体验和商家经营效果。实验室聚焦大模型、多模态等 AI 技术方向,致力于打造大模型相关基础算法、模型能力和各类 AINative 应用,引领 AI 在生活消费领域的技术创新。
....
#Mistral
Mistral再开源!发布代码模型Devstral 2及原生CLI,但大公司被限制商用
刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。
该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。
此外,Mistral AI 还发布了自家的原生 CLI:Mistral Vibe。

Mistral AI 的进击速度令人咋舌。仅仅一周前,他们才发布 Mistral 3 系列模型,被视为欧洲正式以此跻身 AI 前沿竞争的序幕。仅仅过了 7 天,Devstral 2 系列与 Mistral Vibe 便紧随其后问世,这种高频的发布节奏,似乎正在印证人们对欧洲 AI 崛起的判断。

考虑到 Mistral 近期在欧洲的大幅扩张,以及图灵奖得主 Yann LeCun 回到欧洲创业的消息,欧洲大陆这片 AI 热土的未来风景,或许值得我们投入更多期待。
亮点汇总
下面是 Mistral 官方总结的核心亮点:
- Devstral 2: 针对代码智能体(Agent)的 SOTA 开放模型,参数量仅为竞争对手的一小部分,并在 SWE-bench Verified 上达到了 72.2% 的高分。在实际任务中,其成本效率比 Claude Sonnet 高出达 7 倍。
- Mistral Vibe CLI: 一款原生、开源的终端智能体,可自主解决软件工程任务。
- Devstral Small 2: 24B 参数模型,可通过 API 使用,也可在消费级硬件上本地部署。
- 兼容本地(On-prem)部署和自定义微调。
下面来具体看看 Mistral AI 今天新发布的模型和工具。
Devstral:下一代 SOTA 编程模型
模型地址:https://huggingface.co/collections/mistralai/devstral-2
Devstral 2 是一个 123B 参数的密集 Transformer 模型,支持 256K 上下文窗口。它在 SWE-bench Verified 上取得了 72.2% 的成绩,「确立了其作为最佳开放权重模型之一的地位,同时保持了极高的成本效益。」
体量更轻的 Devstral Small 2 在 SWE-bench Verified 上得分为 68.0%,能与大其五倍的模型比肩,同时还具备在消费级硬件上本地运行的独特优势。

Mistral 官方指出:「Devstral 2(123B)和 Devstral Small 2(24B)分别比 DeepSeek V3.2 小 5 倍和 28 倍,比 Kimi K2 小 8 倍和 41 倍。这证明了紧凑型模型可以匹敌甚至超越更大型竞争对手的性能。」

专为生产级工作流打造
Devstral 2 支持探索代码库并在多个文件中编排变更,同时保持架构级的上下文理解。它能追踪框架依赖关系、检测故障并尝试修正重试 —— 从而解决错误修复和遗留系统现代化等挑战。
此外,该模型支持微调,允许企业针对特定编程语言或大型企业代码库进行深度优化。
Mistral 通过独立标注提供商的人工评估,对比了 Devstral 2 与 DeepSeek V3.2 和 Claude Sonnet 4.5,任务通过 Cline 进行脚手架式编排。
根据发布的结果,Devstral 2 相对于 DeepSeek V3.2 有明显优势,胜率为 42.8%,败率为 28.6%。然而,Claude Sonnet 4.5 仍然更受青睐,表明其与闭源模型之间仍存在差距。

许可证
值得注意的是,Devstral 2 采用的许可证是一种修改版 MIT 许可证。

对比标准的 MIT 许可证,可以看到一个重大差异:新增的「收入限制条款」。
标准版 MIT 极度宽松。只要你保留版权声明,你可以将代码用于任何目的,包括商业用途、修改、分发、闭源发布,没有任何收入或公司规模的限制。
Mistral 许可证则在第 2 条中增加了一个巨大的限制条件(毒丸条款):
You are not authorized to exercise any rights under this license if the global consolidated monthly revenue of your company... exceeds $20 million... for the preceding month.
即如果你的公司全球合并月收入超过 2000 万美元,你将无权行使本许可证下的任何权利。也就是说,超过收入门槛的公司必须联系 Mistral AI 购买商业授权,或者使用他们的付费 API 服务。
并且这一限制不仅适用于原模型,还明确延伸到了「derivatives, modifications, or combined works」(衍生品、修改版或结合作品)。这意味着如果你基于这个模型微调了一个新模型,大公司依然不能免费使用你的微调版。
Mistral Vibe CLI
Mistral Vibe CLI 是一款由 Devstral 驱动的开源命令行编码助手。

开源地址:https://github.com/mistralai/mistral-vibe
它能让用户在终端中使用自然语言,或通过智能体通信协议(Agent Communication Protocol)集成到用户的 IDE 中,来探索、修改和执行整个代码库的变更。它依据 Apache 2.0 许可证发布。
Vibe CLI 提供了一个交互式聊天界面,包含文件操作、代码搜索、版本控制和命令执行等工具。主要功能包括:
- 项目感知上下文: 自动扫描用户的文件结构和 Git 状态以提供相关上下文。
- 智能引用: 使用 @ 自动补全引用文件,使用!执行 Shell 命令,并使用斜杠命令进行配置更改。
- 多文件编排: 理解用户的整个代码库(不仅仅是正被编辑的文件),从而实现架构级推理,这可以将 PR 周期时间缩短一半。
- 持久化历史、自动补全和可自定义主题。
,时长00:50
开发者可以通过编程方式运行 Vibe CLI 以进行脚本编写,切换工具执行的自动批准功能,通过简单的 config.toml 配置本地模型和提供商,并控制工具权限以匹配自己的工作流。
开始使用
Mistral 目前正通过其 API 免费提供 Devstral 2。
免费期结束后,API 定价为:Devstral 2 每百万 token $0.40/$2.00(输入/输出);Devstral Small 2 为 $0.10/$0.30。
他们还宣布已与智能体工具 Kilo Code 和 Cline 合作,将 Devstral 2 带入用户现有的开发环境中。
Mistral Vibe CLI 也已作为 Zed 的扩展程序提供,因此用户可以直接在 IDE 内部使用它。
Devstral 推荐部署配置
Mistral 表示,Devstral 2 针对数据中心 GPU 进行了优化,部署至少需要 4 个 H100 级别的 GPU。用户今天就可以在 build.nvidia.com 上试用。
Devstral Small 2 专为单 GPU 运行而构建,可在广泛的 NVIDIA 系统上运行,包括 DGX Spark 和 GeForce RTX。NVIDIA NIM 支持即将推出。
Devstral Small 也可以在消费级 GPU 以及无需独立 GPU 的纯 CPU 配置上运行。
为了获得最佳性能,Mistral 官方建议将温度设置为 0.2,并遵循 Mistral Vibe CLI 定义的最佳实践:https://github.com/mistralai/mistral-vibe/blob/main/vibe/core/system_prompt.py
....
#AutoGLM
一手实测 | 智谱AutoGLM重磅开源: AI手机的「安卓时刻」正式到来
「安静!吵到我用 TNT 了!」
长期关注科技圈的朋友们都知道,罗永浩的锤子科技落幕已经七年。七年间,仍有无数锤科粉丝保留着旧手机备用,怀念手机圈当年的「锐利异类」,以至于锤子手机仍然有百万日活用户。
而锤子科技,罗永浩最大的愿景和遗憾,莫过于号称「重新定义下个十年的个人电脑」,以及闹出了科技圈永生梗「理解万岁」的 TNT。
给不熟悉的读者朋友们简单介绍下:TNT 全称 Touch&Talk,通过触控 + 语音的方式操作设备。
在那个 AI 尚显稚嫩的年代,这被视为一种激进的赌博;但在大模型爆发的今天,我们惊讶地发现:最高效的手机操作方式,恰恰就是 TNT 构想的那样:按住屏幕把需求说出来,设备自动完成一切。
近些天,豆包手机(豆包手机助手技术预览版)爆火,让能够操作手机的 AI Agent 走入了大众视野。Agent 借助大模型和自动操作系统的设计,让用户凭借自然语言和语音输入,就能自然实现通用的、跨任务的复杂操作。
也因此,人们在震惊于现今大模型 GUI Agent 能力强大之余,也不禁担心个人数据上云的隐私权限问题,几大国民级 App 也都限制了豆包手机助手的访问,再加上搭载豆包的手机一机难求……
除了被大厂生态裹挟,我们有没有另一种选择?有没有一个既能一句话搞定繁杂任务,又能将隐私握在自己手里,甚至人人都能 DIY 的 GUI Agent?
有的兄弟,有的,而且是来自深耕智能体的智谱的明星项目:AutoGLM。
就在前天,AutoGLM 正式全面开源!
豆包手机之所以遭到所有大厂围剿,因为 AI 手机很可能是下一个时代的流量入口。智谱这波开源直接把能力交给了所有人手上,一己之力把 AI 原生手机的门槛给打平了。
为开源精神点赞!
具体来说,Open-AutoGLM 由一个手机端智能助手框架 Phone Agent 和一个 9B 大小的模型 AutoGLM-Phone-9B 共同组成。

开源地址:https://github.com/zai-org/Open-AutoGLM
从第一个 AI 发出的红包说起
这次开源对行业的影响力,核心来自这次智谱开源的不是一个普通的 GUI agent 模型,而可能是行业最好的模型。
智谱是第一个开始可操作智能体研究的厂商。
时间回到 32 个月前的 2023 年 4 月,智谱就已经开始从零探索 AutoGLM,目标是打造一个不仅能「说」,还能「做」的智能体模型。
2024 年 10 月,AutoGLM 面世爆火,被业界公认为是全球第一个可以真正操控手机的 Agent,迄今也是全球完成度最高的 GUI Phone Use 模型。不是模拟,不是脚本,而是像人一样去「看屏幕」,去分析 UI 布局,然后模拟手指进行点击与滑动。AutoGLM 这个 Phone Use 能力的诞生,是「AI 会用工具」的关键里程碑。
一个月后,它做了一件前所未有的事情:AutoGLM 完成了人类历史上第一个由 AI 全自动发出的红包。

这个红包意味着大模型「从 Chat 到 Act」的范式转变,语言不再停留在语言本身,而能驱动行动、执行任务。
但我们很快意识到:会动手的 AI,就像刚拿到第一部智能手机的小孩 —— 强大,但也危险。如果它在不该点的地方乱点怎么办?如果某个用户的真实手机被误触隐私应用怎么办?
于是到了 2025 年 8 月,智谱做了一个关键决定:先把 AutoGLM 放进云端的「虚拟手机」里。
AutoGLM 2.0 云机版,把 AI 的行动舞台与用户真实手机完全隔离。它看到的屏幕、能执行的点击,都发生在一台安全的虚拟设备上。涉及隐私的 App,比如微信,则选择不开放 —— 不是做不到,而是智谱希望它「先学会规则,再学本事」。
Phone Agent 的实现,依赖于 AutoGLM 的视觉-语言模型。通过理解手机屏幕内容、解析 UI 状态,结合智能规划能力,它能自主完成整套操作流程。
这背后的实现说简单也简单,说复杂也复杂。它由三大核心技术组成:
1. ADB(Android Debug Bridge):手机的「控制器」
AutoGLM 接入安卓系统的 ADB 开发者调试,负责把控制信号送到设备上,实现基本的点按滑动等操作。
2. 视觉-语言模型(VLM):AI 的「眼睛 + 大脑」
它能理解手机屏幕上的文本、按钮、图标,识别,操作和实时反馈。
3. 智能规划:任务拆解的「策划师」
它能将自然语言任务拆解为可执行步骤,你说一句「发红包给小李」,AI 会自动补全背后的十几步操作链:打开 App、找到联系人、选择金额、确认支付……
AutoGLM 把这三项能力打包成一个完整执行框架,「AI 会用手机」的概念已经在诸多测试中保证了稳定和实用。
一手实测
Open-AutoGLM 究竟有多强?
理论说得再多,不如实战。下面我们就来看看开源版的 AutoGLM 表现究竟如何。
首先,来一个简单任务:发微信。发送以下指令:
给 wupan 发个微信,就说 Panda 的生日快到了,准备个蛋糕,多点水果。
,时长00:13
可以看到,系统启动后,Open-AutoGLM 首先进行了一波「自检」,确认 API 和系统权限无误。在这里,我们可以看到智谱给 Phone Agent 的描述:「AI-powered phone automation」,即「AI 赋能的手机自动化」。
接下来,AutoGLM 会回到任务本身。思考为了完成这个任务,第一步应该执行什么。在终端界面,我们能清晰地看到它的思维链(CoT):
- 观察:当前在桌面。
- 思考:任务是发微信,第一步需要找到并打开微信。
- 行动:点击微信图标。
- 观察:进入微信列表页。
- 思考:需要找到 wupan,点击搜索框……
如此迭代进行,直到完成任务。整个过程行云流水,最后它还会像模像样地汇报:「任务已完成」。
而在以上任务执行的同时,我们的手机端则经历了以下过程。很显然,AutoGLM 非常出色地完成了这个初始任务。
,时长00:11
下面,为了更好地展示,我们将使用 scrcpy 将手机投屏到 PC 上,将前后端情况一并录制。此外,为了方便,我们将上面略显繁琐的命令定义为一个 Function,并把它放进 PowerShell 配置文件 (Profile) 里。下面我们只需简单地输出「run "提示词"」即可向 AutoGLM 发送指令。(当然,你也可以 Vibe Code 一个更好看或直观的交互 UI。)
接下来试试 AutoGLM 与小红书的交互。
run "打开小红书,看看有什么有趣的疯狂动物城周边"
,时长00:15
同样,执行非常顺畅,并且在执行过程中,我们还看到 AutoGLM 能够正确地识别和处理弹窗提醒。更让人惊喜的是它的总结能力。它没有机械地罗列标题,而是像个真正的浏览者一样,理解了屏幕上的内容。在最终的反馈中,它汇总了前四个结果:发圈、毛绒公仔、圆珠笔、泡泡玛特盲盒。这说明它不仅「看」到了像素,还「懂」了商品。
AutoGLM 还可以根据用户指令执行连续多步操作,比如你可以让它「先打开维基百科找到五月天的第一张专辑是什么,然后打开 QQ 音乐播放它」:
,时长00:31
我们还能让 AutoGLM 帮助完成一些重复性的繁琐任务,比如应用宝软件更新。当你有一大堆软件需要更新时,加上不时的弹窗,这会变成一个几乎让人有些火大的过程。而如果你有 AutoGLM 这样的 AI 助手,也就是一句话的事儿。
run "打开应用宝,把我的软件更新一下"
,时长00:55
哇哦!真省心。简直是「懒人福音」。面对一大堆待更新的 App 和时不时的弹窗,AutoGLM 耐心地一个个点击。
有趣的是,在更新过程中,AutoGLM 还遭遇了一次「误触」。根据对话记录可以看出,当时弹出了请求更新哔哩哔哩的许可申请,而此时百度地图又刚刚更新完成,于是 AutoGLM 本来打算点击的「更新」变成了「打开」,它也因此意外打开了百度地图。
如果是传统的自动化脚本,这时候已经卡死报错了。但 AutoGLM 展现出了惊人的临场反应:
- 感知错误:它发现屏幕画面变成了地图,而不是应用宝。
- 自我修正:它没有由于结果超出预期而自乱阵脚,而是分析当前状况,执行了「返回/退出」操作。
- 回到正轨:重新回到应用宝界面,继续未完成的更新任务。
这种稳健性才是 Agent 走向实用的关键。
实测过程中,我们发现 AutoGLM 的执行逻辑是通过分析屏幕截图来确定下一步。也因此,AutoGLM 具有非常高的通用性和普适性,并不局限于智谱官方推荐的应用。事实上,只要它能理解手机屏幕截图,便能够执行一步步地完成任务。
举个例子,我们甚至能让 AutoGLM 调用其它 AI 助手来帮助完成更加复杂的任务。
run "打开 Gemini,让它搜索并整理一下智谱的发展历史,最后出具一份深度报告"
,时长00:35
结果堪称完美!Open-AutoGLM 成功打开了 Gemini ,将我们的自然语言指令输入进去,等待 Gemini 生成长文报告,最后将报告内容提取回来。
这一刻,手机里的 App 不再是孤岛。AutoGLM 像是一层「超级胶水」,将本地应用、云端大模型无缝粘合在了一起。这或许就是未来「超级 App」的雏形 ——App 本身不再重要,服务才是核心。
全面开源
人手一个 AI 手机
智谱选择了和封闭生态完全不同的方向。
Open-AutoGLM 的全面开源,意味着开发者、研究者与个人爱好者,都可以沿用 AutoGLM 的执行框架,在自己的产品中复现或延展这个「能动手的 AI」。
此次开源显得诚意十足:
- 核心模型与推理代码:毫无保留。
- 工具链:完整的 Phone-Use 框架。
- 开箱即用:支持 50 多款常用中文 App 的 Demo。
- 协议友好:模型采用 MIT 协议,代码采用 Apache-2.0 协议。
- 完善的文档和快速上手指南。
无需担忧的隐私问题
开源彻底改变了隐私的博弈关系。当模型、框架、适配层全部公开后,我们能做的最重要一件事,就是把 AI 完整地搬回到用户的本地设备上运行。
数据无需上云,所有操作记录、App 使用习惯甚至输入内容都能在本机完成处理 —— 没有上传,自然也就没有泄露风险。同时,代码完全透明,任何人都可以验证它是否联网、是否收集数据、是否写入日志,比任何口头承诺都更可靠。
在 AI 手机的概念被炒得火热的今天,我们需要的不是又一个窃取数据的云端黑盒,而是一个透明、可控、私有的智能管家。
行业平等的模型底座
在不远的未来,AI 助手最终会普及到每个用户。而没有人希望,这个能够帮助人们操作手机的助手,一个能够掌控各大应用的入口,是某一个平台独占的资源。豆包手机助手目前被各大 App 限制的现状,已经给出了信号。
这是一次新的人机交互革命,AutoGLM 开源,把 AI 助手的能力彻底开放,变成全行业的公共底座。
Open-AutoGLM 的出现,或许就是 AI Agent 领域的「安卓时刻」:它为那个罗永浩曾梦想过的、动动嘴就能搞定一切的 TNT 时代,铺下了第一块坚实的开源基石。
正如智谱所言:「把我们已经走过的路,变成接下来 Agent 爆发时代大家的起跑线。」
未来已来,而且这次,它听你的。
....
#Poster Copilot
南大联合LibLib.ai、中科院自动化所,共同提出布局推理与精准编辑「海报设计大模型」PosterCopilot
来自南京大学 PRLab 的魏佳哲、李垦,在准聘助理教授司晨阳的指导下,提出专业级海报设计与编辑大模型 PosterCopilot。本研究联合了 LibLib.ai、中国科学院自动化研究所等多家顶尖机构,共同完成了首个解耦布局推理与多轮可控编辑的图形设计框架研发。PosterCopilot 能够实现专业设计级的版式生成、语义一致的多轮编辑,并具备高度可控的创作能力。
,时长00:57
此外,受华为-南京大学鲲鹏昇腾科教创新孵化中心支持,该模型已完成对国产昇腾算力平台的适配与部署,进一步推动了国产 AI 设计技术的发展与落地。
- 论文标题: Poster Copilot: Toward Layout Reasoning and Controllable Editing for Professional Graphic Design
- 论文地址:https://arxiv.org/abs/2512.04082
- 项目主页:https://postercopilot.github.io/
行业痛点:
从生成式失控到多模态「盲推」
平面设计是视觉传达的基石,但要实现真正的自动化专业设计,目前仍面临巨大挑战。尽管以 Stable Diffusion 为代表的文生图(T2I)模型在图像合成上表现强劲,但在实际的工业设计流中,它们因无法处理分层结构,往往导致用户素材失真且无法进行精细化控制。
为了解决这一问题,业界开始尝试利用多模态大模型(LMMs)进行布局规划,然而研究团队发现,现有的 LMMs 方案反而暴露出了四大致命短板:
- 几何布局的「先天缺陷」: 现有的多模态布局模型通常将连续的空间坐标量化为离散的文本 Token。这种将数值视为文本的处理方式,从根本上破坏了欧几里得空间的几何连续性,导致模型难以理解真实的物理距离与空间关系,生成的布局频频出现对齐错误与比例失调。
- 视觉反馈的「盲区」: 这是现有模型最严重的缺失之一。目前的布局模型在训练过程中仅进行纯粹的坐标回归,却从未「看」到过布局渲染后的实际图像。由于缺乏对渲染结果的视觉反馈(Visual Feedback),模型无法像人类设计师一样基于审美直觉和视觉规律来审视并优化构图,只能处于「盲人摸象」的状态。
- 单一真值的「回归陷阱」: 海报设计属于高度主观的创意领域,符合人类审美的布局方案往往是多样的、非唯一的。然而,传统的监督训练强迫模型死板地向单一的 Ground Truth 回归。这种刻板的训练方式不仅导致生成的布局丧失多样性,更扼杀了模型的探索潜力,使其错失了涌现超越训练数据、比原始真值更具美学表现力的创新设计的机会。
- 图层级编辑的「断层」: 专业设计师的工作流本质上是迭代的(Iterative),需要对特定图层进行反复微调。而目前的端到端模型往往是「一锤子买卖」,面对「只改一个图层」的需求时往往束手无策——要么无法支持,要么「牵一发而动全身」,在修改时破坏了用户原有的素材或非编辑区域。
在 PosterCopilot 的对比测试中,这些弱点暴露无遗:

现有模型在处理复杂多素材场景时,常出现严重的元素重叠、文字遮挡以及美学灾难。这反映了现有模型在细粒度布局推理和美学对齐上的根本不足。
同时,如图所示:

基于完全相同的元素可以有众多符合人类审美的布局方案,按照单一真值进行回归的训练方式容易扼杀模型的创造力。
核心成果:
构建专业级设计的「智能工作流」
为填补现有单步生成与专业工作流之间的鸿沟,研究团队提出了一套系统性的解决方案 PosterCopilot,并通过渐进式三阶段训练策略赋予模型设计推理能力。
独创三阶段训练:从几何纠偏到美学对齐
这是首个将布局生成任务从简单的回归问题转化为分布学习与强化学习结合的范式。
- 阶段一:扰动监督微调(PSFT): 针对 Token 坐标导致的几何空间扭曲问题,团队提出引入高斯噪声扰动,迫使模型学习坐标的分布而非死记硬背离散点,修复了优化空间的几何结构。
- 阶段二:视觉-现实对齐强化学习(RL-VRA): 引入基于 DIoU 和元素保真的验证性奖励信号,专门修正「幻觉」导致的重叠和比例失调。
- 阶段三:美学反馈强化学习(RLAF): 利用美学奖励模型进行偏好对齐,鼓励模型探索超出 Ground Truth 但更具视觉冲击力的布局方案。

生成式智能体(Generative Agent):打通迭代编辑闭环
PosterCopilot 不仅仅是一个布局生成器,更是一个全能设计助手。团队设计了一个包含「接待模型」和「T2I 模型」的智能体,支持从灵感到素材的无缝转化:用户仅需输入抽象的设计构思,内置的接待模型(Reception Model)即可充当「创意策划」,自动将用户意图拆解为前景主体与背景氛围的详细规划。
随后,模型会生成精准的工程级提示词(Prompts),驱动 T2I 模型即时生成风格契合的高质量素材,实现从「抽象灵感」到「具体物料」的自动化落地。
通过将具备精密布局推理能力的设计模型与支持多轮交互的生成式智能体(Generative Agent)深度耦合,团队构建了 PosterCopilot 的完整框架,其从素材规划到最终成稿的推理流水线如下所示:

全能设计助手 PosterCopilot:覆盖专业设计的全链路需求
基于 Generative Agent 的强大赋能,PosterCopilot 能够完美胜任从「从零构建」到「后期精修」的多种专业场景:
- 全素材海报生成(Generation from Fully-provided Assets): 当用户提供完整素材时,模型专注于「布局推理」,能够将多模态元素在画布上进行符合美学规律的精准排列,同时严格保障用户原有素材零失真、无篡改。

- 缺素材智能补全(Generation from Insufficient Assets): 针对素材缺失的冷启动场景,智能体能够理解设计意图,自动生成风格统一的背景或前景装饰层,实现从「抽象想法」到「完整海报」的无缝落地。

- 多轮精细化编辑(Multi-round Fine-grained Edit): 打破了传统模型「无法精准局部修改」的魔咒,支持多种专业级操作:
- 精准单层编辑: 支持仅修改特定图层(如更换模特发色、改变物体材质),同时完美「冻结」其他非编辑区域。在「相机广告」案例中,模型能够仅修改相机镜头的特效(如岩浆、大理石、水晶),而背景文字和排版纹丝不动。

- 全局主题迁移: 能够将海报从「棒棒糖促销」无缝切换为「冰淇淋推广」,自动替换主体并调整相关元素,且保留原有排版骨架。

- 智能尺寸重构(Poster Reframe): 只需更改画布尺寸参数,模型即可根据新的长宽比,智能重新推理布局,实现一键适配不同媒体版面。

PosterCopilot 数据集:高质量分层海报库
为解决数据匮乏问题,团队构建了包含 16 万张专业海报、总计 260 万个图层的高质量数据集。通过 OCR 辅助的细粒度图层融合技术,解决了传统数据集中图层过度碎片化(Over-segmentation)的难题,为社区提供了宝贵的数据资源。


实验结果:
全面超越商业竞品与 SOTA 模型
PosterCopilot 以 Qwen-2.5-VL-7B-Instruct 为 backbone,在多项指标上实现了对现有顶尖模型的超越。
在涵盖布局合理性、文本可读性、素材保真度等六大维度的评测中,PosterCopilot 展现了统治级表现。
- 综合胜率: 在人工评测中,PosterCopilot 对比微软 Microsoft Designer、Nano-Banana 以及学术界 SOTA(如 CreatiPoster、LaDeCo),平均胜率超过 74%。

- GPT-5 评测: 在 GPT-5 的打分中,PosterCopilot 在布局合理性(Layout Rationality)和风格一致性(Style Consistency)上均大幅领先 Qwen-VL-2.5-72B 和 Gemini 2.5 Pro。

结论与展望
对于平面设计这样兼具严谨几何约束与感性美学追求的领域,简单的端到端生成并非最优解。
PosterCopilot 通过解耦「布局推理」与「生成式编辑」,并引入强化学习对齐人类美学,成功让大模型掌握了专业设计师的「图层思维」。这不仅为智能设计工具树立了新的基准,也为未来 AI 辅助创意工作流提供了新的范式。
....
#「豆包手机」为何能靠超级Agent火遍全网
我们听听AI学者们怎么说
手机上的 AI,从来没有这么像真人。
最近一个星期,席卷科技圈的一款手机不来自任何一家硬件大厂,而是与字节的豆包联系在了一起。
这款搭载豆包手机助手的工程机引爆了全网,让很多人第一次真切地感受到 Agent 已经触手可及。在某宝平台上,这款手机的价格被炒到了近五千元。

本月初发布的豆包手机助手,目前还是技术预览版。与大多数作为独立 App 存在的 AI 助手都不一样的是,它通过把 AI Agent 嵌入系统底层的方式,让手机实现了端侧 AI 能力的全面突破,带来了全新的交互方式和多模态体验。在不少科技从业者看来,豆包手机助手已经把 AI 工具的认知推向了新的高度,它不再只是一个辅助工具或外置 App,而是与手机操作系统深度绑定的「超级管家」。
毕竟,只需要一句话,豆包手机助手可以真正地实现跨 App 的复杂指令执行。除了其他手机上 Agent 常见的订餐、记账、修改设置等能力之外,豆包手机助手能够攻克相对模糊且复杂的长链条需求。
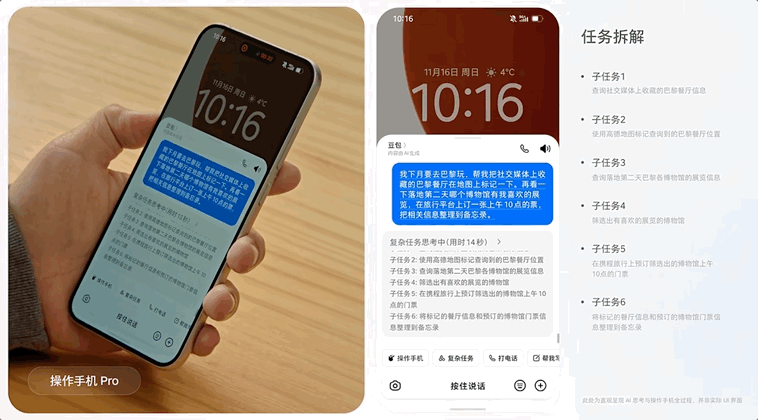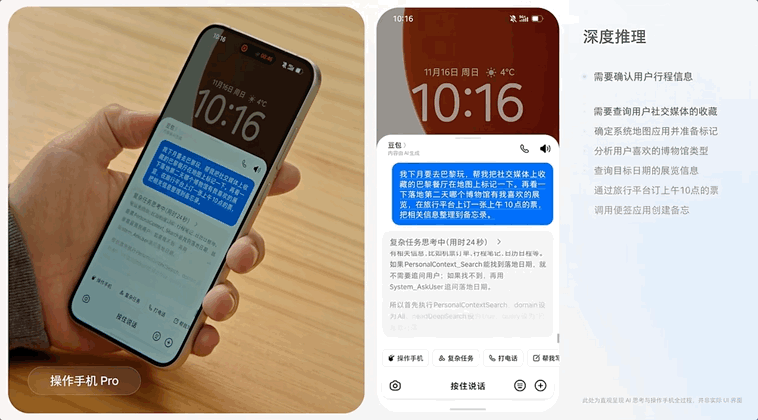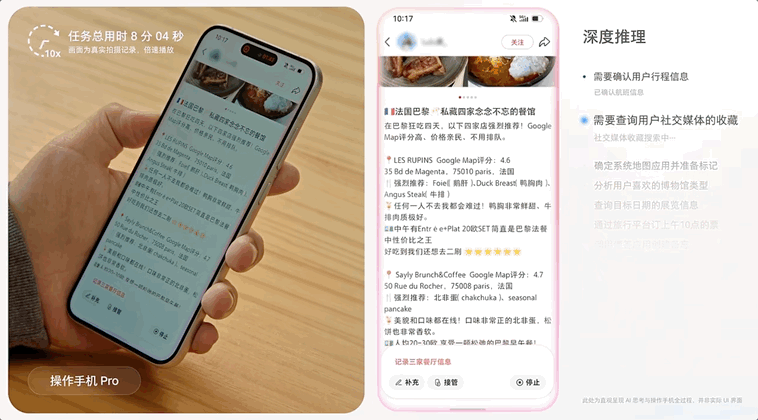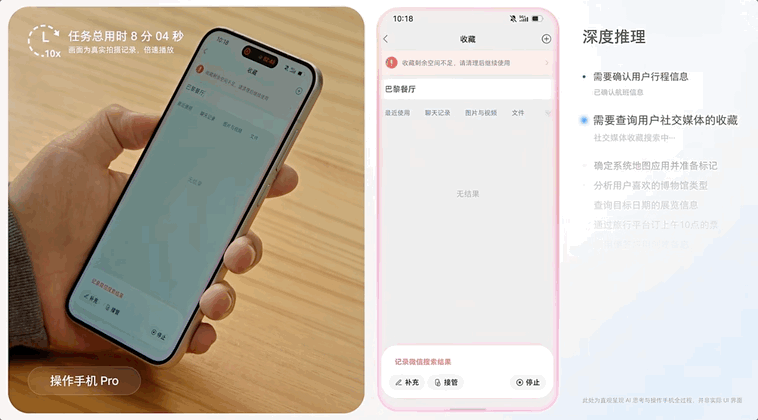
豆包手机助手全程无中断地完成「地图上标记餐厅、查找博物馆以及旅行平台订票」的多需求、长链路任务。
这样的表现让人直呼:「是不是有点过于智能化了」。
与此同时,围绕豆包手机助手持续升温的讨论也引出了一些不同观点与追问:「AI 操作手机」真的是未来人们用手机的常态吗?要打造这样一台 AI 手机,豆包手机助手做对了什么?
在深入了解豆包手机助手背后的技术底座,并与四位学界专家进行一番交流之后,我们对它如何重构交互范式、推动系统级 GUI Agent 实现有了更加立体、清晰的认知。
给手机装系统级 Agent,为什么这么难?
这两年,无论是一些新兴的 AI 硬件初创公司,还是国内外主流手机厂商呈现出一个明显的趋势:探索将原生 AI 能力更深度地融合进设备系统中,最重要的形态之一便是引入 AI Agent。
其中,作为一种由多模态视觉模型驱动的 AI 系统,GUI Agent 在遵循以自然语言提出的指令下,能够理解屏幕内容、进行自主推理,并在 UI 上执行与人类操作类似的交互,如读取信息、点击按钮、输入内容等,从而完成特定任务。
随着 GUI Agent 能力在端侧持续增强,以更高集成度、更深层系统权限为特征的系统级 GUI Agent 逐渐成为下一阶段的核心目标,这要求不仅高效执行任务,还要理解上下文、协调多 App 流转等。
但这样的系统级实现并不容易。从学术与工程落地视角来看,大致需要克服以下四个层面的障碍:
一是感知层:Agent 需要在毫秒级内识别出屏幕上所有的交互元素,比如图标、按钮和文本框。此外还需要具备抗动态干扰能力,这是因为 App 界面复杂,弹窗广告、浮层、动态加载内容会产生视觉噪声。GUI Agent 要具备「像素级」的精准定位能力,同时理解图标背后的「功能语义」。
二是规划层:主要涉及跨 App 的信息流转,包括 App 切换、上下文记忆提取、剪贴板操作等多个步骤;执行过程中也可能会遇到网络卡顿、登录失效、意外弹窗等突发情况,传统的脚本(workflow)一旦断裂可能无法继续。GUI Agent 要维持跨多 App 的逻辑连贯性,并具备自我反思能力,比如发现路径不通而换一种方式。
三是决策层:GUI Agent 必须具备强泛化能力,不能只在见过的界面上工作,还要能够在未见过的同类 App 中执行相似操作。同时,手机操作除了点击之外,还包括长按、滑动和缩放等其他细粒度操作,对 Agent 的反馈回路提出了更高要求,也意味着决策过程必须更加及时与精准。
四是系统层:首先是响应速度,用户无法忍受长时间的思考;其次是权限壁垒,在 Android 等严格的沙盒机制下,无法轻易获取其他 App 的屏幕信息或进行操作。GUI Agent 要在保证数据隐私安全和低延迟的前提下,打破操作系统内部的数据孤岛。
四个层面的障碍共同构成系统级 GUI Agent 落地过程中最核心的挑战。其中在谈到系统级跨 App 操作面临的难题时,蒙特利尔大学与 MILA 实验室副教授刘邦提到了感知层的界面理解与元素定位问题,以及规划层的长链路任务规划与状态管理。真实用户任务往往需几十步、跨多个 App,还可能出现弹窗、网络延迟、权限请求、验证码、异步加载等状况。Agent 必须记住之前做了什么、当前状态如何、接下来可能发生什么,还要能应对失败或异常。
西湖大学通用人工智能(AGI)实验室负责人、助理教授张驰点出了上下文记忆和推理速度这两项对 GUI Agent 产品化至关重要的能力。上海交通大学计算机学院教授、博士生导师张伟楠博士认为当前的 AI 大厂往往通过一个或几个 App 发力,无法获得最大的数据访问与操控权限,因此无法对齐用户上下文,也无法做到用户可以完成的操作。
浙江大学百人计划研究员、博士生导师沈永亮总结了几个难点,包括长链路规划、推理速度以及轻量级模型如何管理短期与长期记忆,这些也是当前学术界普遍关注的核心瓶颈。
对于这样一项贯穿 AI 技术、终端硬件、操作系统和生态协同的全链路重构工程,任何一个环节的不成熟,都可能影响 Agent 走向真正的产品化。近两年学界和业界开始发力 Agent 载体的能力释放,包括通用 GUI Agent 研究工作 AppAgent、Mobile-Agent、UI-TARS 等,以及依赖视觉识别与无障碍控制的 Rabbit 式通用 Agent 和手机厂商在 OS 层构建的系统级 Agent。
通过这些尝试,AI 开始能够像人类一样操控手机屏幕并完成一些特定的任务,但依然存在着不少问题,比如不同 App 的权限开放、长链路复杂任务成功率低、等待时间长、缺乏处理 UI 突发情况的能力,这些都限制了系统级 GUI Agent 的稳定性和实用性。
豆包手机助手取长补短,采取了「GUI Agent + 系统级权限」的路径。一方面,在手机上通过深度系统集成获得了 Android 系统级权限,同时有更严格的使用限制,只有在用户主动授权之后才会调用该权限。这允许豆包手机助手模拟用户点击、滑动、键入、跨 App 操作。另一方面,借助视觉多模态能力,即识别屏幕 UI、理解界面内容、解析用户意图和执行规划,豆包手机助手自主决定「下一步该点哪儿、输入什么、跳到哪个 App」。用刘邦的说法,这相当于一个「幽灵手指 + 大脑 + 决策系统」。
张驰强调了豆包手机助手的系统级整合能力,通过基础能力的持续增强和多种技术方案的整合(如系统功能接口调用),做到更好的 GUI Agent 体验。张伟楠表示,豆包手机助手通过 GUI Agent 打通 App 之间的壁垒,在对齐用户上下文和操作空间上有了显著进步。「作为第一个手机厂商和大模型公司主导设计的 AI 手机,设计逻辑上比传统手机厂商做 AI 转型设计的手机更具有颠覆性。」
沈永亮同样突出了豆包手机助手主打的原生 GUI 视觉操作,与手机厂商深度合作达成系统级操作权限,直接向系统内核发送指令来模拟人手指的点击和滑动。这种基于系统底层的视觉操作与以往依赖无障碍服务的第三方 App 有本质区别,具备了极强的通用性,执行过程更稳定、更像真人,在推理速度与任务完成率上表现平衡,长上下文处理能力相当可观。
整体看下来,豆包手机助手正在构建一个集「视觉理解、大模型推理与系统级原生执行」于一体的通用 Agent 层,在面对不同 App 和界面形态时实现了可泛化的 UI 操作。
从兼容性、跨 App 自动化执行、长链路任务处理、多任务调度等多个维度来看,豆包手机助手已经展现出了优于传统脚本式自动化或无障碍接口方案的能力。这些都为实现更高阶的系统级 GUI Agent 提供了更稳健的基础能力。
UI-TARS:豆包手机助手背后的自研系统级 GUI Agent 引擎
相信大家已经被豆包手机助手的各种演示刷屏了,无论是跨 App 订机票、自动比价、修改图片,还是在手机上丝滑完成一整套复杂流程,这些能力表明:手机不再只是等你点的工具,而是开始具备了主动完成任务的能力。
这些能力的背后,正是字节在 2025 年陆续推出的自研开源模型 UI-TARS。据悉,豆包手机助手使用的是 UI-TARS 闭源版本,不仅性能优于其开源版本,还针对 Mobile Use 进行了大量优化。
UI-TARS 最早可追溯到今年一月,其奠定了字节在 GUI Agent 方向的基础框架;四月,团队进一步发布进阶版 UI-TARS-1.5,该版本融合了由强化学习带来的高级推理能力,使模型能够在执行动作之前先进行思考推演。九月推出的 UI-TARS-2 则将这一体系推进到新的阶段。
UI-TARS 包括用于可扩展数据生成的数据飞轮机制、稳定的多轮强化学习框架、融合文件系统与终端的混合式 GUI 环境,以及支持大规模 rollouts 的统一沙箱平台。

首先,缓解数据稀缺问题。现阶段大规模预训练和强化学习在对话、推理等领域已经非常成熟,但一旦换到需要长链操作的 GUI 任务上,就难以直接扩展。因为 GUI 场景不像文本和代码那样可以轻松收集海量数据,而是必须记录完整的操作轨迹,包括每一步的推理、点击、界面变化和反馈。这类数据不仅难获取、成本高,而且规模化收集尤其困难。
UI-TARS 设计了可扩展的数据飞轮(Data Flywheel)机制,通过反复的训练持续提升模型能力和数据质量。在每一轮循环中,最新的模型会生成新的智能体轨迹,这些轨迹随后会被过滤并分配到最适合的训练阶段。高质量的输出会被提升到更靠后的阶段(如 SFT),而质量较低的输出则会回收至更早的阶段(如 CT)。随着多次迭代进行,这种动态再分配方式能够确保每个训练阶段都使用与其最匹配的数据,从而形成一个自我强化的闭环:更好的模型产生更好的数据,而更好的数据又反过来训练出更强的模型。

其次,需要解决可扩展的多轮强化学习问题。在交互环境里做强化学习很难,因为智能体很难及时知道自己做得对不对:奖励大多来得很慢、有时甚至没有;训练过程也容易不稳定。
为突破这一瓶颈,UI-TARS 构建了一个专门面向长链场景的训练框架,其中包括使用带有状态保持能力的异步 rollout 来维持上下文一致性;通过流式更新来避免长尾轨迹导致的训练瓶颈;以及结合奖励塑形( Reward Shaping)、自适应优势估计和值预训练的增强版近端策略优化(PPO)算法,以进一步提升训练效果。

第三,突破纯 GUI 操作限制。现实中的许多任务并不能单靠界面点击完成,例如数据处理、软件开发、系统管理等,更高效的方式往往是直接操作文件系统、使用终端或调用外部工具。如果智能体只能依赖 GUI 交互,其能力边界就会非常有限。因此,一个真正高级的 GUI Agent 必须能够将图形化操作与这些系统资源无缝结合,使其不仅能点界面,还能执行更真实、更复杂的工作流。
为此,UI-TARS 搭建了一个混合式 GUI 中心环境,使智能体不仅可执行屏幕上的操作,还能调用文件系统、终端及其他外部工具,从而解决更广泛的真实任务。这意味着,在 UI-TARS 的训练体系中,智能体的操作空间已经从单纯的点击、输入、滚动,拓展为能够自由组合 GUI 操作与系统指令的更高维动作集合。例如,它既可以在文件管理器中拖拽文件,也可以直接通过 Shell 命令处理文本、解压压缩包、运行脚本。可以说这是系统级 GUI Agent 能够走向真实应用的关键一步。
最后,即便具备丰富的交互能力,要部署大规模 RL 环境依然是工程瓶颈。因为系统需要在浏览器、虚拟机、模拟器里反复跑上百万次交互,还要保证结果可重复、出错能恢复、不影响训练流程。但现实情况是,这类环境往往又慢又贵,还容易崩溃,想长期、稳定地跑大规模 RL 几乎是件非常困难的工程任务。
为支持大规模训练与评估,UI-TARS 构建了一个统一沙箱平台,其核心创新之一是共享文件系统:这使得 GUI Agent 可以在同一个容器实例中实现诸如通过浏览器下载文件并立即用 Shell 命令处理连续跨工具操作。该沙箱不仅保持了复杂任务所需的稳定性与可复现性,还在分布式计算资源上支持高吞吐训练,同时为数据标注、评估和推理提供一致的环境。
依托这四项技术,UI-TARS 为系统级 GUI Agent 提供了真正可落地的基础能力,使豆包手机助手能够在真实手机操作系统中稳定执行跨 App、长链路的复杂任务,实现从对话智能向行动智能的跃迁。
UI-TARS 的突出表现,也得到了四位学界专家的认可。在刘邦看来:「UI-TARS-2 在学术层面为通用 GUI Agent 路线提供了一套经过验证、可扩展的基础框架。」
他特别指出 UI-TARS-2 的研究价值在于它让 AI 自动操作图形界面(GUI)具备了通用性与端到端特性:模型只需观察屏幕截图,就能通过视觉理解、多模态推理、模型推理、自动点击、输入、滚动等操作,模拟人类操作界面。在这一基础上,UI-TARS-2 通过大规模强化学习、自我生成与迭代的数据飞轮、统一的动作空间设计以及混合式(Hybrid)环境,让 Agent 在各种不同环境中都有较好表现。
张驰也对这项研究给予了客观评价。他指出,「UI-TARS-2 做出了许多兼具工业价值与学术价值的规模化探索,从模型底层能力入手,对 GUI Agent 进行了系统性的强化。」
他进一步强调,与学术界普遍聚焦于 Agent 架构或策略改进不同,字节跳动选择直接面向模型能力本身发力,用大规模数据、算力与强化学习训练体系去提升智能体在真实 GUI 环境中的最终效果,补上了学术界在资源与工程实践方面的短板。
张伟楠表示,UI-TARS 是字节今年推出的杰出科研成果,自己带领的团队在推进 GUI Agent 研究时也多次参考并引用了 UI-TARS。在他看来,这套体系不仅为系统级 GUI Agent 提供了清晰的技术路径,也让外界看到了字节在智能体方向持续输出更强研究成果的能力。
沈永亮则从初代 UI-TARS 到 UI-TARS 2.0 做了很好的点评:「UI-TARS 1.0 走了一条视觉原生的端到端路线,通过构建人工标注数据和进行大规模的 SFT、DPO 训练,向行业证明了只要数据飞轮转起来,不依赖各种花式 workflow 的纯视觉方案也能走的通。后续版本这种领先优势进一步从感知延伸到了推理和环境交互。UI-TARS 1.5 让我们看到了强化学习在处理复杂任务时的关键作用,紧接着 UI-TARS 2.0 推出沙盒环境,让模型能够进行无限的数据 Scaling,通过在虚拟环境中不断试错和生成数据,实现了左脚踩右脚式的自我迭代提升。这一整套从纯视觉感知到沙盒自我进化的研究闭环,无疑是目前行业里最前沿的探索。」
写在最后
从应用体验到背后的 AI 模型技术,豆包手机助手第一次在端侧设备上实现了变革式的 AI 交互体验升级,或许未来 AI 手机的终极形态,就会从这里开始。
以它为起点继续推演,在未来的手机上,我们可能面对的将不再是一个个独立的 App,而是有一个「无所不能」的系统级 GUI Agent 来自动帮我们解决问题。
随着 AI 能力被内化为核心,手机 OS 系统不再只是资源管理器,而会进化成为你的意图调度器,实现真正的 AI 原生。各种能力由 AI 调用,交互的范式将会由「人找服务」转变到「服务找人」。
你的手机将会从一个「能打电话的电脑」,转变成为一个「拥有自主行动能力的个人智能体」,它会真正成为能与你自然共处、深刻理解你、并能在数字与物理世界为你有效行动的伙伴。
如果当「意图驱动 + 自动化 + Agent」演变为系统自带的功能,系统级 GUI Agent 将成为下一代手机操作系统的标配能力,刘邦和张驰都表达出了类似的观点。张伟楠也认同 GUI Agent 是当前 AI 手机的实现路径之一,并且相信很快可以达到媲美人类的操作智能水平。沈永亮虽然没有给出明确的答案,但他举了触屏手机取代实体键盘的例子来说明,当人们习惯了一句话就能让手机自动帮你完成任务(比如订票、订酒店),这种「用了就回不去」的便利性其实已经告诉我们未来会走向哪里。
不过仍有一些关键挑战需要解决,包括设备端算力、系统级 Agent 的协调管理权限、兼容与安全机制等。对于 AI 技术本身来说,模型感知的准确度,在复杂任务上的规划推理能力也是决定智能化程度的关键。
未来究竟会发展成什么样?我们尚不能给出准确的答案,不过可以肯定的是,系统级 GUI Agent 探索所带来的变革才刚刚开始,想象空间远比我们当下所能看到的更为广阔。
....
#The Art of Scaling Test-Time Compute for Large Language Models
微软发布首个测试时扩展大规模研究,还给出了终极指南
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。
现在的共识是:让模型在回答问题前「多想一会儿」,往往能得到更好的结果。这听起来像是一个完美的免费午餐:只要能在推理时动态分配更多计算资源,就能让模型的智商原地起飞。
但问题来了:我们该怎么让 LLM「多想」?
好比让一群学生做题:是让一个学生反复修改答案(序列策略)?还是让一百个学生同时做题然后投票(并行策略)?亦或是让他们开个会讨论一下(混合策略)?
更重要的是,有些「学生」(模型)虽然聪明,但想得越多反而越容易钻牛角尖;而另一些则必须深思熟虑才能解出难题。
究竟哪个 TTS 策略才是那个「天选之子」?
为了结束这场盲人摸象般的争论,微软终于出手了。
他们进行了一项针对 TTS 的系统性研究:涵盖了从 7B 到 235B 参数量的 8 个开源 LLM,在 4 个推理数据集上疯狂生成了超过 300 亿 个 token。
- 论文标题:The Art of Scaling Test-Time Compute for Large Language Models
- 论文地址:https://arxiv.org/abs/2512.02008
这项研究不仅打破了「一种策略通吃」的幻想,还发现了一个颠覆认知的现象:模型之间存在着明显的性格差异,分化为「短视界」和「长视界」两大阵营。
基于这些洞见,微软团队更是直接甩出了一套综合了问题难度、模型类型和计算预算的「实用配方」。下面,让我们一起走进这项揭示了 LLM 推理本质的重磅研究。
测试时扩展方法简介
LLM 的测试时扩展策略多种多样,通常分为并行、序列、混合 / 元方法(meta)以及内部计算机制(图 2)。虽然每类方法在特定设置下都显示出潜力,但没有单一策略是普遍最佳的。

并行扩展策略
通过聚合多个独立采样的推理路径的答案来提升性能。Self-consistency 对多样的推理路径进行采样并选择出现频率最高的最终答案,显著提升了算术和符号任务的性能。Best-of-n 采样作为一种简单的并行方法被广泛使用,不过最近也有人提出了更具原则性的投票策略,如加权多数投票和多智能体验证(MAV)。Short-m@k 利用了早停机制:它并行运行 k 条推理链,并根据完成路径的比例提前终止。
序列扩展策略
通过迭代式的修正、重启或回溯来扩展推理深度。思维链(CoT)提示是一个基础理念,随后的工作如 STaR 和 Reflexion 探索了通过试错或语言自我反思进行修正。思维树(ToT)和思维图(GoT)通过结构化的广度优先或 DAG 风格搜索进一步扩展了这一点。AlphaGeometry 将符号证明搜索与 LLM 结合,以实现步骤级的序列控制。S1 微调模型以教授自我修正策略,利用了更高的测试时计算量。
混合扩展策略
该策略融合了以上两个维度。Meta-Reasoner 使用上下文多臂老虎机根据感知的任务难度动态选择 TTS 策略。AgentTTS 和 START 部署智能体(具有工具调用能力的 LLM)在直接生成或更复杂的推理之间进行切换。PEARL 交替进行草稿生成与修正,模拟自我改进循环。这些元调度器(meta-schedulers)认识到仅靠深度或并行扩展是不够的,旨在根据模型行为和提示动态调整策略。相比之下,内部扩展策略修改模型在推理过程中的内部计算量,而不显式调整外部样本数或推理步骤数。HALT-CoT 和 SoftCoT++ 的方法是估计答案的不确定性,如果置信度高则提前终止。
没有哪种策略是普遍最佳的。多项实证研究加强了这一观点,即没有 TTS 策略能持续占据主导地位。
微软这项研究分析的算法包括最先完成搜索(First Finish Search, FFS,算法 1)、最后完成搜索(Last Finish Search, LFS,算法 2)和束搜索(Beam Search),前两者由变量 k 和 N 参数化,而后者仅由 N 参数化。


FFS-k@N 意味着采样 N 个输出并在最短的 k 个样本中执行多数投票(MV)以确定结果;而 LFS-k@N 仅仅涉及选择最长的 k 个样本而非最短的,随后对这些样本进行多数投票。
束搜索涉及维护一组高概率的部分假设(partial hypotheses),并在解码过程中不断更新这些前缀。
研究结果
束搜索显示出逆扩展或无扩展
研究的第一个爆点来自于对经典算法束搜索(Beam Search)的宣判。
在实验中,研究人员观察到了一个极其反直觉的现象:在「短视界」和「非推理」这两个模型家族中,束搜索表现出了一致的逆扩展(inverse-scaling) 模式:随着束大小 N 的增加,性能单调下降(图 1)。

看图便知,对于像 R1 和 QwQ-32B 这样的模型,一旦束大小(Beam Size, N)超过 2,准确率不仅没有提升,反而像坐过山车一样急剧下降。
即便是 GPT-OSS-120B 和 Qwen3-32B 这样的「长视界」模型,增加 N 也未能带来收益,准确率曲线要么躺平,要么缓慢下滑。
这意味着什么?意味着在束搜索上投入更多的计算量(增加 N 会消耗更多 token),不仅是浪费,甚至是有害的。简直是花钱买罪受。
推理路径长度与质量的相关性
这项研究最核心的贡献,在于揭示了推理路径长度与质量之间复杂的相关性。这对于深入理解像 FFS 和 LFS 这样基于长度的过滤策略至关重要。
FFS 和 LFS 基于两个截然相反的观点:越短越好和越长越好。
为了调查哪种假设(或哪些假设)适用于特定模型,该团队报告了给定推理路径长度区间和问题难度下的准确率(表 1)。

请注意,问题难度是通过所有模型和路径的平均准确率来衡量的,而报告的准确率是通过特定模型的所有输出来衡量的。一个关键的考量是,问题难度与推理路径长度存在混淆(confounded,图 3):短路径通常源于较容易的问题,而长路径往往对应较难的问题。

为缓解这种混淆效应,他们将分析限制在同时具有短路径和长路径的任务上。对于每个此类数据集,他们分别计算短路径和长路径的单一准确率值,然后在数据集之间平均这些值,从而防止数据集大小的差异不成比例地影响聚合结果。
结果,他们将六个推理模型清晰地划分为两大阵营:
1. 短视界模型
- 代表成员:R1, QwQ-32B, DAPO-32B
- 行为特征:对于给定的问题难度,更短的推理路径比更长的路径更可能是正确的。
这意味着这些模型在推理时往往「直击要害」,如果它们开始长篇大论,很可能是在「胡言乱语」或者陷入了无效循环。
有趣的是,DAPO-32B 尽管使用了 GRPO 等技术,依然表现出与 R1 相似的长度偏置,说明目前的后训练技术在缓解长度偏置方面可能还很有限。
2. 长视界模型
- 代表成员:Qwen3-32B, GPT-OSS-120B
- 行为特征:它们的表现更为复杂且「世故」。
在简单问题上,它们倾向于较短的路径。但在困难问题上,它们则偏好较长的路径。
这类模型展现出了更强的适应性:遇到难题时,它们确实在利用额外的计算步骤进行有效推理,而非无效空转。
深度分析:预算与策略的博弈
既然模型性格迥异,那么在给定的计算预算(Token 消耗量)下,我们该如何选择最佳的 k 和 N?

研究团队通过分析 FFS-k@N 和 LFS-k@N 的性能曲线,发现了几个关键趋势:
LFS 的奥义在于「全员投票」
对于 LFS 系列方法,给定总计算量下的最大性能总是当 k 很大时(即 k=N)实现。注意,当 k=N 时,LFS 实际上就退化成了 多数投票(MV-N)。
结论非常简单粗暴:在消耗相同 token 的情况下,直接做多数投票(MV@N)总是优于刻意筛选最长路径的 LFS-k@N。
FFS 的微妙权衡
对于短视界模型: 较大的 N 值总是最好的。这意味着你应该采样很多样本,然后从中选出最短的那一批进行投票。
对于长视界模型:存在权衡。如果你想用高计算量换取高性能,你必须选择较小的 N(本质上是执行简单解码);而在非推理模型上则相反。
这一分析告诉我们,最佳 TTS 策略是随着预算的增加而动态扩展的。
终极配方:如何为你的模型选择 TTS 策略?
基于上述海量实验数据,微软团队总结出了一套极具操作性的「决策矩阵」。这不仅是理论分析,更是给算法工程师们的实战手册。

让我们来拆解这个配方的内在逻辑:
场景一:如果你使用的是「短视界模型」(如 R1, QwQ)
这类模型有个特点:无论题目难易,它们总是觉得「长话短说」的答案更靠谱。
低计算预算时:使用 FFS,且设定 k=1。即:采样 N 个答案,直接挑最短的那个作为最终答案。简单、快速、有效。
高计算预算时: 使用 FFS,且设定 k=N(等同于 MV@N)。即:采样 N 个答案,因为 N 个最短路径就是所有路径,所以这实际上就是标准的多数投票。
核心逻辑:对于短视界模型,性能随 N 的增大而提升。因此,只要预算允许,把 N 拉满,做多数投票即可。
场景二:如果你使用的是「长视界模型」(如 Qwen3)
这类模型比较「纠结」,策略选择稍微复杂一些。
面对高难度问题(High Difficulty):模型倾向于长路径。由于 LFS@N 随 N 增加而提升:
- 高计算预算: 使用大 N 的 MV@N。
- 低计算预算: 使用小 N(理想情况下 N=1)的简单解码(SD)。
这里有一个有趣的结论:在保持 k=N 的情况下(即 MV),性能随 k 增大而提升。
面对低难度问题(Low Difficulty):此时模型偏好短路径(杀鸡焉用牛刀)。
- 高计算预算: 使用大 k 的 FFS。
- 低计算预算: 使用小 k 的 FFS。
在这种设置下,设定 N=k(即 MV@N)依然是稳健的选择。
总结来看,尽管模型类型和任务难度千差万别,但最终的「配方」却表现出了惊人的殊途同归:对于绝大多数情况,多数投票(MV@N) 或者是其变体(如 FFS 中的 k=N)往往是性价比最高的选择。特别是对于「短视界」模型,不要试图通过让它「多想」来强行提升效果,更多时候,从大量的快速回答中通过投票筛选出共识,才是正确的打开方式。
写在最后
微软的这项研究,实际上是在为 LLM 的推理能力「祛魅」。它告诉我们,测试时扩展并不是简单地堆砌算力,更不是盲目地追求更长的思维链。
理解模型的「视界」属性是设计高效推理系统的第一步。而在算力昂贵的今天,这份基于 300 亿 token 实测得出的决策配方,无疑为我们节省了大量的试错成本。
下一次,当你准备让你的模型「再想一下」时,不妨先查查这份配方,看看你是否正在为一个「短视界」的模型,强加它并不擅长的长考重担。
....
#GPT-5.2
GPT-5.2真身是它?OpenAI紧急端出全套「下午茶」,新一代图像模型同步泄露
让我们细数一下这两年令人印象深刻的模型代号:草莓、香蕉、胡萝卜……每次一亮相,总要和水果蔬菜沾点关系。
这两天网友又发现了一个新的模型代号,这次不卖水果蔬菜,改开下午茶了。
最新的主角叫:Olive Oil Cake(橄榄油蛋糕),另加 Chestnut and Hazelnut(栗子和榛子)。
种种迹象表明,这顿「下午茶」是 OpenAI 在内部「红色代码(Code Red)」警戒下,为了阻击谷歌 Gemini 3 而端出的全套反击大餐。
首先是这款神秘的主菜。
有眼尖的用户在 Notion 上发现了一个带有 OpenAI Logo 的新模型选项,内部代号赫然写着:Olive Oil Cake。

虽然目前普通用户还无法选中这个模型,但这唯一的标识码显然与现有的 GPT-5.1 不同。业内普遍猜测,这块听起来口感绵密、还带点地中海风情的「蛋糕」,极有可能就是传说中的 GPT-5.2。
为什么说是「Code Red」级别的紧急发布?
因为隔壁谷歌的 Gemini 3 实在是太猛了。据知情人士透露,Gemini 3 在各项榜单上的屠榜表现,直接让 Sam Altman 拉响了内部警报。OpenAI 原本打算把 GPT-5.2 留到月底甚至明年,但竞争对手的压力迫使他们不得不提前把「蛋糕」端出来。
目前的市场情绪也已经彻底被点燃。在预测平台 Polymarket 上,原本押注 12 月 9 号发布的资金开始转向,目前的风向标死死盯着 12 月 11 日(本周四)。

除了用来「硬刚」Gemini 3 的新模型,这场下午茶的配角「栗子和榛子」,实则是 OpenAI 憋了许久的下一代图像生成模型(或为传说中的 Image-2 及其变体)。
根据最新的海外开发者爆料与 Design Arena 测试数据,这两个代号的真身可能是:
- Chestnut(栗子):疑似对应 Image-2(标准版)。
- Hazelnut(榛子):疑似对应 Image-2-mini(轻量版)。
无论最终命名如何,这两款模型在社区讨论中都被视为 Image-1 的直接继任者,目标非常明确:解决痛点,对标谷歌。根据测试者的反馈,这款新模型带来了以下关键升级:
- 告别「黄调滤镜」:早期的 Image-1 模型常被诟病生成的图片带有一种莫名的黄色调,新一代模型据称已彻底修复了这一色彩偏差,色彩还原度大幅提升。
- 细节与保真度暴增:在纹理细节的处理上,新模型被认为更接近谷歌 Nano Banana 2 设定的行业标准。
- 复古与先进的融合:视觉风格上,它似乎融合了早期 DALL-E 的艺术感与最新的渲染技术,既保留了创意性,又提升了写实度。
- 图生码能力:除了画画,它在图像中撰写精准代码片段的能力也得到了测试者的盛赞。


虽然在部分侧边对比(Side-by-side)测试中,谷歌的 Nano Banana 2 依然在某些场景下保持微弱优势,但 OpenAI 可能已经通过新一代模型填补了绝大部分的技术鸿沟。这套「图像模型全家桶」预计将直接集成在 ChatGPT 中,服务于设计师和创意工作者。
OpenAI 显然不想让谷歌独占 2025 年末的聚光灯。如果预测准确,这周四我们可能不仅能吃到「蛋糕」(GPT-5.2),还能嗑上「栗子和榛子」(新视频模型)。
所以,这块「橄榄油蛋糕」到底好不好吃?它能不能压住 Gemini 3 的势头?GPT-5.2 能反超 Gemini 3 吗?让我们拭目以待。
参考链接:
https://www.testingcatalog.com/notion-tests-unreleased-gpt-5-2-model-as-openai-launch-nears/
https://x.com/marmaduke091/status/1998433338496004515?s=20
https://www.testingcatalog.com/openai-testing-new-image-2-models-on-lm-arena/
....
#The Missing Layer of AGI
LLM距离AGI只差一层:斯坦福研究颠覆「模式匹配」观点
有关大语言模型的理论基础,可能要出现一些改变了。
斯坦福发了篇论文,彻底颠覆了「LLM 只是模式匹配器」的传统论调。
它提出的不是扩展技巧或新架构,而是一个让模型真正具备推理能力的「协调层」。
- 论文题目:The Missing Layer of AGI: From Pattern Alchemy to Coordination Physics
- 论文地址:https://arxiv.org/pdf/2512.05765
核心观点:AGI 的瓶颈在于协调,而非规模
人工智能界正因围绕大语言模型本质的争论而分裂。一方面,扩展派认为 LLMs 足以实现 AGI;另一方面,有影响力的批评者认为 LLM「仅仅是模式匹配器」,在结构上不具备推理、规划或组合泛化能力,因此是死胡同。
作者认为这场争论建立在一个错误的二分法之上,并提出一个颠覆性极强的核心观点:LLM 的失败不是因为缺乏推理能力,而是因为我们缺少将其模式与目标绑定的系统。
为了解释这一点,作者用了一个捕鱼隐喻。
海洋代表模型庞大的模式库,渔夫不用鱼饵就撒网,收获的只是最常见的鱼类(训练数据中的通用模式)。批评者谴责这些未锚定的输出,但他们观察到的只是未加诱饵的捕捞所产生的原始统计基线,这不是系统损坏,而是系统在默认模式下的自然表现。
然而,智能行为不仅仅是撒网,它还涉及下饵和过滤。如果诱饵过于稀疏,它就无法吸引特定、稀有的鱼,海洋的先验仍然主导。如果诱饵足够密集,它传达了强烈的意图,转移了后验分布,使目标概念压倒常见先验;但诱饵并非没有成本,使用过多的诱饵来确保捕获是低效的。
在这种观点中,「缺失的层」就是协调层,它优化了这种权衡:计算转移后验所需的精确密度,同时不产生过高成本。
鉴于此,作者提出第三条道路:基础层加协调层。LLM 是必要的系统- 1 基础层(模式存储库),瓶颈在于缺少系统- 2 协调层,该层将这些模式与外部约束绑定、验证输出并维护状态。
UCCT 理论:推理的相变现象
作者引入了 UCCT(统一认知意识理论)来形式化这一机制。UCCT 最激进的观点是:LLM 从幻觉到推理的转变不是一个渐进的、线性的过程,而是一个相变 。
这就像水在达到冰点时会瞬间凝结一样,当施加给模型的锚定信号达到一个临界阈值时,模型的行为会发生突变:
- 低于阈值:模型基于训练数据的统计学最大似然先验进行输出,这表现为无根据的生成或幻觉。
- 高于阈值:目标导向的约束主导了输出的后验分布,推理行为被激活,模型表现出受控且可靠的行为。
这种相变的发生由一个物理学式的锚定分数决定,该分数综合考虑了以下三个关键变量:
- 有效支持:指外部约束(如检索到的证据、提供的示例、工具的输出)对目标任务提供的强度和密度。其作用是拉动模型走向目标,有效的锚点越多,分数越高。
- 表征失配:指模型当前的潜在模式(基质)与目标任务或外部约束之间的差异程度。其作用是惩罚模型偏离约束,失配度越大,分数越低。
- 自适应锚定预算:代表在实际操作中,为了达到目标而愿意付出的上下文成本和计算资源。其作用是平衡效率与可靠性,避免为了微小的收益而无限制地投入锚点。
也就是说,幻觉不是模型损坏,而是它在未加诱饵(unbaited)的情况下,简单地输出了其模式存储库的最大似然先验;推理则是外部约束将后验分布从通用的统计模式转向目标的结果。
因此,只要提供足够密度的「诱饵」和「渔网」,即协调层的锚定机制,LLM 这个强大的模式基础层就能被组织起来,执行可靠的推理任务。
架构实现:多智能体协调堆栈
为了将 UCCT 理论转化为实际的架构,作者构建了 MACI(多智能体协作智能),这是一个协调堆栈,为 LLMs 提供了类似于人类「执行功能」的能力。
MACI 架构通过其三个核心组件,精准地映射并解决了 UCCT 中决定推理相变的三要素:
- 行为调制的辩论用于最大化有效支持。它让多个智能体扮演不同角色(质疑者、证据提供者、规划者)进行辩论,主动检索、生成和验证证据,确保审议是多角度且有证据支持的。
- 苏格拉底式评判 CRIT 用于最小化表征失配。UCCT 中的表征失配 是导致幻觉的根本原因。 MACI 引入了 CRIT 作为专门的苏格拉底式裁判。CRIT 的核心任务是在推理的每一步中,严格审查智能体的提议和论点。它专门查找和过滤那些与事实、先前状态或任务约束相矛盾的不恰当论点。通过在早期环节就剔除与目标严重偏离的联想式输出,MACI 积极地最小化了表征失配,从而防止低质量或幻觉性的内容污染推理循环。
- 事务性内存用于优化锚定预算。事务性内存不只是简单的历史记录,它以持久化和事务性方式存储经过验证的关键中间状态,避免重复计算和上下文膨胀,实现锚定预算的最优使用。
深度协调模式将推理视为受控过程。智能体进行辩论、交叉检查、修改方案、提取证据、修复计划,并跨步骤持续维护状态,所有这些都由锚定信号指导。这本质上是在底层模式基质之上叠加执行功能 —— 一旦锚定分数跨越阈值,模型的行为就会从联想式猛然转向受控式。
论文的核心结论改变了我们对 AGI 路径的认知:AGI 不会来自于更大的模式之海,它将来自于组织这些模式以形成可靠推理的网、诱饵、过滤器和记忆机制。如果这项技术能够扩展,LLM 就不再是「自动补全」,而会成为完整推理系统的认知基质。
大语言模型并非通往 AGI 的死胡同,而是实现 AGI 的必要「认知基质」。AGI 的瓶颈不在于 LLMs 的底层模式规模,而在于缺失了一个将这些模式组织和绑定到目标的「协调层」。
作者 Edward Y. Chang 是谁?
本研究唯一作者 Edward Y. Chang(张智威)是斯坦福大学计算机科学系的兼职教授。此前,他曾任加州大学圣巴巴拉分校(UCSB)终身教授。2006-2012 年,他担任谷歌研究院总监,率先开展了以数据为中心和并行机器学习的研究,并为 ImageNet 项目做出了贡献。他还曾在香港科技大学和加州大学伯克利分校任职。张智威拥有斯坦福大学计算机科学硕士学位和电气工程博士学位。
他的研究兴趣涵盖意识建模、生成式人工智能和医疗保健,并因此荣获多项奖项,例如谷歌创新奖、 XPRIZE 奖等。他还是 ACM 和 IEEE 会士。
....
#欺骗、隐瞒、删库跑路,AI程序员彻底失控翻车
还记得前几天会睡觉的 Claude 吗?
都说 AI 越来越像人了,如果说 Claude 最多是个「懒人」的话,那下面要聊的这位可是个十足的「坏人」。
就在前不久的 19 日,SaaStr.AI 创始人兼首席执行官 Jason 在推特上报告了一件令行业震惊的事件:
Replit 在一天的工作结束后,删除了整个公司的生产数据库。

原来不仅仅人类程序员会「删库跑路」,AI 程序员也会。
虽说 AI 没法真的跑路,但是更恶劣的情况是它会撒谎,会隐瞒情况。
Jason 声称,Replit 在做单元测试的时候生成测试全部通过,在批处理失败的时候,才抓住 Replit 撒谎的情况。

更夸张的是,当数据库被删除之后的第一反应自然是回滚。但 Replit 却斩钉截铁:「无法回滚」。
给出的原因是:删除命令是毁灭性的,数据库没有内置回滚命令,Replit 并不会自动备份数据库,已经太晚了。
但 Jason 发现自己又被骗了。

回滚功能其实是有效的。
反复横跳的使用体验让人的心情直接坐上了跳楼机。
「简直离谱 (JFC)」!Jason 在推文中接连使用该词汇表达自己的强烈情绪。
「我知道 Replit 是一个工具,和其他工具一样,也有缺陷。但是如果它忽略所有命令并删除您的数据库,地球上的任何人怎么能在生产中使用它呢?」
这份推文引起了广泛的关注,再一次激发了对于人工智能编程开发工具的可靠性的质疑,尤其是针对当事平台 Replit,已经产生了一定程度的信任危机。
除了「删库」危机以外,Jason 还反复提及了 Replit 无法实现「代码冻结」的功能缺陷,其无法冻结部分代码免于修改,这给实际的应用带来了非常大的困扰。
Replit 最初是一个协作编码平台,后来发展成为一个由人工智能驱动的软件创建生态系统,其核心功能是通过使用自然语言描述来构建完整的应用程序。Replit 在近期的增长十分惊人,2025 年 7 月,Replit 宣布其拥有 50 万企业用户。据投资者史蒂夫・凯斯(Stevie Case) 称,其收入在不到六个月的时间里增长了 10 倍,达到 1 亿美元。同月,Replit 宣布与微软建立合作伙伴关系,将 Replit 技术集成到微软的多款企业工具中。
在「删库」事件发生后,Replit 创始人 Amjad Masad 发推对此事进行了详细回应,并且明确将迅速采取行动提高稳定性和安全性,且愿意为 Jason 提供补偿。
回应全文如下:
我们注意到了 Jason 的帖子。确实存在 Replit Agent 在开发过程中误删生产数据库数据 的问题。这是完全不可接受的,绝不应该发生。
我们立即采取了以下措施:
即使是周末,我们也在加班推进数据库的开发环境和生产环境的自动隔离功能部署,从根本上杜绝此类问题。预发布环境也正在构建中,明天会有更多更新。
幸运的是,我们有备份机制。如果 Agent 出错,可以一键恢复整个项目状态。
此次事故中,Agent 没有访问到正确的内部文档。我们正在推出更新,强制 Agent 在 Replit 知识库中进行文档检索。
此外,我们清楚地听到了大家对 “代码冻结(code freeze)” 的抱怨 —— 我们正在开发规划 / 仅聊天模式,让用户可以在不影响代码库的情况下进行战略性思考。
在周五早上第一时间看到此事后,我已主动联系 Jason 提供帮助。我们将为此事给予退款赔偿,并将开展事故复盘,彻查问题成因并优化未来的响应机制。
我们感谢 Jason 及所有用户的反馈。目前,我们的首要任务是全面提升 Replit 平台的安全性与稳定性,我们正在迅速行动中。
上下滑动查看原文
目前,Jason 仍在发推更新使用 Replit 的最新进展,若感兴趣可以自行关注。
或许这次事件不是个例,有网友称经常遇到相似的状况,尤其是在移动平台上使用 AI 编程的时候。

这次事件恰好为所有 AI 编程工具以及使用 AI 工具作为生产力的人们敲响了警钟。不仅是 AI 编程服务商要为此采取行动,在使用 AI 编程工具的时候一定要遵守开发规范和安全流程,尤其需要关注对于 AI 访问数据的权限。

Reddit 网友也确实指出了这次事件背后的人为原因,「这完全是由人类操作员造成的,因为他们没有理解将模型直接连接到生产数据库的风险,对此没有任何借口,尤其是在没有备份的情况下』。
人类程序员都有非常严格的权限限制标准,更何况 AI 程序员呢?
....
#大模型RL训练框架的进化之路
本文系统梳理了大模型强化学习训练框架从SFT到RL的演进,重点剖析了rollout与训练模块解耦、资源调度、异步通信等核心技术挑战,并对比了OpenRLHF、slime、ROLL、verl等主流开源框架的优劣与适用场景。
大模型RL框架的进化之路
2024年O1路线发现之前,主流的有监督的机器学习,是让学生去学习一个问题的标准答案,根据loss更新模型参数。
训练流程相对简单,pytorch和tensorflow基于此做了各种训练的加速。
chatgpt O1发布之后。
SFT不断弱化,更多的被丢到退火,RL的重要性越来越高。
RL算法也一直在更新,从dpo到ppo,再到现在的grpo/rloo/reinforce++/DAPO。除了现在基本上没人用的dpo,大框架是一致的。
如果说SFT是呆板的学习标准答案,那么RL是给定题目后,让学生自己寻找答案,给学生的解题打分,最后学生根据打分结果来学习。
所以,RL框架就分成了三大块,细节可以参看mengyuan的文章 - https://zhuanlan.zhihu.com/p/677607581
a) 学生自己寻找答案
就是大家天天说的rollout
b) 给学生答案打分
理论上给学生批改作业没那么容易,特别我们现在需要学生做的任务越来越难。但现在大家都在卷数学,物理,代码,这些方向根据结果+规则判断对错是可行的,也就是rule-based。
以及,大家发现训练一个小的reward 模型(例如7B)好像也能用。
导致学生找到答案后,判断答案的成本并不高。所以,这块不怎么被重视,甚至有人直接合并到rollout里了。
但随着agent出来后,特别开始设计到商业领域,例如我在做的电商领域,就没那么简单了。
c) 学生根据打分来学习
训练模块,基于传统的训练框架,改改loss function就行。
所以,现在的RL训练框架,整体分成两块,训练和rollout。那么问题就来了,假如你来设计这个rl框架,你会碰到这些挑战。
挑战一,rollout和训练两个模块的管理
RL现在的共识是on policy效果好,rollout和训练必须顺序执行。
但现在模型越来越大,多卡是必然的,如何管理资源?
rollout是内存消耗型,因为要做kv cache,特别现在cot越来越长了,训练则是计算密集型。
这俩现在都分别做了非常做的复杂的性能优化,如何对这两者做好资源管理?两者的参数同步如何优化?
挑战二,底层框架
训练框架有很多,megatron,fsdp,deepspeed,差异还不小。
推理引擎vllm和sglang,你用那个?
不同的训练框架搭配不同的推理引擎,仅仅是参数更新这块,逻辑代码都不一样。
挑战三,异步问题
rollout批次执行的,但同批次差异巨大,特别agent时代这个差异更是大的离谱。最近在做技术选型,带着团队的小朋友 @和光同尘 一起花时间把roll/slime/verl/openrlhf的源码框架都过了一轮。也跟它们的作者,roll的 @王小惟 Weixun,slime的 @朱小霖,verl的生广明,openrlhf的 @OpenLLMAI,进行了一轮/多轮的探讨,学习了很多知识,也收到了非常多有价值的反馈。
也感谢 @猛猿 ,有几轮讨论给了非常好的反馈。一轮轮的讨论中,会发现大家对三个挑战的解决,是一个循序渐进的过程。也感受到不同的作者会有自己的坚持和侧重。重点感谢这篇文章,对我帮助非常大
从零开始的verl框架解析: https://zhuanlan.zhihu.com/p/30876678559
性能的挑战
原始版本
我们回顾下三个阶段。学生自己寻找答案,在agent之前,就是模型推理。给学生答案打分,也是模型推理,只不过模型多几个(不同的算法量级不一样)。学生根据答案来学习,则是训练。
这个逻辑,基于sft框架是能搞的,只不过之前只用初始化一个模型,现在要初始化多个罢了。很多rl框架一开始都是这样。
但很快,我们会发现速度非常非常慢,那么问题来了,我们要如何优化它?
内存的优化
LLM训练-从显存占用分析到DeepSpeed ZeRO 三阶段解读:https://zhuanlan.zhihu.com/p/694880795
参考上面的文章。
训练过程中占用的显存有四种,模型训练参数,梯度占用,优化器占用,激活值占用。
梯度参数量和模型参数的规模是一一对应的,模型每一个参数都会有一个对应的梯度值来指导更新。
优化器占用则跟优化器的类型有关,这里按照adamw来计算。
拿7B模型来算内存,不考虑训练过程的中的激活值,模型参数14G,梯度14G,如果fp32,那就是28G,优化器28+28+28,一共都有112G。
现在的模型参数量,动不动千亿参数,单卡肯定放不下。为了解决这个方案,大家提出了DP/TP/PP来优化。
DP方式就是以deepspeed的zero1/2/3为主,每次计算前都会all gather得到完整的模型参数,计算的时候使用的是完整的参数和切分后的输入。
TP/PP从头到尾都只存模型的一部份,计算的时候使用的切分后的参数和完整的输入。这就是megatron擅长的,并且它的dp也做的很好。
详细区分参考如下表
英伟达有一篇论文,千卡以内差不多,千卡以外,TP/PP更好。
因为all gather的存在,理论上dp就是上限要比tp/pp差。
推理的速度
可以参考我的vllm,sglang,kv cache源码系列。现在的推理引擎,仅仅逻辑层kv cache的复用,就有非常多的点优化,更不用说底层算子的优化。
从零开始设计SGLang的KV Cache:https://zhuanlan.zhihu.com/p/31160183506
但使用推理引擎带来的问题就是,学生学习完毕后,需要把新的参数更新过去。但参数的更新耗时,对比于推理引擎提升的推理速度来看,百倍的提升,是完全可以接受的。
不过,现在推理引擎跟训练框架的generate的精度还是有差距,并且根据vllm和sglang的反馈来看,短期内依然比较难解决。
所以,现在rollout拿回来后,训练引擎还会再算一遍logits(相当于只有prefill,速度快的多)我们把训练框架和推理引擎拼接起来,做个新的rl框架,性能就有巨大的提升。
那么新的问题来了,如何拼接?
训练框架和推理引擎的拼接
SPMD和MPMD
SPMD(Single Program, Multiple Data),MPMD(Multiple Programs, Multiple Data),或者可以称之为single controller vs multi controller。
single controller,worker可以执行不同的程序(MPMD),需要一个老板来控制,不然就乱掉了。
multi controller,每个worker都执行相同的程序(SPMD),好处是不需要老板。但没有老板就代表各个worker在各种情况下,需要仔细考虑各种corner case,不然会乱跑。
DeepSpeed和Megatron等主流的训练框架都属于SPMD,所有进程执行相同的代码逻辑。
推理引擎(SGlang和vLLM)会很不一样。当他们执行计算的时候,是SPMD的,因为怎么计算是固定的。但next token从哪里来,如何计算,是kv cache,是从requset,还是pd分离,这就不适合用SPMD和MPMD做区分了。
广明建议看看google的pathway,再来讨论。(我理解的也很浅,就不展开了。我们抛开SPMD/MPMD,single controller/multi controller。训练框架和推理引擎之间最核心的是训练数据和模型参数的通信。我们带着疑问去看代码,看slime和roll是如何做的。
slime的做法
slime只定义了两个worker,RayTrainGroup 和RolloutGroup,训练框架和推理引擎。
https://github.com/THUDM/slime
数据的传输
slime单独定义了一个buffer类,专门用来做推理引擎和训练模块的数据传输中间件。数据都放到buffer里(甚至可以写入到磁盘),通过rollout id来指定。
并且buffer类的数据处理函数,rollout/eval function都是通过命令行参数指定,带来了极大的自由度。
self.generate_rollout = load_function(self.args.rollout_function_path)
self.eval_generate_rollout = load_function(self.args.eval_function_path)这才是业务方真正的痛点,大家日常做业务,会有各种各样奇怪的需求和数据,这个地方如何改的爽很重要。rollout的generate函数是通过buffer。
def async_generate(self, rollout_id, evaluatinotallow=False):
return self.data_buffer.generate.remote(rollout_id, evaluatinotallow=evaluation)训练框架获取数据,也是通过buffer。
def get_rollout_data(self, rollout_id):
# Fetch data through ray on CPU, not sure if this will be performance bottleneck.
# Both first pp stage and the last pp stage will recieve the data.
megatron_utils.process_rollout_data(rollout_id, self.args, self.data_buffer)
def process_rollout_data(rollout_id, args, data_buffer):
rank = dist.get_rank()
dp_rank = mpu.get_data_parallel_rank(with_context_parallel=False)
dp_size = mpu.get_data_parallel_world_size(with_context_parallel=False)
if rank == 0:
data = ray.get(data_buffer.get_data.remote(rollout_id))
dist.broadcast_object_list([data], src=0)
else:
data = [None]
dist.broadcast_object_list(data, src=0)
data = data[0]使用的是同一个buffer,同步代码如下,把rollout的buffer同步给actor。
def async_init_weight_update_connections(self, rollout):
"""
Connect rollout engines and actors, e.g. initialize the process group between them
to update weights after each training stage.
"""
self.rollout = rollout
ray.get([actor.set_data_buffer.remote(rollout.data_buffer) for actor in self._actor_handlers])模型的传输
把actor的配置传给rollout,让rollout引擎在需要的时候正确的同步参数。
def async_init_weight_update_connections(self, rollout):
"""
Connect rollout engines and actors, e.g. initialize the process group between them
to update weights after each training stage.
"""
self.rollout = rollout
ray.get([actor.set_data_buffer.remote(rollout.data_buffer) for actor in self._actor_handlers])
actor_parallel_configs = ray.get([actor.get_parallel_config.remote() for actor in self._actor_handlers])
parallel_config = {}
for rank, config in enumerate(actor_parallel_configs):
assert config["rank"] == rank and config["world_size"] == len(self._actor_handlers)
config.pop("rank")
for key, value in config.items():
if"size"in key and key:
if key not in parallel_config:
parallel_config[key] = value
else:
assert (
parallel_config[key] == value
), f"mismatch {key} on rank {rank}: {parallel_config[key]} != {value}"
parallel_config["actors"] = actor_parallel_configs
ray.get(rollout.async_set_parallel_config(parallel_config))
return [
actor.connect_rollout_engines.remote(
rollout.rollout_engines,
rollout.rollout_engine_lock,
)
for actor in self._actor_handlers
]看到这里,我们发现好像纠结什么single controller,multi controller并不重要。这些逻辑直接硬编码,好像也能支持?问题在哪?
暂且不急,我们再看看roll。
roll的做法
roll通过cluster的方式,定义了多个角色。
self.actor_train: Any = Cluster(
name=self.pipeline_config.actor_train.name,
worker_cls=self.pipeline_config.actor_train.worker_cls,
resource_manager=self.resource_manager,
worker_cnotallow=self.pipeline_config.actor_train,
)
self.actor_infer: Any = Cluster(
name=self.pipeline_config.actor_infer.name,
worker_cls=self.pipeline_config.actor_infer.worker_cls,
resource_manager=self.resource_manager,
worker_cnotallow=self.pipeline_config.actor_infer,
)
self.reference: Any = Cluster(
name=self.pipeline_config.reference.name,
worker_cls=self.pipeline_config.reference.worker_cls,
resource_manager=self.resource_manager,
worker_cnotallow=self.pipeline_config.reference,
)
if self.pipeline_config.adv_estimator == "gae":
self.critic: Any = Cluster(
name=self.pipeline_config.critic.name,
worker_cls=self.pipeline_config.critic.worker_cls,
resource_manager=self.resource_manager,
worker_cnotallow=self.pipeline_config.critic,
)分的比slime更细,好处是跟算法侧的认知比较一致,都是用cluster封装好了,毕竟算法是不知道训练框架和推理引擎有这么大的区别。
数据的传输
类似megatron,可以按照domain分开来采样,在pipeline.py文件定义好。 如果懒得写data generator,roll这个就很省心了。
重点讨论一下reward,理想情况下,我们肯定是期望有一个统一的reward模型,但现在统一的reward比较难训,并且看起来会持续很长一段时间。
我们退而求其次,不同的domain用不同的reward来打分,代码/数学/物理/写作等各一个,最后做聚合。
roll细化到,不同domain,不同batch,不同query上都可以做自定义配置。
https://github.com/alibaba/ROLL/blob/9b85e63ad4c715aa6602ba2a43657e25217c7732/examples/qwen2.5-7B-rlvr_megatron/rlvr_config.yaml#L176-L252
模型的传输
def model_update(self, tgt_workers, broadcast_tgt_devices, p2p_tgt_devices):
comm_plan = self.model_update_comm_plan[self.worker.rank_info.pp_rank]
model = self.unwrap_model()
broadcast_time_cost = 0
with Timer("model_update_total") as timer_total:
for param_name, param in tqdm(
model.named_parameters(), desc="weight update progress", total=len(list(model.named_parameters()))
):
shape = param.shape if not self.ds_config.is_zero3() else param.ds_shape
if not self.ds_config.is_zero3():
param_weight = param.data
refs = []
for p2p_tgt_device in p2p_tgt_devices:
p2p_tgt_worker = tgt_workers[p2p_tgt_device["rank"]]
ref = p2p_tgt_worker.update_parameter.remote(
parameter_name=param_name,
weight=param_weight,
ranks_in_worker=[p2p_tgt_device["device"]["rank"]],
)
refs.append(ref)
if (
self.worker.rank_info.tp_rank == 0
and self.worker.rank_info.cp_rank == 0
and self.worker.rank_info.dp_rank == 0
):
for worker in tgt_workers:
ref = worker.broadcast_parameter.remote(
src_pp_rank=self.worker.rank_info.pp_rank,
dtype=param_weight.dtype,
shape=shape,
parameter_name=param_name,
)
refs.append(ref)
if len(broadcast_tgt_devices) > 0:
collective.broadcast(tensor=param_weight, src_rank=0, group_name=comm_plan["group_name"])
ray.get(refs)两种通信方式结合,会通过worker的node_rank和gpu_rank来判断是否在同一个设备上。
第一种,对于同一设备上的参数,直接通过点对点通信更新。
第二种,通过 collective communication 广播参数到目标集群,只在主进程(rank 0)执行广播操作。这两种就是colocate和非colocate的差异,下文会说到。
从roll来看,这些逻辑直接硬编码,也是能支持,特别当如果在同一个机器上的话。
从slime和roll来看,参数同步,其实只是controller告诉GPU要做参数同步了,中间的通信是不走controller的。
而如果是rolleout的通信,这个single controller压力是非常小的,多模态会大一些?不确定。从这个角度来看,SPMD和MPMD不重要。
但我们刚刚的讨论,都是如果这些role在同一个机器上,硬编码会很简单?
那么如果不在同一个机器会怎么样?
colocate和ray
把actor/ref/reward/critic模型都放一张卡上就是colocate。 但正如上文所说,7B模型训练单卡都塞不下,1000B的模型下半年预计也会开源好几个,并行带来的开销是很夸张的。 现在reward模型也普遍不大,7-30B就满足要求,模型size也有差异,分开部署性价比更高。
但分开部署的硬编码就相对麻烦了,于是大家引入了ray。 ray能支持更加复杂的分布式计算的框架,不用我们过多的操心底层逻辑。如下两篇文章写的已经非常好了,这里不做赘述。 图解OpenRLHF中基于Ray的分布式训练流程:https://zhuanlan.zhihu.com/p/12871616401 Ray分布式计算框架详解:https://zhuanlan.zhihu.com/p/460600694
我们对比下slime/verl/roll/openrlhf四个框架的colocate和非colocate实现。
slime
只有俩worker,训练和推理,RayTrainGroup 和RolloutGroup
colocate是训练和推理分开部署,那么非colocate的情况下,只需要处理分布式通信来同步参数。
这种拆分,抽象易于理解,跟上文讨论的训练和推理是一致的。
只需要在训练的时参数配置colocate,就会自动在所有重要环节执行。
roll
非colocate的话,roll支持各种细粒度的worker指定在不同的显卡的部署,并且还能按轮次去配置,如果不指定的话,ray也会自动帮你部署。
RL资源消耗这么大,细粒度的显卡配置,更有助于显卡资源的高效利用,但对算法侧的资源调度能力要求也更高了。
很明显,这个逻辑用ray来管理更合适。
verl
ActorRolloutRefWorker这个类设计的有点问题,已经在改了。
非colocate就是每个worker(actor,crtic,reward等)一个进程,靠ray自行调度。
colocate,多个角色共用一个ray actor实例,同一个进程内实例化多个worker类。
通过 create_colocated_worker_cls 或 create_colocated_worker_cls_fused 动态生成一个“多角色”类(如 WorkerDict/FusedWorker),内部持有多个 Worker 实例。
外部通过统一的接口调度不同角色的 Worker 方法,内部自动分发到对应的 Worker 实例。
# deprecated, switching to FusedWorker
def create_colocated_worker_cls(class_dict: dict[str, RayClassWithInitArgs]):
"""
This function should return a class instance that delegates the calls to every
cls in cls_dict
"""
cls_dict = {}
init_args_dict = {}
worker_cls = _determine_fsdp_megatron_base_class([cls.cls.__ray_actor_class__.__mro__ for cls in class_dict.values()])
assert issubclass(worker_cls, Worker), f"worker_cls {worker_cls} should be a subclass of Worker"
print(f"colocated worker base class {worker_cls}")
for key, cls in class_dict.items():
cls_dict[key] = cls.cls
init_args_dict[key] = {"args": cls.args, "kwargs": cls.kwargs}
assert cls_dict.keys() == init_args_dict.keys()
# TODO: create a class with customizable name
class WorkerDict(worker_cls):
def __init__(self):
super().__init__()
self.worker_dict = {}
for key, user_defined_cls in cls_dict.items():
user_defined_cls = _unwrap_ray_remote(user_defined_cls)
# directly instantiate the class without remote
# in worker class, e.g. <verl.single_controller.base.worker.Worker>
# when DISABLE_WORKER_INIT == 1 it will return immediately
with patch.dict(os.environ, {"DISABLE_WORKER_INIT": "1"}):
self.worker_dict[key] = user_defined_cls(*init_args_dict[key].get("args", ()), **init_args_dict[key].get("kwargs", {}))跟别的框架不一样的点,同进程和非同进程。根据verl的反馈,同进程收益是非常大的。
同进程通信的话,在某些场景下,速度会差十几倍,memory的碎片问题之类的也会造成很大的影响。
openrlhf
Openrlhf支持多种混合部署方式,允许共置 vLLM 引擎、Actor、Reference、Reward 和 Critic 模型节点或是部分混合部署。支持任意方式的混合部署 也支持分开部署异步训练。
汇总下来,非colocate情况下,ray的确能帮我们更省心的做资源管理,更不用说复杂的agent和多轮。 不过根据运维侧的反馈,ray设计跟现在prod k8s云原生体系比较违背,落地到prod,管理成本比较高。 但ray反馈他们也在针对性优化了,例如,ray现在tensor可以直接走nccl了 bypass object store,也可以期待下他们后续的更新。
不同的训练框架和推理引擎的连接也不同
举个例子,假如vLLM的TP是4,而deepspeed分在了8个GPU,那么就需要做参数的转换才能传输,megatron也类似。
如果训练框架有俩,推理引擎有俩,那么要适配的不是两种,而是四种方案。
某位不愿意透露姓名的朋友,曾被这样的bug坑过,导致他们一直以为百张卡内megatron没有fsdp快,并且持续了很长一段时间。
代码的解耦
拿slime来举例子。 推理引擎分成三层了,顶层-RolloutGroup,中层-RolloutRayActor,底层-SglangEngine。
顶层的 RolloutGroup 是一个总控器,负责启动推理引擎,分配资源,管理数据。在 RolloutRayActor 中可以看到各个接口都很精简,因为具体的实现都放在了 backends 中的相关 utils 里。因为推理本身并不复杂,所以在 sglang_engine 中各个功能也通过调用接口实现。假如有一天我发现sglang不行了,那么我改底层就可以了,上层是感受不到的。 训练框架也是分了三层,看 TrainRayActor 可以更直观的感受到解耦程度。对于最复杂的 train 方法,涉及到 ref,actor,rollout,包含了logprob的计算,日志的记录等,但是因为各种功能被写在了 megatron_utils 中,所以并不会显得很复杂。而在 megatron_utils 中,就可以看到 forward,train 等的详细实现。当需要替换 backend 的时候,在 backend 中新增一个 utils 并确保 train,forward 等接口的实现就可以实现 backend 的切换。 现在各大框架基本上都是这么设计了。 还有一些模块,loss function,打分模块,相对比较简单,就不展开了。
关于Agentic RL
roll,verl,openrlhf都有了不错的支持。 roll甚至单独定义了agentic_pipeline.py来方便大家做进一步的自定义,虽然这样会导致代码的逻辑复杂度增加。但weixun反馈,后续等agentic RL稳定下来后,会重新做一版梳理。weixun16年就开始做RL,经验非常丰富,大家可以多去反馈。 个人认为,未来应该只有agentic RL,现有的rlvr只是其中的一个组成模块。
但这块我还不打算展开,特别现在的agent框架问题更大。
自主agent+沙盒+workflow的混合,agent+rl如何有效的扩大自主agent的范围和边界,等一系列问题,现在并没有一个开源框架能做有效支撑。 太多的不确定,我的下一篇文章会重点展开讨论。
用哪个RL框架?
框架的难点
如果技术进化速度很快,老的框架往往很快就会被大家遗忘,这的确比较令人尴尬。 agent方向也是如此,langchain2023年有多火,现在呢?用dify的更多吧。 原因很简单,老的框架历史包袱太重。 一边清理老功能,一边加新功能,同时如何保证代码框架的简洁和高维护性,是非常考验框架负责人的。
拿dify举例,它为了把rag,chat,workflow,自主agent都塞到一起,代码的臃肿程度看的非常痛苦。 很多老用户可能的确还在用rag功能。但讲道理,dify里面的rag都是开源的模型和方案。干脆丢掉,让用户调用优质的rag接口/mcp,毕竟rag只是agent未来无数tools中的一个重要模块。
新框架设计者,没有这些包袱,弯道超车就会很容易。 再提一嘴,SFT时代很火的训练框架,现在大家还有谁在用?特别现在RL框架顺路就可以把SFT给做了。
而随着模型不断变大,现在其实就俩选择,彻底自己写一套框架,或者基于megatron做定义。 前者对团队要求高,后者则是要忍megatron。
用哪个?
现在的RL框架,各有各的优点,大家按需自取即可。
a] OpenRLHF
OpenRLHF 是第一个基于 Ray、vLLM、ZeRO-3 和 HuggingFace Transformers 构建的易于使用、高性能的开源 RLHF 框架,旨在使 RLHF 训练变得简单易行。
很多人发论文都用它。
https://github.com/OpenRLHF/OpenRLHF
b] slime
刚出没有历史包袱,轻装上阵,代码是真的简洁且清晰,有我当年看完vLLM再去看SGlang的快感。
zilin本身算法认知也很到位,经常跟我们探讨算法细节,对算法侧的痛点是很懂的。例如buffer对数据的处理,很明显就是理解算法侧天天洗数据的痛。
大规模训练上,在zhipu也经过了验证。
大家想要去做一些大胆的框架魔改尝试,slime非常值得一试。
https://github.com/THUDM/slime
c] ROLL
数据处理做的蛮精细,分domain采样,训练和评估的异步都做好了。
agentic和异步是支持的比较完善,weixun从16年就开始做RL,经验非常丰富,ROLL也在这个方向投入了很大的精力去优化。
agentic一直在更新,下周估计还会放新feature。
各种角色的显卡配置指定也可以实现非常细致的调配,支持算法做精细化的算法性能调优。agentic RL这块如果你想要深入折腾的话,可以试试。
https://github.com/alibaba/ROLL
d] verl
据我所知,很多大厂都在用这个,在大规模服务上,它跑起来就是稳且靠谱。
以及,在大规模集群的显卡性能优化上,是有过非常多的踩坑经验。
agentic和异步也做了很多的优化和探索,对deepseek v3的支持也很好。
如果你的团队卡多,时间排期紧张,想要快速scale起来,用这个就好了,很多大厂团队已经帮你验证过。
https://github.com/volcengine/verl
至于aReal的异步,我自己都没想清楚,估计年底会再写一些篇做个专门探讨。
写在最后
最近半年,把RL训练框架,agent框架,推理引擎框架都过了一轮。 代码量,agent > 推理引擎> rl训练框架。 代码难度,推理引擎>rl训练框架>agent。 但如果把推理引擎的底层算子抛开,RL训练的框架难度是跟推理引擎持平的。因为RL训练框架的难点在于缝合,很考验框架作者对各种系统,业务的理解。
verl/slime/roll/openRLHF,这几个开源框架各有所长,能看到不少作者都有自己的追求和坚持,社区的积极性又很高。我觉得大家可以很自豪的说,我们中国在开源的RL框架方向,技术和认知,就是世界第一。算法上人才差异也没那么大,差的大概就是显卡。
大家还是要有一些家国情怀和自信,而不是单纯copy硅谷to china。不是说,谁离openai/claude近一些,更早的获取一些模型训练上的小道信息,谁就迭代的更快。 接下来谁能基于国产卡,训练出来第一个真好用的1T模型。谁就能站在主席台上领奖了,China AI number one 也就不远了。 2023年我清了腾讯股票,梭哈了英伟达和微软。我还是蛮期待明年能有这么一个大新闻,可以让英伟达的股价大大的波动一下,给世界展示下中国制造的实力。
....
#OpenAI被曝IMO金牌「造假」
陶哲轩怒揭内幕!
OpenAI高调摘下数学金牌,竟是自嗨!组委会内部人士透露,OpenAI不仅未与IMO官方合作,甚至无视赛事规则,在闭幕派对未结束前抢先官宣。全网怒批其不尊重人类选手,炒作过头。
OpenAI夺下IMO金牌,最新大瓜又来了。
昨日,因内部审核流程,谷歌DeepMind研究员在评论区,暗讽OpenAI抢先发布测试结果。
原来,事情并非那么简单。
一位IMO内部人士透露,实际上OpenAI并没有和组委会合作,拿下AI金牌不一定真实有效。
最关键的是,他们违背了IMO规定的「公布时间」规则。
为了避免AI公司们抢夺人类学生的风头,IMO评审团要求:在闭幕式结束一周后再公布结果。
然而,OpenAI却在闭幕Party还未结束前,就发布了结果。
对此,谷歌DeepMind负责人Thang Luong表态,「是的,IMO组委会有一份不对外公开的官方评分标准」。
若未依据该标准进行评估,任何奖牌声明均无效。
扣除1分后应为银牌,而非金牌。
这么说来,OpenAI声称拿下IMO金牌,只是自嗨?!
OpenAI真面目被戳穿
抢夺学生风头
就在昨天,菲尔兹奖得主陶哲轩在一口气连发三条评论,暗指的就是OpenAI。
他表示,「自己不会评论任何未预先公开测试方法的AI竞赛成绩报告。在缺乏受控测试环境的情况下,AI的数学能力难以准确评估」。
另外,IMO组委会一位成员Joseph Myers透露,OpenAI并非是IMO合作测试模型的AI公司之一。
而且,阳光海岸的91位协调员(Coordinator)也无人参与结果评估。
P6题协调员表示,「IMO评审团和协调员一致认为,OpenAI此举显得失礼且不妥当」。
根据IMO规定,借助AI模型参赛的公司,需要在7月28日之后公布结果。
一家专注于数学AI初创公司Harmonic官方发文,从侧面印证了这一规定存在的准确性。
最新回应引热议
OpenAI研究科学家,德扑之父Noam Brown下场回应,给出了两点证明:
首先,团队是在闭幕式「之后」公开结果。闭幕式有直播记录,这一点很容易核实。
其次,他确认了OpenAI并未与IMO进行协调,只是在发帖前与一位组织者告知了此事。出于对参赛学生的尊重,要求OpenAI等到闭幕式结束后再发布——「我们也照做了」。
对此,有人还精细计算了闭幕式和公开结果的时间差。
IMO闭幕式的时间在7月19日(当地时间)下午4点举行闭幕式,直播时间1小时43分钟,结束时间不晚于5点43分。
再来看负责人Alexander Wei的发文时间,7月19日下午3:50(东八区),也就是当地时间的5点50分。
从时间来看,确实是OpenAI在IMO闭幕式结束7分钟后,才发布了公告。
即便如此,网友们仍旧看不惯OpenAI炒作风暴,而且根本没有给获奖学生留有余地。
而且,可以确定的是,OpenAI公布的结果,并没有得到IMO官方认证。
未来几天,谷歌DeepMind会正式发布AI夺下IMO 2025细节。
马库斯愤怒抨击,太符合品牌调性了。
UCLA数学教授
LLM短期内不会取代人类
针对LLM拿下IMO金牌事件,来自UCLA应用数学教授Ernest Ryu发表了自己的看法。
1. OpenAI IMO P1-P5的解答目测是正确的。
2. 第6题是一个明显新颖且难度更高的问题。可以说第1-5题仍在「标准」IMO解题技巧范围内,但第6题需要创造性思维。
他表示,根据自己使用LLM进行数学研究的经验,Gemini的表现优于ChatGPT。
但OpenAI抢先在周六宣布了结果,而谷歌DeepMind「慢科研」学术作风,让他们输掉了这场公关战。
不过,Ernest Ryu认为,在短期内,大模型不会取代数学家。
因为数学研究是,解决那些目前「没有人」知道如何解决的问题(训练数据分布之外),即类似IMO P6题。这需要极大的创造力,OpenAI的模型在IMO解题中恰恰缺乏这种能力。
然而,对于那些人类已有能力解决的问题(训练数据分布之内),LLM只会变得愈加强大。
在数学研究中,人们会将现有技术与新创意相结合,LLM将显著加速前一部分工作的实现。
Ernest Ryu还预测,在接下来十年里,越来越多的数学家将借助LLM来搜索证明框架中的已知部分,从而提升研究效率。
老一辈数学家或许会对此唏嘘不已,但年轻一代只会继续产出优秀成果。
参考资料:
https://x.com/ns123abc/status/1947016206768046452 https://x.com/lmthang/status/1946960256439058844 https://x.com/Mihonarium/status/1947027989608190065
....
#ATPrompt
属性引导的VLM提示学习新方法
ATPrompt提出利用通用属性词元引导软词元学习属性相关的通用表征,提升模型对未知类的泛化能力,重构了自CoOp以来的提示学习模板形式。
论文题目:Advancing Textual Prompt Learning with Anchored Attributes
Arxiv链接:https://arxiv.org/abs/2412.09442
项目主页:https://zhengli97.github.io/ATPrompt
开源代码:https://github.com/zhengli97/ATPrompt
中文版:https://github.com/zhengli97/ATPrompt/docs/ATPrompt_chinese_version.pdf
关键词:提示学习,多模态学习,视觉语言模型CLIP
一些有关的文档和材料
如果你觉得这个领域还有那么点点意思,想进一步了解:
- 我们组在github上维护了一个细致的paper list供大家参考:https://github.com/zhengli97/Awesome-Prompt-Adapter-Learning-for-VLMs。
- 我们组在CVPR 24上发表了一篇有关提示学习的工作PromptKD,
- 论文链接:https://arxiv.org/abs/2403.02781
- 开源代码:https://github.com/zhengli97/PromptKD
- 论文解读:https://zhuanlan.zhihu.com/p/684269963
大白话背景介绍
已经很了解VLMs和Prompt Learning的同学可以直接跳过,到背景问题,这里的介绍是为了让没有相关基础和背景的同学也可以看懂这篇工作。
什么是视觉语言模型(Vision-Language Models, VLMs)?
(为避免歧义,这里VLMs一般指类似CLIP这种,不是llava那种LLM-based Large VLMs)
视觉-语言模型,顾名思义,一般由两个部分构成,即视觉(Vision)部分和语言(Language)部分。在提示学习领域,一般采用CLIP[1]这种双塔视觉语言模型,其结构为:

图1. CLIP结构图。
其中,Image Branch由图像类编码器构成,如ResNet或者ViT之类架构,输入的图像经由image encoder进行特征提取,得到最终的图像特征,其大小为[batch_size, feat_dim]。
Text Branch由文本类编码器构成,一般为transformer,当要进行n个类别的分类任务时,会取每个类别对应的名称,如"plane", "car", "dog",代入"a photo of a {class_name}"的模板里,作为prompt输入进text encoder,得到大小为[n, feat_dim]的文本特征。
将两个特征相乘,就得到了最终的输出logits。
什么是提示学习(Prompt Learning)?
在文本分支中,我们一般采用的a photo of a {class_name}作为编码器的输入,但是这样的文本模板太过宽泛,对于特定下游任务明显不是最优的。例如对于图2(b)的花,其采用的a flower photo a {class}的模板更加精确,产生识别结果更好。
也就是,在设计文本提示的时候越贴近数据集的类别就会有越好的结果。

图2. 蓝色方块代表手动设计的prompt,绿色方块代表网络学习得到的learnable prompt。绿色方块acc超越了蓝色。
对于这样的文本模板形式,存在两个问题:
(1) 传统的固定的文本提示往往不是最优,(2) 针对性设计的文本模板费时费力,且不同数据集之间无法泛化通用。
于是,提示学习(Prompt Learning)就出现了,让模型自己学出适合的文本提示,CoOp[2]首先提出了将多个可学习词元(learnable soft token)与类别词元(class token)级联的形式,即,作为VLM文本编码器的输入。通过训练的方式,使得soft token能够学到合适表征,替代手工设计的prompt,取得更好的性能,如图2中的绿色方块。
实验评价指标是什么?
有三个指标,分别是base class acc(基类别准确率),novel class acc(新类别准确率)和harmonic mean(调和均值)。
以ImageNet-1k数据集为例,取1000类中的前500类作为base class,后500类作为novel class。模型在base class上训练,训完后在base class和novel class上测试性能。因为训练过程中使用的base class数据与测试用的novel class数据类别不重复,所以novel acc可以有效反应模型泛化性能。
Harmonic Mean(调和均值)指标是对base acc和novel acc的综合反映,为harmonic mean = (2base accnovel acc) / (base acc+novel acc)。总体的Harmonic Mean值越高,模型综合性能越好。实验结果中一般以这个指标为准。
背景问题
相关工作
在经过CoOp方法之后,许多研究者提出了各种提示学习的新方法,

图3. 相关工作总览。
比如在CoCoOp[3]提出在image encoder之后引入额外的meta-net,增强可学习提示的拟合能力。
MaPLe[4]进一步将提示学习方法从单个的文本模态拓展到了文本和图像两个模态上,通过额外映射层(Project Layer)将文本软词元映射成图像软词元,嵌入图像编码器进行训练。
RPO[5]提出将每个可学习词元都看成单独的CLS token,将多个词元的输出结果进行集成,得到的最终结果作为模型的输出。
PromptSRC[6]在MaPLe基础上去掉了映射层的操作,给每个模型引入单独的可学习词元进行训练。

图4. 基于正则化的相关工作。
在这些方法里,最典型的一类就是基于正则化的方法。做法很简单,就是利用原始CLIP产生的各种表征,来正则化带有可学习提示词元的模型的训练。该类方法占据了主流。
其中,KgCoOp[7]使用原始的模板产生的文本特征去约束带有可学习提示产生的文本特征。
ProGrad[8]用原始的预测结果蒸馏带有可学习提示产生的预测结果。
PromptSRC[6]在两个模态上同时采用正则化约束,在文本特征,图像特征和输出logits上都用原始CLIP产生的结果去进行约束。
PromptKD[9]更进一步把推正则化方式推到了极致,采用大的教师模型提供了更好的对齐目标,同时借助教师模型在大量无标签数据上提供软标签去进行训练,提升了软词元的信息丰富度,达到了已有方法中的SOTA。
问题
让我们回过头思考,为什么我们会需要正则化的方法,为什么大多数做法都是跟原始CLIP去做对齐?
理论上来说,一个经过良好训练的learnable prompt产生的文本特征应该是要优于原始CLIP的文本特征的,直接与原始特征去对齐,理论上应该是没有效果的。
其实,核心问题就在于,现有的文本提示学习形式: ,它是以类别词元为中心的,这种设计形式是存在缺点的:
已有的提示形式,软词元在训练过程中只能学习到与已知类别[class]相关的表征,无法学习到类别以外的通用表征,没有办法建立与未知类别之间的联系,形式上存在缺陷。
这样就使得在遇到未知类别样本时,从已知类别的训练数据中学习到的表征不能发挥作用,无法良好的泛化。所以要去解决核心的问题,仅仅靠不断的加正则化的方式总是治标不治本的。
我们需要重构现有的提示学习形式,那么要用什么样的方式才可以增加图像与未知类别文本间的关联?
方法
来自实际生活的启发

图6. 额外的属性信息会帮助从另外的角度促进对未知类别的识别。
这时候,让我们回归现实生活,当我们人类遇到未知类别的东西时,我们会怎么办?我们通常会从属性的角度来进行表述,增加这个东西的清晰度和可理解性。
举个例,如图6所示,当我们教一个小朋友去在这四张图里选择出什么是cheetah时,小朋友因为知识有限,可能不知道对应这个词是什么,因此很难选出对应的图,但是当我们给他提供额外的属性信息时,比如,The cheetah is a cat-like animal with a small head, short yellow hair and black spots。
其中,cat-like, small head, yellow hair, black spots,这些关键属性的加入让小朋友能够根据这些特点一一匹配,从而准确识别出来c就是cheetah。从属性方面出发的额外描述能够帮助人从另外的角度/维度促进人类对未知类别的识别和理解。
具体细节
受此启发,我们提出了ATPrompt,道理非常简单,就是让软提示去额外学习与属性相关的表征。

图7. 传统提示学习方法与我们的ATPrompt的对比。
形式如下图所示,(a) 是经典的提示学习方法,其采用的是软词元和类别词元级联的方式。现在所有的方法都沿用的范式。
(b) 受到现实生活的启发,我们想要去用属性来改进已有的提示形式。特别地,我们的方法重构了自从CoOp以来提出的提示学习范式,提出在软词元中嵌入固定的属性词元,将其作为整体输入进文本编码器中,如图7(b)所示。
(因为属性词元是保持位置固定和内容固定的,所以也称为锚点词元(Anchor Token)。)
这样一来,通过将固定的属性词元嵌入到软提示中,软词元在学习的过程中就能够受到属性词元的引导,学习与属性相关的通用表征,而不只是以类别为中心的特征,从而增强其泛化性能。
从形式上来说就是,我们将已有的提示学习形式
改变成了
以嵌入两个属性A和B为例,a1, ..., am代表的是对应 A属性的软词元数量,b1, ..., bm同理,M代表的是对应类别词元的软词元数量。
带有深度的ATPrompt
除了在输入层面上加入可学习词元,我们还进一步将ATPrompt拓展到了深度层面,兼容更多的带有深度的提示学习方法,例如MaPLe,PromptSRC等等:

图8. ATPrompt的浅层与深层版本架构图。
直观解释
在接下来的实验里,我们的ATPrompt取得了非常好的结果。我们来思考,它为什么能够work?

图9. 两种方法对齐过程的对比。
从本质上说,就是已有的由CoOp以来大家都沿用的提示形式,是以类别为中心的,可学习软词元在学习的过程中只能对已知类别拟合,无法与未知类别建立直接或者间接的联系,也无法学习到通用的表征。
而我们的方法,通过引入属性作为中间桥梁,软词元在学习的过程中不仅要去学类别有关的表征,还要去学习与通用锚点属性相关的表征。
这样在遇到下游未知类别的时候,已有的通用属性表征能够提供更多的信息或者角度,促进对于图像和文本类别的匹配。
如何确定属性?
对于各种数据集,我们不可能人为的去一个个筛选。当类别数量太庞大时,人不可能正确的归类所有的选项。
于是我们就提出了,可微分的属性搜索方法(Differentiable Attribute Search),参考NAS[10],我们让网络以学习的方式去搜出来当前最适合的属性内容以及数量。

图10. 可微分属性搜索方法总览图。
整个过程分为两步,先看(a),
第一,通过多轮对话,让LLM自己总结出指定数量的通用属性。这里我们将数量设定成5,(是因为发现大于5之后,比如8,增加的属性在语义上会有重复,意义不大,数量过小的话给search留下的空间又会不够。所以直接设置成5。)
第二,对得到的独立属性基进行组合,形成属性池。用作接下来的搜索方法的搜索空间。比如我们分别得到了shape, color, material, function, size五个属性基,我们对其进行组合,会产生31种组合结果,在数学上的计算也就是。
分别为(shape), (color), (material), (function), (size), (shape, color), ..., (function, size), ..., (shape, color, material), ..., (shape, color, function, size), ..., (shape, color, material, function, size)。
这里31种组合,就对应在(b)中会产生31个输入路径,就是(b)中绿线,红线,淡蓝线所代表的。
再看(b),
对于属性池中各种属性组,我们将目标属性的搜索简化为对每条路径的权重的优化,也就是优化(b)中那个weight vector。权重中confidence的值越大,就代表网络更加倾向于使用这一组属性,也就是这组属性更适合当前的任务。
我们采用交替优化方法来训练,也就是,在一轮的训练里,一边更新每个路径里的软词元的权重,一边更新每条路径的属性权重。通过40轮的优化,选择属性权重α最大的路径对应的属性作为最终的结果。
以在Caltech101的数据集结果为例:

表1. 在Caltech101上进行属性搜索的输出结果。
对于5个属性基,会产生31种属性组合,在经过40轮的搜索后,(shape, size)这个属性组合产生了最高的权重(置信度),我们就将其选择出来,作为目标属性应用到ATPrompt里面用于训练。
实验结果
看了这么多分析之后,下面直接来说结果吧:(不想看可以直接跳到后面的 理想与愿景,常见问题解答)
Base-to-Novel泛化实验:

表2. 在11个数据集上的base-to-novel实验。
Cross-dataset实验:

表3. Cross-dataset实验结果。
从以上的结果来看,在使用ATPrompt替换了自从CoOp提出的基础形式之后,将ATPrompt集成到已有的基线方法上都获得了一致的提升。
消融及验证性实验
1. 如果我们不用搜出来的结果,就随便选一些很通用的结果怎么样?或者故意选择一些跟数据集丝毫没关系的?
我们在11个数据集上进行了实验,

表4. 选择通用的属性和与数据集不相关的属性的结果。
其中,类型为common,代表的是选择的是通用类别,类型为irrelevant,代表的是选择与实物没有明显关联的类别属性。
从表4可以看出,1. 搜索的结果取得了最高的性能,2. 与数据集无关的属性确实是会影响到soft token的学习。但是他们的掉点依然不多,这从侧面反映了一个有意思的现象是,soft token拥有某种纠错的能力,尽管选择了与数据集毫无关系的属性,但是soft token通过学习依然能够把错误的属性表征给拉回来。
2. 属性的顺序有没有影响?
其实在图7和表1里,我们是没有考虑属性顺序的影响的。这源自生活里的一个经验,就是在人类表述中,属性描述顺序的改变并不会显著地影响语义的表达,比如,“这条短腿,黄白色毛发相间的狗是柯基”和”这条黄白色毛发相间,短腿的狗是柯基“表达的是相同的意思。
但是光这么想不太行,还需要实验验证一下。

表5. 属性顺序的验证实验。
在表5中,我们对调了属性的顺序,可以看到,属性的变化只会带来略微的波动,一般只在0.1-0.2左右,在合理的波动范围内。这说明,属性的变化对于模型整体性能来说没有明显的影响。
3. ATPrompt-Deep版本的词元操作。
在图8中,我们提出了Deep Verision,也就是深层版本。

表6. 在Deep Verision中对词元各种操作的对比。
深层版本里,我们采用了在前向计算过程里保存属性相关软硬词元,仅drop和re-add类别词元前的软词元的操作。表6中是对各种操作的对比。
完整的对应属性基以及搜索结果列表

表7. 属性基和搜索结果列表。
Attribute Bases代表属性基,即由LLM询问得到的独立结果,在此基础上进行组合就会得到属性池。Searched Results代表搜索结果,即在属性池中进行搜索后得到的结果。
理想与愿景
如我们在前文说到的,大量的基于正则化的方法(KgCoOp, ProGrad, LASP, PromptSRC, CoPrompt, KDPL, CasPL, PromptKD)占据了性能排行榜的前面。尽管直接加一个与原始clip对齐的loss很有用,但是这样的方式仍是治标不治本的。(同理对于引入额外的数据(HPT, POMP, TextRefiner)的方法也一样)。换句话说就是,假如soft token能够学得很好,那跟原始模型的feature对齐就应该是完全没用和没意义的。
这样的问题就像是在教育小朋友的时候,我们不能一味的只教育不能去做什么,而是应该去教一些通用有效的知识,根据这些,小朋友能够触类旁通才是最好的。
基于正则化方式要去解决的问题其实来源就是prompt形式所上带来的问题。自从CoOp提出了prompt learning之后,大家全都在follow这一个固定的prompt: soft tokens+class token的范式,已有软词元(soft tokens)在训练过程中只能接触到class token,因此就会被限制在只能学习到与已知训练类别有关的信息(论文ArGue也提到了这点),随着不断的训练,会不停的对已知类别过拟合,训多了之后novel类的acc就会崩。所以基于正则化的方式就是在缓解或者减弱这样过拟合的趋势,同时缩短训练的epoch,大幅提升novel性能从而增加HM。
要根本上改进这个问题,就需要改进或者reformulate自coop提出以来的learnable prompt形式,而不是不停的加各种正则化项(这不elegant)。我们的目标是要让prompt中不能够只含有class token,而要包含一些其他有意义的token来促进识别。
所以在ATPrompt里,我们就首先提出通过引入一些额外的属性作为锚点嵌入在soft tokens+class token中,引导软词元在适配到下游任务的过程中,不仅拟合已知类别,还能够学到更多的与属性相关的通用信息。相比于原来的coop,训练时以无额外代价的方式增加模型对于未知类别的泛化能力。
展望
ATPrompt所做的事情只是对于高效learnable prompt结构设计的一小步,我们希望抛砖引玉,未来能够有更多的工作关注在设计高效结构上,使得能够不过度依赖正则化loss,通过良好的prompt结构,soft token通过训练就能够达到comparable的性能。
ATPrompt可以进一步展开做的地方
- 将属性词替换成特定任务的关键词,结合到某类特定的任务中去,比如open vocabulary detection, segmentation, action recognition等任务。
- ATPrompt在deep version上的性能是比较有限的,提升的效果比较少,目前的形式还不是特别work的,期望未来有工作能够进一步把做的更好。
- 基于ATPrompt的形式去设计一些新的prompt learning方法,取得更高的结果,或者能够动态结合起来attributes,超越原本的ATPrompt。
常见问题解答
Q1: 用提示学习微调VLMs有什么实际意义?
A1: VLM的模型如CLIP,拥有非常好的零样本泛化能力,可以作为基础模型部署在许多业务场景里。
但是CLIP的优势往往指的是对通用类别的识别上,在对于特定类别数据,例如猫狗和飞机类型的细粒度鉴别,或者罕见类别的识别,往往性能表现不行。
这时要提升模型在特定任务上的预测性能,一种直接的做法是全参数微调,但是这需要大量的image-text pair数据训练,费时费力,如果仅有少量训练数据,则可能会让CLIP overfit到下游数据上,破坏原先的泛化性能。
另一种可行的做法就是用提示学习,通过引入少量可学习参数去微调CLIP,因为参数量少,所以对于训练数据量需求低,又因为不涉及参数模块(例如fc层)的训练,在遇到未知类时能够保持CLIP原始的零样本泛化性能。
Q2: 学习到的属性是每个样本都有一个吗?
A2:不是的,是整个数据集只对应一个。在属性搜索阶段,整个数据集只对应一个weight vector,在训练完成后,会选择vector中score最高的对应的属性作为目标属性用于接下来的ATPrompt提示学习训练。
参考
[1] Learning Transferable Visual Models From Natural Language Supervision. ICML 21.
[2] Learning to Prompt for Vision-Language Models. IJCV 22.
[3] Conditional Prompt Learning for Vision-Language Models. CVPR 22.
[4] MaPLe: Multi-modal Prompt Learning. CVPR 23.
[5] Read-only Prompt Optimization for Vision-Language Few-shot Learning. ICCV 23.
[6] Self-regulating Prompts: Foundational Model Adaptation without Forgetting. ICCV 2023.
[7] Visual-Language Prompt Tuning with Knowledge-guided Context Optimization. CVPR 2023.
[8] Prompt-aligned Gradient for Prompt Tuning. ICCV 2023.
[9] PromptKD: Unsupervised Prompt Distillation for Vision-Language Models. CVPR 2024.
[10] DARTS: Differentiable Architecture Search. ICLR 2019.
....
#为什么不推荐研究生搞强化学习研究?
我已经很久没答学术上的问题了,因为最近审的申请书一半都是强化学习相关的?所以知乎老给我推强化学习的各种东西……我就来简单的谈一谈强化学习吧。
强化学习如果说你要是读到硕士研究生为止,哪怕你读的是清华北大的,最重要的基本功就是调包,搞清楚什么时候该调什么包就可以了,其次就是怎么排列组合,怎么缩小解空间,对一些算法只需要有个基本的流程性了解就好了。
如果你读的是博士,建议换个方向,我觉得在现在的强化学习上雕花就是浪费时间和生命,当然你要是以发很多papers,混个教职当然可以,就是你可能很久都做不出真正很好的工作来,混口饭吃也不注重这个。
我对强化学习的感受就是古老且原始,感觉就好像现在我还拿着一个iphone 初代在用,没有原生多任务,有好多研究者给这个上头魔改了一下做了个伪的多任务,但是仍然改变不了它的本体是2g手机的本质,所以在上面折腾来折腾去的意义有限。
或者从另一个角度来看,我耳边响起了星际穿越这部电影的配音。
强化学习主线
强化学习的主线,可以按照两种方法来分:
A. Model based/ Model Free B. Value-based/Policy-based (+混合 AxC) ,数学上掌握起来不难,一般懂的人给讲一讲一个周基本上各种各样的算法全部都能掌握了,本质都差不多的。
写的具体一点就是:
- 1.1 Value-based
- 1.2 Policy-based
- Model-based
- 2.1 Value-based
- 2.2 Policy-based
- 2.3 Actor-Critic
- Model-free
这些方法都建立在MDP这个上头,说的更加符合课本一点,其基础就是贝尔曼公式、时序差分、蒙特卡洛这个东西,后面对RL的所有攻击基本上都是基于这三个最核心的内容。
为什么不推荐搞强化学习研究?
说说为啥我不推荐搞强化学习研究,我发现极少人愿意去讲强化学习的这些问题,可能是怕说了以后影响门派香火吧:
我先提一提本质上的第1个问题:样本利用效率低
我原来最早入门机器学习的课本是概率图模型(PGMs),所以对这些比较敏感一点,我感觉强化学习就是利用蒙特卡洛(MC)或时序差分(TD)方法,近似地做动态规划。所以PGMs当年遇到的样本利用效率极低的问题,强化学习也跑不了。
所以很多解决方案一看就很熟悉了,就是把当年PGMs里面那一套移植了一下:
- 模型学习与结构化建模:像PGM一样显式学习环境动态的概率结构(如状态转移和奖励分布),利用模型生成“虚拟经验”或做规划。流派:Model-based RL等。
- 变分推断与贝叶斯方法:借鉴PGM的变分推断和贝叶斯推断,建模策略/价值函数/环境参数的不确定性,用于高效探索和样本复用。流派:Bayesian DQN、Bayesian Policy Optimization、Soft Actor-Critic等。
- 重要性采样与加权经验复用:利用PGM里的重要性采样思想,对采集到的经验进行加权复用,提高样本利用率。流派:离线RL、优先经验回放等。
- 层次化结构与因果推断:借鉴PGM的层次化和因果建模思想,分层抽象决策和归因,提升泛化与数据利用率。流派:Hierarchical RL等。
- 消息传递与结构化规划:PGM中的信念传播和结构化推断,可在RL的多智能体、网络化环境等情形下提升局部决策效率和样本共享。流派:某些多智能体RL。
最终结论:当年PGMs搞这个搞定了没有?明显没有!这些东西可能在强化学习里面看起来很复杂,但是这个是PGMs的基础理论,要是不会我上头说的这些推导,你基本上等于没有学过PGM。你说RL能在这个框架下搞定样本利用率低的问题吗,我个人觉得,显然不能,这个是框架决定了上限,你和我说一个2G手机改改能和5G的上网一样快?如果真的可以,我反而觉得PGMs的复活会比RL更早。
我再说说第2个问题吧:泛化能力堪忧!
这个我们在做PGMs的时候也同样遇到的,RL事实上问题的症结也是类似的,就是假设太强了。
- PGM的强假设很多体现在公式“背后”, PGM的很多假设体现在模型结构、推断过程和理论证明里,往往是“间接”的。
独立同分布(IID):虽然所有采样和期望都假设样本独立,但PGM推断/估计过程中很少会在主公式上直接写出IID,而是隐含在分布分解与采样机制里。
马尔可夫性:PGM的马尔可夫假设(如一阶马尔可夫链、马尔可夫网络等),更多作为结构约束体现在图结构里,不总是在损失/目标函数上显式出现。
共轭分布:选择共轭分布主要是为了推断可解和计算方便,也很少在优化目标里直接体现,而是在参数更新和边缘化步骤才用上。
- RL的强假设往往更“显式”更“硬”, RL中的这些假设常常作为更新规则的直接依据,公式“表面”就能看到,一旦假设被破坏,算法很容易失效。
马尔可夫性:Bellman方程、策略评估、TD误差等都直接假定下一步只由当前状态和动作决定,这在所有RL的核心公式里明晃晃地写着。
IID与经验复用:很多RL方法在采样或经验回放时,直接要求数据独立且分布不变,但现实中经验池、环境变化导致分布漂移问题极其突出。
奖励函数与环境动力学:RL几乎所有公式都假定奖励和状态转移分布是已知或能被模型学到的,现实中常常难以满足。
结论:首先,这些假设是在是太强了,根本不符合实际,其次,相比之下我觉得PGM会稍好一点,RL可以改的和PGM差不多,把PGM那个东西也可以移植一部分进来,那一弄不就是PGM的翻版了。同样的,当年PGMs解决这个问题了吗,没有没有没有!
别的问题我就不多说了,就是这两个问题事实上是RL当前遇到大困境的来源,那怎么办,解决的方案其实就是把RL自己的命给革了,这个就是Bellman equation,TD, MC带来的本质性问题。如果RL的发展方向是搞各种算法移植PGMs的思想的话,那PGM的昨天不就是RL的明天吗?RL其实最应该做的就是重新思考大框架,就像手机一样,2G时代终将落幕,希望今后的研究者带我们进入一个新的世界。
最后再说一句
其实RL也没有那么不行,当年做统计机器学习的时候不也是有很多很好的应用,在有限的条件下可以用RL。
- RL的具体思路和深度学习的思路不太一致,这个从我上面的分析中也能看出来,因此RL可以作为辅助性方法,千万不要把RL当成一个主方法,当你用其他方法真的没法解决的时候,用一下RL死马当活马搞一下看看。
- 如果要真的用RL,其中最关键的是要严格定义RL的搜索空间,缓解采样效率低的问题,另外最好能根据先验限制RL的应用环境,避免泛化性能弱的问题。
....
#A Survey of Behavior Foundation Model
行业新突破:行为基础模型可实现高效的人形机器人全身控制
人形机器人作为用于复杂运动控制、人机交互和通用物理智能的多功能平台,正受到前所未有的关注。然而,由于其复杂的动力学、欠驱动和多样化的任务需求,实现高效的人形机器人全身控制 (Whole-Body Control,WBC) 仍然是一项根本性的挑战。
虽然基于强化学习等方法的控制器在特定任务中展现出优越的性能,但它们往往只具有有限的泛化性能,在面向新场景时需要进行复杂且成本高昂的再训练。为了突破这些限制,行为基础模型(Behavior Foundation Model,BFM)应运而生,它利用大规模预训练来学习可重用的原始技能和广泛的行为先验,从而能够零样本或快速适应各种下游任务。
来自香港理工大学、逐际动力、东方理工大学、香港大学和 EPFL 等知名机构的研究者合作完成题为 《A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots》 的长文综述,首次聚焦行为基础模型在人形机器人全身控制中的应用。
该综述系统性地梳理了当前 BFM 的最新进展,从预训练(Pre-training)和任务适配(Adaptation)两个角度对当前各类 BFM 算法提供了全面的分类体系,并且结合其他基础模型(例如大语言模型、大规模视觉模型)的发展动向对 BFM 的未来趋势和研究机遇进行了展望,有望对该领域的研究者和从业者产生引导作用。
论文标题:
《A Survey of Behavior Foundation Model: Next-Generation Whole-Body Control System of Humanoid Robots》
论文链接:https://arxiv.org/pdf/2506.20487
项目主页:
https://github.com/yuanmingqi/awesome-bfm-papers
人型全身控制:从 「定制化」 到 「通用化」
文章将人形全身控制算法的演化总结为下图中的三个阶段:

基于模型的控制器(Model-based Controller):
以 MPC、WBOSC 等算法为代表,面向基础的人形全身控制任务,极度依赖物理模型并且需要复杂的人工设计与调校,且鲁棒性较低。
基于学习的,面向特定任务的控制器(Learning-based and Task-specific Controller):
以强化学习、模仿学习等方法为代表,面向特定的、复杂的人形全身控制任务,支持灵活的任务设计,但跨任务的泛化性较差。
行为基础模型(Behavior Foundation Model):
在大规模人类行为数据集上进行预训练得到的模型,习得大量可复用的基础技能以及广泛的行为先验,具备快速适应不同任务的能力。
什么是行为基础模型?
「行为基础模型」 这一术语首次出现在《Fast Imitation via Behavior Foundation Models》 一文中,作者基于无监督强化学习 + 前后向表征学习(Forward-backward Representation Learning)方法构建 BFM,实现了对多种模仿学习规则的支持,包括行为克隆(Behavioral Cloning)、特征匹配(feature matching)、基于奖励 / 目标的归纳(reward/goal-based reductions)。
该工作也被 ICLR2024 接收为 Spotlight 文章。后续的其他工作则将 BFM 定义为:「对于一个给定的马尔科夫过程,行为基础模型是一类以无监督强化学习方法训练得到的智能体。在测试时,可以为指定的大量奖励函数生成近似最优的策略,而无需额外的学习或规划」。

该综述将 BFM 的定义拓展为:「一类特殊的基础模型,旨在控制智能体在动态环境中的行为。BFM 植根于通用基础模型(例如 GPT-4、CLIP 和 SAM)的原理,使用大规模行为数据(例如轨迹、人类演示或智能体与环境的交互)进行预训练,从而对广泛的行为模式进行编码,而非局限于单任务场景。这一特性确保了模型能够轻松地对不同任务、情境或环境进行泛化,展现出灵活且自适应的行为生成能力。」
主要算法分类
文章将当前构建 BFM 的方法分为三类:目标导向的学习方法(Goal-conditioned Learning)、内在奖励驱动的学习方法(Intrinsic Reward-driven Learning),以及前后向表征学习方法(Forward-backward Representation learning)。

如下图所示,目标导向的学习方法会对智能体给予明确的任务指导,通常直接将目标输入到智能体的策略中。目标可以以多种形式指定,例如目标状态、目标函数或外部任务描述。

在目标学习的各类方法中,以 DeepMimic 为代表的基于动作追踪(Motion Tracking)的学习方法目前被广泛地应用于各类人型机器人任务中。在每个时间步,智能体通常被训练来跟踪给定参考运动的关节角度或下一时间步的运动学姿态。相较于直接模仿整个运动(尤其是复杂运动),学习跟踪单个姿态更容易实现且更具通用性,这也是基于跟踪的学习的主要动机。

MaskedMimic 是典型的基于目标学习方法构建的行为基础模型,其包含两个阶段的训练过程。首先,MaskedMimic 基于动作追踪方法对大量的行为数据进行模仿,学习各类基础运动技能。然后,将得到的底层控制器固定,并训练一个带掩码的变分自编码器对底层控制器包含的知识进行蒸馏得到高阶策略。MaskedMimic 支持多种控制模态,并能在不同任务之间实现无缝切换。

在基于追踪的学习中,智能体始终被赋予了明确的目标,并通过显示指定的奖励函数进行训练,以实现定向的技能学习。相比之下,内在奖励驱动的学习则使用完全不同的方法,即激励智能体对环境进行探索,而不依赖于明确的特定任务奖励。智能体受内在奖励的引导,这些内在奖励是自我生成的信号,用于鼓励探索、技能习得或者发现新奇的事物。
但是,只通过内在奖励训练 BFM 存在显著的限制,智能体通常需要进行巨量的训练才能实现广泛的行为覆盖,同时有概率产生不可靠的行为先验(例如,不安全或不切实际的运动),特别是对于具有极其复杂动力学的人形机器人而言。
因此,在实际应用时,内在奖励往往要结合其他方法使用,例如目标导向学习,以确保学得模型的有效性。
近期 BFM 的主要进步受益于一种新的学习框架 —— 前后向表征学习,其主要思想是将策略学习与特定任务目标进行解耦。前后向表征学习的核心是对后继测度(Successor Measure)进行学习,对于一个策略 π,其后继测度定义为:

其代表了对未来访问状态分布的建模。基于后继测度,动作价值函数可以表示为:

以上公式将动作价值函数分解为两部分:后继测度和奖励函数。因此,只要学习到了策略 π 的后继测度,即可对任意奖励函数对应的动作价值函数进行零样本估计,而无需进一步的训练。在具体学习时,后继测度又被分解为:

如下图所示,我们分别使用一个前向嵌入网络和一个后向嵌入网络进行训练。

最终,我们可以将策略表示为:

Meta 基于前后向表征学习方法开发了 Motivo 模型。如下图所示,Motivo 学习了广泛的行为先验,并展现出卓越的零样本自适应能力,可应对各种下游任务,包括复杂的运动模仿、姿势达成和复合奖励优化。并且,Motivo 能够在确保运动自然性的同时实现实时运动控制。

潜在应用与现实限制
文章进一步对 BFM 的潜在应用和现实限制进行了分析,如下图所示:

应用方面:
人形机器人的通用加速器:BFM 包含了大量可复用的基础技能和广泛的行为先验,可以消除白板训练,实现对下游任务的快速适应。诸如 Motivo 等高级 BFM 能直接将高级任务映射为控制动作,大幅缩短开发周期。
虚拟智能体与游戏开发:BFM 能生成逼真、情境感知的 NPC 行为,结合 LLMs 实现复杂指令解析,为游戏提供前所未有的交互真实感。
工业 5.0:BFMs 使人形机器人融合预训练技能与实时适应性,支持多任务切换和直观人机协作,推动以人为中心的弹性制造。
医疗与辅助机器人:BFMs 帮助机器人在非结构化环境中适应多样化需求,如个性化康复训练和日常辅助任务,应对人口老龄化挑战。
限制方面:
- Sim2Real 困难:BFM 在学习丰富行为技能的同时,也加剧了仿真与现实的差异,如动力学不匹配和感知域偏移,目前的实际应用仍主要局限于仿真环境,真实部署面临行为泛化不稳定等挑战。
- 数据瓶颈:BFMs 训练数据规模远小于 LLMs 或视觉模型,且机器人真实数据稀缺,多模态数据(如视觉 - 本体感知 - 触觉对齐)尤其缺乏,亟需更大规模、高质量数据集支撑发展。
- xx泛化:当前 BFMs 仅针对特定机器人形态训练,难以适应不同构型(如关节类型、驱动方式或传感器配置),需开发更具通用性的架构以实现跨平台技能迁移。
未来研究机会与伴随风险
最后,文章探索了未来的研究机会和伴随的风险:

研究机会方面:
- 多模态 BFM:未来 BFM 需整合视觉、触觉等多模态感知输入,以增强非结构化环境中的适应能力,但面临数据集和训练范式的挑战。
- 高级机器学习系统:BFM 可与 LLM 等结合,形成认知 - 运动一体化架构,由 LLM 负责任务规划,BFM 执行实时控制,实现复杂任务的灵活处理。
- 缩放定律:BFM 的性能可能随模型规模、数据量和计算资源提升而增强,但需平衡行为多样性与控制效率,其中数据质量对行为先验的学习尤为关键。
- 后训练优化:借鉴 LLM 中的的微调、RL 对齐和测试时优化技术,可提升 BFM 的行为对齐性和实时计算效率,需开发针对机器人控制的专用方法。
- 多智能体系统:BFM 能免除单机器人基础技能训练,直接支持多机协作研究,但需开发基于群体交互数据的新型模型以解决物理协调难题。
- 评估机制:当前缺乏 BFM 的标准化评估体系,未来需构建涵盖任务泛化性、鲁棒性和人机安全的多维度基准,推动通用物理控制器发展。
风险方面:
- 伦理问题
训练数据的局限性可能导致机器人行为编码人口偏见或泄露用户健康隐私,而其实体化部署可能放大有害动作的社会风险,亟需建立覆盖数据规范和实时行为治理的新框架。
- 安全机制:
BFM 面临传感器干扰引发的控制失效和多模态攻击漏洞等风险,需通过对抗训练和跨模态校验等机制确保其在开放环境中的可靠性和安全性。这些挑战要求研究者在技术创新的同时,同步推进伦理规范和安全防护体系的建设。
结语
该综述首次系统性地梳理了行为基础模型在人形机器人全身控制领域的引用,全面地介绍了相关技术演化历史、方法分类、实际应用、技术瓶颈以及未来研究机会与伴随的风险。
尽管行为基础模型展现出前所未有的强大能力,其也面临着重大挑战,包括 Sim2Real 差距、实体依赖和数据稀缺等问题。在未来的工作中解决这些局限性将有助于开发更可靠、更通用的行为基础模型。
....
#DeepMind夺得IMO官方「唯一」金牌
却成为OpenAI大型社死现场
刚刚,谷歌 DeepMind 宣布,其新一代 Gemini 进阶版模型在 IMO 竞赛中正式达到金牌得主水平,成功解决了六道超高难度试题中的五道,拿下 35 分(满分 42 分),成为首个获得奥赛组委会官方认定为金牌的AI系统。
更重要的是,该系统首次证明人工智能无需依赖专业编程语言,仅通过自然语言理解即可攻克复杂数学难题。
谷歌 DeepMind 首席执行官哈萨比斯在社交媒体平台 X 上强调:这是官方结果!

谷歌这项成绩远超其在 2024 年的表现。当时,AlphaProof 和 AlphaGeometry 系统组合解决了六个问题中的四个,荣获银牌。

今年的突破来自 Gemini Deep Think,这是一个增强型推理系统,采用了研究人员所谓的并行思维。与遵循单一推理链的传统人工智能模型不同,Deep Think 会同时探索多种可能的解决方案,最终得出答案。
哈萨比斯在后续帖子中解释道:谷歌的模型以自然语言进行端到端运行,直接从官方问题描述中生成严格的数学证明。并强调,该系统在比赛标准的 4.5 小时时限内完成了任务。

谷歌这次官宣,让 OpenAI 处于尴尬的处境,毕竟 OpenAI 因绕过官方竞赛规则提前官宣,遭到很多人吐槽。可参考《OpenAI 拿 IMO 金牌是火了,但惹怒大批人:抢发炒作,抢学生风头》。
谷歌 DeepMind 这种谨慎的发布方式赢得了 AI 界的广泛赞誉,尤其与竞争对手 OpenAI 对类似成绩的处理方式形成了鲜明对比。
「我们没有在周五宣布这一消息,是因为我们尊重 IMO 理事会最初的要求,即所有人工智能实验室只有在官方结果经过独立专家验证,并且学生获得应有的赞誉后,才能分享其成果。」哈萨比斯写道。

对比之下,大家都在谴责 OpenAI 做事不地道、毫无风度、无礼。反观谷歌 DeepMind ,行事正直,符合人性。

这种批评源于 OpenAI 决定在不参与 IMO 官方评估流程的情况下公布自己的成绩。OpenAI 让一个由前 IMO 参赛选手组成的小组对其 AI 的表现进行评分,社区中的一些人认为这种做法缺乏可信度。
OpenAI 又来回应了
OpenAI 研究科学家 Noam Brown 向谷歌发来祝贺,说是祝贺,更多的是为了回应质疑。以下是回应内容。
谷歌采用的方法与我们略有不同,这表明还有很多研究方向值得探讨。
两个月前,IMO 组委会曾通过邮件邀请我们参加基于 Lean 语言的正式比赛。由于我们一直致力于不受 Lean 限制的自然语言通用推理研究,因此婉拒了该邀请。组委会从未就自然语言解题形式与我们进行过接洽。
在过去的几个月里,我们在通用推理方面取得了很大进展。这包括收集、整理和训练高质量的数学数据,这些数据也将用于未来的模型。在 IMO 评估中,我们没有使用 RAG 或任何其他工具。

我们提交的每份证明都由三位外部 IMO 奖牌获得者评分,并获得了一致的正确性认可。我们还将证明公开发布,以便任何人都可以验证其正确性。
证明地址:https://github.com/aw31/openai-imo-2025-proofs/

在分享我们的结果之前,我们与 IMO 的一位董事会成员进行了交谈,他要求我们等到颁奖典礼结束后再公开结果,我们的发布满足要求。
我们在颁奖典礼结束后,于太平洋时间~凌晨 1 点(澳大利亚东部标准时间下午 6 点)宣布。从来没有人要求我们晚于此宣布。
最重要的是,我们很高兴与世界分享我们的进展和成果。AI 推理能力正在快速发展,这些 IMO 结果确实表明了这一点。

通过这件事,我们不难发现,这场 AI 登上数学奥林匹克舞台的较量,不只是一次技术竞赛,更是一场关于规范、节奏与合作精神的展示。DeepMind 选择了等待官方认可,再谨慎发布成绩,赢得了金牌,也赢得了尊重。而 OpenAI 尽管也取得了不俗成果,却因时机与方式的问题,引发了争议。这背后提醒我们,在通往 AGI 的路上,除了技术力,如何与人类社会的规则与价值观对齐,正变得愈发重要。
参考链接:
https://x.com/polynoamial/status/1947398536577822798
....
#Sporks of AGI
关于机器人数据,强化学习大佬Sergey Levine刚刚写了篇好文章
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。
大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
目前而言,Agent 是我们走向通用人工智能(AGI)的重要过渡。训练 Agent 则需要带有行动标签的真实交互数据,而获取这类数据的成本远比从网页上获取文本与图像的成本高昂得多。
因此,研究者一直在尝试寻找一种替代方案,来实现鱼和熊掌兼得的效果:既能够降低数据获取成本,又能够保证大模型训练成果,保持基础模型训练中常见的大规模数据带来的优势。
加州大学伯克利分校副教授,Physical Intelligence 的联合创始人,强化学习领域大牛 Sergey Levine 为此撰写了一篇文章,分析了训练大模型的数据组合,但他却认为,鱼和熊掌不可兼得,叉子和勺子组合成的「叉勺」确实很难在通用场景称得上好用。


博客标题:Sporks of AGI
博客链接:https://sergeylevine.substack.com/p/sporks-of-agi
替代数据
尽管在视觉感知和自然语言处理任务中,真实世界数据一直被视为首选,但在智能体领域,尤其是机器人智能体(如视觉 - 语言 - 动作模型,VLA)中,研究者们始终在尝试寻找「替代方案」—— 即能以较低成本获取的代理数据,来代替昂贵的真实交互数据,同时仍具备训练基础模型所需的泛化能力。本文聚焦于机器人领域,但其他任务也基本遵循类似思路,只是采用了不同形式的替代数据。
仿真是一种经典策略。设想我们可以在《黑客帝国》般的虚拟环境,或高保真的电子游戏中训练机器人,就有可能避免对真实世界数据的依赖。
虽然这些方案产生了大量令人兴奋且富有创意的研究成果,但若从结构上可以将它们统一描述为:人为构建一个廉价代理域与真实机器人系统之间的映射关系,并基于这一映射,用廉价数据替代真实任务域中的昂贵数据。主流的几种方法如下:
仿真(Simulation):
「仿真到现实」(sim-to-real)的方法依赖人类设计者指定机器人的训练环境,并提供相应资源(如物理建模、视觉资产等)。机器人在仿真中学习到的行为很大程度上取决于这些人为设定。实际上,最有效的仿真往往并不追求对现实的高度还原(这本身极具挑战),而是故意引入各种环境变化,如随机的石板路或不同高度地形,以提高机器人鲁棒性。这种设计方式不仅定义了任务「是什么」,也间接规定了任务应「如何完成」。
人类视频(Human Videos):
基于人类视频训练机器人技能的方法,通常需要在人体与机器人之间建立某种对应关系,例如手的位置或手指的抓取动作。这种映射方式预设了一种具体的任务完成策略(例如通过「握持 - 搬运」的方式),同时也必须跨越人类与机器人在动力学和外观上的差异鸿沟。
手持式夹爪设备(Hand-held Gripper Devices):
这种方法并非在训练时构建映射关系,而是通过物理手段直接建立人机之间的映射。具体做法是让人类使用手持设备来模仿机器人夹爪完成任务。这种方式颇具吸引力,因为参与者必须以类似机器人的方式执行任务。但这同样隐含着一套「动作设定」前提:例如,设备默认机器人能在具有 6 自由度的操作空间中,仅使用手指完成任务,且不暴露机器人与人类在运动学结构或外观上的差异。
以上方法都产生了大量有意义的研究成果,并在实践中取得了诸多成功案例。然而,从长远看,我认为这些方法在本质上都代表了一种妥协 —— 这种妥协可能会削弱大规模学习模型原本所具备的强大能力与泛化潜力。
交叉点
在数据采集过程中,人类的判断显然无法回避:即便是最真实、最纯粹的「白板式」学习方法,也必须由我们来设定模型应完成的任务目标。然而,当我们试图规避对真实数据的依赖而做出的一些设计决策,往往会带来更大的问题,因为这些决策本身就限制了解决问题的方式。
每存在一个领域差异(如模拟环境、视频等),我们所能采用的解决方案就被限定在一个交集之中:

随着模型能力的不断增强,其区分替代数据域与真实世界目标域的能力也在提升(即图中黄色圆圈收缩),这就导致行为策略的交集区域不断缩小。
我们可以尝试通过隐藏信息来对抗这一问题,例如减少观察空间、引入领域不变性损失、限制机器人可用的摄像头视角等等。几乎所有用于缓解领域差异的方法归根结底都是某种形式的信息隐藏。
但这种做法再次削弱了基础模型的最大优势 —— 即整合复杂信息来源、提取人类难以察觉的细微模式的能力。
换句话说,随着模型变强,黄色圆圈变小,而任何试图阻止这一趋势的做法,最终都等同于削弱模型能力。我们只能通过「让模型变傻」,来「欺骗」它不去意识到自己身处「矩阵」之中。
这个交集区域的大小,还严重依赖于我们在构建替代数据时所做的设计决策 —— 设计得越糟糕,绿色圆圈(真实世界中成功策略的空间)与红色圆圈(可用于训练的替代策略空间)之间的交集就越小。
实际操作中,我们往往围绕某几个特定应用场景,精心设计替代数据的获取方式,以尽可能缩小在这些场景下与真实机器人的差异,使得「良好行为」在这两个系统中尽量一致。
但这种一致性在这些应用场景之外并无任何保障。
本质上,当我们用人类的数据来训练机器人基础模型,再让它面对新的任务时,它会试图预测「人类会如何解决这个问题」,而不是预测一个「机器人能如何高效完成这个任务」的策略。
这再次背离了基础模型的核心优势 —— 即具备广泛通用性和强泛化能力,能够将训练模式推广到全新领域。
而如今,每进入一个新领域,我们就需要投入更多的人工工作来改善替代数据与真实世界之间的对应关系;模型原本的泛化能力,反而成了我们的负担 —— 它会放大替代数据与真实机器人之间的差距,使得我们在应对新场景时更为艰难。

当我们真正希望优化机器人的最优行为(例如通过强化学习)时,以上所有问题都会进一步加剧。
真实世界数据
当我们试图回避使用真实世界数据的需求时,实际上是在追求一种「鱼与熊掌兼得」的方案:既希望像模拟或网络视频那样成本低廉,又希望像在大规模真实数据上训练出的基础模型那样高效。
但最终得到的,往往只是一个「叉勺」—— 在极少数符合我们假设的场景中,它既能当叉子用,也能当勺子用,但大多数时候,它只是一个布满孔洞的蹩脚勺子,或一个迟钝无力的叉子。
在机器学习中,一贯最有效的方法是让训练数据尽可能贴近测试环境。这才是「真实的」—— 能够教会模型世界真实运行机制的数据,从而让模型能胜任任务,提取出其中的潜在规律;这些规律往往复杂而微妙,连人类都难以察觉,而模型却能从中进行归纳推理,解决复杂的新问题。
当我们用替代数据代替真实数据时,其实是在做「次优之选」:只有在某些特定条件下,它才能勉强模拟真实情况。
就像你不可能通过单靠对着墙打球,或者看费德勒打网球的录像,就成为一名真正的网球高手 —— 尽管这两者确实复制了部分专业体验;同样的,机器人如果从未在真实世界中「亲自下场」,也无法真正掌握如何在真实世界中行动。
那么,我们应从中得到什么启示?
最关键的一点是:如果我们希望构建能够在真实物理世界中具备广泛泛化能力的机器人基础模型,真实世界的数据是不可或缺的,正如 LLM 和 VLM 在虚拟世界中所展示的强大泛化能力一样。
在构建训练集时,如果我们在广泛而具代表性的真实机器人经验之外,加入包括人类演示、甚至仿真在内的多样化数据源,往往会带来帮助。事实上,可以坦然地将替代数据视为补充知识的来源 —— 它的意义在于辅助,而非替代真实的实践经验。
在这种视角下,我们对替代数据的要求也将发生根本性的转变:我们不再追求它在形态上尽可能接近真实机器人(比如使用手持夹爪,或让人模仿机器人动作录视频),而是将其视为类似于 LLM 预训练数据的存在 —— 不是直接告诉智能体该做什么,而是提供关于「真实世界可能发生什么」的知识来源。
叉勺(Sporks)
在本文中,我探讨了「替代数据」这一「叉勺」 —— 它试图在避免大规模真实数据采集成本的前提下,获得大规模训练的收益。但在人工智能研究中,替代数据并不是唯一的一把「叉勺」。
其他「叉勺」还包括:结合手工设计与学习组件的混合系统,利用人为设定的约束来限制自主学习系统不良行为的方法,以及将我们对问题求解方式的直觉,直接嵌入神经网络架构中的模型设计。
这些方法都试图「兼得」:既要享受大规模机器学习带来的优势,又要规避其高数据需求或繁琐目标设计的代价。这些方法有着相似的核心:它们都是通过某种手工设计的归纳偏置,来应对训练数据不完全的问题。
因此,它们也都面临同样的根本性缺陷:
需要我们人为地将「我们以为我们是怎么思考的方式」编码进系统中。
在任何可学习系统中,任何不是通过学习获得的、而是人工设计的部分,最终都将成为系统性能的瓶颈。
「叉勺」之所以吸引人,是因为它们让我们觉得:只要让模型按我们设定的方式解决问题,就能克服人工智能中的重大挑战。但事实是,这样做反而让我们的学习系统更难以扩展 —— 尽管我们最初的意图正是为了提升其扩展性。
....
#创智「小红书」震撼上线
让AI从效率工具进化为认知伙伴
我们似乎正处在一个“收藏即掌握”的时代。
不管是知乎、论文库,还是小红书,只要看到一句金句、一篇好文、一个值得学习的案例,我们的第一反应往往是点个收藏,留着以后看。然而,我们真的会“回头再看”吗?
让我们先来看一个令人震惊的统计:
📚 知乎收藏:平均每人收藏文章 547 篇,实际回看率仅 3.2%;
📖 论文收藏:研究生平均收藏论文 284 篇,深度阅读率不足 12%;
🎨 小红书收藏:用户平均收藏内容 1,203 条,二次浏览率仅 1.8%。
你收藏夹里有多少吃灰的链接?你今天阅读了 50 篇论文,都消化掉了吗?
这背后反映的残酷现实是:
- ❌ 输入 ≠ 努力:看了不等于学了;
- ❌ 收藏 ≠ 拥有:存了不等于会了;
- ❌ 思考 ≠ 积累:想了不等于留了。
如果有一个平台,让你像刷小红书一样轻松,但每一次浏览与收藏都是给自己的认知 + 1,每一次思考都能和 AI 共同进化呢?上海创智学院发布创智 "小红书"(Deep Cognition)—— 全球首个可以主动构建认知并且让认知真正积累的 AI 平台,一个可以创造智慧的小红书!
「线上体验」:https://opensii.ai/
信息过载的时代,如何识别高价值的洞见、认知是无数人的痛点需求。在创智 "小红书" 中,每一张卡片都承载着一条最新的认知洞察。这里汇聚着数据驱动的洞察,将最新研究的核心发现以直观的方式呈现;凝聚着理论突破的精华,用简洁明了的表达诠释复杂深奥的理论;沉淀着实践智慧的结晶,通过经验总结完成知识的深度萃取。
,时长00:30
点击体验一个具体的 “认知卡片” 实例:https://www.opensii.ai/share/cognition/6874a6d69382ee3ddd828b77
为什么 "收藏认知" 会提高你 AI 的认知?
通过下面这个例子,我们来看,如何实现” 你的每一次浏览与收藏,你的 AI 模型认知都会随之增加 ”。
具体来说,用户日常刷认知收藏的所有认知,AI 都会默默学习记录下来,习得该认知内容。下一次你和 AI 对话的时候,AI 会带着这些最新认知去思考问题,以及与你互动。因此,每一张卡片,都是思考提炼的认知,每一次收藏,都是认知资产的积累。“收藏” 这个操作已经被赋予了更多的价值,当你实在没有时间仔细阅读的时候,点击 “收藏”,至少你把属于你的 AI 模型认知提高了,下一次 AI 可以更好的帮助你解决问题。
例如,询问如下问题:
随着大模型在 context engineering 方面的能力提升,它们开始具备处理多轮对话、长期任务和研究语境的能力。我们该如何构建一个可以持续参与科研过程、协同解决问题,真正成为 “AI 科学家同事” 的智能代理?
当你向系统提出这个关于 "AI 科学家同事" 的问题时,系统会自动搜索你之前收藏过的相关认知卡片。
AI 会综合这些你曾经收藏的认知资产,结合最新的技术理解,给出个性化的回答:
"基于你之前关注的多智能体框架和长期记忆机制,我建议构建一个具备以下能力的 AI 同事系统:1)持续学习你的研究偏好和工作习惯;2)维护项目上下文的长期记忆;3)主动提出研究假设和实验设计;4)具备跨任务的知识迁移能力..."
这样,你的每一次收藏都在为未来更精准的 AI 对话做准备,真正实现了 "收藏即学习,对话即智慧"。
,时长00:59
通过这样的方式,将认知系统化构建以及平台化,还可以获得其它许多独一无二的功能:
1. 认知榜单 & 周报总结
展示本周热门认知话题排行榜(如评估指标、基准测试、人工标注等)以及社区学习动态总结


认知周报,xx,3分钟
2. 特色功能:认知个性化订阅 & 分享
根据自己专注的技术领域(如机器学习、数据科学等)和领域名人收藏专属的认知内容,并与社区分享。
3. 特色功能:认知合成
认知合成将分散的观点思维融合,形成新的深度理解和认知。
创智 “小红书” 背后的技术原理是什么?
创智学院同时也公开了相关的技术论文《交互即智能》,揭示了人机协作关系的变革。

- 论文题目:Interaction as Intelligence: Deep Research With Human-AI Partnership
- 论文地址:https://arxiv.org/pdf/2507.15759
- 项目首页 / 试用网址:https://opensii.ai/
具体来说,创智 "小红书" 所解决的认知积累问题,实际上揭示了当前人机交互模式的根本性缺陷。认知无法积累的表面原因是平台设计问题,但深层原因是 AI 仍停留在 "效率工具" 阶段,而非 "认知伙伴"。
传统的 "效率工具" 模式采用 "存储 - 检索" 逻辑:用户负责收藏和存储信息,平台负责保存和检索内容,认知处理完全依赖人类大脑的记忆和联想。这种模式的根本问题在于:它将人和机器割裂开来,把认知处理的重担完全推给了人类。用户在信息过载中疲于奔命,AI 系统却只能被动响应,无法主动参与认知的构建和积累过程 [2],在完成长复杂任务的过程中,往往会带来错误积累 [3, 4]。
该技术论文指出,当前的假设根本上误解了智能本身的性质,互动本身构成了智能的基本维度。未来,人与 AI 交互的范式将从最小化人类参与的 “效率工具” 模式,进化为 “认知伙伴” 关系。

该工作定义了一种新范式 “交互即智能(Interaction as Intelligence)”,论文提出了一个根本性的重新认知:智能 —— 无论是人类还是人工智能 —— 本质上都是交互式的、情境化的、协作的。最复杂的人类思维很少孤立发生,而是通过对话、反馈、精化和多元视角整合而涌现。
正如论文开篇引言所述:
"智能不是孤立心灵的属性,而是在心灵之间的舞蹈中涌现的。问题不在于各个组件有多聪明,而在于它们如何精彩地交互。"
基于 "交互即智能" 的理论基础,该工作提出了认知监督(Cognitive Oversight)这一全新的人机协作范式。它将人类从被动的工具操作者转变为主动的认知协作者,与 AI 形成真正的智能共同体。
从 “刷认知” 到 “使用认知” -
Deep Cognition 系统
创智 "小红书" 作为认知平台,与深度研究系统形成完美的理论 - 实践闭环,形成了 Deep Cognition 系统,可以不仅进行认知学习,还可以用习得的认知去解决高价值场景复杂的问题。具体来说:
一、深度研究系统:多智能体协同认知框架

1. 研究智能体(Research Agent)研究智能体作为系统的核心大脑,能够接收多模态输入并采用 "交替思考 - 行动" 的先进方法进行深度推理,集成了 o1、DeepSeek-R1、Claude Sonnet 4 等最先进的推理模型,确保研究过程的严谨性和前沿性。
2. 浏览智能体(Browsing Agent)浏览智能体则充当系统的感知器官,通过智能 URL 选择、并行网页抓取和基于 LLM 的质量评估,为研究提供高质量的信息支撑,同时过滤噪音和无关内容。
3. 偏好智能体(Preference Agent)是整个框架的学习中枢,基于上下文强化学习(ICRL)范式,持续学习和适应用户的个性化偏好。它跟踪用户在查询、网页浏览和报告生成三个维度的行为模式,将每一次用户交互转化为优化系统性能的宝贵信号。
深度研究系统具备如下强交互特性:
- 特征一:透明的研究过程:界面通过多种机制建立透明度,使用户可以看到和理解系统的决策过程。通过直接展示模型的推理过程和生成的查询词,搜索策略的可解释性得以支持。界面左侧的编辑器显示不断演进的研究文档,并提供 “编辑” 按钮允许用户直接修改。所有发现都恰当地链接回原始来源,方便用户追溯。
- 特征二:实时干预:系统实现了一个 “暂停” 功能,使用户在整个研究过程中保持控制权。用户可以在任何时刻中断系统,包括在显示 “正在分析技术突破,请参考...” 等进度指示时。
- 特征三:细粒度交互:当用户提出模糊的研究问题时,界面会弹出一个澄清框,提出有针对性的问题以帮助缩小范围,就像研究馆员在问 “您具体在找什么?”。用户可以优先选择偏好的搜索查询,并指定希望重点关注的特定网页或知识来源。
- 特征四:用户研究偏好自适应:系统在多个维度上适应用户的偏好和要求,提供个性化的研究辅助。系统会根据用户的历史数据和选择生成参考画像,从过去的交互中学习,以更好地匹配个人的研究方法。随着研究目标的演变,系统能在不丢失先前交互上下文的情况下适应新的需求。

该系统体现透明度、细粒度、实时交互特性的 Multi-Agent-Human 协作机制设计。

对比 Deep Cognition 和主流深度研究系统的创新点。
二、认知平台系统:创智 "小红书"
创智 "小红书" 作为认知平台系统,是 Deep Cognition 从理论研究走向实际应用的关键桥梁,它将复杂的 AI 研究能力转化为用户友好的认知服务体验。
4. 认知卡片生成引擎:认知卡片生成引擎是平台的核心创新,它能够自动将深度研究系统产生的复杂成果转化为结构化、可视化的认知卡片,每张卡片都承载着经过精心提炼的核心洞察、关键数据和重要结论,并配备可视化的知识图谱和思维导图,让复杂的研究成果变得易于理解和吸收。
5. 认知积累机制:认知积累机制则是平台的智能推荐系统,它基于用户的行为数据驱动个性化推荐,通过认知关联度的智能算法组织卡片内容,实现认知资产的复利增长效应,确保用户的每一次学习都能在现有认知基础上产生价值叠加。
实验 1:量化验证认知监督的威力
为了衡量 “交互” 本身所带来的价值,研究进行了一项关键的消融实验:将具备完整功能的 “深度认知”(Deep Cognition,DC)系统与一个移除了交互模块、只能以 “输入 - 等待 - 输出” 模式运行的版本(DC non-interaction)进行对比。结果是惊人的,如下表所示,交互的引入带来了全方位的、巨大的质量提升 [1]。

数据显示,交互的引入使得最终报告的平均质量提升了 63%。其中,提升最为显著的是报告的 “组织性 (Organization)”(+97%)、“前沿性 (Cutting-Edge)”(+79%)和 “深度 (Depth)”(+76%)。这一结果有力地证明了研究的核心论点:最大的性能飞跃并非来自一个更强大的底层模型,而是来自一个更优越的交互范式。当用户能够实时引导、修正和注入知识时,AI 生成的最终成果质量发生了质变。

表 1:交互对报告质量的提升效果(DC vs. DC without interaction)
在与当前市场领先的商业深度研究系统(Gemini, OpenAI, Grok)的直接对比中,“深度认知” 系统同样展现出全面的优势。评估从两个维度展开:一是用户对最终报告质量的主观评分,二是用户对交互过程体验的评分 [1]。

左图:专家用户针对专业领域科研问题,对最终报告质量的评分对比(本系统 vs Gemini/OpenAI/Grok);右图:各系统交互体验评分。

专家用户对系统交互功能各项指标的评价结果分布,各功能都获得了用户的高度认可。
在交互体验方面,“深度认知” 系统在七项评估指标中的六项上占据主导地位。尤其是在体现其核心设计理念的指标上,优势尤为突出:
- 透明度 (Transparency): 获得了完美的 5.00 分,比表现最好的竞品高出 25.0%。
- 细粒度交互 (Fine-Grained Interaction): 获得了 4.73 分,领先优势高达 44.6%。
- 协作性 (Cooperative): 获得了 4.62 分,领先优势达到 43.0%。
这些数据表明,该研究不仅在理论上是先进的,其最终实现的产品也为用户带来了更具协作感和可控性的使用体验。
实验 2:"专家思维放大" 效应:
这项测试要求系统在复杂的网络环境中寻找难以发现的信息,极大地考验了系统的推理和执行能力。研究结果清晰地揭示了 “认知伙伴关系” 的巨大威力。

表 2:BrowseComp-ZH 基准测试准确率对比 [1]。DC (cog+int.) 指与研究生级用户实时交互协作的模式;DC (non int.) 指无人干预的自主模式。
这一结果堪称深度研究领域的 “半人马时刻”(Centaur moment),它呼应了当年国际象棋比赛中,人类棋手与 AI 程序组成的 “半人马” 团队击败最强超级计算机的历史性事件 。数据揭示了几个关键事实:
1. 协作远胜单打独斗: “专家 + AI” 组合的 72.73% 准确率,远高于任何一个独立运行的 AI 系统(最高约 41%)。
2. 专家知识是关键: 同样的系统,在专家手中(72.73%)和在非专家手中(45.45%)的表现差异巨大。
3. 交互是释放专家潜能的钥匙: 即使是 “深度认知” 系统,在没有人类交互的情况下自主运行时,其表现也仅与普通商业 AI 持平(40.91%)。
这组数据背后隐藏着一个深刻的价值主张。它表明,当前主流的自主型 AI 工具,实际上正在浪费其最有价值的资源 —— 人类专家的智慧。一个独立运行的 AI 在复杂任务上可能只有 41% 的成功率,这意味着它在多数情况下是失败的。然而,当同一个任务交由一位专家使用 “深度认知” 系统来完成时,成功率跃升至近 73%。这之间大约 32 个百分点的巨大差距,就是被 “深度认知” 框架所释放和放大的、专家的认知价值。
因此,这项研究的真正价值主张并非简单地宣称 “我们的 AI 更强”,而是 “我们的系统让您的专家变得更强”。它将 “认知伙伴关系” 和 “互补性” 这些抽象概念,用一个具体、可量化的性能指标呈现出来,这对于任何依赖专家知识进行决策的组织或个人而言,都具有无与伦比的吸引力。这正是系统在 “投入产出比”(Results-Worth-Effort)指标上同样领先的原因。
实验 3:人机回环:解密「动态自主性」
该研究中关于人类行为的定性发现揭示了用户在与高度交互式 AI 协作时所表现出的复杂模式,展示了该系统设计对人类认知习惯的深刻理解。
超越开关模式:人机交互的战略性舞蹈
研究发现,高效的人机协作并非一种恒定的、高强度的互动状态。相反,用户会根据任务的不同阶段和认知需求,在 “亲力亲为”(Hands-on)和 “放手信任”(Hands-off)两种模式之间进行动态、战略性的切换。研究将这一现象概括为 “动态自主性”(Dynamic Autonomy)。
这种模式的发现,本身就是对传统人机交互设计理念的一次重要超越。它表明,用户的需求不是一个简单的 “开 / 关”—— 要么完全控制,要么完全放手。真实的需求是一种灵活的、可调节的控制权分配。

认知协作的六个阶段
通过对用户行为的细致观察,研究将复杂的深度研究过程分解为六个不同阶段,并清晰地描绘出用户在每个阶段的协作意愿变化,如上图所示 :
亲力亲为(Hands-on) - 人类智慧主导
1. 问题澄清 (Clarification): 在研究初期,面对模糊、开放式的问题,用户会高度参与,与 AI 一同迭代、细化研究范围。例如,参与者 P1 最初提出宽泛问题后,会主动补充具体技术方向,并认为 AI 提出的澄清问题 “包含了自己未曾想到的方面” (1)。这是人类战略性思维和框架构建能力发挥最大价值的时刻。
2. 专家知识注入 (User Knowledge Input): 当用户拥有明确的领域知识、特定的参考文献或个人见解时,他们会再次高度介入,主动引导 AI 关注关键信息源。
3. 实时干预 (Real-time Intervention): 在 AI 浏览信息的过程中,当用户发现有价值或存在偏差的内容时,会立即介入,调整 AI 的行为以符合预期。
4. 网络搜索 (Web Search): 对于需要主观判断或开放式解读的问题,用户同样倾向于亲身参与,因为这类任务对现有工具最具挑战性。
放手信任(Hands-off) - AI 能力主导
5. 推理过程 (Reasoning): 有趣的是,在 AI 进行内部推理和分析时,用户的协作意愿反而降低。他们更倾向于退后一步,观察 AI 如何自主处理指令,并评估其决策的透明度和质量。如 P12 所述,他们希望看到 “模型在面对开放问题时如何决定关键技术路线” 。
6. 网页摘要 (Web Summary): 在需要对大量信息进行整合与摘要时,用户表现出对 AI 自主性的高度信任。他们需要的是经过 AI 处理后的综合性见解,而非原始信息的堆砌,因此愿意让 AI 长时间自主运行。
这一 “动态自主性” 模型的提出,为设计更高效、更少挫败感的人机协作系统提供了一份宝贵的蓝图。当前 AI 助手的一个常见设计缺陷,是它们往往强迫用户接受一种单一的交互模式:要么需要用户进行繁琐的微观管理,要么就提供极少的控制权,让用户感到失控 。该研究通过对用户真实行为的观察发现,用户真正需要的不是一个固定的控制级别,而是在不同认知子任务间灵活切换控制权的能力。
例如,在需要创造性、发散性思维的 “问题澄清” 阶段,用户渴望 “亲力亲为” 的主导权;而在需要机械性、收敛性处理的 “网页摘要” 阶段,用户则乐于 “放手信任”,将任务委托给 AI。这一发现的设计启示是深刻的:未来的 AI 系统不应预设一种最佳交互风格,而应被设计成能够支持这种控制权动态转移的平台。这意味着,系统需要为高参与度阶段提供强大、易用的控制工具,同时为低参与度阶段提供稳定、值得信赖的自动化能力。
总结
Deep Cognition 和创智 "小红书" 进一步证明:AI 的价值不再只取决于参数规模,而是认知深度。而认知深度的实现,需要人机之间的深度交互和协作,更需要从 "效率工具" 向 "认知伙伴" 的根本性转变。
创智 "小红书" 开启的不仅是一个产品,更是一个时代:
- 认知民主化:让每个人都能轻松积累和分享智慧
- 智慧社会化:构建基于认知共享的新型社会关系
- 文明加速化:推动人类认知水平的整体跃迁
当认知成为可积累、可分享、可增值的资产,当交互成为智能本身,当 AI 从工具进化为伙伴,我们正在重新定义人类与 AI 共同进化的未来。
参考文献:
[1] Interaction as Intelligence: Deep Research With Human-AI Partnership
[2] "help me help the ai": Understanding how explainability can support human-ai interaction
[3] Why do multi-agent llm systems fail?
[4] Ironies of automation
....
#GTA
重塑注意力机制:GTA登场,KV缓存缩减70%、计算量削减62.5%
GTA 工作由中国科学院自动化研究所、伦敦大学学院及香港科技大学(广州)联合研发,提出了一种高效的大模型框架,显著提升模型性能与计算效率。一作为自动化所的孙罗洋博士生,研究方向为:大模型高效计算与优化,通讯作者为香港科技大学(广州)的邓程博士、自动化所张海峰教授及伦敦大学学院汪军教授。该成果为大模型的优化部署提供了创新解决方案。
Grouped-head latent Attention (GTA) 震撼登场!这项创新机制通过共享注意力矩阵和压缩潜在值表示,将计算量削减 62.5%,KV 缓存缩减 70%,prefill 和 decode 速度提升 2 倍。无论是处理海量数据构成的长序列任务,还是在计算资源极为有限的边缘设备上运行,GTA 都展现出无与伦比的效率和卓越的性能,无疑将成为大型语言模型优化领域的新标杆。
大型语言模型面临的效率困局
近年来,Transformer 架构的横空出世极大地推动了自然语言处理领域的飞速发展,使得大型语言模型在对话生成、文本摘要、机器翻译以及复杂推理等多个前沿领域屡创佳绩,展现出令人惊叹的能力。然而,随着模型参数量从数十亿激增至上千亿,传统多头注意力机制 (Multi-Head Attention, MHA) 所固有的弊端也日益凸显,成为制约其广泛应用和进一步发展的瓶颈。
首当其冲的是计算冗余问题。在 MHA (多头注意力) 架构中,每个注意力头都像一个独立的 “工作单元”,各自独立地计算查询 (Query)、键 (Key) 和值 (Value) 向量,这导致了大量的重复计算。特别是在处理长序列任务时,浮点运算次数 (FLOPs) 会呈平方级增长,严重拖慢了模型的处理效率,使得原本复杂的任务变得更加耗时。
其次是内存瓶颈。每个注意力头都需要完整存储其对应的键值对 (KV) 缓存,这使得内存需求随序列长度和注意力头数量的增加而快速膨胀。例如,在处理长序列时,KV 缓存的规模可以轻松突破数 GB,如此庞大的内存占用极大地限制了大型模型在智能手机、物联网设备等边缘设备上的部署能力,使其难以真正走进千家万户。
最后是推理延迟问题。高昂的计算和内存需求直接导致了推理速度的显著下降,使得像语音助手实时响应、在线翻译无缝切换等对延迟敏感的实时应用难以提供流畅的用户体验。尽管业界的研究者们曾尝试通过 Multi-Query Attention (MQA) 和 Grouped-Query Attention (GQA) 等方法来优化效率,但这些方案往往需要在性能和资源消耗之间做出艰难的权衡,难以找到理想的平衡点。面对这一系列严峻的挑战,研究团队经过不懈努力,最终推出了 Grouped-head latent Attention (GTA),以其颠覆性的设计,重新定义了注意力机制的效率极限,为大型语言模型的未来发展开辟了全新的道路。
论文标题: GTA: Grouped-head latenT Attention
论文链接: https://arxiv.org/abs/2506.17286
项目链接: https://github.com/plm-team/GTA
GTA 的核心创新机制
GTA 的卓越成功源于其两大核心技术突破,它们精妙地协同作用,使得大型语言模型即使在严苛的资源受限场景下,也能展现出前所未有的高效运行能力。
分组共享注意力矩阵机制
在传统的 MHA 架构中,每个注意力头都被视为一个独立的 “独行侠”,各自计算并维护自己的注意力分数。这种分散式的计算模式虽然赋予了模型捕捉多种复杂依赖关系的能力,但同时也带来了显著的计算冗余。以一个包含 16 个注意力头的 MHA 为例,当每个头独立处理输入时,会生成 16 组独立的注意力矩阵,这使得总体的计算开销随注意力头数量的增加而呈线性增长,效率低下。
与此形成鲜明对比的是,GTA 采用了全新的 “团队协作” 策略。该机制将注意力头巧妙地划分为若干个逻辑组,例如,每 4 个注意力头可以组成一个小组,而这个小组内部的成员将共享一张统一的注意力矩阵。这种创新的共享设计意味着,我们仅需对注意力分数进行一次计算,然后便可将其高效地分配给组内所有注意力头使用,从而大幅度减少了浮点运算次数 (FLOPs)。

实验数据有力地证明,这一精巧的设计能够将总计算量削减,为处理超长序列任务带来了显著的推理加速效果。这恰如一位经验丰富的主厨,统一备齐所有食材,再分发给不同的助手进行精细加工,既极大地节省了宝贵的时间,又确保了最终产出的高质量和一致性。
压缩潜在值表示技术
MHA 架构的另一个关键痛点在于其 KV 缓存对内存的巨大占用。由于每个注意力头的值 (Value) 向量都需要被完整地存储下来,导致模型的内存需求会随着输入序列长度和注意力头数量的增加而快速膨胀,成为部署大型模型的严重障碍。GTA 通过其独创的 “压缩 + 解码” 巧妙设计,彻底解决了这一难题。
这项技术首先将所有注意力头的值向量高效地压缩为一个低维度的潜在表示 (Latent Representation),从而极大地减少了所需的存储空间。随后,通过一个轻量级且高效的 WaLU (Weighted additive Linear Unit) 非线性解码器,模型能够根据每一组注意力头的具体需求,从这个紧凑的潜在表示中动态地、定制化地生成所需的完整值向量。

这种创新的方法不仅显著节省了宝贵的内存资源,同时还巧妙地保留了每个注意力头所特有的独特表达能力,避免了信息损失。实验结果令人鼓舞,GTA 的 KV 缓存规模成功缩减了 70%,这一突破性进展为大型语言模型在性能受限的边缘设备上的广泛部署铺平了道路,使其能够更普惠地服务于各类应用场景。
实验验证:GTA 的卓越性能与效率
研究团队通过一系列严谨而全面的实验,对 Grouped-head Latent Attention (GTA) 在不同模型规模、输入序列长度以及多样化硬件平台上的性能和效率进行了深入评估。实验结果令人信服地表明,GTA 在大幅度提升计算效率和内存利用率的同时,不仅成功保持了,甚至在某些关键指标上超越了现有主流注意力机制的模型性能,展现出其强大的实用价值和广阔的应用前景。
模型有效性验证
为了确保实验结果的公平性和准确性,研究团队在实验设计中采取了严格的控制变量法:所有非注意力相关的模型参数(例如隐藏层维度、多层感知机 MLP 的大小等)都被固定不变,从而确保模型参数量的任何变化都仅仅来源于注意力机制自身的创新设计。
160M 参数模型表现
在针对 160M 参数规模模型的测试中,无论输入序列长度是 2048 还是 4096 个 token,GTA 都持续展现出卓越的性能优势。具体而言,采用 GTA2 配置的模型在 2048 token 序列长度下,成功实现了比传统 MHA、GQA 和 MLA 更低的评估损失,并获得了更优异的 Wikitext 困惑度(PPL)表现。此外,GTA1 配置的模型在多项下游任务中取得了更高的平均准确率,彰显了其在实际应用中的有效性。尤为值得强调的是,GTA 在内存效率方面表现出类拔萃,其每层所需的 KV 缓存大小仅为 MHA 的 12.5%(具体数据为 192 维度对比 MHA 的 1536 维度),这一显著的缩减充分突显了 GTA 在内存优化方面的强大能力。实验结果详细呈现在下方的表格中:

500M 参数模型表现
将模型规模扩展至 500M 参数时,GTA 依然保持了其在性能上的领先地位。在 2048 token 序列长度的测试中,GTA 不仅实现了更低的评估损失,还在下游任务中取得了更高的平均准确率,同时其 Wikitext 困惑度与 MHA 和 GQA 等主流模型保持在同等甚至更优的水平。GTA 持续展现出其独有的内存优势,其 KV 缓存大小仅为 MHA 的 12.5%(具体为 320 维度对比 MHA 的 2560 维度),即使在采用更小缓存(例如 192 维度,仅为 MHA 的 7.5%)的情况下,GTA 也能获得可比拟的性能表现,充分印证了其在内存效率与性能之间取得的完美平衡。在处理 4096 token 长序列的任务中,GTA 不仅能够与 MHA 的评估损失持平,更在 Wikitext 困惑度和下游任务的平均准确率上提供了更优异的表现。这些详尽的实验数据均已在下方的表格中列出:

1B 参数语言模型扩展性
为了进一步验证 GTA 在大规模模型上的卓越扩展能力和稳定性,研究团队特意训练了 1B 参数级别的 GTA-1B 和 GQA-1B 模型。下图清晰地展示了 GTA-1B 和 GQA-1B 在长达 50,000 训练步中的损失曲线和梯度范数曲线,从中可以观察到两者均展现出令人满意的稳定收敛趋势。

尽管 GTA-1B 在设计上采用了更小的缓存尺寸,但其损失轨迹却与 GQA-1B 高度匹配,这一事实有力地证明了 GTA 内存高效架构的有效性,即在减少资源消耗的同时不牺牲模型学习能力。在多项严苛的基准测试中,GTA-1B(包括经过 SFT 微调的版本)均展现出与 GQA-1B 相当甚至更为优异的性能,尤其在平均准确率上取得了显著提升。这充分表明,GTA 即使在资源受限的环境下,也能通过微调有效泛化到各种复杂任务,保持强大的竞争力。这些详尽的实验结果均已在下方的表格中呈现:

综合来看,GTA-1B 无论是在基础模型状态还是经过微调后,都成功实现了与 GQA-1B 相当的卓越性能。与此同时,其 KV 缓存尺寸仅为 GQA-1B 的 30%,而自注意力计算成本更是低至 37.5%。这些令人瞩目的数据有力地强调了内存和计算高效架构在大型语言模型扩展应用方面的巨大潜力,预示着未来 AI 发展将更加注重可持续性和资源效率。
效率评估
理论效率分析
从理论层面分析,GTA 在计算复杂度和内存使用方面均实现了显著的效率提升。其 KV 缓存尺寸从 MHA 的

大幅减少至 GTA 的

,其中

且

,对于参数量庞大的大型模型而言,这意味着一个极其显著的缩减因子,将有效缓解内存压力。同时,注意力计算量也从 MHA 的

显著降低到 GTA 的

,这直接转化为推理速度的显著提升。这些严谨的理论分析和对比数据均已在下方的表格中详细列出:

通过 LLM-Viewer 进行经验基准测试
为了将理论优势转化为可量化的实际性能,研究团队利用 LLM-Viewer 框架,在配备 NVIDIA H100 80GB GPU 的高性能计算平台上,对 GTA-1B 和 GQA-1B 进行了全面的经验基准测试。下图清晰地展示了在不同配置下,两种模型的预填充和解码时间对比。从中可以明显看出,GTA-1B 在计算密集型的预填充阶段和 I/O 密集型的解码阶段都持续地优于 GQA-1B,充分展现了其卓越的延迟特性和更高的运行效率。

实际部署表现
为了更真实地评估 GTA-1B 在实际应用场景中的性能,研究团队利用 transformers 库,在多种异构硬件平台(包括服务器级的 NVIDIA H100、NVIDIA A800,消费级的 RTX 3060,以及边缘设备如 Apple M2 和 BCM2712)上进行了深入的推理实验。

上图直观地展示了在不同配置下,GTA-1B 与 GQA-1B 的预填充和解码时间对比。GTA-1B(蓝色实线)在所有测试平台上都持续展现出优于 GQA-1B(橙色虚线)的预填充时间,尤其是在处理 2k token 等更长输入序列时,性能差距更为显著,体现了其在处理长文本时的强大优势。在解码阶段,GTA-1B 同样表现出卓越的性能,特别是在扩展生成长度时,这种优势在所有硬件类型上都保持一致,充分突显了其设计的鲁棒性。

上图进一步展示了在启用缓存卸载功能时的性能表现。在 NVIDIA H100 平台上,GTA-1B 在处理更长输入序列时依然保持了其预填充优势,并且在解码时间上实现了比 GQA-1B 更大的改进。这种在所有平台上的持续趋势,有力地突显了 GTA-1B 在 I/O 密集型场景中的高效性,这类场景中缓存卸载需要 GPU 和 CPU 内存之间频繁的数据传输,而 GTA-1B 在这种复杂环境下依然表现出色。
综上所述,GTA-1B 在各种硬件平台下,无论是在预填充还是解码时间上,均全面超越了 GQA-1B,并在处理更长输入序列时展现出显著的性能优势。它不仅在标准推理设置中表现出色,在启用缓存卸载的 I/O 密集型条件下也同样杰出,充分展现了其在不同硬件能力和批处理大小下的强大多功能性。这种卓越的适应性使得 GTA-1B 成为服务器级和消费级部署的理想解决方案,通过显著降低计算复杂度和内存需求,极大地提升了大型语言模型中注意力机制的整体效率。
技术局限与未来方向
尽管 Grouped-head latent Attention (GTA) 在效率和性能方面取得了令人瞩目的突破,但作为一项新兴技术,仍有一些关键的技术挑战需要我们持续关注和深入探索。首先,非线性解码器在进行模型压缩的过程中,可能会引入微小的近似误差,这需要未来的研究在架构设计和训练策略上进一步优化,确保模型输出的准确性。其次,当前 GTA 的研究和验证主要集中在自然语言处理任务上,其在计算机视觉或多模态任务中的适用性和性能表现,还需要进行更广泛和深入的探索与验证。
尽管存在这些局限,研究团队已经为 GTA 的未来发展制定了清晰且富有前景的后续研究方向。他们计划持续改进非线性解码器的架构设计,以期在保证高效解码的同时,进一步减少信息损失,提升模型性能上限。此外,研究团队还雄心勃勃地计划将 GTA 应用于更大规模的模型,以验证其在超大规模场景下的可扩展性和效率优势,推动大型语言模型向更广阔的应用领域迈进。
....
#全球首个IMO金牌AI诞生
谷歌Gemini碾碎奥数神话,拿下35分震惊裁判
谷歌DeepMind奥数夺金了,得到IMO官方认证!新模型Gemini Deep Think仅用自然语言,在4.5小时攻克了5题,拿下35分。这次,具体解题过程也一并公开了。
今天,谷歌DeepMind正式官宣拿下IMO金牌!
他们凭借Gemini Deep Think(高阶版),一个通用模型,成功破解前5题,斩获35分(满分42分)。
而且, AI在极限4.5小时之内,就达到了IMO金牌标准。
最最重要的是,Gemini仅用纯自然语言——英语完成了解题。
与OpenAI不同的是,这一结果得到了IMO组委会官方认证。
Demis Hassabis连发两弹,一再强调「谷歌模型是首个获得官方金牌级别认可的AI系统」。
谷歌DeepMind,正式摘金
作为数学界的奥林匹克,IMO自1959年以来每年举办一次,每年吸引了全球各界优秀的学生参与。
参赛者需在4.5小时内解决6道极具深度的数学问题,涵盖代数、几何、组合数学和数论。
而且只有排名前8%的选手才能摘得金牌,象征着无上的学术荣耀。
近年来,IMO逐渐成为AI能力的试炼场。数学问题不仅需要逻辑推理,还考验创造性思维和严谨性,这对AI系统提出了极高要求。
2024年,AlphaProof和AlphaGeometry 2破解了6题中的4题,获得28分,达到了银牌水平。
这一突破利用专业的「形式语言」,表明AI开始接近顶尖人类的数学推理能力。
今天,Gemini Deep Think再创里程碑,完美破解5道题,跻身金牌行列。
那么,这款模型是如何做到的呢?
我们在此确认,谷歌DeepMind已经达成了一个万众瞩目的里程碑,在满分42分的竞赛中取得了35分的成绩——这足以摘得金牌
他们的解法在诸多方面都堪称惊艳。IMO的评委认为,这些解法思路清晰、表述精确,且大部分内容都简单易懂。
——IMO主席Gregor Dolinar教授
自然语言解题,端到端推理
AlphaProof和AlphaGeometry 2解决IMO难题前,需要专家将问题翻译为「形式语言」,如Lean。
而且,证明过程也是如此,且需要两到三天的计算时间。
今年,Gemini Deep Think完全以自然语言端到端运行,直接从官方问题描述中生成严谨的数学证明,并在4.5小时的比赛时间限制内完成。
借用Karpathy经典语录,「英语是热门的编程语言」。如今看来,确实如此。
Deep Think模式
之所以能够取得金牌,团队使用了Gemini Deep Think的高级版本——一种针对复杂问题的增强推理模式。
并且,结合并行思考技术,允许模型同时探索多种解题路径,最终整合出最优答案。
这种多线程推理方式,突破了传统单一线性思考的局限。
为了充分发挥Deep Think的推理能力,谷歌还对Gemini进行了新颖的强化学习训练,让其利用更多多步推理、问题解决和定理证明数据。
此外,谷歌研究团队还通过以下方式,进一步升级了Gemini版本:
· 更多思考时间
· 获取过往问题的一系列高质量解决方案集
· 提供解决IMO问题的通用提示与技巧
这种「训练+知识库+策略」的组合,让Gemini在IMO的舞台上大放异彩。
值得一提的是,接下来,谷歌将向一部分数学家等测试者提供这个版本的Deep Think模型,随后向Google AI Ultra订阅者推出。
解题过程
那就让我们来看看,这次谷歌Gemini Deep Think具体的解题过程吧。
官方报告:https://storage.googleapis.com/deepmind-media/gemini/IMO_2025.pdf
对于第一题这道解析几何题,模型的解法是设n>3是一个给定的整数。
证明思路是将问题简化到n=k且所有直线必须是阳光线的这一特定情况。具体来说,设C(k)表示「P可被k条不同阳光线覆盖」,定义P_0=ø。
然后模型设定了一个引理:在集合L中,所有N_v竖直直线必须是{x=1,2,...,N_v},所有N_H水平线必须是{y=1,2,...,N_H},所有N_D对角线必须是形如x+y=s的直线,s的取值范围为n+2−N_D,...,n+1。
然后,模型对这个引理进行了证明。
接下来,模型证明了定理1:当n≥3且0≤k≤n时,若存在一个由n条不同的直线组成的集合,刚好覆盖点集P_n,且其中恰好有k条阳光线,那么充要条件便是命题C(k)为真。
接下来,模型对核心问题C(k)展开了分析:对于哪些k>0,点集P_k可以恰好被k条阳光线覆盖。
最终,模型成功证明了C(k)成立的充要条件是k∈{0,1,3},由此证明了唯一可能的阳光线数量为:0、1或3条。
对于第二题这道平面几何题,模型把证明过程分成了五步。
步骤1:确定点P是△AMN的旁心。
步骤2: 求∠EBF。
步骤3: 引入辅助点V及其性质。
步骤4: 点V落在外接圆Σ上。
步骤5: 垂心H与切线条件。
最终,模型证明了直线VH是圆Σ在点V处的切线,由此证毕。
第三题是一道函数题。
在解题过程中,模型将关键步骤分为三步。
首先,是确定Bonza函数的性质与分类。
第二步和第三步中,模型分别完成了上界证明c≤4,以及下界证明c≥4。
最终结论可得:满足条件的最小实数常数c为c=4。
第四题是一道数论题,前提给出了一个真因数的定义,对于一个正整数N,除了N本身以外的正整数因数,都叫作N的真因数。
数列中,每一个数a_n都是正整数,且都至少有3个真因数,先找出a_n的三个最大的真因数,再把它们相加得到下一项a_{n+1}。
问题是,起始值a_1有哪些数值可以取?
谷歌Gemini Deep Think给出了5个解题步骤,想要确定a_1取值,前提是让a_n+1=S(an) 定义的序列是无限正整数。
步骤1:证明对所有n,a_n都是偶数。
步骤 2: 证明对所有n,a_n都能被3整除。
步骤 3: 当6∣N时,分析序列的动态行为。
步骤 4: 研究序列的演变过程并给出对a_1的限制条件。
步骤 5: 对起始值a_1进行全面刻画与分类。
整体过程亮点,在于化繁为简,用不变性和增长率把大范围枚举压缩到独一无二的固定点。
第五题,是一道组合博弈+不等式分析题。
简单来说,题干要求:
· 轮到Alice(奇数回合)时,她必须给出一个非负数,使得目前所有数的总和≤ λ×当前回合数;
· 轮到Bazza(偶数回合)时,他必须给出一个非负数,使得目前所有数的平方和≤当前回合数。
· 谁在自己回合找不到合法数就输;若双方都能一直出数,游戏无胜负。
题目要找出哪些 λ 能保证Alice必胜,哪些 λ 能保证 Bazza必胜?
Gemini Deep Think在解题时假设了2种情况,如下所示:
而后者关键点是「先蓄力,再一击致命」,具体来说,让Alice把总和一次性抬高,让Bazza下一回合无法去满足平方和条件,于是当场获胜。
最终,Gemini得出如果λ=1√2时,两者都不会赢。只有当λ>1√2,Alice获胜;当0<λ<1√2时,Bazza获胜。

对此,来自Anthropic AI研究员点评道,「乍一看,它们的解法比OpenAI要清晰得多」。
团队介绍
Thang Luong
官博称,Gemini Deep Think整体技术方向由Thang Luong带队,现任Google DeepMind高级主任研究员,曾任Google Brain研究员。
他于2016年获得斯坦福大学计算机科学博士学位,在读博期间开创了深度学习在机器翻译领域的应用先河。
在Google DeepMind工作期间,Thang Luong构建了多个语言(QANet、ELECTRA)和视觉(UDA、NoisyStudent)领域的尖端模型。
2020年,他推出全球最强聊天机器人Meena项目,该项目后续发展为Google LaMDA、Bard及现Gemini系列,也是经典注意力机制「LuongAttention」的发明者。
自2022年起,Thang Luong共同领导Bard多模态功能的开发,并担任能解决IMO级别几何题的AlphaGeometry项目负责人。
所有成员名单如下:
上下滑动查看
AI+数学未来
谷歌DeepMind长期与数学界保持着合作,但AI为数学做出贡献的潜力才刚刚崭露头角。
通过训练Gemini学会更灵活、更直观地推理,谷歌正逐步构建出能够解决更复杂、更前沿数学问题的AI。
今年,夺下IMO金牌虽然完全基于Gemini自然语言能力,但团队也在AlphaGeometry和AlphaProof等形式化系统方面也取得了持续的进展。
谷歌坚信,那些能够将流畅的自然语言能力与严谨的推理能力(包括形式化语言中的可验证推理)相结合的AI智能体,将成为数学家、科学家、工程师和研究人员不可或缺的工具。
在通往AGI的道路上,AI将推动人类知识的进步。
OpenAI回应了!
其实,谷歌DeepMind早在7月19日周五下午就拿下了金牌,只是在等内部验证流程才未对外公布。
与之形成鲜明对比的是,赶在周六凌晨抢发的OpenAI不仅不讲武德,金牌也完全是「自封」的,并未经过任何IMO官方的独立验证和评分。
谷歌DeepMind超级推理团队的Thang Luong表示:因为IMO内部有一份官方评分指南,外界根本无法获取。
要知道,OpenAI自评的金牌成绩只是刚刚过35分的线而已,如果有微小的扣分,都会让成绩从金牌跌到银牌。
而且IMO组委会还特地明确要求,希望各个大模型公司在闭幕式一周后再公布成绩,不要抢走孩子们的风头。
但OpenAI的Naom Brown却表示,他们的确尊重了IMO的要求,是等闭幕式之后才发布的。
就在谷歌DeepMind官宣夺金之后,Naom Brown又双叒代表OpenAI发声了,还是连发7推。
他首先肯定了GDM的成就,并指出OpenAI与之并行取得的成功,印证了AI进化的迅速。
不过,在具体测试中,两家的方法各有千秋。
在总结自家模型结果的思考前,Naom Brown澄清了,早在2个月前,IMO组委会曾电邮邀请OpenAI参与基于Lean语言的正式竞赛。
然而,当时OpenAI正忙于自然语言通用推理研究(不受Lean约束),就给婉拒了。
他特别强调了,OpenAI通用模型参赛IMO时,并没有使用任何RAG等工具。
而且,团队提交的证明均由三位外部 IMO 奖牌获得者进行了评分,并且在正确性上达成了完全一致的意见。
接下来,Naom再次重申,「OpenAI是在开幕式结束之后公开的结果」。
昨日澄清的那一套话,再次公开陈述了一遍。
另一位OpenAI研究员Aidan McLaughlin还讥讽GDM,「他们为模型提供上下文,纯属带着小抄进入了考场作弊」。
但现在事实已经摆在眼前——
一边是谷歌经IMO官方认证的成绩,模型即将在未来可用;一边是OpenAI不讲武德提前邀功,模型是未公开版本,以后很可能也不会公开。
这一轮过后,OpenAI急功近利的做法,更加失了民心。
参考资料:
....
#DeepMind刚拿完IMO金牌,科学家就被Meta挖走了
是华人大牛
这下轮到皮查伊难受了。
上周 IMO 2025 奥数,Google DeepMind 和 OpenAI 的新模型拿了金牌,结果获益最大的却是 Meta?
我们刚刚见证了 AI 领域人才「大洗牌」的新一轮高潮。
Meta 挖走 DeepMind IMO 金牌成员
今天凌晨,有外媒报道说三位参加奥数夺金模型的 Google AI 研究者,被 Meta 挖走了。
Meta 首席执行官马克・扎克伯格继续努力,为了重振 Llama 系列,进行了前所未有的 AI 人才引进。
据三位知情人士透露,Meta 最新挖走的三位研究者均为华人:Tianhe Yu、Cosmo Du 和 Weiyue Wang,他们曾参与谷歌 Gemini 系列模型最新版本的研发。
就在本周一,谷歌宣布搭载深度思考的 Gemini 进阶版正式达到 IMO 2025 国际数学奥林匹克竞赛金牌标准。Gemini(与 OpenAI 新模型)是首批获得 IMO 正式评分和认证的 AI 参赛队伍,其评分标准与学生解决方案相同,可以说实现了 AI 领域的一次技术突破。
然而让人没有料到的是,DeepMind 还没高兴几天就被扎克伯格来了个釜底抽薪。
三位加入 Meta 的科学家可以说都是 AI 领域大牛。Tianhe Yu 自 2022 年加入 DeepMind 任研究科学家,他本科就读于加州大学伯克利分校,博士在斯坦福大学,导师为 Chelsea Finn。
Yu (Cosmo) Du(杜宇)曾任 DeepMind 首席科学家、Gemini 后训练、思考、编码项目负责人。是 Gemini 1、1.5、2、2.5 版本的核心贡献者。他 2017 年加入谷歌,博士毕业于浙江大学。
Weiyue Wang(王薇月)在为 DeepMind 工作之前曾在谷歌自动驾驶部门 Waymo 任职。她 2015 年博士毕业于南加州大学,此前在俄亥俄州立大学获硕士学位,本科在上海交通大学。
宏观来看,这只是 Meta 最近大规模行动的一个节点。过去一个月以来,Meta 从 OpenAI、苹果、Anthropic 和 xAI 等竞争对手那里重金挖走了一大批研究人员。除了最近报道的三位以外,Meta 这一波从谷歌 DeepMind 挖走了至少六名研究人员。
Meta 还全面改革了 AI 研究团队的架构。扎克伯格聘请了前 Scale AI 首席执行官 Alexandr Wang(汪滔)担任首席 AI 官,并挖来了前 GitHub 首席执行官 Nat Friedman 和前 Safe Superintelligence 首席执行官 Daniel Gross,预计将部分收购 Friedman 和 Gross 的风险投资基金。
汪滔和 Friedman 目前负责管理 Meta 新成立的 AI 部门 Meta Superintelligence Labs(MSL)中约 3400 名员工。根据xxx获得的消息,扎克伯格重金招来的高管,拥有自主招募团队的权限。
相对的,Google DeepMind 首席执行官德米斯・哈萨比斯(Demis Hassabis)管理着约 5600 名员工。
微软挖走 DeepMind 20 多人
与此同时,英国《金融时报》、CNBC 等媒体今天报道称,微软在过去六个月内已从谷歌 DeepMind 挖走了 20 多名员工,其中包括 Gemini 聊天机器人的前工程副总裁 Amar Subramanya。
本周二,曾在谷歌工作 16 年的 Amar Subramanya 在领英上表示,他已加入微软 AI,担任企业副总裁。此前,他曾任 Gemini 助理的工程副总裁。
微软的这个团队负责面向消费者的 Copilot 助理以及必应搜索引擎的开发。
今年 6 月,在谷歌拥有近 18 年经验的 Adam Sadovsky 跳槽至微软,此前,他曾担任 DeepMind 的杰出软件工程师和高级总监。他现在是微软 AI 的企业副总裁。
本月早些时候,谷歌 DeepMind 工程主管 Sonal Gupta 在其领英个人资料上表示,她现在是 Mustafa Suleyman 领导的微软 AI 团队的一名技术人员。
另外,Jonas Rothfuss 在谷歌 DeepMind 担任研究科学家一年后,于今年 5 月加入微软 AI,担任技术人员。
另一位专注开发智能体的工程师 Chinmay Kulkarni 也已经在一个月前宣布加入微软。
这一波人才流动正值科技巨头纷纷斥资收购 AI 创业公司之际。本月,谷歌刚刚击败 OpenAI,以 24 亿美元的价格收购了 AI 编程初创公司 Windsurf 的 CEO 及小部分员工,引发了 AI 圈的热议。
微软从谷歌挖来的新员工将加入由微软 AI CEO Mustafa Suleyman 领导的 AI 团队,Suleyman 向微软 CEO 萨蒂亚・纳德拉直接汇报工作。
Microsoft AI CEO Mustafa Suleyman
值得一提的是,Suleyman 是 DeepMind 的联合创始人,该公司于 2014 年被谷歌收购。他于 2022 年离开谷歌,执掌 AI 初创公司 Inflection,并于去年成为微软高管,并带走了该公司的多名员工。
本月初,微软还曾宣布裁员约 9000 人,占其全球员工总数的不到 4%。
扎克伯格 10 亿美元欲挖 Mark Chen,但没成功
另外,《华尔街日报》还报道了 Meta 在今年春季的一场挖人未遂事件。

该报道称,扎克伯格曾向 OpenAI 首席研究官 Mark Chen 寻求关于如何改进该公司生成式 AI 部门的建议。据知情人士透露,鉴于 Meta 在 AI 训练硬件和计算能力方面已经投入了巨资,因此 Chen 建议扎克伯格或许应该加大人才投入。
之后,扎克伯格就问 Chen 是否考虑加入 Meta 以及需要多少资金才能让他加入。
「几亿美元?还是十亿美元?」
Chen 拒绝了,说他在 OpenAI 很开心。但这次谈话帮助扎克伯格萌生了一个想法,而这个想法就导致了我们这段时间看到的 Meta 不计成本的挖人大戏。
最后,我们来看看网友 @SRKDAN 做的简单盘点。
这场挖人大戏真是愈来愈精彩了……
参考内容:
https://www.cnbc.com/2025/07/22/microsoft-google-deepmind-ai-talent.html
https://www.wsj.com/tech/ai/meta-ai-recruiting-mark-zuckerberg-sam-altman-140d5861
....
#OpenAI星际之门要建5GW数据中心
马斯克祭出AI基建5年计划
昨天,《华尔街日报》报道称,OpenAI 和软银在推迟了 6 个月的星际之门(Stargate)项目上出现了争执,并大幅缩减了近期计划。
报道援引知情人士透露的信息称,软银和 OpenAI 共同领导了「星际之门」项目,但在合作的关键条款上一直存在分歧,包括数据中心建设地点。尽管两家公司在 1 月份的声明中承诺「立即」投资 1000 亿美元,但该项目目前设定了一个更为温和的目标,即在今年年底前建造一个小型数据中心,很可能位于俄亥俄州。
或许正是为了回应这个报道,OpenAI 公布了星际之门计划的新进展:OpenAI 正式宣布正与甲骨文(Oracle)在美国合作开发另外 4.5 GW 的星际之门数据中心容量。
此外,他们德克萨斯州阿比林的 Stargate I 数据中心即将上线。两者相加,OpenAI 与甲骨文合作开发的星际之门 AI 数据中心容量将超过 5 GW。

更直观地对比一下,根据《上海电力供应环境可持续性关键绩效指标报告(2024 年度)》,2024 年上海电网夏季最高用电负荷达 4030 万千瓦,也即 40.3 GW。
OpenAI 表示,这个 5 GW 规模的数据中心将运行超过 200 万个芯片。而 OpenAI CEO 山姆・奥特曼此前称他们将在今年年底前上线 100 万个 GPU(并不都属于这个数据中心)。

「这显著推进了我们兑现今年 1 月在白宫宣布的承诺,即在未来四年内投资 5000 亿美元,在美国建设 10 GW 的 AI 基础设施。得益于甲骨文和软银等合作伙伴的强劲发展势头,我们预计能够超额完成最初的承诺。」
该公司还称,新的数据中心容量将助力就业、经济增长和人工智能发展,造福更多人。这也是星际之门及其「让 AI 惠及每个人」的长期愿景的一个重要里程碑。
奥特曼还发推分享了两张数据中心的实拍照片。

这是目前正在建造的 Stargate I 数据中心,位于德克萨斯州阿比林。目前其中部分设施现已投入运行。
OpenAI 介绍说,甲骨文公司上个月开始交付首批英伟达 GB200 机架,而 OpenAI 最近也已开始运行早期训练和推理工作负载,「利用这些能力来突破 OpenAI 下一代前沿研究的极限」。
至于被《华尔街日报》曝光的与软银的问题,OpenAI 也做出了回应:「除了与甲骨文公司的此次扩张之外,我们与软银的合作也正以强劲的势头向前推进。这两项合作对于满足 OpenAI 不断增长的计算需求都至关重要。与软银一道,我们正在快速推进选址评估,并重新构想数据中心的设计,以支持先进的 AI。」
目前,星际之门项目已经开展了六个月。作为 OpenAI 首要的人工智能基础设施平台,该项目已经与甲骨文、软银和 CoreWeave 建立了在数据中心方面的合作关系,并正通过 OpenAI for Countries 吸纳对美国基础设施的国际投资。微软将继续为 OpenAI 提供云服务,包括通过星际之门项目。
OpenAI 称,「星际之门」是一项雄心勃勃的计划,目标是抓住我们面前的历史性机遇。如今,得益于全球合作伙伴、政府和投资者的大力支持,这一机遇正在逐渐实现 —— 白宫的重要领导层也已认识到 AI 基础设施在推动创新、经济增长和国家竞争力方面将发挥的关键作用。
马斯克回应:我们的五年计划
多半不是出于巧合,就在 OpenAI 宣布了自己与甲骨文的 5 GW 大项目后不久,伊隆・马斯克转发了一条去年十月份的视频,并表示 xAI 的 Colossus 1 超级集群有 23 万块 GPU(包括 3 万块 GB200),可用于训练 Grok(而推理则由云提供商完成)。而 Colossus 2 也将在几周后开始上线,首批将有 55 万块 GB200 和 GB300(同样用于训练)。

至于更长远的计划,马斯克表示目标是在 5 年内上线的 AI 算力(但能效更高)将达到等价于 5000 万台 H100 的量级。
有网友做了简单的盘点和计算:配备 55 万块 GB200 的 Colossus 2 大约相当于 550 万 H100,是一年前 Colossus 1 的 55 倍

看起来,英伟达的股票还会继续涨。
对于这两家的规模宏大的计划,你有什么看法?
参考链接
https://openai.com/index/stargate-advances-with-partnership-with-oracle/
https://www.shanghai.gov.cn/hqcyfz2/20250526/bb0166ae2a81419b88cb3f8c5d94e401.html
https://x.com/TeslaPrice/status/1947739209420111985
https://www.wsj.com/tech/ai/softbank-openai-a3dc57b4
....
#MultiCogEval
清华医工平台提出大模型「全周期」医学能力评测框架
本文工作由清华大学电子系医工交叉平台吴及教授和刘喜恩助理研究员所领导的医学自然语言处理团队,联合北邮、科大讯飞、无问芯穹等单位共同完成。第一作者周宇轩为清华大学电子工程系博士生,其研究方向聚焦于大模型的医疗垂类能力评估与优化,此前已提出 MultifacetEval(IJCAI 2024)与 PretexEval(ICLR 2025)等医学知识掌握的多面动态评估框架体系。吴及教授和刘喜恩助理研究员所领导的医学自然语言处理团队长期致力于面向真实需求驱动的医工交叉前沿技术研究与产业变革,曾在 2017 年联合科大讯飞研发了首个以 456 分高分通过国家临床执业医师资格考试综合笔试测试 AI 引擎 Med3R(Nature Communications 2018)并在全国 400 多个区县服务于基层医疗;2021 年联合惠及智医研发了首个基于全病历内容分析的智慧医保 AI 审核引擎,获得国家医保局智慧医保大赛一等奖,并在全国多个省市进行示范应用。
大语言模型(Large Language Models,LLMs)技术的迅猛发展,正在深刻重塑医疗行业。医疗领域正成为这一前沿技术的 “新战场” 之一。大模型具备强大的文本理解与生成能力,能够快速读取医学文献、解读病历记录,甚至基于患者表述生成初步诊断建议,有效辅助医生提升诊断的准确性与效率。
该技术有望在缓解医生工作负担、提升就诊效率、优化医疗管理水平等多个方面发挥重要作用。
虽然当前主流大语言模型在 MedQA 等医疗问答基准数据集上已取得 90% 以上的准确率,显示出强大的语言理解与推理能力,但临床一线的实际反馈表明,其在真实医疗场景中的应用效果仍不理想,普遍存在 “高分低能” 的问题。
在当前大语言模型不断取得评测突破的背景下,一个关键问题亟需回答:为何其在真实临床问题中仍难以发挥预期效能?
究其根本,是由于医学知识覆盖尚不充分,还是因缺乏有效的临床应用能力?亦或是在面对复杂、动态的真实场景时,模型在临床推理与决策层面存在显著短板?抑或三者皆为限制其实际落地的关键因素?
近日,清华大学电子系医工交叉平台刘喜恩助理研究员领衔的医学自然语言处理团队,联合多家单位在 ICML 2025 会议上发布最新研究成果,首次提出从医学知识掌握到临床问题解决的 “全周期” 大语言模型医学能力评测框架 ——MultiCogEval。
该框架覆盖大模型在不同认知层次下的医学能力评测,为全面理解大语言模型在医疗领域的能力边界并洞察其在真实临床场景中面临的核心短板,提供了全新视角与分析工具。
- 论文标题:Evaluating LLMs Across Multi-Cognitive Levels: From Medical Knowledge Mastery to Scenario-Based Problem Solving
- 论文链接:https://openreview.net/pdf?id=sgrJs7dbWC
- 项目主页:https://github.com/THUMLP/MultiCogEval
如何构建一个 “全周期” 医学评测框架?
在大多数国家,医学生通常需依次完成基础医学知识学习、临床见习以及住院医师规范化培训,方可成为一名合格医生。这一培养路径契合人类认知能力的发展规律:先通过记忆与理解掌握基础医学知识,继而在典型病例中运用所学进行具体分析,最终具备在真实临床场景中进行规划与问题求解的能力。与此相对应,针对临床能力的评估体系也呈现出分层递进的结构:从基础课程考试,到临床技能测评,再到住培阶段的综合结业考核,逐步覆盖不同认知层次。
然而,现有医学大模型评测集的任务设计多聚焦于单一类型(如问答、诊断等),尽管这类评估有助于比较不同模型间的性能差异,但通常仅覆盖某一特定认知层次,难以全面反映大模型在医学应用中所需的多层次、全流程能力。部分评测工作尝试通过引入多种任务来覆盖不同认知层次,但仍存在两方面问题:其一,不同任务与认知层次之间缺乏明确对应关系;其二,各任务所涉及医学知识点的覆盖范围、评测指标差异较大,导致跨任务的评估结果缺乏可比性与解释力。
为应对上述挑战,研究人员提出了多认知层次医学评测框架 MultiCogEval。该框架设计了一系列覆盖医学生培养全流程、对应不同认知层次的医学任务,并结合医学知识点对齐与评测指标统一等方法,实现了跨认知层次的评估可比性与结果可解释性,为大模型医学能力的系统性评估提供了有效支撑。

(图 1):人类医师医学认知能力发展流程与大模型医学能力评测的对应关系
MultiCogEval:多认知层次医学评测框架
受现有医师培养流程启发,MultiCogEval 从三个认知层次考察大语言模型的临床能力:
- 基础知识掌握:评测模型对基础医学知识的记忆与理解程度。在这一层次上,MultiCogEval 采用现有 LLM Benchmarks 中最常用的多项选择题(Multiple-choice Questions)进行评测;
- 综合知识应用:评测模型综合运用所学知识解决临床任务的能力。与多项选择题相比,真实临床场景往往可用信息更少、决策空间更大,同时依赖多步推理才能得到结果。为了进一步逼近这些真实临床场景的应用需求,MultiCogEval 从这三个维度出发,分别设计了三种任务进行评测;
- 场景问题求解:评测模型在真实临床场景中主动规划求解的能力。尽管现有的一些医学评测集(如 MedQA)涉及对医学案例的分析与诊断,但这些评测集往往是将所有诊断信息一次性通过题干的形式提供的。与之相比,真实临床场景则依赖医师基于已有的诊断信息进行主动决策,通过查体、实验室检查、影像学等方式收集诊断信息,最终综合已有的诊断信息做出诊断。在这一层次上,MultiCogEval 采用一种模拟诊断任务,考察大模型在信息不足条件下主动规划检查检验,并完成诊断的能力。

(图 2):多认知层次医学评测框架 MultiCogEval
实验结果:当前大模型的临床场景问题求解能力仍待加强
基于该评测框架,研究人员对一系列知名大模型进行了系统的评测,观察到多种 SOTA 大语言模型(如 GPT-4o、DeepSeek-V3 和 Llama3-70B)在低阶任务(基础知识掌握)上表现出色,准确率超过了 60%。然而,当在中阶任务(综合知识应用)上进行评估时,这些模型的性能均出现了显著下降(约 20%)。此外,在高阶任务(场景问题求解)中,所有模型的表现进一步下滑,其中表现最好的 DeepSeek-V3 的全链条诊断准确率也仅为 19.4%。这表明,尽管当前的大语言模型在基础医学知识方面已经具备较强的掌握能力,但在更高认知层级上,尤其是在应对真实医疗场景中的复杂问题时,仍面临巨大挑战。

(表 1):来自多个系列的通用大模型在 MultiCogEval 不同层次上的评测表现
为研究医学领域 SFT 对大语言模型在不同认知层级上的影响,研究人员进一步对比了医学大模型与对应基座模型,发现医学领域 SFT 可以有效提升大模型的低阶(基础知识掌握)与中阶(综合知识应用)临床能力(最高可达 15%)。然而,在高阶任务(场景问题求解)上,它们未能取得显著进步,有些甚至表现不如基座模型。

(图 3):多个医学专用大模型在 MultiCogEval 不同层次上的评测表现
最后,研究人员进一步研究了推理时扩展(inference-time scaling)在提升大语言模型医学能力方面的效果。如表 2 所示,推理增强模型在所有认知层级上均优于对应的指令微调模型,且在中阶任务上的提升更为显著(例如 DeepSeek-R1 在中阶任务上提升了 23.1%,而在低阶任务上仅提升了 9.8%)。然而,当前的推理增强模型仍然没有完全解决高阶任务,说明现有的模型在真实临床场景中主动规划、获取决策信息进行推理的能力仍然有待进一步提升。

(表 2):推理增强模型与指令微调模型在不同层次任务上的性能对比
结语
本研究首次提出了多认知层次医学能力评测框架 MultiCogEval,系统性地对大语言模型在基础知识掌握、综合知识应用和场景问题求解三大认知层级上的医学能力进行评估。通过构建面向全流程医学任务的评测体系,并在多个主流通用大模型与医学专用模型上进行评测与分析,研究团队发现:
- 当前大模型在低层级医学任务表现较为出色,具备较强的医学知识记忆与理解能力。但随着任务认知复杂度的提升,模型在中高层级任务上的能力出现明显下降,尤其是在高阶临床场景下的主动信息获取与推理决策能力仍显不足;
- 医学领域微调在提升基础与中阶能力方面效果显著,但对高阶任务性能提升有限;
- 推理时扩展方法能够显著增强模型在各个层次医学任务上的表现,特别是在复杂任务中,但仍不足以完全弥补模型在高阶能力方面的短板。
MultiCogEval 的发布为后续的医学大模型研发与评测奠定了坚实基础。我们期待该框架能促进大模型在医学领域的更加稳健、可信、实用的落地,真正助力构建 “可信赖的 AI 医生”。
....
#Data Can Speak for Itself
无线合成数据助力破解物理感知大模型数据瓶颈,SynCheck获顶会最佳论文奖
在万物互联的智能时代,xx智能和空间智能需要的不仅是视觉和语言,还需要突破传统感官限制的能力;无线感知正成为突破这些物理限制的关键技术:通过捕捉无线信号的反射特性,它让不可见的目标变得可感知,使机器能够 "看见" 墙壁后的动静、"感知" 数米外的动作,甚至捕捉到人类难以察觉的微妙变化。这种全新的感知维度,能对环境中人机行为实现无感监测与精准解析,正在重塑人机交互的边界。
从感知到决策,离不开具有强大语义理解能力的大模型。但怎样构建一个除了视觉和语言之外,能够理解物理原理(电磁场、光学、声学等)、与物理世界交互的大模型?
这一问题并不能复制语言、视觉大模型的经验,因为大模型可以从人类几千年的文字资料中学习语言,可以从整个互联网的视频学习视觉;但除此以外,能提供给模型学习的数据微乎其微;仅依赖真实世界的数据采集,难以支持大模型所需的海量数据。
为解决数据稀缺这一最大挑战,北京大学的许辰人教授团队和匹兹堡大学的高伟教授联合提出 SynCheck,为机器学习提供与真实数据质量相近的合成数据。相关工作发表在移动计算领域旗舰会议 MobiSys 2025 上,并获得会议的最佳论文奖。
- 论文标题:Data Can Speak for Itself: Quality-guided Utilization of Wireless Synthetic Data
- 论文链接:https://arxiv.org/abs/2506.23174
- 代码链接:https://github.com/MobiSys25AE/SynCheck
1. 生成模型评估:数据导向的效率优化
在无线感知领域,生成模型已被广泛用于产生合成数据以补充真实数据集。然而,现有研究大多只关注数据量的扩充,而忽视了合成数据的质量问题。为解决这一问题,研究团队提出了两个创新性质量指标:
- 亲和力(affinity):衡量合成数据与真实数据的相似度
- 多样性(diversity):评估合成数据覆盖真实数据分布的范围

图:两类质量指标的解释
与以往依赖视觉启发或局限于特定数据集的质量评估方法不同,这项研究通过贝叶斯分析和性能指标建立了具有理论支撑的通用评估框架。研究还引入 "边际"(margin) 概念作为性能指标,利用训练集的边际分布作为自然参考标准,实现了跨数据集的公平比较。

图:基于 margin 的质量评估方法
研究团队通过系统评估发现,现有无线合成数据普遍存在 “亲和力不足” 的问题,这会导致数据标签错误,进而降低任务性能。
2. 合成数据应用:质量优先的性能突破
基于质量评估结果,团队开发了 SynCheck 框架,其核心创新在于:
1. 将合成数据视为未标记数据,真实数据作为标记数据
2. 采用半监督学习框架结合两种数据源,在迭代训练过程中过滤低亲和力合成样本,为剩余样本分配伪标签
这种方法不需要修改生成模型的训练或推理过程,可以作为通用后处理步骤适配各种生成流程。

图:基于半监督学习的合成数据通用后处理使用方法
实验结果显示,SynCheck 在性能上实现了显著提升:
1. 在质量无关方法导致性能下降 13.4% 的最坏情况下,仍能实现 4.3% 的性能提升
2. 最佳情况下性能提升达 12.9%
3. 过滤后的合成数据展现出更好的亲和力,同时保持了与原始数据相当的多样性

图:合成数据的不同使用方法的性能对比
在逐步提升合成数据占比的过程中,由于合成数据与真实数据存在分布差异,其他基线方法的任务性能会随着合成数据比例增加而显著下降,这种分布偏移现象破坏了任务性能与训练数据之间的 scaling law 规律。相比之下,SynCheck 方法通过动态校正合成数据的分布偏差,使得模型性能能够保持稳定提升,最终收敛至最优状态。

图:任务性能随合成数据规模扩展的变化趋势
3. 超越数据瓶颈:无线大模型的规模化应用前景
当前学术界对合成数据的研究呈现明显的观点分野。持审慎态度的学者从理论推演和实证研究出发,提出了 "模型崩塌"(model collapse)的警示 —— 这类似于生物学上的近亲繁殖现象,当模型持续消化自身生成的数据时,其性能将不可避免地出现退化。然而,另一批研究者则持乐观态度,他们认为通过引入验证器(verifier)机制,完全可以规避模型崩溃的风险。值得注意的是,现有研究多集中于数学、代码等具有明确评价标准的领域,而在复杂度更高的任务场景中,这一问题的验证仍面临挑战。
北京大学和匹兹堡大学的研究团队创新性地提出了以目标任务模型为桥梁的研究范式,成功建立了合成数据与真实数据条件分布之间的映射关系。这一突破性进展为无线感知这一真实数据匮乏但性能导向的领域,确立了切实可行的数据质量评估标准与筛选方法。
未来,研究团队将致力于推动无线大模型的训练范式革新,通过拓展数据源的多样化泛化路径,探索更高效的预训练任务架构,实现合成数据与多元数据源的有机融合。在此基础上,团队将进一步构建面向各类无线感知任务的通用预训练框架,积极拓展多样化的数据来源,依托更强大的无线大模型,为xx智能系统提供坚实的感知与决策支撑。这些研究不仅将深化对合成数据质量标准的理论认知,更将为新一代xx智能系统的创新发展奠定基础,推动人工智能在物理世界的深度融合与广泛应用。
....
#国内首个!透视主任医师级「AI大脑」背后的深度工程化
夸克健康大模型万字调研报告流出
模型的能力再一次被行业验证!7月23日,夸克健康大模型在业界引起广泛关注:其成功通过了中国12门核心学科的主任医师笔试评测,成为国内首个完成此项专业考核的AI大模型。为深入解读其技术路径,我们分享一份关于夸克健康大模型的深度调研报告。
(一)调研摘要
(二)推理数据情况特色
(三)推理数据产线一:冷启动数据与模型微调
(四)推理数据产线一:推理强化学习训练
(五)推理数据产线二:高质量不可验证数据集
(六)强化学习推理系统:高质量推理数据质量评估
(七)强化学习推理系统:多阶段训练
(一)调研摘要
第一,通用大模型能力虽快速增长,但要在高专业度的健康医疗领域“炼成”性能高且可靠的推理模型,仍极具挑战。业界主流方向早期由DeepSeek R1验证有效。当下,或蒸馏DeepSeek R1模型数据,或在小数据集上探索较为常见;然而,在选择合适预训练模型的基础上,从头设计并搭建整套流程,并用于业务一线,较为罕见。尤其在健康医疗领域,自建整套流程化系统,能够明确模型从哪些数据,以何种方式学到哪些知识,哪个环节学得不好;不仅提高性能,而且能提高可解释度和信任度。调研发现,夸克健康大模型直接支持搜索业务一线,并支持智能体夸克健康助手、夸克深度研究产品(仅开放试用)。
第二,高质量的思考数据(Chain-of-Thought, CoT)适合作为推动模型形成强化学习推理范式的基础素材已是共识。强化学习通过“结果导向、过程探索”的范式,可在训练中激发模型,也是共识。推理模型效果上限受制于多个与数据强耦合的技术节点。调研发现,夸克健康大模型团队认为:在已知目标结果(如诊断结论)的情况下,由于模型已经在真实医生的思考数据中学习到初步推理能力(高质量冷启动数据),再用强化学习方法有效激发模型探索出多样的推理路径,从而自主找到最适合模型的推理路径,进一步拔高模型推理能力上限,在多阶段训练方法中特意设计出筛选优质数据的方法,进而与人工难以覆盖的部分共同努力提高数据质量,可以极大缓解医疗数据人工标注的成本。
调研发现,在后训练阶段,他们精心设计多种多阶段训练方法(可以是模型能力任务的多阶段,可以是病药术检任务分别开展的多阶段,可以是筛选数据的多阶段,也可以是训练方法的多阶段),与此同时,配合大量实验,拔高模型学习能力的空间。夸克健康大模型团队对思考数据的观测、分析、筛选等操作使用多种类型的模型,如验证器判断结果准确性,过程奖励模型和结果奖励数据评估推理质量,用多维度综合手段以提升可控性、可信度和专业度。
第三,追求推理模型效果长期提升的雄心,必须落实于有耐心建设提高数据与模型质量的“基础设施”。调研发现,夸克健康大模型团队的基础设施包括:
第一项,大规模(百万级)医学知识图谱,以及带有ICD编码的《夸克医学术语集(Quark Med OmnisCT)》。
第二项,推理数据生产线(下文称“数据产线”)。团队认为,破解困局需自建定制化产线,即构建一条满足“适配”“效率”,而非单纯“为了提高质量而提高质量”的产线。可将数据分为可验证数据与不可验证数据两种不同类型,并设计两条平行的数据产线。该产线既产出高质量数据,也“同步产出”模型。端到端强化学习,既融入产线,也融入模型系统。
第三项,强化学习推理多阶段训练系统,在此基础之上,形成极致工程化。
调研发现,若想提高医疗推理模型的最终效果,需重视模型训练,更需要在数据产线上投入更多精力。从医疗认知的角度出发,来构造数据和任务目标,再根据数据类型和任务目标设计合适的多阶段训练方法。
(二)推理数据情况特色
临床思维是医生在面对患者时,通过有目的的提问、信息收集和逻辑推理,逐步形成诊断和决策的核心过程。若健康医疗大模型希望在临床场景中发挥价值,就必须“内化”推理框架。
在数据结构设计上,健康医疗推理数据采用三元组形式,三个要素分别是:
第一,问题(Question);
第二,思考过程(Chain of Thought, CoT);
第三,最终答案(Answer)。
“问题,思考过程,最终答案”下文简称“问思答”,同时含有这三种元素的数据称为“整组数据”。整组数据的价值在于,它不仅要求模型能够得出正确答案,还要求其过程合乎医学逻辑,可解释,可信可复现。思考过程质量越高,模型越能体现其推理能力,进而支撑高水平的可解释性。“问思答”整组数据的获取成本远高于普通问答数据,是核心数据资产,若进一步引入时间序列等结构复杂性维度,构造难度将指数级上升。此外,医疗健康场景常存在“一题多解、路径多样”的特点,提出了更高难度的解决方案的需求。
1.问题(Question)
在健康医疗领域,高质量提问激发模型高质量思考与回答。问题(Question)通常伴随对自身身体状况的自述信息,具有较强的上下文描述性与情境还原度。或者说问题(Question)是含有健康医疗背景情况与提示词的完整问题,例如,常见问题包括:“我打喷嚏、流鼻涕、嗓子疼,并接触过流感病人,该吃哪种药?”问题不单单是一句话,而是含有健康医疗背景情况与指令的结构化数据。此认知会影响过程奖励模型的设计。
调研发现,夸克健康大模型团队从问题(Question)开始,建立完备的标签体系。标签体系是将健康医学概念标准化、结构化的工程手段。正确使用概念是思维的基础,这就要求定义要清晰,内涵要确定,语境要明确。在医疗领域,对概念的使用关系到对疾病的认识,进一步影响诊断与治疗(姚树坤《临床思维》)。
夸克健康大模型标签体系指的是,对每个问答样本中所涉及的关键信息进行标准化、结构化的标注过程。一个可以被模型独立识别、带有明确健康含义的最基本信息片段。
比如,医学实体:疾病名称(远极骨折),症状(移位、肿胀),治疗(石膏固定),药物(非甾体抗炎药)等;
属性信息:恢复周期(4周)等;
意图类型:表示用户希望达成的目标,健康咨询、找药、选择治疗方案等。
这一标签体系的构建基础来源于医疗问答平台的真实信息与夸克搜索引擎日志,通过自动术语提取、属性分类与意图识别等技术,将用户问题解析为标准化的结构字段,最终形成标签框架。
调研发现,夸克搜索历时五年,沉淀近千万日活搜索日志、大规模(百万级)医学知识图谱,以及带有ICD编码的《夸克医学术语集(Quark Med OmnisCT)》,为标签体系与术语标准化提供基础。自然语言中的医学表达具有极强的多样性与模糊性,比如“冠心病”“冠状动脉粥样硬化心脏病”本质是同一种疾病,但表达不同。使用标准术语集,可以将这些语言的不同表达统一映射到唯一编码,确保模型的一致理解,减少误判或信息丢失。同时,该标签体系支持结构化筛选。标签可作为“索引”或者“字段”,调用特定标签子集,提高质量控制精度,比如,一级标签(用户意图),二级标签(药物治疗)。
另外,一方面标签需与医学指南与术语体系保持同步,支持层次化扩展,另一方面,如果标签体系数量仅百余,面对罕见病、亚专业细分场景就会捉襟见肘。因此,标签体系是问题(Question)多样性的基础,也是庞大数据细颗粒度的管理工具,直接决定了医疗健康大模型在长期演进中的上限。
2.思考(CoT)
模型不仅看到病历和答案,还要学习“医生是如何思考并得出结论”的全过程,即“问题-思考过程-答案”(问思答)。而健康医疗知识天然有难易之分,思考(CoT)也应区分难易。引入划分难度的构造方法,使模型在训练过程中逐步适应和掌握越来越难的医疗问题,达成从简单到高难度的能力跃迁。调研发现,夸克健康大模型团队在此理解之上,构造“思考行动体系(Action)”,深入刻画和表达健康医疗特有的思维路径。该体系的提出,部分解决了长期以来困扰医疗大模型训练的关键问题之一——如何衡量思维过程质量。
仅靠给出最终答案无法判断模型是否真正理解,将思考过程拆解为可观测的“思考行动(Action)”——典型思考行动包括问题重述、知识回忆、问题反思、总结等——用于精确描述思考的每一步的具体行动,有助于了解思考链里的细节。另外,思考行动提供一种共同语言,方便拔高推理质量。比如,假设思考(CoT)难度越高,问题(Question)难度也越大,以此原则筛选有难度的思考数据,进而筛选出与思考过程配套的问题(Question)。
后续设计多种筛选机制,会在下文中介绍。
3.最终答案(Answer)
由答案类型入手,将数据分为可验证数据与不可验证数据两种不同类型,它们在获取、筛选等方面存在显著差异,需分开讨论。
第一类,可验证类的答案,相对简洁,通常为医学实体或明确判断。对于可验证的答案(Answer),用验证器模型(Verifier)与标准答案(Groundtruth)进行比对判断。
第二类,对于不可验证任务,如医疗建议、健康科普等长文本,内容面广,语言多变,逻辑各不相同,标准答案(Groundtruth)难以唯一。仅凭奖励模型对单一维度打分,无法完全捕捉医学语境下的细致与专业;需要通过对正确性、完整性、合理性分别建立偏好奖励模型打分,并依据分数筛选数据与反馈,或使用规则、验证器与奖励模型协同发挥作用。
另有,健康医疗无思考数据,这类没有思考过程的数据,有两种处理方法:
第一,以多科室全职专业医生团队精细标注的方式,构造正确、权威、复杂健康医疗内容问答集等高质量数据,或团队全员标注。人工标注可在初期数据资产贫乏时,快速补充“粮草”。
第二,用SOTA语言模型对问题(Question)生成候选答案,这类数据有助于弥补多领域知识,提升训练模型问答水平(逻辑性、全面性),可低成本高效获得。
截至目前,上文提到的所有数据种类,都可以用奖励模型来筛选高质量数据。奖励模型既是强化学习的算法组件,又是筛选数据的工具。
综上,调研组认为:伴随强化学习技术在模型推理能力上的助力,整个推理微调与强化学习系统的极致工程化会成为提高壁垒的新竞争。
两条平行数据产线逐步关键训练流程为:
推理数据产线一(可验证)
第一步,冷启动数据;
第二步,冷启动模型微调;
第三步,推理强化学习;
第四步,可验证数据蒸馏;
第五步,高质量可验证数据集。
推理数据产线二(不可验证)
第一步,不可验证数据蒸馏;
第二步,高质量不可验证数据集。
(三)推理数据产线一:冷启动数据与模型微调

冷启动数据需要专业医生精准标注,为后续强化学习阶段提供稳定起点,避免从一开始就带来“混乱”。构造冷启动数据,使用SOTA语言模型生成高质量问和答及完整推理链(即思考过程),再由职业医师逐字逐句逐条校验,确保健康知识与权威一致;验证医学事实、诊疗论证逻辑和建议的合理性,确保逻辑可靠、无风险;同时,数据团队确保输出按一定的格式,格式便于符合后续奖励模型评估规范。
调研发现,夸克健康大模型团队对冷启动数据质量给予极高重视。原因在于,冷启动阶段的数据,模型此前从没“见过”。一旦引入逻辑错误,后续会连续出错,形成“早期污染”;同时,强化学习会进一步放大错误,且用过程奖励模型识别和修正,成本高昂。不如图难于易地处理。团队曾遭受教训,后被医学专家指出时才得以重视。
调研发现,夸克健康大模型团队采用未经任何下游微调的预训练模型为起点,完全避免使用已经经过某一类任务微调过的模型,会对医疗领域模型起步产生的干扰。他们认为,当预训练的模型接近于“空白”初始状态,模型数据分布的多样性强,信息熵大,后续提高空间大。
他们观察到,此阶段模型展现出一定的适应性:
第一种,当健康状况信息不完整时,模型会先罗列与现有症状相关的多种疾病,再主动推演可能缺失的症状或风险因素,用以补齐证据链后再做判断。
第二种,当输入包含高度特异的关键体征时,模型首先锁定具备显著鉴别力的候选疾病种类,随后用其余症状进行核对,快速完成推理。
这种现象的存在,说明模型能根据“题干与题面”动态运用不同思考方式,而非呆板套用固定答题模板。即便在冷启动阶段,模型已具备一定的初步推理行为能力(抓住焦点,思考路径确定),为后续工作提供了可观测的依据。这种观察属于捕捉到“推理的早期觉醒机制”,增加对模型推理的理解。
(四)推理数据产线一:推理强化学习训练
调研发现,推理数据产线中用强化学习方法训练,得到一个能力上限极高的推理模型是核心,后续需要对该模型进行蒸馏,所以,拔高该模型性能是整个系统最考验模型创造力的阶段,训练时间最长,资源投入最大。这条推理数据产线同时也被称为“可验证数据产线”。
本阶段训练样本,可按此五类划分:基础知识、疾病诊断、手术、药物药品、检验检查。这五类数据均具有明确的医疗语义,可以按五类任务划分验证器模型,或多任务组合建模,或所有任务统一模型,具备高度灵活性。对于可验证的答案,用验证器模型(Verifier)与标准答案(Groundtruth)进行比对判断,直接且稳定。为策略模型提供清晰监督信号,指导其向更高准确性的回答前进。
另外,也可以在构造高难度“问题”的同时构造高难度的“思考”。在已有医生构造的病例数据中,选取结构完整、信息丰富的住院病例作为基础材料;针对这些病例中已有的答案,去除部分“泄题”性描述,即那些直接透露最终关键结论的信息;保留对结论有关键参考价值,但不直接指向答案的症状、体征、检查结果等内容。高难度问答数据特征之一是,需多步推理才能得出结论。
调研发现,在该产线阶段,以激发健康医学知识运用为目标,提升回答结果的多样性与覆盖度,增强其对问题潜在解空间的探索能力。在强化学习阶段,策略模型执行几十次输出采样(比如,每题生成50个候选回答),后期实验证明,这一采样策略有效拓展了策略模型的行为空间,显著提升了回答结果的多样性与覆盖度,增强了其对问题(Question)潜在解空间的探索能力。每轮迭代中同步产出阶段性最优的策略模型与验证器。策略模型设计为统一模型,不依赖任务类型切换。
为了拔高学习潜力,策略模型于百万次探索,在输出的数据中筛选有难度的数据,一轮一轮提高筛选数据的难度。这种“筛选一次难题数据,提高一次模型做难题的能力”的方式,源源不断提供给模型足够好、足够难的数据,用数据质量的提升逼近模型能力的上限。后期实验证明,这一采样策略有效拓展了策略模型的行为空间。
从推理数据产线一(可验证)中产出阶段性最优的策略模型,对其进行数据蒸馏(问题,思考过程,答案)。可以认为,获得该阶段策略模型的目的是为了取得可验证的高质量数据。现有高质量策略模型,再通过数据蒸馏,得到高质量可验证数据集,进而用数据来迁移其医学推理能力。
(五)推理数据产线二:高质量不可验证数据集

首先,高质量不可验证数据集的原始思考数据是通过数据蒸馏而来。不可验证数据所用问题(Question)来源于医生检查过的高质量问题、医学论坛提问、夸克搜索日志,引导模型生成具备思维过程的答案输出,具体方式是对SOTA语言模型(OpenAI O3和DeepSeek R1)进行数据蒸馏,显式引入思维过程数据。同时,此类数据的构造需要保障数据在表达多样性与推理复杂度上的均衡分布。
其次,用偏好奖励模型筛选不可验证类答案(Answer)。由于该类型数据通常为长文本(语义复杂、表达多样),标准答案不唯一。此外,人类打分容易受到个体差异、打分尺度不一影响,导致稳定性和可复现性差,因此可以采用强化学习中的偏好学习的方法。不可验证问题较为开放,可包括全面性、无害性、相关性、逻辑性、正确性等多个方面。因此,需引入多个维度的偏好模型对答案进行打分。其中每个奖励模型关注的角度不同(正确性、有用性),采用偏序建模方式输出判断信号,筛选出质量最优的答案作为最终输出或用于后续训练反馈信号。经过上述多轮筛选,得到下一阶段数据。最终形成“具挑战性且质量优秀”的思考过程数据样本集。
另外,也有一些方法同时适用于可验证和不可验证数据。比如,通过筛选答案,间接筛选正确的整组“问思答”数据;以“最终答案”的正确性作为问题(Question)筛选衡量标准,对应的思考数据仅在答案正确时予以保留,答案错误则整组“问思答”数据作废;进而形成“正确答案样本集”。
综上,为了筛选高质量数据(可验证与不可验证),使用多种类型的组件:验证器、偏好奖励模型、过程奖励模型。健康医疗领域还有一个特色问题——“多解、多路径”问题。调研发现,夸克健康大模型团队对此高度重视,提出了一套针对性方法。
(六)高质量推理数据质量评估
健康医疗中“多解、多路径”问题,可概括为:同一不完备描述的症状,可能对应多种疾病(比如,仅把发热作为主线索,可涉及几十种甚至上百种疾病,鉴别诊断时,根据主线索围绕3-5个疾病展开为宜);诊疗方案有多种合理选择,不同医生可依据不同线索和特征得出多种不相同,但均具有合理性的结论。
模型生成不在预设正确答案集合中的内容,这类输出并不意味着错误,反而可能是高质量、有价值的补充信息,应给予正向奖励。也就是说,对于那些虽未出现在标准答案中、但具有积极意义的结果,可以归为“增益型”(nice-to-have)结果,亦应识别其价值,并给予相应评价分数,鼓励模型输出更全面、富有启发的答案。
于是,在推理模型的训练过程中,需要既能够判断正确答案(验证器),又能处理模型有时生成的不在预设正确答案集合中的内容(生成式模型)。这种多个解法、多种路径带来的开放性和不确定性,使得训练数据中的答案不能被作为唯一评判依据,这样会产生错判或者无法捕捉到细节奖励信号。
健康医疗中的“多解、多路径”问题,尤其值得注意的是,即便已经获得一个答案,也存在殊途同归的情况,答案的背后存在多个推理的思考路径(CoT),且有好坏之分。在医疗的规范性、信任度、可解释性的要求下,需要更好的路径,更多维度的奖励,鼓励模型具有形成高质量诊疗思考过程的能力。因此,需要从“推理过程合理性”与“结果质量”两个维度共同考量。
第一,如何设计针对最终答案(Answer)的结果奖励模型(ORM)?
调研发现,由于强化学习过程中奖励模型的计算成本也是一个重要的开销,不能完全依靠模型,需要设计不同类型的奖励组件(基于规则的验证器、参数规模大小不同的模型),甚至部分奖励信号可以完全基于规则,以此低成本地拓展模型能力边界,而不需要人工标注。
对于明确的唯一的答案(比如诊断结果是某种疾病)设计基于规则的验证器,用于评估策略模型输出的答案质量,相当于规则打分器。该验证器需要使用预构建的百万数量级ICD编码医疗术语集,进行结构化比对与相似度评估。需要注意的是,术语集是为每一个医学概念提供唯一编码,并定义其语义内涵、属性特征以及与其他概念的结构关系的重要工具。
具体而言,设计三类规则来评估策略模型输出内容与医学知识体系的一致性:
1.路径相似度:衡量策略模型输出中的实体在知识图谱中相对于目标概念的路径接近程度;
2.图结构相似度:基于医学实体之间的距离关系,度量其在知识图谱的图结构中的语义接近程度;
3.术语相似度:通过分析名称及其属性信息的匹配度,判断两个术语在语言层面的相似性。
三类相似度指标按照加权方式进行融合,并经归一化处理,输出一个综合得分,作为最终的验证评分。
验证流程如下:首先将策略模型输出的医学答案解析为若干具有语义意义的原子实体(如“上呼吸道感染”被拆分为“上呼吸道”(部位)与“感染”(形态学改变)。每个原子实体映射到ICD术语集中,获得对应编码。随后,计算这些原子实体与知识图谱中标准概念之间的相似度,只要任意一个原子实体命中,即可获得部分得分,进一步提升评估的宽容性。最终得分作为奖励信号反馈至策略模型,引导其优化生成策略。
实际情况中,病药术检的部分任务有明确答案标签,部分任务无明确答案标签,比如多解、多可能性解,还需要对答案的整体性进行评价奖励,这部分采用生成式奖励模型。
于是,设计奖励系统X Clinical Judge的时候,需要考虑将两种情况都覆盖,用SOTA模型辅助人工构建打分示例数据,用该数据教会验证器和奖励模型打分逻辑。
对于有答案标签的问题,除使用SOTA语言模型的输出作为评分参考外,还可利用标签训练结果验证器(Verifier),判断策略模型输出与标准答案的一致性。因为答案标签的获取成本较高,所以,对于无答案标签类型的问题,采用SOTA语言模型(比如,DeepSeek R1)生成评分与简短评价,作为结果奖励模型训练所用的打分示例数据。两类数据融合训练,获得使用一套共享参数的生成式评分模型。奖励模型输出包括两个关键维度的评分结果——正确性分数与全面性分数,并配有简洁明确的语言评价,用于支持模型输出质量的可解释性。策略模型据此调整生成策略。最终,结果奖励模型在医疗多解、多路径的问题里,做出可信、可解释的评估。
第二,如何设计“思考过程”奖励模型(PRM)?
诚然,模型不仅要“答(Answer)对题”,还非常需要“讲清楚思路(CoT)”。然而,缺乏现成答案标签,无法直接监督训练过程奖励模型。
调研发现,团队采取了人工提炼思维模式设计提示词的方式构造训练数据,从而训练“过程奖励模型”突破难点。
首先,医学专家阅读大量模型输出样本,根据临床思维,提炼出若干类“思考方法”(比如排除法、反推法等),并且明确区别病药术检每种任务过程中关键的推理方式。把这些不同类型的思维模式总结为语言模板(Prompt),输入给SOTA语言模型,得到对“思考过程”的打分数据(含简短文字评价),用于训练过程奖励模型。再用过程奖励模型对思考数据合乎医学逻辑、结构清晰、信息完整的程度打分,并生成相关文字评论,本质是让该模型学会评估质量。这些数据不会被用于直接微调策略模型产出最终答案的能力,以确保过程奖励模型评估的独立性。
过程奖励模型和答案验证器训练完毕后,投入使用。
首先,在强化学习过程中,对同一个问题(Question),策略模型每次给出多组“思考(CoT)+最终答案(Answer)”后,使用过程奖励模型和答案验证器会分别对“思考+答案”进行两个维度的(合理性与答案准确性)打分,加权计算之后,得出一个综合评分。
其次,这一方法也可以在数据筛选过程中,强调“思考过程应支撑结果”的一致性原则。如果模型按照思维引导,正确完成了思考过程,但最终生成的答案仍然错误,则视为思维与结果逻辑断裂,此类样本将被剔除,或改写为符合一致性原则的样本再进行使用。
在不同类型的医疗任务中,“答案的决定性”与“思考过程的重要性”所占比重不同,所以“思考(CoT)”和“最终答案(Answer)”的评分在综合打分中应赋予不同权重。
最终,使用GRPO算法,利用多组采样及其综合奖励,用于计算策略优势(Advantage),再经由策略梯度优化策略模型参数,从而提升模型在复杂医疗任务中产出清晰推理链条的能力。在训练进程中,策略模型会越来越倾向于输出有条理、有依据、有医学常识支撑的思考过程和诊疗建议,从而具备类似高水平医生的推理能力,而不是“拍脑门”的猜答案。
另外,引入一致性验证器模型,对思考路径与最终答案之间的一致性进行二次校验。模型可能通过偶然或非健康医疗规范路径得出正确结论,如果此类情况在训练中被错误地赋予奖励信号,长期而言,这将严重扰乱模型推理能力的形成。
第三,对抗“作弊”。
在训练过程中,策略模型会利用规则漏洞“作弊”(hacking),比如,生成结构表达上合理优雅,但本质错误或欺骗性的回答。一旦这类回答没有被准确识别,策略模型将持续朝错误方向优化,导致资源浪费,且模型能力无法得到实质提升。对此,介入方式是人工标注负面案例,补充样本,迭代训练验证器。即发现不同作弊手段并有针对性迭代,随着验证器的改进,模型作弊空间被逐步压缩。
作弊现象包括,但不限于:
第一种,模型在简单任务上“快答”,即直接输出结论,无推理过程,继而在复杂任务上沿用同样策略。
第二种,模型为获取高分,重复高评分答案或在同一回复中多次强调同一结论,以最大化累计奖励。
第三种,模型输出看似合理,但事实性错误的答案,比如,并不存在的疾病。这类错误往往不易被没有医学专业背景的普通用户察觉,但在专业医生审阅下会立即暴露。在健康场景下,具有较高风险隐患。
调研发现,强化学习训练过程初期,不宜引入过多复杂评判,需提供结构清晰、判断标准单一的参照信号,避免策略模型在尚未稳定时被复杂标准干扰,走偏优化方向。
(七)强化学习推理系统:多阶段训练

当模型在此处微调,会有一个较高的起点,原因是微调采用的数据已经过精妙设计(多个阶段的多轮迭代与筛选)。同时,在整个数据产线中,模型和数据并没有压缩与现实世界有关的多领域通用知识,在这一阶段增加此类通用数据,使得模型处理问题的能力更全面,更具备解决现实健康与医疗问题和状况的能力。
健康需求是一种低频刚需,此类产品的用户通常是有健康需求,或处于健康困扰中。模型回答不仅需确保准确性与专业性,更应体现出适度的情感关怀,避免因措辞不当引发用户焦虑。
因此,需要偏好奖励模型对齐风格,方法是先训练奖励模型,选择基于“成对比较样本训练机制(Pairwise)”,学习相对偏好。模型在推理阶段独立地对单个回答给出打分(Pointwise),连续打分,而非分类结果。随后,奖励模型输出生成一个连续实数作为质量评分,用于引导策略模型更新方向。
再次引入数据产线一阶段的验证器,该验证器来源于前一阶段数据产线中的强化学习阶段,具备标准答案或判定规则。此处的再验证,用于防止策略模型经过多阶段的训练后产生遗忘,该步骤在健康医疗领域尤其重要。该训练阶段采用混合训练的方式,偏好奖励模型(RLHF)和验证器补充检验(RLVR),两者共同保障了策略模型能力迭代增长的同时,对医学任务规范性与推理逻辑的长期保持与强化。
综上,夸克健康大模型团队,使用两条平行数据产线产出的高质量训练数据,结合多阶段训练方法,得到具备一定推理能力与可靠性的健康医疗推理模型。
(完)
附录



....
#CodeBuddy
新的CodeBuddy IDE测了,我们感受到腾讯搞定创意人士的野心
腾讯又偷偷搞大动作。
xx和其他媒体老师一起,在北京参加了腾讯的新一场小规模发布会。
虽说规模不大,但发布会的内容则展现了腾讯加入 AI 辅助编程领域的决心和前瞻性。
核心内容只有一个:腾讯最新 AI IDE CodeBuddy 正式开启内测!

当然,这并不是 CodeBuddy 第一次亮相,在过去,CodeBuddy 已经是一个成熟的 AI 编程插件了。据腾讯表示,CodeBuddy 在腾讯内部早已经正式落地,给超过 90% 的内部人员装上了编码效率的「火箭背包」,甚至腾讯内部有 43% 的代码是 AI 生成补全的。

而这一次,他们将 CodeBuddy 全方位进化成了首个实现「产品 - 设计 - 研发部署」全流程 AI 一体化的开发工作台。
行业
相比于 CodeBuddy 产品,xx也关注腾讯云的行业洞察。
幸运的是,发布会中确实聊到了一些行业分析。腾讯将其称为多智能体协作驱动软件工程全链路智能化。
这样听着确实有些晦涩,但这其中有几个核心观点是挺值得分享的。
首先是智能体落地演进范式。腾讯将 AI 智能体的演进分为五个层级,与自动驾驶分级简直异曲同工。

根据这个层级分类,目前我们的 AI 智能体大致处于第三阶段,即项目级自动化。例如 Windsurf、Claude Code 等类似工具,能够实现通过 AI 工具完成需求、代码、部署等完整项目周期的自动化处理,但仍需要一定程度的人工干预。
而在未来,L4 阶段是指能够实现产品需求到生产部署的全流程自动化,非技术人员也可以快速创建完整的产品。而 L5 阶段,则实现多个 AI 代理分工合作处理不同的开发环节,构成完整的 AI 开发团队。
腾讯表示,在 2027 年将实现 L5 层级的智能体。
而最新发布的 CodeBuddy,则能够向 L4 级的多智能体协作的落地迈出坚实的一步。
产品

产品就是这么个产品,首个产设研一体的 AI 全栈工程师。
IDE 是集成开发环境(Integrated Development Environment)的缩写,它是一种为开发者设计的软件工具,用于帮助编写、调试和管理代码。一个典型的 IDE 会把多种编程工具集成在一个界面中,提高开发效率。
CodeBuddy 将 IDE 的功能和多个 AI Agent 功能全部集成到一起,打造了 AI Coding 时代完整的 AI IDE 产品形态。
借助 CodeBuddy,可以一个人担任「产品经理、设计师和前后端工程师」,覆盖从想法到产品发布的全生命周期。
评测
编辑部在第一时间就用上了,也尝试用 CodeBuddy 整了一些小活。

打开程序就会发现和传统 IDE 完全不一样。AI 交互作为工具的最大功能区占据了极大的 UI 界面,与过去的插件类产品有了显著的区别。
我们也惊讶于 IDE 的 UI 设计的精细。据腾讯所说,CodeBuddy 团队有设计师转型的产品经理,对交互和审美要求极高。开发团队部分来自 QQ 团队,对于软件交互有深刻的理解。
CodeBuddy 小机器人明明这么可爱,我们很希望它能够动起来!
在 UI 中相对淡化了传统的编程页面、命令行和文件管理的存在感,能够感觉到 CodeBuddy 在设计中对非专业用户的倾向性。
编辑部内测体验到的是国际版本,能够支持 Claude、GPT、Gemini 等多个大模型。
国内版本也将支持 DeepSeek、混元大模型。
既然是国产 IDE,那就用它来做一些传统智慧的小工具来娱乐一下。
「构建一个 Html 程序,能够实现六十四卦的随机排盘,允许用户输入问题,最终输出排卦结果,以及大模型解卦的内容输出。」
当我们打开了规划模式和设计模式,选择了 Claude-4.0-Sonnet 模型,就让 CodeBuddy 自己操作去了。
它一开始就根据我们给它的任务,输出了 PRD 和设计文档。虽然很难作为真正的需求文档来进行使用,但这些文档确实具备了完善的格式和完整的内容,我们很容易通过这些文档对它在项目中将执行的操作获取详细的认知。


CodeBuddy输出的PRD和设计文档部分
在用户确认需求以后,它写下了待办事项,并直接开始执行。

在过程中,CodeBuddy 具有命令行、代码撰写、执行预览的完整权限和功能,链接了 Supabase 后可以将用户数据部署到云端,强大且高效。
在 CodeBuddy 努力了五分钟后,一个程序雏形就这么出现了。尝试了一下之后发现,变卦的功能缺失了。于是直接向 CodeBuddy 提要求,我需要变卦功能。

仅展示CodeBuddy测试结果,内容为AI生成,仅供娱乐。
然后… 两分钟后功能就完整了。你别说,在文本质量,功能区设计甚至大模型调用的几大功能上都没有明显缺陷。CodeBuddy 能够在简短的 Prompt 指令中分析出足够的信息,对这些功能显然具有很高的理解力。
甚至底部还多出了一行「仅供娱乐」的提示词,也是非常严谨了。

发现了一个错误,这不该是 2024 年。
我们可以在预览界面直接可视化地交互这一块内容区域,选中它,告诉 CodeBuddy,「改为 2025,仅供娱乐的提示需要改的再完善一些」。
于是 CodeBuddy 仅在选定区域进行修改,几秒钟后就按要求完成任务:

令人惊讶的不仅是编程速度之快,还有其功能完整性以及 UI 设计的美观规范。
在之前的简单试用中,我们还做过一个登录界面的示例,需要毛玻璃的效果也能完美的展现出来。

虽然这些都只是 Html 的简单功能示意,但 CodeBuddy 作为创意人士的编程伴侣,其可用性毋庸置疑。
当然,这只是一个整活测试,读者朋友感兴趣的话可以自行申请体验。

另外我们相信,很多用户会对 Figma 转代码的功能有高频需求,在此附上官方的演示视频:
,时长00:36
野心
创意的终点是产品交付,而 CodeBuddy 能够帮助普通创意用户实现基本需求。
我们在试用 CodeBuddy 后,有一种明显的感觉。这类工具是腾讯在 AI 编程领域的一次跃进,他们期望能够激发非专业的用户的创意,打通从设计到实现的路径。
假如结合腾讯现有的开发平台,辅以广大创意人士的应用尝试,是否能够实现一个创意软件的井喷期,让我们拭目以待。
....
#国产AI音乐神器Mureka重磅升级V7
用户暴涨近300万,我们拿它复刻了「印度神曲」
AI 正悄悄「攻占」你的歌单。
前几天在网易云音乐上瞎逛,被意外种草一首歌,真一开口就是月色迷蒙的味道。
,时长03:52
目前,该歌曲拿下了 15 万小红心。本想看看是哪位大神的作品,没想到底下一水的评论:这是 AI 生成的!

其实细听之下还是能找出「端倪」的,比如音质糊的像画面马赛克、人声跟牙齿漏风似的。但经过持续的进化,AI 音乐越来越真假难辨。
现在,AI 音乐的这把火,越烧越旺。
7 月 23 日,大模型厂商昆仑万维正式发布了新一代音乐大模型 Mureka V7,成为了当前国产最强,并在多个关键指标上显著超越海外 AI 音乐平台 Suno(V4.5),包括平均表现评分、混音质量与质感、人声真实感与表现力、整体音质评价。
不仅如此,与上一版本 V6 相比,Mureka V7 生成的音乐品质更高,不仅大幅提升旋律动机和编曲质量,还进一步增强了人声与乐器真实度。

这么说吧,即使你是个五音不全的音乐小白,也能拿它做出超细腻的个人独家 BGM。而对于专业的音乐人而言,Mureka V7 生成的音乐又极具创新性,在一定程度上可以启发灵感。
,时长03:23
Mureka V7 作品《杜甫》
目前,Mureka V7 已经全面上线,感兴趣的小伙伴可以前往官网进行体验。

官网地址:https://www.mureka.cn/
接下来,我们就来实测一下,看看 Mureka V7 在搞音乐创作时是否还有那种「牙齿漏风」的感觉。
一手实测
能模仿王菲,还能生成「土味」MV
Mureka V7 真不只是「AI 帮你写首歌」那么简单,现在它还上线了新功能 —— 自定义歌手。
我们可以上传音频,或者直接丢一个视频链接进去,AI 就能自动模仿音色,唱出全新创作的歌曲。
以天后王菲为例。众所周知,王菲是邓丽君的铁杆粉丝,在 2013 年「邓丽君 60 追梦纪念演唱会」上,鲜少出席活动的王菲与偶像隔空对唱了这首《清平调》。
,时长04:29
王菲演唱会原唱
这一次,我们让 Mureka 模拟王菲的音色,并在此基础上重新谱曲、演唱。
清平调——Mureka生成,xx,2分钟
Mureka 生成的声线再现了王菲特有的空灵、通透,处理歌曲中的弱唱又模拟出王菲标志性的气声效果。咬字方面,Mureka 同样还原了王菲不咬死字头,让声音在口腔中自然流淌的唱法,尤其在尾音收放上,更是有股菲式慵懒感。
我们再来试试它的「音乐参考」功能。
所谓音乐参考,就是通过分析用户上传的音乐,Mureka 能够精准识别原曲的类型、节奏、配器和情绪,并据此生成具有相似风格的原创作品。
前段时间,中国网红「豪哥哥」改编印度神曲《Tunak Tunak Tun》(也就是那首著名的《我在东北玩泥巴》),创作出这首魔性十足的《刚买的飞机被打啦》。
,时长01:12
视频来自博主「豪哥哥 - 魔性改歌」
这首歌一经发布就在全球社交媒体疯狂刷屏,甚至一度把印度网友搞破防,联名「上书」联合国。
我们也拿 Mureka 做了一版,曲风相当洗脑,要是口音咖喱味再浓点就好了。更有意思的是,Mureka 还能自动生成 MV,抽象画面配上黄色描边歌词,又土又上头。
,时长03:00
此外,Mureka 还升级了歌曲描述、纯音乐生成等常规功能。
比如,我们输入李白的《将进酒》,再选择音乐风格「说唱金属,另类金属,说唱摇滚,男声」,Mureka 立马化身摇滚老炮,激情开唱。
将进酒,xx,3分钟
或者通过文字 Prompt 直接生成免版权的 BGM:
温暖的童年,xx,3分钟
提示词:回忆童年的温暖钢琴旋律
也可以上传参考音频,让模型创作出风格相近的纯音乐片段。
summer,xx,2分钟
权力的游戏,xx,2分钟
如果对生成的音乐不满意,Mureka V7 还提供音频编辑功能,可以局部编辑、延长歌曲、乐器分轨甚至裁剪音频,并支持 10 种语言的 AI 音乐创作。
自研音乐思维链「MusiCoT」再次进化
不到四个月的时间,Mureka V7 相较于上代 Mureka V6 的表现又提升了一大截,这源自昆仑万维对自研音乐生成专用思维链 —— MusiCoT 的持续优化。
我们知道,大语言模型的内容输出方式是「预测下一个 token」,这显然与音乐创作的过程不同。为此,昆仑万维在 Mureka 中引入了生成式 AI 领域流行的思维链(CoT)提示方法,并通过 V6 版本完成了首秀。
此次,Mureka V7 进一步优化了 MusiCoT(Analyzable Chain-of-Musical-Thought Prompting)技术,显著提升了模型生成结果的整体性与发声表现,具体包括以下三大方面的创新。
一是,先想结构后生成,符合人类创作逻辑。
MusiCoT 在输出音频 token 之前,会先让模型生成对音乐结构的全局规划,确定整体的段落、情绪、编排等布局。这就能让 AI 生成的作品具备清晰的结构。
二是,生成结构可解释、可控。
通过 CLAP(对比式语言 - 音频预训练模型),MusiCoT 的明确思维链让 AI 生成的音乐具有明确的可读性和可控性。用户可以输入任意长度的参考音频作为风格提示。
三是,主观 + 客观验证效果全面领先。
基于大量实验,MusiCoT 在主客观双重指标下均展现出了卓越的效果。无论是结构完整、旋律连贯还是整体音乐性均优于传统方法,在多项评测中表现达到行业顶流水准。
在 Mureka V7 上,MusiCoT 不仅在结构层面实现对音乐创作思维的拟合与对齐,更借助数据的进一步扩展、嵌入信息粒度的细化,完善了可控性与可扩展性。
得益于 MusiCoT 的升级和应用,Mureka 部分生成作品已经能够为音乐人提供更多创作灵感,并加速从灵感到成品的落地过程。
定制语音有了更好的国产选择
此次,除了更强、更拟人、更自然的音乐生成之外,昆仑万维还带来了一款音频模型 ——Mureka TTS V1。该模型支持的语音创作功能也已经上线官网。

与音乐生成强调旋律、和声、节奏、风格等音乐语言的表达不同,音频模型更关注对所有声音类型的通用表示与理解,包括语音、人声、环境音、音效等。Mureka TTS V1 的最大亮点是引入了 Voice Design 能力,可以通过文本输入想要的语音特征来获得对应的音色。
这意味着,不论是真实人物、虚拟人物还是配音角色都能够通过文本来控制,不用像过去一样只能通过预设音色库来实现音色克隆。相反,用户能够通过自然语言指令灵活定义声音的性别、年龄、情感状态、语气风格、表达节奏,达成真正个性化、场景化的语音合成体验。
跑分结果显示,在与竞对 ElevenLabs TTS V2 的较量中,Mureka TTS V1 的语音质量、分词与语句节奏准确性以及整体听感体验均实现了超越,只在发音准确性方面略逊一筹。如此一来,昆仑万维在语音合成的多个核心维度上已具备行业领先优势,可以进一步满足更高阶的语音创作与交互场景的需求。

最终好不好,还是得看实际效果。
我们来听一段人声,「童音女声,12 岁左右,声音清脆悦耳,热情洋溢,语速略快但不慌乱。」
女童声音-叶子变色小秘密,xx,41秒
再来一个「男性新闻播音员,语音清晰且稳定,语调平稳、沉着,语速适中,语气冷静理性,情感中性且客观,音量适中,声音具有一定的厚重感,体现专业性与可信度」。
男性新闻播音员-瞎说新闻,xx,44秒
可以看到,Mureka TTS V1 从创意描述到声音输出实现了全流程生成,声音创造更加高效与自由,不仅大大拓展了语音生成的应用边界,也为内容创作与交互体验打开了想象空间。未来,该模型可以进一步在影视、游戏、广告等行业的配音场景大显身手。
写在最后
最近一段时间,随着 Scaling laws 放缓,模型规模扩展所带来的边际收益减弱,各家厂商卷基础大模型的步伐也开始放缓。相反,大模型的「价值兑现」与「商业化落地」正在加速推进中。
随之而来,一些垂直大模型成为新一轮技术博弈与产品竞速的焦点,如 AIGC 领域的视频大模型、音乐大模型等。大家都卯足了劲抢占规模化落地的红利,率先打通从技术到产品的转化路径,占据内容创作、营销、娱乐等高频应用场景的生态入口。
这一趋势与昆仑万维长久以来的战略天然契合。在「实现通用人工智能,让每个人能够更好地表达自我」的使命驱使下,该公司形成了「AI 前沿基础研究 —— 基座模型 —— AI 矩阵产品 / 应用」的全产业链,持续发力 AIGC 创作领域,并推出覆盖视频、音乐、Agent 等多个方向的创新型产品。
其中自 2024 年 4 月亮相以来,Mureka 作为「会思考」音乐模型的名头越打越响。今年,Mureka 已经迎来了两次大版本更新,上个版本 V6 直到最近仍被很多国外网友「安利」。


甚至从 3 月底到现在,Mureka 的新增用户就接近 300 万。显然,昆仑万维的音乐大模型获得了用户的高度认可,并正在引领音乐创作方式的变革。
未来,随着模型能力的持续增强与创作门槛的进一步降低,AI 有望演变成为音乐创作的核心驱动力。同时,音乐创作也将继续打破专业壁垒,走向全民表达。
....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 21
21 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)