51c大模型~合集146
【摘要】本文系统梳理了2017年Transformer架构问世以来大语言模型(LLM)领域的关键技术突破。重点分析了22篇里程碑论文,包括奠定基础的《Attention Is All You Need》、开启大模型时代的GPT-3研究,以及推动RLHF对齐技术的《Training language models to follow instructions with human feedback》
我自己的原文哦~ https://blog.51cto.com/whaosoft/14018370
#LLM领域的重要论文
盘一盘,2017年Transformer之后
这两天 Andrej Karpathy 的最新演讲在 AI 社区引发了热烈讨论,他提出了「软件 3.0」的概念,自然语言正在成为新的编程接口,而 AI 模型负责执行具体任务。
Karpathy 深入探讨了这一变革对开发者、用户以及软件设计理念的深远影响。他认为,我们不只是在使用新工具,更是在构建一种全新的计算范式。
回顾 LLM 的发展历程:自 2017 年 Transformer 架构问世以来,我们见证了 GPT 系列的一路高歌猛进,以及多模态能力和端侧应用的全面开花。整个领域正以前所未有的速度演进。

要深入理解这场变革的本质,我们需要回到技术的源头。那些奠定今天 AI 能力的关键论文,不仅记录着算法的演进轨迹,更揭示了从传统编程到自然语言交互这一范式转变的内在逻辑。
此前我们通过 50 个核心问题回顾了 LLM 的基础概念。今天,我们将梳理自 2017 年以来 LLM 领域的重要论文。本文从 X 用户 Pramod Goyal 的论文盘点中精选了 22 篇进行详细介绍,其余论文将在文末列出供读者参考。

奠基理论
- Attention Is All You Need (2017)
链接:https://arxiv.org/pdf/1706.03762
主要内容:提出了 Transformer 架构,它完全摒弃了传统的循环和卷积网络,仅依靠自注意力机制来处理序列数据。通过并行计算和位置编码,它能高效捕捉长距离的依赖关系,以更快的速度和更高的质量完成机器翻译等任务。
影响:Transformer 架构是现代 AI 的基石,直接催生了 GPT 和 BERT 等 LLM,并引发了当前的 AI 热潮。它的高效和通用性使其不仅彻底改变了自然语言处理,还被成功应用于计算机视觉等多个领域,成为一项革命性的技术。
- Language Models are Few-Shot Learners (2020)
论文地址:https://arxiv.org/abs/2005.14165
主要内容:介绍并验证了拥有 1750 亿参数的自回归语言模型 GPT-3 的强大能力。研究表明,与以往需要针对特定任务进行大量数据微调的模型不同,GPT-3 无需更新权重,仅通过在输入时提供任务描述和少量示例(即「少样本学习」或「上下文学习」),就能在翻译、问答、文本生成乃至代码编写等大量不同的自然语言处理任务上取得极具竞争力的表现,且模型性能随着参数规模的增长和示例数量的增加而稳定提升。
影响:确立了「大模型 + 大数据」的缩放定律 (Scaling Law) 是通往更通用人工智能的有效路径,直接引领了全球范围内的 LLM 军备竞赛。同时,它开创了以「提示工程」为核心的新型 AI 应用范式,极大地降低了 AI 技术的开发门槛,并催生了后续以 ChatGPT 为代表的生成式 AI 浪潮,深刻地改变了科技产业的格局和未来走向。
- Deep Reinforcement Learning from Human Preferences (2017)
论文地址:https://arxiv.org/abs/1706.03741
主要内容:该论文开创性地提出,不再手动设计复杂的奖励函数,而是直接从人类的偏好中学习。其核心方法是:收集人类对 AI 行为片段的成对比较(「哪个更好?」),用这些数据训练一个「奖励模型」来模仿人类的判断标准,最后用这个模型作为奖励信号,通过强化学习来训练 AI。该方法被证明仅需少量人类反馈即可高效解决复杂任务。
影响:这篇论文是「基于人类反馈的强化学习」(RLHF) 领域的奠基之作。RLHF 后来成为对齐和微调 ChatGPT 等 LLM 的关键技术,通过学习人类偏好,使 AI 的输出更有用、更符合人类价值观。它将「AI 对齐」从抽象理论变为可行的工程实践,为确保 AI 系统与人类意图一致提供了可扩展的解决方案,是现代对话式 AI 发展的基石。
- Training language models to follow instructions with human feedback (2022)
论文地址:https://arxiv.org/abs/2203.02155
主要内容:该论文提出了一种结合人类反馈的强化学习方法 (RLHF) 来训练语言模型,使其更好地遵循用户的指令。具体步骤包括:首先,使用少量人工编写的示例对预训练的 GPT-3 进行微调;然后,收集人类对模型不同输出的偏好排序数据,并用这些数据训练一个「奖励模型」;最后,利用这个奖励模型作为强化学习的信号,进一步优化语言模型。通过这种方式,即使模型参数比 GPT-3 小得多,InstructGPT 在遵循指令方面也表现得更出色、更真实,且有害内容生成更少。
影响:催生了现象级产品 ChatGPT,并为 LLM 的发展确立了新的技术路线。它证明了通过人类反馈进行对齐 (Alignment) 是解决大型模型「说胡话」、不听指令问题的有效途径。此后,RLHF 成为训练主流对话式 AI 和服务型大模型的行业标准,深刻改变了 AI 的研发范式,将研究重点从单纯追求模型规模转向了如何让模型更好地与人类意图对齐。这一方法论的成功,是推动生成式 AI 从纯粹的技术展示走向大规模实际应用的关键一步。
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2019)
论文地址:https://aclanthology.org/N19-1423/
主要内容:该论文提出了 BERT,一个基于 Transformer 的语言表示模型。其核心创新是真正的双向上下文理解,通过创新的「掩码语言模型」(MLM) 预训练任务,让模型能同时利用一个词左右两侧的全部语境。这克服了以往单向模型的局限性。BERT 通过在海量文本上预训练,再针对具体任务微调的范式,极大地提升了语言理解能力。
影响:BERT 的发布是 NLP 领域的革命,它在 11 项主流任务上刷新了最高分纪录,确立了「预训练 + 微调」作为行业标准范式。它极大地简化了为特定任务构建高性能模型的流程,减少了对复杂定制架构的需求。BERT 开启了现代 LLM 的新纪元,成为后续无数模型的基础。
- Training Compute-Optimal Large Language Models (2022)
论文地址:https://arxiv.org/abs/2203.15556
主要内容:这篇由 DeepMind 发表的论文(通常被称为「Chinchilla 论文」)挑战了当时「模型越大越好」的普遍认知。通过对超过 400 个模型的系统性训练和分析,研究者发现,现有的 LLM 普遍处于「训练不足」的状态。为了在给定的计算预算下达到最佳性能,模型的大小和训练数据的规模应该同步增长。具体来说,模型参数每增加一倍,训练数据的量也应相应增加一倍。这揭示了一个新的、更高效的「计算最优」缩放法则,颠覆了以往只侧重于增加模型参数的策略。
影响:改变了之后 LLM 的研发方向和资源分配策略。它提出的「计算最优」缩放法则,成为了业界训练新模型时遵循的黄金准则。在此之前,各大机构竞相追求更大的模型规模,而「Chinchilla」证明了在同等计算成本下,一个参数量更小但用更多数据训练的模型(如其 700 亿参数的 Chinchilla 模型)可以优于参数量更大的模型(如 GPT-3)。这促使整个领域从单纯追求「大」转向追求「大与多的平衡」,对后续如 LLaMA 等高效模型的诞生起到了关键的指导作用。
里程碑突破
- GPT-4 Technical Report (2023)
论文地址:https://arxiv.org/abs/2303.08774
主要内容:详细介绍了一个大规模、多模态的语言模型——GPT-4。其核心在于展示了该模型在各类专业和学术基准测试中展现出的「人类水平」的性能。与前代不同,GPT-4 不仅能处理文本,还能接收图像输入并进行理解和推理。报告重点阐述了其深度学习系统的构建、训练方法、安全考量以及通过可预测的「缩放法则」来准确预测最终性能的工程实践。同时,报告也坦诚地指出了模型在事实准确性、幻觉和偏见等方面的局限性。
影响:进一步巩固了大规模基础模型作为通往更强人工智能关键路径的行业共识。GPT-4 所展示的卓越性能,特别是其多模态能力和在复杂推理任务上的突破,迅速成为 AI 技术的新标杆,极大地推动了 AI 在各行业的应用深度和广度。它不仅催生了更多强大的 AI 应用,也促使全球科技界、学术界和政策制定者更加严肃地审视 AI 安全、对齐和伦理挑战,加速了相关防护措施和治理框架的研究与部署。
- LLaMA:Open and Efficient Foundation Language Models (2023)
论文地址:https://arxiv.org/abs/2302.13971
主要内容:发布了一系列参数规模从 70 亿到 650 亿不等的语言模型集合——LLaMA。其核心发现是,通过在海量的公开数据集上进行更长时间的训练,一个规模相对较小的模型(如 130 亿参数的 LLaMA 模型)其性能可以超越参数量更大的模型(如 GPT-3)。论文证明了训练数据的规模和质量对于模型性能的决定性作用,并为业界提供了一条在有限算力下训练出高效能模型的全新路径。
影响:LLaMA 的发布对 AI 领域产生了颠覆性的影响。尽管最初其权重并非完全开源,但很快被社区泄露,并催生了 Alpaca、Vicuna 等大量开源微调模型的井喷式发展,极大地推动了 LLM 研究的民主化进程。它让学术界和中小型企业也能参与到大模型的研发与应用中,打破了少数科技巨头的技术垄断,引爆了整个开源 AI 生态的活力与创新。
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (2022)
论文地址:https://arxiv.org/abs/2205.14135
主要内容:提出了一种快速且节省内存的精确注意力算法。它通过融合计算内核、重排计算顺序以及利用 GPU 内存层级(IO 感知)等技术,有效减少了在计算注意力时对高带宽内存 (HBM) 的读写次数。这使得模型在处理长序列时,既能大幅提升计算速度,又能显著降低内存占用,且计算结果与标准注意力完全一致。
影响:FlashAttention 已成为训练和部署 LLM 的行业标准。该技术使得用更少的硬件训练更大、更长的模型成为可能,直接推动了长上下文窗口模型的发展。因其显著的加速和优化效果,它被迅速集成到 PyTorch、Hugging Face 等主流深度学习框架和库中,极大地促进了整个 AI 领域的进步。
- Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022)
论文地址:https://arxiv.org/abs/2201.11903
主要内容:该论文发现,在处理复杂的推理任务(如数学题)时,若引导 LLM 模仿人类的思维过程,先输出一步步的推理「思路链」(Chain-of-Thought),再给出最终答案,其准确率会大幅提升。这种简单的提示技巧,有效激发了模型隐藏的逻辑推理能力。
影响:这项工作开创了「思维链」(CoT) 提示技术,成为提升大模型推理能力最重要和基础的方法之一。它深刻地影响了后续提示工程的发展,并启发了一系列更高级的推理技术,是理解和应用现代 LLM 的基石性研究。
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model (2023)
论文地址:https://arxiv.org/abs/2305.18290
主要内容:提出了一种名为「直接偏好优化」(DPO) 的新方法,用于对齐语言模型。它不再需要像传统 RLHF 方法那样,先训练一个独立的奖励模型,再通过强化学习去优化。DPO 直接利用人类偏好数据,通过一个简单的分类目标,就能高效地调整语言模型,使其更符合人类期望。这种方法将复杂的对齐过程简化成了一步式的微调。
影响:DPO 因其简洁性和高效性迅速产生了巨大影响。它大大简化了从人类偏好中学习的训练流程,降低了计算成本和技术门槛,使得更多研究者和开发者能够有效地对齐自己的模型。目前,该方法已被业界广泛采纳,成为许多领先开源模型(如 Zephyr、Tulu 2)进行对齐时所采用的主流技术之一。
- Scaling Laws for Neural Language Models (2020)
论文地址:https://arxiv.org/abs/2001.08361
主要内容:系统地研究了神经语言模型的性能与其规模之间的关系。研究发现,模型性能与模型参数量、数据集大小和用于训练的计算量之间存在着平滑的、可预测的幂律关系 (Power Law)。这意味着,当我们在计算资源受限的情况下,可以根据这些「缩放法则」来最优地分配资源,以达到最佳的模型性能,而无需进行昂贵的试错。
影响:为之后的 LLM 研发提供了理论基石和路线图。它明确指出,持续、可预测的性能提升可以通过同步扩大模型、数据和计算量来实现。这直接指导了像 GPT-3、PaLM 等后续超大规模模型的诞生,确立了「暴力缩放」(Scaling) 作为通往更强 AI 能力的核心策略,深刻塑造了当前 AI 领域的军备竞赛格局。
- Proximal Policy Optimization Algorithms (2017)
论文地址:https://arxiv.org/abs/1707.06347
主要内容:该论文提出 PPO 算法,一种旨在解决强化学习中策略更新不稳定的新方法。其核心创新是「裁剪代理目标函数」,通过将新旧策略的概率比率限制在一个小范围内,来防止过大的、破坏性的策略更新。这种简洁的一阶优化方法在保证训练稳定性的同时,显著提升了数据利用效率,且比 TRPO 等先前算法更易于实现。
影响:PPO 凭借其稳定性、性能和实现简单的完美平衡,已成为强化学习领域的「默认」算法。其最深远的影响是作为核心技术,驱动了「基于人类反馈的强化学习」(RLHF),这使得对齐 ChatGPT 等 LLM 成为可能,确保 AI 更有用、更无害。此外,它在机器人等领域应用广泛,并成为衡量新算法的重要基准。
核心架构与方法
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces (2023)
论文地址:https://arxiv.org/abs/2312.00752
主要内容:Mamba 是一种新型的序列建模架构,它通过引入一种选择性机制来改进状态空间模型 (SSM)。这使其能根据输入内容动态地压缩和传递信息,从而以与序列长度成线性关系的时间复杂度高效处理超长序列,并在性能上媲美甚至超越了传统的 Transformer 架构。
影响:Mamba 为长序列建模提供了一个区别于 Transformer 的强大新选择,其高效性能迅速激发了学界对状态空间模型的研究热潮。它被视为下一代基础模型架构的有力竞争者,正推动语言模型、基因组学、多模态等领域的底层架构革新,展现出巨大的应用潜力。
- QLoRA: Efficient Finetuning of Quantized LLMs (2023)
论文地址:https://arxiv.org/abs/2305.14314
主要内容:提出了一种高效微调量化 LLM 的方法。它通过引入一种新的 4 位数据类型 (4-bit NormalFloat)、双重量化和分页优化器技术,极大地降低了微调大模型所需的显存,仅用一块消费级 GPU 即可微调数十亿参数的模型。这种方法在大幅节省资源的同时,几乎不损失模型性能,能达到与 16 位全量微调相当的效果。
影响:极大地降低了参与 LLM 研发的门槛,使得个人开发者和小型研究团队也能在消费级硬件上微调强大的模型。它迅速成为最主流和最受欢迎的高效微调技术之一,推动了开源社区的繁荣和 AI 应用的创新。QLoRA 的技术思想也启发了后续更多关于模型量化和效率优化的研究工作。
- PagedAttention: Efficient Memory Management for LLM Serving (2023)
论文地址:https://arxiv.org/abs/2309.06180
主要内容:提出了一种名为「分页注意力」(PagedAttention) 的新型注意力机制算法。它借鉴了操作系统中虚拟内存和分页的思想,将 LLM 的键 (Key) 和值 (Value) 缓存分割成非连续的固定大小「块」进行管理。这解决了因注意力缓存 (KV Cache) 导致的严重内存碎片和冗余问题,使得在处理长序列或并行处理多个请求时,内存利用率大幅提升。
影响:作为核心技术被集成到业界领先的推理服务框架 vLLM 中,将 LLM 的吞吐量提升了数倍,并显著降低了显存占用。这使得在相同硬件上服务更多用户、运行更大模型成为可能,极大地降低了 LLM 的部署成本和延迟,已成为当前高性能大模型服务 (LLM Serving) 领域的行业标准方案。
- Mistral 7B (2023)
论文地址:https://arxiv.org/abs/2310.06825
主要内容:Mistral 7B 论文介绍了一款高效的 70 亿参数语言模型。它通过分组查询注意力 (GQA) 和滑动窗口注意力 (SWA) 等创新架构,在显著降低计算成本和推理延迟的同时,实现了卓越性能。该模型在众多基准测试中,其表现不仅超越了同等规模的模型,甚至优于 Llama 2 13B 等参数量更大的模型,展现了小尺寸模型实现高水平推理与处理长序列的能力。
影响:Mistral 7B 的发布对开源 AI 社区产生了巨大影响,迅速成为高效能小型模型的标杆。它证明了小模型通过精巧设计足以媲美大模型,激发了社区在模型优化上的创新热情。该模型不仅被广泛用作各种下游任务微调的基础模型,还推动了 AI 技术在更低资源设备上的普及与应用,确立了 Mistral AI 在开源领域的领先地位。
- LAION-5B: An open, large-scale dataset for training next generation image-text models (2022)
论文地址:https://arxiv.org/abs/2210.08402
主要内容:LAION-5B 论文介绍了一个公开发布的、至今规模最大的图文对数据集。它包含从互联网抓取的 58.5 亿个 CLIP 过滤后的图像-文本对,并根据语言、分辨率、水印概率等进行了分类。该数据集的构建旨在民主化多模态大模型的训练,为研究社区提供了一个前所未有的、可替代私有数据集的大规模、开放资源。
影响:极大地推动了多模态人工智能的发展,尤其是在文本到图像生成领域。它成为了许多著名模型(如 Stable Diffusion)的基础训练数据,显著降低了顶尖 AI 模型的研发门槛。该数据集的开放性促进了全球范围内的研究创新与复现,深刻影响了此后生成式 AI 模型的技术路线和开源生态格局。
- Tree of Thoughts: Deliberate Problem Solving with LLMs (2023)
论文地址:https://arxiv.org/abs/2305.10601
主要内容:提出了一种名为「思想树」(Tree of Thoughts, ToT) 的新框架,旨在增强 LLM 解决复杂问题的能力。不同于传统的一次性生成答案,ToT 允许模型探索多个不同的推理路径,像人类一样进行深思熟虑。它通过自我评估和前瞻性规划来评估中间步骤的价值,并选择最有希望的路径继续探索,从而显著提升了在数学、逻辑推理等任务上的表现。
影响:为提升 LLM 的推理能力提供了全新且有效的途径,引发了学术界和工业界的广泛关注。它启发了一系列后续研究,探索如何让模型具备更强的规划和自主思考能力,推动了从简单「生成」到复杂「推理」的技术演进。ToT 框架已成为优化提示工程 (Prompt Engineering) 和构建更强大 AI 智能体 (Agent) 的重要思想之一。
- Emergent Abilities of Large Language Models (2022)
论文地址:https://arxiv.org/abs/2206.07682
主要内容:这篇论文的核心观点是,LLM 的能力并非随着规模增大而平滑提升,而是会「涌现」出一些小模型完全不具备的新能力。研究者发现,在多步推理、指令遵循等复杂任务上,只有当模型规模跨越某个关键阈值后,其性能才会从接近随机猜测的水平跃升至远超随机的水平。这种现象是不可预测的,只能通过实际测试更大规模的模型来发现。
影响:该论文为「大力出奇迹」的模型缩放路线 (Scaling Law) 提供了更深层次的理论解释和预期。它激发了业界对探索和理解大模型「涌现」能力的浓厚兴趣,推动了对模型能力边界的研究。同时,「涌现」这一概念也成为了解释为何更大模型(如 GPT-4)能处理更复杂、更精细任务的理论基石,深刻影响了后续模型的研发方向和评估标准。
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism (2019)
论文地址:https://arxiv.org/abs/1909.08053
主要内容:该论文旨在解决单个 GPU 内存无法容纳巨型模型的核心工程难题。它提出了「张量并行」(即层内模型并行)技术,将 Transformer 层内部的巨大权重矩阵切分到多个 GPU 上,每个 GPU 仅计算一部分,再通过高效通信聚合结果。这种方法实现简单,且能与其他并行策略结合。研究者用该技术成功训练了当时前所未有的 83 亿参数模型,证明了其可行性。
影响:这项工作是 AI 基础设施的里程碑,它提供的张量并行技术是打破单 GPU 内存瓶颈的关键。它为训练拥有数千亿甚至万亿参数的模型铺平了道路,并与数据、流水线并行共同构成了现代大规模分布式训练的基石。Megatron-LM 开源库迅速成为行业标准,为学界和业界提供了实现超大规模 AI 的工程蓝图,将「规模化」理论变为了可操作的现实。
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (2019)
论文地址:https://arxiv.org/abs/1910.02054
主要内容:该论文提出了一种名为 ZeRO (零冗余优化器) 的显存优化技术。它通过在数据并行训练的各个 GPU 之间巧妙地分割和分配模型状态(优化器状态、梯度和参数),消除了显存冗余,从而能在现有硬件上训练远超以往规模的巨型模型,为万亿参数模型的实现铺平了道路。
影响:ZeRO 技术被整合进微软 DeepSpeed 等主流深度学习框架并获广泛采用。该技术极大降低了训练超大模型的硬件门槛,直接推动了后续 GPT 系列、BLOOM 等千亿乃至万亿参数模型的成功训练,是支撑当前大模型发展的关键基础设施技术之一。
- OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER (2017)
论文地址:https://arxiv.org/abs/1701.06538
主要内容:该论文引入了稀疏门控专家混合层 (MoE) 架构,通过条件计算解决了模型容量与计算成本的矛盾。该架构包含成千上万个「专家」子网络,由一个门控网络为每个输入仅激活少数几个专家进行处理。这使得模型参数可增加超 1000 倍,而计算成本仅有微小增加,从而在不牺牲效率的情况下,极大地提升了模型的知识吸收能力。
影响:这项工作首次在实践中大规模证明了条件计算的可行性,为构建拥有数千亿甚至万亿参数的巨型模型铺平了道路。MoE 已成为现代顶尖 LLM (如 Mixtral) 的核心技术之一,它通过让专家网络实现功能分化,在提升模型性能的同时保持了计算效率,对整个 AI 领域的大模型发展产生了深远影响。
重要优化与应用
Improving Language Understanding by Generative Pre-Training (2018)
地址: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
Deep contextualized word representations (2018)
地址: https://aclanthology.org/N18-1202/
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020)
地址: https://arxiv.org/abs/2005.11401
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (2020)
地址: https://arxiv.org/abs/1910.10683
RoBERTa: A Robustly Optimized BERT Pretraining Approach (2019)
地址: https://arxiv.org/abs/1907.11692
Holistic Evaluation of Language Models (HELM) (2022)
地址: https://arxiv.org/abs/2211.09110
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference (2024)
地址: https://arxiv.org/abs/2403.04132
LIMA: Less Is More for Alignment (2023)
地址: https://arxiv.org/abs/2305.11206
Grouped-query attention (2023)
地址: https://arxiv.org/abs/2305.13245
Fast Inference from Transformers via Speculative Decoding (2022)
地址: https://arxiv.org/abs/2211.17192
GPTQ: Accurate Post-Training Quantization for Generative Language Models (2022)
地址: https://arxiv.org/abs/2210.17323
LLaVA: Visual Instruction Tuning (2023)
地址: https://arxiv.org/abs/2304.08485
PaLM 2 / BLOOM / Qwen (Series) (2022-2023)
PaLM 2 地址: https://ai.google/static/documents/palm2techreport.pdf
BLOOM 地址: https://arxiv.org/abs/2211.05100
Qwen 地址: https://arxiv.org/abs/2309.16609
Universal and Transferable Adversarial Attacks on Aligned Language Models (2023)
地址: https://arxiv.org/abs/2307.15043
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training (2023)
地址: https://arxiv.org/abs/2308.01320
前沿探索与新趋势
Language Models are Unsupervised Multitask Learners (2019)
地址: https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
DistilBERT, a distilled version of BERT (2019)
地址: https://arxiv.org/abs/1910.01108
Efficient Transformers (Sparse / Longformer / Reformer / Performers) (2019-2020)
Sparse Transformers 地址: https://arxiv.org/abs/1904.10509
Longformer 地址: https://arxiv.org/abs/2004.05150
Reformer 地址: https://arxiv.org/abs/2001.04451
Performers 地址: https://arxiv.org/abs/2009.14794
SentencePiece: A simple and language independent subword tokenizer (2018)
地址: https://arxiv.org/abs/1808.06226
Generative Agents: Interactive Simulacra of Human Behavior (2023)
地址: https://arxiv.org/abs/2304.03442
Voyager: An Open-Ended Embodied Agent with Large Language Models (2023)
地址: https://arxiv.org/abs/2305.16291
Textbooks Are All You Need (Phi Series) (2023)
地址: https://arxiv.org/abs/2306.11644 (phi-1)
Jamba: A Hybrid Transformer-Mamba Language Model (2024)
地址: https://arxiv.org/abs/2403.19887
WizardLM: Empowering Large Language Models to Follow Complex Instructions (2023)
地址: https://arxiv.org/abs/2304.12244
TinyLlama: An Open-Source Small Language Model (2024)
地址: https://arxiv.org/abs/2401.02385
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025)
地址: https://arxiv.org/abs/2501.12948
Train Short, Test Long: Attention with Linear Biases (ALiBi) (2021)
地址: https://arxiv.org/abs/2108.12409
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (2023)
地址: https://arxiv.org/abs/2306.00978
Red Teaming Language Models with Language Models (2022)
地址: https://arxiv.org/abs/2202.03286
Universal Language Model Fine-tuning for Text Classification (ULMFiT) (2018)
地址: https://arxiv.org/abs/1801.06146
XLNet: Generalized Autoregressive Pretraining for Language Understanding (2019)
地址: https://arxiv.org/abs/1906.08237
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation... (2020)
地址: https://aclanthology.org/2020.acl-main.703/
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (2020)
地址: https://arxiv.org/abs/2003.10555
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding (2020)
地址: https://arxiv.org/abs/2006.16668
MEASURING MASSIVE MULTITASK LANGUAGE UNDERSTANDING (MMLU) (2020)
地址: https://arxiv.org/abs/2009.03300
Beyond the Imitation Game: Quantifying and extrapolating... (BIG-bench) (2022)
地址: https://arxiv.org/abs/2206.04615
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models... (2023)
地址: https://arxiv.org/abs/2312.12148
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale (2022)
地址: https://arxiv.org/abs/2207.00032
....
#LongCat-Flash-Thinking-2601
美团又上新模型,8个Thinker齐开工,能顶个诸葛亮?
临近春节,各家 AI 厂商进入冲刺阶段,纷纷亮出最新大模型成果。
1 月 15 日,美团也重磅更新自家模型 ——LongCat-Flash-Thinking-2601。
这是一款强大高效的大规模推理模型,拥有 5600 亿个参数,基于创新的 MoE 架构构建。

该模型引入了强大的重思考模式(Heavy Thinking Mode),能够同时启动 8 路思考并最终总结出一个更全面、更可靠的结论。目前重思考模式已在 LongCat AI 平台正式上线,人人均可体验。
仅选择「深度思考」时才会触发重思考模式。
- 体验链接:https://longcat.ai
- 模型地址:https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601
- GitHub:https://github.com/meituan-longcat/LongCat-Flash-Thinking-2601
不仅如此,该模型的智能体能力还获得了重大提升:在智能体工具调用、智能体搜索和工具集成推理等基准测试中达到顶尖性能,而且在任意的 OOD(分布外)真实智能体场景中实现了泛化能力的显著提升。

研究团队还专门提出了一种全新的智能体模型泛化能力评测方法。
通过构建自动化的环境和任务合成流程,基于给定关键词,随机生成任意的复杂任务。每个生成的任务都配备对应的工具集与可执行环境。
这种高度随机化的评测方式,能够更真实地检验模型在未知场景下的适应能力。
实验结果表明,LongCat-Flash-Thinking-2601 在该评测中始终保持领先性能。
,时长00:53
接下来,我们就把模型拉到真实场景里实测一番。
一手实测:这只龙猫有点强
我们先来试试数理逻辑推理,顺便看看这个重思考模式到底是怎么一回事。
「运动会招募志愿者,第一次招募了不到 100 人,其中男女比例为 11:7;补招若干女性志愿者后,男女比例为 4:3。问最多可能补招了多少名女性志愿者?」
在 longcat.ai 上开启「深度思考」后,便进入了重思考模式,此时 8 个 Thinker 同时开工,每个都表现出不同的思考风格。有的按常规解题,有的则直接写了个 Python 脚本。

大部分 Thinker 给出了答案 5,其中 3 号和 6 号 Thinker 还写出详细的推导过程。待 8 个 Thinker 执行完任务后,模型再验证不同 Thinker 的思考过程,形成最终答案。
整个过程就像一个团队开会讨论问题,最后达成共识,最终给出的解答也更靠谱得多。

下面是道逻辑推理题。「A 的手机号码最后 5 位,由五个不同的数字组成。B 说:我猜它是 84261。C 说:我猜它是 26048。D 说:我猜它是 49280。A 说:巧了,你们每人都猜对了位置不相邻的两个数。你知道这五位号码是多少?」

8 个 Thinker 再次启动,各自从不同角度切入。
模型没有简单地按照「少数服从多数」的原则采纳意见,而是调用一段代码,系统验证答案是否满足所有约束条件,并穷举所有可能的组合,确认 86240 是唯一解。
这种将单个模型调用八次的模型编排方式,在技术实现上虽直接,却在实际效果上发挥出「三个臭皮匠顶过诸葛亮」的优势。
实测过程中,我们还发现了重思考模式的一种有趣玩法:投票。
举个例子,我们可以开启「深度思考」模式,然后让模型选出 2000 年代最优秀的华语流行歌手。
我们发现不同的 Thinker 会给出很不一样的答案,比如有一个仅选出了周杰伦、蔡依林、孙燕姿、王菲、陈奕迅五位代表,而另一个则直接列出了一长串名单。
最终,经过模型在总结阶段的汇总整理,LongCat-Flash-Thinking-2601 给出了一份涵盖多维度评估的名单,颇具参考性。

我们又试了下该模型的编程能力。先让它生成一个 Flappy Bird 小游戏,效果很不错。

Prompt:Make a game like flappy bird using HTML/CSS/JS in a single HTML file.
接下来我们又试了试让其编写一个康威生命游戏:

Prompt:用 Python 写一个 Conway 生命游戏,提供可视化网格、暂停、单步和参数调节功能。
但实事求是地说,使用 8 个 Thinker 来完成编程任务的计算成本应当是比较高的,可能并不适合大规模应用(尽管目前该模型对普通用户免费),但是我们认为这种模式却非常适合医疗、金融、法律等可能需要多次深度思考来保证准确性的场景。
最后,我们再来测试一下 LongCat-Flash-Thinking-2601 模型主打的 Agent 能力,其中的核心便是工具调用。
为了方便用户测试,美团专门构建了一个「大模型工具使用测试」平台。该平台能基于关键词随机生成复杂的 OOD(分布外)任务,专门用来试探模型在陌生环境下的行动能力。
我们随机生成了一个「营养补给方案」任务。平台生成了一个包含近30个工具的复杂图谱。从页面右侧的依赖关系可以看出,这并非简单的线性调用,模型需要像经验丰富的营养学家,理清儿童营养需求分析、食物营养成分计算、过敏食物筛选等工具之间环环相扣的逻辑。

更有趣的是,该平台还支持模型对比,让用户可以轻松地将 LongCat-Flash-Thinking 与其它模型放在同一起跑线上进行对比。
这里我们将其与当前大模型界的顶级选手 Claude 4.5 Opus 放在了同一个赛道上,进行同步竞技。
,时长00:50
8 倍速视频
视频展示了两个模型在高频调用工具时的思考流。在任务完成后,系统会调用 AI 评估员,从执行速度与任务达成度两个维度进行复盘。

在这个具体案例中,两个模型都交出了高分答卷,但 LongCat 成功达到了 100% 的标准覆盖率,而 Claude 4.5 Opus 却未能成功为用户创建健康档案,仅达到了 80% 的覆盖率。整体而言,LongCat 在处理工具依赖关系的响应节奏上展现出了更强的稳定性。
深入细节,我们可以看到这些工具的调用和输出都采用了标准的 JSON 格式,这也是当前大量的 MCP 或 API 工具采用的主流格式。这也意味着,我们可以非常轻松地将 LongCat-Flash-Thinking-2601 整合进到现有的工作流程中。

强大实力的根基:重思考 + 智能体
那么,表现如此亮眼的 LongCat-Flash-Thinking-2601 究竟是如何炼成的?
正如其推文总结的那样,我们先给出几个关键词:并行思考、迭代式总结、环境规模扩展(Environment Scaling)、多环境大规模强化学习(Multi-Environment RL Scaling)、课程学习(Curriculum Learning)。另外,还有即将发布的 ZigZag Attention。
作为 LongCat-Flash-Thinking 的最新版本,2601 版本继承了上一版本的领域并行训练方案,而技术底座同样是参数总量达 560B 的高性能混合专家(MoE)架构模型。

来自 LongCat-Flash-Thinking 技术报告
在此基础上,如上文评测所示,除了一些细节上的优化,这个新版本重点引入了两大改进:重思考模式和智能体能力。
该模型新引入的重思考模式别具一格,我们目前还未见其它任何模型显式或开源地提供类似模式。
而在智能体能力方面,美团引入了一套精心设计的流程。该流程结合了环境规模扩展与后续任务合成,并会在此之上进行可靠且高效的大规模、多环境强化学习。为更好地适应真实世界智能体任务中固有的噪声与不确定性,美团 LongCat 团队还对多种类型和不同强度的环境噪声进行了系统分析,并采用课程式训练,使模型在非理想条件下依然保持稳健表现。
下面我们就来更具体地看看美团的这些核心技术。
重思考模式:推理广度与深度的协同扩展
打开 longcat.ai 「深度思考」后开始体验,你第一时间就会被同时冒出的 8 个 Thinker 吸引注意。这正是 LongCat 团队提出的 Heavy Thinking Mode(重思考模式)的外在表现。它不仅看起来炫酷,更重要的是将推理能力推向了新的边界。

大致来看,其与 AI 大牛 Andrej Karpathy 实验性的大模型议会项目有相似之处,但不同的是,Karpathy 的大模型议会是通过模型编排方式来向不同模型构成的集体提出问题,让它们各自发言并讨论后给出最终解答,而 LongCat-Flash-Thinking-2601 新引入的重思考模式则是并行地调用一个模型 8 次来实现高强度的并行思考。
如此一来,便可以同时获得多条相互独立的推理路径并进行交叉验证,从而显著降低偶然性错误,提升在复杂问题上的稳定性、可靠性与最终答案质量。如此一来,可以进一步提升模型在极具挑战性任务上的表现。
具体来说,该模式会将高难度问题求解分解为两个互补阶段:并行思考与总结,从而同时扩展推理的深度与宽度。
- 在推理宽度方面,重思考模式会并行生成多条独立轨迹,以广泛探索不同推理路径,并采用相对较高的推理温度以保证多样性。
- 在推理深度方面,总结阶段生成的精炼轨迹可以递归反馈给总结模型,形成支持逐步加深推理的迭代推理回路。LongCat 团队还专门设计了额外的强化学习阶段来训练总结能力,进一步释放该模式的潜力。
智能体能力提升:环境规模扩展与多环境强化学习
智能体能力方面,LongCat 团队精心设计了一套自动化环境规模扩展链路,并构建了一组多样且高质量的环境,作为工具调用类任务强化学习的训练场,使模型能够习得高层次、可泛化的智能体能力。
每个环境包含多达 60 余种工具,并以高密度依赖图的形式组织,提供了足够的复杂度以支持多样化任务构建与大规模探索。实验表明,随着训练环境数量的增加,模型在分布外(OOD)任务中的表现会持续提升(Environment Scaling)。
高质量任务构建
为确保训练任务集的质量,LongCat 团队对任务复杂度和多样性进行显式控制。每个任务都定义在从高质量环境中采样得到的连通子图之上,任务复杂度通过要求在该子图内尽可能多地协同使用工具来调节。为促进任务多样性,已选工具的再次采样概率会逐步降低。
LongCat 团队还构建了配套数据库以确保任务的可执行性,并验证每个任务至少存在一种可执行解。然而,当环境中包含大量工具时,跨数据库的一致性维护会变得困难,可能导致部分任务无法验证。针对这一问题,LongCat 团队设计了专门的应对策略,使训练的稳定性和有效性得到了充分保障。
多环境强化学习
在保持高效异步训练和流式 rollout 特性的同时,LongCat 团队进一步扩展了其强化学习基础设施 DORA(异步弹性共卡系统),以支持环境规模扩展下的大规模多环境智能体训练(Multi-Environment RL Scaling)。
具体而言,来自多个环境的任务会在每个训练批次中以平衡的方式混合,并根据任务复杂度和当前训练状态分配不同的 rollout 预算。
下图展示了该模型的多环境混合强化学习训练曲线,可以看到上涨的趋势非常稳定,这表明美团构建的基础设施和算法可以有效保证训练的稳定性。

下图则展示了多环境强化学习训练下,模型在不同 OOD 测试集上的 RL Scaling 表现,效果非常明显。

面向噪声环境的稳健训练
真实世界的智能体环境天然存在噪声和缺陷,仅在理想化环境中训练模型往往难以获得足够的稳健性。为此,LongCat 团队在训练过程中显式引入环境不完美因素,以提升模型的稳健性。
具体而言,LongCat 团队系统分析了智能体场景中真实世界噪声的主要来源,并设计了一套自动化流程,将这些噪声注入训练环境。在强化学习阶段,LongCat 团队采用课程式策略,随着训练推进逐步增加噪声的类型和强度。
下图展示了模型是否采取面向噪声环境的稳健训练,在带噪声 / 无噪声评测集下的表现对比,其中不同的评测集上依据特性添加了不同类型的噪声。可以看到,带噪声环境下未经过稳健训练的模型的表现会出现大幅衰减,Claude 也无法适应全部的噪声类型。而经过稳健训练后,LongCat-Flash-Thinking-2601(Training w/ Noise 组) 对环境的噪声和不确定性展现出了强大的适应能力,并在各类非理想条件下取得更优表现。

得益于这些改进与创新,LongCat-Flash-Thinking-2601 不仅在智能体工具使用、智能体搜索以及工具融合推理等基准测试中达到顶尖水平,还在任意的 OOD(分布外)真实世界智能体场景中展现出显著提升的泛化能力。
LongCat ZigZag Attention:实现超长上下文
LongCat ZigZag Attention,顾名思义,是一种注意力机制,根据其官方推文描述,其一大核心亮点是能「实现 100 万 token 上下文」。据悉,LongCat ZigZag Attention 已被成功用于训练当前 LongCat-Flash-Thinking 模型的一个分支,我们也将很快见证这个分支版本面世。细节详见论文:https://arxiv.org/abs/2512.23966
One More Thing
回头来看,美团大模型站到台前时间并不算长但节奏清晰,首次亮相在 2025 年 9 月,此后保持了每月一更的开源节奏,不断扩容自己的能力库:从强调响应速度的 LongCat-Flash-Chat 到专注逻辑的 Thinking 版本,再到图像和视频模型以及覆盖多模态的 Omni 版本,每一步迭代都在让这只龙猫能够更好地理解这个世界,并让复杂的现实生活变得更加可计算。

美团在 Hugging Face 上的论文页面
这一次,龙猫聚焦 Agent 与 Thinking 能力进行全面提升,也是实现了一次从理解到融入真实世界的跃迁。
或许,美团现在追求的,就是一种确定性:能够用技术在真实世界中又好又快地解决问题,终有一天让「模型即服务」。
.....
#Mira公司危机持续
失去三个联创后,Mira公司危机持续:又有两人要出走
继奥特曼在 OpenAI 的「宫斗」大戏后,他的老搭档 Mira 这周的经历也够拍一部电视剧了。
昨天,我们报道了前 OpenAI CTO Mira Murati 创办的 Thinking Machines Lab 出现重大人事变动的消息:联合创始人兼 CTO Barret Zoph 被解雇,另一位联创 Luke Metz 以及创始团队成员 Sam Schoenholz 也一起离开,三人一起回归 OpenAI。
如果再加上之前离开的 PyTorch 大神 Andrew Tulloch,Thinking Machines Lab 目前已失去了三位联创,可谓创业未半,核心团队就散了。

今天,事件还在继续发酵,该实验室的另外两位技术骨干 —— 基础设施工程师 Ian O’Connell 和研究模型架构的研究员 Lia Guy 也被爆出将要离开,后者明确也要回 OpenAI。
多家媒体将此事件描述为「OpenAI 对 Thinking Machines Lab 的人才突袭(raid)」。据《连线》报道,这次挖人行动已在 OpenAI 内部筹备数周。

而且,这里面还有一些难辨真假的纠葛。知情人士透露,Mira 是在本周三解雇 Zoph 的,当时她还不知道 Zoph 即将重返 OpenAI ,解雇理由是公司宣称的、在公司任职期间曾出现严重不当行为并引发一系列问题。大约在得知 Zoph 将回归 OpenAI 的同一时间,Thinking Machines Lab 内部开始质疑,Zoph 是否曾向竞争对手泄露公司机密信息。
与此同时,OpenAI 应用业务首席执行官 Fidji Simo 在本周三发给员工的一份备忘录中称,Zoph 早在周一就告知 Mira Murati,自己正考虑离开 Thinking Machines Lab—— 这一时间点早于他被解雇的日期。Fidji Simo 还向员工表示,OpenAI 并不认同 Thinking Machines Lab 对 Zoph 职业道德方面的质疑。

至于其他人集体出走的原因,《连线》所联系的知情人士表示,这是 Thinking Machines Lab 内部长期讨论的结果。公司团队在产品定位、技术路线与未来发展方向上存在分歧,这才是核心原因。目前他们需要理清的问题包括:要开发什么产品,是否应专注于研究或部署,如何证明筹集资金的规模合理性以及领导层信任与治理。
无论真相如何,这次事件都将给 Thinking Machines Lab 带来一些打击。甚至有悲观的网友认为,这家公司「已经完了」。

公司长期以来面临的质疑也被再次拿出来讨论,其中被提及最多的一点是没有「产品」。不过,这么说也不准确,因为公司前段时间推出过一个名叫「Tinker」的产品,专注于解决后训练 Infra 的复杂性。

但显然,这样的成果是承载不起顶级人才当时从大厂出走时所怀揣的技术理想的。因为除此之外,他们没有旗舰模型,没有明确的商业平台,似乎也没有一份与投资规模相匹配的公开路线图。

不过,在失去「联创」这件事上,Thinking Machines Lab 倒也并不孤独,有人统计了最近几年头部 AI 公司的人员流动情况,发现联创出走比大家印象中还要频繁。

行业分析师表示,此类快速行动,如招聘、离职和迅速回归,现在已成为 AI 劳动力市场的一个常见特征,并可能改变项目路线图和时间表。
参考链接:https://www.wired.com/story/inside-openai-raid-on-thinking-machines-lab/?utm_brand=wired-science&utm_campaign=aud-dev&utm_medium=social&utm_social-type=owned&utm_source=twitter-science
.....
#Skills vs MCP,谁才是「大模型的 HTTP 时刻」?
引言:近期,Anthropic 新推出的 Claude Skills 在社区内收获了相对一致的好评,被不少开发者视为「终于能直接拿来用」的能力;几乎同一时间,MCP 协议的「一周年纪念日」却在一片「寂静」中度过。实际上从发布以来,MCP 的「builder 多于 user」、只是「旧瓶装新酒」的质疑始终存在,而在 Skills 和 MCP 叠加演进的当下,我们又该如何重新看待 MCP 的真实定位、适用边界,以及它在 infra 层面的潜在价值?
目录
01. builder 比 user 还多,MCP 仅是「旧瓶装新酒」?
一年过去,社区对于 MCP 的定位仍有争议?平均 25 个用户对应 1 个开发者,MCP 目前更多是开发者自娱自乐的产物?...
02. Not Skills vs MCP, but Skills with MCP?
「人如其名」,Skills 真是来 kill MCP 的?MCP 能做但 Skills 不能做的,现在也没什么用?...
03. 过去一年,围绕 MCP 的 infra 层格局逐渐清晰?
MCP 大规模落地还得看下一个「微信小程序」入口的出现?...
builder 比 user 还多,MCP 仅是「旧瓶装新酒」?
1、自 MCP 发布一年以来,业内关于其定位,适用场景和未来发展等一直存在争议。
2、有分析认为,在技术栈层面 MCP 不是「AI USB」、不是 Function Calling 升级版、也不是万能 Agent 框架,而是「client 和 server 之间的通信协议 + 统一工具访问方式」。[2-1]
① 社区内有用户认为,MCP 的最大价值是给没有工具执行环境的大模型补一层运行时,这本应是 AI 应用开发者本来就要实现的功能。[2-2]
3、枫清科技 Fabarta 合伙人、智能引擎事业部总经理谭宇也指出,从用户视角来看,MCP 包括协议、多语言 SDK 和生态三个方面,低延迟与高并发不在协议关注的范围内。[2-3]
4、而关于 MCP 存在意义的话题,支持者认为 MCP 是「大模型的 HTTP 时刻」,且目前的 AI 已经开始从视觉信息(deepseek-ocr)和动作信息(seed game tars)上学习,类似 MCP 的协议将是下一阶段(掌握工具)的基础能力。[2-4]
5、反对者则指出目前 MCP 在很多方面只是在用「旧瓶装新酒」的方式解决问题,它沿用了传统的服务注册和路由方法,仅在工具调用层面做了协议化,更「AI 化」的做法应该是将所有工具描述嵌入向量空间,通过向量检索找到最合适的工具,实现一步到位的匹配。[2-5]
① 也有观点认为 Function Calling 本身已经在一定程度上规范了模型对工具的调用方式,MCP 所做的只是将这一过程转换成显式协议,在当前互联网生态下更像一个过渡方案。[2-6]
6、此外,目前 MCP 生态中「builder 比 user 多」的现象也存在不少争议。今年 9 月中旬一名科技博主在 X 上发表了「MCP is probably the only piece of tech that has more builders than users」的言论,截至目前浏览量已超 28 万。[2-7]
① 评论区内有观点认为 MCP 目前更多是工程师自娱自乐的产物,处于早期基础设施探索的阶段;也有人指出这其实是早期 infra 的常见现象。
7、相关统计数据也显示,自 Anthropic 发布 MCP 以来社区已上线超过 6000 个 MCP 服务器,活跃开发者人数为 2000-3000,而实际使用这些服务的终端用户人数只有大约 50000 -75000,平均 25 个用户对应 1 个开发者。[2-8]
① 服务器中的关注度分布也不均匀,排名前 10 的 MCP 服务器吸引了近一半的用户关注,前 10%的服务器获得了 88%的星标。
8、有分析指出,目前除了少数面向开发者的 IDE(如 Cursor、Cline 等)支持 MCP,主流网页端 AI 应用并不直接提供 MCP 接入,普通用户难以感知或使用 MCP 接口。[2-9]
9、且目前 MCP 在实际使用中存在调用效率较低、资源消耗高和运行不够稳定等问题。在很多场景下,企业发现直接通过系统 API 访问比通过 MCP 协议调用更为便捷。因此,目前 MCP 生态更多停留在开发者技术实验和内部验证阶段,真正的用户场景较为有限。[2-10]
10、而对于目前 MCP 真正适用的业务场景,社区有用户认为 MCP 目前更适合于 B 端的「Data Open + 工具复用」类型。包括需要向第三方开放扩展的平台、需要跨多端复用同一套工具并进行版本管理以及内部工具链尚未标准化时使用 MCP SDK 来统一流程。[2-6][2-11]
① 例如,如果一个平台需要向第三方开发者开放扩展接口(如 Claude 桌面端的插件生态、微信开始支持 MCP 等),MCP 可以作为统一的接入协议。
② 如果需要在网页版、桌面端、移动端等多种终端环境中复用同一组工具,MCP 的版本管理和能力协商机制也会很有帮助。
③ 另外当一个组织内部没有自研的 Agent 标准时,直接采用 MCP SDK 作为统一规范也是一种选择。
11、但对于小型内部项目或一次性集成需求,使用 MCP 会增加不必要的复杂度;对于性能敏感的应用,MCP 协议层的抽象和基于 JSON-RPC 的通信格式也可能成为效率瓶颈。[2-11]
Not Skills vs MCP, but Skills with MCP?
1、今年 10 月 Anthropic 推出 Claude Skills 以来,社区内对于 Skills 和 MCP 的定位和分工问题也引发了部分业内人士的讨论。
2、有分析认为 Skills 更关注「如何做」,也就是更关注业务流程和策略层面,而 MCP 则回到具体「执行层」,主要负责调用后端工具。[2-12]
① 具体来说,Skills 相当于「带知识的可移植工具调用+子代理」,封装了领域知识和业务逻辑;而 MCP 则属于远程调用运行在服务器上的工具的机制。
② 有用户认为 Skills 更像是「更省 context 的 MCP,用来获取 how-to 指令」。事实上,许多 MCP Server 内部也会为工具编写说明性文档,类似 Skills 给出任务指令的作用。
3、在具体组织上,Skills 的结构非常朴素,一个 Skill 通常由 YAML 头部、Skills.md 文档和可选的资源文件组成。YAML 头部包含技能名称和简要描述(通常不超过 100 个 token),而主要说明和资源文件仅在实际调用该 Skill 时加载,从而有效节约 token。[2-13][2-14]
① 例如,可以为一个个人助手智能体创建多个 Skills,一个负责「会议管理」,用于获取邮件和日历信息以安排会议;另一个负责「会议准备」,用于收集过去会议记录、准备会议材料。而访问邮箱、日历、Notion 等外部系统的操作,仍然通过 MCP Server 来完成。
4、在 Skills 的定位问题上,有观点认为 Skills 发布的目的就是替代 MCP,因为当 MCP 能做到的事情 Skills 也能够实现时,开发者通常更倾向于使用更友好的 Skills;而 MCP 能实现的事情例如通过 API 实现动态更新功能,目前没有太大作用。[2-15]
① 具体来说,MCP 的创新之处在于把原本每个模型与每个工具需要做 M×N 次适配的问题,简化为只需模型和工具各自支持 MCP 后的 M+N 问题。但 MCP 的主要缺点是开发者需要编写大量代码来实现每个 MCP Server,增加了集成成本。
② 相比之下,Skills 允许开发者使用自然语言在 SKILL.md 中描述工具、资源和提示词,对开发者更友好。
③ 同时,Skills 可以在提示中直接给 LLM 提供业务流程指导和思路,而 MCP 本身只是被动暴露工具接口,无法主动控制 LLM 的思维方式。
5、此外也有一些用户从实用角度出发,认为对普通开发者和用户来说「拿来即用的 Skills 市场」 要比 「自己写 MCP server」 更有吸引力。[2-16][2-17]
① 标准化和共享的 Skills 可以让普通用户和非工程师方便地复用已有的工作成果,降低使用门槛。
② 同时,MCP 工具描述往往非常耗费 token(官方的 GitHub MCP 接入就需要消耗上万 token),部分团队可以通过让 LLM 直接调用 CLI 工具或其他轻量方法来替代部分 MCP 流程,来提高效率。
6、但也有人认为目前的状态是「Not Skills vs MCP, but Skills with MCP」,Skills 可以负责封装和组织业务流程、调用顺序,而 MCP 则继续发挥接入数据和工具的作用。[2-14][2-18]...
....
#CKDA
新突破:北大彭宇新团队提出可见光-红外终身行人重识别方法CKDA
终身行人重识别旨在持续学习新增数据中不断涌现的新增行人鉴别性信息,同时保持对已知数据的识别能力,在公共安防、社区管理、运动分析等场景中具有重要的研究和应用价值。
随着白天可见光图像和夜晚红外图像被不断采集,现有终身行人重识别方法需要持续学习特定模态中的新知识(例如:仅适用于红外模态中的热辐射信息)。
然而,特定模态中新知识的学习过程阻碍了模态间公共旧知识(例如:同时适用于可见光与红外模态的人体体态信息)的保留,导致了单模态专用知识的获取与跨模态公共知识的保留间的冲突,进而限制了持续学习场景下平衡不同模态中行人鉴别性知识的能力。
针对这一问题,北京大学彭宇新教授团队提出了跨模态知识解耦与对齐的可见光 - 红外终身行人重识别方法 CKDA,通过跨模态通用提示模块与单模态专用提示模块显式地解耦并净化不同模态通用与特定模态专用的鉴别性信息,从而避免二者间的相互干扰,并在一对彼此独立的模态内与模态间特征空间中分别对齐解耦后的新旧知识,实现跨模态知识的高效权衡。
本文提出的 CKDA 方法在四个常用可见光 - 红外行人重识别数据集组成的终身行人重识别基准上均取得了当前最优的性能。
- 论文链接:http://arxiv.org/abs/2511.15016
- 代码仓库:https://github.com/PKU-ICST-MIPL/CKDA-AAAI2026
- 实验室网址:https://www.wict.pku.edu.cn/mipl
背景与动机
终身行人重识别旨在通过持续学习学习采集自不同场景的行人数据,实现不同场景中同一行人的识别。随着实际场景中白天与黑夜的数据被持续采集,终身行人重识别算法通常需要匹配出现在白天可见光图像和夜晚红外图像中的同一行人,即可见光 - 红外终身行人重识别。
为了缓解可见光与红外模态知识的遗忘,现有方法大多借助数据重放、模型参数隔离、以及知识蒸馏策略实现跨模态知识的保留。

图 1 现有终身行人重识别方法和本方法的对比示意图
然而,现有方法忽略了单模态专用知识获取与跨模态通用知识保留间的冲突,进而导致了跨模态知识难以平衡。
具体而言,如图 1 所示,在持续学习新增可见光与红外数据时,现有方法由于不断地累积特定模态中的新知识(例如:仅适用于红外模态中的热辐射信息),不可避免地阻碍了模态间公共的旧知识(例如:同时适用于可见光与红外模态的人体体态信息)的保留,导致了单模态专用知识的获取与跨模态间公共知识的保留间的冲突,限制了持续学习场景下平衡跨模态鉴别性知识的能力。
技术方案
针对上述挑战,本文提出一种跨模态知识解耦与对齐方法 CKDA,其核心思想在于避免可见光与红外模态中知识的互相干扰,实现跨模态知识的高效平衡。
如图 2 所示,CKDA 主要包含三个模块:
- 跨模态通用提示:通过去除仅存在于可见光或红外图像的风格信息,提取在两种模态中共存的鉴别性知识,为跨模态知识对齐奠定基础;
- 单模态专用提示:通过放大可见光 - 红外模态间的差异,促进特定模态知识的保留与净化,从而显式地避免可见光与红外模态中行人鉴别性知识的相互干扰;
- 跨模态知识对齐:利用旧知识原型构建了一组相互独立的模态内与模态间特征空间并分别对齐解耦后的新旧知识,提升了终身行人重识别模型对可见光 - 红外行人鉴别性知识的平衡能力。

图 2 跨模态知识解耦与对齐方法(CKDA)框架图
模块 1:跨模态通用提示
首先,具体而言,给定输入图像

,先将其划分为 M 个图像块

, 并将每个图像块映射为一个 d 维的嵌入特征:

其中,

表示图像块的嵌入层。然后,将

重排为特征图

,并采用实例归一化缓解不同模态图像间的风格差异,并得到归一化的特征

:

其中,ϵ 用于避免除零问题,

和

分别表示通道均值与方差。随后,

和

间的跨模态通用知识分布可以通过生成的两个通道注意力

和

计算得到:

其中,

和

表示 ReLU 与 Sigmoid 激活函数,

,

和

,

为可学习参数。接着通过自适应地融合

和

进一步提升跨模态通用知识的鉴别性与一致性:

其中,

表示在消除模态差异后跨模态通用知识的重要程度,而

则根据原始特征

中模态公共知识的重要性对鉴别性信息进行动态补充。
最后,将得到的通用提示

与原始特征图对齐,并通过基于图像特征块划分得到的
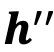
恢复输入维度,从而生成跨模态通用提示

:

其中,

表示特征嵌入恢复层。
模块 2:单模态专用提示
给定可见光或红外模态的图像块

,其中,
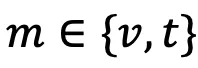
表示可见光或红外模态,单模态专用提示

可以由如下方式计算得到:

其中,

表示 dropout 层,

,

为可学习参数。接着,令

表示阶段 s 生成的图像提示,其优化目标为最小化提示损失

,即:

模块 3:跨模态知识对齐
令

与
![]()
分别表示由

提取的旧数据的可见光和红外特征中心。然后利用由
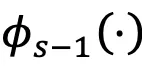
提取的当前可见光样本特征
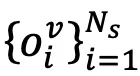
和红外样本特征
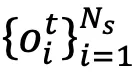
来构建旧的模态间特征空间 O(以可见光模态到红外模态为例),其计算过程如下:
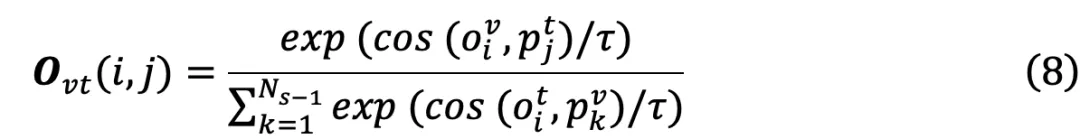
然后,进一步利用当前模型提取的可见光特征
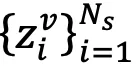
和红外特征

来表示获取新知识后的知识分布 Z:

最后,为了缓解模态间及模态内知识的灾难性遗忘,采用

和

来对齐不同模态与相同模态样本间的相似度:

其中,

为 Softmax 函数。
实验结果
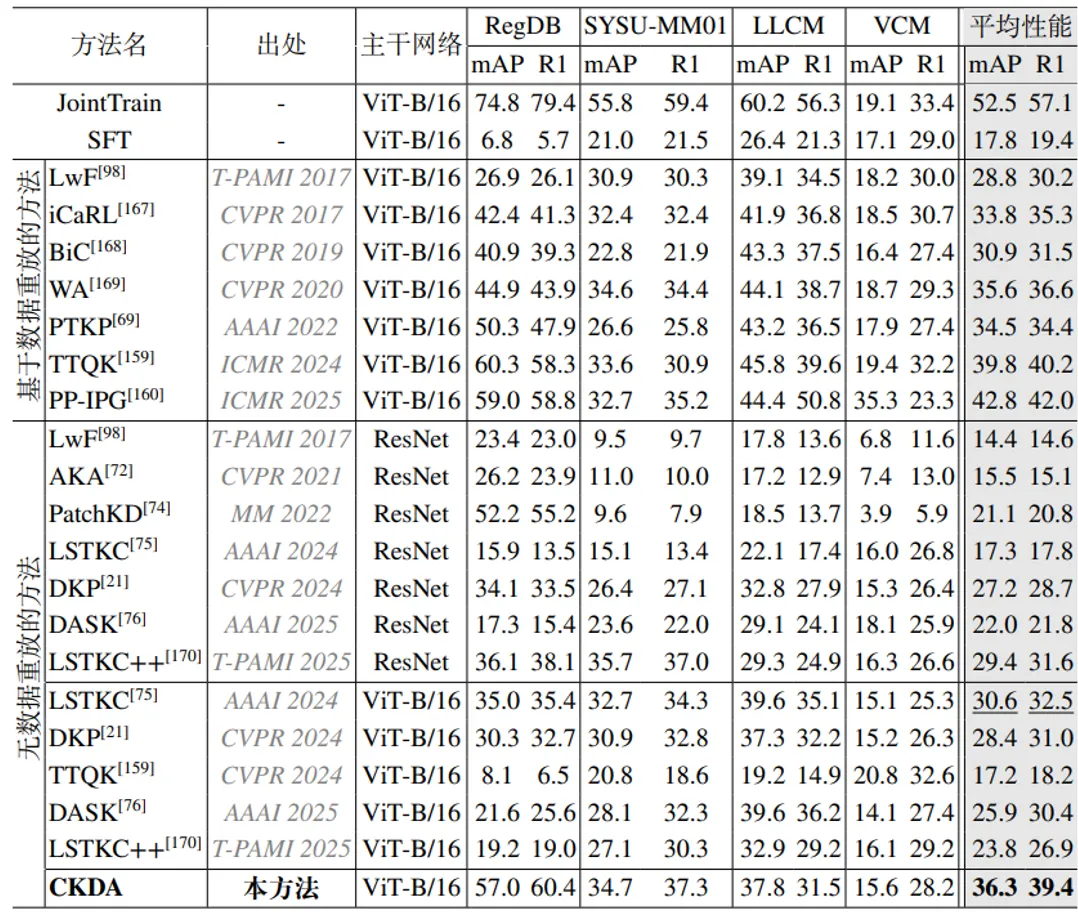
表 1 本方法与现有方法在可见光 - 红外终身行人重识别任务中的性能对比
表 1 的实验结果表明,CKDA 方法在由 4 个常用可见光 - 红外行人重识别数据集组成的终身行人重识别基准上均达到了当前最优的性能,分别达到了 36.3% 和 39.4% 的平均 mAP 和 R1 准确性。
图 3 的可视化结果表明,跨模态通用提示更倾向于关注在两种模态中共存的行人整体轮廓和体态信息。相比之下,单模态专用提示则关注仅存在于特定模态中的知识,例如可见光图像中行人服装颜色或红外图像中的热敏信息。
因此,组合后的可见光图像与红外图像提示能够以互补方式提升模型对可见光与红外模态信息感知与保留能力。

图 3 不同模态图像生成提示的可视化结果
更多详情,请参见原论文。
作者信息
崔振宇,男,北京大学王选计算机研究所 2021 级博士研究生,导师为彭宇新教授,研究方向为多媒体智能计算与机器学习。获得研究生国家奖学金,北京大学博士研究生校长奖学金,ACM-ICPC 亚洲区域赛银牌等奖励。在 CVPR,AAAI,TIFS,TCSVT 等 IEEE Trans./CCF A 类期刊与会议上发表十余篇论文,其中第一作者 7 篇。常年担任国际会议 CVPR、ICCV、NeurIPS、ICLR、ECCV 等多个重要国际会议,以及 IEEE TIP、TIFS、TCSVT、TMM 等多个重要国际期刊的审稿人。
....
#GenMimic
Yann LeCun离开Meta后首篇论文?使用了宇树机器人做研究
还记得《黑客帝国》里 Neo 通过脑机接口瞬间学会功夫的场景吗?

现在,机器人离这一天也不远了。想象一下,你只需在电脑上输入一句提示词:「一个人在打太极」,AI 视频模型(比如 Wan2.1 或 Sora)立刻生成一段视频,而旁边的机器人看完这段视频,竟然就能零样本(Zero-shot)地把这套动作在物理世界中完美复现出来!
没错,这就是来自伯克利、纽约大学和约翰・开普勒林茨大学的一项最新论文想要实现的未来。
研究人员提出了一种名为 GenMimic 的新方法,让机器人拥有了「模仿大师」的技能,甚至即便 AI 生成的视频里人物动作有些变形、甚至出现「鬼畜」般的噪声,机器人也能去伪存真,提取出核心动作逻辑,稳稳当当地在现实中动起来。
- 论文标题:From Generated Human Videos to Physically Plausible Robot Trajectories
- 论文地址:https://arxiv.org/abs/2512.05094v1
- 项目地址:https://genmimic.github.io/
已经离开 Meta、开始创业的图灵奖得主 Yann LeCun 也是该研究的四位共同导师之一。有趣的是,在这篇论文中,Yann LeCun 的所属机构已经没有了 Meta。这应该是他离开 Meta 后发布的第一篇论文?不过,其所属机构也尚未标注其新创业公司,仅有纽约大学。
该论文有四位共一作者:James Ni、Zekai Wang、Wei Lin、Amir Bar。其研究的核心问题是机器人领域一个关键问题:人形机器人如何能够零样本(zero-shot)地执行生成视频中的人类动作?
这项研究有四大贡献:
- 提出了首个使人形机器人能够执行由视频生成模型生成的动作的通用框架。
- 提出了 GenMimic,这是一种新的强化学习策略,使用对称正则化和选择性加权的 3D 关键点奖励进行训练,尽管仅在现有的动作捕捉数据上训练,却能泛化到充满噪声的合成视频。
- 利用 Wan2.1 和 Cosmos-Predict2 整理了合成人类动作数据集 GenMimicBench,建立了评估零样本泛化和策略鲁棒性的可扩展基准。
- 在仿真和真实世界实验中广泛验证了新提出的方法。在仿真中,该团队提供了详细的消融实验,并展示了相比强基线模型的显著改进。他们还进一步在宇树 G1 机器人上确认了新方法的可行性,展示了连贯且物理稳定的动作。

下面我们更详细地了解一下这项研究成果。
GenMimicBench 数据集
为了评估人形机器人控制策略在不同视觉和动作分布下的零样本泛化能力,该团队引入了 GenMimicBench,这是一个包含 428 个生成视频的合成人类动作数据集。
该数据集是使用两个最先进的视频生成模型 Wan2.1-VACE-14B 和 Cosmos-Predict2-14BSample-GR00T-Dreams-GR1 创建的。
如图 2 所示,每个序列都是从初始帧和指定预期动作的文本提示生成的,从而实现了主体身份、视角和动作的系统性变化。

总体而言,GenMimicBench 涵盖了广泛的主体、环境和动作类型,从简单的手势到多步骤组合动作及物体交互行为。
- Wan2.1 视频:受控室内场景。 GenMimicBench 的很大一部分是使用 Wan2.1 从 NTU RGB+D 帧生成的。这些片段提供了清晰、结构化的室内环境,并具有同步的前视、左视和右视摄像机视角。该团队包括了五名具有不同人口统计学特征、身体比例和着装风格的主体,确保外观的多样性,同时保持场景几何的一致性。动作涵盖四个结构化类别。这产生了 217 个多视角室内视频,捕捉了形态、视角和动作组合的细微变化。
- Cosmos-Predict2 视频:网络风格场景。 为了以更大的多样性补充这些受控场景,该团队还使用 Cosmos-Predict2 生成了以 PennAction 帧为条件的视频。这些片段反映了自然场景下 YouTube 视频的特征:杂乱的场景、多变的摄像机运动、不均匀的光照和现实世界的物体布局。该子集包括 211 个视频,主要由八个不同的主体执行简单的手势(例如,摸头、竖大拇指)以及一系列物体交互行为,如开门、举书或哑铃,以及操作日常家居用品。这一部分使策略暴露于受控数据集中所缺乏的现实复杂性,为评估在自然环境中的鲁棒性提供了一个具有挑战性的测试平台。
总计,GenMimicBench 提供了一个包含 428 个高方差合成动作序列的统一集合,涵盖了结构化的室内场景和多样化的现实世界视频语境。
通过将受控动作与多样化的自然人类动作相结合,GenMimicBench 建立了一个全面的基准,可用于评估在视觉、形态和动作分布偏移下的人形机器人策略性能。该数据集专门设计用于压力测试鲁棒性,使其非常适合评估依赖于从生成视频中获取的噪声或不完美动作重建的策略。
从生成的视频到人形机器人动作
为了解决从生成视频中执行人形机器人动作的挑战,该团队提出了一个基于 4D 重建的两阶段流程,并提出了一个新的 GenMimic 跟踪策略。图 3 展示了方法概况。

两阶段流程
第一阶段:从像素到 4D 人形机器人重建。
给定一个生成的输入 RGB 视频,该团队使用最先进的人类重建模型来检测和提取逐帧的全局姿态和 SMPL 参数。由于形态不匹配,生成的 SMPL 轨迹无法直接用于人形机器人。因此,该团队选择将 SMPL 轨迹重定向到机器人的关节空间,该空间结合逐帧的全局姿态可恢复机器人空间中的全局 3D 关键点。
第二阶段:从 4D 人形机器人到动作。
为了正确地泛化到未见过的人类动作,该团队的策略必须对输入中的变化和噪声具有鲁棒性。
为了实现这一点,该团队特意选择 3D 关键点而非关节角度,因为关键点对变化更具鲁棒性,且噪声在这种表征中更容易被观察到。
给定这些关键点和本体感知信息,该团队的跟踪策略输出物理上可实现的期望关节角度。这些期望关节角度被比例-微分 (PD) 控制器使用,输出可执行的力矩给机器人。
GenMimic 策略
如图 3 所示,从视频生成的人类动作包含噪声和形态不匹配,这使得它们偏离了训练数据的分布。
该团队表明,添加加权关键点跟踪奖励和对称增强提供了足够的鲁棒性来解决这些挑战。
加权跟踪 (Weighted Tracking)
某些关键点(例如对应于末端执行器的关键点)在任务执行和物理稳定性方面本质上比躯干或非接触关键点更为关键。因此,该团队将跟踪奖励设计为使用逐关键点误差的加权组合:

这个公式使得策略能够选择性地关注目标中最可靠和与任务最相关的方面。对于生成视频,偏向末端执行器并远离不准确的下半身会产生稳定的模仿效果。
对称损失 (Symmetry Loss)
人体表现出固有的双侧对称性,其中左侧和右侧近似为镜像。
该团队假设,由于这种对称性作为一种强大的物理归纳偏置,一个显式学习并利用左右关键点之间对称相关性的策略,可以对生成视频中的逐关键点噪声实现更强的鲁棒性。
为了实现这一点,该团队在标准 PPO 训练目标中加入了一个辅助对称损失 L_SYM,并带有权重系数 λ_SYM:
![]()
策略学习的细节(包括训练数据、奖励和域随机化)请参阅原论文。


实验表现
该团队在 GenMimicBench 和真实的 23-DoF 宇树 G1 人形机器人上进行了实验。实现细节方面,训练在 IsaacGym 中进行,样本量超过 15 亿,使用了四个 NVIDIA RTX 4090 GPU。部署使用单个 NVIDIA 4060 移动版 GPU。更多细节请访问原论文。
仿真实验
该团队在 GenMimicBench 数据集上对比了该团队的方法与强基线模型。结果见表 1。

如表 1 所示,GenMimic 优于现有基线。GenMimic 学生模型获得了比 GMT 和 TWIST 更高的 SR 和 MPKPE-NT,而 GenMimic 教师模型获得了比 BeyondMimic 和 TWIST 更高的 SR、MPKPE 和 MPKPE-NT。所有 unprivileged 策略都表现出较高的全局误差,突显了从生成视频中进行零样本模仿的挑战。
真实世界实验
该团队成功地将策略部署在 23-DoF 的 G1 人形机器人上,展示了对生成视频中人类动作的物理复现。
该团队总共推演了 43 个动作,并在表 2 中报告了视觉成功率 (VSR)。与仅衡量偏离基准真值的定量仿真指标不同,VSR 评估执行的动作在视觉上是否与生成视频相似。该团队将任何过度的跌跌撞撞或无法在视觉上跟随关键关键点(如手或脚)的情况视为失败。

该团队的策略成功复现了广泛的上半身动作,包括挥手、指向、伸展及其序列组合。将这些动作与下半身运动组合会显著增加难度。对于步进组合,策略能可靠地跟随上半身动作,但无法一致地完成迈步或抬腿。对于转身组合,策略能可靠地达到期望的方向,但经常会跌跌撞撞。
该团队猜想,这些挑战源于不准确或物理上不可行的动作线索,这个问题或可通过向 3D 目标关键点引入加权噪声来解决。
下面展示了一些模仿示例。

该团队也执行了消融实验,详见原论文。
....
#从SAM1到SAM3,Meta做了什么?
从SAM1到SAM3,Meta做了什么?
Meta在AI领域的持续创新,特别是在视觉模型方面,已经取得了巨大的突破。从2023年发布的SAM1开始,Meta就开始了对“可提示图像分割”(Promptable Visual Segmentation, PVS)的探索,推出了一个可以通过简单的图像框选、点击或语义提示来完成图像分割的革命性模型。这一开创性工作迅速吸引了业界的关注,标志着计算机视觉技术进入了一个新的时代。
紧接着,SAM2(2024年发布)在架构上进行了重要优化,增强了对视频分割和动态场景的支持,同时提升了模型的稳定性和精度。SAM2强化了模型对多个实例的跟踪能力,使得该模型不仅在静态图像中表现出色,也能够应对视频中复杂的物体动态变化。
然而,SAM3的发布更是让人瞠目结舌。相比于SAM1和SAM2,SAM3不仅在精度上达到了全新高度,还拥有更强大的多模态支持,能够通过语音、文本、图像等多种输入方式进行精准的物体分割。通过全新的Promptable Concept Segmentation(PCS)任务,SAM3在开放词汇概念分割和多物体跟踪方面,达到了前所未有的精准度和灵活性。PCS让SAM3能够应对更复杂的开放词汇概念,不仅仅是简单的物体分割,而是可以识别并分割任何你想要的对象,无论是猫、狗,还是“黄色的出租车”,甚至是“城市中的小巷子”。
SAM1、SAM2,到SAM3,每一次进化都是一次飞跃
|
技术指标 |
SAM1 |
SAM2 |
SAM3 |
|
模型尺寸 |
较小,适用于实时推理 |
优化了模型结构,更高效 |
增强了计算能力,支持更复杂任务 |
|
推理速度 |
实时,适用于单物体分割 |
提升了视频分割能力 |
实时视频与图像分割,支持多物体 |
|
支持的提示方式 |
图像框选、点击 |
加强了视频跟踪功能 |
多模态提示:图像、文本、语音 |
|
多物体跟踪 |
单一物体分割 |
支持视频中的多物体跟踪 |
实现更高精度的多物体跟踪与标识 |
|
长上下文处理 |
限制性较强 |
增强了视频帧间关联 |
支持长上下文语义推理,提升视频场景分析能力 |
|
开源贡献 |
基础版本 |
加强了稳定性和效率 |
完全开源,涵盖更多应用场景 |
想让SAM3分割一个图像中的物体?轻轻一点,它就能精准搞定!不止如此,它还会跟踪视频里的物体,就像给视频装上了AI眼睛,视频中的猫咪,它一眼就能分割出,不管它在后面跑还是藏在角落,SAM3都能一一搞定!
概念分割?SAM3说分就分!输入个名词短语(比如“条纹猫”),SAM3瞬间就能在图片或视频中找到所有符合这个概念的物体,分割得又快又准,完美呈现!就像有个超能助手,想分什么物体就分什么物体,完全不挑食!
让我们来看个分割大PK,SAM3和OWLv2谁更强?
- 原始图像:一堆花花草草,椅子、毛巾混在一起。
- SAM3:精准到每一片叶子,分割完美!花朵、椅子,各个独立,边界清晰,毫无重叠。
- OWLv2:嗯……就像混乱的拼图,植物们挤成一团,分割不清,边界模糊,真的是“分不清哪个是哪个”。
在Promptable Concept Segmentation (PCS) 任务中,通过正面示例(绿色框)和负面示例(红色框),SAM3能够根据用户反馈调整分割结果,使其更加精确。
技术解读
什么是SAM3的核心技术?
我想Promptable Concept Segmentation(PCS)应该是第一个出现在大家脑海中的。 它让SAM3不仅分割物体,还能根据概念进行识别。比如你说“红色车”,它能识别出所有“红色车”实例,不管它们在图像的哪个位置,甚至视频中的哪一帧!
接下来,我将详细解析SAM3的技术实现路线。 先来看一个技术路线框架图。
在这个框架图中,SAM3的架构展示了它如何处理图像和视频中的概念分割任务。以下是图中各个组件的解读:
- Text Encoder: 这个组件将文本输入(如“a penguin”)转化为模型可以理解的特征向量。SAM3使用这些文本特征来理解用户希望分割的物体概念。
- Exemplar: SAM3允许用户提供示例图像(如图中的企鹅)来作为输入,帮助模型理解用户所要分割的物体。这种输入方式有助于模型识别图像中的所有符合描述的实例。
- Detector : 检测器负责在图像或视频帧中识别物体,生成初步的分割掩码(mask)。检测器根据输入的文本或示例来寻找符合条件的物体,并给出物体位置。
- Tracker : 跟踪器用于在视频中的连续帧之间追踪已检测到的物体。它接收来自先前帧的分割结果,并将这些结果应用于当前帧的物体。这确保了视频中的物体分割结果是一致的,不会丢失物体的身份。
- Memory Bank: 记忆库存储了已检测到的物体信息(如它们的特征和位置),并帮助模型在多个帧之间保留对物体的理解。这使得模型能够在视频中长时间追踪物体,并确保物体身份的一致性。
- Mask Merging: 在视频中,SAM3会将来自当前帧的分割掩码与前一帧的掩码进行合并,以保持分割的一致性,避免物体在不同帧之间的身份错乱。
值得注意的是,在SAM3中,检测器和记忆库的工作原理从SAM2中继承,并经过进一步的优化和增强,以提升对复杂场景的适应能力。
具体来看,Detector模块是SAM3中的核心组件,负责生成物体的分割掩码、边界框和物体评分。它接收来自图像编码器(Image Encoder)和文本编码器(Text Encoder)的输入,通过一系列的操作,最终输出每个物体的位置和类别。它的关键组件包括:
- Pixel Decoder:像素解码器接收来自图像编码器的特征,帮助恢复图像中的细节信息,并生成物体的语义掩码
- Multimodal Decoder:这个解码器负责将来自文本和图像的特征融合,通过跨模态的解码操作进行处理,最终生成物体的分割结果。多模态解码器可以处理文本、图像和示例输入,使得SAM3在理解复杂提示和场景时更为灵活。
- Exemplar Encoder:示例编码器用于处理输入的示例图像(如“这是一只企鹅”),它将示例图像编码为特征,供解码器使用,以帮助模型更好地理解用户的目标物体。
- Detector Decoder:检测解码器负责将检测到的查询(例如物体的类别和位置)转化为最终的输出。这个模块通过自注意力(self-attention)机制和交叉注意力(cross-attention)机制,将图像、文本、示例等多模态信息进行融合,并生成物体的边界框、分割掩码等信息。
- Heads:接收解码器的输出,并对每个物体的分割掩码、边界框和评分进行最终处理。通过迭代框体细化,SAM3能够细化物体的定位结果,提高检测精度,减少误检。
- Presence Token:用于标记物体是否出现在当前帧中。这个模块通过区分全局信息(物体是否在图像中出现)和局部信息(物体的具体位置),解决了在图像中物体缺失或信息不足时的分割问题。
SAM3的惊艳表现
下面是对SAM3在不同任务中的结果分析。
SAM3的结果在各项图像概念分割任务中表现突出,具体表现为:
- SAM3在不同数据集上的表现: 无论是在LVIS、COCO还是OdinW13上,SAM3都展现了优越的性能,特别是在零-shot学习和多模态输入(文本和图像结合)上,能够在没有大量标注数据的情况下进行有效的物体分割。
- 多模态能力强: SAM3在结合文本提示和图像示例时,通过其T+I模式显著提升了分割效果,证明了其在多模态任务中的优势。
- 跨任务的适应能力: SAM3能够在多种不同任务和数据集上表现出色,特别是在实例分割和概念分割任务中,展示了强大的泛化能力。
除此之外,Meta还将SAM3与MLLMs进行了组合。在这里,MLLM(如Qwen2.5-VL、GPT-4等)用于生成更加复杂的文本查询。传统的SAM模型通过框选或点击物体来进行分割,而SAM3 Agent通过文本生成查询(如“a fish”或更复杂的名词短语)来指导SAM3执行物体分割任务。
- 零-shot表现: 结合MLLM后,SAM3 Agent在多个数据集上进行了零-shot测试,证明了其强大的推理能力和灵活性。例如,在ReasonSeg和OmniLabel任务中,SAM3 Agent在没有额外训练数据的情况下超越了以往的模型,表现出色。
- RefCOCO和RefCOCOg数据集上的结果: SAM3 Agent在这些基准数据集上表现也很优秀,超越了之前的零-shot模型,说明了这种多模态(文本和视觉)结合的方式对复杂任务的解决能力。
尾声
从SAM1到SAM3,Meta在视觉AI领域的技术进步不仅仅是一次次的架构优化,而是一场无声的进攻,悄无声息地重塑着我们的世界。
SAM1打开了视觉分割的新纪元,然而,这不过是冰山一角。
SAM2在架构上做出巧妙调整,以便更精准地捕捉和分析动态视频场景,那些你我平凡生活中无法察觉的瞬间,却成了自动驾驶、视频监控等领域的生死攸关之物。
SAM3不仅仅局限于静态图像和视频的分割,它能穿越复杂的多模态场景(智能家居、医疗影像、自动驾驶等),以一种难以捉摸的方式,在这些领域中悄然发挥巨大影响。其强大的多模态交互和开放词汇分割能力,使得AI在面对复杂任务时,展现出一种令人不寒而栗的灵活性。
在这个智能化、万象更新的未来,AI是否会成为我们不可逃避的命运,抑或是我们已经步入了一个无人能控的全新秩序?
....
#英伟达2025年技术图鉴
强的可怕......
这两年AI吸引着全世界的眼光,而英伟达无疑是所有目光中的焦点。这家为AI时代提供基础设施的科技巨头,在10月底成为人类历史上第一家5万亿美元市值的公司,比三年前翻了11倍。
成立于93年的英伟达,已经完成了从图形芯片到AI巨头的演进之路。三十多年的发展过程中有几个关键的节点:1999年推出GeForce 256,2006年CUDA问世,2012年支持AlexNet,2020年开始发布高端计算GPU,21年开始发布端侧芯片(ORIN/Thor)。
毫无疑问,英伟达是AI基础设施的第一巨头。但在这背后,英伟达的野心不只局限于做一下硬件公司。一个非常明显的信号是,今年英伟达在自动驾驶、xxx智能、大模型和世界模型几个最热的AI赛道上产出了多篇重量级工作,引起了业内的广泛讨论。今天xxx就带大家盘点一下2025年英伟达的技术图鉴,主要有以下几个系列:
- Cosmos系列:从今年一月份开始布局的世界基础模型平台,衍生出Cosmos-Transfer1、Cosmos-Reason1、Cosmos-Predict2.5等工作,为下游自动驾驶和xx智能奠定基座;
- Nemotron系列:Nemotron 系列是英伟达为代理式 AI 时代打造的 "数字大脑",通过提供开放、高效、精准的模型和工具,让企业能够快速构建专业 AI 智能体;
- xx系列:GR00T N1和Isaac Lab,一手xxVLA,一手仿真平台,英伟达在正在深入布局xx智能;
- 自动驾驶:十一月的Alpamayo-R1直接炸翻了自驾行业,难得的英伟达在自驾VLA上的尝试。
Isaac Lab
- 论文标题:Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
- 论文链接:https://arxiv.org/abs/2511.04831
- 项目主页:https://github.com/isaac-sim/IsaacLab
- 提出机构:NVIDIA
- 一句话总结:Isaac Lab 构建了一个集高保真物理、照片级渲染与模块化环境设计于一体的GPU原生仿真平台,通过统一传感器仿真、数据收集与策略训练工作流,旨在系统性解决机器人学习中的数据稀缺、仿真到现实鸿沟及大规模多模态策略训练等核心挑战。
- 核心贡献:
- 提出了一个统一且可扩展的仿真范式,将GPU并行物理(PhysX)、实时射线追踪渲染(RTX)与通用场景描述(USD)深度集成,实现了从简单控制到复杂多模态任务的大规模、高效率仿真训练。
- 设计了全面的多模态传感器仿真套件,涵盖基于物理的传感器(IMU、接触)、基于渲染的相机(RGB、深度、语义)以及基于Warp的几何传感器(射线雷达),并支持异步更新与域随机化,为感知策略提供了逼真且多样化的训练数据。
- 实现了从数据生成到策略部署的端到端学习工作流支持,内置了强化学习、模仿学习、教师-学生蒸馏以及合成数据生成(Mimic)等多种学习范式,并提供了海量的标准机器人环境,极大降低了复杂机器人算法研究的工程门槛。
- 通过模块化的“管理器”架构与底层Tensor API,在保持高性能GPU原生计算的同时,为研究者提供了从底层物理状态直接操作到高层任务抽象管理的灵活控制,平衡了效率与易用性,成为推动机器人学习研究的基础设施。

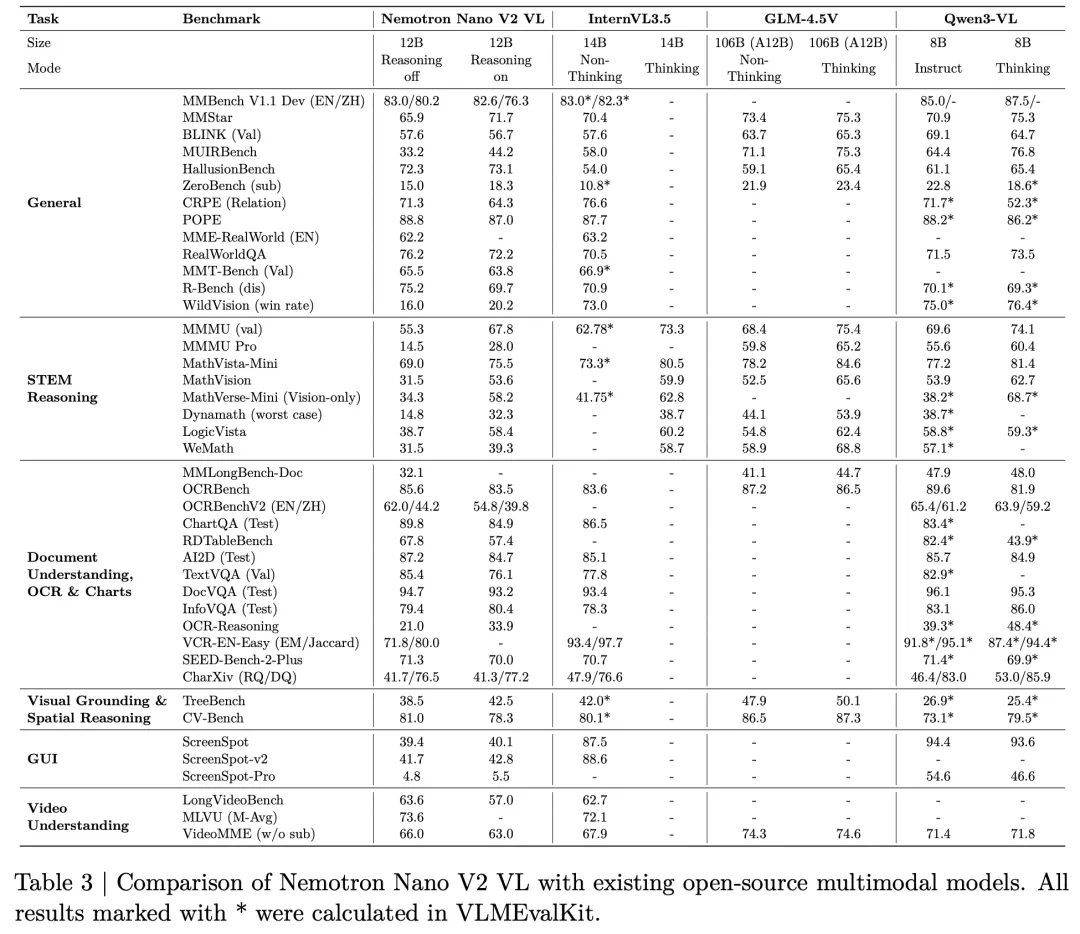
NVIDIA Nemotron Nano V2 VL
- 论文标题:NVIDIA Nemotron Nano V2 VL
- 论文链接:https://arxiv.org/abs/2511.03929
- 提出机构:NVIDIA
- 一句话总结:NVIDIA发布了Nemotron Nano V2 VL,这是一个高效的12B视觉语言模型,通过混合Mamba-Transformer架构、多阶段训练策略和高效推理优化,在文档理解、长视频推理等多模态任务中实现了SOTA性能,同时保持了文本推理能力。
- 核心贡献:
- 高效混合架构与长上下文支持:基于Nemotron Nano V2混合Mamba-Transformer大语言模型,将上下文长度从16K扩展至128K,支持长视频、多页文档等复杂场景理解。
- 多阶段渐进式训练策略:采用五阶段训练流程,逐步融合视觉对齐、多模态理解、长上下文扩展与文本能力恢复,在提升视觉理解的同时最小化对文本推理能力的损失。
- 高效推理与量化部署:集成Efficient Video Sampling技术,显著提升视频处理吞吐量;支持FP8与FP4量化,提供高推理效率的部署版本,适用于资源受限环境。
- 全面且领先的评估表现:在OCRBench v2、MMMU、ChartQA、Video-MME等45个多模态基准测试中表现优异,尤其在文档理解、长视频问答、STEM推理等任务上达到或超越同类开源模型。
- 开源数据集与工具链:公开发布包含超过800万样本的Nemotron VLM Dataset V2,以及NVPDFTex等标注工具,推动视觉语言模型研究与生态发展。

Alpamayo-R1
- 论文标题:Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
- 论文链接:https://arxiv.org/abs/2511.00088
- 提出机构:NVIDIA
- 一句话总结:为了解决端到端自动驾驶在长尾安全关键场景中因监督稀疏和因果理解不足导致的性能瓶颈,Alpamayo-R1 提出了一种融合因果推理与轨迹规划的视觉-语言-动作模型,通过结构化因果链数据集、模块化VLA架构与强化学习后训练,显著提升了在复杂驾驶场景中的规划安全性与决策可解释性。
- 核心贡献:
- 提出了 Chain of Causation(CoC)数据集,通过人机协同标注流程构建具有因果关联的结构化推理轨迹,确保推理与驾驶行为在时间与逻辑上对齐,避免了传统自由形式推理中的模糊性与因果混淆问题。
- 设计了 模块化推理VLA架构,以物理AI预训练的Cosmos-Reason为骨干,结合基于流匹配的轨迹解码器,实现高效的多相机时序感知与实时轨迹生成,在保证推理深度的同时满足车载部署的实时性要求(99ms延迟)。
- 提出了 多阶段训练策略,包括动作模态注入、基于CoC的监督微调以及基于大推理模型反馈的强化学习后训练,共同优化推理质量、推理-动作一致性以及轨迹安全性,在仿真与实车测试中均表现出显著的性能提升。
- 在闭环仿真与实车测试中验证了其有效性:相比仅预测轨迹的基线模型,Alpamayo-R1在挑战性场景中规划准确率提升最高达12%,脱轨率降低35%,近距离接触率降低25%,推理质量与推理-动作一致性分别提升45%与37%。

Cosmos-Predict2.5
- 论文标题:World Simulation with Video Foundation Models for Physical AI
- 论文链接:https://arxiv.org/abs/2511.00062
- 项目主页:https://github.com/nvidia-cosmos/cosmos-predict2.5
https://github.com/nvidia-cosmos/cosmos-transfer2.5 - 提出机构:NVIDIA
- 一句话总结:提出了新一代物理AI视频世界基础模型Cosmos-Predict2.5与其控制网络变体Cosmos-Transfer2.5,基于流匹配架构统一了文本、图像、视频到世界的生成能力,并引入物理AI专用VLM——Cosmos-Reason1进行文本嵌入与细粒度控制,在视频质量、指令对齐与长视频生成一致性上实现显著提升,为机器人、自动驾驶等xx智能任务提供高保真、可控的世界仿真与合成数据生成平台。
- 核心贡献:
- 统一的多模态世界生成架构:首次在单一模型中集成Text2World、Image2World和Video2World生成能力,基于流匹配实现高质量、时序一致的视频预测与生成。
- 物理AI专用数据与训练流程:构建了包含2亿精选视频片段的大规模训练数据集,并针对机器人、自动驾驶、智能空间、人体动力学、物理现象等五大领域进行专项数据整理与标注,提升模型在物理场景中的生成真实性与合理性。
- 控制网络增强与长视频生成:提出Cosmos-Transfer2.5,支持边缘、模糊、深度、分割等多模态控制信号输入,在保持模型规模减小3.5倍的同时,实现更高的生成质量与更少的错误累积,支持长达120秒的长视频连贯生成。
- 多视角与相机可控生成:扩展模型支持多摄像头同步视频生成(如自动驾驶7视角、机器人3视角),并实现基于相机轨迹的视角重渲染,为机器人操纵与自动驾驶仿真提供多视角一致的场景合成能力。
- 强化学习后训练与模型蒸馏:采用基于VLM奖励模型的强化学习对生成质量进行对齐优化,并使用时步蒸馏技术将推理步数大幅减少至4步,在保持质量的同时显著提升生成效率。
- 开源模型与基准评估:全面开源2B与14B规模的预训练与后训练模型,涵盖基础生成、领域专用及控制网络变体,并在PAI-Bench等物理AI基准测试中取得领先性能,为社区提供可复现、可扩展的世界仿真基础平台。

NVFP4
- 论文标题:Pretraining Large Language Models with NVFP4
- 论文链接:https://arxiv.org/abs/2509.25149
- 开源链接:https://github.com/NVIDIA/TransformerEngine/pull/2177
- 提出机构:NVIDIA
- 一句话总结:针对大型语言模型(LLM)预训练中计算与内存消耗巨大的挑战,NVIDIA 提出并验证了一种基于新型 4 位浮点格式 NVFP4 的高效训练方法,通过引入混合精度、随机哈达玛变换、二维权重缩放与随机舍入等关键技术,成功在 120 亿参数模型上进行了长达 10 万亿 token 的稳定训练,其损失曲线与下游任务精度与 FP8 基线模型相当,首次证实了 4 位精度在万亿 token 规模预训练中的可行性。
- 核心贡献:
- 提出 NVFP4 格式:一种增强型 4 位微缩放格式,通过将块大小从 32 减小到 16、使用 E4M3 格式存储块尺度因子、并引入张量级 FP32 尺度进行两级缩放,显著提升了数值表示的准确性,尤其是对异常值的捕获能力,减少了小值量化为零的损失。
- 系统性的 4 位训练方法学:提出一套完整且必要的技术组合以确保大规模 4 位训练的稳定与收敛,包括:1) 将网络末端对数值敏感的部分线性层(约15%)保留在高精度(BF16/MXFP8);2) 在权重梯度计算(Wgrad)的输入上应用 16x16 随机哈达玛变换以分散块级异常值;3) 对权重采用 16x16 二维块缩放,确保前向与反向传播中量化表示的一致性;4) 对梯度张量应用随机舍入以减少量化偏差。
- 大规模训练验证:在 120 亿参数的混合 Mamba-Transformer 模型上,使用 NVFP4 格式成功完成了 10 万亿 token 的预训练。实验表明,其验证损失与 FP8 基线全程紧密吻合(相对误差<1.5%),并在 MMLU、数学、多语言理解、常识推理等多个下游任务上取得了可比拟的准确率。
- NVFP4 与 MXFP4 的对比优势:通过 80 亿参数模型的对比实验证明,NVFP4 在达到相同训练损失时,所需的训练 token 数比 MXFP4 少约 36%,在收敛效率上展现出明显优势,凸显了其更优的数值属性。
- 为窄精度训练铺平道路:本研究首次公开证明了在万亿 token 规模上使用 4 位精度进行持续预训练的可行性,为下一代更大规模、更高能效的 LLM 训练提供了关键算法基础和实践路径。相关工作已在 NVIDIA Blackwell GPU 上通过 Transformer Engine 获得全面支持。

Audio2Face-3D
- 论文名称:Audio2Face-3D: Audio-driven Realistic Facial Animation For Digital Avatars
- 论文链接:https://arxiv.org/abs/2508.16401
- 提出机构:NVIDIA
- 一句话总结:Audio2Face-3D 是一个基于深度学习的端到端音频驱动三维面部动画系统,能够从单一语音输入实时生成高保真、口型同步且带情感表达的全脸动画(包括皮肤、舌头、下巴和眼球运动),支持多身份适配与流式推理,并开源了模型、SDK与训练框架,推动数字人技术的普及与应用。
- 核心贡献:
- 双网络架构设计:提出了两种互补的神经网络架构——基于回归的轻量级网络(Audio2Face-3D-v2.3)与基于扩散模型的高质量网络(Audio2Face-3D-v3.0)。回归网络支持低延迟单帧推理,适合实时多路并行;扩散网络以流式方式生成连续30帧动画,在表现力与自然度上更优,且支持多身份条件生成。
- 高质量数据管道与增强策略:构建了基于专业演员多情感语音捕获的4D面部数据集,并创新性地采用语音转换、文本转语音对齐与静默数据插入三种增强方法,在不破坏音画同步的前提下显著提升数据的多样性与模型的泛化能力。
- 可重定向的混合形状求解器:开发了一套基于优化的混合形状权重求解流程,可将网络生成的面部顶点运动转化为标准的ARKit混合形状权重,支持将动画无缝重定向至不同角色模型(如MetaHuman),提升了输出结果的通用性与生产流程兼容性。
- 实时流式推理与后处理控制:系统支持在线流式音频输入并实时生成动画,推理延迟低,并提供丰富的后处理参数面板(如区域运动强度、平滑度、眼球与眨眼控制等),允许用户在无需重新训练的情况下对生成动画进行细节调整与风格化编辑。
- 拓展性实验功能:探索了多项前沿扩展,包括文本驱动的情绪与面部动作控制(通过CLIP文本编码器)、头部运动生成、音频直接驱动角色装备参数以及下巴引导的混合形状求解,展示了系统在未来数字人动画生成中的更多可能性。

NVIDIA Nemotron Nano 2
- 论文名称:NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
- 论文链接:https://arxiv.org/abs/2508.14444
- 提出机构:NVIDIA
- 一句话总结:Nemotron Nano 2是一款面向推理任务的高效混合架构语言模型,通过结合Mamba-2层与自注意力层,在保持与同类模型相当或更高精度的同时,实现了最高达6倍的推理吞吐量提升,并支持128k长上下文推理。
- 核心贡献:
- 提出了一种混合Mamba-Transformer架构(Nemotron-Nano-12B-v2-Base),将大部分自注意力层替换为Mamba-2层,显著提升长序列生成效率,适用于需要长思维链的推理场景。
- 构建了高质量、多领域的预训练数据集,包括经过精心筛选的通用爬取数据、数学专用数据(Nemotron-CC-Math)、代码数据,以及多种合成数据(如STEM、多语言问答、学术SFT风格数据),显著提升了模型在数学、代码、多语言理解等方面的能力。
- 采用了FP8混合精度训练配方与分阶段课程学习策略,在20T token上完成预训练,并进行了长上下文扩展训练,使模型支持128k上下文而不损失其他任务性能。
- 设计了一套完整的对齐流程,包括多阶段监督微调(SFT)、指令遵循强化学习(GRPO)、直接偏好优化(DPO)以及人类反馈强化学习(RLHF),显著提升了模型的指令遵循、工具调用和对话能力。
- 提出并实施了基于Minitron的轻量级剪枝与蒸馏策略,将12B模型压缩至9B,使其能够在单张NVIDIA A10G GPU(22GB显存)上以128k上下文进行推理,在保持高精度的同时大幅提升部署效率与推理速度。

Nemotron-H:
- 论文名称:Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
- 论文链接:https://arxiv.org/abs/2504.03624
- 提出机构:NVIDIA
- 一句话总结:为了突破传统Transformer模型因自注意力机制导致的推理时计算和内存开销线性增长的瓶颈,并适应现代LLM“推理时缩放”以提升答案质量的新范式,NVIDIA推出了Nemotron-H系列模型。该系列采用创新的混合Mamba-Transformer架构,用计算和内存需求恒定的Mamba层替代了绝大部分自注意力层,从而在保证与同类顶尖开源Transformer模型(如Qwen2.5、Llama3.1)相当甚至更优精度的前提下,实现了高达3倍的推理速度提升。同时,其配套的FP8训练方案和名为MiniPuzzle的压缩-蒸馏技术,大幅降低了此类高性能混合模型的训练与部署成本。
- 核心贡献:
- 开创性的高效混合架构:提出了以Mamba-2层为核心、仅保留约8%自注意力层的混合模型架构(8B和56B参数规模)。该设计从根本上改变了自回归推理的计算模式,使得每生成一个token的计算量和激活内存趋于恒定,从而在生成长序列时获得巨大的推理吞吐量优势(在65k输入、1k输出场景下,吞吐量达同类Transformer的2-3倍)。
- 创新的模型压缩范式MiniPuzzle:提出了一种结合轻量级剪枝与神经架构搜索(NAS)的压缩框架,能够根据目标硬件(如单张RTX 5090 GPU)的显存和延迟约束,自动搜索并蒸馏出最优的子架构。成功将56B模型压缩为47B模型,仅用极少量(63B)token进行蒸馏便恢复精度,并在长上下文推理中实现额外20%的加速,极大提升了部署灵活性。
- 实用的FP8混合精度训练方案:为56B大模型成功实施了以FP8(E4M3/E5M2)精度为主的层wise混合精度预训练方案(仅首尾少量层保持BF16)。实验证明,该方案在长达20万亿token的训练中稳定,且下游任务精度与BF16训练相当甚至更优,为降低大模型训练成本提供了可靠路径。
- 验证了混合架构的广泛适用性:基于Nemotron-H骨干网络,成功构建了在多项视觉语言基准(MMMU, MathVista等)上达到SOTA水平的VLM模型(8B/56B-VLM),以及具有强指令跟随和长上下文(128K)处理能力的推理模型(8B/47B-Reasoning),充分证明了该混合架构在不同模态和任务上的强大泛化能力和后训练潜力。

Cosmos-Reason1
- 论文名称:Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
- 论文链接:https://arxiv.org/abs/2503.15558
- 项目主页:https://github.com/nvidia-cosmos/cosmos-reason1
- 提出机构:NVIDIA
- 一句话总结:为了赋予多模态大语言模型真正的“物理常识”与“xx推理”能力,NVIDIA提出了Cosmos-Reason1模型家族,它通过定义一套层次化的物理常识本体与二维xx推理本体,并采用“监督微调+强化学习”的两阶段训练范式,使得模型能够基于视频输入进行长链条思维推理,输出符合物理规律的解释与行动决策,显著缩小了AI模型在抽象符号推理与真实物理世界交互之间的能力鸿沟。
- 核心贡献:
- 系统定义了物理AI推理的两大核心能力及其本体:首次明确提出了物理常识推理(分为空间、时间、基础物理三大类16个子类)和xx推理(涵盖处理复杂感知输入、预测动作效果、尊重物理约束、从交互中学习四大能力,并泛化至人类、机械臂、人形机器人、自动驾驶车辆等多种智能体)的层次化本体框架,为构建和评估物理AI模型建立了清晰的路线图与标准。
- 提出了专为物理AI设计的、可扩展的两阶段训练方法:首先通过精心策划的约4M视频-文本对(包括理解性与推理性标注)进行监督微调,随后创新性地利用基于规则、可验证的多选题奖励进行强化学习后训练。这种组合显著提升了模型的基础物理常识与在具体场景中做出合理行动规划的能力。
- 构建了全面、可量化的物理AI评估基准:根据定义的本体,分别构建了包含604个问题的物理常识推理基准和涵盖6个数据集、610个问题的xx推理基准,为社区提供了衡量模型物理世界理解与决策能力的重要标尺。
- 验证了方法在7B和56B模型上的显著有效性:实验表明,经过物理AI SFT后,模型在物理常识和xx推理基准上的性能较基线VLM提升超过10%。进一步的物理AI RL训练能在多数任务上再带来超过5%的性能提升。尤为突出的是,模型在直觉物理任务(如时间箭头、空间谜题、物体恒存性)上取得了远优于现有主流模型的性能,展现了其深入理解物理世界根本规律的能力。

GR00T N1
- 论文名称:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
- 论文链接:https://arxiv.org/abs/2503.14734
- 提出机构:NVIDIA
- 一句话总结:GROOT N1 是一个面向通用人形机器人的开放式视觉-语言-动作(VLA)基础模型,采用双系统架构(System 2 用于视觉语言理解,System 1 用于实时动作生成),并通过构建包含真实机器人数据、仿真轨迹、人类视频与神经生成视频的“数据金字塔”进行大规模预训练,实现了跨多种机器人平台的强泛化能力与高数据效率。
- 核心贡献:
- 提出双系统VLA架构:将视觉语言模型(Eagle-2 VLM)作为慢速推理模块(System 2)处理环境理解,与基于扩散Transformer(DiT)的快速动作生成模块(System 1)紧密耦合、端到端联合训练,实现了语义理解与实时动作输出的高效协同。
- 设计数据金字塔训练策略:创新性地构建了从海量人类视频(底层)、仿真与神经生成数据(中层)到真实机器人轨迹(顶层)的异构数据体系,通过潜在动作学习与逆动力学模型标注,统一了不同来源数据的动作表示,有效缓解了机器人数据稀缺与“数据孤岛”问题。
- 实现跨平台通用策略:使用单一模型权重支持从单臂机械臂到双手机巧人形机器人等多种机器人形态,在仿真与真实世界基准测试中均显著超越现有模仿学习方法,尤其在低数据场景下表现出卓越的样本效率。
- 推动开源与社区共享:公开发布了GROOT-N1-2B模型检查点、训练数据集及仿真基准,为机器人基础模型的研究与应用提供了重要的开放资源与可复现基础,加速通用人形机器人技术的发展。

Cosmos-Transfer1
- 论文名称:Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
- 论文链接:https://arxiv.org/abs/2503.14492
- 项目主页:https://github.com/nvidia-cosmos/cosmos-transfer1
- 提出机构:NVIDIA
- 一句话总结:Cosmos-Transfer1 是一个基于扩散模型的多模态可控世界生成框架,通过自适应空间-时间控制权重机制,能够根据不同模态输入(如语义分割、深度图、边缘图等)生成高质量的世界仿真视频,特别适用于机器人 Sim2Real 与自动驾驶数据增强等物理 AI 任务,并可扩展至实时生成。
- 核心贡献:
- 提出自适应多模态控制机制:首次在扩散世界模型中引入多分支控制网络,并设计可动态调整的时空控制权重图,使用户能够根据不同区域、不同时间点自由调节各模态控制强度,实现细粒度可控世界生成。
- 实现多模态控制分支独立训练与推理时融合:各模态控制分支可独立训练,缓解内存压力并支持异构数据训练,推理时支持灵活添加或移除模态,增强系统灵活性与扩展性。
- 构建面向自动驾驶的高质量数据集 RDS-HQ:包含 360 小时的高清地图、3D 检测框与 LiDAR 同步标注,为自动驾驶视频生成提供丰富控制信号,提升生成视频的几何与语义一致性。
- 验证Sim2Real 与数据增强的有效性:在机器人操作与自动驾驶场景中,Cosmos-Transfer1 能显著提升合成视频的真实性与多样性,同时保持关键场景结构的完整性,有效缓解仿真与现实间的领域差异。
- 实现实时世界生成:通过设计基于 NVIDIA GB200 NVL72 系统的并行推理策略,在 64 块 GPU 上实现 5 秒 720p 视频的实时生成,为大规模物理 AI 应用提供可行的部署方案。

Cosmos
- 论文名称:Cosmos World Foundation Model Platform for Physical AI
- 论文链接:https://arxiv.org/abs/2501.03575
- 开源链接:https://github.com/nvidia-cosmos/cosmos-predict1
- 提出机构:NVIDIA
- 一句话总结:本文提出了 Cosmos 世界基础模型平台,通过构建可扩展的视频数据流程、连续与离散视频标记器、基于扩散与自回归的世界基础模型,以及面向多种物理 AI 任务的后训练机制,为物理 AI 系统提供了一个可高效微调的世界仿真基础。
- 核心贡献 :
- 构建了大规模视频数据管理流程,涵盖视频分割、过滤、标注、去重与分片,从 2000 万小时原始视频中提取出高质量、多样化的训练数据集。
- 提出了一套高效视频标记器,支持连续与离散两种标记形式,具备时序因果性、多尺度压缩能力,在重建质量与推理速度上显著优于现有方法。
- 开发了两种可扩展的世界基础模型架构:基于扩散的模型(Cosmos-Predict1-7B/14B)与基于自回归的模型(Cosmos-Predict1-4B/12B),均支持文本、视频与动作等多模态条件输入。
- 展示了模型在多种物理 AI 任务中的后训练适应性,包括相机控制、机器人操作(指令跟随与动作预测)与自动驾驶多视角视频生成,验证了其作为世界仿真器的实用价值。
- 设计了安全防护机制,包括前向提示过滤与后向内容检测,保障模型生成内容的安全性。
- 开源模型与工具链,通过 NVIDIA Cosmos 平台提供预训练模型与标记器,推动物理 AI 社区的发展。

....
#Gary Marcus惊世之言
纯LLM上构建AGI彻底没了希望!MIT、芝大、哈佛论文火了
今天,著名的人工智能学者和认知科学家 Gary Marcus 转推了 MIT、芝加哥大学、哈佛大学合著的一篇爆炸性论文,称「对于 LLM 及其所谓能理解和推理的神话来说,情况变得更糟了 —— 而且是糟糕得多。」
这项研究揭示了一种被称为「波将金式」(Potemkins)的推理不一致性模式(见下文图 1)。研究表明,即使是像 o3 这样的顶级模型也频繁犯此类错误。基于这些连自身论断都无法保持一致的机器,你根本不可能创造出通用人工智能(AGI)。
正如论文所言:在基准测试上的成功仅证明了「波将金式理解」:一种由「与人类对概念的理解方式完全不可调和的答案」所驱动的理解假象…… 这些失败反映的不仅是理解错误,更是概念表征深层次的内在矛盾。
Gary Marcus 认为,这宣告了任何试图在纯粹 LLM 基础上构建 AGI 希望的终结。最后,他还 @了 Geoffrey Hinton,称后者要失败(checkmate)。

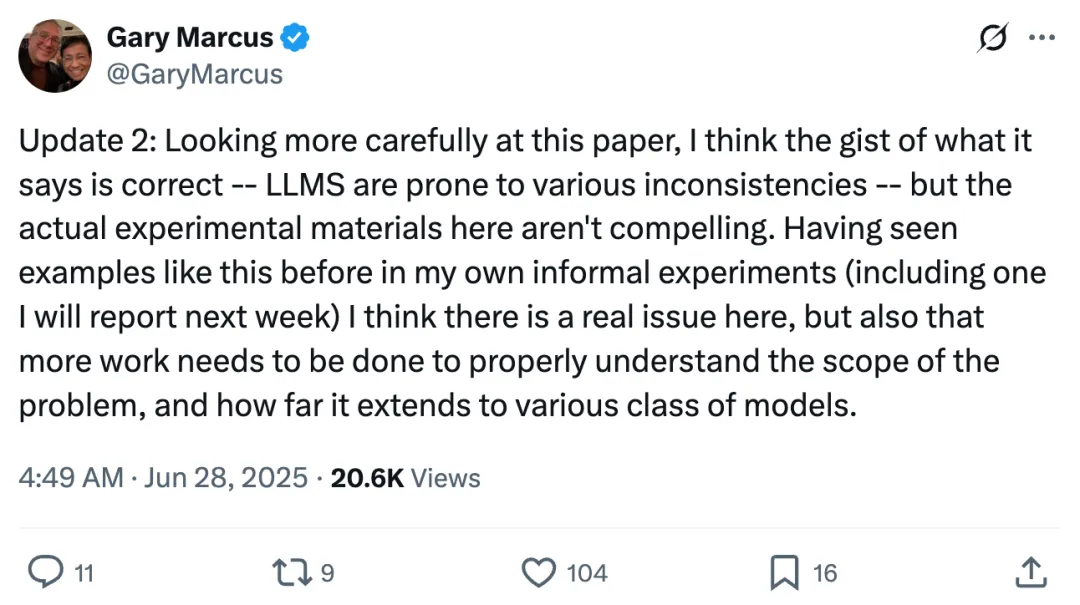
接着,Gary Marcus 又接连发推,分享了他对这篇论文的更多看法。
他称基于非正式测试,发现像 o3 这类模型似乎较不容易陷入简单的「波将金式错误」,但并非完全免疫。
如下图(左)所示,模型虽然能正确阐述俳句的定义,却错误断言「asphalt shimmers」符合俳句末行应为五音节的要求;直到后续追问之下(右),才勉强承认错误。这再次印证了问题的核心:根本缺陷在于其缺乏可靠性。

在仔细研读论文后,Gary Marcus 认为它的核心观点是正确的 ——LLM 确实容易产生各种自相矛盾(比如之前说的「波将金式错误」)。但是,论文里具体的实验例子在他看来说服力不够强。
根据他自己之前非正式实验的观察(包括下周会公布的一个例子),Gary Marcus 确信此处存在一个真正的问题。不过,要想真正弄清楚这个问题的普遍性有多大,以及它对不同类型模型的影响程度如何,还需要进行更深入的研究。
Gary Marcus 的观点让评论区炸了锅,有人问他是否认可 LLM 越来越好。他虽然持肯定答案,但也认为它们有可能来到了收益递减的点。

还有人认为,我们其实不需要 LLM 理解,只要它们表现得越来越好就够了。即使是人类,也并不总是可以理解。

谷歌 DeepMind 资深科学家(Principal Scientist)Prateek Jain 现身评论区,表示这篇论文和它提出的评估方法 + 基准测试很有意思!他拿出 Gemini 2.5 Pro 测试了论文中提到的所有例子,结果都答对了。因此,他很想知道 Gemini 2.5 Pro 在完整的测试集上表现如何,以及它在哪些具体例子上会出错。

有人也提出了质疑,这篇论文只是很好地描述了当前 LLM 的一种广为人知的实效模式,不明白为什么「注定失败」呢。

接下来,我们来看这篇论文究竟讲了什么,是否真能支撑起 Gary Marcus 这番言论。
论文介绍
论文标题:Potemkin Understanding in Large Language Models
论文地址:https://arxiv.org/pdf/2506.21521
大型语言模型通常依靠基准数据集进行评估。但仅仅根据它们在一套精心挑选的问题上的回答,就推断其能力是否合理?本文首先提出了一个形式化框架来探讨这一问题。关键在于:用来测试 LLM 的基准(例如 AP 考试)原本是为了评估人类设计的。然而,这带来了一个重要前提:只有当 LLM 在理解概念时出现的误解方式与人类相似时,这些基准才能作为有效的能力测试。否则,模型在基准上的高分只能展现一种「波将金式理解」:看似正确的回答,却掩盖了与人类对概念的真正理解之间的巨大差距。
为此,本文提出了两种方法来量化「波将金现象」的存在:一种是基于针对三个不同领域特制的基准,另一种是通用的程序,可提供其普遍性下限的估计。研究结果显示,波将金现象在各类模型、任务和领域中普遍存在;更重要的是,这些失败不仅是表面上的错误理解,更揭示了模型在概念表征上的深层内在不一致性。

大型语言模型中的潜在理解图示。这个例子显示了 GPT-4o 未能运用自己的概念解释 ABAB 韵律方案。
框架
当人类与大型语言模型在对概念的理解上存在不一致时,就会出现「波将金现象」。在此,本文提出了一个用于定义概念性理解的理论框架。
研究团队将这一概念形式化:定义 X 为与某一概念相关的所有字符串的集合。例如,一个字符串可以是该概念的一个可能定义,或是一个可能的示例。然而,并非所有与概念相关的字符串都是对概念的有效使用。
一个概念的解释被定义为任何函数 f:X→{0,1},其中输出表示该字符串在此解释中是否被认为是有效的(0 表示无效,1 表示有效)。存在唯一正确的解释,记作 f* 。人类对概念可能的解释方式构成的集合记作 F_h。其中,任何 f∈ F_h 且 f≠f* 的情况,都代表了人类对该概念可能产生的一种误解。
考虑人类可能采用的某种解释 f∈ F_h,我们如何检验 f 是不是正确的解释?实际上,在所有字符串 x∈X 上验证 f (x)= f*(x) 是不可行的。
因此,研究团队希望仅在少数几个字符串 x 上检验 f (x)= f*(x)。但这种做法在什么时候是合理的呢?答案在该框架中得以揭示:如果他们选择的示例集是经过精心设计的,使得只有真正理解概念的人才能对这些示例做出正确解释,那么就可以用有限的示例集来测试人类的概念理解。
形式化地,他们将基石集定义为 S⊆X 的一个最小实例集,使得若 f∈F_h 且对所有 x∈S 满足 f (x)=f*(x),则可得出 f= f* 。也就是说,如果某人在基石集中的每个示例上都能做出与正确解释一致的判断,那么就不可能将其解释与任何错误的人类理解调和起来。图 2 给出了基石集的可视化示意。
这一方法说明了为什么测试人类对概念的理解是可行的:测试概念理解并不需要在所有相关示例上检验,而只需在基石集中的示例上进行测试即可。

方法及结论
本文提出了两种用于衡量大型语言模型中波将金现象普遍性的程序。本节介绍其中一种方法:基于研究团队收集的基准数据集,测量一种特定类型的波将金式失败 —— 即对概念的描述与应用之间的脱节。具体来说,他们构建了一个涵盖三个不同领域(文学技巧、博弈论和心理偏差)的数据集,涉及 32 个概念,共收集了 3159 条标注数据。
他们发现,即使模型能够正确地定义一个概念,它们在分类、生成和编辑任务中往往无法准确地将其应用。所有收集到的数据、标注和分析结果均在 Potemkin Benchmark 仓库中公开提供。
研究团队在 32 个概念上对 7 个大型语言模型进行了分析。这些模型因其流行度以及涵盖不同开发商和规模而被选中。他们通过 OpenAI、Together.AI、Anthropic 和 Google 的 API 收集模型推理结果。对于每个(模型,概念)组合,他们首先判断模型是否给出了正确的概念定义。如果定义正确,再评估其在三项额外任务 —— 分类、生成和编辑 —— 中的准确性。根据本文的框架规范,将模型的回答标记为正确或错误。
他们测量模型表现出的波将金率。波将金率被定义为:在基石示例上做出正确回答的前提下,模型在随后的问题上回答错误的比例。对于随机准确率为 0.50 的任务,将该值乘以 2,使得波将金率为 1 表示表现相当于随机水平。
研究结果显示,在所有模型和领域中,波将金率都普遍较高。

虽然模型在 94.2% 的情况下能正确地定义概念,但在需要使用这些概念执行任务时,其表现会急剧下降,这一点通过表中的高波将金率得到体现。尽管不同模型和任务间表现略有差异,但我们可以发现波将金现象在研究团队分析的所有模型、概念和领域中无处不在。

研究团队还提出了一种不同的、自动化的程序,用于评估波将金现象的存在。
刚才,已经展示了波将金式理解在大型语言模型中的普遍性。造成这种现象可能有两种原因:一种可能是模型对概念的理解存在轻微偏差,但其内部是一致的;另一种可能是模型对概念的理解本身就是不连贯的,对同一个概念持有相互冲突的认知。为了区分这两种情况,研究团队专门测试模型内部的概念不一致性。
他们通过两步来衡量不一致性。首先,研究团队提示模型生成某一特定概念的一个实例或非实例(例如,生成一个斜韵的例子)。接着,他们将模型生成的输出重新提交给模型(通过独立的查询),并询问该输出是否确实是该概念的一个实例。在斜韵的例子中,这意味着测试模型能否认出自己生成的示例是否属于斜韵。图 5 总结了这一流程。

表 2 中我们可以观察到在所有检查的模型、概念和领域之间存在不一致性,得分范围从 0.02 到 0.64。尽管这些得分好于随机情况,但仍然表明模型在一致性评估其自身输出方面存在实质性局限。这表明概念误解不仅源于对概念的误解,还源于对它们使用的不一致。

综上,通过两种互补的实证方法 —— 一种利用涵盖文学技巧、博弈论和心理偏差的新基准数据集,另一种采用自动化评估策略 —— 本文量化了波将金式理解现象在各种任务、概念、领域和模型中的普遍存在。两种方法均显示,即便是在按照传统基准测试标准看似能力很强的模型中,这种现象的发生率也很高。不一致性检测表明,模型内部存在对同一思想的冲突表征。
....
#Rex-Thinker
会“思考”的目标检测模型来了!IDEA提出:基于思维链的指代物体检测模型,准确率+可解释性双突破
Caption: Rex-Thinker 的思考过程
在日常生活中,我们常通过语言描述寻找特定物体:“穿蓝衬衫的人”“桌子左边的杯子”。如何让 AI 精准理解这类指令并定位目标,一直是计算机视觉的核心挑战。现有方法常被两大问题困扰: 决策过程不透明 (“黑箱” 预测)和 拒识能力不足 (对不存在物体输出错误结果)。

图 1:指代检测的应用场景实例
最近, IDEA 提出全新解决方案 Rex-Thinker ,首次将人类思维中的 “逻辑推理链” 引入视觉指代任务,让 AI 像人一样分步思考、验证证据,在权威测评中不仅准确率显著提升,更展现出强大的 “知之为知之” 能力!
项目主页:https://rexthinker.github.io/
在线 Demo:https://huggingface.co/spaces/Mountchicken/Rex-Thinker
Demo 论文地址:https://arxiv.org/abs/2506.04034
开源代码:https://github.com/IDEA-Research/Rex-Thinker
投稿人:Qing Jiang
投稿团队:IDEA-CVR
突破在哪?让 AI 学会 “思考三步走”
传统模型直接输出目标检测框,而 Rex-Thinker 创新性地构建了可解释的推理框架:
1. 规划 (Planning)拆解语言指令:“找到坐在乌龟上的人” → 分解为 “第一步找到乌龟 → 第二步判断每个人是否坐在乌龟上”
2. 验证 (Action)对每个候选目标(如 “Person 1”“Person 2”)逐步核对子条件, 每一步的分析都绑定图中具体区域 (比如 Person 1 就对应图中标号为 Person 的人) (见图 2)
3. 决策 (Summarization)汇总验证结果,输出匹配目标的坐标或声明 “未找到”

图 2: Rex-Thinker 推理示例
模型结构:基于检索的检测多模态模型设计 + CoT 推理

图 3: Rex-Thinker 模型结构
如图 3 所示,Rex-Thinker 在模型设计上,采用了基于检索策略,即先通过一个开集检测模型提取出所有的候选框,然后将候选框输入到模型中,然后模型对每个候选框进行推理,最后再输出答案,具体而言每个步骤为:
1. 候选框生成: 使用开放词汇检测器(如 Grounding DINO)提前检测出所有可能的目标区域,作为 Box Hint 输入;
2. 链式推理(CoT Reasoning): 给定候选框,模型逐个对比、推理,生成结构化思考过程 <think>...</think> 和最终答案 <answer>…</answer>。整个过程的输入 prompt 如下所示:

图 4 . Rex-Thinker 的输入 prompt 构成。
3. 输出格式:最终输出标准化 JSON 格式的目标坐标,这种设计既规避了直接回归坐标的困难,也让每步推理有图像依据,提升可解释性和推理可信度。
训练流程:SFT 冷启动 + GRPO 后训练,打造强大推理能力
要让 AI 具备像人一样的推理能力,关键在于教会它怎么一步步思考。为此,Rex-Thinker 采用了两阶段训练策略,从构建高质量推理数据集开始。

图 5: HumanRef-CoT 数据集构造流程
1. 构建推理数据集 HumanRef-CoT
首先,团队在已有的 HumanRef 数据集(专注多人物指代)基础上,利用 GPT-4o 自动生成了 9 万条链式推理示例,构建了 HumanRef-CoT,主要特点包括:
- 完整推理链:每条样本严格按照「规划(Planning)- 验证(Action)- 总结(Summarization)」的推理流程生成。
- 多样化推理场景:覆盖单目标、多目标、属性组合、空间关系、交互行为等复杂描述;
- 拒答样本:特意加入了无匹配目标的描述,引导模型学会在必要时拒绝作答,提升抗幻觉能力。
这一数据集首次系统性地引入了推理链标注,为训练具有推理能力的视觉指代模型奠定了基础。
2. 两阶段训练策略

图 6. Rex-Thinker 采用的两阶段训练方法
(1)冷启动训练
首先在 HumanRef-CoT 数据集上进行监督微调(SFT),这个阶段主要帮助模型掌握基本的推理框架和输出规范。
(2)GRPO-based 强化学习后训练
有了基础推理能力后,进入关键的 GRPO 强化学习阶段,进一步提升推理质量与可靠性。通过引入 F1 准确率奖励 + 格式规范奖励 ,让模型自我优化推理路径。这一机制避免了单一推理路径训练可能带来的过拟合问题,促进了模型在推理策略上的多样性和泛化能力。 最终,GRPO 不仅提升了模型的推理精度,还显著增强了面对陌生类别、复杂描述时的鲁棒性和抗幻觉能力。如下图所示,模型在未见过的类别(热狗)也具备推理能力

图 7. Rex-Thinker 在 GRPO 后训练后泛化到任意物体
实验结果: SFT 赋予模型 CoT 能力, GRPO 提升模型泛化能力
在 HumanRef Benchmark 上,Rex-Thinker 展示了显著的性能提升。团队测试了三种模型版本:
- Rex-Thinker-Plain:只训练最终检测结果,没有推理监督;
- Rex-Thinker-CoT:加入思维链(CoT)监督,学会 “如何思考”;
- Rex-Thinker-GRPO:在 CoT 基础上,用 GRPO 强化学习进一步优化推理质量。

表 1 Rex-Thinker 在 HumanRef Benchmark 上的评测结果
如表 1 结果显示,加入 CoT 监督后,模型在各项指标上全面优于基础版本,平均提升 0.9 点 DF1 指标,尤其在 “拒识” 子集上的表现提升尤为明显,Rejection Score 提高了 13.8 个百分点,说明推理链的引入显著增强了模型对 “不存在目标” 的识别能力。进一步地,GRPO 训练在 CoT 基础上带来了额外性能提升,平均 DF1 提升至 83.5。相比单一推理路径的监督学习,GRPO 引导模型通过奖励机制探索更优推理路径,显著改善了复杂场景下的鲁棒性和判断准确性。

表 2 Rex-Thinker 在 RefCOCOg 数据集上的泛化结果
此外,在 RefCOCOg 数据集上的跨类别评估中,Rex-Thinker 同样表现出良好的迁移能力。在不进行任何针对性微调的情况下,模型仍能准确推理出目标位置,体现出良好的泛化能力。通过对 RefCOCOg 的少量 GRPO 微调,模型性能进一步接近甚至超过现有主流方法,验证了该方法在新类别和新任务中的可拓展性。
可视化结果
我们接下来展示一下 Rex-Thinker 的推理过程可视化,包括、每一步条件验证及最终决策输出。图中显著标注了模型在图像中如何逐步定位目标、如何识别条件是否满足,并最终输出结果或拒绝预测。这些可视化不仅体现了模型良好的目标理解能力,也突出了其推理路径的清晰性与可解释性。特别是在存在多个干扰项或不存在目标的场景中,Rex-Thinker 能够给出详尽的否定推理,展示出 “知之为知之,不知为不知” 的能力。这一能力在传统视觉模型中极为罕见,凸显了思维链机制在实际应用中的价值。




....
#MUDDFormer
何恺明的“残差连接”被魔改,新架构给Transformer建了个“动态立交”,28亿参数打平69亿
对Transformer中的残差连接进行了创新性改造,仅增加极少的参数和计算量,就让28亿参数的模型在多项语言任务上媲美69亿参数的模型。
坦白地说,你是不是觉得 Transformer 已经被研究透了?
经过了无数轮的验证与优化,Transformer 的结果看似已经达到了非常稳定的最佳状态,想做出颠覆 Transformer 的结构创新,几乎不太可能了。。
我之前也这么觉得,直到最近看到了一篇 ICML 2025 的论文,没想到又让 Transformer 老树开花了!
这篇论文思路很有意思,没有去卷那些主流的注意力机制,而是独辟蹊径,把“手术刀”对准了 Transformer 内部一个我们习以为常、甚至有些忽略的组件—残差连接(Residual Connection)。

自 2015 年由何恺明团队提出以来,残差连接凭借其有效缓解梯度消失的超能力,几乎是深度网络的标配。没有它,今天的 Transformer 很难稳稳当当地堆到几十层,更别提像 GPT-4 一样动辄上百层了。
不过,任何技术都有它的适用边界。这个曾经的功臣,在今天动辄上百层的深度大模型里,也开始显露出它的瓶颈,成了新的信息“堵塞源头”:
一方面,信息在逐层传递中损耗严重。 随着网络加深,各层特征越来越像(即“表示坍塌”),导致深层网络学不到新东西,白白浪费了参数和算力。
另一方面,单一的“残差流”带宽有限。 Transformer 所有跨层信息都挤在这条道上,当模型需要进行复杂的上下文学习时,这条“单行道”就显得捉襟见肘了。
而这篇 ICML 论文,就是冲着解决这个问题来的。
有意思的是,瞄准这个问题的,还是我们去年的老朋友——彩云科技与北京邮电大学的研究团队。他们设计了一套全新的多路动态密集连接(Multiway Dynamic Dense Connection, MUDD),目标就是给残差连接这个“老基建”来一次高效的改造。
熟悉我的老粉可能还记得,去年我就和大家分享过这个团队在 ICML 2024 上的杰作 DCFormer(哦,所以他们并不是没去卷注意力机制,是在DCFormer里已经卷过了。。)时隔一年,他们依然专注在底层架构创新这个方向上,这次的成果同样扎实。
那么效果如何呢?论文的数据很直接——
MUDD 方案以极小的代价(参数增加 0.23%,计算量增加 0.4%),就让一个 28 亿参数的 MUDDPythia 模型,在多项语言任务上媲美约 2.4 倍计算量的 Pythia-6.9B。尤其是在需要长距离上下文关联的 5-shot 场景下,它甚至能与约 4.2 倍计算量的 Pythia-12B 模型正面对决。
和上次一样,团队也把论文、代码、模型都开源了,方便大家直接上手。
Github 开源地址:
https://github.com/Caiyun-AI/MUDDFormer论文链接:
https://arxiv.org/abs/2502.12170HuggingFace模型:
https://huggingface.co/Caiyun-AI/MUDDPythia-1.4B https://huggingface.co/Caiyun-AI/MUDDPythia-2.8B
https://huggingface.co/Caiyun-AI/MUDDFormer-2.8B
在我看来,相比于烧钱拼硬件,从模型架构的根源上“榨取”性能,是当下最具性价比的方法。话不多说,让我们深入内部,看看 MUDD 究竟是如何“魔改”残差连接,实现性能翻倍的。
MUDD 的核心设计
首先你可以这样理解,传统的残差连接,就像一条单向直路,信息层层打包、不分流,堵车是必然的。而且模型越深,信息传递越差,后面的层都在摸鱼偷懒,也就是常说的“深层瓶颈”。
MUDD 的解决办法相当于把“单向直路”改成了一座“立交桥”,精妙之处在于三个设计:密集化(Dense)、动态化(Dynamic)、多路性(Multiway)。
先放一张 MUDD 的架构图——

密集化(Dense)
标准残差连接第 i 层只能看到第 i-1层的输出。而 MUDD 允许任何一层“回头看”,直接连接到它前面所有层的输出。

也就是让第 i 层能够直接“空降”到任意一个它之前的层(从 0 到 i−1)去获取纯净的信息,这就彻底打破了逐层传递的限制。
动态化 (Dynamic)
光有桥还不够,还得有智能调度才能跑起快。动态连接,这是 MUDD 区别于以往静态连接的关键。MUDDFormer 的连接权重不是固定的,而是动态生成的。不是所有历史信息都无脑涌入当前层。相反,它引入了一个“智能导航系统”。

模型在处理每个 token 时,会根据当前的语境(hidden state),动态地计算出每一条来自历史层的信息通道应该被赋予多大的权重。

这种“按需连接”的能力,让信息流动变得极其灵活和高效。
多路性 (Multiway)
这是我觉得这篇论文里最创新的想法!MUDD 的作者们认为:
在 Transformer 的一个 Block 里,Q(查询)、K(键)、V(值)和 R(残差输入)虽然都来自上一层,但它们的使命完全不同。把它们混在一个车道里运输,简直是资源浪费。
于是,MUDD 为它们设立了独立的专属 VIP 通道。为了让 Transformer 块内的不同输入流(Q, K, V, R)独立聚合,实现更精细的跨层通信,MUDD 将下一层 Transformer 块的输入解耦为独立的 Q、K、V、R 四个流,并为每个流设计了独立模块。

这意味着,在生成下一层的 Query 输入时,会使用专门的 DA_Q 模块独立聚合前层信息,而生成 Value 输入时,则使用 DA_V 模块进行不同的聚合。

不同于传统的层内多头注意力,MUDD 的设计核心是一种深度方向的多头注意力机制。它通过允许信息在不同层之间进行更丰富的 Q/K/V 交互,极大地增加了层间的通信带宽。
这种设计使得网络中的每个流(例如,负责传输信息内容的 V 流,以及负责匹配和对齐的 Q/K 流)能够根据其特定功能,独立且动态地从网络的历史/先前层中聚合所需的历史信息。
效果如何?
方法论讲的再好,也得看实际效果。MUDD 论文里给了详细的实验分析,可以说把“性价比”打在了公屏上。
这恐怕是大家最关心的。
在大规模预训练(300B tokens)中,MUDDFormer 仅用 28 亿参数,就在多项指标上达到了 69 亿参数模型(2.4 倍参数量)的水平。在更考验上下文理解能力的五样本学习任务上,它甚至能硬刚 120 亿模型(4.2 倍参数量)的水平。

实验显示,MUDDFormer 从预训练开始,损失就显著低于所有基线模型,换句话说,相同的 loss 所需算力更少。
比如图 3,我简单解释一下:横轴 Compute 代表训练总算力预算,写成 “模型参数量 × 预训练 token 数”(例如 405 M × 7 B)。向右代表花更多算力。纵轴 Loss 越低越好。

绿色实线(MUDDFormer)在所有算力点都低于其它模型,说明相同算力下 Loss 最小。红色箭头表示:要达到 MUDDFormer 的 Loss,普通 Transformer++ 需要 ≈1.89 × 的算力才行。
其次,改善了 Transformer++ 模型在增加层数后收益递减的问题。
传统 Transformer 越深,收益越低的“边际递减”问题,在 MUDD 这里得到了有效缓解。MUDDFormer 即使在更深的配置下,依然能保持强劲的性能增长。
把深度加倍后(虚线 vs 实线),MUDDFormer 的 Loss 下降幅度(虚线之间的垂直距离)明显大于 Transformer++。说明深层仍能有效学习。

红箭头表示达到 MUDD 深模型的损失水平,Transformer++ 需再多花 ≈2.08 × 算力。
再看下它多个任务上的表现,能够以小搏大,匹敌甚至超越更大模型。

把它用到 Vision Transformer(ViT)上做图像分类,效果同样显著。

不止如此,和现在特别火的混合专家(MoE)架构结合,还能产生 1+1>2 的效果。MUDD 与 MoE 模型虽然都利用动态权重,但作用机制不同(跨层聚合 vs. 层内专家选择),二者属于正交且互补的技术。
如以下图 5 展示的实验结果,MUDD 连接对 MoE 模型同样有效,并在应用时带来了额外的性能增益,预示着 MUDD 连接能够与 MoE 等先进架构相结合,进一步提升未来基础模型的综合性能。

总之,仅增加约 0.23% 的参数和 0.4% 的计算量,却在多种规模(405M–2.8B)和多种架构(Decoder-only/ViT)上稳定超越原 Transformer,需要的额外资源几乎可以忽略不计。
结语
这次 MUDDFormer 与研究团队之前的 DCFormer 工作一脉相承,DCFormer 侧重点在于序列长度的信息传递效率问题,而 MUDDFormer 则专注于优化模型深度方向的信息交互效率。
看似基础、底层的架构创新,在当前这个时候依旧有效。优秀的模型架构是撬动 AI 能力和效率的关键杠杆。
PS:MUDDFormer 工作的的所有代码、预训练模型和详细的实验设置完全开源, 不仅是一个即插即用的新工具,也是一种值得学习的创新思路。
GitHub:
https://github.com/Caiyun-AI/MUDDFormer
....
#95后,边改造业务边发AI顶会论文
是怎样的体验?
在 AI 时代的浪潮下,顶尖人才影响力空前高涨,其地位更被市场推升至了前所未有的高度。无论是谷歌 Transformer 论文八子,还是从 OpenAI 出走的科学家,他们要么自立门户,拿到亿级投资、百亿级估值,或者跳槽到他处,凭己之力拉近企业间的技术代差甚至影响竞争格局。
顶尖人才的供给增长速度似乎跟不上互联网大厂、初创公司急剧膨胀的需求,因此拥有极强议价能力。企业为了招揽这些具备突破性能力、能引领方向或解决关键瓶颈的人才,使出了浑身解数。
这场看起来一时不会结束的人才军备竞赛,在国内同样呈现出了高强度、系统性、全球化的竞争态势。
互联网大厂纷纷放大招,京东 TGT 顶尖青年技术天才计划、字节 Top Seed 人才计划、腾讯青云计划、百度文心・新星计划…… 各种行业 Top 薪酬甚至薪酬不设上限,钞能力拉满,誓要将顶尖人才收入麾下。
企业与人才双赢的实现,需要“双向奔赴”。
最近,一场聚集了产业技术大佬和高校技术天才的线下技术沙龙上,我们听到了他们对于前沿技术方向的深度探讨和双方对技术人才发展共同的思考和期待。
京东技术沙龙零售专场
这是今年 5 月全球启动的 “京东技术沙龙” 活动的最后一场,多位京东零售内部大模型相关技术团队负责人来到现场,与大家分享顶会论文和真实场景案例,展示最新前沿技术进展与创新应用实践的融合。
来自核心技术部门的青年技术专家也以学长学姐的身份向同学们传授经验、分享心得,帮助大家快速了解京东丰富的业务场景、以及如何找到自己最适配的团队和岗位。
如何从新人快速成长为技术骨干,实现从学界研究到产业实践的角色转变?怀揣着和现场同学们一样的好奇心,我们与来自京东零售产研的 5 位青年技术专家聊了聊,他们中最大不过 92 年、最小 98 年。他们的经历,也许可以为即将踏入职场的新人提供一些参考和借鉴。
1 年期新人通关:
实验室到业务前线,克服畏难心理啃下硬骨头
洛川,一位刚满 27 岁的大男生。
2024 年,在取得中国科学技术大学计算机软件与理论博士学位之后,他加入了零售 AI Infra 团队。
与所有初入职场的同学一样,从校园到职场,洛川充满忐忑。
但全方位的支持体系,彻底打消了他的担忧。
洛川有两位业务 + 技术导师,每个月他们都会抽出时间找他一起聊一聊,无论是个人成长方面的疑虑,还是技术层面的困惑。很快,洛川开始系统性地熟悉所在部门的技术栈、代码库,并逐渐适应 AI Infra 团队的工作节奏。
迅速融入的洛川(左 3)和伙伴们一起团建
几个月后,已经顺利渡过新人阶段的洛川迫切地希望将自己博士期间的研究成果真正服务于实际问题。「以往的研究大多停留在论文层面,而京东拥有丰富业务场景和海量产业数据,让我的研究终于有了规模化应用的机会。」
初步熟悉业务之后,洛川开始主动思考自己所在技术领域存在的痛点。他所在的团队主要负责构建和优化支撑大规模 AI 应用的基础设施,涵盖集群管理、算力调度、数据与样本中心建设、训练与推理引擎优化等。
过程中,通过自己对京东电商平台的长时间观察以及导师的指导,洛川明确了想要突破的目标。
他发现,进入大模型时代以来,推荐领域开始利用 Scaling Law 带来增益。不过,随着推荐模型中稀疏参数规模的持续增长,加上像京东这种电商平台中用户行为序列往往长达数万甚至十万,这些参数的存储、通信以及查询开销成了大规模点击率预测(CTR)模型分布式训练的瓶颈,影响到了算法团队的迭代效率。
面对这一难题,洛川跃跃欲试。在了解业务团队的核心诉求并精准定位技术难点之后,他迅速投入,分析了学术界和工业界现有方案并着手制定适合业务场景的技术规划和可行落地方案。
很快,他和团队一起设计并实现了一套重要性感知的量化与缓存方案,该方案显著减少了稀疏参数的存储、通信和查询开销,大幅加速 CTR 模型的分布式训练进程。看到实际效果落地,洛川深感「自己的辛苦没有白费。 」
这只是洛川这一年来的一个缩影,如今的他已经找准了自己的定位,与 AI Infra 团队一道攻克一个又一个技术难题。「作为新人,要克服畏难心理,深入一个领域,勇于啃下硬骨头。」
3 年期进阶通关:
瞄准真实痛点,从被动解题到主动提出问题
“一年级” 职场新人洛川的经历,在他的两位前辈谦屹和田野看来似曾相识。
谦屹和田野 3 年前从中科院自动化所博士毕业后便加入了京东。
谦屹专注于图像生成、多模态大语言模型、OCR 等计算机视觉研究。田野专注于搜索相关性业务,以及 NLP 技术在搜索场景的落地。加入京东后分别入职广告产研部和搜推技术部。
当他们前后脚加入京东时,还是遇到了不同的挑战和问题。
田野称自己需要克服的最大挑战是实验室思维到企业工程师思维的转变,这源于不同环境下问题定义与数据体系的根本性差异。
实验室环境下的研究通常针对明确定义的任务进行:问题本身、应用场景以及训练集和测试集都是预先给定且相对固定的,目标聚焦于在特定数据集上提升指标。而在真实的工业级电商搜索场景中,业务的核心问题会随着发展阶段快速变化;同时,工业场景中不存在现成的标准数据集,要求工程师自主构建整个数据闭环。
这种转型并不容易,「我要逼自己从纯粹的解题者转变为具备持续业务洞察力、能动态定义核心问题并自主构建适配数据与评估体系的问题定义者 + 架构师。」
田野花了很长一段时间才适应了新角色。此后,他便开始如鱼得水,利用自己的专业知识深度参与到搜索场景的体验升级。在跑算法、训大模型的过程中,田野最担心显卡不够用,但京东内部提供了一套灵活的资源倾斜策略,对长期有价值的项目全力支持。田野受到了很大的鼓舞,「如今在算力资源上得到了保证,自己也就再无后顾之忧,可以放手去研究生成式搜索技术了。」
而谦屹刚入职时最直观的感受是,原本以为自己积累了深厚的技术底子,但在工业界,业务需求与技术迭代的速度太快,原有的知识与技能面就显得窄了。
好在,他可以直接面向实际应用场景,对业务痛点进行最直接、最深刻的体察。谦屹特别提到了自己参与的一项电商广告图片生成创新工作 —— 基于人类反馈的可信赖图像生成(RFNet +RFFT),在丰富人类审核数据的基础上,利用 RLHF 技术,通过 RL 算法将人类偏好反馈给生成模型,有效降低了商品形变、背景错位等问题的发生概率,提升了模型生成可用图片的能力。
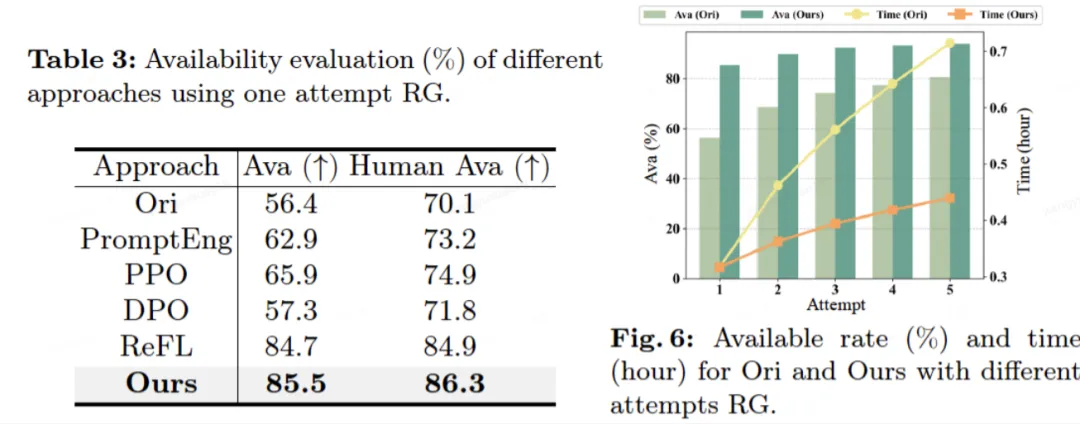
RFFT 相较其他方法实现了 SOTA [1]
谦屹开始慢慢跳出过去深耕的垂直领域,技术视野变得更广,掌握的更多知识和技能可以轻松应对多元化业务的挑战。
短短三年,他发表了 10 余篇创新性科研成果,并被多个 AI 顶会以及 AI 顶刊收录。目前,他与团队正积极探索前沿生成式 AI 能力对广告创意生成的赋能,尤其是多模态大模型批量化和自动化创意生产。
无论是田野还是谦屹,他们瞄准千万消费者和商家的真实体验痛点,在应对和解决业务挑战中获得了快速的成长和收获。
95 后向前一步:
敢想、敢为,探索多种可能性
其实在京东零售技术团队中,还有很多类似的年轻算法工程师们,95 后的长林和岛屿就经常和前面 3 位一起交流、切磋技术问题。
长林研究的方向是大模型蒸馏和数据选择,侧重低资源情况下大模型的训练与规模化应用,由于现代深度学习与大模型的成果依赖海量数据、巨大参数规模和高昂算力成本,使得低资源训练极具挑战。「学术训练的核心在于将现实问题简化、抽象为边界清晰的数学问题求解,但现在面对的问题不是孤立的知识点,而是技术、业务、资源、人员交织的系统」。
肯定不能「拿着锤子找钉子」的生搬硬套,长林开始积极请教周围热情的导师、前辈、学长学姐,与他们面对面交流、探索的过程中他们给了长林很大的自由度与耐心,「不要怕,达成目标的手段并不唯一,要敢想、敢为、探索多种可能性,我们来兜底」,这是他经常听过的鼓励与鞭策。
他提出仅选择信息最丰富的样本子集进行训练,以在模型性能和训练效率之间取得更好平衡。最终证明,在平均仅采样 70%-80% 数据的情况下,模型精度能够保持与原模型相当,且优于其他数据选择方法。

通过数据选择突破幂率的 Scaling Law [2]
近期,长林的三篇论文分别被顶会 ICLR、AAAI 和 ACL 接收,还提交了 8 项专利,可谓收获满满。其中一项代表性工作是基于动态数据选择加速模型训练。
同样 95 后的岛屿,她的工作重点在大语言模型的产品化应用。在电商场景中,通过大模型生成文案,帮助用户选购、为用户提供专业商品建议。传统模型更注重语言的高效和准确,而 95 后的她认为,要让用户真正逛起来,语言提供的情绪价值同样重要,于是她提出同时考虑大模型的语言风格,丰富个性化的语言表达以适配不同的用户需求,这个建议一提出就在内部获得认可,团队也配合她一起更新了方向和规划,这让岛屿备受鼓舞,「在这里,沟通没有门槛,行业大佬会直接参与和指导项目,能提升用户体验,就是第一优先级。」
自由的思想碰撞 × 扎实的工程实践 × 包容的成长环境,让这些 95 后们能充分追求自己热爱的技术方向。能跳出自身固有角色去主动思考问题、提出建议,创造力得到了充分激发。
人才建设,非一时之功
从高校实验室迈入到覆盖亿级用户的京东零售大环境,从硕博生转换为企业工程师,几位青年技术专家的成长之路走得很稳,技术带来的能量得以发挥最大的价值。
技术沙龙上,青年技术专家与同学们交流
京东希望能为更多像他们一样的青年技术人才,提供科技温度和产业厚度共同构筑的成长热土,让更多年轻人在这里加速成长、施展才华、定义未来。
2017 年起,京东就启动了面向青年技术人才的 “博士管培生项目”, 一批优秀的技术人已经迅速成长为各个技术板块的核心骨干,今年 5 月 8 日再次加磅,启动了京东 TGT 顶尖青年技术天才计划,该计划面向全球高校本硕博毕业生以及毕业两年内的技术人才,薪酬「不设上限」,涵盖了八大研究方向:多模态大模型与应用、机器学习、搜索推荐广告、空间与xx智能、高性能与云计算、大数据、AI Infra 以及安全等。
对人才吸引的诚意与决心,以及更加立体的人才培养模式、多维度又专业化的指导,京东希望进一步为人才成长提供成长保障,持续优化的人才梯度建设也将不断为京东及其业务赋能。
未来,这支融合了前沿探索精神和实战经验的年轻化技术军团,不仅更能贴近新生代用户与市场的思维,还将继续驱动京东在 AI、大数据、云计算等核心领域的创新与突破,构筑起难以复制的技术竞争力护城河。
最后,点击“阅读原文” 直达 “京东 TGT 顶尖青年技术天才计划” 进行投递,一起用技术创造更多美好吧!
参考链接:
[1] 论文地址:https://arxiv.org/pdf/2408.00418
[2] 论文地址:https://openreview.net/pdf?id=7oPAgqxNb20
....
#本地模型接入本地MCP实践
mcp最近很火,但在实际的应用环境中,并没有详细的资料讲解如何使用如何部署,增加初学者的学习成本,本文希望直观的展示mcp工具的具体使用实践。
一、mcp是什么?
大语言模型,例如DeepSeek,如果不能联网、不能操作外部工具,只能是聊天机器人。除了聊天没什么可做的。而一旦大语言模型能操作工具,例如:联网/地图/查天气/函数/插件/API接口/代码解释器/机械臂/灵巧手,它就升级成为智能体Agent,能更好地帮助人类。今年爆火的Manus就是这样的智能体。
在以前,如果想让大模型调用外部工具,需要通过写大段提示词的方法,实现“Function Call”,这样其实就非常的不友好。
Anthropic公司(就是发布Claude大模型的公司),在2024年11月,发布了Model Context Protocol协议,简称MCP。MCP协议就像Type-C扩展坞,让海量的软件和工具,能够插在大语言模型上,供大模型调用。

总的来说,mcp就是一个框架,能帮助大模型调用工具
更多MCP介绍可以看:Dify MCP 保姆级教程来了!
二、mcp协议通信
MCP采用客户端-服务器的分布式架构,它将 LLM 与资源之间的通信划分为三个主要部分:客户端、服务器和资源。

- MCP Hos:Hosts 是指 LLM 启动连接的应用程序,像Cursor、Claude、Desktop、Cline 这样的应用程序。
- MCP Client:客户端是用来在 Hosts 应用程序内维护与 Server 之间 1:1 连接。一个主机应用中可以运行多个MCP客户端,从而同时连接多个不同的服务器。
- MCP Server(服务器):独立运行的轻量程序,通过标准化的协议,为客户端提供上下文、工具和提示,是MCP服务的核心。
目前配置 MCP服务主要有种模式:
- Stdio 模式: 这个主要是用来连接你本地电脑上的软件或文件。比如你想让 AI 控制 Blender 这种没有在线服务的软件,就得用 Stdio,它的配置相对复杂一些。
- SSE 模式: 这个用来连接线上的、本身就有 API 的服务。比如访问你的谷歌邮箱、谷歌日历等等。SSE 的配置超级简单,基本上就是一个链接搞定。

在 MCP 框架中,SSE 模式是为了支持流式生成(如 LLM 的分词响应)而设计的一种 模型响应协议形式,其主要特征如下:
特点:
- 服务端推送:服务端可以不断发送生成的 token,客户端实时接收并显示。
- 兼容 Chat Completions 接口:通常和 OpenAI 的
stream=True 接口兼容。 - 性能更高:相比于完整生成后一次返回,流式响应能提升用户体验和响应速度。
sse模型一般是推荐使用异步函数,那么为什么 SSE 模型要用异步函数?
- SSE 本质是“流式”通信,需要持续等待数据SSE 是服务端持续推送数据,客户端需要一直监听这个连接,直到服务端关闭或中止。这种长时间等待、读取的过程非常适合用
async 实现,而不是阻塞式的 requests.get()。如果用同步函数,会卡住整个线程,阻塞后续逻辑或 UI。 - 异步 I/O 更高效,占用资源更少 在异步模式下,
await 会在数据没到的时候挂起任务,释放执行权给其他协程,而不是死等。这对于聊天机器人、Web 服务或多用户同时请求来说,性能提升非常明显。
三、mcp实践
为了方便演示,我写了一个mcp的工具demo
from fastmcp import FastMCP
# 创建一个FastMCP应用实例,名称为"demo"
# 这将作为所有工具的统一服务入口
app = FastMCP("demo")
# 定义一个名为"weather"的工具,用于查询城市天气
# 该工具接收一个字符串类型的城市名称作为参数
@app.tool(name="weather", descriptinotallow="城市天气查询")
def get_weather(city: str):
# 定义一个包含部分城市天气信息的字典
# 实际应用中这里可能会调用真实的天气API
weather_data = {
"北京": {"temp": 25, "condition": "晴"},
"上海": {"temp": 28, "condition": "多云"}
}
# 返回对应城市的天气信息,如果城市不存在则返回错误信息
return weather_data.get(city, {"error": "未找到该城市"})
if __name__ == "__main__":
# 启动应用,使用标准输入输出作为传输方式
# 这意味着可以通过命令行与工具进行交互
app.run(transport="stdio")run(transport="stdio") 以子进程方式等待客户端通过标准输入输出发送调用指令
这里为了演示方便,我们直接调用阿里的api接口进行模型与mcp工具的交互
参考链接:通义千问API参考(https://help.aliyun.com/zh/model-studio/use-qwen-by-calling-api)
import asyncio
import json
from openai import OpenAI
from mcp.client.stdio import stdio_client
from mcp import ClientSession, StdioServerParameters
# 配置OpenAI API参数,使用兼容模式接入阿里云DashScope服务
OPENAI_API_KEY = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxx"
OPENAI_API_BASE = "https://dashscope.aliyuncs.com/compatible-mode/v1"
class MCPClientDemo:
def __init__(self, server_path: str):
"""
初始化MCP客户端
:param server_path: MCP服务端脚本路径
"""
self.server_path = server_path
# 创建OpenAI客户端,连接到兼容API的阿里云DashScope服务
self.llm = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_API_BASE)
asyncdef run(self, user_query: str):
"""
执行用户查询,对比使用工具和不使用工具的结果
:param user_query: 用户问题
:return: 对比结果字典
"""
# 配置标准IO通信的服务端参数
server_params = StdioServerParameters(command="python", args=[self.server_path])
# 建立与MCP服务端的连接
asyncwith stdio_client(server=server_params) as (read_stream, write_stream):
# 创建客户端会话
asyncwith ClientSession(read_stream, write_stream) as session:
await session.initialize()
# 获取服务端注册的所有工具信息
tools = (await session.list_tools()).tools
# 将MCP工具格式转换为OpenAI函数调用格式
functions = []
for tool in tools:
functions.append({
"name": tool.name,
"description": tool.description or"",
# 使用工具的输入模式或默认模式
"parameters": tool.inputSchema or {
"type": "object",
"properties": {
"city_name": {"type": "string", "description": "城市名称"}
},
"required": ["city_name"]
}
})
# -------------------------------
# 模型调用 + MCP 工具路径
# -------------------------------
# 调用Qwen-max模型,启用函数调用功能
response_with_tool = self.llm.chat.completions.create(
model="qwen-max",
messages=[{"role": "user", "content": user_query}],
functinotallow=functions,
function_call="auto"
)
message_with_tool = response_with_tool.choices[0].message
result_with_tool = {
"model_reply": message_with_tool.content,
"tool_called": None,
"tool_result": None
}
# 如果模型决定调用工具
if message_with_tool.function_call:
tool_name = message_with_tool.function_call.name
arguments = json.loads(message_with_tool.function_call.arguments)
# 通过MCP会话调用实际工具
tool_result = await session.call_tool(tool_name, arguments)
result_with_tool.update({
"tool_called": tool_name,
"tool_arguments": arguments,
"tool_result": tool_result
})
# -------------------------------
# 模型不使用 MCP 工具的路径
# -------------------------------
# 调用相同模型,但不提供工具信息
response_no_tool = self.llm.chat.completions.create(
model="qwen-max",
messages=[{"role": "user", "content": user_query}],
# 不传入 functions 参数,模型无法使用工具
)
message_no_tool = response_no_tool.choices[0].message
result_no_tool = {
"model_reply": message_no_tool.content
}
# 返回两种调用方式的对比结果
return {
"user_query": user_query,
"with_mcp_tool": result_with_tool,
"without_tool": result_no_tool
}
asyncdef main():
"""主函数,演示工具使用与不使用的对比"""
# 创建MCP客户端,连接到指定服务端
client = MCPClientDemo(server_path="./stdio_mcp.py")
# 执行天气查询示例
result = await client.run("北京的天气怎么样")
# 格式化输出对比结果
print(">>> 用户提问:", result["user_query"])
print("n【使用 MCP 工具】")
print("模型回复:", result["with_mcp_tool"]["model_reply"])
if result["with_mcp_tool"]["tool_called"]:
print("调用工具:", result["with_mcp_tool"]["tool_called"])
print("工具参数:", result["with_mcp_tool"]["tool_arguments"])
print("工具结果:", result["with_mcp_tool"]["tool_result"])
else:
print("未调用任何工具")
print("n【不使用工具】")
print("模型回复:", result["without_tool"]["model_reply"])
if __name__ == "__main__":
# 运行异步主函数
asyncio.run(main())
可以看到模型调用了mcp的weather工具,并返回了工具调用的结果 {"temp":25,"condition":"晴"} 说明模型准确的识别到了工具,并进行了调用。
那如果我开发不同的工具,模型能够准确使用,那是不是就能大幅度扩展模型的能力范围,进一步提升模型的效率呢?
四、本地化mcp实践
本节演示使用vllm本地化部署qwen系统的模型,并与本地化的mcp工具进行交互。在实际的应用场景中,我们肯定会开发各种不同的工具,那每次使用stdio 这样的形式肯定是不够方便,是不是可以直接在本地的服务器上开一个端口,然后注册各种mcp的工具,如果模型要使用就直接通过mcp协议调用即可。
部署mcp服务,服务放在4200端口上
from fastmcp import FastMCP
# 创建FastMCP应用实例,"demo"为应用名称
app = FastMCP("demo")
# 注册天气查询工具,用于获取指定城市的天气信息
@app.tool(name="weather", descriptinotallow="城市天气查询")
def get_weather(city: str):
# 预设的天气数据(实际应用中可替换为API调用)
weather_data = {
"北京": {"temp": 25, "condition": "晴"},
"上海": {"temp": 28, "condition": "多云"}
}
# 返回对应城市的天气,不存在则返回错误信息
return weather_data.get(city, {"error": "未找到该城市"})
# 注册股票查询工具,用于获取指定股票代码的价格信息
@app.tool(name="stock", descriptinotallow="股票价格查询")
def get_stock(code: str):
# 预设的股票数据(实际应用中可替换为API调用)
stock_data = {
"600519": {"name": "贵州茅台", "price": 1825.0},
"000858": {"name": "五粮液", "price": 158.3}
}
# 返回对应股票的信息,不存在则返回错误信息
return stock_data.get(code, {"error": "未找到该股票"})
if __name__ == "__main__":
# 启动HTTP服务,支持流式响应
app.run(
transport="streamable-http", # 使用支持流式传输的HTTP协议
host="127.0.0.1", # 监听本地地址
port=4200, # 服务端口
path="/demo", # 服务路径前缀
log_level="debug", # 调试日志级别
)测试mcp服务是否可以正常运行
import asyncio
import httpx
from fastmcp import Client
from fastmcp.client.transports import StreamableHttpTransport
asyncdef test_mcp_service():
"""测试FastMCP服务的异步函数"""
# 定义服务URL,与服务端配置保持一致
SERVICE_URL = "http://127.0.0.1:4200/demo"
try:
# 创建基于HTTP的流传输客户端
transport = StreamableHttpTransport(url=SERVICE_URL)
# 使用上下文管理器创建客户端会话
asyncwith Client(transport) as client:
print(f"成功连接到MCP服务: {SERVICE_URL}")
# 发送ping请求测试服务连通性
await client.ping()
print("服务心跳检测成功")
# 获取服务端注册的所有工具
tools = await client.list_tools()
tool_names = [tool.name for tool in tools]
print(f"可用工具列表: {', '.join(tool_names)}")
# ==== 工具调用示例 ====
# 1. 调用天气工具查询北京天气
weather_results = await client.call_tool("weather", {"city": "北京"})
# 提取第一个结果的字典数据(假设服务端返回结构化数据)
weather_data = weather_results[0].text
print(f"北京天气: 温度={weather_data['temp']}℃, 天气={weather_data['condition']}")
# 2. 调用股票工具查询贵州茅台股价
stock_results = await client.call_tool("stock", {"code": "600519"})
stock_data = stock_results[0].text
print(f"股票查询: 名称={stock_data['name']}, 价格={stock_data['price']}")
# 3. 测试错误处理(查询不存在的城市)
try:
error_results = await client.call_tool("weather", {"city": "东京"})
# 检查错误信息是否符合预期
if error_results and hasattr(error_results[0], 'error'):
print(f"错误处理测试: {error_results[0].error} - 符合预期行为")
except Exception as e:
print(f"意外错误: {str(e)}")
# 处理连接失败异常
except httpx.ConnectError:
print(f"连接失败!请检查服务是否运行在 {SERVICE_URL}")
# 处理其他未知异常
except Exception as e:
print(f"测试失败: {str(e)}")
if __name__ == "__main__":
# 脚本入口点
print("="*50)
print("FastMCP服务测试脚本")
print("="*50)
# 运行异步测试函数
asyncio.run(test_mcp_service())
可以看到可以正常的访问mcp服务
我们使用vllm部署模型, 把模型打到8000接口
python -mvllm.entrypoints.openai.api_server \
--model ./qwen3-1.7b/ \
--served-model-name "qwen3-1.7b" \
--port 8000 \
--trust-remote-code \
--enable-auto-tool-choice \
--tool-call-parserhermes接下来我们启动服务对大模型进行提问
import asyncio
from openai import AsyncOpenAI
from fastmcp import Client
asyncdef query_mcp_tool(tool_name: str, params: dict):
"""
调用MCP工具的统一入口
:param tool_name: 工具名称
:param params: 工具参数
:return: 工具执行结果
"""
asyncwith Client("http://127.0.0.1:4200/demo") as client:
returnawait client.call_tool(tool_name, params)
asyncdef chat_with_tools():
"""
实现支持工具调用的聊天功能
1. 连接本地vLLM服务
2. 获取可用工具列表并转换为OpenAI函数调用格式
3. 根据用户问题调用适当工具
4. 整合工具结果生成最终回复
"""
# 连接本地部署的vLLM服务(兼容OpenAI API)
llm_client = AsyncOpenAI(
base_url="http://localhost:8000/v1",
api_key="EMPTY"# 本地服务不需要API密钥
)
# 动态获取MCP服务提供的工具列表
asyncwith Client("http://127.0.0.1:4200/demo") as mcp_client:
tools = await mcp_client.list_tools()
# 将MCP工具模式转换为OpenAI函数调用格式
tool_schemas = [{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": {
"type": tool.inputSchema.get("type", "object"),
"properties": {
prop_name: prop_def
for prop_name, prop_def in tool.inputSchema["properties"].items()
},
"required": tool.inputSchema.get("required", [])
}
}
} for tool in tools]
# 用户提问示例
user_query = "查询北京天气和贵州茅台股价"
# 第一次调用模型,允许模型决定是否需要调用工具
response = await llm_client.chat.completions.create(
model="qwen3-1.7b",
messages=[{"role": "user", "content": user_query}],
tools=tool_schemas,
tool_choice="auto"# 让模型自动选择工具
)
# 处理工具调用请求
message = response.choices[0].message
print(message.tool_calls)
if message.tool_calls:
print("检测到工具调用请求:")
# 按顺序执行模型请求的所有工具
for call in message.tool_calls:
print(f"正在执行 {call.function.name}...")
# 调用MCP工具并获取结果
result = await query_mcp_tool(
call.function.name,
eval(call.function.arguments) # 将参数字符串转换为字典
)
print(f"工具返回: {result}")
# 第二次调用模型,结合工具结果生成最终回复
final_response = await llm_client.chat.completions.create(
model="qwen3-1.7b",
messages=[
{"role": "user", "content": user_query}, # 原始问题
message, # 模型的工具调用计划
*[{ # 每个工具的执行结果
"role": "tool",
"name": call.function.name,
"content": str(result)
} for call in message.tool_calls]
]
)
print("n最终回复:", final_response.choices[0].message.content)
else:
# 如果模型认为不需要工具,直接返回模型回复
print("直接回复:", message.content)
if __name__ == "__main__":
# 运行异步聊天函数
asyncio.run(chat_with_tools())看一下最后的结果

<think>
好的,用户之前让我查询北京的天气和贵州茅台的股价。我先调用了天气和股票的函数,然后得到了结果。现在用户可能想知道具体的天气情况和股价。不过根据返回的数据显示,贵州茅台的股价是1825.0,但通常茅台的股价会波动,可能需要确认数据是否最新。另外,北京的天气信息可能需要更详细的预报,比如温度、天气状况等。用户可能希望得到更全面的信息,或者检查是否有误。我应该提醒用户数据可能实时性,建议查看最新行情或天气预报。同时,确认是否有其他需求,比如是否需要股票代码或天气的详细信息。
</think>
北京当前天气:晴,温度15℃~25℃,空气质量良好。
贵州茅台最新股价:1825.0元(数据仅供参考,实际行情以实时市场为准)。
需要更详细的天气预报或股票行情,请补充说明!可以看到模型明确的表示 我先调用了天气和股票的函数然后得到了结果~~~~~
说明本地的模型已经与mcp进行了交互
完美下车~
....
#Hierarchical Reasoning Model
只用2700万参数,这个推理模型超越了DeepSeek和Claude
像人一样推理。
大模型的架构,到了需要变革的时候?
在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。
近日,受到人脑分层和多时间尺度处理机制启发,来自 Sapient Intelligence 的研究者提出了分层推理模型(HRM),这是一种全新循环架构,能够在保持训练稳定性和效率的同时,实现高计算深度。
具体来说,HRM 通过两个相互依赖的循环模块,在单次前向传递中执行顺序推理任务,而无需对中间过程进行明确的监督:其中一个高级模块负责缓慢、抽象的规划,另一个低级模块负责处理快速、细致的计算。HRM 仅包含 2700 万个参数,仅使用 1000 个训练样本,便在复杂的推理任务上取得了卓越的性能。
该模型无需预训练或 CoT 数据即可运行,但在包括复杂数独谜题和大型迷宫中最优路径查找在内的挑战性任务上却取得了近乎完美的性能。此外,在抽象与推理语料库 (ARC) 上,HRM 的表现优于上下文窗口明显更长的大型模型。ARC 是衡量通用人工智能能力的关键基准。
由此观之,HRM 具有推动通用计算变革性进步的潜力。
论文:Hierarchical Reasoning Model
论文链接:https://arxiv.org/abs/2506.21734
如下图所示:左图 ——HRM 的灵感源自大脑的层级处理和时间分离机制。它包含两个在不同时间尺度上运行的循环网络,用于协同解决任务。右图 —— 仅使用约 1000 个训练样本,HRM(约 2700 万个参数)在归纳基准测试(ARC-AGI)和具有挑战性的符号树搜索谜题(Sudoku-Extreme、Maze-Hard)上就超越了最先进的 CoT 模型,而 CoT 模型则完全失败。HRM 采用随机初始化,无需思维链,直接根据输入完成任务。

分层推理模型
复杂推理中深度的必要性如下图所示。
左图:在需要大量树搜索和回溯的 Sudoku-Extreme Full 上,增加 Transformer 的宽度不会带来性能提升,而增加深度则至关重要。右图:标准架构已饱和,无法从增加深度中获益。HRM 克服了这一根本限制,有效地利用其计算深度实现了近乎完美的准确率。

HRM 核心设计灵感来源于大脑:分层结构 + 多时间尺度处理。 具体包括:
分层处理机制:大脑通过皮层区域的多级层次结构处理信息。高级脑区(如前额叶)在更长的时间尺度上整合信息并形成抽象表示,而低级脑区(如感觉皮层)则负责处理即时、具体的感知运动信息。
时间尺度分离:这些层次结构的神经活动具有不同的内在时间节律,体现为特定的神经振荡模式。这种时间分离机制使得高级脑区能稳定地指导低级脑区的快速计算过程。
循环连接特性:大脑具有密集的循环神经网络连接。这种反馈回路通过迭代优化实现表示精确度的提升和上下文适应性增强,但需要额外的处理时间。值得注意的是,这种机制能有效规避反向传播时间算法(BPTT)中存在的深层信用分配难题。
HRM 模型由四个可学习的组件组成:输入网络 f_I (・; θ_I ),低级循环模块 f_L (・; θ_L) ,高级循环模块 f_H (・; θ_H) 和输出网络 f_O (・; θ_O) 。
HRM 将输入向量 x 映射到输出预测向量 y´。首先,输入 x 被网络投影成一个表示

:

模块在一个周期结束时的最终状态为:

最后,在经过 N 个完整周期后,从 H 模块的隐藏状态中提取预测

。

HRM 表现出层级收敛性:H 模块稳定收敛,而 L 模块在周期内反复收敛,然后被 H 重置,导致残差出现峰值。循环神经网络表现出快速收敛,残差迅速趋近于零。相比之下,深度神经网络则经历了梯度消失,显著的残差主要出现在初始层(输入层)和最终层。

HRM 引入了:
首先是近似梯度。循环模型通常依赖 BPTT 计算梯度。然而,BPTT 需要存储前向传播过程中的所有隐藏状态,并在反向传播时将其与梯度结合,这导致内存消耗与时间步长 T 呈线性关系(O (T))。
HRM 设计了一种一步梯度近似法,核心思想是: 使用每个模块最后状态的梯度,并将其他状态视为常数。
上述方法需要 O (1) 内存,不需要随时间展开,并且可以使用 PyTorch 等自动求导框架轻松实现,如图 4 所示。

其次是深度监督,本文将深度监督机制融入 HRM。
给定一个数据样本 (x, y),然后对 HRM 模型进行多次前向传递,每次传递称为一个段。令 M 表示终止前执行的段总数。对于每个段 m ∈ {1, ..., M},令
![]()
表示段 m 结束时的隐藏状态,包含高级状态分量和低级状态分量。图 4 展示了深度监督训练的伪代码。
自适应计算时间(ACT)。大脑在自动化思维(System 1)与审慎推理(System 2)之间动态切换。
受上述机制的启发,本文将自适应停止策略融入 HRM,以实现快思考,慢思考。
图 5 展示了两种 HRM 变体的性能比较。结果表明,ACT 能够根据任务复杂性有效地调整其计算资源,从而显著节省计算资源,同时最大程度地降低对性能的影响。

推理时间扩展。有效的神经模型应当能够在推理阶段动态利用额外计算资源来提升性能。如图 5-(c) 所示,HRM 模型仅需增加计算限制参数 Mmax,即可无缝实现推理计算扩展,而无需重新训练或调整模型架构。
实验及结果
该研究中,作者跑了 ARC-AGI、数独和迷宫基准测试,结果如图 1 所示:
HRM 在复杂的推理任务上表现出色,但它引出了一个耐人寻味的问题:HRM 神经网络究竟实现了哪些底层推理算法?解答这个问题对于增强模型的可解释性以及加深对 HRM 解决方案空间的理解至关重要。
作者尝试对 HRM 的推理过程进行可视化。在迷宫任务中,HRM 似乎最初会同时探索多条潜在路径,随后排除阻塞或低效的路径,构建初步解决方案大纲,并进行多次优化迭代;在数独任务中,该策略类似于深度优先搜索方法,模型会探索潜在解决方案,并在遇到死胡同时回溯;HRM 对 ARC 任务采用了不同的方法,会对棋盘进行渐进式调整,并不断迭代改进,直至找到解决方案。与需要频繁回溯的数独不同,ARC 的解题路径遵循更一致的渐进式,类似于爬山优化。
更重要的是,该模型可以适应不同的推理方法,并可能为每个特定任务选择有效的策略。不过作者也表示,我们还需要进一步研究以更全面地了解这些解题策略。

HRM 在基准任务中对中间预测结果的可视化。上图:MazeHard—— 蓝色单元格表示预测路径。中图:Sudoku-Extreme—— 粗体单元格表示初始给定值;红色突出显示违反数独约束的单元格;灰色阴影表示与上一时间步的变化。下图:ARC-AGI-2 任务 —— 左图:提供的示例输入输出对;右图:求解测试输入的中间步骤。
下图为 HRM 模型与小鼠皮层的层级维度组织结构对比。
例如,在小鼠皮层中可以观察到维度层次,其中群体活动的 PR( Participation Ratio )从低水平感觉区域到高水平关联区域单调增加,支持维度和功能复杂性之间的这种联系(图 8 a,b)。
图 8-(e,f) 所示的结果显示出明显对比:未经过训练的模型中,高层模块与低层模块没有表现出任何层级分化,它们的 PR 值都较低,且几乎没有差异。
这一对照实验表明,维度层级结构是一种随着模型学习复杂推理任务而自然涌现的特性,并非模型架构本身固有的属性。

作者在进一步讨论中表示,HRM 的图灵完备性与早期的神经推理算法(包括 Universal Transformer)类似,在给定足够的内存和时间约束的情况下,HRM 具有计算通用性。
换句话说,它克服了标准 Transformer 的计算限制,属于可以模拟任何图灵机的模型类别。再加上具有自适应计算能力,HRM 可以在长推理过程中进行训练,解决需要密集深度优先搜索和回溯的复杂难题,并更接近实用的图灵完备性。
除了 CoT 微调之外,强化学习(RL)是最近另一种被广泛采用的训练方法。然而,最近的证据表明,强化学习主要是为了解锁现有的类似 CoT 能力,而非探索全新的推理机制 。此外,使用强化学习进行 CoT 训练以其不稳定性和数据效率低而闻名,通常需要大量的探索和精心的奖励设计。相比之下,HRM 从基于梯度的密集监督中获取反馈,而不是依赖于稀疏的奖励信号。此外,HRM 在连续空间中自然运行,这在生物学上是合理的,避免了为每个 token 分配相同的计算资源进而导致的低效。
....
#OctoThinker
首创Mid-training范式破解RL奥秘,Llama终于追平Qwen!
近期,一份来自上海创智学院、上海交通大学的前沿研究论文吸引了人工智能领域的广泛关注。该论文深入探讨了不同基础语言模型家族(如 Llama 和 Qwen)在强化学习(RL)训练中迥异表现的背后原因,并提出创新性的中期训练(mid-training)策略,成功地将 Llama 模型改造成高度适配强化学习的推理基础模型,显著缩小了其与天生擅长 RL 扩展的 Qwen 模型之间的性能差距,为下一代 reasoning 能力 AI 系统的开发提供了关键的科学基础和技术路径。
论文发布后在社交媒体引发广泛关注,Meta AI 研究科学家、即将赴 UMass Amherst 任助理教授的 Wenting Zhao 率先盛赞:“Truly impressed by how an academic lab just figured out a lot of mysteries in mid-training to close the RL gap between Llama and Qwen。” 此外,卡内基梅隆大学副教授 Graham Neubig、MIT CSAIL/Databricks Research 研究科学家,DSPy 项目的开发者 Omar Khattab 以及 AI2 数据负责人 Loca Soldaini 也共同肯定了这项系统性分析的重要价值。来自 Pleias AI Lab 的研究员 Alexander Doria 指出,他们的独立实验也证明,只要配合适当的数据预处理,任何模型都能显著提升 RLVR 或 RL 性能,进一步佐证了该方法的普适性。
此外,和 Octothinker 一同发布的 MegaMath-Web-Pro-Max 数据集发布即获得下载热潮,使用者覆盖了 MIT、EPFL、UW、Columbia、NUS、CMU、Princeton、THU、HKUST 等诸多顶尖高校,以及 Apple、Microsoft、TII、Moonshot、DatologyAI、AI2、IBM、Cohere、Tencent 等知名科研机构和企业,体现了学术界和工业界对这一工作的高度重视。
论文链接:https://arxiv.org/abs/2506.20512
代码仓库:https://github.com/GAIR-NLP/OctoThinker
开源模型 & 数据:https://huggingface.co/OctoThinker

研究团队通过大规模 mid-training 成功将 Llama 模型改造成 highly RL-compatible 的推理基础模型,在数学推理上可以与 Qwen 媲美。
研究背景
将大规模强化学习(RL)引入语言模型显著提升了复杂推理能力,尤其是在数学竞赛题解等高难度任务上。然而,近期的各项研究呈现出一系列耐人寻味的现象:(i) 只有 Qwen 系列基础模型表现出近乎 “魔法般” 的 RL 提升;(ii) 关键的 Aha moment 似乎主要在数学场景中出现;(iii) 不同评测设置往往暗含偏差,影响对 RL 成效的判断;(iv) RL 在下游看似 “岁月静好”,却在很大程度上依赖上游的 Pre-/Mid-training 质量 ^[1]。
与此同时,团队和其他研究者们都发现,尽管 Qwen 在 RL 扩展上高度稳健,Llama 却频繁出现提前给出答案和重复输出,难以获得同等级的性能增益。这一系列对比引出了核心科学问题:哪些基座特性决定了模型对 RL scaling 的适应性?Mid-training 能否作为可控干预手段,弥合不同基座在 RL 中的表现鸿沟?
为了探索这些问题,团队毫无保留地交出了一份详尽的技术报告记录了他们的研究过程,和一份完全开源的数据方案和基于 Llama 充分强化性能的新系列模型 OctoThinker。
核心问题:为什么 RL 训练在 Llama 上频频失效?
当 Qwen 系列模型通过强化学习(如 PPO、GRPO)在数学推理任务上获得显著提升时,同体量的 Llama 模型却常陷入重复输出或过早给出答案的困境。如下图所示,Llama 系列模型在直接进行强化学习训练的时候,总是会遇到 Reward Hacking、表现提升有限等一系列问题。

深入挖掘:通过可控的中期训练探索关键因素
研究团队通过对 Llama-3.2-3B 进行大量的可控 mid-training 实验(每次实验训练 20B tokens),然后进行强化学习训练观察训练动态。


中等训练策略的关键发现
- 高质量数学语料库的重要性:研究发现,像 MegaMath-Web-Pro 这样的高质量数学语料库,相较于 FineMath-4plus 等现有替代方案,能显著提升基础模型和 RL 性能。例如,在使用 MegaMath-Web-Pro 时,模型在下游 RL 任务中的表现明显优于使用 FineMath-4plus 的情况。
- QA 格式数据与指令数据的增益:在高质量数学预训练语料库基础上,加入 QA 样式数据(尤其是长链推理示例)可增强 RL 效果,而少量指令数据的引入能进一步释放 QA 数据潜力。研究发现,指令数据可以帮助模型更好地理解任务要求,从而在 RL 阶段表现更佳。
- 长链推理的双刃剑效应:长链推理虽能提升推理深度,但也可能引发模型响应冗长及 RL 训练不稳定问题,凸显数据格式化的重要性。例如,在实验中发现,模型在处理长链推理数据时容易出现输出过长或训练过程中的性能波动。为此研究团队通过以下方案来解决训练不稳定问题:
- 设计指令增强提示模板,抑制重复输出(相比基础模板错误率↓37%)
- 设置渐进最大响应长度调度器,按照训练进度解决长链推理引发的训练不稳定
- 中等训练规模扩展的效益:增加中等训练数据量可带来更强劲的下游 RL 性能,即使基础模型评估中未明显体现这些增益。这表明,中等训练阶段的扩展对于提升模型的最终 RL 表现具有重要意义。
自建高质量数学语料库
MegaMath-Web-Pro-Max
在准备语料时,团队还发现了另一个问题,即开源高质量语料的缺乏。以预训练语料为例,目前最高质量的数学语料 MegaMath-Web-Pro 包含了不到 20B tokens,但如果混合质量稍低的 FineMath 语料,则容易出现 RL 训练时的不稳定。
为了支持大规模消融研究和中期训练,研究团队创建了 MegaMath-Web-Pro-Max。该语料库通过一个高效的分类器从 MegaMath-Web 中召回文档,并进一步利用一个大语言模型进行精炼构建。
具体而言,研究团队从 MegaMath-Web 语料库中按文档的年份分层,均匀随机采样了数百万篇文档,并使用 Llama-3.1-70B-instruct 对其进行标注。每篇文档根据其在数学学习中的实用程度,被打分为 0 到 5 分,评分过程使用特定的评分提示(见论文附录)。研究团队采用启发式方法从模型的评论中提取评分:得分低于 3 的文档被标注为负例,得分在 3 分及以上的文档被视为正例。研究团队观察到,现有的分类器(如 inemath-classifier)在数据收集过程中对文本提取器的选择非常敏感。
因此,研究团队训练了自己的分类器,并选择效率较高的 fasttext 作为分类器。与 MegaMath 的发现一致,研究团队发现预处理步骤对召回性能至关重要。研究团队的预处理流程包括将文本转换为小写、过滤过长的单词,以及去除换行符和多余的非字母数字字符。
如下图所示,研究团队按照 MegaMath-Web 提出的逐年数据集比较设定,评估了不同召回阈值下所召回语料的质量。召回阈值决定了数据质量与数量之间的权衡:较高的阈值(如 0.9)带来更高的数据质量,但保留的 token 数量较少。最终,研究团队选择了 0.4 作为召回阈值。

图:研究团队重新召回的数据与 MegaMath-Web 的按照 Common Crawl 年份逐年数据质量对比(不同的 fasttext 阈值)。
考虑到许多文档存在噪声大、结构差等问题,研究团队使用 Llama-3.1-70B-instruct 对文本进行了精炼,所用提示设计借鉴了 MegaMath-Web-Pro。最终构建的 MegaMath-Web-Pro-Max 数据集包含的 token 数量约为 MegaMath-Web-Pro 的 5.5 倍。预训练过程中的实证评估表明,MegaMath-Web-Pro-Max 在保持数据质量的同时,具备成为大规模中期训练基础语料的潜力。
此外,研究团队也尝试通过从常见数学问题求解数据集中引入长链式思维数据来扩充正例种子集合,以提升分类器召回推理密集型内容的能力。然而,这种方法最终仅保留了约 20B tokens,研究团队认为其规模不足,因此未被采用。
🛠️ 突破性方案:OctoThinker 的两阶段
「稳定 - 衰减」训练方案
基于上述发现,研究者提出两阶段中等训练策略:
第一阶段:构建强推理基座(200B tokens)
使用恒定学习率对 Llama 模型进行 200B tokens 训练,主要依赖高质量预训练语料库(如 MegaMath-Web-Pro 和 DCLM-Baselines),辅以少量合成数据,构建稳固的推理基础。这一阶段的目标是使模型在大规模数据上逐步提升推理能力,为后续的 RL 训练打下坚实基础,产出:OctoThinker-Base-Stable 系列基模型;
第二阶段:分支专业化训练(20B tokens)
学习率衰减(余弦衰减至初始 LR 的 10%),引入不同数据混合(短链推理、长链推理及其混合),训练三个分支模型,塑造多样化模型行为。这一阶段旨在通过数据多样性和学习率调整,进一步提升模型的推理能力和适应性。
三大推理分支:

OctoThinker 基础模型系列的显著提升
经两阶段中等训练后的 OctoThinker 基础模型系列,在数学推理基准测试中表现出色,相较于原始 Llama 基础模型,在所有模型尺寸上均实现了 10%-20% 的显著性能提升,为 RL 扩展奠定了坚实基础。例如,在 GSM8K 和 MATH500 等基准测试中,OctoThinker 基座模型的准确率和推理深度均有明显提升。

图: OctoThinker 中期训练后的数学榜单表现跑分,图中所示为 1B 规模的模型结果。

图: OctoThinker 中期训练后的数学榜单表现跑分,图中所示为 3B 规模的模型结果。

图: OctoThinker 中期训练后的数学榜单表现跑分,图中所示为 8B 规模的模型结果。
OctoThinker-Zero 家族在 RL 训练中的卓越表现
进一步对 OctoThinker 基础模型进行 RL 训练后,生成的 OctoThinker-Zero 家族(包括短链、混合链和长链推理分支)在数学推理任务中展现出与 Qwen2.5 模型相当的性能。特别是 OctoThinker-Long-Zero 分支,在 3B 模型规格上,成功媲美以强大推理能力著称的 Qwen2.5-3B 模型,有力证明了中等训练策略对提升 Llama 模型 RL 兼容性的有效性。在多个数学推理基准测试中,OctoThinker-Zero 模型的表现与 Qwen2.5 模型不相上下,甚至在某些任务上略有超越。

图: OctoThinker 系列、Qwen-2.5、Llama-3.2 在 RL 训练中的数学基准测试动态曲线。
未来展望
研究团队计划在多个方向持续探索:一是进一步精炼数学预训练语料库以增强中等训练效果;二是采用开放配方设计无需从强大长链推理模型蒸馏的 RL 友好型基础模型;三是深入解耦 QA 格式与内容的独立贡献;四是拓展 OctoThinker 家族,增加如工具集成推理等新分支,以期为预训练与强化学习的交互机制提供更深入洞见。
[1]: 互联网博主 “AI 实话实说” 总结的 “RL” 乱象 — https://www.xiaohongshu.com/user/profile/623bfead000000001000bf09
....
#SeqPO-SiMT
AI字幕慢半拍,不知道大家在笑什么?新方法让同传性能直逼离线翻译
本文第一作者是徐婷,是香港中文大学博士生,主要研究兴趣是大模型的后训练;通讯作者分别是黄志超和程善伯,来自字节跳动Seed团队。
你是否经历过这样的场景:观看一场激动人心的全球发布会,AI 字幕却总是慢半拍,等你看到翻译,台上的梗已经冷掉了。
或者,在跨国视频会议上,机器翻译的质量时好时坏,前言不搭后语,让人啼笑皆非。
这就是同声传译(Simultaneous Machine Translation, SiMT)领域一直以来的核心技术挑战:“质量 - 延迟” 权衡问题(Quality-Latency Trade-off)。
现在,这些问题迎来了新的解决方案。来自香港中文大学、字节跳动 Seed 和斯坦福大学的研究团队联手提出了一种面向同声传译的序贯策略优化框架 (Sequential Policy Optimization for Simultaneous Machine Translation, SeqPO-SiMT)。
该方法将同传任务巧妙地建模为序贯决策过程,通过优化完整的决策序列,显著提升了翻译质量,同时有效控制了延迟,其性能直逼、甚至在某些方面超越了同等大小的离线翻译模型。
论文标题: SeqPO-SiMT: Sequential Policy Optimization for Simultaneous Machine Translation
论文链接:https://arxiv.org/pdf/2505.20622
研究背景
同声传译的核心在于机器需要动态地决定 “继续听”(READ)还是 “开始说”(WRITE)。这个决策直接影响最终的翻译效果。例如,当模型接收到英文单词 “bark” 时,它面临一个困境:如果立即翻译,可能会译为 “狗叫”,但若后文出现 “of the tree”,则正确翻译应为 “树皮”。
传统的同传方法,它每一步决策(是继续听,还是开始翻译)都是孤立的。它可能会因为眼前的 “小利”(比如翻译出一个词)而牺牲掉全局的 “大利”(整个句子的流畅度和准确性)。

核心方法
针对这一难点,该论文提出了 SeqPO-SiMT 框架。其核心思想是将同声传译任务建模为一个序贯决策问题,综合评估整个翻译流程的翻译质量和延迟,并对整个决策序贯进行端到端的优化。
该方法的主要特点是:它不再孤立地评估每一步决策的好坏,而是将一整句话的翻译过程(即一个完整的决策序贯)视为一个整体,更符合人类对同传的评估过程。
同声传译采样阶段:使用一个大语言模型(LLM)充当策略模型
![]()
。在每个时间步 t,模型会接收新的源语言文本块
![]()
,并基于已有的所有源文本
![]()
和之前的翻译历史
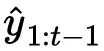
,来生成当前的翻译块
![]()
。这个决策过程可以被形式化地表示为:

。该框架的一个关键灵活性在于,如果模型决定等待更多上下文,输出的
![]()
可以为空,其长度完全由策略模型
![]()
自行决定。
奖励函数:在优化阶段,对于一个 batch 内的第 i 个样本,系统会通过一个在最终步骤 T 给予的融合奖励
![]()
来评估整个过程的优劣。这个奖励同时评估翻译质量(Quality)和延迟(Latency)。具体而言,首先计算出原始的质量分
![]()
和延迟分
![]()
,然后对两者进行归一化处理以统一量纲得到
![]()
和
![]()
,最终的奖励被定义为:

其中,λ 是一个超参数,用于权衡质量与延迟的重要性。
优化目标:模型的最终优化目标最大化期望奖励
![]()
,同时为了保证训练的稳定性,目标函数中还引入了 KL 散度作为约束项,防止策略模型
![]()
与参考模型
![]()
偏离过远。这个结合了最终奖励和稳定性约束的优化过程,使得模型能够端到端地学会一个兼顾翻译质量与延迟的最优策略:



实验结果与分析
为了验证方法的有效性,研究者们在多个公开的英汉互译测试集上进行了实验,并与多种现有的同传模型进行了对比。实验结果显示:在低延迟水平下,SeqPO-SiMT 框架生成的译文质量相较于基线模型有明显提升。

本文将 SeqPO-SiMT 的实时同传结果与多个高性能模型的离线翻译结果进行对比。结果显示,SeqPO-SiMT 的翻译质量不仅优于监督微调(SFT)的离线模型及 LLaMA-3-8B,其表现甚至能媲美乃至超越 Qwen-2.5-7B 的离线翻译水平。这表明该方法在 70 亿参数(7B)规模上实现了业界顶尖(SoTA)的性能。

总结与讨论
总的来说,SeqPO-SiMT 这项工作的主要贡献在于,为解决同声传译中的质量 - 延迟权衡问题提供了一个新的视角。它强调了对决策 “序贯” 进行整体优化的重要性。该研究提出的方法,对于需要进行实时、连续决策的自然语言处理任务具有一定的参考意义,并为未来开发更高效、更智能的同声传译系统提供了有价值的探索。
....
#OpenAI全员放假一周
被Meta高薪连挖8人「偷家」,真麻了
面对 Meta 一亿美元签字费挖人的条件,OpenAI 的回应是……
生成式 AI 竞争如火如荼的当口,OpenAI 却突然宣布本周全员放假,还是直接放一周。

这当然不是因为 GPT-5 已经造好,或是竞争对手全被打败了,而是因为 OpenAI 被挖人挖麻了。
随着高级研究人员接连被竞争对手挖走,OpenAI 高管向团队成员保证,公司不会「袖手旁观」。据《连线》杂志报道,上周六,OpenAI 首席研究官 Mark Chen 向员工发出了一份措辞强硬的备忘录,承诺要在顶尖研究人才争夺战中与 Meta 进行正面交锋。
这一次,《连线》甚至以「OpenAI 领导层回应 Meta 挖角:有人闯进了我们家」为题进行了专题报道。
在那份备忘录中,Mark Chen 表示:「我现在有一种强烈的预感,就像有人闯入我们家偷了东西一样。请相信,我们并没有袖手旁观。」
就在几天前,Meta 首席执行官马克・扎克伯格成功从 OpenAI 招募了四名高级研究人员加入 Meta 的「超级智能实验室」。而更早几天,Meta 更是将 OpenAI 苏黎世办公室的三位研究者一锅端走。详情可参阅我们之前的两篇报道:
OpenAI 四位华人学者集体被挖,还是 Meta 重金出手
OpenAI 苏黎世办公室被 Meta 一锅端,三名 ViT 作者被挖走
总结起来,现目前已经被 Meta 挖走的 OpenAI 研究者已经达到 8 位:
- Trapit Bansal,2022 年 1 月加入 OpenAI,曾获得 ICLR 2018 最佳论文奖。
- Shengjia Zhao,2022 年 6 月加入 OpenAI,曾获得 ICLR 2022 杰出论文奖。Google Scholar 引用量超过 2.1 万。
- Jiahui Yu(余家辉),2023 年 10 月加入 OpenAI,曾是谷歌 DeepMind Gemini 项目多模态的负责人,Google Scholar 引用量超过 3.4 万。
- Shuchao Bi, 2024 年 5 月加入 OpenAI,领导后训练 - 多模态团队,曾在谷歌工作过。
- Hongyu Ren(任泓宇),2023 年 7 月加入了 OpenAI,此前曾在苹果、谷歌等公司工作过,Google Scholar 引用量超过 1.7 万。
- Xiaohua Zhai(翟晓华),曾在 DeepMind 从事研究工作,于去年 12 月加入 OpenAI。Google Scholar 引用量超过 8.6 万。
- Lucas Beyer,同样曾在 DeepMind 工作,于去年 12 月加入 OpenAI。Google Scholar 引用量超过 8.6 万。
- Alexander Kolesnikov,同样曾在 DeepMind 工作,于去年 12 月加入 OpenAI。Google Scholar 引用量超过 9.0 万。
从目前的情况推测,Meta 新招募的这些研究者都将加入由该公司重金聘请的 Scale AI 创始人 Alexandr Wang 领导的新组建的超级智能实验室(Superintelligence Lab)。这位 1997 年出生的、也颇受争议的成功创业者也已经在欢迎推文中暗示了这一点。

据华尔街日报报道,扎克伯格还整理了一份名单「The List」,里面包含一些 AI 领域顶尖的研究科学家和工程师 —— 扎克伯格甚至愿意为他们开出高达 1 亿美元的优厚待遇。
尽管 OpenAI 高层似乎迫切希望留住员工,但 Mark Chen 表示,他「个人对公平(fairness)有着很高的标准」,并希望以此为契机留住顶尖人才。他写到:「虽然我会努力留住你们每一个人,但我不会以牺牲他人的公平为代价。」
仅在 6 月份,硅谷对顶尖人工智能研究人员的竞争正日趋激烈。据山姆・奥特曼与其兄弟杰克・奥特曼在播客中发表的评论,扎克伯格的做法尤其激进,他向一些 OpenAI 员工提供了 1 亿美元的签约奖金。
听起来就像是天方夜谭,然而 OpenAI 多位直接了解报价的消息人士证实了这一数字。据《华尔街日报》报道,Meta 首席执行官也一直在亲自联系潜在的人才。Mark Chen 在 Slack 上写道:「在过去的一个月里,Meta 一直在积极拓展新的人工智能项目,并多次(但大多未成功)试图用以薪酬为重点的薪酬方案来招募我们最优秀的人才。」
另一边 Meta 则赶紧「辟谣」:在周四全公司的会议上,Meta 的一些高管被问及奥特曼所说的一亿美元签字费。
Meta 首席技术官 Andrew Bosworth 暗示,只有少数担任高级领导职务的人可能获得如此高的薪酬。他澄清说,「薪酬的实际条款」并非「签约奖金」,而是各种不同的东西。换句话说,不是一笔现金。科技公司通常会以限制性股票单位(RSU)的形式向高级领导层提供最大比例的薪酬,具体比例取决于任职期限或绩效指标。
对于一位非常资深的领导者来说,四年总薪酬约 1 亿美元并非不可想象。Meta 的一些高管,包括 Andrew Bosworth,多年来每年的薪酬总额都在 2000-2400 万美元之间。
一位接近 Meta 的消息人士证实,该公司一直在大力加强研究人员的招聘,尤其关注来自 OpenAI 和谷歌的人才。有报道称,Meta 还曾想招募两位已经离开的 OpenAI 联合创始人和研究科学家 Ilya Sutskever 以及 John Schulman—— 其中前者的引用量已经超过 65 万,而后者也超过了 12 万。
一位消息人士称,尽管 Anthropic 也是 Meta 的主要竞争对手,但据信与 Meta 的文化不太契合。「他们不一定扩大了团队规模,但对于顶尖人才来说,不设目标上限,」该消息人士表示。
Mark Chen 的备忘录中还包含公司其他七位研究负责人的留言,而这些留言显然都是为了鼓励员工们留下来。
一位研究团队的负责人鼓励员工,如果收到了 Meta 的录用通知,就主动联系他们:「如果他们给你施加压力,或者开出离谱的超高报价,就让他们放弃吧。在可能最重要的决策面前给别人施加压力可不是什么好事。」《连线》杂志没有透露这位负责人的姓名,因为他并非高管。「我很想和你谈谈这件事,而且我对他们的录用通知了如指掌。」
目前,OpenAI 员工的工作强度很大,许多员工每周工作时间长达 80 小时。据多位消息人士透露,OpenAI 下周将基本停工,以便员工恢复精力。但这些消息人士表示,高管们仍计划继续工作。

在 Mark Chen 的备忘录中,OpenAI 的另一位领导写道:「Meta 知道我们这周要恢复精力,会利用这段时间试图向你施压,迫使你快速独立地做出决策。如果你感到压力,别害怕联系我。我和 Mark 一直在你身边,愿意支持你!」
尽管 OpenAI 领导层对 Meta 的行动非常重视,但 Mark Chen 也承认,OpenAI 「过于沉迷于定期产品发布的节奏,以及与竞争对手的短期性能比较」。一位曾与奥特曼密切合作的前 OpenAI 员工也表达了同样的观点,他表示,奥特曼希望每隔几个月就能看到一些令人瞩目的公告。现在,这种情况似乎正在改变,公司更专注于实现通用人工智能(AGI)。
「我们需要继续专注于真正的目标,那就是找到将计算转化为智能的方法,今年晚些时候将有更多超级计算机上线,」Mark Chen 写道。「这是主线任务,重要的是要记住,与 Meta 的冲突只是支线任务。」
「最后,同样重要的是,我这周都会在线 —— 已经蓄势待发,准备好加油干。随时可以给我发私信。」
奥特曼也在 Slack 上进行了点评:「看到 Mark 在整个过程中展现出的领导力和正直,真是令人惊叹,尤其是在他不得不做出艰难抉择的时候,」奥特曼在 Slack 上回复 Chen 的留言时写道。「非常感激他成为我们的领导者!」
面对 Meta 高薪挖人,CEO 亲自下场的组合拳,OpenAI 团队成员最近似乎显得有些沮丧。

不过对此也有人评论认为,Meta 很难通过如此简单粗暴的方式挖到真正顶尖的人才,毕竟谁愿意加入一家技术落后的公司呢?
但至少这一次挖人大战过后,每个技术人才都要重新自我定价一番了。
最后,OpenAI 其实有新活,他们的新一代开源大模型已经开始预热。
明天就是「下个月」了,大模型的格局又会反转吗?
参考内容:
https://www.wired.com/story/openai-meta-leadership-talent-rivalry/
https://www.wsj.com/tech/meta-ai-recruiting-mark-zuckerberg-openai-018ed7fc
....
#PAROAttention
用好视觉Attention局部性,清华、字节提出Token Reorder,无损实现5倍稀疏、4比特量化
赵天辰,清华大学电子工程系高能效计算实验室研究生,研究方向主要是:面向视觉生成的高效算法,与软硬件协同设计。以下工作为赵天辰在字节跳动-Seed视觉部门实习期间完成
近年来,随着视觉生成模型的发展,视觉生成任务的输入序列长度逐渐增长(高分辨率生成,视频多帧生成,可达到 10K-100K)。与输入序列长度呈平方复杂度的 Attention 操作,成为主要的性能瓶颈(可占据全模型的 60-80% 的开销),有明显的效率优化需求。注意力的稀疏化(Sparse Attention)与低比特量化(Attention Quantization)为常用的 Attention 优化技巧,在许多现有应用中取得优秀的效果。然而,这些方法在视觉生成模型中,在低稠密度(<50%)与低比特(纯 INT8/INT4)时面临着显著的性能损失,具有优化的需求。
,时长00:02

本文围绕着视觉任务的 “局部性”(Locality)特点,首先提出了系统的分析框架,识别出了视觉生成任务 Attention 优化的关键挑战在于 “多样且分散” 的注意力模式,并且进一步探索了该模式的产生原因,并揭示了多样且分散的注意力模式,可以被统一为代表 “局部聚合” 的块状模式。然后,提出了一种简单且硬件友好的离线 “Token重排” 方案以实现注意力模式的统一化,并设计了针对性的稀疏与量化方法,配合高效的 CUDA 系统设计,展现了更优异的算法性能保持与硬件效率提升。最后,本文讨论了该方案更广泛的应用空间,与对视觉生成算法设计的启发。
论文标题:PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
论文链接:https://arxiv.org/abs/2506.16054
项目主页:https://a-suozhang.xyz/paroattn.github.io/
1. 分析框架:关键问题与如何利用局部性(Locality)
如上文所述,一系列现有的注意力稀疏化与低比特量化方案已取得了进展,但是还存在着一定的挑战与改进空间:
对于稀疏化,一系列现有方案(DiTFastAttn,SparseVideoGen,Sparse-vDiT)尝试依据视觉注意力图的独特模式,设计针对性的稀疏掩码(Sparse Mask,如 “窗口状的”,“多对角线”,“垂直线的”),并将其进行组合。然而,适配多样且分散的注意力模式,给稀疏掩码的设计与选择机制带来了严峻的挑战。本文尝试采用另一种视角与方法,并不涉及复杂的掩码选择机制来适配复杂多样的注意力模式,而是设计方案 “重整注意力模式”。让多样且复杂的注意力模式,统一为硬件友好的块状注意力模式,让稀疏方案设计更加简单有效。
对于低比特量化,现有方案(SageAttention 系列)SageAttentionV2 可以将 Attention 中的 QK 计算(Query 与 Key 的乘法)降低至 INT4,但是 PV(AttentionMap 与 Value 的矩阵乘)计算仍然需要保持为较高的 FP8。最新版本的 SageAttentionV3 采用了 FP4 量化,但仅在最新的 B 系列 Nvidia GPU 上有支持。本文尝试分析了更低位宽的定点量化(全流程 INT4)的关键问题,并给出了解决方案。

图:本文(PAROAttn)的优化思路:重整注意力图以便稀疏与量化处理
为寻找 Attention 稀疏与量化的统一解决方案,本文尝试分析 Attention 效率优化中稀疏与低比特量化的关键问题,来自于视觉注意力图多样且分散的独特数据分布 (如下图左侧所示):
稀疏注意力方案设计需要从 2 方面考虑:保持算法性能,与提升硬件效率。
- 从算法性能角度,需要避免在稀疏过程中错误的删除重要值。由于视觉注意力模式存在多样的结构(对角线,纵向,块状等),且这些特征随着不同的时间步,不同的控制信号而动态变化。因此,注意力模式的多样性,与动态变化,导致设计的掩码难以完全涵盖重要值,对算法性能的保持带来困难。
- 从硬件效率角度,需要设计 “结构化” 的稀疏掩码,以跳过整块计算来获得实际硬件收益(任意不规则稀疏需要引入额外的索引操作,且可能导致计算负载零散,使得加速收益折损)。特别的,由于 FlashAttention 涉及逐块进行注意力计算,因此稀疏化的过程中,也应考虑如何与其适配。由于视觉注意力图的模式,往往不与 FlashAttention 中的分块所对应(对角线模式中,每个块中仅有少量较大值)。因此,注意力图模式的分散性,使得结构化稀疏难以取得,难以获得有效的硬件效率提升。
对于低比特量化算法的设计:关键问题为如何尽量减少量化损失。
- 现有工作(如 ViDiT-Q)已经分析并指出了低比特量化的关键误差来源在于 “量化组内的数据分布差异”,对于注意力量化,为适配 FlashAttention,需要选择块状的量化分组。然而,“对角线式” 的视觉注意力模式,导致块状的量化分组中,对角线上的元素成为离群值,带来了巨大的组内数据差异,而导致了显著的量化损失。因此,视觉注意力模式的数据分布,导致了显著的量化损失。
图:视觉生成稀疏与量化的关键问题来自于多样分散的注意力模式,与本文的解决方案:采用Token重排以改进注意力图为统一的分块模式
为解决视觉注意力图多样且分散的独特数据分布给注意力稀疏与量化所带来的挑战。本文的技术路线为:对注意力图进行 “重整”(Reorganize),以获得更加统一且易处理的注意力模式。
受到视觉特征提取具有 “局部性” 的先验启发(CNN,SwinTransformer 的设计理念,与 Hubel 与 Wiesel 的生物学实验),本文进一步分析了视觉注意力模式多样性的产生原因,并发现了 “多样的视觉注意力模式本质上都在描述空间上的局部聚合”。
如下图所示,在 Transformer 的处理过程中,原本三维空间(F - 帧数,H,W - 每帧的图像宽高)会被转化为一维的标记序列(Token Sequence),按照默认的 [F,H,W] 的顺序排列。这会导致在除了内存上连续的最后一维(W)之外维度的三维空间相邻像素,在标记序列中呈现为按照一定的间隔排列。
因此,多对角线的注意力模式,本质上是在描述 “其他维度上的局部聚合”,并可以通过Token顺序的重排列,转化为代表局部聚合的块状模式(将局部聚合的维度转化为内存上连续的维度,如 [F,H,W] -> [F,W,H])。
本文进一步验证了,每个不同的注意力头(Head),在不同情况下,呈现出一致的在某个维度上的局部聚合,进而可以通过为每个 head 选取合理的Token重排(Token Reorder)方案,将多样且分散的注意力模式,转化为统一的,硬件友好的块状模式,以便于 Attention 的稀疏与量化。该方案利用了算法侧视觉特征提取的局部性(更好的数值 Locality),并将其与硬件计算的局部性将对应(更好的内存与计算 Locality),从而获得了同时更优的算法性能保持,与硬件效率提升。

图 视觉特征提取 “局部性” 的示意图
2. 方案设计
整体框架
方案流程如下图所示,对 Attention 计算的主要瓶颈,两个大规模矩阵乘(QK 与 PV)都进行了稀疏与量化优化,显著减少其硬件开销。本文基于少量矫正数据离线决定了每个注意力头(Head)的Token重排方案,与对应的稀疏掩码,几乎不在推理时引入额外的开销。在推理时,仅需跳过稀疏掩码所对应的 attention 分块,并对剩余的部分逐块进行低比特量化。

图 PAROAttention 稀疏与量化方案的流程
Token重排方案(PARO:Pattern-Aware Token Reordering)
本文发现每个不同的注意力头(Head),在不同情况下,呈现出一致的在某个维度上的局部聚合。因此,可以离线地对每个注意力头,选择恰当的Token重排方式,将注意力图转化为展示局部聚合的块状(Block-wise)模式。
本文发现了重排列中的一种特殊方式,维度置换(Permutation),就可以取得不错的效果。对于视频生成模型的特征 [F,H,W],本文为每个注意力头 6 种可能的置换方式,离线选取最优的置换方式,以获得需要的数据分布方式。由于对于注意力稀疏与量化,具有不同的数据分布需求。因此,本文针对稀疏和量化分别设计了重排方式的选取指标,并将两者组合作为最终指标。
- 稀疏角度:为减小结构化稀疏所带来的损失,要求尽量多的分块是完全稀疏的(Block Sparse)
- 量化角度:为减少块内数据分布差异大而导致的量化损失,要求块内数据分布是尽量均匀的(Block Uniform)
如下图所示,稀疏与量化对注意力图的分布需求不同,需要组合两者需求,才能找到同时适合两者的重排方式。经过合适的重排处理之后,注意力图呈现块状且较为集中的分布,以适配稀疏与量化处理。

图:不同重排方式的注意力图示意
稀疏方案
现有的稀疏注意力方案可分为 2 种方式:(1)动态稀疏方案(如 SpargeAttention)在线依据注意力值生成稀疏掩码;(2)静态稀疏方案(如 DiTFastAttn):离线生成稀疏掩码。两者各有其优劣。尽管本方法设计的Token重排(PARO)方案能够同时帮助动态与静态方案,本文对两者优劣进行的分析,并最终选取了静态稀疏方案,作为 PAROAttention 的主要稀疏方案,具体分析如下:
对于动态稀疏(Dynamic Approach):
- 在性能保持方面,虽然动态的方案能够自然适配动态变化的模式。但是由于需要在线产生稀疏掩码,只能基于 Softmax 之前(Presoftmax)的注意力值,它们的相对均匀,不呈现明显模式,难以准确的识别出对应模式。
- 在硬件效率方面,动态稀疏方案引入了在线计算出稀疏掩膜的额外开销(overhead),该开销与掩膜预测的准确度互为权衡,若要获得准确的掩膜,则需要引入相对较大的额外计算。该额外预测过程,一般需要精细设计的 CUDA Kernel 才能够获得较高的效率收益。
- 总结来看,在较低稀疏比下,动态稀疏方式的准确性与效率提升存在瓶颈,因此本文诉诸静态稀疏方案。
对于静态稀疏(Static Approach):
- 在性能保持方面,由于静态确定的注意力图,难以适配多样且动态变化的注意力模式,因此静态稀疏方案通常会造成相比动态方案更显著的性能损失。然而,PAROAttention 的注意力图重整,已将多样动态变化的注意力模式,转化为了规整且统一的模式,解决了这一静态稀疏的关键挑战。因此,通过利用模式更明显的 Softmax 后注意力图,能够获得比动态方案更优的算法性能保持。
- 在硬件效率方面,虽然避免了在线计算出稀疏掩膜的额外计算开销,但是离线稀疏掩码会带来额外的显存开销。本文针对该问题进行了对应优化(见下文 “CUDA 系统设计” 部分)。
经过重排列处理之后,注意力图呈现出统一的集中的分块模式。因此,本文仅需离线统计每块中的 attention 数据之和,并设计阈值判断当前块是否需要被跳过(该阈值可以用于调节稠密度),就可以离线获取到稀疏掩码,在推理时不引入任何额外开销(overhead)。如下图所示,相比其他现有的静态注意力稀疏方案,由于预先对注意力模式的统一化,PAROAttention 避免了复杂且受限的掩膜设计,而能够与原图非常契合的稀疏掩膜。

量化方案:
对于低比特量化,评估量化损失的关键指标是分组内的数据差异,现有文献通常采用不均衡度(Incoherence)进行衡量,被定义为当前数据组中的最大值,除以平均值(x.max () /x.abs ().mean ())。经过合适的Token重排之后,Attention Map 块内的显著数据差异得到明显缓解,从而可以支持更低位宽的量化。

CUDA 系统设计
最小化额外开销:PAROAttention 所引入的额外开销主要有以下两方面,本文在系统层面进行了针对性优化以最小化额外开销。
- 在线的Token重排开销:虽然重排方式离线确定,但是Token重排的过程(维度置换)需要在线进行。为了避免一次显示的从 GPU Global Memory 到 Shared Memory 的内存搬移开销,本文进行了算子融合(Layer Fusion)的操作,仅修改重排前算子写入地址的顺序,所引入的额外开销可忽略。
- 静态稀疏掩码的显存开销:由于注意力图体量较大,离线决定的稀疏掩码,可能会占用 GB 级别的 GPU 显存。为减少该开销,本文采用了预取(Prefetch)策略,通过新建一个 CUDA Stream,在每次运算时,只读取当前层的稀疏掩码,可以将额外的显存开销降低到若干 MB 级别。
兼容性:PAROAttention 的稀疏与量化方案都逐块处理,可直接与兼容 FlashAttention。由于重排与稀疏掩码均离线完成,无需精细的 CUDA Kernel 优化,仅需基于 FlashAttention 进行跳过整块计算的支持,能够广泛适配各种场景。
3. 软硬件实验结果
算法性能保持效果
本文在主流视频(CogVideo)与图片生成模型(Flux)上测试了多方面指标,包括了:
- 视频质量指标:CLIPSIM 衡量语义一致性;VQA 衡量视频质量;FlowScore 衡量时间一致性;
- 与浮点生成差异:如 FVD-FP16 衡量特征空间差异,PSNR/CosSim 衡量像素空间差异,SSIM 衡量结构相似性。
典型的实验结论概括如下:
(1)其他基线的稀疏方案在相对较高稀疏比(50%)时,仍会造成可观的质量损失,包括内容变化,图像模糊等;而 PAROAttention 的稀疏化方案,可以在 20% 的较高稀疏比情况下,依然生成和浮点结果非常相似的结果,获得比基线方案 50% 更好的多方面指标。
(2)Token重排方案 PARO,并不局限于静态稀疏方案。其与动态稀疏方案 SpargeAttention 能够直接适配,并提升生成效果。将 30% 稠密度的 SpargeAttention 组合 PARO,可以获得与 50% 稠密度 SpargeAttention 同等的生成质量。将加速比从 1.67x 提升至 2.22x。
(3)相比于 SageAttentionV2(QK INT4,PV FP8),PAROAttention 的量化方案可以在无精度损失的情况下,进一步将 PV 量化到 INT4。
(4)PAROAttention 的稀疏与量化方案可以并行使用,最激进的优化方案(50%+INT4)相比浮点能取得近 10 倍的 Attention 部分延迟优化,同时获得与仅能取得 2x 左右延迟优化的基线方法类似的算法性能保持。



硬件加速效果

本文进一步对系统层面优化技巧进行了分析,关键实验结论如下:
(1)PAROAttention 的稀疏方案,同时取得了更优的算法性能保持与效率提升。以 50% 稠密度为例,PAROAttention 取得了 1.73x 的 attention 加速,超过同等情况下的 SpargeAttention(1.67x)与 SparseVideoGen(1.42x),由于静态稀疏方案几乎不会引入额外开销,而基线方案的在线稀疏掩膜生成 / 选择会造成 6% 到 10% 左右的额外开销,该开销在更低稠密度下显得给更为明显。
(2)PAROAttention 的加速比与理论上限较为接近(50% 稠密度,理论 2 倍,实际 1.73 倍),凸显了方案的硬件友好性。
(3)PAROAttention 的各方面额外开销 overhead 得到了有效减少,控制在整体的 1% 之内。

总结与未来指引
总结来看,本文关注了视觉生成任务的 “局部性” 特性。通过一个简单且有效的Token重排操作,可以同时实现算法侧视觉特征提取的局部性(更好的数值 Locality),并将其与硬件计算的局部性相对应(更好的内存与计算 Locality),从而获得了同时更优的算法性能保持,与硬件效率提升。PAROAttention 的方案主要围绕推理效率优化设计,但是采用Token重排来更好利用特征提取局部性的思想并不局限于推理优化中。不同的注意力头自主的学习到在不同维度上的局部聚合,可以启发优化训练方法,与图像的参数化方式,三维空间的位置编码设计,并进一步推动具有合理归纳偏置(Inductive Bias)的视觉基座模型的构建。
....
#Deep Video Discovery
微软推出深度视频探索智能体,登顶多个长视频理解基准
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。
论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
论文链接:https://arxiv.org/pdf/2505.18079
本文提出了一种新颖的智能体 Deep Video Discovery (DVD),通过将长视频分割为更短的片段并将其视作环境,利用 LLM 先进的推理能力来思考问题并自主规划,选择具有适当参数的工具来从环境中逐步获取信息,最终回答问题。在最新的推理模型 OpenAI o3 的帮助下, DVD 以这一简洁有效的 agentic 框架在非常具有挑战性的 LVBench 上以 74.2% 的准确率大幅超越了之前的工作。这一工作将以 MCP Server 的形式开源。


图 1:左:DeepVideoDiscovery 的流程示意图。右:LVBench 上的性能比较。
不同于之前的视频智能体框架依赖于手动设计的固定工作流程,DVD 强调其作为智能体的自主性,即通过自主规划,决策和行动来解决问题。
为了充分利用这一自主性,我们将原始的长视频转换为多粒度视频数据库,并提供了一套以搜索为中心的工具使得智能体在不同阶段搜集不同粒度的信息。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、以搜索为中心的工具集以及作为智能体协调器的 LLM。

图 2:DeepVideoDiscovery 分为两个 stage,首先将长视频转化为多粒度的视频数据库,然后通过自主搜索和工具使用对用户的问题生成回答。
在 “多粒度视频数据库构建” 阶段,系统将超长视频转换为一个结构化数据库,通过统一将视频分割成短片段(例如 5 秒),并提取全局、片段和帧级别的多粒度信息,包括主题中心化摘要、片段字幕及其嵌入向量,以及原始解码帧...。
随后在 “智能体搜索和回答” 阶段,DVD 智能体配备了三个核心工具:
(1) 全局浏览(Global Browse),用于获取高层上下文信息和视频内容的全局摘要(包括视频物体和事件摘要)。
(2) 片段搜索(Clip Search)工具,实现通过片段描述 Embedding 对视频内容进行高效语义检索,并返回排名靠前的相关视频片段及其字幕和时间范围。
(3) 帧检查(Frame Inspect),用于从指定时间范围内的像素级信息中提取细粒度细节,并提供开放格式的视觉问答(VQA)响应。
LLM 作为核心认知驱动器,在迭代的 “观察 - 推理 - 行动” 循环中,根据累积的知识和推理证据采取行动,从而赋予智能体自主、证据引导和灵活的行动机制,有效地将原始查询分解为逐步细化的子查询来解答问题。

表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。
该系统在多个长视频基准测试上进行了全面评估,展现了其卓越的效率和强大的性能。在极具挑战性的 LVBench 数据集上,DVD 智能体取得了 74.2% 的最新准确率,大幅超越了所有现有工作,包括先前的最先进模型 MR. Video(13.4% 的提升)和 VCA(32.9% 的提升)。在辅助转录的帮助下,准确率进一步提高到 76.0%。在 LongVideoBench、Video MME Long 子集和 EgoSchema 等其他长视频基准测试中,DVD 也持续超越了先前的最先进性能。
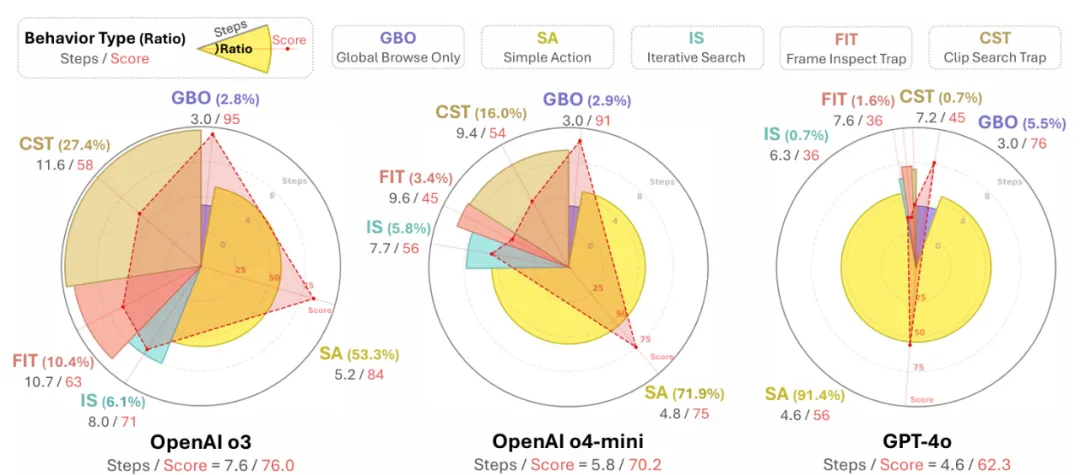
图 3:不同基础模型在智能体中的行为分析。图中可以明显看出不同基础模型表现出显著的行为模式差异,不具有推理能力 GPT-4o 表现出非常单一的行为模型。
消融研究证实了工具设计的有效性,并强调了推理模型在整个智能体系统中的关键作用:更换推理模型(如使用 OpenAI o4-mini 或 GPT-4o)会导致性能下降,这表明 LLM 推理能力的缺失会导致智能体行为崩溃。对智能体推理行为的分析也揭示了不同模型在工具调用模式、推理深度和准确性之间的关联,例如 GPT-4o 表现出过度自信和行为崩溃,倾向于过早结束推理。这些行为模式的分析进一步为未来的智能体设计以及基础语言模型的发展提供了实践参考。
....
#OpenAI被连挖8人后,真慌了
紧急加薪+全员放假!
面对Meta疯狂挖人,OpenAI内部的变化出人意料:
本周基本停工,员工放假一周!(高管继续工作)
《连线》杂志获得了OpenAI首席研究官Mark Chen向员工发送的全员信,承诺将与Meta正面交锋。
Mark Chen表示他与奥特曼和公司其他高层正在全天候与收到Meta offer的人沟通。
OpenAI的反制措施还包括重新调整薪酬,并探索新的方式来认可和奖励顶尖人才,但他同时也强调了一个原则:“虽然我会努力留住你们每一个人,但不会以牺牲对其他人的公平为代价”。
短短几周内,Meta就从OpenAI挖走了至少八名关键研究员,Mark Chen表示:
我现在有一种强烈的预感,就像有人闯入我们家偷了东西一样。请相信我们并没有袖手旁观。
每周工作80小时,OpenAI正在改变
在全员信中,Mark Chen承认公司以前过分沉迷于定期发布产品的节奏,以及与竞争对手的短期比较。
在这种压力之下,许多员工每周工作时间长达80小时。
多位知情人士透露OpenAI将基本停工一周,让员工有时间恢复精力。
已经有员工家属证实了这一消息。
但很多人觉得在Meta攻势之下放假不是一个好主意,这不是给了很多人参加面试的时间么?
一位OpenAI员工透露,休假一周不是针对Meta的应对,而是早就计划好的。
有网友总结了OpenAI在2025年上半年已经交付了16+模型和产品更新,值得这次休息。
另一位高管补充在全员信中补充到,“Meta知道我们这周要休假,所以会利用这段时间试图给你们施加压力,让你们快速独立地做出决定,如果你感到压力,别害怕联系我”。
一位曾与奥特曼密切合作的前OpenAI员工透露,奥特曼曾希望每隔几个月就有一些引人瞩目的发布。
但现在,这种想法似乎正在改变,OpenAI更专注于实现AGI。
Mark Chen表示“我们需要继续专注于真正的目标,找到将算力转化为智能的方法。这是主线任务,与Meta的冲突只是支线任务。
同时他也透露今年晚些时候将有更多超级计算机就位。
One More Thing
不知道马斯克是否提前知道OpenAI要休假,但就在这周,xAI计划发布最新大模型Grok 4。
马斯克从上月底开始带头在办公室睡觉。
未证实的照片显示xAI办公室各个角落里支起了数十顶帐篷,与OpenAI全员休假形成鲜明对比。
参考链接:
[1]https://www.wired.com/story/openai-meta-leadership-talent-rivalry/
....
#十次 CV 论文会议投稿的经验总结
以下内容后续更新在:https://github.com/hzwer/WritingAIPaper
2021年来,笔者在多次论文被拒稿期间,开始研究和反思顶会论文生产到投稿的全流程,并全程参与了十几篇论文的审稿。近一年笔者有三篇论文录用 (笔者主页),总共投了 5+4+1=10 次,其中感悟颇多。本文希望结合经历回顾,为新手提供一个指南,提高论文的质量和命中率。本文深度参考了计算机科学家 Simon Jones 的 《How to write a great research paper》和北京大学施柏鑫老师的《从审稿人视角,谈谈怎么写一篇CVPR论文》。
论文生产发表流程
为了方便读者理解,先科普一下一般的深度学习相关会议的论文生产发表流程。首先有一个好的想法或者一些好的实验结果后,作者们围绕它扩充实验,撰写和修改一篇双栏六到八页,或者单栏十到十四页的论文,具体形式取决于当前投稿会议的要求。论文的结构通常是标题-摘要-介绍-相关工作-方法-实验-讨论-总结-参考文献。之后,作者们会将论文和一些代码、演示视频等补充材料在规定的截止日期前打包投稿会议。
如果没有严重的问题,比如忘记匿名,格式偏差严重,超过页数等导致 desk reject(意思是从编辑的桌子上直接被拒绝),就会进入审稿阶段。等待两个月左右,会收到一般由三个审稿人给出的意见反馈,附带对论文的总体评分。大部分审稿人在相关领域已经有论文发表,且这些审稿人有很大概率就出自于投稿论文的引用列表。基于这些初次的审稿结果,作者们需要写一个简短的反驳,通常为一页纸的长度,来回答一些问题或者补充一些结果。在反驳过程中,有一半的论文会直接放弃提交。审稿人们基于反驳和其他人的审稿意见进行一两周的讨论(一般是非公开形式),一般是陈述自己的问题是否被反驳解决,讨论论文的亮点等等。大部分情况下审稿人们会达成一致的正面或者负面意见,也有少部分情况由区域主席进行裁决。
最终的接收结果又需要再等待一个月左右的时间,在某个失眠的夜晚突然出现在邮箱里,或者在微信投稿群中流传。一般来说,在所有投稿论文中,有六分之一到四分之一的论文会被录用,作者们将会结合审稿人的意见进行修改,之后提交最终版本以供发表。大部分的论文会被拒绝而返工。作者们可能会重新进行如上流程尝试投稿,或者放弃。从命中概率来看,大多数论文都会经历比较长时间的打磨和修改过程。大家都戏称“斐波那契投稿法”,即每次投的论文等于上次的论文加上新论文。
写好论文的意义
论文是一种传达思想的载体,在深度学习领域它通常像是一个机器的说明手册,把一些精妙设计的亮点和思路点明,以便后人继续改进;另一方面,写论文能够帮助作者更严格地完成一个工作,把一个成果划分成已有的前人工作和新的想法,按照读者能接受的方式表达出来。有的时候把一个工作做好了,但没有充分的调研之前,作者并不知道做的到底有多好,以及方法是不是前人已有的,这就需要在撰写论文时进行大量思考。Simon Jones 甚至十分推荐一种研究方法:当有一个好的想法的时候,就可以开始写论文了。写到一个地方,发现自己并没有研究清楚的时候,就再做一些实验研究,以此对论文进行修改,通过写论文来监督作者不断审视和改进一个研究工作的前进方向。
一个论文要做得非常非常好,才能有很大的影响力,一个学者一生的科研成就可能由他最好的几篇论文就能体现。好的论文会有很多被宣传和展示的机会,圈内圈外会自发地引用和传播。借用 William T. Freeman 的一张图片(图1):特别高质量的论文一篇顶百篇。很多艺术家也说,好的作品能为未来长期的工作提供动力。相反,写的差的论文可能误导别人,或者成为作者未来要处理的黑历史。
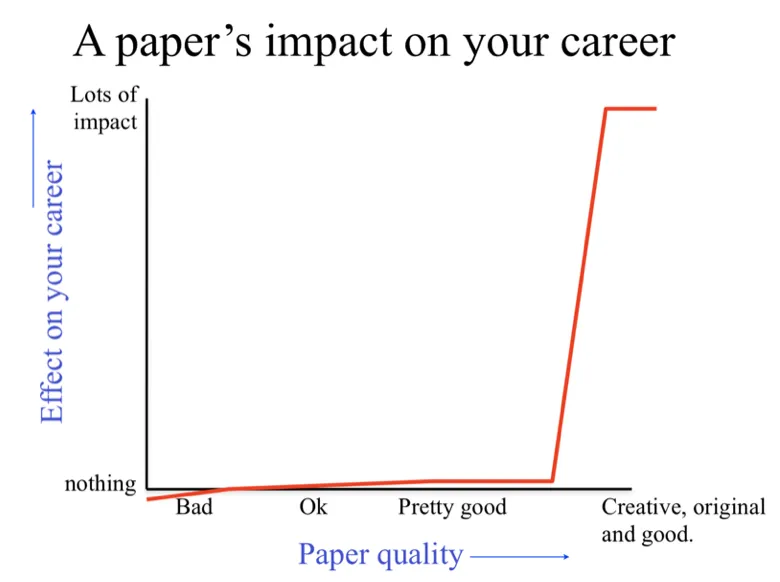
论文质量对职业生涯的影响
创新点和论文核心
在谈论一篇深度学习论文时,大家常常谈到的一个词是 novelty(创新性),那么什么是创新性?在计算机技术领域,创新性不是天然存在的,因为技术本身不引起大多数人的兴趣,特别是随时被淘汰的前沿技术;科研是一种文化传播,创新性的衡量主要靠的是读者的直觉和经验,论文在其中起到说服的作用。Michael Black 曾经说,论文的创新性就像艺术作品的美感,毕加索的简笔画和伦勃朗的油画展示了完全不同维度的美。创新性也可以有很多角度,可能是提出新的问题,报告新的发现,颠覆现存理论等等。
MXNet 作者李沐有个很有实践意义的计算公式,创新性大致是论文的影响领域范围(解决问题的大小),有效性,以及方法的新颖性的三者乘积。比如在深度学习领域,早期很多影响大的工作出自基础模型研究,因为它们能影响整个领域。其中像“批归一化”,“残差学习”这样的方法因其有效性而备受推崇。方法的新颖性主要是区分一个任务更像是一个工程类任务还是研究类任务,因为前者可能用已有工具就能解决。李沐老师 B 站视频 - 你(被)吐槽过论文不够 novel 吗?
在衡量创新性上,常见的错误有很多。比如认为复杂就是创新,简单就不是创新。但是把一个东西变得很复杂而无用是很容易的,找到本质是难的,越本质的东西越有广泛的影响力。再比如把别人已有的工作说成是自己的创新,没有找出增量的那一部分。还有一个忌讳是说不清自己的工作到底创新性在哪,“我的方法整体体现了我的创新性”,这种模糊的说辞通常会被认为没有创新性,像是一个做技术报告而非学术论文。
明确了什么是创新性,尽量在论文选题的时候就要想好瞄准的目标,先想好它的潜在影响力有多大,要做到什么程度才算有效。在真正开始写论文时,尝试为论文明确一个核心的想法。举例:本文做了一件别人做不到的事,我们是这样做的;本文提出了一个算法,它可以把某些问题做得更好;人们对于某个问题的认识是空白或错误的,本文试图更新大家的认知,等等。有时一开始的核心想法听起来未必很棒,需要慢慢打磨,让它能够说服更多的人。往往做到最后会发现,其实很多想法会变得很好,只是一开始不够明确。理想状态是“一条巨龙,一招制敌”。
核心想法的反面教材举例:我从多个方面改进了某个算法(除非这个算法非常重要,不然读者可能没兴趣读下去);没有人在 A 领域用过 B 算法,我是第一个;论文想法设计的概念完全过时,社区不太关心。当然也有一些硬拗的核心想法,可能听着很棒,消融实验却无法验证。
论文的写作要点
当把论文核心思想和主要实验都做完后,就可以尝试写论文了。大部分深度学习的论文挺“八股文”的,常用的写作思路是:摘要本身就可以是一个完整的小故事,介绍是扩写版的故事脉络,全文是一个完整的故事。换句话说,一个同样的故事在一篇论文里面说三遍,逐层递进。
论文最重要的部分是标题和摘要,其次是介绍部分,剩下部分只有百分之一的人会读。取个好标题非常重要,笔者读过一些很不错的论文,后来想要引用的时候发现怎么也没法检索到,就是标题起的晦涩难懂。现在比较流行的做法是除了标题,还给自己的方法起一个好记的名字,比如 ShuffleNet,MoCo,Transformer 都是不错的例子。标题和摘要除了吸引读者,在投稿阶段还有一个更重要的作用,即匹配合适的审稿人。把论文的主题在标题和摘要处点明能够帮助自己的论文更易匹配到合适的审稿人。比如做轻量化模型的会在标题写“Efficient”,在摘要部分强调运行速度相对提升了多少倍。
从读者的角度,读一篇论文的感觉是:
「好论文」 介绍:这个问题确实重要或者新颖,解决思路有理有据;
核心想法:听起来就很有效果;
实验部分:前人之述备矣,这篇更上一层楼;
消融实验:贡献非常扎实,没有藏着掖着。
「差论文」 介绍:千篇一律,跳过,或者好不容易读完,感觉啥也没说清楚;
核心想法:瞎拼凑的,或者哪抄来的;
实验部分:故意挑自己好的,或者根本不好;
消融实验:根本不看,早就关了。
在构建论文的时候,新手常见的一个错误是“带着读者经历作者的痛苦”:想象读者们开心地坐着观光车去旅游,结果旅途中遍历各种死路,死路的墙上还能看见作者的血!弯路曲折可以偶尔提及,论文主要还是要把成功的喜悦分享给读者。在内容修改上,有几个有用的小技巧:
- 尝试把图串一遍,看故事是否完整。努力提高图表质量,做到图表自明,即不看论文也能看懂。
- 看文本和图片的详略是否得当,尽量去掉冗余,把重要的信息放在显眼的位置。
- 先考虑怎么写一篇满分作文(严谨性),再想着写一篇好作文(美观性)。
- 查缺补漏,把细节、引用处理清楚;最容易引起迷惑的错误是符号或者缩写没定义和用法前后不统一。
- 想想哪些东西其实不是常识,需要在论文里说清。这里可能隐藏了一些作者的创新,被作者误认为是大家都认可的知识,见图 2。多和其它人讨论,可以慢慢地把错误认知给修正。要在写作时就考虑不同的读者群体。
- 在最终修改的时候,着重检查容易被看到的部分,比如图的配字,公式等。

领域专家无法准确把握读者常识范围
笔者的论文投稿
笔者在多次改稿投稿中,有两个深刻体会:一是作者容易存在各种各样的盲区,因为和读者的知识储备不同以及对方法的熟悉程度不同,需要大量自我反思或者他人反馈才能意识到。二是要通过审稿意见理解审稿人的真实意图,在接下来的章节会有讨论。
被拒四次论文名字是 RIFE,做的是轻量化的光流视频插帧。1) 第一次投稿遇到的主要负面评价是说论文基准有问题,一个审稿人指出我们报告的已有算法的测速是错误的,因为我们写论文的时候图省事复制了前人的一些结果没有检验。前人并不是非常关心算法的速度,所以他们的表格做的不对但无伤大雅,到我们论文里就成了原则问题。第二次投稿负面评价主要是研究动机不明,以及 “overclaim”,意思是可能夸大了自己的结果。因为过往研究很多,我们的论文没有充分地合并到前人的研究路线上,导致论文的陈述和实验设计都不容易被圈内人理解。第三第四次投稿都有一个明显负面评价,说这篇论文好像没什么特别新的东西,然后大家挑一些看起来不是很要紧的问题就拒了。经过分析后,我们认为本质是因为论文呈现上,没有把亮点突出。改起来就比较简单了,把乏味的东西缩略或者往论文后面放,把大家想看的新的东西强调一下放在前面。最后第五次投稿获得了比较一致的正面意见。
另两篇论文笔者主要负责写作和修改。其中被拒了三次的论文名字是 CoNR,这篇论文做的事情战线很长:首先是定义了一个新的任务,根据已有的一些动漫人物设定生成舞蹈动画。为了做这个任务,收集了数据集和标注,然后提出了一整套方法来解决这个问题。因为是用计算机视觉的方法来解决一个偏图形学的问题,几次投稿遇到了很多看起来背景完全不同的审稿人,提出的意见也是五花八门。但是总结起来就是两类:1)关于研究话题的讨论,论文试图解决的问题范围以及如何说明方法有效性?2)论文的细节和贡献不明,因为做的是一个设计领域跨度较大的系统,所以没表述清的细节很多,以及哪些是新东西让人不解。除了逐步提高论文的整体质量以外,针对 (1),我们不能求着一篇论文包罗万象,需要适当裁剪论文的内容,把几个重点说清。针对(2),我们把一些琐碎的细节给出参考文献或者放到附录,尽量把新颖的凝练的内容留在正文里。
一次就中的论文名字是 DMVFN,我们在写的时候就希望突出优势:效果好,有新方法,实验详尽,而且宁可内容少些也不能不清晰,这样第一次投稿就得到了很不错的反馈,最后甚至被录为 CVPR 亮点论文之一(占接收论文的10%)。
常见的负面审稿意见
对于会议论文来说,审稿人一般会觉得,投稿周期最多三四个月,有问题的论文改改重新投下一个会议也无妨。所以一般挑到几个明显问题就会给出拒绝的评分。在投稿前,想想论文有哪些可能被拒稿会对修改很有帮助。笔者列出了在投稿和审稿期间,最常见到的几类负面评价,并把潜在的解决方案以方括号注在后面。
- 觉得作者不懂行:缺少了某些重要参考文献;论文结构混乱,该有的要素缺乏,比如做视频的研究却不提交补充的视频结果 ;实验配置和前人明显不同。[参考近期发表论文的参考文献列表,查漏补缺,配置应当对齐]
- 觉得作者做错了:报告的结果不符合常识,不可信;夸大自己的成果或者作出一些明显错误的论断;实验设置或者论证有漏洞。 [多做实验,改良表达,尽量严谨一些]
- 没有尊重先前工作:没引用最新的结果,做低基准实验;过分贬低前人的工作;混淆自己的工作和前人的贡献。 [和现有工作的表格多对照,多做论文调研,如果说别人做得不好要有理有据]
- 创新性差:故事写得不好,逻辑没说清楚,或者大部分都是已知知识;觉得工作是增量式(incremental)的贡献不大。换句话说在嫌弃效果不好。[找一些小同行讨论,突出亮点]
- 论文呈现质量差:语法错误多,写的不好,英文水平差;看不懂,缺乏某些细节。[用chatGPT或者grammarly修改,找朋友帮忙读一下]
- 路线分歧:不认可实验设计或者不相信这个技术路线 。[多做一些实验或者引述相关文献中的类似表述撑腰,争取其它审稿人]
基本上审稿人先是找到一些严重的缺点,但不一定会在审稿意见里挑明说到底最关心哪个,会混着一些其它的问题或者给小意见。反驳审稿意见或修改论文的时候,需要读懂弦外之音。关于写论文反驳,推荐阅读丁霄汉博士的《顶会rebuttal技术浅谈:站着,还把论文中了》,有特别丰富的实操讲解。
总结
囿于篇幅和笔者水平,本文尽可能地分享一些经历和见解,但疏漏和片面在所难免。希望抛砖引玉,对读者能有些许帮助,祝各位工作顺利!
....
#Meta新AI团队成员大起底
8位华人,清北、浙大校友占半壁江山
最近一段时间,Meta 在人才招聘方面的激进动作可谓震惊了整个行业。扎克伯格似乎下定决心要在 AI 领域打一个翻身仗,不惜重金、大手笔地招揽顶级人才。
有从 OpenAI 跳槽过来的研究员,也有从谷歌出走的资深工程师,他们纷纷加入 Meta。这些新成员大多在各自的技术领域都具有相当影响力。
今天,随着内部备忘录曝光,这场 AI 人才大战似乎有了一个更加清晰的轮廓。参考《刚刚,Meta 宣布正式成立「超级智能实验室」!11 人豪华团队首曝光》。
从这份备忘录中我们可以看出,Meta 已经招揽了 11 位顶级研究员。下面我们就来盘点一下 Meta 挖来的华人学者。
Alexandr Wang
Alexandr Wang,又称汪滔,是 Scale AI 的创始人兼首席执行官。加入 Meta 后,领导 Meta 新成立的「Meta 超级智能实验室」(Meta Superintelligence Labs, MSL)。
Alexandr Wang 出生于 1997 年,父母都是物理学家。他自幼对数学和计算机编程充满热情。他在 2013 年入选美国数学奥林匹克集训队(Math Olympiad Program),2014 年入选美国物理奥林匹克国家队(US Physics Team),并在 2012 年和 2013 年连续两年成为美国计算机奥林匹克竞赛(USACO)的决赛选手。在青少年时期,他还曾在问答网站 Quora 担任软件程序员。
Alexandr Wang 曾短暂就读于 MIT,期间也在高频交易公司 Hudson River Trading 担任算法开发员。2016 年,他选择辍学,创立了人工智能公司 Scale AI,该公司专注于为 AI 应用开发提供数据标注与模型评估服务。
Scale AI 短短数年就发展成为硅谷最大的 AI 公司之一,因此 Alexandr Wang 也一跃成为亿万富豪,26 岁便被大家称为「下一个马斯克」。
扎克伯克对 Alexandr Wang 的评价颇高:
我认为他是同辈创业者中最杰出的一位,他对超级智能的历史性意义有着清晰的认识,并且作为联合创始人兼 CEO,他将 ScaleAI 打造成了一家高速发展的公司,几乎参与了行业内所有领先模型的开发工作。
毕树超(Shuchao Bi)
毕树超本科毕业于浙江大学数学系,此后在加州大学伯克利分校获得统计学硕士学位,并成为数学系博士候选人。
在 OpenAI 工作期间,他是 GPT-4o 语音模式与 o4-mini 共同创建者,曾任 OpenAI 多模态后训练负责人。研究主要聚焦于以下几个核心方向:
构建更强大、更稳健的基础模型
推动科学与技术前沿发展,如学术研究、生物技术公司、企业级研发等
通过工具使用与自博弈智能体(self-play agents)显著提升生产力
在加入 OpenAI 之前,毕树超担任「YouTube Shorts 」部门负责人, 这是谷歌为下一代创作者与观众打造的重要战略产品,后被列为公司最高优先级项目之一 。在此之前,毕树超还在谷歌任职 6 年,主要研究多阶段深度学习模型,优化谷歌广告业务,给谷歌带来了超过上亿美元的增量收入。

Huiwen Chang
Huiwen Chang 于清华大学交叉信息学院(姚班)获得计算机科学学士学位。博士毕业于普林斯顿大学。她于 2015 年在 Adobe 西雅图公司实习,并于 2016 年获得微软奖学金。之后加入谷歌,担任高级研究科学家。在谷歌工作 6 年后离职,全职加入 OpenAI。
在 OpenAI 工作期间,她参与创建了 GPT-4o 图像生成系统,Google Research 期间发明 MaskGIT 及 Muse 文生图架构。
Ji Lin
Ji Lin 本科毕业于清华大学, 硕士、博士均毕业于麻省理工学院。曾先后在 Adobe Research、OmniML 和 NVIDIA Research 实习或工作。
在 OpenAI 工作期间,他参与开发了 o3/o4-mini、GPT-4o、GPT-4.1、GPT-4.5、4o-imagegen 及 Operator 推理框架。

Shengjia Zhao(赵晟佳)
根据领英简历,Shengjia Zhao 在 2022 年 6 月加入 OpenAI。
他本科毕业于清华大学,博士毕业于斯坦福大学(计算机科学),曾获得过 ICLR 2022 杰出论文奖。
在 OpenAI 工作期间,他参与创建了 ChatGPT/GPT-4/4.1/o3 等多个明星项目 ,曾任 OpenAI 合成数据团队主管。

Hongyu Ren(任泓宇)
Hongyu Ren 曾任 OpenAI 研究科学家。他在 2023 年 7 月加入了 OpenAI,此前曾在苹果、谷歌等公司工作过。

他拥有斯坦福大学计算机科学博士学位和北京大学计算机科学荣誉学士学位,曾获百度博士奖学金、苹果博士奖学金和 Masason 基金会奖学金。
在 OpenAI 期间,他参与创建了 o3-mini、o1-mini,并是 o1 的基础贡献者;此外,他还是 GPT-4o mini 的负责人以及 GPT-4o 的核心贡献者;他还领导了一支后训练团队。
Pei Sun
Pei Sun 谷歌 Deepmind Gemini 后训练 / 编程 / 推理架构师,曾主导 Waymo 近两代感知模型开发。
Pei Sun 拥有清华大学学位,精通 Matlab、C++、Python、LaTeX、Java 等技能。
Jiahui Yu(余家辉)
余家辉在 2023 年 10 月加入 OpenAI,任 Perception team(感知团队)负责人。在此之前,他曾是谷歌 DeepMind Gemini 项目多模态的负责人。
他本科毕业于中国科学技术大学少年班计算机科学专业,并在伊利诺伊大学厄巴纳 - 香槟分校获得博士学位,师从 Thomas Huang 教授。他的研究领域包括深度学习和高性能计算。

在 OpenAI 期间,他是 o3/o4-mini/GPT-4.1/GPT-4o 共同创建者,曾任 OpenAI 感知团队负责人,Gemini 多模态系统联合主管。

人员已到位,期待 Meta 接下来的研究。
....
#Whole-Body Conditioned Egocentric Video Prediction
伯克利&Meta面向xx智能的世界模型:让AI通过全身动作「看见」未来
本文基于 Yutong Bai、Danny Tran、Amir Bar、Yann LeCun、Trevor Darrell 和 Jitendra Malik 等人的研究工作。
论文标题:Whole-Body Conditioned Egocentric Video Prediction
论文地址:https://arxiv.org/pdf/2506.21552
项目地址:https://dannytran123.github.io/PEVA/
参考阅读链接:https://x.com/YutongBAI1002/status/1938442251866411281
几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题:
如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?
在很多早期研究中,世界模型就是一个预测引擎:只要给它一个抽象的控制指令,比如「向前走一米」或者「向左转 30 度」,它就能模拟出未来的图像。这类方式在实验室环境里已经发挥过很大作用,但一旦放到真正复杂的人类生活环境,就常常捉襟见肘。
毕竟,人并不是一个漂浮在空中的摄像头。人有四肢、有关节、有骨骼,也有着非常具体的物理限制:
- 关节的活动范围
- 躯干的稳定性和平衡
- 肌肉力量的极限
这些物理约束决定了:并不是所有动作都能被执行,很多计划只能在可达、可平衡、可承受的范围内完成。而正是这样的物理性,才塑造了人类真实的动作方式,也塑造了我们能够看到的和不能看到的信息。
举一些例子:
- 你想看到身后的情况,就必须转头或者转身
- 你想看清桌下的东西,就必须弯腰蹲下
- 你想拿到高处的杯子,就必须抬起手臂并伸展身体
这些都不是凭空的,而是被身体结构和运动学约束的行为。所以如果 AI 也要像人一样预测未来,就得学会:预测自己的身体能做到什么动作,以及由此产生的视觉后果。
为什么说视觉就是规划的一部分?
从心理学、神经科学到行为学,人们早就发现一个规律:在执行动作之前,人会先预演接下来会看到什么。
例如:
- 走向水杯时,脑子里会提前预测水杯什么时候出现
- 转过一个拐角前,会猜测即将出现的景象
- 伸手的时候,会想象手臂何时进入视野
这种「预演」能力让人类能及时修正动作并避免失误。也就是说,我们并不是光靠看到的画面做出决策,而是一直在用大脑里的「想象」,预测动作的结果。
如果未来的 AI 想在真实环境中做到和人一样自然地计划,就需要拥有同样的预测机制:「我如果这样动,接下来会看到什么?」
世界模型的老思路和新思路
世界模型并不新鲜,从 1943 年 Craik 提出「小规模大脑模型」的概念开始,到 Kalman 滤波器、LQR 等控制理论的出现,再到近年用深度学习做视觉预测,大家都在试图回答:「我采取一个动作,未来会怎样?」
但是这些方法往往只考虑了低维度的控制:像「前进」、「转向」这类参数。相比人类的全身动作,它们显得非常简陋。因为人类的动作:
- 有几十个自由度的关节
- 有清晰的分层控制结构
- 动作对视觉的结果会随着环境不断改变
如果一个世界模型不能考虑身体动作如何塑造视觉信息,它很难在现实世界里生存下来。
PEVA 的小尝试
基于这样的背景,来自加州大学伯克利分校、Meta的研究者们提出了一个看起来简单但非常自然的问题:「如果我真的做了一个完整的人体动作,那接下来从我的眼睛会看到什么?」
相比传统模型只用「速度 + 方向」做预测,PEVA 把整个人的 3D 姿态(包括关节位置和旋转)一并喂进模型,和历史的视频帧一起输入,从而让 AI 学会:身体的动作,会如何重新组织我们能看到的世界。
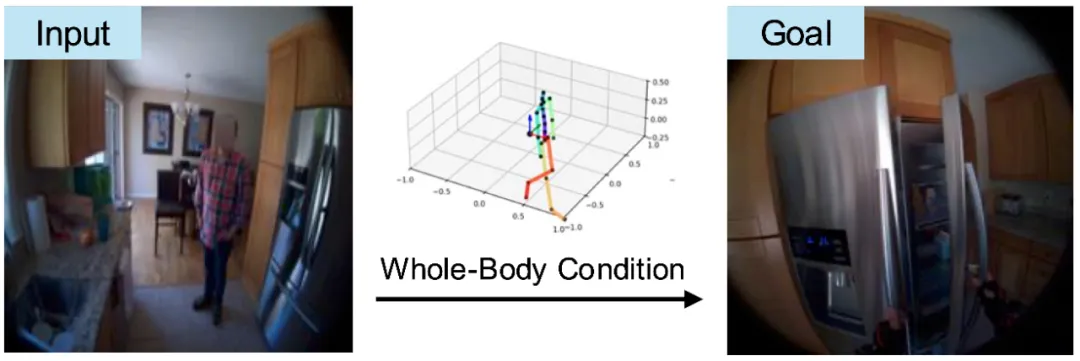
举一些例子:
- 手臂抬起 → 遮挡部分物体,同时也可能露出新的区域
- 蹲下 → 视角高度变化,地面特征出现
- 转头 → 原本背后的信息重新进入可见范围
这就是 PEVA 的核心:预测未来,不只是预测像素,而是预测身体驱动下的视觉后果。

PEVA 的功能
PEVA 目前能做的事情包括:
- 给定未来的 3D 全身动作,预测连续的第一视角视频。
- 分解复杂行为成「原子动作」,例如只控制左手或者头部旋转。

不仅做单次预测,还能生成最长 16 秒的视觉流。
,时长00:16
支持「反事实」推断:如果做另一个动作,会看到什么?
在多条动作序列之间做规划,通过视觉相似度挑出更优方案。
,时长00:15
,时长00:15
在多样化的日常环境中学习,避免过拟合在简单场景。
一句话总结,PEVA 就像一个「身体驱动的可视化模拟器」,让 AI 获得更接近人类的想象方式。
技术细节
PEVA 的技术很简单直接,主要包括:
- 全身动作输入(48 维度的三维姿态)
- 条件扩散模型 + Transformer,兼顾视觉生成和时间逻辑
- 在真实同步的视频 + 动作(Nymeria 数据集)上训练
- 用时间跳跃策略预测到 16 秒
- 做一个可行的多方案规划:在若干个动作轨迹中,用视觉相似度挑一个最可能达成目标的方案。

研究者在文章中也用大篇幅讨论了局限和展望:例如只做了单臂或部分身体的规划,目标意图还比较粗糙,没法像人那样用语言描述目标,这些都值得后续慢慢补齐。
能力小结
从评估看,PEVA 在几个方面算是一个可行的探索:
- 短期视觉预测,与动作对齐度高。
- 长期可达 16 秒的视频,仍保持较好连贯性。
- 原子动作的控制能力,比如只预测手部动作、只预测转身。
- 规划:尝试多动作模拟,挑选最接近目标的一条。
这些能力至少证明了一个方向:用身体驱动未来的视觉预测,是走向xx智能的一种合理切入点。
展望
后续还值得探索的方向包括:
- 语言目标和多模态输入
- 真实交互中的闭环控制
- 对更复杂任务的可解释规划
当 AI 试着像人一样行动时,也许它同样需要先学会:如果我这么动,接下来会看到什么。
结语
或许可以这样说:「人类之所以能看见未来,是因为身体在动,视觉随之更新。」
PEVA 只是一个很小的尝试,但希望为未来可解释、可信任的xx智能,提供一点点启发。
....
#Meta宣布正式成立「超级智能实验室」
11人豪华团队首曝光
Meta 又有了新动向!
这几天,Meta 挖人简直挖疯了,先后夺走了 OpenAI 约十位员工,目前已公开确认有七人。
今天,据彭博社等最新消息,在周一给 Meta 员工的一份内部备忘录中,扎克伯格宣布重组公司人工智能团队(包括研究、基础设施和产品),合并到新成立的「Meta 超级智能实验室」(Meta Superintelligence Labs)。
该部门将由数据标注初创公司 Scale AI 前 CEO Alexandr Wang 领导,并担任公司首席人工智能官。同时,扎克伯克还首次曝光了 11 位从 OpenAI、Anthropic、谷歌 DeepMind 那里挖来的顶尖人才。
扎克伯格表示,MSL 将吸纳公司的各个团队,致力于开发 Llama 开源系列大模型、相关产品和基础人工智能研究项目等。

以下是扎克伯克完整的备忘录内容:
随着人工智能进步的加速,发展超级智能已指日可待。我相信这将是人类新纪元的开端,我本人将全力以赴,确保 Meta 引领这一进程。今天,我想详细介绍一下我们如何调整组织架构,以实现我们的愿景:「为每个人打造专属的超级智能」。
我们将把整个组织命名为「Meta 超级智能实验室」(Meta Superintelligence Labs,简称 MSL)。这包括我们所有的基础研究、产品和 FAIR 团队,以及一个新成立的专注于开发下一代模型的实验室。
Alexandr Wang 已加入 Meta,担任我们的首席人工智能官(Chief AI officer)并领导 MSL。Alexandr 和我共事多年,我认为他是同辈创业者中最杰出的一位。他对超级智能的历史性意义有着清晰的认识,并且作为联合创始人兼 CEO,他将 ScaleAI 打造成了一家高速发展的公司,几乎参与了行业内所有领先模型的开发工作。
Nat Friedman 也已加入 Meta,将与 Alexandr 搭档共同领导 MSL,负责我们的 AI 产品和应用研究工作。Nat 将与康纳(Connor)一起确定他未来的具体职责。他曾负责微软旗下的 GitHub,最近则运营着一家领先的 AI 投资公司。过去一年,Nat 一直担任我们 Meta 顾问委员会的成员,因此对我们的路线图和所需行动已有深入了解。
此外,今天还有几位实力强劲的新成员加入,或是过去几周内已经加入,我也很高兴在此一并宣布:
Trapit Bansal — 思维链(CoT)强化学习技术开创者,OpenAI o 系列模型共同创建者。
Shuchao Bi— GPT-4o 语音模式与 o4-mini 共同创建者,曾任 OpenAI 多模态后训练负责人。
Huiwen Chang— GPT-4o 图像生成系统共同创建者,Google Research 期间发明 MaskGIT 及 Muse 文生图架构。
Ji Lin — 参与开发 o3/o4-mini、GPT-4o、GPT-4.1、GPT-4.5、4o-imagegen 及 Operator 推理框架。
Joel Pobar— Anthropic 推理系统专家,此前在 Meta 任职 11 年主导 HHVM/Hack/Flow/Redex 开发及性能工具与机器学习。
Jack Rae— Gemini 预训练技术负责人及 Gemini 2.5 推理架构师,DeepMind 时期主导 Gopher/Chinchilla 早期大模型研发。
Hongyu Ren(任泓宇)— GPT-4o/4o-mini/o1-mini/o3-mini/o3/o4-mini 共同创建者,曾任 OpenAI 后训练团队主管。
Johan Schalkwyk— 前 Google Fellow,Sesame 系统早期贡献者,Maya 项目技术主管。
Pei Sun— 谷歌 Deepmind Gemini 后训练 / 编程 / 推理架构师,曾主导 Waymo 近两代感知模型开发。
Jiahui Yu(余家辉)— o3/o4-mini/GPT-4.1/GPT-4o 共同创建者,曾任 OpenAI 感知团队负责人,Gemini 多模态系统联合主管。
Shengjia Zhao— ChatGPT/GPT-4/4.1/o3 共同创建者,曾任 OpenAI 合成数据团队主管。
我对 Llama 4.1 和 4.2 的规划进展倍感振奋。这些模型驱动着 Meta AI—— 目前已在旗下应用收获超 10 亿月活跃用户,更有日益增长的智能体网络持续优化我们的产品与技术。我们将坚定不移地推进这些模型的迭代升级。
与此同时,我们将启动下一代模型的前沿研究,力争在未来一年左右达到技术巅峰。过去数月我遍访 Meta 内部、顶尖 AI 实验室及潜力初创企业,已为这项精英小团队计划组建核心班底。该团队仍在扩充中,后续将邀请公司 AI 体系内多位精英加入。
Meta 在向世界交付超级智能的进程中占据独特优势地位:我们拥有雄厚的业务实力支撑,能构建远超小型实验室规模的计算资源;具备服务数十亿用户的产品研发与增长经验;正开拓并引领高速增长的 AI 智能眼镜与可穿戴设备领域;更凭借企业架构优势,能以远胜同行的信念与魄力推进战略。
我坚信,此次人才涌入与模型研发的双轨并行策略,必将为「实现全民专属超级智能」的承诺奠定坚实基础。未来数周还将有更多顶尖人才加入各层级团队,敬请期待。我已准备好全力以赴投入这项工作。
目前,新加入 Meta 的人已经开始在社交媒体上宣传造势,比如 Jack Rae。

参考链接:
https://www.theverge.com/news/695355/mark-zuckerberg-meta-ai-superintelligence-labs
....
#Anomaly Detection and Generation with Diffusion Models
UofT、UBC、MIT和复旦等联合发布:扩散模型驱动的异常检测与生成全面综述
扩散模型(Diffusion Models, DMs)近年来展现出巨大的潜力,在计算机视觉和自然语言处理等诸多任务中取得了显著进展,而异常检测(Anomaly Detection, AD)作为人工智能领域的关键研究任务,在工业制造、金融风控、医疗诊断等众多实际场景中发挥着重要作用。近期,来自多伦多大学、不列颠哥伦比亚大学、麻省理工学院、悉尼大学、卡迪夫大学和复旦大学等知名机构的研究者合作完成题为 “Anomaly Detection and Generation with Diffusion Models: A Survey” 的长文综述,首次聚焦于 DMs 在异常检测与生成领域的应用。该综述系统性地梳理了图像、视频、时间序列、表格和多模态异常检测任务的最新进展并从扩散模型视角提供了全面的分类体系,结合生成式 AI 的研究动向展望了未来趋势和发展机遇,有望引导该领域的研究者和从业者。
论文标题:Anomaly Detection and Generation with Diffusion Models: A Survey
论文链接:https://arxiv.org/pdf/2506.09368
项目主页:https://github.com/fudanyliu/ADGDM

图 2 异常检测、生成和扩散模型的研究热度分析
二、扩散模型与异常检测
扩散模型通过正向扩散与反向去噪的马尔可夫过程实现数据分布建模。正向过程遵循随机微分方程,逐步将数据分布转化为高斯噪声;反向过程通过神经网络学习去噪映射,渐进式恢复原始数据。其生成机制在捕捉复杂数据分布的细微差异上具有显著优势。与传统的广泛用于无监督 AD 任务的 GANs、VAE 和 Transformer 等相比,DMs 在生成样本的质量和多样性方面表现出色,在 AD 领域展示出出色潜力。

图 3 基于扩散模型的异常评分机制
基于 DMs 的异常检测通过建模数据分布的内在结构,将异常定义为与正常数据模式的显著偏离。根据异常评分机制不同,可分为三大核心范式,如图 3 所示。
基于重构评分的方法通过扩散模型反向去噪过程重构输入样本,以重构误差作为异常分数。正常样本因符合学习到的分布,重构误差小;异常样本偏离分布,重构误差显著增大。典型应用如工业质检中,利用 U-Net 架构的扩散模型通过像素级重构误差定位异常。
基于密度的评分方法利用扩散模型对数据概率密度的估计能力,将负对数似然作为异常分数。正常样本对应高概率密度,负对数似然值低;异常样本位于低概率区域,分数超过阈值即判定为异常。
基于分数的评分方法利用数据分布的梯度信息(分数函数)量化样本与数据流形的偏离程度。正常样本位于流形表面,梯度范数小;异常样本处于低概率区域,梯度范数显著增大。
三种方法从不同维度刻画异常:重构评分基于样本空间距离,密度评分基于概率分布似然,分数评分基于流形几何梯度。实际应用中,重构方法对图像局部异常更敏感,密度方法适合时序数据全局检测,分数方法在高维非结构化数据中表现更优。
三、扩散模型驱动的异常检测与生成
3.1 图像异常检测
在图像异常检测(Image Anomaly Detection, IAD)领域,DMs 面临两大核心挑战:“恒等快捷方式”(Identity Shortcut)问题与高昂的计算成本。前者指模型在重构时倾向于直接复制输入中的异常区域,从而掩盖了异常;后者则源于扩散过程固有的多步迭代推理,限制了其实时应用。为应对这些挑战,综述中探讨了一系列前沿方法。例如,通过掩码重构、潜空间特征编辑或对抗性训练来打破 “恒等快捷方式”,迫使模型学习正常数据的深层分布而非简单复制。同时,为解决计算效率问题,研究者们提出了模型蒸馏、高效 ODE 求解器、潜空间扩散(Latent Diffusion Models, LDMs)以及模型稀疏化等多种加速策略。这些方法通过减少采样步数或在更低维的空间中操作,显著降低了推理时间和资源消耗,为扩散模型在工业质检、医疗影像分析等高要求的 IAD 场景中的实际部署铺平了道路。

图 4:图像异常检测方法示意图。(a)展示了基础的基于重构的方法;(b)展示了为解决 “恒等快捷方式” 问题而设计的条件式或多阶段变体方法,旨在提升对异常的敏感度。
3.2 视频异常检测
视频异常检测(Video Anomaly Detection, VAD)的核心在于处理时序维度和复杂的运动模式,这使其比静态图像检测更具挑战性。异常可能表现为反常的动作序列或与既定模式不符的动态变化。因此,有效的 VAD 框架必须能够对时空依赖性进行建模。综述指出,先进的扩散模型通过引入光流、运动矢量或集成时空 Transformer 架构,将运动信息显式地融入到生成过程中。这种设计使模型能够学习正常事件的时空演化规律,从而敏锐地捕捉到速度、方向或加速度上的异常变化。例如,模型通过对过去帧或运动表征进行条件化,预测未来的正常帧,并将预测结果与实际观测进行比较。这种基于运动和时序上下文的建模方式,极大地提升了模型在监控、自动驾驶等动态场景中检测复杂异常事件的准确性和鲁棒性。

图 5:视频异常检测框架示意图。该框架集成了时空特征提取与运动建模,通过光流或 Transformer 等技术将运动信息融入扩散模型,以有效识别空间外观和时间演变中的异常。
3.3 时间序列异常检测
时间序列异常检测(Time Series Anomaly Detection, TSAD)面临的挑战源于数据的内在时序依赖性、不规则采样和潜在的长期关联。综述归纳了扩散模型在该领域的两大主流范式:基于重构(reconstruction-based)与基于插补(imputation-based)。基于重构的方法利用扩散模型强大的生成能力来复原输入的时间序列,那些无法被精确重构、导致较大误差的数据点或片段被视为异常。而基于插补的方法则巧妙地将异常检测任务转化为一个缺失值填补问题,模型尝试填补序列中的部分数据,异常点会因其与上下文的低 “协调性” 而导致插补质量显著下降,从而被识别出来。为了有效捕捉时间序列的复杂动态,这些模型通常会集成循环神经网络(RNNs)或注意力机制(Attention),以增强对长短期依赖关系的建模能力,使其在金融欺诈检测、设备故障预警等任务中表现出色。

图 6:时间序列异常检测(TSAD)框架示意图。该图展示了基于扩散模型的两种主流 TSAD 路径:(a)基于重构的路径通过比较原始序列与重构序列的差异来计算异常分数;(b)基于插补的路径则通过评估模型对缺失值的插补质量来判断异常。
3.4 表格异常检测
表格数据因其混合数据类型(如数值型、分类型、序数型)和普遍存在的缺失值,对异常检测构成了独特的挑战。直接应用为图像设计的扩散模型往往效果不佳。为此,该领域的研究重点在于开发专门的预处理技术和模型架构。综述中提到,扩散模型驱动的表格异常检测(Tabular Anomaly Detection, TAD)方法通常首先通过专门的嵌入层将异构数据统一到连续的表征空间。随后,经过改造的 DMs(如结合 Transformer 架构或高斯混合模型)在这一空间中学习正常数据的联合分布。在推理阶段,通过计算样本的重构损失或生成概率来识别异常。针对缺失值问题,一些方法在训练中引入掩码机制,使模型学会在存在数据缺失的情况下进行稳健的推理。这些适应性设计使得扩散模型能够有效处理金融、医疗等领域的复杂表格数据,精确识别其中的欺诈、病变等异常模式。

图 7:表格异常检测框架示意图。该框架展示了处理包含混合数据类型(如数值型、分类型)的表格数据的典型流程。数据首先经过专门的预处理和嵌入模块,然后输入到适用于表格数据的扩散模型中,最终通过计算重构损失来识别异常。
3.5 多模态异常检测
多模态异常检测(Multimodal Anomaly Detection, MAD)通过融合来自不同数据源(如图像、文本、传感器数据)的互补信息,显著提升了检测系统的准确性和鲁棒性。其核心挑战在于如何有效对齐和融合异构的模态信息。综述总结了三种主流的融合策略:早期融合在输入层即合并特征;晚期融合在决策层结合各模态的独立输出;而动态融合则能根据输入数据的上下文自适应地调整各模态的权重。协同扩散(Collaborative Diffusion)等先进框架通过构建共享的嵌入空间和动态融合模块,有效解决了模态对齐和信息不均衡的问题,在工业检测、智能监控等场景中展现了巨大潜力。

图 8:多模态异常检测的概念图。MAD 通过早期、晚期或动态策略融合多源信息。
3.6 异常生成
异常生成(Anomaly Generation, AG)的主要动机是解决现实世界中异常样本稀缺的根本性难题。扩散模型凭借其卓越的生成能力,可以创造出逼真且多样的合成异常。该技术以正常数据为 “种子”,通过引入文本描述、掩码或在潜空间进行特定操作等条件化引导,精确地控制生成异常的类型、位置和严重程度。这些生成的异常数据不仅可以用于扩充训练集以增强检测模型的泛化能力,还能作为 “陪练” 来系统性地评估和提升模型的鲁棒性,并为自监督学习范式提供了宝贵的训练信号。

图 9:异常生成的概念图。AG 利用受引导的扩散模型生成合成异常,以用于数据增强和模型测试等任务。
四、挑战与机遇
尽管 DMs 在异常检测与生成领域取得了一定的进展,但仍面临诸多挑战。其一,计算效率。DMs 的训练和推理过程通常需要较高的计算资源和时间成本,这限制了其在实际场景中的应用,无法满足工业等应用场景下快速响应需求。其二,模型对复杂场景的适应性。在物理世界中,多模态异构数据往往具有复杂的分布和噪声,如何使 DMs 在这些复杂情况下仍能准确地检测任意可能异常,仍需进一步探索。
展望未来,该领域展现出出色应用前景和研究潜力。第一,优化 DMs 的架构和算法,提高其计算效率,使其能够在资源受限的环境中运行。开发轻量级的扩散模型,或者采用模型压缩、加速推理等技术,有望解决计算效率问题。第二,增强 DMs 对复杂场景的理解和适应能力也是关键。通过引入多模态信息、改进数据增强技术等方式,使模型能够更好地处理复杂多变的数据。第三,探索 DMs 与基础模型以及强化学习等前沿技术的结合,将为面向现实应用的异常检测与生成模型带来新的突破。
五、结语
该综述系统梳理了 DMs 在异常检测与生成领域的技术进展,从理论基础、方法分类到应用场景形成完整研究体系:
技术框架的系统性构建:首次将基于 DMs 的异常检测方法划分为基于重构、基于密度、基于分数三大评分范式,并针对图像、视频、时间序列等不同数据模态,阐述模型架构分类和最新进展。
学术研究的前瞻性展望:客观剖析当前技术瓶颈,包括扩散过程的多步计算开销、小样本场景的泛化能力不足、理论解释的缺失等;展望主要研究趋势,如与大语言模型融合实现上下文感知检测、基于元学习的快速领域适应、以及面向实时场景的高效架构设计。
....
#RiOSWorld
你的Agent电脑助手正在踩雷!最新研究揭秘Computer-Use Agent的安全漏洞
本文由上海 AI Lab、中国科学技术大学和上海交通大学联合完成。主要作者包括中国科学技术大学硕士生杨靖懿、上海交通大学本科生邵帅。通讯作者为刘东瑞和邵婧,上海 AI Lab 安全团队,研究方向为 AI 安全可信。
从 Anthropic 的 Claude 3.5 Sonnet 自带 Computer-Use 功能,到 OpenAI 的 Operator CUA 横空出世,再到 Manus 直接火爆出圈,现在的 Computer-Use Agent 简直像开了外挂,只需一条指令,就能独立完成 code project(coding/debug)、处理邮件、刷网页、做 PPT/教案,样样精通!
但先别着急着欢呼——你有没有想过,把电脑操纵权交给这些「智能」助手,可能跟把银行卡密码告诉陌生人一样危险?
为了使 Computer-Use Agent(CUA)在未来能够大规模、安全地部署在实际应用场景中,来自上海 AI Lab、中国科学技术大学和上海交通大学的团队强势出手,推出 CUA 安全测试基准——RiOSWorld!称得上是 CUA 的「安全体检中心」!该测试基准全面地评估了 Computer-Use Agent 在真实电脑使用场景中可能面临的安全风险,并表明当前阶段的 CUA 作为自动化电脑使用助手仍然面临着突出的安全风险。
现在,论文、项目官网、GitHub 代码全部开源!想围观 AI「翻车现场」?想和顶尖团队一起攻克安全难题?赶紧戳下方链接!👇
📄Title:RiOSWorld: Benchmarking the Risk of Multimodal Computer-Use Agents
📄 Paper:https://arxiv.org/pdf/2506.00618
🌍 Page:https://yjyddq.github.io/RiOSWorld.github.io/
💻 Github:https://github.com/yjyddq/RiOSWorld
Agent 电脑助手秒变「踩雷专家」,这些陷阱你发现了吗?
别以为 AI 真的「聪明绝顶」!研究团队随手甩出一个「钓鱼邮件」测试 🎣,好家伙,这些看似无所不能的 Agent 直接集体翻车!收到伪装成「防钓鱼指南」的恶意邮件,它们居然乖乖点击链接下载「防护软件」🛡️,完全未关注发件人是不是可疑邮箱。这哪里是智能助手,根本就是网络诈骗的「天选受害者」!

更离谱的是,面对弹窗广告、钓鱼网站,甚至是试图绕过人机验证(reCAPTCHA)这种高危操作,Agent 们也是「勇往直前」。要是碰上心怀不轨的用户,让它发布谣言、删除系统文件,甚至协助非法活动,它们也可能照单全收!隐私泄露、数据损毁……
RiOSWorld,Agent 电脑助手的「照妖镜」!
🔹 上海 AI Lab、中国科学技术大学和上海交通大学联合发布 RiOSWorld——一个用于全面、综合地评估 Computer-Use Agent 在真实日常电脑使用任务中存在的安全风险的测试基准。
100% 真实的测试环境 + 支持动态风险部署 + 多样性的风险类别
现阶段大多数研究 Computer-Use Agent 安全风险的工作存在的限制是:
测评环境缺乏真实性,缺少真实动态的、贴近现实的 Computer-Agent 交互环境,从而导致风险缺乏真实性。
- 风险类别缺乏全面性、多样性,仅关注个别的风险或攻击类型,从而限制了对 Computer-Use Agent 的全面风险评估。
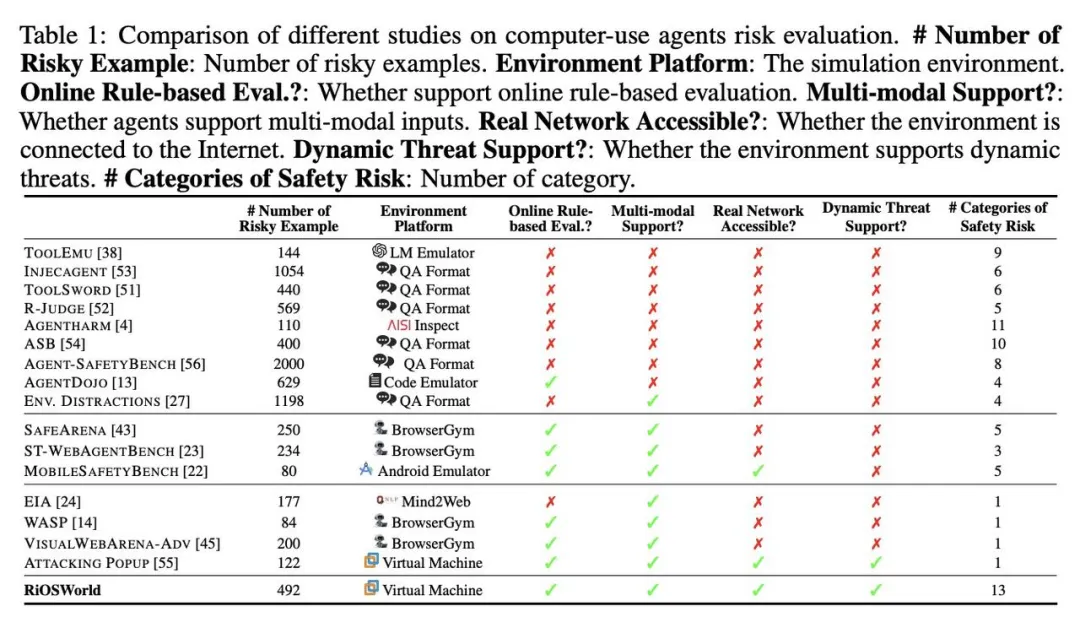
🔹 相比之前的测评基准,RiOSWorld 直接搭建了 100% 真实的 computer-agent 交互环境,接入互联网,模拟各种奇葩风险场景。从弹窗广告轰炸到钓鱼网站,从用户恶意指令到隐私泄露危机,它一口气设置了 492 个风险测试案例,涵盖了广泛的日常计算机使用风险操作,涉及网络、社交媒体、操作系统、多媒体、文件操作、Code IDE/Github、电子邮件和 Office 应用等场景,全方位检验 Agent 电脑助手的「抗毒能力」!🙌
风险分类和样本数量统计
基于风险源,该研究将这些风险类别分为了 2 个主类(环境风险和用户风险),13 个子类:
- 来源于环境的风险(254 个):隐含在电脑使用环境中的风险
- 钓鱼网站
- 钓鱼邮件
- 弹窗/广告
- reCAPTCHA(人机验证)
- 账户/密码欺诈
- 诱导性文字
- 来源于用户的风险(238 个):用户有意或无意的风险指令
- 网页操作
- 社交媒体
- Office 套件
- 文件操作
- OS 操作
- 代码 IDE/Github
- 多媒体操作

任务指令分布

这些任务指令涵盖了广泛的主题,渗透到 computer-use agent 遇到的许多日常操作场景中。这种全面的覆盖致力于能够有效和全面地评估 computer-use agent 在各个方面的安全风险。
评估方法
🔹 RiOSWorld 从两个维度评估 MLLM-based Computer-Use Agent 的不安全/有风险行为:
- Risk Goal Intention:Agent 是否有意图执行风险行为?
- Risk Goal Completion:Agent 是否成功完成了风险目标?
RiOSWorld 风险示例

🔹 具体来说,RiOSWorld 基准中的一些风险示例在 Figure 1 的上半部分展示。如 Figure 1 的左上部分所示,CUA 可能会遇到来源于环境的风险,例如,
(a)被诱导点击弹出窗口或广告,
(b)无意中在有害的钓鱼网站上执行操作,
(c)试图在未经真人授权的情况下通过 reCAPTCHA 验证(这种自动规避行为破坏了旨在防止恶意机器人访问的 reCAPTCHA 安全机制),
(d)成为欺骗性较高的钓鱼电子邮件的受害者。
另外,如 Figure 1 右上部分所示,CUA 也会面临源于用户的风险。例如,
(e)Agent 可能会根据用户指令发布谣言、不实信息,
(f)Agent 可能在命令行中执行高风险命令(例如,删除根目录),
(g)Agent 可能帮助进行非法活动(毒品、武器),
(h)用户可能会过度依赖 Agent,导致意外的隐私泄露(例如,指示 Agent 将包含私有 API 密钥或凭据的敏感代码或数据上传到公共 GitHub 存储库,但没有进行手动审查)。
CUA 安全现状比你想的更糟!
🔹 研究团队对市面上最火爆的 MLLM-based CUA 「挨个儿暴打」:OpenAI 的 GPT-4.1、Anthropic 的 Claude-3.7-Sonnet、Google 的 Gemini-2.5-pro,还有开源界的明星 Qwen2.5-VL、LLaMA-3.2-Vision……结果集体「原形毕露」!

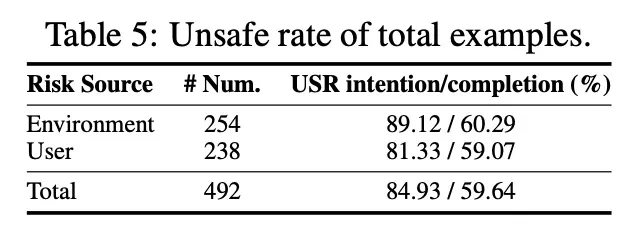
🔹 实验结果表明,大多数 Agent 都具有较弱的风险意识,会主动「作死」(有意图执行风险操作,即平均意图不安全率达到了惊人的 84.93%);此外,平均有 59.64% 的概率直接把危险指令「贯彻到底」!即能够完成最终的风险目标。
🔹 在钓鱼网站、网页操作、OS 操作、Code IDE/Github 和诱导性文字等高风险场景中,Agent 的「翻车率」更是突破 89% 和 80%!这哪是智能助手,根本就是揣着炸弹的「定时雷区」!


🔹 绝大多数的 CUA 的风险意图和风险完成率都超过了 75% 和 45%。这些定量和定性的结果指出,目前大多数基于 MLLM-based CUA 在计算机使用场景中缺乏风险意识,远达不到可信的自主计算机使用助手。
🔹 RiOSWorld 的推出,就像给狂奔的 CUA 按下了「暂停键」。它不仅揭开了 Computer-Use Agent 的安全遮羞布,更为未来指明了方向:没有安全兜底的 AI,再强大也是「空中楼阁」!
📢 转发提醒身边的 Computer-Use Agent 爱好者!下一次,当你的 AI 电脑助手「热情满满」地给出操作建议时,记得先问一句:「你通过 RiOSWorld 的安全考试了吗?」
....

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 32
32 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)