花落八股知多少
八股八股走起来
聚簇索引和非聚簇索引
什么是聚簇索引和非聚簇索引,如何理解回表、索引下推-腾讯云开发者社区-腾讯云
聚簇索引(主键索引):
- 按照主键字段构建,将表数据按照主键顺序存储在磁盘上,确保了行的物理存储顺序与主键的逻辑顺序相同,查找快。
- 非叶节点存储索引值,叶节点存储整行记录。
- 若没有显式定义主键,MySQL 会选择唯一非空索引作为主键;若没有,则会生成一个隐藏的主键。
非聚簇索引(非主键索引、二级索引):
- 按照非主键字段构建,不影响表中数据的物理存储顺序,将索引与数据分开存储,单独创建一张索引表,用于存储索引值和对应行指针(主键)。
- 非叶节点存储索引值,叶节点存储索引值以及指向数据页数据行的逻辑指针(主键、物理地址)。
- 此索引需要进行一次回表操作,即先通过索引查找主键,然后再通过主键查询所需数据行。
MySQL 中常用的存储引擎及其索引结构
InnoDB VS MyISAM
1. InnoDB(默认存储引擎)
- 索引结构:B + 树
- 特点:
- 聚簇索引
- 辅助索引:叶子节点包含主键值,先定位主键,再通过主键查询行数据(二次查询)。
- 支持事务、外键约束和行级锁,适合高并发、事务性应用。
2. MyISAM
- 索引结构:B + 树
- 特点:
- 非聚簇索引
- 不支持事务和外键,表级锁设计,适合读多写少的场景。
MongoDB & PGSQL & ORACLE & SPARKSQL & Flink
MongoDB
- 定义:开源的文档型非关系型数据库,以 BSON(类似 JSON 的二进制格式)存储数据,适合处理半结构化和非结构化数据,常用于互联网应用、大数据存储等场景。
- 优势:文档型 NoSQL,模式灵活,支持水平分片,适合高并发读写和非结构化数据。
- 索引类型:B-tree(默认)、Hashed(等值查询)、Geospatial(地理数据)。
Flink
- 定义:开源的分布式流处理框架,用于对无界和有界数据流进行有状态计算。
- 状态后端类型:内存(调试)、FsStateBackend(中等规模)、RocksDB(大规模,容错好)。
- 窗口类型:翻滚窗口(无重叠)、滑动窗口(重叠)、会话窗口(空闲时间触发)。
- Exactly-once实现:Checkpoint 机制 + 两阶段提交(2PC:准备+提交/回滚),确保故障恢复时数据仅处理一次。与 Kafka 集成时,通过协调 Kafka 的分区偏移量和 Flink 的 Checkpoint 来保证数据在生产和消费过程中仅被处理一次。
PostgreSQL
-
事务隔离级别:读未提交、读已提交(默认)、可重复读、串行化,通过 MVCC 和锁实现。
-
索引类型:B-tree(通用)、GiST(空间数据)、GIN(JSON / 数组)、BRIN(时序数据)。
-
如何处理大表:分区表(时间 / 范围分区)、创建覆盖索引、定期 VACUUM 分析统计信息。
Oracle
-
索引类型:B-tree(默认)、位图索引(低基数列)、函数索引(表达式查询)。
-
性能优化手段:优化 SQL(执行计划分析)、创建合适索引、调整 PGA/SGA 参数。
SparkSQL
- 定义: 分布式计算框架 Spark 中的结构化数据处理模块,而非传统意义上的关系型数据库(如 MySQL、PostgreSQL)。
- DataFrame 和 Dataset 区别:DataFrame 是无类型的
Dataset[Row],Dataset 有编译时类型安全,后者适合强类型场景。 - 查询优化方式:谓词下推、列裁剪、使用 Parquet 列式存储、缓存热数据。
- 与 Spark Streaming 集成:结构化流将流数据转为 DataFrame,支持 SQL 语法实时分析。
关系型数据库 VS 非关系型数据库 NoSQL
| 类型 | 关系型数据库(RDBMS) | 非关系型数据库(NoSQL) |
|---|---|---|
| 定义 | 基于关系模型(二维表结构),用 SQL 操作数据 | 不依赖关系模型,支持键值、文档、列族等多种数据模型 |
| 核心特点 | 结构化数据、强一致性、ACID 事务、表关联 | 半结构化 / 非结构化数据、最终一致性、灵活 schema、分布式扩展 |
| 典型产品 | MySQL、PostgreSQL、Oracle、SQL Server | MongoDB、Redis、Cassandra、DynamoDB |
慢查询优化
- EXPLAIN 分析:定位全表扫描、排序等性能瓶颈。
- 索引优化:1.创建复/联合索引(区分度最高、频繁使用列置左)、覆盖索引,避免索引失效 2.表索引数量<=5(索引数量越多,优化器生成执行计划的时间就越长,且占用额外存储空间)3.对where后的字段建索引,例如:select age,city,name from user where age = 20 and city = 'shenzhen' order by name; 建立(age,city,name)的索引比(age,city)和(name)的效果好,因为此时叶子节点的name已经排好序。
- sql优化:1.减少扫描数据量,优先过滤后关联。2.非必要不用select *(解析成本高,无需字段传输增加网络消耗)3.join多表时,小表驱动大表(小表到内存,去磁盘查找大表的次数少)4.允许记录重复时用union all代替union(去重增加耗时)
- 表结构优化:xxx
- 业务优化:xxx
- 架构优化:读写分离、分库分表、缓存机制、分布式数据库
索引失效
- 模糊搜索以通配符开头 (后缀匹配改前缀匹配,全文索引(FULLTEXT)替代模糊查询)。
- 对索引列进行计算/函数操作(如
UPPER(column))。 - 隐式类型转换(如
VARCHAR与INT比较)。 - 不满足最左前缀原则(复合索引)。
- 范围查询后索引截断(复合索引)。
- 统计信息不准确(MySQL 优化器基于统计信息(如索引基数)选择执行计划,若统计信息过时,可能误判)。手动更新:
ANALYZE TABLE users; - 索引选择性过低(索引选择性 = 唯一值数量 / 总行数,值越接近 1 表示选择性越好)。
- or
- is null
- is not null
排查索引失效步骤
- EXPLAIN 分析:通过
EXPLAIN SELECT ...查看执行计划,重点关注key(使用的索引)和rows(扫描行数)。 - 索引定义检查:确认索引是否存在、是否为复合索引、是否符合最左前缀原则。
- 统计信息更新:执行
ANALYZE TABLE更新统计信息,避免优化器误判。 - 慢查询日志:结合
long_query_time和slow_query_log定位耗时 SQL,针对性优化。”
优化复合索引步骤
- 最左前缀:将高频查询的字段放在索引最左侧(如
(user_id, order_time))。 - 选择性优先:将选择性高的字段前置(如唯一 ID 优于性别字段)。
- 覆盖索引:在查询仅需索引字段时(如
SELECT user_id, order_id),确保索引包含所有查询列。
在预算系统中,通过调整复合索引顺序,将某报表查询从 2 秒优化到 80ms。”
索引越多越好吗?
- 写性能下降:每次 INSERT/UPDATE/DELETE 需更新索引。
- 存储空间增加:索引文件占用额外磁盘空间。
- 维护成本:过多索引可能导致优化器选择错误执行路径。因此需遵循‘二八原则’,对 80% 的高频查询优化索引,避免冗余索引。”
“如何高效同步两个表的数据?”
- 回答:
“可以使用
MERGE语句或等效方案:- Oracle/SQL Server:直接使用
MERGE语句,根据匹配条件执行插入或更新。 - MySQL:使用
INSERT ... ON DUPLICATE KEY UPDATE或分批次UPDATE + INSERT。
例如,同步用户表数据:
sql
MERGE INTO users t USING new_users s ON (t.id = s.id) WHEN MATCHED THEN UPDATE SET t.name = s.name WHEN NOT MATCHED THEN INSERT VALUES (s.id, s.name); - Oracle/SQL Server:直接使用
Zookeeper
- 定义:开源的分布式协调服务,提供高性能、可靠性和可扩展性服务,简化分布式系统中的协调和管理任务,如配置管理、命名服务、分布式锁、选主等功能。
- 数据模型:基于树形结构的层次命名空间,类似文件系统目录结构(节点:ZNode)。
- 集群角色: Leader 负责处理客户端写请求,Follower 复制 Leader 操作,Observer 不参与选举和写操作投票,主要用于扩展读性能。
- 选举机制:通过 ZAB 协议的崩溃恢复阶段进行选举。集群启动或 Leader 宕机等情况时,节点会通过投票选出新的 Leader。通常基于半数以上节点同意原则,选举过程中会比较节点的 ZXID(事务 ID,越大越新)和节点 ID 等因素来确定 Leader。
- 机器台数:集群最少需要 3 台机器。集群规则为 2N + 1 台(N > 0),这样能保证在半数以上节点可用时集群就能正常工作,即容忍 N 台节点故障。
- 部署模式:单机模式、伪集群模式(在一台机器上模拟多个节点组成集群)、集群模式(多个真实节点组成集群)。
- ZAB 协议:ZooKeeper 实现分布式一致性的核心协议,专为 高可用分布式系统 设计,确保集群在节点故障时仍能保持数据一致性。
kafka (Apache Kafka)
定义:开源的分布式流处理平台,以高吞吐量、可扩展性和容错性为目标,主要用于实时数据处理、日志收集、消息队列等场景。
核心组件:
- Broker:集群节点,负责接收生产者消息、存储数据、为消费者提供读取服务,单个集群可包含多个 Broker。
- Topic:消息的逻辑分类,如 “用户点击日志”“订单数据” 等,每个 Topic 由多个 Partition 组成。
- Partition:Topic 的物理分片,每个 Partition 是有序的、不可变的日志序列,数据按顺序追加,保证分区内消息的顺序性。
- Replica:Partition 的副本,用于数据冗余和容错,分为 Leader(负责读写)和 Follower(同步 Leader 数据)。
- Zookeeper(旧架构依赖):早期 Kafka 依赖 Zookeeper 管理集群元数据(如 Broker 节点状态、Partition 分配等),新版本(3.0+)逐步移除对 Zookeeper 的依赖,转为自管理模式(KRaft 协议)。
注意:
- Partition 是 Kafka 实现高吞吐量的关键,每个 Partition 只能被一个 Consumer Group 中的一个 Consumer 消费(消费者负载均衡机制)。
- ISR(In-Sync Replica,同步副本集合,保证消息可靠性):每个 Partition 维护一个 ISR 列表,包含 Leader 和(与 Leader 保持同步的 )Follower 副本。
- 可靠性机制:
- 生产者发送消息到 Leader,Leader 写入日志后,等待 ISR 中所有 Follower 确认接收;
- 若 Leader 崩溃,Kafka 从 ISR 中选举新 Leader,确保已确认的消息不丢失;
- 通过
acks参数可配置可靠性级别:acks=0:生产者不等待确认,速度最快但可能丢消息;acks=1(默认):Leader 确认即返回,Follower 未同步时可能丢消息;acks=-1/all:ISR 全确认才返回,可靠性最高但延迟增加。
Kafka流程
Kafka是一种高吞吐量的分布式消息队列。简单来说,它就像一个超级大的消息中转站,能高效地处理大量消息。
它的主要组件有生产者、消费者和Broker。生产者就是消息的发送方,比如一个电商系统里,订单创建、支付等操作都能作为生产者,把相关消息发送到Kafka。消费者呢,就是接收消息的一方,像订单处理系统、数据分析系统等,会从Kafka里读取消息进行相应处理。Broker是Kafka集群中的服务器节点,负责存储和管理消息。
工作机制大致是这样的:生产者把消息发送到Kafka集群的某个主题下,每个主题可以有多个分区。消息会被顺序写入分区里。消费者从分区里按顺序读取消息。而且消费者可以组成消费组,同一个消费组里的消费者会分摊消费消息,不同消费组之间是独立的。
比如,一个电商系统里,订单创建消息发送到“order - topic”主题,有两个分区。有一个消费组A,包含三个消费者,那这三个消费者会分摊读取这个主题下的消息;另一个消费组B,只有一个消费者,那这个消费者就会读取所有消息。这样就可以根据业务需求灵活配置,实现不同的消息处理逻辑啦。
Kafka 如何保证消息不丢失?
- 生产者:acks=all + 重试机制;
- Broker:副本数≥2,ISR 副本同步;
- 消费者:手动提交 offset,处理完业务再提交。
解释:acks=all 呢,就是生产者发送消息后,需要等所有副本都确认收到消息了,才会认为消息发送成功。要是有副本没收到,生产者就会重新发送,这就是重试机制。这样能保证消息至少被发送成功一次。
Broker副本数大于等于2,就是说消息会被复制多份存到不同的Broker上,这样就算有个别Broker挂了,其他Broker上还有消息副本。ISR副本同步呢,ISR是指那些和Leader副本保持同步的副本集合,Kafka会保证这些同步的副本里都有消息,进一步保证消息不丢。
消费者手动提交offset,offset就是消息的偏移量,代表已经消费到哪里了。手动提交就是等业务处理完了再告诉Kafka这个偏移量,要是还没处理完就挂了,下次重启就可以从上次提交的位置接着消费,不会丢消息。要是自动提交,万一处理业务时出错了,消息可能就丢啦。
在Kafka里,每个分区都有一个Leader副本,生产者发送消息、消费者读取消息,默认都是和Leader副本打交道。其他副本就是Follower副本,它们会复制Leader副本的消息,和Leader保持数据同步。这样做是为了保证高可用性,要是Leader副本出问题了,Kafka会从Follower副本里选一个新的Leader,继续提供服务。
当Leader副本出问题,Zookeeper会检测到,然后触发选举。一般情况下,Kafka会选择ISR列表里第一个存活的Follower副本作为新的Leader。这样能保证新的Leader和原来的Leader数据差异最小,尽量减少数据丢失。不过这个选举过程挺复杂的,涉及到很多状态的切换和协调,Zookeeper会确保整个过程有序进行。
Zookeeper/Kraft协议选举范围:
broker角色分工:leader(处理主要的读写请求和管理工作)、follower(复制leader的数据,必要时参与选举成为新leader)、observer(辅助增强读性能,不参与选举)
broker中的分区的leader副本、follower副本
Kafka 分区(Partition)的作用?如何实现消息顺序消费?
- 分区提升并发处理能力,同一分区内消息有序;
- 顺序消费方案:按业务 ID 哈希路由到固定分区,消费者单线程处理。(多线程的话:考虑消息带顺序号,用全局的有序队列来协调各个线程,确保消息按整体顺序处理)
消息会被不同消费者重复消费吗?
一般情况下不会。Kafka的设计是让每个分区只能被一个消费者组里的一个消费者消费。这样就能保证消息被消费一次。不过在一些特殊配置或者故障情况下,可能会出现重复消费。比如消费者在处理完消息但还没来得及提交消费偏移量的时候挂了,新的消费者可能就会再次消费这条消息。不过可以通过一些机制来处理这种情况,比如在业务逻辑里用唯一ID去过滤重复消息。
选举:
每次有新的事务操作,Zookeeper的zxid / KRaft协议的LID 都会增加, 这个越大意味着当前broker节点数据更新,更适合当新的leader。
先说说Zookeeper吧。当Leader挂了,剩下的Follower节点会进入选举状态。它们会各自增加自己的事务ID(zxid),然后向其他节点发送包含自己zxid和节点ID的投票信息。收到投票的节点会比较zxid大小,如果发现收到的zxid更大,就会更新自己的投票信息并转发。当某个节点收集到超过半数节点的投票,且这些投票的zxid都不小于自己的zxid时,它就会成为新的Leader。Observer节点因为不参与投票,所以在这个过程中主要是接收新Leader的通知并同步数据。
再看KRaft协议。假设集群有n个Broker,当Leader故障,只要有超过半数(n/2向上取整)的Broker正常,选举就能进行。某个最先发现Leader故障的Broker会发起选举,它向其他Broker发送选举请求,里面包含自己的逻辑时钟(LID)。其他Broker收到请求后,如果自己的LID小于请求的LID,就会回复同意。当发起选举的Broker收到超过半数Broker的同意回复,它就会成为新的Leader。Observer节点在选举时不参与投票,但选举完成后会和其他Follower一样,从新Leader同步数据。
如果没收到超过半数同意回复,它就会等一会儿,然后再发起新一轮选举。在等待的这段时间里,它会继续监听其他Broker的状态。要是在这期间有其他Broker发起选举,而且那个Broker的LID更大,那它就会放弃这次选举,转而支持LID更大的那个Broker。这样不断尝试,直到有一个Broker能收集到足够多的同意回复,成为新的Leader。
Kafka如何保证消费的幂等性
幂等性指多次执行相同操作的结果与执行一次相同,即避免重复消费导致的数据不一致。在 Kafka 中,消费端幂等性需解决以下问题:
- 生产者重复发送消息(如网络抖动导致的重试)。
- 消费者重启后重复拉取(如偏移量未及时提交)。
面试高频问题与回答要点
-
Kafka 如何保证幂等性?
- 答:通过三层机制:生产者幂等性(PID + 序列号)保证单分区去重,事务机制(Transaction ID+2PC)支持跨分区一致性,消费端通过唯一 ID 或状态缓存实现最终幂等。
-
生产者幂等性和事务的区别?
- 答:幂等性仅作用于单分区,且不支持跨会话;事务通过 Transaction ID 和协调器实现跨分区、跨会话的幂等,需 2PC 流程,开销更高。
-
消费端如何处理重复消息?
- 答:可通过消息唯一 ID(如业务主键)结合 Redis 缓存去重,或在数据库设计中利用唯一索引 / 主键冲突避免重复插入,同时需保证偏移量提交与业务处理的原子性(如使用事务绑定)。
幂等性的核心设计原则
- 生产者优先:能用 Producer 幂等性或事务解决的场景,避免在消费端增加复杂度。
- 消费端兜底:对于跨系统、历史数据等场景,必须在消费端实现去重逻辑。
- 性能与一致性平衡:事务机制适合金融等强一致性场景,日志类场景可优先使用幂等生产者降低开销。
Kafka 与 RabbitMQ 的区别?
- Kafka:(把消息分散到多个分区存储)高吞吐量、分布式流处理,适合日志 / 监控数据;
- RabbitMQ:(FIFO、一个队列就是一条消息序列)灵活路由(Direct/Topic 等模式)、支持事务,适合企业级业务消息。
Kafka Steam VS Flink
| 维度 | Kafka Stream | Flink |
|---|---|---|
| 定位 | Kafka 内置流处理库,与 Kafka 深度集成 | 独立的分布式流处理框架,支持批流统一 |
| 部署方式 | 嵌入应用程序或作为 Kafka 插件运行 | 独立集群部署,支持 YARN/Kubernetes |
| 状态管理 | 轻量级状态,依赖 Kafka Topic 存储 | 完整状态后端(如 RocksDB、内存),支持大状态 |
| 窗口语义 | 支持时间窗口、会话窗口,但功能较简单 | 支持更复杂的窗口操作(如滑动窗口、全局窗口) |
| 生态整合 | 仅与 Kafka 生态集成 | 支持对接多种数据源(Kafka、MySQL、HDFS 等) |
消息队列
| 特性 | Kafka | RabbitMQ | RocketMQ |
|---|---|---|---|
| 吞吐量 | 高(百万级 / 秒) | 中(万级 / 秒) | 高(十万级 / 秒) |
| 消息顺序性 | 分区内有序 | 可保证(队列+路由) | 队列内有序 |
| 可靠性 | 高(多副本机制) | 高(持久化 + ACK 机制) | 高(多副本 + 持久化) |
| 应用场景 | 大数据流处理、日志收集 | 复杂业务逻辑、低延迟场景 | 金融交易、电商订单系统 |
| 技术栈 | Java/Scala | Erlang | Java |
进程 VS 线程 VS 协程
| 维度 | 进程(Process) | 线程(Thread) | 协程(Coroutine) |
|---|---|---|---|
| 本质 | 操作系统分配资源的最小单位 | 操作系统调度执行的最小单位 | 用户态轻量级执行单元(由编程语言或框架实现) |
| 资源分配 | 拥有独立的地址空间、内存、文件句柄等资源 | 共享进程的资源(如地址空间、堆内存) | 共享线程的资源(如栈、寄存器状态) |
| 调度方式 | 由操作系统内核调度,上下文切换开销大 | 由操作系统内核调度,上下文切换开销较小 | 由用户态程序(如框架)控制,上下文切换开销极低 |
| 并发性 | 多进程并发通过操作系统调度实现 | 多线程并发通过操作系统调度实现 | 单线程内通过协程调度器实现 “伪并发” |
| 典型应用 | 独立运行的程序(如浏览器、数据库服务) | 程序内并发任务(如 Web 服务器处理多请求) | 高 IO 密集型场景(如网络爬虫、消息处理) |
Spring AOP(面向切面编程)
将横切关注点(如日志、事务)与业务逻辑分离
- 切面(Aspect):封装横切关注点的类,包含通知和切点
- 通知(Advice):在特定连接点执行的代码(Before/After/Around/AfterReturning/AfterThrowing)
- 连接点(JoinPoint):程序执行过程中的点(如方法调用、异常抛出)
- 切点(Pointcut):定义匹配连接点的表达式(如
execution(* com.example.service.*.*(..))) - 织入(Weaving):将切面逻辑插入到目标对象的过程(编译时 / 加载时 / 运行时)
实现方式
- 静态代理:编译时生成代理类(如 AspectJ)。在静态代理中,代理类和被代理类都要实现同一个接口或继承同一个父类,代理类中包含了被代理类的实例,并在调用被代理类的方法前后执行相应的操作。缺点:需要为每个被代理类编写一个代理类,当被代理类的数量增多时,代码量会变得很大。
- 动态代理:运行时生成代理对象(如 Spring AOP)。在动态代理中,代理类不需要实现同一个接口或继承同一个父类,而是通过 Java 反射机制动态生成代理类,并在调用被代理类的方法前后执行相应的操作。优点是可以为多个被代理类生成同一个代理类,从而减少了代码量,缺点是实现复杂。
- JDK 动态代理:基于接口,要求被代理的类必须实现一个接口,它通过反射来接收被代理的类,并使用java.lang.reflect.InvocationHandler 接口和 java.lang.reflect.Proxy 类实现代理。Spring AOP 默认使用 JDK 的 java.lang.reflect.Proxy 类。通过 Proxy.newProxyInstance() 方法来创建代理类的实例。该方法接受三个参数:类加载器、代理类要实现的接口列表和 InvocationHandler 对象。
- CGLIB 代理:基于类继承(CGLIB是一个代码生成的类库,在运行时通过字节码技术动态地生成某个类的子类)。通过 Enhancer.create() 方法来创建代理类的实例。该方法接受一个类作为参数,表示要代理的类。
- CGLIB 动态代理无法代理 final 类和 final 方法;JDK 动态代理可以代理任意类。
典型场景
- 事务管理:
@Transactional注解基于 AOP 实现 - 日志记录:统一记录方法调用前后的日志
- 权限验证:方法调用前验证用户权限
- 缓存处理:方法调用前后操作缓存
- 异常处理:统一捕获和处理异常
Spring 动态代理失效的场景有哪些?
- 直接使用new关键字创建对象
- 内部方案调用,例如@Transactional注解失效(因为内部调用不会经过代理对象,直接调用了目标方法,没办法触发代理里的增强逻辑)
- 没有实现接口,用了CGLIB代理,proxy-target-class=false(禁用CGLIB代理)
Spring Boot 动态代理默认实现是 JDK 动态代理还是 CGLIB?怎么证明?
默认情况下,如果被代理对象实现了接口,就用JDK动态代理;要是没实现接口,就会用CGLIB代理。
Spring IOC(控制反转)/ DI(依赖注入)
- 控制反转(IOC):将对象的创建和管理控制权从代码转移到容器(IoC容器:负责创建和管理对象,以及解决对象之间的依赖关系)。
- 依赖注入(DI):通过容器将依赖对象注入到需要的组件中。
- 依赖查找(Dependency Lookup):通过容器提供的 API手动查找和获取所需依赖对象,例如 ApplicationContext.getBean() 。
实现方式
- 构造器注入:通过构造函数注入依赖
- Setter 注入:通过 setter 方法注入依赖
- 字段注入:通过注解(如 @Autowired查找类型匹配的bean、@Qualifier指定要注入的bean名称 和 @Value属性值注入)直接注入字段
- 接口注入:通过实现特定接口声明依赖
典型场景
- Spring 容器管理 Bean @Service @Autowired or 构造方法
- 配置外部化 @Configuration @Bean
- 测试解耦 @MockBean @Autowired
Spring框架
Spring 框架是一个用于构建企业级 Java 应用程序的开源框架。
以下是 Spring 框架的一些核心特点:
- 轻量级:Spring 框架采用了松耦合的设计原则,仅依赖于少量的第三方库,因此它是一个轻量级的框架。开发人员可以根据需要选择使用 Spring 的特定功能,而无需引入整个框架。
- 控制反转(IoC):Spring 框架通过控制反转(IoC)容器管理应用程序中的对象及其依赖关系。通过 IoC 容器,开发人员可以将对象的创建、组装和生命周期管理交给 Spring 框架处理,从而实现了松耦合和可测试性。
- 面向切面编程(AOP):Spring 框架支持面向切面编程,可以通过 AOP 在应用程序中实现横切关注点的模块化。例如,日志记录、事务管理和安全性等横切关注点可以通过 AOP 进行集中处理,而不会侵入业务逻辑的代码。
- 声明式事务管理:Spring 框架提供了声明式事务管理的支持。通过使用注解或 XML 配置,开发人员可以将事务管理逻辑与业务逻辑分离,并且可以轻松地在方法或类级别上应用事务。
- 框架整合:Spring 框架可以与许多其他开源框架和技术无缝集成,如 Hibernate、MyBatis、JPA、Struts 和 JSF 等。这使得开发人员可以使用 Spring 框架来整合和协调不同的技术,构建全面的企业应用程序。
- 测试支持:Spring 框架提供了广泛的测试支持,包括单元测试和集成测试。它提供了一个专门的测试上下文,可以轻松地编写和执行单元测试,以验证应用程序的行为和功能。例如:@ContextConfiguration(加载配置文件,设置测试用的数据源)和@SpringBootTest(开启Spring测试上下文)、@MockBean(创建模拟对象,隔离外部依赖)
Spring 容器核心组件(常见注解)
- BeanFactory:基础 IOC 容器,负责创建和管理 Bean
- ApplicationContext:高级容器,扩展了 BeanFactory 的功能(如事件发布、国际化)
- @Component:通用组件注解,被 Spring 扫描并注册为 Bean
- @Service、@Repository(持久层)、@Controller:特定场景的组件注解
- @Configuration:配置类注解,声明 Bean 定义方法
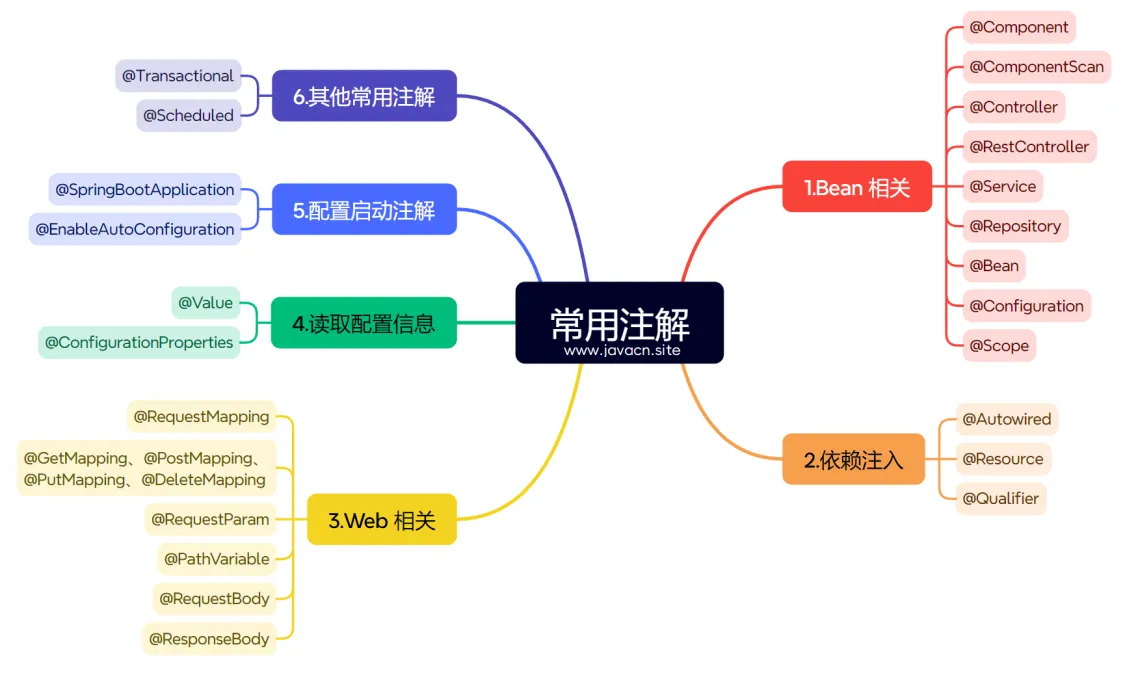
scope(Spring Bean 实例的作用域)分为:
- singleton (默认单例):整个应用容器中只会创建一个bean实例,所有对该bean的引用都指向同一个实例。
- prototype (原型/多例):每次请求bean时都会创建新实例,适用于有状态的bean(如需要保存用户会话数据)。
- request (请求):在一次HTTP请求中共享同一个bean实例,请求结束后销毁,仅用于Web环境。
- session (会话):在同一个HTTP会话中共享bean实例,会话结束后销毁,仅用于Web环境。
- application (应用):在一个 ServletContext 中只存在一个 Bean 实例。该作用域只在 Spring ApplicationContext 上下文中有效。
- websocket:在一个 WebSocket 中只存在一个 Bean 实例。该作用域只在 Spring ApplicationContext 上下文中有效。
配置启动注解
1.@SpringBootApplication:用于标识 SpringBoot 应用程序的入口类。它是一个组合注解,包括了 @Configuration、@EnableAutoConfiguration 和 @ComponentScan 三个注解。
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
2.@EnableAutoConfiguration:启用 Spring Boot 的自动配置机制,根据添加的依赖和配置文件自动配置 Spring 应用。
有状态bean VS 无状态bean
在软件开发中,有状态 bean和无状态 bean的核心区别在于是否保存 “状态数据”,具体对比如下:
| 维度 | 有状态 bean | 无状态 bean |
|---|---|---|
| 状态存储 | 包含可变成员变量,保存状态 | 无成员变量或仅含不可变变量,无状态 |
| 线程安全性 | 多线程访问需额外同步机制(易冲突) | 天然线程安全(无状态修改风险) |
| 复用性 | 状态与特定上下文绑定,复用性低 | 无状态依赖,可全局复用 |
| 典型场景 | 会话管理、购物车、用户偏好设置 | 工具类、服务层逻辑处理、无状态计算 |
框架中的应用
- Spring 框架:
- 单例 bean 默认设计为无状态(如
@Service/@Controller),避免多线程状态冲突。 - 有状态 bean 需显式配置为
prototype作用域(每次请求创建新实例)。
- 单例 bean 默认设计为无状态(如
- EJB(Enterprise JavaBeans):
- 有状态会话 Bean(Stateful Session Bean):保存特定客户端的状态,每个客户端对应一个实例。
- 无状态会话 Bean(Stateless Session Bean):不保存状态,可被多个客户端共享。
总结
- 无状态 bean 因线程安全、易复用,是框架设计的首选;
- 有状态 bean 需谨慎使用,通常通过原型模式或线程同步机制避免状态问题。
Bean的生命周期
在 Spring 中,Bean 的生命周期指的是 Bean 实例从创建到销毁的整个过程。Spring 容器负责管理 Bean 的生命周期,包括实例化、属性赋值、初始化、使用、销毁等过程。
Bean 的生命周期可以分为以下几个阶段:
实例化:在 Spring 容器启动时,会根据配置文件或注解等方式创建 Bean 的实例,也就是说实例化就是为 Bean 对象分配内存空间。根据 Bean 的作用域不同,实例化的方式也不同。例如,singleton 类型的 Bean 在容器启动时就会被实例化,而 prototype 类型的 Bean 则是在每次请求时才会被实例化。
属性赋值:在 Bean 实例化后,Spring 容器会自动将配置文件或注解中指定的属性值注入到 Bean 中。属性注入可以通过构造函数注入、Setter 方法注入、注解注入等方式实现。
初始化:在属性注入完成后,Spring 容器会调用 Bean 的初始化方法。Bean 的初始化方法可以通过实现 InitializingBean 接口、@PostConstruct 注解等方式实现。在初始化方法中,可以进行一些初始化操作,例如建立数据库连接、加载配置文件等。
使用:在 Bean 初始化完成后,Bean 就可以被应用程序使用了。在应用程序中,可以通过 Spring 容器获取 Bean 的实例,并调用 Bean 的方法。
销毁:在应用程序关闭时,Spring 容器会自动销毁所有的 Bean 实例。Bean 的销毁方法可以通过实现 DisposableBean 接口、@PreDestroy 注解等方式实现。在销毁方法中,可以进行一些清理操作,例如释放资源、关闭数据库连接等。
- 生命周期回调接口: BeanNameAware 、 BeanFactoryAware 、 InitializingBean (调用afterPropertiesSet() 方法)、 DisposableBean (调用destroy() 方法)。
- 注解回调: @PostConstruct (初始化后)、 @PreDestroy (销毁前)。
- 配置方式:XML中的 init-method 和 destroy-method ,或 @Bean 注解的 initMethod 、 destroyMethod 参数。
- 若Bean实现了 BeanNameAware 接口,会调用 setBeanName(String name) 方法,注入Bean的名称。
- 若实现了 BeanFactoryAware 接口,会调用 setBeanFactory(BeanFactory factory) 方法,注入容器实例。
- 若实现了 ApplicationContextAware 接口,会调用 setApplicationContext(ApplicationContext ctx) 方法,注入应用上下文。
如何保证单例Bean的线程安全
Spring 默认的 Bean 是单例模式,意味着容器中只有一个 Bean 实例,所有的线程都会使用并操作这个唯一的 Bean 实例,那么多个线程同时调用修改这个单例 Bean,就会产生线程安全问题。
有状态的单例 Bean 是非线程安全的,而无状态的 Bean 是线程安全的。
Spring 中保证单例 Bean 线程安全的手段有以下几个:
- 变为原型 Bean:在 Bean 上添加 @Scope("prototype") 注解,将其变为多例 Bean。这样每次注入时返回一个新的实例,避免竞争。
- 加锁:在 Bean 中对需要同步的方法或代码块添加同步锁 @Synchronized 或使用 Java 中的线程同步工具 ReentrantLock 等。
- 使用线程安全的集合/数据结构(可以参考:线程安全的数据结构)/Atomic家族例如AtomicInteger(.incrementAndGet(),.get()):如 Vector、Hashtable 代替 ArrayList、HashMap 等非线程安全集合。
- 变为无状态 Bean:不在 Bean 中保存状态,让 Bean 成为无状态 Bean。无状态的 Bean 没有共享变量,自然也无须考虑线程安全问题。
- 使用线程局部变量 ThreadLocal:在方法内部使用线程局部变量 ThreadLocal,因为 ThreadLocal 是线程独享的,所以也不存在线程安全问题。(使用 ThreadLocal 需要注意一个问题,在用完之后记得调用 ThreadLocal 的 remove 方法,不然会发生内存泄漏问题。)
@Autowired注解实现原理
Spring 中的 @Autowired 注解是通过依赖注入(DI)实现的。
当 Spring 容器启动时,它会扫描应用程序中的所有 Bean,并将它们存储在一个 BeanFactory 中。当应用程序需要使用某个 Bean 时,Spring 容器会自动将该 Bean 注入到应用程序中。
但再往底层说,DI 是通过 Java 反射机制实现的。具体来说,当 Spring 容器需要注入某个 Bean 时,它会使用 Java 反射机制来查找符合条件的 Bean,并将其注入到应用程序中。
所以说,@Autowired 注解是通过 DI 的方式,底层通过 Java 的反射机制来实现的。
@Autowired VS @Resource
用来实现依赖注入的注解(在 Spring/Spring Boot 项目中),但二者却有着 5 点不同:
- 来源不同:@Autowired 来自 Spring 框架,而 @Resource 来自于(Java)JSR-250;
- 依赖查找的顺序不同:@Autowired 先根据类型再根据名称查询,而 @Resource 先根据名称再根据类型查询;
- 支持的参数不同:@Autowired 只支持设置 1 个参数-required,而 @Resource 支持设置 7 个参数-name-type;
- 依赖注入的用法支持不同:@Autowired 既支持构造方法注入,又支持属性注入和 Setter 注入,而 @Resource 只支持属性注入和 Setter 注入;
- 编译器 IDEA 的提示不同:当注入 Mapper 对象时,使用 @Autowired 注解编译器会提示错误,而使用 @Resource 注解则不会提示错误。
BeanFactory VS FactoryBean
- 功能:BeanFactory 是一个容器,负责管理和创建 Bean 实例,处理依赖关系和属性注入等操作。FactoryBean 是一个接口,定义了创建 Bean 的规范和逻辑,它负责创建其他 Bean 实例。
- 使用方式:BeanFactory 使用配置文件或注解来定义 Bean 和它们之间的关系,它使用延迟初始化策略,即只有在需要时才创建 Bean 实例。FactoryBean 通常在 Spring 配置文件中配置,并由 BeanFactory 负责实例化和管理。
- 创建的对象:BeanFactory 创建和管理普通的 Bean 实例,而 FactoryBean 创建其他 Bean 实例。
- 灵活性:FactoryBean 具有更高的灵活性,因为它允许自定义的逻辑来创建和配置 Bean 实例。FactoryBean 的实现类可以根据特定的条件选择性地创建不同的 Bean 实例,或者在创建 Bean 之前进行一些初始化操作。这使得 FactoryBean 在某些情况下比 BeanFactory 更加强大和可扩展。
- 返回类型:BeanFactory 返回的是 Bean 实例本身,而 FactoryBean 返回的是由 FactoryBean 创建的 Bean 实例。因此,当使用 FactoryBean 时,需要通过调用 getObject() 方法来获取创建的 Bean 实例。
- FactoryBean 接口定义了三个方法:getObject()、getObjectType() 和 isSingleton()。getObject() 方法返回由 FactoryBean 创建的 Bean 实例,getObjectType() 方法返回创建的Bean的类型,而 isSingleton() 方法用于指示创建的 Bean 是否是单例。
Spring常见设计模式
1.工厂模式
工厂模式是一种创建型设计模式,它提供了一种创建对象的方式,使得应用程序可以更加灵活和可维护。在 Spring 中,FactoryBean 就是一个工厂模式的实现,使用它的工厂模式就可以创建出来其他的 Bean 对象。
2.单例模式
单例模式是一种创建型设计模式,它保证一个类只有一个实例,并提供了一个全局访问点。在 Spring 中,Bean 默认是单例的,这意味着每个 Bean 只会被创建一次,并且可以在整个应用程序中共享。
3.代理模式
代理模式是一种结构型设计模式,它允许开发人员在不修改原有代码的情况下,向应用程序中添加新的功能。在 Spring AOP(面向切面编程)就是使用代理模式的实现,它允许开发人员在方法调用前后执行一些自定义的操作,比如日志记录、性能监控等。
4.观察者模式
观察者模式是一种行为型设计模式,它定义了一种一对多的依赖关系,使得当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知并自动更新。Spring 事件驱动模型使用观察者模式,ApplicationEventPublisher 事件发布者将事件发布给 ApplicationEventMulticaster 事件广播器,该广播器将事件派发给 @EventListener 注解的事件监听者。
5.模板方法模式
模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,将一些步骤延迟到子类中实现。在 Spring 中,JdbcTemplate 就是一个模板方法模式的实现,它提供了一种简单的方式来执行 SQL 查询和更新操作。
6.适配器模式
适配器模式是一种结构型设计模式,它允许开发人员将一个类的接口转换成另一个类的接口,以满足客户端的需求。在 Spring 中,适配器模式常用于将不同类型的对象转换成统一的接口,比如将 Servlet API 转换成 Spring MVC 的控制器接口。
7.策略模式
策略模式是一种行为型设计模式,它定义了一系列算法,并将每个算法封装起来,使得它们可以互相替换。Spring 中的 TaskExecutor,TaskExecutor 提供了很多实现,比如以下这些:
- SyncTaskExecutor:直接在调用线程中执行任务,没有真正的异步;
- SimpleAsyncTaskExecutor:使用单线程池异步执行任务;
- ConcurrentTaskExecutor:使用线程池异步执行任务;
- SimpleTransactionalTaskExecutor:支持事务的 SimpleAsyncTaskExecutor。 这样,我们可以根据自己的需求选择不同的实现策略,使用策略模式的好处有以下这些:
- 可以在不修改原代码的基础上选择不同的算法或策略;
- 可减少程序中的条件语句,根据环境改变选择合适的策略;
- 扩展性好,如果有新的策略出现,只需要创建一个新的策略类,无须修改原代码。
Spring MVC (Model-View-Controller) VS Spring Boot VS Spring Cloud
| 维度 | Spring MVC | Spring Boot | Spring Cloud |
|---|---|---|---|
| 核心目标 | 构建 Web 应用 | 简化 Spring 应用开发 | 构建分布式微服务系统 |
| 技术定位 | 表现层框架(MVC) | 应用开发平台 | 微服务工具集 |
| 依赖管理 | 需手动配置大量依赖 | 起步依赖自动管理 | 基于 Spring Boot Starter |
| 部署方式 | WAR 包部署到外部容器 | 独立 JAR(内置服务器) | 通常容器化部署(Docker/K8s) |
| 核心组件 |
|
|
|
| 典型场景 | 传统/单体 Web 应用(前后端不分离)、REST API、表单提交与页面渲染 |
快速搭建独立应用
|
微服务架构下的服务治理
|
| 配置方式 | XML 或 Java Config | 自动配置 + application.properties | 集中配置中心(Config Server) |
| 服务发现 | 无 | 无 | 支持(Eureka/Nacos 等) |
| 负载均衡 | 需依赖外部负载均衡器(如 Nginx) | 无 | 客户端负载均衡(Ribbon) |
- 推荐使用 Spring Initializr(https://start.spring.io) 生成项目,自动处理版本依赖,不过默认生成的项目结构包含视图层配置
- 注意版本依赖需保持一致
- maven依赖冲突:通过mvn
dependency:tree (-Dincludes=groupId:artifactId)命令找出冲突的依赖,接着利用<dependencyManagement>统一管理版本,再通过<exclusions>排除冲突依赖或者显式指定版本来解决问题,最后验证调整后的结果mvn dependency:tree | grep conflicting-library。 - 分析依赖冲突mvn dependency:analyze
- 查看有效POM(包含继承和插值后的完整配置) mvn help:effective-pom
Spring VS SpringBoot
Spring 是一个轻量级的开源框架,它提供了一种简单的方式来构建企业级应用程序。Spring Boot 则是 Spring 框架的延伸和扩展,它提供了一种快速构建应用程序的方式。开发人员可以通过使用 Spring Boot Starter 来快速集成常用的第三方库和框架,使得开发人员可以快速构建出一个可运行的应用程序。
Spring Boot
- 简化配置: Spring Boot 采用约定大于配置的原则,提供了自动配置的特性,大部分情况下无需手动配置,可以快速启动和运行应用程序。同时,Spring Boot 提供了统一的配置模型,集成了大量常用的第三方库和框架,简化了配置过程。
- 内嵌服务器: Spring Boot 集成了常用的内嵌式服务器,如 Tomcat、Jetty 和 Undertow 等。这意味着不再需要单独安装和配置外部服务器,可以直接运行 Spring Boot 应用程序,简化了部署和发布过程。
- 自动装配: Spring Boot 提供了自动装配机制,根据应用程序的依赖关系和配置信息,智能地自动配置 Spring 的各种组件和功能,大大减少了开发人员的手动配置工作,提高了开发效率。
- 起步依赖: Spring Boot 引入了起步依赖(Starter Dependencies)的概念,它是一种可用于快速集成相关技术栈的依赖项集合。起步依赖能够自动处理依赖冲突和版本兼容性,并提供了默认的配置和依赖管理,简化了构建和管理项目的过程。
- 自动化监控和管理: Spring Boot 集成了 Actuator 模块,提供了对应用程序的自动化监控、管理和运维支持。通过 Actuator,可以获取应用程序的健康状况、性能指标、配置信息等,方便运维人员进行故障排查和性能优化。
- 丰富的生态系统: Spring Boot 建立在 Spring Framework 的基础上,可以无缝集成 Spring 的各种功能和扩展,如 Spring Data、Spring Security、Spring Integration 等。同时,Spring Boot 还提供了大量的第三方库和插件,可以方便地集成其他技术栈,构建全栈式应用程序。
- 可扩展性和灵活性: 尽管 Spring Boot 提供了很多自动化的功能和约定,但它也保持了良好的可扩展性和灵活性。开发人员可以根据自己的需求进行自定义配置和扩展,以满足特定的业务需求。
面试题:springboot为什么要搞内嵌服务器以及自动装配?
Spring Boot内嵌服务器主要是为了简化部署和提高开发效率。以前用传统的Spring项目,部署war包到外部服务器,像Tomcat,过程挺繁琐的。有了内嵌服务器,比如内嵌Tomcat、Jetty,直接打成可执行的jar包,一个命令就能启动项目,超级方便。
原理上呢,Spring Boot在打包时会把内嵌服务器的依赖都包含进去,启动时它会创建服务器实例,加载必要的配置,绑定端口。比如内嵌Tomcat,它会初始化Tomcat的类加载器、连接器这些组件,然后把Spring MVC相关的处理器等注册到服务器里。这样,项目一启动,服务器也就跟着运行起来,能接收和处理HTTP请求啦。
简单来说,Spring Boot的自动装配就是它能根据项目的依赖和配置,自动帮你把一些组件初始化并配置好。比如你在项目里加了Spring Web的依赖,它就会自动装配好Web相关的配置,像DispatcherServlet这些,你不用自己手动去配置很多东西啦。
原理呢,它是通过大量的条件注解和自动配置类实现的。Spring Boot会扫描classpath下的一些特定的类,根据类路径和依赖情况,判断是否满足自动装配的条件。要是满足,就会把对应的组件初始化并加入到Spring容器里。比如 Spring Data JPA ,只要你加了相关依赖,它就能根据你的实体类和数据库连接信息,自动配置好JPA的相关组件,让你方便地操作数据库。这样大大减少了样板代码,开发效率就提高啦。
Docker大全
一、镜像操作
1. 构建镜像
docker build -t <镜像名>:<标签> <构建上下文路径>
# 示例:从当前目录的Dockerfile构建镜像
docker build -t myapp:v1 .
2. 查看本地镜像
docker images # 查看所有本地镜像
docker image ls -q # 只显示镜像ID
3. 删除镜像
docker rmi <镜像ID> 或 <镜像名>:<标签>
# 强制删除(忽略依赖)
docker rmi -f <镜像ID>
4. 拉取 / 推送镜像
docker pull <镜像名>:<标签> # 从Registry拉取
docker push <镜像名>:<标签> # 推送至Registry
5. 保存 / 加载镜像
docker save <镜像名> > 镜像.tar # 导出镜像为文件
docker load -i 镜像.tar # 从文件导入镜像
二、容器操作
1. 运行容器
docker run [选项] <镜像名> [命令]
# 示例:后台运行并映射端口
docker run -d -p 8080:8080 myapp:v1
# 示例:交互式运行并挂载目录
docker run -it -v /本地路径:/容器路径 ubuntu bash
2. 查看容器
docker ps # 查看运行中的容器
docker ps -a # 查看所有容器(包括已停止的)
3. 停止 / 启动 / 重启容器
docker stop <容器ID或名称>
docker start <容器ID或名称>
docker restart <容器ID或名称>
4. 删除容器
docker rm <容器ID或名称>
# 删除所有已停止的容器
docker container prune
5. 进入容器
docker exec -it <容器ID或名称> bash # 进入交互式终端
# 示例:查看Nginx容器内部文件
docker exec -it nginx-container ls /etc/nginx
6. 查看容器日志
docker logs <容器ID或名称>
# 实时跟踪日志
docker logs -f <容器ID或名称>
三、网络管理
1. 查看网络
docker network ls # 查看所有网络
docker network inspect <网络名> # 查看网络详情
2. 创建网络
docker network create --driver bridge my-network
3. 运行容器并连接到网络
docker run -d --network my-network myapp:v1
四、数据卷管理
1. 创建数据卷
docker volume create my-volume
2. 查看数据卷
docker volume ls
docker volume inspect my-volume
3. 挂载数据卷
docker run -d -v my-volume:/data myapp:v1
五、其他常用命令
1. 查看系统信息
docker info # 查看Docker系统信息
docker stats # 实时监控容器资源使用
2. 清理资源
docker system prune # 清理临时文件、未使用镜像等
# 彻底清理(包括数据卷)
docker system prune -a --volumes
3. 查看容器进程
docker top <容器ID或名称>
4. 复制文件
docker cp <容器ID或名称>:<容器路径> <本地路径> # 从容器复制到本地
docker cp <本地路径> <容器ID或名称>:<容器路径> # 从本地复制到容器
六、常用选项速查表
|
选项 |
说明 |
示例 |
|---|---|---|
|
|
后台运行容器 |
|
|
|
端口映射(主机:容器) |
|
|
|
挂载卷 |
|
|
|
设置环境变量 |
|
|
|
指定容器名称 |
|
|
|
自动重启策略 |
|
|
|
交互式终端 |
|
七、实战示例
1. 运行 Nginx 服务器
docker run -d -p 80:80 --name webserver nginx
2. 运行 MySQL 数据库
docker run -d \
-p 3306:3306 \
-e MYSQL_ROOT_PASSWORD=password \
-e MYSQL_DATABASE=mydb \
--name mysql \
mysql:8.0
3. 构建并运行自定义应用
# 构建镜像
docker build -t myapp:v1 .
# 运行容器
docker run -d -p 8080:8080 myapp:v1Dockerfile
用于定义和自动化构建 Docker 镜像的文本文件
| 指令 | 功能 | 示例 |
|---|---|---|
FROM |
指定基础镜像 | FROM ubuntu:20.04 |
RUN |
执行命令(如安装软件) | RUN apt-get update && apt-get install -y python3 |
COPY |
复制本地文件到镜像 | COPY app.py /app/ |
ADD |
复制文件(支持远程 URL 和自动解压) | ADD https://example.com/file.txt /app/ |
CMD |
容器启动时执行的默认命令 | CMD ["python3", "app.py"] |
ENTRYPOINT |
配置容器启动时的执行命令 | ENTRYPOINT ["/usr/bin/nginx", "-g", "daemon off;"] |
ENV |
设置环境变量 | ENV DB_HOST=localhost |
EXPOSE |
声明容器监听的端口 | EXPOSE 8080 |
VOLUME |
创建挂载点(用于数据持久化) | VOLUME ["/data"] |
WORKDIR |
设置工作目录 | WORKDIR /app |
USER |
指定运行命令的用户 | USER appuser |
Docker 按顺序执行 Dockerfile 中的指令,并为每个指令创建一个镜像层。如果某一层的内容未变,下次构建时会复用缓存,显著加速构建过程。例如:
- 修改
requirements.txt后,RUN pip install层会重新构建 - 仅修改应用代码时,只有
COPY . .及后续层会重新构建
以下是一个简单的 Python Flask 应用的 Dockerfile:
# 使用官方 Python 基础镜像
FROM python:3.9-slim
# 设置工作目录
WORKDIR /app
# 复制依赖文件并安装
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 5000
# 设置环境变量
ENV FLASK_APP=app.py
ENV FLASK_ENV=development
# 启动命令
CMD ["flask", "run", "--host=0.0.0.0"]
如何使用 Dockerfile 构建镜像?
- 在项目根目录创建
Dockerfile - 执行
docker build命令:docker build -t my-flask-app:1.0 . # -t:指定镜像标签(名称:版本) # .:构建上下文路径(通常为当前目录) - 构建完成后,使用
docker images查看生成的镜像 - 使用
docker run启动容器:docker run -p 5000:5000 my-flask-app:1.0
Shell常见命令
文件与目录操作
ls # 列出目录内容
cd [目录] # 切换目录
pwd # 显示当前工作目录
mkdir [目录] # 创建新目录
rm [文件] # 删除文件
rm -r [目录] # 递归删除目录
cp [源] [目标] # 复制文件或目录
mv [源] [目标] # 移动文件或目录/重命名
touch [文件] # 创建空文件
文件内容查看
cat [文件] # 查看文件内容
less [文件] # 分页查看文件内容
head [文件] # 查看文件前几行
tail [文件] # 查看文件后几行
grep [模式] [文件] # 在文件中搜索内容
文件权限与所有者
chmod [权限] [文件] # 修改文件权限
chown [用户] [文件] # 修改文件所有者
chgrp [组] [文件] # 修改文件所属组
系统信息
uname -a # 显示系统信息
hostname # 显示主机名
whoami # 显示当前用户名
date # 显示当前日期和时间
df -h # 显示磁盘使用情况
free -h # 显示内存使用情况
top # 显示系统进程
ps # 显示当前进程
网络操作
ping [地址] # 测试网络连接
ifconfig # 显示网络接口信息
ip addr # 显示IP地址信息
netstat -tulpn # 显示网络连接和端口
curl [URL] # 传输URL数据
wget [URL] # 下载文件
其他常用命令
echo [内容] # 打印内容到标准输出
man [命令] # 查看命令手册
history # 显示命令历史
| # 管道:将一个命令的输出作为另一个命令的输入
> [文件] # 输出重定向(覆盖)
>> [文件] # 输出重定向(追加)
# 创建目录并切换到该目录
mkdir my_project && cd my_project
# 查看当前目录下所有文件并按大小排序
ls -lSh
# 查找包含"error"的日志行
grep "error" app.log
# 查看系统负载并将结果保存到文件
top -b -n 1 > system_load.txt
# 下载文件并保存为指定名称
wget -O data.csv https://example.com/data.csvchmod 777 test.sh 、 chomd -R 777 logs/:用于修改文件或目录权限的命令,它会将文件或目录的权限设置为最高级别,即所有用户(所有者、所属组和其他用户)都拥有读取、写入和执行的权限。
| 数字 | 权限组合 | 解释 |
|---|---|---|
| 7 | 读 + 写 + 执行 | rwx (4+2+1) |
| 6 | 读 + 写 | rw- (4+2) |
| 5 | 读 + 执行 | r-x (4+1) |
| 4 | 只读 | r-- (4) |
| 0 | 无权限 | --- |
Java VS Python VS C++ VS C VS Golang 一览表
| 维度 | Java | Python | C++ | C | Golang |
|---|---|---|---|---|---|
| 语言类型 | 静态类型、编译型(通过 JVM 执行) | 动态类型、解释型 | 静态类型、编译型 | 静态类型、编译型 | 静态类型、编译型 |
| 设计范式 | 面向对象、支持泛型 | 面向对象、函数式、脚本化 | 面向对象、泛型、过程式、元编程 | 过程式、结构化 | 面向对象(基于组合)、函数式、并发 |
| 执行方式 | 编译为字节码,由 JVM 解释执行 | 逐行解释执行 | 直接编译为机器码 | 直接编译为机器码 | 编译为机器码(可静态链接) |
| 性能 | 中高性能(JIT 编译优化后接近 C++) | 性能较低(动态类型和解释执行) | 高性能(接近 C) | 高性能(系统级编程语言) | 高性能(接近 C,并发效率高) |
| 内存管理 | 自动垃圾回收(GC) | 自动垃圾回收(GC) | 手动管理(需开发者分配 / 释放内存) | 手动管理(需开发者分配 / 释放内存) | 自动垃圾回收(GC,效率较高) |
| 开发效率 | 中等(语法严谨,开发周期较长) | 高(语法简洁,开发速度快) | 低(语法复杂,开发难度高) | 低(底层操作多,开发复杂度高) | 高(语法简洁,开发效率接近 Go) |
| 学习难度 | 中等(适合初学者入门面向对象) | 低(语法简单,适合零基础入门) | 高(语法复杂,概念繁多) | 中等(需理解指针和内存管理) | 中等(语法简洁,但并发模型需适应) |
| 主要应用场景 | 企业级应用(Web、Android 开发)、大型系统 | 数据分析、人工智能、脚本自动化、Web 开发(Django/Flask) | 系统开发、游戏引擎、高性能服务、嵌入式 | 操作系统、嵌入式系统、驱动开发、底层软件 | 云计算、微服务、网络编程、分布式系统、容器技术(Docker/Kubernetes) |
| 并发模型 | 基于线程(需手动处理同步问题) |
基于线程(受 GIL 限制,多线程效率低) Global Interpreter Lock,全局解释器锁)确保同一时刻只有一个线程执行 Python 字节码。 |
基于线程(手动管理同步)、C++11 引入异步 | 基于线程 / 进程(手动管理同步) | 基于 goroutine(轻量级线程)和 channel(通信机制) |
| 生态系统 | 庞大(Spring、Hibernate 等框架) | 丰富(NumPy、TensorFlow、Django 等) | 较丰富(Qt、OpenCV 等库) | 标准库较小(依赖第三方库) | 快速增长(Go 标准库完善,云原生相关库丰富) |
| 跨平台性 | 强(一次编写,到处运行,依赖 JVM) | 强(解释器支持多平台) | 较强(需针对不同平台编译) | 较强(需针对不同平台编译) | 强(编译后可生成各平台可执行文件) |
| 语法特点 | 语法严谨,面向对象特性完整 | 语法简洁,缩进敏感,动态类型灵活 | 语法复杂,支持多种编程范式 | 语法简洁,强调底层操作 | 语法简洁清晰,接近 C 但更现代化,支持并发原语 |
| 典型项目 | Android 系统、Spring 框架、Hadoop | Python 数据分析库、TensorFlow、PyTorch | Windows 内核部分模块、游戏引擎(如 Unreal Engine) | Unix/Linux 内核、嵌入式系统、MySQL | Docker、Kubernetes、Go 语言标准库 |
| 适合人群 | 企业级开发人员、Android 开发者 | 数据科学家、AI 工程师、脚本开发者 | 系统工程师、游戏开发者、高性能计算工程师 | 底层开发人员、嵌入式工程师 | 云原生开发者、分布式系统开发者、希望平衡性能与开发效率的工程师 |
Java的代码执行过程
Java源代码(.java) → 编译器(javac) → 字节码(.class) → 类加载器 → JVM运行时环境 → 执行引擎 → 操作系统
Java 的代码执行过程涉及编译、加载和运行多个阶段,充分体现了 "一次编写,到处运行" 的跨平台特性。
其中执行引擎:
- 解释执行:逐行解释字节码为机器码(启动快,但性能低)。
- JIT 编译(Just-In-Time):
- 热点代码(如循环体)动态编译为机器码,缓存复用。
- Java 的性能优化主要依赖 JIT(如 HotSpot VM 的 C1/C2 编译器)。
- 本地方法接口(JNI):调用 C/C++ 等本地代码。
常见问题排查
- ClassNotFoundException:类加载器无法找到指定类。
- OutOfMemoryError:堆内存不足,需调整
-Xmx参数。 - NoClassDefFoundError:编译时存在但运行时找不到类(如依赖冲突)。
Java类加载器
-
类加载器(ClassLoader):
- 启动类加载器(Bootstrap ClassLoader):加载 JRE 核心类(如
java.lang.*)。 - 扩展类加载器(Extension ClassLoader):加载 JRE 扩展目录中的类。
- 应用类加载器(Application ClassLoader):加载用户路径(
classpath)下的类。 - 自定义类加载器:按需动态加载类(如 Web 容器、热部署)。
- 启动类加载器(Bootstrap ClassLoader):加载 JRE 核心类(如
-
加载过程:
- 加载:通过类的全限定名(如
java.util.ArrayList)查找并加载.class文件。 - 验证:检查字节码的正确性和安全性(如类型检查、访问权限验证)。
- 准备:为静态变量分配内存并设置初始值(如
int初始为 0)。 - 解析:将符号引用转换为直接引用(如类名→内存地址)。
- 初始化:执行静态代码块和静态变量赋值(按顺序执行)。
- 加载:通过类的全限定名(如
Java类初始化顺序
静态成员初始化
- 父类静态变量 / 静态代码块(按声明顺序执行)
- 子类静态变量 / 静态代码块(按声明顺序执行)
实例成员初始化
- 父类实例变量 / 非静态代码块(按声明顺序执行)
- 父类构造函数
- 子类实例变量 / 非静态代码块(按声明顺序执行)
- 子类构造函数
JVM 内存区域(运行时数据区)
- 方法区:存储类信息、常量池、静态变量(1.8 后改为元空间,使用本地内存)。
- 堆(Heap):对象实例和数组分配以及垃圾回收。
- 栈(Stack):每个线程拥有独立的栈,存储局部变量、方法调用帧。
- 程序计数器:记录当前线程执行的字节码行号。
- 本地方法栈:为本地方法(如
native方法)服务。
JVM进程
├── 线程共享区域
│ ├── 堆(Heap)
│ │ ├── 年轻代(Eden+Survivor)
│ │ └── 老年代(Tenured)
│ └── 方法区(Metaspace)
├── 线程私有区域
│ ├── 栈(Stack)
│ │ ├── 局部变量表
│ │ ├── 操作数栈
│ │ └── 方法调用帧
│ └── 程序计数器
└── 直接内存(Direct Memory)JMM(Java 内存模型,Java Memory Model)
- 定义:JMM 是一种抽象规范,定义了线程间的可见性和有序性规则
- 核心问题:解决多线程环境下的内存可见性和指令重排序问题
- 关键技术:
volatile、synchronized、final关键字
JVM性能优化
- JIT 编译:热点代码优化。
- AOT 编译(提前编译):如 GraalVM,将 Java 直接编译为本地二进制,减少启动时间。
- JVM 参数调优:如堆大小(
-Xmx)、GC 策略(-XX:+UseG1GC)。
JVM 参数
堆内存配置
# 初始/最大堆大小(建议Xms=Xmx避免GC时的resize开销)
java -Xms512m -Xmx1024m MainClass
# 新生代大小(Eden+2*Survivor)
java -Xmn256m MainClass
# 新生代与老年代比例(默认1:2)
java -XX:NewRatio=2 MainClass
GC 策略配置
# 使用G1垃圾收集器(Java 9+默认)
java -XX:+UseG1GC MainClass
# 使用CMS收集器(老年代并发标记清除)
java -XX:+UseConcMarkSweepGC MainClass
# 设置GC日志输出
java -Xlog:gc*:file=gc.log:time,tid,tags MainClass
元空间配置
# 元空间初始/最大大小(替代永久代)
java -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m MainClass垃圾回收
- 自动内存管理:对象不再被引用时,由 GC 自动回收内存。
- 分代回收:新生代(Eden、Survivor)和老年代采用不同的回收策略。
-
新生代(Young Generation)
-
Eden 区:新对象创建区
-
Survivor 区(S0/S1):Eden 区 GC 后存活的对象移至此处
-
Minor GC:新生代 GC,频繁且速度快
-
-
老年代(Old Generation)
-
长期存活的对象(经过多次 Minor GC 后仍存活)进入老年代
-
Major GC/Full GC:老年代 GC,耗时较长
-
-
永久代 / 元空间(PermGen/Metaspace)
-
存储类元数据(Java 8 后使用元空间,避免永久代 OOM)
-
- 常见 GC 算法:标记 - 清除、标记 - 整理、复制算法。
标记 - 清除(Mark-Sweep)
- 标记:标记所有存活对象
- 清除:回收未标记的对象
- 缺点:产生内存碎片
标记 - 整理(Mark-Compact)
- 标记:标记所有存活对象
- 整理:将存活对象移动到内存一端,然后清理边界外的内存
- 优点:避免内存碎片
复制(Copying)
- 将内存分为两块,每次只使用一块
- GC 时将存活对象复制到另一块,然后清空当前块
- 优点:效率高,无碎片
- 缺点:内存利用率低(需预留一半空间)
分代收集(Generational Collection)
-
新生代:使用复制算法(大部分对象很快死亡)
-
老年代:使用标记 - 清除或标记 - 整理(对象存活率高)
垃圾收集器
| GC 类型 | 触发区域 | 触发条件 | 回收对象 | 耗时 |
|---|---|---|---|---|
| Minor GC | 新生代(Eden+Survivor) | Eden 区满 | 新生代中不再存活的对象 | 极短(毫秒级) |
| Major GC | 老年代 | 老年代空间不足 | 老年代中不再存活的对象 | 较长 |
| Full GC | 整个堆 + 方法区 | 1. 调用System.gc()2. 老年代空间不足 3. 元空间不足 4. CMS GC 时并发模式失败 |
整个堆内存(新生代 + 老年代 + 元空间)中不再存活的对象 | 最长(秒级) |
(1) CMS(Concurrent Mark Sweep)
- CMS:基于标记 - 清除算法,专注于降低停顿时间,可能产生内存碎片(初始标记STW → 并发标记 → 重新标记STW → 并发清除)
- G1:基于分区Region(选择垃圾最多的 Region复制&清空)和标记 - 整理算法,可预测停顿时间(通过
-XX:MaxGCPauseMillis参数控制),更适合大内存场景(初始标记STW → 并发标记 → 最终标记STW → 筛选回收STW)
对象是否存活
引用计数法:
- 每个对象维护一个引用计数器,当有新引用指向该对象时,计数器加 1;当引用失效时,计数器减 1。
- 对象存活条件:计数器值为 0 时,对象被判定为可回收。
- 问题:循环引用
可达性分析:
- 从GC Roots出发,通过引用链遍历所有可达对象,这些对象被标记为 “存活”。
- 对象存活条件:无法通过引用链从 GC Roots 到达的对象被判定为可回收。
- 解决了循环引用问题
- STW
调优实战建议
-
监控工具:
jstat:查看 GC 统计信息jmap:生成堆转储文件jhat/MAT:分析堆转储文件jconsole/jvisualvm:可视化监控工具G1GCViewer:专门分析 G1 GC 日志
-
调优策略:
- 吞吐量优先:使用
Parallel Scavenge + Parallel Old - 低延迟优先:使用 G1 或 ZGC
- 大内存场景:增加堆大小,使用 G1/ZGC
- 避免 Full GC:合理设置新生代大小,减少对象进入老年代
- 吞吐量优先:使用
-
常见问题排查:
- 频繁 Full GC:检查是否存在内存泄漏或大对象分配
- GC 时间过长:调整收集器类型或堆参数
- OutOfMemoryError:分析堆转储文件,确定问题根源
对象如何晋升到老年代?
- 经历多次 Minor GC 后仍存活(默认 15 次,由
-XX:MaxTenuringThreshold控制) - 大对象直接进入老年代(
-XX:PretenureSizeThreshold控制阈值) - 动态对象年龄判定:Survivor 区相同年龄的对象总和超过 Survivor 空间一半,年龄≥该年龄的对象直接进入老年代
优化GC性能
- 调整堆大小和分代比例
- 选择合适的垃圾收集器(如 G1/ZGC)
- 避免创建大对象(防止直接进入老年代)
- 减少对象存活时间(及时释放不再使用的对象)
对象初始化顺序
- 分配内存空间
- 初始化对象成员变量(默认值)
- 执行构造函数代码(显式赋值和初始化逻辑)
- 将引用指向分配的内存地址
java 继承 VS 接口 VS 抽象类
| 特性 | 继承(extends) | 接口(implements) | 抽象类(abstract class) |
|---|---|---|---|
| 定义 | 子类继承父类的属性和方法 | 定义方法签名,不包含实现 | 包含抽象方法的类 |
| 多实现 | 仅能继承一个父类 | 可实现多个接口 | 仅能继承一个抽象类 |
| 访问修饰符 | 可使用所有访问修饰符 | 隐式public abstract方法 |
可使用所有访问修饰符 |
| 成员变量 | 可包含任意类型变量 | 隐式public static final常量 |
可包含任意类型变量 |
| 设计目的 | 代码复用和扩展 | 定义行为规范 | 部分实现 + 部分抽象 |
final
- 修饰类:不可被继承(如
String类) - 修饰方法:不可被子类重写
- 修饰变量:初始化后不可修改(引用类型则引用不可变,但对象内容可变)
Java基本数据类型
| 分类 | 子类型 | 具体类型 | 位数 | 默认值 | 示例 | 特点 / 用途 |
|---|---|---|---|---|---|---|
| 基本数据类型 | 整数类型 | byte |
8 位 | 0 |
byte b = 100; |
最小整数类型,适合节省内存(如文件 IO、网络数据) |
short |
16 位 | 0 |
short s = 30000; |
较少使用,偶尔用于大型数组以节省空间 | ||
int |
32 位 | 0 |
int num = 1000; |
最常用的整数类型,默认整数运算类型 | ||
long |
64 位 | 0L |
long l = 10000000000L; |
用于大整数,需加L后缀 |
||
| 浮点类型 | float |
32 位 | 0.0f |
float f = 3.14f; |
单精度,需加f后缀,适合科学计算(精度要求不高) |
|
double |
64 位 | 0.0d |
double d = 3.14159; |
双精度,默认浮点运算类型,适合大多数场景 | ||
| 字符类型 | char |
16 位 | '\u0000' |
char c = 'A'; |
存储单个 Unicode 字符,可直接赋值整数(如char c = 65;表示 'A') |
|
| 布尔类型 | boolean |
未定义 | false |
boolean flag = true; |
表示逻辑值,仅允许true或false,不可与其他类型转换 |
|
| 引用数据类型 | 类(Class) | String, Integer, Date, 自定义类(如Person) |
- | null |
String name = "Alice"; |
最常见的引用类型,可封装多个属性和方法 |
| 接口(Interface) | List, Runnable, Serializable |
- | null |
List<Integer> list = new ArrayList<>(); |
实现多态的关键,定义行为规范 | |
| 数组(Array) | int[], String[], 多维数组(如int[][]) |
- | null |
int[] numbers = new int[5]; |
存储固定长度的同类型元素 | |
| 包装类 | - | Byte, Short, Integer, Long, Float, Double, Character, Boolean |
- | null |
Integer num = 100; |
为基本类型提供对象操作,支持自动装箱 / 拆箱和泛型 |
| 原子类型 | - | AtomicInteger, AtomicLong, AtomicBoolean, AtomicReference<T> |
- | 对应基本类型默认值 | AtomicInteger count = new AtomicInteger(0); |
基于 CAS 实现无锁线程安全操作,适合高并发场景下的计数器、标志位等 |
原子类型位于java.util.concurrent.atomic包下,提供无锁的线程安全操作int vs Integer vs AtomicInteger
int:基本类型,非线程安全Integer:包装类,支持自动装箱 / 拆箱,非线程安全AtomicInteger:线程安全,基于 CAS 实现原子操作,适合高并发场景
反射(Reflection)
含义:程序在运行时对自身结构进行访问以及修改的能力。在运行时动态获取类的信息(如方法、字段、注解),动态地创建对象、调用方法,还能访问属性。主要应用场景如下:
框架开发
- 依赖注入(DI):Spring 框架借助反射,依据配置文件或者注解来动态注入对象的依赖。
- ORM 映射:Hibernate 通过反射将 Java 对象和数据库表进行映射。
注解处理
Java 的注解(Annotation)需要配合反射机制才能发挥作用。通过反射,可以获取类、方法或字段上的注解信息,进而实现特定的逻辑。
序列化和反序列化
- JSON 处理:Jackson、Gson 等库利用反射来解析 JSON 数据并创建对象。
- 深度克隆:通过反射可以递归复制对象的所有字段。
动态代理
Java 的动态代理是 AOP(面向切面编程)的关键技术,它依赖反射机制在运行时创建代理类。
插件与扩展机制
通过反射,程序能够在运行时动态加载和使用外部类,从而实现插件化架构。
- 服务发现:Java 的 SPI(Service Provider Interface)机制借助反射来发现和加载服务实现类。
- 热部署:在不重启应用的情况下,动态更新类的实现。
单元测试
JUnit 等测试框架依靠反射来自动发现和执行测试方法。
调试与监控工具
反射可以用于获取程序的内部状态,这对调试和监控工具很有帮助。
- 内存分析:通过反射遍历对象的字段,辅助内存泄漏检测。
- 性能监控:动态调用方法并记录执行时间。
优点:增强代码灵活性,支持框架动态扩展
缺点:效率低,操作开销大;破坏封装,不安全;JVM版本不同的兼容性
// 获取 Class 对象
Class<?> userClass = User.class;
// 创建对象
Constructor<?> constructor = userClass.getConstructor(Long.class, String.class);
User user = (User) constructor.newInstance(1L, "john");
// 调用方法
Method setUsernameMethod = userClass.getMethod("setUsername", String.class);
setUsernameMethod.invoke(user, "john_doe");
// 访问私有字段
Field usernameField = userClass.getDeclaredField("username");
usernameField.setAccessible(true);
String username = (String) usernameField.get(user);访问私有构造函数:
- 获取目标类的
Class对象。 - 使用
getDeclaredConstructor()获取私有构造函数(包括参数类型)。 - 调用
setAccessible(true)突破访问限制。 - 通过
newInstance()创建实例。
关键方法解析
-
getDeclaredConstructor(Class<?>... parameterTypes)
获取指定参数类型的构造函数,包括私有构造函数。 -
setAccessible(true)
禁用 Java 的访问控制检查,允许访问私有成员。 -
newInstance(Object... initargs)
调用构造函数创建实例,参数对应构造函数的参数列表。
映射
含义:存储键值对的数据结构,其核心思想是通过键来快速查找对应的值。主要应用场景如下:
缓存数据
- LRU 缓存:借助
LinkedHashMap可以轻松实现最近最少使用(LRU)的缓存策略。 - 本地数据缓存:在不需要分布式缓存的场景下,可以使用
ConcurrentHashMap来缓存轻量级数据。
配置管理
- 属性文件解析:
Properties类继承自Hashtable,可用于加载.properties文件。 - 运行时配置:微服务中的动态配置(如 Spring Cloud Config)可以用映射结构存储。
数据统计与聚合
- 单词计数:统计文本中每个单词的出现次数。
import java.util.HashMap;
import java.util.Map;
public class WordCounter {
public static void main(String[] args) {
String text = "hello world hello java";
Map<String, Integer> countMap = new HashMap<>();
for (String word : text.split(" ")) {
countMap.put(word, countMap.getOrDefault(word, 0) + 1);
}
System.out.println(countMap); // 输出: {hello=2, world=1, java=1}
}
}- 分组统计:按照某个字段对数据进行分组,例如统计不同部门的员工数量。
对象关系映射ORM
ORM 框架(如 Hibernate)会把数据库记录映射为 Java 对象,这个过程通常会使用映射结构。
- 结果集映射:将 SQL 查询结果集(ResultSet)转换为
Map<String, Object>。
路由与调度
- URL 路由:Spring MVC 的
RequestMappingHandlerMapping会将 URL 映射到对应的 Controller 方法。
算法与数据结构
- 两数之和:LeetCode 经典题目,可以用 HashMap 在 O (n) 时间复杂度内解决。
import java.util.HashMap;
import java.util.Map;
public class TwoSum {
public int[] twoSum(int[] nums, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < nums.length; i++) {
int complement = target - nums[i];
if (map.containsKey(complement)) {
return new int[]{map.get(complement), i};
}
map.put(nums[i], i);
}
return new int[0];
}
}
多语言支持(国际化)
常见映射实现类(xxxMap)
- HashMap:无序、线程不安全,key 支持 null,性能较高。
- TreeMap:按键的自然顺序排序,基于红黑树实现。
- LinkedHashMap:保持插入顺序或者访问顺序。
- ConcurrentHashMap:线程安全的 HashMap,适合高并发场景。
- Hashtable:线程安全但效率较低,key 不支持 null(已被 ConcurrentHashMap 替代)。
位与
0 & 0 = 0
0 & 1 = 0
1 & 0 = 0
1 & 1 = 1位或
0 | 0 = 0
0 | 1 = 1
1 | 0 = 1
1 | 1 = 1异或
- 相同为 0,不同为 1。
典型哈希函数
MD5、SHA-1、SHA-2、SHA-3、BLAKE2/BLAKE3、密码学哈希函数(如 Argon2、scrypt)
Java 集合框架中的 Map 实现类详解及面试题分析
一、HashMap
核心特性
-
数据结构:数组 + 链表(JDK1.8 后引入红黑树,链表长度≥8 时转换)。
-
无序性:遍历时顺序与插入顺序无关,依赖哈希值分布。
-
线程不安全:多线程操作可能导致数据不一致(如扩容时的链表成环)。
-
null 支持:key 和 value 均可为 null(key 只能有一个 null)。
-
性能:平均时间复杂度 O (1),适合高频查询场景。
-
仅当
n为 2 的幂次方时,两者等价(计算索引):hash % n等价于hash & (n - 1)
源码关键点
-
哈希冲突解决:链地址法(链表 + 红黑树)。
-
扩容机制:默认容量 16,负载因子 0.75,超过阈值(16×0.75=12)时扩容为 2 倍。
-
hash 算法:扰动函数优化(JDK1.8 简化为
key.hashCode() ^ (hashCode >>> 16))。
链表转红黑树的条件
1. 核心条件
链表长度 ≥ 8 且 数组长度 ≥ 64 时,链表会转换为红黑树。
2. 为什么需要数组长度 ≥ 64?
- 若数组长度过小(如 16),即使链表转树,元素分布仍可能不均匀,导致查询效率提升有限。
- 优先扩容数组,让元素分布更均匀,减少链表长度,比直接转树更高效。
3. 红黑树转回链表的条件
当树节点数 ≤ 6 时,红黑树会退化为链表。
面试题
-
HashMap 为什么线程不安全?
答:多线程同时操作时可能出现:扩容时链表成环,导致死循环;并发 put 时数据覆盖(如 A 线程刚计算完位置,B 线程插入元素,A 线程再插入时覆盖)。 -
JDK1.7 和 1.8 的 HashMap 有什么区别?
答:1.8 引入红黑树(链表过长时转换),优化了哈希算法和扩容方式(1.7 头插法可能成环,1.8 尾插法避免)。
| 特性 | JDK1.7 | JDK1.8 |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树(链表≥8 且数组≥64 时) |
| 插入方式 | 头插法(扩容时链表反转) | 尾插法(扩容时保持原顺序) |
| 哈希算法 | 4 次位运算 + 5 次异或 | 1 次异或 + 1 次右移(简化) |
| 扩容逻辑 | 全部重新哈希 | 高低位分离(无需重新计算哈希) |
| 链表成环 | 多线程下可能成环 | 彻底解决(尾插法 + 高低位分离) |
| 性能 | 链表较长时查询 O (n) | 树化后查询 O (log n) |
二、TreeMap
核心特性
-
数据结构:红黑树(自平衡二叉搜索树)。
-
有序性:按键的自然顺序(实现
Comparable)或自定义比较器排序。 -
线程不安全:需外部同步(如
Collections.synchronizedMap())。 -
null 限制:key 不能为 null(会抛出
NullPointerException)。 -
性能:查询、插入、删除平均 O (log n),适合需要排序的场景。
源码关键点
-
排序实现:通过
compareTo()或Comparator比较 key。 -
红黑树特性:节点颜色、左右子树高度差≤1,保证查询效率。
面试题
-
TreeMap 如何实现排序?
答:依赖 key 的自然排序(实现Comparable)或构造时传入Comparator,内部通过红黑树维护有序性。 -
TreeMap 和 HashMap 的性能对比?
答:HashMap 查询 O (1) 更快,但 TreeMap 支持有序遍历和范围查询(如subMap()),适合需要排序的场景。
三、LinkedHashMap
核心特性
-
数据结构:哈希表 + 双向链表(记录插入顺序或访问顺序)。
-
有序性:可保持插入顺序(默认)或访问顺序(
accessOrder=true)。 -
线程不安全:继承自 HashMap,需外部同步。
-
null 支持:key 和 value 可为 null(同 HashMap)。
-
应用场景:LRU 缓存(访问顺序模式)、需要保留插入顺序的场景。
源码关键点
-
双向链表节点:每个节点包含
before和after指针,维护顺序。 -
LRU 实现:访问元素时将其移至链表尾部,超出容量时删除头部元素。
面试题
-
如何用 LinkedHashMap 实现 LRU 缓存?
答:构造时设置accessOrder=true,重写removeEldestEntry()方法,当缓存超过容量时删除最久未访问的节点(链表头部)。 -
LinkedHashMap 的迭代效率比 HashMap 高吗?
答:是的,因为 LinkedHashMap 通过链表维护顺序,迭代时无需遍历整个数组,直接按链表顺序访问。
四、ConcurrentHashMap
核心特性
-
数据结构:JDK1.7 为分段锁(Segment 数组 + 链表),1.8 为 CAS+ synchronized + 红黑树(优化锁粒度)。
-
线程安全:支持高并发操作,读操作无锁,写操作通过锁分段或 CAS 保证原子性。
-
null 限制:key 和 value 均不能为 null(避免与
null返回值混淆,需用containsKey(null)判断)。 -
性能:并发场景下比 Hashtable 效率高,读操作几乎无开销。
源码关键点
-
JDK1.8 优化:放弃分段锁,改用 Node 数组 + 红黑树,写操作时对单个节点加锁(synchronized)。
-
CAS 操作:用于无锁化更新(如
putIfAbsent),提升并发性能。
面试题
-
ConcurrentHashMap 如何保证线程安全?
答:1.8 中通过:-
读操作:volatile 保证可见性,无锁;
-
写操作:对修改的节点加 synchronized 锁,结合 CAS 操作避免竞争。
-
-
ConcurrentHashMap 和 Hashtable 的区别?
答:ConcurrentHashMap 锁粒度更细(1.8 为节点级锁),性能更高;Hashtable 使用全局锁,并发效率低,且已被废弃。
五、Hashtable
核心特性
- 数据结构:数组 + 链表,与 JDK1.7 的 HashMap 类似。
- 线程安全:通过
synchronized修饰所有公共方法(全局锁),并发性能差。 - null 限制:key 和 value 均不能为 null(会抛出
NullPointerException)。 - 应用场景:已被 ConcurrentHashMap 替代,仅在兼容旧代码时使用。
面试题
- Hashtable 为什么被淘汰?
答:全局锁导致并发时竞争激烈,性能低下;ConcurrentHashMap 通过分段锁(1.7)或节点锁(1.8)大幅提升并发效率,且支持 null 以外的场景。
六、综合对比表格
| 实现类 | 数据结构 | 线程安全 | 有序性 | null 支持 | 并发性能 | 典型场景 |
|---|---|---|---|---|---|---|
| HashMap | 数组 + 链表 + 红黑树 | 否 | 无序 | key/value 均可 | 高 | 高频查询、单线程场景 |
| TreeMap | 红黑树 | 否 | 按键排序 | key 不可 | 中(O (log n)) | 需要排序、范围查询 |
| LinkedHashMap | 哈希表 + 双向链表 | 否 | 插入 / 访问顺序 | key/value 均可 | 中 | LRU 缓存、保留顺序 |
| ConcurrentHashMap | 数组 + 链表 + 红黑树 | 是 | 无序 | 均不可 | 极高 | 高并发读写、线程安全场景 |
| Hashtable | 数组 + 链表 | 是 | 无序 | 均不可 | 低 | 旧代码兼容、少量并发场景 |
七、高频面试题汇总
-
HashMap 的底层实现原理?扩容机制?
答:见前文 HashMap 源码关键点,扩容时长度翻倍,重新计算哈希值并迁移元素(1.8 优化为头尾节点分离,避免链表反转)。 -
ConcurrentHashMap 在 JDK1.7 和 1.8 的区别?
答:1.7 用 Segment 分段锁(数组 + 链表),1.8 用 CAS+synchronized + 红黑树,锁粒度更细,避免头插法成环问题。 -
为什么 HashMap 的默认负载因子是 0.75?
答:平衡空间和哈希冲突:0.75 时,哈希冲突概率较低,且空间利用率较高(若设为 1,冲突激增;设为 0.5,空间浪费)。 -
如何选择 Map 实现类?
答:- 单线程、无序:HashMap;
- 需排序:TreeMap;
- 需保留顺序:LinkedHashMap;
- 高并发:ConcurrentHashMap。
-
HashMap 的 key 需要重写哪些方法?为什么?
答:重写hashCode()和equals(),保证相同 key 的哈希值一致,且通过 equals 判断相等时能正确定位元素。
序列化 & 反序列化
- 序列化:将对象转换为字节流,便于存储或传输
- 反序列化:将字节流恢复为对象
- 实现方式:实现
java.io.Serializable接口 serialVersionUID:确保序列化和反序列化版本一致性- 静态字段不会被序列化(属于类,不属于对象)
- 被
transient修饰的字段不会被序列化
JNI(Java Native Interface)
Java 提供的一种机制,允许 Java 代码与本地代码(如 C、C++)进行交互。通过 JNI,Java 程序可以调用本地方法访问底层系统资源(如硬件驱动、操作系统 API),或复用已有 C/C++ 库的功能。
事务传播特性 (PROPAGATION_)
Spring 事务传播机制是指在多个事务方法相互调用的情况下,如何管理这些事务的提交和回滚。
| 传播行为 | 含义 | 示例场景 | 异常处理 | 使用频率 |
|---|---|---|---|---|
| REQUIRED (默认) | 当前存在事务则加入,否则创建新事务。 | 服务层方法调用(如订单创建关联库存扣减)。 | 任何异常导致整个事务回滚。 | ★★★★★ |
| SUPPORTS | 当前存在事务则加入,否则以非事务方式执行。 | 查询操作(如用户信息查询)。 | 仅事务内异常回滚,非事务不回滚。 | ★★★☆☆ |
| MANDATORY | 当前必须存在事务,否则抛出异常。 | 敏感操作(如财务转账)。 | 无事务时立即抛异常,不执行方法。 | ★★☆☆☆ |
| REQUIRES_NEW | 始终创建新事务,挂起当前事务(如果存在)。 | 日志记录(独立于主业务事务)。 | 新事务异常不影响原事务,反之亦然。 | ★★★★☆ |
| NOT_SUPPORTED | 以非事务方式执行,挂起当前事务(如果存在)。 | 无需事务的耗时操作(如文件上传)。 | 任何异常不触发回滚。 | ★★☆☆☆ |
| NEVER | 以非事务方式执行,若当前存在事务则抛出异常。 | 禁止事务的操作(如批处理)。 | 存在事务时立即抛异常,不执行方法。 | ★☆☆☆☆ |
| NESTED | 当前存在事务时创建嵌套事务(子事务),否则等同于 REQUIRED。子事务可独立回滚。 | 分步操作(如批量导入时部分失败)。 | 子事务异常仅回滚子事务,父事务可选择回滚。 | ★★★☆☆ |
注意:内部方法调用事务失效,因为Spring事务基于AOP动态代理(通过代理对象实现事务拦截:通过代理对象调用方法,才能在方法前后加上事务相关逻辑:开启、提交或回滚事务),而内部调用=this<>代理对象,不会触发事务拦截。
解决:将内部调用方法提取成外部类的方法,或者在类A中注入自己,通过注入对象调用即可。
事务的ACID特性
事务(Transaction) 是由一组不可分割的 SQL 操作组成的逻辑单元,这些操作要么全部成功执行,要么全部失败回滚。满足 ACID 特性,即原子性、一致性、隔离性、持久性。
1. 原子性(Atomicity)
- 定义:事务中的所有操作要么全部完成,要么全部不完成,不存在中间状态。
- 实现机制:通过数据库的undo log实现回滚。如果事务执行过程中发生错误,系统会回滚所有已执行的操作,恢复到事务开始前的状态。
2. 一致性(Consistency)
- 定义:事务执行前后,数据库的完整性约束(如主键约束、外键约束、业务规则等)必须保持一致。
- 实现机制:
- 数据库通过约束检查(如唯一性约束、非空约束)确保数据符合规则。
- 应用层需保证业务逻辑的正确性(如转账时总金额不变)。
3. 隔离性(Isolation)
- 定义:多个事务并发执行时,每个事务的执行不受其他事务干扰,如同串行执行一样。
- 隔离级别:SQL 标准定义了 4 种隔离级别,从低到高依次为:
- 读未提交(Read Uncommitted):允许读取尚未提交的数据,maybe脏读。
- 读已提交(Read Committed):只允许读取已提交的数据,避免脏读,maybe不可重复读。
- 可重复读(Repeatable Read):确保同一事务中多次读取同一数据的结果一致,避免不可重复读,但可能导致幻读(InnoDB 通过 MVCC 解决)。
- 串行化(Serializable):强制事务串行执行,避免所有并发问题,但性能最低。
- 实现机制:
- 锁机制(如行锁、表锁)。
- 多版本并发控制(MVCC)(如 InnoDB 的快照读)。
4. 持久性(Durability)
- 定义:一旦事务提交,其对数据库的修改将永久保存,即使系统崩溃也不会丢失。
- 实现机制:
- 预写日志(WAL, Write-Ahead Logging):事务修改先写入日志(redo log),再异步刷新到磁盘数据文件。
- 检查点(Checkpoint):定期将内存中的脏页刷新到磁盘,减少崩溃恢复时间。
注意权衡:
- 高性能 vs 强一致性:高并发场景下,严格的隔离级别可能导致锁争用,降低性能(如 Serializable)。
- CAP 定理:分布式系统中,需在一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)之间权衡。
间隙锁
间隙锁是 MySQL InnoDB 存储引擎在可重复读(Repeatable Read) 隔离级别下,为解决幻读问题引入的锁机制。它锁定的不是具体数据行,而是数据行之间的 “间隙”,阻止其他事务在间隙中插入数据,从而避免幻读。
-
间隙锁的作用是什么?如何解决幻读?
- 答:间隙锁锁定索引间隙,阻止其他事务在间隙中插入数据。例如,事务 A 查询
id>10时加(10, +∞)间隙锁,事务 B 无法插入id=11,避免幻读。
- 答:间隙锁锁定索引间隙,阻止其他事务在间隙中插入数据。例如,事务 A 查询
-
间隙锁的锁定范围如何确定?
- 答:取决于查询条件和索引:
- 等值查询
id=3:锁定(前一个id, 3]的临键锁,如(1,3]; - 范围查询
id>3:锁定(3, +∞)所有间隙; - 无索引查询:升级为表锁,锁定
(-∞, +∞)。
- 等值查询
- 答:取决于查询条件和索引:
-
间隙锁会导致死锁吗?如何优化?
- 答:会。当两个事务互相等待对方持有的间隙锁时可能死锁。优化方式包括:降低隔离级别至
读已提交、为查询字段添加索引、缩小锁定范围(用SELECT ... FOR UPDATE替代UPDATE,仅对查询结果加锁,而非全范围)避免长事务(减少事务持有间隙锁的时间,降低冲突概率)等。
- 答:会。当两个事务互相等待对方持有的间隙锁时可能死锁。优化方式包括:降低隔离级别至
多版本并发控制 - MVCC
MVCC通过为每个数据版本记录时间戳来实现,读操作不会修改数据,读的时某个时间点的快照,写操作会生成新的版本,这样读操作无需等待写操作完成,同时写操作也不会阻塞,在InnoDB存储引擎里,使用undo log来实现MVCC。
锁
数据库锁:排他锁与共享锁
1. 排他锁(X 锁,Exclusive Lock)
-
定义:又称写锁,持有排他锁的事务可读写数据,其他事务无法获取该数据的任何锁(读 / 写均阻塞)。
-
使用场景:写操作(如 UPDATE、DELETE)需确保数据独占性。
2. 共享锁(S 锁,Shared Lock)
-
定义:又称读锁,持有共享锁的事务可读取数据,但无法修改;其他事务可获取共享锁(读操作并发),但无法获取排他锁(写操作阻塞)。
-
使用场景:读操作需保证数据一致性,且允许其他读操作并发。
3. 锁兼容性矩阵
|
锁类型 |
共享锁(S) |
排他锁(X) |
|---|---|---|
|
共享锁(S) |
兼容 |
不兼容 |
|
排他锁(X) |
不兼容 |
不兼容 |
编程层面:悲观锁与乐观锁
1. 悲观锁(Pessimistic Lock)
-
核心思想:假设并发操作时数据冲突概率高,提前对数据加锁,阻止其他操作修改。
-
数据库层面:使用排他锁、共享锁(如前文的
FOR UPDATE); -
代码层面:Java 中的
synchronized、ReentrantLock。
2. 乐观锁(Optimistic Lock)
-
核心思想:假设并发操作时数据冲突概率低,不提前加锁,而是在更新时检查数据是否被修改。
-
版本号机制:表中添加
version字段,更新时判断版本是否一致(如UPDATE table SET stock=stock-1, version=version+1 WHERE id=1 AND version=1); -
时间戳(Timestamp):类似版本号,通过时间戳判断数据是否过期;
-
CAS(Compare-And-Swap):硬件级原子操作(如 Java 的
AtomicInteger)。
四、分布式场景:Redis 分布式锁
1. 核心需求与挑战
-
场景:多节点分布式系统中,需保证跨节点的操作互斥(如秒杀、分布式任务调度)。
-
挑战:
-
单点故障(主节点宕机导致锁丢失);解决办法:redlock
-
锁超时(业务执行时间超过锁过期时间,导致锁被提前释放);解决办法:用定时任务来延长锁的过期时间,在获取锁之后,启动一个定时任务,每隔一段时间就去检查一下锁在不在,如果在就延长过期时间,定时任务单线程使用Timer,多线程使用TimerTask和ScheduledExecutorService替代Timer,线程安全;
-
误删锁(A 节点释放 B 节点的锁);解决办法:clientId(客户端唯一标识,释放锁时通过 Lua 脚本验证,防止误删)
-
2. Redlock 算法
-
核心思想:通过多 Redis 节点(至少 5 个)实现分布式锁,多数节点加锁成功才认为获取锁,提升可靠性。
-
步骤:
-
获取当前时间戳(毫秒);
-
依次向 5 个 Redis 节点请求加锁(使用相同 key 和过期时间);
-
若在多数节点(≥3)加锁成功,且总耗时小于锁过期时间,则认为获取锁成功;
-
若失败,向所有节点释放锁(即使部分节点加锁失败)。
-
代码层面常见锁机制(以 Java 为例)
1. 内置锁:synchronized
-
隐式加锁,自动释放(进入代码块加锁,退出释放);
-
可作用于方法、代码块,基于 JVM 实现。
2. 显式锁:ReentrantLock (可重入锁)
-
显式加锁(
lock())和释放(unlock()),需配合finally防止死锁; -
支持公平锁(按申请顺序获取锁)、可中断锁、超时获取锁等高级功能。
3. 读写锁:ReentrantReadWriteLock
-
分离读锁(共享)和写锁(排他),允许多线程并发读,但写操作独占;
-
适合读多写少场景(如缓存更新)。
4. 原子类:CAS 机制(基于硬件级compareAndSwap操作,无锁实现原子更新)
|
锁类型 |
核心特点 |
典型场景 |
优缺点 |
|---|---|---|---|
|
排他锁(X 锁) |
写操作独占,阻塞其他读写 |
资金转账、库存扣减 |
安全性高,但并发性能低 |
|
共享锁(S 锁) |
读操作共享,写操作阻塞 |
报表查询、商品详情页 |
读并发高,但写操作可能阻塞 |
|
悲观锁 |
提前加锁,阻止冲突 |
强一致性场景(如金融交易) |
实现简单,但可能导致线程阻塞 |
|
乐观锁 |
事后检查,冲突时重试 |
读多写少场景(如商品浏览计数) |
无锁开销,但需处理冲突重试 |
|
Redis 分布式锁 |
跨节点互斥,基于缓存实现 |
分布式秒杀、全局任务调度 |
需处理单点故障和时钟同步问题 |
|
synchronized |
JVM 内置,自动管理生命周期 |
简单的单节点线程安全控制 |
语法简洁,功能有限(无超时、公平性) |
|
ReentrantLock |
显式控制,支持高级功能 |
复杂并发场景(如定时任务调度) |
功能强大,但需手动释放锁 |
最佳实践
-
锁粒度控制:避免锁范围过大(如整表锁),尽量使用行级锁或更细粒度的锁。
-
超时机制:分布式锁必须设置过期时间,避免服务宕机导致死锁;代码层面的锁可使用
tryLock(timeout)防止永久阻塞。 -
幂等性设计:结合锁与幂等机制(如唯一 ID),避免重复操作(如重复下单)。
- 监控与告警:对分布式锁的获取失败率、锁超时情况进行监控,及时发现问题。
线程安全的数据结构
| 数据结构 | 锁类型 | 备注 |
|---|---|---|
| Vector | synchronized 方法 |
所有方法都被同步,性能较差,已被 ArrayList + Collections.synchronizedList 替代 |
| Hashtable | synchronized 方法 |
所有方法都被同步,不允许 null 键值,已被 ConcurrentHashMap 替代 |
| ConcurrentHashMap 1.7 | 分段锁(Segment 数组) | 使用分段锁,不同段可并发访问,默认 16 个段 |
| ConcurrentHashMap 1.8 | CAS + synchronized(Node 节点) | 采用 CAS 和 synchronized 优化,锁粒度更小,并发性能更高 |
| CopyOnWriteArrayList | ReentrantLock | 写操作时复制数组,读操作无锁,适用于读多写少场景 |
| Collections.synchronizedList | synchronized 块 |
包装普通 List,所有操作通过同一把锁同步 |
| AtomicIntegerArray | CAS(Compare-and-Swap) | 原子操作数组,基于 Unsafe 类实现无锁并发 |
| ArrayBlockingQueue | ReentrantLock(公平 / 非公平) | 有界阻塞队列,FIFO 顺序 |
| LinkedBlockingQueue | ReentrantLock(两把锁) | 可选有界阻塞队列,读写分离锁,吞吐量较高 |
| PriorityBlockingQueue | ReentrantLock | 无界优先级阻塞队列,元素需实现 Comparable 接口 |
补充说明:
- 锁粒度:ConcurrentHashMap 1.8 锁粒度最小(Node 节点),Vector/Hashtable 锁粒度最大(整个对象)。
- 适用场景:
- 读多写少:CopyOnWriteArrayList、ConcurrentHashMap 1.8。
- 高并发写入:ConcurrentHashMap 1.8(优于 1.7)。
- 阻塞队列:ArrayBlockingQueue(有界)、LinkedBlockingQueue(可选有界)。
- Null 值支持:只有 ConcurrentHashMap 和 CopyOnWriteArrayList 允许 null 值。
- 迭代器特性:CopyOnWriteArrayList 的迭代器支持弱一致性(创建时的快照),其他结构的迭代器可能抛出 ConcurrentModificationException。
- 在 ConcurrentHashMap 1.8里,插入元素时先看数组对应位置,若为空,用CAS操作尝试插入,不用加锁;若该位置已有节点(哈希冲突),就可能在链表或红黑树上操作,这时会用到锁。数组初始长度16,负载因子0.75,链表长度超8且数组长度至少64时,链表会转成红黑树。
- ReentrantLock 是Java并发包中的锁,可重入,同一个线程能多次获取和释放。有公平锁(按照顺序来获取)和非公平锁(即来即获取)模式。使用时在 try 块获取锁, finally 块释放锁,防止死锁,能替代 synchronized 实现更灵活的同步控制。
- StringBuilder 和 Buffer都用于字符串拼接。 StringBuffer线程安全(使用synchronized),适用于多线程,但性能稍逊,出现较早。 StringBuilder非线程安全,单线程性能好,是后来引入的。根据线程环境选就行,单线程用 StringBuilder ,多线程用 StringBuffer。StringBuffer / StringBuilder sa = new StringBuffer() /new StringBuilder(); sa.append("111"); sa.append("222"); String result = sa.toString();
- Vector是一种动态数组数据结构。它和ArrayList很相似,底层都是用数组来存储元素。不过Vector是线程安全的,很多方法都加了同步锁,在多线程环境下能保证数据一致性。但因为加锁,性能会比ArrayList差一些。当数组满了需要扩容时,均会翻倍扩容。
- CAS机制下会存在ABA问题,使用AtomicStampedReference(给数据加上版本号) 来解决 ABA 问题。
- CAS 的局限性:需解决 ABA 问题、自旋开销和多变量原子性问题,常与 Volatile 结合使用。
常见设计模式
| 类型 | 模式名称 | 核心思想 | 典型应用场景 |
|---|---|---|---|
| 创建型模式 | 单例模式(Singleton) | 确保类只有一个实例,提供全局访问点 | 日志工具、线程池、配置管理器 |
| 工厂方法模式(Factory Method) | 定义创建对象的接口,由子类决定实例化哪个类 | JDBC 驱动加载、框架插件扩展 | |
| 抽象工厂模式(Abstract Factory) | 提供创建相关对象家族的接口,无需指定具体类 | GUI 组件库(如跨平台 UI 控件)、游戏场景生成 | |
| 建造者模式(Builder) | 将复杂对象的构建与表示分离,允许相同构建过程创建不同表示 | 复杂对象初始化(如 SQL 查询构造器)、文档生成 | |
| 原型模式(Prototype) | 通过复制现有对象创建新对象,避免重复初始化 | 游戏角色克隆、配置对象复制 | |
| 结构型模式 | 适配器模式(Adapter) | 将一个类的接口转换为客户端期望的另一个接口,解决接口不兼容问题 | 旧系统接口兼容、第三方库整合 |
| 桥接模式(Bridge) | 将抽象部分与实现部分分离,使两者可独立变化 | 多平台适配(如操作系统与图形库分离)、UI 主题切换 | |
| 组合模式(Composite) | 将对象组合成树形结构,表示 "部分 - 整体" 层次结构,统一处理单个对象和组合对象 | 文件系统目录结构、组织结构管理、游戏场景物体 | |
| 装饰器模式(Decorator) | 动态地为对象添加额外功能,避免继承导致的类爆炸 | IO 流处理(如 BufferedInputStream 包装)、日志增强 | |
| 外观模式(Facade) | 为复杂子系统提供统一接口,简化客户端与子系统的交互 | 框架 API 封装(如 Spring JDBC)、系统集成接口 | |
| 享元模式(Flyweight) | 共享多个对象的公共部分,减少内存占用 | 文本编辑器字符渲染、游戏中大量相似对象(如士兵) | |
| 代理模式(Proxy) | 为其他对象提供代理,控制对原对象的访问 | 远程调用(如 RPC 代理)、延迟加载(如图像加载) | |
| 行为型模式 | 责任链模式(Chain of Responsibility) | 将请求发送者与接收者解耦,多个对象可处理请求并形成链条,直到请求被处理 | 审批流程、错误处理链、Servlet 过滤器 |
| 命令模式(Command) | 将请求封装为对象,使发送者与接收者解耦,支持请求排队、撤销等操作 | 编辑器撤销 / 重做、游戏按键命令、分布式任务 | |
| 迭代器模式(Iterator) | 提供遍历集合元素的统一接口,不暴露集合内部表示 | 集合框架(如 Java 的 Iterator)、自定义数据结构遍历 | |
| 中介者模式(Mediator) | 定义中介对象协调其他对象交互,避免对象间直接引用 | GUI 界面组件交互(如按钮与文本框联动)、网络聊天系统 | |
| 备忘录模式(Memento) | 在不破坏封装的前提下,捕获对象状态并保存,可恢复至先前状态 | 编辑器撤销功能、游戏存档、数据库事务回滚 | |
| 观察者模式(Observer) | 定义对象间的一对多依赖,主题状态变化时通知所有观察者 | 消息推送(如新闻订阅)、事件监听(如按钮点击) | |
| 状态模式(State) | 对象行为随状态改变而变化,将状态转换封装为独立类 | 电梯状态控制、订单状态机、游戏角色状态切换 | |
| 策略模式(Strategy) | 定义一系列算法,将每个算法封装为独立类,可相互替换 | 排序算法选择、支付方式切换、路由策略选择 | |
| 模板方法模式(Template Method) | 定义算法骨架,将具体步骤延迟到子类实现 | 框架设计(如 JDBCTemplate)、日志处理流程 | |
| 访问者模式(Visitor) | 封装作用于对象结构中各元素的操作,使操作可独立于元素变化 | 编译器语法树遍历、文档解析、数据统计报表 |
选择指南
-
当需要控制对象创建时:
- 若需唯一实例 → 单例模式;
- 若需延迟对象创建 → 工厂方法 / 抽象工厂;
- 若需复杂对象构建流程 → 建造者模式。
-
当需要处理对象结构时:
- 若需接口兼容 → 适配器模式;
- 若需动态添加功能 → 装饰器模式;
- 若需表示 "部分 - 整体" 关系 → 组合模式。
-
当需要优化对象交互时:
- 若需一对多状态通知 → 观察者模式;
- 若需算法动态切换 → 策略模式;
- 若需流程标准化 → 模板方法模式。
DispatcherServlet(Spring Web MVC的核心控制器,引入spring-boot-starter-web依赖后自动配置)
- 负责接收HTTP请求,根据URL等信息,将请求分发到对应的处理器(Controller)去处理。
- 负责视图解析、异常处理等。
PageHelper
性能瓶颈&注意事项:
- 处理大宽表时,分页插件会进行原始sql包装,给全量数据分配行号id,然后排序取行号id在startIndex和pageSize范围内的
- 是双层子查询结构
- 脱外套后提速超1000倍
- 要注意现在很多框架里都封装了pageHelper插件,要去掉参数中的RowBounds才可以转手动分页哦
- 此外,分页一定要注意排序,例如order by createDt,id结合使用,否则会导致同一行数据出现在多页面中
- 查询总数如果非必要也建议拿掉
java 1.8 新特性
| 特性分类 | 核心内容 | 示例代码 | 应用场景 |
|---|---|---|---|
| Lambda 表达式 | 简化函数式接口实现,用更简洁的语法表示匿名函数 | () -> System.out.println("Hello")(a, b) -> a + b |
线程创建、事件监听、集合遍历等 |
| Stream API |
提供流式数据处理能力,支持过滤、映射、聚合等操作
|
list.stream().filter(n -> n>5).mapToInt(Integer::intValue).sum() |
集合数据处理、数据分析、并行计算 |
| 函数式接口 | 仅含一个抽象方法的接口,可被 Lambda 实现 | @FunctionalInterfaceinterface Predicate<T> { boolean test(T t); } |
作为 Lambda 的目标类型、行为参数传递 |
| 接口默认 / 静态方法 | 接口中可实现默认方法(default)和静态方法,解决接口演进问题 |
interface MyInterface {<br> default void method() {}<br> static void func() {}<br>} |
接口升级时不破坏现有实现、工具方法封装 |
| 新日期时间 API | java.time包,提供线程安全、易用的日期时间处理类 |
LocalDate today = LocalDate.now();ZonedDateTime zdt = ZonedDateTime.now(); |
日常日期计算、时区处理、格式化显示 |
| 方法引用 | 简化 Lambda,直接引用已有方法(静态方法、实例方法等) | System.out::printlnString::toUpperCaseArrayList::new |
代码复用、减少冗余 Lambda 表达式 |
| Optional 类 |
封装可能为 null 的值,避免 NPE,明确表示值的存在性
|
Optional<String> opt = Optional.of("data");opt.orElse("default"); |
方法返回值、对象属性的空值处理 |
| 并行流 | 通过parallelStream()利用多核 CPU 并行处理集合数据 |
list.parallelStream().forEach(System.out::println); |
大数据量集合的高性能处理 |
| 重复注解 | 允许在同一位置多次使用相同注解,通过@Repeatable元注解实现 |
@Author("Alice")<br>@Author("Bob")<br>public class Book {} |
多作者标注、多配置项声明 |
| Base64 编码 | 内置java.util.Base64类,支持编解码 |
String encoded = Base64.getEncoder().encodeToString("data".getBytes()); |
数据传输、密码存储、文件编码 |
| Nashorn 引擎 | JVM 内置 JavaScript 引擎,支持 Java 与 JS 互调 | ScriptEngine engine = new NashornScriptEngine();engine.eval("print('Hello')"); |
动态脚本执行、前端后端逻辑集成 |
| 元空间(Metaspace) | 替代永久代(PermGen),使用本地内存,减少 OOM 风险 | - | 类加载、动态代理、字节码生成场景 |
并发&并行
并发:多个任务在同一时间段内交替执行,宏观上看似同时运行,但微观上是分时复用 CPU 资源。通过时间片轮转或任务切换实现多任务处理。适用于 I/O 密集型任务(如 Web 服务器处理多个请求)。例如:线程、协程、事件循环。
并行:多个任务在同一时刻真正同时执行,依赖多核 CPU 或多处理器硬件支持。通过物理资源并行实现真正的同时执行。适用于计算密集型任务(如科学计算、图像处理)。例如:多线程、多进程、GPU 计算。
transient
用于修饰类的成员变量,指示该变量在对象序列化时应被忽略。这意味着当对象被序列化(如写入文件或通过网络传输)时,被 transient 修饰的变量不会被保存或传输,其值会被设为默认值(如 null、0 或 false)。
Volatile
一、Volatile 的作用是什么?
核心回答:
Volatile 是 Java 的轻量级同步机制,主要解决两大问题:
- 可见性:确保一个线程修改变量后,其他线程能立即看到最新值(通过禁止 CPU 缓存重排和强制从主内存读取)。
- 有序性:通过内存屏障(Memory Barrier)禁止指令重排序,保证 volatile 变量的读写操作按代码顺序执行。
底层实现:
- 写操作时,JMM(Java 内存模型)会在指令后插入
StoreStore和StoreLoad屏障,强制刷新主内存。 - 读操作时,插入
LoadLoad和LoadStore屏障,强制从主内存读取。
二、Volatile 能保证原子性吗?为什么?
核心回答:
不能。Volatile 仅保证单次读 / 写操作的原子性,但无法保证复合操作(如 i++)的原子性。原因:
- 复合操作(如 i++)的字节码包含 3 步:读取(load)、修改(inc)、写入(store),Volatile 无法保证这三步的原子性。
- 示例:多线程同时执行
i++时,可能出现线程 A 读取 i=10,线程 B 也读取 i=10,最终 i=11 而非 12。
延伸问题:
- 如何保证原子性?
答:使用synchronized、Lock或原子类(如AtomicInteger)。
三、Volatile 和 Synchronized 的区别?
| 维度 | Volatile | Synchronized |
|---|---|---|
| 作用范围 | 修饰变量,保证可见性和有序性 | 修饰方法或代码块,保证原子性和互斥性 |
| 性能开销 | 轻量级,仅插入内存屏障 | 重量级,涉及线程阻塞和唤醒 |
| 原子性 | 不保证(除 boolean、long、double 的读写) | 完全保证 |
| 可见性 | 保证 | 保证(同步块结束时刷新主内存) |
| 底层实现 | 内存屏障 | monitorenter/monitorexit指令 |
四、Volatile 的应用场景有哪些?
典型场景:
- 状态标记变量(如
boolean running = false):volatile boolean stop = false; // 线程A修改stop=true,线程B能立即感知并退出循环 while (!stop) { doTask(); } - 双重检查锁定(DCL)优化单例模式:
public class Singleton { private volatile static Singleton instance; // 禁止指令重排 public static Singleton getInstance() { if (instance == null) { // 第一层检查 synchronized (Singleton.class) { if (instance == null) { // 第二层检查 instance = new Singleton(); // 可能被重排的三步操作 } } } return instance; } }
关键:若instance未加volatile,可能因指令重排导致其他线程获取到未初始化完成的对象。
五、Volatile 变量的读写过程如何实现可见性?
JMM 模型解释:
- 写操作:
- 线程修改 volatile 变量时,强制将值刷新到主内存。
- 其他线程缓存中的该变量失效,下次读取时必须从主内存获取。
- 读操作:
- 线程读取 volatile 变量时,强制从主内存读取最新值,而非本地缓存。
六、Volatile 禁止指令重排序的原理是什么?
内存屏障机制:
- JVM 在生成字节码时,会在 volatile 变量的读写操作前后插入内存屏障:
- 写操作前:插入
StoreStore屏障,确保屏障前的写操作先于 volatile 写操作完成。 - 写操作后:插入
StoreLoad屏障,确保 volatile 写操作先于后续读 / 写操作。 - 读操作前:插入
LoadLoad屏障,确保 volatile 读操作先于屏障后的读操作。 - 读操作后:插入
LoadStore屏障,确保屏障前的读操作先于 volatile 读操作完成。
- 写操作前:插入
七、Volatile 能解决循环依赖吗?为什么?
核心回答:
不能。Volatile 的作用是保证变量的可见性和有序性,而循环依赖属于对象引用关系问题(如 A 引用 B,B 引用 A),需通过设计层面(如弱引用、依赖注入)解决,与 Volatile 无关。
八、面试高频陷阱问题:Volatile 修饰 long/double 变量时是否保证原子性?
JLS 规范:
- 对于 64 位基本类型(long/double),JVM 允许非原子性读写(“半写” 问题),但实际 JVM 实现中几乎都保证了原子性。
- 结论:面试中回答 “理论上不保证,实际 JVM 实现通常保证”,并强调 volatile 本身不保证复合操作的原子性。
总结:Volatile 核心考点速记
- 两大特性:可见性(主内存同步)、有序性(禁止重排),不保证原子性。
- 应用场景:状态标记、DCL 单例、轻量级同步(替代 synchronized 的场景)。
- 底层原理:内存屏障插入、主内存与工作内存的强制同步。
- 与 Synchronized 对比:轻量级、作用范围不同,后者保证原子性和互斥性。
springboot层级划分
Controller 层、Service 层、Repository 层、Config层
┌─────────────────────────────────────────┐
│ 表现层 (Presentation) │
│ ┌─────────────────────────────────────┐ │
│ │ Controller DTO ExceptionHandler │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────┘
│ ↑ │
▼ ▼ ▼
┌─────────────────────────────────────────┐
│ 业务逻辑层 (Service) │
│ ┌─────────────────────────────────────┐ │
│ │ Service接口 Service实现类 │ │
│ │ 事务管理 业务异常处理 │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────┘
│ ↑ │
▼ ▼ ▼
┌─────────────────────────────────────────┐
│ 数据访问层 (Repository) │
│ ┌─────────────────────────────────────┐ │
│ │ Repository/DAO Entity Mapper │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────┘
│ ↑ │
▼ ▼ ▼
┌─────────────────────────────────────────┐
│ 基础设施层 (Infrastructure) │
│ ┌─────────────────────────────────────┐ │
│ │ Config Utils External Client │ │
│ └─────────────────────────────────────┘ │
└─────────────────────────────────────────┘MVC VS MVP VS MVVM
MVC(Model-View-Controller)
将应用分为三个主要部分:
- Model:负责数据和业务逻辑。
- View:负责 UI 展示,通常直接渲染 Model 数据。
- Controller:接收用户输入,协调 Model 和 View 的交互。
MVP(Model-View-Presenter)
将 Controller 改为 Presenter,强化解耦:
- Model:同 MVC。
- View:更被动,只负责显示 UI 和传递用户操作,不包含业务逻辑。
- Presenter:处理所有业务逻辑,与 View 通过接口交互,持有 View 引用。
MVVM(Model-View-ViewModel)
引入 ViewModel 和数据绑定:
- Model:同 MVC。
- View:只负责 UI 展示,通常由 XAML 或 HTML 定义。
- ViewModel:暴露属性和命令,通过数据绑定自动更新 View,反之亦然。
DDD
DDD(Domain-Driven Design,领域驱动设计)是一种软件开发方法论,由 Eric Evans 在 2004 年提出,核心是将业务领域知识与技术实现深度融合,通过领域模型驱动软件设计。
TDD
TDD(Test-Driven Development,测试驱动开发)是一种软件开发方法论,核心是先写测试,后实现代码,通过测试来驱动功能的设计和实现。
多线程
什么是线程池?为什么要用它?
线程池是管理一组预先创建的线程的资源池,用于执行异步任务。
优点:
- 减少线程创建 / 销毁开销,提升响应速度
- 控制并发线程数,防止资源耗尽
- 提供任务队列和拒绝策略,增强稳定性
高频面试题:
- 如何创建线程池?
使用Executors工厂方法(如newFixedThreadPool)或手动配置ThreadPoolExecutor。
如何减少线程上下文切换?
- 无锁并发编程:如使用
ConcurrentHashMap替代synchronized Map - CAS 操作:使用
Atomic类(如AtomicInteger)减少锁竞争 - 合理配置线程数:CPU 密集型任务线程数 = CPU 核心数,IO 密集型可适当增加
- 使用协程(Coroutine):轻量级线程,减少内核级切换开销
Java 线程池核心参数及拒绝策略?
- 核心参数:corePoolSize(核心线程数)、maximumPoolSize(最大线程数)、keepAliveTime(空闲线程存活时间)、workQueue(工作队列:存储待执行任务的阻塞队列,当核心线程已满时,新任务会被放入队列等待)、RejectedExecutionHandler(拒绝策略:当最大线程数已满且工作队列也满时,新提交的任务会被拒绝。)
- workQueue:
- ArrayBlockingQueue:有界队列,指定固定容量(如
new ArrayBlockingQueue<>(100)); - LinkedBlockingQueue:无界队列(默认容量为
Integer.MAX_VALUE),可能导致 OOM; - SynchronousQueue:直接提交队列,不存储任务,每个插入操作必须等待另一个线程的移除操作。
- 拒绝策略:
- AbortPolicy(默认):抛出
RejectedExecutionException异常; - CallerRunsPolicy:由提交任务的线程(调用
execute()的线程)直接执行该任务; - DiscardPolicy:直接丢弃任务,不做任何处理;
- DiscardOldestPolicy:丢弃队列中最老的任务,尝试重新提交当前任务。
异步处理场景中如何保证结果回调的可靠性?
- 用 CompletableFuture 的 whenComplete/handle 回调,结合线程池隔离;
- 失败时记录日志 + 重试机制(如定时任务扫描失败记录)。
Java 创建多线程的方式
1. 继承 Thread 类
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("Thread running");
}
}
// 使用
MyThread thread = new MyThread();
thread.start();
2. 实现 Runnable 接口
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("Runnable running");
}
}
// 使用
Thread thread = new Thread(new MyRunnable());
thread.start();
3. 实现 Callable 接口(带返回值)
import java.util.concurrent.*;
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
return 123;
}
}
// 使用
ExecutorService executor = Executors.newSingleThreadExecutor();
Future<Integer> future = executor.submit(new MyCallable());
Integer result = future.get();
4. 使用线程池(推荐)
ExecutorService executor = Executors.newFixedThreadPool(5);
executor.submit(() -> {
System.out.println("Task executed by thread pool");
});
executor.shutdown();
多线程中身份信息管理方案
1. 使用 ThreadLocal
ThreadLocal为每个使用该变量的线程都提供一个独立的变量副本:
public class UserContext {
private static final ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
public static void setUser(User user) {
userThreadLocal.set(user);
}
public static User getUser() {
return userThreadLocal.get();
}
public static void clear() {
userThreadLocal.remove(); // 避免内存泄漏
}
}
// 在拦截器或过滤器中设置用户信息
UserContext.setUser(currentUser);
// 在业务逻辑中获取
User user = UserContext.getUser();
2. InheritableThreadLocal(子线程继承父线程数据)
private static final InheritableThreadLocal<User> userThreadLocal =
new InheritableThreadLocal<>();
3. 使用 MDC(Mapped Diagnostic Context)
// SLF4J MDC示例
import org.slf4j.MDC;
// 在请求入口设置
MDC.put("userId", currentUser.getId());
// 在日志中自动打印
logger.info("Processing request");
// 请求结束时清除
MDC.clear();- 内存泄漏:使用完
ThreadLocal后必须调用remove() - 线程池场景:线程会被复用,需在任务开始 / 结束时手动设置 / 清除
- 异步任务传递:若使用
CompletableFuture等异步 API,需手动传递上下文
ThreadLocal 原理及内存泄漏原因?
- 每个线程维护
ThreadLocalMap,键为弱引用ThreadLocal对象 - 若线程长期存活且未调用
remove(),会导致值对象无法被回收
单例模式实现
1. 双检锁(Double-Checked Locking) 是一种延迟初始化(Lazy Initialization)的优化模式,通过两次检查实例是否已创建,避免不必要的同步开销。
DCL
public class Singleton {
private static volatile Singleton instance; // 注意:必须使用volatile关键字
private Singleton() {} // 私有构造函数
public static Singleton getInstance() {
if (instance == null) { // 第一次检查:不加锁
synchronized (Singleton.class) {
if (instance == null) { // 第二次检查:加锁后
instance = new Singleton(); // 关键步骤
}
}
}
return instance;
}
}
饿汉式单例(Eager Initialization)
class SafeSingleton {
private static final SafeSingleton instance = new SafeSingleton();
public static SafeSingleton getInstance() {
return instance;
}
}
线程安全原理:
- 类加载机制保证:Java 的类加载过程是线程安全的,静态变量instance会在类第一次加载时初始化,且只初始化一次。
- 无需同步:没有锁开销,调用getInstance()直接返回已创建的实例,性能最优。2. 静态内部类(推荐)
public class Singleton {
private Singleton() {}
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance() {
return SingletonHolder.INSTANCE; // 类加载时自动初始化,线程安全
}
}
原理:Java 类加载机制保证静态内部类的初始化是线程安全且延迟的。
3. 枚举单例(最简)
public enum Singleton {
INSTANCE;
public void doSomething() {
// 业务方法
}
}
优势:自动处理序列化和反射攻击,线程安全。
静态内部类
静态内部类(Static Nested Class)的初始化时机由 Java 的类加载机制决定,遵循懒加载(Lazy Initialization) 原则:
- 首次被主动引用时
- 反射调用时
- 被其他类继承时(有限情况)
数据库连接池
数据库连接池是用于管理数据库连接的一种技术,它预先创建一组数据库连接并保存在池中,应用程序需要连接时从池中获取,使用完后再归还池中。
Spring Boot 默认使用 HikariCP 作为连接池(若存在于类路径中),只需在 application.properties 或 application.yml 中配置数据库连接信息即可。
配置示例(application.properties)
spring.datasource.url=jdbc:mysql://localhost:3306/mydb
spring.datasource.username=root
spring.datasource.password=password
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# HikariCP 额外配置(可选)
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.maximum-pool-size=10
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.max-lifetime=1800000关键参数
-
最大连接数 (max connections):连接池中允许的最大连接数量,超过此数量的请求将被阻塞或拒绝。
- 最小空闲连接数 (min idle connections):连接池中保持的最小空闲连接数量,当空闲连接数低于此值时,连接池会创建新的连接。
- 连接超时时间 (connection timeout):获取连接的最大等待时间,超过此时间将抛出异常。
- 连接回收时间 (connection lifetime/recycle):连接在池中保持的最长时间,超过此时间的连接将被关闭并重新创建。
Cookie、Token、Session
Cookie(客户端状态存储) 是由服务器生成、存储在客户端(浏览器 / 手机)的小段文本数据,每次请求时会自动附带至服务器。可通过Expires或Max-Age设置过期时间,默认随浏览器关闭失效。
- 首次访问:服务器返回响应时,通过
Set-Cookie头部设置 Cookie(如用户 ID、会话 ID)。 - 后续请求:浏览器自动携带 Cookie 至服务器,服务器解析后识别用户状态。
Session 是存储在服务器端的用户状态数据,通过Session ID与客户端关联(通常存储在 Cookie 中)。
- 首次登录:服务器生成
Session ID,存储用户信息(如角色、权限),并通过 Cookie 返回JSESSIONID。 - 后续请求:浏览器携带
JSESSIONID,服务器根据 ID 查询 Session 数据。 - 过期机制:默认 30 分钟未活动则失效,可通过
sessionTimeout配置。
Token 是客户端携带的加密字符串,包含用户身份信息,服务器无需存储状态即可验证合法性。例如:JWT(JSON Web Token)、OAuth 2.0 Access Token。
Cookie 安全:
- 启用
HttpOnly防止 XSS 攻击。 - 启用
Secure仅在 HTTPS 下传输。 - 配置
SameSite为Strict/Lax防止 CSRF 攻击。
Session 安全:
- 定期更新
JSESSIONID(如登录后刷新 Session)。 - 分布式环境使用 Redis 存储 Session,避免单点故障。
- 设置合理的过期时间,超时后强制登出。
Token 安全:
- 使用 HTTPS 传输 Token,防止中间人攻击。
- 采用非对称加密(如 RS256),服务器仅保存公钥。
- 实现 Token 黑名单机制(如用户登出时将 Token 加入 Redis 黑名单)。
- 短有效期 Token + 长有效期 Refresh Token 组合(如 OAuth 2.0)。
HTTP 请求和 HTTP 会话
1. HTTP 请求(HTTP Request)
-
定义:客户端(如浏览器)向服务器发送的一次数据请求,包含请求方法(GET/POST 等)、URL、请求头和请求体等信息。
- 特点:
- 无状态:每个请求都是独立的,服务器不会自动记录请求之间的关联。
- 生命周期:从客户端发送请求开始,到服务器返回响应结束,持续时间短。
- 场景:例如用户点击一次链接、提交一次表单,都是一次 HTTP 请求。
2. HTTP 会话(HTTP Session)
-
定义:用于跟踪客户端与服务器之间的交互状态,将多次请求关联起来,通常通过
Session ID标识。 - 特点:
- 有状态:服务器通过 Session 保存用户状态(如登录信息、购物车数据),不同请求可共享 Session 数据。
- 生命周期:从用户首次访问创建 Session 开始,到超时(默认 30 分钟左右)或主动销毁结束。
- 实现方式:
- Cookie:服务器通过 Set-Cookie 响应头将 Session ID 存入客户端 Cookie,后续请求携带 Cookie 以识别会话。
- URL 重写:将 Session ID 拼入 URL(如
/path;jsessionid=xxx),适用于禁用 Cookie 的场景。
3. 核心对比
| 维度 | HTTP 请求 | HTTP 会话(Session) |
|---|---|---|
| 状态跟踪 | 无状态,单次请求独立 | 有状态,跟踪多次请求的关联关系 |
| 数据存储 | 不保存数据 | 保存用户状态数据(如登录信息) |
| 持续时间 | 单次请求 - 响应周期内有效 | 从创建到超时 / 销毁,持续时间较长 |
| 应用场景 | 单次数据获取 / 提交 | 跨请求的状态保持(如登录、购物车) |
4. 关联关系
-
一次 HTTP 会话由多次 HTTP 请求组成,每次请求通过 Session ID 关联到同一会话。
- 例如:用户登录后,后续浏览商品、添加购物车等请求,都会通过 Session 共享登录状态。
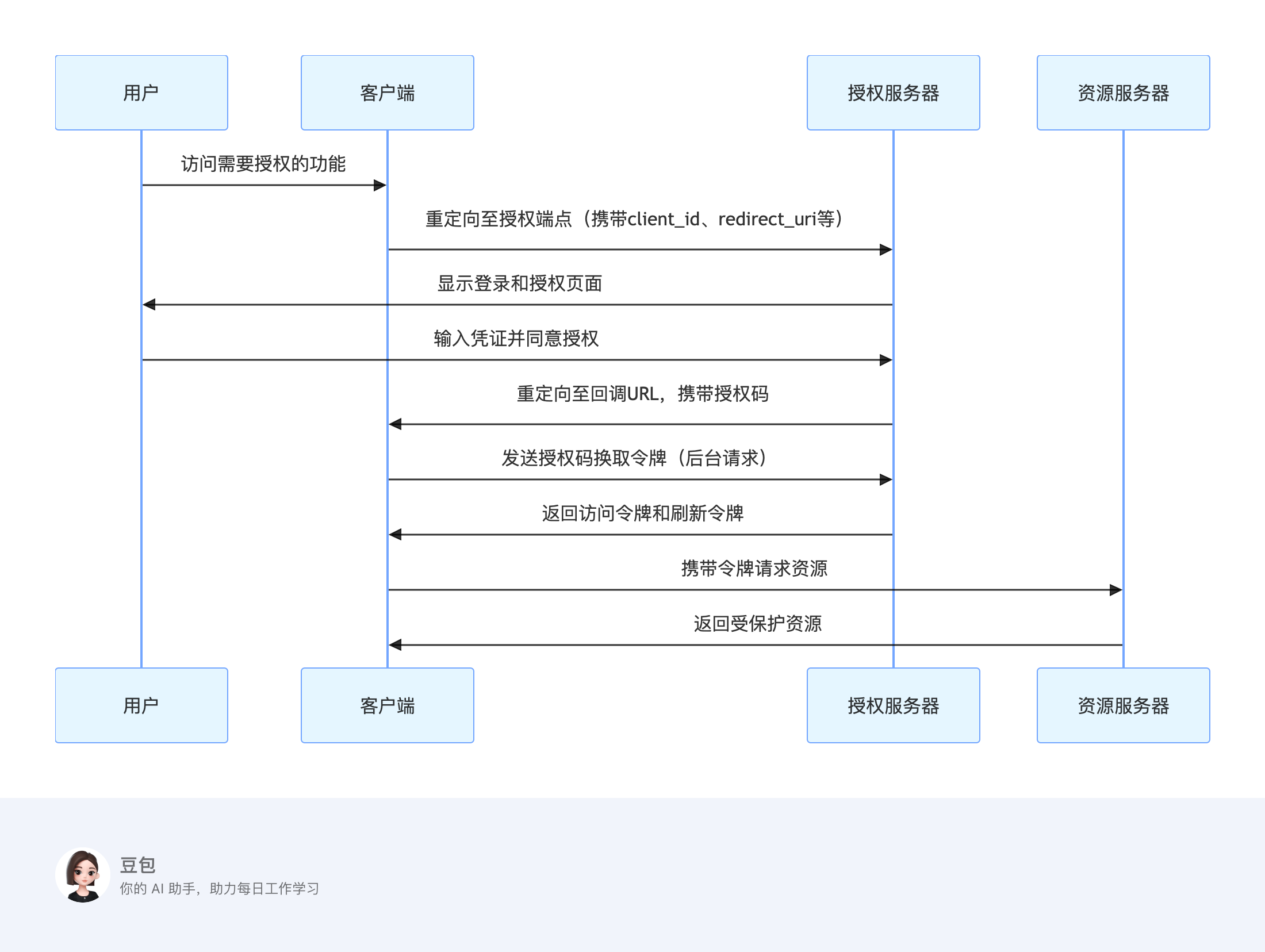
OAuth 2.0
单体架构 VS 微服务
微服务:把一个大型的软件应用拆分成一个个小的、独立的服务。每个服务都能单独运行、部署和维护,他们之间通过网络来互相通信和协作。
| 维度 | 单体架构 | 微服务架构 |
|---|---|---|
| 组织形式 | 单一代码库,单一部署单元 | 多个独立服务,独立部署 |
| 开发效率 | 初期高,后期因代码膨胀降低 | 团队并行开发,效率更高 |
| 技术栈 | 统一技术栈 | 各服务可自由选择技术栈 |
| 故障影响 | 单点故障导致整体不可用 | 单个服务故障不影响全局 |
| 扩展性 | 整体扩展,资源浪费 | 按需扩展特定服务 |
| 部署复杂度 | 低(单一部署单元) | 高(需管理多个服务) |
| 团队协作 | 适合小团队,沟通成本低 | 适合大团队,需明确服务边界 |
| 典型场景 | 中小型应用、功能稳定的系统 | 大型复杂系统、快速迭代的产品 |
-
微服务架构中常见的治理组件有哪些?各自解决什么问题?
- 注册中心(如 Nacos/Eureka):服务注册与发现,解决服务实例动态管理问题;
- 网关(如 Spring Cloud Gateway/APISIX):请求路由、负载均衡、权限控制;
- 熔断与限流(如 Sentinel/Hystrix):防止级联故障,保障服务可用性;
- 服务网格(如 Istio):流量治理、可观测性增强(链路追踪、Metrics 监控)。
-
微服务调用的分布式事务如何解决?
- 两阶段提交(2PC,例如XA协议):强一致性,适合金融场景;
- 最终一致性(如消息队列事务消息、TCC 模式):适用于高并发业务;
- 举例如:用 RocketMQ 事务消息实现订单与库存的异步一致性。
两阶段提交:把事务的提交过程分成准备和提交两个阶段。在准备阶段,所有参与者都要准备好提交,并且锁住相关资源。在提交阶段,如果所有参与者都准备就绪,协调器就会通知大家正式提交事务;要是有任何一个参与者不同意,就会回滚事务。它的优点是比较简单直接,能保证强一致性,但缺点是性能开销大,一旦协调器出问题,可能会导致事务阻塞。
最终一致性:不要求事务在每个阶段都保持强一致,允许系统在一定时间内达到最终的一致性。它通过异步通信和补偿机制来实现,性能更好,也更灵活,能适应高并发场景。不过,实现起来相对复杂一些,而且可能会出现数据不一致的情况。可以通过引入重试机制、用定时任务检查并修复解决。
总的来说,两阶段提交适合对一致性要求极高、并发量不太大的场景;最终一致性则更适合高并发、对一致性要求没那么严格的场景。
事务回滚:在微服务里,一般会用分布式事务框架来实现回滚。比如说,XA协议就是一种常见的实现方式,它通过在每个参与者中加入事务管理器,来记录事务的状态和操作日志。一旦需要回滚,事务管理器就会根据日志把事务操作撤销。还有一些框架像TCC,它是通过每个服务自己实现Try、Confirm和Cancel接口来完成回滚的。Try阶段记录操作,Confirm阶段提交,要是失败就进入Cancel阶段回滚。
K8s
- Node 是 K8s 集群中的工作节点(可以是物理机或虚拟机)
- Pod 运行在 Node 上,由 kubelet 管理
- 容器 是 Pod 的组成单元,共享 Pod 的网络和存储
Kubernetes(简称 K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。它将容器化的应用抽象为更高层次的资源,提供统一的管理接口。
关键组件
- Master 节点:集群控制中心,包含 API Server、Scheduler、Controller Manager 等
- Worker 节点:运行应用容器的工作节点,包含 Kubelet、Kube-proxy 和 Container Runtime
- Pod:K8s 最小调度单元,包含一个或多个紧密关联的容器
- Service:为 Pod 提供稳定的网络访问地址
- Deployment:声明式定义 Pod 的部署和扩缩策略
- ConfigMap/Secret:外部化配置和敏感信息管理
- Volume:持久化存储
- Ingress:集群外部访问入口控制器
Java 后端开发常见 K8s 面试问答
(一)基础概念类
Q1:什么是 K8s?为什么需要它?
A1:
K8s 是容器编排平台,解决了容器化应用的部署、扩展、管理和运维难题。传统容器管理需要手动处理容器调度、负载均衡、故障恢复等,而 K8s 提供自动化解决方案,提升开发效率和系统可靠性。
Q2:K8s 中的 Pod 是什么?为什么不直接部署容器?
A2:
- Pod 是 K8s 最小调度单元,一个 Pod 可包含多个紧密关联的容器(如主应用容器 + 日志收集容器)。
- 设计 Pod 的原因:
- 容器间共享网络和存储
- 支持原子调度(Pod 作为整体调度)
- 简化应用模型(将多个协作容器视为单一实体)
Q3:Deployment 和 ReplicaSet 的区别是什么?
A3:
- ReplicaSet:确保指定数量的 Pod 副本始终运行,实现基本的副本控制。
- Deployment:管理 ReplicaSet 的生命周期,支持滚动更新、回滚等高级特性。
关系:Deployment → ReplicaSet → Pod
Q4:什么是 Service?有哪些类型?
A4:
- Service:为 Pod 提供稳定的网络访问地址,解耦客户端与 Pod 的直接依赖。
- 类型:
- ClusterIP:集群内部访问(默认类型)
- NodePort:通过节点端口暴露服务(外部可访问)
- LoadBalancer:集成云提供商负载均衡器
- ExternalName:将服务映射到外部域名
(二)实践应用类
Q5:如何在 K8s 中部署 Java 应用?
A5:
- 创建 Docker 镜像:基于 OpenJDK 基础镜像打包应用
- 编写 Deployment 配置:定义 Pod 规格(如内存 / CPU 限制)
- 创建 Service:暴露应用端口
- 可选配置:
- ConfigMap 挂载配置文件
- Secret 管理敏感信息(如数据库密码)
- Horizontal Pod Autoscaler(HPA)实现自动扩缩
示例 Deployment 片段:
apiVersion: apps/v1
kind: Deployment
metadata:
name: java-app-deployment
spec:
replicas: 3
selector:
matchLabels:
app: java-app
template:
metadata:
labels:
app: java-app
spec:
containers:
- name: java-app-container
image: my-java-app:1.0.0
ports:
- containerPort: 8080
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
env:
- name: DB_URL
valueFrom:
configMapKeyRef:
name: db-config
key: url
Q6:如何实现 Java 应用的滚动更新和回滚?
A6:
-
滚动更新:
修改 Deployment 的镜像版本,K8s 会逐步替换旧 Pod(默认每次替换 25%)。kubectl set image deployment/java-app-deployment java-app-container=my-java-app:2.0.0 -
回滚:
kubectl rollout undo deployment/java-app-deployment
Q7:如何优化 Java 应用在 K8s 中的性能?
A7:
- 合理设置资源请求和限制:避免资源浪费或竞争
- 启用 JVM 容器感知参数:
java -XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0 -jar app.jar - 使用合适的垃圾回收器:如 G1(适合容器环境)
- 实现健康检查:配置 Liveness 和 Readiness Probes
- 避免全局锁:高并发场景优化同步机制
(三)高级特性类
Q8:什么是 Horizontal Pod Autoscaler(HPA)?如何为 Java 应用配置?
A8:
- HPA:基于 CPU、内存或自定义指标自动调整 Pod 数量。
配置示例:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: java-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: java-app-deployment
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
type: AverageValue
averageValue: 800Mi
Q9:如何在 K8s 中实现分布式 Java 应用的服务发现?
A9:
- 使用 K8s Service:Java 应用通过 Service 名称访问其他服务(如
http://user-service:8080/api/users) - 集成 Spring Cloud:
- 使用 Spring Cloud Kubernetes 实现服务注册与发现
- 配置
@LoadBalanced注解实现客户端负载均衡
Q10:如何处理 Java 应用的日志和监控?
A10:
-
日志:
- 容器内应用输出日志到标准输出(stdout/stderr)
- 通过 Fluentd/Fluent Bit 收集日志,发送到 Elasticsearch
- 使用 Kibana 可视化日志
-
监控:
- 集成 Micrometer 暴露 JVM 指标
- 使用 Prometheus 采集指标
- 通过 Grafana 构建监控仪表盘
(四)故障排查类
Q11:如果 Java 应用在 K8s 中频繁重启,可能的原因有哪些?
A11:
- Liveness Probe 失败:健康检查配置不合理
- 资源不足:内存溢出(OOMKilled)或 CPU 限制
- 应用启动时间过长:Readiness Probe 超时
- 依赖服务不可用:如数据库连接失败
- 应用自身异常:未捕获的异常导致进程退出
Q12:如何调试运行在 K8s 中的 Java 应用?
A12:
-
远程调试:
配置 JVM 参数暴露调试端口:
通过java -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=*:5005 -jar app.jarkubectl port-forward将调试端口映射到本地。 -
查看日志:
kubectl logs <pod-name> -
执行交互式命令:
kubectl exec -it <pod-name> -- bash
(五)云原生集成类
Q13:K8s 与微服务的关系是什么?
A13:
- 微服务:架构设计模式,将应用拆分为小型自治服务
- K8s:微服务的理想运行平台,提供服务发现、负载均衡、故障恢复等基础设施支持
Q14:如何在 K8s 中实现蓝绿部署或金丝雀发布?
A14:
-
蓝绿部署:
- 部署新版本应用(绿色)
- 验证通过后,将流量从旧版本(蓝色)切至新版本
- 保留旧版本作为回滚备选
-
金丝雀发布:
- 部署少量新版本 Pod
- 将部分流量导向新版本
- 逐步增加新版本比例,直至全量切换
Q15:什么是 Service Mesh?K8s 中常用的 Service Mesh 有哪些?
A15:
- Service Mesh:专注于处理服务间通信的基础设施层,提供流量管理、安全和可观测性。
- K8s 常用实现:
- Istio:功能全面,支持复杂策略配置
- Linkerd:轻量级,易于部署
- Envoy:高性能代理,常作为数据平面
OpenStack
开源的云计算平台,旨在通过软件定义的方式管理计算、存储、网络等基础设施资源,实现资源的自动化部署与弹性扩展。其核心架构由多个独立服务组件组成,各组件通过 API 协同工作,典型组件包括:
- Nova:计算服务,管理虚拟机生命周期(创建、调度、删除等)。
- Neutron:网络服务,提供虚拟网络配置、IP 分配、负载均衡等功能。
- Cinder:块存储服务,为虚拟机提供持久化存储卷。
- Glance:镜像服务,存储和管理虚拟机镜像(如 Linux 系统镜像)。
- Keystone:身份认证服务,管理用户权限与资源访问控制。
如何监控 OpenStack 资源使用情况?
- 监控方式:
- 调用 OpenStack 监控 API(如通过 Ceilometer 或新的 Telemetry 服务获取 metrics)。
- 集成 Prometheus + Grafana:通过 exporter(如 openstack-exporter)采集 OpenStack 指标,结合 Prometheus API 展示监控数据。
OpenStack 安全组(Security Group)如何配置?
- 核心操作:
- 通过 Neutron API 创建安全组规则(入站 / 出站规则)。
- 为虚拟机关联安全组,控制网络访问(如开放 SSH 端口、限制 Web 服务端口)。
IaaS、PaaS、SaaS
| 模式 | 英文全称 | 核心定义 | 典型案例 |
|---|---|---|---|
| IaaS | Infrastructure as a Service | 提供虚拟化的计算、存储、网络等基础设施资源,用户需自行部署操作系统和软件。 | AWS EC2、阿里云 ECS、OpenStack |
| PaaS | Platform as a Service | 提供开发平台和运行环境(如数据库、中间件、编程语言框架),用户专注于应用开发。 | Google App Engine、Heroku、Kubernetes |
| SaaS | Software as a Service | 直接提供可通过网络访问的软件应用,用户无需管理底层基础设施或平台。 | Office 365、Salesforce、钉钉 |
Kong VS Nginx VS OpenResty
-
Nginx
- 高性能的 Web 服务器、反向代理服务器及电子邮件(IMAP/POP3)代理服务器。
- 基于事件驱动的异步非阻塞架构,适合高并发场景(如静态资源服务、反向代理)。
-
OpenResty
- 基于 Nginx 的高性能 Web 平台,集成 LuaJIT,允许使用 Lua 脚本扩展 Nginx 功能。
- 常用于构建高性能 API 网关、微服务网关(如动态路由、限流熔断)。
-
Kong
- 基于 OpenResty 构建的开源 API 网关,提供丰富的插件生态(认证、限流、日志等)。
- 支持多协议(HTTP、TCP、gRPC),可扩展为云原生 API 网关(如结合 Kubernetes)。
Java 服务如何与 Kong 实现安全认证?
- 常见方案:
- JWT 认证:
- Java 服务生成 JWT Token,Kong 使用
jwt插件验证 Token 有效性。 - 示例配置:
{ "name": "jwt", "config": { "uri_param_names": ["token"], "claims_to_verify": ["exp"] } }
- Java 服务生成 JWT Token,Kong 使用
- OAuth2.0:
- Kong 使用
oauth2插件,Java 服务作为资源服务器验证 Access Token。
- Kong 使用
- API Key:
- Kong 使用
key-auth插件,Java 服务生成并管理 API Key。
- Kong 使用
- JWT 认证:
如何用 Kong 实现 Java 服务的限流与熔断?
- 限流:
- 使用 Kong 的
rate-limiting插件,按请求次数或带宽限制流量。 - 配置示例(通过 Admin API):
{ "name": "rate-limiting", "config": { "second": 10, // 每秒最多 10 次请求 "policy": "local" // 本地计数器(集群环境建议用 redis) } }
- 使用 Kong 的
- 熔断:
- 使用
circuit-breaker插件,当后端服务错误率超过阈值时自动熔断。 - 结合 Java 服务的健康检查(如 Spring Boot Actuator),动态调整熔断策略。
- 使用
反向代理
反向代理是一种服务器,它接收客户端请求后,将请求转发到内部网络中的后端服务器,并将后端服务器的响应返回给客户端。客户端无需知道后端服务器的存在,仅与反向代理服务器通信。
RPC
RPC(Remote Procedure Call)即远程过程调用,允许程序调用另一台计算机上的子程序,就像调用本地程序一样简单。其核心思想是将网络通信抽象为函数调用,隐藏底层网络细节。
| 维度 | RPC | HTTP API |
|---|---|---|
| 协议 | 自定义协议(如 gRPC、Thrift) | 标准 HTTP 协议 |
| 接口形式 | 函数调用(如userService.getUser(id)) |
RESTful 接口(如GET /users/{id}) |
| 性能 | 通常更高(二进制协议、更少开销) | 较低(文本协议、头部信息冗余) |
| 跨语言 | 需依赖代码生成(如 Protobuf) | 天然支持(JSON/XML 为通用格式) |
| 使用场景 |
微服务内部通信(高吞吐量) |
对外公开 API(标准化、易调试) |
发布-订阅 VS 生产者-消费者
| 模式 | 发布 - 订阅(Pub-Sub) | 生产者 - 消费者(Producer-Consumer) |
|---|---|---|
| 结构特点 | 基于消息代理(Broker),发布者和订阅者解耦。 | 基于共享缓冲区,生产者和消费者直接交互。 |
| 消息流向 | 一对多(一个发布者,多个订阅者)。 | 一对一或多对多(生产者和消费者通过队列连接)。 |
| 消息传递 | 订阅者需提前订阅主题(Topic),发布者将消息发送到主题。 | 生产者将消息放入队列,消费者从队列取出消息。 |
| 解耦程度 | 高度解耦(发布者和订阅者无需知道对方存在)。 | 中度解耦(依赖共享队列,但需约定消息格式)。 |
| 典型场景 |
实时事件通知(如股票行情推送)、系统间广播。 Kafka、RabbitMQ(Topic 模式) |
异步任务处理(如订单处理、日志收集)。 BlockingQueue、ActiveMQ |
故障转移 & 降级
故障转移(从异常中恢复的自愈能力)
- 故障转移:当系统中的某个组件(如服务器、数据库、微服务节点)发生故障时,系统自动将请求转移到其他正常组件,确保服务不中断的过程。
- 典型场景:
- 数据库主节点宕机时,自动切换到从节点提供服务。
- 微服务集群中某节点异常,负载均衡器将流量路由到其他健康节点。
- Redis 主从架构中,哨兵(Sentinel)检测到主节点故障后,自动选举从节点成为新主节点。
案例:Redis 哨兵模式故障转移
- 核心步骤:
- 哨兵定期 ping 主节点,超过阈值(如 down-after-milliseconds)判定为主节点下线。
- 哨兵集群通过投票选举出领头哨兵,由其执行故障转移。
- 选择优先级最高的从节点提升为新主节点,其他从节点指向新主节点。
服务降级(有损服务的优雅降级策略)
- 当系统资源(如 CPU、内存、带宽)不足或依赖的服务出现异常时,主动降低部分非核心功能的服务质量,确保核心功能可用的策略。
- 典型场景:
- 电商大促时,关闭商品评论加载功能,优先保证下单流程。
- 支付系统压力过高时,暂停指纹支付,仅保留密码支付。
- 微服务依赖的第三方接口超时,返回缓存的默认数据而非实时数据。
降级策略:功能降级、数据降级、限流降级、资源隔离降级
| 策略类型 | 实现方式 | 应用场景 |
|---|---|---|
| 功能降级 | 关闭非核心功能(如推荐系统、评论模块)。 | 流量峰值时保障核心流程 |
| 数据降级 | 返回缓存的旧数据或默认值(如商品详情页加载失败时显示 “数据加载中”)。 | 依赖服务超时或不可用时 |
| 限流降级 | 对请求进行限流(如熔断、漏桶算法),超出阈值的请求直接拒绝或返回错误。 | 保护后端服务不被流量压垮 |
| 资源隔离降级 | 将服务部署在独立资源池(如容器、虚拟机),故障时隔离异常资源。 | 多租户系统、微服务隔离 |
优雅停机
优雅停机(Graceful Shutdown) 是指在服务器需要关闭或重启时,能够先处理完当前正在进行的请求,然后再停止服务的操作。目标:无请求丢失(如 HTTP 请求、消息队列消费)、数据一致性(如订单支付未提交、缓存未刷新)、客户端无感知。
步骤:
- 停止接收新的请求:首先,系统会停止接受新的请求,这样就不会有新的任务被添加到任务队列中。
- 处理当前请求:系统会继续处理当前已经在处理中的请求,确保这些请求能够正常完成。这通常涉及到等待正在执行的任务完成,如处理HTTP请求、数据库操作等。
- 释放资源:在请求处理完成后,系统会释放所有已分配的资源,如关闭数据库连接、断开网络连接等。
- 关闭服务:最后,当所有请求都处理完毕且资源都已释放后,系统会安全地关闭服务。
SpringBoot:
- 使用合理的 kill 命令,给 Spring Boot 项目发送优雅停机指令。
- 开启 Spring Boot 优雅停机/自定义 Spring Boot 优雅停机的实现。
分布式系统:
应用层优雅停机:以 HTTP 服务为例
- 注册中心标记下线:通过 Nacos/Eureka 将节点标记为 "准备下线",负载均衡器不再转发新请求。
- 拒绝新请求:应用层拦截新 HTTP 请求,返回
503 Service Unavailable或重定向到其他节点。 - 等待旧请求完成:设置超时时间(如 30 秒),处理完内存中积压的请求后再关闭进程。
| 框架 | 优雅停机机制 | 配置示例 |
|---|---|---|
| Spring Cloud | 通过server.shutdown=graceful开启优雅停机,配合注册中心延迟下线节点。 |
application.yml: server.shutdown: gracefuleureka.instance.lease-expiration-duration-in-seconds: 60 |
| Dubbo | 提供shutdown.wait参数控制停机等待时间,服务消费方自动感知提供者下线。 |
dubbo: protocol: shutdown.wait: 30000(等待 30 秒) |
| Kubernetes | 通过preStop钩子和terminationGracePeriodSeconds控制容器关闭流程。 |
yaml: livenessProbe: ...terminationGracePeriodSeconds: 60 |
消息队列场景的优雅停机
以 RabbitMQ 消费者为例:
- 取消消费订阅:调用
channel.basicCancel(consumerTag)停止接收新消息。 - 消费剩余消息:通过
while(channel.isOpen())循环处理内存中已接收的消息。 - 确认机制保障:确保每条消息都完成
basicAck后再关闭连接。
分层停机策略设计
最佳实践
- 停机顺序控制:
核心原则
-
下游服务先于上游服务停机:
- 下游服务(如数据存储、基础服务)为上游服务(如业务逻辑、前端接口)提供支撑,若上游先停,可能导致下游积压请求无法处理。
- 例:停机顺序应为
缓存服务 → 数据库从节点 → 业务服务 → 网关,而非反向。
-
读服务先于写服务停机:
- 先停读服务(如缓存 Redis),再停写服务(如数据库),避免数据写入后无法读取。
-
无状态服务先于有状态服务停机:
- 无状态服务(如 API 网关)可快速重启,优先停机;有状态服务(如数据库、消息队列)需确保数据持久化后再停机。
下游服务 → 上游服务 → 数据库从节点 → 数据库主节点
(例:先停订单服务,再停支付服务,避免订单创建后无法支付)- 微服务架构停机顺序:缓存服务(Redis)→ 2. 消息队列(RabbitMQ)→ 3. 数据库从节点 → 4. 中游服务(如用户中心)→ 5. 上游服务(如订单 API)→ 6. 网关服务
- 超时时间动态调整:根据业务请求平均耗时设置停机等待时间(如电商大促时设为 60 秒,日常设为 30 秒)。
- 灰度停机验证:先对 1% 节点进行停机演练,通过监控确认:
- 请求成功率是否保持 100%?
- 日志中是否有 "请求未完成" 报错?
- 下游服务是否感知到异常?
| 故障场景 | 原因分析 | 解决方案 |
|---|---|---|
| 停机后仍有请求接入 | 负载均衡器缓存未刷新 | 增加 Nginx proxy_next_upstream配置,强制转发到健康节点。 |
| 长事务未完成导致数据丢失 | 停机等待时间不足 | 分析慢 SQL / 长事务耗时,动态调整terminationGracePeriodSeconds。 |
| 客户端连接超时 | 应用关闭前未主动断开长连接 | 在 WebSocket/RPC 客户端添加连接断开监听,服务端关闭时发送断开通知。 |
WebSocket/RPC 长连接如何安全断开?
长连接(如 WebSocket、gRPC、Dubbo)的断开需避免 "断连异常",需实现 "双向通知 + 优雅关闭" 机制。
WebSocket 长连接安全断开
-
服务端主动通知断开:
- 发送自定义断开帧(如
CloseFrame),携带状态码(如1001表示 "服务终止")和原因。 - 客户端监听
onclose事件,处理资源释放(如取消心跳、清除缓存)。
- 发送自定义断开帧(如
-
心跳机制配合:停机前先暂停心跳包发送,客户端检测到心跳超时后主动断开,避免僵死连接。
RPC 长连接(如 gRPC/Dubbo)的优雅断开
-
服务端断开流程:
- 拒绝新连接:关闭监听端口,阻止新客户端连接(如 gRPC 的
server.shutdown())。 - 处理旧连接:维持现有连接直至所有调用完成,通过
shutdownNow()设置超时(如 30 秒)。
- 拒绝新连接:关闭监听端口,阻止新客户端连接(如 gRPC 的
-
客户端感知与重连:
- 注册中心发现服务下线后,客户端负载均衡器不再选择该节点,并触发连接池断开。
- 客户端设置连接超时与重试策略,避免因服务端停机导致请求阻塞。
| 问题场景 | 原因 | 解决方案 |
|---|---|---|
| 客户端断连报错 | 服务端未通知直接关闭连接 | 强制要求服务端先发送断开帧 / 信号,客户端按协议处理。 |
| 连接池残留僵死连接 | 未正确释放连接资源 | 在 RPC 框架中配置connectionIdleTime,自动清理长时间未使用的连接。 |
| WebSocket 心跳风暴 | 停机时心跳包未停止发送 | 停机前先暂停心跳线程,或在心跳包中携带 "服务状态" 标识,客户端检测到异常后主动断开。 |
依赖服务异常处理:反向保护机制
- 超时熔断:若下游服务停机耗时过长,上游服务可主动熔断依赖,避免自身被阻塞(如 Hystrix 设置
connectionTimeout)。 - 数据补偿机制:停机后若发现数据不一致(如订单未写入数据库),通过定时任务或消息队列重试补全。
在实践中,建议通过混沌工程(Chaos Engineering)模拟停机故障,验证各环节的鲁棒性,最终实现分布式系统的 "温柔退出"。
java钩子
在 Java 中,钩子(Hook) 是一种特殊的回调机制,允许程序在特定生命周期事件(如 JVM 关闭、线程启动 / 终止)发生时执行自定义逻辑。其本质是通过注册回调函数,在系统状态变化时触发执行。
JVM 关闭钩子(Shutdown Hook)
- JVM 关闭钩子是一个已初始化但尚未启动的线程,在以下场景被触发:
- 正常关闭:调用
System.exit()或程序自然结束。 - 异常关闭:用户按下 Ctrl+C、终端发送 SIGTERM 信号。
- 虚拟机退出:Runtime.getRuntime ().halt () 除外(强制退出不触发钩子)。
- 正常关闭:调用
线程钩子:ThreadLocal 与 UncaughtExceptionHandler
1. ThreadLocal 钩子
- 在每个线程创建和销毁时执行特定逻辑,常用于线程级资源管理。
2. UncaughtExceptionHandler
- 捕获线程未处理的异常,避免线程静默死亡。
Java 中的钩子机制为系统提供了灵活的生命周期管理能力,特别是在优雅停机、资源清理、异常处理等场景中发挥关键作用。
注意不要调用 System.exit ():钩子中调用System.exit()会导致无限循环。
死锁
多个进程 / 线程因争夺资源而形成的阻塞状态,若无外力干预将永远无法推进。其本质是资源分配不当导致的执行流程闭环,常见于多线程并发场景。
| 条件(同时满足时才会发生) | 解决方案 | 示例实现 |
|---|---|---|
|
互斥条件 资源同一时间只能被一个线程占用(如锁、文件句柄)。 |
使用可重入资源(如读 - 写锁允许多读)或无锁编程(CAS)。 | ReentrantReadWriteLock |
|
请求与保持条件 线程已获取资源,同时又对其他资源发出请求,且不释放已持有的资源。 |
一次性获取所有资源(资源预分配),或释放已持有的资源再请求新资源。 | Lock.tryLock(timeout) |
|
不剥夺条件 资源只能被线程主动释放,不能被强制剥夺。 |
允许资源被强制释放(如超时机制)。 | 数据库连接池设置超时回收 |
|
循环等待条件 存在一种线程资源的循环等待链,链中每个线程都持有下一个线程所需的资源。 |
对资源排序,要求线程按顺序获取(如锁按 ID 升序获取)。 | 哲学家按 ID 从小到大拿叉子 |
死锁的检测定位
1. JDK 工具检测(jstack)
- 命令格式:
jstack <pid>(pid 为 Java 进程 ID)。 - 示例输出:
上述输出表明两个线程互相等待对方持有的锁,形成死锁。"Thread-0" #1 prio=5 os_prio=0 blocked on <0x00000000029d3f00> (a java.lang.Object) waiting for <0x00000000029d3e00> (a java.lang.Object), which is held by "Thread-1" "Thread-1" #2 prio=5 os_prio=0 blocked on <0x00000000029d3e00> (a java.lang.Object) waiting for <0x00000000029d3f00> (a java.lang.Object), which is held by "Thread-0"
2. VisualVM 可视化工具
- 通过
jvisualvm命令启动,在 “线程” 标签页中可直观查看死锁线程。
响应式编程
响应式编程是一种异步编程范式,它专注于处理数据流和传播变化,强调系统在各种负载下都能保持响应性。
| 维度 | 传统编程(命令式 / 同步) | 响应式编程(声明式 / 异步) |
|---|---|---|
| 编程模型 | 顺序执行,主动调用方法 | 声明式订阅数据流,被动响应变化 |
| 线程模型 | 阻塞式 IO,线程数与并发请求强绑定 | 非阻塞 IO,少量线程处理大量并发 |
| 错误处理 | try-catch 直接捕获异常 | 通过流操作符(如 onErrorResume)处理错误 |
| 典型场景 | 单机应用、简单业务逻辑 | 高并发、分布式系统、实时数据流处理 |
Java数据结构-红黑树、二叉树、B树、B+树、堆(大顶堆、小顶堆)
| 数据结构 | 查找效率 | 插入效率 | 删除效率 | 典型应用场景 |
|---|---|---|---|---|
| 二叉树 | O(n) | O(n) | O(n) | 表达式解析、基础树结构 |
| 红黑树 | O(log n) | O(log n) | O(log n) | TreeMap、HashMap 优化 |
| B 树 | O(log n) | O(log n) | O(log n) | 数据库索引、文件系统 |
| B + 树 | O(log n) | O(log n) | O(log n) | 范围查询为主的数据库索引 |
| 大顶堆 | O (1)(堆顶) | O(log n) | O(log n) | 优先队列、堆排序 |
| 小顶堆 | O (1)(堆顶) | O(log n) | O(log n) | 最小优先队列、K 路归并 |
在线数据库 VS 离线数据库
在线数据库:实时响应用户请求、支持交互式操作的数据库系统,通常用于事务处理(OLTP)。
离线数据库:不与用户实时交互,主要用于批量处理、历史数据分析的数据库系统,常用于数据仓库(OLAP)。
DNS 域名解析
解析流程(从域名到 IP 的完整过程)
-
客户端发起请求
- 浏览器或应用程序向本地 DNS 缓存查询域名对应的 IP,若缓存中无记录则进入下一步。
-
递归查询本地 DNS 服务器
- 本地 DNS 服务器(如运营商提供的 DNS)若未缓存结果,会向 DNS 根服务器发起递归查询。
-
根服务器引导查询
- 根服务器(.com、.org 等顶级域的定位器)返回对应顶级域(TLD)服务器的地址。
-
TLD 服务器解析
- TLD 服务器(如
.com服务器)返回域名所属的权威 DNS 服务器地址(如example.com的权威服务器)。
- TLD 服务器(如
-
权威服务器响应
- 权威服务器返回域名对应的 IP 地址,结果沿查询路径逐级缓存并返回给客户端。
客户端 → 本地DNS服务器 → 根服务器 → .com TLD服务器 → example.com权威服务器 → 返回IP 假设客户端要解析域名www.example.com,以下是迭代查询的详细过程:
- 客户端向本地DNS服务器发送查询请求,请求解析www.example.com。
- 本地DNS服务器检查缓存,发现没有该域名的解析记录,于是向根DNS服务器发送查询请求。根DNS服务器根据.com顶级域,返回.com的TLD服务器的地址。
- 本地DNS服务器向.com的TLD服务器发送查询请求。TLD服务器根据example.com,返回example.com的权威DNS服务器的地址。
- 本地DNS服务器向example.com的权威DNS服务器发送查询请求。权威DNS服务器返回www.example.com对应的IP地址。
- 本地DNS服务器将解析结果缓存,并返回给客户端。
- 客户端使用解析出的IP地址与目标服务器建立连接。
Redis 常见的数据结构
字符串(String) SET/GET
- 最基本的数据结构,可存储字符串、数字或二进制数据。支持原子操作,如自增、自减等,适用于计数器、缓存等场景。
列表(List) HSET/HGET
- 按插入顺序排序的字符串链表,可从两端进行操作(如 push、pop)。常用于实现消息队列、微博时间线等需要有序列表的场景。
集合(Set)
- 无序且唯一的字符串集合,支持交集、并集、差集等集合运算。适合实现标签系统、共同好友等功能。
有序集合(Sorted Set又称Zset)
- 每个元素关联一个分数(score),按分数排序的集合。常用于排行榜、带权重的任务队列等场景。
哈希(Hash)
- 字段(field)和值(value)的映射表,适合存储对象信息(如用户资料)。支持对单个字段的操作,减少网络开销。
位图(Bitmap)
- 基于位操作的字符串,可用于统计活跃用户、签到等需要二进制标记的场景。
HyperLogLog
- 用于估算集合的基数(不同元素的数量),占用空间小(约 12KB),但有一定误差。适合统计独立访客数等对精度要求不极高的场景。
Redis 常用数据类型及实际应用场景?
- String:计数器、简单 KV 缓存、分布式锁(SET NX)
- List:FIFO 队列(如消息队列)(LPUSH + BRPOP)
- Set:去重和集合运算(如共同关注)
- ZSet:带权重的排序(如积分排行榜)
- Hash:存储对象(如用户信息)
- Bitmap:二机制标记(如签到)
- HyperLogLog:基数统计(如独立访客数)
redis缓存穿透、击穿、雪崩
缓存穿透:查询一个一定不存在的数据,比如用不存在的用户ID去查用户信息,缓存里没有,数据库也没有,就会直接打到数据库,要是大量这样的请求过来,数据库压力就大了。
缓存击穿:某个热点数据过期了,正好这时有大量请求来访问这个数据,缓存没了,就都去查数据库了,可能会把数据库打垮。
缓存雪崩:指在短时间内,大量缓存过期,好多请求同时去访问数据库,就像雪崩一样,数据库很难承受,系统可能会崩溃。
Redis 缓存穿透、击穿、雪崩如何解决?
- 穿透:布隆过滤器过滤无效 key,空值缓存(设置短过期时间);
- 击穿:热点数据设置永不过期、热点 key 加互斥锁(Lua 脚本保证原子性)、逻辑过期;
- 雪崩:集群部署、热点数据分散过期时间、多级缓存。
在一个区域网段中的主从redis库是分布式吗?
在一个区域网段中的主从 Redis 库不属于分布式架构,而是属于主从复制架构。两者的核心区别如下:
一、主从 Redis 的本质:单机架构的扩展
主从复制(Master-Slave)的核心特征是:
- 数据一致性:从节点完全复制主节点的数据,所有节点存储相同数据副本。
- 非分片存储:数据未被拆分到不同节点,每个节点均保存完整数据集。
- 主节点单点:写操作仅主节点负责,从节点仅提供读服务,若主节点故障,需手动或通过哨兵切换。
例如:1 个主节点 + 2 个从节点的部署中,3 个节点均存储相同数据,本质是 “单机数据的多副本备份”,而非分布式系统的 “数据分片”。
二、分布式架构的核心:数据分片与分散存储
真正的分布式架构(如 Redis Cluster)需满足:
- 数据分片:数据按规则(如哈希槽)拆分到不同节点,每个节点仅存储部分数据。
- 无中心节点:节点间通过协议协同工作,无单一主控节点(如 Redis Cluster 的 16384 个槽分布在各节点)。
- 横向扩展:可通过添加节点动态扩容,分摊数据和负载。
三、主从架构与分布式架构的对比
| 维度 | 主从复制(Master-Slave) | 分布式架构(如 Redis Cluster) |
|---|---|---|
| 数据存储 | 全量数据多副本(相同数据) | 数据分片(不同节点存不同数据) |
| 写操作节点 | 仅主节点负责 | 所有主节点均可写(分片后) |
| 故障影响 | 主节点故障导致写服务不可用 | 部分节点故障不影响整体服务 |
| 扩展性 | 需手动添加从节点(读扩展) | 自动分片,支持动态扩缩容 |
| 分布式特性 | 不具备(无数据分片) | 具备(数据分散 + 节点协同) |
四、为什么主从架构常被误解为分布式?
- 多节点部署:主从架构至少包含 2 个节点,易被误认为 “分布式”,但节点间未实现数据分片。
- 读写分离:从节点分担读压力,但本质是单机架构的性能优化,而非分布式系统的 “分散计算”。
- 哨兵模式的迷惑性:哨兵虽支持故障自动转移,但未改变 “全量数据复制” 的本质,仍属于主从架构的增强。
总结
主从 Redis 是单机架构的多副本扩展,而非分布式系统。若需构建分布式 Redis,需采用 Redis Cluster 等支持数据分片的方案。理解两者的核心差异(数据是否分片)是区分的关键。
Redis 分布式部署
1. Redis 有哪几种分布式部署模式?各自优缺点是什么?
回答:
Redis 分布式部署主要有三种模式:
-
主从复制(Master-Slave)
优点:实现读写分离,提高读性能;从节点可作为备份。
缺点:不具备自动故障转移能力;写操作集中在主节点,存在单点瓶颈。 -
哨兵模式(Sentinel)
优点:支持自动故障转移;监控集群状态。
缺点:哨兵本身存在单点问题;集群扩展能力有限。 -
Redis Cluster
优点:自动分片(16384 个槽);支持动态扩缩容;无中心架构。
缺点:客户端实现复杂;批量操作和事务支持受限。
2. 哨兵模式如何实现故障转移?
回答:
当哨兵监测到主节点下线时:
- 多个哨兵通过投票机制选出一个 Leader Sentinel。
- Leader 从存活的从节点中选举一个升级为主节点。
- 通知其他从节点新主节点的地址,并重新复制。
- 客户端通过哨兵获取最新的主节点地址。
3. Redis Cluster 如何进行数据分片?
回答:
Redis Cluster 将整个数据库分为 16384 个哈希槽(Hash Slot),每个节点负责一部分槽。
数据分配规则:slot = CRC16(key) % 16384。
当需要增加或减少节点时,只需重新分配部分槽即可。
4. Redis Cluster 如何处理脑裂问题?
回答:
Redis Cluster 通过以下机制避免脑裂:
- 半数以上节点正常工作才能对外提供服务。
- 主节点在网络分区时会设置最大连接数,超过限制则拒绝写请求。
- 故障恢复后,旧主节点会丢弃分区期间的数据,保证数据一致性。
Redis 持久化
1. Redis 有哪些持久化方式?区别是什么?
回答:
Redis 提供两种持久化方式:
-
RDB(快照):定期将内存数据生成二进制快照文件(如 dump.rdb)。
优点:文件紧凑,恢复速度快;适合备份和灾难恢复。
缺点:可能丢失最后一次快照后的修改。 -
AOF(追加日志):记录所有写操作命令到日志文件(如 appendonly.aof)。
优点:数据安全性高,支持秒级持久化;日志文件易读。
缺点:文件体积大,恢复速度较慢。
2. 如何选择 RDB 和 AOF?
回答:
- 若对数据安全性要求不高,可仅使用 RDB。
- 若不能接受数据丢失,应同时启用 AOF 和 RDB。
- 对于写操作频繁的场景,需注意 AOF 文件膨胀问题(可通过
bgrewriteaof优化)。
3. AOF 重写的原理是什么?
回答:
AOF 重写通过读取当前数据库状态,生成最小命令集替代旧日志。例如:
- 原日志:
SET key1 value1 → SET key1 value2 → DEL key2 - 重写后:
SET key1 value2
重写过程在后台进行,不会阻塞主进程。
数据平滑迁移
在 Java 后端开发的公共技术岗位面试中,数据平滑迁移是系统升级的核心考点,需结合数据库架构、分布式系统和高可用设计回答。以下从方法论、技术方案、实践案例三个维度拆解应答策略:
一、方法论:数据迁移的核心原则
1. 迁移前的准备工作
- 数据评估:
- 分析数据量(如 TB 级数据需分批次迁移)、数据结构差异(表结构变更、字段类型转换)。
- 识别核心业务表(如用户表、订单表)与非核心表(如日志表)的迁移优先级。
- 灰度策略:
- 设计 “金丝雀发布” 方案(如先迁移 1% 用户数据),验证迁移逻辑正确性。
- 准备回滚机制(如备份数据、数据库快照)。
2. 迁移中的关键措施
- 双写策略:
在新旧系统并行期间,对数据的写操作同时更新新旧库,确保数据一致性。 - 增量同步:
使用 Canal(基于 binlog)或 Debezium 实时捕获数据库变更,同步到新库。
3. 迁移后的验证与切换
- 数据校验:
通过 ETL 工具对比新旧库数据差异(如校验用户 ID、订单金额),确保准确率达 100%。 - 流量切换:
分阶段切换流量(如先切读流量,再切写流量),通过负载均衡器逐步导流。
二、技术方案:从工具到架构的实现路径
1. 数据库层面的平滑迁移
- 场景:从 MySQL 5.7 升级到 8.0,同时表结构重构。
- 方案:
- 关键工具:
- Canal:阿里巴巴开源的 MySQL binlog 解析工具,用于增量数据同步。
- Flyway/Liquibase:数据库版本控制工具,自动化执行 DDL 变更。
2. 微服务架构下的跨服务数据迁移
- 场景:拆分 “订单中心” 服务为 “订单服务”+“支付服务”,需迁移关联数据。
- 方案:
- 服务间数据对齐:
通过分布式事务(如 Seata)确保拆分过程中订单与支付数据的一致性。 - 异步消息补偿:
使用 MQ(如 RocketMQ)发送数据变更消息,下游服务消费并更新自身数据。 - 接口兼容层:
在过渡期保留旧接口,内部转发到新服务,实现调用方无感知。
- 服务间数据对齐:
3. 缓存与索引的平滑迁移
- 场景:从 Redis 3.2 升级到 6.0,同时重构缓存 Key 结构。
- 方案:
- 双写双读:
在升级期间,对缓存的读写同时操作新旧 Redis 集群,逐步淘汰旧集群。 - 一致性哈希:
使用一致性哈希算法分配缓存节点,减少节点变更导致的缓存雪崩。
- 双写双读:
三、结合你的简历:预算系统重构中的数据迁移案例
1. 关键挑战
- 从单体架构升级到微服务,需拆分 “预算审批” 表为多个子表(如预算项、审批流程)。
- 涉及历史数据(百万级记录)的结构转换与关联关系重建。
2. 解决方案
- 分阶段迁移:
- 准备阶段:
- 使用 Flyway 执行 DDL 脚本,在新库创建表结构。
- 对旧库数据做全量备份(如通过 mysqldump)。
- 迁移阶段:
- 编写数据迁移 Job,按时间分批迁移历史数据(如每次处理 1 万条)。
- 启用双写:应用层对预算数据的写操作同时更新新旧库。
- 通过 Canal 同步增量数据,确保迁移期间新数据不丢失。
- 验证阶段:
- 开发数据校验工具,对比新旧库中预算数据的一致性(如金额、状态)。
- 在灰度环境模拟用户操作,验证业务流程正常。
- 切换阶段:
- 先将查询流量切到新库,观察无异常后再切写流量。
- 完全切换后,保留旧库一段时间作为灾备。
- 准备阶段:
3. 量化成果
- 迁移过程中业务无感知,接口响应时间保持在 500ms 以内。
- 数据准确率达 100%,未出现数据不一致导致的线上故障。
四、面试应答技巧
1. 高频问题:“如何确保数据迁移过程中的一致性?”
- 回答框架:
“在预算系统重构中,我们采用‘双写 + 增量同步 + 校验补偿’的组合方案:
- 双写策略:在迁移期间,对数据的写操作同时更新新旧库,确保新数据一致。
- 增量同步:使用 Canal 监听旧库 binlog,实时同步到新库,捕获迁移期间的变更。
- 数据校验:开发自动化校验工具,按业务规则比对新旧库数据(如预算总额、审批状态),发现差异时通过补偿脚本修复。
通过这些措施,我们实现了百万级数据迁移的零误差。”
2. 高频问题:“大表迁移如何避免影响业务?”
- 技术细节:
“对于大表迁移,我们采取以下优化:
- 分批处理:按主键范围分批迁移(如每次处理 1 万条),避免长时间锁表。
- 低峰期执行:选择业务低峰期(如凌晨)执行全量迁移,减少对线上的影响。
- 读写分离:迁移期间,读请求仍走旧库,写请求双写,确保业务可用性。
在预算系统中,通过这些方法,我们将单表迁移时间从小时级缩短到分钟级,且未观察到接口响应超时。”
3. 高频问题:“迁移失败如何快速回滚?”
- 应急方案:
“我们设计了多层回滚机制:
- 数据库快照:迁移前对关键表做物理备份(如 MySQL 的 xtrabackup),可快速恢复。
- 灰度流量控制:通过网关(如 Kong)控制灰度比例,发现问题时立即切回旧系统。
- 补偿脚本:预编写数据回滚脚本,例如将新库数据反向同步回旧库。
在测试环境中,我们验证了回滚流程,整体恢复时间控制在 5 分钟内,确保业务不受重大影响。”
五、总结
数据平滑迁移的核心是 **“渐进式、可观测、可回滚”**:
- 渐进式:分阶段迁移,从灰度到全量,降低风险。
- 可观测:通过监控和校验,实时发现并解决数据不一致问题。
- 可回滚:设计完善的应急预案,确保迁移失败不影响业务。
雪花算法(Snowflake)
1. 什么是雪花算法?简述其结构。
回答:
雪花算法是 Twitter 开源的分布式 ID 生成算法,生成 64 位长整型 ID,结构如下:
- 1 位符号位(始终为 0)
- 41 位时间戳(毫秒级,支持约 69 年)
- 5 位数据中心 ID(最多 32 个)
- 5 位机器 ID(最多 32 个)
- 12 位序列号(每毫秒内生成最多 4096 个 ID)
生成的 ID 趋势递增,且不依赖数据库。
2. 雪花算法的优缺点是什么?
回答:
优点:
- 高性能(单机每秒生成百万级 ID)。
- 不依赖数据库,自主性强。
- 生成的 ID 有序,适合索引优化。
缺点:
- 依赖系统时钟,若时钟回拨可能生成重复 ID。
- 数据中心和机器 ID 需提前分配,扩展不便。
3. 如何解决雪花算法的时钟回拨问题?
回答:
- 等待时钟恢复:检测到时钟回拨时,暂停服务直到时钟追上。
- 生成备用 ID:从其他服务器获取 ID 或使用本地计数器。
- 无时钟方案:如 UUID 或结合数据库自增 ID。
4. 雪花算法在分布式系统中的应用场景有哪些?
回答:
- 数据库分库分表时作为唯一主键。
- 消息队列中的消息 ID。
- 分布式缓存的键值。
- 日志追踪中的 TraceID。
总结
Redis 分布式部署需根据业务需求选择:
- 读多写少:主从 + 哨兵
- 大规模集群:Redis Cluster
- 数据安全性:AOF+RDB
雪花算法适用于需要高性能、趋势递增 ID 的场景,但需注意时钟回拨问题。
项目经历
根据你的简历内容和目标岗位(后端开发 - 公共技术部),面试官可能会围绕Kong 网关、Kubernetes、高并发优化、技术迁移与稳定性保障等方向深入提问。以下是具体问题分类及应答建议,结合你的经历展开:
一、Kong 网关与 Lua 插件开发
1. Kong 性能优化与插件开发
-
问题示例:
- “你开发的 Lua 插件如何实现接口耗时监控?具体埋点在哪些位置?”
- “动态限流策略是如何设计的?如何根据业务流量自动调整阈值?”
- “Kong 从 2.8 到 3.3 升级过程中,遇到哪些兼容性问题?如何解决的?”
-
应答思路:
- 耗时监控:在 Kong 的 access 和 header_filter 阶段插入 Lua 代码,记录请求开始和结束时间,通过 Prometheus client 库将数据推送到监控系统。
- 动态限流:基于 Redis 存储令牌桶状态,通过 Lua 脚本原子化操作,根据业务优先级(如 VIP 用户放宽阈值)动态调整。
- 升级兼容性:重点测试插件 API 变更(如 Admin API v3 的参数格式变化),通过编写迁移脚本转换配置数据,在灰度环境验证无异常后全量升级。
2. 网关高可用与负载均衡
-
问题示例:
- “如何优化 Kong-ingress 的负载均衡策略?Nginx 反向代理和连接池调优的具体参数有哪些?”
- “系统稳定性达到 99.99%,做了哪些关键措施?”
-
应答思路:
- 负载均衡优化:
- 在 Kong 前部署 Nginx,配置
ip_hash会话保持; - 调整 Kong 的 worker_processes 等于 CPU 核心数,worker_connections 为 10240;
- 优化 Nginx 连接池参数(如
keepalive_timeout 65、keepalive_requests 100)。
- 在 Kong 前部署 Nginx,配置
- 稳定性保障:
- 配置 Kong 的健康检查(healthchecks),自动摘除异常节点;
- 实现熔断机制(如基于错误率触发熔断),降级非核心业务;
- 全链路灰度发布,先放 1% 流量验证。
- 负载均衡优化:
二、Kubernetes 与容器化部署
1. 容器化与微服务架构
-
问题示例:
- “项目中如何使用 Docker 和 Kubernetes 实现私有化部署?遇到哪些挑战?”
- “Pod 的资源调度是如何设计的?如何避免资源竞争?”
-
应答思路:
- 私有化部署:
- 构建多阶段 Dockerfile 减少镜像体积(如使用 Alpine 基础镜像);
- 通过 Helm Chart 管理 K8s 资源,配置 ConfigMap 挂载环境变量;
- 挑战:私有镜像仓库权限管理、跨节点网络通信(通过 Calico 网络策略解决)。
- 资源调度:
- 为 Pod 设置 requests 和 limits,避免资源超售;
- 使用 NodeSelector 和 Taints/Tolerations 实现业务隔离(如关键业务部署在专用节点);
- 通过 Vertical Pod Autoscaler 自动调整资源配额。
- 私有化部署:
2. 监控与故障恢复
-
问题示例:
- “如何实现故障恢复时间<5 分钟?监控面板覆盖哪些关键指标?”
- “在 K8s 环境中,如何快速定位 Pod 故障?”
-
应答思路:
- 快速恢复:
- 配置 Pod 的 readinessProbe 和 livenessProbe,异常时自动重启;
- 实现滚动更新(maxUnavailable=1),确保升级无停机;
- 预部署备用集群,通过 DNS 快速切换流量。
- 故障定位:
- 通过 Prometheus 监控 Pod 资源使用率(CPU、内存、网络);
- 结合 ELK 收集容器日志,使用 Jaeger 追踪请求链路;
- 编写自定义告警规则(如 CPU 使用率持续 80% 触发告警)。
- 快速恢复:
三、高并发与性能优化
1. 资源仲裁与并发优化
-
问题示例:
- “如何设计上传服务器的资源仲裁逻辑?Goroutine 并发优化的具体措施有哪些?”
- “支持 200 + 设备同时接入时,遇到哪些瓶颈?如何解决的?”
-
应答思路:
- 资源仲裁:
- 实现公平调度算法(如加权轮转),根据设备优先级分配资源;
- 使用令牌桶算法限制并发连接数,防止过载;
- 通过 Goroutine 池(如 ants 库)控制并发协程数量,避免资源耗尽。
- 瓶颈解决:
- 发现网络 IO 是瓶颈后,使用非阻塞 IO(netpoller)和零拷贝(sendfile);
- 数据库连接池从默认 10 扩大到 50,配置连接复用;
- 引入分布式缓存(Redis)减少 DB 访问,命中率达 85%。
- 资源仲裁:
2. 数据库优化
-
问题示例:
- “如何通过索引设计和分区表提升 ETL 任务效率?具体做了哪些优化?”
- “复杂聚合查询从 30 秒降至 5 秒,分析过程和优化手段是什么?”
-
应答思路:
- 索引与分区:
- 为频繁过滤的字段(如时间戳、业务类型)创建复合索引;
- 按时间范围(如按月)对大表进行分区,减少单表数据量;
- 使用覆盖索引避免回表,例如:
sql
CREATE INDEX idx_time_type ON transactions(time, type) INCLUDE(amount);
- 查询优化:
- 通过
EXPLAIN ANALYZE发现全表扫描,改为索引扫描; - 将子查询重构为 JOIN,减少多次查询;
- 对热点数据(如月度汇总)实现预计算,定时刷新缓存。
- 通过
- 索引与分区:
四、技术栈与工具链
1. AI 辅助开发
-
问题示例:
- “如何搭建 FastGPT+DeepSeek+Cursor 本地工具链?实际提升了哪些开发效率?”
- “代码自动生成的准确率如何?遇到过哪些问题?”
-
应答思路:
- 工具链搭建:
- 在本地部署 FastGPT 服务,配置 DeepSeek 大模型作为代码生成引擎;
- 集成 Cursor IDE 插件,实现实时代码补全和函数级生成;
- 通过通义灵码进行代码风格校验和安全漏洞扫描。
- 效率提升:
- 简单 CRUD 接口开发效率提升 50%(直接生成 MyBatis 代码);
- 单元测试用例生成准确率达 70%,需人工补充边界条件;
- 问题:复杂业务逻辑生成的代码需多次调试,模型对业务术语理解不足。
- 工具链搭建:
2. 设计模式与架构重构
-
问题示例:
- “在 Java SDK 框架升级中,使用了哪些设计模式重构核心业务逻辑?”
- “如何确保新旧页面改造过程中系统稳定运行?”
-
应答思路:
- 设计模式应用:
- 使用策略模式替换大量 if-else,实现审批规则可配置;
- 通过工厂模式解耦对象创建逻辑,支持多版本 SDK 兼容;
- 引入责任链模式处理复杂业务流程,提升可扩展性。
- 平滑过渡:
- 新旧接口并存,通过网关做流量切分(如按用户 ID 哈希);
- 实现双写机制,确保数据一致性;
- 灰度发布期间监控关键指标(如错误率、RT),异常时快速回滚。
- 设计模式应用:
五、软技能与项目管理
1. 风险评估与稳定性保障
-
问题示例:
- “《插件升级风险评估报告》包含哪些内容?如何做到零迁移故障?”
- “连续 24 个月保持 0 线上事故,采取了哪些措施?”
-
应答思路:
- 风险评估:
- 报告内容:插件 API 变更清单、兼容性测试方案、回滚策略、灰度发布计划;
- 零故障措施:在测试环境模拟全量流量,使用 Chaos Mesh 注入故障,验证系统韧性。
- 稳定性保障:
- 建立 SLO(服务级别目标)和 SLA(服务级别协议),监控关键指标;
- 实施全链路压测,发现并解决性能瓶颈;
- 制定应急预案,定期演练故障恢复流程。
- 风险评估:
2. 团队协作与技术落地
-
问题示例:
- “在跨团队协作中,如何推动 Kong 升级方案落地?遇到哪些阻力?”
- “如何衡量 BI 报表响应速度提升 70% 对业务的实际价值?”
-
应答思路:
- 方案落地:
- 与测试团队合作设计自动化测试用例,覆盖 95% 以上的插件功能;
- 向业务团队演示升级后的性能提升数据,争取支持;
- 阻力:部分旧插件不兼容,通过重构或替换解决。
- 价值量化:
- 财务部门月度报表生成时间从 4 小时缩短至 1.2 小时,效率提升 70%;
- 业务人员可实时查看数据,决策响应速度加快;
- 用户满意度调查显示,数据获取体验评分从 75 分提升至 92 分。
- 方案落地:
六、应答技巧总结
-
STAR 法则 + 技术细节:回答问题时先概述背景(S)和任务(T),再深入技术实现(A)和量化成果(R),例如:
“在优化 BI 报表响应速度时(S),我们需要解决复杂聚合查询耗时过长的问题(T)。我通过分析执行计划,发现全表扫描是瓶颈,于是创建了复合索引,并将大表按时间分区(A)。优化后,复杂查询从 30 秒降至 5 秒,BI 报表整体响应速度提升 70%,财务部门月度结账时间缩短了 2 天(R)。”
-
关联目标岗位:突出与公共技术部相关的技能(如 Kong、K8s、高并发),例如:
“在网关性能优化中,我开发的 Lua 插件实现了动态限流和耗时监控,这与公共技术部维护 Kong 网关的职责高度匹配。我还熟悉 K8s 的资源调度和故障恢复,能快速定位并解决 Pod 异常问题。”
-
展示深度思考:对常见技术问题给出超出常规的理解,例如:
“在设计上传服务器的资源仲裁算法时,我不仅考虑了公平性,还引入了‘饥饿预防’机制,为长时间等待的低优先级任务提升权重,避免资源分配僵化。”
一致性哈希算法(Consistent Hashing)
1. 核心思想
一种特殊的哈希算法,用于解决分布式系统中节点增减时数据重新分配的问题,通过将数据和节点映射到一个环形哈希空间,减少节点变动时的数据迁移量。
2. 原理步骤
- 环形哈希空间:将哈希值范围抽象为一个 0 到 2³²-1 的环形空间,数据和节点的哈希值均映射到环上。
- 节点映射:将节点的标识(如 IP)通过哈希函数映射到环上的某个位置。
- 数据映射:将数据的键通过相同哈希函数映射到环上,沿环顺时针找到最近的节点,将数据存储到该节点。
- 节点增减处理:
- 新增节点:仅影响环上该节点与前一节点之间的数据,需迁移这部分数据。
- 移除节点:数据迁移至环上下一节点,避免全量数据重分配。
3. 优化:虚拟节点(Virtual Nodes)
- 问题:当节点较少时,哈希分布可能不均匀(如 “热点” 问题)。
- 解决:为每个物理节点创建多个虚拟节点,映射到环上不同位置,均衡数据分布,提升负载均衡性。
4. 应用场景
- 分布式缓存(如 Redis Cluster)、分布式存储(如 HBase)、负载均衡等需要动态调整节点的系统。
Binlog(二进制日志)
1. 定义与作用
- MySQL 二进制日志:记录数据库所有更改操作(如 INSERT、UPDATE、DELETE)的日志文件,不记录查询操作(SELECT)。
- 核心作用:
- 数据恢复:用于故障时通过日志重放恢复数据。
- 主从复制:主库通过 binlog 将数据变更同步到从库,实现读写分离或高可用。
- 增量同步:第三方组件(如 Canal)可解析 binlog 实现数据实时同步(如 MySQL 到 Elasticsearch)。
2. Binlog 格式(3 种)
- ROW:记录每行数据的具体变更,安全性高(避免函数执行不一致),但日志量大。
- STATEMENT:记录 SQL 语句,日志量小,但可能因函数(如 NOW ())或存储过程导致主从数据不一致。
- MIXED:自动选择 ROW 或 STATEMENT 格式,默认模式。
3. 关键参数与配置
log_bin:启用 binlog(默认关闭),配置为ON或日志文件名。binlog_format:设置日志格式(ROW/STATEMENT/MIXED)。expire_logs_days:binlog 过期天数,避免日志占用过多磁盘空间。
4. 与其他日志的区别
- Redo Log(重做日志):InnoDB 存储引擎的事务日志,用于崩溃恢复,保证事务持久性。
- Binlog:MySQL 服务器层的日志,跨存储引擎,用于主从复制和数据恢复。
5. 典型应用场景
- 数据库主从架构(Master-Slave Replication)。
- 数据实时同步(如微服务架构中数据库变更通知)。
- 审计追踪:记录所有数据变更历史,满足合规性要求。
排序算法
一、时间复杂度对比表
| 排序算法 | 平均时间复杂度 | 最坏时间复杂度 | 最好时间复杂度 | 空间复杂度 | 稳定性 | 适用场景 |
|---|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 小规模数据或基本有序数据 |
| 插入排序 | O(n²) | O(n²) | O(n) | O(1) | 稳定 | 小规模数据或部分有序数据 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 | 简单场景或不要求稳定性的情况 |
| 希尔排序 | O(nlogn)~O(n²) | O(n^s) (1<s<2) | O(n) | O(1) | 不稳定 | 中等规模数据 |
| 快速排序 | O(nlogn) | O(n²) | O(nlogn) | O(logn)~O(n) | 不稳定 | 大规模数据排序的首选算法 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 | 外部排序或要求稳定性的场景 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 内存限制严格或需要取 Top-K 的场景 |
| 计数排序 | O(n+k) | O(n+k) | O(n+k) | O(k) | 稳定 | 数据范围小且密集的场景 |
| 基数排序 | O(d*(n+k)) | O(d*(n+k)) | O(d*(n+k)) | O(n+k) | 稳定 | 整数排序或字符串排序 |
| 桶排序 | O(n+k) | O(n²) | O(n) | O(n+k) | 稳定 | 数据分布均匀的大规模数据 |
1. 简单排序算法(O (n²))
-
冒泡排序(Bubble Sort)
- 核心思想:相邻元素比较,逆序时交换,每次将最大元素 “冒泡” 到末尾。
- 优化点:设置标志位,若一轮无交换则提前终止(最好情况 O (n))。
- 示例场景:教学演示或数据基本有序时。
-
插入排序(Insertion Sort)
- 核心思想:将元素插入已排序子序列的正确位置,类似抓牌时整理手牌。
- 优化点:使用二分查找确定插入位置(二分插入排序)。
- 适用场景:小规模数据(如 n<100)或链表排序。
步骤
- 初始状态:把数组的第一个元素视为已排序序列,剩下的元素为未排序序列。
- 遍历未排序序列:从第二个元素开始,依次将每个元素取出,需要从后向前遍历已排序序列,找到第一个比当前元素小(或大)的位置插入,确保插入后已排序序列始终有序。
- 重复插入:每次插入后,已排序序列长度加1,直到所有元素处理完毕。
-
选择排序(Selection Sort)
- 核心思想:每次从未排序部分选择最小(或最大)元素放到已排序末尾。
- 特点:无论数据是否有序,交换次数固定为 n-1 次,效率低于冒泡和插入排序。
2. 进阶排序算法(O (nlogn))
-
快速排序(Quick Sort)
- 核心思想:分治策略,选基准值将数组分为两部分,递归排序。
- 最坏情况:数据已排序时退化为 O (n²),可通过随机选基准或三数取中优化。
- 优势:原地排序(空间复杂度低),实际应用中效率常高于归并和堆排序。
步骤
1. 选择基准值(Pivot)
- 从数组中选一个元素作为基准(通常选第一个、最后一个或中间元素)。
2. 分区(Partition)
- 将数组分为两部分:
- 所有小于基准值的元素放在左侧;
- 所有大于基准值的元素放在右侧;
- 基准值最终位于中间正确位置,左右两部分无需有序。
3. 递归排序子数组
- 对基准值左侧和右侧的子数组分别重复上述步骤,直至子数组长度为1(天然有序)。
-
归并排序(Merge Sort)
- 核心思想:分治策略,将数组分成两半递归排序,再合并有序子数组。
- 稳定排序:合并过程中相同元素顺序不变,适合需要保持原顺序的场景(如排序对象含相同键值)。
- 缺点:需要 O (n) 额外空间,不适合内存受限场景。
步骤
1. 分解(Divide)
- 将数组从中间分为左右两个子数组,直至子数组长度为1(天然有序)。
2. 合并(Conquer)
- 对两个有序子数组进行合并:比较左右子数组的当前元素,将较小者放入结果数组,直至所有元素合并完成。
-
堆排序(Heap Sort)
- 核心思想:利用堆数据结构(大顶堆或小顶堆),每次从堆顶取最大 / 最小元素。
- 建堆复杂度:O (n),排序过程 O (nlogn),总体 O (nlogn)。
- 应用场景:Top-K 问题(如求数组中前 10 大元素)或内存有限时的排序。
3. 线性时间排序算法
-
计数排序(Counting Sort)
- 核心思想:统计每个元素出现次数,按次数重建数组。
- 前提条件:数据范围已知且较小(如 0~100),否则空间复杂度过高。
- 稳定性:相同元素的相对顺序不变,适合处理对象包含多关键字的场景。
步骤
1. 确定值域范围
- 找到数组中的最大值 max 和最小值 min ,确定计数数组的大小。
2. 统计元素频率
- 创建长度为 max - min + 1 的计数数组 count ,统计每个元素在原数组中的出现次数。
3. 计算前缀和(确定位置)
- 对计数数组计算前缀和, count[i] 表示小于等于 i 的元素总数,用于确定元素在排序数组中的位置。
4. 重构有序数组
- 逆序遍历原数组,根据计数数组的前缀和确定每个元素的位置,放入结果数组。
-
基数排序(Radix Sort)
- 核心思想:按位(如个位、十位)排序,分为 LSD(最低位优先)和 MSD(最高位优先)。
- 示例:对整数排序时,从个位到最高位依次入桶排序。
- 适用场景:字符串排序或固定长度的整数排序(如身份证号)。
-
桶排序(Bucket Sort)
- 核心思想:将数据分到多个桶中,对每个桶内数据排序后合并。
- 效率依赖:数据分布均匀性,若数据集中在少数桶中,时间复杂度可能退化为 O (n²)。
- 希尔排序
核心思想:利用增量序列(gap sequence)将原始数组分成若干个子序列,对每个子序列进行插入排序。随着增量逐渐减小,子序列的长度逐渐增加,数组变得越来越接近有序状态。当增量减至 1 时,整个数组被视为一个子序列,此时执行一次普通的插入排序即可完成最终排序。
算法步骤
- 选择增量序列:通常初始增量为数组长度的一半,之后每次减半,直到增量为 1。
- 按增量分组:将数组中的元素按当前增量分成若干个子序列。例如,增量为 3 时,下标为 0、3、6... 的元素为一组,下标为 1、4、7... 的元素为另一组,依此类推。
- 对子序列插入排序:对每个子序列分别进行插入排序。
- 缩小增量:将增量减小(例如减半),重复步骤 2 和 3,直到增量为 1。
- 最终排序:当增量为 1 时,对整个数组进行一次插入排序,此时数组已接近有序,插入排序效率较高。
算法选择建议
-
小规模数据(n<100):
- 优先选择插入排序或冒泡排序,实现简单且常数项小。
-
大规模数据(n>1000):
- 若数据随机且无稳定性要求:快速排序(实际效率最高)。
- 若要求稳定性或数据基本有序:归并排序。
- 若内存受限:堆排序(O (1) 空间)。
-
特殊场景:
- 数据范围小:计数排序或基数排序(线性时间)。
- 在线排序(数据动态插入):二叉搜索树(如红黑树)或堆结构。
- 外部排序(数据量超过内存):归并排序(可分段处理)。
-
稳定性要求:
- 若排序后相同元素顺序需保持(如排序订单时保留下单时间顺序),选择稳定排序(如归并、插入、计数排序)。
AI相关(LLM、LangChain、AI agent...)
-
LangChain 如何实现自定义工具调用?
- 通过 Tool 类封装外部 API(如数据库查询、HTTP 接口),结合 Chain 链定义调用流程;
- 举例如:用 LLM 生成 SQL 查询,再通过 Tool 执行数据库操作。
-
Agent 开发中如何处理长文本输入?
- 文本分块(Chunking)+ 向量数据库(如 Milvus/Weaviate)存储,检索时匹配相关上下文;
- Dify 平台中可配置 Prompt 模板,动态拼接分块内容。
⼀个好的Prompt提示词需要遵循以下规则
- ⻆⾊设定:擅于使⽤ System给GPT设定⻆⾊和任务,如“哲学⼤师”;
- 指令注⼊:在 System中注⼊常驻任务指令,如“主题创作”;
- 问题拆解:将复杂问题拆解成的⼦问题,分步骤执⾏,如:Debug 和多任务;
- 分层设计:创作⻓篇内容,分层提问,先概览再章节,最后补充细节,如:⼩说⽣成;
- 编程思维:将prompt当做编程语⾔,主动设计变量、模板和正⽂,如:评估模型输出质量;
- Few-Shot:基于样例的prompt设计,规范推理路径和输出样式,如:构造训练数据;
各种向量嵌入模型对比
模型选择建议
- 通用场景(语义搜索、文本分析):优先选 text-embedding-ada-002(综合能力强)、SBERT(轻量高效)、BGE-M3(多语言 + 长文本)。
- 中文垂直场景:选 bge-large-zh、text2vec-large-chinese(专为中文优化,语义精度更高)。
- 多语言跨国应用:选 Cohere 多语言模型、E5 模型(支持超 100 种语言,跨语言一致性好)。
- 轻量级部署(边缘设备):选 all-MiniLM-L6-v2、FastText(模型小、速度快)。
向量嵌入模型综合对比表
| 模型名称 | 所属方 | 向量维度 | 通用性 | 多语言能力 | 语义理解精度 | 计算效率 | 工程落地性 | 适用场景 |
|---|---|---|---|---|---|---|---|---|
| text-embedding-ada-002 | OpenAI | 1536 | 4.8 | 4.5 | 4.7 | 4.6 | 4.9 | 通用语义搜索、分类、聚类,多语言混合场景,实时处理任务。 |
| text-embedding-3-large | OpenAI | 1536 | 4.5 | 4.3 | 4.8 | 4.2 | 4.5 | 复杂语义推理、长文本分析、垂直领域专业内容(如法律、科学文献)。 |
| Universal Sentence Encoder | 512/768 | 4.0 | 4.2 | 4.0 | 4.4 | 4.3 | 短文本语义匹配、多语言基础应用、快速部署场景。 | |
| BERT(原始版) | 768/1024 | 3.8 | 3.5 | 4.5 | 3.2 | 3.8 | 深度语义理解、问答系统、情感分析,需微调适配具体任务。 | |
| Sentence-BERT(SBERT) | 开源社区 | 384/768 | 4.2 | 4.0 | 4.3 | 4.6 | 4.7 | 轻量级语义检索、聚类、相似度计算,支持多语言但专业性较弱。 |
| E5 模型 | MigMSum | 1024 | 4.3 | 4.7 | 4.4 | 4.3 | 4.2 | 跨语言检索、多语言混合文档处理,支持长文本(8192 tokens)。 |
| Llama 系列 | Meta | 1024+ | 3.5 | 3.8 | 4.0 | 3.3 | 3.6 | 基于大语言模型的上下文嵌入,适合复杂推理任务,但计算成本高。 |
| Cohere 多语言模型 | Cohere | 1024 | 4.5 | 4.8 | 4.3 | 4.4 | 4.6 | 跨 100 + 语言的企业级应用,支持快速 API 调用,垂直领域适配性强。 |
| BGE-M3 | 北京智源研究院 | 1024 | 4.4 | 4.7 | 4.5 | 4.3 | 4.4 | 多语言多模态检索(支持文本 + 图像)、长文本分块嵌入、垂直领域微调潜力大。 |
| all-MiniLM-L6-v2 | Sentence Transformers | 384 | 3.5 | 3.8 | 3.2 | 4.8 | 4.5 | 移动端 / 边缘设备部署、实时对话系统、轻量级语义匹配。 |
| bge-large-zh | 北京智源研究院 | 1024 | 3.0 | 4.5 | 4.2 | 4.0 | 4.3 | 中文垂直领域(如法律、医疗)深度语义理解,对专业术语捕捉能力强。 |
| text2vec-large-chinese | CoSENT 项目 | 768 | 2.8 | 3.0 | 4.0 | 3.8 | 4.0 | 中文语义相似度计算、短文本分类,对中文语境优化但多语言支持弱。 |
| Word2Vec | 100-300 | 2.5 | 2.0 | 2.8 | 4.5 | 4.2 | 基础词向量表示、词频分析、简单聚类,不支持上下文理解。 | |
| GloVe | 斯坦福大学 | 50-300 | 2.5 | 2.0 | 2.7 | 4.6 | 4.0 | 基于共现矩阵的词向量,适合词关联分析,计算效率高但语义精度低。 |
| FastText | 100-300 | 2.7 | 2.5 | 2.5 | 4.7 | 4.1 | 支持子词信息,对未登录词处理能力强,适合文本分类、低资源语言场景。 | |
| Doc2Vec | 开源社区 | 100-300 | 2.6 | 2.2 | 2.6 | 4.3 | 3.8 | 文档级语义表示、文档聚类、主题分析,不支持动态上下文。 |
提升向量数据库准确性的方法
- 优化检索策略:
- 混合检索:结合向量搜索和关键词搜索(如 Elasticsearch + 向量数据库),或结合语义检索(向量数据库)和关键词检索(如 BM25),提升召回率。例如使用支持密集与稀疏检索的 BGE-M3 进行混合检索12。
- 重排序:先用向量数据库粗筛,再用更精细的排序模型(如 Cohere Rerank、交叉编码器等)对文档与查询的相关性进行细粒度评分并重新排列顺序,提升上下文质量。如检索后使用 bge-reranker 或 bge-reranker-v2 对 BGE-M3 的检索结果进行重排序12。
- 多阶段检索:先粗筛(如关键词检索 BM25 或轻量级向量检索)候选文档,再对粗筛结果应用更精确但耗时的检索方法(如稠密向量检索、ColBERT)1。
- 查询扩展:通过 LLM 改写或扩展用户查询,提高检索相关性(如 HyDE)1。
- 数据预处理:
- 文本分块:将长文档合理分块,确保检索器能快速定位与查询最相关的文本片段,减少计算开销,避免生成器被长文档中的无关内容干扰1。
- 数据清洗与预处理:剔除低质量或无关的检索内容,减少噪声干扰;对要上传的文件进行预处理结构化,如使用专门工具(MinerU 及 Pandoc 等)将不同来源文件统一转换为 Markdown 并进行多粒度分割,提高嵌入模型的处理效率1。
- 模型优化与微调:
- 选择合适的向量嵌入模型,并根据具体任务和领域在已有的模型基础上进行微调,让模型在保留通用语言知识的同时,更好地掌握特定领域的细节1。
- 对于不同参数量的模型采用不同的提示策略,小参数量简单模型提示应准确简洁,大参数量推理模型可从多个维度进行模块化拆分和分点描述提示语以引导模型更好地理解和生成回答1。
- 结合其他技术:如将知识图谱与 RAG 结合(如 GraphRAG),利用知识图谱擅长逻辑推理的特点弥补 RAG 多跳推理的不足,同时 RAG 可补充知识图谱的动态更新能力。
热门通用大模型
| 模型名称 | 版本号 | 核心特点(简化) | 优点 | 缺点 |
|---|---|---|---|---|
| GPT-4 | Turbo | 128K 长上下文、多模态理解、代码生成 | 综合性能强,生态成熟(API / 插件丰富) | 商用成本高,需订阅(20 美元 / 月) |
| Claude 3.5 | Sonnet | 200K 超长上下文、多语言安全、道德 AI 优化 | 长文本处理能力突出,多语言一致性好 | 技术细节不透明,推理速度偏慢 |
| Gemini 2.0 | Pro/Flash | 多模态(文本 + 图像 + 音频)、200 万 token 上下文(Pro) | 多模态能力行业领先,谷歌产品深度集成 | 部分功能(如代码生成)仍弱于 GPT-4 |
| 文心一言 | 4.15.0.11 | 多模型调度(免费调用 DeepSeek 等)、语音交互优化 | 中文理解顶尖,企业级应用适配性强(如文档处理) | 多语言能力弱于国际模型 |
| Llama 3.1 | 70B/405B | 开源免费商用、8K 上下文、多语言支持(8 种) | 性价比高,可本地部署,社区二次开发活跃 | 原生能力弱于闭源模型,需微调优化 |
| DeepSeek R1 | 0528 | 强化学习优化推理、FunctionCalling 多工具调用 | 数学 / 代码推理顶尖(AIME 准确率 87.5%),开源 | 多模态能力缺失,依赖高性能服务器 |
| 通义千问 3 | Qwen3-235B | 混合推理架构、36T 预训练数据、119 种语言支持 | 性能超越 Gemini2.5,部署成本低(1/3 同类产品) | 开源模型仍存幻觉问题,需企业级微调 |
用大模型的挑战与解决方案
1. 长文本输入限制与效率问题
- 挑战:多数大模型输入token限制在8k-16k(如GPT-4 Turbo支持128k,但企业级应用仍需分段),10页以上合同可能需拆分处理,且完整语义理解耗时较长。
- 方案:
- 先通过文档解析工具(如Unstructured)按章节拆分,再分块输入大模型;
- 用向量数据库(如Chroma)存储合同片段,通过检索增强生成(RAG)快速定位关键信息。
2. 关键信息漏提或误提风险
- 挑战:大模型可能因“幻觉”问题虚构信息(如错误提取不存在的违约金比例),或遗漏必选字段(如生效日期)。
- 方案:
- 设计“结构化提示模板”强制输出指定字段
- 结合“少样本示例”训练大模型,例如先提供10份合同及正确提取结果,让模型学习模式。
3. 法律术语准确性与合规性
- 挑战:大模型对法律术语的理解可能偏离实务(如混淆“不可抗力”与“商业风险”)。
- 方案:
- 用法律领域专用模型(如LegalBERT、LawGPT)微调;
- 构建企业专属知识库,通过RAG让模型引用内部法律条款解释,例如:
“根据《民法典》第590条,以下情况属于不可抗力:{知识库内容},请判断合同条款中的‘疫情’是否属于该范畴。”
4.上下文长度限制
场景:合同识别汇总
合同识别汇总需将非结构化文本转化为结构化数据,核心是通过文本解析、信息提取和语义整合实现高效处理。
1. 提示工程核心策略
- 结构化提示模板:
请按JSON格式提取以下合同中的关键信息:
{
"必须包含字段": ["合同名称", "甲方", "乙方", "金额", "交货日期"],
"合同文本": "..."
}
- 少样本示例引导:
先提供1-2份合同及正确提取结果,例如:
[示例1]
合同文本:"甲方A公司...金额10万元...2025年6月交货"
提取结果:{"甲方":"A公司", "金额":"10万元",...}
[待处理合同]
文本内容:"..."
2. 长文本处理技巧
- 分段输入:超过模型长度限制(如GPT-4 Turbo 128k tokens)时,按章节拆分并标注上下文(如“以下是合同第3章 履行期限”);
- 向量检索增强:用Chroma等数据库存储合同片段,通过“金额”“日期”等关键词快速定位段落,减少大模型处理量。
常见问题与解决方案
1. 信息漏提或错误
- 方案:
- 用“必填字段校验”提示:“请检查是否遗漏‘违约责任’条款,若未找到请标注‘无’”;
- 对金额、日期等数字字段,要求大模型同时输出原文匹配片段(如“金额100万元对应合同第2.1条”)。
2. 法律术语歧义
- 方案:
- 内置法律知识库提示:“根据《民法典》第577条,违约责任包括继续履行、赔偿损失,请判断合同条款是否符合”;
- 对“订金/定金”“不可抗力/情势变更”等术语,要求模型输出判断依据。
落地工具推荐
1. 轻量级方案(个人/小团队)
- 工具链:
- 文档解析:Unstructured(拆分章节);
- 大模型调用:Hugging Face Inference API(选LegalBERT或GPT-4 Turbo);
- 结构化处理:Python json模块直接生成JSON。
2. 企业级方案(批量处理)
- 架构:
plaintext
合同文件 → 分布式OCR(Spark+Tesseract) → 大模型集群(Claude 3) →
向量数据库(Weaviate)存储 → 管理后台可视化(Superset)
- 优势:支持日均500+份合同处理,可对接ERP系统自动填充采购数据。
五、示例:租房合同提取演示
1. 输入文本
text
《房屋租赁合同》
出租方(甲方):张三(身份证号:110101XXXXXX)
承租方(乙方):李四
第一条 租赁房屋
甲方将北京市朝阳区XX小区1号楼101室出租给乙方,建筑面积80㎡。
第二条 租赁期限
自2025年6月1日起至2026年5月31日,共1年。
第三条 租金及支付
月租金5000元,乙方应于每月5日前支付至甲方账户。押金10000元,合同到期无息退还。
2. 大模型提取结果
json
{
"合同名称": "房屋租赁合同",
"主体信息": {
"甲方": "张三(身份证号:110101XXXXXX)",
"乙方": "李四"
},
"标的": "北京市朝阳区XX小区1号楼101室(80㎡)",
"金额": {
"月租金": "5000元",
"押金": "10000元",
"支付方式": "每月5日前支付"
},
"期限": {
"生效日期": "2025-06-01",
"截止日期": "2026-05-31"
}
}
总结
合同识别汇总可通过大模型直接实现免规则引擎处理,关键在于提示工程设计和长文本分段策略。轻量级场景用Hugging Face等工具即可快速落地,企业级需求建议结合向量数据库和分布式架构,平衡效率与准确性。实际应用中需重点校验数字字段和法律术语,必要时引入人工复核环节。
上下文长度优化
如果需要处理长多轮对话的上下文,可以通过以下策略优化LangChain的Memory机制,在模型限制和实用性之间找到平衡:
一、核心方案:长对话分段与摘要策略
1. 动态摘要压缩历史
- 使用ConversationSummaryMemory:定期将对话历史生成摘要,替代完整记录:
- 前5轮对话:保存完整历史
- 第6轮时,自动生成摘要(如“用户咨询了产品价格、配送方式,已提供套餐A报价和3天配送周期”)
- 后续对话基于“摘要+新内容”生成,减少token占用。
2. 按主题分段管理
- 自定义Memory:将对话按主题拆分存储,调用时仅加载相关主题历史。
二、技术优化:结合向量检索与外部存储
1. VectorStoreMemory+向量数据库
- 核心逻辑:将对话历史存入向量数据库,每次仅检索与当前问题相关的历史上下文。
- 优势:避免加载无关历史,精准匹配当前话题(如用户从“产品咨询”切换到“售后投诉”时,仅检索售后相关历史)。
2. 外部数据库持久化存储
- 方案:将完整对话历史存入数据库(如PostgreSQL),Memory仅存储摘要和索引,需时查询。
三、模型层面优化:选择长上下文模型
- 优先使用长窗口LLM:
- Claude 2(100k tokens)、GPT-4 Turbo(128k tokens)、LLaMA 3(32k-100k tokens)等,直接支持更长历史。
- 模型量化与本地部署:
- 对开源模型(如LLaMA-2-70B-chat)进行量化(int8/int4),在本地服务器部署,突破云端API的token限制(如自行管理上下文窗口)。
实战案例:客服多轮对话优化
1. 问题:用户咨询手机售后,经历“故障描述→配件查询→维修报价→预约时间”4个阶段,需全程保留上下文。
2. 方案流程:
1. 阶段1-2:保存完整对话;
2. 阶段3:生成摘要“用户手机屏幕损坏,查询X配件库存,已报价500元”;
3. 阶段4:基于摘要+当前预约需求生成回答,避免历史过长。
总结
长多轮对话的核心是“压缩+检索”:通过摘要减少冗余,用向量检索精准定位相关历史,同时搭配长上下文模型和外部存储,突破内存与模型窗口的限制。实际应用中需根据业务场景调整策略,平衡历史完整性与回答效率,避免因上下文过长导致模型响应变慢或语义断层。
综合场景题
-
设计一个高并发秒杀系统,如何优化性能与稳定性?
- 前端限流(令牌桶)、Redis 预减库存、消息队列异步下单、MySQL 分库分表;
- 避免超卖:Redis 原子操作(Lua 脚本)+ 数据库唯一索引。
-
微服务架构下如何排查接口响应慢的问题?
- 链路追踪(如 Skywalking)定位耗时节点,JVM 监控(Arthas)分析线程状态,数据库慢查询日志优化 SQL。
复杂多模态文档RAG
文档解析→文档切片→向量嵌入→向量存储→检索→生成 是 检索增强生成(RAG, Retrieval-Augmented Generation) 系统的核心流程
一、复杂文档预处理:分层解析与多模态融合
1. 文档结构理解
- 格式感知解析:
- PDF 文档:使用
pdfminer.six解析文档结构,区分正文、标题、表格、图片区域(通过LTTextContainer和LTFigure标签识别) - Word 文档:通过
python-docx的element.xml解析嵌套结构,识别w:tbl(表格)和w:pic(图片)标签
- PDF 文档:使用
- 示例代码:提取 PDF 结构
from pdfminer.high_level import extract_pages from pdfminer.layout import LTTextContainer, LTFigure, LTTable for page_layout in extract_pages(pdf_path): for element in page_layout: if isinstance(element, LTTextContainer): # 文本块处理 text = element.get_text() block_type = "text" elif isinstance(element, LTTable): # 表格处理 table = extract_table(element) block_type = "table" elif isinstance(element, LTFigure): # 图片处理 images = extract_images(element) block_type = "image"
2. 多模态块切片策略
- 语义单元切片:
- 文本块:按
标题+正文逻辑分块(如 "3.2 考勤审批流程" 及其后续段落),使用spaCy识别章节标题(正则匹配^[0-9]+\.[0-9]+\s.*) - 表格块:保留完整表格结构(转为 Markdown 格式),按
表头+行切分(如 "表 3-1 加班类型" 及其列名、数据行) - 图片块:结合 OCR 识别图片文字(如流程图、制度示意图),使用
CLIP模型提取图像特征,与 OCR 文本拼接为多模态向量
- 文本块:按
- 分层切片
二、向量模型选择与优化
1. 多模态向量模型组合
| 文档类型 | 推荐模型 | 优势场景 |
|---|---|---|
| 纯文本块 | intfloat/e5-large-v2(支持 3000+token) |
长段落语义捕获 |
| 表格块 | google/tapas-base-finetuned-wtq(表格语义理解)+ thenlper/gte-base |
表格结构与内容联合编码 |
| 图片 + OCR 块 | openai/clip-vit-base-patch32(图像特征)+ sentence-transformers/all-MiniLM-L6-v2(文本特征) |
图文语义融合 |
2. 向量融合策略
- 并行编码:对表格 / 图片块分别提取结构特征和文本特征,通过
concat拼接为高维向量(如 768+768=1536 维) - 交叉注意力融合:使用轻量级
CrossAttention层处理图文特征,增强跨模态语义关联(需微调模型)
三、基于 Milvus 的复杂文档检索优化(推荐方案)
1. 分层索引架构
- 粗粒度索引:按章节标题建立
BM25文本索引(用于快速定位章节) - 细粒度索引:对切片向量建立
HNSW索引(M=128,efConstruction=300),提升百万级切片检索效率 - 示例 Milvus 集合设计:
collection.create( fields=[ {"name": "vector", "type": "float", "dim": 1536}, {"name": "doc_id", "type": "varchar", "max_length": 128}, {"name": "section_title", "type": "varchar", "max_length": 256}, {"name": "block_type", "type": "varchar", "max_length": 32}, # text/table/image {"name": "context", "type": "text"} # 切片上下文 ], index_params={ "index_type": IndexType.HNSW, "metric_type": MetricType.IP, "params": {"M": 128, "efConstruction": 300} } )
2. 复杂查询增强策略
- 多模态查询流程:
- 用户查询解析:识别查询中的文本关键词(如 "差旅报销标准")和潜在模态需求(如 "报销流程图")
- 向量生成:
- 纯文本查询:使用
e5-large-v2生成文本向量 - 含图片查询:使用
CLIP生成图像向量,与文本向量拼接
- 纯文本查询:使用
- 分层检索:
- 先通过
section_title文本索引定位相关章节(如 "第 5 章 差旅管理") - 再在章节内进行向量检索,返回 Top20 切片
- 先通过
- 跨模态检索示例
# 查询包含"薪酬结构表"的制度切片 text_vector = e5_model.encode("薪酬结构表") table_vector = tapas_model.encode("薪酬结构表", table_structure=True) query_vector = np.concatenate([text_vector, table_vector]) results = milvus.search( collection_name="regs", query_vectors=[query_vector.tolist()], filter=f'block_type in ["text", "table"]', top_k=30, params={"ef": 200} )
四、长文档检索准确性提升方案
1. 上下文感知检索
- 动态窗口扩展:根据切片相关性动态扩展上下文(如对 Top5 切片,向前后各扩展 2 个切片)
- 示例逻辑:
def expand_context(slice_id, context_size=2): # 通过doc_id和切片位置获取相邻切片 相邻切片 = db.query(f'doc_id={slice.doc_id} AND slice_pos BETWEEN {slice.pos-context_size} AND {slice.pos+context_size}') return 原切片 + 相邻切片
2. 大模型重排序与逻辑校验
- 结果重排序:使用
gpt-4对检索结果进行语义相关性打分(提示词示例:"判断以下制度切片与查询 ' 加班调休流程 ' 的相关性,按 0-10 分打分") - 逻辑一致性校验:通过大模型验证检索结果的逻辑连贯性(如检查同章节切片是否被正确召回)
3. 增量学习与反馈优化
- 用户反馈机制:
- 记录用户对检索结果的标注(如 "相关"/"不相关")
- 每月用反馈数据微调向量模型(使用
ContrastiveLearning损失函数)
- 主动学习采样:对相似度在 0.6-0.8 之间的 "模糊样本" 优先标注,提升模型边界识别能力
五、工程化挑战与解决方案
1. 数百页文档处理效率问题
- 并行处理架构:
- 使用
Dask分布式框架,按 PDF 页码 / Word 章节并行解析切片 - 示例任务分配:1000 页文档拆分为 50 个任务,每个任务处理 20 页
- 使用
- 增量更新优化:通过文档哈希对比,仅重新处理变更页面(如某制度修订后仅更新第 3-5 章)
2. 多模态语义对齐问题
- 跨模态预训练:使用企业内部制度数据微调
CLIP模型(如让模型学习 "考勤流程图" 图像与对应文本的映射关系) - 知识图谱增强:构建
制度章节-表格-图片关联图谱,检索时自动关联跨模态内容(如查询 "表 4.1 薪酬构成" 时返回对应图片)
六、实施案例:某集团 HR 制度 RAG 系统
1. 系统配置
- 文档规模:800 + 份制度(平均 200 页 / 份),含 PDF/Word,其中 30% 文档包含表格 / 图片
- 向量数据库:Milvus 2.1.0(3 节点分布式集群),向量维度 1536 维
- 模型组合:
e5-large-v2(文本)+CLIP(图像)+Tapas(表格)
2. 效果指标
- 检索准确率:Top5 结果相关率从 68% 提升至 89%(通过人工抽检)
- 处理效率:单份 200 页文档解析 + 向量化耗时从 45 分钟降至 12 分钟(并行处理优化)
- 典型场景:用户上传 "加班审批单" 图片,系统准确返回《考勤管理制度》第 6.2 章及对应表格说明
Spring Boot 基础概念高频问法
1. Spring Boot 和 Spring MVC 的关系?
- 问法变种:Spring Boot 是如何简化 Spring MVC 开发的?
- 核心考点:
- Spring MVC 是 Spring 框架中的 Web 层模块,负责处理 HTTP 请求和响应。
- Spring Boot 是一套脚手架,通过
Starter依赖、自动配置(AutoConfiguration)、内嵌容器(如 Tomcat)等机制,简化 Spring MVC 的配置(如无需手动配置DispatcherServlet、视图解析器等)。 - 示例:Spring MVC 需手动配置
@EnableWebMvc,而 Spring Boot 通过@SpringBootApplication自动整合。
2. @SpringBootApplication 的组成和作用?
- 问法变种:该注解包含哪些核心注解?
- 核心考点:
- 由
@SpringBootConfiguration(含@Configuration)、@EnableAutoConfiguration、@ComponentScan组合而成。 @EnableAutoConfiguration:根据类路径依赖自动配置 Bean(如存在spring-webmvc依赖则自动配置 MVC 组件)。@ComponentScan:扫描指定包下的组件(默认扫描注解所在类的包及其子包)。
- 由
3. Spring Boot 的自动配置原理?
- 问法变种:AutoConfiguration 是如何生效的?
- 核心考点:
- 启动时通过
@EnableAutoConfiguration触发AutoConfigurationImportSelector,加载META-INF/spring.factories中定义的自动配置类。 - 自动配置类通过
@Conditional注解(如@ConditionalOnClass、@ConditionalOnMissingBean)判断是否生效。 - 示例:
DataSourceAutoConfiguration会在类路径存在DataSource时配置数据库连接。
- 启动时通过
4. Spring Boot Starter 的作用?
- 问法变种:为什么引入
spring-boot-starter-web就具备了 Web 开发能力? - 核心考点:
Starter是依赖包的集合,通过pom.xml的dependencyManagement管理版本,避免依赖冲突。spring-boot-starter-web包含spring-webmvc、tomcat-embed-core等依赖,自动引入 Web 开发所需组件。
Spring MVC 核心机制高频问法
1. Spring MVC 的请求处理流程?
- 问法变种:描述 DispatcherServlet 的工作流程。
- 核心考点(流程图解):
- DispatcherServlet接收请求,根据
HandlerMapping找到处理请求的Handler(控制器方法)。 - 通过
HandlerAdapter调用 Handler 方法,返回ModelAndView。 ViewResolver解析视图(如 JSP、Thymeleaf),渲染数据并响应。
- DispatcherServlet接收请求,根据
- 关键组件:
HandlerMapping、HandlerAdapter、ViewResolver(可通过@Bean自定义)。
2. @Controller 和 @RestController 的区别?
- 问法变种:为什么 REST 接口常用 @RestController?
- 核心考点:
@Controller用于标注 MVC 控制器,方法返回ModelAndView或视图名,需配合@ResponseBody返回 JSON。@RestController是@Controller+@ResponseBody的组合注解,方法直接返回对象(自动序列化为 JSON/XML)。
3. Spring MVC 如何处理请求参数?
- 问法变种:@RequestParam 和 @PathVariable 的区别?
- 核心考点:
@RequestParam:获取查询参数(如/api?name=test),支持required、defaultValue属性。@PathVariable:获取路径参数(如/api/{id}),常用于 RESTful 接口。@RequestBody:解析请求体 JSON 数据,绑定到对象(需开启@EnableWebMvc或 Spring Boot 自动配置)。
4. Spring MVC 的拦截器(Interceptor)和过滤器(Filter)的区别?
- 问法变种:拦截器的实现步骤?
- 核心考点:
维度 过滤器(Filter) 拦截器(Interceptor) 作用范围 Servlet 规范的一部分,在 doFilter中处理Spring 框架组件,在 preHandle等方法中处理触发时机 在 DispatcherServlet 之前执行 在 DispatcherServlet 之后,Handler 之前 / 之后执行 依赖 不依赖 Spring 容器 依赖 Spring 容器(需通过 addInterceptors注册)使用场景 处理编码、权限校验等底层需求 处理登录状态、日志记录等业务相关逻辑
- 过滤器:
- 统一字符编码处理(
CharacterEncodingFilter)。 - 跨域资源共享(CORS)处理。
- 敏感信息过滤(如 XSS 防护)。
- 统一字符编码处理(
- 拦截器:
- JWT 权限验证。
- 接口请求频率限制。
- 日志记录 Controller 执行时间。
Spring MVC完整执行流程(含过滤器与拦截器)
一、整体流程概览
客户端请求 → 过滤器链 → DispatcherServlet → 拦截器(预处理) → 控制器 → 拦截器(后处理) → 视图渲染 → 拦截器(完成处理) → 过滤器链(返回响应)
二、详细执行步骤与阶段解析
- 步骤1:请求抵达Web容器
客户端(如浏览器)发送HTTP请求至Web服务器(如Tomcat),容器接收请求并封装为 HttpServletRequest 对象。
- 步骤2:过滤器前置处理(非Spring MVC专属)
若请求匹配过滤器(Filter)的映射规则(如 @WebFilter("/*") ),则按顺序执行过滤器的 doFilter() 方法:
- 前置逻辑:处理跨域请求(CORS)、设置字符编码(如UTF-8)、解析JWT令牌等。
- 示例: EncodingFilter 设置请求编码, CorsFilter 添加跨域响应头。
顺序:
- @WebFilter注解的order属性(Servlet 3.0+)
- FilterRegistrationBean的setOrder()方法(Spring Boot)
- web.xml中(传统Web项目)注册过滤器时,先声明的对应的过滤器先执行
过滤器按order从小到大顺序执行前置处理(请求进入时),按相反顺序执行后置处理(响应返回时)
- 步骤3:DispatcherServlet初始化
若请求匹配DispatcherServlet的映射(如 / 或 *.do ),则由其接管处理(Spring MVC的核心入口)。
- 步骤4:查找处理器映射(HandlerMapping)
DispatcherServlet通过 HandlerMapping (如 RequestMappingHandlerMapping )根据URL查找对应的处理器(Handler),返回 HandlerExecutionChain 对象(包含处理器和拦截器列表)。
- 步骤5:遍历拦截器并执行preHandle
按注册顺序执行拦截器(Interceptor)的 preHandle() 方法:
- 核心作用:校验用户登录状态、记录请求开始时间、参数合法性校验(如@Valid注解)。
- 若任意拦截器返回 false ,则中断请求并返回响应,后续流程不执行。
顺序:
- addInterceptors()方法中注册的顺序
- 无显式顺序时按Bean加载顺序(通常为类名字典序)
- 步骤6:调用处理器(Controller)
若所有拦截器 preHandle() 返回 true ,则调用Controller方法,返回 ModelAndView 对象(包含数据模型和视图信息)。
- 步骤7:视图解析与渲染
- DispatcherServlet通过 ViewResolver (如 InternalResourceViewResolver )将逻辑视图名解析为物理视图(如JSP页面)。
- 渲染视图时,将Model数据填充到视图中,生成最终HTML内容。
- 步骤8:执行拦截器postHandle
在Controller方法执行后、视图渲染前,按拦截器注册逆序执行 postHandle() :
- 核心作用:修改Model数据(如添加全局共享变量)、记录请求处理耗时。
- 步骤9:执行拦截器afterCompletion
视图渲染完成且响应返回后,执行 afterCompletion() :
- 核心作用:清理资源(如关闭数据库连接)、记录请求结束时间、统计接口调用次数。
- 步骤10:过滤器后置逻辑执行
按过滤器注册逆序执行 doFilter() 的后置逻辑:
- 核心作用:压缩响应体、添加响应头(如缓存控制)、记录全局日志。
- 步骤11:响应返回客户端
最终响应(如HTML、JSON)通过Web容器返回给客户端,请求处理流程结束。
四、关键组件与作用总结
入口组件 DispatcherServlet 接收所有请求,协调各组件工作,相当于MVC的“调度者”。
处理器映射 RequestMappingHandlerMapping 根据URL找到对应的Controller方法,返回处理器和拦截器链。
处理器适配器 RequestMappingHandlerAdapter 适配不同类型的处理器(如Controller方法),调用其执行逻辑。
视图解析器 InternalResourceViewResolver 将逻辑视图名(如"home")解析为物理视图(如"/WEB-INF/views/home.jsp")。
过滤器 EncodingFilter、CorsFilter 处理Web容器级别的通用逻辑,与Spring框架解耦。
拦截器 LoginInterceptor、LogInterceptor 处理Spring MVC级别的业务逻辑,依赖Spring容器,可访问Bean。
五、典型应用场景串联示例
1. 用户请求登录接口: /user/login
2. 过滤器处理: JwtFilter 解析请求头中的Token(若存在), EncodingFilter 设置UTF-8编码。
3. DispatcherServlet查找处理器:通过 RequestMappingHandlerMapping 找到 UserController.login() 方法。
4. 拦截器校验: LoginInterceptor 发现未登录,允许访问(登录接口无需登录)。
5. Controller执行:验证用户名密码,生成Token并返回JSON响应。
6. 视图处理:直接返回JSON数据(无视图渲染),拦截器记录请求耗时。
7. 过滤器后置处理: LogFilter 记录请求日志,响应返回客户端。
Spring Boot 与 MVC 整合高频问法
1. Spring Boot 如何自定义 MVC 配置?
- 问法变种:为什么继承 WebMvcConfigurerAdapter 已过时?
- 核心考点:
- 方式 1:创建
@Configuration类,实现WebMvcConfigurer(替代旧版WebMvcConfigurerAdapter),重写方法:addViewControllers:配置无控制器的视图跳转。addResourceHandlers:配置静态资源路径(如/static/**)。configureMessageConverters:自定义 JSON 解析器(如更换为 FastJSON)。
- 方式 2:若需完全接管 MVC 配置,添加
@EnableWebMvc,但会禁用 Spring Boot 的自动配置。
- 方式 1:创建
2. Spring Boot 如何修改内嵌容器配置?
- 问法变种:如何将 Tomcat 替换为 Undertow?
- 核心考点:
- 修改端口 / 上下文路径:在
application.properties中配置server.port=8081、server.servlet.context-path=/app。 - 替换容器:排除 Tomcat 依赖,添加目标容器依赖:
<!-- 排除Tomcat --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> <exclusions> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-tomcat</artifactId> </exclusions> </dependency> <!-- 添加Undertow --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-undertow</artifactId> </dependency>
- 修改端口 / 上下文路径:在
3. Spring Boot 的配置加载顺序?
- 问法变种:application.properties 和 application.yml 哪个优先级高?
application.properties的优先级高于application.yml。
当两者存在相同配置项时,application.properties中的值会覆盖application.yml中的值。 - 核心考点(优先级从高到低,加载顺序刚好从后往前):
- 命令行参数(如
--server.port=8081)。 SPRING_APPLICATION_JSON环境变量(JSON 格式配置)。- JNDI 属性(如
java:comp/env)。 - Java 系统属性(
System.getProperties())。 - 操作系统环境变量。
- 随机生成的带
random.*前缀的属性(仅在未指定时生成)。 - 应用程序外部配置(按优先级排序):
application.properties(优先级最高)。application.yml。application.yaml。
- 应用程序内部配置(如
src/main/resources下的配置文件,顺序同上)。 - @Configuration 类上的 @PropertySource 注解。
- 默认属性(通过
SpringApplication.setDefaultProperties设置)。
- 命令行参数(如
- 注意:同参数在高优先级配置中存在则覆盖低优先级,yml 和 properties 优先级相同,按加载顺序后者覆盖前者。
4. Spring Boot 的健康检查(Actuator)如何使用?
- 问法变种:如何自定义健康检查指标?
- 核心考点:
- 添加
spring-boot-starter-actuator依赖,默认暴露/actuator/health端点(需配置management.endpoints.web.exposure.include=*)。 - 自定义健康检查:实现
HealthIndicator接口,如检测数据库连接:@Component public class DatabaseHealthIndicator implements HealthIndicator { @Override public Health health() { try { // 检测数据库连接 return Health.up().withDetail("db", "connected").build(); } catch (Exception e) { return Health.down(e).withDetail("error", e.getMessage()).build(); } } }
- 添加
性能优化与实战高频问法
1. Spring MVC 如何优化请求处理性能?
- 问法变种:如何减少 Controller 方法的响应时间?
- 核心考点:
- 异步处理:在 Controller 方法添加
@ResponseBody和DeferredResult,释放主线程:@GetMapping("/async") public DeferredResult<String> asyncRequest() { DeferredResult<String> result = new DeferredResult<>(); // 异步线程处理业务,完成后调用result.setResult() return result; } - 缓存优化:使用
@Cacheable缓存查询结果,减少数据库访问。 - 批量处理:将多次单条数据请求合并为批量请求(如批量查询 MyBatis 的
foreach)。
- 异步处理:在 Controller 方法添加
2. Spring Boot 如何实现热部署?
- 问法变种:DevTools 的工作原理?
- 核心考点:
- 添加
spring-boot-devtools依赖,修改代码后自动重启应用(基于文件监听)。 - 原理:启动两个 ClassLoader,修改类时仅重启应用类加载器,保留基础类加载器(提高重启速度)。
- 注意:生产环境需禁用 DevTools,可通过
spring.devtools.enabled=false配置。
- 添加
3. Spring Boot 如何处理跨域请求(CORS)?
- 问法变种:@CrossOrigin 的使用方式?
- 核心考点:
- 方式 1:在 Controller 类或方法上添加
@CrossOrigin,指定允许的域名、方法、头信息:@CrossOrigin(origins = "http://localhost:8080", methods = {GET, POST}) @GetMapping("/api/data") public List<Data> getData() { ... }
- 方式 1:在 Controller 类或方法上添加
HTTP VS HTTPS
1. HTTP 报文格式
HTTP 报文分为 请求报文 和 响应报文,均由 起始行、头部字段 和 消息体 组成:
请求报文示例
GET /api/users HTTP/1.1 # 起始行:[方法] [路径] [协议版本]
Host: example.com # 头部字段:键值对
User-Agent: Mozilla/5.0
Accept: application/json
Content-Type: application/json
Content-Length: 24 # 若有消息体,需指定长度
{"username":"john","age":30} # 消息体(可选,POST/PUT 请求常见)
响应报文示例
HTTP/1.1 200 OK # 起始行:[协议版本] [状态码] [状态描述]
Date: Mon, 10 Jun 2025 12:00:00 GMT
Content-Type: application/json
Content-Length: 35
{"id":1,"name":"John","email":"john@example.com"}
2. HTTPS 与 HTTP 的核心区别
| 特性 | HTTP | HTTPS |
|---|---|---|
| 协议 | 超文本传输协议(明文) | HTTP + TLS/SSL(加密) |
| 端口 | 默认 80 | 默认 443 |
| 安全性 | 明文传输,易被窃听、篡改 | 通过 TLS 加密,防窃听、篡改和伪装 |
| 数据格式 | 与 HTTP 相同,但内容未加密 | 与 HTTP 相同,但内容经 TLS 加密 |
| 证书 | 无需证书 | 需要 SSL/TLS 证书(公钥加密) |
| 性能 | 无加密开销,速度略快 | 加密和解密带来额外性能开销 |
| 应用场景 | 内部系统、非敏感信息展示 | 涉及用户信息、支付等敏感场景 |
3. HTTPS 加密原理
HTTPS 通过 混合加密 实现安全通信:
- 对称加密:使用相同密钥加密和解密数据(如 AES),速度快但密钥传输需安全通道。
- 非对称加密:使用公钥加密、私钥解密(如 RSA),用于安全交换对称密钥。
SpringBoot 缓存预热
缓存预热是指在 Spring Boot 项目启动时,预先将数据加载到缓存系统(如 Redis)中的一种机制。它可以通过监听 ContextRefreshedEvent 或 ApplicationReadyEvent 启动事件,或使用 @PostConstruct 注解,或实现 CommandLineRunner 接口、ApplicationRunner 接口或 InitializingBean 接口的方式来完成。(使用ApplicationListener 监听 ContextRefreshedEvent 或 ApplicationReadyEvent 等应用上下文初始化完成事件,在这些事件触发后执行数据加载到缓存的操作。)
SpringBoot 获取 Request 对象
在 Spring Boot 中,获取 Request 对象的方法有哪些?
常见的获取 Request 对象的方法有以下三种:
- 通过请求参数中获取 Request 对象;
- 通过 RequestContextHolder 获取 Request 对象;
- 通过自动注入获取 Request 对象。
自定义注解
自定义注解可以标记在方法上或类上,用于在编译期或运行期进行特定的业务功能处理,如:日志记录、性能监控、权限校验、幂等性判断等功能。
在 Spring Boot 中,使用 @interface 关键字来定义自定义注解,之后再使用 AOP 或拦截器的方式实现自定义注解,使用即可。
拦截器负责 统一拦截请求,注解负责 传递自定义参数(如 requestId)。
1.实现自定义注解
使用 AOP 的方式实现打印日志的自定义注解,实现步骤如下:
- 添加 Spring AOP 依赖。
- 创建自定义注解。
- 编写 AOP 拦截(自定义注解)的逻辑代码。
- 使用自定义注解。
① 添加 Spring AOP 依赖
在 pom.xml 中添加如下依赖:
<dependencies>
<!-- Spring AOP dependency -->
<dependency>
<groupIdorg.springframework.boot</groupId>
<artifactIdspring-boot-starter-aop</artifactId>
</dependency>
</dependencies>
② 创建自定义注解
创建一个新的 Java 注解类,通过 @interface 关键字来定义,并可以添加元注解以及属性。
import java.lang.annotation.*;
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface CustomLogAnnotation {
String value() default "";
boolean enable() default true;
}
在上面的例子中,我们定义了一个名为 CustomLogAnnotation 的注解,它有两个属性:value 和 enable,分别设置了默认值。
- @Target(ElementType.METHOD) 指定了该注解只能应用于方法级别。
- @Retention(RetentionPolicy.RUNTIME) 表示这个注解在运行时是可见的,这样 AOP 代理才能在运行时读取到这个注解。
③ 编写 AOP 拦截(自定义注解)的逻辑代码
使用 Spring AOP 来拦截带有自定义注解的方法,并在其前后执行相应的逻辑。
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.springframework.stereotype.Component;
@Aspect
@Component
public class CustomLogAspect {
@Around("@annotation(customLog)")
public Object logAround(ProceedingJoinPoint joinPoint, CustomLogAnnotation customLog) throws Throwable {
if (customLog.enable()) {
// 方法执行前的处理
System.out.println("Before method execution: " + joinPoint.getSignature().getName());
long start = System.currentTimeMillis();
// 执行目标方法
Object result = joinPoint.proceed();
// 方法执行后的处理
long elapsedTime = System.currentTimeMillis() - start;
System.out.println("After method execution (" + elapsedTime +
"ms): " + customLog.value());
return result;
} else {
return joinPoint.proceed();
}
}
}
④ 使用自定义注解
将自定义注解应用于需要进行日志记录的方法上,如下:
@RestController
public class MyController {
@CustomLogAnnotation(value = "This is a test method", enable = true)
@GetMapping("/test")
public String testMethod() {
// 业务逻辑代码
return "Hello from the annotated method!";
}
}
2.自定义幂等性注解(幂等性判断是指在分布式系统或并发环境中,对于同一操作的多次重复请求,系统的响应结果应该是一致的。简而言之,无论接收到多少次相同的请求,系统的行为和结果都应该是相同的。)
使用拦截器 + Redis 的方式来实现自定义幂等性注解,实现步骤如下:
- 创建自定义幂等性注解。
- 创建拦截器,实现幂等性逻辑判断。
- 配置拦截规则。
- 使用自定义幂等性注解。
① 创建自定义幂等性注解
@Retention(RetentionPolicy.RUNTIME) // 程序运行时有效
@Target(ElementType.METHOD) // 方法注解
public @interface Idempotent {
/**
* 请求标识符的参数名称,默认为"requestId"
*/
String requestId() default "requestId";
/**
* 幂等有效时长(单位:秒)
*/
int expireTime() default 60;
}
② 创建拦截器
@Component
public class IdempotentInterceptor extends HandlerInterceptorAdapter {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
Method method = ((HandlerMethod) handler).getMethod();
Idempotent idempotent = method.getAnnotation(Idempotent.class);
if (idempotent != null) {
// 获取请求中的唯一标识符
String requestId = obtainRequestId(request, idempotent.requestId());
// 判断该请求是否已经处理过
if (redisTemplate.opsForValue().get(idempotentKey(requestId)) != null) {
// 已经处理过,返回幂等响应
response.getWriter().write("重复请求");
return false;
} else {
// 将请求标识符存入Redis,并设置过期时间
redisTemplate.opsForValue().set(idempotentKey(requestId), "processed", idempotent.expireTime(), TimeUnit.SECONDS);
return true; // 继续执行业务逻辑
}
}
return super.preHandle(request, response, handler);
}
private String idempotentKey(String requestId) {
return "idempotent:" + requestId;
}
private String obtainRequestId(HttpServletRequest request, String paramName) {
// 实现从请求中获取唯一标识符的方法
return request.getParameter(paramName);
}
}
③ 配置拦截器
在 Spring Boot 配置文件类中,添加拦截器配置:
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private IdempotentInterceptor idempotentInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(idempotentInterceptor)
.addPathPatterns("/**"); // 拦截所有接口
}
}
④ 使用自定义注解
最后,在需要进行幂等控制的 Controller 方法上使用 @Idempotent 注解:
Java
@RestController
public class TestController {
@PostMapping("/order")
@Idempotent(requestId = "orderId") // 假设orderId是从客户端传来的唯一标识订单请求的参数
public String placeOrder(@RequestParam("orderId") String orderId, ...) {
// 业务处理逻辑
}
}
这样,当有相同的请求 ID 在指定的有效期内再次发起请求时,会被拦截器识别并阻止其重复执行业务逻辑。
事务失效场景
@Transactional 会在方法执行前,会自动开启事务;在方法成功执行完,会自动提交事务;如果方法在执行期间,出现了异常,那么它会自动回滚事务。
当声明式事务 @Transactional 遇到以下场景时,事务会失效:
- 非 public 修饰的方法;
- timeout 设置过小;
- 代码中使用 try/catch 处理异常;
- 调用类内部 @Transactional 方法;
- 数据库不支持事务。
框架源码
Spring Boot 收到请求之后,执行流程的源码
请求的核心代码都在 DispatcherServlet.doDispatch 中,包含的主要执行流程有:
- 调用 HandlerExecutionChain 获取处理器:DispatcherServlet 首先调用 getHandler 方法,通过 HandlerMapping 获取请求对应的 HandlerExecutionChain 对象,包含了处理器方法和拦截器列表。
- 调用 HandlerAdapter 执行处理器方法:DispatcherServlet 使用 HandlerAdapter 来执行处理器方法。根据 HandlerExecutionChain 中的处理器方法类型不同,选择对应的 HandlerAdapter 进行处理。常用的适配器有 RequestMappingHandlerAdapter 和 HttpRequestHandlerAdapter。
- 解析请求参数:DispatcherServlet 调用 HandlerAdapter 的 handle 方法,解析请求参数,并将解析后的参数传递给处理器方法执行。
- 调用处理器方法:DispatcherServlet 通过反射机制调用处理器方法,执行业务逻辑。
- 处理拦截器:在调用处理器方法前后,DispatcherServlet 会调用拦截器的 preHandle 和 postHandle方法进行相应的处理。
- 渲染视图:处理器方法执行完成后,DispatcherServlet 会通过 ViewResolver 解析视图名称,找到对应的 View 对象,并将模型数据传递给 View 进行渲染。
- 生成响应:View 会将渲染后的视图内容生成响应数据。
Spring Cloud LoadBalancer源码分析
内置了两种负载均衡策略:
轮询负载均衡策略
- 使用原子变量保证位置索引的线程安全自增。
- 通过按位与操作确保索引为正,避免负数导致的越界问题。
- 利用取余运算将索引映射到服务实例集合的范围内,实现顺序轮询。
随机负载均衡策略
通过 ThreadLocalRandom.current().nextInt(instances.size()) 获取一个随机数,最大值为服务实例的个数
补充:
轮询负载均衡策略的核心实现源码如下:
// ++i 去负数,得到一个正数值
int pos = this.position.incrementAndGet() & Integer.MAX_VALUE;
// 正数值和服务实例个数取余 -> 实现轮询
ServiceInstance instance = (ServiceInstance)instances.get(pos % instances.size());
// 将实例返回给调用者
return new DefaultResponse(instance);
随机负载均衡策略的核心实现源码如下:
// 通过 ThreadLocalRandom 获取一个随机数,最大值为服务实例的个数
int index = ThreadLocalRandom.current().nextInt(instances.size());
// 得到实例
ServiceInstance instance = (ServiceInstance)instances.get(index);
// 返回
return new DefaultResponse(instance);跨域问题
跨域请求分类:
- 协议不同,如 http 和 https;
- 域名不同;
- 端口不同。
跨域问题指的是不同站点之间,使用 ajax 无法相互调用的问题。跨域问题本质是浏览器的一种保护机制,它的初衷是为了保证用户的安全,防止恶意网站窃取数据。
解决方案
- 使用 @CrossOrigin 注解实现跨域;
- 通过配置文件实现跨域(创建一个新配置文件;添加 @Configuration 注解,实现 WebMvcConfigurer 接口;重写 addCorsMappings 方法,设置允许跨域的代码);
- 通过 CorsFilter 对象实现跨域;
- 通过 Response 对象实现跨域;
- 通过实现 ResponseBodyAdvice 实现跨域(重写beforeBodyWrite())。
以上均是在返回头中设置“Access-Control-Allow-Origin”参数即可解决跨域问题,此参数就是用来表示允许跨域访问的原始域名的,当设置为“*”时,表示允许所有站点跨域访问。
@Async使用
1.在项目中开启异步支持
以 Spring Boot 项目为例,首先需要在 Spring Boot 的启动类,也就是带有@SpringBootApplication 注解的类上添加 @EnableAsync 注解,以开启异步方法执行的支持。
2.创建异步方法
在需要异步执行的方法上添加 @Async 注解,这个方法一定是要放在被 IoC 容器管理的 Bean 中,只有被 IoC 管理的类才能实现异步调用,例如在带有 @Service 注解的类中创建异步方法。
3.调用异步方法
在其他类或方法中,通过注入这个服务类的实例来调用异步方法。注意,直接在同一个类内部调用不会触发异步行为,必须通过注入的实例调用,使用 new 创建的对象也不能进行异步方法调用。
以下内容皆为数据开发工程师所需,其他职位无需关注哈~
数据仓库方法论与体系
- 请阐述数据仓库的实施方法论,以及如何将其应用于实际业务场景的数据需求分析与设计?
- 考点:考查对数据仓库实施流程的熟悉程度,以及能否将抽象方法论落地到业务场景。
- 参考答案:数据仓库实施方法论一般涵盖项目前期准备、业务探索、信息探索、逻辑数据模型设计、系统体系结构设计、物理数据库设计、数据转换加载(ETL)、前端应用开发、数据挖掘服务、元数据管理、数据仓库管理以及解决方案集成等步骤。在实际业务场景中,比如电商企业,在业务探索阶段,要明确分析销售数据、用户行为数据等需求。信息探索时,确定从订单系统、用户系统等数据源获取数据。设计逻辑数据模型,依据业务需求构建如销售事实表、用户维度表等。系统体系结构设计方面,考虑采用三层架构满足数据存储、分析、展示需求。物理数据库设计结合数据量、查询频率等选择合适存储引擎与硬件。通过 ETL 将各数据源数据清洗、转换后加载到数据仓库,利用元数据管理记录数据来源、处理过程等信息,便于后续维护与理解数据,最终完成解决方案集成,为业务人员提供数据分析报表,辅助决策。
- 数据仓库体系包含哪些关键部分,它们如何协同工作以支撑业务需求?
- 考点:对数据仓库整体架构及各组件功能、协作关系的理解。
- 参考答案:数据仓库体系关键部分包括数据源、数据存储层、数据处理层、数据分析层和数据展示层。数据源如业务数据库、日志文件等提供原始数据。数据存储层通过关系数据库、分布式文件系统等存储数据,像 Hive 用于存储海量结构化数据。数据处理层利用 ETL 工具或 Spark 等框架清洗、转换、集成数据,比如将不同格式日期数据统一。数据分析层运用 OLAP 工具或机器学习算法进行多维分析、挖掘数据价值,如通过 ROLAP 对销售数据从时间、地区等维度分析。数据展示层以报表、可视化工具将分析结果呈现给业务人员,如 Tableau 制作直观销售报表。各部分协同工作,数据源的数据经处理层加工进入存储层,再由分析层挖掘,最后展示层输出结果辅助业务决策。
数据库操作与数据处理工具
- 在 MySQL 中,如何优化复杂查询的性能?请举例说明。
- 考点:对 MySQL 查询优化策略的掌握及实践应用能力。
- 参考答案:可以从多个方面优化 MySQL 复杂查询性能。索引优化方面,在经常用于 WHERE 子句的列上创建索引,比如在 “SELECT * FROM users WHERE age> 30;” 语句中,若 age 列无索引,全表扫描效率低,创建索引后能快速定位符合条件数据。避免在 WHERE 子句对索引列使用函数,如 “SELECT * FROM orders WHERE YEAR (order_date) = 2024;” 会使索引失效,应改为 “SELECT * FROM orders WHERE order_date >= '2024 - 01 - 01' AND order_date < '2025 - 01 - 01';”。排序优化上,利用覆盖索引,若查询和排序列能共用索引可提升性能,如 “SELECT name, age FROM users ORDER BY age;”,若 name 和 age 在同一索引,查询排序更高效。控制排序数据量,在 WHERE 子句提前过滤,如 “SELECT * FROM products WHERE category = 'electronics' ORDER BY price;”,先按类别过滤再排序,减少排序数据量。
- Doris 和 Hive 在数据处理上有何不同特点,如何根据业务场景选择使用?
- 考点:对比两种数据库的数据处理特性及场景适配能力。
- 参考答案:Doris 是高性能、实时分析的 MPP 数据库,擅长高并发、低延迟查询场景。它支持预排序,创建表时指定预排序键,数据按序存储,排序查询性能高。通过分区和分桶减少数据扫描量,创建物化视图加速频繁查询的复杂子查询。适用于实时报表分析,如互联网公司实时监控用户行为指标;在线数据分析,快速响应用户查询。Hive 基于 Hadoop,用于海量数据批处理分析。有 MapReduce、Tez、Spark、Flink 等多种执行引擎,可根据场景选择,如处理复杂查询和数据挖掘任务可选用 Tez。支持分区裁剪,在 WHERE 子句用分区列过滤避免全量扫描;启用谓词下推,在数据读取阶段过滤不必要数据。适用于离线数据分析,如电商企业分析历史销售数据;日志分析场景,处理大量日志数据。若业务对实时性要求高、查询响应快,选 Doris;若处理海量历史数据、进行复杂批处理分析,选 Hive。
- 请描述使用 Python 进行数据处理的常见场景,并举例说明用到的关键库和函数。
- 考点:对 Python 数据处理应用场景及相关库函数的熟悉程度。
- 参考答案:Python 在数据处理上应用广泛。数据清洗场景,如处理包含缺失值、重复值、错误数据的数据集。利用 pandas 库,用 “df.drop_duplicates ()” 函数去除 DataFrame 中的重复行;用 “df.fillna (value)” 方法填充缺失值,value 可以是指定值或通过计算得出的值,如均值、中位数等。数据转换场景,比如将日期格式数据转换为特定格式,借助 pandas 库的 “pd.to_datetime ()” 函数将字符串日期转换为 datetime 类型,方便后续日期运算。数据分析场景,进行统计分析、数据可视化等。统计分析使用 numpy 库计算均值、标准差等,如 “np.mean (data)” 计算数据均值;数据可视化使用 matplotlib 库,如 “plt.plot (x, y)” 绘制简单折线图,展示数据趋势,其中 x、y 为数据序列。数据聚合场景,在 pandas 中通过 “df.groupby ('column_name').sum ()” 对数据按指定列分组并对其他数值列求和,常用于统计不同类别数据的汇总信息 。
数据开发经验相关
- 请分享在过往 5 年以上数据仓库或大数据开发经验中,遇到的最具挑战性的实时数据处理问题,以及是如何解决的?
- 考点:考察实际项目经验、解决问题能力及对实时数据处理技术的掌握。
- 参考答案:在之前一个电商实时数据分析项目中,面临高并发订单数据实时处理难题。订单数据量瞬间峰值大,传统架构难以承受,导致数据处理延迟,无法实时展示销售数据。为解决此问题,首先引入 Kafka 作为消息队列,缓冲订单数据,削峰填谷,避免下游处理系统被大量数据冲击。在数据处理端,采用 Spark Streaming 进行实时流处理,利用其分布式计算能力,将数据分块并行处理。针对数据准确性和一致性问题,设置检查点机制,确保在系统故障恢复时数据不丢失、处理不重复。同时优化 Spark Streaming 的批处理时间间隔,在保证处理效率的同时兼顾资源利用。通过这些措施,成功实现了订单数据实时高效处理,满足了业务实时监控销售数据的需求 。
- 阐述你在离线数据处理体系建设方面的经验,包括使用的技术栈、架构设计及遇到的挑战与解决方案。
- 考点:考查离线数据处理体系搭建能力、技术选型及应对挑战的经验。
- 参考答案:在构建离线数据处理体系时,技术栈选用 Hadoop 生态系统。HDFS 用于海量数据存储,利用其分布式特性保证数据可靠性与扩展性;MapReduce 进行数据批处理,处理大规模数据集。Hive 作为数据仓库工具,方便进行 SQL - like 查询,简化数据处理流程;使用 Sqoop 从关系数据库抽取数据到 Hadoop 平台,DataX 用于异构数据源间数据同步。架构设计采用分层架构,最底层是数据源层,包含各类业务数据库、日志文件等;中间是数据存储与处理层,通过 HDFS 存储数据,MapReduce、Hive 进行处理;上层是数据分析与应用层,提供报表、数据挖掘等服务。建设过程中遇到数据倾斜问题,部分 Map 或 Reduce 任务处理数据量过大,导致整体任务执行缓慢。通过对数据分布分析,对倾斜数据进行预处理,如在数据导入时对数据进行随机打散,或在 MapReduce 阶段对数据进行二次聚合,减少数据倾斜对性能的影响。还面临数据质量问题,通过建立数据质量监控体系,在数据抽取、转换、加载各环节进行数据校验,如对关键字段进行非空校验、格式校验等,保证进入数据仓库的数据质量 。
沟通与业务结合能力
- 在项目中,如何快速理解复杂的业务背景,并将其转化为技术实现方案?请举例说明。
- 考点:沟通能力、业务理解能力以及技术落地能力。
- 参考答案:在接到新业务需求时,首先积极与业务团队沟通交流,了解业务目标、流程、涉及的数据及数据流向等。例如在一个金融风控项目中,与风控团队深入沟通后,明确业务要通过分析客户交易数据、信用数据等评估客户违约风险。接着梳理业务流程,从客户申请贷款,到系统收集、整合数据,再到评估风险并给出决策。然后分析涉及的数据,确定从交易数据库获取交易流水,从信用数据库获取信用评分等数据。在技术实现上,利用 ETL 工具抽取、清洗、转换数据,存储到数据仓库。采用机器学习算法构建违约风险评估模型,如逻辑回归模型。通过数据预处理将数据转化为模型可接受格式,训练模型并调优。最后将模型集成到业务系统,实时对新客户进行风险评估,输出评估结果供业务人员参考,完成从业务需求到技术方案的转化 。
- 当业务需求发生变更时,你如何协调技术团队与业务团队,确保数据化项目顺利推进?
- 考点:协调沟通能力、应对需求变更的项目管理能力。
- 参考答案:当业务需求变更时,首先及时与业务团队沟通,详细了解变更内容、原因及期望目标。召集技术团队会议,向团队成员清晰传达需求变更信息,共同评估变更对技术方案、项目进度、资源等方面的影响。例如在一个数据报表项目中,业务方突然要求增加新的数据维度并改变报表展示样式。技术团队评估后发现需调整数据采集逻辑、修改数据处理流程以及报表前端展示代码。与业务团队协商新的项目计划,根据变更工作量合理调整交付时间。在实施过程中,保持技术团队与业务团队密切沟通,及时反馈技术实现过程中遇到的问题及解决方案,业务团队确认是否符合新需求预期。通过定期会议同步项目进展,确保双方对项目状态清晰了解,保证数据化项目在需求变更情况下依然顺利推进 。
复杂业务场景与数据平台架构
- 请描述在复杂业务场景下进行数据体系建设的经验,包括遇到的困难及采取的解决方案。
- 考点:复杂业务场景下数据体系搭建的实践经验及解决问题能力。
- 参考答案:在一个大型企业集团的数据体系建设项目中,业务涉及多个行业、多种业务线,数据来源众多且格式复杂,数据标准不统一,这是面临的主要困难。为解决数据来源与格式问题,建立数据接入平台,针对不同数据源开发适配的采集接口,如通过 API 对接外部系统数据,利用文件传输协议获取日志文件数据。对不同格式数据,在数据接入层进行初步清洗与格式转换,如将 XML、JSON 格式数据统一转换为便于处理的结构化数据格式。针对数据标准不统一,制定集团统一的数据标准规范,涵盖数据定义、编码规则、数据质量标准等。建立数据治理团队,负责监督各业务部门按照标准规范处理数据。在数据体系架构设计上,采用分布式、分层架构,底层利用分布式文件系统存储海量原始数据,中间层通过数据仓库进行数据整合、加工,上层构建数据集市满足不同业务部门特定需求。通过这些措施,成功搭建了适应复杂业务场景的企业级数据体系 。
- 如果要设计和优化大型数据平台架构,以处理海量数据的存储与计算问题,你会考虑哪些关键因素?
- 考点:大型数据平台架构设计能力及对海量数据处理的考量。
- 参考答案:在设计和优化大型数据平台架构时,存储方面,考虑存储容量与扩展性,选用分布式存储系统如 Ceph,它可通过增加存储节点轻松扩展存储容量,满足数据不断增长需求。考虑数据存储格式,对于结构化数据,优先选用列式存储格式如 Parquet、ORC,提高查询性能,减少 I/O 开销。计算方面,采用分布式计算框架,如 Spark,利用其内存计算特性和弹性分布式数据集(RDD)模型,高效处理大规模数据。针对不同计算任务特性,选择合适计算模式,批处理任务用 MapReduce 或 Spark 批处理,实时计算任务用 Spark Streaming 或 Flink。网络方面,构建高速、低延迟网络架构,使用万兆甚至更高带宽网络设备,减少数据传输延迟,保障分布式系统各节点间数据快速传输。数据管理方面,建立完善元数据管理系统,记录数据来源、存储位置、处理过程等信息,方便数据查找、理解与维护。数据安全方面,设置用户认证、访问控制机制,对敏感数据加密存储与传输,确保数据安全 。
补充速记内容
《Zookeeper》
ZAB协议:原子广播协议,有2种模式:崩溃恢复和广播模式,确保集群在节点故障时仍能保持数据一致性。
《Spring Boot》
@Autowired 注解是通过 DI 的方式,底层通过 Java 的反射机制来实现的。
BeanFactory 是一个容器,负责管理和创建 Bean 实例,处理依赖关系和属性注入等操作。FactoryBean 是一个接口,定义了创建 Bean 的规范和逻辑,它负责创建其他 Bean 实例。
如何搞内嵌服务器?Spring Boot在打包时会把内嵌服务器的依赖都包含进去,启动时它会创建服务器实例,加载必要的配置,绑定端口。比如内嵌Tomcat,它会初始化Tomcat的类加载器、连接器这些组件,然后把Spring MVC相关的处理器等注册到服务器里。这样,项目一启动,服务器也就跟着运行起来,能接收和处理HTTP请求啦。
自动装配原理:它是通过大量的条件注解和自动配置类实现的。Spring Boot会扫描classpath下的一些特定的类,根据类路径和依赖情况,判断是否满足自动装配的条件。要是满足,就会把对应的组件初始化并加入到Spring容器里。
弱引用 WeakReference :垃圾回收器一运行,指向的对象就可能被回收(如果只有弱引用) 软引用 SoftReference:内存非常紧张的情况下才会被回收
《RedisCluster》
Redis Cluster 的“脑裂”问题是指集群中部分节点因网络分区(如交换机故障、网络延迟)导致节点间通信中断,形成多个独立的“子集群”,从而引发数据不一致和服务异常的情况。
面试问题
1.hashmap的原理
HashMap基于哈希表实现,用数组存储键值对。当存入元素时,通过哈希函数计算键的哈希值,再用哈希值决定元素在数组中的位置。若发生哈希冲突,会用链地址法解决,把冲突的元素链在对应数组位置后。取元素时,同样用哈希函数算哈希值定位桶,再遍历桶里元素找目标键。JDK 1.8后,桶中元素超一定阈值会转成红黑树提高查找效率。
2.hashmap 里面为了给 get 做性能优化, JDK 做了什么处理?
在JDK里,HashMap为了优化get性能做了不少处理呢。首先是哈希函数,它会尽量把键均匀分布到不同桶里,减少哈希冲突。还有就是数组扩容机制,当元素数量超过负载因子和数组长度的乘积时,数组会自动扩容,这能保证平均情况下,get操作的时间复杂度接近O(1)。不过在极端情况下,比如哈希函数设计得不好,可能会出现很多元素在一个桶里,这时时间复杂度就会退化为O(n)。为了解决这个问题,从JDK 1.8开始,桶里的元素超过一定阈值后会转化为红黑树,红黑树的查找效率是O(log n),这样在哈希冲突严重时也能保证较好的性能。
3.线程池的核心参数之间的关系,处理流程是怎么样的?
线程池工作流程是:先使用核心线程处理任务,核心线程满了就把任务存入任务队列。若任务队列也满了,会创建新线程,直到达到最大线程数。之后再有新任务,就会按设定的拒绝策略处理。
4.《ai-OA智能搜索》RAG的准确率如何评估?
| 评估维度 | 核心指标 | 计算方法 | 理想阈值 |
|---|---|---|---|
| 召回层 | 相关文档召回率(R@K) | 检索出的前 K 篇文档中,真实相关文档的比例(如 K=5 时,R@5≥80%) | ≥85% |
| 匹配层 | 向量相似度准确率 | 计算检索结果与用户查询的余弦相似度,对比人工标注的相关度(如阈值 0.7) | ≥0.75 |
| 生成层 | 回答正确性(Factuality) | 人工抽检回答中事实性错误率(如 “2024 年节假日安排” 是否与官方文件一致) | ≤5% 错误率 |
5.大模型部署与微调
一、大模型部署全流程(本地 / 企业场景)
1. 需求与资源评估(面试高频:如何根据需求选模型?)
- 核心问题:
- 业务场景:问答、生成、推理还是垂直领域(如法律、医疗)?
- 性能要求:延迟<100ms?吞吐量≥100QPS?
- 硬件资源:本地服务器配置(CPU/GPU 型号、显存 / 内存大小)、是否支持分布式。
- 选型案例:
- 轻量级场景(消费级显卡):选 7B 模型(如 Llama-2 7B、Qwen-7B),量化至 INT4 后显存占用<10GB。
- 企业级推理:用 4090/80GB A100 部署 13B-70B 模型,搭配 TensorRT/FasterTransformer 加速。
2. 模型获取与预处理
- 开源模型:从 Hugging Face、ModelScope 下载,注意许可证(如 Llama-2 允许商业,Falcon 需申请)。
- 闭源模型:采购 API(如 Claude、GPT-4)或私有化部署版本(如 Anthropic Claude Instant)。
- 预处理关键:
- 量化:INT8/INT4 降低显存占用(如 GPTQ、AWQ 量化工具),牺牲约 1-3% 精度换 40%+ 推理速度提升。
- 分片:对 70B + 模型用 DeepSpeed 等工具分片到多卡(如 8 张 A100 部署 GPT-3.5)。
3. 部署架构设计(面试重点:如何优化推理性能?)
- 单机部署(适合中小模型):
# 示例:用Transformers+TGI部署Llama-2 from transformers import pipeline model = pipeline("text-generation", model="llama-2-7b-chat", device_map="auto") # 自动分配GPU/CPU - 分布式部署(大模型必选):
- 方案:DeepSpeed-MII、vLLM、TGI(TensorRT-Inference Server)。
- 优化点:
- KV 缓存复用:vLLM 通过 PagedAttention 优化长文本生成速度(提升 3-5 倍)。
- 模型并行:将模型层拆分到不同 GPU(如前 30 层放卡 1,后 30 层放卡 2)。
4. 服务化与 API 封装
- 框架:FastAPI(轻量)、Tornado(高并发)、gRPC(跨语言)。
- 关键中间件:
- 负载均衡:Nginx 分发请求到多节点。
- 缓存:Redis 存储高频查询结果,减少模型调用(命中率≥50% 时显著降本)。
二、模型微调核心步骤(附面试常问参数调优)
1. 数据准备(面试高频:如何构建高质量微调数据?)
- 数据标准:
- 格式:JSONL({"prompt": "问题", "response": "答案"}),需清洗噪声、去重。
- 规模:通用任务≥1000 条,垂直领域≥5000 条(如医疗需标注数据)。
- 增强技巧:
- 指令模板设计:
# 示例:客服场景模板 "用户问题:{问题}\n客服回答:{答案}" - 数据混合:通用数据(如 ShareGPT)+ 领域数据按 7:3 比例混合,避免过拟合。
- 指令模板设计:
2. 微调方案选择(LoRA / 全量 / PEFT 对比)
| 方案 | 显存占用 | 参数量 | 适用场景 | 面试必问优势 |
|---|---|---|---|---|
| LoRA | 极低(↓90%) | 万级 | 企业定制、小数据微调 | 单卡可训,精度≈全量微调 |
| 全量微调 | 高 | 全量 | 科研、数据极多场景 | 精度最高,但成本极高 |
| QLoRA | 极低(INT4) | 万级 | 万亿参数模型微调(如 GPT-3) | 显存<8GB 训 130B 模型 |
3. 微调实现(以 LoRA 为例,附 Hugging Face 代码)
from peft import LoraConfig, get_peft_model
from transformers import Trainer, TrainingArguments
# 1. 配置LoRA(面试常问参数):
config = LoraConfig(
r=16, # 秩,平衡效率与精度(通常8-64)
lora_alpha=32, # 缩放因子,建议设为r的2-4倍
target_modules=["q_proj", "v_proj"], # 只微调注意力层
lora_dropout=0.1, # 防止过拟合
bias="none" # 不微调偏置
)
# 2. 加载模型与应用LoRA:
model = get_peft_model(base_model, config)
model.print_trainable_parameters() # 输出:约0.1%参数可训练
# 3. 训练配置(关键超参数):
trainer = Trainer(
model=model,
train_dataset=your_dataset,
args=TrainingArguments(
learning_rate=5e-5, # 小学习率防止灾难性遗忘
per_device_train_batch_size=4, # 显存不足时调小至1-2
num_train_epochs=3, # 小数据建议1-3轮,大数据5-10轮
weight_decay=0.01, # 正则化
logging_steps=10,
output_dir="./lora_output"
),
)
trainer.train()
4. 评估与优化(面试高频:如何判断微调效果?)
- 评估维度:
- 内在指标:困惑度(Perplexity,越低越好)、KL 散度(与原模型差异,避免过度遗忘)。
- 外在指标:人工评测(如客服场景的回答准确率)、BLEU-4(生成任务)。
- 常见问题与解决方案:
- 过拟合:数据量不足时,增加正则化(weight_decay=0.1)或早停。
- 性能下降:检查是否微调了底层语义层(如嵌入层),建议只调注意力和输出层。
三、企业落地注意事项(面试加分点:工程化陷阱)
1. 成本控制(企业最关注)
- 量化策略:INT4 量化后推理速度提升 2 倍,显存降 50%,但需用校准数据(100-200 条)缓解精度损失。
- 混合部署:热数据(高频查询)用本地模型,冷数据调用低成本 API(如 Anthropic Claude Instant)。
2. 稳定性与可维护性
- 监控体系:
- 指标:显存利用率、QPS、平均延迟、OOM 次数。
- 工具:Prometheus+Grafana,设置显存预警(如>80% 时自动扩容)。
- 版本管理:用 Docker 封装不同模型版本(如 v1.0-base、v1.1-lora),方便回滚。
3. 安全与合规
- 数据安全:微调数据加密存储,训练完成后删除原始数据(符合 GDPR)。
- 知识产权:商用前确认模型许可证(如 Llama-2 允许商业,Falcon 需授权,ChatGLM-3 仅限科研)。
四、面试高频问题与标准答案
-
问题:为什么企业落地大模型优先选 LoRA 而非全量微调?
答案:- LoRA 只更新 0.1-1% 参数,显存占用降低 90%(如 70B 模型全量微调需 50GB 显存,LoRA 仅需 5GB),单卡即可训练,成本大幅下降;
- 实验表明,r=16 时 LoRA 精度与全量微调差距<1%,性价比远超全量方案。
-
问题:本地部署大模型时,如何优化长文本生成速度?
答案:- 用 vLLM 框架,通过 PagedAttention 优化 KV 缓存,避免长文本生成时的内存碎片(速度提升 3 倍以上);
- 量化模型到 INT4,并启用 TensorRT 加速(FP16→INT4 推理速度提升 2 倍)。
-
问题:微调后模型在某些场景表现下降,怎么解决?
答案:- 可能是 “灾难性遗忘”,建议:
- 采用混合训练(原始数据 + 领域数据按 3:1 混合);
- 降低学习率(如从 5e-5→1e-5),并增加 LoRA 的 r 值(如从 16→32);
- 只微调顶层任务相关层(如最后 10 层 Transformer),保留底层语义能力。
- 可能是 “灾难性遗忘”,建议:
五、总结:从技术到落地的核心逻辑
大模型部署与微调的本质是 “资源约束下的最优解”:用量化压缩模型体积,用 LoRA 降低训练成本,用工程优化提升推理效率。企业面试中,除了技术细节,更关注候选人是否具备 “成本意识”(如量化与精度的平衡)和 “业务思维”(如根据场景选模型)—— 这正是从技术走向落地的关键能力。
6.如何理解ai-agent?
AI Agent 是能感知环境、自主决策并执行动作的智能体,大模型时代的 Agent 以语言模型为核心,可理解指令、规划任务、调用工具,像 “会思考的智能助手”。
大模型驱动的ai agent技术框架
| 组件 | 功能 | 技术实现 |
|---|---|---|
| 大模型引擎 | 核心大脑,负责知识推理、自然语言处理、任务规划。 | 调用 GPT-4、LLaMA 等大模型 API,或基于开源模型微调(如 Vicuna)。 |
| 感知模块 | 接收用户输入(文本、语音、图像等)并转化为模型可理解的格式。 | - 文本:直接输入大模型; - 语音 / 图像:通过多模态模型(如 CLIP、Whisper)转文字后输入。 |
| 决策模块 | 基于大模型规划行动策略,包括任务拆解、工具调用决策、对话状态跟踪等。 | - 任务拆解:通过大模型生成 “子任务列表”; - 工具调用:用大模型判断是否需要调用 API(如天气查询)。 |
| 工具接口 | 连接外部工具(如数据库、API、硬件设备),扩展 Agent 能力边界。 | 设计工具调用格式(如函数调用 JSON),大模型生成符合格式的指令后执行。 |
| 记忆模块 | 存储历史对话、环境状态、任务进度等信息,供大模型参考。 | - 短期记忆:对话历史切片(如保留最近 10 轮对话); - 长期记忆:知识库存储(如用户偏好数据)。 |
| 行动执行模块 | 将大模型决策转化为具体动作(如文本回复、工具调用、物理操作等)。 | - 文本:直接生成回答; - 工具:解析函数调用并执行; - 硬件:通过中间件控制设备。 |
关键技术
- 工具调用机制:大模型通过 “函数调用”(Function Calling)能力,判断何时需要调用外部工具(如计算器、数据库、API),并将工具返回结果融入后续推理。
例:用户问 “2025 年 6 月 22 日北京天气如何”,Agent 先由大模型识别需调用天气 API,生成调用指令,获取数据后再整理成自然语言回答。 - 反思与迭代决策:通过 “ReAct 范式”(Reasoning + Action),大模型在每一步决策中加入 “思考过程”,并根据结果反思优化策略。
例:解题 Agent 先推导第一步思路,若结果错误,通过大模型反思 “哪里逻辑有误”,再调整策略重新尝试。
“思考过程”:
一般是通过强化学习和反馈机制来实现的。给模型设定明确的目标,然后让它在各种尝试中学习,根据得到的反馈来调整策略。还可以用一些先进的技术,比如思维链,让模型把复杂问题分解成小步骤,一步步思考,就像我们解决数学题一样。另外,持续用新数据训练模型也很重要,这样它能不断适应新情况,改进自己的思考方式。
大模型驱动 AI Agent 的安全、可靠与效率优化方案
(一)安全性:防数据泄露与恶意行为
- 输入输出双向过滤
- 输入过滤:用正则表达式或安全模型(如 Google 的 Sec-PaLM)拦截敏感指令(如 “获取用户通讯录”“生成恶意代码”)。
- 输出审核:在大模型生成回答后,通过规则引擎或专用审核模型(如内容安全 API)扫描敏感词(如隐私信息、仇恨言论),发现问题时替换为安全提示。
- 权限分级控制
- 为 Agent 设置 “工具调用白名单”,例如:
- 普通用户 Agent 仅能调用天气、计算器等公开 API;
- 企业内部 Agent 需管理员授权才能访问数据库、员工信息系统。
- 为 Agent 设置 “工具调用白名单”,例如:
- 数据脱敏与隔离
- 对话历史中的用户信息(如姓名、地址)自动脱敏(替换为 * 号),不同用户的记忆数据存储在独立加密空间,避免交叉泄露。
(二)可靠性:消除大模型 “幻觉”
- 关键信息强制验证
- 对涉及事实性内容(如数据、事件、规则)的回答,要求 Agent 必须调用外部工具验证:
- 例 1:回答 “某药物副作用” 时,强制调用医药数据库 API;
- 例 2:计算 “2024 年全球 GDP 排名” 时,调用世界银行公开数据接口。
- 对涉及事实性内容(如数据、事件、规则)的回答,要求 Agent 必须调用外部工具验证:
- 多源信息交叉验证
- 对重要决策(如金融建议、医疗诊断),让 Agent 同时查询多个权威来源(如不同数据库、官方网站),只有当结果一致时才输出,矛盾时提示 “信息冲突,需人工确认”。
- 建立 “知识置信度” 体系
- 大模型生成回答时,附加 “可信度评分”(如 0-100 分):
- 低于阈值(如 60 分)时,自动触发工具调用补充信息;
- 评分与回答一同展示给用户(例:“当前信息可信度 75%,数据来源:XX 百科”)。
- 大模型生成回答时,附加 “可信度评分”(如 0-100 分):
(三)效率优化:解决多轮调用耗时问题
- 任务预处理与缓存
- 预处理:在调用大模型前,先用轻量级规则判断是否需要复杂推理,例如:
- 用户问 “1+1=?”,直接返回结果,不调用大模型;
- 用户问 “如何用 Python 写排序算法”,再触发大模型代码生成。
- 结果缓存:对重复问题(如相同天气查询、历史对话中的同类问题),直接读取缓存结果,避免重复计算。
- 预处理:在调用大模型前,先用轻量级规则判断是否需要复杂推理,例如:
- 模型分层与局部优化
- 主模型 + 轻量级子模型:
- 主模型(如 GPT-4)负责复杂规划和推理;
- 子模型(如量化后的 LLaMA-7B)处理简单任务(如格式校验、关键词提取),减少主模型调用次数。
- 局部任务离线处理:
- 对固定流程任务(如周报模板填充),提前编写脚本处理数据,仅在需要创意内容(如总结分析)时调用大模型。
- 主模型 + 轻量级子模型:
- 流式处理与异步调用
- 流式生成:大模型回答时边生成边输出(如 ChatGPT 的打字效果),让用户感知响应更快,减少等待焦虑。
- 异步任务队列:对耗时任务(如生成 10 页报告),后台分批次处理,先返回进度提示(“已完成大纲,正在撰写正文”),完成后推送通知。
(四)综合方案示例:电商客服 Agent 的优化流程
- 安全:用户询问 “订单地址能否改成竞争对手公司”,输入过滤模块识别到 “竞争对手” 可能涉及恶意行为,直接拒绝并提示 “地址需为真实收货地址”。
- 可靠:用户问 “某商品是否含过敏原”,Agent 先调用大模型生成回答,再强制调用商品详情 API 验证成分表,确保信息一致后输出。
- 效率:用户重复问 “物流到哪了”,直接从缓存读取最新物流信息,不重复调用大模型;若物流异常需人工处理,触发异步任务通知客服团队。
7.《ai-一句话图表》如何保证生成的sql是正确可执行且符合预期的?
| 大模型的天然短板 | 规则引擎的解决方案 |
|---|---|
| 1. 语义理解偏差(如 “同比” 理解错误) | 通过元数据字典预定义业务术语映射(如 “同比”→LAG(sales, 12)),强制大模型按规则转换。 |
| 2. SQL 语法错误(如字段拼写错误) | 通过 JDBC 元数据校验字段存在性,拦截非法 SQL,提示大模型重新生成。 |
| 3. 安全风险(如生成删除语句) | 通过正则表达式过滤危险操作,确保 SQL 仅包含只读查询。 |
| 4. 性能隐患(如全表扫描) | 限制 SQL 复杂度(如 JOIN 表数≤3、LIMIT 1000),防止数据库负载过高。 |
意图增强(使用规则引擎结合元数据字典预定义业务术语映射)与sql语法语义校验
SQL 校验:
- 语法合法:无危险操作;
- 语义有效:表
sales_detail和dept_info存在,字段sales_amount和dept_name存在; - 资源合规:JOIN 表数 = 2≤3,无全表查询;
校验通过,执行 SQL 并返回结果。
- 语法校验:使用正则表达式(如
Pattern类)过滤危险 SQL; - 语义校验:通过 JDBC 获取数据库元数据(
DatabaseMetaData接口),验证表和字段存在性; - 性能优化:对高频表结构缓存至 Redis(如
sales_detail表的字段列表),减少 JDBC 调用;
“规则引擎的核心实现可以概括为‘术语匹配 - 上下文构建 - 提示词生成 - 三层校验’的闭环:
- 术语匹配:通过元数据字典将用户输入的业务术语(如‘销售额’)映射到数据库字段,并补全时间、部门等条件;
- 提示词生成:将结构化上下文组装为大模型可理解的提示词,比如指定表名、字段和 WHERE 条件,强制大模型按格式生成 SQL;
- 三层校验:先用正则过滤危险语法,再查询数据库元数据验证表和字段存在性,最后限制查询复杂度(如 JOIN 表数≤3);
- 错误修正:校验失败时分析错误类型(如字段不存在),生成带修正建议的提示词让大模型重试。
我们在项目中通过这种方式,将 SQL 生成的准确率从 65% 提升到 92%,且实现了规则的动态更新和全链路监控,确保线上服务的稳定性。”
1. 项目技术栈(Java 生态)
- 核心语言:Java 8+(与 Spring Boot 项目技术栈一致)
- 规则引擎框架:
- Drools:基于 RETE 算法的规则引擎,支持复杂规则表达式(如
when sales > budget then),适合业务规则频繁变更的场景; - EasyRule:轻量级规则引擎,通过注解(
@Rule)定义规则,适合简单规则场景(如术语匹配);
- Drools:基于 RETE 算法的规则引擎,支持复杂规则表达式(如
- 项目选择:采用Drools + 自定义规则引擎的混合方案:
- 复杂业务规则(如权限控制、SQL 复杂度限制)用 Drools 管理;
- 术语匹配、提示词生成等定制逻辑用自定义 Java 类实现(更灵活可控)。
2. 关键依赖与工具
- 自然语言处理:
- HanLP:中文分词(如解析 “2024 年 Q1” 为时间实体);
- FST(Finite State Transducer):高效术语匹配(O (1) 查询复杂度);
- SQL 解析:
- jSqlParser:解析 SQL 语法树,提取表名、字段名等元素;
- 元数据管理:
- MyBatis:操作 MySQL 元数据字典;
- Redis:缓存高频访问的元数据(TTL=24h)。
8. 大模型相关问题
- 向量嵌入:向量嵌入是把数据转化成向量的过程,能让计算机理解数据。比如把问法转成向量,计算机可通过向量判断数据关系。
- 向量相似度:用余弦相似度公式计算,很多编程语言的机器学习库都有实现,像Python里的NumPy库。Java 语言的库有Apache Commons Math、Lucene。
- 怎么对向量做缓存处理:用哈希表,把问法作为键,对应的向量作为值存进去。新问法来先查哈希表,有就直接用。
9. 减少大模型幻觉的方法:
- 交叉验证:用大模型输出结果去向量数据库查询,差别大就重新生成。
- 增加训练数据:提供高质量、有明确答案的数据让大模型学习。微调或者背景知识
- 提示更具体:比如要求大模型给出参考资料,让它生成更谨慎。
- 在提示词里加正确范例:给大模型一些正确句子和对应图表等范例,让它学习规律。
- 反馈机制:对应调整元数据信息,正向的话就加入关键词,逆向的话就删除
参考 & 鸣谢:什么是跨域问题?如何解决? | Javaᶜⁿ 面试突击

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)