
minerU,PDF文件转markdown神器
minerU是由上海AI实验室OpenDataLab团队研发的智能数据提取工具,可以一键将pdf文档转换为josn或者markdown文档,效果不错,今天咱们来体验下。检查了一圈,哦...原来漏了一步,忘记装pytorch了。这就是我搭建测试的整个过程,大家在搭建的过程中有遇到什么问题,或者有什么想实现的功能欢迎公众号留言,大家一起讨论学习。4、下载模型文件,需要从modelscope上面下载,先
minerU是由上海AI实验室OpenDataLab团队研发的智能数据提取工具,可以一键将pdf文档转换为josn或者markdown文档,效果不错,今天咱们来体验下。
1、首先来下载源码
git clone https://gitee.com/myhloli/MinerU.git2、创建环境、安装环境
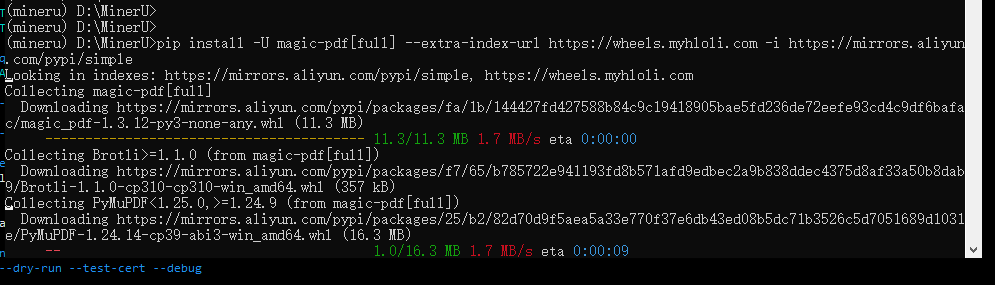
conda create -n mineru python=3.10conda activate minerupip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://mirrors.aliyun.com/pypi/simple
安装过程很顺利,没出什么问题。
3、查看下安装mineru的版本
magic-pdf --version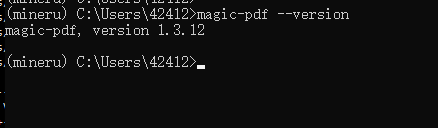
4、下载模型文件,需要从modelscope上面下载,先安装modelscope
pip install modelscope然后去该目录下面运行脚本,下载模型文件
5、下载好后咱们就可以去试验下了。
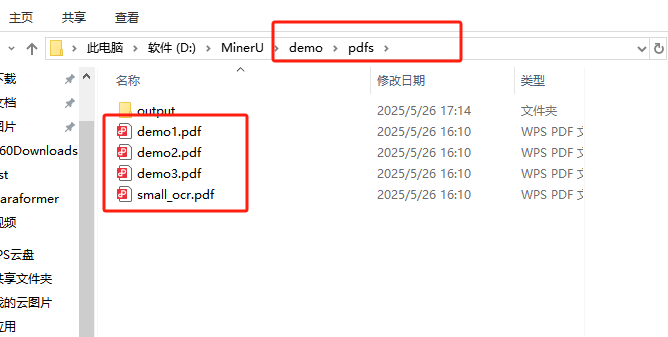
进入到demo/pdfs文件下面,里面有提供的demo,可以测试用。
magic-pdf -p demo1.pdf -o ./output
执行的结果在output文件下面
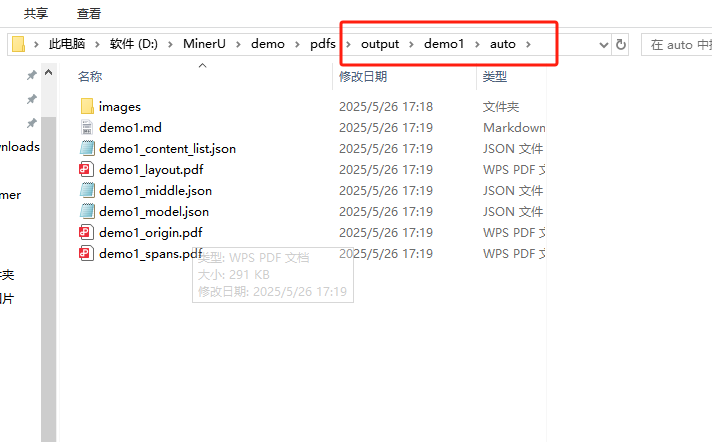
咱们来看下效果。
还是很不错的。然后pdf的内容都在这个json文件里面。
感觉到这里应该已经完成了,但是突然感觉不太对。我看了下资源管理器,怎么没有用GPU,用的cpu在跑?检查了一圈,哦...原来漏了一步,忘记装pytorch了。
6、根据自己cuda版本安装pytorch
https://pytorch.org/get-started/previous-versions/
7、安装好后需要将magic-pdf.template.json 复制一份,并修改“device-mode” 为“cuda”
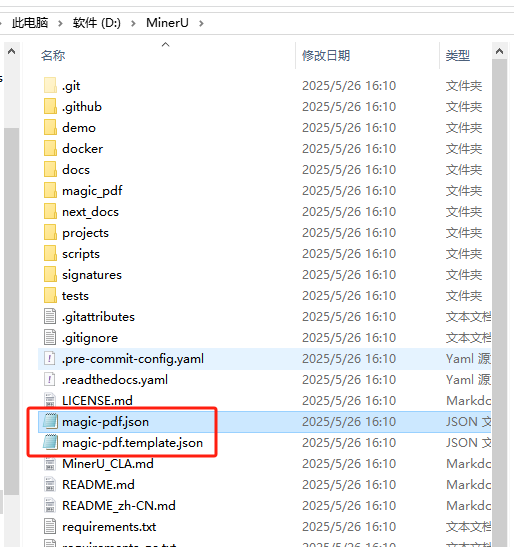

接着再去执行下面代码就是使用gpu了。
magic-pdf -p demo1.pdf -o ./output这就是我搭建测试的整个过程,大家在搭建的过程中有遇到什么问题,或者有什么想实现的功能欢迎公众号留言,大家一起讨论学习。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)