
【paddleocr3.0运行虚拟环境搭建踩坑经验】
PaddleOCR 3.0在文字识别领域进行了显著升级,支持多文字类型和手写体识别,提升了文档解析和信息抽取的精度,并新增了对国产硬件的支持。然而,在环境搭建过程中,用户遇到了模型下载和文件路径相关的报错问题,导致无法正常使用。具体表现为无法找到模型文件inference.json,可能是由于文件路径或下载过程中出现问题。建议检查文件路径是否正确,或重新下载模型文件以解决该问题。
前言:
paddleocr在文字识别领域还是做的比较好的,听说最近升级到3.0了,有了很多提升,我就想着搭建一个来玩一玩,结果一直卡bug,记录一下作为备份
本次升级的亮点:
PaddleOCR自发布以来凭借学术前沿算法和产业落地实践,受到了产学研各方的喜爱,并被广泛应用于众多知名开源项目,例如:Umi-OCR、OmniParser、MinerU、RAGFlow等,已成为广大开发者心中的开源OCR领域的首选工具。2025年5月20日,飞桨团队发布PaddleOCR 3.0,全面适配飞桨框架3.0正式版,进一步提升文字识别精度,支持多文字类型识别和手写体识别,满足大模型应用对复杂文档高精度解析的旺盛需求,结合文心大模型4.5 Turbo显著提升关键信息抽取精度,并新增对昆仑芯、昇腾等国产硬件的支持。
PaddleOCR 3.0新增三大特色能力:
🖼️全场景文字识别模型PP-OCRv5:单模型支持五种文字类型和复杂手写体识别;整体识别精度相比上一代提升13个百分点。
🧮通用文档解析方案PP-StructureV3:支持多场景、多版式 PDF 高精度解析,在公开评测集中领先众多开源和闭源方案。
📈智能文档理解方案PP-ChatOCRv4:原生支持文心大模型4.5 Turbo,精度相比上一代提升15.7个百分点。
环境搭建-以cpu版为例
1、paddlepadde下载pip指令:
pip install -U paddlepaddle==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
2、paddleocr下载pip指令
pip install paddleocr -i https://pypi.org/simple
主要的坑就在模型下载这里,我不知道是不是只有我遇见了,我按照官方提供的python代码直接执行,然后就报错了
官方提供的代码:
from paddleocr import PaddleOCR
ocr = PaddleOCR(
use_doc_orientation_classify=False, # 通过 use_doc_orientation_classify 参数指定不使用文档方向分类模型
use_doc_unwarping=False, # 通过 use_doc_unwarping 参数指定不使用文本图像矫正模型
use_textline_orientation=False, # 通过 use_textline_orientation 参数指定不使用文本行方向分类模型
)
# ocr = PaddleOCR(lang="en") # 通过 lang 参数来使用英文模型
# ocr = PaddleOCR(ocr_version="PP-OCRv4") # 通过 ocr_version 参数来使用 PP-OCR 其他版本
# ocr = PaddleOCR(device="gpu") # 通过 device 参数使得在模型推理时使用 GPU
result = ocr.predict("./general_ocr_002.png")
for res in result:
res.print()
res.save_to_img("output")
res.save_to_json("output")
报错展示:
Creating model: ('PP-OCRv5_mobile_det', None)
Using official model (PP-OCRv5_mobile_det), the model files will be automatically downloaded and saved in C:\Users\路西25801\.paddlex\official_models.
��Ϣ: ���ṩ��ģʽ���ҵ��ļ���
D:\Anaconda2\envs\OCR3_\lib\site-packages\paddle\utils\cpp_extension\extension_utils.py:711: UserWarning: No ccache found. Please be aware that recompiling all source files may be required. You can download and install ccache from: https://github.com/ccache/ccache/blob/master/doc/INSTALL.md
warnings.warn(warning_message)
Traceback (most recent call last):
File "D:\OCR3\快速使用ocr.py", line 3, in <module>
ocr = PaddleOCR(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddleocr\_pipelines\ocr.py", line 144, in __init__
super().__init__(**base_params)
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddleocr\_pipelines\base.py", line 73, in __init__
self.paddlex_pipeline = self._create_paddlex_pipeline()
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddleocr\_pipelines\base.py", line 107, in _create_paddlex_pipeline
return create_pipeline(config=self._merged_paddlex_config, **kwargs)
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\pipelines\__init__.py", line 165, in create_pipeline
pipeline = BasePipeline.get(pipeline_name)(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\utils\deps.py", line 195, in _wrapper
return old_init_func(self, *args, **kwargs)
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\pipelines\_parallel.py", line 103, in __init__
self._pipeline = self._create_internal_pipeline(config, self.device)
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\pipelines\_parallel.py", line 158, in _create_internal_pipeline
return self._pipeline_cls(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\pipelines\ocr\pipeline.py", line 114, in __init__
self.text_det_model = self.create_model(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\pipelines\base.py", line 99, in create_model
model = create_predictor(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\__init__.py", line 77, in create_predictor
return BasePredictor.get(model_name)(
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\text_detection\predictor.py", line 57, in __init__
self.pre_tfs, self.infer, self.post_op = self._build()
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\text_detection\predictor.py", line 77, in _build
infer = self.create_static_infer()
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\base\predictor\base_predictor.py", line 240, in create_static_infer
return PaddleInfer(self.model_dir, self.MODEL_FILE_PREFIX, self._pp_option)
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\common\static_infer.py", line 274, in __init__
self.predictor = self._create()
File "D:\Anaconda2\envs\OCR3_\lib\site-packages\paddlex\inference\models\common\static_infer.py", line 342, in _create
config = paddle.inference.Config(str(model_file), str(params_file))
RuntimeError: (NotFound) Cannot open file C:\Users\路西25801\.paddlex\official_models\PP-OCRv5_mobile_det\inference.json, please confirm whether the file is normal.
[Hint: Expected paddle::inference::IsFileExists(prog_file_) == true, but received paddle::inference::IsFileExists(prog_file_):0 != true:1.] (at ..\paddle\fluid\inference\api\analysis_config.cc:117)
报错分析排查
初次运行时会下载模型,提示网络连接超时,我多试了几次,依然是报错,但是下载其他的库能够正常,排除了网络原因,那接下来看看是不是提供的下载链接有问题,我就去网站上找了下载链接,和内置链接进行比对,链接是一样的,单独用浏览器打开也是可以打开的,说明链接也没问题,我就尝试跳过模型下载,我在官网下载好,然后直接调用,
在这里花了蛮长时间去查阅源代码的,终于终于找到了配置文件,在这个位置,就是在你的虚拟环境里面paddlex这个库里面,在这里指定你的模型位置
修改方法
在paddlex库修改configs设置
D:\Anaconda2\envs\OCR3\Lib\site-packages\paddlex\configs\pipelines\ocr.yaml
原配置文件截图
修改之后的截图
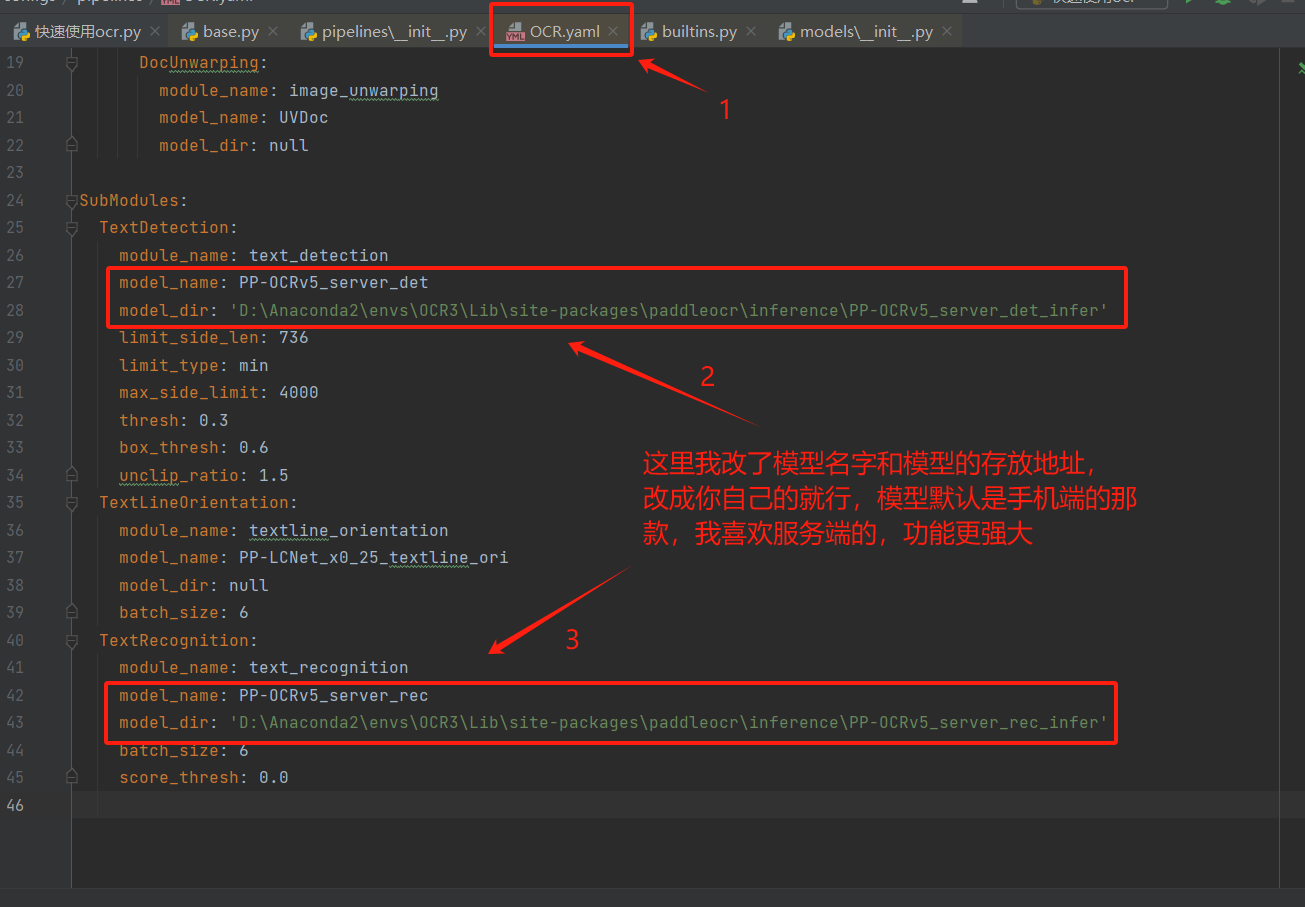
然后我再去运行官方代码,还是会报错,一样的错,因为在你没有指定用哪个模型的时候,他有一个默认的模型,就是那个手机端的,所以需要在代码里面指定一下,改过之后的代码就能运行了
改完了,能跑了
from paddleocr import PaddleOCR
ocr = PaddleOCR(
text_detection_model_name='PP-OCRv5_server_det',
text_recognition_model_name='PP-OCRv5_server_rec',
text_detection_model_dir=r'D:\Anaconda2\envs\OCR3\Lib\site-packages\paddleocr\inference\PP-OCRv5_server_det_infer',
text_recognition_model_dir=r'D:\Anaconda2\envs\OCR3\Lib\site-packages\paddleocr\inference\PP-OCRv5_server_rec_infer',
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False
)
result = ocr.predict(r"D:\OCR3\0497ce92168708822102ac5b6b9c582.jpg")
for res in result:
res.print()
res.save_to_img("./output")
res.save_to_json("./output")
到这里就能跑了,就是在初始化的时候指定了文字检测模型和文字识别模型,结束了,对了,在输入图片的时候文件地址避免出现中文,会报错,打不开,因为cv2读取图片不支持中文地址
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)