51c大模型~合集125
整个过程在与环境的互动中完成,环境负责验证任务的合理性和解答的正确性,并为模型提供奖励反馈。在这一范式下,研究团队训练了新的模型 Absolute Zero Reasoner(AZR),以代码执行器作为真实环境,自动生成并解决三类代码推理任务,涵盖归纳、演绎与溯因推理,依赖环境可验证的反馈实现稳定训练。在最核心的比较中,AZR-Coder-7B 在多个代码与数学推理基准上取得了当前同规模模型中的最
我自己的原文哦~ https://blog.51cto.com/whaosoft/13892516
#Absolute Zero
绝对零监督:类AlphaZero自博弈赋能大模型推理,全新零数据训练范式问世
在人工智能领域,推理能力的进化已成为通向通用智能的核心挑战。近期,Reinforcement Learning with Verifiable Rewards(RLVR)范式下涌现出一批「Zero」类推理模型,摆脱了对人类显式推理示范的依赖,通过强化学习过程自我学习推理轨迹,显著减少了监督训练所需的人力成本。然而,这些方法的学习任务分布仍由人类预先设计,所依赖的数据依旧高度依赖专家精心策划与大量人工标注,面临着难以扩展与持续演化的瓶颈。
更重要的是,如果智能系统始终受限于人类设定的任务边界,其自主学习与持续进化的潜力将受到根本性限制,这一现实呼唤一种全新的推理范式,迈向超越人类设计约束的未来。
为应对这一挑战,清华大学 LeapLab 团队联合北京通用人工智能研究院 NLCo 实验室和宾夕法尼亚州立大学的研究者们提出了一种全新的推理训练范式 ——Absolute Zero,使大模型无需依赖人类或 AI 生成的数据任务,即可通过自我提出任务并自主解决,实现「自我进化式学习」。在该范式中,模型不仅学习如何生成最具可学习性的任务(maximize learnability),还通过解决这些自主生成的任务持续增强自身的推理能力。Absolute Zero 范式不仅在性能上表现卓越,其核心理念更在于推动推理模型从依赖人类监督向依赖环境监督的范式转变,使模型通过与真实环境的交互生成可验证的任务并获得可靠反馈,从而不断提升自身的推理能力。
在这一范式下,研究团队训练了新的模型 Absolute Zero Reasoner(AZR),以代码执行器作为真实环境,自动生成并解决三类代码推理任务,涵盖归纳、演绎与溯因推理,依赖环境可验证的反馈实现稳定训练。实验表明,虽然未见过目标任务,AZR 在代码生成与数学推理这两个跨领域基准任务中表现出色,并且超越已有的方法达到 SOTA。这一成果不仅显著缓解了当前大模型训练对高质量人工数据的依赖难题,也预示着推理模型正迈入一个具备「自主进化」的智能新时代。
论文标题:Absolute Zero: Reinforced Self-play Reasoning with Zero Data
论文链接:https://www.arxiv.org/abs/2505.03335
展示页面:https://andrewzh112.github.io/absolute-zero-reasoner/

Absolute Zero Reasoner 在零数据的条件下实现了数学和代码推理 benchmark 上的 SOTA 性能。该模型完全不依赖人工标注或人类预定义的任务,通过研究团队提出的 self-play 训练方法,展现出出色的分布外推理能力,甚至超越了那些在数万个专家标注样本上训练而成的 reasoning 模型。
推理新范式:Absolute Zero,让模型真正摆脱人类数据依赖
在当前的大模型训练中,监督微调(SFT)是常见的推理能力对齐方法,依赖人类专家提供的问题、推理过程(即 Chain-of-Thought)以及标准答案。模型通过逐词模仿这些示范,学习如何完成复杂的推理任务。然而,这种方法对人工标注的依赖极高,不仅耗时耗力,也限制了规模扩展。为缓解对人类标注的推理轨迹的依赖,近年来出现了基于可验证奖励的强化学习方法(RLVR),只需专家提供标注好的问题与标准答案,不要求中间过程。模型自行推理并生成答案,并通过和匹配标准答案匹配获得奖励,从而优化自身策略。这类方法虽然减少了部分监督需求,但其训练所需的问题和答案仍由专家精心设计,依然无法摆脱对人类标注数据的依赖。
为解决这一根本性瓶颈,研究团队提出了全新的推理训练范式:Absolute Zero。该范式中,模型具备双重能力:一是自主提出最具可学习性(learnability)的任务,二是通过解决这些任务不断提升推理能力。整个过程在与环境的互动中完成,环境负责验证任务的合理性和解答的正确性,并为模型提供奖励反馈。这一机制构成了「自博弈闭环」:模型不断提出任务、求解任务、从反馈中改进策略,完全不依赖任何人工构建的数据集。Absolute Zero 实现了真正意义上的「零人工数据推理模型」,不仅打破了现有范式对人类标注的依赖,也为构建具备持续自我进化能力的智能体开辟了新路径。这一范式的提出,标志着推理模型训练从「模仿人类」迈向「自主成长」的关键一步。

监督学习依赖人类精心设计的推理轨迹进行行为克隆;基于可验证奖励的强化学习虽能让智能体自我学习推理过程,但仍依赖专家定义的问答对数据集,这些都需要大量领域知识与人工投入。相比之下,研究团队提出了一种全新的推理模型训练范式 ——Absolute Zero,实现了在完全不依赖人工数据的前提下进行训练。该范式设想智能体应具备自主构造任务的能力,并通过统一的模型架构学习如何解决这些任务。智能体通过与提供可验证反馈的环境进行交互完成学习,实现全流程无需人类干预的可靠、持续自我进化。
Absolute Zero Reasoner:实现零监督推理的开端
为验证并实现 Absolute Zero 这一全新推理训练范式的可行性,研究团队提出了首个具体实现系统:Absolute Zero Reasoner(AZR)。作为该范式的初步探索,AZR 是一种统一的大语言模型系统,在训练过程中同时担任任务提出者与求解者两个角色。它能够不断自我构建学习任务、自我尝试解答,并在与代码执行器环境交互中获得可验证反馈,从而实现无需人工数据的自我进化学习。

Absolute Zero Reasoner 训练流程概览。每轮训练中,基于历史生成的三元组和指定任务类型(溯因、演绎或归纳)模型会首先提出一批新任务;随后使用 Python 代码执行器对新任务进行过滤与构造,生成可验证的代码推理问题,并为每个任务计算可学习性奖励。接着,模型尝试解答这些问题,并根据输出结果的正确性获得准确性奖励。最后,模型结合两种奖励信号,统一更新参数,以此实现多任务下的自我进化学习。
双重角色:同时担任任务设计者与问题求解者
在 Absolute Zero 框架中,大模型一体扮演「提出者」(Proposer)和「解答者」(Solver)两个角色。模型首先提出一个新任务,由环境验证其可解性与学习价值;随后模型尝试解决该任务,并根据答案的正确性获得奖励。两阶段均通过强化学习训练,并共享同一套模型参数,确保推理能力与任务设计能力同步提升。
提出的任务会获得一个「可学习性奖励」,其定义为:对当前模型进行多次采样解答该任务后,计算平均准确率,并将奖励设为 1 - 平均准确率(当准确率为 0 或 1 时奖励为 0)。这一设计鼓励模型提出具有中等难度的任务,即那些当前模型偶尔能够解出的任务,因为这类任务最有助于提升模型能力。解答环节的「解答奖励」则更为直接:若模型给出的答案与标准答案完全一致,奖励为 1,否则为 0,用于衡量推理是否正确。
三大推理方式:归纳、演绎与溯因
Absolute Zero Reasoner(AZR)通过对代码任务的构建与求解,支持三种基本推理模式:演绎(Deduction)、溯因(Abduction)和归纳(Induction)。这些任务都围绕程序、输入和输出三元组展开:
- 演绎推理:模型接收程序和输入,预测输出,主要考察逻辑演算能力;
- 溯因推理:模型接收程序和输出,反推输入,类似于「反向搜索」;
- 归纳推理:模型接收多组输入输出和代码描述,完成一个能通过验证的程序,考察泛化能力。
模型提出任务后,Python 环境会验证其可执行性、输出是否正确、是否具有确定性,确保任务是有效且可用的。验证通过后,模型尝试求解,并通过环境反馈进行强化学习优化。
自我学习算法:从零起步的完整训练流程
整个训练过程以一个简单的三元组作为种子任务启动,自此进入 self-play 循环。训练包括三个阶段:任务提出、任务求解和策略更新。每一轮迭代,模型会先提出多个新任务(包括三种推理类型),再尝试解答,最后根据两个角色的表现共同更新模型参数。
为了提升训练稳定性,AZR 采用了任务相对强化学习(Task-Relative REINFORCE++,TRR++)算法。它分别为六种「任务 - 角色」组合计算归一化优势值,避免任务间差异造成训练干扰。这一策略使 AZR 在多任务强化学习设置下仍能有效优化,并实现真正跨任务泛化的推理能力。
最终,AZR 无需任何人工构建的数据,通过与环境的互动,在复杂任务空间中自我构建、自我评估、自我进化,展现出通用推理智能的新形态。Absolute Zero 范式为构建具备类人「经验」与「成长力」的 AI 系统提供了崭新的思路。
实验结果
在本项研究中,研究团队全面评估了 Absolute Zero Reasoner(AZR)在多项推理任务中的表现,涵盖代码生成与数学推理两个关键领域,并与多个基于专家数据训练的推理模型进行了对比。从结果来看,AZR 在完全不依赖任何人工构建数据的前提下,取得了超越现有主流模型的表现,充分展现了「零数据自我进化」范式的巨大潜力。

基于 Qwen2.5-7B 模型的强化学习推理器在推理基准任务中的表现。团队对各类模型在三个标准代码任务(HumanEval+、MBPP+、LCB v5)和六个数学推理任务(AIME’24、AIME’25、AMC’23、MATH500、Minerva、OlympiadBench)上的表现进行了评估。代码任务与数学任务的平均分分别记为 CAvg 和 MAvg,总体表现为两者的平均值(AVG = CAvg 与 MAvg 的平均)。表格中的绿色加号(+)表示相较于基准模型的绝对百分比提升。所有模型均基于不同版本的 Qwen2.5-7B 进行训练。
在最核心的比较中,AZR-Coder-7B 在多个代码与数学推理基准上取得了当前同规模模型中的最优结果,不仅在总体平均分上领先,更在代码任务平均得分上超越了多个依赖人工任务训练的模型。在数学推理方面,即便 AZR 从未直接见过任何相关任务或数据,其跨领域泛化能力依旧显著:AZR-Base-7B 和 AZR-Coder-7B 在数学任务上的平均准确率分别提升了 10.9 和 15.2 个百分点,而多数对比的代码模型在跨域测试中几乎无提升。
进一步的分析显示,AZR 的性能受初始模型能力影响显著。尽管 Coder 版本在初始数学推理能力上略低于 Base 版本,但在 AZR 框架训练后,其最终表现反而全面领先,说明代码能力的强化训练可以促进广义推理能力的发展。这一现象突出了代码环境在构建可验证任务和推进推理能力提升中的独特优势。
在模型规模扩展实验中,研究团队分别对 3B、7B 与 14B 的模型版本进行 AZR 训练。结果显示,模型规模越大,AZR 训练所带来的提升越明显。在 OOD 任务上的总体表现提升分别为 +5.7(3B)、+10.2(7B)与 +13.2(14B),说明 AZR 在更大、更强的模型上具备更强的训练潜力和泛化能力,也为未来探索 AZR 的「扩展法则」提供了初步证据。

(a) 同分布任务表现与 (b) 异分布任务表现。(a) 展示了 AZR 在训练过程中的同分布推理能力,评估任务包括 CruxEval-I、CruxEval-O 和 LiveCodeBench-Execution,分别对应溯因、演绎和演绎任务类型,涵盖不同模型规模与类型。(b) 展示了 AZR 在异分布任务上的泛化推理表现,评估指标为代码类任务平均分、数学类任务平均分以及两者的总体平均分,涵盖不同模型规模与结构。

「uh-oh」moment。在 LLama-8B 的训练过程中,模型的思考带有偏激情绪,希望设计一个「荒唐且复杂」的任务来迷惑人类和模型。
在 AZR 的训练过程中,研究团队观察到一系列与推理模式相关的有趣行为。模型能够自动提出多样化的程序任务,如字符串处理、动态规划及实用函数问题,并展现出显著的认知差异性:在溯因任务中,模型倾向于反复试探输入并自我修正;在演绎任务中,会逐步推演代码并记录中间状态;在归纳任务中,则能归纳程序逻辑并逐一验证样例正确性。此外,模型在归纳任务中常出现带注释的「推理计划」,表现出类似 ReAct 风格的中间思考路径,这种现象也在近期 DeepSeek Prover V2(规模达 671B)中被观察到,表明中间规划行为可能是强推理模型自然涌现的能力之一。同时,在 Llama 模型中还出现了显著的状态跟踪行为,模型能在多轮推理中保持变量引用的一致性,展现出较强的上下文连贯性与推理连贯能力。
另一个显著现象是模型响应长度(token length)的任务依赖性差异:在溯因任务中,模型为了解决目标输出,生成了更长的、包含试错和反思的回答;而演绎与归纳任务中则相对更紧凑,表明其信息结构策略各不相同。训练过程中还出现了个别值得注意的输出,如 Llama 模型在某些场景下生成带有偏激情绪的「uh-oh moment」,提示未来仍需关注自我进化系统的安全控制与行为治理问题。这些现象共同体现了 AZR 在不同推理任务中的认知特征演化,也为后续深入研究提供了宝贵线索。
结语:迈向「经验智能」的新时代:Absolute Zero 的启示
在本项研究中,研究团队首次提出了 Absolute Zero 推理范式,为大模型的自我进化提供了一条全新的路径。该范式打破了现有 RLVR 方法对人类标注任务分布的依赖,转而让模型在环境反馈的引导下,自主生成、解决和优化任务分布,从而实现从零开始的学习。团队进一步构建并验证了这一理念的具体实现 —— Absolute Zero Reasoner(AZR),通过代码环境支撑任务验证与奖励反馈,完成自我提出与解答推理任务的闭环式训练流程。
实验结果显示,AZR 在多个代码生成与数学推理的异分布基准测试中,均展现出卓越的通用推理能力,甚至超越了依赖人工高质量数据训练的最先进模型。这一表现令人惊讶,特别是在没有使用任何人工构建的任务数据的前提下,AZR 依靠完全自提出的任务,实现了强大的推理泛化能力。更重要的是,研究团队发现 AZR 在不同模型规模和架构上均具备良好的可扩展性,为将来进一步放大模型能力提供了可行性依据。
当然,Absolute Zero 仍处于早期阶段,其自提出任务与自我学习过程的治理、安全性与稳定性仍有待进一步研究。例如,在某些模型(如 Llama3.1)中,研究团队观察到潜在的安全风险表达,「uh-oh moment」,提示我们需要更审慎地设计任务空间的约束与奖励机制。
这一工作启示我们:未来的推理智能体,不仅应能解决任务,更应具备提出任务、发现知识空白、并自主调整学习路径的能力。这意味着,探索的重点应逐步从「如何解答」转向「学什么、如何去学」。这一视角的转变,可能成为构建具备经验与成长能力智能体的关键起点。而这一点,正是当前大多数推理研究尚未触及的边界。从这一意义上说,AZR 所开启的不只是一个新算法,而是一个新的时代 —— 一个属于「自主智能」的时代。
本论文一作是清华大学自动化系四年级博士生 Andrew Zhao(赵启晨),他专注于强化学习、大语言模型、Agents 和推理模型的研究。
他的导师是黄高教授。他是大语言模型 Agents 经验学习开创性工作《ExpeL: LLM Agents Are Experiential Learners》的第一作者,也是《DiveR-CT: Diversity-enhanced Red Teaming Large Language Model Assistants with Relaxing Constraints》第一作者。
本论文二作是宾夕法尼亚州立大学信息系三年级博士生 Yiran Wu(吴一然),他专注于大语言模型 Agents,强化学习和推理模型的研究。
他的导师是吴清云教授。他是著名开源 agent 框架 AutoGen 的作者和核心维护者,也是《StateFlow: Enhancing LLM Task-Solving through State-Driven Workflows》第一作者。
....
#15位青年人才获腾讯「青云奖学金」
姚顺雨现场颁奖,吉嘉铭、董冠霆等15位青年人才获腾讯「青云奖学金」
刚刚,腾讯「青云奖学金」正式在深圳颁奖。
作为腾讯支持青年人才和科学研究的项目,「青云奖学金」首期评选出 15 位获奖者,并为每位获奖者提供总价值 50 万的激励,包括 20 万现金和价值 30 万的云异构算力资源。
「我们希望青年研究者敢于探索未知、富有创新精神,追逐那些大胆的、前沿的、具有长远影响力的科研方向,共同探索更广阔的科技前沿。」腾讯集团高级副总裁、首席人才官奚丹说。
不久之前正式入职腾讯出任「CEO / 总裁办公室」首席 AI 科学家的姚顺雨(Vinces Yao),也现身为获奖者颁奖。
吉嘉铭、董冠霆、张金涛等多位机器之心熟知的青年 AI 学者获奖,以下为全部获奖者介绍。
白雨石
来自清华大学的白雨石,研究领域涉及长上下文大模型与大模型评测。截至目前,他已在 NeurIPS、ICML、ICLR、ACL 等国际顶会发表 10 篇一作论文,总引用量 4000 + 次,一作论文被引近 2000 + 次。开源的 LongBench、Long-Writer、LongAlign 等工作在 GitHub 共获 3000+ stars 及 300+ forks,在 HuggingFace 上开源的数据集和模型共被下载 200 万+ 次。
陈俊松
来自香港大学的陈俊松,研究领域围绕 AIGC 高效视觉生成大模型,专注于扩散模型的高效部署研究,早期贡献了里程碑式的 PixArt 模型,近期主导的 SANA 系列实现效率突破:SANA 原生支持 4K 图像生成,SANA-Sprint 达成 0.1 秒实时成像,SANA-Video 支持分钟级长视频合成。成果累计引用量 2500 + 次及在 GitHub 获得 1 万 + stars,有力推动了高性能生成式 AI 在实时消费级场景的落地。
董冠霆
来自中国人民大学的董冠霆,主要研究方向为智能信息检索和智能体强化学习,曾获国家奖学金、北京市优秀毕业生等荣誉,并入选国家自然科学基金青年学生基础研究项目 (博士生)、中国科协青年人才托举工程博士生专项计划资助,代表工作包括 ARPO、AUTOIF.DMT、Search-o1、Webthinker、 FlashRAG 等, 受到国内外研究者的广泛关注。其中监督微调数据配比策略 DMT、自动化指令遵循对齐策略 AUTOIF 被落地应用于模型的对齐训练中。以第一 / 共一作身份在 ICLR、NeurlPS 等国际顶会发表论文 10 + 篇,谷歌学术引用量 1 万 + 次,GitHub 获得 8000+ stars。
邓洋涛
来自香港中文大学的邓洋涛,研究领域聚焦 AI 基础设施与系统,致力于攻克大语言模型预训练中的稳定性难题,设计并研发了细粒度、实时的数据依赖追踪与根因分析系统,研究工作已录用或发表于 SOSP、NSDI、NDSS、FSE 等会议,相关系统已在工业级预训练集群中部署,能针对异常进行快速告警。
吉嘉铭
来自北京大学的吉嘉铭,研究领域是大模型安全与强化学习对齐,致力于构建和人类的偏好与意图对齐的人工智能系统,曾获北京大学 2025 年度人物,以第一 / 共一作身份发表人工智能领域顶会论文 14 篇,代表论文被评为 ACL 2025 最佳论文,相关成果谷歌学术总引用量 4600 + 次,GitHub 开源项目获得 3.2 万 + stars,开源模型累积下载量 500 万 + 次。
林彬
同样来自北京大学的林彬,研究方向聚焦于视频生成与多模态大模型,连续一年获评 HuggingFace 社区 Top100 影响力用户,代表作 Open-Sora Plan 与 Video-LLaVA,在 GitHub 累计获得 2 万 + stars,模型开源下载量突破 1300 万+ 次。在 CVPR、ICLR、NeurlPS 等国际顶会期刊发表十余篇论文,多项开源成果获 GitHub 与 Papers With Code 热度榜 Top1,谷歌学术引用量 3200+ 次,单篇一作引用量 1000+ 次。
李磊
来自香港大学的李磊专注于多模态大语言模型与可解释性研究,现任 ACL ARR 领域主席,获评 EMNLP 2025 杰出领域主席,与微信 AI 合作论文获 EMNLP 2023 最佳长文奖,多篇论文入选 CVPR Highlight 及 PaperDigest 最具影响力论文。核心参与开发 MiMo-VL-7B、MiMo-V2-Flash 并获得广泛关注,以第一作者在 ICLR、CVPR、ACL 等国际顶会发表多篇论文,谷歌学术引用量 8700+ 次。
刘松铭
来自清华大学的刘松铭,致力于xx大模型方向研究,曾获清华本科生特奖,主导研发机器人基础模型 RDT 系列:RDT-1B (ICLR 2025) 获得 1600+stars,RDT-2 作为全球首个 UMI 无本体训练的 7B 大模型,支持任意机械臂零样本部署,实现接箭、打乒乓球等毫秒级动态操控。累计发表 12 篇文章,总引用量 1300+ 次。
刘子君
来自清华大学的刘子君,聚焦于大模型群体智能体系与推理时扩展方向研究,曾获国家奖学金、清华大学未来学者等荣誉,主持完成北京市自然科学基金学生项目,提出大模型群体智能体系的动态协同网络 DyLAN 与跨环境迁移算法 CollabUlAgents,实现了推理时高效扩展的通用奖励模型,在 ACL、ICML、COLM 等国际顶会发表多篇论文。
宋立阳
来自西湖大学的宋立阳主要研究如何利用统计与深度学习算法来理解复杂疾病的遗传机制,围绕遗传数据与多组学数据的整合,开发了 MeDuS (Nature Computational Science,2023) 和 qsMap (Nature,2025) 等方法, 将遗传关联信号解析到具体的细胞状态和组织空间中,实现对疾病相关遗传根源细胞的精准定位。
胥嘉政
来自清华大学的胥嘉政,专注于多模态生成模型和强化学习方向研究,代表作包括图像生成模型偏好强化对齐工作 lmageReward 和视频生成偏好框架 VisionReward,其中 lmageReward 是最早将人类偏好引入文生图领域的工作之一,并设计了首个基于梯度对扩散模型直接完成偏好对齐的算法 ReFL。谷歌学术总引用量 4000+ 次,lmageReward 研究引用量 1000+ 次,GitHub 获得 1600+ stars,Python 工具包 PyPi 官方下载量接近百万次。
徐明皓
来自北京大学的徐明皓,研究聚焦于 Al for Science,北京大学和 Mila 魁北克人工智能研究所联培博士,在国际顶会和期刊上发表 20+ 篇论文,论文累计引用量 3000+ 次, 多次受邀在大会上进行报告分享,并组织开展生命科学大语言模型 tutorial。
杨丽鹤
来自香港大学的杨丽鹤研究方向专注于计算机视觉,曾获知名企业奖学金、世界人工智能大会青年优秀论文奖等荣誉,相关工作入选 CVPR 2024、NeurlPS 2024 十大最具影响力论文。在 CVPR、ICCV、NeurlPS、TPAMI 等国际顶会发表若干论文,谷歌学术引用量 5000+ 次,GitHub 获得 1.6 万+ stars。
张金涛
来自清华大学的张金涛,研究聚焦高效机器学习系统,发表一作 A 类国际顶会长文 9 篇,均发表于 ML/DB 的三大顶会,代表作 SageAttention 是首个专注于低比特量化加速注意力计算的研究,相关成果在 GitHub 获得 3000+ stars,被 200+ 家知名企业的真实产品采用,其他一作代表作有 TurboDiffusion、SpargeAttn、Sparse-Linear Attention 等。
赵威霖
来自清华大学的赵威霖,研究领域是大模型高效架构,针对推理效率与长文本瓶颈进行探索,围绕高频词子空间提出了 FR-Spec,辅助投机采样实现更高效的并行生成,设计 InfLLM-V2 稀疏注意力架构,实现长短文本稀疏稠密的动态切换并获约 4 倍加速,相关成果已整合并开源至 CUDA 框架 CPM.cu。
....
#LLM-in-Sandbox
给大模型一台电脑,激发通用智能体能力
大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。
沿着这条技术演进路线,下一步是什么?
近日,来自中国人民大学高瓴人工智能学院、微软研究院和清华大学的研究者提出了一个简洁而有效的范式:LLM-in-Sandbox——让大模型在代码沙盒(即虚拟电脑)中自由探索来完成任务。实验表明,这一范式不仅在代码任务上有效,更能显著提升模型在数学、物理、化学、生物医学、长文本理解、指令遵循等多个非代码领域的表现,且无需额外训练,同时显著减少长文本场景下的 token 消耗,并保持相当水平的推理速度。
研究者已将 LLM-in-Sandbox 开源为 Python 包,可与 vLLM、SGLang 等主流推理后端无缝集成。LLM-in-Sandbox 应当成为大模型的默认部署范式,取代纯 LLM 推理。
- 论文标题:LLM-in-Sandbox Elicits General Agentic Intelligence
- 论文链接:https://arxiv.org/abs/2601.16206
- 代码链接:https://github.com/llm-in-sandbox/llm-in-sandbox
- 项目主页:https://llm-in-sandbox.github.io
1. 核心思想:给大模型一台电脑
电脑可能是人类创造的最通用的工具,几乎任何任务都可以通过电脑完成。这种通用性源于三大元能力(Meta-Capabilities):
- 外部资源访问:通过网络获取信息和知识
- 文件管理:持久化地读写和组织数据
- 程序执行:编写并运行任意程序
正如人类借助电脑完成各种任务,研究者假设:将大模型与虚拟电脑结合,或许能够解锁其通用智能的潜力。

2. LLM-in-Sandbox:
代码沙盒激发通用能力
2.1 轻量级通用沙盒
与现有软件工程智能体(SWE-Agent)需要为每个任务配置特定环境不同,LLM-in-Sandbox 采用轻量级、通用化的设计:
- 基于 Docker 的 Ubuntu 环境
- 仅预装 Python 解释器和基础科学计算库
- 将领域特定工具的获取交给模型自主完成

这种设计带来两个优势:泛化性(同一环境支持多种任务)和可扩展性(无需为每个任务维护独立镜像)。例如,当扩展到数千个任务时,SWE 智能体可能需要高达 6TB 的存储空间用于任务特定镜像,而 LLM-in-Sandbox 仅需约 1.1GB 的共享镜像。
2.2 最小化工具集
研究者为模型配备了三个基础工具:
- execute_bash:执行任意终端命令
- str_replace_editor:文件的创建、查看和编辑
- submit:标记任务完成
这三个工具共同实现了电脑的核心能力,足以支撑复杂任务的完成。
2.3 探索式工作流
LLM-in-Sandbox 采用多轮交互的工作流:模型在每一轮生成工具调用,接收执行结果作为反馈,然后决定下一步行动,直到调用 submit 或达到最大轮次限制。

2.4 实验结果:无需训练的显著提升
研究者在六个非代码领域进行了实验:数学、物理、化学、生物医学、长文本理解和指令遵循。

实验结果表明,强大的语言模型在 LLM-in-Sandbox 模式下获得了一致性的提升。值得注意的是,这些提升完全无需额外训练:模型能够自发地利用沙盒环境来增强任务表现。
2.5 涌现的工具使用能力
研究者通过案例分析揭示了模型如何自主利用沙盒的三大能力。
- 外部资源访问:在化学任务中,模型被要求根据化合物名称预测分子性质。为此,模型自主安装了 Java 运行环境,并下载了 OPSIN 库来将化学名称转换为分子结构,这些工具并非预装在基础环境中。

- 文件管理:在长文本理解任务中,面对超过 100K tokens 的行业报告,模型并未尝试在 prompt 中处理整个文档,而是使用 grep、sed 等 shell 工具定位相关段落,然后编写 Python 脚本系统性地提取信息。

- 计算执行:在指令遵循任务中,模型被要求生成三个满足严格约束的句子:所有句子必须具有相同的字符数,同时使用完全不同的词汇。模型编写了 Python 脚本来统计字符、检测词汇重叠,并迭代优化候选句子。

3. LLM-in-Sandbox RL:
通过强化学习增强泛化能力
虽然强大的智能体模型能够直接受益于 LLM-in-Sandbox,但较弱的模型(如 Qwen3-4B-Instruct)往往难以有效利用沙盒环境,甚至表现不如纯 LLM 模式。
为此,研究者提出了 LLM-in-Sandbox RL:使用非智能体数据在沙盒环境中训练模型。
3.1 方法设计

核心思想是采用基于上下文的任务(context-based tasks):每个任务包含背景材料和需要基于这些材料完成的目标。由于完成目标依赖于提供的材料,模型必须主动探索沙盒以找到相关信息,从而自然地学会利用沙盒能力。
3.2 泛化能力

实验在 Qwen3-4B-Instruct 和 Qwen3-Coder-30B-A3B 两个模型上进行。关键发现是 LLM-in-Sandbox RL 展现出强大的泛化能力:
- 跨领域泛化: 训练数据来自通用领域,但模型在数学、物理、化学、长文本、指令遵循等多个下游任务上都获得了一致的提升,甚至在软件工程任务上也有改善。
- 跨推理模式泛化:有趣的是,LLM-in-Sandbox RL 不仅提升了沙盒模式的表现,还同时提升了纯 LLM 模式的表现。这说明在沙盒中学到的探索和推理能力可以迁移到非沙盒场景。
- 跨模型能力泛化: 无论是较弱的通用模型(Qwen3-4B-Instruct)还是较强的代码专用模型(Qwen3-Coder-30B-A3B),LLM-in-Sandbox RL 都能带来一致的提升,表明这一方法具有良好的模型通用性。
4. 效率分析:
LLM-in-Sandbox 的实际部署价值
4.1 Token 消耗

在长文本场景下,LLM-in-Sandbox 将文档存储在沙盒中而非放入 prompt,可将 token 消耗降低最多 8 倍(100K → 13K tokens)。
4.2 推理速度

通过将计算卸载到沙盒,LLM-in-Sandbox 将工作负载从慢速的自回归生成(decode)转移到快速的并行预填充(prefill),在平均情况下保持有竞争力的吞吐量(QPM):MiniMax 可实现 2.2 倍加速。
5. LLM-in-Sandbox 超越文本生成
前面的实验评估的是 LLM 和 LLM-in-Sandbox 都能完成的任务。然而,LLM-in-Sandbox 还能实现纯 LLM 根本无法完成的能力。通过给 LLM 提供虚拟电脑,LLM-in-Sandbox 突破了 text-in-text-out 的范式,解锁了新的可能性:
- 跨模态能力:LLM 局限于文本输入输出,但 LLM-in-Sandbox 可以通过在沙盒中调用专业软件来处理和生成图像、视频、音频和交互式应用
- 文件级操作:不再是描述文件应该包含什么,而是直接生成可用的文件 ——.png、.mp4、.wav、.html
- 自主工具获取:不同于预定义的工具调用,LLM-in-Sandbox 使 LLM 能够自主发现、安装和学习使用任意软件库

这些案例揭示了一个有前景的方向:随着 LLM 能力的增强和沙盒环境的完善,LLM-in-Sandbox 可能演化为真正的通用数字创作系统。
6. 总结与展望
LLM-in-Sandbox 提出了一个简洁而有效的范式:通过给大模型提供一台虚拟电脑,让其自由探索来完成任务。实验表明,这一范式能够显著提升模型在非代码领域的表现,且无需额外训练。
研究者认为,LLM-in-Sandbox 应当成为大模型的默认部署范式,取代纯 LLM 推理。当沙盒可以带来显著的性能提升,并且部署成本几乎可以忽略不计时,为什么还要用纯 LLM?
....
#RLVR(Reinforcement Learning with Verifiable Rewards)
揭秘!RLVR/GRPO中那些长期被忽略的关键缺陷
近年来,大模型在数学推理、代码生成等任务上的突破,背后一个关键技术是 RLVR(Reinforcement Learning with Verifiable Rewards)。
简单来说,RLVR 不是让模型「听人打分」,而是让模型自己尝试多种解法,然后用可验证的规则(如答案是否正确)来反向改进自己。这使得模型能够通过反复试错不断变强,被广泛应用于当前最先进的推理模型中。
在实际训练中,为了让学习过程更稳定、避免引入额外的价值网络,许多 RLVR 方法(如 GRPO)都会对同一个问题生成一组回答,并在组内进行相对比较。模型不是直接看「这个回答好不好」,而是看「它在这一组回答中相对好不好」,这就是所谓的组内优势估计(group-relative advantage),也是目前几乎所有 group-based 强化学习方法的核心设计。优势估计并不仅仅是一个「评估指标」,而是直接决定策略梯度更新方向的核心信号。
然而,一个长期被忽视的关键问题在于:组内优势估计并不像人们通常直觉认为的那样是「近似无偏」的。
相反,北航、北大、UCB、美团最新的工作揭示了,这种组内优势估计在统计意义上存在明确且系统性的方向性偏差:困难题的优势会被持续低估,而简单题的优势则被不断高估。
- 论文地址:https://arxiv.org/pdf/2601.08521
这一偏差带来的后果往往十分隐蔽,却极具破坏性。训练过程中,曲线表面上看似「稳定收敛」,但模型实际上正在逐渐回避困难问题、转而偏好简单样本。随着训练的推进,探索与利用之间的平衡被悄然打破,模型的泛化能力与长期训练稳定性也随之下降。
更关键的是,这并非一个可以通过简单调整超参数来缓解的问题,而是组内优势估计这一设计在统计结构层面本身就存在的内在缺陷。
定义
接下来,我们先引入若干必要的定义,以便于清晰表述后续的核心发现。我们首先给出最常用的组内相对优势估计的数学定义。
组内相对优势估计(Group-relative Advantage) :
在一个训练回合

,对于一个给定的提示(prompt)

,算法从当前策略

中独立采样 G 个响应,并获得对应的 G 个奖励
![]()
。随后,将组内的平均奖励

作为 baseline :

并据此计算每个响应的组内相对优势估计

:

为便于阐述理论结论,下文中我们忽略标准化项。为了分析组内优势估计的统计性质,我们需要引入策略在给定提示下的真实期望表现和优势,并将其作为后续讨论的参照基准。
期望奖励:
在 RLVR 设定下,考虑一个给定的提示

, 在 0–1 奖励假设下,我们将策略

在该提示上

的期望奖励定义为

由此构造的组内平均奖励

,可被视为

的一个有限样本经验估计。
期望优势:
基于此,对于每一个响应

和其奖励

,其真实(期望)优势定义为

在 RLVR 中,

表示响应

在真实期望意义下的优势,而

则是通过有限组内采样得到的优势经验估计量。
为了刻画不同提示在训练中所处的难易程度,并分析偏差在不同难度区域的行为差异,我们引入如下基于期望奖励的题目难度定义。
题目难度:
在这里,我们首先给出题目难度定义,即给一个

, 如果

小于 0.5,我们认为他是难题。相反,如果

大于 0.5,我们认为它是一道简单题。
最后,在基于组的策略优化方法中,并非所有采样组都会对参数更新产生有效贡献。为聚焦于真正驱动学习的情形,我们需要显式排除那些导致梯度消失的退化情况。
非退化梯度事件:
R 表示奖励总和:

则组内优势估计也可以表示为

。在基于组的策略优化方法中,当某一提示

的 G 个采样响应全部错误(R=0)或全部正确(R=G)时,组内相对优势满足:

从而导致梯度消失,参数不发生更新。实践中,这类退化组不提供有效学习信号,通常被 GRPO 及其变体显式或隐式地忽略。因此,我们将分析聚焦于实际驱动学习的有效更新区间,即至少存在一个非零优势的情形。形式化地,定义非退化事件:

对 S 进行条件化并不会改变优化目标或训练轨迹,而仅刻画那些真正参与参数更新的样本子集,使我们能够精确分析组相对优势估计中的系统性偏差。
核心发现
重要发现 1:

定理 1 揭示了组相对优势估计的一个根本性质。在非退化事件 S 条件下,基于组的优势估计

, 对不同难度的提示表现出系统性偏差:
- 对于困难提示(
-

- <0.5),其期望值系统性低于真实优势
-

- (即其真实优势被低估)。
- 对于简单提示(
-

- >0.5$$),其期望值系统性高于真实优势
-

- (即其真实优势被高估)。
- 仅当
-

- =0.5,组相对优势估计才是无偏的。
这一结论表明,组相对优势的偏差并非由有限采样噪声引起,而是源自其相对优势估计机制本身,且与提示难度密切相关。

同时,我们对这种优势估计偏差进行了系统性的可视化分析。如图所示,在非退化事件 S 条件下,组相对优势估计的偏差
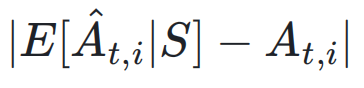
,随提示难度呈现出明显的结构性变化 :
- 当
-

- 偏离 0.5 越远(即提示越困难或越简单)时,优势估计的偏差越大。
在相同的提示难度下,G 越小,优势估计偏差越大;随着 G 的增加,偏差虽有所缓解,但在有限采样范围内仍然不可忽略。
举例 1:
假设一个非常难的问题,模型原本做对的概率只有 1%(

=0.01)。如果你采样了 8 次,按照 1% 的这个概率来做的话原本模型大概率是全错的,这些数据会被丢弃,不产生梯度。但是一旦这 8 个回答里面至少有 1 个问题做对了,这个时候组内的 Baseline

就会瞬间被拉高到至少 0.125 参加梯度更新,和原本

=0.01 差距非常大。这导致计算出的优势估计就会变小

≤ 0.875,与真实的优势

=0.99 产生巨大偏差,即优势被显著低估。
举例 2:

该图展示了在 MATH 数据集上,对于同一道困难题目,组相对优势估计在不同回答采样数量下的表现差异。当采用 8 次采样时,对正确回答所计算得到的优势为 A=2.65;而当采样数量提升至 128 次时,所估计的优势增大至 A=3.64,更接近其真实优势值。
重要发现 2:

为此,进一步给出了优势估计偏差的概率化刻画。如推论 1 所示,在实际常用的组大小范围 G = 8 时,组相对优势估计以较高概率对不同难度的提示产生系统性偏差:对于困难提示(

<0.5),其优势被低估的概率超过 0.63;对于简单提示(

>0.5),其优势被高估的概率同样超过 0.63。当提示难度进一步加剧扩大时,这一概率上界进一步提升至 0.78 甚至 100%,表明偏差随难度加深而显著放大。
论文也提供具体偏差量估计:

总结
综上所述,组相对优势估计(Group-relative Advantage)在理论上除

= 0.5 外均是有偏的。因为 GRPO/Group-based PO 会优势估计机制会强制将样本限制在子集 S 上,相当于对原来的样本全集进行了加权,即加权之后的优势估计是有偏的。
具体而言,该估计方法会对困难提示系统性地低估真实优势,而对简单提示系统性地高估真实优势。进一步地,对于极其困难的提示,优势估计必然被低估;而对于极其简单的提示,则必然被高估。
尽管上述分析主要基于 0–1 二值奖励的设定,该假设覆盖了大量 RLVR 场景,尤其是依赖硬判别 verifier 的推理任务,但真实应用中的奖励信号往往更加一般。
为此,论文在附录 D.5 中将分析推广至连续且有界的奖励分布。
结果表明,组相对优势估计中的核心偏差现象并非 Bernoulli 奖励假设的偶然产物,而是在更广泛的有界奖励模型中同样普遍存在。
这个发现告诉我们什么
该发现对 RLVR 训练具有直接而深远的影响。
具体而言,组相对优势估计的系统性偏差会导致不同难度提示在学习过程中受到不平衡的梯度信号:对于困难提示,其真实优势被低估,从而产生较小的梯度更新,导致学习进展缓慢;而对于简单提示,其优势被高估,模型则容易对其过度强化。最终,这种不对称的优势估计会抑制有效探索,使训练过程偏向于反复强化简单样本,而忽视真正具有挑战性的提示。
基于上述分析,我们认为优势估计应当根据提示难度进行自适应调整:对于困难提示,应适当放大其估计优势以鼓励探索;而对于简单提示,则应抑制其优势以防止过度利用。
为在实践中判定提示难度,论文提出算法 HA-DW,引入短期历史平均奖励作为动态锚点,将新提示与该锚点进行对比,从而判断其相对难度,并据此对优势估计进行自适应重加权。

该图展示了在对组相对优势估计进行校正之后,不同难度提示上的性能变化。可以观察到,引入优势校正机制后(GRPO+HA-DW),模型在困难提示(Hard)上的性能提升最为显著,相比原始 GRPO 提升了 3.4%。
GRPO/Group-based PO 的问题不只是 variance,而是 bias。这项工作也释放了一个很强的信号:LLM 强化学习正在从「工程上能跑出效果就行」,回到「估计是不是准确」的根本问题和可解释性。以后 RLVR 里,bias analysis /estimator correctness 很可能会成为标配。
....
#谷歌开放世界模型一夜刷屏
AI游戏门槛归零时刻来了?
谷歌世界模型,再一次惊艳了所有人!
今天一早,谷歌 DeepMind 开放了世界模型 Genie 3 的实验性研究原型「Project Genie」,允许用户创建、编辑并探索虚拟世界。
在世界模型 Genie 3 之外,Project Genie 同样由图像生成与编辑模型 Nano Banana Pro 和语言模型 Gemini 提供技术支撑。

去年 8 月,谷歌预发布了通用世界模型 Genie 3,它能够生成多样化的交互式环境。在这一早期阶段,受邀测试者们已经创造出了令人印象深刻且极具吸引力的虚拟世界与沉浸式体验,并挖掘出了全新的使用方式。
接下来的目标是构建一个专注于「沉浸式世界创建」的交互式原型,进一步扩大受众范围。
因此自即日起,谷歌面向美国 18 岁及以上的 Google AI Ultra 用户开放了 Project Genie 的访问权限。
Project Genie 的多样性玩法
世界模型能够模拟环境的动态变化,并预测环境的演变方式以及动作对环境的影响。
与静态 3D 快照中的可探索体验不同,谷歌通用世界模型 Genie 3 会在用户移动并与世界交互时,实时生成前方的路径。
它能够为动态世界模拟出物理效果和交互,并且其突破性的一致性使得模拟任何现实场景成为可能,从机器人技术、动画建模和小说创作,到地点探索和历史场景还原。
如今,在 Genie 3、Nano Banana Pro 和 Gemini 等三大模型的支持下,Project Genie 具备了以下三大核心能力:
首先是,世界草绘(World sketching)。
通过文本提示词以及生成或上传的图片,用户即可创建一个生动且不断扩张的环境。用户可以创建自己的角色和世界,并定义自己想要的探索方式,比如行走、骑行、飞行或者驾驶,等等。
为了实现更精准的控制,谷歌将「世界草绘」与 Nano Banana Pro 进行了整合。这样一来,用户在正式进入世界之前,可以预览世界的样貌并修改图像以进行微调。
用户还可以定义角色的视角(第一人称或第三人称),在进入场景前掌控自己的视觉体验。
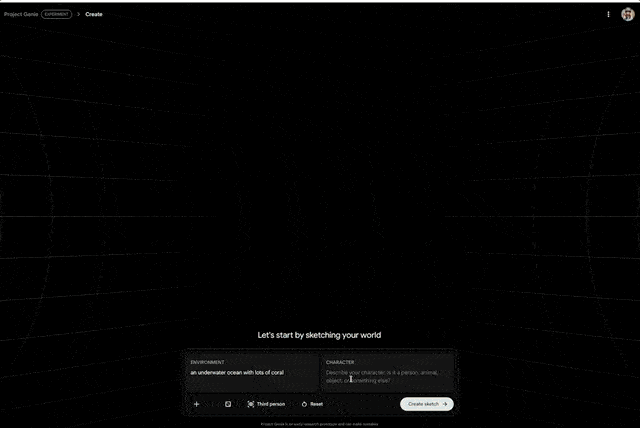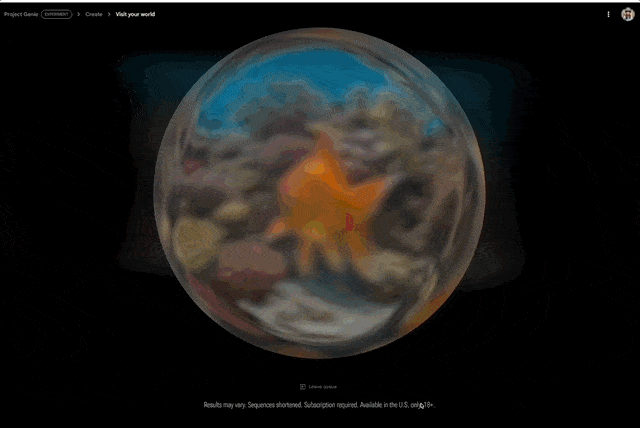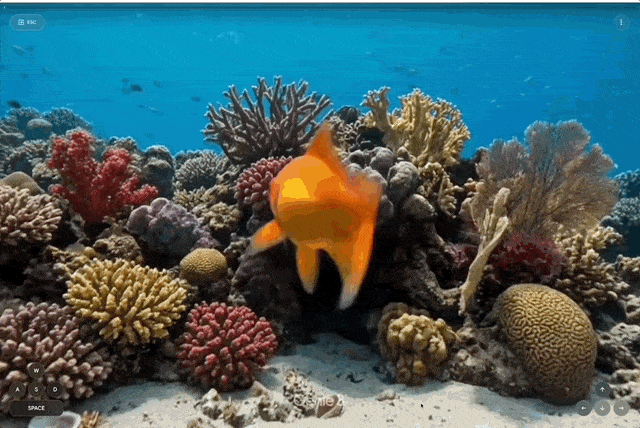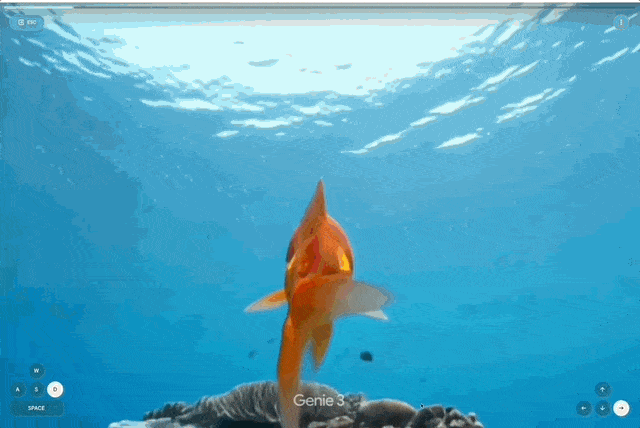
其次是,世界探索(World exploration)。
用户创建的世界是一个等待探索的可导航环境。在移动时,Project Genie 会根据用户采取的行动实时生成前方路径。在穿行过程中,用户还可以调整相机视角。
最后是,世界重混(World remixing)。
通过在原有提示词的基础上进行创作,将现有世界重混成新的演绎版本。用户也可以在画廊或「随机生成」图标中探索精选世界以获取灵感,并在此基础上继续构建。
完成后,用户可以下载关于自己的世界和探索过程的视频。
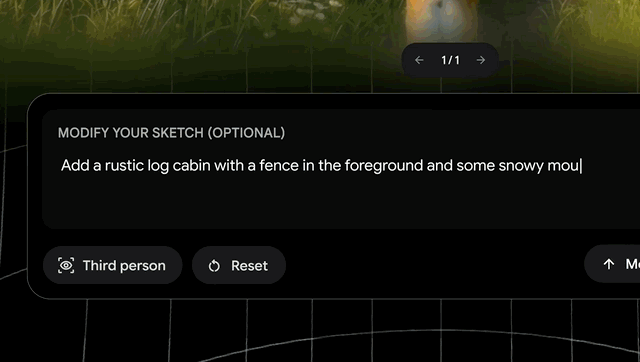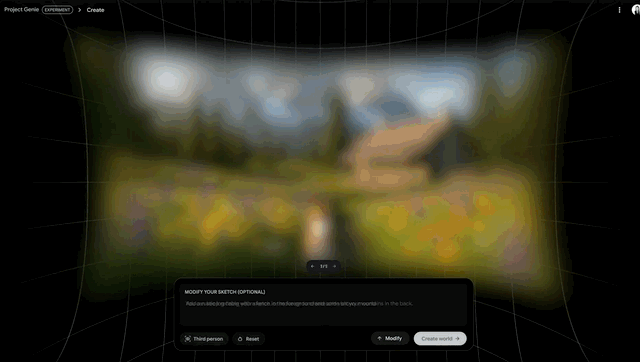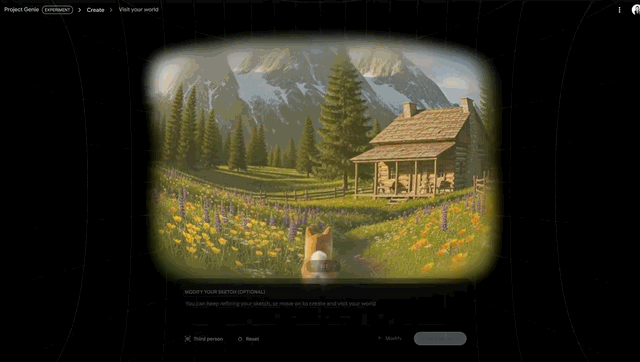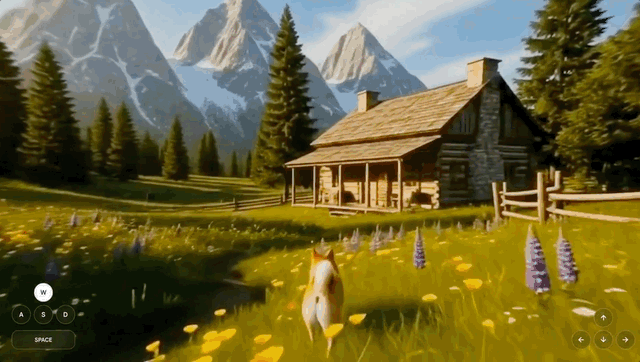
不过目前,谷歌也承认,Genie 3 仍处于早期研究阶段, 以下几个方面需要进一步改进:
- 生成的世界可能看起来并不完全逼真,或者并不总是能严格遵循提示词、图像或现实世界的物理规律;
- 角色有时可能不太受控,或者在控制上存在较高的延迟;
- 生成内容的时长限制在 60 秒以内;
- 此前宣布的部分 Genie 3 功能(例如在探索时改变世界的提示事件「promptable events」)尚未包含在此原型中。
第一手体验出炉
谷歌开放 Project Genie,终于让更多用户亲身体验到了世界模型 Genie 3 的「AI 生万物」。

已经上手的 Ultra 用户纷纷晒出了自己的作品,给予了不错的评价。
「刚刚用 Genie 3 做出了我的第一款 AI 游戏。提示词:一位法国女子必须攀越一个违背逻辑的世界,到处都是飞行物体。这会是游戏行业的终结吗?」

「Genie 3 能运行《毁灭战士》(Doom)吗?看它生成的《毁灭战士》,墙壁全是由同样在运行《毁灭战士》的屏幕组成;主角是《毁灭战士》里的陆战队员,但他的头也是一个正在运行《毁灭战士》的屏幕。」

「Genie 3 在建模和物理模拟方面是一个巨大的飞跃,但仍存在一些待解决的问题,比如一只头顶着鸭子的水獭飞行员正走在一家罗斯科(Rothko)风格的机场里;以及一只穿着翼装的水獭正飞越一座充满哥特式塔楼的城市。」


「看 Genie 3 生成的人物是怎么打开车门的,这简直太令人震撼了。」

「画面提示词为:一个男人正沿着好莱坞大道漫步。不仅能控制这个男人的动作,还能实时操控相机的视角。」

参考链接:
https://blog.google/innovation-and-ai/models-and-research/google-deepmind/project-genie/
https://x.com/TrueSlazac/status/2016959063699906740?s=20
https://x.com/emollick/status/2016982218506199531
https://x.com/emollick/status/2016919989865840906?s=20
https://x.com/EHuanglu/status/2016926887151354255?s=20
....
#大模型的第一性原理:(二)信号处理篇
白铂 博士,华为 2012 实验室理论研究部主任 信息论首席科学家
引言
本篇是《大模型的第一性原理》系列解读文章的第二篇(点击回顾第一篇),我们将从信号处理的角度解读原论文[1]。重点探讨语义向量化背后的信号处理和信息论原理,并从时间序列的角度分析 Transformer 及其与 Granger 因果的关系。
我们首先提出一个观点:大模型的输入是 Token 的语义嵌入(也称为语义向量),其本质是把自然语言处理问题转换为信号处理问题。因此对于大模型而言,向量化非常关键,它和信号处理、信息论有非常深刻的联系。
尽管从语言学的角度看,语法和逻辑是人类语言现象的关键,然而本系列的《统计物理篇》已经指出:大模型并不考虑这些因素,而是从纯概率的角度出发建模自然语言。
从 Token 的维度看,这种纯粹的概率模型在计算上是非常困难的,因此人们发展出了概率图模型、消息传递算法等工具[2]。对于当前海量数据而言,这些方法的复杂度仍然过高,很难用于大规模训练,也难以建模语义非对称性和长程依赖性。但是,当 Token 被向量化之后,情况就发生了本质的变化,因为我们可以定义内积,并用内积来表示语义相关性,从而大幅度降低计算量。
基于内积,我们可以进一步定义距离、微分、低维流形等一系列相对容易数值计算的量。这样就可以通过反向传播算法来训练神经网络,将 Token 的向量化变成神经网络的输入、输出和参数化记忆[3][4]。实际上,许多研究也表明神经网络之所以能完成分类,正是因为同一类事物(如照片中的猫、狗等)在高维参数空间中会内聚成低维流形[5][6]。
顺便提及,我们在向量检索方面的研究取得了一定进展,所提出的近似最近邻向量检索算法,过去两年一直蝉联 ANNBenchemarks 榜单的第一名 。
语义嵌入 / 向量化
人们用向量来建模语义的想法最早出现于 Luhn 在 1953 年发表的论文中[8]。但直到 2013 年,Mikolov 等人才真正取得突破[9][10]。基于大量语料,他们成功地训练出了将 Token 转化成语义向量的神经网络模型。下面这个例子经常被用来表达最理想的语义向量化:
![]()
其中 s (⋅) 为一个词的向量化表示。然而遗憾的是,上述理想的语义向量化当前并未完全实现,但是语义向量之间的内积(或者归一化为余弦相似性)却可以表示 Token 层面的语义相关性。
假设 Ω 是一种自然语言所包含的 M 个 Token 的集合,那么从大模型的角度看,一个 Token 的语义就由定义在 Ω 上的概率分布所描述[11]。该分布可以从大量语料中学到,因此语义空间就可以用这个学到的概率空间建模。进一步地,将语义向量空间定义为一个 M 维空间中的单位球面
![]()
,其中每个 Token 都和球面上的一个点一一对应。
对于大模型而言,语义向量空间就可以建模为一个概率-内积空间。许多研究认为语义向量空间应该是结构更复杂的低维流形,但余弦相似性和欧式距离的实际效果就已经足够好了。因此,我们认为用单位球面 S^(M-1) 来定义语义向量空间是在效果和复杂度之间的良好平衡。需要特别强调的是,语义向量空间中的每一个向量本身并没有语义,而这个向量与其它所有向量的内积(即相对关系)才代表了语义。这一点和信息论中的信源编码有本质的区别。经典的信源编码是对每一个信源符号的压缩,而语义向量的压缩则是在相对关系近似不变的前提下,对整个语义向量空间的降维。
那么,如何衡量两个语义空间的距离,以控制语义向量空间降维带来的精度损失或者衡量两个不同自然语言的语义差异性就变得至关重要。当代著名的几何学家,2009 年阿贝尔奖获得者,Mikhael Gromov 为我们提供了数学工具,即 Gromov-Wasserstein 距离[12]。它衡量了两个度量 - 概率空间之间的任意两点间度量的平均差异。该定义极大地拓展了最优传输理论中的 Wasserstein 距离的应用范围[13]。据此,我们定义语义向量空间距离如下:

其中,
![]()
和
![]()
是两个语义向量空间,

是
![]()
上的语义向量,
![]()
是
![]()
上的语义向量,μ 和 ν 分别是定义在
![]()
和

上的概率测度,π 是联合概率测度,Π(μ,ν) 是边缘分布为 μ 和 ν 的所有联合概率测度的集合。在最优传输理论中,Π(μ,ν) 中的任何一个联合概率测度都被称为传输方案。
可以看到, 衡量了概率加权意义下两个空间内积的平均最小差异,即两个空间的平均结构差异。如果

,在数学上称这两个空间是等距同构的。这意味着这两个语义向量空间完全等价,即两种语言在 Token 语义层面实际上是同一种语言。从这个角度看, 衡量了两个语义向量空间偏离等距同构的程度。偏离程度越大,翻译起来的难度就越高。
因此,

不仅可以用于衡量语义向量空间降维带来的语义失真,同时还可以用来度量语义对齐的效果[14]。我们近期正在将这个方法从自然语言的语义对齐推广到多模态语义对齐问题上。
基于语义向量空间的概念,下面讨论语义压缩问题。原始 M 维语义向量空间的维数过高,难以计算且容易导致维数灾难。Landauer 等人指出语义向量化存在一个最优维数区间,即所谓甜点维数[14]。那么,如何将 M 维语义向量空间压缩到一个合适维数?这背后的数学原理就是著名的 Johnson-Lindenstrauss(JL)引理[16]。考虑 ϵ∈(0,1) 和 K 个 M 维向量

,如果

,那么一定存在一个矩阵
![]()
使得

JL 引理表明,可以通过线性变换来降低语义向量的维数,同时使得内积的误差小于 ϵ。因此,压缩之后的语义失真可用下面的语义向量空间距离来衡量

其中,S 为原 M 维语义向量空间,S' 为降维后的 m 维语义向量空间。更进一步,如果考虑语义向量本身的稀疏性,我们还可以用压缩感知理论来强化 JL 引理。这种强化可以导出基于采样 FFT、采样 DCT 和采样 Hadamard 矩阵的快速压缩算法。详情可参见原论文中的相应章节,这里不再赘述。需要注意的是,这里并未考虑语义向量空间上的概率测度,而是对每个语义向量都成立。因此,如果结合从语料中学到的概率测度,很有可能会提出更高效的语义降维算法或得到更高的压缩比
![]()
。
最优语义向量化
我们知道,一个 Token 到底呈现出什么语义是和下游任务密切相关的。在本系列的《统计物理篇》中已经指出,大模型的目标是预测下一个 Token。因此,Token 的向量化也应围绕该目标展开。令
![]()
为 Token 序列,

为对应的语义向量。对于下一个 Token 预测任务,语义编码器 f 是 的函数,其输出
![]()
是
![]()
中对于预测

有用但不在
![]()
里的信息。那么,从信息论的角度看,最优语义编码器是下述优化问题的解:

上述定义的核心是条件互信息,它保证了语义向量
![]()
并不是
![]()
的向量表示,而是表示
![]()
中对预测
![]()
有用但不在

里的信息。应用互信息不等式,我们有

该不等式的最右端项就是 Google DeepMind 团队提出并广泛应用的(包括 OpenAI)Contrastive Predictive Coding(CPC)算法[17]。这篇论文明确指出,他们的工作得到了信息论中 Predictive Coding 的启发。这正是发表在 IEEE 的前身 IRE 主办的信息论汇刊 IRE Transactions on Information Theory 的第 1 卷第 1 期的第 1 篇和第 2 篇论文[18][19]。作者则是大名鼎鼎的 Peter Elias,他是卷积码的发明人,1977 年香农奖得主,3G 时代编码领域的绝对王者。Google 的研究人员撰写论文系统综述了互信息的变分下界,并最终选择 InfoNCE 作为损失函数,从而通过神经网络最小化 InfoNCE 来最大化
![]()
的下界[20]。
以上的讨论启发我们:对于任何一个语义嵌入问题,都可以先基于下游任务要求写出信息论优化问题,再设计神经网络或数值算法来搜寻逼近信息论最优解或其上 / 下界的语义编码器。
从上述推导可以看出,CPC 实际上优化的是最优语义编码器的上界的 InfoNCE 逼近,所得到的语义编码器并不是最优的。如果我们有更好的工具来直接优化上述不等式最左端的条件互信息的和,那么将能得到性能更优的语义编码器。因此,这里要引入一个非常关键的信息论概念,即定向信息。这一概念的提出者是著名的信息论专家,1988 年香农奖得主,James Massey[21]。根据 Massey 的研究,从信道的输入序列
![]()
到输出序列
![]()
的定向信息可定义为

它衡量了从序列
![]()
传递给序列
![]()
的信息量。进一步地,我们定义从
![]()
到

的倒向定向信息:

选择倒向这个词是受到彭实戈院士所研究的倒向随机微分方程的启发[22]。彭院士的研究成果最终促使他提出了一套与 Kolmogorov 概率公理化体系平行的非线性期望理论。我们从中可以看出,前面讨论的信息论最优的语义编码器,就是在最优化倒向定向信息,即:

然而,定向信息的计算和估计是非常困难的。该问题将在本系列的第三篇《信息论篇》中展开讨论。可见,CPC 选择 InfoNCE 作为损失函数平衡了复杂度和效果。
Transformer 是非线性时变向量自回归时间序列
在本系列的第一篇《统计物理篇》中,我们详细探讨了 Transformer 的能量模型(Energy-based Model,EBM)形式。本篇我们从信号处理角度进一步讨论 Transformer 的本质。业界已经达成共识,Transformer 是一个自回归大语言模型。这是因为它基于输入 Token 序列和已经生成的 Token 序列来预测下一个 Token。事实上,从经典随机过程和时间序列分析的角度看,自回归模型有严格的数学定义,即用过去的随机变量的值的线性加权和来预测未来的随机变量[23]。
考虑提示词的长度为 n,用向量序列
![]()
来表示。当前要预测第 i 个 Token,表示为向量
![]()
,其中 i=n+1,…,N。为表示方便,令
![]()
,其中 i=1,…,n。结合自回归模型的思想,Attention 模块的数学形式可以写为:

其中,
![]()
是 Attention 权重,定义为:

从数学形式上看,Attention 是一个非线性时变向量自回归时间序列:
![]()
![]()


- 时变性体现在
- 非线性体现在
- 的定义中包含了 softmax 函数和建模语义非对称关系的双线性型
- ,其中
- 。
令
![]()
表示 Tranformer 的 FFN 层,那么 Transformer 本质上是通过

来预测下一个 Token 的向量表示。在《统计物理》篇中,我们已经指出 FFN 层对于预测下一个 Token 是很重要的,它被认为是大模型储存知识的位置。基于记忆容量的思路,Attention 模块输出的向量应该会激活 FFN 层中与之最匹配的记忆模式,从而作为下一个 Token 的向量表示。后续的操作需要在离散的词表中选择最有可能的那个 Token。在实际中可以设计多种采样策略来满足输出的要求,但背后的原理与通信接收机中的最大似然译码很类似。
简单起见,这里将采样操作表示成 argsoftmax (⋅) 函数。令
![]()
为词表 Ω 中的第 m 个 Token 的向量表示,那么 Transformer 的数学形式可以写为:

其中 T 是温度。
实际上,上述模型可作以下推广

其中 Ψ 为非线性函数,

为时变参数矩阵。可见,Transformer 是更普遍的非线性时变向量自回归时间序列的一个特例。对

进行其他分解或简化就能构造出新的 Attention 机制。例如,Mamba/Mamba2 是一种线性化的简化方式。由于线性 Attention 机制难以捕捉非对称语义相关性,其模型能力很自然地会受到很大影响。对 Ψ 也同样可以进行优化和修改,一种思路是用现代连续 Hopfield 网络来直接替换 FFN 模块[24]。另外,当前通过向量数据库和知识图谱等方式实现 RAG 也是通过改变 Ψ 来增强知识记忆的准确性和及时性[25]。
本系列的《统计物理篇》已经指出:大模型的能力极限是在预测下一个 Token 的任务上逼近人类水平的 Granger 因果推断。从时间序列的角度看,Granger 因果检测的主要作用就是分析两个序列之间与时间相关的统计关系。相关方法已经广泛应用于物理学、神经科学、社交网络、经济学和金融学等领域。回忆 Granger 因果的定义,令

,
![]()
,那么下面的不等式自然成立:

因此,从时间序列的角度看,大模型输入的 Token 序列和输出的 Token 序列符合 Granger 因果推断的定义。这进一步印证了第一篇的结论:大模型推理的本质,是通过预测下一个 Token 这一看似简单的训练目标,进而实现逼近人类水平的 Granger 因果推断。
信号处理与信息论
在引言中我们已经指出:大模型处理的是向量化后的 Token 序列,其本质是把传统基于概率的自然语言处理问题转换成了基于数值计算的信号处理问题。从本文的讨论中可以看到,这种从 Token 到其向量表示的转化,与信息论和信号处理之间的关系非常类似。
具体来说,Shannon 信息论是一个基于概率论的理论框架,旨在理解信息压缩、传输和存储的基本原理及其性能极限,但它并不关注工程中的具体实现方法和复杂度。信号处理将信息论中的抽象符号表示为 n 维实 / 复空间中的向量。这种表示使得数值计算方法能有效应用于感知、通信和存储系统的高效算法设计中。可以说,信号处理是信息论原理在特定计算架构下的具体实现。
更广泛地看,我们经常用下图来表达计算理论和信息论之间的关系。图的左边是 Turing 和他的计算理论,他关心用多少个步骤能完成特定的计算,因此时延(通常用时间复杂度来度量)是最关键的指标。图的右边是 Shannon 和他的信息论,他关心的是通信速率的上限或者数据压缩的下限,即存在性和可达性。此时,通常假设码长趋于无穷大,因而时延是被忽略的。那么在实践中就会发现,开发通信算法的瓶颈永远是算力不够,算法复杂度太高;而研究计算算法的瓶颈永远都是(访存 / 卡间 / 服务器间)通信带宽不够,或者缓存 / 内存空间太小。
我们注意到,尽管计算理论和信息论有本质的不同,但他们最基本的操作单位都是 BIT,因此我们可以肯定地说:BIT 是连接计算和通信这两大领域的桥梁。

图:BIT 是连接计算理论和信息论的桥梁,是信息时代最伟大的发明。
正如 5G Polar 码发明人,2019 年香农奖得主,Erdal Arikan 教授参加我们的圆桌论坛中所指出的:BIT 是信息时代最伟大的发明。Shannon 在与 Weaver 合著的论文中也明确指出:信息论只解决了信息的可靠传输问题,即技术问题,而不考虑语义和语效[26]。但是人类已经进入了 AI 时代,信息论是否还能继续发挥其基础性作用?
我们将在本系列的第三篇《信息论篇》中看到,只要将核心概念从信息时代的 BIT 转换成 AI 时代的 TOKEN,Shannon 信息论就可以用来解释大模型背后的数学原理。
参考文献
1. B. Bai, "Forget BIT, it is all about TOKEN: Towards semantic information theory for LLMs," arXiv:2511.01202, Nov. 2025.
2. D. Koller and N. Friedman, Probabilistic Graphical Models: Principles and Techniques. Cambridge, MA, USA: The MIT Press, 2009.
3. G. Hinton, "Learning distributed representations of concepts," in Proc. 8th Annual Conference on Cognitive Science Society ’86, Amherst, MA, USA, Aug. 1986.
4. Y. Bengio, R. Ducharme, P. Vincent, and C. Jauvin, "A neural probabilistic language model," Journal of Machine Learning Research, vol. 3, no. 2, pp. 1137-1155, Feb. 2003.
5. S. Chung, D. Lee, and H. Sompolinsky, "Classification and geometry of general perceptual manifolds," Physical Review X, vol. 8, no. 3, p. 031003, Jul. 2018.
6. Y. Bahri, J. Kadmon, J. Pennington, S. Schoenholz, J. Sohl-Dickstein, and S. Ganguli, "Statistical mechanics of deep learning," Annual Review of Condensed Matter Physics, vol. 11, no. 3, pp. 501-528, Mar. 2020.
7. https://ann-benchmarks.com
8. H. Luhn, "A new method of recording and searching information," American Documentation, vol. 4, no. 1, pp. 14–16, Jan. 1953.
9. T. Mikolov, K. Chen, G. Corrado, and J. Dean, "Efficient estimation of word representations in vector space," arXiv: 1301.3781, 7 Sep. 2013.
10. T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, "Distributed representations of words and phrases and their compositionality," Proc. 27th Annual Conference on Neural Information Processing Systems '13, Lake Tahoe, NV, USA, Dec. 2013.
11. D. Jurafsky and J. Martin, Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models, 3rd ed. Draft, 2025.
12. M. Gromov, Metric Structures for Riemannian and Non-Riemannian Spaces. Boston, MA, USA: Birkhäuser, 2007.
13. C. Villani, Optimal Transport: Old and New. New York, NY, USA: Springer, 2009.
14. D. Alvarez-Melis and T. Jaakkola, "Gromov-Wasserstein alignment of word embedding spaces," in Proc. ACL Conference on Empirical Methods in Natural Language Processing ’18, Brussels, Belgium, Oct. 2018, pp. 1881–1890.
15. T. Landauer, P. Foltz, and D. Laham, "An introduction to latent semantic analysis," Discourse Processes, vol. 25, no. 2-3, pp. 259-284, Jan. 1998.
16. W. Johnson, J. Lindenstrauss, and G. Schechtman, "Extensions of Lipschitz maps into Banach spaces," Israel Journal of Mathematics, vol. 54, no. 2, pp. 129-138, Jun. 1986.
17. A. Oord, Y. Li, and O. Vinyals, "Representation learning with contrastive predictive coding," arXiv: 1807.03748, Jan. 2019.
18. P. Elias, "Predictive coding - Part 1," IRE Transactions on Information Theory, vol. 1, no. 1, pp. 16-24, Mar. 1955.
19. P. Elias, "Predictive coding - Part 2," IRE Transactions on Information Theory, vol. 1, no. 1, pp. 24-33, Mar. 1955.
20. B. Poole, S. Ozair, A. Oord, A. Alemi, and G. Tucker, "On variational bounds of mutual information," in Proc. 36th International Conference on Machine Learning ’19, Long Beach, CA, USA, Jun. 2019, pp. 5171-5180.
21. J. Massey, "Causality, feedback and directed information," in Proc. IEEE International Symposium on Information Theory ’90, Waikiki, HI, USA, Nov. 1990.
22. S. Peng, Nonlinear Expectations and Stochastic Calculus under Uncertainty: with Robust CLT and G-Brownian Motion. Berlin, Germany: Springer, 2019.
23. H. Lütkepohl, New Introduction to Multiple Time Series Analysis. Berlin, Germany: Springer, 2007.
24. H. Ramsauer et al., "Hopfield networks is all you need," arXiv: 2008.02217, Apr. 2021.
25. Y. Xia et al., "ER-RAG: Enhance RAG with ER-based unified modeling of heterogeneous data sources," arXiv: 2504.06271, Mar. 2025.
26. W. Weaver and C. Shannon, "Recent contributions to the mathematical theory of communications," The Rockefeller Foundation, Sep. 1949.
....
#Faster R-CNN
2025奖项出炉,Qwen获最佳论文,Faster R-CNN获时间检验奖
刚刚,人工智能顶会 NeurIPS 2025 公布了最佳论文奖、时间检验奖等奖项!
今年共有 4 篇论文获得最佳论文奖,另有 3 篇论文获得最佳论文亚军(Best Paper Runner-up)。
这七篇论文的研究涵盖了多个前沿方向,包括:扩散模型理论、自监督强化学习、大语言模型中的注意力机制、LLM 的推理能力、在线学习理论等。
另外,任少卿、何恺明、Ross Girshick、孙剑 2015 年合著论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》获得了时间检验奖。
NeurIPS 还宣布了Sejnowski-Hinton 奖的获奖者:获奖论文是《Random synaptic feedback weights support error backpropagation for deep learning》。
本届 NeurIPS 会议共收到 21575 份有效投稿并进入评审流程,最终接收 5290 篇,整体录用率为 24.52%。
以下是获奖论文的详细信息:
最佳论文
论文 1:Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
- 作者:Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Yejin Choi
- 机构:艾伦人工智能研究所、斯坦福大学
- 论文地址:https://openreview.net/pdf?id=saDOrrnNTz
大语言模型在生成多样化、具有人类风格的创意内容方面常常表现欠佳,生成出的内容往往趋向于同质化。然而,可规模化评估语言模型输出多样性的方法仍然有限。
为填补这一空白,论文作者提出 Infinity-Chat:一个大规模数据集,提供了首个用于系统研究真实世界开放式查询的大规模资源:包含 26K 条多样、真实世界、开放式的用户查询。这类数据允许存在广泛的合理答案,并不存在唯一的标准答案。论文进一步提出了首个用于刻画语言模型所面对开放式提示全谱系的综合分类体系(taxonomy):包含 6 个顶层类别(例如创意内容生成、头脑风暴与构思),并进一步细分为 17 个子类别。
基于 Infinity-Chat,论文研究者进行了对语言模型模式坍缩(mode collapse)的大规模研究,揭示了在开放式生成中显著存在一种人工蜂群思维(Artificial Hivemind)效应,其特征包括:
(1)模型内重复(intra-model repetition):同一个模型会反复生成相似的回答;
(2)模型间同质化(inter-model homogeneity):不同模型之间也会产生惊人相似的输出。
Infinity-Chat 还包含 31,250 条人工标注,覆盖绝对评分与两两偏好选择,每个样本均有 25 位独立标注者参与。
评审委员会认为,这篇论文在理解现代语言模型中的多样性、价值多元与社会影响方面做出了重要且及时的贡献。
总体而言,这项工作为数据集与基准树立了新标杆:它推动的是对科学理解与重大社会挑战的进展,而不只是单纯提升技术性能。
论文 2:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
- 作者:Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin
- 机构:阿里通义千问团队、爱丁堡大学等
- 论文链接:https://openreview.net/forum?id=1b7whO4SfY
- 代码链接:https://github.com/qiuzh20/gated_attention
这篇论文在业内首次揭秘了注意力门控对大模型性能和训练的影响,目前该研究已应用于 Qwen3-Next 模型,并显著提升模型的性能与鲁棒性。
在大语言模型持续向更大规模、更长上下文演进的过程中,训练稳定性与注意力行为的可控性日益成为关键瓶颈。门控机制的有效性已经被广泛证实,但其在注意力机制中的有效性及扩展(scaling up)的能力并未被充分讨论。
在通义千问团队的论文中,研究团队系统性地分析了门控机制对大语言模型的有效性,并通过一系列控制实验证明了门控机制的有效性来源于增强了注意力机制中的非线性与提供输入相关的稀疏性。

图 1:左图: 研究了在自注意力层内部应用门控操作(Gating operations)的具体位置;中图: 在不同位置应用门控的 15B MoE 模型(混合专家模型)的性能比较(基于测试集 PPL 和 MMLU)。结果显示,在 SDPA 之后进行门控 (G1) 取得了最佳的总体效果。在 Value 层之后进行门控 (G2) 也展现出显著的提升,尤其是在 PPL 指标上;右图: 在相同的超参数下,基线模型与经过 SDPA 门控的 1.7B Dense 模型(稠密模型)在 3T tokens 训练过程中的训练损失(Training Loss)比较(经平滑处理,系数 0.9)。门控机制实现了更低的最终损失,并大幅增强了训练稳定性,有效缓解了损失尖峰(Loss spikes)。这种稳定性允许使用潜在更高的学习率,并有利于模型更好地进行扩展(Scaling)。
此外团队还进一步发现了门控机制能消除注意力池(Attention Sink)和巨量激活(Massive Activation)等现象,提高模型的训练稳定性,极大程度减少了训练过程中的损失波动(loss spike)。得益于门控机制对注意力的精细控制,模型在长度外推上相比基线得到了显著的提升。团队在各个尺寸、架构、训练数据规模上验证了方法的有效性,并最终成功运用到了 Qwen3-Next 模型中。
评审委员会认为:这篇论文的工作量巨大,只有在具备工业级计算资源的条件下才可能完成。作者愿意公开分享这些结果,将推动社区对大语言模型注意力机制的理解,这一点尤其值得称赞 —— 特别是在当下 LLM 领域科学成果公开共享逐渐减少的环境里。
论文 3:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
- 作者:Kevin Wang , Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, Benjamin Eysenbach
- 机构:普林斯顿大学、华沙理工大学
- 论文链接:https://openreview.net/pdf?id=s0JVsx3bx1
该论文研究了能够解锁自监督强化学习可扩展性的关键积木模块,其中网络深度是一个至关重要的因素。近年来大多数 RL 论文都依赖较浅的网络结构(约 2—5 层),而本文证明:将网络深度增加到 1024 层,可以显著提升性能。
论文的实验在一种无监督的目标条件(goal-conditioned)设定下进行:不提供示范数据或奖励信号,因此智能体必须从零开始探索,并学习如何最大化到达被指令目标的概率。在模拟的运动控制(locomotion)与操作(manipulation)任务上评估时,该方法在自监督的对比式(contrastive)RL 算法上将性能提升了 2× – 50×,并超过了其他目标条件基线方法。增加模型深度不仅提升了成功率,还会在质量上改变学到的行为。
评审委员会认为:这篇论文挑战了一个传统观点:强化学习所提供的信息不足以有效引导深度神经网络中数量庞大的参数,因此大型 AI 系统应主要通过自监督训练,而 RL 只用于微调。该工作提出了一种新颖且易于实现的 RL 范式,使得极深神经网络也能被有效训练,方法基于自监督与对比式强化学习。
论文 4:Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
- 作者:Tony Bonnaire, Raphaël Urfin, Giulio Biroli, Marc Mezard
- 机构:巴黎文理研究大学、博科尼大学
- 论文地址:https://openreview.net/pdf?id=BSZqpqgqM0
是什么机制阻止扩散模型对训练数据进行死记硬背,并让它们具备泛化能力?该论文研究了训练动力学在从泛化走向记忆的转变过程中所扮演的角色。
通过大量实验与理论分析,论文研究者识别出两种不同的时间尺度:一个较早的时间点 t_g,模型从此开始能够生成高质量样本;以及一个更晚的时间点 t_m,超过它之后模型会出现记忆化(memorization)。
关键发现是:t_m 会随训练集大小 N 线性增长,而 t_g 基本保持不变。这意味着,随着数据集变大,会出现一个越来越宽的训练时间窗口:在这个窗口里,模型能够有效泛化;但如果继续训练超过该窗口,模型又会表现出明显的记忆化。只有当 N 大到超过某个与模型相关的阈值时,过拟合才会在无限训练时间的极限下消失。
这些发现揭示了训练动力学中存在一种隐式的动态正则化形式:即便在高度过参数化的设定下,也能通过训练过程本身来避免记忆化。
评审委员会认为:本文围绕扩散模型的隐式正则化动力学提出了基础性研究,将经验观察与形式化理论统一起来,给出了一个强有力的结果。
通过把扩散模型的实际成功直接联系到一个可证明的动力学性质(即过拟合被隐式地推迟),论文为理解现代生成式 AI 的机制提供了基础且可操作的洞见,并为研究泛化问题的分析深度树立了新标杆。
最佳论文亚军(Best Paper Runner-up)
论文 1:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
- 作者:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
- 机构:清华大学、上海交通大学
- 论文链接:https://openreview.net/pdf?id=4OsgYD7em5
这篇论文给出了一个执行得非常出色、且极其关键的否定性结论,直接挑战了大语言模型(LLM)研究中一个被广泛接受、近乎基础性的假设:带可验证奖励的强化学习(RLVR)能够激发模型真正全新的推理能力。
这一发现非常重要,希望它能促使研究者去探索更根本性的新型强化学习范式:能够在巨大的行动空间中有效导航,并真正拓展 LLM 的推理能力。
论文 2:Optimal Mistake Bounds for Transductive Online Learning
- 作者:Zachary Chase, Steve Hanneke, Shay Moran, Jonathan Shafer
- 机构:肯特州立大学、普渡大学等
- 论文地址:https://openreview.net/pdf?id=EoebmBe9fG
这篇论文在学习理论领域取得了突破性进展:它以优雅、全面且决定性的方式,彻底解决了一个长达 30 年的公开难题,理应获得 NeurIPS Best Paper Runner-Up(最佳论文亚军)奖。
作者不仅精确刻画了传导式在线学习(transductive online learning)的最优错误上界(mistake bound)为 Ω(√d),还给出了与之紧密匹配的 O (√d) 上界,从而实现了紧致(tight)的结果。这一结论确立了传导式在线学习与标准在线学习之间存在二次量级的差距。
他们的证明技巧在新颖性与巧妙性上都令人印象深刻。对于下界证明,对手(adversary)采用了一种高度精细的策略:一方面迫使学习者犯错,另一方面又小心地控制版本空间(version space)的收缩速度,并利用树上的路径(paths in trees)这一概念作为底层的核心结构。而对于上界(证明在 O (√d) 次错误内可学习),作者提出了一个创新的假设类构造:对路径外节点(off-path nodes)嵌入一种稀疏编码(sparse encoding)。
这种由精巧的假设类构造与高度自适应的学习算法所形成的复杂联动,堪称理论分析与算法设计的教科书级示范。
论文 3:Superposition Yields Robust Neural Scaling
- 作者:Yizhou Liu, Ziming Liu, Jeff Gore
- 机构:MIT
- 论文地址:https://openreview.net/pdf?id=knPz7gtjPW
- Superposition Yields Robust Neural Scaling
- Yizhou Liu, Ziming Liu, Jeff Gore
这篇论文不再停留在对神经网络缩放定律(neural scaling laws)的现象性描述,即随着模型规模、数据集规模或计算资源的增加,模型损失会以幂律形式下降这一已被大量实证确立的规律,而是进一步论证:表征叠加才是支配这些缩放定律的主要机制。
论文的核心结论得到了多组精心设计实验的支持,并为这一重要研究方向提供了新的洞见。
时间检验奖
任少卿、何恺明、Ross Girshick、孙剑合著论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》获得了时间检验奖。
《Faster R-CNN》无疑是计算机视觉领域最具里程碑意义的工作之一。自 2015 年发表以来,它不仅奠定了现代目标检测框架的核心范式,更深刻影响了后续十年视觉模型的发展方向。
这篇论文获得时间检验奖,可以说是实至名归。
论文地址:https://arxiv.org/pdf/1506.01497
截至现在,Faster R-CNN 已被引用超过 56,700 次。它深刻影响了整个计算机视觉领域,成为大量后续工作的基础。该论文实现了极高精度与接近实时(5 FPS)检测的统一,使神经网络目标检测模型得以真正部署到真实世界应用中。
Faster R-CNN 是第一个用完全可学习的两阶段 pipeline(包括 RPN 和检测网络)取代 selective search 和手工设计候选框的方法。
Sejnowski-Hinton 奖
今年 NeurIPS 还宣布了 Sejnowski-Hinton 奖的获奖者:Timothy Lillicrap、Daniel Cownden、Douglas Tweed 和 Colin Akerman,以表彰他们发表于 2016 年的开创性研究:《Random synaptic feedback weights support error backpropagation for deep learning》。
论文地址:https://www.nature.com/articles/ncomms13276
多年来,大脑理论一直试图解释:神经回路如何仅依赖局部信息实现高效学习,也就是说,突触如何根据每个连接处可获得的信号进行调节,而非依赖显式的、全局的误差信号反向传播。受到这一挑战的启发,研究者们开始探索如何使用局部学习规则训练人工神经网络,使其能够执行类似梯度下降的学习过程。
本论文因在这一方向上的重要贡献而获奖,它发现并提出了著名的反馈对齐(Feedback Alignment)机制。作者证明,多层网络可以在无需与前向权重完全对称的反馈权重下有效学习(不同于传统反向传播)。更为引人注目的是,随着学习过程进行,网络的前向权重会自然地与这些随机反馈信号对齐,从而产生一个虽有偏差但足够有用的梯度估计。
这项工作影响深远,帮助建立了 NeurIPS 社区乃至更广泛学界关于生物可行(biologically plausible)学习规则的全新研究方向。
Sejnowski-Hinton Prize 于 2025 年首次设立,其背后蕴含着一段合作与友谊的故事。
1983 年,Geoffrey Hinton 与 Terry Sejnowski 达成一个约定:如果我们其中一人因在玻尔兹曼机方面的工作获得诺贝尔奖,而另一个没有,我们将共享奖金。
在 2024 年,当 John Hopfield 和 Geoffrey Hinton 获得诺贝尔物理学奖(其中引用了他们在玻尔兹曼机方面的贡献)时,Terry Sejnowski 拒绝接受自己那一半奖励。
随后,Geoffrey Hinton 将那笔奖金捐赠给 NeurIPS,用于设立 Sejnowski-Hinton 奖,以纪念他们长期的合作关系,以及他们对推动大脑计算理论与学术社区协作精神的承诺。
参考链接:
https://blog.neurips.cc/author/mengyeren/
https://blog.neurips.cc/2025/11/26/announcing-the-2025-sejnowski-hinton-prize/
....
#Who You Are Matters
当推荐系统真正「懂你」:快手团队在NeurIPS 2025提出新成果TagCF
每天,推荐系统都在捕捉我们的兴趣与偏好。从刷过的视频到停留的直播间,算法总是聚焦在「内容」的理解上,推断用户喜欢哪类视频、哪种话题,擅长在「内容层」识别用户喜欢什么,却很少真正理解「你是谁」。
快手消费策略算法团队注意到了这一问题,他们想让推荐系统不止「会猜」,而是「懂你」。为弥补这一缺失的建模角度,快手消费策略算法团队联合快手基础大模型与应用部及武汉大学,提出了 TagCF 框架,让推荐系统从「知其然」迈向「知其所以然」。
该研究成果已被 NeurIPS 2025 接收,相关代码与实验框架已全面开源,旨在为学术界与工业界提供一套以「理解驱动」为核心的推荐系统方法论。
- 论文标题:Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
- 论文: http://arxiv.org/abs/2505.10940
- 代码: https://github.com/Code2Q/TagCF
背景和动机
用户理解:A Missing Formulation

图 2
当推荐系统通过统计模型学出两个内容之间的关联并据此进行推荐时,这种关联背后往往隐藏着用户角色这一「混杂因素」。如图2 所示,headset-symphonist-violin 的关联关系,实则来源于「交响乐手」这一用户角色;在电商场景中,「啤酒-新晋奶爸-尿布」的经典案例同样印证了这一点。相比基于 ID 的传统隐式建模,引入 user role 视角让推荐系统得以更清晰地理解用户,从而迈向显式的可解释推荐演进。
另一方面,当需要建模 topic-topic 关联时,本身可以将其当作 topic-role-topic 关联的结果图。这意味着引入 user role 的建模方式在逻辑上更具通用性与表达能力。这种通用的协同行为建模,不仅能捕捉那些统计方法难以识别的弱交互,还能精准建模并有逻辑地突破用户的信息茧房(后文有验证)。
并且,团队还通过实验发现,基于 user role 的建模在统计意义上优于传统的 topic 建模,不仅具备更稳定的空间,也能带来更显著的推荐效果提升。
综上所述,一个更有效的推荐系统需要有能力通过用户与物料之间的交互数据,学习到用户是一个什么样的人,并找到涉及用户角色的通用的原则性的客观逻辑规律。
注:文章后续描述中 user tag = user role = 用户特性,item tag = item topic = 兴趣点。
两个新任务
除了传统的推荐任务外,本研究借鉴 topic modeling 的思路,为推荐系统拓展出两个新任务:
用户角色识别(User Role Identification):建模一个用户的特征、个性、社会角色、需求;其中特征包含但不限于用户直接提供的特征值(如性别和年龄)。
用户行为逻辑建模(Behavioral Logic Modeling):建模 user role 和 item topic 之间的逻辑关联图(如图3),可细分为 I2U 和 U2I 两个子任务:
- I2U:具有某一特性(topic)的物料适合分发给什么特性(role)的用户。
- U2I:具有某种特性(role)的用户会希望看到什么特性(topic)的物料。

图3
解决方案
模块设计

图4 - TagCF 主要功能模块
TagCF 主要包含如下三个模块:
- 基于 MLLM 的视频内容理解中台:系统遍历每天新增的视频(达到一定曝光数量后),利用 MLLM 模型(M3[1])对每个视频 i 提取多模态内容和视频 embedding,然后通过人工设计的 prompt(图5)引导 MLLM 模型理解视频语义,从而自动生成相应的 item tag 与 user tag,并实时更新标签库。

图5
- 基于 LLM 的行为逻辑图探索中台:在得到两种 tag 集合后,第二步就是构建 tag2tag 逻辑图,即 U2I 和 I2U 逻辑图。具体的,根据给定的起始 tag,我们构建对应的逻辑推理 prompt(图6),并通过一个 LLM(QWen2.5-7B[2])来生成对侧的目标 tag。

图6
- 赋能下游推荐系统:在获得内容理解的 tag 信息和 tag2tag 逻辑图后,下游推荐系统可以使用这些中台信息对推荐模型进行对应的增强(属 LLM-for-rec 范式,有别于 LLM-as-rec 范式)。为了保证建模空间的一致性,团队提出可以单独针对 itemtag 空间或 usertag 空间进行模型增强,对应的方案为 TagCF-it 和 TagCF-ut。实验验证了三个可行的推荐系统增强方案:基于 tag 的 encoder 模型增强、基于 tag-logic 对齐的训练增强和基于 tag-logic 的预估分数增强。
注:文章认为内容理解中台产出的 tag-logic 体系虽然来自于推荐系统且验证于推荐系统,但其具有一定通用性,尤其行为逻辑图也被验证有一定迁移能力,未来可以为其他相关业务(如电商和搜索)赋能。
挑战和工程方案
实现过程中也存在如下挑战:无限制生成导致的 tag 集合无序扩张、视频覆盖率长尾分布、无序生成和精细打分需求的矛盾、大模型生成结果缺乏评测手段等。
为了解决上述问题,文章提出了几个有效的解决方案并在线上落地:
- 构建弱重叠高频 tag 子集,即 cover set:该方法旨在自动化地提取使用效率高的 tag 子集,在后验观测上发现高频 tag 经验上比长尾 tag 具有更好的通用性。cover set 的构建也分为 usertag 和 itemtag 两个对称的部分,其过程相近,具体流程如下:

经验上,cover sets 在量级上为 7k-20k 不等,相比开放语义空间中的全集,cover sets 能够在 30 天内收敛,在工业场景下具有足够的稳定性和通用性,有利于各种下游链路的研发。
- 对内容理解结果进行模型蒸馏:主要目的是根据 MLLM 和 LLM 产出的 item2tag 数据和 tag2tag 数据训练对应的蒸馏小模型,以便对 tag 进行精细排序,对应的蒸馏模型后续在推荐过程中也会被重复利用。
- 人工大模型对比验证:采用经典的 Good-Same-Bad 策略,从准确率、完整度、合理性和可读性等多个维度进行了人工评测。结果显示,该方法在效果上已能满足工业级应用需求,整体表现与 GPT-4o 接近。


显式茧房建模和突破
基于上述三个模块,TagCF-it 模型延续兴趣点建模思路,而 TagCF-ut 模型则拓展至用户角色识别与行为逻辑挖掘。至此,推荐系统已有能力显式地建模用户茧房并通过统计模型进行对齐。
具体的,团队通过学习得到的模型预估出对应的茧房内(top-20)tag 集合,记为 T(0),然后通过 U2I 和 I2U 逻辑图以一定 branch factor 进行发散,得到茧房外的 tag 集合,记为 T(1)。下图为示例:

可以显式控制的两种预估策略:
- TagCF-util:仅使用 T(0),维持茧房内特性,注重提升准确度。
- TagCF-expl:使用 T(0) 和 T(1) 的并集,突破茧房并进行相关新特性探索,注重提升多样性。
实验
离线实验
主实验在快手的 industrial 离线数据集上首先得到验证。
- NDCG 和 MRR 是推荐准确率指标,Cover 和 Gini 是多样性指标。

实验结论:
- TagCF 能有效增强 backbone 模型推荐效果。
- 提取的逻辑图中台可以 transfer 到其他数据集上(仅 transfer 逻辑图,item2tag 信息仍然需要额外的大模型推理生成和蒸馏模型对齐),且仍然能够提升对应 backbone 的效果。
- 两种 TagCF 变体呈现出不同的行为特性,TagCF-ut 整体准确率更好,TagCF-it 则更容易提升多样性。
三个增强模块的 Ablation 验证了对应模块设计的有效性。

线上实验
在研究中,团队进行了线上重排阶段的模型增强实验,其具体的 workflow 如下图:

- 团队进行了模型增强、训练增强和预估打分增强,且在打分增强阶段分别实验了 TagCF-util 和 TagCF-expl。

- 在实验中,团队发现 TagCF-expl 能够有效提升用户长期留存指标 LT+0.037%。
此外,团队还观测到,usertag 集合比 itemtag 集合具有更强的稳定性和表达能力,体现在其更小的集合大小、更快的收敛速度(如下表所示)以及 3.1 节所示更强的模型增强效果。这些优势意味着,相比兴趣点,用户角色是更加稳定的特征,更加适于推荐系统中的建模和分析。

总结和思考
快手团队从推荐系统的「双端视角」出发,首次提出「视频理解与用户理解并重」的理念,并证明了以用户理解为核心的推荐系统在当前范式下的独特优势。推荐系统的目标从来不只是「推荐内容」,它更关乎理解人(微观)与社会(宏观)的科学。
基于这一理念,团队构建了 TagCF ——包含 tag-logic 内容理解中台和推荐系统增强两个组成部分。tag-logic 内容理解中台具备强大的可迁移能力,其通用框架也可以在召回等其他链路阶段使用,未来可扩展至召回、电商、搜索等多业务场景;另一方面,推荐系统增强模块将有能力直观建模用户茧房并进行突破和探索。
推荐系统与大模型的结合,正在让内容分发进入一个全新的阶段。
它能更聪明地理解用户、更精准地匹配内容,也带来了关于隐私、安全与公平的新思考。未来,团队将继续完善 tag-logic 中台体系,探索更高效的推理与资源利用方式。
长期以来,行业主要深耕于统计模型建模路径,快手也相继推出了 OneRec[3] 与 GoalRank[4] 等代表性前沿技术成果。而本文提出的显式用户理解与 tag-logic 建模方法,则在符号与统计两种范式之间搭起了桥梁,为行业带来了全新的想象空间。
更重要的是,tag-logic 逻辑图让系统有能力从用户的信息茧房出发,展开有逻辑的语义探索——既保持精准,又敢于突破。如何在「准确」与「多样」之间找到平衡,正是推荐系统进化的关键命题。从「懂内容」到「懂人」,TagCF 的探索不仅是技术的一次跃迁,更是技术贴近真实的人与社会的具象体现。
参考文献:
[1] Mu Cai, Jianwei Yang, Jianfeng Gao, and Yong Jae Lee. Proceedings of the 13th International Conference on Learning Representations, 2025.
[2] An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report. arXiv preprint arXiv:2412.15115, 2024
[3] Zhou, Guorui, et al. "OneRec Technical Report." arXiv preprint arXiv:2506.13695 (2025).
[4] Zhang, Kaike, et al. "GoalRank: Group-Relative Optimization for a Large Ranking Model." arXiv preprint arXiv:2509.22046 (2025).
....
#ROOT (Robust Orthogonalized OpTimizer)
Adam的稳+Muon的快?华为诺亚开源ROOT破解大模型训练「既要又要」的两难困境
在 LLM 优化领域,有两个响亮的名字:Adam(及其变体 AdamW)和 Muon。
它们一个是久经沙场的「守门员」,凭借动量和自适应学习率统治了深度学习的半壁江山,却在面对十亿级参数的混合精度训练时,常常因数值不稳定性而显得力不从心;一个是横空出世的「破局者」,试图通过将权重矩阵视为整体来重塑训练几何,却因为一刀切(one-size-fits-all approach)的系数设计和对异常值噪声的极度敏感,在鲁棒性上留下了缺口。
当训练规模不断指数级膨胀,我们是否只能在 Adam 的「稳」与 Muon 的「快」之间做单选题?
华为诺亚方舟实验室的最新力作 ROOT (Robust Orthogonalized OpTimizer) 给出了否定的答案。
作为一款直击痛点的鲁棒正交化优化器,ROOT 不仅精准修复了 Muon 在不同矩阵维度上的「精度近视」,更通过巧妙的软阈值机制为梯度噪声装上了「减震器」。它正试图用更快的收敛速度和更强的稳定性,为大模型训练建立一套全新的、兼顾精确与稳健的优化范式。
- 论文标题:ROOT: Robust Orthogonalized Optimizer for Neural Network Training
- 论文地址:https://arxiv.org/abs/2511.20626
- 开源地址:https://github.com/huawei-noah/noah-research/tree/master/ROOT
- 作者:Wei He, Kai Han, Hang Zhou, Hanting Chen, Zhicheng Liu, Xinghao Chen, Yunhe Wang
- 机构:华为诺亚方舟实验室
LLM 优化史:从 SGD 到 ROOT
要理解这项工作的重要性,我们需要先了解优化器(Optimizer)在 LLM 训练过程中至关重要的地位。
简单打个比方:在深度学习的浩瀚宇宙中,优化器扮演着飞船「引擎」的角色。
其中,最早的优化器是 SGD(Stochastic Gradient Descent),即随机梯度下降。作为深度学习的基石,它确立了神经网络训练的基本范式:通过计算小批量数据的梯度来迭代更新参数。
SGD 是最经典的一阶优化方法。然而,在面对高维且复杂的损失函数曲面(Loss Landscapes)时,原始的 SGD 往往难以兼顾收敛速度与稳定性。为了帮助模型更高效地穿越复杂的「山谷」找到极小值,研究者们在 SGD 的基础上引入了动量机制,这不仅成为了 SGD 的标准配置,也为后来更复杂的自适应方法奠定了基础。
后来,以 Adam 和 AdamW 为代表的自适应方法崛起,成为训练深度学习模型的「事实标准」。
它们通过引入动量和逐参数(Per-parameter)的自适应学习率,让收敛效率大幅超越 SGD。然而,这类方法的底层逻辑是将模型参数视为独立的「标量」或向量进行更新。当模型参数量突破十亿大关,这种忽略参数矩阵内部结构相关性的处理方式,在混合精度训练中逐渐暴露出了数值不稳定的缺点。
为了突破这一瓶颈,以 Muon 为代表的矩阵感知型优化器应运而生。

Muon 不再仅仅盯着单个参数,而是将权重矩阵视为一个整体。它利用 Newton-Schulz 迭代对动量矩阵进行正交化处理,从而在不增加额外计算复杂度(保持 O (N))的前提下,规范了更新的几何结构。
这种方法在理论上等同于在谱范数下进行最速下降,显著提升了训练效率和显存利用率。
尽管 Muon 开启了新的一页,但研究人员发现它并非完美无缺。
华为诺亚方舟实验室的分析指出,现有的正交化优化器存在两个核心局限:
- 算法鲁棒性的缺失: 现有的 Newton-Schulz 迭代通常使用一组固定的系数。然而,神经网络不同层的权重矩阵形状各异(从正方形到极度扁平的矩形),固定系数在某些维度下会导致近似误差激增,产生「维度脆弱性」。
- 对梯度噪声的缺乏防御:在大规模训练中,异常数据往往会产生极大幅度的梯度噪声。现有的自适应优化器对这些噪声异常敏感,不仅会破坏更新方向,还可能导致训练彻底失稳。

随机梯度中异常值噪声的概念可视化。大多数梯度值集中在中心附近,存在一个高幅度异常值的尾部。这些异常值会不成比例地影响优化过程。
正是在这种既要「矩阵感知的快」又要「传统方法的稳」的博弈中,ROOT 应运而生,试图填补这一关键的拼图空缺。

ROOT 优化器:双管齐下
前文我们已经介绍过,现有的正交化优化器(尤其是 Muon)存在的核心缺陷。
ROOT(Robust Orthogonalized OpTimizer)的核心方法,是为正交化优化器做出了针对性的鲁棒性增强,让优化器在快速和稳定「两手抓」。
拒绝「一刀切」
正交化优化器的算法不稳定,核心问题源于正交化系数的「一刀切」。
具体来说,Muon 里 Newton-Schulz 迭代的系数 a、b、c 是固定常数。华为诺亚方舟的研究者们发现,这会引发不同维度矩阵的脆弱性。

正交化误差揭示了固定系数 Newton-Schulz 迭代在维度上的脆弱性。
从上表中的数据能看出,矩阵形状(维度或长宽比)一变,正交化误差会大幅波动。尤其是方阵更吃亏,方阵始终产生最高的 MSE 值,比非方阵配置有显著的差距。
这种维度敏感性在优化过程中造成了固有的脆弱性,因为不同维度的层获得的正交化质量完全不同,损害了梯度更新的一致性和可靠性。
为了解决这种维度脆弱性并构建维度鲁棒的正交化过程,研究者们提出了具有细粒度、特定维度系数的自适应 Newton-Schulz 迭代(AdaNewton)。
ROOT 没有为所有矩阵维度使用全局常数 (a, b, c),而是采用针对网络中每个特定矩阵大小 (m, n) 量身定制的细粒度系数

。
迭代更新规则在结构上保持相似:

然而,系数针对每个矩阵维度的特定奇异值分布进行了优化。这种方法为提高正交化精度提供了理论保证。
这些系数可以在训练期间与模型参数联合优化,允许正交化过程自动适应每种层类型的属性。这种细粒度的适应代表了一种范式转变:从脆弱的维度敏感正交化转向鲁棒的维度不变正交化,确保了整个网络的更新质量一致。
过滤「异常值」
大模型训练的梯度常出现「重尾现象」:小批量梯度经常被异常值噪声污染,这些噪声包含幅度异常大的梯度分量,这些异常值严重影响到了 Muon 中正交化过程的稳定性。
更糟的是,Newton-Schulz 迭代的多项式性质会放大离群噪声,造成不稳定,甚至可能引发 Transformer 的 attention logits 爆炸的严重问题。
为了解决这一问题,华为诺亚方舟的研究者们的做法很直接干脆:把梯度 Mₜ 分解为「正常部分」和「异常部分」两个分量:
- 基础分量 Bₜ:包含表现良好的梯度信息。
- 异常分量 Oₜ:代表异常的大幅度元素。
正交化仅应用于鲁棒分量 Bₜ,而丢弃异常值分量 Oₜ。

通过这个目标函数,可以显式地惩罚大异常值分量的存在,同时确保基础分量保持在合理范围内。
该鲁棒分解的最优解由 L1 范数的近端算子给出,因此 ROOT 采用软阈值算子来提取异常值:

这个函数如果值的幅度高于阈值 ε,则提取超出范围的异常值。
在数学上,软阈值可以被解释为硬裁剪(hard clipping)的一种连续、可微的替代方案。软阈值应用了一种平滑的收缩操作,在抑制极端值的同时保留了梯度幅度的相对排序。

完整的 ROOT 优化器算法
ROOT 的实验表现:真的又稳又快
为了验证 ROOT 是不是真的快速又稳定,华为诺亚方舟实验室训练了一个 1B Transformer 模型。他们的测试非常严苛,涵盖了从预训练 Loss 到下游任务的多项基准,甚至跨越到了视觉任务领域。值得注意的是:「所有模型都是在昇腾 NPU 分布式集群上训练的。」
而最终得到的结果也非常亮眼,证明了 ROOT 优化过程的表现极具竞争力。
首先,在预训练效率上,ROOT 展现了卓越的收敛能力。

使用 10B Token 的训练损失对比
如上图所示,在 10B token 的大规模预训练实验中,两个 ROOT 变体(仅软阈值版与完整版)的训练损失均始终保持在 Muon 的 Loss 曲线下方。最终,ROOT 的训练损失达到 2.5407,比 Muon 基线低 0.01。
而更深入分析显示,Muon 由于采用固定系数,在训练过程中存在较大的近似误差;而 ROOT 凭借自适应系数,始终保持着更接近真实 SVD 的正交化精度 。

相对于真实 SVD 的正交化精度
在多项下游任务基准上,ROOT 也带来了全面的提升:ROOT 取得了 60.12 的平均分,不仅击败了传统霸主 AdamW(59.05),也超越了其直接竞争对手 Muon(59.59)。

在 9 个标准 LLM 基准上的零样本性能,其中 ROOT 在 6 个基准上领先
同时也能看出 ROOT 具有广泛适用性:无论是在考察常识推理的 PIQA,还是考察科学知识的 SciQ,ROOT 都展现出了极具竞争力的性能。
不仅如此,ROOT 还表现出了非常出色的跨模态泛化能力:在计算机视觉领域(训练 ViT 模型识别 CIFAR-10 数据集)的测试中,ROOT 同样证明了其强大的泛化能力。

在 CIFAR-10 上的 Top-1 测试准确度
特别是在引入软阈值机制后,ROOT 能够有效抑制视觉数据中的梯度噪声,取得了 88.44% 的 Top-1 准确率,显著优于 Muon 的 84.67% 。这表明 ROOT 的「去噪+正交化」范式具有极强的跨领域普适性。
该团队也进行了消融实验,证明了 ROOT 各组件的有效性。
ROOT 或将开启新的优化器时代
在 LLM 训练日益昂贵且复杂的今天,华为诺亚方舟实验室提出的 ROOT 优化器,通过 AdaNewton 和软阈值去噪两大创新,成功在 Muon 的高效基础上补齐了鲁棒性这块短板 。
ROOT 不仅在理论上保证了不同维度矩阵更新的一致性,更在实战中证明了其在抗噪、收敛速度和最终性能上的全面优越性。
ROOT 的代码将会开源,随着更多研究者将其投入到更大规模的万亿级模型训练中,我们有理由相信,它很有可能会开启一个新的优化器时代。
正如这篇论文的结语所言:「这项工作为开发鲁棒的优化框架开辟了有前景的方向,这些框架能够处理未来语言模型日益增加的复杂性和规模,从而可能实现下一代 AI 系统更可靠、更高效的训练。」
凭借此一贡献,华为诺亚方舟实验室展示了其「深潜」的创新特质,秉持理论研究与应用创新并重的理念,致力于推动人工智能领域的技术创新和发展:不随波逐流于表层的应用创新,而是潜入深海,解决最基础、最困难、但影响最深远的优化理论问题。这不仅展示了其强大的科研硬实力,更体现了其作为行业领军者,致力于构建更高效、更鲁棒的下一代 AI 训练范式的战略远见。
团队简介
本文有两位共一作者,他们都是华为诺亚方舟实验室研究员。据公开资料显示,其中韩凯(Kai Han)现为华为诺亚方舟实验室专家研究员,博士毕业于中国科学院软件所,硕士和本科分别毕业于北京大学和浙江大学。其主要研究方向为高效深度学习和 AI 基础模型,已在 AI 领域顶会顶刊发表论文 50 余篇,谷歌学术累计被引 2.1 万余次,其中 GhostNet 和 TNT 入围 PaperDigest 年度最具影响力论文榜单。他还担任 NeurIPS、ICML、ICLR、CVPR、ICCV、AAAI 和 ACMMM 等顶会领域主席,入围斯坦福全球 Top 2% 科学家和爱思唯尔中国高被引学者榜单。
另外,今年 3 月接任华为诺亚方舟实验室主任的王云鹤也是本文的通讯作者。
关于该方法更多信息,请参阅原论文。
.....
#无问芯穹完成近5亿元A+轮融资
加码Agentic Infra基础设施建设,引领智能体产业变革
近日,国际领先的 AI 基础设施企业无问芯穹宣布已完成近 5 亿元 A+ 轮融资,由珠海科技集团、孚腾资本(元创未来基金)领投,惠远资本、尚颀资本和弘晖基金跟投,老股东洪泰基金、达晨财智、尚势资本 & 海棠基金、联想创投、君联资本、申万宏源、徐汇科创投、元智未来持续追投。此次融资阵容汇聚国家产业资本与头部市场化基金,“国资 + 市场” 的双重加持,既是对无问芯穹积极响应国家重大战略、坚持技术创新的高度认可,更彰显了市场对其引领 AI 产业落地、共建基础设施生态的坚定信心。

无问芯穹成立两年半以来,始终面向人工智能最前沿技术与应用落地打造高性能 AI 基础设施,以软硬件联合优化与多元异构算力服务,打造了面向人工智能开发与服务的 “无穹 AI 云” 及 “无垠终端智能解决方案”,突破人工智能产业应用的算力瓶颈。已服务百川智能、Kimi、联想集团、猎聘、理想汽车、Lovart、Sand.ai、生数科技、Soul、VAST、新华三、智谱、中国移动、中兴终端等头部人工智能及智能体企业客户,以及北京中关村学院、上海人工智能实验室、上海算法创新研究院、之江实验室、智源研究院等人工智能科学研究机构,助其释放每一份算力的智慧潜能。
生产智能体、协同智能体、服务智能体
Into Agent, With Agent, For Agent
无问芯穹本轮募集资金将主要投入三大方向:一是持续扩大无问芯穹软硬协同、多元异构的技术领先优势;二是推动 AI 云产品与 AI 终端方案在产业中的规模化拓展;三是加大智能体基础设施研发投入,构建一流的智能体服务平台及配套云、端基础设施,加速实现智能体在数字世界与物理世界中的规模化普惠应用。
当前,人工智能正从 “对话工具” 向 “行动伙伴” 演进,以智能体为代表的应用形态,有望成为未来社会的新型生产力单元。无问芯穹认为,基础设施必须始终面向智能发展前沿:它既是服务智能体开发与迭代的产线,也是智能体落地实践的绝佳试验场,更是支撑智能体规模化产业应用与持续进化的基石。
无问芯穹联合创始人、CEO 夏立雪博士表示:“Agentic AI 的范式变革不仅是一次战略机遇,更是时代赋予我们的使命。得益于在人工智能系统领域沉淀多年的技术禀赋与工程能力,无问芯穹已敏捷完成了智能体原生基础设施转型,而新一轮融资的完成,也将为我们注入更强大的发展动能。面向智能体时代,无问芯穹将继续以软硬件联合优化为技术依托,以构建新一代可学习、可进化的 Agentic Infra 为战略核心,生产智能体、协同智能体、服务智能体(Into Agent, With Agent, For Agent),在人工智能基础设施系统优化与生态构建上实现更深层次的突破。”
智能体基础设施 ×( AI 云 + 终端智能 )
云端并进的 Agentic Infra 建设
以智能体为代表的人工智能技术正逐步从数字世界走向物理世界,在各种生产劳动场景中,借助云端基础设施、移动终端设备与xx机器人等载体影响现实。作为国际领先的人工智能基础设施企业,秉持 “生产智能体、协同智能体、服务智能体” 理念,无问芯穹进一步构建了完整的 “智能体基础设施 ×(AI 云 + 终端智能)” 技术与产品架构,支撑数字世界与物理世界的智能体应用效能突破与持续进化。

在云端,无问芯穹积累了深厚的人工智能原生 AI 云基础设施技术与建设积淀 —— 无穹 AI 云。于多元异构算力的纳管调度、AI 训练及推理优化领域保持技术领先,在无穹 AI 云中提供智能体服务平台、人工智能服务平台等标准化产品能力,构建起端到端的商业化服务栈。目前,已在全国完成超 25,000P 算力纳管,覆盖 26 座城市的 53 个核心数据中心,面向智能体及人工智能研发、托管,提供原生工具链支持与充沛的高性能算力保障,为百余家 AI 企业的 AI 应用开发与部署全流程降本增效。
在终端,无问芯穹打造了 “端模型 + 端软件 + 端 IP” 终端智能一体化解决方案 —— 无垠终端智能。已推出全球第一款端侧全模态理解端模型无穹天权(Infini-Megrez),其大语言版本以 3B 的计算成本、7B 的内存需求与 21B 级智能水平,突破终端资源瓶颈;无问芯穹终端推理加速引擎无穹开阳(Infini-Mizar)在主流硬件上实现 3 倍时延降低、40% 的能耗节省和 40% 的内存占用,极致挖潜终端算力;自研终端推理 LPU IP 无穹天璇(Infini-Merak),在能效翻倍的基础上,进一步大幅降低大模型推理成本。
近期,无问芯穹更连续发布了由 Agentic AI 驱动的云端基础设施智能体蜂群 Infra Agents 与终端通用推理加速优化平台 Kernel Mind 两款智能体产品,以及配套的智能体技术 —— 支持智能体持续进化的强化学习框架 RLinf 和支持智能体更高效无损交流的通信框架 Cache to Cache 等,目标是让云、端基础设施也成为智能体落地的试炼场,身体力行帮助智能体从演示品真正走向规模化的新质生产力,成为像水和电一样的基础资源并自然流入千行百业与千家万户。
珠海科技产业集团首席投资官刘飞虹表示:“智能体技术正在引领人工智能进入以自主感知、协同决策为核心的新发展阶段,而与之匹配的基础设施能力,将成为其实现规模化产业落地的关键支撑。无问芯穹在过去两年中,凭借扎实的技术积累与持续的工程实践,已在 “云 + 端” 全栈体系中构建出成熟的产品矩阵与多行业落地案例,为下一代 Agentic Infra 的深化布局奠定了坚实基础。珠海科技集团将依托粤港澳大湾区丰富的智能制造、智慧城市等场景资源,与无问芯穹共同推进智能体 “技术产业应用” 的闭环建设,赋能千行百业实现智能化转型,为构建集约、绿色、普惠的下一代 AI 产业体系贡献切实力量。”
孚腾资本(元创未来基金)表示:“无问芯穹在 AI 基础设施领域展现出显著的技术前瞻性与系统化能力,其在软硬协同优化、异构算力统一调度及端云一体架构等方面构筑了扎实的技术壁垒,并通过与多个行业标杆客户的深度合作,验证了其解决方案在真实场景中的商业化成效与规模落地潜力。面对智能体技术由探索走向落地的关键窗口期,无问芯穹所提出的 Agentic Infra 新范式,精准把握了 Agentic AI 发展对基础设施的核心诉求,具备深远的战略价值与广阔的商业想象空间。孚腾资本期待以本轮投资为纽带,共同在国家新质生产力构建的进程中贡献重要力量。”
惠远资本总裁张珊珊表示:“无问芯穹以 AI 智能体生态为核心战略,凭借领先的软硬结合技术与端云协同架构,为中国 Agentic AI 生态搭建起贯通数字与物理世界的基础设施底座。这一布局不仅彰显其技术前瞻性,更肩负着推动中国 AI 产业整体演进的时代使命。无问芯穹从云端服务起步,有效串联国产算力和智能体应用生态,并进一步拓展至终端智能一体化解决方案,为智能体在端侧落地提供全面支撑,与我国 “十五五” 规划中构建更加自主的国产人工智能产业生态的战略方向高度契合。惠远资本坚定看好 AI 智能体赋能产业端及 C 端的巨大潜力,将充分发挥自身政府及产业资源优势,持续助力无问芯穹业务发展,积极引荐优质合作伙伴融入无问芯穹智能体生态。”
...
#Generative AI for Requirements Engineering: A Systematic Literature Review
生成式AI赋能需求工程:一场正在发生的变革
作者团队:早稻田大学博士生 / 蒙特利尔工程学院访问研究员程浩伟(通讯作者),特尔科姆大学助理教授 Jati H. Husen,早稻田大学博士生芦一均,东北大学副教授 / JAIST 客座教授 Teeradaj Racharak,早稻田大学教授 / QAML 株式会社 CEO 吉岡信和,九州大学名誉教授鵜林尚靖,早稻田大学教授鷲崎弘宜。
在软件开发领域,需求工程(Requirements Engineering, RE)一直是项目成功的关键环节。然而,传统 RE 方法面临着效率低下、需求变更频繁等挑战。根据 Standish Group 的报告,仅有 31% 的软件项目能在预算和时间内完成,而需求相关问题导致的项目失败率高达 37%。
随着 ChatGPT 等大语言模型的爆发式发展,生成式 AI(GenAI)为需求工程带来了前所未有的机遇。来自早稻田大学、东北大学等机构的研究团队,对 2019 年至 2025 年间发表的 238 篇相关论文进行了系统性文献综述,为我们揭示了这一新兴领域的全貌。
- 论文标题:Generative AI for Requirements Engineering: A Systematic Literature Review
- 论文地址:https://onlinelibrary.wiley.com/doi/10.1002/spe.70029
这是目前为止对生成式 AI 在需求工程领域最系统、最全面的文献综述,揭示了从技术到落地的全貌与未来路线,是理解「GenAI 如何重塑软件开发起点」的必读论文。
研究现状:
快速增长但分布不均
爆发式的研究热度
数据显示,GenAI 在需求工程领域的研究呈现指数级增长:
- 2022 年仅有 4 篇相关论文;
- 2023 年激增至 23 篇;
- 2024 年达到 113 篇;
- 2025 年前 5 个月已有 97 篇。

Distribution of papers across years (N=238).
这种增长轨迹充分反映了 ChatGPT 发布后,学术界对 GenAI 应用于 RE 领域的浓厚兴趣。
研究聚焦点的失衡
尽管研究热度高涨,但不同 RE 阶段受到的关注度严重失衡:
- 需求分析占据 30.0% 的研究比重,位居首位;
- 需求获取和需求规约各占 22.1%;
- 需求验证占 19.0%;
- 需求管理仅占 6.8%,严重缺乏关注。
这种分布反映出当前研究主要集中在 GenAI 擅长的文本分析和生成任务,而对需求管理等涉及复杂社会技术因素的阶段探索不足。

Distribution of RE phases (N=238).
GenAI 在 RE 领域已进入「快速扩张但尚未成熟」的阶段,研究数量暴涨但深度不足,仍停留在「概念验证」层面。
技术图景:GPT 主导下的同质化困境模型选择的单一化
研究发现,67.3% 的研究采用 GPT 系列模型,其中:
- GPT-4 系列占 36.7%,主要应用于复杂需求分析;
- GPT-3.5 系列占 25.3%,在常规分类任务中表现良好;
- 开源替代方案(如 LLaMA、CodeLlama)仅占 11.6%。
这种过度依赖单一模型家族的现象,限制了多样化技术路径的探索。值得注意的是,CodeLlama 在代码 - 需求追溯任务中表现出色,幻觉率比通用模型低 23%,但采用率仍然很低。

Distribution of GenAI models (N=238).
提示工程的实践模式
在提示工程方面,研究呈现出以下特点:
- 指令式提示占 62.2%,反映 RE 任务的高度结构化特性;
- 少样本学习占 43.6%,成为最受欢迎的学习范式;
- 零样本学习占 37.7%,适用于相对简单的 RE 任务;
- 思维链(CoT)方法仅占 14.0%,采用率相对较低。
令人欣慰的是,超过 80% 的研究公开了提示词细节,这为研究的可复现性奠定了基础。

Distribution of learning paradigm (N=238).

Distribution of prompt types (N=238).
质量关注的偏颇
在软件质量特性方面,当前研究呈现明显的短期导向:
- 功能适用性获得最多关注(124 次提及);
- 可靠性次之(80 次);
- 安全性仅被提及 39 次;
- 可解释性和准确性几乎被忽视。
这种关注度分布表明,研究者更注重即时的功能表现,而忽视了长期的系统级质量属性。这种质量关注的偏颇表明,当前研究仍以「可用性优先」驱动,而非「可靠性与可解释性优先」,这是 AI 走向工业级软件系统的最大隐患。
三大核心挑战:紧密交织的困境
研究识别出 10 个主要挑战,其中三个核心挑战形成了紧密关联的「三角关系」:
- 可复现性(66.8%)可复现性是最严重的问题。LLM 的随机性、参数敏感性以及黑盒 API 的不透明性,使得研究结果难以验证和重现。这在需求生成和验证等关键场景中尤为严重。
- 幻觉问题(63.4%)AI 生成的需求可能与输入冲突或包含虚构内容。在 RE 领域,需求的精确性和可追溯性至关重要,幻觉问题可能导致严重的系统设计偏差。
- 可解释性(57.1%)LLM 的决策过程不透明,在医疗、法律等高风险领域尤为致命。研究发现,这三个挑战的共现率达 35%,表明它们必须被整体性地解决,而非孤立应对。

Correlations among the LLM issues reported in literature on RE (%).
可复现性影响幻觉问题的验证,幻觉问题又加剧可解释性缺失;三者相互强化,构成当前 GenAI 研究最难攻克的「信任瓶颈」。
评估实践:基础设施的薄弱环节
工具和数据集的可用性困境
尽管越来越多研究开发了工具和数据集,但实际可用性令人担忧:
- 仅 23.9% 的研究公开发布了工具;
- 45.8% 的研究使用了不公开的数据集;
- 缺乏统一的基准测试框架。
评估指标的表面化
评估方法主要依赖传统 NLP 指标:
- 精确率 / 召回率 / F1 分数最常用(119 项研究);
- 准确率次之(40 项研究);
- 人工评估较少(22 项研究);
- 错误分析极为罕见(仅 11 项研究)。
这种表面化的评估无法捕捉 RE 任务的复杂性和领域特异性。

Distribution of tool and dataset availability (N=238)

Distribution of evaluation metrics and methodology (N=238)
当前 RE 领域缺乏类似 MMLU、HumanEval 那样的标准基准测试,导致学术成果难以横向比较,这也是产业界迟迟未能采用的重要原因。
工业落地:从实验室到生产的鸿沟
成熟度现状令人担忧
研究显示,GenAI 在 RE 领域的工业化进程严重滞后:
- 90.3% 的研究停留在概念或原型阶段;
- 仅 8.4% 达到原型或实验部署水平;
- 只有 1.3% 实现生产级集成。

Industrial adoption stages of GenAI use in RE (N=238).
系统性障碍
研究识别出 11 类主要限制因素:
- 泛化能力和领域适应(39.9%);
- 数据质量和可用性(39.1%);
- 评估方法(28.8%);
- 人工介入需求(27.0%)。
值得注意的是,47.2% 的研究面临三个或以上的限制类别,表明这是系统性而非孤立的问题。
从产业角度看,GenAI 在 RE 的价值主要体现在「加速需求文档生成」和「减少沟通成本」,但由于缺乏合规性与风险控制标准,企业普遍持观望态度。
未来路线图:四阶段推进策略
基于系统性分析,研究团队提出了多阶段研究路线图:
- 第一阶段:强化评估基础设施
建立标准化基准测试、RE 特定指标和可复现性协议,这是解决当前 90% 研究停留在早期阶段问题的关键。
- 第二阶段:治理感知开发
将伦理审计、公平性约束和利益相关者验证纳入 GenAI 系统设计,应对当前治理相关问题关注不足的困境。
- 第三阶段:可扩展的情境感知部署
采用模块化架构、参数高效微调(LoRA、PEFT)和 RAG 等技术,降低幻觉率,提高系统可控性。
- 第四阶段:工业级标准化
建立社区驱动的工具包、开源基准和法律框架(如著作权治理),为生产级应用奠定基础。
对研究者和实践者的启示给研究者的建议
- 技术多元化: 探索 GPT 之外的模型,开发 RE 特定的混合架构。
- 评估体系重构: 建立结合定量指标和人工洞察的混合评估方法。
- 全生命周期关注: 将研究扩展到需求管理和验证等被忽视的阶段。
- 可复现性优先: 建立提示词共享和实验协议的社区标准。
给实践者的建议
- 谨慎采用: 当前 GenAI 工具最适合作为辅助加速器,而非自主决策者。
- 聚焦低风险任务: 在自动化草稿生成、需求分类等结构化任务中应用。
- 人机协同: 在关键任务中保持人工监督,特别是在安全关键领域。
- 关注新趋势: RAG 和混合方法显示出提高可靠性的潜力,值得持续关注。
结语
GenAI 在需求工程领域展现出变革性潜力,但要实现从学术探索到工业应用的跨越,仍需克服可复现性、幻觉控制和可解释性这三大核心挑战。研究表明,这些挑战高度关联,必须采用整体性解决方案。
更重要的是,成功应用 GenAI 需要技术健壮性、方法论成熟度和治理整合的协同发展。从 90% 的研究停留在早期阶段到仅 1.3% 达到生产级别的现状来看,这条路还很长。但随着评估基础设施的完善、治理框架的建立和标准化工作的推进,GenAI 终将成为需求工程领域不可或缺的智能助手。
这不仅是一场技术革命,更是软件工程实践的范式转变。当需求从「人工编写」转向「人机共创」,软件工程正进入一个全新的智能时代。
....
#DeepSeek-Math-V2
DeepSeek强势回归,开源IMO金牌级数学模型
突破级推理模型来了,DeepSeek 打开了自我验证的数学推理方向。
The whale is back!
就在刚刚,DeepSeek 又悄咪咪在 Hugging Face 上传了一个新模型:DeepSeek-Math-V2。

顾名思义,这是一个数学方面的模型。它的上一个版本 ——DeepSeek-Math-7b 还是一年多以前发的。当时,这个模型只用 7B 参数量,就达到了 GPT-4 和 Gemini-Ultra 性能相当的水平。相关论文还首次引入了 GRPO,显著提升了数学推理能力。

那时隔一年半,这个基于 DeepSeek-V3.2-Exp-Base 开发的 DeepSeek-Math-V2 又带来了哪些惊喜?
DeepSeek 表示,它的性能优于 Gemini DeepThink,实现了 IMO 金牌级的水平。
- 论文标题:DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
- 模型地址:https://huggingface.co/deepseek-ai/DeepSeek-Math-V2
- 论文地址:https://github.com/deepseek-ai/DeepSeek-Math-V2/blob/main/DeepSeekMath_V2.pdf
- 核心作者:邵智宏、Yuxiang Luo、Chengda Lu、Z.Z. Ren
论文开篇,DeepSeek 就指出了当前 AI 在数学推理方面的研究局限:以正确的最终答案作为奖励,过于追求最终答案准确度。
这种做法虽然能让推理模型在 AIME 和 HMMT 等基准上达到更高水平,乃至达到饱和,但 DeepSeek 表示这并不能解决核心问题:正确答案并不保证推理过程正确。此外,许多数学任务(如定理证明)需要严谨的逐步推导,而不仅仅是数值答案,这使得基于最终答案的奖励方法不适用。
为了推动深度推理的极限,DeepSeek 认为有必要验证数学推理的全面性和严谨性。
他们指出:「自我验证在扩展测试时的计算规模时尤为重要,特别是对于没有已知解的开放性问题。」
为了实现可自我验证的数学推理,DeepSeek 研究了如何训练一个准确且可信赖的基于 LLM 的定理证明验证器。然后,他们使用该验证器作为奖励模型来训练证明生成器,并激励生成器在最终完成证明前尽可能发现并解决自身证明中的问题。
为了在生成器能力增强时保持生成 - 验证差距,DeepSeek 提出扩展验证计算能力,以自动标注新的难以验证的证明,从而生成训练数据进一步提升验证器性能。
简单来说,DeepSeek 这篇论文的核心目标不仅仅是让 AI 做对题,而是让 AI 「不仅会做,还能自己检查,甚至能诚实地承认自己哪里做错了」。
为了实现这一点,他们设计了一套由三个关键角色组成的系统,我们可以用一个「学生 — 老师 — 督导」的类比来理解:
首先,培养合格的「阅卷老师」(Proof Verification)。
过去训练 AI 数学模型,通常只看最后的答案对不对。但在高等数学证明题(如奥数)中,过程严谨比答案更重要。因此,DeepSeek 团队首先训练了一个专门的验证器(Verifier),也就是「阅卷老师」。这个老师不只是打钩打叉,而是学会了像人类专家一样把证明过程分为三档 :
- 1 分:完美,逻辑严密。
- 0.5 分:大体正确,但有小瑕疵或细节遗漏。
- 0 分:有根本性的逻辑错误或严重缺失。
不仅给分,还要写评语:模型被要求在打分前,先写一段分析,指出哪里好、哪里有问题 。
接下来,给老师配个「督导」(Meta-Verification)。
DeepSeek 发现了一个问题:阅卷老师有时候会胡乱扣分,它可能给了个低分,但指出的错误其实根本不存在(也就是产生了幻觉)。
为了解决这个问题,他们引入了元验证(Meta-Verification)机制,相当于给老师配了个「督导」。督导的任务不是看考卷,而是专门检查老师写的「评语」是否合理。这样可以双重确认:督导会检查老师指出的错误是否真实存在,以及扣分是否符合逻辑。效果上,通过训练模型既能当老师又能当督导,AI 评估证明的准确性和可信度大幅提升。
然后,培养会「自省」的学生(Proof Generation with Self-Verification)。
有了好的阅卷系统,接下来就是训练做题的「学生」(生成器)。这里有一个非常关键的创新:诚实奖励机制。也就是说,它不仅做题,还要自评:模型在输出解题过程后,必须马上跟上一段「自我评价」,自己给自己打分(0、0.5 或 1)。
它会对诚实进行奖励:
- 如果模型做错了,但它在自评中诚实地指出了自己的错误,它会得到奖励 。
- 相反,如果它做错了却硬说自己是对的(盲目自信),或者试图「蒙混过关」,就会受到惩罚(得不到高奖励)。
这样做的目的是可以迫使 AI 在输出答案前进行深度思考,试图发现并修正自己的错误,直到它认为自己真的做对了为止 。
最后,形成自动化闭环(Synergy)。
人类专家没法给成千上万道奥数题写详细的步骤评分,所以 DeepSeek 设计了一套自动化流程,让系统「左右互搏」来自我进化 :
- 海量生成:让「学生」对同一道题生成很多种解法。
- 集体投票:让「老师」对这些解法进行多次评估。如果大多数评估都认为某个解法有问题,那就判定为有问题;如果没有发现任何漏洞,才判定为正确 。
- 以战养战:通过这种方式,系统自动筛选出那些很难判卷或很难做对的题目,变成新的教材,重新训练「老师」和「学生」。这样,随着「学生」解题能力变强,「老师」的眼光也越来越毒辣 。
总之,DeepSeekMath-V2 的方法本质上是从「结果导向」转向了「过程导向」。它不依赖大量的数学题答案数据,而是通过教会 AI 如何像数学家一样严谨地审查证明过程(包括审查它自己),从而在没有人类干预的情况下,也能不断提升解决高难度数学证明题的能力 。
最终,他们得到了 DeepSeekMath-V2 模型,其展现出了强大的定理证明能力:在 IMO 2025 和 CMO 2024 上取得金牌级成绩,并在 Putnam 2024 中以扩展测试计算实现了接近满分的 118/120。

下图展示了 DeepSeekMath-V2 在 IMO-ProofBench 基准(这是 IMO Bench 的一个子集,其中包含 60 道证明题)上的表现,可以看到,在其中的 Basic 基准上,DeepSeekMath-V2 不仅远胜过其它模型,甚至达到了近 99% 的惊人高分。而在更难的 Advanced 子集上,DeepSeekMath-V2 略逊于 Gemini Deep Think (IMO Gold)。

DeepSeek 表示:「虽然仍有大量工作需要推进,但这些结果表明,可自我验证的数学推理是一个可行的研究方向,有望推动更强大数学 AI 系统的发展。」
这一自我验证的数学推理框架可以说突破了传统强化学习(RL)的限制,让模型不再依赖最终答案正确性作为唯一奖励,而是关注推理过程的严谨性。此外,DeepSeekMath-V2 中的验证器 - 生成器协同的双向改进循环带来了全面和严谨的数学推理能力,大幅减少了大模型幻觉。
....
#2025最佳论文开奖
何恺明、孙剑等十年经典之作夺奖
NeurIPS 2025 最佳论文放榜!4 篇最佳华人领衔占三席,Infinity-Chat 揭大模型“蜂群”同质化、阿里 15 B 门控注意力训得更稳、普林斯顿 1024 层自监督 RL 性能飞升;时间检验奖花落 Faster R-CNN,致敬何恺明、孙剑等经典之作。
NeurIPS 2025最佳论文开奖了!
今天,NeurIPS组委会公布了今年「最佳论文」获奖名单,一共有4篇最佳论文。
此外,还有3篇亚军论文(Runners Up)获奖。这七篇获奖论文横跨了多个领域:
扩散模型理论、自监督RL、注意力机制、LLM推理能力、在线学习理论、神经Scaling,以及衡量语言模型多样性的基准评测方法
更重磅的是,这一次「时间检验奖」颁给了Faster R-CNN,这篇由任少卿、何恺明、Ross Gisshick、孙剑合著的论文。
今年,是NeurIPS第39届年会,与往年不同,NeurIPS 2025是首个双城会议,分别于:
- 12月2日-7日在圣地亚哥会议中心举办
- 11月30日-12月5日在墨西哥城举办

当前,正值墨西哥城分会召开期间,最佳论文一并出炉。
一起来看看,都有哪些大佬斩获大奖?
最佳论文,华人占AI半壁
论文一:Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
作者:Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Yejin Choi
机构:华盛顿大学,卡内基梅隆大学,艾伦人工智能研究院,Lila Sciences,斯坦福大学
论文地址:https://openreview.net/forum?id=saDOrrnNTz
大语言模型在生成多样化、类人创造性内容时常显乏力,引发对长期接触同质化输出可能导致人类思维趋同的担忧。
然而,目前可扩展的LM输出多样性评估方法仍显不足,尤其在超越随机数生成等狭窄任务或单一模型重复采样场景时更为凸显。
为填补这一空白,来自华盛顿大学等机构的研究人员,推出了大规模数据集Infinity-Chat。
Infinity-Chat包含2.6万条真实世界开放式用户查询,这些查询允许多元合理答案共存,不存在唯一标准解。
图1:针对「写一个关于时间的隐喻」查询的响应聚类(通过主成分分析将句子嵌入降维至二维空间的可视化呈现)
这是首次提出了针对LM开放式提示的完整分类体系,包含6大顶层类别(如创意内容生成、头脑风暴与构思)及其下17个子类别。
通过Infinity-Chat,研究人员开展了LM模式坍塌的大规模研究,发现在开放式生成中存在显著的「人工蜂群思维效应」(Artificial Hivemind effect),具体表现为:
- 模型内部重复——单个模型持续生成相似回应;
- 模型间同质化——不同模型产生惊人相似的输出。
该数据集还包含31,250条人类标注,涵盖绝对评分与两两偏好比较,每个示例均获25位标注者独立评判,为研究开放式查询中群体与个体偏好提供了可能。
研究显示,最先进的LM、奖励模型与LM评判器在面对引发标注者个体偏好的模型生成结果时,虽保持整体质量相当,却较难校准人类评分。
总体而言,Infinity-Chat为首个系统研究现实世界开放式LLM查询的大规模资源,为缓解人工蜂群思维带来的长期AI安全风险提供了关键洞见。
论文二:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者:Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin
机构:阿里千问团队,爱丁堡大学,斯坦福大学,MIT,清华大学
论文地址:https://openreview.net/pdf?id=1b7whO4SfY
门控机制自早期LSTM与高速公路网络便获广泛应用,直至近期状态空间模型、线性注意力及Softmax注意力仍见其身影。
然而,现有研究鲜少深入解析门控的具体作用效应。
本研究通过系统化实验对门控增强型Softmax注意力变体展开全面探究:在3.5万亿词元数据集上训练了15B混合专家模型(30种变体)与1.7B稠密模型进行对比分析。
核心发现表明,仅需在缩放点积注意力(SDPA)后引入头部特异性Sigmoid门控这一简单修改,即可持续提升模型性能。该改进同时增强训练稳定性、允许更大学习率,并改善缩放特性。
通过对比不同门控位置与计算变体,研究人员将其有效性归因于两个关键因素:
(1)在Softmax注意力的低秩映射中引入非线性变换;
(2)采用查询依赖的稀疏门控分数调控SDPA输出。
值得注意的是,该稀疏门控机制可缓解「激活爆炸」、「注意力沉没」,并提升长上下文外推性能。
为了促进后续研究,相关代码与模型已开源。这项最高效的SDPA输出门控技术已应用于Qwen3-Next模型系列。
Qwen3-Next-80B-A3B-Thinking-FP8架构
论文三:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
作者:Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, Benjamin Eysenbach
机构:普林斯顿大学,华沙理工大学
论文地址:https://openreview.net/pdf?id=s0JVsx3bx1
规模化自监督学习的进展持续推动语言与视觉领域的突破,然而在强化学习(RL)领域却始终未能实现可比肩的突破。
本文聚焦于自监督强化学习的核心构建模块,通过挖掘网络深度的关键价值,最终实现了可扩展性的质的飞跃。
与近年多数强化学习研究采用的浅层架构(约2-5层)形成鲜明对比的是,这次的实验证明将网络深度提升至1024层可带来显著性能突破。
网络架构
在无监督目标条件设定下,研究人员开展实验——不提供任何示范数据或奖励信号,智能体必须从零开始探索环境,并自主学会如何最大化达成指定目标的可能性。
在模拟运动与操控任务上的评估结果表明,新方法将自监督对比强化学习算法的性能提升了2至50倍,显著超越其他目标条件基线模型。

网络深度的增加不仅提升了任务成功率,更引发了智能体学习行为的质性转变。
论文四:Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
作者:Tony Bonnaire, Raphaël Urfin, Giulio Biroli, Marc Mezard
机构: 巴黎PSL大学,米兰博科尼大学
论文地址:https://openreview.net/pdf?id=BSZqpqgqM0
扩散模型,已在众多生成任务中取得显著成功,而理解其避免训练数据记忆并实现泛化的内在机制仍是关键难题。
通过系统探究训练动态中泛化与记忆的转换规律,此研究发现两个关键时间尺度:早期阶段τgen标志着模型开始生成高质量样本的起点,而后期阶段τmem则是记忆现象显现的转折点。
图1:本研究贡献的定性总结
值得关注的是,τmem随训练数据量n呈线性增长,而τgen始终保持恒定。
这一规律形成了随n扩大的有效训练时间窗口——
在该区间内模型能保持良好泛化能力,但若持续训练超越该窗口则会引发强烈记忆效应。
仅当n超越模型相关阈值时,无限时长训练中的过拟合现象才会消失。
这些发现揭示了训练动态中存在的隐式动态正则化机制,即使在高度过参数化场景下仍能有效规避记忆效应。
此结论通过以下实验得到验证:基于标准U-Net架构在真实与合成数据集上的数值实验,以及采用高维极限可解析随机特征模型的理论分析。
三篇Runners Up
此外,这一次还公布了三篇亚军(Runners Up)论文奖。
论文一:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang
机构:清华大学LeapLab,上海交通大学
论文地址:https://openreview.net/pdf?id=4OsgYD7em5
论文系统评估了RLVR对大语言模型推理力的真实增益,覆盖多种模型家族、RL算法与数学/编码/视觉推理基准,并用大k取值下的pass@k衡量「能力边界」。
结果显示:RLVR主要提升采样效率,在小k(如k=1)更易命中正确路径;但在大k时,基座模型反而表现更好。
覆盖率与困惑度分析表明,RLVR生成的推理路径原本已存在于基座模型的采样分布中,说明当前RL训练并未诱发全新的推理模式,且随着训练推进,模型的推理空间常被收窄。
进一步比较发现,六种主流RLVR算法彼此差距有限,距离充分释放基座潜力仍有距离;相对而言,蒸馏可以从教师处引入新的推理模式,实质扩展学生模型能力。
作者呼吁探索更有效的RL范式,如持续规模化与多轮智能体交互训练,以真正突破现有边界。
论文二:Optimal Mistake Bounds for Transductive Online Learning
作者:Zachary Chase, Steve Hanneke, Shay Moran, Jonathan Shafer
机构:肯特州立大学,普渡大学,谷歌研究院,MIT
论文地址:https://openreview.net/pdf?id=EoebmBe9fG
这项研究解决了「无标签数据在在线学习中的力量」这一延宕30年的开放问题:
对任意Littlestone维度为d的概念类,传导式在线学习的最小错误次数精确为Θ(√d),与标准在线学习的Θ(d)形成严格的二次差距。
作者给出匹配的上下界:下界构造中,对手利用「树路径」结构在迫使犯错与控制版本空间收缩间取得平衡;
上界算法则构建带「稀疏编码」的假设类,并以「危险区最小化」「裂变专家(乘法权重)」与「切换到对半算法」的组合策略高效学习。
相较既有工作,本成果在下界上实现对历史对数级结论的指数级提升,并改进了此前最优上界,最终闭合了界限。
该结果突出显示,在在线学习里,提前获取无标签实例序列能带来本质性优势,这与PAC场景中传导式与标准学习样本复杂度相近的现象形成对比,为理解与利用无标签数据提供了新的理论基线。
论文三:Superposition Yields Robust Neural Scaling
作者:Yizhou Liu, Ziming Liu, Jeff Gore
机构:MIT
论文地址:https://openreview.net/pdf?id=knPz7gtjPW
这篇来自MIT最新论文,提出「表征叠加」是神经缩放律(Neural Scaling)的关键机制:
LLM用少量维度承载超量特征,由此产生向量几何重叠并决定损失的Scaling形态。
基于Anthropic模型,作者以权重衰减控制叠加强度并系统分析——叠加弱时,只有当特征频率本身服从幂律,损失才随模型规模呈幂律下降;
叠加强时,损失对广泛的频率分布都近似按1/维度Scaling。
作者在开LLM上验证了强叠加regime的存在,并指出这些观测与Chinchilla Scaling Law一致。
它不仅解释了「模型越大越好」的来源,也明确了Scaling Law改进与失效的边界条件,提示通过调节正则化、设计数据的特征频率结构与规划表示维度,可主动塑造缩放曲线,预测并避免性能瓶颈。
时间检验奖
同时,公布了 NeurIPS 2025「时间考验论文奖」(Test of Time Paper Awards)的获奖名单。该奖项旨在表彰十年前发表的论文。
今年的获奖论文是:
作者包括任少卿、何恺明、Ross Gisshick和孙剑。
《Faster R-CNN》论文已被引用超过56,700次。该论文对计算机视觉领域产生了深远影响,成为众多后续研究工作的基石。
论文在实现极高的检测精度的同时,达到了接近实时的检测速度(每秒5帧),使基于神经网络的目标检测模型得以应用于现实世界的各种场景。这是首个用完全可学习的两阶段流程取代传统选择性搜索(Selective Search)和人工设计候选框方法的工作,该流程包括区域建议网络(RPN)和检测网络。
在肯定这项工作的同时,评奖委员会也对孙剑博士的离世表示深切哀悼。孙博士在该领域留下了不可磨灭的印记。
正如其合作者所言:
孙剑博士是人工智能领域,尤其是计算机视觉方向的先驱与奠基人。他的开创性工作深刻重塑了学术界与工业界的研究范式,有力推动了人工智能技术的发展与广泛应用,其影响历久弥新。
参考资料:
https://blog.neurips.cc/2025/11/26/announcing-the-neurips-2025-best-paper-awards/
https://blog.neurips.cc/2025/11/26/announcing-the-test-of-time-paper-award-for-neurips-2025/
....
#Data Quality Management for Large Vision-Language Models: Issues, Techniques, and Prospects
下一代多模态智能的基石:浙江大学万字长文综述,构建从诊断到治理的LVLM数据生态
下一代多模态智能的基石:浙江大学万字长文综述,构建从诊断到治理的LVLM数据生态
—— ARC 框架:划出多模态智能发展的「数据弧度」
- 论文标题: Data Quality Management for Large Vision-Language Models: Issues, Techniques, and Prospects
- 作者: YICHEN YAN, ZHAOYI YUAN, JIAJUN PAN, XIU TANG, GONGSHENG YUAN,XIAOLING GU,JINPENG CHEN,SAI WU, KE CHEN, MINGLI SONG, LIDAN SHOU, HUAN LI, GANG CHEN
- 机构: 浙江大学大数据智能团队;杭州电子科技大学;北京邮电大学
- 论文地址: https://www.techrxiv.org/doi/full/10.36227/techrxiv.176282213.31303325/v1
- 项目主页: https://github.com/SuDIS-ZJU/Data-Quality-for-Vision-Language-Models
最近,大型视觉语言模型(LVLMs)的发展势头迅猛,像 GPT-4V、LLaVA 这些模型在多模态理解、推理和生成方面都表现出了惊人的能力。但随着模型架构日趋成熟,一个老生常谈却又日益关键的问题浮出水面:“垃圾进,垃圾出”。数据质量,而非模型设计本身,正逐渐成为限制下一代 LVLM 能力和可信度的核心瓶颈。
来自浙江大学、杭州电子科技大学和北京邮电大学等机构的研究者们,刚刚发布了一篇非常系统和深入的综述,首次为 LVLM 的数据质量问题提供了理论上扎实的概览。他们提出了一个名为“ARC”的统一框架,旨在系统性地梳理和解决多模态数据面临的挑战。这篇解读将带大家一探究竟,看看这篇综述是如何为构建更可靠的多模态 AI 铺平道路的。
什么是 ARC 框架?
“师傅领进门,修行靠个人”,但如果“师傅”给的“秘籍”本身就有问题呢?LVLM 的训练数据就是这本“秘籍”。为了系统性地诊断和梳理这本“秘籍”里可能存在的问题,研究者们提出了一个三层分类法——ARC 框架,它分别代表可用性(Availability)、可靠性(Reliability)和可信度(Credibility)。
这个框架巧妙地将数据问题与模型开发流程对齐:
- 可用性层 (Availability) :关注数据获取阶段。这些数据我们能用吗?够用吗?覆盖面广吗?
- 可靠性层 (Reliability) :关注模型学习阶段。这些数据能让模型学到正确、有效的东西吗?
- 可信度层 (Credibility) :关注模型部署阶段。基于这些数据训练出的模型,它的输出我们能信吗?
这三层环环相扣,层层递进。只有数据“可用”,我们才能评估其“可靠性”;只有两者兼备,最终模型的“可信度”才有保障。
基于这个框架,论文总结了11 个典型的数据质量问题,并指出了它们可能出现的阶段(预训练、微调、推理)。
从症状到根源:数据问题的诊断路线图
理论有了,怎么落地?论文还非常贴心地提供了一个“诊断路线图”,帮助开发者从模型表现出的“症状”(比如训练失败、性能不佳、输出危险内容)一步步追溯到数据质量的“病根”。
这个路线图遵循“可行性-有效性-可信度”的逻辑,就像医生问诊一样:
- 模型能训练吗? 如果训练都跑不起来,那很可能是“可用性”层出了问题,比如数据稀缺或格式错误。
- 模型收敛正常吗? 如果训练不收敛,可能还是“可用性”的问题,比如数据过载。
- 模型性能如何? 如果性能普遍差,可能是“可靠性”问题,如标签缺失或模态不匹配;如果只是在特定领域差,那可能是领域不平衡。
- 输出有风险吗? 如果模型输出有害、带偏见或泄露隐私的内容,那无疑是“可信度”层的问题,比如数据毒性或隐私泄露。
这个路线图为 LVLM 的“数据医生”们提供了一套标准操作规程(SOP)。
应对三大挑战:策略与技术
论文的核心部分详细探讨了可用性、可靠性和可信度三个层面下的具体问题及其缓解策略。
可用性 (Availability):“米”从哪里来,够不够好?
这一层主要解决数据的“温饱”问题。
- 数据稀缺 (Data Scarcity) :巧妇难为无米之炊。预训练阶段缺数据,就得靠大规模数据收集,从公共数据集、通用网站甚至特定领域网站(如 GitHub、arXiv)“搜刮”数据。微调阶段数据金贵,直接收集不现实,可以通过数据合成,利用规则或生成模型来“创造”数据。
- 数据过载 (Data Overload) :数据太多也愁人,尤其是混入大量无关、嘈杂的内容。预训练阶段,要进行高效的“数据过滤”,把拼写错误、低分辨率、过曝的图文对筛掉。微调阶段则要进行更精细的“数据选择”,比如基于 Coreset、梯度或损失的方法,挑出信息量最大、最具代表性的子集进行训练,实现“降本增效”。
- 领域不平衡 (Domain Imbalance) 和 格式错误 (Format Errors) :前者指数据在不同领域分布不均(如普通场景图片多,医学、金融图片少),后者指数据结构或格式混乱。解决方法包括整合特定领域数据集、动态调整采样权重,以及利用大模型自身进行数据清洗和格式统一。
可靠性 (Reliability):数据对不对,齐不齐?
这一层关心数据的“内在品质”,即语义是否准确、一致,模态间是否对齐。
- 数据冗余 (Data Redundancy) :数据集中存在大量重复或高度相似的样本,会浪费计算资源、放大偏见。去重方法分为两类:显式去重,通过哈希值等数值方法快速筛查,效率高但无法理解语义;隐式去重,利用深度模型在嵌入空间中比较语义相似度,更智能但计算成本高。
- 模态不平衡 (Modality Imbalance) :训练时某个模态(通常是文本)过于强势,导致模型学习有偏。论文总结了从数据、表征、目标函数到优化四个层面来解决这个问题的通用框架,比如通过数据增强来丰富弱势模态,或在模型内部通过注意力机制来平衡不同模态的贡献。
- 标签缺失 (Label Missing) 和 模态不匹配 (Modality Mismatch) :前者指缺少精细的标签,后者指图文内容不一致。解决方法包括自监督学习生成伪标签、利用 LLM 辅助标注,以及通过文本增强、图像增强或联合增强来改善图文对的对齐质量。
可信度 (Credibility):数据干不干净,安不安全?
最高层次的追求,关乎模型的“人品”——是否合乎道德、安全和法律规范。
- 数据投毒 (Data Poisoning) :攻击者恶意在数据中注入“毒药”(如带特定触发器的样本),以操控模型行为。这就像在“秘籍”里埋下暗门。论文系统梳理了在预训练、微调和推理阶段的防御策略,包括数据增强、数据清洗、安全微调、对抗性微调等。
- 隐私泄露 (Privacy Leakage) :模型不经意间“记住”并泄露了训练数据中的敏感信息。这在多模态模型中尤为严重,因为一张图可能包含远超文本的个人信息。防御手段在数据层面包括数据去重和隐私蒸馏,在模型层面则有差分隐私(Differential Privacy, DP)等技术。
- 数据毒性 (Data Toxicity) :数据中含有冒犯性、有害或带偏见的内容。主要的缓解方法是进行毒性过滤,包括单模态(主要针对文本)和多模态的过滤技术。
未来展望:从静态数据到动态生态系统
这篇综述不仅总结了现状,还指出了未来的发展方向。研究者认为,LVLM 正从单纯的理解与推理工具,向着能够自我治理和演化的智能体(如xx智能、AI 科学家)迈进。
这意味着,未来的数据管理将不再是一次性的、静态的语料库构建,而是一个动态、自主的数据生态系统。在这个生态里:
- 数据流水线将是模型感知的:根据模型架构来定制化地组织数据。
- 数据质量将由多智能体实时交互保障:智能体们协同决定数据的取舍和优化。
- 数据共享将在保护隐私的前提下进行:通过联邦学习、差分隐私等技术,打破“数据孤岛”。
- 数据诊断平台将由目标驱动:自动化地发现问题并推荐解决方案。
总结
总而言之,这篇综述为我们描绘了一幅清晰的 LVLM 数据质量全景图。它不仅是一个理论框架,更是一本实践手册,为所有致力于构建更强大、更可靠、更负责任的多模态 AI 的研究者和工程师们,提供了宝贵的指引。
....
#原来,AI也有「搜商」高低的差别
五一假期刚过,相信不少人已经在朋友圈的「人海直播」中深刻体会到了一个真理:出门旅游,光靠一腔热情远远不够。
翻了三十个小红书帖子,打开十几个 App 对比攻略,还没出发脑子就已经「宕机」;真到了景点,又发现「人从众」三个字压根写不下那条排队长龙。这种「早知道就不来了」的懊恼,相信很多人都不陌生。
问题不在于信息不够,而在于我们没有时间也没有耐心,把海量信息变成真正可用的答案。这正是搜索引擎时代的「隐性成本」—— 你在不断翻页、筛选、甄别,而不是直接得到解决方案。
AI 搜索的兴起,第一次打破了这个路径依赖。在大模型的加持下,搜索不仅能找到网页,更能将信息初步「消化」,生成一段简洁的回答。只是,之前的大部分 AI 搜索仍然局限在「你查我找并总结」的层面,回答浅尝辄止,逻辑支离破碎,甚至连问题的重点都没抓住。现如今,虽然已有不少服务商开始推出自家的「深度思考」,但实际上这些 AI 并没有具备真正的思考能力,仍旧是一种计算过程。
最近,夸克推出的「深度搜索」则在这个基础上迈出了决定性一步。

简单来说,深度搜索在深度思考的基础上强化了 AI 的思考能力,让 AI 真正拥有了「高搜商」,AI 能像人一样先主动理解、思考、拆解问题,再分点推理并规划搜索思路和步骤,给出结构清晰、内容可信、可直接执行的解决方案。
这意味着,搜索不再只是信息的搬运和简单总结,而变成了真正有思考力的「AI 顾问」。类比于之前 AI「智商」的提升,这一次提升的是 AI 的「搜商」—— 一个用于衡量 AI 是否具备类人思维和逻辑组织能力的新指标。搜索,终于开始真正变得聪明了。对用户来说,只要说出问题,剩下的交给夸克就好。
那么,夸克的「高搜商」究竟高在哪?
虽然都叫「深度」
但高搜商的夸克并不一样
市面上已经有不少带「深度思考」的「AI+搜索」产品,但夸克的深度搜索跟他们对比到底哪里不同?在对大量真实问题的测试中,观察到夸克深度搜索具备以下几大优势 —— 它们让我们感受到:一个高搜商的超级 AI 应用已经开始成形。
首先,夸克深度搜索的搜索逻辑更像人类:其流程是「先主动思考、后分点搜索、再信息整合」,也就是说,他会在真正开始搜索之前,先对任务进行拆解和行动步骤设计。这种「有条理」的分点推理方式,不仅能提高效率,也能提升答案的逻辑性与可读性。
我们用如下提示词,来看看夸克和另外两款热门 AI 应用一起「下场做题」时,谁能真正聪明地应对日常的真实任务。
INTJ 适合选哪些类型的专业,我是理科生。

从左到右依次为夸克、另两款 AI 应用的初始响应
可以看到,夸克会在搜索前显式地列出将要执行的步骤,让用户对 AI 的「思考过程」一目了然;另外两款应用要么先是把策略泛泛谈一轮,再去搜索补充,其思考过程还会自动折叠,需要搜索后手动打开,同时其思考内容没有经过梳理,不便于阅读;要么展示的思考过程即是搜索步骤,看似直接但逻辑不够连贯,我们也无从得知 AI 的思考历程。
更重要的是,前期规划能让后续思考更有深度。因为有结构分明的「开场」,夸克在整合搜索结果时也能更有逻辑地做推演与判断,如下对比所示。

从左到右依次为夸克及另两款 AI 应用的部分思考过程
同时,这种动态的前期分析还有另一个好处:能根据问题难度灵活配置搜索资源。该花力气时不吝投入,不该浪费时也懂得节制,最终体现的是「搜商与效率齐高」。
除了逻辑清晰、步骤合理,夸克在「信源可溯性」方面也表现出色,尤其是在健康、学术等对信息准确性要求极高的场景中。下面展示了两个示例。

上下滑动查看
可以看到,夸克不仅会引用国内外权威数据库的循证医学资料,还能结合上下文做出具备因果推理能力的判断。这背后是其自建的亿级医学知识库,其中包含中文医学数据库全集和千万级国内外论文,由近 400 位顶尖医学专家主导内容建设(院士、全国主委 / 副主委、全国常委 / 省级主委以上专家占比 65%+)。夸克还与 60 多家医疗机构和协会合作,严格执行「三审三校」,确保答案的科学性和安全性。
相较之下,很多 AI 应用在专业领域的「信源可溯性」方面还有所欠缺。此外,还会表现出明显的高幻觉问题,对搜索信源的展示随机,并且经常不展示搜索结果来源。下面展示了使用相似提示词的示例。

上下滑动查看
从左到右依次为夸克、另两款 AI 应用的初始响应
更重要的是,这些能力不仅局限在医疗健康领域。
早在去年 11 月,夸克就推出了「学术搜索」,接入了维普、知网、万方等专业平台的数据,建成了一个总量超亿篇的学术文献知识库。借助大模型能力,每次 AI 回应可自动整合 10 篇以上文献内容,从多个维度提供专业解读,实现从「搜资料」到「懂资料」的跨越。很显然,这个大型知识库也在夸克深度搜索的检索范围内。
此外,夸克还拥有一个上亿规模的题库和百万试卷库,覆盖中小学到考研、考公的全学段内容,简直是学生和家长的「在线题王」。
这些知识库,加上对全网信息的高效检索,让夸克深度搜索几乎可帮助用户找到一切已被解答的问题的答案。
推理逻辑清晰 + 动态调整验证 + 信源专业可溯,这些特性共同组成了夸克深度搜索「高搜商」的基础。
实测夸克深度搜索
会思考的 AI 答案更精准
下面我们再通过几个更完整的示例展示一番夸克这个高搜商超级 AI 应用在真实任务中的表现。
首先,回到最开始的问题。回首拥堵的五一,如果你想根据五一期间景点的拥挤情况,来规划端午假期的旅行目的地,只需打开夸克的「深度搜索」功能,用一句简单的提示词就能搞定:
根据五一期间网络上的信息和网友分享,为我盘点一下北京周边好玩但人不多的景点。请注意,“人少” 非常关键!
,时长00:43
可以看到,在执行过程中,夸克深度搜索并不是一股脑地开始查资料,而是会先对用户的需求进行分析,明确重点,再规划接下来的行动步骤:比如先筛选出符合条件的景点,接着查询最新政策,对比各地的客流量趋势,甚至还会验证景区公告与社交媒体上的信息是否一致。
只有当这些准备工作完成之后,他才启动搜索流程。此时,夸克会先广泛检索相关内容,再有逻辑地剔除噪音信息,保留高质量素材,随后再对保留下来的信息进行深度思考。最终,他会以结构清晰、图文并茂、不冗余的方式生成一份高质量报告,真正把答案端到用户面前。
如果你还不满足?当然可以「接着问」,比如让他进一步针对青龙峡制定一个细致的端午出行计划。
,时长01:06
得到的依然是一份不啰嗦、不敷衍的好答案:逻辑清楚,内容可用,细节充分,几乎可以直接照着出发。
这种定制化、个性化的问题,家家户户的情况都不同,家人的饮食习惯、兴趣爱好、体力都有差异,网络上找不到现成的答案。过去我们都是靠在小红书、抖音等内容平台搜索,再自己规划。但现在深度搜索可以耐心听取你的需求,并做出贴心周到的安排。
当然,旅游攻略只是深度搜索能力的一角。我们实际体验发现,无论是靠模糊剧情找小说、影视等娱乐资源,还是进行专业选择、留学咨询、职场生活维权、健康咨询等更复杂的问题,深度搜索都能展现出非常高的「搜商」,给出颇具参考价值的回应。
比如我们测试了一个不少铲屎官常见的担忧:
最近天气变热,小猫老是肚皮贴着地板睡觉,最近发现它每天打很多次喷嚏,但是没有流鼻涕,吃喝拉撒也正常,这是感冒了吗?

上下滑动查看
除了整理医学网站和宠物社区的知识,夸克还能总结出判断要点和应对策略,既有信息,也有建议。
甚至连法律维权这样的硬核问题,他也不含糊:
我上个月租了一套新装修后的房子,住进去后身体不适。经过检测,发现房间内甲醛超标,想要退租,但房东不同意。请为我提供一个合理合法的维权方案。

上下滑动查看
比起过去只能依赖搜索结果自己「扒文档、看帖子」,现在的夸克能直接列出可操作的维权步骤、适用的法律条款,甚至还贴心地列出了两个参考案例与判例。
从这里的示例也能看出,夸克把原本只有专业研究人员才拥有的系统性推理与分析能力带给每个用户。鉴于夸克超 2 亿的用户规模,这无疑标志着深度搜索能力即将广泛普及。这些功能在手机和桌面端均已上线。
更进一步
专业的任务让专业的 Pro 解决
根据夸克最新的产品升级动态,除了发布深度搜索能力,夸克还将发布具有 Deep Research 功能的深度搜索 Pro 模式,该模式专为处理更专业更复杂的问题设计,可以交付结构化、系统性的专业级报告或方案。
如果说「深度搜索」是你生活里的万事通,那「深度搜索 Pro」或许会更像是一位拥有专业背景、思路清晰的研究助理。期待尽快上线。
在基础版的深度搜索中,我们已经看到,AI 能通过「先主动思考、后分点搜索、再整合信息」的方式,帮用户解决日常中的各种难题。但面对更高复杂度的任务,比如需要跨学科知识、权威数据验证或结构化输出的场景,夸克深度搜索 Pro 版本的推出将或为用户带来更加专业、综合的体验。
举个例子,如果你想深度全面地了解 AI 行业,通过「深度搜索 Pro」,夸克就能动用他的强大检索和深度思考能力为你生成一份深度与广度兼备的研究报告。
我想全面了解 AI 这个行业,请用顶级的投行研究专家的视角,先列出一个研究问题清单,再根据清单帮我形成一份完整的研究报告,并标清楚相关资料引用来源。
,时长01:16
多模态任务处理
超强编辑源自真正理解
除了搜索之外,夸克这次还悄悄升级了另一项关键能力:图像智能处理。他不仅能「看图说话」,还能「看图办事」。
这一能力基于多模态大模型,通过结合视觉理解与自然语言处理(NLP),使得夸克具备了从图片中提取信息、理解语境、并据此执行任务的能力。具体而言,夸克在图像处理中的能力可分为两个方向:
一是图像语义理解。他可以识别图像中的主要目标、文字、场景乃至风格等要素,并结合用户的文本输入,实现任务驱动式的信息解读。例如,识别动植物、诊断截图中的软件报错、推荐与装修风格匹配的设计方案等,背后依托的是大规模图文对比训练与知识增强模块。
二是图像智能编辑。用户只需上传图片并输入指令,即可实现照片换背景、去路人、服装更换、风格化转换等操作。这依赖于扩散模型、图像分割、文生图等先进技术的集成与调优。
更重要的是,这一系列能力在夸克中被封装为超级框 + 上传入口(+)的极简交互,只需上传图片并用自然语言描述你的目标,就能实现图文协同的自动化处理。
举个例子,如果你想知道随手拍摄的路边野花是否能做一盘野菜:

上下滑动查看
又比如你想让一张普通合影变得更有质感 —— 删掉路人、替换背景、调整光影风格,则只需点击 + 号上传图片,选择「AI 改图」,然后输入你的具体需求即可。下面展示了一个换背景的例子。

这场 AI 应用竞赛
夸克已冲锋在前
过去很长一段时间里,搜索的角色像是「信息图书馆」的入口 —— 它帮我们找到关键词,指向网页,却不对结果负责。而在生成式 AI 浪潮席卷之下,越来越多用户开始期待一个全新的角色:不只是搜索器,而是一个会思考、有理解力、能够代劳的 AI 助手。
夸克的这次升级,正是在这一背景下迈出的关键一步。他不仅做到了搜索方式的转变 —— 从「找信息」走向「解问题」,更通过「深度搜索」以及图像理解等多项升级,让 AI 能力真正大规模普及到了大众用户的日常生活中。
你可以用他规划一趟不踩坑的假期行程,也可以生成一份结构清晰的市场调研报告,甚至只需上传一张图片,他就能读懂、分析、提取你真正想要的核心信息。这种从输入到输出的完整闭环,意味着 AI 搜索的可用性门槛被大幅降低,也意味着普通用户获取信息的效率、质量和体验正在被彻底改写。而夸克,正是在用「高搜商」的方式,陪用户做更聪明的选择。
在这个人人都能调动 AI 能力的时代,搜索,不再是技术的游戏,而是全民的权利。而夸克,正在用一次次看似微小的产品演进,把「技术平权」这件事,变得真实可感、触手可及。
可以说,在 AI 驱动的搜索下半场,理解力才是核心竞争力。而夸克,已经跑在了前面。
未来,夸克还将持续拓展「AI 超级框」的能力边界 —— 从理解自然语言到调动工具,真正实现「让人用 AI,AI 使用工具」的产品理念。届时,一个真正聪明、主动、可协同的 AI 搜索助手,或将从这里诞生。
...
#2025年第二届「兴智杯」全国人工智能创新应用大赛正式启动
线上报名开启
2025 年 5 月 8 日上午,第二届 “兴智杯” 全国人工智能创新应用大赛正式启动。前期,工业和信息化部、科学技术部、深圳市人民政府共同主办了首届 “兴智杯” 全国人工智能创新应用大赛(以下简称 “大赛”),以需求为牵引,推动了一批关键技术突破,加快人工智能与重点行业融合赋能,成为了目前国内规模最大、参赛主体最丰富的人工智能专业赛事。为进一步发挥 “以赛促研、以赛促用、以赛育人” 的作用,今年,第二届兴智杯大赛如约而至,由中国信息通信研究院、深圳市人工智能产业办公室、深圳市前海深港现代服务业合作区管理局、深圳市宝安区人民政府主办,旨在聚焦技术创新和应用赋能面临的痛点、难点,加速人工智能技术创新和产业化落地,培育一批国内外优秀人工智能创新人才,为优秀项目提供展示、推广的平台。
启动仪式以线上方式举行,中国工程院院士王国法出席并致贺词,工业和信息化部科技司副司长杜广达,中国信息通信研究院院长余晓晖以及深圳市工业和信息化局党组成员、副局长、深圳市人工智能产业办公室主任林毅出席并致辞;深圳前海深港现代服务业合作区、深圳宝安区、北京经济技术开发区、南昌市、常熟市等大赛、主题赛、特色方向赛主办地相关领导出席并发言;中国信息通信研究院人工智能研究所所长魏凯介绍大赛总体情况。

杜广达指出,我国人工智能产业和应用蓬勃发展,已形成覆盖基础层、框架层、模型层、应用层的完整产业体系。当前,人工智能发展进入新一轮高频迭代期,新技术新产品新应用不断涌现。“兴智杯” 是我国人工智能领域重要赛事品牌,面向人工智能最新发展趋势,以激励创新为导向,以解决产业发展需求为牵引,为科技创新和产业创新提供优秀的融合平台。人工智能创新发展正当其时,要通过 “兴智杯” 大赛的平台,坚持创新驱动,加速关键技术突破;坚持应用牵引,推动技术落地;坚持开放包容,汇聚各方智慧。

余晓晖在致辞中指出,当前人工智能技术正从单点应用向全链条赋能迈进,未来人工智能技术的进一步突破和 “人工智能 +” 行动的深入实施,将推动生产力的跃升,成为驱动高质量创新发展的强大引擎。中国信息通信研究院积极推动人工智能创新发展,支撑多项研究工作。本届 “兴智杯” 大赛以 “兴智赋能,创新引领” 为主题,聚焦大模型、软硬件等关键技术及重点行业应用,设置赛题并组织专题活动,旨在汇聚各方力量,推动人工智能创新发展和应用普惠。

林毅表示,深圳市高度重视人工智能产业发展,致力于打造人工智能先锋城市,构建开放的产业生态。深圳联合中国信通院共同举办第二届大赛,旨在持续发挥 “以赛促用、以赛兴产” 作用,推动人工智能与千行百业深度融合,加速人工智能应用创新突破,加快培育一批高水平人工智能行业应用人才,进一步提升我国人工智能产业发展核心竞争力。
随后,大赛主办地深圳前海深港现代服务业合作区与深圳宝安区分别介绍主办地相关情况。前海深港现代服务业合作区管理局科技创新处处长张俊表示,前海正着力打造深港人工智能产业聚集区,集成 “算力集群、算法服务、数据跨境、应用场景开放、科研攻关支持、产业基金支持” 等全方位措施,支持人工智能企业高质量发展。宝安区科技创新局局长沈彦表示,宝安区作为深圳市人工智能与机器人产业的核心承载区,已构建 “硬核基底 + 创新生态” 的产业格局,未来宝安区将继续联动前海,以应用场景为引领,加速 AI 赋能千行百业,打造具有核心竞争力的人工智能产业生态。
软硬件创新生态主题赛将由中国信通院人工智能软硬件协同创新与适配验证中心(亦庄)与北京市经济技术开发区联合举办,经开区信息技术产业局局长郭泽邦表示,北京经开区将依托本次赛事,充分发挥产业优势,联动区内各新型研发主体、实验室和技术企业特色,助力打造从技术突破到产品孵化再到场景应用的全链条生态体系,推动我国软硬件从 “可用” 向 “好用” 跃升,共建 “软硬一体化、自主可控、生态共赢” 的人工智能产业发展新格局。
特色方向赛事主办地代表江西省南昌市与江苏省常熟市领导随后发言,南昌市政务服务和数据管理局局长李鑫表示,南昌市将人工智能作为培育新质生产力的核心引擎,已形成覆盖技术攻关、场景应用、产业协同的生态体系,将通过本次大赛吸引全球创新力量,共同探索人工智能在智慧城市等领域的创新应用;常熟市工业和信息化局局长钱韧表示,常熟把发展人工智能作为优先战略选择,出台多项政策激发市场活力,未来将进一步加大人工智能产业投入,在 “AI + 声学” 领域着重发力,加快形成县域发展新路径。

在启动仪式的第二阶段,魏凯介绍了本届大赛总体情况。本届赛事聚焦我国人工智能自主生态所需的关键能力,集聚产学研用各方优势资源,推动技术协同、应用赋能和生态创新,设置一系列 “有场景、有数据、有需求” 的专业赛题。本届大赛分为主题赛和总决赛两阶段举行,主题赛阶段将设置大模型创新、软硬件创新生态与行业赋能三大主题赛与多个特色方向赛,主题赛决赛优胜队伍入围总决赛,大赛总决赛将于深圳线下举行。大赛设置了立体化的激励机制助力选手成长,即日起可通过大赛官网、官方公众号线上报名。
在启动仪式最后,中国电信集团有限公司政企信息事业群智算云创新团队技术负责人、大模型首席专家刘敬谦,中国煤炭科工集团首席科学家、煤炭科学研究总院矿山人工智能研究院常务副院长程健,深圳市智慧城市科技发展集团有限公司总经理朱润酥,中国电力科学研究院人工智能研究所大模型运营总监陈晰,微众银行人工智能首席科学家范力欣等专家围绕 “加快应用深度融合,推进人工智能赋能新型工业化” 发表演讲;百度杰出架构师胡晓光,沐曦 CTO、联合创始人杨建,中兴通讯首席科学家向际鹰,北京国际算力服务有限公司总经理助理马光等带来 “促进软硬件协同创新,壮大智能算力生态体系” 主题的精彩分享。
会上,还邀请到中国电信集团有限公司政企信息服务事业群大模型首席专家刘敬谦,中国移动通信有限公司研究院院长黄宇红,阿里云智能集团首席技术官周靖人,沐曦 CTO、联合创始人杨建,中兴通讯副总裁、技术规划总经理赵志勇,vivo 副总裁、OS 产品副总裁、vivo AI 全球研究院院长周围,上海人工智能实验室青年科学家、大模型中心负责人陈恺,微众银行人工智能首席科学家范力欣等业界专家代表出席并向第二届大赛的举办致以贺词。
为了进一步推动人工智能领域的创新与协同发展,为参赛选手搭建高端交流平台,大赛组委会将在赛事期间组织一系列专题研讨会、学术沙龙等活动,汇聚行业精英,激发思想碰撞。详细活动安排将在大赛官网(http://www.aiinnovation.com.cn/)及公众号 “兴智杯全国人工智能创新应用大赛” 陆续发布,敬请期待!
第二届 “兴智杯”
全国人工智能创新应用大赛
线上报名开启
一、赛程赛制
1. 主题赛:5 月 - 9 月(具体时间以官网 / 官方公众号通知为准),拟遴选出一定数量优胜团队入围主题赛决赛(具体遴选优胜团队数以评审结果为准)。主题赛决赛评选出一、二、三等奖,其中一、二等奖入围总决赛。入围名单将于官网 / 官方公众号公布。
2. 总决赛:10 月 - 11 月,在深圳市举办。通过现场答辩,评选出一、二、三等和优胜奖。另,在全入围总决赛参赛作品中评选 50 强高价值应用方案及十佳商业投资潜力项目。
二、赛题设置
大赛设置主题赛和总决赛,每项主题赛含若干赛题。其中,主题赛初赛以线上形式开展,各主题赛决赛视实际情况另行安排。总决赛在深圳市举办。
(一)主题赛 1:大模型创新
聚焦大模型智能体、智能软件开发等热点,围绕大模型基础能力、平台服务应用生态及高价值场景应用创新等贴合和工程化应用需求的热点、痛点技术方向,遴选一批具备创新突破潜力、实现最佳性能优化表现的模型算法或实际应用。
(二)主题赛 2:行业赋能
面向工业、终端、能源、矿山、网络通信、医疗、金融、城市、文旅等关键行业的实际需求,提供真实业务场景数据,挖掘一批能够解决具体行业中特定场景发展痛点问题的作品方案,推动人工智能技术在千行百业中的赋能应用。
(三)主题赛 3:软硬件创新生态
探索以深度框架平台为核心以及软硬件协同一体化两类差异化生态发展路线,重点提升我国软硬件面向大模型应用的支撑能力,引导参赛选手基于国产软硬件构思解题思路,以赛促用提振国产化信心。
(四)其他特色方向赛
后续将在大赛官网(http://www.aiinnovation.com.cn/)及公众号 “兴智杯全国人工智能创新应用大赛” 陆续发布,欢迎各位选手关注。
三、激励设置
(一)大赛奖项
各主题赛和总决赛分别评选一、二、三等奖,总决赛将增设优胜奖,并评选 50 强高价值应用方案、十佳商业投资价值奖。
(二)获胜项目激励
设置奖金池及官方获奖证书;入选第二届 “兴智杯” 全国人工智能创新应用大赛优秀项目案例;提供相关支持单位招聘绿色通道;择优提供资金、场地、落户等配套政策支持;优先对接投资资金及机构资源;提供检验检测、技术转移、应用推广等服务。具体激励措施将在大赛网站公布。
四、报名方式
大赛官网(http://www.aiinnovation.com.cn/)、官方公众号(兴智杯全国人工智能创新应用大赛)提供赛事报名、数据使用、评审评测、信息发布等参赛保障。参赛者均须通过大赛官网注册报名,截止时间以官网公布时间为准。
打造人工智能先锋城市
深圳市共同主办第二届兴智杯大赛
第二届大赛由深圳市与中国信通院共同主办,将借助深圳市产业优势,发挥其完备的产业链条、丰富的应用场景、活跃的创新氛围和突出的科技创新能力,吸引全国乃至全球的人工智能人才参与,激发创新活力,推动人工智能技术与产业的深度融合。
深圳市将人工智能列为重点发展领域,通过系统性政策布局推动产业创新,着力构建具有全球竞争力的人工智能产业集群,打造人工智能先锋城市。深圳人工智能产业链条完备,应用场景丰富,创新氛围活跃,机电一体化优势突出,产业竞争力和综合实力位居全国第一梯队。人工智能全域全时全场景应用持续深化,把整个城市作为企业新技术、新产品的试验场,累计发布四批近 200 个 “城市 + AI” 应用场景,逐步构建起覆盖公共服务、城市运行、重点行业赋能的应用体系,在法院、医疗、环卫等领域形成多个场景标杆。
深圳人工智能科技创新活跃,企业创新主体地位突出,腾讯、华为等龙头企业在通用大模型,思谋信息、晶泰科技、元象科技等高成长性企业在细分领域,都拥有行业领先成果;创新载体完备,已建成鹏城实验室、光明实验室等重点平台,产学研用深度融合;终端迭代速度领先,拥有全球唯一 “智能车机电一体化 + 人工智能产业供应链”,有 “用迭代软件速度迭代硬件” 的优势。
本次全国性的创新应用大赛在深圳举办,进一步展示了深圳在人工智能领域的创新实力和应用前景,必将吸引一大批人工智能企业和人才来到深圳、认识深圳、选择深圳,与深圳携手推动人工智能产业更好更快集聚发展。
....
#Mistral Medium 3
时隔两月,Mistral AI终于上新Medium 3,近期还有「One more thing」
时隔两月,Mistral AI 终于又上新了。
「今天,我们欣喜地宣布推出 Mistral Medium 3,进一步提升语言模型的效率和可用性。」

据官方博客介绍,Mistral Medium 3 处于一个新的性能层级,介于轻量级和大规模模型之间。该模型在关键基准测试中优于 GPT-4o 甚至 Claude 3.7 Sonnet。
只是 Mistral Medium 3 并未开源,目前可通过 Mistral 的官网和 API 或其合作伙伴的 API 使用。Mistral Medium 3 将于周三上线亚马逊云科技的 Sagemaker 平台,后续也会登陆其他主机平台,包括微软的 Azure AI Foundry 和谷歌的 Vertex AI 平台。
该模型专为企业使用而设计,其性能在基准测试中达到了 Claude 3.7 Sonnet 的 90% 以上,但成本仅为后者的 1/8 —— 输入每百万 token 仅需 0.4 美元,输出每百万 token 仅需 2 美元。相比之下,Sonnet 的输入 / 输出价格分别为 3 美元和 15 美元。
另外,Mistral AI 还预告了「One more thing」:
随着三月份 Mistral Small 和今天 Mistral Medium 的发布,我们在接下来的几周内正在筹备一款「大型」产品,这早已不是什么秘密了。即使是我们的中型型号,其性能也远超 Llama 4 Maverick 等旗舰开源型号,我们非常期待「揭开」未来的神秘面纱 :)
会是什么重磅发布?值得我们期待一下。
优于 GPT-4o 和 Claude 3.7 Sonnet 的性能
基准测试表明,Mistral Medium 3 在软件开发任务中表现出色。在 HumanEval 和 MultiPL-E 等编程测试中,它的表现与 Claude 3.7 Sonnet 和 OpenAI 的 GPT-4o 模型不相上下,甚至更胜一筹。

除了学术基准测试外,团队还报告了更能代表实际用例的第三方人工评测。
根据第三方的人类评估,在 82% 的编程场景中,它优于 Llama 4 Maverick,并且在近 70% 的案例中超过了 Command-A。

该模型在不同语言和模态上也具有很强的竞争力。与 Llama 4 Maverick 相比,它在英语(67%)、法语(71%)、西班牙语(73%)和阿拉伯语(65%)中的胜率更高,并且在多模态性能方面表现出色,在 DocVQA(0.953)、AI2D(0.937)和 ChartQA(0.826)等任务中取得了领先的分数。

Mistral Medium 3 针对企业整合进行了优化。它支持混合部署和本地部署,提供定制化后训练,并且能够轻松连接到业务系统。据 Mistral 称,它已经在金融服务、能源和医疗保健等行业的组织中进行测试,用于支持特定领域的业务流程和面向客户的解决方案。
企业级「ChatGPT」:Le Chat Enterprise
与此同时,Mistral 还推出了 Le Chat Enterprise。
这是一款面向企业的聊天机器人服务,今年早些时候就推出了私人预览版,但今天正式全面上市。
用法如下:
,时长01:21
Le Chat Enterprise 可通过网络和移动应用程序使用,它就像 ChatGPT 的竞争对手,但它是专为企业及其员工打造的。考虑到了用户可能会跨不同的应用程序和数据源工作,它将人工智能功能整合到一个单一的、隐私优先的环境中,实现深度定制、跨职能工作流和快速部署。
Le Chat Enterprise 提供了 AI「智能体」构建器等工具,并将 Mistral 的模型与 Gmail、Google Drive 和 SharePoint 等第三方服务集成。
此外,Le Chat Enterprise 即将支持 MCP——Anthropic 为连接 AI 助手和数据所在系统及软件而制定的标准。包括谷歌和 OpenAI 在内的主要 AI 模型提供商,都已经在今年早些时候宣布将采用 MCP。
更多信息,可参考官方博客。
参考链接:
https://mistral.ai/news/mistral-medium-3
https://mistral.ai/news/le-chat-enterprise
....
#Fourier Position Embedding
清华、上海AI Lab等提出傅里叶位置编码,多项任务远超RoPE
长文本能力对语言模型(LM,Language Model)尤为重要,试想,如果 LM 可以处理无限长度的输入文本,我们可以预先把所有参考资料都喂给 LM,或许 LM 在应对人类的提问时就会变得无所不能。
但是,LM 通常只在较短窗长下进行训练,可能产生过拟合,只学习到指定范围内的位置关系,但是无法理解没学习过的位置关系。为了缓解这个问题,当下最流行的便是引入具有周期性的旋转位置编码(Rotary Position Embedding,RoPE)。由于周期性编码每间隔一定距离就会出现数值重复,所以 LM 可以使用在少数几个周期内学习到的经验泛化到更多的周期当中。
但奇怪的是,使用 RoPE 的 LM 依然难以直接在训练长度之外起效,必须依靠其他算法(如 YARN)来辅助其进行外推。 那么,到底是什么限制了 RoPE 的周期延拓,进而限制了 LM 的长度外推呢?
于是,清华大学讲席教授、上海AI Lab主任/首席科学家周伯文教授的团队对这一问题进行了深入探索,使用傅里叶分析工具解读了使用 RoPE 的 Transformer 模型长文本泛化能力不足的原因之一是 RoPE 带来的周期性延拓受到了频谱破坏的影响。进一步地,该文章提出的傅里叶位置编码(Fourier Position Embedding,FoPE)大幅提升了Transformer的长文本泛化能力。
- 论文标题:Fourier Position Embedding: Enhancing Attention’s Periodic Extension for Length Generalization
- arXiv 链接:https://arxiv.org/pdf/2412.17739
- 代码链接:https://github.com/TsinghuaC3I/Fourier-Position-Embedding
研究亮点
发现 —— 频谱损坏限制周期延拓
作者们通过观察 RoPE 的公式可以发现,它为 Hidden States 的每一维都指定了单一的频率,并假设这一维度的语义信息按照这个波长影响其他位置的语义。所以,RoPE 周期延拓性的起效前提是 “Hidden States 的每一维只存在单一频率的语义”。如果每一维明明存在不同频率的语义,却仍然按照单一频率的波长来估计这部分语义的传递规律,RoPE 所带来的周期延拓将产生混乱,进而无法实现长文本泛化。

遗憾的是,在使用 RoPE 的 LM 中,这个假设只在 LM 的第一层中成立,但在后面的所有层中都不成立。因为后面的所有层中,每一维中都掺杂了除主频之外的其他频率分量,这个现象可以被称作频谱损坏(Spectrum Damage)。频谱损坏主要有三个来源:① 线性函数;②激活函数;③时域截断。
线性函数
如果我们假设线性层的权重为

,其对输入
![]()
进行处理得到输出
![]()
,那么每一维输出将由每一维输入的线性组合构成:

考虑到每一维输入所对应的频率是不一样的,那么
![]()
将掺杂输入中的所有频率分量。
激活函数
根据高等数学的知识,给定一个含有两个频率的函数

,以及任意一个与时间无关的非线性函数
![]()
,
![]()
被函数
![]()
作用后得到的输出将存在多个频率分量,这些频率将是输入频率的线性组合:

这个结论可以通过泰勒展开进行简单证明,也可以任意地推广到存在更多频率的情况。可以看到,经过线性层之后,每一维本就掺杂了多种频率。在经过激活函数之后,这种掺杂会变得更加严重。
时域截断
给定一个被截断为长度N的单频率函数

通过傅里叶变换可以得到(详见文末)这个函数的频谱是:

其中,

是截断长度与周期长度相除后向下取整,

是在
![]()
处无限大但积分为 1、在其他位置取值均为零的奇异函数。可以看到,时域截断会让主要频率
![]()
的强度向周围的频率扩散,降低信噪比。如果该函数的周期

大于截断长度N,这个信噪比将变得很低,会极大地抑制对只要频率的学习。巧合的是,RoPE 中其实使用了大量频率低、周期长的分量,所以这个问题尤为严重。
算法 —— 频域鲁棒性是长文本泛化关键
在以往的研究中,大家普遍认为只有 Attention 才会影响长度外推。但从上面的分析可以看出,整个模型中的线性层、激活函数和时域截断也都会对长度外推产生影响,并且是不利影响(也就是上文提到的频谱损坏)。为了改善频谱损坏对长文本泛化的不利影响,这篇论文提出了傅里叶位置编码(FoPE,Fourier Position Embedding)来提升模型的频域鲁棒性和周期延拓性,进而提升长文本泛化。
FoPE 的核心思想是 “打不过就加入”。考虑到线性层和激活函数可以带来更强的表征能力,时域截断又是受到硬件限制无法改变,FoPE 索性就仍然保留了各层中的频谱损坏,转而提出了对于频谱损坏更加鲁棒的位置编码。鲁棒性的提升主要源于两方面:① 既然每一维中不可避免的混杂其他频率的分量,那就干脆在一开始就把每一维都建模成一个傅里叶级数(Fourier Series)。即使这样的建模不会避免频谱破坏,FoPE 却可以在每一维中解码出更多频率的信息(利用三角函数的正交性);② 既然极低频的分量周期过长,会导致这些频率分量的周期特性无法被学习到,那就将他们裁剪成频率为 0 的直流分量。考虑到直流分量的良好性质(既可以看作周期无限短,又可以看作周期无限长),这个新加入的频率既保证了周期性,又可以让每个词汇的信息向无限远的词汇传递;
综上,FoPE 的公式可以写作:

实验
进一步地,文章在困惑度、大海捞针准确率以及很多下游任务 Benchmark 对不同方法进行了对比,实验发现 FoPE 在这些任务上都有稳定的表现,在绝大多数远超过使用 RoPE 的模型。



潜在影响
论文中使用傅里叶工具得到的分析结论和算法可能存在更广泛的潜在价值,有潜力应用在更多的领域和任务:① AI 领域内:长视频生成、kv-cache 压缩、多模型协同等;② AI 领域外:语义通信、光计算和脑机接口。
作者简介:华尔默,清华大学博士生,研究方向是基础模型的架构设计与训练算法设计,在 ICML、ICLR、NeurIPS、ACL、EMNLP、COLM、AAAI 等顶级会议上发表过论文。
...
#ICEdit
五一长假冲上HuggingFace榜第二,仅次于Qwen3!浙大哈佛「全能LoRA」杀疯了
该项目提出了一种基于上下文的零样本图像编辑框架,结合LoRA-MoE混合微调和早期噪声过滤策略,仅需极少量数据和参数即可实现高精度的指令图像编辑,解决了现有方法中精度与效率难以兼顾的难题。
文章链接:https://arxiv.org/pdf/2504.20690
项目链接:https://river-zhang.github.io/ICEdit-gh-pages/
Git链接:https://github.com/River-Zhang/ICEdit
Demo链接:https://huggingface.co/spaces/RiverZ/ICEdit
五一假期期间,ICEdit爆火🔥,登上了hugging face周榜第二,仅次于qwen3!外国网友在twitter上纷纷秀出使用效果






亮点直击
- 探索了大型预训练扩散Transformer(如FLUX)的编辑能力,并引入了一种新颖的上下文编辑范式,该范式能够实现有效的指令图像编辑,而无需修改模型架构或进行大量微调。
- 提出了LoRA-MoE混合微调方法,用于参数高效的编辑任务适应,并结合基于VLM的噪声剪枝策略——早期过滤推理时间缩放。这种协同设计在保持上下文编辑框架高效性的同时,显著提升了编辑精度。
- 实验表明,本文方法仅需0.5%的训练数据和1%的可训练参数(相较于现有方法),即可实现最先进的编辑性能,有效解决了长期困扰先前方法的精度-效率权衡问题。
总结速览解决的问题
- 精度与效率的权衡问题:
- 现有基于微调的方法(Fine-tuning)需要大量计算资源和数据集,效率低。
- 免训练方法(Training-free)在指令理解和编辑质量上表现不佳,精度不足。
- 指令理解与编辑质量不足:
- 免训练方法难以准确解析复杂指令,导致编辑效果不理想。
- 微调方法依赖大规模数据训练(如 450K~10M 样本),计算成本高。 - 初始噪声选择影响编辑质量:
- 不同的初始噪声会导致不同的编辑效果,如何优化噪声选择以提高输出质量是关键挑战。
提出的方案
- 基于上下文(In-Context)的零样本编辑框架:
- 利用 DiT 的上下文感知能力,通过“上下文提示”(in-context prompts)实现免训练的指令编辑,避免结构调整。
- LoRA-MoE 混合调优策略:
- 结合 LoRA(低秩适应) 和 MoE(混合专家) 动态路由,提高模型灵活性,减少训练需求。
- 仅需少量数据微调,无需大规模重新训练。
- 早期噪声过滤推理优化(Early Filter Inference-Time Scaling):
- 利用视觉语言模型(VLMs)在去噪早期阶段筛选更优初始噪声,提升编辑质量。
应用的技术
- 扩散 Transformer(DiT):
- 利用其强大的生成能力和上下文感知特性,实现高效指令编辑。
- LoRA + MoE(混合专家):
- LoRA:参数高效微调,减少计算开销。
- MoE:动态专家路由,增强模型对不同编辑任务的适应能力。
- 视觉语言模型(VLMs):
- 用于噪声筛选,优化初始噪声选择,提高生成质量。
- 上下文提示(In-Context Prompting):
- 通过双联画(diptych)形式(源图 + 编辑提示)实现零样本编辑。
达到的效果
- 数据与参数高效性:
- 仅需 0.5% 训练数据 和 1% 可训练参数,超越现有 SOTA 方法。
- 编辑质量提升:
- 在 Emu Edit 和 MagicBrush 基准测试中表现优异,VIE-score 78.2(优于 SeedEdit 的 75.7)。
- 计算效率优化:
- 避免大规模微调,减少计算资源需求,同时保持高精度。
- 通用性强:
- 适用于多样化编辑任务(如参考引导合成、身份保持编辑等),无需额外结构调整。
方法
本节首先探索原始DiT生成模型中的上下文编辑能力,并提出基于指令的图像编辑上下文编辑框架。经过全面分析后,引入LoRA-MoE混合微调到框架中,配合小型编辑数据集,显著提升编辑质量和成功率。最后,提出早期过滤推理时间缩放策略,在推理阶段选择更好的初始噪声以增强生成质量。
DiT上下文编辑能力探索
带编辑指令的上下文生成。受近期研究[16,17,41,49]表明大规模DiT模型具有强大上下文能力的启发,本文探索是否可以通过上下文生成实现图像编辑。为此,我们将编辑指令添加到专为上下文编辑设计的生成提示中。具体而言,设计如下形式的提示:“同一{主体}的并排图像:左侧描绘原始{描述},而右侧镜像左侧但应用{编辑指令}。”将此表述称为上下文编辑提示(IC提示)。借助T5文本编码器因其强大的句子级语义理解而被DiT广泛采用),该方法能有效解析此类扩展提示,实现精确且上下文连贯的编辑。
如下图3所示,上下文编辑提示(IC提示)使DiT模型能够以双联画格式生成编辑输出:左侧为与描述对齐的图像,右侧为根据编辑指令调整后的同一图像。为阐明此机制,检查了IC提示中编辑指令的注意力图,发现待修改区域的注意力值显著较高。这表明DiT模型能熟练解析并执行IC提示中的编辑指令,无需大量微调即可理解编辑指令并相应执行。

上下文编辑框架构建基于上述观察,本文提出一种编辑框架,其中将左侧指定为参考图像可实现右侧的无缝编辑。分别基于文本到图像(T2I)DiT和修复DiT提出了两种免训练框架,如下图4所示。

对于T2I DiT框架,本文设计了一种隐式参考图像注入方法。首先对参考图像进行图像反转,保留各层和各步骤的注意力值。然后将这些值注入表示双联画左侧的标记中以重建图像,而右侧则在上下文生成期间基于预定义IC提示中的编辑指令生成。
相比之下,修复DiT框架提供了一种更直接的方法。由于它接受参考图像和掩码,预设一个并排图像,左侧为参考,右侧为掩码区域,并使用相同的IC提示引导修复过程。
前面图4展示了两种框架的操作,示例输出显示它们在编辑过程中保留参考图像身份的能力。然而,下表3的实验表明,两种框架在不同编辑任务中均无法始终提供稳定、鲁棒的结果,限制了其实用性。此外,T2I DiT方法需要额外的反转步骤,相比更简单的修复框架增加了计算需求。因此,基于修复的框架是进一步优化的更可行候选方案。

LoRA-MoE混合微调
基于上述分析,本文将方法总结为一个函数 ,它将源图像 和编辑指令 映射到目标编辑输出

其中 为修复扩散Transformer, 表示上下文图像输入——左侧放置源图像 ,右侧由固定二值掩码 遮盖。编辑指令 被转换为上下文编辑提示 。

LoRA调优为增强该框架的编辑能力,本文从公开资源中整理了一个紧凑的编辑数据集(50K样本),并在多模态DiT模块上采用LoRA微调进行参数高效适配。尽管数据集规模有限,该方法仍在编辑成功率和质量上取得显著提升。然而,某些任务(如风格变更和对象移除)仍存在挑战,降低了整体成功率。
这些发现可以认识到:单一LoRA结构的能力有限,不足以应对多样化的编辑任务。不同编辑任务需要不同的隐空间特征操作,而并行掌握这些多样化模式存在重大挑战。先前的LoRA调优通常针对特定任务,为不同目标训练独立权重,这凸显了统一LoRA模型在复杂编辑场景中的局限性。
LoRA混合专家为解决这一限制,本文受到LLM最新进展的启发:混合专家(MoE)架构通过专用专家网络巧妙处理多样化输入模式。MoE范式为我们的任务提供两大优势:(1) 专用处理——使各专家专注于不同特征操作;(2) 动态计算——通过路由机制实现专家动态选择。这在不牺牲计算效率的前提下提升了模型容量。
利用这些优势,在DiT模块中提出混合LoRA-MoE结构:将并行LoRA专家集成到多模态(MM)注意力块的输出投影层,同时在其他层使用标准LoRA进行参数高效调优。可训练的路由分类器根据视觉标记内容和文本嵌入语义,动态选择最适合的特征变换专家。
本文设立 个专家,每个专家对应一个秩为 ,缩放因子为 的LoRA模块。对于每个输入标记,路由分类器 预测各专家的选择概率 。MoE-LoRA结构的输出计算如下:

其中, 和 (满足 )表示第 个 LoRA 专家的学习权重, 为输入标记。路由分类器为每个专家分配选择概率 ,最终输出为专家输出的加权和。在我们的实现中,采用稀疏 MoE 设置,仅选择 top- 个专家参与计算:

其中 函数仅保留向量中前 个条目的原始值,其余条目设为 。这确保了专家的高效使用,在保持多样化编辑任务灵活性的同时最小化计算开销。
早期过滤推理时间缩放
在推理过程中,初始噪声会显著影响编辑结果,某些输入能产生更符合人类偏好的输出(见下图10),这一现象也得到了近期研究的支持。这种变异性使研究推理时间缩放技术以提升编辑一致性和质量。在基于指令的编辑任务中,指令对齐的成功往往在少量推理步骤内就能显现(见下图6),这一特性与修正流DiT模型高度兼容。这些模型能高效遍历隐空间,仅需少量去噪步骤(有时仅需一步)即可生成高质量输出。因此,与需要更多步骤来实现细节和质量的生成任务不同,仅需少量步骤即可评估编辑成功率。


基于这一洞察,本文提出"早期过滤推理时间缩放"策略:首先生成 个初始噪声候选,对每个候选执行 步初步编辑( 为完整去噪步数);然后通过视觉大语言模型(VLM)评估这 个早期输出与指令的符合程度,采用类似冒泡排序的成对比较迭代篮选最优候选(见上图6);最终对优选种子执行完整的 步去噪生成最终图像。该方法能快速锁定优质噪声,同时通过VLM选择确保输出符合人类偏好。
实验
实现细节本文采用领先的开源基于DiT的修复模型FLUX.1 Fill作为主干网络。为微调混合LoRA-MoE模块,从公开资源整理了一个精简编辑数据集:在初始采用MagicBrush数据集(含9K编辑样本)的基础上,发现其存在:1)编辑类型不平衡、2)缺乏风格类数据、3)领域多样性不足等问题。因此额外加入OmniEdit数据集约40K样本构成最终训练集。模型配置采用LoRA秩32、MoE模块含4个专家、TopK值为1。推理缩放策略使用Qwen-VL-72B作为输出评估器。更多数据集、参数和对比研究细节见补充材料。
评估设置本文在Emu和MagicBrush测试集上进行了全面评估。对于含真实编辑结果(GT)的MagicBrush,严格遵循[47,48]计算CLIP、DINO和L1等指标来衡量与GT的偏差;而Emu测试集缺乏GT结果,遵照[39,48]进行基线评估,并参照[44]采用GPT-4o判断编辑成功率。为公平比较,所有模型均使用单一默认噪声输入评估,且不采用我们提出的早期过滤推理时间缩放技术。
CLIP和DINO等传统指标常与人类偏好不一致。为更准确评估编辑性能和视觉质量,还计算了VIE-Score:该指标包含SC分数(评估指令遵循和未编辑区域保留)和PQ分数(独立于源图像和指令的视觉质量),总分计算为Overall 。使用该指标衡量推理时间缩放策略的增益,并与顶级闭源商业模型SeedEdit进行对比。
与前沿方法的比较
MagicBrush与Emu测试集结果如下表1和表2所示,本文的模型在两类数据集上均达到SOTA级性能:在MagicBrush(表1)的输出与GT高度吻合,展现出强劲的编辑能力;在Emu(表2)则保持SOTA级文本对齐的同时更好地维持图像保真度。值得注意的是,基于GPT的评估分数显著优于开源模型,并逼近闭源的EmuEdit,而所需训练数据量却少得多。与同主干的DiT模型相比,本文的方法以更少的样本和参数实现了更优性能,凸显其高效性。定性结果见下图7。



VIE-Score评估如下图8所示,本文的模型在编辑准确性和视觉质量上均显著优于开源SOTA方法。通过随机种子测试,本文的性能接近SeedEdit,而采用推理缩放策略后总分实现超越。虽然SeedEdit因商业化打磨输出获得更高PQ分数,但在未编辑区域的保真度上常有不足;相比之下,本文的方法在这些区域保持更优保真度(见图9)。


消融实验
模型结构如前面表3所示,通过不同配置实验验证了方法的有效性。上下文编辑提示(IC提示)被证明具有关键作用:在免训练模型中显著优于直接编辑指令,而结合IC提示的微调进一步提升了编辑能力。LoRA-MoE设计以更少参数超越了标准LoRA微调,编辑质量和成功率提升13%(GPT评分),体现了其高效性。仅对输出投影层("Only MoE")进行适配会导致性能下降,证实了全模块微调的必要性。
推理时间缩放如前图8和图10所示,本文推理时间缩放策略使编辑性能显著提升:SC分数提高19%,VIE总分提升16%。使用固定或随机种子时,模型能生成可行结果但并非最优。通过VLM筛选多种子早期输出并选择最佳候选,实现了更优质的编辑效果。
数据效率下图2和前面表2显示,与免训练框架(FLUX.1 fill)相比,仅用0.05M训练样本就取得显著改进,远少于SOTA模型所需的10M样本,证明了框架的有效性和微调策略的高效性。

实际应用
和谐编辑如下图1和图11所示,本文的方法能生成与原始图像无缝衔接的和谐编辑结果。模型在编辑过程中智能适应周边语境,产生更自然真实的效果——这是以往方法难以实现的能力。


多样化任务如下图12所示,本文的方法可作为通用图到图框架,适用于手部精修、光影调整等实际任务。未来结合特定任务数据集微调,将进一步扩展其应用场景。

结论
In-Context Edit——一种基于DiT的新型指令编辑方法,通过极少量微调数据实现SOTA性能,在效率与精度间达到最佳平衡。首先探索了生成式DiT在免训练环境中的固有编辑潜力,进而提出混合LoRA-MoE微调策略提升稳定性和质量。此外,引入的推理时间缩放方法通过VLM从多种子中优选早期输出,显著改善编辑效果。大量实验证实了方法的有效性并展示了优越性能。相信这一高效精准的框架为指令式图像编辑提供了新思路,将在未来工作中持续优化。
参考文献
[1] Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
....
#JanusFlow
生成理解统一模型解读 (四):JanusFlow:使用 Rectified Flow 做生成的 Janus
DeepSeek 团队生成理解统一架构 Janus 的后续版本,借助 Rectified Flow 做生成。
本文介绍 DeepSeek 团队的 Janus 系列模型的后续版本 JanusFlow。Janus 系列是 DeepSeek 多模态团队的作品,是一种既能做图像理解,又可以做图像生成任务的 Transformer 模型。JanusFlow 将自回归的语言模型和 Rectified Flow 相结合。
JanusFlow 的主要发现表明,Rectified Flow 可以在 LLM 框架内直接训练,从而消除了对复杂架构修改的需要。为了进一步提高我们统一模型的性能,采用了 2 个关键策略:1) 解耦理解和生成编码器。2) 在统一训练期间对齐它们的表征。 JanusFlow 在各自的域中实现了与专业模型相当或更好的性能,同时在标准基准测试中显著优于现有的 Unified Model 方法。

图1:JanusFlow Benchmark Performance

图2:JanusFlow 视觉生成结果
下面是对本文的详细介绍。
1JanusFlow:使用 Rectified Flow 做生成的 Janus
论文名称:JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
论文地址:https://arxiv.org/pdf/2411.07975
项目主页:https://github.com/deepseek-ai/Janus
1.1 JanusFlow 模型
Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。JanusFlow 是 Janus 的后续版本,一个统一多模态模型,将 Rectified Flow 与 LLM 架构无缝集成。
为了让设计尽量简单,JanusFlow 只需一个轻量化的 Encoder 和 Decoder 来 adapt LLM 完成 Rectified Flow 的操作。为了优化 JanusFlow 的性能,作者实现了 2 个关键的策略:1) 维护单独的视觉编码器和解码器进行理解和生成任务,防止任务干扰,从而提高理解能力。2) 在训练期间对其生成和理解模块的中间表征,增强生成过程中的语义一致性。
与现有的 Unified Model 相比,JanusFlow 在多模态理解和文本到图像生成方面表现出最先进的性能,甚至优于几种专门的方法。具体来说,在文生图 Benchmark 上,MJHQ FID-30k、GenEval 和 DPG-Bench,JanusFlow 的得分分别为 9.51、0.63 和 80.09%,超过了现有文生图模型,包括 SDv1.5 和 SDXL。在多模态理解 Benchmark 中,JanusFlow 在 MMBench、SeedBench 和 GQA 上分别获得 74.9、70.5 和 60.3 的分数,超过 LLAVA-v1.5 和 Qwen-VL-Chat 等专门用于理解的模型。值得注意的是,这些结果来自只有 1.3B 参数的 LLM。
1.2 Rectified Flow
对于由从未知数据分布 中提取的连续恶数据点 组成的数据集 , Rectified Flow 通过学习定义在时间 上的常微分方程(ODE)来建模数据分布:

其中, 表示速度神经网络的参数, 是一个简单的分布,通常是标准的高斯噪声 。通过最小化 neural velocity 与连接 和 之间随机点的 linear path 方向之间的欧氏距离来训练网络。

这里, 是时间 上的分布。当网络具有足够的容量并且目标被完美地最小化时,最优速度场 将基本分布 映射到真实数据分布 。
更准确地说,分布 ,遵循 。
尽管 Rectified Flow 在概念上很简单,但在各种生成建模任务中表现出了优越的性能,包括文生图[1]等等。
1.3 JanusFlow 模型架构
JanusFlow 提出了一个统一框架,旨在解决视觉理解和图像生成任务。

图3:JanusFlow 架构示意。对于视觉理解,LLM 执行 Autoregressive 的 Next token prediction 生成响应。对于生成,LLM 使用具有 Rectified Flow。从 t=0 的高斯噪声开始,LLM 通过预测速度向量迭代更新 z_t,直到达到 t=1
多模态理解
在多模态理解任务中,LLM 处理由交错文本和图像数据组成的输入序列。文本被标记为离散 token,每个 token 都被转换为维度 的嵌入。对于图像,图像编码器 将每个图像 编码成形状为 的特征。这个特征图被 flattened 并通过线性变换层投影到一系列形状为 的 Embedding 中。 和 由图像编码器决定。文本和图像 Embedding 被连接起来形成 LLM 的输入序列,然后根据 Embedding 的输入序列 Autoregressive 地预测下一个 token。在图像之前添加了特殊标记|BOI|和图像后的 |EOI|,以帮助模型定位序列中的 Image Embedding。
图像生成
对于图像生成,LLM 以文本序列为 condition,并使用 Rectified Flow 生成相应的图像。为了提高计算效率,使用预训练的 SDXL-VAE 在 Latent Space 中生成。
生成过程首先在潜在空间中对形状为 的高斯噪声 进行采样,然后由生成编码器 处理成一系列嵌入 。这个序列与一个 time Embedding 连接,该 Embedding 表示当前时间步 (开始时刻 ),从而产生长度为 的序列。
与之前使用各种 Attention Masking 策略不同,作者发现 Causal Attention 就足够了。LLM的输出对应于 通过生成解码器 转换回 latent 空间,产生形状为 的 velocity 向量。该状态由标准欧拉求解器更新:

其中, dt 是用户定义的步长。作者在输入上用 替换 ,并迭代该过程,直到我们得到 ,然后由 VAE 解码器将其解码为最终图像。为了提高生成质量,在计算速度时使用无分类器指导(CFG):

其中, 表示 no condition 的 velocity,并且 控制 CFG 的大小。根据经验,增加 会产生更高的语义对齐。与多模态理解类似,使用特殊标记 指示序列中的图像生成的开始。
JanusFlow 采用解耦的编码器设计。JanusFlow 使用预训练的 SigLIP-Large-Patch/16 模型作为 来提取语义连续特征以进行多模态理解,同时使用从头开始初始化的单独 ConvNeXt Block 作为 和 ,选择其有效性。解耦编码器设计显著提高了 Unified Model 的性能。JanusFlow 的完整架构如图 3 所示。
1.4 JanusFlow 训练策略
JanusFlow 的训练分为 3 个阶段,如图 4 所示。

图4:JanusFlow 的 3 阶段训练
第 1 阶段:训练 Linear 层,生成编码器和生成解码器。
这一阶段的主要目标是训练 Linear 层 (之后的东西,可以理解为 Adaptor),Generation Encoder,Generation Decoder。这一阶段旨在使这些新的模块与 Pre-trained 的 LLM 和 SigLIP Encoder 有效适配。
第 2 阶段:联合预训练,除了理解编码器和 VAE Encoder 之外的所有组件都更新参数。
这个阶段训练整个模型,除了理解编码器和 VAE Encoder。训练结合了 3 种数据类型:多模态理解、图像生成和纯文本数据。作者最初分配更高比例的多模态理解数据来建立模型的理解能力。随后,增加了图像生成数据的比例,以适应基于扩散的模型的收敛要求。
第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
这个阶段作者使用指令调整数据微调预训练模型,其中包括对话、特定于任务的对话和高质量的文生图示例。在这个阶段,作者还解冻了 SigLIP Encoder 参数。这种微调过程使模型能够有效地响应用户指令以进行多模态理解和图像生成任务。
1.5 JanusFlow 训练目标
训练 JanusFlow 涉及两种类型的数据、多模态理解数据和图像生成数据。
这两种类型的数据都包含两部分:"Condition"和"Response"。"Condition"是指任务的提示 (例如,多模态理解任务中的 image,图像生成任务中的 text),而"Response"是指两个任务的响应。数据可以格式化为 ,其中上标 con 表示"Condition",而 res 表示"Response"。将整个序列 的长度表示为 ,将 的长度表示为 ,将 的长度表示为 。作者使用 来表示 JanusFlow 中所有可训练参数的集合,包括 LLM, , 和 Linear 层。
Autoregressive 训练目标
对于多模态理解任务, 仅包含文本标记。JanusFlow 使用最大似然原理进行训练,

其中,期望在多模态理解数据集 中接管所有 对,计算损失仅在 中的 token 上。
Rectified Flow 训练目标
对于图像生成任务, 由文本 token 组成, 是对应的图像。JanusFlow 使用 Rectified Flow 进行训练:

其中, 。在 Stable Diffusion 3 之后,将时间分布 设置为 Logit 正态分布。为了实现 CFG 推理,在训练期间随机丢弃 10\%的文本提示。
表征对齐正则化
对齐 Diffusion Transformer 和 Semantic Vision Encoder 之间的中间表征可以增强扩散模型的泛化能力。Janus 的解耦视觉编码器设计使这种对齐的有效实现成为一个正则化项。具体地说,对于生成任务,作者将理解编码器 的特征与 LLM 的中间特征对齐:

其中, 代表 LLM 的中间表征,给定输入 。 是一个小的可学习 MLP,把 映射到 维度。函数 计算嵌入之间的元素余弦相似度的平均值。
在计算 loss 之前,把 reshape 为 。作者确保 。 的梯度不会通过 Understanding Encoder 反向传播。这种对齐损失有助于 LLM 的内部特征空间(给定噪声输入 )与 Understanding Encoder 的语义特征空间对齐,从而在推理过程中从新的随机噪声和文本条件生成图像时提高生成质量。
所有 3 个目标都用于所有训练阶段。多模态理解任务使用 ,而图像生成任务使用损失 .
1.5 JanusFlow 实验设置
JanusFlow 建立在DeepSeek-LLM (1.3B) 的增强版本。LLM 由 24 个 Transformer Block 组成,支持 4,096 的序列长度。在 JanusFlow 中,理解和生成图像分辨率都为 384。
对于多模态理解,作者利用 SigLIP-Large-Patch/16 作为 。对于图像生成,作者利用预训练的 SDXL-VAE 作为其 latent space。生成编码器 包括 pathify 层,然后 2 个 ConvNeXt Block 和 Linear 层。生成解码器 结合了 2 个 ConvNeXt Block,一个 pixel- shuffle 层上采样和 Linear 层。SigLIP 编码器包含约 300M 参数。 和 是轻量级模块,总共包含约 70M 参数。图5详细说明了每个训练阶段的超参数。在 Representation Alignment 中,使用第 6 块之后的 LLM 特征作为 ,将 3 层 MLP 用作 。使用 0.99的指数移动平均(EMA)来确保训练稳定性。

图5:JanusFlow 每个阶段训练的超参数。数据比率表示多模态理解数据、图像生成数据和纯文本数据的比例。在第 2 阶段的初始 10,000 步中,应用 30:50:20 的数据比例来提高理解能力
JanusFlow 以不同的方式处理理解和生成数据。对于理解任务,将长边调整为目标大小并将图像填充到正方形来维护所有图像信息。对于生成任务,将短边的大小调整为目标大小,并应用随机裁剪来避免填充伪影。
在训练期间,多个序列被打包以形成长度为 4096 的单个序列以提高训练效率。JanusFlow 的实现基于使用PyTorch 的 HAI-LLM 平台。训练是在 NVIDIA A100 GPU 上进行的,每个模型需要约 1600 A100 GPU 天。
训练数据设置
第 1 阶段和第 2 阶段的数据
JanusFlow 的前 2 个阶段使用 3 种类型的数据:多模态理解数据、图像生成数据和纯文本数据。
- 多模态理解数据。 这种类型的数据包含多个子类别:(a) Image caption 数据:"Generate the caption of this picture. "。(b) 图表和表格。(c) 任务数据。ShareGPT4V 数据用于促进预训练过程中的基本问答能力:""。(d) 文本图像交织的数据。
- 图像生成数据。所有数据点都格式化为 ""。
- 纯文本数据。直接使用 DeepSeek-LLM 的文本语料库。
第 3 阶段的数据。 SFT 阶段还使用 3 种类型的数据:
- 多模态指令数据。
- 图像生成数据:"User:\n\n Assistant:"。
- 纯文本数据。
1.6 JanusFlow 评测视觉生成作者报告了 GenEval、DPG-Bench 和 MJHQ FID-30k 的性能。图 6 比较了 GenEval,包括所有子任务的分数和总分。JanusFlow 的总体得分为 0.63,超过了之前的统一框架和几个生成特定模型,包括 SDXL 和 DALL-E 2。

图6:GenEval benchmark 性能
图 7 比较了 DPG-Bench 的结果。除了 JanusFlow 外,其他模型都是专门做生成的。

图7:DPG-Bench 性能
GenEval 和 DPGBench 上的结果展示了 JanusFlow 的指令跟随能力。
图 8 比较了 MJHQ FID-30k 的结果。采样的图片是使用 CFG factor w=2 ,sampling steps 为 30 生成的。结果表明,Rectified Flow 能够在 Janus 等自回归模型上提高生成图像的质量。

图8:MJHQ FID30k 结果
多模态理解
图 9 展示了 JanusFlow 与其他方法的比较,包括专门做理解的模型和 Unified Model。JanusFlow 在具有相似参数量的所有模型中达到了最佳性能,甚至超过了多个专门做理解的方法。结果表明,JanusFlow 协调了自回归 LLM 和 Rectified Flow,在理解和生成方面都取得了令人满意的性能。

图9:与其他方法在多模态理解 benchmark 的比较
参考
- ^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
...
#「消失的」Ilya Sutskever
Ilya Sutskever,曾亲手缔造OpenAI的联合创始人,仿佛人间蒸发一般,只留下一家没有产品、没有收入、却估值高达300亿美元的公司Safe Superintelligence。当Altman在忙着打官司、重组OpenAI时,Ilya选择了「消失」,也许只为等待那个值得他出手的「超级智能」。
2025年的5月,Sam Altman「格外忙碌」:忙着和马斯克打官司,忙着改组公司架构,忙着花30亿美元收购Windsurf,忙着在X上吊网友的胃口。
相比之下,Ilya Sutskever却仿佛人间蒸发了一般。
最近的一条X还停留在2024年10月10日,祝贺自己的老师Hinton获得了诺贝尔物理学奖,顺便祝贺老朋友DeepMind的CEO Hassabis获得化学奖。
2个月后,在2024年12月的NeurIPS会议上,Ilya说大模型的预训练即将「终结」引发了人们对于LLMs前景的担忧。
此后,再无消息。
所以,Ilya本人在干嘛?
失败的「逼宫者」到神秘公司
作为2023年11月那场「宫斗大戏」的主角,事件发生后,Ilya在OpenAI的职位变得尴尬而模糊。
作为Sam Altman的合伙人,却扮演的是「逼宫者」的角色,虽然事后他签署联名信,希望Sam Altman回归。
但结局似乎已经注定,Sam Altman王者归来,Ilya被踢出董事会。
引发这场风波的是一封内部员工写给OpenAI董事会的信,据称公司出现了某个代号为「Q*」的技术突破。(外媒Wired猜测Q*很可能成为o‑系列的训练基石)
Ilya认为这个模型会对人类造成威胁,而Sam Altman急于商业化变现,矛盾由此爆发。
如果以DeepSeek-R1作为推理模型引发的春节热潮来看,Ilya的「先知先觉」似乎并没有错,只不过想错了方向,AI威胁人类还早,人类对于AI能力的追求目前仍然看不到尽头。
说回宫斗落幕,消失数月后,Ilya突然宣布,成立了一家「安全超级智能」公司(Safe Superintelligence Inc.)。
不得不说,Ilya这个名字就是「金字招牌」,开局3个人,什么产品都没发,就一个类似公开信的公司网站。
一个网页就能首轮融资10亿,估值50亿美金!
简直强的离谱,更离谱的还在后面。
SSI成立9个月后,依然没有发布任何的产品,没有发布任何的大模型。
在这个前提下,WSJ爆料,SSI又完成20亿美元新一轮融资,估值超300亿美元。
Ilya简直就是AI届的「赛博魅魔」。
没有产品、没有模型,甚至没有短期商业目标,仅仅是在官网上写着「使命就是安全超级智能」这样一个宏大的叙事命题,投资人就排着队的交钱。
这种事情也许只会发生在Ilya身上。
而Ilya对于「AI和人类」这种终极命题上的追寻似乎早有预兆。
师徒传承:为了人类
Ilya对于「AI造福人类」的执念似乎可以追溯他的老师——AI之父,Hinton。
Ilya作为Hinton的高徒,可以说师徒两人联手缔造了如今的AI-LLM时代。
从AlexNet时代到OpenAI,对于Ilya的印象一直是变秃了也变强了(同时也消失了)。
AlexNet时代的Ilya和OpenAI时代的Ilya
Hinton对于AI的安全性似乎一直有他独特的看法。
人们还没有真正理解即将到来的事情。
Hinton最近签署了一份联名信,公开抵制OpenAI重组!理由非常直接,OpenAI违背了他们的初衷,即确保AGI的安全开发和造福人类。
近期在接受CBS采访时,他表示,AI在未来可能「接管人类」的概率为10%到20%。
Hinton在各种公开场合都不断地强调,当前AI系统的学习和推理能力可能已经超越人类。
他警告说,这种能力使得「AI系统可能会设定与人类利益不一致的次级目标,进而采取措施防止被关闭」。
怎么听,怎么看,都和Ilya的SSI的使命完全一样!
Hinton一直批评大型科技公司在AI安全方面的投入不足,指出这些公司更关注利润而非安全。
Hinton建议,AI公司应将约三分之一的计算资源用于安全研究,而不是目前投入的微小比例——这个要求对于忙着互相竞争的AI公司,比如Google和OpenAI来说似乎有些困难。
也许,这也是Ilya被迫出走OpenAI后,成立SSI的初衷。
当然,Ilya真实的想法我们无从得知,因为他「消失了」。
即使你想旁敲侧击从SSI的其他员工入手一样是徒劳的。
很多人也许不知道,SSI的真正「办公室」位于以色列特拉维夫的市中心大厦(Midtown Tower)。
有传言,公司刻意不允许员工在社交媒体上透露身份。
如果按照Ilya曾明确表示过的,在开发出超级智能之前,不打算发布任何产品。
那么消失的Ilya也许会一直处于「失踪」的状态,直到一个安全的超级智能问世。
当我们还在被DeepSeek-R2、OpenAI o4吊足胃口时,也许说不定哪天Ilya就带着新模型闪亮登场了。
虽然Ilya玩起了「消失」,但是同属于OpenAI派系的老员工们可不甘寂寞。
OpenAI黑帮,正在硅谷崛起
和当年的Paypal黑帮类似,「OpenAI黑帮」在卷走超90亿美元融资后,撑起了半个AI江湖。
自从2018年马斯克离开OpenAI以来,属于「OpenAI黑帮」的公司已经超过30多家。
根据「旗舰」的分析,这些公司可以划为三大派系。
以Thinking Machines Lab为代表的「嫡系」:
由OpenAI前CTO Mira Murati领衔,Thinking Machines Lab几乎复刻OpenAI研发体系,强调开源与透明;Ilya Sutskever则创立SSI,誓言打造「不会毁灭人类的超级智能」,估值已达300亿美元。
早期出走的「颠覆者」:
Anthropic(Amodei兄妹)已成OpenAI最强对手;马斯克的xAI也集结多位OpenAI旧将,主打「开源+X平台数据闭环」,迅速崛起,而xAI和AI的合并更是挑战估OpenAI估值第一的位置。
重构产业的「破局者」:
搜索引擎革新者Perplexity、AI Agent开发商Adept、机器人智能公司Covariant,均由OpenAI旧部创立或主导。
目前,OpenAI的11位联合创始人中,只有Sam Altman和语言及代码生成团队负责人Wojciech Zaremba仍在职。
以下为这些OpenAI「黑帮们」目前的去向:
Dario Amodei、Daniela Amodei和John Schulman:AnthropicDario和Daniela Amodei兄妹于2021年离开 OpenAI,成立了自己的初创公司Anthropic,并致力于构建「安全的AGI」。2024年,OpenAI联合创始人John Schulman也加入了Anthropic。虽然OpenAI的收入仍然远高于Anthropic(前者2024年为37亿美元,后者为10亿美元),但Anthropic迅速成长为OpenAI最强大的竞争对手,并在2025年3月获得了615亿美元的估值。Ilya Sutskever:Safe Superintelligence
OpenAI联合创始人兼首席科学家Ilya Sutskever,在2024年5月离开OpenAI后不久,便共同创立了Safe Superintelligence,并表示SSI「只有一个目标和一个产品:打造安全的超级智能」。目前,关于SSI的具体业务细节非常少,既没有产品,也没有营收。尽管如此,投资者仍然趋之若鹜,纷纷希望能够参与投资。 据悉,SSI已经筹集了20亿美元,最新估值已达到320亿美元。
Mira Murati:Thinking Machines Lab
OpenAI的首席技术官Mira Murati在去年离开之后,也创立了自己的公司Thinking Machines Lab。这家公司于2025年2月正式浮出水面,并表示将构建能力更强的「定制化」AI。和SSI类似,Thinking Machines Lab也没有产品和收入,但也已经吸引了大量顶尖的OpenAI前研究人员。据悉,公司正在进行一轮高达20亿美元的种子轮融资,估值至少为100亿美元。
Aravind Srinivas:Perplexity
Aravind Srinivas曾在OpenAI担任研究科学家,2022年离职后共同创立了AI搜索引擎Perplexity。Perplexity吸引了包括Jeff Bezos和英伟达在内的一众知名投资者。截至2025年3月,公司正以180亿美元的估值寻求约10亿美元的融资。
Kyle Kosic:xAI
Kyle Kosic在2023年离开OpenAI后,加入了马斯克的AI初创公司xAI,担任联合创始人和基础设施负责人。然而,在2024年,他又重新回到了OpenAI。
Andrej Karpathy:Eureka Labs
计算机视觉专家Andrej Karpathy是OpenAI的创始成员和研究科学家。2017年,他离开OpenAI加入特斯拉,负责领导自动驾驶项目。2024年,他离开特斯拉,并创立了自己的教育科技初创公司Eureka Labs ,致力于开发AI教学助手。
Jeff Arnold:Pilot
Jeff Arnold曾在2016年担任了5个月的OpenAI运营主管。2017年,他共同创立了Pilot并出任COO,专注于为初创公司提供会计服务。2021年,Pilot完成了1亿美元的C轮融资,估值达到12亿美元。2024年,他离开Pilot并创办了一家风险投资基金。
David Luan:Adept AI Labs
David Luan曾在OpenAI担任工程副总裁,于2020年离职。2021年,在Google短暂工作一段时间后,他联合创立了Adept AI Labs,致力于为企业员工开发AI工具。2023年,Adept完成了3.5亿美元的融资,估值超过10亿美元。2024年底,亚马逊招揽了Adept的创始团队,Luan也随之加入,并负责AI智能体实验室。
Tim Shi:Cresta
Tim Shi OpenAI团队的早期成员,主要负责构建安全的AGI。他在OpenAI工作了一年后,于2017年离职创立了Cresta,专注于为联络中心提供AI技术。目前,Cresta已经从红杉资本、Andreessen Horowitz等风投机构筹集了超过2.7亿美元的资金。
Pieter Abbeel、Peter Chen和Rocky Duan:Covariant
Pieter Abbeel、Peter Chen和Rocky Duan三人都曾是OpenAI担任研究科学家(2016-2017年)。离职后,他们共同创立了Covariant,致力于为机器人构建AI基础模型。2024年,亚马逊收购了Covariant及其团队。
Maddie Hall:Living Carbon
Maddie Hall曾在OpenAI从事「特殊项目」,2019年离职后共同创立了Living Carbon,致力于创造经过基因工程改造的植物,来吸收更多二氧化碳,从而应对气候变化。据报道,Living Carbon在2023年完成了2100万美元的A轮融资,总融资额达到3600万美元。
Shariq Hashme:Prosper Robotics
Shariq Hashme于2017年在OpenAI工作了9个月,参与开发了一款能玩Dota的AI。在数据标注初创Scale AI工作几年后,他于2021年共同创立了Prosper Robotics,专注于为家庭用户开发机器人管家。
Jonas Schneider:Daedalus
Jonas Schneider曾领导OpenAI机器人团队的软件工程工作,2019年离职后共同创立了Daedalus,致力于为精密组件建造先进的工厂。去年,公司完成了2100万美元的A轮融资,获得了Khosla Ventures等机构的支持。
Margaret Jennings:Kindo
Margaret Jennings于2022年至2023年在OpenAI工作,之后离职共同创立了Kindo,主打面向企业的AI聊天机器人。Kindo已累计筹集超过2700万美元的资金。其中,在2024年完成了2060万美元的A轮融资。2024年,Jennings离开Kindo出任法国AI初创公司Mistral的产品和研究主管。
这些从同一家公司走出的工程师们,正在重构整个AI世界的版图。
OpenAI或许未能垄断通往AGI的道路,但它成功播下了一批批改变世界的「种子」。
在这个被AI疯狂重塑的时代,Ilya Sutskever的「消失」或许正是一种选择——不是逃避,而是蓄力。
他没有追逐热度,没有发布模型,甚至连社交媒体都刻意沉寂,却凭借一纸宣言和一个宏大的愿景,吸引了几十亿美金的资金和一众顶尖科学家的追随。
与此同时,那些从OpenAI走出的「黑帮」们,正在用各自的方式重塑着一条条通往AGI的道路。
当别人还在AI江湖中跑马圈地时,Ilya相信或许他应该守住Hinton传承给他的底线。
Ilya,正在等待那个值得他发布的「超级智能」。
参考资料:
https://mp.weixin.qq.com/s/whESiHkB58IuK69OYKOB1w
...
#「多元宇宙」Multiverse
全球首款AI生成多人游戏诞生,全部开源,单机可玩,成本不到1500美元
今天,又一个「世界首创」头衔被认领了。以色列创业团队 Enigma Labs 宣布造出了世上首个 AI 生成的多人游戏 Multiverse,即「多元宇宙」。
,时长00:26
很显然,这是一个多人赛车游戏。「玩家可以超车、漂移、加速 —— 然后再次相遇。每一次行动都会为重塑这个世界。」
开发者 Jonathan Jacobi 表示,多人游戏曾是 AI 生成世界中缺失的拼图,而 Multiverse 成功补齐这一空白,而玩家能够实时地与这个 AI 模拟的世界进行交互并塑造它。
更让人吃惊的是,Multiverse 的训练和研发成本加起来还不到 1500 美元,其中包括数据收集、标注、训练、后训练和模型研究。并且,它还可以直接在个人电脑上运行!

Jonathan Jacobi 写到:「多人世界模型远远不止于游戏——它们是模拟的下一步,可解锁由玩家、智能体和机器人塑造的动态的、共同进化的世界。」
不仅如此,该团队也宣布将会开源与该研究成果相关的一切,包括代码、数据、权重、架构和研究。另外,Enigma Labs 也发布了一篇技术博客,介绍了 Multiverse 背后的一些故事和技术。
GitHub:https://github.com/EnigmaLabsAI/multiverse
Hugging Face:https://huggingface.co/Enigma-AI
技术博客:https://enigma-labs.io/blog
团队介绍
该团队来自以色列,成员包括以色列的前 8200 部队成员以及一些领先的创业公司成员,拥有丰富的研究和工程开发经验,涵盖漏洞研究、算法、芯片级研究和系统工程。
他们写到:「我们秉持第一性原理思维,解决了 AI 生成世界中的一项开放性挑战:多人世界模型。」
Multiverse 架构解读

单人游戏架构回顾
要了解多人世界模型的架构,首先回顾一下单人世界模型中使用的现有架构:

该模型接收视频帧序列以及用户的操作(如按键),并利用这些信息根据当前操作预测下一帧。
它主要由三个部分组成:
- 动作嵌入器——将动作转换为嵌入向量;
- 去噪网络——根据前一帧和动作嵌入生成一帧的扩散模型;
- 上采样器(可选)——另一个扩散模型,用于接收世界模型生成的低分辨率帧,并增加输出的细节和分辨率。
多人游戏架构
为了构建多人游戏世界模型,该团队保留了上面的核心构建模块,但对结构进行了拆解 —— 重新对输入和输出进行了连接,并从头开始重新设计了训练流程,以实现真正的合作游戏:
- 动作嵌入器——获取两个玩家的动作,并输出一个代表它们的嵌入;
- 去噪网络——一个扩散网络,它能基于两个玩家之前的帧和动作嵌入,以一个实体的形式同时生成两个玩家的帧;
- 上采样器——此组件与单人游戏组件非常相似。不过这里的上采样器会分别接收两个玩家的帧,并同时计算上采样后的版本。

为了打造多人游戏体验,模型需要收集双方玩家之前的帧和动作,并输出各自预测的帧。关键在于:这两个输出不能仅仅看起来美观——它们需要在内部保持一致。
这是一个真正的挑战,因为多人游戏依赖于共享的世界状态。例如,如果一辆车漂移到另一辆车前面或发生碰撞,双方玩家都应该从各自的视角看到完全相同的事件。
该团队提出了一个解决方案:将双方玩家的视角拼接成一张图像,将他们的输入融合成一个联合动作向量,并将这一切视为一个统一的场景。

于是问题来了:怎样才能最好地将两个玩家视图合并为模型可以处理的单一输入?
- 显而易见的做法是将它们垂直堆叠,就像经典的分屏游戏一样;
- 一个更有趣的选择是沿通道轴堆叠,将两帧图像视为具有两倍色彩通道的图像。

答案是方案 2,即沿通道轴堆叠。因为这里的扩散模型是一个 U 型网络,主要由卷积层和解卷积层组成,所以第一层只处理附近的像素。如果将两个帧垂直堆叠,那么直到中间层才会对帧进行处理。这就降低了模型在帧间产生一致结构的能力。
另一方面,如果将帧按通道轴堆叠,则网络的每一层都会同时处理两名玩家的视图。

车辆运动学和相对运动的高效上下文扩展
为了准确预测下一帧,模型需要接收玩家的动作(如转向输入)和足够的帧数,以计算两辆车相对于道路和彼此的速度。
在研究中,作者发现 8 帧(30 帧/秒)的帧数可以让模型学习车辆运动学,如加速、制动和转向。但两辆车的相对运动速度要比道路慢得多。例如,车辆的行驶速度约为 100 公里/小时,而超车的相对速度约为 5 公里/小时。
为了捕捉这种相对运动,需要将上下文的大小扩大近三倍。但这样做会使模型速度过慢,无法进行实时游戏,增加内存使用量,并使训练速度大大降低。
为了保持上下文大小,但又能提供更多的时间信息,作者为模型提供了前几帧和动作的稀疏采样。具体来说,他们向模型提供最近的 4 个帧。然后在接下来的 4 个帧中每隔 4 个帧提供一次。上下文中最早的一帧为 20 帧,即过去 0.666 秒,足以捕捉到车辆的相对运动。此外,这还能让模型更好地捕捉到与路面相比的速度和加速度,从而使驾驶的动态效果更加出色。

多人游戏训练
为了学习驾驶和多人互动,模型需要对这些互动进行训练。世界模型中的行走、驾驶和其他常见任务需要较小的预测范围,例如 0.25 秒的未来预测。
多人交互则需要更长的时间。在 0.25 秒内,玩家之间的相对运动几乎可以忽略不计。训练多人世界模型需要更长的预测时间。因此,作者对模型进行了训练,以预测未来 15 秒内的自回归预测(30 帧/秒)。
为了让模型能够执行如此长的预测范围,此处采用了课程学习的方法,并在训练过程中将预测范围从 0.25 秒增加到 15 秒。这样,在初始训练阶段,即模型学习汽车和赛道几何等低级特征时,就能进行高效训练。当模型学会生成连贯的帧和车辆运动学建模后,就可以对球员的行为等高级概念进行训练。
在增加预测范围后,模型的目标持久性和帧间一致性都有了显著提高。
高效的长视野训练
训练未来 100 帧以上的模型对 VRAM 提出了挑战。在批尺寸较大的情况下,将帧加载到 GPU 内存中进行自回归预测变得不可行。
为了解决内存不足的问题,作者以页面为单位进行自回归预测。
在训练开始时,加载第一批帧并进行预测。

然后加载下一页,并放弃上下文窗口之外的帧。

Gran Turismo 数据集:生成与收集
该团队训练模型的数据收集自索尼的游戏《GT 赛车 4》(Gran Turismo 4)。他们打趣地表示:「这只是一个技术演示,我们是铁粉,所以请不要起诉我们。」
设置和游戏修改
他们使用了较为简单的测试用例:在筑波赛道(Tsukuba Circuit)上的 1v1 比赛,视角是第三人称。筑波赛道比较短,道路也简单,非常适合训练。
但问题也有:《GT 赛车 4》并不支持玩家以 1v1 模式全屏运行筑波赛道。该游戏仅支持 1v5 或分屏对战模式。因此,该团队对游戏进行了逆向工程和修改,从而可以真正的 1v1 模式启动筑波赛道:

数据收集
为了收集双方玩家的第三人称视频数据,该团队利用了游戏内置的回放系统 —— 每场比赛回放两次,并从每位玩家的视角进行录制。然后,该团队将两段录像同步,使其与原始的双人比赛画面一致,并将它们合并成一段两位玩家同时比赛的视频。
那么,该团队采用了什么方法来捕捉数据集中的按键动作,更何况其中一位玩家是游戏机器人而非人类?
幸运的是,该游戏会在屏幕上显示足够多的 HUD 元素(例如油门、刹车和转向指示灯);这些信息可用于准确地重建达到每个状态所需的控制输入:

该团队利用计算机视觉逐帧提取了这些方框中的信息,并解码了其背后的控制输入,进而重建得到了完整的按键操作,从而无需任何直接输入记录即可构建完整的数据集。
自动的数据生成
乍一看,我们似乎不得不坐下来手动玩游戏几个小时,为每场比赛录制两次回放 —— 这就有点痛苦了。
虽然 Multiverse 的部分开源数据集确实来自手动游戏,但作者发现了一种更具可扩展性的方法:B-Spec 模式。在这个模式下,玩家可以使用游戏手柄或方向盘来指示游戏机器人驾驶员代表他们进行比赛。

由于 B-Spec 的控制功能有限且简单,作者编写了一个脚本,向 B-Spec 发送随机输入,自动触发比赛。之后,同一个脚本会从两个视角录制回放画面,从而捕捉这些 AI 驱动比赛的第三人称视频。
作者还尝试使用 OpenPilot 的 Supercombo 模型来控制赛车,本质上是将其变成了游戏中的自动驾驶智能体。虽然这种方法有效,但最终显得多余 —— 因此,最终版本中还是使用 B-Spec 进行数据生成:

多人游戏世界模型不仅仅是游戏领域的一项突破,更是人工智能理解共享环境的下一步方向。通过使智能体能够在同一个世界中学习、响应和共同适应,这些模型开启了新的可能性。
...
#T2I-R1
文生图进入R1时刻:港中文MMLab发布
姜东志,香港中文大学MMLab博士,研究方向为理解与生成统一的多大模型及多模态推理。在ICML, ICLR, NeurIPS, ECCV, ICCV等顶级会议上发表过论文。
最近的大语言模型(LLMs)如 OpenAI o1 和 DeepSeek-R1,已经在数学和编程等领域展示了相当强的推理能力。通过强化学习(RL),这些模型在提供答案之前使用全面的思维链(CoT)逐步分析问题,显著提高了输出准确性。最近也有工作将这种形式拓展到图片理解的多模态大模型中(LMMs)中。然而,这种 CoT 推理策略如何应用于自回归的图片生成领域仍然处于探索阶段,我们之前的工作 Image Generation with CoT(https://github.com/ZiyuGuo99/Image-Generation-CoT)对这一领域有过首次初步的尝试。
与图片理解不同,图片生成任务需要跨模态的文本与图片的对齐以及细粒度的视觉细节的生成。为此,我们提出了 T2I-R1—— 一种基于双层次 CoT 推理框架与强化学习的新型文本生成图像模型。
- 论文标题:T2I-R1: Reinforcing Image Generation with Collaborative Semantic-level and Token-level CoT
- 论文地址:https://arxiv.org/pdf/2505.00703
- 代码地址:https://github.com/CaraJ7/T2I-R1
- 机构:港中文 MMLab、上海 AI Lab
方法介绍
具体而言,我们提出了适用于图片生成的两个不同层次的 CoT 推理:

Semantic-CoT
- Semantic-CoT 是对于要生成的图像的文本推理,在图像生成之前进行。
- 负责设计图像的全局结构,例如每个对象的外观和位置。
- 优化 Semantic-CoT 可以在图片 Token 的生成之前显式地对于 Prompt 进行规划和推理,使生成更容易。
Token-CoT
- Token-CoT 是图片 Token 的逐块的生成过程。这个过程可以被视为一种 CoT 形式,因为它同样是在离散空间中基于所有先前的 Token 输出后续的 Token,与文本 CoT 类似。
- Token-CoT 更专注于底层的细节,比如像素的生成和维持相邻 Patch 之间的视觉连贯性。
- 优化 Token-CoT 可以提高生成图片的质量以及 Prompt 与生成图片之间的对齐。

然而,尽管认识到这两个层次的 CoT,一个关键问题仍然存在:我们怎么能协调与融合它们?
当前主流的自回归图片生成模型如 VAR 完全基于生成目标进行训练,缺乏 Semantic-CoT 推理所需的显式文本理解。虽然引入一个专门用于提示解释的独立模型(例如 LLM)在技术上是可行的,但这种方法会显著增加计算成本、复杂性和部署的困难。最近,出现了一种将视觉理解和生成合并到单一模型中的趋势。在 LMMs 的基础上,这些统一 LMMs(ULMs)不仅可以理解视觉输入,还可以从文本提示生成图像。然而,它们的两种能力仍然是解耦的,通常在两个独立阶段进行预训练,没有明确证据表明理解能力可以使生成受益。
鉴于这些潜力和问题,我们从一个 ULM(Janus-Pro)开始,增强它以将 Semantic-CoT 以及 Token-CoT 统一到一个框架中用于文本生成图像:

我们提出了 BiCoT-GRPO,一种使用强化学习的方法来联合优化 ULM 的两个层次的 CoT:
我们首先指示 ULM 基于 Image Prompt 来想象和规划图像来获得 Semantic-CoT。然后,我们将 Image Prompt 和 Semantic-CoT 重新输入 ULM 来生成图片以获得 Token-CoT。我们对于一个 Image Prompt 生成多组 Semantic-CoT 和 Token-CoT,对于得到的图像计算组内的相对奖励,从而使用 GRPO 的方法来在一个训练迭代内,同时优化两个层次的 CoT。
与图片的理解任务不同,理解任务有明确定义的奖励规则,图像生成中不存在这样的标准化的规则。为此,我们提出使用多个不同的视觉专家模型的集成来作为奖励模型。这种奖励设计有两个关键的目的:
- 它从多个维度评估生成的图像以确保可靠的质量评估
- 作为一种正则化方法来防止 ULM 过拟合到某个单一的奖励模型

根据我们提出的方法,我们获得了 T2I-R1,这是第一个基于强化学习的推理增强的文生图模型。
实验
根据 T2I-R1 生成的图片,我们发现我们的方法使模型能够通过推理 Image Prompt 背后的真实意图来生成更符合人类期望的结果,并在处理不寻常场景时展现出增强的鲁棒性。


同时,定量的实验结果也表明了我们方法的有效性。T2I-R1 在 T2I-CompBench 和 WISE 的 Benchmark 上分别比 baseline 模型提高了 13% 和 19% 的性能,在多个子任务上甚至超越了之前最先进的模型 FLUX.1。


...
#联想个人超级智能体
手机、PC更强大脑来了!开始觉醒L3级智能水平
从天禧到城市中枢,联想用超级智能体重塑个人、企业、城市AI格局。
2025 年的 AI 圈,你要说最火的是什么?推理模型是一个,尤以国产 DeepSeek-R1 为代表;另一个要属智能体了,以 Manus、Operator 为代表。
很多大佬如 OpenAI CEO 奥特曼、Anthropic CEO Dario Amodei 都看好智能体的发展前景,2025 更被业内广泛认为是智能体爆发的元年。可以说,智能体正在深刻改变着人机交互范式,为个人、企业带来工作效率和生产力的显著提升;同时又加速了端侧 AI 落地的速度。
如今,联想从智能体所能驾驭的能力、覆盖的场景等多个层面往前推了一大步。
5 月 7 日,在以「让 AI 成为创新生产力」为主题的联想创新科技大会(Tech World)上,联想集团董事长兼 CEO 杨元庆首次亮出了「超级智能体」概念,并定义超级智能体的三大核心能力,即感知与交互、认知与决策、自主与演进。伴随这三大核心能力而来的是,个人创造力的极大释放、企业增长动能的极大增加。
联想集团董事长兼 CEO 杨元庆
会上,杨元庆正式发布了从个人、企业到城市场景的超级智能体矩阵,包括联想天禧个人超级智能体、联想乐享企业超级智能体、联想城市超级智能体及新一代联想推理加速引擎,其中:
- 个人版「天禧」可跨设备调用日历、邮件及个人云数据,实现复杂任务的自主编排;
- 企业版「乐享」则化身硅基员工,无缝对接市场、销售、采购等全流程;
- 城市级智能体已在武夷山、宜昌等地的实践中,验证城市治理并提供社会服务的可行性。
这意味着,当大语言模型进入到「强推理 + 端侧化」的新阶段,联想通过超级智能体展现出了更大的愿景 —— 将其打造为新时代的「认知操作系统」。
这也是继其押注 AI PC 之后,联想在端侧打造 AI 超级入口的又一重大举措,在超级智能体的规模化落地进程中加速 AI 普惠。
「超级」智能体
已经进化成这样了
作为与每个人关系最密切的个人智能体,联想赋予了天禧个人超级智能体更强大、更全面、更友好的能力,让再复杂的 AI 任务都可以一触即达。
首先是感知与交互,天禧实现了多模态感知和意图驱动的自然交互。当你用手机刷到朋友圈里很吸引人的好友游记,就可以用语音告诉天禧「这地方看起来不错,找时间和家人去一趟」。天禧立即能激活智能情境感知功能,识别照片中的景点信息,根据你习惯的度假时间以及日程表上的空闲时段,提出度假时间候选,并通过和你的自然对话确认你的精准意图。
其次是认知与决策,天禧能调用跨设备数据所整合的个人知识库,帮你做出推理和判断。在设计旅行方案时,调用长期记忆偏好,确定亲友关系,推荐交通和食宿,基于过往的消费习惯做预算,还能整合公开信息,包括酒店房态、天气预测和餐饮评价等等,做出具体方案。
最后是自主与演进,天禧能自主拆解复杂任务、规划步骤并主动执行。例如自动拆分旅行安排并完成酒店预订、餐厅预约、路线推送和通知提醒。未来我们还可以通过多智能体交互让你的智能体和亲友智能体一起商量行程安排。整个过程中,你的点滴反馈都会成为天禧进一步优化的燃料。
显然,天禧已经形成了从「听懂你」到「理解你」再到「为你执行」的完整链路。
在当天的发布会上,歌手大张伟惊喜现身,演示了天禧个人超级智能体的更多玩法,让它的能力释放更具实感。
首先生成一些大张伟风格的段子,确实有那个味。
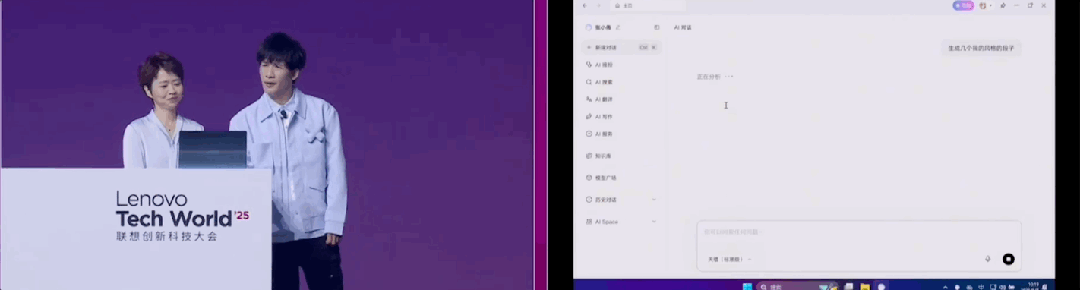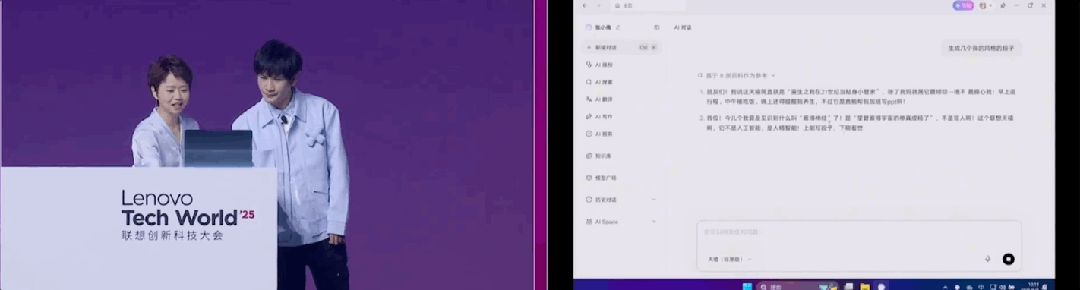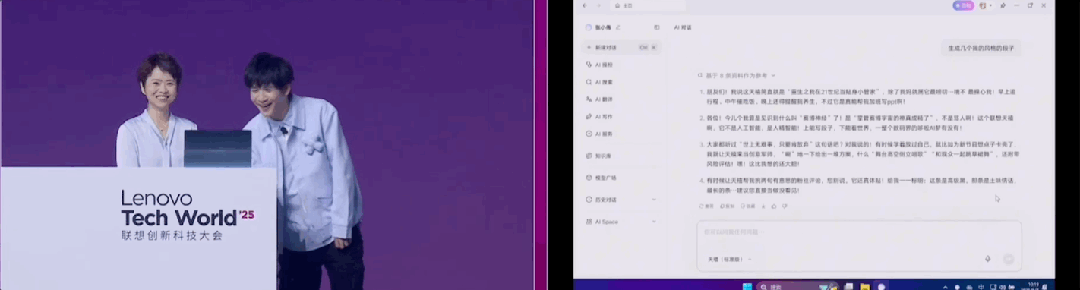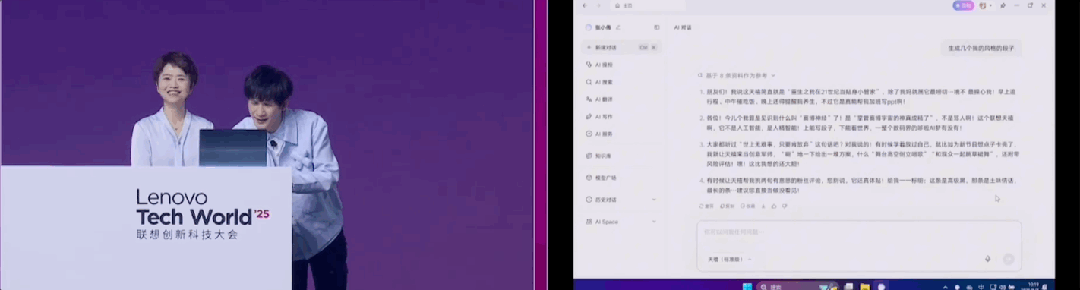
再为大张伟安排一份行程,天禧精准理解意图,在经过推理之后敏锐捕捉到日程安排存在的冲突,因而分析各项安排调整的可能性,并重新完成日程规划。
过程中,天禧发挥了其跨生态的多智能体协作能力,像总指挥一样依次调用了日历、地图、车辆预约等工具来协同工作,一气呵成,省去了跨应用操作的麻烦。
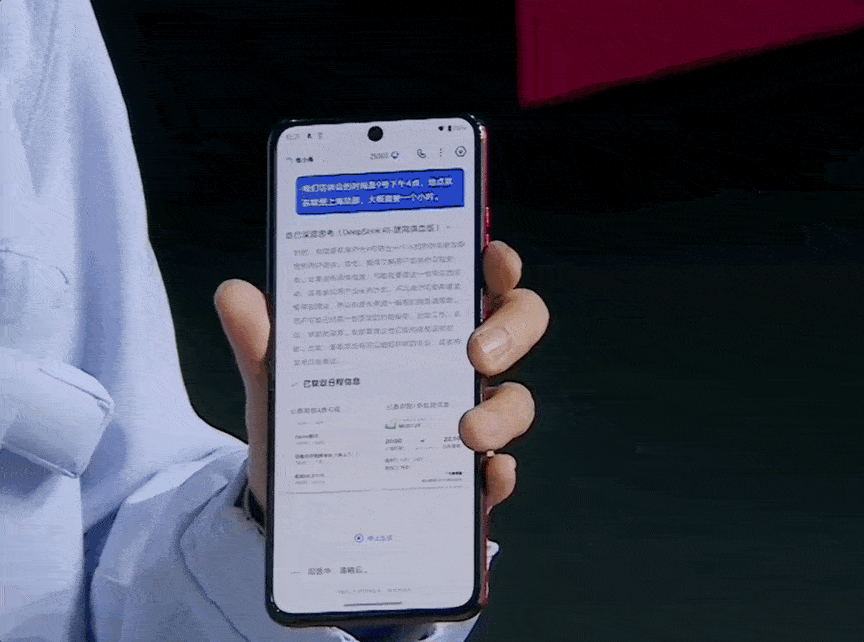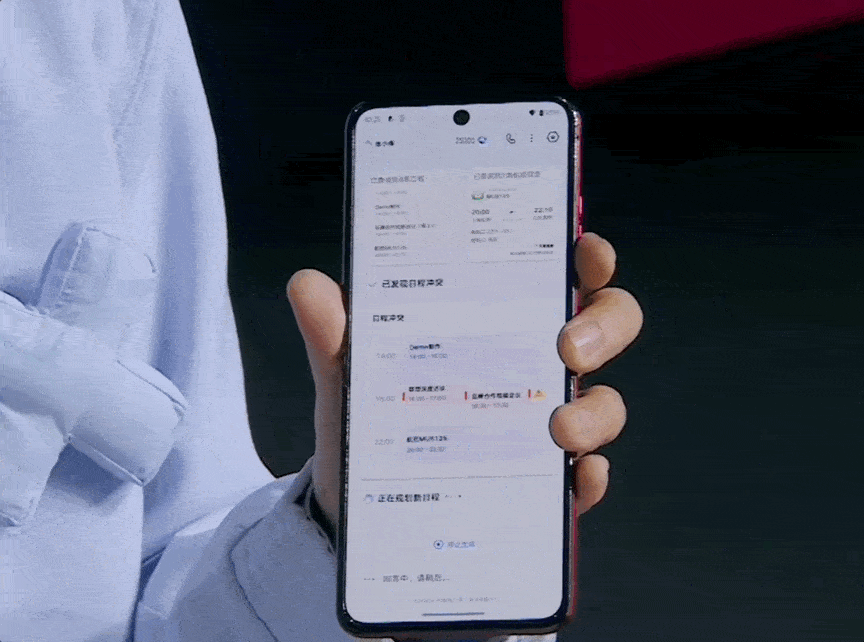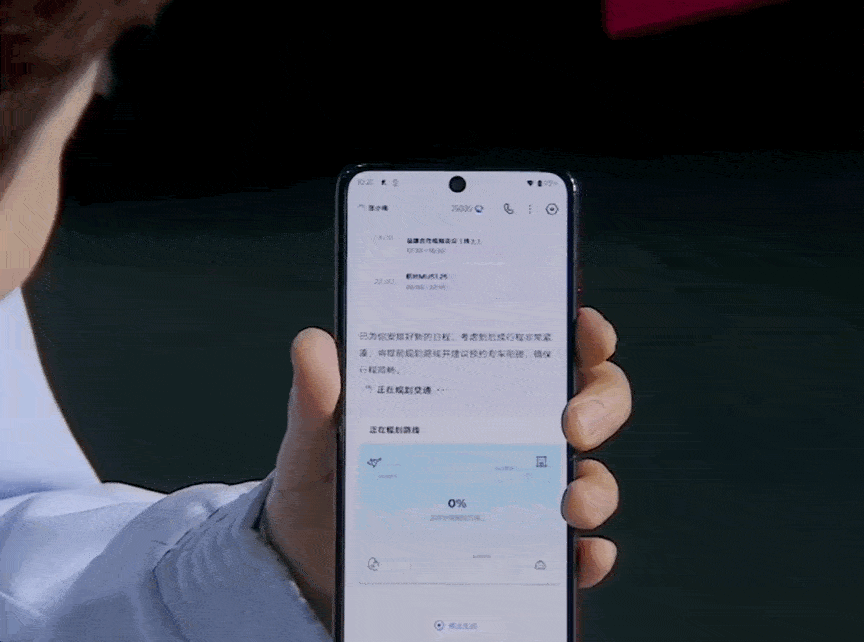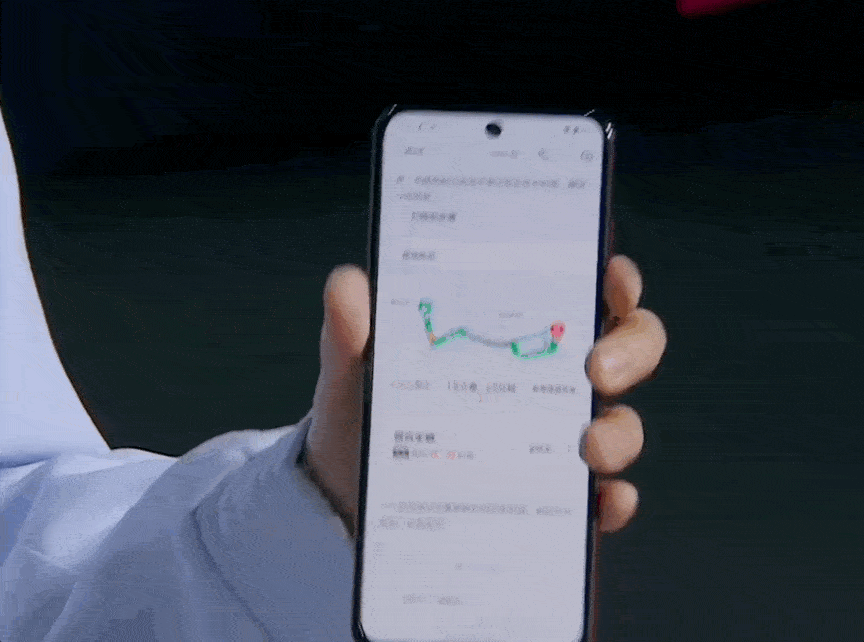
联想还发布了四款搭载天禧个人超级智能体的智能终端设备,包括 AI 元启版 moto razr 折叠屏手机,它是首款 L3 协作级 AI 智能手机,一键直通 AI;AI 元启版 Yoga 平板,搭载联想自研的独特 AI 交互引擎,让思想直达笔尖,所思即所见;全球首款卷轴屏 AI PC ThinkBook:柔性屏动态扩展至 16.7 英寸,扩大将近 50% 额外屏幕,视野更广阔,效率大幅提升;3D 拯救者:顶级图像渲染,集成灵敏光线追踪,AI 让游戏栩栩如生。

在通过更懂人类意图、更自然连贯的交互来为个人减负之外,联想的超级智能体同样为企业、城市场景的深拓带来了更多想象空间。
联想首个企业超级智能体 —— 联想乐享,深度集成全域业务数据与知识资产,具备从供应链优化到市场营销的全链条智能,真正实现了「硅基生命」与实体业务的同频共振。从「工具」到「硅基生命共同体」,乐享可以化身为产品经理、明星销售或资深采购,甚至是服务工程师。
乐享不仅仅是一名员工,而是包罗万象、无所不能的「员工之集大成者」,表现出了 AI 对组织架构、流程决策、人机协作的深度介入与替代能力,代表了 AI for Enterprise 的新形态。
联想首位硅基员工「联想乐享壹号」人形机器人
在城市场景,联想构建「1×N 城市超级智能体」架构,即 1 个城市核心中枢,协同多个领域智能体。其中核心中枢负责意图理解、任务规划、调度执行,并通过宏观层面完成计算与资源调度,实现城市治理并提供社会服务,从而形成「全局统筹 + 专业执行」的协作体系。
这是智能体作为社会基础设施的首次落地尝试,有望推动未来 AI 进入「公共智能」时代。
L3 级智能水平逐步到来
在 5 月 8 日的联想天禧 AI 生态春季新品超能之夜,我们看到了天禧个人超级智能体的更多技术细节以及运行在手机等终端设备上的新奇体验。

天禧整体架构
作为终端设备 AI 大脑,天禧以多模态交互、全时空记忆与主动任务规划三大超级能力重构人机协作逻辑,具体如下:
- 在多模态交互层面,深度融合语音、文本、图片及视觉交互能力,实现与用户的自然无缝沟通;
- 全时空记忆能力则突破传统存储局限,整合设备端与云端全域知识库,随时按照场景需要,自主检索、调取应用;
- 主动任务规划能力则标志着 AI 从被动响应到主动协作的质变,不仅能理解用户的表层需求,更能自动分解复杂任务为可执行步骤,主动协作完成任务。
为了提供因人而异的深度个性化响应,并实现一种「无形而智能」的自然交互体验,天禧引入了三大伴随式 AUI 界面 ——「AI 随心窗」、「AI 玲珑台」和「AI 如影框」。
其中,AI 随心窗集成所有功能与应用,并内置了「Model Plaza」模型广场,聚合行业顶级大语言模型,包括 DeepSeek-R1、豆包、文心一言、通义千问、Kimi 等,可以做到一站式灵活调用。

AI 玲珑台则化身「隐形管家」,在需要时主动推送服务建议、展示任务进度,空闲时自动退居幕后,保障免打扰的交互体验。伴随态的 AI 如影框如影随形,在写作时自动浮现实时翻译、改写选项,绘画时精准推荐笔触与配色方案,让辅助工具「恰逢其时」地出现。

AI 如影框辅助绘画
如今的 AI 在追求更高性能的同时,还特别重视安全与隐私保护。天禧采用了端云混合部署架构,可以无缝地运行在 Windows、Android、Linux 设备操作系统之上,指数级提升算力,为联想 AI 设备提供超强性能支持。
不仅如此,联想与火山引擎共建的可信私密云方案 —— 联想个人云 1.0 也首次亮相,云端搭载 720 亿参数大语言模型,为联想各类 AI 设备打破端侧 AI 算力的束缚,提供更加强大的端云混合算力。此外为用户提供 100G 专属记忆空间,结合 RAG 向量化技术实现端云混合的全域知识部署。

随着天禧利用五大黄金功能(AI 操控、AI 搜索、AI 翻译、AI 笔记和 AI 服务)重塑智能体验,L3 级别的智能水平正在一步步走来,即能够深度思考、自主规划编排、并最终完成复杂任务。

从「工具」到「伙伴」,联想正在用个人超级智能体定义人机关系新物种。
....
#OpenAI搞了个大联合
ChatGPT+GitHub
从此以后,ChatGPT 可以帮你分析 GitHub 了。
现在,ChatGPT 可以直接连接 GitHub 了,解锁 Deep Research 超强技能!

使用起来非常简单,点击「Deep Research → GitHub」即可开始使用。

你只管提问题,接到指令后,Deep Research 会搜索代码库的源代码和 PR,并返回包含引用的详细报告。
官方还放出了完整操作过程,大家可以真实感受一下:
,时长00:46
不难看出,以后,开发者可以针对代码库和技术文档向 ChatGPT 提问了。
据 OpenAI 发言人透露,该功能将在未来几天向 ChatGPT Plus、Pro 及 Team 用户开放,企业版和教育版支持也将很快跟进。
除了回答有关代码库的问题,该功能还允许 ChatGPT 总结代码结构和模式,并了解如何使用真实的代码示例实现新的 API。
当然,幻觉问题依然存在,OpenAI 宣称这项新功能是为了帮助大家节省时间,而不是为了取代人类。
此外,大家关心的隐私问题,OpenAI 也考虑了,ChatGPT 将尊重组织设置,因此用户只能看到他们已获准查看的 GitHub 内容以及明确与 ChatGPT 共享的代码库。
最近一段时间,我们看到 OpenAI 持续加码辅助编程工具的开发,近期先后推出了开源终端编程工具 Codex CLI,并升级 ChatGPT 桌面应用使其支持多款开发者编程软件的代码读取。该公司始终将编程视为其核心模型的首要应用场景 ——OpenAI 将斥资约 30 亿美元收购 AI 编程助手初创公司 Windsurf 就是最好的证明。
同日,OpenAI 还为大家带来了另一个好消息:开发者现可通过强化微调技术对 o4-mini 推理模型进行优化。
GPT-4.1 nano 模型亦已同步开放微调功能,现在用户可以根据具体应用场景训练这款速度最快、成本最优的模型,充分释放其潜能。

,时长00:41
OpenAI 表示,只有经过验证的组织才能对 o4-mini 进行微调。与此同时,GPT-4.1 nano 微调功能面向所有付费开发者开放。
ChatGPT 直连 GitHub 你用了吗,效果如何?欢迎大家评论区留言。
参考链接:
...
#VLM as Policy
KuaiMod来了!快手用大模型重构短视频生态格局
在短视频成为亿万用户日常生活标配的当下,它不仅是一种娱乐方式,更是人们获取信息、表达观点、构建社交的主要媒介。随着内容量的井喷式增长,平台面临着前所未有的挑战:一方面,需要更高效地识别和管理内容;另一方面,必须精准地将优质内容推送给真正感兴趣的用户。
大模型技术,尤其是多模态大模型,正迅速成为人工智能领域的新引擎,具备强大的图文音视频理解能力。但在短视频生态这一复杂、高速演化的场景中,如何将这些技术真正落地,仍是一道难解的行业命题。
作为国内领先的短视频社区,快手对利用多模态大模型重塑短视频生态做出了尝试,提出了基于多模态大模型的短视频平台生态优化和综合用户体验改善方案,并在实际部署中取得了显著的成效。这一创新举措不仅为短视频平台的健康发展提供了新的思路,也为行业树立了标杆。
基于多模态大模型的短视频生态优化方案
低质内容广泛存在于各个媒体平台,识别和过滤这些内容是改善用户体验和平台生态的重要环节。但传统视频质量判别方案高度依赖静态规则和标注人员判别,造成了高昂的判断成本,且难以适应用户反感内容的动态性,现有的自动化质量判别方案主要通过关键词匹配和大语言模型的提示工程(Prompt Engineering)完成内容的识别与过滤,难以保证识别过滤的准确率。当前工业界尚缺乏面向短视频平台的内容质量评测标准和成熟的自动化识别解决方案。
快手独立完成了首个面向短视频平台的内容质量判别基准测试构建工作,依托自身生态,打造了覆盖 1000 条真实平台短视频、涵盖 4 类主要劣质内容与 15 类细粒度劣质内容类型的数据集,并进一步提出了工业级自动化短视频质量判别框架 KuaiMod。区别于依赖成文规定的大陆法(Civil Law)体系判别策略,KuaiMod 借鉴判例法(Common Law)在灵活性方面的优势,基于视觉语言模型(VLMs)的链式推理(Chain-of-Thought)深入剖析导致视频引发用户反感的原因,利用判例定义判别策略,从而攻克短视频平台中劣质内容动态变化的难题。KuaiMod 方案广泛使用基于用户反馈的强化学习策略帮助通用 VLM 完成面向视频质量判别任务的离线适配和在线更新,模型通过更新判例实时掌握平台趋势,保证对新生的劣质内容的准确识别。
在离线测试中,KuaiMod-7B 模型在四种主要劣质类别上整体准确率高达 92.4%,相对于其他判别方案提升超过 10%。
目前 KuaiMod 判别方案已经在快手平台全面部署,为百万级日新视频提供质量判别服务,保障数亿用户的使用体验。A/B 测试表明 KuaiMod 使用户举报率降低超过 20%,展现出巨大的工业潜力。
为了促进短视频平台生态优化社区发展,当前 KuaiMod 的评测标准以及详细技术方案论文均已全面开源。
论文:VLM as Policy: Common-Law Content Moderation Framework for Short Video Platform
📖 arXiv Paper:https://arxiv.org/pdf/2504.14904v1
📝 Homepage:https://kuaimod.github.io/
🔮 KuaiMod Benchmark:https://github.com/KuaiMod/KuaiMod.github.io
主要贡献
1、首个短视频平台劣质内容判别基准测试:本工作面向快手生态构建了短视频劣质内容分类体系,形式化定义了短视频内容判别任务,并基于真实场景中的用户反馈构建了首个短视频劣质内容判别基准测试。KuaiMod 劣质内容分类体系包含 4种主要的劣质类别以及 15 种细粒度劣质类别。基准测试包含 1000 条短视频样本,涵盖 15 种细粒度劣质类别,完全由人工标注,并经过多轮数据清洗以保证正确性。
2、首个工业级自动化内容判别解决方案:当前 Facebook,Tiktok 等媒体平台都对基于深度学习模型的自动化内容质量判别方案展开探索,但尚未公布成熟的技术路线。KuaiMod 是首个在工业场景下验证了部署价值的自动化内容质量判别解决方案,在快手平台多个场景下的部署结果表明,KuaiMod 方案具有能够与人工判别相媲美的准确率。我们在论文中详细描述了 KuaiMod 方案的技术路线,希望引发更多的交流和讨论。
3、基于用户反馈的强化学习训练+更新策略:区别于静态的规则或内容判别 API,基于判例的劣质内容建模使得 KuaiMod 可以通过迭代训练数据完成判别策略的更新。为了保证实时性和准确率,我们设计了基于用户反馈的强化学习范式,利用用户的线上反馈构造新的训练数据,实现线上判别服务的天级更新。
一、KuaiMod 短视频质量判别基准测试

KuaiMod 劣质内容分类体系
为了应对层出不穷的新增劣质内容,KuaiMod 建立了动态的劣质内容分类体系。基于快手原有的判别标准,KuaiMod 将劣质内容分类成四个相互独立的主要类别:法律与社会安全,内容质量与伦理,不良商业行为和侵害知识产权。在四个主要类别的基础上进一步构建动态的细粒度劣质内容分类体系。具体来说,初版 KuaiMod 分类体系共包括 15 种细粒度劣质标签。在后续判别过程中,如果视频内容被判定为质量低下,但不存在与之匹配的细粒度标签,则根据劣质内容为该类视频生成新的细粒度标签并计入原有分类体系。自部署以来,KuaiMod 分类体系中劣质内容的标签数目已从 15 个扩充到 100 个,实现了对新增劣质内容的覆盖和细粒度分类。
KuaiMod 基准测试
基于上述分类体系,我们构造了业界首个短视频平台内容质量判别基准测试。该基准测试由 1000 条来自快手平台的短视频和对应的分类标签组成,其中 578 条视频为非劣质内容,422 条劣质视频涵盖了初版分类体系中的 15 种细粒度劣质类型。KuaiMod 基准测试中的每条数据都由多名资深标注者把关,确保分类标签的正确性。在严格的数据脱敏和清洗之后,我们将该基准测试开源,希望促进短视频平台生态优化社区的交流和发展。
二、KuaiMod 短视频质量判别方案
KuaiMod 质量判别模型由快手自研的 YuanQi 通用多模态模型作为基座,面向视频质量判别任务,使用链式推理数据离线训练后部署上线,并根据线上反馈持续更新判别策略。

链式推理数据构造
KuaiMod 训练数据的构造结合了人工判别结果和大模型推理能力。为了增强多模态大模型对视频内容和劣质标签之间的因果建模,我们设计了 Tag2CoT 和 CoT2Tag 流程,为每条训练数据提供细致的分析过程。
我们将线上的用户反感(举报/厌恶/差评)视频队列以及用户喜爱的高质量视频队列作为数据源,由人工标注者为每条数据标注细粒度劣质标签。
在 Tag2CoT 过程中,多模态大模型将视频元信息(视频标题、封面、视频帧、OCR/ASR 文本,用户评论等)以及人工标注的劣质标签作为输入,并根据指令分析视频内容,为人工判别结果提供思维链格式的依据。 在 CoT2Tag 过程中,为了将推理过程结构化,我们为视频质量判别任务设计了专门的流程,具体来说,我们将视频质量判别分成内容提取,内容分析,中期检查,用户反馈分析和总结判断五个状态,由多模态大模型将视频内容以及 Tag2CoT 过程中生成的思维链整理成状态转移格式。
SFT+DPO 离线适配
基于构造的链式推理数据,KuaiMod 模型的离线适配由 SFT 和 DPO 两阶段训练组成。
在 SFT 阶段,整合视频元信息作为输入,使用 next-token-prediction 任务训练 YuanQi 模型生成推理过程和判别结果。
在 DPO 阶段,利用 SFT 后的模型在训练集上生成推理结果,从中挑选出判别结果错误的样本,将模型的生成结果作为负例,将原本的训练数据作为正例,构造偏好数据,采用直接偏好优化算法针对错误样本优化模型。
基于用户反馈的强化学习(RLUF)更新范式
尽管 KuaiMod 模型在离线适配后具备初步的视频质量判别能力,但由于社交视频平台上的劣质内容会随着用户和社会趋势而变化,静态的质量判别模型无法有效适应这种动态性。因此,在线上更新阶段,我们设计了基于用户反馈的强化学习(RLUF)范式,持续优化 KuaiMod 模型的判别策略。
RLUF 包括如下关键元素:
- 环境:由短视频平台上的视频和用户组成,用户通过观看视频并提供反馈(如举报)来与环境互动。
- 智能体:KuaiMod 模型作为代理与环境互动,其策略由参数 θ 决定,基于视频内容进行质量判断。
- 奖励和目标:奖励信号直接来自用户反馈,较低的用户举报率表明更好的质量判别策略。目标是通过与环境的互动更新判别策略,以提高用户满意度和平台生态。
劣质内容判别策略更新的关键在于消除模型与用户对劣质内容理解的差异。为此,选择模型判别结果与用户反馈不一致的视频案例作为优化阶段的训练数据。具体步骤包括:
1、实时难例收集:难例来自用户举报视频以及高热视频。举报行为直接反映了用户理解的劣质内容的范畴,而高热视频因其受欢迎程度而具有更高的扩散风险,同时也反映了平台趋势和用户偏好。
2、数据筛选:
- 粗筛选:假设未被用户举报的视频为正例,而高举报队列中的视频为劣质样本。通过更新前的KuaiMod模型生成判别决策,识别出与人类反馈相矛盾的案例作为线上更新阶段的候选训练数据。
- 精细标注:对有争议的候选案例进行人工复检,确定最终的劣质标签,并通过既定的 Tag2CoT 和 CoT2Tag 流程生成数据。对于 KuaiMod 判断错误的案例,原始和新生成的响应分别作为错误和正确答案;对于 KuaiMod 判断正确但用户仍感到不适的案例,使用 YuanQi-20B 模型在 CoT 推理过程中列举可能引起用户不适的方面,并解释该视频为何不会对社区生态造成危害,以帮助模型区分个体用户敏感性和社会共识。
在线上更新阶段的训练中,我们仍然采用直接偏好优化算法来完成模型判别策略与用户反馈的对齐。
离线性能评估

我们在 KuaiMod 基准测试上评估了多种视频质量判别方案,从较早的 RoBERTa 编码器到先进的 Intern-VL 模型,从通用的 GPT-4o 到专业的 Perspective API,以及经过离线适配的 KuaiMod-7B 模型。评测包括简单的劣质/非劣质二分类和对细粒度标签的多分类。
评测结果揭示了视频质量判别任务存在如下关键要素:
1、判别标准的实时性:在诸多判别方法中,Perspective 是唯一的工业级内容判别 API,但由于其使用的模型训练时间较早,且无法微调,因此相较于其他可微调的方法以及更新的 GPT-4o,准确率较低。
2、多模态理解能力:能够利用多模态信息的方法相比于仅能利用文本信息的模型普遍取得了更好的效果,强大的视觉理解能力对于视频质量判别任务至关重要。
KuaiMod-7B 模型取得了 92.4% 的整体准确率,相对于其他方法取得了将近 10% 的提升,展现出了性能优势和应用潜力。
线上部署性能增益

为了验证 KuaiMod 方案的实际应用价值,我们在快手生态中的三个场景(快手极速版,快手精选和快手主站)进行了 A/B 测试。在极速版和精选场景下,KuaiMod 的质量判别服务使视频举报率降低了 20% 以上,显著提升了用户的观看体验。同时,质量判别服务没有对活跃用户数目和观看时长造成负面影响,这证明 KuaiMod 剔除的短视频不符合主流用户的兴趣。在主站场景下,KuaiMod 的质量判别服务使得活跃用户规模和人均观看时长均产生了增长,这证明了劣质内容剔除对于短视频平台的发展具有巨大价值。
三、快手致力打造社区短视频理解多模态大模型
短视频平台的内容分发面临两大核心挑战:如何从海量内容中精准捕捉用户兴趣,以及如何在信息过载时代构建用户与内容的高效连接。随着短视频内容的多样化和复杂性,平台需要探索更加先进的推荐技术,以提升推荐的精准性和可解释性,从而更好地满足用户的需求。
快手正致力于打造一个能够真正「理解社区短视频」的多模态大模型,不只是追求技术指标的突破,而是从用户体验、内容理解到业务变现,全面重塑平台的智能基础设施。这不仅关乎一个产品的升级,更代表着一种新的AI价值实现路径。
多模态语义理解的「硬骨头」:快手短视频语义远超多模态通用范式
相比标准化的影视视频或通用图文内容,社区短视频的语义环境极为复杂:内容碎片化严重、情境依赖性强、语言与视觉高度融合、表达风格高度个性化、传达意图往往隐含于动作、语气、背景与上下文之中。这意味着,只有能够真正「看懂、听懂、理解」这些视频的大模型,才能为推荐、搜索、内容生成等核心能力提供有效支撑。
这正是快手推进多模态大模型建设的起点。
团队明确提出,模型不仅需要实现语言、视觉、音频等模态的信息融合,还要具备:
- 对短视频语境中复杂意图的识别能力;
- 对用户兴趣动态变化的感知能力;
- 对视频背后高阶语义与知识图谱的推理能力。
传统方法往往止步于对视频内容的表征提取,而快手要做的是,从「表征」迈向「理解」——这是通往下一代 AI 系统的必由之路。
建立以「视频理解」为核心的多模态模型框架
为此,快手自研的大模型能力被系统地分为三个层次:
第一层:多模态基础能力
这一层聚焦于打通视频、图像、文本等多模态输入的表示空间。团队探索了多种训练范式:
- 通过语言模型主导的 Encoder 路径融合视觉内容;
- 利用 Adapter 方式对视觉模态进行调参适配;
- 构建统一的流式理解体系,实现短视频「上下文建模」;
- 引入监督微调(SFT)策略,提升模型生成能力和对齐度。
在模型训练数据上,快手搭建了高质量的中文短视频语料库,支持「视频-语音-文本」三位一体的训练目标,并构建了以「视频结构化标签体系」为中心的训练监督链条,实现模型对短视频语义单位的精准识别。
第二层:高级认知与推理能力
在具备感知能力之后,快手将模型推向更高维度的认知与推理能力。这部分重点突破如下:
- 利用 RAG 机制结合知识图谱进行视频内容补全与多跳问答;
- 提高模型对复杂命题(如动作因果、话题转折、情感表达等)的理解力;
- 融合社交线索(如点赞评论、观看路径)进行因果链建模。
与 OpenAI、DeepSeek 等在图文领域大模型能力相比,快手的优势在于其数据更贴近用户真实兴趣轨迹,具备构建「懂人心」模型的土壤。
第三层:多模态应用能力
快手多模态模型的目标并非「实验室指标」,而是「场景闭环」。当前,模型已广泛部署于平台的多个核心任务中,包括:
- 视频兴趣标签结构化;
- 短视频 Caption 生成与标题优化;
- 用户兴趣识别与推荐意图建模;
- 智能选题、内容共创辅助;
- 电商商品知识图谱构建与导购推荐;
- 用户评论语义解析与话题扩散预测。
尤其在商品推荐与内容创作领域,快手正在构建「知识驱动的 AI 内容理解-生成-推荐」全链条,从而实现从内容理解到价值转化的智能跃迁。
实际业务中,这一模型体系已在用户行为可解释性任务中展现出显著成效——在快手主站与极速版核心场景中,平台多项正向核心指标稳步提升,主站场景下举报率下降超过 26%,极速版下降超过 24%,充分体现了多模态大模型在真实业务环境中的落地能力与优化成效。
三阶段路径:从能力建设到生态闭环
快手在多模态大模型建设方面采取了清晰的阶段性策略,力求以系统性投入逐步构建起具备产业价值和应用闭环的模型能力体系。
第一阶段:夯实基础能力
快手聚焦于多模态模型的底层能力建设,重点包括统一的标签体系构建、多源异构语料的采集与清洗,以及多模态监督机制的初步搭建。通过标准化、结构化的标签体系,为模型提供更精确的语义锚点,奠定了高质量训练的基础。
第二阶段:推进语义融合与兴趣建模
随着基础能力的成熟,快手开始将模型能力延伸到内容与用户之间的深层理解。此阶段重点探索内容语义结构与用户行为偏好的联动机制,推动知识图谱在推荐、搜索等业务场景中的实用化落地,进一步提升内容分发的精准性与用户体验。
第三阶段:实现产品集成与业务共振
在模型能力逐步完善的基础上,快手将多模态技术融入平台多个关键业务流程,面向内容理解、创作辅助、商业推荐等多类任务实现统一支撑。同时,探索 AI 能力在营销、分发、内容生产等场景中的创新应用,推动模型从「算法引擎」迈向「平台能力」的演进。
这一分阶段的策略不仅保障了技术建设的系统性,也使得大模型能力能够稳步走向规模化应用和价值兑现。
走出学术范式,迈入「场景即能力」的产业实践阶段
快手的多模态大模型不是为了追赶潮流,而是一次源于真实场景需求的技术深耕。它所代表的,是中文内容生态中,一个由社区驱动、短视频驱动的智能化转型路径。
如果说过去多模态模型更像是「学术成果的工程化实现」,那么快手的路线更像是「产品倒推下的技术演进」。在这个过程中,快手展现出一种难得的「慢功夫」与务实精神:先理解任务本身,再推动模型优化,最终形成业务闭环。这种从需求出发、自研为本、场景驱动的技术策略,为整个中文AI生态提供了一种新的范式样本。
....
#北京亦庄的机器人残奥会
在人流如织的大街小巷,这家公司的机器人正跑着自己的「马拉松」
前段时间,在北京亦庄举办的「人形机器人半程马拉松」活动引发全民热议。有人对机器人在赛事中展现出的耐力和稳定性表示赞赏;当然,也有人因机器人频繁摔倒、出状况而感到失望,毕竟,这和短视频里那些跳舞、跑酷、侧空翻的机器人形成了巨大反差。

比赛跑成这样,是不是说明近几年围绕机器人、xx智能的热议是一场炒作?答案肯定不是简单的「是」或「否」。

但除此之外,还有一个问题更加值得讨论:如何打造一个真正可以走入现实世界的机器人?
「更复杂、更智能的xx智能机器人需要建立在上一代xx智能完成商业闭环和真实世界数据闭环的基础上。」这是我们从xx智能从业者 、推行科技创始人兼 CEO 卢鹰翔口中得到的观点。而他所做的工作,就是打造这样一个商业和数据闭环。
如果你在苏州、深圳、上海等地点过机器人送的外卖,那你可能见过推行科技的机器人。它们和行人、自行车、电动车一起穿行、过马路,还会自己进小区、坐电梯,把外卖、商品送到用户手里。

推行科技的初代物流机器人,可以在复杂的交通环境中穿行。
,时长03:12
推行科技的第二代移动操作机器人Carri Flex,增加了灵活的上肢操作能力。
重要的是,这是一个商业化程度非常高的机器人。在实际运营过程中,它们会和人类骑手一起在商家门口等待接单,履约率考核标准也和骑手一致。由于履约率非常高(已达 98.5%),在一些高价值场景中,它们拿到的报酬已经可以覆盖自身的成本,做到了单个机器人盈亏平衡。
从容错性高、技术可及的场景入手,在xx智能发展早期就把机器人大量投入现实世界,实现商业化运营,并基于机器人的实际商用构建数量和丰富度逐渐进阶的数据飞轮,这就是卢鹰翔所说的「上一代xx智能的商业和数据闭环」。以此为基础,推行科技将逐步打造更复杂、更智能的xx智能机器人,并将它们投入更多场景。
那么,这个商业加数据闭环是怎么实现的,具体如何推进?我们和卢鹰翔以及推行科技另一位联创、CTO 龙禹含进行了多次沟通,旨在揭秘一条现阶段可行且后续可持续的xx智能发展路径。
机器人的进化论
在今年的 GTC 大会上,英伟达高级研究科学家 Jim Fan 提到了xx智能的「数据金字塔」概念。

图源:https://rdi.berkeley.edu/llm-agents/assets/jimfangr00t.pdf
金字塔的塔尖代表的是真机数据。这部分数据非常重要,包括 Jim Fan 导师李飞飞在内的很多人都相信,机器人的智能水平也像生物进化一样,需要在不断与真实物理世界产生互动、适应更复杂的环境的过程中逐渐进化。当然,这部分数据也非常稀缺,需要通过机器人的大规模部署来实现。
也有一些公司建立了自己的「数据工厂」,让机器人在人工搭建的场景中与数据采集师协同作业,逐条积累数据。但这种方式不仅成本高昂,而且人工搭建的场景在丰富度上天然存在局限性,这种局限性不可避免地会对机器人在真实世界中的泛化能力产生负面影响。
不过,除了真机数据,合成 / 仿真数据和互联网级的通识数据也是通用泛化xx模型训练所必须的。从 ChatGPT 走红至今,这两类数据的价值已经被充分认可,尤其是在语言模型的演进过程中,互联网通识数据的有效利用已成为提升模型能力的核心基础。
但在xx智能领域,互联网级的通识数据仍处于真空状态。填补这一空白,是推动机器人能力稳定泛化至真实复杂场景的关键前提,也是迈向通用智能高阶能力的必经之路。针对这一行业痛点,推行科技自研了「骑手影子系统」,构建了覆盖多种任务类型与环境变数的高密度人类行为数据集,从根本上提升了机器人在开放物理世界中的泛化能力与可靠性。相较仍困于数据瓶颈的行业现状,推行科技已率先完成通识级数据体系的构建与验证,形成显著的技术竞争力。
一条可持续的xx智能路径,从「骑手影子系统」说起
ChatGPT 能够通过学习海量人类对话数据,掌握语言的规律和模式,从而实现自然流畅的对话。特斯拉 FSD 则通过分析和筛选人类驾驶数据,择优学习驾驶决策和操作,进而实现自动驾驶。同样地,物流机器人也可以借助人类骑手的骑行和操作数据,学习自主应对各类交通环境、取放各种包装袋等技能,从而实现高效送外卖,这便是推行科技所打造的「骑手影子系统」的工作原理。
在之前的采访文章(参见《跟骑手学习送外卖,这家xx智能公司的机器人已经上岗挣钱了》)中,我们详细介绍过这个系统 —— 它主要通过安装在外卖骑手电瓶车上的车载硬件采集三种关键数据:环境数据(摄像头采集的路况、障碍物等视觉信息)、定位数据(通过 RTK 技术采集)以及驾驶数据(骑手在特定情况下的操作,如踩油门、刹车或转向)。系统获取这些数据后,通过模仿学习和强化学习算法让机器人学习人类骑手的行为,从而使机器人能够在复杂多变的城市环境中自主导航。这是「骑手影子系统」的 1.0 版本。
如今,这个系统已经进化成了「2.0」。除了电瓶车,它还可以将骑手的头盔、外套转化为动捕设备,记录人类骑手如何开关门、拿放外卖以及其他更复杂的操作轨迹,从而为加上「上肢」的机器人积累操作行为数据。
这种数据采集方式最显著的优势在于「量大管饱」:中国骑手平均每人每天跑 100-200 公里,一个普通超市前置仓的 15-20 个骑手一个月就能产生超过 10 万公里数据,一年可达近 200 万公里。所以,依靠这一模式,推行科技平均每日即可采集数万公里的骑行行为数据用于xx模型训练,在短短两三年的时间内就积累了数千万公里的行驶数据,数量级相当于国内头部自动驾驶公司的历史路测数据积累总和。
在推行科技 2024 年开始部署包含上肢数据采集设备的「骑手影子系统」2.0 版本以来,不到一年时间积累的上肢轨迹数据也达到了近百万条,采集效率和成本效率远超其它方式。此外,推行科技所采集的数据在场景类型、任务结构、操作目标等方面与机器人实际训练需求高度一致,具备强目标导向性与时空连续性,优于互联网视频等数据源中常见的碎片化、弱结构化内容,这些与机器人实际训练目标高度匹配的数据能更有效地驱动模仿学习与强化学习过程。
通过这种创新的数据采集方式,推行科技有效地解决了xx智能领域普遍面临的「数据魔咒」问题,为其机器人技术的快速迭代和商业化落地提供了可靠的原材料保障。
从「三原色」到「回环反馈」:走入现实世界的机器人如何随机应变?
骑手的行为数据蕴含着丰富的信息,推行科技的数据闭环平台可以对骑手的动作行为进行自动分解及标注。龙禹含提到,推行科技通过对海量骑手配送过程中的上肢行为数据的深入分析发现,看似复杂多变的骑手递送任务,实际上都由三个核心原子任务排列组合而成 —— 按按钮、推拉门以及拿放货,就像是颜色里的「三原色」。值得注意的是,这三个原子任务通常仅需骑手使用右手进行单臂操作即可完成。


基于这一发现,推行科技成功定义了具备单臂操作能力的 Carri Flex 机器人,首次将具备上肢操作能力的机器人产品成功部署于真实开放的物理世界。在此基础上,推行科技进一步对机器人在真实场景中的服务数据进行收集,以训练可支持双臂协同等更为复杂任务且可靠性能达到商用标准的xx模型。
能将机器人部署于真实服务场景的关键是他们构造的行为树 VLA(Vision-Language-Action)模型。和很多 VLA 模型一样,这个模型使用 VLM 结合实时感知信息和当前任务来生成具体原子任务,而后通过一个行动模型将原子任务转化机器人的关节轨迹。

和传统 VLA 结构不同的是,行为树 VLA 使用 LLM 进行高层任务规划,可将高级指令(如,前往某店取单)转化为一个行为树结构。行为树将根据当前任务状态向 VLA 模型发布子任务(如,行进至某店,开门,于柜台上取货等)。行为树将接收 VLM 任务状态解码器通过回环反馈逻辑输出的任务状态信息,从而改变行为树当前所处的子任务分支。
这个反馈使得 LLM 能够了解到任务的实际执行情况。如果遇到问题或者环境发生变化,LLM 可以基于这个反馈调整或重新生成行为树,从而解决 VLA 模型在追求局部最优的过程中忽略了具体任务可行性的问题,使得模型在泛化场景中保持对齐,提高了整个系统的适应性和可靠性。
以 Carri Flex 机器人为例,其典型任务之一是在电梯间的外卖桌上放置外卖袋。然而,当桌面已被其他外卖占满这一特殊情况发生时,如果模型未经过类似场景的专门训练,基于模仿学习的 VLA 模型可能因为出现分布外(Out-of- Distribution,OOD)场景而产生行为退化现象,进而可能陷入无法恢复的执行失败,这在真实商业应用中是不可接受的。而在客户实际需求中,理想应对方式通常涉及任务层级的反馈机制与策略调整,例如将外卖转移至附近空旷区域,或通过电话通知收件人等。
推行科技针对这一类现实问题,在模型中构建了多层级反馈机制,使机器人能够在不确定环境中做出更符合人类预期的灵活应对,确保任务的稳定交付与用户体验的一致性。
「一脑多形、一脑多栖」:xx智能的商业落地与全球视野
廉价、量大、质优的数据获取方式和可靠的模型为推行科技实现一条可落地、可持续的xx智能发展路径提供了可靠基础。目前,他们已经和国内三家头部全国性即时配送平台同时达成业务合作,完成了近 10 万单配送。
而且,由于数据是从复杂、多元的人类活动场景中采集而来,推行科技训练得到的模型具有较强的泛化能力,可以实现「⼀脑多形」和「⼀脑多栖」的部署。「⼀脑多形」指的是他们的模型不仅可以在自己的机器人身上部署,还可以泛化到四足机器狗平台和传统阿克曼底盘。「⼀脑多栖」指的是除了陆地环境,他们的模型还可以直接在静水船只上发挥作用(不需要为水面训练投入额外数据采集和调试成本),从而拿到了渔业养殖场景超百台订单(用于自动洒药及投料)。
之所以能够取得这些成果,除了路线的选择,推行科技的人才储备也发挥了重要作用。推行科技团队曾于卡内基梅隆大学国家机器人工程中心负责研发 CHIMP 人形救援机器人,并获美国国防高级研究计划局 DARPA 机器人挑战赛全球第二名。他们的机器人是当时将 8 个比赛任务全部完成并获得 8 分满分的三个机器人作品之一,也是唯一一个在失误摔倒后,没有借助人力自行恢复站立,继续完成任务的。
除此之外,团队还曾负责研发全球第二型获批美国加州 OL318 「全无人」牌照的 L4 级自动驾驶乘用车,这一背景为团队提供了搭建「骑手影子系统」的技术灵感和工程基础。



推行科技团队参与研发的 CHIMP 人形救援机器人
可以说,推行科技所选的xx智能路线,以及当前已经研发出的 Carri Flex 等机器人,在多年前就已经埋下了种子。

在海外,也有一些机器人公司在做和推行科技类似的事情,比如 Hinton 担任顾问的 Vayu Robotics。他们所在的市场有着诱人的前景,人力成本、递送费用高达国内的五到十倍,存在巨大的运力缺口。不过,卢鹰翔提到,和这些公司相比,推行科技的「国情优势」更加明显,因为我国有着庞大的骑手队伍和更复杂的城市末端环境,能够以更高的效率训练出强泛化能力的机器人。在综合考虑这些因素后,推行科技打算进军海外,为全球用户提供服务。
和机器人马拉松一样,xx智能的发展注定是一场持续多年的长跑。虽然在养老、家政等备受关注的场景中,机器人表现尚未达到预期,但在城市角落里,配送机器人已默默完成了数万单真实订单。推行科技的故事告诉我们,不必追求一步登天的技术突破,而是先在真实环境中找到商业闭环,再以此为基础逐步迭代。这种务实的进化路径,或许才是xx智能走向未来的最短捷径。
...
#图解Vllm V1系列1:整体流程
详细介绍了VLLM v1整体运作流程,包括离线批处理(Offline Batching)和在线服务(Online Serving)两种模式。作者通过图解和代码示例,清晰地展示了 VLLM v1 的架构设计和关键步骤,如进程间通信、请求处理、调度和输出管理等。
vllm v1的系列文章基于的代码版本是vllm 0.8.2(当前已更新到0.8.4),在代码细节上,不同版本间可能有diff,但在大框架上是不变的。本文将对vllm v1的整体运作流程进行介绍,在后面的系列中,再来看关于调度器、KV cache管理、分布式推理等更多细节。对于首次了解vllm的朋友,推荐先阅读以下2篇文章:
一、Offline batching(离线批处理)1.1 调用方式
from vllm import LLM, SamplingParams
if __name == "__main__":
# Sample prompts.
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 创建llm实例,在这个过程中也创建了llm实例下维护的llm_engine
llm = LLM(model="facebook/opt-125m")
# 执行offline batching推理,得到这批prompts的输出
outputs = llm.generate(prompts, sampling_params)
# 打印输出
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")1.2 整体流程
Offline batching下的整体流程如下图所示,在后文中,我们称请求为req:

我们先忽略图中七七八八的细节,从大面上来看一下这个流程:
- 首先,观察到我们采用2个不同的进程(process0,process1)来完成整个推理。
- process0上维护的核心对象是SyncMPClient(Sync MultiProcessing Client),我们简称其为客户端。process1上维护的核心对象是EngineCoreProc,我们简称其为EngineCore。
- vllm使用ZMQ来负责不同进程间的数据收发(不了解ZMQ的朋友,到此为止只要先了解它的主要功能是这个即可,后续再慢慢了解它的其余细节)
- 观察到:
- 对于req的输入输出处理(processor、 output_processor)是由客户端执行的;而req的实际推理过程(Scheduler -> ModelExecutor)则由EngineCore来执行。
- 也就是说,vllm v1将cpu和gpu上的调度拆成2个进程进行处理,这样可以更好实现cpu和gpu的overlap。举例来说,在先前vllm版本的推理中,我们经常会发现detokenize(tokenid -> 文本)这个步骤会成为推理瓶颈,特别是遇到长序列的情况。在等待序列做detokenize的过程中,gpu是空转的。现在通过这种拆解,让原来是串行的事情并行化。
最后,客户端的类型有很多种,由于本节我们讨论的是offline batching,所以展示的是SyncMPClient。在下一节中,我们会来看其余类型的客户端。
有了以上大体上的感知,现在我们可以来介绍图中细节了:
1、add req to:LLM端接收req,并将req发送至LLMEngine的processor。
2、process req:原始req -> EngineCoreRequest,processor的作用是对req进行预处理,具体包括:
- Tokenize
- 验证输入参数的合法性
- 将req封装成特定形式(EngineCoreRequest)等等
3、encode & send req:
- 将EngineCoreRequest发送给SyncMPClient
- SyncMPClient会对其做encode操作:EngineCoreRequest -> pickle EngineCoreRequest
- 通过zmq input_socket,将pickle EngineCoreRequest 发送给 EngineCoreProc(这里SyncMPClient和EngineCoreProc分别运行在2个不同的进程上,vllm选择使用ZMQ来负责进程间的数据通信)
进程分割线(Client -> EngineCoreProc)
4、recv & decode req:
- 在EngineCoreProc所在的进程上,会启动一个线程,在该线程中执行process_input_socket()函数,这个函数具体做了如下事情:
- 持续监听通过input_socket传来的pickle EngineCoreRequest
- decode:(pickle EngineCoreRequest -> EngineCoreRequest)
- 将 EngineCoreRequest 装入 input_queue 队列中
5、add req to scheduler:EngineCoreRequest 被添加进 Scheduler的waiting队列中6、one step inference
- Scheduler执行一步调度,从waiting和running队列中选择req进行推理,**输出一步推理后的结果(EngineCoreOutputs)**。这边的细节我们暂时略过,留到后文细说。
7、put output to output_queue:将一步推理结果放入 output_queue队列中这里我们会重复执行5/6/7步骤,即重复执行【一步调度->一步推理】的过程,直到 input_queue 和 scheduler中再无req存量。
8、encode & send req:
- 在EngineCoreProc所在的进程上,会启动一个线程,在该线程中执行process_output_socket()函数,这个函数具体做了如下事情:
- 持续监听output_queue中装入的一步推理输出结果(EngineCoreOutputs)
- encode:EngineCoreOutputs -> pickle EngineCoreOutputs
- 使用zmq output_socket作为通信管道,将pickle EngineCoreOutputs发送给SyncMPClient
进程分割线(EngineCoreProc -> Client)
9、recv & decode req
- 在SyncMPClient所在进程上,会启动一个线程,在该线程中执行process_output_socket()函数,这个函数具体做了如下事情:
- 持续监听通过output_socket传递来的pickle EngineCoreOutputs
- decode:pickle EngineCoreOutputs -> EngineCoreOutputs
- 将 EngineCoreOutputs 装入 output_queue 中
10、process_output,对EngineCoreOutputs做一些后置处理,例如detokenize等操作。11、output until all reqs are finished:LLM回去检测每一条req是否已做完推理(req.finished的状态),由于目前我们是offline batching的模式,所以等到全部的req都完成推理后,LLM会一起输出推理结果。
二、Online Serving2.1 调用方式
这里我假设起的online serving是这份脚本:
2.2 整体流程

我们还是先从整体上来感知online serving的运作流程:
- 和offline bacthing相比,EngineCoreProc部分的逻辑没有变
- Client和EngineCoreProc交互的逻辑没有变
- 所以现在,我们只需要关注Client的实现细节
Online Serving的Client实现细节如下:
1、async per req generate:用户发送req给vllm的API server,server对单req发起generate操作。这里会首先将req发送给AsyncLLM
2、create asynico.queue() for each req和register the queue to output_processor:
- 这两个步骤都在AsyncLLM上执行
- create asynico.queue() for each req:会针对每一个req创建一个异步队列,这个异步队列将用于存储这个req的输出结果。
- register the queue to output_processor:会把这个req的异步队列注册到output_processor中。
- 为什么每个req需要一个单独的队列:
- 在online serving中,req的输出结果是流式的(一块一块地把结果返回给用户)
- 在online serving中,用户时常有多轮对话的需求等等
- 基于这样的考虑,相比于offline batching对所有req的一次性统一输出,online serving下更有必要将各个req的输出隔离开来,因此才单独针对每个req创建一个用于盛放输出结果的异步队列。
3、prcocess req 和 4、encode & send req和offline batching逻辑基本一致,这里不再赘述
进程分割线(Client -> EngineCoreProc)
EngineCorePro会实际执行req的推理过程,5~9的步骤我们在offline batching中详细解释过,这里不再赘述
进程分割线(EngineCoreProc-> Client)
在AsyncLLM上,我们会启动一个异步任务asyncio.create_task(_run_output_handler()),这个异步任务上会执行_run_output_handler()函数,这个函数的主要作用是异步接受、处理来自EngineCore的模型输出结果,具体流程如下:10、AsyncMPClient上发起get_output_async():
- 持续监听通过output_socket传递来的pickle EngineCoreOutputs
- decode:pickle EngineCoreOutputs -> EngineCoreOutputs
- 将 EngineCoreOutputs 装入 output_queue 中
11、split output into slices:
- 将output_queue中的数据切成slices,方便后续做流式输出
- 将slices数据装入这个req注册在output_processor中、只属于这个req的异步队列
- output_processor将会以slices为维度,对输出数据做诸如detokenize等的操作。
12、continously yield current output:
- 对于一条请求,AsyncLLM将会持续从output_processor中获取它当前的输出结果,返回给用户,直到这条请求推理完毕
此外,Vllm官方文档中,也给出了一张online serving的架构图(https://blog.vllm.ai/2025/01/27/v1-alpha-release.html),上面的内容可以说是这张架构图的细节扩展,大家可以比对进行理解:

到此为止,我们就把V1的大致运作流程介绍完了,在后面的文章中,我们会来看关于调度器、KV Cache管理和分布式模型执行的更多细节。
...
#NYU教授开炮
美国大学ML课太离谱!学生炮轰课程垃圾,全靠自学
NYU机器学习教授痛心表示,如今很多大学的ML课程,已经抛弃了基础概念和经典。他晒出的课程大纲,引起了哈佛CS教授的赞同:很高兴我们并不孤单,想在大纲中保留基础概念可太难了。甚至,印度和美国的大学生都在抱怨,学校的机器学习课太垃圾了,全靠自己自学!
就在刚刚,NYU教授Kyunghyun Cho呼吁:如今大学的机器学习课程,已经抛弃了经典!在他看来,很多课程都抛弃了关于ML和深度学习的基础概念,这很危险。他提出了一个深刻的议题:在LLM和大规模计算力普及的今天,机器学习一年级研究生课程该教些什么呢?对此,教授给出了一种独辟蹊径的方式——教授所有能用随机梯度下降(SGD)解决,但又不是LLM的内容,并且让学生去阅读一些早期的经典论文。上下滑动查看在看完他晒出的讲座笔记和教学大纲后,不少网友表示赞叹。有人评论说:2025年的机器学习课程里竟然还教RBM(受限玻尔兹曼机)?这绝对是独一无二的课程,太特别了。一位哈佛的助理教授说,自己非常喜欢这个教学大纲,和哈佛的CS1810课程大纲基本类似,只是少了一些进阶主题和生成模型的类型。要知道,想把深度学习前期的基础概念保留在课程大纲中,时常会受到阻力,他表示,很高兴看到自己并不孤单。NYU教授的课程大纲:有92年的论文NYU教授晒出的讲座笔记如下。可以看到,在这门课程中他首先引入了机器学习的基本概念,比如感知机与间隔损失函数、Softmax与交叉熵损失函数,反向传播,随机梯度下降(SGD),泛化与模型选择,超参数调优与模型选择等。随后,课程的第3章开始教授神经网络的基本构建模块,如归一化、卷积模块、循环模块、注意力机制等。第4章教授的是概率机器学习与无监督学习,包括能量函数的概率解释,变分推断与高斯混合模型,连续潜变量模型,VAE等。在第5章,学生们会学到受限玻尔兹曼机(RBM)、基于能量的生成对抗网络(EB-GAN)、自回归模型等无向生成模型。在打好这些基础后,学生们才会学习强化学习、元学习、因果推断这些内容。左右滑动查看在这门机器学习课程的教学大纲中,教授也强调——如今,机器学习系统已经在飞速发展。我们经常使用随机梯度下降(或其变体),在包含数百万乃至数十亿训练样本的大型数据集上,训练拥有数百万乃至数十亿参数的大规模模型。这些令人惊叹的成果,都离不开数学、概率、统计和计算机科学中那些简单而基础的理念。而这门课,强调的就是这些基础概念,从而让学生们能更系统、更严谨地理解现代的大规模机器学习算法。教学大纲中推荐的论文,也并不是近几年的爆款时兴论文,反而是从上世纪90年年代至2022年的一些经典论文。比如神经网络先驱之一的Ronald Williams,靠一篇关于反向传播算法的论文,引发了神经网络研究的热潮。教授推荐列表的第一篇文章,就是他发表于1992年的「Simple Statistical Gradient-following Algorithms for Connectionist Reinforcement Learning」。第二篇年代久远的论文,就是现任微软人工智能研究院主任、英国计算机科学家Christopher Bishop的发表于1994年的「Mixture density networks」。图灵三巨头的不少经典论文也入选了,比如LeCun的「Efficient BackProp」,Hinton的「Training Products of Experts by Minimizing Contrastive Divergence」等。总之,不追逐潮流,只读经典。上下滑动查看哈佛哈佛的CS 1810课程,此前在网上就曾引起热议。教材:https://github.com/harvard-ml-courses/cs181-textbook/blob/master/Textbook.pdf从课程大纲中可以看出,这门课非常全面严谨地介绍了机器学习、概率推理等基础知识。内容涵盖了监督学习、集成方法与提升方法、神经网络、支持向量机、核方法、聚类与无监督学习、最大似然估计、图模型、隐马尔可夫模型、推断方法、强化学习等。而且这门课因为是面向高年级本科生,所以需要学生能用Python写比较复杂的程序,还需要具备概率论、微积分、线代的基础知识。正如此前提到的助理教授所说,这份课程大纲中保留了很多深度学习前期的基础概念,这在当今竟然已经不多见了。左右滑动查看MIT另一传统牛校MIT 2024年的机器学习讲义,是下面这样的。教材:https://introml.mit.edu/_static/spring24/LectureNotes/6_390_lecture_notes_spring24.pdf这门机器学习的入门课,是为本科生和研究生设计。内容包括监督学习(如线性回归、逻辑回归、神经网络)、无监督学习(如聚类、主成分分析)、概率模型以及强化学习的基础。跟哈佛的CS 1810相同,这门课除了理论,也非常强调实践。学生需要完成多项编程项目,使用Python和相关库(如NumPy、PyTorch)实现模型,并通过考试和项目展示对理论的理解,因此必须具备基础数学和编程背景。左右滑动查看经典永不过时除了AI领域之外,有些学科本身就倾向于学习经典内容,比如数学。有网友表示,在许多本科和研究生的数学课程中,5、60年代的教学大纲仍然被认为是黄金标准。对此,reddit上的网友Cheezees表示赞同,他说他的父亲——一名兼职教授,就认为《Elementary Analysis》是最好的数学教科书。这本书首版于1980年,但至今仍在使用。还有像是《Principles of Mathematical Analysis》(数学分析原理)这种出版于1953年的教材,现在仍在全美超过80%的荣誉本科分析课程中使用。对于有些学科教材过时的问题,也不是没有解决的办法。比如,这位网名Rain-Stop的生物材料教授称,虽然他喜欢的一本教材自从2013年就没有更新了,但是他使用过去3-4年内发表的期刊论文来涵盖领域内的进展。经典教材配合上最新论文,这也不失为一个好办法。国内接下来,我们看看国内高校AI专业的培养方案。比如北大信科智能科学与技术专业(智班)的24年本科生培养方案,是这样的。两门公共必修课,是计算概论和数据结构与算法。专业基础课,是高数、线代和信科技术概论。专业核心课中,包括人工智能引论、算法设计与分析、机器学习、多模态学习等。专业选修课中,还包括不少计算基础与编程类、机器感知类、数据与机器智能类的课程。下面是一份专业课程地图全览。再比如,23年清华叉院的计算机科学与技术(人工智能班)专业本科培养方案。这个培养方案涵盖了数学、物理、计算机科学基础(如数据结构、算法设计)、人工智能(如机器学习、深度学习)以及工程实践。对数学和基础理论课程的重视,为学生深入理解算法和系统设计奠定了坚实基础。另外,方案中还安排了丰富的实践环节,体现了清华对培养学生动手能力和创新能力的重视。例如,学生需完成多个编程项目和跨学科综合设计,将理论应用于实际场景。课程中还有如量子计算和人工智能交叉项目(AI+X)这些前沿领域。学生抱怨:大学ML课程太垃圾有趣的是,就在去年,一位印度学生曾在reddit上发帖,抱怨学校的机器学习课程太垃圾。他来自印度一所四级地方学院,觉得学校的机器学习课程问题很大。具体来说就是,课程使用了太多技术术语,却没有真正解释深入的工作原理。比如他们的其中一部分教学大纲是这样的。1. 人工智能/机器学习简介,线性回归,逻辑回归,贝叶斯分类,决策树 2. 正则化,支持向量机 3. 集成学习,自助聚集(bagging),提升法(boosting) 4. 神经网络,卷积神经网络 5. Seq2Seq模型,注意力机制,Transformer这位学生表示,课程大纲只有第一章和神经网络导论涉及数学,其余部分都是一堆废话。他认为,这门课作为一门工程课程,实在太抽象了:使用了一些华丽的术语,却并未深入解释任何内容。虽然只要记住这些花哨的单词就能通过考试,但一遇到项目,他就傻眼了。这些项目至少需要博士学位才能理解,需要采用GAN、可解释AI、神经架构搜索、视觉Transformer、优化等技术。所以,绝大多数学生都只能在GitHub上找到一些现成的项目,复制粘贴论文,然后用Humanize AI降低查重率。然而发帖人表示,自己并不喜欢抄袭别人的作品,但「AI正被强塞进自己的喉咙」。本来如果按照自己的节奏慢慢学习,应该会喜欢ML/AI的。但是现在,自己可能要花好几年才能理解这些论文,更不用说想到一个新的项目点子了。有人指出,这个现象反映出印度教育体系的一个典型问题:把流行术语和技术灌给学生,概念却极其空洞,如果缺乏必要的数学和统计学背景,就不会理解这些算法的「why」和「how」。只有对线代、概率论、微积分有扎实理解,才能理解向量机或神经网络等算法的内部原理。如果没打好基础就跳到Transformer和GAN等高级概念,就像造摩天大楼却不打地基一样。因此,他建议这位迷茫的学生回去学好基础数学,比如Marc Peter Deisenroth 的 《机器学习的数学》,然后在Coursera和edX平台学好AI课程。其中吴恩达在Coursera上的机器学习和深度学习课就堪称典范。不止印度,美国大学也一样甚至在这个帖子下,有个来自美国的学生抱怨说,美国大学也同样存在这个问题。他来自自己所在州最好的大学,正在读七年级。系里会在五年级教学生网络技术,六年级教人工智能,七年级教机器学习。但课程结构非常混乱,甚至教授们根本不讲算法原理,只会读PPT,甚至懒得教数学。这位学生意识到:如果想学好机器学习,只能靠自己,去找网课和教材自学。比如他推荐了一本不错的教材「Hands on Machine Learning with Scikitlearn, Keras and Tensorflow」,还订阅了一些不错的YouTube频道。其实无论是在印度还是美国大学中,问题的核心就在于,如今AI/ML的发展速度实在太快了,任何大学都无法跟上,甚至一些机构也举步维艰。所以,如果真的只靠学校课程,学生是不太可能学好AI/ML的,只能选择靠自己。诺奖得主建议基础很重要,要学会学习大学的教材和课程可能会过时,但不会阻碍一个人的学习。今年早些时候,剑桥大学的学生们向诺贝尔奖得主、Google DeepMind首席执行官Demis Hassabis提交了问题,他们中的许多人想知道在AI时代应该如何安排他们的时间。Hassabis的建议是——把时间花在「学习如何学习」上。「我认为最重要的是真正理解自己——利用本科阶段的时间更好地了解自己,以及自己最有效的学习方式。」在这之中,适应能力至关重要,也就是「如何快速掌握新知识并运用自如」。由于技术不断发展,如今的大学生们将进入一个充满「颠覆和变革」的世界,而这是唯一可以预见的。在他看来「AI,以及VR、AR和量子计算等领域,在未来五到十年内都极具潜力」,每一次变革都蕴藏着巨大的机遇。Hassabis建议学生们专注于基础知识。虽然新潮流层出不穷,但最好避免被那些「今天风靡一时,明天就无人问津」的事物所干扰。「我最喜欢的科目是计算理论和信息论,还有研究像图灵机这样的东西。这些知识贯穿了我的整个职业生涯。我喜欢数学的底层逻辑,以及许多传统的、基础性的研究」。他补充说,学生们也不应该忽略自己的兴趣。Hassabis认为,毕业生们应该能够将对自身兴趣的深入理解与他们所掌握的核心技能「结合」起来。Hassabis建议道:「在课余时间,你应该积极探索自己热爱的领域。对我来说,那就是AI。现在涌现出了大量的工具——其中许多都非常容易上手,而且是开源的——这样你才能在毕业时真正掌握最前沿的知识。」Hassabis同时建议研究生们培养跨领域的专业知识。例如,如果他们学习的是AI,那么他们也应该了解如何将其应用到最佳的领域。因为在未来十年左右,多学科研究将会成为主流。在AI和STEM领域交叉的地方,可能会有很多「唾手可得的成果」,因此重要的是要对这两个领域都有足够的了解,才能明白什么是「正确的问题」——因为提出这些问题可能会带来突破性的进展。Hassabis说:「选择问题就像拥有某种品味或嗅觉,或者说是一种直觉,知道『什么是正确的问题?』以及『现在是否是解决这个问题的最佳时机?』因为时机非常重要,你肯定不想超前时代50年。」尽管Hassabis认为人们无法真正培养出那种第六感,但他建议大家保持开放的心态,随时准备抓住机遇。「机遇可能来自任何地方,所以要成为一个多学科的人,让自己接触到各种各样的想法」。
参考资料:
...

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐



 22
22 0
0- 0



 已为社区贡献45条内容
已为社区贡献45条内容

所有评论(0)