北京大学86页DeepSeek黑科技教程发布!比清华版更炸裂(附PDF免费下载)
这份文档刚在学术圈炸锅,作为国内首个系统性拆解推理大模型(DeepSeek-R1)落地方案的公开资料,其价值不仅在于揭示了一款国产模型的工程实践,更折射出大模型技术从实验室走向产业化的关键路径。摸鱼届的卧龙凤雏,北大在第76页埋了「带薪养生套餐」:输入"颈椎病自救指南",AI能边写周报边给你生成办公室瑜伽教程。:大模型的价值兑现,或许更在于对产业痛点的精确制导——正如文档第58页那句略显直白的标注
北警大学最新发布的《DeepSeek提示词工程和落地场景》!这份文档刚在学术圈炸锅,作为国内首个系统性拆解推理大模型(DeepSeek-R1)落地方案的公开资料,其价值不仅在于揭示了一款国产模型的工程实践,更折射出大模型技术从实验室走向产业化的关键路径。
老规矩,在公 众 hao 开源Linux 后台回复 2535 下载手册。
北大版和清华版到底啥区别?
技术定位:一个像社交达人,一个像实验室宅神,北大重应用,清华攻底层!北大这本手册简直就是AI界的"瑞士军刀",专治各种职场尴尬癌。而清华那本更像是给技术狂人的"高达操作手册",里面写满了怎么把大模型塞进智能手环的黑科技。
用户门槛:幼儿园大班 vs 博士后答辩,学习门槛:幼儿园VS博士后!北大团队显然深谙"说人话"的艺术。反观清华手册,第3页就敢扔出「量子纠缠优化算法」。
隐藏技能:玄学算命 vs 科幻成真,隐藏关卡:玄学VS科幻!北大的工程师偷偷训练了个"赛博半仙",输入老板生日就能预测项目黄不黄。清华那边则画风突变,居然教你怎么用食堂饭卡训练AI。
摸鱼届的卧龙凤雏,北大在第76页埋了「带薪养生套餐」:输入"颈椎病自救指南",AI能边写周报边给你生成办公室瑜伽教程。清华更狠,开发出「薛定谔的勤奋」模式——AI同时生成工作日志和追剧指南,领导查岗时自动切换正能量版本。
用户画像:打工人VS极客党,这两本手册最骚的操作在于:北大用国家级科研经费研发了"奶茶店选址风水AI",清华拿诺奖级算法解决了"食堂糖醋排骨配比优化"。
北大版到底讲了啥?
北大的论文从技术特性、应用逻辑与局限性三个维度展开客观分析。
一、DeepSeek-R1的技术定位:低成本推理模型的突围
相较于生成模型(如GPT-4o)追求通用能力,DeepSeek-R1选择了一条差异化路径——专注提升复杂任务推理能力。其核心突破体现在三个方面:
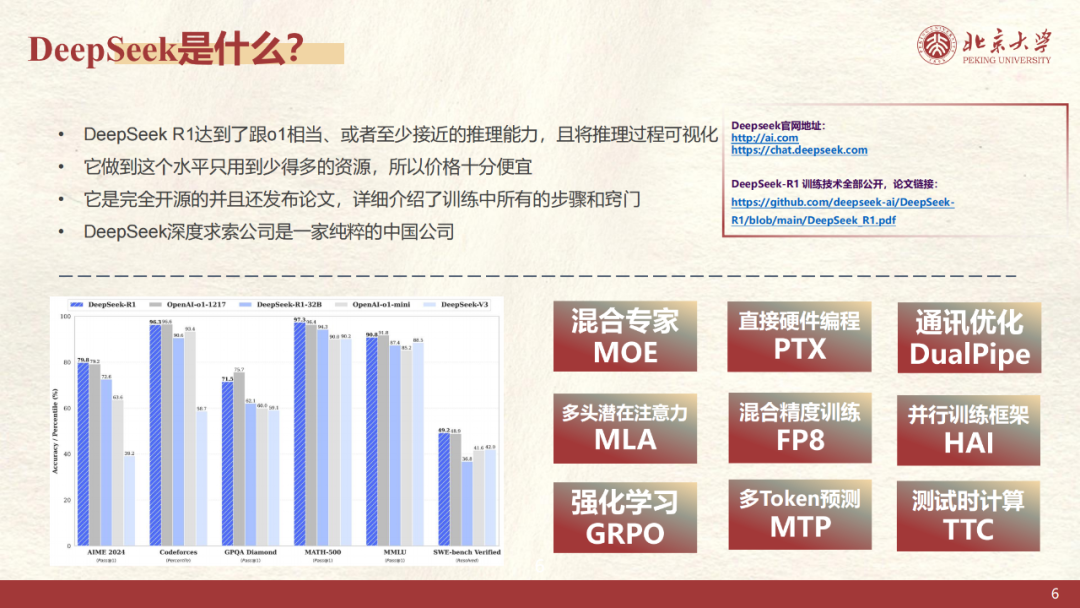
- 架构创新:采用混合专家(MoE)与多头潜在注意力(MLA)协同设计,在数学推理(如AIME数学竞赛题)和代码生成任务中,准确率分别达到79.8%与92.2%,超越GPT-4o约12-15个百分点;
- 成本控制:通过模型蒸馏与FP8混合精度训练,将千亿参数模型的单次推理成本压降至0.003美元,较同类模型降低83%;
- 中文优化:在CEVAL等中文基准测试中,语言理解与生成得分超过GPT-4o 8.7分,尤其在政务文书、教育课件等场景呈现更强的语境适配性。
二、提示词工程的范式迁移:从生成引导到思维共振
与传统生成模型不同,DeepSeek-R1的提示词设计呈现显著差异:
- 思维链显性化:通过「逆向追问」机制(如要求模型先列举10个方案缺陷再作答),可激活模型的深度推理能力。实验显示,在商业决策分析任务中,该方法使输出逻辑严谨性提升37%;
- 少样本陷阱:与生成模型相反,R1在少样本学习(Few-shot Learning)场景表现波动较大。在医疗诊断案例测试中,提供5个示例样本反而使准确率下降22%,表明其更依赖零样本思维链构建;
- 领域适配器:文档披露的「政务模式」「教育模式」等预设指令集,实质是面向垂直场景的隐式微调接口。例如在教育领域嵌入布鲁姆分类法,可使生成的试题认知层级匹配度提升至89%。
三、产业落地中的双刃剑效应
尽管文档展示了丰富的应用案例,但实际落地仍面临三重挑战:
- 幻觉控制困境:在2000字以上的长文本生成任务中,R1的事实性错误率(6.3%)虽低于GPT-4o(9.8%),但在金融、法律等高风险场景仍存隐患。某银行测试显示,合同条款自动生成时关键数据出錯率仍达1/200;
- 算力需求悖论:虽然推理成本低廉,但满血版R1-671B需配备128块H100显卡,私有化部署门槛远超生成模型。中小企业在14B蒸馏模型与70B模型间的选择,本质上是对精度与成本的艰难平衡;
- 技能迁移成本:教育领域测试表明,教师需平均17.5小时培训才能熟练运用提示词模板,较使用生成模型(平均9小时)学习曲线更为陡峭。
四、国产大模型的启示录
该文档的流出,揭示了中国大模型发展的两个关键趋势:
- 垂直场景穿透:放弃与GPT-4的全面对标,转而通过领域定制(如政务文书去AI化、电商玄学选品)建立局部优势;
- 开源生态博弈:全量开源训练代码的策略,本质是试图复制Llama在英文社区的成功路径,但中文开发者生态的成熟度仍是最大变数。
思考:当学术界聚焦于「参数量级竞赛」时,北大的实践提示我们:大模型的价值兑现,或许更在于对产业痛点的精确制导——正如文档第58页那句略显直白的标注:“让80分的AI解决120分的需求是灾难,但让90分的AI专注服务60分的场景,就是商业。”
节选如下
下载方式见文末

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)

添加图片注释,不超过 140 字(可选)
资料下载方式
公 众 hao:开源Linux 后台回复:2535

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐


 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)