

14、论文阅读:SuperYOLO:多模态遥感图像中的超分辨率辅助目标检测
在遥感图像 (RSI) 中,准确且及时地检测包含几十个像素的多尺度小物体仍然充满挑战。现有的大多数解决方案主要设计复杂的深度神经网络,以从背景中分离出物体并学习强特征表示,但这通常会导致高计算负担。本文提出了一种名为SuperYOLO的 RSI 目标检测方法,具有准确且快速的特点。该方法通过融合多模态数据和辅助超分辨率 (SR) 学习,在多尺度目标的高分辨率 (HR) 检测中兼顾检测精度和计算成本
SuperYOLO: Super Resolution Assisted Object Detection in Multimodal Remote Sensing Imagery
前言
在遥感图像 (RSI) 中,准确且及时地检测包含几十个像素的多尺度小物体仍然充满挑战。现有的大多数解决方案主要设计复杂的深度神经网络,以从背景中分离出物体并学习强特征表示,但这通常会导致高计算负担。
本文提出了一种名为 SuperYOLO 的 RSI 目标检测方法,具有准确且快速的特点。该方法通过融合多模态数据和辅助超分辨率 (SR) 学习,在多尺度目标的高分辨率 (HR) 检测中兼顾检测精度和计算成本。
(1)首先,我们利用对称的紧凑多模态融合 (MF) 从各种数据中提取补充信息,以提升 RSI 中小物体的检测效果。
(2)此外,我们设计了一个简单灵活的 SR 分支,来学习 HR 特征表示,以便在低分辨率 (LR) 输入的情况下区分出广阔背景中的小物体,从而进一步提升检测精度。
(3)此外,为了避免引入额外计算量,在推理阶段将丢弃 SR 分支,并通过 LR 输入减少网络模型的计算负担。
实验结果表明,在广泛使用的 VEDAI RS 数据集上,SuperYOLO 的准确率达到 75.09%(以 mAP50 计算),比 SOTA 大型模型(如 YOLOv5l、YOLOv5x 和专为 RS 设计的 YOLOrs)高出 10% 以上。同时,SuperYOLO 的参数量和 GFLOPs 分别比 YOLOv5x 低约 18 倍和 3.8 倍。相比当前的先进模型,我们提出的模型在精度和速度之间展现了良好的平衡。
代码将会在 GitHub 开源。
介绍
目标检测在包括计算机辅助诊断和自动驾驶在内的多个领域中发挥着重要作用。过去几十年中,已经提出、更新和优化了许多基于深度神经网络 (DNN) 的优秀目标检测框架。DNN 基于的目标检测框架的显著精度提升得益于具有精确标注的大规模自然数据集的应用。
与自然场景相比,在遥感图像 (RSI) 中实现准确目标检测面临一些重要挑战。首先,标注样本数量相对较少,限制了 DNN 的训练,难以获得较高的检测精度。其次,RSI 中的物体尺寸通常较小,仅占据几十个像素,与复杂而广阔的背景相比显得微不足道。此外,这些物体的尺度多样且类别繁多。如图 1(a) 所示,物体(如汽车)在广阔区域中显得非常小;如图 1(b) 所示,物体的尺度变化较大,例如汽车的尺寸小于露营车的尺寸。
目前,大多数目标检测技术仅针对单一模态(如红绿蓝 (RGB) 和红外 (IR))进行设计和应用。因此,在目标检测方面,由于缺乏不同模态间的互补信息,这些技术在识别地表物体的能力上仍显不足。随着成像技术的发展,多模态采集的 RSI 变得可获取,为提高检测精度提供了机会。例如,如图 1 所示,融合两种不同的多模态(RGB 和 IR)可以有效提升 RSI 的检测精度。有时,一种模态的分辨率较低,这需要提升分辨率的技术来增强信息。近来,超分辨率 (SR) 技术在遥感领域展示了巨大潜力。受益于卷积神经网络 (CNN) 的快速发展,遥感图像的分辨率达到了可以解析高纹理信息的水平。然而,由于 CNN 网络的高计算成本,SR 网络在实时实际任务中的应用已成为当前研究的热点。
本研究的动机是提出一种适用于多模态遥感图像 (RSI) 的车载实时目标检测框架,以在不增加额外计算负担的情况下实现高检测精度和高推理速度。受最近实时紧凑型神经网络模型进展的启发,我们选择小尺寸 YOLOv5s结构作为检测基线,以降低部署成本并促进模型的快速部署。
考虑到小物体的高分辨率 (HR) 保留需求,我们移除了基线 YOLOv5s 模型中的 Focus 模块,这不仅有利于小而密集的物体定位,还提升了检测性能。
考虑到不同模态的互补特性,我们提出了多模态融合 (MF) 方案,以改善 RSI 的检测性能。
我们评估了不同的融合方案(像素级和特征级),并选择了计算成本较低的像素级融合。
最后且最重要的是,我们开发了一个 SR 模块,以引导网络生成能够识别广阔背景中小物体的高分辨率 (HR) 特征,从而减少 RSI 中由背景污染物体引起的误报。然而,直接使用 SR 解决方案会显著增加计算成本。因此,我们在训练过程中设置了辅助 SR 分支,并在推理阶段将其移除,从而在不增加计算成本的情况下实现 HR 空间信息的提取。
综上所述,本文做出以下贡献:
(1)我们提出了一种计算友好的像素级融合方法,以对称紧凑的方式双向结合内部信息。与特征级融合相比,该方法在不牺牲精度的情况下有效降低了计算成本。
(2)我们首次将辅助 SR 分支引入多模态目标检测。我们的方法不仅在有限的检测性能上实现了突破,还为研究能够在低分辨率 (LR) 输入下区分广阔背景中小物体的优秀高分辨率 (HR) 特征表示提供了更灵活的途径。
(3)考虑到对高质量结果和低计算成本的需求,在推理阶段移除了作为辅助任务的 SR 模块,而没有引入额外的计算负担。SR 分支具有通用性和可扩展性,可以嵌入到现有的全卷积网络 (FCN) 框架中。
(4)所提出的 SuperYOLO 显著提升了目标检测的性能,在实时多模态目标检测中超过了当前最先进的检测器。与最先进的模型相比,我们提出的模型在精度与速度之间展现了良好的平衡。
相关工作
使用多模态数据进行物体检测
最近,多模态数据已广泛应用于许多实际应用场景,包括视觉问答、自动驾驶车辆、显著性检测和遥感分类。研究发现,结合多模态数据的内部信息可以有效传递互补特征,从而避免单一模态的信息被忽略。
在遥感图像 (RSI) 处理领域,存在多种模态(例如,RGB、合成孔径雷达 (SAR)、激光雷达 (LiDAR)、红外 (IR)、全色 (PAN) 和多光谱 (MS) 图像),这些模态来自不同的传感器,可以融合其互补特性以提升各种任务的性能。例如,额外的红外模态捕捉更长的热波长,以改善在恶劣天气条件下的检测。Manish 等人提出了一种用于多模态遥感成像的实时目标检测框架,其中扩展版本进行了中层融合并合并了来自多种模态的数据。尽管多传感器融合能够提高检测性能,如图 1 所示,但其低精度检测性能和待改善的计算速度难以满足实时检测任务的要求。

融合方法主要分为三种策略,即像素级融合、特征级融合和决策级融合方法。决策级融合方法在最后阶段融合检测结果,这可能会由于对不同多模态分支的重复计算而消耗大量计算资源。在遥感领域,主要采用特征级融合方法,通常采用多分支结构。多模态图像将输入到并行分支中,以提取不同模态的各自独立特征,然后通过一些操作(如注意力模块或简单连接)将这些特征结合起来。随着模态数量的增加,并行分支会导致重复计算,这在遥感的实时任务中并不友好。
在对比之下,采用像素级融合方法可以减少不必要的计算。在本文中,我们提出的 SuperYOLO 在像素级融合多种模式,以显著降低计算成本,并在空间和通道域设计了操作,以提取不同模式中的内部信息,从而帮助提高检测准确性。
目标检测中的超分辨率
在最近的文献中,通过多尺度特征学习和基于上下文的检测方法来提升小目标检测的性能。这些方法通常在不同尺度上增强网络的信息表示能力,但忽略了高分辨率(HR)上下文信息的保留。
在预处理步骤中,超分辨率(SR)已被证明在各种目标检测任务中有效。Shermeyer 和 Van Etten 通过多分辨率遥感影像(RSI)量化了其对卫星成像检测性能的影响。基于生成对抗网络(GANs),Courtrai 等人利用 SR 生成 HR 图像并输入检测器,以提升检测性能。Rabbi 等人使用拉普拉斯算子从输入图像中提取边缘,以增强 HR 图像重建的能力,从而提高目标定位和分类的性能。Ji 等人引入了循环一致性 GAN 结构作为 SR 网络,并修改了 Faster R-CNN 架构,以从 SR 网络生成的增强图像中检测车辆。在这些研究中,采用 SR 结构有效地解决了小目标的检测难题。然而,相较于单一检测模型,由于 HR 设计导致输入图像的尺度增大,额外的计算量被引入。
(图像超分辨率(SR)是指从低分辨率(LR)图像中恢复高分辨率(HR)图像的过程,是计算机视觉和图像处理中一种重要的图像处理技术)
最近,Wang 等人提出了一种超分辨率(SR)模块,该模块可以在使用低分辨率(LR)输入的同时保持高分辨率(HR)表示,并减少分割任务中的模型计算量。受 Wang 等人研究的启发,我们设计了一个 SR 辅助分支。与上述工作中在起始阶段实现 SR 的方法不同,我们的辅助 SR 模块用于引导检测器学习高质量的 HR 表示,不仅加强了对小而密集目标的响应,还提升了目标检测在空间域的性能。此外,在推理阶段移除 SR 模块,以避免额外的计算量。
基线架构
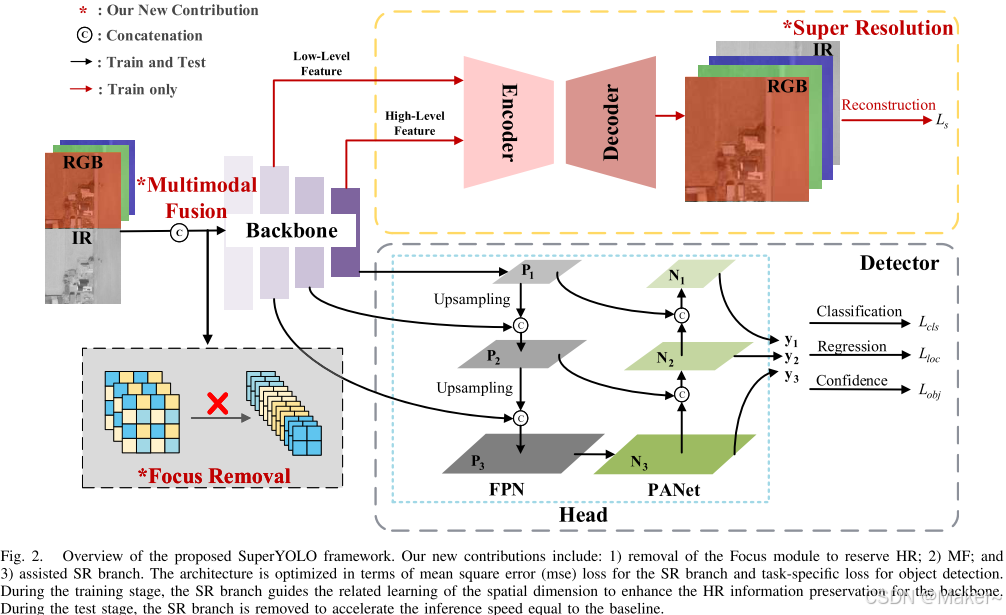
图 2. 提出的 SuperYOLO 框架概述。我们的新贡献包括:1) 移除 Focus 模块以保留高分辨率(HR);2) 多模态融合(MF);以及 3) 辅助超分辨率(SR)分支。该架构通过 SR 分支的均方误差(MSE)损失和目标检测的任务特定损失进行优化。在训练阶段,SR 分支引导空间维度的相关学习,以增强主干网络的 HR 信息保留。在测试阶段,移除 SR 分支以加速推理速度,使其与基线模型相等。
如图 2 所示,基线 YOLOv5 网络主要由两个部分组成:主干网络和检测头(包括颈部)。
主干网络用于提取低级纹理特征和高级语义特征。
接下来,这些特征被输入检测头,构建自上而下的增强特征金字塔网络,以传递稳健的语义特征,同时自下而上传播强烈的局部纹理和模式特征响应。这种结构通过增强多尺度检测,解决了对象在不同尺度下的检测问题。
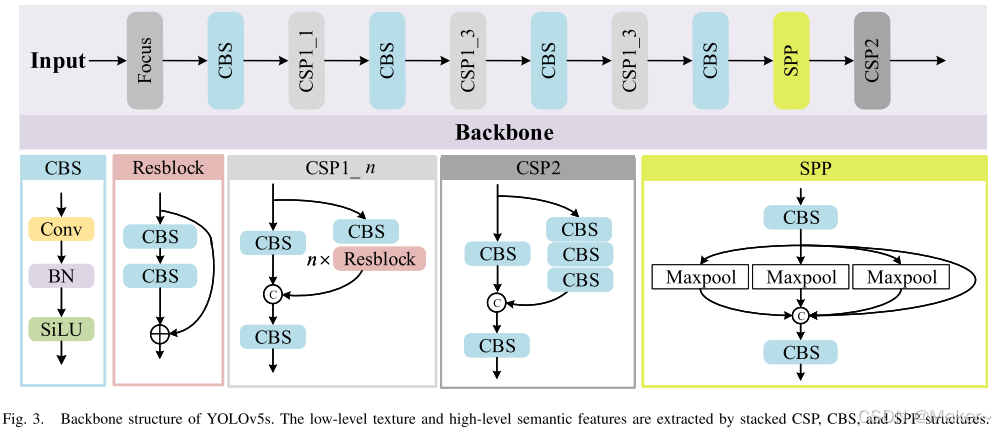
YOLOv5s 的主干结构。通过堆叠的 CSP、CBS 和 SPP 结构来提取低级纹理特征和高级语义特征。
在图 3 中,CSPNet 被用作主干网络来提取特征信息,它由多个卷积-批归一化-SiLu(CBS)组件和交叉阶段部分(CSP)模块组成。
CBS 包括卷积、批归一化和激活函数 SiLu 的操作。
CSP 模块将上一层的特征图复制成两个分支,然后通过 1×1 卷积将通道数减半,从而减少计算量。对于这两份特征图,一份连接到阶段末尾,另一份作为输入进入 ResNet 块或 CBS 块。最终,这两份特征图会被连接起来以整合特征,之后再经过一个 CBS 块。
空间金字塔池化(SPP)模块由具有不同核大小的并行最大池化层组成,用于提取多尺度深度特征。
低级纹理特征和高级语义特征通过堆叠的 CSP、CBS 和 SPP 结构提取。
局限性 1:值得注意的是,引入 Focus 模块是为了减少计算量。如图 2(左下角)所示,输入被分割成单独的像素,间隔重构后在通道维度上进行拼接。输入被缩小到较小的尺度,以降低计算成本并加快网络训练和推理速度。然而,这可能在一定程度上牺牲目标检测的准确性,特别是对于容易受分辨率影响的小目标。
局限性 2:YOLO 的主干网络采用深度卷积神经网络,以步长为 2 提取分层特征,因此提取特征的大小减半,保留用于多尺度检测的特征尺寸远小于原始输入图像。例如,当输入图像尺寸为 608 时,最后一层检测输出的特征尺寸分别为 76、38 和 19。低分辨率(LR)特征可能导致一些小目标的丢失。
SuperYOLO架构
如图 2 所示,我们在 SuperYOLO 网络架构中引入了三项新贡献。
- 首先,我们移除了主干网络中的 Focus 模块,并用多模态融合(MF)模块替代,以避免分辨率和准确性的下降。
- 其次,我们探索了不同的融合方法,最终选择了计算效率较高的像素级融合,用于融合 RGB 和红外(IR)模式,以优化差异性和互补信息。
- 最后,我们在训练阶段添加了辅助超分辨率(SR)模块,通过重建高分辨率(HR)图像来引导主干网络在空间维度上的相关学习,从而保持 HR 信息。在推理阶段,SR 分支被移除,以避免引入额外的计算开销。
Focus模块移除
如第 III 节和图 2(左下角)所示,YOLOv5 主干网络中的 Focus 模块在空间域上按间隔对图像进行分割,然后重新组织这些图像以调整输入图像的大小。具体而言,该操作通过收集图像中每组像素的一个值来重构图像,从而获得较小的互补图像。随着通道数的增加,重建图像的尺寸会缩小,从而导致分辨率下降和小目标的空间信息丢失。鉴于小目标检测更依赖于高分辨率,因此放弃了 Focus 模块,并用多模态融合(MF)模块替代(如图 4 所示),以防止分辨率下降。
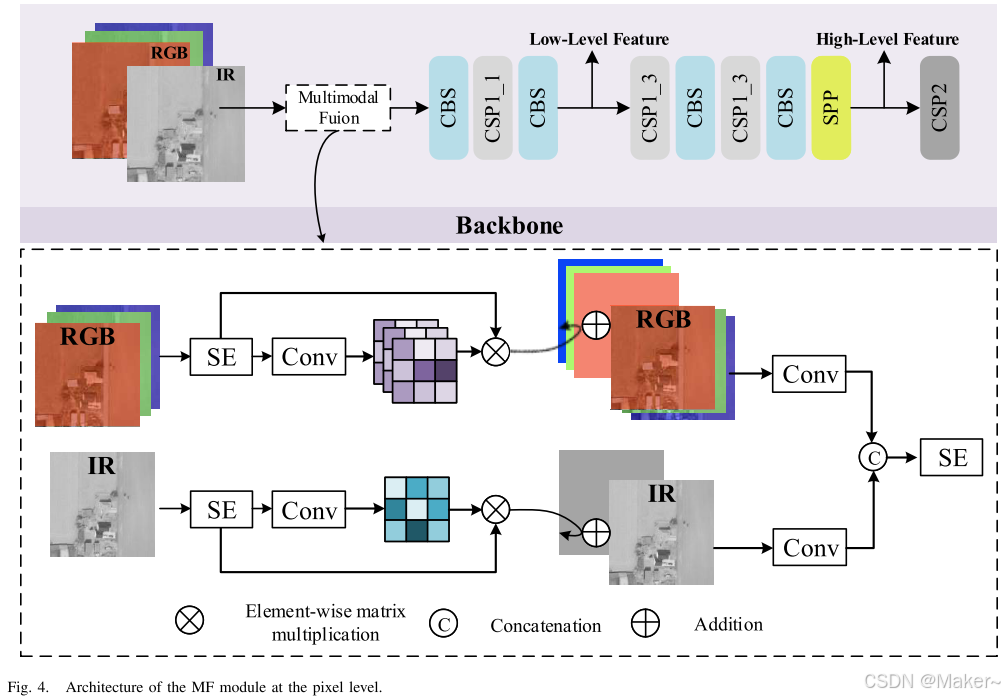
多模态融合



超分辨率(SR)
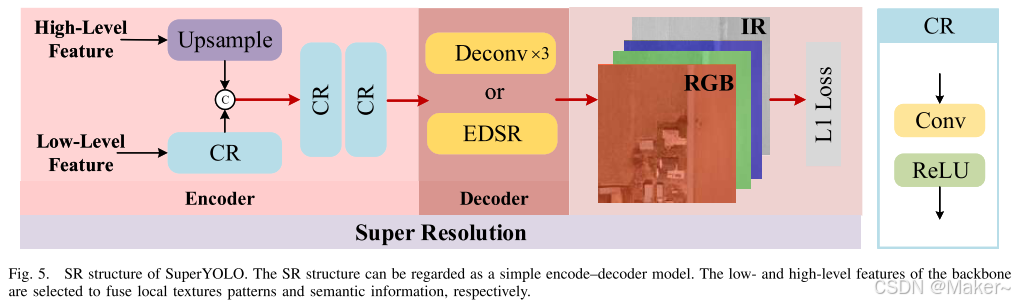
如第 III 节所述,主干网络中保留用于多尺度检测的特征尺寸远小于原始输入图像。大多数现有方法通过上采样操作来恢复特征尺寸,但由于纹理和模式信息的损失,这种方法效果有限,难以有效检测需要高分辨率保持的小目标。
为了解决这一问题,我们在图 2 中引入了辅助超分辨率(SR)分支。首先,该分支有助于在主干网络中提取高分辨率信息,从而实现令人满意的性能。其次,该分支不会增加额外计算,从而不会降低推理速度。这种设计在推理阶段实现了准确性和计算时间的平衡。受到 Wang 等人提出的 SR 结构的启发,我们在框架中引入了一个简单有效的 SR 分支。该分支能够提高检测精度而不会导致计算和内存超载,尤其在低分辨率输入的情况下表现尤佳。
具体而言,SR 结构可以被视为一个简单的编码-解码模型。我们选择主干网络中的低级和高级特征,分别融合局部纹理、模式信息以及语义信息。图 4 所示,我们选取了第四和第九模块的输出作为低级和高级特征。
编码器将主干网络中生成的低级和高级特征整合在一起。如图 5 所示,编码器中对低级特征进行 CR 模块操作。对于高级特征,我们使用上采样操作使其空间尺寸与低级特征匹配,然后使用拼接操作和两个 CR 模块来融合低级和高级特征。
CR 模块包含卷积和 ReLU。
在解码器中,低分辨率特征被上采样到高分辨率空间,其中 SR 模块的输出尺寸是输入图像的两倍。图 5 所示,解码器通过三个反卷积层实现。SR 分支引导空间维度的相关学习并将其传递到主分支,从而提升目标检测的性能。
此外,我们引入 EDSR【43】作为编码器结构,以探索 SR 性能及其对检测性能的影响。
为提供更直观的描述,我们在图 6 中可视化了 YOLOv5s、YOLOv5x 和 SuperYOLO 的主干网络特征。这些特征被上采样至与输入图像相同的尺度以便于比较。通过对比图 6 中的 ©、(f) 和 (i);(d)、(g) 和 (j);以及 (e)、(h) 和 (k) 图像,可以观察到 SuperYOLO 在 SR 的辅助下包含更清晰的目标结构和更高的分辨率。最终,通过 SR 分支,我们获得了高质量的高分辨率特征表示,并利用 YOLOv5 的检测头来检测小目标。

图 6 显示了 YOLOv5s、YOLOv5x 和 SuperYOLO 主干网络的特征层级可视化,输入相同:(a) RGB 输入,(b) IR 输入,©–(e) 为 YOLOv5s 特征,(f)–(h) 为 YOLOv5x 特征,(i)–(k) 为 SuperYOLO 特征。这些特征都被上采样到与输入图像相同的尺度,以便于比较。©、(f) 和 (i) 分别为第一层的特征;(d)、(g) 和 (j) 为低级特征;(e)、(h) 和 (k) 为相同深度层中的高级特征。
损失函数

实验
数据集
实验中使用了广受欢迎的 VEDAI(Vehicle Detection in Aerial Imagery)数据集,该数据集包含从更大的 Utah Automated Geographic Reference Center (AGRC) 数据集中裁剪得到的图像。AGRC 中每张图像的分辨率约为 12.5 厘米 × 12.5 厘米,每张图像的大小约为 16 000 × 16 000 像素。RGB 和红外 (IR) 是相同场景中每张图像的两种模态。VEDAI 数据集由 1246 张较小的图像组成,涵盖了草地、高速公路、山区和城市区域等多种背景。所有图像的尺寸为 1024 × 1024 或 512 × 512。任务是检测 11 种不同类型的车辆类别,如小汽车、皮卡、露营车和卡车等。
实现细节
我们提出的框架在 PyTorch 中实现,并在配备 NVIDIA 3090 GPU 的工作站上运行。使用 VEDAI 数据集训练 SuperYOLO。根据【27】的方法,对 VEDAI 数据集进行十折交叉验证。每次分割中,1089 张图像用于训练,121 张图像用于测试。在第一折数据上进行消融实验,而与先前方法的比较通过十折平均结果完成。每个图像中对象的标注包含边界框中心的坐标、相对于正 x 轴的方向、边界框的四个角、类别 ID、识别对象是否遮挡的二进制标志,以及对象是否被裁剪的二进制标志。
我们不考虑数据集中少于 50 个实例的类别,例如飞机、摩托车和公交车。因此,将 VEDAI 数据集的标注转换为 YOLOv5 格式,并将关注的类别 ID 转换为 0, 1, …, 7,即 N = 8。然后,对边界框的中心坐标进行归一化,并将绝对坐标转换为相对坐标。类似地,边界框的长宽被归一化到 [0, 1] 范围内。为实现 SR 辅助分支,网络的输入图像在训练过程中从 1024 × 1024 缩小到 512 × 512。测试过程中图像大小为 512 × 512,与其他算法输入一致。此外,数据通过色调饱和度值 (HSV)、多尺度、平移、左右翻转和拼接进行增强,测试阶段取消数据增强。网络训练使用标准随机梯度下降 (SGD)【46】,动量设为 0.937,Nesterov 加速梯度的权重衰减为 0.0005,批量大小为 2。学习率初始设为 0.01,整个训练过程包括 300 个周期。

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)