
四足机器人控制算法汇总
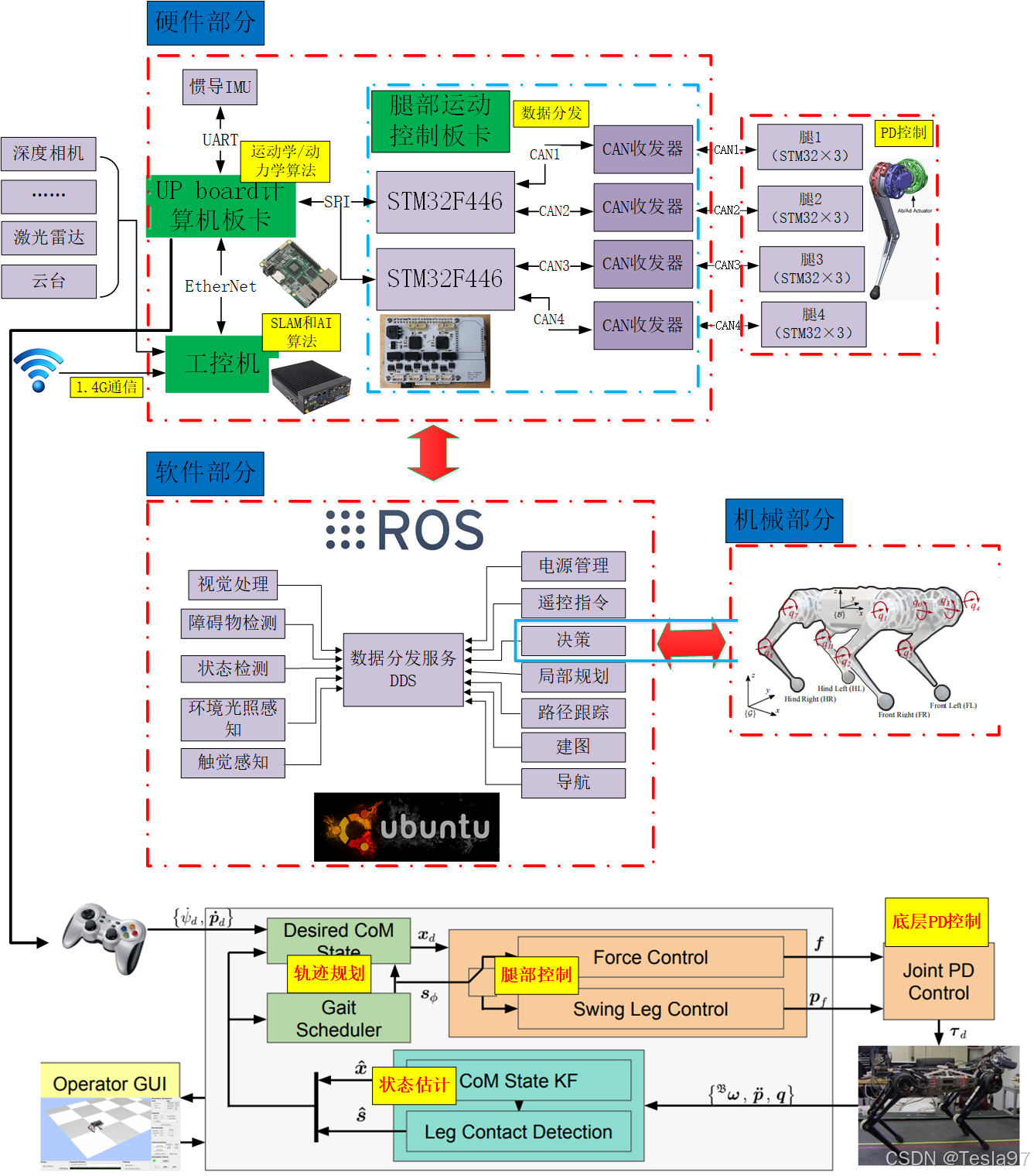
硬件部分传感器模块:包括深度相机、激光雷达和惯性测量单元(IMU),用于环境感知和导航。计算板卡:使用UP board和STM32F446微控制器进行数据处理和控制。SLAM算法用于定位与建图。腿部运动控制板卡:通过CAN总线与多个腿部驱动器通信,实现精确的运动控制。无线通信:4G通信模块用于远程操作和数据传输。软件部分ROS(机器人操作系统):用于集成各种软件模块,包括视觉处理、障碍物检测、状态
(一)四足机器人硬件、软件架构简介:(以MIT机器狗为模板)
硬件部分
- 传感器模块:包括深度相机、激光雷达和惯性测量单元(IMU),用于环境感知和导航。
- 计算板卡:使用UP board和STM32微控制器进行数据处理和控制。SLAM算法用于定位与建图。
- 腿部运动控制板卡:通过CAN总线与多个腿部驱动器通信,实现精确的运动控制。
- 无线通信:1.4G通信模块用于远程操作和数据传输。
软件部分
- ROS(机器人操作系统):用于集成各种软件模块,包括视觉处理、障碍物检测、状态检测等。
- 决策与规划:负责路径规划、避障和导航,确保机器人在复杂环境中的自主移动。
- 底层控制:包括力控、摆动腿控制和关节PD控制,以实现稳定的运动。
机械部分
- 四足机器人结构:显示了机器人的腿部配置和运动自由度,支持多种步态的实现。
- 用户界面:通过操控GUI和手柄进行实时控制和监控。
(二)四足机器人控制算法:
四足机器人的控制涉及多个层次和方面。自1960年第一个可控四足步行机器人诞生以来,研究者们在运动规划和控制上取得了显著进展。然而,目前仍然缺乏一个通用的控制框架和算法。尽管许多方法经过实验验证,但找到一种高效且通用的控制框架仍是研究的难点。下面从四足机器人运动规划与运动控制算法两个方面来介绍
1、四足机器人运动规划
四足机器人的运动规划涉及在运动过程中选择适当的地面接触点和规划腿部轨迹,以防止倾倒并减少与地面的冲击。常见的步态包括对角(trot)步态、蹦跃(jump)步态和疾驰(gallop)步态,各适用于不同的速度。此外,四足机器人的步态可以简化为双足步态。
步态周期与相位
- 步态周期:一个完整的步态循环被视为一个周期,腿部的步态相位从0到1变化。周期开始时,相位为0,结束时为1。
- 相位差:不同腿之间的相位差决定了不同的步态。例如,在对角步态中,左前腿和右后腿共享相同的相位,而右前腿与左后腿也共享相同的相位,相位差为0.5。
(1)ZMP的运动规划
零力矩点(Zero Moment Point,ZMP)是针对静态步态稳定的足式机器人的一种通用方法。在机器人步态规划过程中,ZMP 的计算涉及确定一个地面上的点 P,使得该点在与地面平行的轴方向上,由惯性力 F=ma和重力 G 所产生的净力矩为零。这意味着 ZMP 必须始终位于机器人足端与地面多个接触点所围成的多边形内,从而确保机器人保持理想的静平衡状态。基于 ZMP 的稳定性方法在双足和四足机器人中得到了广泛应用。然而,该算法也存在明显的局限性:它主要适用于静态步态,对于复杂的动态步态,ZMP 算法的应用效果较差。
(2)CPG的运动规划
中央模式发生器(CPG)通过模拟生物低级神经元来生成机器人的步态规划。该方法利用数学模型生成振荡曲线,将其作为腿部关节的位置和速度输入,从而具备一定的自稳定能力。此外,通过调节振荡曲线,可以方便地调整四足机器人各腿之间的相位关系。然而,这种方法存在显著的局限性。由于依赖于已知的振荡器,尽管具有一定的自稳定性,CPG 算法在面对复杂地形时会受到较大扰动,导致其适用性降低。在许多情况下,野外地形的高度变化会加剧这一问题。为了解决这一挑战,Saputra 等人提出了可变神经元的神经振荡器,这种新型振荡器具有更强的适应性,能够更好地应对复杂环境带来的变化。
(3)SLIP的运动规划
四足机器人的动态运动规划是其运动控制的核心问题,目前广泛应用的动态运动模型是弹簧加载倒立摆理论(Spring Loaded Inverted Pendulum,SLIP)模型。该模型将四足机器人的每条腿简化为具有柔性和阻抗的单自由度单杆结构。利用 SLIP 模型,波士顿动力公司的创始人 Raibert 在20世纪80年代实现了平衡腿的控制步态,包括单足、双足和四足的运动。Raibert 提出的“弹跳高度-前进速度-机体位姿”三体解耦控制方法,被视为工程技术与理论分析的完美结合,近30年来仍然是足式机器人动态平衡中最有效的手段之一。此外,Piovan 等人也对主动 SLIP 模型的控制进行了研究。
(4)贝塞尔曲线的轨迹规划
MIT猎豹系列机器人的一代和二代采用了基于贝塞尔曲线的腿部轨迹生成方法。这种方法使得MIT猎豹机器人能够在高速运动状态下实现步态切换。对于机器人脚部的轨迹规划,其主要目标是确保足够的离地间隙,以便机器人能够跨越适当的障碍物。同时,理想的摆动腿回缩率也至关重要,因为适当的回缩率可以提高机器人的稳定性,而合适的腿部攻角则有助于降低冲击能量损失。在轨迹生成过程中,贝塞尔曲线通过一定数量的关键点来满足机器人运动中的速度和加速度要求,从而规划出腿部运动轨迹。摆动相与支撑相是分别设计的,其中支撑相的轨迹采用正弦曲线,两者围绕一个共同的参考点进行设计。这一方法显著提升了MIT猎豹机器人的运动规划效率,但在面对复杂地形时仍然存在局限性,未能成为一种通用解决方案。
2、四足机器人运动控制
动态稳定性是机器人运动中的关键因素。四足机器人的运动控制涉及在动态运动过程中,通过合理的算法对机器人的位置和关节力矩进行调节,以实现动态稳定性和鲁棒性,并减少与地面的冲击力。为适应复杂环境,开发的足式机器人需要具备良好的跟踪性能和环境适应性的控制器。这种控制器能够有效应对多变的外部条件,从而确保机器人在各种环境下的稳定运行。
(1)柔顺阻抗控制
柔顺性可以分为主动柔顺性和被动柔顺性两种。被动柔顺性是指机器人通过柔顺机构(如弹簧)在与环境接触时自然地对外部作用力做出响应;而主动柔顺性则是机器人利用力反馈信息,通过特定的控制方法主动调节作用力。被动柔顺控制的一个典型应用是串联弹性驱动器(Series Elastic Actuator,SEA)。这种设计在传统刚性致动器和连杆之间加入了被动柔顺元件,使得机器人在与地面接触时能够表现出更好的鲁棒性。例如,StarLETH 机器人采用了 SEA 技术,可以精确控制关节扭矩并存储大量能量。通过将弹簧与变速箱分离,该设计有效减少了能量损耗,总功率低于230W。主动阻抗控制的一个典型例子是 HYQ 机器人。该机器人通过实时调整电机 PID 控制器的 PD 参数,相当于实时改变机器腿部的刚度和阻尼,将电机模拟为被动柔顺元件。其控制回路分为内环和外环,外环利用关节角位置作为反馈以输出扭矩信号,而该信号则作为内环扭矩控制回路的参考。基于低阶模型,该系统成功设计了高性能扭矩控制器,实现了可调阻抗,而无需实际使用弹簧。
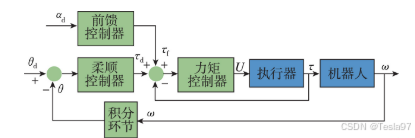
(2)前馈控制
机器人的力矩控制是实现动态响应的最快方法,尤其在四足机器人的控制中,前馈力矩控制是最常见的策略。MIT二代猎豹机器人在跳跃运动中,通过实现接触界面的前馈力来进行力矩控制。该方法通过检测驱动电机的输出电流来完成关节力矩的监测,从而实现对地面反作用力的高保真控制。HYQ机器人则将扭矩信号作为前馈参考,并基于低阶模型设计了高性能的扭矩控制器。这种前馈力矩控制与柔顺控制可以同时应用,使四足机器人具备柔顺阻抗特性和快速的动态响应能力。这种结合不仅提高了机器人的适应性,还增强了其在复杂环境中的稳定性。
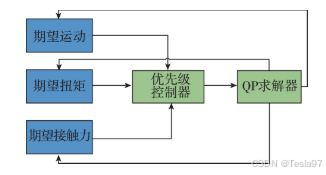
(3)分层操作空间(OSC)控制
StarLETH 机器人采用了基于分层任务优化的四足运动操作空间控制(Object-based Storage Controller,OSC)。该方法通过一系列简单的最小二乘问题来描述复杂的机器人行为,并将运动任务、扭矩任务和接触力优化任务分为不同的优先级。系统利用多个接触点的浮动基础系统进行投影动力学建模。在这一框架下,建立了三个优化变量:期望的运动、期望的关节扭矩和期望的地面接触力,其中期望的运动被赋予最高优先级。采用分割优化的方法,通过线性算子降低模型的复杂度,分别忽略关节扭矩和地面接触力,并利用二次规划(QP)求解器进行求解。最后,通过最小二乘法对这三种任务进行独立优化,从而实现高效的运动控制。
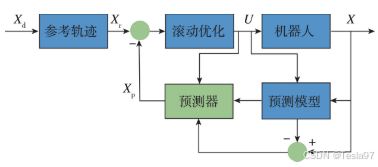
(4)模型预测(MPC)控制
模型预测控制(MPC)是一种特殊的控制策略,其当前控制动作是在每个采样时刻通过求解一个有限时域的开环最优控制问题获得的。这种方法不需要建立复杂的非线性机器人模型。控制器将当前的控制状态视为一个控制周期的初始状态,并将求解得到的控制输出作为第一个控制指令。实际上,这一过程本质上是解决开环最优控制问题,这种控制方式是四足机器人主流经典控制算法的核心,也是我硕士毕业论文所采用算法的核心。
(5)深度强化学习(DRL)
不管是MPC还是LQR,我都对一个非线性系统进行了一定程度上的简化,当然虽然简化,但控制效果也不错。足式机器人系统多呈现为非线性,故对系统控制模型的建立往往需要一些特殊的手段,将机器人的非线性系统反馈到线性化控制器,其控制特点是基于模型的状态或输出的反馈,将非线性系统的动态特性转换为线性的动态特性,然后采用传统控制算法进行控制。针对传统方法需要构建动力学模型的缺点,特别是真实环境还存在大量的噪声,换句话说就是传统方法通过动力学模型,输入x(k)得到的是确定的是x(k+1),而真实环境得到的却不是,而这种不确定的情况深度强化学习是可以学到的,也就是深度强化学习连噪声都可以直接学到,另外就是深度强化学习可以解决状态维度灾难的问题,机器人主流的深度强化学习算法是PPO和SAC,PPO是一种基于策略梯度的方法,旨在通过优化智能体的决策函数来完成复杂任务。它是对信任区域策略优化(TRPO)的改进,旨在提高训练的稳定性和效率(PPO已被成功应用于控制机器人手臂、在Dota 2中击败职业玩家以及在Atari游戏中表现出色),SAC是一种基于最大熵强化学习框架的离线策略-评论家算法。它结合了策略优化和价值函数学习,旨在同时最大化预期回报和策略的熵,也有一定的问题。
1、其一就是上面说的奖励函数的设计比较困难;
2、深度强化学习虽然可以对动力学环境进行强有力的拟合,但也带来了比较难收敛的问题;
3、试错法不适合于真实的物理环境,不同于游戏可以在虚拟环境中进行上百万次的模拟,而机器人控制问题无法在真实的物理环境中进行几百万次的试错。
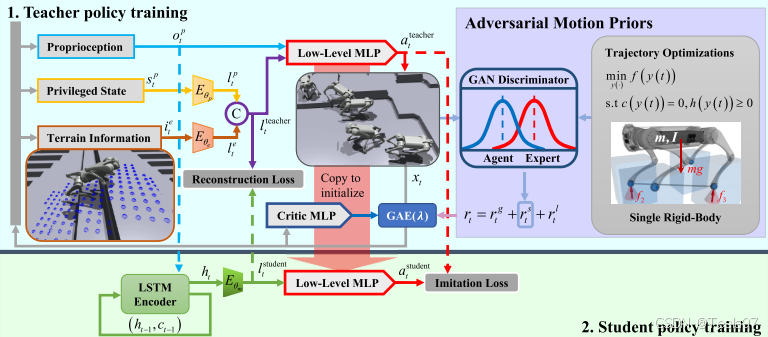 《深度强化学习理论及其在机器人运动控制中的应用实践》有详细的对倒立摆模型的DDPG与DQN公式推导
《深度强化学习理论及其在机器人运动控制中的应用实践》有详细的对倒立摆模型的DDPG与DQN公式推导
即通过细节奖励函数,引入强化学习算法,如深度Q网络(基于价值)、DDPG(基于策略),上述我们介绍了传统控制算法以及比较新颖的动态规划和深度强化学习算法在机器人控制中的应用,各有优缺点,目前还没有一种非常完美的控制方法,因此想要实现一个完美的控制,还是有必要汲取各家所长,并将这些长处运用到深度强化学习当中。
参考博客:https://zhuanlan.zhihu.com/p/717100787

欢迎加入北京社区
更多推荐

 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)