
深度学习基础之反向传播算法
在我们训练模型的过程中,我们是要对训练的权重即w,进行更新,我们是通过得到损失函数对w的导数,从而得到w的更新。通俗讲,反向传播算法通过把神经网络看成是一张图,我们可以在图上来传播梯度,最终根据链式法则求出梯度。反向传播,顾名思义,是从后向前传播的一种方法。因此计算完误差后,需要将这个误差向不断的向前一层传播。反向传播是为了解决偏导数计算量大的问题。(因为不同神经元的重要性不同,因此回传时需要考虑
·
一、为什么会有反向传播?
在我们训练模型的过程中,我们是要对训练的权重即w,进行更新,我们是通过得到损失函数对w的导数,从而得到w的更新。
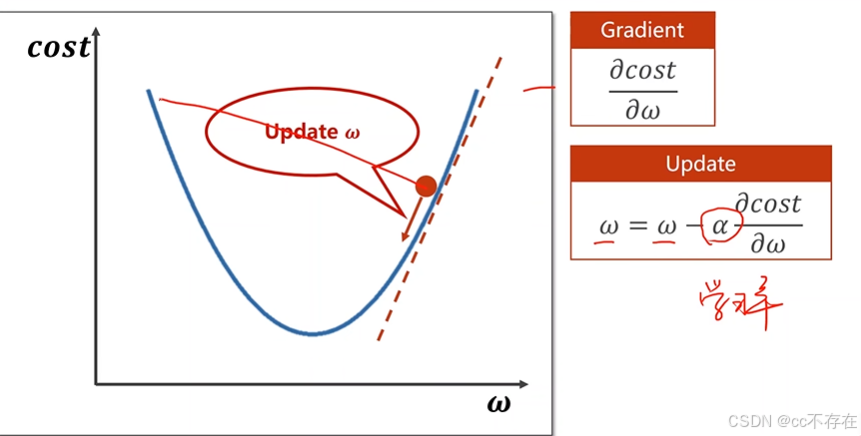
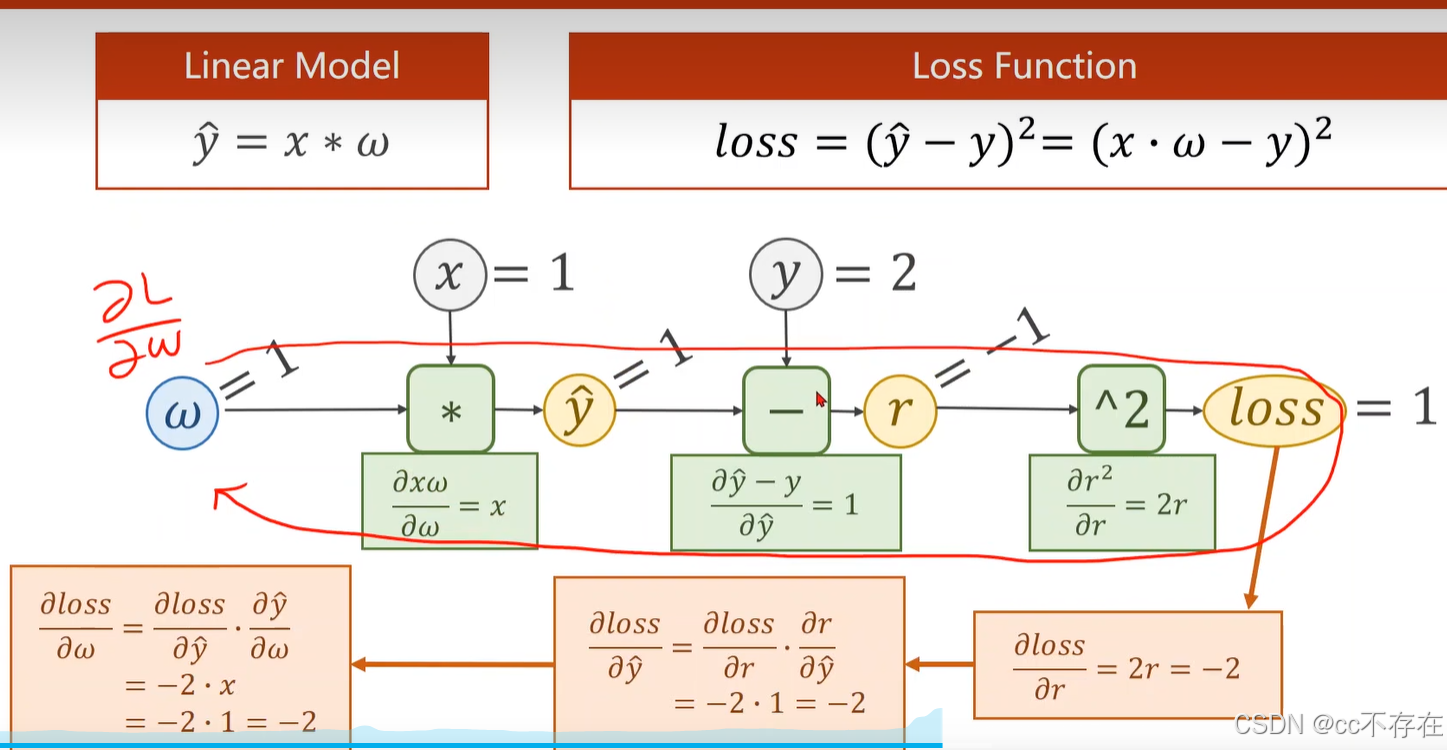
如下图所示,我们很难通过写出解析式得到计算结果。反向传播是为了解决偏导数计算量大的问题。
二、反向传播算法内容
1、反向传播算法(Backpropagation,简称BP算法)是“误差反向传播”的简称,是适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。
通俗讲,反向传播算法通过把神经网络看成是一张图,我们可以在图上来传播梯度,最终根据链式法则求出梯度。
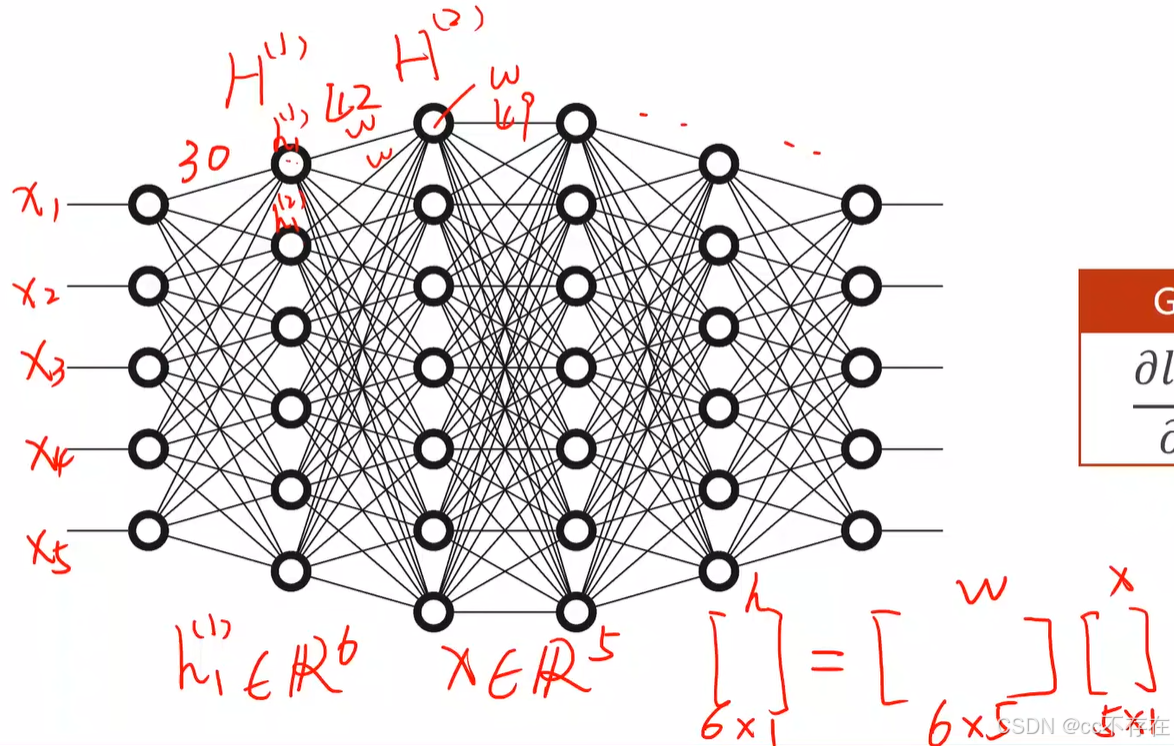
2、前向传播
如图所示,是一个简单的全连接三层的神经网络,
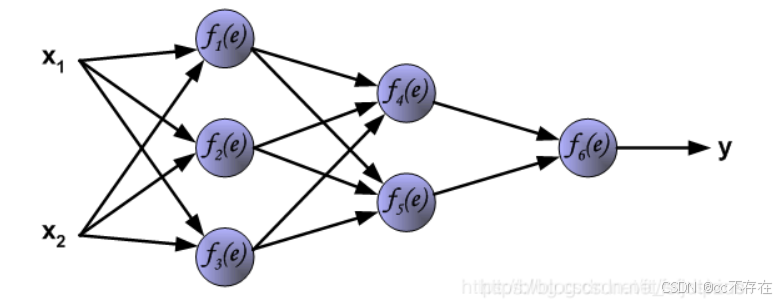
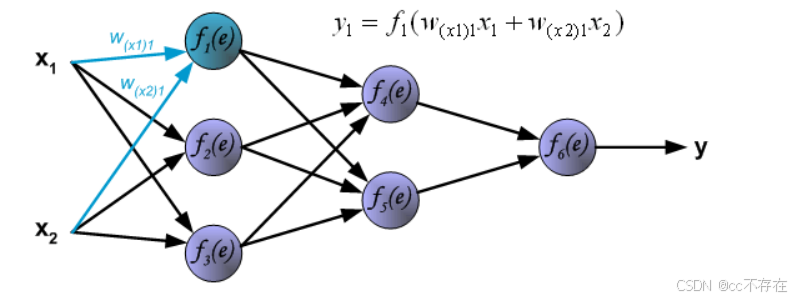
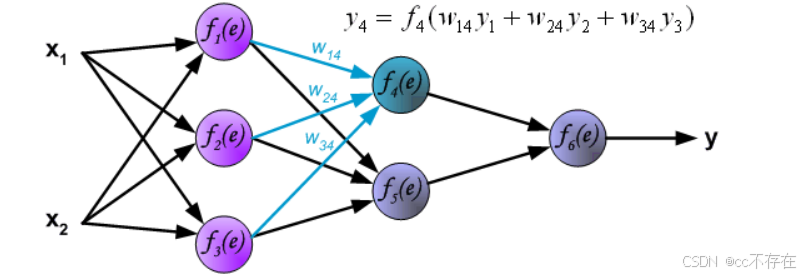
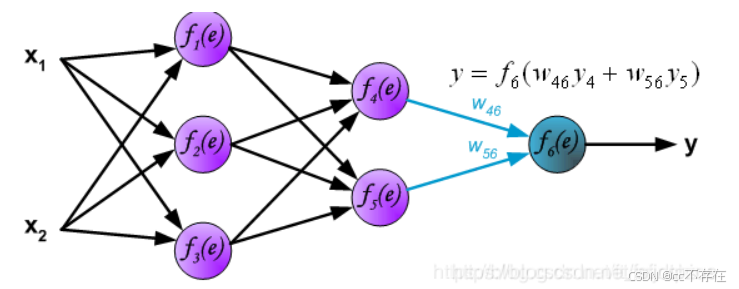
2,反向传播
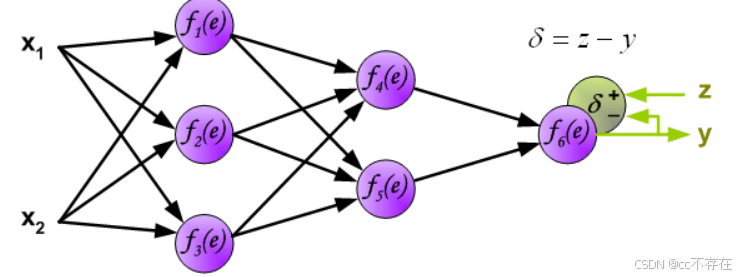
(1)计算误差
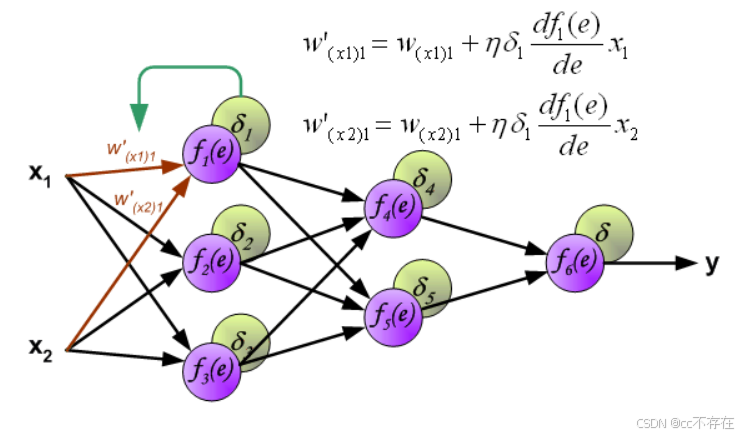
反向传播,顾名思义,是从后向前传播的一种方法。因此计算完误差后,需要将这个误差向不断的向前一层传播。向前一层传播时,需要考虑到前一个神经元的权重系数(因为不同神经元的重要性不同,因此回传时需要考虑权重系数)。
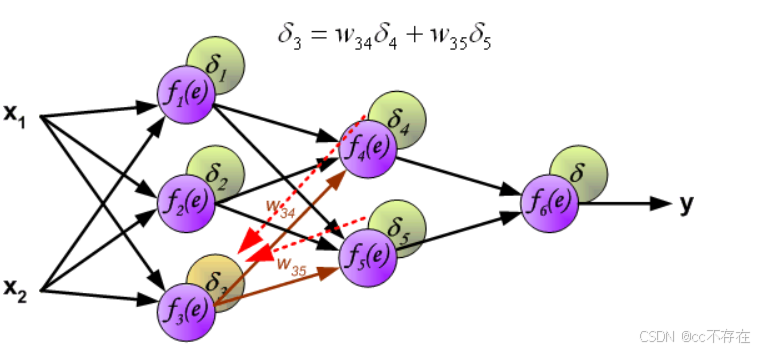
(2)更新权重
图中的η ηη代表学习率,w ′ 是更新后的权重
三、代码
import torch
# 定义一个简单的神经网络
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
# 定义第一个全连接层,输入维度为10,输出维度为20
self.fc1 = torch.nn.Linear(10, 20)
# 定义第二个全连接层,输入维度为20,输出维度为1
self.fc2 = torch.nn.Linear(20, 1)
def forward(self, x):
# 前向传播过程,使用ReLU激活函数
x = torch.relu(self.fc1(x))
# 输出层不使用激活函数
x = self.fc2(x)
return x
# 创建一个随机的输入数据和目标数据
x = torch.randn(100, 10)
y = torch.randn(100, 1)
# 创建网络实例
net = Net()
# 定义损失函数和优化器
# 使用均方误差作为损失函数
criterion = torch.nn.MSELoss()
# 使用随机梯度下降作为优化器,学习率为0.01
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
# 训练网络
for epoch in range(100):
# 前向传播
y_pred = net(x)
# 计算损失
loss = criterion(y_pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新参数
optimizer.step()
# 打印损失
print(f'Epoch {epoch}, Loss: {loss.item()}')
import torch
x_data = torch.Tensor([[1.0],[2.0],[3.0]])
y_data = torch.Tensor([[2.0],[4.0],[6.0]])
#在此类中,我们并没有发现backward方法,这是因为:用Moduel构造出来的对象会自动地根据计算图去实现backward的过程
#当然,如果我们需要自己实现backward的过程,我们可以通过继承Function类来实现反向传播的过程。
class LinearModel(torch.nn.Module): #在定义模型类时,所有的模型都要继承自Moduel,
def __init__(self):#构造函数,初始化对象时要调用的
super(LinearModel,self).__init__()
self.linear = torch.nn.Linear(1,1)#torch.nn.Linear(1,1)这是在构造对象,这个对象包含了权重w和偏置b,
# 他可以帮我们自动完成输入x到得到y_hat的计算过程,
# 这里的Linear也是继承自Moduel,也可以进行自动的反向传播
#所以self.linear的类型是torch.nn.Linear类
def forward(self, x):#forward必须实现,在进行前馈的过程中要执行的计算
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)#这里是设置了False,表示损失不求均值
# criterion需要y和y_hat,就可以计算出损失
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)#优化器,不是Moduel,不能构建计算图
# 这里是对优化器进行实例化
# model.parameters()会检查Moduel里的所有成员,如果有相应的权重,就会将其加入到要训练的集合上
# x_test = torch.Tensor([[4.0]])
# y_test = model(x_test)
# print('y_pred = ',y_test.data)
y_test = torch.Tensor([[8.0]])
#训练过程
for epoch in range(100):
y_pred = model(x_data) #算出y_pred
loss = criterion(y_pred,y_data) #求出损失
print(epoch,loss.item())
optimizer.zero_grad() #梯度归0
loss.backward() #反向传播
optimizer.step() #根据梯度和学习率进行更新
#输出weight和bias
print('w = ',model.linear.weight.item())
print('b = ',model.linear.bias.item())
# # 测试模型
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ',y_test.data)
点击阅读全文

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)