k8s基础学习
一、Pod1、核心资源Pod介绍1.1Pod是什么官方文档:https://kubernetes.io/docs/concepts/workloads/pods/Pod是Kubernetes中的最小调度单元,k8s是通过定义一个Pod的资源,然后在Pod里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。一个Pod封装一个容器(也可以封装多个容器),Pod里的容器共享存储、网络等。也
一、Pod
1、核心资源Pod介绍
1.1 Pod是什么
官方文档:https://kubernetes.io/docs/concepts/workloads/pods/
Pod是Kubernetes中的最小调度单元,k8s是通过定义一个Pod的资源,然后在Pod里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。一个Pod封装一个容器(也可以封装多个容器),Pod里的容器共享存储、网络等。也就是说,应该把整个pod看作虚拟机,然后每个容器相当于运行在虚拟机的进程。


pod相当于一个逻辑主机–比方说我们想要部署一个tomcat应用,如果不用容器,我们可能会部署到物理机、虚拟机或者云主机上,那么出现k8s之后,我们就可以定义一个pod资源,在pod里定义一个把tomcat容器,所以pod充当的是一个逻辑主机的角色。
1.2 Pod工作方式
在K8s中,所有的资源都可以使用一个yaml文件来创建,创建Pod也可以使用yaml配置文件。或者使用kubectl run在命令行创建Pod(不常用)。
1.2.1 自主式Pod
所谓的自主式Pod,就是直接定义一个Pod资源,如下:
vim pod-tomcat.yaml
=========================================================
apiVersion: v1 #版本
kind: Pod #资源类型pod
metadata:
name: tomcat-test #pod名称
namespace: default #pod命名空间
labels:
app: tomcat
spec:
containers:
- name: tomcat-java #容器名称
ports:
- containerPort: 8080
image: xianchao/tomcat-8.5-jre8:v1 #镜像
imagePullPolicy: IfNotPresent
=========================================================
#可以使用下面命令查看
kubectl explain pod
#创建pod
kubectl apply -f pod-tomcat.yaml
#查看pod是否创建成功
kubectl get pods -o wide -l app=tomcat
#但是自主式Pod是存在一个问题的,假如我们不小心删除了pod:
kubectl delete pods tomcat-test
#查看pod是否还在
kubectl get pods -l app=tomcat
#结果是空,说明pod已经被删除了
#通过上面可以看到,如果直接定义一个Pod资源,那Pod被删除,就彻底被删除了,不会再创建一个新的Pod,这在生产环境还是具有非常大风险的,所以今后我们接触的Pod,都是控制器管理的。
1.2.2 控制器管理的Pod(一般用于生产)
常见的管理Pod的控制器:Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。
控制器管理的Pod可以确保Pod始终维持在指定的副本数运行。
如,通过Deployment管理Pod。
#1、拉取nginx镜像
ctr image pull docker.io/library/nginx:alpine
#2、创建一个资源清单文件
vim nginx-deploy.yaml
=========================================
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
labels:
app: nginx-deploy
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: my-nginx
image: docker.io/library/nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
=========================================
#可以使用下面命令查看
kubectl explain deployment
#3、创建pod
kubectl apply -f nginx-deploy.yaml
#查看Deployment
kubectl get deploy -l app=nginx-deploy
#查看Replicaset
kubectl get rs -l app=nginx
#4、查看pod
kubectl get pods -o wide -l app=nginx
#5、删除nginx-test-64d46f6fbf-hfvm8这个pod
kubectl delete pods nginx-test-64d46f6fbf-hfvm8
#查看pod
kubectl get pods -o wide -l app=nginx
#发现重新创建一个新的pod是nginx-test-64d46f6fbf-ls25r
通过上面可以发现通过deployment管理的pod,可以确保pod始终维持在指定副本数量
2、如何创建一个Pod资源

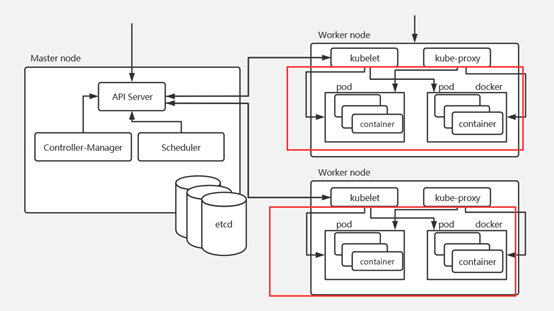
master节点:kubectl -> kube-api -> kubelet -> CRI容器环境初始化
-
第一步:客户端提交创建Pod的请求,可以通过调用API Server的Rest API接口,也可以通过kubectl命令行工具。如kubectl apply -f filename.yaml(资源清单文件)
-
第二步:apiserver接收到pod创建请求后,会将yaml中的属性信息(metadata)写入etcd。
-
第三步:apiserver触发watch机制准备创建pod,信息转发给调度器scheduler,调度器使用调度算法选择node,调度器将node信息给apiserver,apiserver将绑定的node信息写入etcd
调度器用一组规则过滤掉不符合要求的主机。比如Pod指定了所需要的资源量,那么可用资源比Pod需要的资源量少的主机会被过滤掉
scheduler 查看 k8s api ,类似于通知机制
首先判断:pod.spec.Node == null?
若为null,表示这个Pod请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的node。
然后将信息在etcd数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
ps:同样上述操作的各种信息也要写到etcd数据库中中 -
第四步:apiserver又通过watch机制,调用kubelet,指定pod信息,调用Docker API创建并启动pod内的容器。
-
第五步:创建完成之后反馈给kubelet, kubelet又将pod的状态信息给apiserver,
apiserver又将pod的状态信息写入etcd。
2.1 资源清单YAML文件书写技巧
apiVersion: v1 #api版本
kind: Pod #创建的资源
metadata:
name: tomcat-test #Pod的名字
namespace: default #Pod所在的名称空间
labels:
app: tomcat #Pod具有的标签
spec:
containers:
- name: tomcat-java #Pod里容器的名字
ports:
- containerPort: 8080 #容器暴露的端口
image: xianchao/tomcat-8.5-jre8:v1 #容器使用的镜像
imagePullPolicy: IfNotPresent #镜像拉取策略
#1、通过kubectl explain 查看定义Pod资源包含哪些字段
kubectl explain pod
#2、查看pod.metadata字段如何定义
kubectl explain pod.metadata
#3、查看pod.spec字段如何定义
kubectl explain pod.spec
#3.1、查看pod.spec.containers字段如何定义
kubectl explain pod.spec.containers
#3.2、查看pod.spec.container.ports字段如何定义
kubectl explain pod.spec.containers.ports
2.2 通过资源清单文件创建第一个Pod
vim pod-first.yaml
========================================
apiVersion: v1
kind: Pod
metadata:
name: pod-first
namespace: default
labels:
app: tomcat-pod-first
spec:
containers:
- name: tomcat-first
ports:
- containerPort: 8080
image: xianchao/tomcat-8.5-jre8:v1
imagePullPolicy: IfNotPresent
========================================
#1、创建pod
kubectl apply -f pod-first.yaml
#2、查看pod是否创建成功
kubectl get pods -o wide -l app= tomcat-pod-first
#3、查看pod详细信息
kubectl describe pods pod-first
#4、查看pod日志
kubectl logs pod-first
#查看pod里指定容器的日志
kubectl logs pod-first -c tomcat-first
#5、进入到刚才创建的pod,刚才创建的pod名字是web
kubectl exec -it pod-first -- /bin/bash
#假如pod里有多个容器,进入到pod里的指定容器,按如下命令:
kubectl exec -it pod-first -c tomcat-first -- /bin/bash
2.3 通过kubectl run创建Pod
kubectl run tomcat --image=xianchao/tomcat-8.5-jre8:v1 --image-pull=policy='IfNotPresent' --port=8080
3、导出pod yaml文件
#查看pod
kubectl get pods -n kube-system -owide
#假如我们想把kube-proxy的配置文件导出成1.yaml文件
kubectl get daemonset kube-proxy -o yaml -n kube-system > 1.yaml
二、命名空间
1、命名空间介绍
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间。
命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命 名空间,例如,可以为 test、devlopment、production 环境分别创建各自的命名空间。
2、namespace 应用场景
命名空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本 不需要创建或考虑命名空间。
3、namespacs 使用案例分享
#查看namesapce
kubectl get namespace
kubectl get ns
#查看namesapce的详细信息
kubectl describe namespace $NAME
#创建一个 test 命名空间
kubectl create ns test
注意:
1、namespace的名称仅能由字母、数字、下划线、连接符等字符组成。
2、删除namespace资源会级联删除其包含的所有其他资源对象。
#切换命名空间
kubectl config set-context --current --namespace=kube-system
#切换命名空间后,kubectl get pods如果不指定-n,查看的就是kube-system命名空间的资源了
#查看那些资源属于命名空间级别的
kubectl api-resources --namespaced=true
4、namespace 资源限额
如何对 namespace 资源做限额呢?
#对test命名空间做限制
vim namespace-quota.yaml
===================================
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-quota
namespace: test
spec:
hard:
requests.cpu: "2"
requests.memory: 2Gi
limits.cpu: "4"
limits.memory: 4Gi
===================================
#应用
kubectl apply -f namespace-quota.yaml
#创建的 ResourceQuota 对象将在 test 名字空间中添加以下限制:
#每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu 请求(cpu request)和 cpu 限额(cpu limit)。
#所有容器的内存请求总额不得超过 2GiB。
#所有容器的内存限额总额不得超过 4 GiB。
#所有容器的 CPU 请求总额不得超过 2 CPU。
#所有容器的 CPU 限额总额不得超过 4CPU。
#查看
kubectl describe ns test
#创建pod时候必须设置资源限额,否则创建失败,如下:
vim pod-test.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: pod-test
namespace: test
labels:
app: tomcat-pod-test spec:
containers:
- name: tomcat-test
ports:
- containerPort: 8080
image: xianchao/tomcat-8.5-jre8:v1
imagePullPolicy: IfNotPresent
resources:
requests:
memory: "100Mi"
cpu: "500m"
limits:
memory: "2Gi"
cpu: "2"
===================================
三、标签
1、label 简介
Label以key/value键值对的形式附加到任何对象上,如Pod,Service,Node, RC(ReplicationController)/RS(ReplicaSet)等;
同一个资源是可以拥有多个标签的,比如我们的Pod-A,既可以拥有app=tomcat,也可以具有web=nihao的标签,使用上更加方便。
标签的作用是为了统一管理,具有相同特点的pod,可以让其具有同一个label,这样子的话后面管理起来非常方便,也可以指定这个pod在哪个node节点上运行,如果你有特殊需要的话。
2、给pod资源打标签
#对已经存在的pod打标签
kubectl label pods pod-first release=v1
#查看标签是否打成功
kubectl get pods pod-first --show-lables
3、查看资源标签
#查看默认名称空间下所有pod资源的标签
kubectl get pods --show-labels
#查看指定名称空间下所有pod资源的标签
kubectl get pods -n kube-system --show-labels
#查看所有命名空间pod资源的标签
kubectl get pods --all-namespaces --show-labels
#查看指定标签下的pod
kubectl get pods -l release=v1
四、Pod资源高级用法
pod资源清单详细解读:
#版本号
apiVersion: v1
#资源类型
kind: Pod
#元数据
metadata:
#Pod名字
name: string
#pod所属命名空间
namespace: string
#自定义标签
labels:
#自定义标签名字
- name: string
#自定义注释列表
annotations:
- name: string
#pod中容器的详细定义
spec:
#pod中容器列表
containers:
#容器名称
- name: string
#容器镜像名称
image: string
#获取镜像的策略(Always表示下载镜像,IfNotPresent表示优先使用本地镜像,Never表示仅使用本地镜像)
imagePullPolicy: Always|Never|IfNotPresent
#容器的启动命令列表,如不指定,使用打包时使用的启动命令
command: [string]
#容器的启动命令参数列表
args: [string]
#容器的工作目录
workingDir: string
#挂载到容器内的存储卷位置
volumeMounts:
#引用pod定义的共享存储卷的名称,需用volumes[]部分定义的卷名
- name: string
#存储卷在容器内mount的绝对路径,应小于512字符
mountPath: string
#是否为只读模式
readOnly: boolean
#需要暴露的端口号
ports:
#端口号名称
- name: string
#容器需要监听的端口号
containerPort: int
#容器所在主机需要监听的端口号,默认与Container相同
hostPort: int
#端口协议,支持TCP/UDP,默认是TCP
protocol: string
#容器运行前需设置需设置的环境变量列表
env:
#环境变量名称
- name: string
#环境变量的值
value: string
#资源限制和请求的设置
resources:
#资源限制的设置
limits:
#cpu限制,单位为core数
cpu: string
#内存限制,单位为Mib/Gib
memory: string
#资源请求的设置
requests:
#cpu请求,容器启动的初始可用数量
cpu: string
#内存请求,容器启动的初始可用内存
memory: string
#对Pod内容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方式有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方式即可
livenessProbe:
#容器健康检查方式设置为exec方式
exec:
#exec方式需指定的命令或脚本
command: [string]
#容器健康检查方式设置为HttpGet,需要指定Path、port
httpGet:
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
#容器健康检查方式为tcpSocket
tcpSocket:
port: number
#容器启动完成后首次探测的时间,单位为秒
initialDelaySeconds: 0
#对容器健康检查方式探测等待响应的超时时间,默认为1秒
timeoutSeconds: 0
#对容器健康检查的定期探测时间设置,默认10秒一次
periodSeconds: 0
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
#Pod重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启pod,OnFailure表示只有Pod以非0状态码退出才重启,Never表示不再重启该pod。
restartPolicy: Always|Never|OnFailure
#设置nodeSelector表示该pod调度到包含这个label的node,以key:value的格式指定
nodeSelector: object
#pull镜像时使用的serect名称,以key:secretkey格式指定
imagePullSecrets:
- name: string
#是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
hostNetwork: false
#在该pod上定义共享存储卷
volume:
#共享存储卷名称
- name: string
#如果 Pod 设置了 emptyDir 类型 Volume, Pod 被分配到 Node 上时候,会创建 emptyDir,只要 Pod 运行在 Node 上,
#emptyDir 都会存在(容器挂掉不会导致 emptyDir 丢失数据),但是如果 Pod 从 Node 上被删除(Pod 被删除,或者 Pod 发生迁移),
#emptyDir 也会被删除,并且永久丢失。
emptyDir: {}
#hostPath 允许挂载 Node 上的文件系统到 Pod 里面去。如果 Pod 需要使用 Node 上的文件,可以使用 hostPath
hostPath:
#pod所在宿主机的目录,将被用于挂载到容器中
path: string
#挂载集群与定义的secret对象到容器内部
secret:
secretname: string
items:
- key: string
path: string
#挂载预定义的configmap对象到容器内部
configMap:
name: string
items:
- key: string
path: string
1、验证k8s证书
#(1)查看具体证书:
openssl x509 -in /etc/kubernetes/pki/apiserver.crt -noout -text |grep Not
#(2)查看所有证书:
for item in `find /etc/kubernetes/pki -maxdepth 2 -name "*.crt"`;do openssl x509 -in $item -text -noout| grep Not;echo ======================$item===================;done
2、node节点选择
2.1 nodeName
在Kubernetes中,NodeName是每个Node节点的唯一标识符,它是一个字符串,通常是节 点的主机名(hostname)。在创建Pod时,可以通过指定 nodeName字段来将Pod调度到特定的 Node 节点上。
#指定pod节点运行在具体node上(spec.nodeName)
vim pod-node.yaml
===================================================
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: busybox-tomcat
env: pro
spec:
nodeName: k8sn1
containers:
- name: tomcat
ports:
- containerPort: 8080
image: tomcat:8.5.34-jre8-alpine
imagePullPolicy: IfNotPresent
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command:
- "/bin/sh"
- "-c"
- "sleep 36000"
===================================================
#创建pod
kubectl apply -f pod-node.yaml
#查看 pod 调度到哪个节点
kubectl get pods -o wide
#查看pod详情
kubectl describe pods demo-pod
#强制删除pod
kubectl delte pods demo-pod --force --grace-period=0
2.2 nodeSelector
在Kubernetes中,nodeSelector是一种用于在 Pod 级别上选择运行节点的方法。通过使用nodeSelector字段,你可以指定一组键值对(标签),以便将Pod调度到具有匹配标签的节点上运行。
每个节点都可以使用一组标签进行标识,这些标签可以根据硬件规格、操作系统、地理位置或其他特 定的属性来定义。当创建Pod时,你可以通过在Pod的配置中指定nodeSelector字段,来告诉Kubernetes调度器选择具有匹配标签的节点来运行该 Pod。
#查看pod节点标签
kubectl get nodes --show-labels
#给node2节点打标签
kubectl label nodes k8sn2 disk=ssd
kubectl label nodes k8sn2 region=us-west
#创建配置文件
vim nodeSelector-pod.yaml
===================================================
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-container
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
disk: ssd
region: us-west
===================================================
在上述示例中,nodeSelector字段包含了两个键值对:disk:ssd和region:us-west。这意味着Kubernetes将尝试将这个Pod调度到具有标签disk=ssd和region=us-west的节点上。
3、亲和性affinity
在k8s中亲和性有两种:节点亲和性(nodeaffinity)和Pod亲和性(podaffinity)。
- Pod亲和性(Pod Affinity):Pod亲和性用于指定Pod之间的关系,使它们倾向于在同一节点或具有相似特征的节点上运行。这可以在以下场景中发挥作用:
- 数据本地性:当两个或多个Pod需要访问相同的本地数据时,可以使用Pod亲和性将它们调度到同一节点上。例如,在分布式数据库中,多个数据库实例需要访问相同的数据卷或存储,可以通过Pod亲和性将它们调度到同一节点上,减少网络传输延迟。
- 互为依赖:当两个或多个Pod之间存在依赖关系,需要相互通信或协同工作时,可以使用Pod亲和性将它们调度到同一节点上。例如,在微服务架构中,某个服务需要与特定的缓存服务进行交互,可以使用Pod亲和性将它们调度到同一节点上,提高性能和减少网络开销。
- 服务发现和负载均衡:在需要实现服务发现和负载均衡的场景中,可以使用Pod亲和性将属于同一服务的多个实例调度到同一节点或相近的节点上。这样可以提高服务的可用性、降低延迟,并简化负载均衡配置。
- 节点亲和性(NodeAffinity):节点亲和性用于指定Pod与节点之间的关系,使Pod倾向于在具有特定标签或节点特征的节点上运行。这可以在以下场景中发挥作用:
- 资源需求:当某个Pod对计算资源(如CPU、内存)或其他特定硬件资源(如GPU)有特定需求时,可以使用节点亲和性将它调度到具有相应资源的节点上。这有助于优化资源利用和性能。
- 逻辑分组:当需要将相关的Pod分组部署到特定节点上时,可以使用节点亲和性。例如,在分布式系统中,某个节点需要承担特定的角色或任务,可以使用节点亲和性将相关的Pod调度到该节点上,以便实现逻辑上的分组和管理。
- 特定硬件或软件要求:当某个Pod需要依赖特定的硬件设备或软件环境时,可以使用节点亲和性将它调度到具备所需条件的节点上。例如,某个Pod需要与具有特定硬件加速器的节点进行通信,可以使用节点亲和性将它调度到具备所需硬件的节点上。
3.1 node 节点亲和性
#node节点亲和性:nodeAffinity
kubectl explain pods.spec.affinity
kubectl explain pods.spec.affinity.nodeAffinity
preferredDuringSchedulingIgnoredDuringExecution:preferredDuringSchedulingIgnoredDuringExecution是Kubernetes中节点亲和性(NodeAffinity)的一种规则类型,它允许用户指定Pod调度器尽可能将Pod调度到与指定节点亲和的节点上,但如果没有可用的这样的节点,Pod也可以调度到其他节点上。
requiredDuringSchedulingIgnoredDuringExecution:这个字段指定了一个节点选择器,Pod只能被调度到满足这个节点选择器的节点上。如果没有节点满足这个要求,Pod就无法被调度。
#例1:使用 requiredDuringSchedulingIgnoredDuringExecution (硬亲和性)
vim nodeaffinity.yaml
======================================
apiVersion: v1
kind: Pod
metadata:
name: nodeaffinity-1
namespace: default
labels:
app: myapp
item: pro
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: a
operator: In
values:
- b
======================================
#我们检查当前节点中有任意一个节点拥有a=b标签,就可以把pod调度到有a=b这个标签的节点上。
#给node1打标签
kubectl label nodes k8sn1 a=b
#执行
kubectl apply -f nodeaffinity.yaml
#此时可以看到po在k8sn1上
kubectl get pods -owide
#例2:使用 preferredDuringSchedulingIgnoredDuringExecution(软亲和性)
vim nodeaffinity-2.yaml
======================================
apiVersion: v1
kind: Pod
metadata:
name: nodeaffinity-2
namespace: default
labels:
app: myapp2
item: pro2
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: a1
operator: In
values:
- b1
weight: 80
======================================
#执行
kubectl apply -f nodeaffinity-2.yaml
kubectl get pods -owide -l app=myapp2
#上面说明软亲和性是可以运行这个pod的,尽管没有任何一个节点具有a1=b1这个标签
3.2 Pod和Pod亲和性
podAffinity:表示Pod与其它Pod的亲和性。
可以使用equiredDuringSchedulingIgnoredDuringExecution、preferredDuringSchedulingIgnoredDuringExecution等字段来指定Pod与其它Pod的亲和性规则。这些字段中可以使用topologyKey和labelSelector字段来指定Pod之间的关系。
pod亲和性分两种:
- podaffinity(pod亲和性):Pod亲和性是指一组Pod可以被调度到同一节点上,即它们互相吸引,倾向于被调度在同一台节点上。例如,假设我们有一组具有相同标签的Pod,通过使用Pod亲和性规则,我们可以让它们在同一节点上运行,以获得更高的性能和更好的可靠性。
- podunaffinity(pod反亲和性):Pod反亲和性是指一组Pod不应该被调度到同一节点上,即它们互相排斥,避免被调度在同一台节点上。例如,如果我们有一组应用程序Pod,我们可以使用Pod反亲和性规则来避免它们被调度到同一节点上,以减少单点故障的风险和提高可靠性。
kubectl explain pods.spec.affinity.podAffinity
requiredDuringSchedulingIgnoredDuringExecution:硬亲和性
preferredDuringSchedulingIgnoredDuringExecution:软亲和性
#例1:pod和pod亲和性
#定义两个 pod,调度到同一个位置
vim podaffinity-require.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: first
labels:
app: first
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
===================================
#执行
kubectl apply -f podaffinity-require.yaml
#查看
kubectl get pods -owide -l app=first
#此时我们看到上面的pod在node2上
#新建pod
vim podaffinity-require-2.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: second
labels:
app: second
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["first"]}
topologyKey: kubernetes.io/hostname
===================================
#上面表示创建的second这个pod与拥有app=first标签的pod进行亲和性。
#topologyKey:kubernetes.io/hostname:这个是Kubernetes中一个用于指定节点位置拓扑的关键字,kubernetes.io/hostname是一个节点标签的key值,不同的节点这个key对应的value值是节点主机名,它表示Pod应该与具有相同的主机名的节点进行亲和性或反亲和性调度。也就是两个pod调度到同一个node节点或者不同的node节点上。
#查看
kubectl get pods -owide
#此时我们看到上面的pod在node2上,表示亲和
#例2:pod节点反亲和性
#定义两个pod,第一个pod做为基准,第二个pod跟它调度到不同的节点上
vim podunaffinity-1.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: first-1
labels:
app: first-1
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
===================================
kubectl apply -f podunaffinity-1.yaml
kubectl get pods -l app=first-1 -owide
#发现上面的pod运行在node1上
#创建第二个pod
vim podunaffinity-2.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: second-1
labels:
app: second-1
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["first-1"]}
topologyKey: kubernetes.io/hostname
===================================
kubectl apply -f podunaffinity-2.yaml
#查看
kubectl get pods -l app=first-1 -owide
kubectl get pods -l app=second-1 -owide
#上面结果表示两个pod不在一个node节点上,这就是pod节点反亲和性
4、污点和容忍度
我们给节点打一个污点,不容忍的pod就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些pod,容忍度是定义在pod上的,用来指定能容忍哪些污点。
taints是键值数据,用在节点上,定义污点;
tolerations是键值数据,用在pod上,定义容忍度,能容忍哪些污点
#查看污点定义
kubectl explain node.spec.taints
- NoSchedule: 仅影响pod调度过程,当pod能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的pod不能容忍了,那这个pod会怎么处理,对现存的pod对象不产生影响
- NoExecute:既影响调度过程,又影响现存的pod对象,如果现存的pod不能容忍节点后来加的污点,这个pod就会被驱逐
- PreferNoSchedule:最好不,也可以,是 NoSchedule 的柔性版本
#查看master这个节点是否有污点
kubectl describe nodes k8sm1
#显示如下
================================
Taints: node-role.kubernetes.io/control-plane:NoSchedule
================================
#上面可以看到master这个节点的污点是Noschedule,所以我们创建的pod都不会调度到master上,因为我们创建的pod没有容忍度
kubectl describe pods kube-apiserver-k8sm1 -n kube-system
#显示如下
================================
Tolerations: :NoExecute op=Exists
================================
#可以看到这个pod的容忍度是NoExecute,则可以调度到xianchaomaster1上
#管理节点污点
kubectl taint --help
#例1:把k8sn1当成是生产环境专用的。
kubectl taint node k8sn1 node-type=production:NoSchedule
#给k8sn1打污点,pod 如果不能容忍就不会调度过来
vim pod-taint.yaml
================================
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
================================
kubectl apply -f pod-taint.yaml
kubectl get pods -o wide
#上面pod执行后,因为pod没定义容忍度,所以不会调度到k8sn1节点上。
#例2:定义容忍度
vim pod-demo-1.yaml
================================
apiVersion: v1
kind: Pod
metadata:
name: taint-pod2
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
tolerations:
- key: node-type
value: production
operator: Equal
effect: NoSchedule
================================
#上面定义了容忍度a=b
kubectl apply -f pod-demo-1.yaml
kubectl get pods -o wide
#上面pod执行后,因为pod定义容忍度,所以会调度到k8sn1节点上。
#删除污点:
kubectl taint nodes k8sn1 node-type-
5、Pod内的容器做健康探测
在k8s集群中,可以使用健康探测来监测Pod的状态,并根据探测结果来实现自动化容器的重启或故障切换等操作,从而提高应用的可靠性和可用性。下面介绍几种常用的健康探测方式及其应用场景:
- LivenessProbe(存活探测):LivenessProbe用于监测pod内的容器是否处于运行状态。当LivenessProbe探测失败时,Kubernetes根据重启策略决定是否重启该容器。适用于需要在容器发生故障时立即进行重启的应用场景,比如Web服务器和数据库等应用。
- ReadinessProbe(就绪探测):ReadinessProbe用于监测pod内的容器是否已经准备好接受流量,即容器是否已经完成初始化并已经启动了应用程序。当容器的ReadinessProbe探测失败时,Kubernetes将停止将新的流量转发到该容器。适用于需要应用程序启动较长时间的应用场景,比如大型Web应用程序。
- StartupProbe(启动探测)StartupProbe用于监测pod内的容器是否已经启动成功并准备好接受流量。与LivenessProbe不同的是,StartupProbe只会在容器启动时执行一次。当StartupProbe探测失败时,Kubernetes将自动重启该容器。适用于需要较长启动时间的应用场景,比如应用程序需要大量预热或者需要等待外部依赖组件的应用程序。
5.3 为什么要对容器做探测
在Kubernetes中Pod是最小的计算单元,而一个Pod又由多个容器组成,相当于每个容器就是一个应用,应用在运行期间,可能因为某些意外情况致使程序挂掉。那么如何监控这些容器状态稳定性,保证服务在运行期间不会发生问题,发生问题后进行重启等机制,就成为了重中之重的事情,考虑到这点kubernetes推出了活性探针机制。有了存活性探针能保证程序在运行中如果挂掉能够自动重启,但是还有个经常遇到的问题,比如说,在Kubernetes中启动Pod,显示明明Pod已经启动成功,且能访问里面的端口,但是却返回错误信息。还有就是在执行滚动更新时候,总会出现一段时间,Pod对外提供网络访问,但是访问却发生404,这两个原因,都是因为Pod已经成功启动,但是Pod的的容器中应用程序还在启动中导致,考虑到这点Kubernetes推出了就绪性探针机制。
默认的健康检查
Kubernetes默认的健康检查机制:每个容器启动时都会执行一个进程,此进程由Dockerfile的CMD或ENTRYPOINT指定。如果进程退出时返回码非零,则认为容器发生故障,Kubernetes就会根据restartPolicy策略决定是否重启容器。
#创建check配置文件 vim check.yaml ============================ apiVersion: v1 kind: Pod metadata: name: check namespace: default labels: app: check spec: containers: - name: check image: busybox:1.28 imagePullPolicy: IfNotPresent command: - /bin/sh - -c - sleep 10;exit ============================ kubectl apply -f check.yaml kubectl get pods -w #在上面的例子中,容器进程返回值非零,Kubernetes则认为容器发生故障,需要重启。有不少情况是发生了故障,但进程并不会退出。比如访问Web服务器时显示500内部错误,可能是系统超载,也可能是资源死锁,此时httpd进程并没有异常退出,在这种情况下重启容器可能是最直接、最有效的解决方案。
k8s提供了三种来实现容器探测的方法,分别是:
- startupProbe:探测容器中的应用是否已经启动。如果提供了启动探测(startupprobe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success
- livenessprobe:用指定的方式(exec、tcp、http)检测pod中的容器是否正常运行,如果检测失败,则认为容器不健康,那么Kubelet将根据Pod中设置的restartPolicy策略来判断Pod是否要进行重启操作,如果容器配置中没有配置livenessProbe,Kubelet将认为存活探针探测一直为success(成功)
- readnessprobe:就绪性探针,用于检测容器中的应用是否可以接受请求,当探测成功后才使Pod对外提供网络访问,将容器标记为就绪状态,可以加到pod前端负载,如果探测失败,则将容器标记为未就绪状态,会把pod从前端负载移除。
可以自定义在 pod 启动时是否执行这些检测,如果不设置,则检测结果均默认为通过,如果设置, 则顺序为 startupProbe>readinessProbe 和 livenessProbe,readinessProbe 和 livenessProbe 是并发 关系
目前 LivenessProbe 和 ReadinessProbe、startupprobe 探测都支持下面三种探针:
1、exec:在容器中执行指定的命令,如果执行成功,退出码为0则探测成功。
2、TCPSocket:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
3、HTTPGet:通过容器的IP地址、端口号及路径调用HTTPGet方法,如果响应的状态码大于等于200且小于400,则认为容器健康
探针探测结果有以下值:
1、Success:表示通过检测。
2、Failure:表示未通过检测。
3、Unknown:表示检测没有正常进行。
Pod 探针相关的属性:
探针(Probe)有许多可选字段,可以用来更加精确的控制Liveness和Readiness两种探针的行为
initialDelaySeconds:容器启动后要等待多少秒后探针开始工作,单位“秒”,默认是0秒,最小值0
periodSeconds:执行探测的时间间隔(单位是秒),默认为10s,单位“秒”,最小值是1
timeoutSeconds:探针执行检测请求后,等待响应的超时时间,默认为1,单位“秒”。
successThreshold:连续探测几次成功,才认为探测成功,默认为1,在Liveness探针中必须为1,最小值为1。
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在readiness探针中,Pod会被标记为未就绪,默认为3,最小值为1
两种探针区别:
ReadinessProbe和livenessProbe可以使用相同探测方式,只是对Pod的处置方式不同:
readinessProbe当检测失败后,将Pod的IP:Port从对应的EndPoint列表中删除。
livenessProbe当检测失败后,将杀死容器并根据Pod的重启策略来决定作出对应的措施。
5.2 启动探测startupprobe
1、exec模式
vim startup-exec.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: startupprobe
spec:
containers:
- name: startup
image: docker.io/library/tomcat:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
exec:
command:
- "/bin/bash"
- "-c"
- "ps aux | grep tomcat"
initialDelaySeconds: 20 #容器启动后多久开始探测
periodSeconds: 20 #执行探测的时间间隔
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
==================================
kubectl apply -f startup-exec.yaml
kubectl get pod startupprobe -w
#可以看到只有在40秒之后,才可以真正成功
备注:第一次探测失败多久会重启
initialDelaySeconds + (periodSeconds + timeoutSeconds)* failureThreshold
2、tcpsocket模式
vim startup-tcpsocket.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: startuptcp
spec:
containers:
- name: startup
image: docker.io/library/tomcat:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 20 #容器启动后多久开始探测
periodSeconds: 20 #执行探测的时间间隔
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
==================================
kubectl apply -f startup-tcpsocket.yaml
kubectl get pod tcp -w
#可以看到只有在40秒之后,才可以真正成功
3、httpget 模式
vim startup-httpget.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: startuphttp
spec:
containers:
- name: startup
image: docker.io/library/tomcat:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
startupProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 20 #容器启动后多久开始探测
periodSeconds: 20 #执行探测的时间间隔
timeoutSeconds: 10 #探针执行检测请求后,等待响应的超时时间
successThreshold: 1 #成功多少次才算成功
failureThreshold: 3 #失败多少次才算失败
==================================
kubectl apply -f startup-httpget.yaml
kubectl get pod tcp -w
#可以看到只有在40秒之后,才可以真正成功
5.3 存活探测livenessprobe
LivenessProbe用于检查pod内的容器是否在运行,并在容器出现故障时重新启动容器。LivenessProbe支持三种探针:httpGet、exec和tcpSocket。
#查看命令
kubectl explain pods.spec.containers.livenessProbe
#1、使用HTTP接口进行探测: vim live-http.yaml ======================================= apiVersion: v1 kind: Pod metadata: name: liveness-http labels: app: nginx spec: containers: - name: liveness image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 livenessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 30 periodSeconds: 10 readinessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 20 periodSeconds: 10 restartPolicy: Always =======================================
- initialDelaySeconds:首次探测之前等待的时间,单位是秒。在容器启动之后,等待指定的时间后才开始进行探测,避免容器还未启动完成就开始进行探测,导致探测失败。
- periodSeconds:探测器的周期时间,单位是秒。探测器将在每隔一定时间间隔内进行一次探测。默认周期时间是10秒。
#应用 kubectl apply -f live-http.yaml #查看 kubectl get pods liveness-http #模拟探测失败的情况:在Nginx容器中删除/usr/share/nginx/html/index.html文件,这样httpGet探针将无法访问该文件,从而导致探测失败。 #提前打开另一个窗口观测pod变化 kubectl get pods -l app=nginx -w #进到liveness-http这个pod: kubectl exec -it liveness-http -- /bin/bash #进入后删除 rm -rf /usr/share/nginx/html/index.html #查看pod,可以看到pod里的容器重启了一次。因为默认的重启策略是always,只要探测失败就重启。 #2、使用TCP接口进行探测 vim live-tcp.yaml ======================================= apiVersion: v1 kind: Pod metadata: name: liveness-tcp spec: containers: - name: liveness image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 livenessProbe: tcpSocket: port: 80 initialDelaySeconds: 15 periodSeconds: 20 ======================================= #执行 kubectl apply -f live-tcp.yaml #查看 kubectl get pods liveness-tcp #模拟探测失败的情况:在Nginx容器中停止nginx服务,这样80端口将无法访问进到liveness-http这个pod: kubectl exec -it liveness-tcp -- /bin/bash #进入后停止nginx nginx -s stop #查看pod,发现刚重启 kubectl get pods liveness-http
5.4 就绪探测readinessprobe
ReadinessProbe用于检查容器是否已经准备好接收流量。ReadinessProbe支持三种探针:httpGet、exec和tcpSocket。
vim readiness-http.yaml ======================================= apiVersion: v1 kind: Pod metadata: name: my-pod labels: app: my-pod spec: containers: - name: nginx-container image: nginx imagePullPolicy: IfNotPresent ports: - containerPort: 80 readinessProbe: httpGet: path: /index.html port: 80 initialDelaySeconds: 60 periodSeconds: 60 failureThreshold: 3 successThreshold: 1 =======================================#YAML文件说明:
1、initialDelaySeconds:首次探测之前等待的时间,单位是秒。在容器启动之后,等待指定的时间后才开始进行探测,避免容器还未启动完成就开始进行探测,导致探测失败。
2、periodSeconds:探测器的周期时间,单位是秒。探测器将在每隔一定时间间隔内进行一次探测。默认周期时间是10秒。
3、failureThreshold:探测失败的阈值,failureThreshold:3是指在连续失败了3次探测后,探测就会被认定为失败,容器将被认为是不健康的,并且将被终止并重新启动。
4、successThreshold:探测成功的阈值,假设successThreshold:1,则当容器探测成功一次后,容器将被认为是健康的,继续运行。所以上面最终探测方式如下:
探测将在容器启动后等待60秒钟,然后开始执行。探测周期的时间间隔为60秒,也就是每隔60秒进行一次探测。如果在探测期间出现3次失败,则Pod将被标记为NotReady,如果探测成功一次,才会将其标记为Ready。#创建svc四层代理 vim readiness-svc.yaml ======================================= apiVersion: v1 kind: Service metadata: name: readiness spec: selector: app: my-pod ports: - port: 80 targetPort: 80 ======================================= #创建svc kubectl apply -f readiness-svc.yaml #查看svc kubectl describe svc readiness #创建pod kubectl apply -f readiness-http.yaml #查看 kubectl get pods my-pod -w #上面可以看到pod没有立即ready,因为initialDelaySeconds:60表示pod启动后60s才开始探测,所以至少要等60s,探测没问题才会就绪。 #当测试成功后可以看到pod的ip和端口已经加到svc的Endpoints中了 kubectl describe svc readiness #模拟探测失败的情况:在Nginx容器中删除/usr/share/nginx/html/index.html文件,这样httpGet探针将无法访问该文件,从而导致探测失败。 kubectl exec -it my-pod -- /bin/bash #进入后删除 rm -rf /usr/share/nginx/html/index.html #检查Pod的状态: kubectl get pods my-pod -w #上面可以看到pod已经不就绪了,在64s时候删除index.html文件。然后每隔60s探测一次,失败了3次,pod内的容器就会处于非就绪状态。 #修复探测失败的情况:重新创建/usr/share/nginx/html/index.html文件。 #进入pod后执行 echo hello > /usr/share/nginx/html/index.html #检查Pod的状态: kubectl get pods my-pod -w #此时,Pod的状态应该变为Ready,并且Kubernetes会将流量发送到该容器
5.5 三种探针配合使用
一般程序中需要设置三种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔,下面列一个简单的SpringBoot项目的例子。
vim start-read-live.yaml
==================================
apiVersion: v1
kind: Service
metadata:
name: springboot-live
labels:
app: springboot
spec:
type: NodePort
ports:
- name: server
port: 8080
targetPort: 8080
nodePort: 31180
- name: management
port: 8081
targetPort: 8081
nodePort: 31181
selector:
app: springboot
---
apiVersion: v1
kind: Pod
metadata:
name: springboot-live
labels:
app: springboot
spec:
containers:
- name: springboot
image: mydlqclub/springboot-helloworld:0.0.1
imagePullPolicy: IfNotPresent
ports:
- name: server
containerPort: 8080
- name: management
containerPort: 8081
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
livenessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
startupProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 8081
path: /actuator/health
==================================
五、k8s控制器
1、Replicaset
前面我们学习了Pod,那我们在定义pod资源时,可以直接创建一个kind:Pod类型的自主式pod,但是这存在一个问题,假如pod被删除了,那这个pod就不能自我恢复,就会彻底被删除,线上这种情况非常危险,所以今天就给大家讲解下pod的控制器,所谓控制器就是能够管理pod,监测pod运行状况,当pod发生故障,可以自动恢复pod。也就是说能够代我们去管理pod中间层,并帮助我们确保每一个pod资源始终处于我们所定义或者我们所期望的目标状态,一旦pod资源出现故障,那么控制器会尝试重启pod或者里面的容器,如果一直重启有问题的话那么它可能会基于某种策略来进行重新布派或者重新编排;如果pod副本数量低于用户所定义的目标数量,它也会自动补全;如果多余,也会自动终止pod资源。
1.1 Replicaset概述、原理
1、概述:
ReplicaSet是kubernetes中的一种副本控制器,简称rs,主要作用是控制由其管理的pod,使pod副本的数量始终维持在预设的个数。它的主要作用就是保证一定数量的Pod能够在集群中正常运行,它会持续监听这些Pod的运行状态,在Pod发生故障时重启pod,pod数量减少时重新运行新的Pod副本。官方推荐不要直接使用ReplicaSet,用Deployments取而代之,Deployments是比ReplicaSet更高级的概念,它会管理ReplicaSet并提供很多其它有用的特性,最重要的是Deployments支持声明式更新,声明式更新的好处是不会丢失历史变更。所以Deployment控制器不直接管理Pod对象,而是由Deployment管理ReplicaSet,再由ReplicaSet负责管理Pod对象。
2、工作原理:如何管理 Pod
Replicaset核心作用在于代用户创建指定数量的pod副本,并确保pod副本一直处于满足用户期望的数量,起到多退少补的作用,并且还具有自动扩容缩容等机制。
Replicaset控制器主要由三个部分组成:
1)、用户期望的pod副本数:用来定义由这个控制器管控的pod副本有几个
2)、标签选择器:选定哪些pod是自己管理的,如果通过标签选择器选到的pod副本数量少于我们指定的数量,需要用到下面的组件
3)、pod资源模板:如果集群中现存的pod数量不够我们定义的副本中期望的数量怎么办,需要新建pod,这就需要pod模板,新建的pod是基于模板来创建的。
1.2 资源清单文件编写
##查看定义Replicaset资源需要的字段有哪些?
kubectl explain rs
##查看replicaset的spec字段如何定义?
kubectl explain rs.spec
#查看replicaset的spec.template字段如何定义?
#对于template而言,其内部定义的就是pod,pod模板是一个独立的对象
kubectl explain rs.spec.template
通过上面可以看到,ReplicaSet资源中有两个spec字段。第一个spec声明的是ReplicaSet定义多少个Pod副本(默认将仅部署1个Pod)、匹配Pod标签的选择器、创建pod的模板。第二个spec是spec.template.spec:主要用于Pod里的容器属性等配置。
.spec.template里的内容是声明Pod对象时要定义的各种属性,所以这部分也叫做PodTemplate(Pod模板)。还有一个值得注意的地方是:在.spec.selector中定义的标签选择器必须能够匹配到spec.template.metadata.labels里定义的Pod标签,否则Kubernetes将不允许创建ReplicaSet。
1.3 Replicaset使用案例
#提前拉去所需要的镜像(所有节点)
ctr i pull docker.io/yecc/gcr.io-google_samples-gb-frontend:v3
#创建配置文件
mkdir rs
vim replicaset.yaml
===============================
kind: ReplicaSet
metadata:
name: frontend
namespace: default
labels:
app: guestbook
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier1: frontend1
template:
metadata:
labels:
tier1: frontend1
spec:
containers:
- name: php-redis
image: docker.io/yecc/gcr.io-google_samples-gb-frontend:v3
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
startupProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
livenessProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
readinessProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
===============================
#创建
kubectl apply -f replicaset.yaml
#查看
kubectl get rs
kubectl get pod
1.4 管理pod:扩容、缩容、更新
1)Replicaset实现pod的动态扩容
#ReplicaSet最核心的功能是可以动态扩容和回缩,如果我们觉得两个副本太少了,想要增加,只需要修改配置文件replicaset.yaml里的replicas的值即可,原来replicas:3,现在变成replicaset:4,修改之后,执行如下命令更新:
kubectl apply -f replicaset.yaml
kubectl get rs
kubectl get pods
2)Replicaset实现pod的动态缩容
#如果我们觉得5个Pod副本太多了,想要减少,只需要修改配置文件replicaset.yaml里的replicas的值即可,把replicaset:4变成replicas:2,修改之后,执行如下命令更新:
kubectl apply -f replicaset.yaml
kubectl get rs
kubectl get pods
3)Replicaset实现pod的更新
#修改镜像,变成ikubernetes/myapp:v2:
kubectl apply -f replicaset.yaml
kubectl get rs
kubectl get pods
#上面可以看到,虽然replicaset.yaml修改了镜像,执行了kubectlapply-freplicaset.yaml,但是pod还是用的frontend:v3这个镜像,没有实现自动更新
#删除对应pod后才会更新
kubectl delete pods frontend-glb2c
2、Deployment
Deployment 官方文档:
https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
2.1 Deployment概述
1)介绍
Deployment是kubernetes中最常用的资源对象,为ReplicaSet和Pod的创建提供了一种声明式的定义方法,在Deployment对象中描述一个期望的状态,Deployment控制器就会按照一定的控制速率把实际状态改成期望状态,通过定义一个Deployment控制器会创建一个新的ReplicaSet控制器,通过ReplicaSet创建pod,删除Deployment控制器,也会删除Deployment控制器下对应的ReplicaSet控制器和pod资源。
使用Deployment而不直接创建ReplicaSet是因为Deployment对象拥有许多ReplicaSet没有的特性,例如滚动升级、金丝雀发布、蓝绿部署和回滚。
扩展:声明式定义是指直接修改资源清单yaml文件,然后通过kubectlapply-f资源清单yaml文件,就可以更改资源。
Deployment控制器是建立在rs之上的一个控制器,可以管理多个rs,每次更新镜像版本,都会生成一个新的rs,把旧的rs替换掉,多个rs同时存在,但是只有一个rs运行。

rsv1控制三个pod,删除一个pod,在rsv2上重新建立一个,依次类推,直到全部都是由rsv2控制,如果rsv2有问题,还可以回滚,Deployment是建构在rs之上的,多个rs组成一个Deployment,但是只有一个rs处于活跃状态。
2)Deployment工作原理:如何管理rs和Pod?
Deployment可以使用声明式定义,直接在命令行通过纯命令的方式完成对应资源版本的内容的修改,也就是通过打补丁的方式进行修改;Deployment能提供滚动式自定义自控制的更新;对Deployment来讲,我们在实现更新时还可以实现控制更新节奏和更新逻辑。
什么叫做更新节奏和更新逻辑呢?
比如说Deployment控制5个pod副本,pod的期望值是5个,但是升级的时候需要额外多几个pod,那我们控制器可以控制在5个pod副本之外还能再增加几个pod副本;比方说能多一个,但是不能少,那么升级的时候就是先增加一个,再删除一个,增加一个删除一个,始终保持pod副本数是5个;还有一种情况,最多允许多一个,最少允许少一个,也就是最多6个,最少4个,第一次加一个,删除两个,第二次加两个,删除两个,依次类推,可以自己控制更新方式,这种滚动更新需要加readinessProbe和livenessProbe探测,确保pod中容器里的应用都正常启动了才删除之前的pod。
启动第一步,刚更新第一批就暂停了也可以;假如目标是5个,允许一个也不能少,允许最多可以10个,那一次加5个即可;这就是我们可以自己控制节奏来控制更新的方法。
通过 Deployment 对象,你可以轻松的做到以下事情:
1、创建 ReplicaSet 和 Pod
2、滚动升级(不停止旧服务的状态下升级)和回滚应用(将应用回滚到之前的版本)
3、平滑地扩容和缩容
4、暂停和继续 Deployment
2.2 Deployment资源清单文件编写
#查看Deployment资源对象由哪几部分组成
kubectl explain deployment
#查看Deployment下的spec字段
kubectl explain deployment.spec
#查看Deployment下的spec.strategy字段
kubectl explain deploy.spec.strategy
#查看Deployment下的spec.strategy.rollingUpdate字段
kubectl explain deploy.spec.strategy.rollingUpdate
#查看Deployment下的spec.template字段
#template为定义Pod的模板,Deployment通过模板创建Pod
kubectl explain deploy.spec.template
2.3 Deployment创建一个web站点
deployment是一个三级结构,deployment管理replicaset,replicaset管理pod
#提前拉去镜像到所有节点
ctr i pull docker.io/janakiramm/myapp:v1
#创建配置文件
mkdir deploy
cd deploy
vim deploy-demo.yaml
=================================
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-v1
spec:
replicas: 2
selector:
matchLabels:
app: myapp
version: v1
template:
metadata:
labels:
app: myapp
version: v1
spec:
containers:
- name: myapp
image: docker.io/janakiramm/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
startupProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
livenessProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
readinessProbe:
periodSeconds: 5
initialDelaySeconds: 20
timeoutSeconds: 10
httpGet:
scheme: HTTP
port: 80
path: /
=================================
#更新资源清单文件:
kubectl apply -f deploy-demo.yaml
#kubectl apply:表示声明式的定义,既可以创建资源,也可以动态更新资源
#查看deploy状态:
kubectl get deploy
1.NAME :列出名称空间中 deployment 的名称。
2.READY:显示 deployment 有多少副本数。它遵循 ready/desired 的模式。
3.UP-TO-DATE: 显示已更新到所需状态的副本数。
4.AVAILABLE: 显示你的可以使用多少个应用程序副本。
5.AGE :显示应用程序已运行的时间。
创建deploy的时候也会创建一个rs(replicaset),67fd9fc9c8这个随机数字是我们引用pod的模板template的名字的hash值
1.NAME:列出名称空间中ReplicaSet资源
2.DESIRED:显示应用程序的所需副本数,这些副本数是在创建时定义的。这是所需的状态。
3.CURRENT:显示当前正在运行多少个副本。
4.READY:显示你的用户可以使用多少个应用程序副本。
5.AGE:显示应用程序已运行的时间。
2.4 扩容、缩容
#通过deployment管理应用,实现扩容,把副本数变成3
vim deploy-demo.yaml
#直接修改replicas数量,变成3
kubectl apply -f deploy-demo.yaml
#注意:apply不同于create,apply可以执行多次;create执行一次,再执行就会报错复。
kubectl get pods
##通过deployment管理应用,实现缩容,把副本数变成2
vim deploy-demo.yaml
#直接修改replicas数量,变成2
kubectl apply -f deploy-demo.yaml
kubectl get pods
2.5 实现pod滚动升级
查看网络策略:ipvsadm -Ln
在Kubernetes中,可以使用Deployment资源来管理Pod的滚动更新和回滚。Deployment是一种控制器(Controller),它提供了声明式的方式来定义和管理Pod的副本集,并支持滚动更新策略。
#如果需要回滚到先前的版本,可以使用下面的命令查看历史版本:
kubectl rollout history deployment my-deployment
#回滚到指定版本:
kubectl rollout undo deployment my-deployment --to-revision=1
2.6 基于反亲和性创建pod
基于k8s的deployment控制器运行nginx服务,指定pod副本数是2,根据pod反亲和性让两个pod调度到不同的工作节点。
使用背景和场景:
业务中的某个关键服务,配置了多个replicas副本数,结果在部署时,发现多个相同的副本同时部署在同一个主机上,结果主机故障时,所有副本同时漂移了,导致服务间断性中断
基于以上背景,实现一个服务的多个副本分散到不同的主机上,使每个主机有且只能运行服务的一个副本,这里用到的是Pod反亲和性,特性是根据已经运行在node上的pod的label,不再将相同label的pod也调度到该node,实现每个node上只运行一个副本的pod
#创建配置文件
vim deployment-nginx.yaml
============================================
piVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"
containers:
- name: nginx
image: nginx
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 80
name: http
protocol: TCP
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
============================================
#基于上面 Deployment 创建的两个 pod 不会调度到一个 node 节点上。
3、Statefulset
3.1 概念、原理解读
StatefulSet 是 Kubernetes 中的一种控制器(Controller),用于管理有状态应用程序的部署。与 Deployment 控制器不同,StatefulSet 为每个 Pod 实例分配了一个唯一的标识符,并确保这些标识符 在 Pod 重新创建时保持不变。这为有状态应用程序提供了一些关键的功能和保证,例如稳定的网络标识 符、有序的部署和扩展以及持久化存储。
下面是 StatefulSet 的一些基本介绍:
- 唯一标识符:每个 StatefulSet 管理的 Pod 实例都被分配了一个唯一的标识符,通常是一个整数 索引。这个标识符可以用于在网络中唯一地标识每个 Pod 实例。
- 稳定的网络标识符:StatefulSet 中的每个 Pod 实例都有一个稳定的网络标识符,通常是一个 DNS 名称。这使得其他应用程序可以通过名称轻松地访问特定的 Pod 实例,而不需要关注其具体的 IP 地址变化。
- 有序的部署和扩展:StatefulSet 控制器确保 Pod 实例按照定义的顺序逐个启动和关闭。这对于 依赖先前实例状态的应用程序非常重要。此外,扩展 StatefulSet 时,新的 Pod 实例也会按照指定的顺 序逐个创建。
- 持久化存储:StatefulSet 允许每个 Pod 实例关联一个持久化卷(Persistent Volume),这使 得有状态应用程序可以在 Pod 重新创建时保留其数据。这为应用程序提供了持久化存储的能力,使得数 据不会丢失或重置。
3.2 使用案例:部署 web 站点
#查看用法
kubectl explain statefulset
#编写一个 Statefulset 资源清单文件,包含pod和service
mkdir /root/statefulset
cd /root/statefulset
vim statefulset.yaml
=========================================
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
=========================================
#更新资源清单文件
kubectl apply -f statefulset.yaml
#查看 statefulset 是否创建成功
kubectl get statefulset
#查看 pod
kubectl get pods -l app=nginx
#使用 kubectl run 运行一个提供 nslookup 命令的容器的,通过对 pod 主机名执行 nslookup, 可以检查它们在集群内部的 DNS 地址:
kubectl run busybox --image docker.io/library/busybox:1.28 --image-pull-policy=IfNotPresent --restart=Never --rm -it busybox -- sh
#在里面输入命令,解析service
nslookup nginx
nslookup web-0.nginx.default.svc.cluster.local
说明:service中写了clusterIP: None和不写的区别
1、当写了clusterIP: None的时候,系统就不会给service分域名
2、如果没有写系统就会默认给祁分配域名,通过serviename.default.svc.cluster.local可以访问到
**问题:**有 ip 的 service 和没有 ip 的 service 有什么区别,那种方式代理 pod 效率高?
从效率的角度来看,解析带有 IP 的 SVC 和解析没有 IP 的 SVC,这两种方式的效率可能会有所不同。
- 解析带有 IP 的 SVC:解析 SVC 的名字会直接会找到 SVC 的 IP 地址,可以直接将请求发送到指定的 IP 地址,省略了额外的 DNS 查询步骤,因此通常具有较高的效率。这种方式适用于从集群外部或其他命名空间访问 SVC,或者需要直接使用 SVC 的 IP 地址进行访问的场景。
- 解析没有 IP 的 SVC:解析到没有 IP 的 SVC,DNS 解析会将 SVC 名称解析为与之关联的后端 Pod 的 IP 地址。这涉及到额外的 DNS 查询和解析步骤,解析到后端 Pod 的 IP 地址后,请求需要通过负载均衡机制(如轮询或基于权重的负载均衡)选择一个后端 Pod 来处理请求,这可能会增加一定的延迟。这种方式适用于集群内部访问 SVC 的场景,其中请求在集群内部的服务间进行通信。
总体而言,解析带有 IP 的 SVC 通常比解析没有 IP 的 SVC 具有更高的效率,因为它可以直接将请求发送到指定的 IP 地址,避免了额外的 DNS 查询和负载均衡步骤。
3.3 管理 pod:扩容、缩容、更新
#1、Statefulset 实现 pod 的动态扩容
#如果我们觉得两个副本太少了,想要增加,只需要修改配置文件 statefulset-extend.yaml 里的 replicas 的 值即可,原来 replicas: 2,现在变成 replicaset: 3,修改之后,执行如下命令更新:
vim statefulset-extend.yaml
=================================
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
name: web
=================================
kubectl apply -f statefulset-extend.yaml
#查看statefulset
kubectl get sts
#查看pod
kubectl get pods -l app=nginx
#也可以直接编辑控制器实现扩容
kubectl edit sts web
#这个是我们把请求提交给了 apiserver,实时修改
#2、Statefulset 实现 pod 的动态缩容
#如果我们觉得 3 个 Pod 副本太多了,想要减少,只需要修改配置文件 statefulset-extend.yaml 里的replicas 的值即可,把 replicaset:3 变成 replicas: 2,修改之后,执行如下命令更新:
kubectl apply -f statefulset-extend.yaml
#查看pod
kubectl get pods -l app=nginx
#3、Statefulset 实现 pod 的更新
kubectl explain sts.spec.updateStrategy
4、Daemonset
4.1 概念、原理解读
1、DaemonSet概述:
DaemonSet控制器能够确保k8s集群所有的节点都运行一个相同的pod副本,当向k8s集群中增加node节点时,这个node节点也会自动创建一个pod副本,当node节点从集群移除,这些pod也会自动删除;删除Daemonset也会删除它们创建的pod
2、DaemonSet工作原理:如何管理Pod?
DaemonSet的控制器会监听kuberntes的daemonset对象、pod对象、node对象,这些被监听的对象之变动,就会触发syncLoop循环让kubernetes集群朝着daemonset对象描述的状态进行演进。
3、Daemonset典型的应用场景
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd等。
4、DaemonSet 与 Deployment 的区别
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
4.2 资源清单文件编写技巧
#查看定义Daemonset资源需要的字段有哪些?
kubectl explain ds
#查看DaemonSet的spec字段如何定义?
kubectl explain ds.spec
4.3 部署日志收集组件fluentd
#所有节点拉取fulentd
docker pull fluentd
#编写一个DaemonSet资源清单
mkdir /root/daemonset
cd /root/daemonset
vim daemonset.yaml
=====================================
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: fluentd
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
=====================================
#更新资源文件
kubectl apply -f daemonset.yaml
#查看ds
kubectl get ds -n kube-system
#查看pod部署到那个节点
kubectl get pods -n kube-system -o wide
#资源清单详细说明
apiVersion: apps/v1 #DaemonSet使用的api版本
kind: DaemonSet # 资源类型
metadata:
name: fluentd-elasticsearch #资源的名字
namespace: kube-system #资源所在的名称空间
labels:
k8s-app: fluentd-logging #资源具有的标签
spec:
selector: #标签选择器
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels: #基于这回模板定义的pod具有的标签
name: fluentd-elasticsearch
spec:
tolerations: #定义容忍度
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers: #定义容器
- name: fluentd-elasticsearch
image: xianchao/fluentd:v2.5.1
resources: #资源配额
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log #把本地/var/log目录挂载到容器
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
#把/var/lib/docker/containers/挂载到容器里
readOnly: true #挂载目录是只读权限
terminationGracePeriodSeconds: 30 #优雅的关闭服务
volumes:
- name: varlog
hostPath:
path: /var/log #基于本地目录创建一个卷
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #基于本地目录创建一个卷
4.4 管理pod:滚动更新
#DaemonSet实现pod的滚动更新
#查看daemonset的滚动更新策略
kubectl explain ds.spec.updateStrategy
#查看rollingUpdate支持的更新策略
kubectl explain ds.spec.updateStrategy.rollingUpdate
#上面表示rollingUpdate更新策略只支持maxUnavailabe,先删除在更新;因为我们不支持一个节点运行两个pod,因此需要先删除一个,在更新一个。
#更新镜像版本,可以按照如下方法:
kubectl set image daemonsets fluentd-elasticsearch fluentd-elasticsearch=ikubernetes/filebeat:5.6.6-alpine -n kube-system
六、四层负载均衡Service
1、概念、原理解读
引言:为什么要有Service?
在kubernetes中,Pod是有生命周期的,如果Pod重启它的IP很有可能会发生变化。如果我们的服务都是将Pod的IP地址写死,Pod挂掉或者重启,和刚才重启的pod相关联的其他服务将会找不到它所关联的Pod,为了解决这个问题,在kubernetes中定义了service资源对象,Service定义了一个服务访问的入口,客户端通过这个入口即可访问服务背后的应用集群实例,service是一组Pod的逻辑集合,这一组Pod能够被Service访问到,通常是通过LabelSelector实现的。

1、pod ip经常变化,service是pod的代理,我们客户端访问,只需要访问service,就会把请求代理到Pod
2、pod ip在k8s集群之外无法访问,所以需要创建service,这个service可以在k8s集群外访问的。
1.1 概述
service是一个固定接入层,客户端可以通过访问service的ip和端口访问到service关联的后端pod,这个service工作依赖于在kubernetes集群之上部署的一个附件,就是kubernetes的dns服务(不同kubernetes版本的dns默认使用的也是不一样的,1.11之前的版本使用的是kubeDNs,较新的版本使用的是coredns),service的名称解析是依赖于dns附件的,因此在部署完k8s之后需要再部署dns附件,kubernetes要想给客户端提供网络功能,需要依赖第三方的网络插件(flannel,calico等)。每个K8s节点上都有一个组件叫做kube-proxy,kube-proxy这个组件将始终监视着apiserver中有关service资源的变动信息,需要跟master之上的apiserver交互,随时连接到apiserver上获取任何一个与service资源相关的资源变动状态,这种是通过kubernetes中固有的一种请求方法watch(监视)来实现的,一旦有service资源的内容发生变动(如创建,删除),kube-proxy都会将它转化成当前节点之上的能够实现service资源调度,把我们请求调度到后端特定的pod资源之上的规则,这个规则可能是iptables,也可能是ipvs,取决于service的实现方式。
1.2 工作原理
k8s在创建Service时,会根据标签选择器selector(lableselector)来查找Pod,据此创建与Service同名的endpoint对象,当Pod地址发生变化时,endpoint也会随之发生变化,service接收前端client请求的时候,就会通过endpoint,找到转发到哪个Pod进行访问的地址。(至于转发到哪个节点的Pod,由负载均衡kube-proxy决定)
2、创建service
service 只要创建完成,我们就可以直接解析它的服务名,每一个服务创建完成后都会在集群 dns 中 动态添加一个资源记录,添加完成后我们就可以解析了,资源记录格式是:
服务名.命名空间.域名后缀
集群默认的域名后缀是 svc.cluster.local.
例如服务名为my-nginx,它的完整名称解析就是 my-nginx.default.svc.cluster.local
2.1 Service的四种类型
#查看定义Service资源需要的字段有哪些?
kubectl explain service
#查看service的spec字段如何定义?
kubectl explain service.spec
#查看定义Service.spec.type需要的字段有哪些?
kubectl explain service.spec.type
type有以下4种:
1、ExternalName:
适用于k8s集群内部容器访问外部资源,它没有selector,也没有定义任何的端口和Endpoint。以下Service定义的是将prod名称空间中的my-service服务映射到my.database.example.com
kind: Service
apiVersion: v1
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: my.database.example.com
2、ClusterIP:
通过k8s集群内部IP暴露服务,选择该值,服务只能够在集群内部访问,这也是默认的ServiceType。
3、NodePort:
通过每个Node节点上的IP和静态端口暴露k8s集群内部的服务。通过请求:可以把请求代理到内部的pod。Client----->NodeIP:NodePort----->ServiceIp:ServicePort----->PodIP:ContainerPort。
4、LoadBalancer:
使用云提供商的负载均衡器,可以向外部暴露服务。外部的负载均衡器可以路由到NodePort服务和ClusterIP服务。
2.2 Service的端口
#查看service的spec.ports字段如何定义?
kubectl explain service.spec.ports
nodePort:宿主机上映射的端口,比如一个 Web 应用需要被 k8s 集群之外的其他用户访问,那么需要配置 type=NodePort,若配置 nodePort=30001,那么其他机器就可以通过浏览器访问 scheme://k8s 集群中的 任何一个节点 ip:30001 即可访问到该服务,例如 http://192.168.1.63:30001。如果在 k8s 中部署 MySQL 数据库,MySQL 可能不需要被外界访问,只需被内部服务访问,那么就不需要设置 NodePort
targetPort 是 pod 上的端口,从 port 和 nodePort 上来的流量,经过 kube-proxy 流入到后端 pod 的 targetPort 上,最后进入容器。与制作容器时暴露的端口一致(使用 DockerFile 中的 EXPOSE),例如 官方的 nginx 暴露 80 端口。
2.3 type类型是ClusterIP
#1、前期准备
#拉去nginx镜像
docker pull nginx
#2、创建Pod
mkdir service
cd service
vim pod_test.yaml
==================================
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80 #pod 中的容器需要暴露的端口
==================================
#更新资源清单文件
kubectl apply -f pod_test.yaml
#查看刚才创建的 Pod ip 地址
kubectl get pods -l run=my-nginx -o wide
#如果 pod 被删除了,重新生成的 pod ip 地址会发生变化,所以需要在 pod 前端加一个 固定接入层。接下来创建 service:
#3、创建 Service
vim service_test.yaml
=================================
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: ClusterIP
ports:
- port: 80 #service 的端口,暴露给 k8s 集群内部服务访问
protocol: TCP
targetPort: 80 #pod 容器中定义的端口
selector:
run: my-nginx #选择拥有 run=my-nginx 标签的 pod
=================================
#上述 yaml 文件将创建一个 Service,具有标签 run=my-nginx 的 Pod,目标 TCP 端口 80,并且在一 个抽象的 Service 端口(targetPort:容器接收流量的端口;port:抽象的 Service 端口,可以使任何 其它 Pod 访问该 Service 的端口)上暴露。
#更新资源文件
kubectl apply -f service_test.yaml
#查看
kubectl get svc -l run=my-nginx
#在 k8s 控制节点访问 service 的 ip:端口就可以把请求代理到后端 pod
curl 10.102.9.15:80
#查看 service 详细信息
kubectl describe svc my-nginx
#查看endpoint
kubectl get ep my-nginx
service 可以对外提供统一固定的 ip 地址,并将请求重定向至集群中的 pod。其中“将请求重定向 至集群中的 pod”就是通过 endpoint 与 selector 协同工作实现。selector 是用于选择 pod,由 selector 选择出来的 pod 的 ip 地址和端口号,将会被记录在 endpoint 中。endpoint 便记录了所有 pod 的 ip 地址和端口号。当一个请求访问到 service 的 ip 地址时,就会从 endpoint 中选择出一个 ip 地址 和端口号,然后将请求重定向至 pod 中。具体把请求代理到哪个 pod,需要的就是 kube-proxy 的轮询实 现的。service 不会直接到 pod,service 是直接到 endpoint 资源,就是地址加端口,再由 endpoint 再 关联到 pod。
2.4 type类型是NodePort
#1、创建pod和上面一样,只不过标签变成了run: my-nginx-nodeport
#2、创建svc
vim service_nodeport.yaml
=================================
apiVersion: v1
kind: Service
metadata:
name: my-nginx-nodeport
labels:
run: my-nginx-nodeport
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30380
selector:
run: my-nginx-nodeport
=================================
#3、创建nodeport类型后,就可以通过控制节点ip+30380在外部访问服务
2.5 type类型是ExternalName
应用场景:跨名称空间访问
需求:default 名称空间下的 client 服务想要访问 nginx-ns 名称空间下的 nginx-svc 服务
#拉去nginx、busybox:说明,busybox作为客户端访问nginx
docker pull nginx
docker pull busybox:latest
#1、创建busybox的pod作为客户端
vim client.yaml
=================================
apiVersion: apps/v1
kind: Deployment
metadata:
name: client
spec:
replicas: 1
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox
command: ["/bin/sh","-c","sleep 36000"]
=================================
#更新资源文件
kubectl apply -f client.yaml
#1、创建nginx-ns命名空间,并且创建pod
kubectl create ns nginx-ns
#创建pod配置文武兼
vim server_nginx.yaml
=================================
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: nginx-ns
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
=================================
#创建pod
kubectl apply -f server_nginx.yaml
#查看 pod 是否创建成功
kubectl get pods -n nginx-ns
#3、创建svc配置文件
vim nginx_svc.yaml
=================================
apiVersion: v1
kind: Service
metadata:
name: nginx-svc
namespace: nginx-ns
spec:
selector:
app: nginx
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
=================================
#更新资源文件
kubectl apply -f nginx_svc.yaml
#查看svc
kubectl get svc my-nginx
#4、创建类型为externalName的svc
vim client_svc.yaml
=================================
apiVersion: v1
kind: Service
metadata:
name: client-svc
spec:
type: ExternalName
externalName: nginx-svc.nginx-ns.svc.cluster.local
ports:
- name: http
port: 80
targetPort: 80
=================================
#该文件中指定了到 nginx-svc 的软链,让使用者感觉就好像调用自己命名空间的服务一样
#更新资源文件
kubectl apply -f client_svc.yaml
#5、测试,进入busybox这个pod里面测试
kubectl get pod -l app=busybox
kubectl exec -it client-75865778c6-v2gxc -- /bin/sh
#无论访问下面哪一行都可以访问到nginx,说明外链已经做好
wget -q -O - client-svc.default.svc.cluster.local
wget -q -O - nginx-svc.nginx-ns.svc.cluster.local
wget -q -O - client-svc
七、持久化存储
在 k8s 中为什么要做持久化存储?
在 k8s 中部署的应用都是以 pod 容器的形式运行的,假如我们部署 MySQL、Redis 等数据库,需要对这些数据库产生的数据做备份。因为 Pod 是有生命周期的,如果 pod 不挂载数据卷,那 pod 被删除或 重启后这些数据会随之消失,如果想要长久的保留这些数据就要用到 pod 数据持久化存储。
1、持久化存储emptyDir
#查看 k8s 支持哪些存储
kubectl explain pods.spec.volumes
常用的如下:
emptyDi、hostPath、nfs 、persistentVolumeClaim、glusterfs 、cephfs 、configMap 、secret
我们想要使用存储卷,需要经历如下步骤
- 定义 pod 的 volume,这个 volume 指明它要关联到哪个存储上的
- 在容器中要使用 volumemounts 挂载对应的存储
emptyDir 类型的 Volume 是在 Pod 分配到 Node 上时被创建,Kubernetes 会在 Node 上自动分配一个 目录,因此无需指定宿主机 Node 上对应的目录文件。 这个目录的初始内容为空,当 Pod 从 Node 上移除 时,emptyDir 中的数据会被永久删除。emptyDir Volume 主要用于某些应用程序无需永久保存的临时目 录,多个容器的共享目录等。
#创建一个 pod,挂载临时目录 emptyDir
#Emptydir 的官方网址:
#https://kubernetes.io/docs/concepts/storage/volumes#emptydir
#1、创建pod
mkdir volume
cd volume
vim emptydir.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: pod-empty
spec:
containers:
- name: container-empty
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- emptyDir:
{}
name: cache-volume
==================================
#更新资源文件
kubectl apply -f emptydir.yaml
#2、查看本机临时目录存在的位置,可用如下方法:
#查看 pod 调度到哪个节点
kubectl get pods -o wide | grep empty
#查看 pod 的 uid
kubectl get pods pod-empty -o yaml | grep uid
#登录到 k8sn1 上,如下命令进入上面的临时目录
cd /var/lib/kubelet/pods/4d08250a-111e-4c38-ae40-4b2744c1a999/volumes/kubernetes.io~empty-dir/cache-volume/
2、持久化存储hostPath
hostPath Volume 是指 Pod 挂载宿主机上的目录或文件。 hostPath Volume 使得容器可以使用宿主机的文件系统进行存储,hostpath(宿主机路径):节点级别的存储卷,在 pod 被删除,这个存储卷还是 存在的,不会被删除,所以只要同一个 pod 被调度到同一个节点上来,在 pod 被删除重新被调度到这个节点之后,对应的数据依然是存在的。
#查看 hostPath 存储卷的用法
kubectl explain pods.spec.volumes.hostPath
#1、创建一个 pod,挂载 hostPath 存储卷
vim hostpath.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: test-hostpath
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: test-nginx
volumeMounts:
- mountPath: /test-nginx
name: test-volume
- image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
name: test-tomcat
volumeMounts:
- mountPath: /test-tomcat
name: test-volume
volumes:
- name: test-volume
hostPath:
path: /data1
type: DirectoryOrCreate
==================================
注意: DirectoryOrCreate 表示本地有/data1 目录,就用本地的,本地没有就会在 pod 调度到的节点自 动创建一个
#更新资源清单文件
kubectl apply -f hostpath.yaml
#2、查看 pod 调度到了哪个物理节点
kubectl get pods -o wide | grep hostpath
#由上面可以知道 pod 调度到了 k8sn1 上,登录到 k8sn1 机器,查看是否在这台机器创建了存储目录
ll /data1/
#上面可以看到已经创建了存储目录/data1,这个/data1 会作为 pod 的持久化存储目录
#3、在 k8sn1 上的/data1 下创建一个目录
mkdir aa
#测试存储卷是否可以正常使用,登录到 nginx 容器
kubectl exec -it test-hostpath -c test-nginx -- /bin/bash
#在容器里面执行
cd /test-nginx/
#/test-nginx/目录存在,说明已经把宿主机目录挂载到了容器里
ll
#通过上面测试可以看到,同一个 pod 里的 test-nginx 和 test-tomcat 这两个容器是共享存储卷 的。
hostpath 存储卷缺点:
单节点 、pod 删除之后重新创建必须调度到同一个 node 节点,数据才不会丢失
3、持久化存储nfs
上节说的 hostPath 存储,存在单点故障,pod 挂载 hostPath 时,只有调度到同一个节点,数据才不 会丢失。那可以使用 nfs 作为持久化存储。
#1、搭建 nfs 服务
#以 k8s 的控制节点作为 NFS 服务端
yum install nfs-utils -y
#控制节点创建 NFS 需要的共享目录
mkdir /data/volumes -pv
#配置 nfs 共享服务器上的/data/volumes 目录
systemctl start nfs
systemctl enable nfs
vim /etc/exports
==================================
/data/volumes *(rw,no_root_squash)
==================================
#no_root_squash: 用户具有根目录的完全管理访问权限
#使 NFS 配置生效
exportfs -arv
#其他两个节点上也安装 nfs 驱动
yum install nfs-utils -y
systemctl start nfs
systemctl enable nfs
#在其他两个节点上手动挂载测试:
mkdir /test
mount k8sm1:/data/volumes /test/
#查看挂载情况
df -h
#手动卸载
umount /test
#2、创建 Pod,挂载 NFS 共享出来的目录
#Pod 挂载 nfs 的官方地址:https://kubernetes.io/zh/docs/concepts/storage/volumes/
vim nfs.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: test-nfs-volume
spec:
containers:
- name: test-nfs
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
protocol: TCP
volumeMounts:
- name: nfs-volumes
mountPath: /usr/share/nginx/html
volumes:
- name: nfs-volumes
nfs:
path: /data/volumes
server: k8sm1
==================================
注:
path: /data/volumes #nfs 的共享目录
server:k8sm1 是 控制节点的主机名,这个是安装 nfs 服务的地址
#更新资源清单文件
kubectl apply -f nfs.yaml
#查看 pod 是否创建成功
kubectl get pods -o wide | grep nfs
#登录到 nfs 服务器(k8sm1机器),在共享目录创建一个 index.html
cd /data/volumes
vim index.html
==================================
Hello, Everyone
My name is xianchao
My Chat is luckylucky421302
==================================
#进入容器内部,查看
kubectl exec -it test-nfs-volume -- /bin/bash
#在里面输入命令,可以看到刚才创建的index.html已经被挂在上来
cd /usr/share/nginx/html/
cat index.html
#上面说明挂载 nfs 存储卷成功了,nfs 支持多个客户端挂载,可以创建多个 pod,挂载同一个 nfs 服务器共享出来的目录;但是 nfs 如果宕机了,数据也就丢失了,所以需要使用分布式存储,常见的分布式存储有 glusterfs 和 cephfs
4、持久化存储PVC
参考官网:
https://kubernetes.io/docs/concepts/storage/persistent-volumes/#access-modes
4.1 k8s PV 是什么
PersistentVolume(PV)是群集中的一块存储,由管理员配置或使用存储类动态配置。 它是集群中的资源,就像 pod 是 k8s 集群资源一样。 PV 是容量插件,如 Volumes,其生命周期独立于使用 PV 的任 何单个 pod。
4.2 k8s PVC 是什么
PersistentVolumeClaim(PVC)是一个持久化存储卷,我们在创建 pod 时可以定义这个类型的存储 卷。 它类似于一个 pod。 Pod 消耗节点资源,PVC 消耗 PV 资源。 Pod 可以请求特定级别的资源(CPU 和 内存)。 pvc 在申请 pv 的时候也可以请求特定的大小和访问模式(例如,可以一次读写或多次只读)。
4.3 PVC 和 PV 工作原理
PV 是群集中的资源。 PVC 是对这些资源的请求。
PV 和 PVC 之间的相互作用遵循以下生命周期:
(1)pv 的供应方式
可以通过两种方式配置 PV:静态或动态。
-
静态的:集群管理员创建了许多 PV。它们包含可供群集用户使用的实际存储的详细信息。它们存在于 Kubernetes API 中,可供使用。
-
动态的: 当管理员创建的静态 PV 都不匹配用户的 PersistentVolumeClaim 时,群集可能会尝试为 PVC 专门动 态配置卷。此配置基于 StorageClasses,PVC 必须请求存储类,管理员必须创建并配置该类,以便进行 动态配置。
(2)绑定
用户创建 pvc 并指定需要的资源和访问模式。在找到可用 pv 之前,pvc 会保持未绑定状态
(3)使用
- 需要找一个存储服务器,把它划分成多个存储空间;
- k8s 管理员可以把这些存储空间定义成多个 pv;
- 在 pod 中使用 pvc 类型的存储卷之前需要先创建 pvc,通过定义需要使用的 pv 的大小和对应的 访问模式,找到合适的 pv;
- pvc 被创建之后,就可以当成存储卷来使用了,我们在定义 pod 时就可以使用这个 pvc 的存储 卷
- pvc 和 pv 它们是一一对应的关系,pv 如果被 pvc 绑定了,就不能被其他 pvc 使用了;
- 我们在创建 pvc 的时候,应该确保和底下的 pv 能绑定,如果没有合适的 pv,那么 pvc 就会处 于 pending 状态。
(4)回收策略
当我们创建 pod 时如果使用 pvc 做为存储卷,那么它会和 pv 绑定,当删除 pod,pvc 和 pv 绑定就会 解除,解除之后和 pvc 绑定的 pv 卷里的数据需要怎么处理,目前,卷可以保留,回收或删除:
Retain 、Recycle (不推荐使用,1.15 可能被废弃了) 、Delete
- Retain :当删除 pvc 的时候,pv 仍然存在,处于 released 状态,但是它不能被其他 pvc 绑定使用,里面的数 据还是存在的,当我们下次再使用的时候,数据还是存在的,这个是默认的回收策略
- Delete:删除 pvc 时即会从 Kubernetes 中移除 PV,也会从相关的外部设施中删除存储资产
#创建 pod,使用 pvc 作为持久化存储卷
#1、创建 nfs 共享目录
#在k8sm1创建 NFS 需要的共享目录
mkdir /data/volume_test/v{1,2} -p
#配置 nfs 共享宿主机上的/data/volume_test/v1..v2 目录
vim /etc/exports
==========================================
/data/volumes *(rw,no_root_squash)
/data/volume_test/v1 *(rw,no_root_squash)
/data/volume_test/v2 *(rw,no_root_squash)
==========================================
#重新加载配置,使配置成效
exportfs -arv
systemctl restart nfs
#2、如何编写 pv 的资源清单文件
#查看定义 pv 需要的字段
kubectl explain pv
#查看定义 nfs 类型的 pv 需要的字段
kubectl explain pv.spec.nfs
#3、创建 pv
vim pv.yaml
==========================================
apiVersion: v1
kind: PersistentVolume
metadata:
name: v1
spec:
capacity:
storage: 1Gi #pv 的存储空间容量
accessModes: ["ReadWriteOnce"]
nfs:
path: /data/volume_test/v1 #把 nfs 的存储空间创建成 pv
server: k8sm1 #nfs 服务器的地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: v2
spec:
capacity:
storage: 2Gi
accessModes: ["ReadWriteMany"]
nfs:
path: /data/volume_test/v2
server: k8sm1
==========================================
#更新资源清单文件
kubectl apply -f pv.yaml
#查看 pv 资源
kubectl get pv
#4、创建 pvc,和符合条件的 pv 绑定
vim pvc.yaml
==========================================
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 2Gi
==========================================
#更新资源清单文件
kubectl apply -f pvc.yaml
#查看 pv 和 pvc
kubectl get pv
#STATUS 是 Bound,表示这个 pv 已经被 my-pvc 绑定了
kubectl get pvc
#pvc 的名字-绑定到 pv-绑定的是 v2 这个 pv-pvc 可使用的容量是 2G
#5、创建 pod,挂载 pvc
vim pod_pvc.yaml
==========================================
apiVersion: v1
kind: Pod
metadata:
name: pod-pvc
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nginx-html
mountPath: /usr/share/nginx/html
volumes:
- name: nginx-html
persistentVolumeClaim:
claimName: my-pvc
==========================================
#更新资源清单文件
kubectl apply -f pod_pvc.yaml
#查看 pod 状态
kubectl get pods | grep pod-pvc
#6、测试
#在nsf服务器的/data/volume_test/v2目录下创建文件
mkdir aa
#进入pod查看
kubectl exec -it pod-pvc -- /bin/bash
#进入pod的/usr/share/nginx/html目录,可以看到aa文件夹,证明挂载成功
注:使用 pvc 和 pv 的注意事项
1、我们每次创建 pvc 的时候,需要事先有划分好的 pv,这样可能不方便,那么可以在创建 pvc 的时 候直接动态创建一个 pv 这个存储类,pv 事先是不存在的
2、pvc 和 pv 绑定,如果使用默认的回收策略 retain,那么删除 pvc 之后,pv 会处于 released 状 态,我们想要继续使用这个 pv,需要手动删除 pv,kubectl delete pv pv_name,删除 pv,不会删除 pv 里的数据,当我们重新创建 pvc 时还会和这个最匹配的 pv 绑定,数据还是原来数据,不会丢失。
4.4 k8s存储类storageclass
上面介绍的 PV 和 PVC 模式都是需要先创建好 PV,然后定义好 PVC 和 pv 进行一对一的 Bound,但是如 果 PVC 请求成千上万,那么就需要创建成千上万的 PV,对于运维人员来说维护成本很高,Kubernetes 提供一种自动创建 PV 的机制,叫 StorageClass,它的作用就是创建 PV 的模板。k8s 集群管理员通过创建 storageclass 可以动态生成一个存储卷 pv 供 k8s pvc 使用。
每个 StorageClass 都包含字段 provisioner,parameters 和 reclaimPolicy。
具体来说,StorageClass 会定义以下两部分:
1、PV 的属性 ,比如存储的大小、类型等;
2、创建这种 PV 需要使用到的存储插件,比如 Ceph、NFS 等
有了这两部分信息,Kubernetes 就能够根据用户提交的 PVC,找到对应的 StorageClass,然后 Kubernetes 就会调用 StorageClass 声明的存储插件,创建出需要的 PV。
#查看定义的 storageclass 需要的字段
kubectl explain storageclass
(1)provisioner:供应商,storageclass 需要有一个供应者,用来确定我们使用什么样的存储来创建 pv,常见的 provisioner 如下
https://kubernetes.io/zh/docs/concepts/storage/storage-classes/
provisioner 既可以由内部供应商提供,也可以由外部供应商提供,如果是外部供应商可以参考 https://github.com/kubernetes-incubator/external-storage/下提供的方法创建。
https://github.com/kubernetes-sigs/sig-storage-lib-external-provisioner
以 NFS 为例,要想使用 NFS,我们需要一个 nfs-client 的自动装载程序,称之为 provisioner,这 个程序会使用我们已经配置好的 NFS 服务器自动创建持久卷,也就是自动帮我们创建 PV。
(2)reclaimPolicy:回收策略
(3)allowVolumeExpansion:允许卷扩展,PersistentVolume 可以配置成可扩展。将此功能设置为 true 时,允许用户通过编辑相应的 PVC 对象来调整卷大小。当基础存储类的 allowVolumeExpansion 字段设 置为 true 时,以下类型的卷支持卷扩展。
注意:此功能仅用于扩容卷,不能用于缩小卷。
1、安装 nfs provisioner,用于配合存储类动态生成 pv
#下载镜像
docker pull registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
#1、创建运行 nfs-provisioner 需要的 sa 账号
vim serviceaccount.yaml
==========================================
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
==========================================
#更新资源
kubectl apply -f serviceaccount.yaml
什么是 sa?
sa 的全称是 serviceaccount。
serviceaccount 是为了方便 Pod 里面的进程调用 Kubernetes API 或其他外部服务而设计的。
指定了 serviceaccount 之后,我们把 pod 创建出来了,我们在使用这个 pod 时,这个 pod 就有了 我们指定的账户的权限了。
#2、对 sa 授权
kubectl create clusterrolebinding nfs-provisionerclusterrolebinding --clusterrole=cluster-admin --serviceaccount=default:nfs-provisioner
#3、安装 nfs-provisioner 程序(作为外部供应商)
mkdir /data/nfs_pro -p
#把/data/nfs_pro 变成 nfs 共享的目录
vim /etc/exports
==========================================
/data/volumes *(rw,no_root_squash)
/data/volume_test/v1 *(rw,no_root_squash)
/data/volume_test/v2 *(rw,no_root_squash)
/data/nfs_pro *(rw,no_root_squash)
==========================================
#刷新配置
exportfs -arv
#创建pod
vim nfs-deployment.yaml
==========================================
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-provisioner
spec:
selector:
matchLabels:
app: nfs-provisioner
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: example.com/nfs
- name: NFS_SERVER
value: k8sm1
- name: NFS_PATH
value: /data/nfs_pro
volumes:
- name: nfs-client-root
nfs:
server: k8sm1
path: /data/nfs_pro
==========================================
#更新资源清单文件
kubectl apply -f nfs-deployment.yaml
#查看 nfs-provisioner 是否正常运行
kubectl get pods | grep nfs
2、创建 storageclass,动态供给 pv
vim nfs-storageclass.yaml
==========================================
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: nfs
provisioner: example.com/nfs
==========================================
#更新资源
kubectl apply -f nfs-storageclass.yaml
#查看 storageclass 是否创建成功
kubectl get storageclass
注意:provisioner 处写的 example.com/nfs 应该跟安装 nfs provisioner 时候的 env 下的 PROVISIONER_NAME 的 value 值保持一致,如下:
env:
- name: PROVISIONER_NAME
value: example.com/nfs
3、创建 pvc,通过 storageclass 动态生成 pv
vim claim.yaml
==========================================
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim1
spec:
accessModes: ["ReadWriteMany"]
resources:
requests:
storage: 1Gi
storageClassName: nfs
==========================================
#更新资源清单文件
kubectl apply -f claim.yaml
#查看是否动态生成了 pv,pvc 是否创建成功,并和 pv 绑定
kubectl get pvc
#通过上面可以看到 test-claim1 的 pvc 已经成功创建了,绑定的 pv 是 pvc-da737fb7-3ffb-43c4-a86a-2bdfa7f201e2,这个 pv 是由 storageclass 调用 nfs provisioner 自动生成的。
注意:如果报错以下
Normal ExternalProvisioning 107s (x5 over 2m47s) persistentvolume-controller waiting for a volume to be crea ted, either by external provisioner “example.com/nfs” or manually created by system administrator
有可能上面那些步骤没有正确(供应商没有创建成功),请重新查看
步骤总结:
- 供应商:创建一个 nfs provisioner
- 创建 storageclass,storageclass 指定刚才创建的供应商
- 创建 pvc,这个 pvc 指定 storageclass
4、创建 pod,挂载 storageclass 动态生成的 pvc:test-claim1
vim read-pod.yaml
==========================================
kind: Pod
apiVersion: v1
metadata:
name: read-pod
spec:
containers:
- name: read-pod
image: nginx
imagePullPolicy: IfNotPresent
volumeMounts:
- name: nfs-pvc
mountPath: /usr/share/nginx/html
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim1
==========================================
#更新资源清单文件
kubectl apply -f read-pod.yaml
#查看 pod 是否创建成功
kubectl get pods | grep read
八、配置管理中心
1、ConfigMap
1.1 Configmap 概述
1)什么是 Configmap
Configmap 是 k8s 中的资源对象,用于保存非机密性的配置的,数据可以用 key/value 键值对的形式保存,也可通过文件的形式保存。
2)Configmap 能解决哪些问题
我们在部署服务的时候,每个服务都有自己的配置文件,如果一台服务器上部署多个 服务:nginx、tomcat、apache 等,那么这些配置都存在这个节点上,假如一台服务 器不能满足线上高并发的要求,需要对服务器扩容,扩容之后的服务器还是需要部署 多个服务:nginx、tomcat、apache,新增加的服务器上还是要管理这些服务的配置, 如果有一个服务出现问题,需要修改配置文件,每台物理节点上的配置都需要修改, 这种方式肯定满足不了线上大批量的配置变更要求。 所以,k8s 中引入了 Configmap 资源对象,可以当成 volume 挂载到 pod 中,实现统一的配置管理。

1、Configmap 是 k8s 中的资源, 相当于配置文件,可以有一个或者多个 Configmap;
2、Configmap 可以做成 Volume,k8s pod 启动之后,通过 volume 形式映射到容器内 部指定目录上;
3、容器中应用程序按照原有方式读取容器特定目录上的配置文件。
4、在容器看来,配置文件就像是打包在容器内部特定目录,整个过程对应用没有任何 侵入。
3) Configmap 应用场景
1、使用 k8s 部署应用,当你将应用配置写进代码中,更新配置时也需要打包镜像, configmap 可以将配置信息和 docker 镜像解耦,以便实现镜像的可移植性和可复用 性,因为一个 configMap 其实就是一系列配置信息的集合,可直接注入到 Pod 中给容 器使用。configmap 注入方式有两种,一种将 configMap 做为存储卷,一种是将 configMap 通过 env 中 configMapKeyRef 注入到容器中。
2、使用微服务架构的话,存在多个服务共用配置的情况,如果每个服务中单独一份配 置的话,那么更新配置就很麻烦,使用 configmap 可以友好的进行配置共享。
4) 局限性
ConfigMap 在设计上不是用来保存大量数据的。在 ConfigMap 中保存的数据不可超过 1 MiB。如果你需要保存超出此尺寸限制的数据,可以考虑挂载存储卷或者使用独立的数 据库或者文件服务。
1.2 Configmap 创建方法
1) 命令行创建
#直接在命令行中指定 configmap 参数创建,通过--from-literal 指定参数
kubectl create configmap tomcat-config --from-literal=tomcat_port=8080 --from-literal=server_name=myapp.tomcat.com
#查看configmap
kubectl get cm
#查看详情信息
kubectl describe configmap tomcat-config
2) 通过文件创建
#通过指定文件创建一个 configmap,--from-file=<文件>
mkdir /root/configmap
cd /root/configmap
vim nginx.conf
==================================
server {
server_name www.nginx.com;
listen 80;
root /home/nginx/www/
}
==================================
#定义一个 key 是 www,值是 nginx.conf 中的内容
kubectl create configmap www-nginx --from-file=www=./nginx.conf
#查看configmap的详细信息
kubectl describe configmap www-nginx
3) 指定目录创建
mkdir test-a
cd test-a
vim my-server.cnf
==================================
server-id=1
==================================
vim my-slave.cnf
==================================
server-id=2
==================================
#指定目录创建 configmap
kubectl create configmap mysql-config --from-file=/root/configmap/test-a/
#查看 configmap 详细信息
kubectl describe configmap mysql-config
4) 资源清单YAML创建
cd /root/configmap
vim mysql-configmap.yaml
==================================
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
labels:
app: mysql
data:
master.cnf: |
[mysqld]
log-bin
log_bin_trust_function_creators=1
lower_case_table_names=1
slave.cnf: |
[mysqld]
super-read-only
log_bin_trust_function_creators=1
==================================
#更新资源配置文件
kubectl apply -f mysql-configmap.yaml
#查看 configmap 详细信息
kubectl describe configmap mysql
1.3 使用Configmap
1) 通过环境变量引入:使用 configMapKeyRef
#创建一个存储 mysql 配置的 configmap
vim mysql-configmap2.yaml
==================================
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql2
labels:
app: mysql2
data:
log: "1"
lower: "1"
==================================
kubectl apply -f mysql-configmap2.yaml
#创建 pod,引用 Configmap 中的内容
vim mysql-pod.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod
spec:
containers:
- name: mysql
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh", "-c", "sleep 3600" ]
env:
- name: log_bin #定义环境变量 log_bin
valueFrom:
configMapKeyRef:
name: mysql2 #指定 configmap 的名字
key: log #指定 configmap 中的 key
- name: lower #定义环境变量 lower
valueFrom:
configMapKeyRef:
name: mysql2
key: lower
restartPolicy: Never
==================================
#更新资源清单文件
kubectl apply -f mysql-pod.yaml
#进入pod
kubectl exec -it mysql-pod -c mysql -- /bin/sh
#在里面查看环境变量
printenv
2) 通过环境变量引入:使用 envfrom
vim mysql-pod-envfrom.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-envfrom
spec:
containers:
- name: mysql
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh", "-c", "sleep 3600" ]
envFrom:
- configMapRef:
name: mysql2 #指定 configmap 的名字
restartPolicy: Never
==================================
#更新资源清单文件
kubectl apply -f mysql-pod-envfrom.yaml
kubectl exec -it mysql-pod-envfrom -- /bin/sh
3) configmap 做成 volume,挂载到 pod(最常用)
#创建configmap
vim mysql-configmap-volume.yaml
==================================
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql3
labels:
app: mysql3
data:
log: "1"
lower: "1"
my.cnf: |
[mysqld]
Welcome=xianchao
==================================
kubectl apply -f mysql-configmap-volume.yaml
#创建pod
vim mysql-pod-volume.yaml
==================================
apiVersion: v1
kind: Pod
metadata:
name: mysql-pod-volume
spec:
containers:
- name: mysql
image: busybox
imagePullPolicy: IfNotPresent
command: [ "/bin/sh","-c","sleep 3600" ]
volumeMounts:
- name: mysql-config
mountPath: /tmp/config
volumes:
- name: mysql-config
configMap:
name: mysql3
restartPolicy: Never
==================================
#更新资源文件
kubectl apply -f mysql-pod-volume.yaml
#进入容器挂载目录
kubectl exec -it mysql-pod-volume -- /bin/sh /
#执行如下命令,一行一行执行
cd /tmp/config/
ls
1.4 Configmap 热更新
kubectl edit configmap mysql3
#把 logs: “1”变成 log: “2”
kubectl exec -it mysql-pod-volume -- /bin/sh
cat /tmp/config/log
#发现 log 值变成了 2,更新生效了
注意: 更新 ConfigMap 后:
使用该 ConfigMap 挂载的 Env 不会同步更新
使用该 ConfigMap 挂载的 Volume 中的数据需要一段时间(实测大概 10 秒)才能同步更新
2、Secret
2.1 Secret 概述
Secret 解决了密码、token、秘钥等敏感数据的配置问题,而不需要把这些敏感数据 暴露到镜像或者 Pod Spec 中。Secret 可以以 Volume 或者环境变量的方式使用。
要使用 secret,pod 需要引用 secret。Pod 可以用两种方式使用 secret:作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里,或者当 kubelet 为 pod 拉取 镜像时使用。
secret 可选参数有三种:
generic: 通用类型,通常用于存储密码数据。
tls:此类型仅用于存储私钥和证书。
docker-registry: 若要保存 docker 仓库的认证信息的话,就必须使用此种类型来创建。
Secret 类型:
Service Account:用于被 serviceaccount 引用。serviceaccout 创建时 Kubernetes 会默认创建对应的 secret。Pod 如果使用了 serviceaccount,对应的 secret 会自动挂载到 Pod 的 /run/secrets/kubernetes.io/serviceaccount 目录中。
Opaque:base64 编码格式的 Secret,用来存储密码、秘钥等。可以通过 base64 --decode 解码获得原始数据,因此安全性弱。
kubernetes.io/dockerconfigjson:用来存储私有 docker registry 的认证信息。
2.2 使用 Secret
1) 通过环境变量引入 Secret
#1、把 mysql 的 root 用户的 password 创建成 secret
mkdir /root/secret
cd /root/secret
kubectl create secret generic mysql-password --from-literal=password=xianchaopod**lucky66
kubectl get secret
#查看secret详细信息,发现value已经加密
kubectl describe secret mysql-password
#password 的值是加密的,
#但 secret 的加密是一种伪加密,它仅仅是将数据做了 base64 的编码.
#2、创建 pod,引用 secret
#所有节点拉取镜像
docker pull ikubernetes/myapp:v1
#创建pod配置文件
vim pod-secret.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: pod-secret
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
env:
- name: MYSQL_ROOT_PASSWORD #它是 Pod 启动成功后,Pod 中容器的环境变量 名.
valueFrom:
secretKeyRef:
name: mysql-password #这是 secret 的对象名
key: password #它是 secret 中的 key 名
===================================
#更新资源文件
kubectl apply -f pod-secret.yaml
#进入pod的容器
kubectl exec -it pod-secret -- /bin/sh
#在容器中查看环境变量
printenv
2)通过 volume 挂载 Secret
#手动加密,基于 base64 加密
echo -n 'admin' | base64
echo -n 'xianchao123456f' | base64
#解密
echo eGlhbmNoYW8xMjM0NTZm | base64 -d
#1、创建 Secret
vim secret.yaml
===================================
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: eGlhbmNoYW8xMjM0NTZm
===================================
kubectl apply -f secret.yaml
#查看secret
kubectl describe secret mysecret
#2、将 Secret 挂载到 Volume 中
vim pod_secret_volume.yaml
===================================
apiVersion: v1
kind: Pod
metadata:
name: pod-secret-volume
spec:
containers:
- name: myapp
image: registry.cn-beijing.aliyuncs.com/google_registry/myapp:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: secret-volume
mountPath: /etc/secret
readOnly: true
volumes:
- name: secret-volume
secret:
secretName: mysecret
===================================
#更新资源文件
kubectl apply -f pod_secret_volume.yaml
#进入pod的容器
kubectl exec -it pod-secret-volume -- /bin/sh
#容器内查看
ls /etc/secret
cat /etc/secret/username
#由上可见,在 pod 中的 secret 信息实际已经被解密。
九、K8s安全管理
1、认证、授权、准入控制概述
k8s 对我们整个系统的认证,授权,访问控制做了精密的设置;对于 k8s 集群来说,apiserver 是整 个集群访问控制的唯一入口,我们在 k8s 集群之上部署应用程序的时候,也可以通过宿主机的 NodePort 暴露的端口访问里面的程序,用户访问 kubernetes 集群需要经历如下认证过程:认证 ->授权->准入控制(adminationcontroller)
1.认证(Authenticating)是对客户端的认证,通俗点就是用户名密码验证
2.授权(Authorization)是对资源的授权,k8s 中的资源无非是容器,最终其实就是容器的计算,网 络,存储资源,当一个请求经过认证后,需要访问某一个资源(比如创建一个 pod),授权检查会根 据授权规则判定该资源(比如某 namespace 下的 pod)是否是该客户可访问的。
3.准入(Admission Control)机制:
准入控制器(Admission Controller)位于 API Server 中,在对象被持久化之前,准入控制器拦 截对 API Server 的请求,一般用来做身份验证和授权。其中包含两个特殊的控制器:
MutatingAdmissionWebhook 和 ValidatingAdmissionWebhook。分别作为配置的变异和验 证准入控制 webhook。
变更(Mutating)准入控制:修改请求的对象
验证(Validating)准入控制:验证请求的对象
准入控制器是在 API Server 的启动参数配置的。一个准入控制器可能属于以上两者中的一种,也 可能两者都属于。当请求到达 API Server 的时候首先执行变更准入控制,然后再执行验证准入控制。
我们在部署 Kubernetes 集群的时候都会默认开启一系列准入控制器,如果没有设置这些准入控制 器的话可以说你的 Kubernetes 集群就是在裸奔,应该只有集群管理员可以修改集群的准入控制器。
例如我会默认开启如下的准入控制器。
–admission
control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQ uota,MutatingAdmissionWebhook,ValidatingAdmissionWebhook
k8s 的整体架构也是一个微服务的架构,所有的请求都是通过一个 GateWay,也就是 kubeapiserver 这个组件(对外提供 REST 服务),k8s 中客户端有两类,一种是普通用户,一种是集群 内的 Pod,这两种客户端的认证机制略有不同,但无论是哪一种,都需要依次经过认证,授权,准 入这三个机制。
1.1 认证
1、认证支持多种插件
(1)令牌(token)认证:
双方有一个共享密钥,服务器上先创建一个密码下来,客户端登陆的时候拿这个密码登陆即可,这个 就是对称密钥认证方式;k8s 提供了一个 restful 风格的接口,它的所有服务都是通过 http 协议提 供的,因此认证信息只能经由 http 协议的认证首部进行传递,这种认证首部进行传递通常叫做令
牌;
(2)ssl 认证:
对于 k8s 访问来讲,ssl 认证能让客户端确认服务器的认证身份,我们在跟服务器通信的时候,需要 服务器发过来一个证书,我们需要确认这个证书是不是 ca 签署的,如果是我们认可的 ca 签署的, 里面的 subj 信息与我们访问的目标主机信息保持一致,没有问题,那么我们就认为服务器的身份得 到认证了,k8s 中最重要的是服务器还需要认证客户端的信息,kubectl 也应该有一个证书,这个证 书也是 server 所认可的 ca 签署的证书,双方需要互相认证,实现加密通信,这就是 ssl 认证。
2、kubernetes 上的账号
客户端对 apiserver 发起请求,apiserver 要识别这个用户是否有请求的权限,要识别用户本身能否 通过 apiserver 执行相应的操作,那么需要哪些信息才能识别用户信息来完成对用户的相关的访问 控制呢?
kubectl explain pods.spec 可以看到有一个字段 serviceAccountName(服务账号名称),这个 就是我们 pod 连接 apiserver 时使用的账号,因此整个 kubernetes 集群中的账号有两类, ServiceAccount(服务账号),User account(用户账号)
User account:实实在在现实中的人,人可以登陆的账号,客户端想要对 apiserver 发起请求, apiserver 要识别这个客户端是否有请求的权限,那么不同的用户就会有不同的权限,靠用户账号表 示,叫做 username
ServiceAccount:方便 Pod 里面的进程调用 Kubernetes API 或其他外部服务而设计的,是 kubernetes 中的一种资源
sa 账号:登陆 dashboard 使用的账号
user account:这个是登陆 k8s 物理机器的用户
1.2 授权
如果用户通过认证,什么权限都没有,需要一些后续的授权操作,如对资源的增删该查等, kubernetes1.6 之后开始有 RBAC(基于角色的访问控制机制)授权检查机制。
Kubernetes 的授权是基于插件形成的,其常用的授权插件有以下几种:
1)Node(节点认证)
2)ABAC(基于属性的访问控制)
3)RBAC(基于角色的访问控制)
4)Webhook(基于 http 回调机制的访问控制)
什么是 RBAC(基于角色的访问控制)?
让一个用户(Users)扮演一个角色(Role),角色拥有权限,从而让用户拥有这样的权限,随后在 授权机制当中,只需要将权限授予某个角色,此时用户将获取对应角色的权限,从而实现角色的访问 控制。如图:

k8s 的授权机制当中,采用 RBAC 的方式进行授权,其工作逻辑是,把对对象的操作权限定义到 一个角色当中,再将用户绑定到该角色,从而使用户得到对应角色的权限。如果通过 rolebinding 绑定 role,只能对 rolebingding 所在的名称空间的资源有权限,上图 user1 这个用户绑定到 role1 上,只对 role1 这个名称空间的资源有权限,对其他名称空间资源没有权限,属于名称空间级 别的;
另外,k8s 为此还有一种集群级别的授权机制,就是定义一个集群角色(ClusterRole),对集群内 的所有资源都有可操作的权限,从而将 User2 通过 ClusterRoleBinding 到 ClusterRole,从而使 User2 拥有集群的操作权限。
Role、RoleBinding、ClusterRole 和 ClusterRoleBinding 的关系如下图:

通过上图可以看到,可以通过 rolebinding 绑定 role,rolebinding 绑定 clusterrole, clusterrolebinding 绑定 clusterrole。
上面我们说了两个角色绑定:
(1)用户通过 rolebinding 绑定 role
(2)用户通过 clusterrolebinding 绑定 clusterrole
(3)rolebinding 绑定 clusterrole
rolebinding 绑定 clusterrole 的好处:
假如有 6 个名称空间,每个名称空间的用户都需要对自己的名称空间有管理员权限,那么需要定义 6 个 role 和 rolebinding,然后依次绑定,如果名称空间更多,我们需要定义更多的 role,这个是很 麻烦的,所以我们引入 clusterrole,定义一个 clusterrole,对 clusterrole 授予所有权限,然后用 户通过 rolebinding 绑定到 clusterrole,就会拥有自己名称空间的管理员权限了。
注:RoleBinding 仅仅对当前名称空间有对应的权限。
1.3 准入控制
一般而言,准入控制只是用来定义我们授权检查完成之后的后续的其他安全检查操作的,进一步补充 了授权机制,由多个插件组合实行,一般而言在创建,删除,修改或者做代理时做补充;
Kubernetes 的 Admission Control 实际上是一个准入控制器(Admission Controller)插件列 表,发送到 APIServer 的请求都需要经过这个列表中的每个准入控制器插件的检查,如果某一个控 制器插件准入失败,就准入失败。
控制器插件如下:
AlwaysAdmit:允许所有请求通过
AlwaysPullImages:在启动容器之前总是去下载镜像,相当于每当容器启动前做一次用于是否有权 使用该容器镜像的检查
AlwaysDeny:禁止所有请求通过,用于测试
DenyEscalatingExec:拒绝 exec 和 attach 命令到有升级特权的 Pod 的终端用户访问。如果集中 包含升级特权的容器,而要限制终端用户在这些容器中执行命令的能力,推荐使用此插件 ImagePolicyWebhook
ServiceAccount:这个插件实现了 serviceAccounts 等等自动化,如果使用 ServiceAccount 对 象,强烈推荐使用这个插件
SecurityContextDeny:将 Pod 定义中定义了的 SecurityContext 选项全部失效。
SecurityContext 包含在容器中定义了操作系统级别的安全选型如 fsGroup,selinux 等选项
ResourceQuota:用于 namespace 上的配额管理,它会观察进入的请求,确保在 namespace 上 的配额不超标。推荐将这个插件放到准入控制器列表的最后一个。ResourceQuota 准入控制器既可 以限制某个 namespace 中创建资源的数量,又可以限制某个 namespace 中被 Pod 请求的资源总量。ResourceQuota 准入控制器和 ResourceQuota 资源对象一起可以实现资源配额管理。
LimitRanger:用于 Pod 和容器上的配额管理,它会观察进入的请求,确保 Pod 和容器上的配额不 会超标。准入控制器 LimitRanger 和资源对象 LimitRange 一起实现资源限制管理 NamespaceLifecycle:当一个请求是在一个不存在的 namespace 下创建资源对象时,该请求会 被拒绝。当删除一个 namespace 时,将会删除该 namespace 下的所有资源对象。
2、ServiceAccount 介绍
kubernetes 中账户区分为:User Accounts(用户账户) 和 Service Accounts(服务账户) 两种。
UserAccount 是给 kubernetes 集群外部用户使用的,例如运维或者集群管理人员,,kubeadm 安装的 k8s,默认用户账号是 kubernetes-admin;
APIServer 需要对客户端做认证,使用 kubeadm 安装的 K8s,会在用户家目录下创建一个认 证配置文件 .kube/config 这里面保存了客户端访问 API Server 的密钥相关信息,这样当用 kubectl 访问 k8s 时,它就会自动读取该配置文件,向 API Server 发起认证,然后完成操作请求。
#用户名称可以在 kubeconfig 中查看
cd ~/.kube/
cat config
ServiceAccount 是 Pod 使用的账号,Pod 容器的进程需要访问 API Server 时用的就是 ServiceAccount 账户;ServiceAccount 仅局限它所在的 namespace,每个 namespace 创建时都会 自动创建一个 default service account;创建 Pod 时,如果没有指定 Service Account,Pod 则会使 用 default Service Account。
3、RBAC 认证授权策略
RBAC 介绍 :
在 Kubernetes 中,所有资源对象都是通过 API 进行操作,他们保存在 etcd 里。而对 etcd 的操作 我们需要通过访问 kube-apiserver 来实现,上面的 Service Account 其实就是 APIServer 的认证过 程,而授权的机制是通过 RBAC:基于角色的访问控制实现。
RBAC 有四个资源对象,分别是 Role、ClusterRole、RoleBinding、ClusterRoleBinding
3.1 Role:角色
一组权限的集合,在一个命名空间中,可以用其来定义一个角色,只能对命名空间内的资源进行 授权。如果是集群级别的资源,则需要使用 ClusterRole。例如:定义一个角色用来读取 Pod 的权限 。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: rbac
name: pod-read
rules:
- apiGroups: [""]
resources: ["pods"]
resourceNames: []
verbs: ["get","watch","list"]
rules 中的参数说明:
1、apiGroups:支持的 API 组列表,例如:"apiVersion: batch/v1"等
2、resources:支持的资源对象列表,例如 pods、deplayments、jobs 等
3、resourceNames: 指定 resource 的名称
4、verbs:对资源对象的操作方法列表。
3.2 ClusterRole:集群角色
具有和角色一致的命名空间资源的管理能力,还可用于以下特殊元素的授权
1、集群范围的资源,例如 Node
2、非资源型的路径,例如:/healthz
3、包含全部命名空间的资源,例如 Pods
#例如:定义一个集群角色可让用户访问任意 secrets
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: secrets-clusterrole
rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get","watch","list"]
3.3 RoleBinding:角色绑定、ClusterRolebinding:集群角色绑定
角色绑定和集群角色绑定用于把一个角色绑定在一个目标上,可以是 User,Group,Service Account,使用 RoleBinding 为某个命名空间授权,使用 ClusterRoleBinding 为集群范围内授权。
#例如:将在 rbac 命名空间中把 pod-read 角色授予用户 es
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: pod-read-bind
namespace: rbac
subjects:
- kind: User
name: es
apiGroup: rbac.authorization.k8s.io
roleRef:
- kind: Role
name: pod-read
apiGroup: rbac.authorizatioin.k8s.io
#RoleBinding 也可以引用 ClusterRole,对属于同一命名空间内的 ClusterRole 定义的资源主体进 行授权, 例如:es 能获取到集群中所有的资源信息
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: es-allresource
namespace: rbac
subjects:
- kind: User
name: es
apiGroup: rbac.authorization.k8s.io
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
#集群角色绑定的角色只能是集群角色,用于进行集群级别或对所有命名空间都生效的授权 例如:允许 manager 组的用户读取所有 namaspace 的 secrets
apiVersion: rabc.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: read-secret-global
subjects:
- kind: Group
name: manager
apiGroup: rabc.authorization.k8s.io
ruleRef:
- kind: ClusterRole
name: secret-read
apiGroup: rabc.authorization.k8s.io
4、资源的引用方式
多数资源可以用其名称的字符串表示,也就是 Endpoint 中的 URL 相对路径,例如 pod 中的日志是 GET /api/v1/namaspaces/{namespace}/pods/{podname}/log
如果需要在一个 RBAC 对象中体现上下级资源,就需要使用“/”分割资源和下级资源。
#例如:若想授权让某个主体同时能够读取 Pod 和 Pod log,则可以配置 resources 为一个数组
apiVersion: rabc.authorization.k8s.io/v1
kind: Role
metadata:
name: logs-reader
namespace: default
rules:
- apiGroups: [""]
resources: ["pods","pods/log"]
verbs: ["get","list"]
资源还可以通过名称(ResourceName)进行引用,在指定 ResourceName 后,使用 get、 delete、update、patch 请求,就会被限制在这个资源实例范围内
#例如,下面的声明让一个主体只能对名为 my-configmap 的 Configmap 进行 get 和 update 操作:
apiVersion: rabc.authorization.k8s.io/v1
kind: Role
metadata:
namaspace: default
name: configmap-update
rules:
- apiGroups: [""]
resources: ["configmap"]
resourceNames: ["my-configmap"]
verbs: ["get","update"]
5、常见角色示例
(1)允许读取核心 API 组的 Pod 资源 rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get","list","watch"]
(2)允许读写 extensions 和 apps 两个 API 组中的 deployment 资源 rules:
- apiGroups: ["extensions","apps"]
resources: ["deployments"]
verbs: ["get","list","watch","create","update","patch","delete"]
(3)允许读取 Pod 以及读写 job 信息 rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get","list","watch"]、 - apiVersion: ["batch","extensions"]
resources: ["jobs"]
verbs: ["get","list","watch","create","update","patch","delete"]
(4)允许读取一个名为 my-config 的 ConfigMap(必须绑定到一个 RoleBinding 来限制到一个 Namespace 下的 ConfigMap):
rules:
- apiGroups: [""]
resources: ["configmap"]
resourceNames: ["my-configmap"]
verbs: ["get"]
(5)读取核心组的 Node 资源(Node 属于集群级的资源,所以必须存在于 ClusterRole 中,并使 用 ClusterRoleBinding 进行绑定):
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get","list","watch"]
(6)允许对非资源端点“/healthz”及其所有子路径进行 GET 和 POST 操作(必须使用 ClusterRole 和 ClusterRoleBinding):
rules:
- nonResourceURLs: ["/healthz","/healthz/*"]
verbs: ["get","post"]
6、常见的角色绑定示例
(1)用户名 alice
subjects:
- kind: User
name: alice
apiGroup: rbac.authorization.k8s.io
(2)组名 alice
subjects:
- kind: Group
name: alice
apiGroup: rbac.authorization.k8s.io
(3)kube-system 命名空间中默认 Service Account
subjects:
- kind: ServiceAccount
name: default
namespace: kube-system
(4)qa 命名空间中的所有 Service Account:
subjects:
- kind: Group
name: system:serviceaccounts:qa
apiGroup: rbac.authorization.k8s.io
(5)所有 Service Account
subjects:
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
(6)所有认证用户
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
(7)所有未认证用户
subjects:
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
(8)全部用户
subjects:
- kind: Group
name: system:authenticated
apiGroup: rbac.authorization.k8s.io
- kind: Group
name: system:unauthenticated
apiGroup: rbac.authorization.k8s.io
7、对 Service Account 的授权管理
Service Account 也是一种账号,是给运行在 Pod 里的进程提供了必要的身份证明。需要在 Pod 定义中指明引用的 Service Account,这样就可以对 Pod 的进行赋权操作。例如:pod 内可获取 rbac 命名空间的所有 Pod 资源,pod-reader-sc 的 Service Account 是绑定了名为 pod-read 的 Role 。
apiVersion: v1
kind: Pod
metadata:
name: nginx
namespace: rbac
spec:
serviceAccountName: pod-reader-sc
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
默认的 RBAC 策略为控制平台组件、节点和控制器授予有限范围的权限,但是除 kube-system 外 的 Service Account 是没有任何权限的。
(1)为一个应用专属的 Service Account 赋权,此应用需要在 Pod 的 spec 中指定一个 serviceAccountName,用于 API、Application Manifest、kubectl create serviceaccount 等创建 Service Account 的命令。
例如为 my-namespace 中的 my-sa Service Account 授予只读权限
kubectl create rolebinding my-sa-view --clusterrole=view --serviceaccount=mynamespace:my-sa --namespace=my-namespace
(2)为一个命名空间中名为 default 的 Service Account 授权
如果一个应用没有指定 serviceAccountName,则会使用名为 default 的 Service Account。注 意,赋予 Service Account “default”的权限会让所有没有指定 serviceAccountName 的 Pod 都具有这些权限
例如,在 my-namespace 命名空间中为 Service Account“default”授予只读权限: kubectl create rolebinding default-view --clusterrole=view --serviceaccount=mynamespace:default --namespace=my-namespace
另外,许多系统级 Add-Ons 都需要在 kube-system 命名空间中运行,要让这些 Add-Ons 能够使 用超级用户权限,则可以把 cluster-admin 权限赋予 kube-system 命名空间中名为 default 的 Service Account,这一操作意味着 kube-system 命名空间包含了通向 API 超级用户的捷径。 kubectl create clusterrolebinding add-ons-add-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default
(3)为命名空间中所有 Service Account 都授予一个角色,如果希望在一个命名空间中,任何 Service Account 应用都具有一个角色,则可以为这一命名空间 的 Service Account 群组进行授权。
kubectl create rolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts:my-namespace --namespace=my-namespace
(4)为集群范围内所有 Service Account 都授予一个低权限角色,如果不想为每个命名空间管理授权,则可以把一个集群级别的角色赋给所有 Service Account。
kubectl create clusterrolebinding serviceaccounts-view --clusterrole=view --group=system:serviceaccounts
(5)为所有 Service Account 授予超级用户权限
kubectl create clusterrolebinding serviceaccounts-view --clusterrole=cluster-admin --group=system:serviceaccounts
8、使用 kubectl 命令行工具创建资源对象
(1)在命名空间 rbac 中为用户 es 授权 admin ClusterRole:
kubectl create rolebinding bob-admin-binding --clusterrole=admin --user=es --namespace=rbac
(2)在命名空间 rbac 中为名为 myapp 的 Service Account 授予 view ClusterRole:
kubctl create rolebinding myapp-role-binding --clusterrole=view --serviceaccount=rbac:myapp --namespace=rbac
(3)在全集群范围内为用户 root 授予 cluster-admin ClusterRole:
kubectl create clusterrolebinding cluster-binding --clusterrole=cluster-admin --user=root
(4)在全集群范围内为名为 myapp 的 Service Account 授予 view ClusterRole:
kubectl create clusterrolebinding service-account-binding --clusterrole=view --serviceaccount=myapp
yaml 文件进行 rbac 授权:https://kubernetes.io/zh/docs/reference/access-authn-authz/rbac/
9、限制不同的用户操作 k8s 集群
#1、ssl 认证
#生成一个证书
#(1)生成一个私钥
cd /etc/kubernetes/pki/
#生成一个lucky.key的秘钥
(umask 077; openssl genrsa -out lucky.key 2048)
#(2)生成一个证书请求
openssl req -new -key lucky.key -out lucky.csr -subj "/CN=lucky"
#(3)生成一个证书
openssl x509 -req -in lucky.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out lucky.crt -days 3650
#2、在 kubeconfig 下新增加一个 lucky 这个用户
#需要吧lucky用户添加到/root/.kube/config里面
#(1)把 lucky 这个用户添加到 kubernetes 集群中,可以用来认证 apiserver 的连接
kubectl config set-credentials lucky --client-certificate=./lucky.crt --client-key=./lucky.key --embed-certs=true
#查看lucky这个用户
vim /root/.kube/config
#(2)在 kubeconfig 下新增加一个 lucky 这个账号的上下文
kubectl config set-context lucky@kubernetes --cluster=kubernetes --user=lucky
#(3)切换账号到 lucky,默认没有任何权限
kubectl config use-context lucky@kubernetes
#这时候执行kubectl get pod是没有权限的
#kubectl config use-context kubernetes-admin@kubernetes 这个是集群用户,有任何权限
#3、把 lucky 这个用户通过 rolebinding 绑定到 clusterrole 上,授予权限,权限只是在 lucky 这个名称 空间有效
#切换到admin
kubectl config use-context kubernetes-admin@kubernetes
#(1)把 lucky 这个用户通过 rolebinding 绑定到 clusterrole 上
kubectl create ns lucky
kubectl create rolebinding lucky -n lucky --clusterrole=cluster-admin --user=lucky
#(2)切换到 lucky 这个用户
kubectl config use-context lucky@kubernetes
#(3)测试是否有权限
kubectl get pods -n lucky
#有权限操作这个名称空间
kubectl get pods
#没有权限操作其他名称空间
#4、添加一个 lucky 的普通用户,后面如果给其他人暴露就必须添加普通账号
useradd lucky
#把整体目录拷贝到
cp -ar /root/.kube/ /home/lucky/
#删除config中admin信息,以免被lucky用户看到
vim /home/lucky/.kube/config
#(1)删除contexts地下kubernetes-admin相关信息
#(2)删除users地下的kubenete证书相关信息
#授权给lucky用户
chown -R lucky.lucky /home/lucky/
#切换到lucky用户下
su - lucky
#查询pod
kubectl get pods -n lucky

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)