K8S简单学习文档
上段代码为Linux中创建一个新进程的代码,返回pid该段代码中的CLONE_NEWPID会“误导”进程,认为自己是当前容器里的1号进程,既看不到宿主机里的真正进程空间,也看不到其他PID NameSpace里的具体情况。NameSpace实际上只修改了应用看待计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。Master组件的YAML文件会被生成在/etc/kuber
K8S
摘自极客时间张磊
Docker
🌞进程
容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个"边界"。
通过NameSpace(修改进程视图)、UTS NameSpace 、 IPC NameSpace 、 NetworkNameSpace、PID NameSpace 、Mount Namespace(docker内文件系统)、Cgroup(资源限制)

🌛隔离
⭐介绍隔离的本质:以PID NameSpace为例
int pid = clone(main_function, stack_size, SIGCHLD, NULL);
上段代码为Linux中创建一个新进程的代码,返回pid
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL);
该段代码中的CLONE_NEWPID会“误导”进程,认为自己是当前容器里的1号进程,既看不到宿主机里的真正进程空间,也看不到其他PID NameSpace里的具体情况。
NameSpace实际上只修改了应用看待计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。
⭐虚拟机比对Docker

- 虚拟机会运行OS会占用内存,Docker只是以进程的形式运行。
- 因为虚拟机虚拟化软件的原因,对计算资源、网络磁盘、磁盘I/O的损耗很大。
- Docker使用NameSpace作为隔离手段,不需要单独的Guest OS
- Docker是以进程的形式管控。
“敏捷”和“高性能”是容器相较于虚拟机最大的优势
隔离得不彻底是容器的弊端
既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
※ 在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
🌛限制
虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。
这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。
⭐Linux Cgroups (Linux Control Group)
$ mount -t cgroup
cpuset on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cpu on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
cpuacct on /sys/fs/cgroup/cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct)
blkio on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
memory on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,可以看到该类资源具体可以被限制的方法。
**它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。**此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。
Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,**它就是一个子系统目录加上一组资源限制文件的组合。**而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
root@ubuntu:/sys/fs/cgroup/cpu$ mkdir 新目录
root@ubuntu:/sys/fs/cgroup/cpu$ ls 新目录/
cgroup.clone_children cpu.cfs_period_us cpu.rt_period_us cpu.shares notify_on_release
cgroup.procs cpu.cfs_quota_us cpu.rt_runtime_us cpu.stat tasks
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的**/sys/fs/cgroup** 路径下。
在**/sys/fs/cgroup**下
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制;
- cpu, 进程限制cpu使用率。
⭐Cgroups 的不足
/proc文件系统问题。
Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
该问题会导致应用程序在容器里读取到的CPU信息、内存信息都是宿主机上的数据
案例:当时在容器上运行的java应用,由于当时jvm参数没正确配置上,就用默认的,而容器设置的内存为4g,最后oom了,当时用命令查看容器的内存占用情况,竟然发现内存竟然有60多g。 那应该显示的是宿主机的内存了,jvm按照宿主机内存大小分配的默认内存应该大于4g 所以还没full gc 就oom了。
⭐lxcfs

以内存限制为例:
当我们把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到 Docker 容器的 /proc/meminfo 位置后,容器中进程读取相应文件内容时,lxcfs 的 /dev/fuse 实现会从容器对应的 Cgroup 中读取正确的内存限制。从而使得应用获得正确的资源约束。 cpu 的限制原理也是一样的。
🌛文件系统
⭐Mount NameSpace
- Mount Namespace 修改的,是容器进程对文件系统“挂载点”的认知。
- Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它对容器进程视图的改变,一定是伴随着挂载操作(mount)才能生效。

- 启用Linux NameSpace配置;
- 设置指定的Cgroups参数;
- 切换进程的根目录。
Docker 项目在最后一步的切换上会优先使用 pivot_root 系统调用,如果系统不支持,才会使用 chroot。
$ chroot $HOME/test /bin/bash
#将/bin/bash的根目录设置为$HOME/test
⭐UnionFIleSystem
联合挂载
$ tree
.
├── A
│ ├── a
│ └── x
└── B
├── b
└── x
#存在AB两个目录
$ mkdir C
$ mount -t aufs -o dirs=./A:./B none ./C
#将AB联合挂载到C目录
$ tree ./C
./C
├── a
├── b
└── x
#在这个合并后的目录 C 里,有 a、b、x 三个文件,并且 x 文件只有一份。这,就是“合并”的含义。
#如果在目录 C 里对 a、b、x 文件做修改,这些修改也会在对应的目录 A、B 中生效。
⭐Docker引入了Layer(层)的概念
这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成:

$ docker image inspect ubuntu:latest
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
#这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
#信息记录在 AuFS 的系统目录 /sys/fs/aufs 下面。
$ cat /proc/mounts| grep aufsnone /var/lib/docker/aufs/mnt/6e3be5d2ecccae7cc0fc... aufs rw,relatime,si=972c6d361e6b32ba,dio,dirperm1 0 0
#si=972c6d361e6b32ba
#然后使用这个 ID,你就可以在 /sys/fs/aufs 下查看被联合挂载在一起的各个层的信息:
$ cat /sys/fs/aufs/si_972c6d361e6b32ba/br[0-9]*
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...=rw
/var/lib/docker/aufs/diff/6e3be5d2ecccae7cc...-init=ro+wh
/var/lib/docker/aufs/diff/32e8e20064858c0f2...=ro+wh
/var/lib/docker/aufs/diff/2b8858809bce62e62...=ro+wh
/var/lib/docker/aufs/diff/20707dce8efc0d267...=ro+wh
/var/lib/docker/aufs/diff/72b0744e06247c7d0...=ro+wh
/var/lib/docker/aufs/diff/a524a729adadedb90...=ro+wh

图片来源于极客时间 张磊 《深入剖析 Kubernetes》
第一部分,只读层。
它是这个容器的 rootfs 最下面的五层,对应的正是 ubuntu:latest 镜像的五层。可以看到,它们的挂载方式都是只读的(ro+wh,即 readonly+whiteout)
whiteout 白障
第二部分,可读写层。
它是这个容器的 rootfs 最上面的一层,它的挂载方式为:rw,即 read write。在没有写入文件之前,这个目录是空的。而一旦在容器里做了写操作,你修改产生的内容就会以增量的方式出现在这个层中。
删除xxx会产生一个.wh.xxx的文件
第三部分,Init层
init层用于挂载一些仅对当前容器生效的文件。
它是一个以“-init”结尾的层,夹在只读层和读写层之间。Init 层是 Docker 项目单独生成的一个内部层,专门用来存放 /etc/hosts、/etc/resolv.conf 等信息。
比如hostname
既然容器的 rootfs(比如,Ubuntu 镜像),是以只读方式挂载的,那么又如何在容器里修改 Ubuntu 镜像的内容呢?
上面的读写层通常也称为容器层,下面的只读层称为镜像层,所有的增删查改操作都只会作用在容器层,相同的文件上层会覆盖掉下层。知道这一点,就不难理解镜像文件的修改,比如修改一个文件的时候,首先会从上到下查找有没有这个文件,找到,就复制到容器层中,修改,修改的结果就会作用到下层的文件,这种方式也被称为copy-on-write。
⭐Docker File
# 使用官方提供的Python开发镜像作为基础镜像
FROM python:2.7-slim
# 将工作目录切换为/app
WORKDIR /app
# 将当前目录下的所有内容复制到/app下
ADD . /app
# 使用pip命令安装这个应用所需要的依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 允许外界访问容器的80端口
EXPOSE 80
# 设置环境变量
ENV NAME World
# 设置容器进程为:python app.py,即:这个Python应用的启动命令
CMD ["python", "app.py"]
COPY命令的源文件必须是“构建上下文”。
COPY ./a.txt /tmp/a.txt # 把构建上下文里的a.txt拷贝到镜像的/tmp目录 COPY /etc/hosts /tmp # 错误!不能使用构建上下文之外的文件ARG和ENV
它们区别在于 ARG 创建的变量只在镜像构建过程中可见,容器运行时不可见,而 ENV 创建的变量不仅能够在构建镜像的过程中使用,在容器运行时也能够以环境变量的形式被应用程序使用。
CMD = ENTRYPOINT CMD
**Dockerfile 中的每个原语执行后,都会生成一个对应的镜像层。**即使原语本身并没有明显地修改文件的操作(比如,ENV 原语),它对应的层也会存在。只不过在外界看来,这个层是空的。所以 Dockerfile 里最好不要滥用指令,尽量精简合并,否则太多的层会导致镜像臃肿不堪。
如果目录里有的文件(例如 readme/.git/.svn 等)不需要拷贝进镜像,可以在“构建上下文”目录里再建立一个 .dockerignore 文件,语法与 .gitignore 类似,排除那些不需要的文件。
# docker ignore *.swp *.sh
一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
⭐Volume
允许将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
-
只需要在 rootfs 准备好之后,在执行 chroot 之前,把 Volume 指定的宿主机目录(比如 /home 目录),挂载到指定的容器目录(比如 /test 目录)在宿主机上对应的目录(即 /var/lib/docker/aufs/mnt/[可读写层 ID]/test)上,这个 Volume 的挂载工作就完成了。
-
由于执行这个挂载操作时,“容器进程”已经创建了,也就意味着此时 Mount Namespace 已经开启了。所以,这个挂载事件只在这个容器里可见。你在宿主机上,是看不见容器内部的这个挂载点的。这就保证了容器的隔离性不会被 Volume 打破。
-
这里要使用到的挂载技术,就是 Linux 的绑定挂载(bind mount)机制。它的主要作用就是,允许你将一个目录或者文件,而不是整个设备,挂载到一个指定的目录上。并且,这时你在该挂载点上进行的任何操作,只是发生在被挂载的目录或者文件上,而原挂载点的内容则会被隐藏起来且不受影响。
K8S简介
🌞架构&组件简介
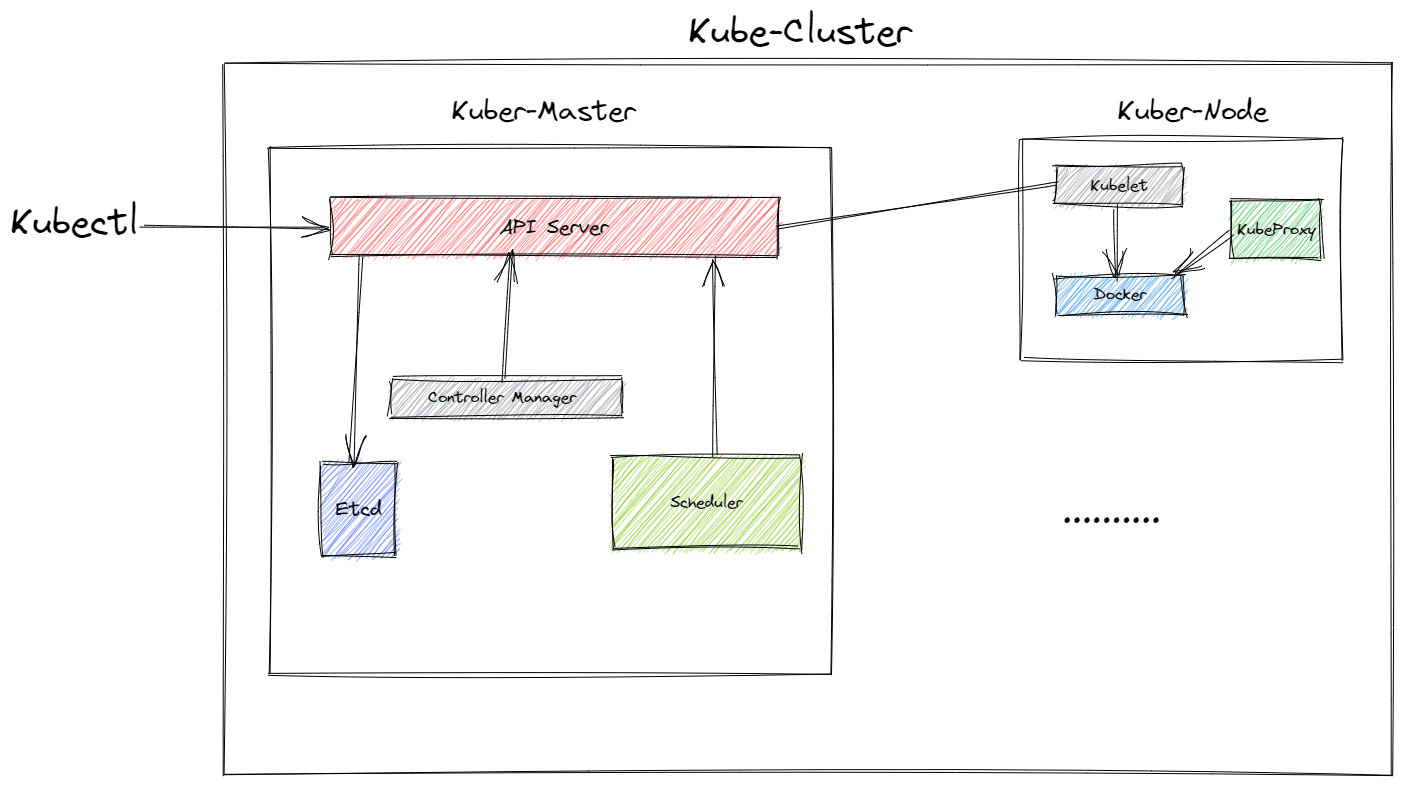
🌛k8s-cluster

- Master组件的YAML文件会被生成在/etc/kubernetes/manifests路径下。
$ kubeadm init --config kubeadm.yaml #可以通过自创kubeadm.yaml修改覆盖/etc/kubernetes/manifests下的文件配置
- Kubectl 通过HTTPS与APIserver通信,证书由集群内部颁发。
- 除了kubelet,其他组件都以容器形式存在。
- apiserver 是 Master 节点——同时也是整个 Kubernetes 系统的唯一入口,它对外公开了一系列的 RESTful API,并且加上了验证、授权等功能,所有其他组件都只能和它直接通信,可以说是 Kubernetes 里的联络员。
- etcd 是一个高可用的分布式 Key-Value 数据库,用来持久化存储系统里的各种资源对象和状态,相当于 Kubernetes 里的配置管理员。注意它只与 apiserver 有直接联系,也就是说任何其他组件想要读写 etcd 里的数据都必须经过 apiserver。
- scheduler 负责容器的编排工作,检查节点的资源状态,把 Pod 调度到最适合的节点上运行,相当于部署人员。因为节点状态和 Pod 信息都存储在 etcd 里,所以 scheduler 必须通过 apiserver 才能获得。
- controller-manager 负责维护容器和节点等资源的状态,实现故障检测、服务迁移、应用伸缩等功能,相当于监控运维人员。同样地,它也必须通过 apiserver 获得存储在 etcd 里的信息,才能够实现对资源的各种操作。
- kubelet 是 Node 的代理,负责管理 Node 相关的绝大部分操作,Node 上只有它能够与 apiserver 通信,实现状态报告、命令下发、启停容器等功能,相当于是 Node 上的一个“小管家”。
- kube-proxy 的作用有点特别,它是 Node 的网络代理,只负责管理容器的网络通信,简单来说就是为 Pod 转发 TCP/UDP 数据包,相当于是专职的“小邮差”。
- container-runtime 我们就比较熟悉了,它是容器和镜像的实际使用者,在 kubelet 的指挥下创建容器,管理 Pod 的生命周期。
🌛Pod

极客时间 张磊 《深入剖析Kubernetes》
- Kubernetes 项目提供了一种叫作 Secret 的对象,它其实是一个保存在 Etcd 里的键值对数据。这样,你把 Credential 信息以 Secret 的方式存在 Etcd 里,Kubernetes 就会在你指定的 Pod(比如,Web 应用的 Pod)启动时,自动把 Secret 里的数据以 Volume 的方式挂载到容器里。这样,这个 Web 应用就可以访问数据库了。
🌛持久化
就是用来保存容器存储状态的重要手段:存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论你在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。这就是“持久化”的含义。
-
Rook项目是一个基于 Ceph 的 Kubernetes 存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对 Ceph 的简单封装,Rook 在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
$ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/common.yaml $ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/operator.yaml $ kubectl apply -f https://raw.githubusercontent.com/rook/rook/master/cluster/examples/kubernetes/ceph/cluster.yaml
🌛Deployment
用于管理Pods

一个简单的deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.8
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/usr/share/nginx/html"
name: nginx-vol
volumes:
- name: nginx-vol
emptyDir: {}
POD
🌞Pod简介
🌛原子调度单位
k8s里的最小的调度单位,减少了容器紧密协作但是不在同一Node上的问题。
比如,Mesos 中就有一个资源囤积(resource hoarding)的机制,会在所有设置了 Affinity 约束的任务都达到时,才开始对它们统一进行调度。而在 Google Omega 论文中,则提出了使用乐观调度处理冲突的方法,即:先不管这些冲突,而是通过精心设计的回滚机制在出现了冲突之后解决问题。
可是这些方法都谈不上完美。资源囤积带来了不可避免的调度效率损失和死锁的可能性;而乐观调度的复杂程度,则不是常规技术团队所能驾驭的。
但是,到了 Kubernetes 项目里,这样的问题就迎刃而解了:Pod 是 Kubernetes 里的原子调度单位。这就意味着,Kubernetes 项目的调度器,是统一按照 Pod 而非容器的资源需求进行计算的。
像这样容器间的紧密协作,我们可以称为“超亲密关系”。这些具有“超亲密关系”容器的典型特征包括但不限于:互相之间会发生直接的文件交换、使用 localhost 或者 Socket 文件进行本地通信、会发生非常频繁的远程调用、需要共享某些 Linux Namespace(比如,一个容器要加入另一个容器的 Network Namespace)等等。
🌛容器设计模式
Pod,其实是一组共享了某些资源的容器。
Pod 里的所有容器,共享的是同一个Network Namespace,并且可以声明共享同一个 Volume。
- 首先,关于 Pod 最重要的一个事实是:它只是一个逻辑概念。
Kubernetes 真正处理的,还是宿主机操作系统上 Linux 容器的 Namespace 和 Cgroups,而并不存在一个所谓的 Pod 的边界或者隔离环境。那么,Pod 又是怎么被“创建”出来的呢?

对于 Pod 里的容器 A 和容器 B 来说:
- 它们可以直接使用 localhost 进行通信;
- 它们看到的网络设备跟 Infra 容器看到的完全一样;
- 一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
- 当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
⭐一个简单war包+tomcat部署Pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: javaweb-2
spec:
initContainers:
- image: geektime/sample:v2
name: war
command: ["cp", "/sample.war", "/app"]
volumeMounts:
- mountPath: /app
name: app-volume
containers:
- image: geektime/tomcat:7.0
name: tomcat
command: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]
volumeMounts:
- mountPath: /root/apache-tomcat-7.0.42-v2/webapps
name: app-volume
ports:
- containerPort: 8080
hostPort: 8001
volumes:
- name: app-volume
emptyDir: {}
我们定义了两个容器,第一个容器使用的镜像是 geektime/sample:v2,这个镜像里只有一个 WAR 包(sample.war)放在根目录下。而第二个容器则使用的是一个标准的 Tomcat 镜像。
不过,你可能已经注意到,WAR 包容器的类型不再是一个普通容器,而是一个 Init Container 类型的容器。
在 Pod 中,所有 Init Container 定义的容器,都会比 spec.containers 定义的用户容器先启动。并且,Init Container 容器会按顺序逐一启动,而直到它们都启动并且退出了,用户容器才会启动。
所以,这个 Init Container 类型的 WAR 包容器启动后,我执行了一句"cp /sample.war /app",把应用的 WAR 包拷贝到 /app 目录下,然后退出。
而后这个 /app 目录,就挂载了一个名叫 app-volume 的 Volume。接下来就很关键了。Tomcat 容器,同样声明了挂载 app-volume 到自己的 webapps 目录下。
所以,等 Tomcat 容器启动时,它的 webapps 目录下就一定会存在 sample.war 文件:这个文件正是 WAR 包容器启动时拷贝到这个 Volume 里面的,而这个 Volume 是被这两个容器共享的。
像这样,我们就用一种“组合”方式,解决了 WAR 包与 Tomcat 容器之间耦合关系的问题。
实际上,这个所谓的“组合”操作,正是容器设计模式里最常用的一种模式,它的名字叫:sidecar。(边车)
sidecar 指的就是我们可以在一个 Pod 中,启动一个辅助容器,来完成一些独立于主进程(主容器)之外的工作。
比如,在我们的这个应用 Pod 中,Tomcat 容器是我们要使用的主容器,而 WAR 包容器的存在,只是为了给它提供一个 WAR 包而已。所以,我们用 Init Container 的方式优先运行 WAR 包容器,扮演了一个 sidecar 的角色。
⭐容器的日志收集。
比如,我现在有一个应用,需要不断地把日志文件输出到容器的 /var/log 目录中。
这时,我就可以把一个 Pod 里的 Volume 挂载到应用容器的 /var/log 目录上。
然后,我在这个 Pod 里同时运行一个 sidecar 容器,它也声明挂载同一个 Volume 到自己的 /var/log 目录上。
这样,接下来 sidecar 容器就只需要做一件事儿,那就是不断地从自己的 /var/log 目录里读取日志文件,转发到 MongoDB 或者 Elasticsearch 中存储起来。这样,一个最基本的日志收集工作就完成了。
🌞Pod基本概念
凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。
apiVersion: v1
kind: Pod
...
spec:
nodeSelector:
disktype: ssd
-
NodeSelector:是一个供用户将 Pod 与 Node 进行绑定的字段
这样的一个配置,意味着这个 Pod 永远只能运行在携带了“disktype: ssd”标签(Label)的节点上;否则,它将调度失败。
NodeName:一旦 Pod 的这个字段被赋值,Kubernetes 项目就会被认为这个 Pod 已经经过了调度,调度的结果就是赋值的节点名字。所以,这个字段一般由调度器负责设置,但用户也可以设置它来“骗过”调度器,当然这个做法一般是在测试或者调试的时候才会用到。
apiVersion: v1
kind: Pod
...
spec:
hostAliases:
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
...
- HostAliases:定义了 Pod 的 hosts 文件(比如 /etc/hosts)里的内容
在这个 Pod 的 YAML 文件中,我设置了一组 IP 和 hostname 的数据。这样,这个 Pod 启动后,/etc/hosts 文件的内容将如下所示:
cat /etc/hosts # Kubernetes-managed hosts file. 127.0.0.1 localhost ... 10.244.135.10 hostaliases-pod 10.1.2.3 foo.remote 10.1.2.3 bar.remote在 Kubernetes 项目中,如果要设置 hosts 文件里的内容,一定要通过这种方法。否则,如果直接修改了 hosts 文件的话,在 Pod 被删除重建之后,kubelet 会自动覆盖掉被修改的内容。
- 凡是跟容器的 Linux Namespace 相关的属性,也一定是 Pod 级别的。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
shareProcessNamespace: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
shareProcessNamespace: true 共享了PID
定义了两个容器:一个是 nginx 容器,一个是开启了 tty 和 stdin 的 shell 容器。
docker run -it ,-it交互是窗口,i表示的是stdin,t表示的是tty,后者表示的是终端交互窗口,可以接收用户的输入,并且输出结果,而若要需要实现输入信息,需要同时开启标准输入流,stdin正式用来做这个操作
- 凡是 Pod 中的容器要共享宿主机的 Namespace,也一定是 Pod 级别的定义
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
hostNetwork: true
hostIPC: true
hostPID: true
containers:
- name: nginx
image: nginx
- name: shell
image: busybox
stdin: true
tty: true
共享宿主机的 Network、IPC 和 PID Namespace。
init containers 初始化容器,生命周期先于所有的Containers,并且严格按照定义的顺序执行。
containers 定义容器
Kubernetes 项目中对 Container 的定义,和 Docker 相比并没有什么太大区别。我在前面的容器技术概念入门系列文章中,和你分享的 Image(镜像)、Command(启动命令)、workingDir(容器的工作目录)、Ports(容器要开发的端口),以及 volumeMounts(容器要挂载的 Volume)都是构成 Kubernetes 项目中 Container 的主要字段。不过在这里,还有这么几个属性值得你额外关注。
- 首先,是 ImagePullPolicy 字段。它定义了镜像拉取的策略。而它之所以是一个 Container 级别的属性,是因为容器镜像本来就是 Container 定义中的一部分。
默认是Always,当镜像标签是nginx或者nginx:latest,也是Always。
值也可以是: Never 和 ifNotPresent。
- 其次,是 Lifecycle 字段。它定义的是 Container Lifecycle Hooks。
apiVersion: v1 kind: Pod metadata: name: lifecycle-demo spec: containers: - name: lifecycle-demo-container image: nginx lifecycle: postStart: exec: command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"] preStop: exec: command: ["/usr/sbin/nginx","-s","quit"]postStart :在容器启动后,立刻执行一个指定的操作。需要明确的是,postStart 定义的操作,虽然是在 Docker 容器 ENTRYPOINT 执行之后,但它并不严格保证顺序。也就是说,在 postStart 启动时,ENTRYPOINT 有可能还没有结束。
如果 postStart 执行超时或者错误,Kubernetes 会在该 Pod 的 Events 中报出该容器启动失败的错误信息,导致 Pod 也处于失败的状态。
preStop : ,preStop 发生的时机,则是容器被杀死之前(比如,收到了 SIGKILL 信号)。而需要明确的是,preStop 操作的执行,是同步的。所以,它会阻塞当前的容器杀死流程,直到这个 Hook 定义操作完成之后,才允许容器被杀死,这跟 postStart 不一样
- Pod生命周期变化
Pod 生命周期的变化,主要体现在 Pod API 对象的Status部分,这是它除了 Metadata 和 Spec 之外的第三个重要字段。
- Pending。这个状态意味着,Pod 的 YAML 文件已经提交给了 Kubernetes,API 对象已经被创建并保存在 Etcd 当中。但是,这个 Pod 里有些容器因为某种原因而不能被顺利创建。比如,调度不成功。
- Running。这个状态下,Pod 已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行中。
- Succeeded。这个状态意味着,Pod 里的所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。
- Failed。这个状态下,Pod 里至少有一个容器以不正常的状态(非 0 的返回码)退出。这个状态的出现,意味着你得想办法 Debug 这个容器的应用,比如查看 Pod 的 Events 和日志。
- Unknown。这是一个异常状态,意味着 Pod 的状态不能持续地被 kubelet 汇报给 kube-apiserver,这很有可能是主从节点(Master 和 Kubelet)间的通信出现了问题。
- Pod 对象的 Status 字段,还可以再细分出一组 Conditions(状态)。
值:PodScheduled、Ready、Initialized,以及 Unschedulable。
比如,Pod 当前的 Status 是 Pending,对应的 Condition 是 Unschedulable,这就意味着它的调度出现了问题。
Ready 这个细分状态非常值得我们关注:它意味着 Pod 不仅已经正常启动(Running 状态),而且已经可以对外提供服务了。这两者之间(Running 和 Ready)是有区别的。
为什么
-
Pod Running但是应用没提供服务。
比如,我用pod 拉起一个服务,但是后面该服务不具备对外服务能力。但是pod不知道我的服务是不是正常运行的(即正常对外提供服务)。这时候就需要一种探针,来检测我的服务是不是健康的。服务异常场景如下:服务启动是会创建一个 master 服务,然后master 服务会创建多个 worker 服务,接下来所有业务处理都是经过 worker 服务的,可是我不小心 写了一个 bug,导致所有的 worker 服务被 killed。
🌞Pod进阶
🌛投射卷(Projected Volume)
存在的意义不是为了存放容器里的数据,也不是用来进行容器和宿主机之间的数据交换。这些特殊 Volume 的作用,是为容器提供预先定义好的数据。
- Secret
- ConfigMap
- Downward API
- ServiceAccountToken
⭐Secret 初入门
把 Pod 想要访问的加密数据,存放到 Etcd 中。然后通过在 Pod 的容器里挂载 Volume 的方式,访问到这些 Secret 里保存的信息。
apiVersion: v1
kind: Pod
metadata:
name: test-projected-volume
spec:
containers:
- name: test-secret-volume
image: busybox
args:
- sleep
- "86400"
volumeMounts:
- name: mysql-cred
mountPath: "/projected-volume"
readOnly: true
volumes:
- name: mysql-cred
projected:
sources:
- secret:
name: user
- secret:
name: pass
如上所示:mysql-cred不是emptyDir 或者hostPath,而是project类型。
source代表了数据来源,key为user和pass。
以命令行给kubenets保存的方法:
$ cat ./username.txt
admin
$ cat ./password.txt
c1oudc0w!
$ kubectl create secret generic user --from-file=./username.txt
$ kubectl create secret generic pass --from-file=./password.txt
$ kubectl get secrets
NAME TYPE DATA AGE
user Opaque 1 51s
pass Opaque 1 51s
以Yaml形式创建:
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
user: YWRtaW4=
pass: MWYyZDFlMmU2N2Rm
Secret 对象要求这些数据必须是经过 Base64 转码的,以免出现明文密码的安全隐患。
$ echo -n 'admin' | base64
YWRtaW4=
$ echo -n '1f2d1e2e67df' | base64
MWYyZDFlMmU2N2Rm
在真正的生产环境中,你需要在 Kubernetes 中开启 Secret 的加密插件,增强数据的安全性。
创建pod并验证:
$ kubectl create -f test-projected-volume.yaml
$ kubectl exec -it test-projected-volume -- /bin/sh
$ ls /projected-volume/
user
pass
$ cat /projected-volume/user
root
$ cat /projected-volume/pass
1f2d1e2e67df
文件名是Key名
文件内容是Value值
通过该种方法挂载的Secret,一旦Etcd里的数据被更新,该Volume的文件内容也会更新。
更新有一定延时。
因为这是Kubelet定时维护这些Volume。
⭐ConfigMap 初入门
与 Secret 类似。
它与 Secret 的区别在于,ConfigMap 保存的是不需要加密的、应用所需的配置信息。
例子:
# .properties文件的内容
$ cat example/ui.properties
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
# 从.properties文件创建ConfigMap
$ kubectl create configmap ui-config --from-file=example/ui.properties
# 查看这个ConfigMap里保存的信息(data)
$ kubectl get configmaps ui-config -o yaml
apiVersion: v1
data:
ui.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
how.nice.to.look=fairlyNice
kind: ConfigMap
metadata:
name: ui-config
...
⭐Downward API初入门
有两种方式可以将 Pod 和 Container 字段呈现给运行中的容器: 1、Environment variables 2、Volume Files 这两种呈现 Pod 和 Container 字段的方式都称为 Downward API。
例子:
apiVersion: v1
kind: Pod
metadata:
name: test-downwardapi-volume
labels:
zone: us-est-coast
cluster: test-cluster1
rack: rack-22
spec:
containers:
- name: client-container
image: k8s.gcr.io/busybox
command: ["sh", "-c"]
args:
- while true; do
if [[ -e /etc/podinfo/labels ]]; then
echo -en '\n\n'; cat /etc/podinfo/labels; fi;
sleep 5;
done;
volumeMounts:
- name: podinfo
mountPath: /etc/podinfo
readOnly: false
volumes:
- name: podinfo
projected:
sources:
- downwardAPI:
items:
- path: "labels"
fieldRef:
fieldPath: metadata.labels
每5s输出一次label文件的值,可在logs里看
$ kubectl logs test-downwardapi-volumecluster="test-cluster1"rack="rack-22"zone="us-est-coast" cluster="test-cluster1" rack="rack-22" zone="us-est-coast"
目前支持的字段:
1. 使用fieldRef可以声明使用:
spec.nodeName - 宿主机名字
status.hostIP - 宿主机IP
metadata.name - Pod的名字
metadata.namespace - Pod的Namespace
status.podIP - Pod的IP
spec.serviceAccountName - Pod的Service Account的名字
metadata.uid - Pod的UID
metadata.labels['<KEY>'] - 指定<KEY>的Label值
metadata.annotations['<KEY>'] - 指定<KEY>的Annotation值
metadata.labels - Pod的所有Label
metadata.annotations - Pod的所有Annotation
2. 使用resourceFieldRef可以声明使用:
容器的CPU limit
容器的CPU request
容器的memory limit
容器的memory request
不过,需要注意的是,Downward API 能够获取到的信息,一定是 Pod 里的容器进程启动之前就能够确定下来的信息。
而如果你想要获取 Pod 容器运行后才会出现的信息,比如,容器进程的 PID,那就肯定不能使用 Downward API 了,而应该考虑在 Pod 里定义一个 sidecar 容器。
其实,Secret、ConfigMap,以及 Downward API 这三种 Projected Volume 定义的信息,大多还可以通过环境变量的方式出现在容器里。但是,通过环境变量获取这些信息的方式,不具备自动更新的能力。所以,一般情况下,我都建议你使用 Volume 文件的方式获取这些信息。
⭐ServiceAccountToken
任何运行在 Kubernetes 集群上的应用,都必须使用这个 ServiceAccountToken 里保存的授权信息,也就是 Token,才可以合法地访问 API Server。
Kubernetes 已经提供了一个默认“服务账户”(default Service Account)。并且,任何一个运行在 Kubernetes 里的 Pod,都可以直接使用这个默认的 Service Account,而无需显示地声明挂载它。
如果你查看一下任意一个运行在 Kubernetes 集群里的 Pod,就会发现,每一个 Pod,都已经自动声明一个类型是 Secret、名为 default-token-xxxx 的 Volume,然后 自动挂载在每个容器的一个固定目录上。比如:
$ kubectl describe pod nginx-deployment-5c678cfb6d-lg9lw
Containers:
...
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-s8rbq (ro)
Volumes:
default-token-s8rbq:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-s8rbq
Optional: false
默认路径为:/var/run/secrets/kubernetes.io/serviceaccount
$ ls /var/run/secrets/kubernetes.io/serviceaccount
ca.crt namespace token
这种把 Kubernetes 客户端以容器的方式运行在集群里,然后使用 default Service Account 自动授权的方式,被称作“InClusterConfig”
🌛容器健康检查和恢复机制
⭐livenessProbe
在Pod里的容器定义一个健康检查探针,根据探针的返回值决定容器的状态。(应该说的就是应用的健康检查,这个应该用于正在提供服务的Pod)
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: test-liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
#initialDelaySeconds 容器启动5s后执行
#periodSeconds 每5s执行一次
查看容器状态:
$ kubectl create -f test-liveness-exec.yaml
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
test-liveness-exec 1/1 Running 0 10s
30s后查看,抛出异常,RESTART变成1
$ kubectl describe pod test-liveness-exec
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
$ kubectl get pod test-liveness-exec
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
RESTART是新容器。
是重新创建,而不是重启。但是,是当前节点的重启,不会迁移到别的节点。
一旦一个 Pod 与一个节点(Node)绑定,除非这个绑定发生了变化(pod.spec.node 字段被修改),否则它永远都不会离开这个节点。
而如果你想让 Pod 出现在其他的可用节点上,就必须使用 Deployment 这样的“控制器”来管理 Pod,哪怕你只需要一个 Pod 副本。
可以通过设置 restartPolicy,改变 Pod 的恢复策略。除了 Always,它还有 OnFailure 和 Never 两种情况:
- Always:在任何情况下,只要容器不在运行状态,就自动重启容器;
- OnFailure: 只在容器 异常时才自动重启容器;
- Never: 从来不重启容器。
如果你要关心这个容器退出后的上下文环境,比如容器退出后的日志、文件和目录,就需要将 restartPolicy 设置为 Never。因为一旦容器被自动重新创建,这些内容就有可能丢失掉了。(感觉在测试和开发或者预发环境可以使用这个功能,生产一般还是要各种监控加日志持久化为主)
只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态 。
对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod 都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数
一个简单的http探针和tcp探针:
...
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
...
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
⭐readinessProbe
用法与livenessProbe相似。
区别:
readiness检查结果成功与否,决定的这个Pod是不是能通过Serive的方式访问,不影响Pod的生命周期。
(感觉可以用于蓝绿发布)
⭐PodPreset
一个简单的PodPreset(像是用来打标签,或者指定挂载目录,指定连接的后端数据库之类的操作,应该是类似于模板):
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
例子:
apiVersion: settings.k8s.io/v1alpha1
kind: PodPreset
metadata:
name: allow-database
spec:
selector:
matchLabels:
role: frontend
env:
- name: DB_PORT
value: "6379"
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir: {}
$ kubectl create -f preset.yaml
$ kubectl create -f pod.yaml
$ kubectl get pod website -o yaml
apiVersion: v1
kind: Pod
metadata:
name: website
labels:
app: website
role: frontend
annotations:
podpreset.admission.kubernetes.io/podpreset-allow-database: "resource version"
spec:
containers:
- name: website
image: nginx
volumeMounts:
- mountPath: /cache
name: cache-volume
ports:
- containerPort: 80
env:
- name: DB_PORT
value: "6379"
volumes:
- name: cache-volume
emptyDir: {}
PodPreset 里定义的内容,只会在 Pod API 对象被创建之前追加在这个对象本身上,而不会影响任何 Pod 的控制器的定义。
如果你定义了同时作用于一个 Pod 对象的多个 PodPreset,Kubernetes 项目会帮你合并(Merge)这两个 PodPreset 要做的修改。而如果它们要做的修改有冲突的话,这些冲突字段就不会被修改。
总而言之:会合并配置文件,但是同一处的修改就会都放弃修改
🌞总结
Pod的设计之初有两个目的:
(1)为了处理容器之间的调度关系
(2) 实现容器设计模式: Pod会先启动Infra容器设置网络、Volume等namespace(如果Volume要共享的话),其他容器通过加入的方式共享这些Namespace。
如果对Pod中的容器启动有顺序要求,可以使用Init Contianer。所有Init Container定义的容器,都会比spec.containers定义的用户容器按顺序优先启动。Init Container容器会按顺序逐一启动,而直到它们都启动并且退出了,用户容器才会启动。
Pod使用过程中的重要字段:
(1)pod自定义/etc/hosts: spec.hostAliases
(2)pod共享PID : spec.shareProcessNamespace
(3)容器启动后/销毁前的钩子: spec.container.lifecycle.postStart/preStop
(4)pod的状态:spec.status.phase
(5)pod特殊的volume(投射数据卷):
5.1) 密码信息获取:创建Secrete对象保存加密数据,存放到Etcd中。然后,你就可以通过在Pod的容器里挂载Volume的方式,访问到这些Secret里保存的信息
5.2)配置信息获取:创建ConfigMap对象保存加密数据,存放到Etcd中。然后,通过挂载Volume的方式,访问到ConfigMap里保存的内容
5.3)容器获取Pod中定义的静态信息:通过挂载DownwardAPI 这个特殊的Volume,访问到Pod中定义的静态信息
5.4) Pod中要访问K8S的API:任何运行在Kubernetes集群上的应用,都必须使用这个ServiceAccountToken里保存的授权信息,也就是Token,才可以合法地访问API Server。因此,通过挂载Volume的方式,把对应权限的ServiceAccountToken这个特殊的Secrete挂载到Pod中即可
(6)容器是否健康: spec.container.livenessProbe。若不健康,则Pod有可能被重启(可配置策略)
(7)容器是否可用: spec.container.readinessProbe。若不健康,则service不会访问到该Pod
容器编排
🌞Deployment
🌛Deploymen简介
一个简单的Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
确保了在这个deployment中 app=nginx的Pod副本数永远为2。
该特性由Controller-Manager提供
$ cd kubernetes/pkg/controller/ $ ls -d */ deployment/ job/ podautoscaler/ cloud/ disruption/ namespace/ replicaset/ serviceaccount/ volume/ cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/ ...
控制循环:循环对比实际状态和期望状态,然后执行某种动作以达到期望状态(就是循环查看状态,再做相应动作)
for {
实际状态 := 获取集群中对象X的实际状态(Actual State)
期望状态 := 获取集群中对象X的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}
实际状态数据来源:
- kubelet通过心跳汇报
- 监控系统中保存的应用监控数据
- 控制器自己收集
期望状态,一般来自于用户提交的 YAML 文件。

- Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
- Deployment 对象的 Replicas 字段的值就是期望状态;
- Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod。
这个操作,通常被叫作调谐(Reconcile)。这个调谐的过程,则被称作“Reconcile Loop”(调谐循环)或者“Sync Loop”(同步循环)。
被控制对象的定义,则来自于一个“模板”。比如,Deployment 里的 template 字段。
Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate(Pod 模板)。

🌛作业副本与水平扩展
⭐ReplicaSet

rolling update(滚动升级)依托于ReplicaSet
ReplicaSet 是Deployment的子集
Deployment控制的事RS的个数
一个简单的RS:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-set
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
一个简单的Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
ReplicaSet 确保在任何给定时间运行指定数量的 pod 副本。然而,Deployment 是一个更高级别的概念,它管理 ReplicaSet 并为 Pod 提供声明性更新以及许多其他有用的功能。因此,我们建议使用 Deployments 而不是直接使用 ReplicaSets,除非您需要自定义更新编排或根本不需要更新。
通过命令行扩缩容:
$ kubectl scale deployment nginx-deployment --replicas=4
deployment.apps/nginx-deployment scaled
⭐滚动更新
通过增加 --record 参数来记录每次操作所执行的命令
$ kubectl create -f nginx-deployment.yaml --record
检查创建后的状态信息
$ kubectl get deployments
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 0 0 0 1s
- DESIRED: 用户期待的Pod副本数(space.rplicas)
- CURRENT:当前RUNNING的pod的个数
- UP-TO-DATE:当前处于最新版本的Pod个数。
- AVAILABLE:当前可用的Pod的个数。既是Running又是最新版本,并且已经处于Ready状态的Pod个数。
使用命令查看滚动更新状态:
$ kubectl rollout status deployment/nginx-deployment
Waiting for rollout to finish: 2 out of 3 new replicas have been updated...
deployment.apps/nginx-deployment successfully rolled out
$ kubectl rollout status deployment/nginx-deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx-deployment 3 3 3 3 20s
“2 out of 3 new replicas have been updated”意味着已经有 2 个 Pod 进入了 UP-TO-DATE 状态。
查看Deployment控制的ReplicaSet状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-3167673210 3 3 3 20s
Name后面的3167673210为 pod-template-hash
Deployment比rs多了UP-TO-DATE字段。(因为deployment可以滚动更新)
通过kubectl edit
例子:
$ kubectl edit deployment/nginx-deployment
...
spec:
containers:
- name: nginx
image: nginx:1.9.1 # 1.7.9 -> 1.9.1
ports:
- containerPort: 80
...
deployment.extensions/nginx-deployment edited
kubectl edit 是讲API对象内容下载到本地,修改完后提交上去
查看滚动更新的流程
$ kubectl describe deployment nginx-deployment
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
...
Normal ScalingReplicaSet 24s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 1
Normal ScalingReplicaSet 22s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 2
Normal ScalingReplicaSet 22s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 2
Normal ScalingReplicaSet 19s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 1
Normal ScalingReplicaSet 19s deployment-controller Scaled up replica set nginx-deployment-1764197365 to 3
Normal ScalingReplicaSet 14s deployment-controller Scaled down replica set nginx-deployment-3167673210 to 0
- 先创建一个新的ReplicaSet,初始副本数为0
- 把新的ReplicaSet扩容到1
- 缩容ReplicaSet缩容1个
- 。。。。。
滚动升级后,RS的状态:
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 3 3 3 6s
nginx-deployment-3167673210 0 0 0 30s
通过yaml文件定义滚动更新:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
...
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
maxSurge:指除了DESIRED之外,在一次滚动中,Deployment还可以创建多少新pod
maxUnavailable:指在一次滚动中,Deployment最多可以删除多少旧Pod
可以用百分比形式: maxUnavailable=50%
kubectl set image 可以用来修改Deployment的镜像
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1
deployment.extensions/nginx-deployment image updated
⭐回滚
当滚动失败时:
$ kubectl set image deployment/nginx-deployment nginx=nginx:1.91
deployment.extensions/nginx-deployment image updated
#故意将nginx镜像设置为一个不存在的版本
$ kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-1764197365 2 2 2 24s
nginx-deployment-3167673210 0 0 0 35s
nginx-deployment-2156724341 2 2 0 7s
#旧的RS已停止缩容,新的RS两个POD无法进入READY
$ kubectl rollout undo deployment/nginx-deployment
deployment.extensions/nginx-deployment
#回滚到上个版本
$ kubectl rollout history deployment/nginx-deployment
deployments "nginx-deployment"
REVISION CHANGE-CAUSE
1 kubectl create -f nginx-deployment.yaml --record
2 kubectl edit deployment/nginx-deployment
3 kubectl set image deployment/nginx-deployment nginx=nginx:1.91
#通过kubectl rollout history 查看滚动版本,前提是打开了--record
$ kubectl rollout history deployment/nginx-deployment --revision=2
#通过命令回滚到版本2
⭐暂停滚动与恢复
暂停:
$ kubectl rollout pause deployment/nginx-deployment
deployment.extensions/nginx-deployment paused
恢复:
$ kubectl rollout resume deployment/nginx-deployment
deployment.extensions/nginx-deployment resumed
是为了不让编辑yaml文件的时候发版太频繁吧
可以通过Deployment中的spec.revisionHistoryLimit字段保留历史版本个数
🌞StatefulSet
略
🌞DeamonSet
在K8S集群里,运行一个DeamonPod,特点:
- 这个Pod运行在K8S的每一个节点上
- 每个节点上只有一个这样的Pod
- 当有新的节点加入K8S集群后,该Pod会自动在新节点创建,被删除的节点这个Pod也会直接回收
可以是:
- 网络插件Agent
- 存储插件Agent
- 监控插件,日志组件
API对象定义:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
nt.extensions/nginx-deployment paused
恢复:
```shell
$ kubectl rollout resume deployment/nginx-deployment
deployment.extensions/nginx-deployment resumed
是为了不让编辑yaml文件的时候发版太频繁吧
可以通过Deployment中的spec.revisionHistoryLimit字段保留历史版本个数
🌞StatefulSet
略
🌞DeamonSet
在K8S集群里,运行一个DeamonPod,特点:
- 这个Pod运行在K8S的每一个节点上
- 每个节点上只有一个这样的Pod
- 当有新的节点加入K8S集群后,该Pod会自动在新节点创建,被删除的节点这个Pod也会直接回收
可以是:
- 网络插件Agent
- 存储插件Agent
- 监控插件,日志组件
API对象定义:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 43
43 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)