
Spark--Scala基础知识总结(第二章)
Scala会区分不同类型的值,并且会基于使用值的方式确定最终结果的数据类型,这称为类型推断Scala使用类型推断可以确定混合使用数据类型时最终结果的数据类型如在加法中混用Int和Double类型时,Scala将确定最终结果为Double类型,如下图常量在程序运行过程中值不会发生变化的量为常量或值,常量通过val关键字定义,常量一旦定义就不可更改,即不能对常量进行重新计算或重新赋值。变量变量是在程序
目录
7.1 获取映射中的key 【keySet函数/keys函数】
了解Scala语言
- Scala是Scalable Language的缩写,是一种多范式的编程语言,由洛桑联邦理工学院的马丁·奥德斯在2001年基于Funnel的工作开始设计,设计初衷是想集成面向对象编程和函数式编程的各种特性。
- Scala 是一种纯粹的面向对象的语言,每个值都是对象。Scala也是一种函数式语言,因此函数可以当成值使用。
- 由于Scala整合了面向对象编程和函数式编程的特性,因此Scala相对于Java、C#、C++等其他语言更加简洁。
- Scala源代码会被编译成Java字节码,因此Scala可以运行于Java虚拟机(Java Virtual Machine,JVM)之上,并可以调用现有的Java类库。
了解Scala特性
- 面向对象
- 函数式编程
- 静态类型
- 可扩展
一、安装与运行Scala
1.1 在网页上运行Scala
- 通过浏览器查找Scastie并进入,即可进入Scala在线运行环境
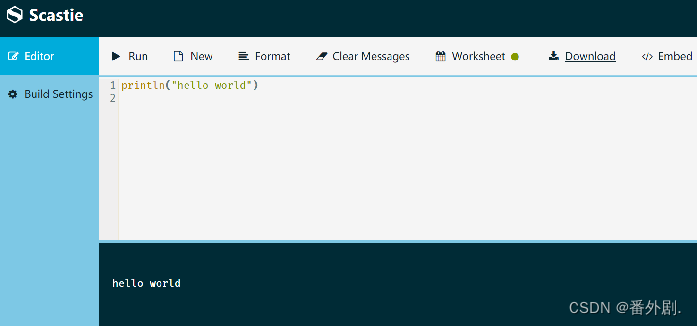
- 进入Scastie界面后,在上窗格中输入“println("hello world")”
- 单击“Run”按钮,输出信息将显示在下窗格中,如下图
1.2 Scala环境设置
- Scala运行环境众多,可以运行在Windows、Linux、macOS等系统上。Scala是运行在JVM上的语言,因此必须确保系统环境中安装了JDK,即Java开发工具包,而且必须确保JDK版本与本书安装的Spark的JDK编译版本一致,本书中使用的JDK是JDK(Java 1.8)
- 查看Java版本

1.3 Scala安装
1.3.1 在Linux和macOS系统上安装Scala
- 从Scala官网下载Scala安装包,安装包名称为“scala-2.12.15.tgz”
- 将其上传至/opt目录
- 解压安装包至/usr/local目录下
- 配置Scala环境变量
1.3.2 在Windows系统上安装Scala
- 从Scala官网下载Scala安装包,安装包名称为“scala.msi”
- 双击scala.msi安装包,开始安装软件
- 进入欢迎界面,单击右下角的“Next”按钮后出现许可协议选择提示框,选择接受许可协议中的条款并单击右下角的“Next”按钮
- 选择安装路径,本文Scala的安装路径选择在非系统盘的“D:\Program Files (x86)\spark\scala\” ,单击“OK”按钮进入安装界面

- 在安装界面中单击右下角的“Install”按钮进行安装,安装完成时单击“Finish”按钮完成安装
- 右键单击“此电脑”图标,选择“属性”选项,在弹出的窗口中选择“高级系统设置”选项。在弹出的对话框中选择“高级”选项卡,并单击“环境变量”按钮,在环境变量对话框中,选择“Path”变量并单击“编辑”按钮,在Path变量中添加Scala安装目录的bin文件夹所在路径,如“D:\Program Files (x86)\spark\scala\bin”
1.4 Scala运行
- Scala解释器也称为REPL(Read-Evaluate-Print-Loop,读取-执行-输出-循环)
- 在命令行中输入“scala”,即可进入REPL,如下图

- REPL是一个交互式界面,用户输入命令时,可立即产生交互反馈
- 输入“:quit”命令即可退出REPL,如下图

- 右图是一个Scala类,该类实现了两个数相加的方法
- 如果要使用该方法,那么需要通过import加载该方法,如左图,其中,add是类名,addInt是方法名

二、定义函数识别号码类型
2.1了解数据类型
2.1.1 Scala常用数据类型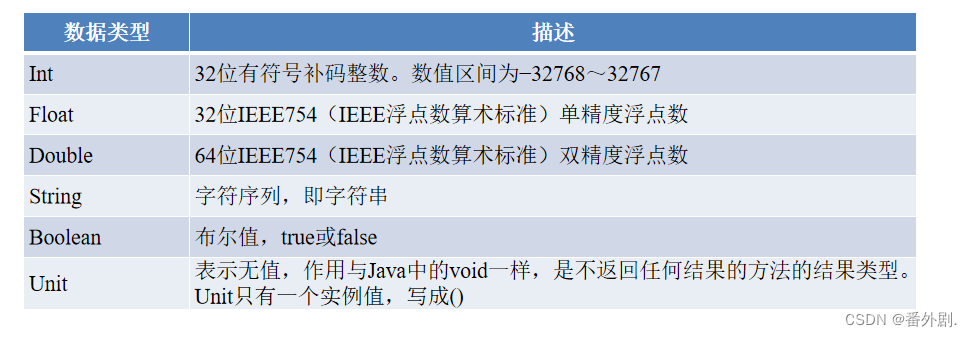
- Scala会区分不同类型的值,并且会基于使用值的方式确定最终结果的数据类型,这称为类型推断
- Scala使用类型推断可以确定混合使用数据类型时最终结果的数据类型
- 如在加法中混用Int和Double类型时,Scala将确定最终结果为Double类型,如下图

2.1.2 定义与使用常量、变量
- 常量
在程序运行过程中值不会发生变化的量为常量或值,常量通过val关键字定义,常量一旦定义就不可更改,即不能对常量进行重新计算或重新赋值。
- 变量
变量是在程序运行过程中值可能发生改变的量。变量使用关键字var定义。与常量不同的是,变量定义之后可以重新被赋值。
2.1.3使用运算符


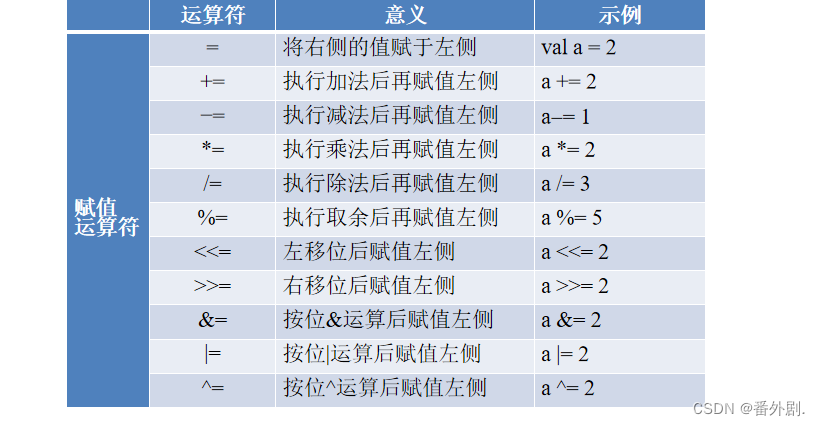 2.1.4 定义与使用数组
2.1.4 定义与使用数组
- 数组常用的方法

- 数组的使用

- Scala可以使用range()方法创建区间数组
- 使用range()方法前同样需要先通过命令“import Array._”导入包
2.1.5 定义与使用函数
- 函数是Scala的重要组成部分,Scala作为支持函数式编程的语言,可以将函数作为对象
- Scala提供了多种不同的函数调用方式
- 如果函数定义在一个类中,那么可以通过“类名.方法名(参数列表)”的方式调用
2.1.6 匿名函数
- 匿名函数即在定义函数时不给出函数名的函数
- Scala中匿名函数是使用箭头“=>”定义的,箭头的左边是参数列表,箭头的右边是表达式,表达式将产生函数的结果
- 通常可以将匿名函数赋值给一个常量或变量,再通过常量名或变量名调用该函数
- 若函数中的每个参数在函数中最多只出现一次,则可以使用占位符“_”代替参数。
2.1.7 高阶函数—函数作为参数
- 高阶函数指的是操作其他函数的函数
- 高阶函数可以将函数作为参数,也可以将函数作为返回值
- 高阶函数经常将只需要执行一次的函数定义为匿名函数并作为参数。一般情况下,匿名函数的定义是“参数列表=>表达式”
- 由于匿名参数具有参数推断的特性,即推断参数的数据类型,或根据表达式的计算结果推断返回结果的数据类型,因此定义高阶函数并使用匿名函数作为参数时,可以简化匿名函数的写法
2.1.8 高阶函数—函数作为返回值
- 高阶函数可以产生新的函数,并将新的函数作为返回值
- 定义高阶函数计算矩形的周长,该函数传入一个Double类型的值作为参数,返回以一个Double类型的值作为参数的函数,如下图
 (9)函数柯里化
(9)函数柯里化 - 函数柯里化是指将接收多个参数的函数变换成接收单一参数(最初函数的第一个参数)的函数,新的函数返回一个以原函数余下的参数为参数的函数。
- 定义两个整数相加的函数,一般函数的写法及其调用方式 如下图

- 使用函数柯里化

三、循环控制
3.1 for循环
- 基本语法:
for ( 循环变量 <- 数据集 ) {
循环体
}
这里的数据集可以是任意类型的数据集合
object ScalaLoop {
def main(args: Array[String]): Unit = {
for ( i <- Range(1,5) ) { // 范围集合 [1,5)
println("i = " + i )
}
for ( i <- 1 to 5 ) { // [1,5]
println("i = " + i )
}
for ( i <- 1 until 5 ) { // 不包含5
println("i = " + i )
}
}
}- 循环守卫
循环时可以增加条件来决定是否继续循环体的执行,这里的判断条件我们称之为循环守卫
for ( i <- Range(1,5) if i != 3 ) {
println("i = " + i )
}- 循环步长
scala的集合也可以设定循环的增长幅度,也就是所谓的步长step
for ( i <- Range(1,5,2) ) {
println("i = " + i )
}
for ( i <- 1 to 5 by 2 ) {
println("i = " + i )
}3.2 while循环
- 语法
while( 循环条件表达式 ) {
循环体
}
- 循环中断
scala是完全面向对象的语言,所以无法使用break,continue关键字这样的方式来中断,或继续循环逻辑,而是采用了函数式编程的方式代替了循环语法中的break和continue
Breaks.break是依靠抛出异常来中断程序。
scala.util.control.Breaks.breakable {
for ( i <- 1 to 5 ) {
if ( i == 3 ) {
scala.util.control.Breaks.break
}
println(i)
}
}四、面向对象编程
4.1 面向对象编程基础
4.1.1 包
Scala中的基本的package的语法和Java完全一致。
package 包名
- 扩展语法
①Scala中的包和类的物理路径没有关系
②package关键字可以嵌套声明使用
③子包可以直接访问父包中的内容,而无需import
④Scala中package也可以看作对象,并声明属性和函数。可以将一个包中共通性的方法或属性在包对象中声明。那么这个包中的所有的类都可以直接访问这个包对象。
4.1.2 导入
Scala中基本的import导入语法和Java完全一致。
import 类名
- 扩展语法
①Scala中使用下划线代替java中的 * 。eg: import java.util._
②scala中默认导入的类: java. lang包中所有的类、scala包中的类、Predef (类似 java中静态导入)
③Scala中的import语法可以在任意位置使用
④Scala中可以导包,而不是导类
⑤Scala中可以在同一行中导入多个类,简化代码
⑥Scala中可以屏蔽某个包中的类
import java.sql.{ Date=>_, Array=>_} //屏蔽sql中的Date、Array⑦Scala中可以给类起别名,简化使用。eg: import java.util.{ArrayList=>AList}
4.1.3 类
Scala中有伴生类和伴生对象之分。
class修饰的类就是普通的伴生类,在使用时需要new对象。而Object用于修饰伴随着这个类所产生的一个单例对象,用于模仿java中的静态语法。object中的方法和属性都可以通过类名直接访问,类似于静态语法。
4.1.4 属性
类的属性就是类变量。在声明的时候,必须进行初始化。也可以使用下划线进行属性的初始化,但是必须明确属性的类型,使用下划线进行初始化的属性一般声明为val的,后面可能要对这个属性进行更改。
Scala中的属性其实在编译后也会生成方法
val name = "HelloWorld"
//编译后的结果
final String name = "HelloWorld";
public String name() {
return this.name;
}
public void name_$eq(final String x$1) {
this.name = x$1;
}Scala为了迎合Java中的get和set方法,在Scala要想使用get和set方法,需要添加特殊的注解@BeanProperties,添加注解的不能设置为private的
4.1.5 访问权限
private : 私有访问权限:同类
private[包名]: 包访问权限 --> 包可以向上使用:同类,同包, 包名只能跟本包有关系
protected : 受保护权限 : 同类,子类
(default) : 公共访问权限
4.1.6 方法
方法其实就是函数。
但是伴生类中的私有的方法和属性,在其伴生对象中也可以使用。所以当类中的构造器私有化的时候,可以在伴生对象中创建apply方法,通过伴生对象来创建类的对象,在调用时,scala会自动识别apply方法,所以apply方法名可以省略。
伴生对象只能初始化一次,所以通过伴生对象来创建对象是线程安全的。
apply主要用来构建对象,不一定是当前类的对象。apply可以重载。
object ScalaMethod{
def main(args: Array[String]): Unit = {
val user = new User //通过new来创建User 的对象
user.login("zhangsan", "000000")
val user2 = User.apply() //通过伴生类创建对象,
val user3 = User() // 必须加上小括号,若不加小括号,则user3就是User伴生对象
}
}
class User {
def login( name:String, password:String ): Boolean = {
false
}
}
object User{ //User 的伴生对象,静态,可以通过类名直接访问,只会初始化一次
def apply():User={ //不能省略小括号
new User()
}
}小知识点:
- 重写和重载
方法重载
- 多个方法名称相同,但是参数列表(参数个数,参数类型,参数顺序)不相同
- 参数为数值类型,在进行方法重载时,若参数类型符合,则直接调用对应的方法,若无对应的参数类型,则会提高精度。
Byte a = 1
fun(a) //由于没有Byte的类型,故进行精度提升,调用参数类型为Int的方法。
def fun(n:Int)={}
def fun(n:Long)={}引用类型,在重载的方法如果找不到对应的类型。会从类树往上查找
方法重写
- 方法的重写一定要存在父子类
- 子类重写父类的方法。子类重写父类相同方法的逻辑
- 方法名一致,参数列表保持一致
- 既然父类和子类有相同的方法,形成了方法的重写
- 那么在调用时,无法确定到底执行哪一个方法, 那么需要遵循动态绑定机制
- 动态绑定机制:程序执行过程,如果调用了对象的“成员”“方法”时会将方法和对象的实际内存进行绑定,然后调用
- 动态绑定机制和属性无关
4.1.7构造方法
Scala中类其实也是一个函数,类名其实就是函数名,类名后面可以增加括号,表示函数参数列表。这个类名所代表的函数其实就是主构造方法,构造方法执行时,会完成类的主体内容的初始化。
- scala中提供了2种不同类型的构造方法。
①主构造方法:在类名后的构造方法, 可以完成类的初始化
②辅助构造方法:为了完成类初始化的辅助功能而提供的构造方法。声明方式为: def this0
在使用辅助构造方法时,必须直接或间接地调用主构造方法。
Scala中一般构造方法的参数用于属性的初始化,所以为了减少数据的冗余,可以使用关键字var, val将构造参数当成类的属性来用。
class User() { // 主构造函数 ,形参中可以添加var、val将形参作为类的属性直接使用
var username : String = _
def this( name:String ) { // 辅助构造函数,使用this关键字声明
this() // 辅助构造函数应该直接或间接调用主构造函数
username = name
}
def this( name:String, password:String ) {
this(name) // 构造器调用其他另外的构造器,要求被调用构造器必须提前声明
}
}4.2 面向对象进阶
4.2.1 继承
跟Java一样,使用extends关键字表示类的继承关系。
4.2.2 抽象
抽象方法:不完整的方法,可以不使用abstract关键字
若类中含有抽象方法/抽象属性,则此类必须为抽象类,用abstract关键字进行声明。
抽象类中可以有完整的方法,若子类重写父类的完整方法,必须要用override关键字进行修饰。子类实现父类的抽象方法,可以使用或者不用override关键字。
抽象属性:没有初始化的属性。
子类重写父类的完整属性必须是val的,不能重写var的属性,实现抽象属性则没有要求。重写抽象属性,相当于普通属性的声明,这个属性可以是val和var的,可以使用或者不用override关键字。但是重写普通属性,只能是val的,必须要用override关键字进行修饰。
4.2.3 特质
scala中没有接口。但是增加了特质(trait)。scala可以将多个类中相同的特征,从类中剥离出来,形成特殊的语法"特质"。特质中可以声明抽象方法,也可以声明普通方法。特质的使用需要混入到类中。特质的一个重要的功能:可以进行功能的扩展。
特质也可以看做抽象类,继承其他的类,并用with混入其他的特质。特质又可以使用extends,又可以使用with。
java中所有的接口在scala中当成特质使用。
- 基本语法
trait 特质名称{ //特质的声明
方法
}
class 类名 extends 父类(特质1) with 特质2 with特质3 //类中混入多个特质
new 类 with 特质1 with 特质2 //动态混入特质如果类混入多个特质,那么特质的初始化顺序为从左到右
类混入多个特质的时候,功能的执行顺序从右向左
特质中的super其实有特殊的含义,表示的不是父特质,而是上级特质。
eg:注意理解super的含义。
object ScalaTrait {
def main(args: Array[String]): Unit = {
val mysql: MySQL = new MySQL
mysql.operData() //功能执行,从右到左
}
}
trait Operate{
def operData():Unit={
println("操作数据。。")
}
}
trait DB extends Operate{
override def operData(): Unit = {
print("向数据库中。。")
super.operData()
}
}
trait Log extends Operate{
override def operData(): Unit = {
print(“hello”)
super.operData()
}
}
class MySQL extends DB with Log {
}
最终结果:hello向数据库中。。操作数据。。五、集合
Scala的集合有三大类:序列Seq、集Set、映射Map。对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本。
5.1 数组
5.1.1 不可变数组
Array为不可变数组,Array可以通过new的方式创建数组,也可以通过伴生对象创建。
数组的遍历:arr.foreach(print)
数组的合并:Array.concat(arr1, arr2)
创建并填充指定数量的数组:Array.fill [Int] (5)(-1)
5.1.2 可变数组
ArrayBuffer。
数据增加: buffer.append(1,2,3,4)
数据修改: buffer.update(0,5) //0表示索引 ;buffer(1) = 6
数据删除:buffer.remove(2); buffer.remove(2,2)
- 可变数组 -->不可变数组 : buffer.toArray
- 将不可变数组转换为可变数组: array.toBuffer
5.2 Seq集合
5.2.1 不可变List
List是抽象的,不能new,只能用伴生对象创建。
空集合: val list2: List[Nothing] = List() 等同于Nil集合
连接集合:List.concat(list3, list4)
创建一个指定重复数量的元素列表: List.fill [String] (3)(“a”)
5.2.2 可变List
ListBuffer。
增加数据:append方法或者buffer1 :+ 5、buffer1 += 5
可变集合转变为不可变集合: buffer.toList
不可变集合转变为可变集合:list.toBuffer
5.3 Set集合
5.3.1 不可变Set
5.3.2 可变Set
mutable.Set。
可变Set创建:mutable.Set(1,2,3,4); new mutable.Set()
增加数据:set1.add(5)
添加数据,更新完成以后包含: set1.update(6,true)
删除数据,更新完成以后不包含: set1.update(3,false)
删除数据: set1.remove(2)
遍历数据: set1.foreach(println)
5.4 Map集合
Map(映射)是一种可迭代的键值对(key/value)结构。所有的值都可以通过键来获取。Map 中的键都是唯一的。Map中的数据都是元组。
5.4.1 不可变Map
创建: val map1 = Map( “a” -> 1, “b” -> 2, “c” -> 3)
添加数据: map1 +(“d” -> 4)
创建空集合: Map.empty
获取指定key的值: map1.apply(“c”)
获取可能存在的key值: val maybeInt: Option[Int] = map1.get(“c”)
获取可能存在的key值, 如果不存在就使用默认值: println(map1.getOrElse(“c”, 0))
5.4.2 可变Map
val map1 = **mutable.**Map( “a” -> 1, “b” -> 2, “c” -> 3 )
添加数据: map1.put(“d”, 4)
修改数据: map1.update(“a”,8)
删除数据: map1.remove(“a”)
Map可以转换为其他数据类型:map1.toSet、 map1.toList、map1.toSeq、map1.toArray
获取可能存在的key值, 如果不存在就使用默认值: println(map1.getOrElse(“c”, 0))
5.5 元组
在Scala语言中,我们可以将多个无关的数据元素封装为一个整体,这个整体我们称之为:元素组合,简称元组。有时也可将元组看成容纳元素的容器
创建元组,使用小括号: val tuple = (1, “zhangsan”, 30)
根据顺序号访问元组的数据:println(tuple._1)
迭代器: val iterator: Iterator[Any] = tuple.productIterator
根据索引访问元素: tuple.productElement(0)
如果元组的元素只有两个,那么我们称之为对偶元组,也称之为键值对: val kv: (String, Int) = (“a”, 1)
5.6 常用方法
- 常用方法
object ScalaCollection{
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
// 集合长度
println("size =>" + list.size)
println("length =>" + list.length)
// 判断集合是否为空
println("isEmpty =>" + list.isEmpty)
// 集合迭代器
println("iterator =>" + list.iterator)
// 循环遍历集合
list.foreach(println)
// 将集合转换为字符串
println("mkString =>" + list.mkString(","))
// 判断集合中是否包含某个元素
println("contains =>" + list.contains(2))
// 取集合的前几个元素
println("take =>" + list.take(2))
// 取集合的后几个元素
println("takeRight =>" + list.takeRight(2))
// 查找元素
println("find =>" + list.find(x => x % 2== 0))
// 丢弃前几个元素
println("drop =>" + list.drop(2))
// 丢弃后几个元素
println("dropRight =>" + list.dropRight(2))
// 反转集合
println("reverse =>" + list.reverse)
// 去重
println("distinct =>" + list.distinct)
}
}object ScalaCollection{
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
val list1 = List(3,4,5,6)
// 集合头
println("head => " + list.head)
// 集合尾
println("tail => " + list.tail)
// 集合尾迭代
println("tails => " + list.tails)
// 集合初始化
println("init => " + list.init)
// 集合初始化迭代
println("inits => " + list.inits)
// 集合最后元素
println("last => " + list.last)
// 集合并集
println("union => " + list.union(list1))
// 集合交集
println("intersect => " + list.intersect(list1))
// 集合差集
println("diff => " + list.diff(list1))
// 切分集合
println("splitAt => " + list.splitAt(2))
// 滑动 : 窗口
println("sliding => " + list.sliding(2))
// 滚动 有步长的滑动窗口
println("sliding => " + list.sliding(2,2))
// 拉链
println("zip => " + list.zip(list1))
// 数据索引拉链
println("zipWithIndex => " + list.zipWithIndex)
}
}object ScalaCollection{
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
val list1 = List(3,4,5,6)
// 集合最小值
println("min => " + list.min)
// 集合最大值
println("max => " + list.max)
// 集合求和
println("sum => " + list.sum)
// 集合乘积
println("product => " + list.product)
// 集合简化规约
println("reduce => " + list.reduce((x:Int,y:Int)=>{x+y}))
println("reduce => " + list.reduce((x,y)=>{x+y}))
println("reduce => " + list.reduce((x,y)=>x+y))
println("reduce => " + list.reduce(_+_))
// 集合简化规约(左) 简约的数据类型可以不一样 op: (B, Int) => B ,参数B和Int有关系,泛型
println("reduceLeft => " + list.reduceLeft(_+_))
// 集合简化规约(右)
println("reduceRight => " + list.reduceRight(_+_))
// 集合折叠
/**
fo1d方法存在两数柯里化,有2个参数列表
第一个参数列表中的参数=z : AI 【z为zero,表示数据的初始值】
第二个参数列表中的参数=> (AI, A1)=>A1
*/
println("fold => " + list.fold(0)(_+_))
// 集合折叠(左)
println("foldLeft => " + list.foldLeft(0)(_+_))
// 集合折叠(右)
println("foldRight => " + list.foldRight(0)(_+_))
// 集合扫描 类似于fold方法,会将之间计算的结果保留下来
println("scan => " + list.scan(0)(_+_))
// 集合扫描(左)
println("scanLeft => " + list.scanLeft(0)(_+_))
// 集合扫描(右)
println("scanRight => " + list.scanRight(0)(_+_))
}
}object ScalaCollection{
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4)
// 集合映射
println("map => " + list.map(x=>{x*2}))
println("map => " + list.map(x=>x*2))
println("map => " + list.map(_*2))
// 集合扁平化
val list1 = List(
List(1,2),
List(3,4)
)
println("flatten =>" + list1.flatten)
// 集合扁平映射
println("flatMap =>" + list1.flatMap(list=>list))
// 集合过滤数据
println("filter =>" + list.filter(_%2 == 0))
// 集合分组数据
println("groupBy =>" + list.groupBy(_%2))
// 集合排序
println("sortBy =>" + list.sortBy(num=>num)(Ordering.Int.reverse))
println("sortWith =>" + list.sortWith((left, right) => {left < right}))
}
}六、模式匹配
6.1 基本语法
模式匹配语法中,采用match关键字声明,每个分支采用case关键字进行声明,当需要匹配时,会从第一个case分支开始,如果匹配成功,那么执行对应的逻辑代码,如果匹配不成功,继续执行下一个分支进行判断。如果所有case都不匹配,那么会执行case_分支,类似于Java中default语句。如果不存在case _分支,那么会发生错误。
6.2 匹配规则
6.2.1 匹配常量
def describe(x: Any) = x match {
case 5 => "Int five"
case "hello" => "String hello"
case true => "Boolean true"
case '+' => "Char +"
}6.2.2 匹配类型
类型的匹配不考虑泛型。
def describe(x: Any) = x match {
case i: Int => "Int"
case s: String => "String hello"
case m: List[_] => "List" //下划线在泛型中表示任意类型
case c: Array[Int] => "Array[Int]"
case someThing => "something else " + someThing //相当于下划线,其他任何类型
}6.2.3 匹配数组
for (arr <- Array(Array(0), Array(1, 0), Array(0, 1, 0), Array(1, 1, 0), Array(1, 1, 0, 1), Array("hello", 90))) { // 对一个数组集合进行遍历
val result = arr match {
case Array(0) => "0" //匹配Array(0) 这个数组
case Array(x, y) => x + "," + y //匹配有两个元素的数组,然后将将元素值赋给对应的x,y
case Array(0, _*) => "以0开头的数组" //匹配以0开头和数组
case _ => "something else"
}
println("result = " + result)
}6.2.4 匹配列表
for (list <- Array(List(0), List(1, 0), List(0, 0, 0), List(1, 0, 0), List(88))) {
val result = list match {
case List(0) => "0" //匹配List(0)
case List(x, y) => x + "," + y //匹配有两个元素的List
case List(0, _*) => "0 ..."
case _ => "something else"
}
println(result)
}6.2.5 匹配元组
for (tuple <- Array((0, 1), (1, 0), (1, 1), (1, 0, 2))) {
val result = tuple match {
case (0, _) => "0 ..." //是第一个元素是0的元组
case (y, 0) => "" + y + "0" // 匹配后一个元素是0的对偶元组
case (a, b) => "" + a + " " + b
case _ => "something else" //默认
}
println(result)
}6.2.6 匹配对象& 样例类
Scala中模式匹配对象时,会自动调用对象的unapply方法进行匹配
这里的匹配对象,其实匹配的是对象的属性是否相同
class User(val name: String, val age: Int)
object User{
def apply(name: String, age: Int): User = new User(name, age)
def unapply(user: User): Option[(String, Int)] = {
if (user == null)
None
else
Some(user.name, user.age)
}
}
val user: User = User("zhangsan", 11)
val result = user match {
case User("zhangsan", 11) => "yes"
case _ => "no"
}一般使用样例类
- l 样例类就是使用case关键字声明的类
- l 样例类仍然是类,和普通类相比,只是其自动生成了伴生对象,并且伴生对象中自动提供了一些常用的方法,如apply、unapply、toString、equals、hashCode和copy。
- l 样例类是为模式匹配而优化的类,因为其默认提供了unapply方法,因此,样例类可以直接使用模式匹配,而无需自己实现unapply方法。
- l 构造器中的每一个参数都默认为val,除非它被显式地声明为var(不建议这样做)
- l 样例类自动实现序列化
case class User(name: String, age: Int) //样例类
object ScalaCaseClass {
def main(args: Array[String]): Unit = {
val user: User = User("zhangsan", 11)
val result = user match {
case User("zhangsan", 11) => "yes"
case _ => "no"
}
println(result)
}
}七、映射的遍历
7.1 获取映射中的key 【keySet函数/keys函数】
不管是列表还是数组的遍历都离不开for循环,我们的映射也不例外,只是我们在遍历映射的时候并不是通过下标遍历,而是使用keySet方法来获取映射对应的key键,之后我们再使用得到的key去访问value值,如下:
scala> map_hash
res47: scala.collection.mutable.HashMap[String,String] = Map(上海 -> 11k, 北京 -> 10k, 广州 -> 12k)
scala> for(k <- map_hash.keySet)println(s"key:${k},value:${map_hash(k)}") // 遍历map映射
key:上海,value:11k
key:北京,value:10k
key:广州,value:12k
scala> for(key <- map_hash.keys)println(s"key:${key},value:${map_hash(key)}") // 使用keys方法
key:上海,value:11k
key:北京,value:10k
key:广州,value:12k从上面我们可以看到keySet和keys函数都是一样的,用于获取映射中的key键。
7.2 获取映射中的键值对 【不使用函数】
如果不想要像上面那样只想要直接一次性获取到key,而是key和value都想要同时遍历到的话可以让两个变量来存储映射中的键值对即可,如下:
scala> for((key,value) <- map_hash)println(s"key:${key},value:${value}") // 不使用函数
key:上海,value:11k
key:北京,value:10k
key:广州,value:12k7.3 获取映射中的value值 【values函数】
如果只想要获取映射中的value值的话可以直接使用values函数得到,如下:
scala> for(value <- map_hash.values)println(s"value:${value}")
value:11k
value:10k
value:12k
scala> map_hash
res60: scala.collection.mutable.HashMap[String,String] = Map(上海 -> 11k, 北京 -> 10k, 广州 -> 12k)
欢迎加入西安开发者社区!我们致力于为西安地区的开发者提供学习、合作和成长的机会。参与我们的活动,与专家分享最新技术趋势,解决挑战,探索创新。加入我们,共同打造技术社区!
更多推荐



 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)