
由Google、OPPO、ARM、华为等大厂程序员贡献的Linux Large Folios大页在社区和产品的现状和未来...
本文对 Linux 内核目前热点项目 Large Folios 的社区与产品现状进行剖析,并预测未来趋势。文中讲述的技术内容,来自 Google、OPPO、ARM、Nivida、Samsung、华为、alibaba 等多家公司的社区与产品贡献。作者 | Barry Song,Yu Zhao责编 | 梦依丹出品 | CSDN(ID:CSDNnews)在 Linux 内核中,一个 folio...

本文对 Linux 内核目前热点项目 Large Folios 的社区与产品现状进行剖析,并预测未来趋势。文中讲述的技术内容,来自 Google、OPPO、ARM、Nivida、Samsung、华为、alibaba 等多家公司的社区与产品贡献。
作者 | Barry Song,Yu Zhao 责编 | 梦依丹
出品 | CSDN(ID:CSDNnews)
在 Linux 内核中,一个 folio 可以只包含 1 个 page,也可以包含多个 page。当一个 folio 包含多个 page 的时候,我们称它为一个 large folio,在中文社区,我们一般称呼其为大页。采用 large folio 可潜在带来诸多好处,比如:
1. TLB miss 减小,比如许多硬件都支持 PMD 映射,可以直接把 2MB 做成一个 large folio,只占用一个 TLB entry;部分硬件支持 contiguous PTE 映射,比如 ARM64 可以让 16 个连续的 page 通过 CONT-PTE 只占一个 TLB entry。
2. page fault 次数减小,比如 do_anonymous_page() 在某个 PTE 的 page fault 后,直接申请一个 large folio 并映射一个 CONT-PTE 的话,则剩下的 15 个 PTE 不再发生 page fault。
3. 降低 LRU 的规模和内存 reclamation 的成本,以 large folio 为单位进行回收,整个 large folio 在 folio_referenced() 等的反向映射成本低于多个 small folio 单独进行 rmap 的成本;try_to_unmap_one() 理论上也如此。
4. 潜在的以更大粒度在 zRAM/zsmalloc 进行压缩/解压的机会,从而降低压缩/解压的 CPU 利用率、提高压缩率。比如 64KiB 的 large folio 整体压缩,比分成 16个4KiB 的 small folio 来进行压缩,有明显优势。
在 Linux 内核的整个内存管理中,large folios 将与 small folios(只有一个page)混合存在。比如在 LRU 链表上,挂在上面的 folio 既可能是 large,也可能是 small;一个进程的某个 VMA 里面的内存,可由 large folios 和 small folios 混合组成;文件的 pagecache 上,不同的 offset 上面对应的可能是 small folios 也可能是 large folios。
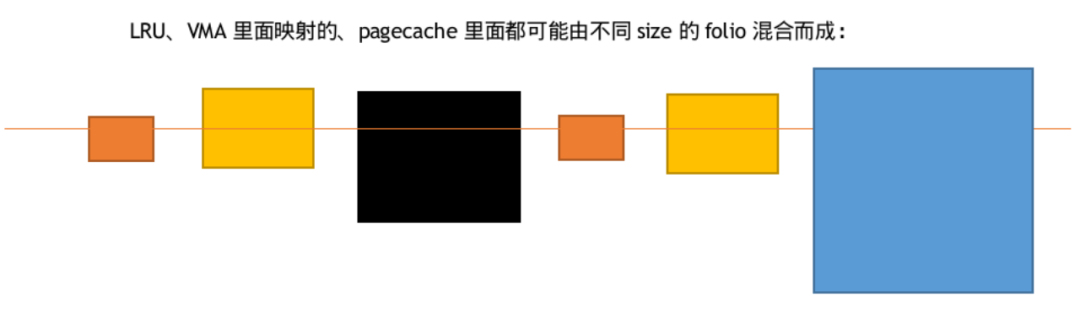

文件页 large folios
Linux 社区在文件页方面,发展出多个文件系统支持 large folio。这类文件系统会通过 mapping_set_large_folios()告诉 page cache 这层,它支持 large folio:
afs
bcachefs
erofs非压缩文件
xfs
而 pagecache 这层,则会关注到这一情况,在 mapping_large_folio_support() 为真的情况下,允许申请 large folios 来填充 pagecache 的 xarray:
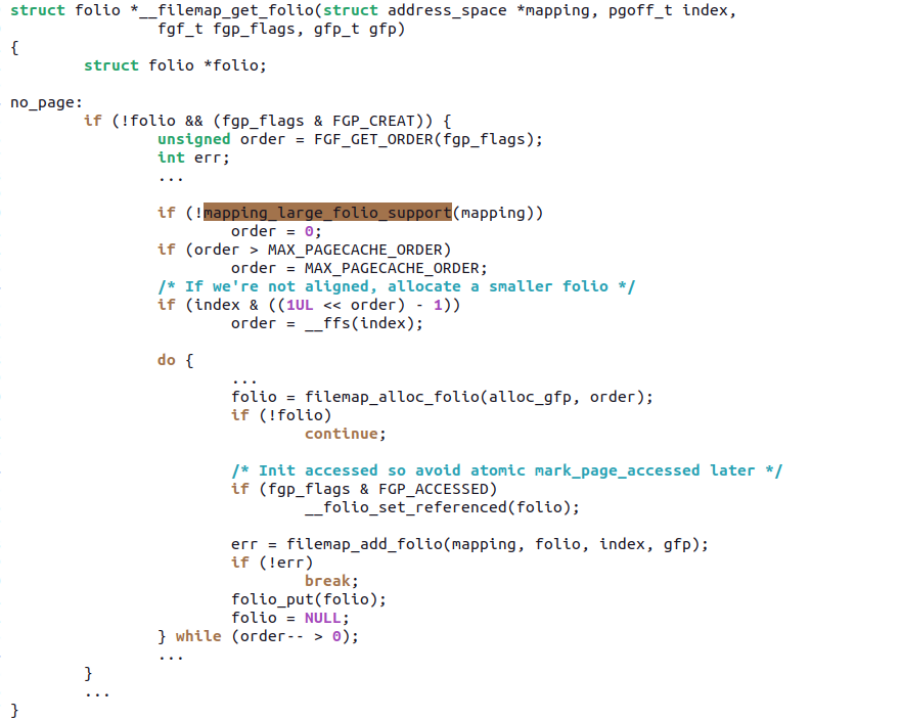
目前文件页 large folios 支持的文件系统非常有限,所以在许多行业还没法用起来,比如手机行业广泛使用的 erofs、f2fs 等。目前我们看到,社区里面华为公司 Zhang Yi 正在完成一个 patchset:ext4: use iomap for regular file's buffered IO path and enable large foilo[1],寻求对 ext4 的 iomap 和 large folios 支持。Zhang Yi 提供的性能数据,在某种意义上可以证明文件系统支持 large folios 的好处:


匿名页 large folios
社区里面 ARM 公司 Ryan Roberts 是这个项目的主要发起者以及相关 patchset 的主要贡献者之一。目前匿名页相关的 patchset 有多个议题,部分已经merge,部分在 Andrew Morton 的 mm tree 迭代,部分还在社区讨论或萌芽阶段。
1. Ryan Roberts(ARM)贡献的 Multi-size THP for anonymous memory[2]
这个 patchset,允许匿名页发生缺页中断的时候,申请多种不同 size 的 PTE-mapped 的 large folios。而内核原先的 THP 主要针对的是 PMD-mapped 的2MiB size,在支持多种 size 后,我们把 multi-size THP 简称为 mTHP。现在 /sys/kernel/mm/transparent_hugepage 目录下面,会有多个 hugepages- 子目录:

比如你开启 64KiB 的 large folios:

这样在发生 PF 的时候,do_anonymous_page () 可以申请 64KiB 的 mTHP,并一次性透过 set_ptes 把 16 个 PTE 全部设置上:
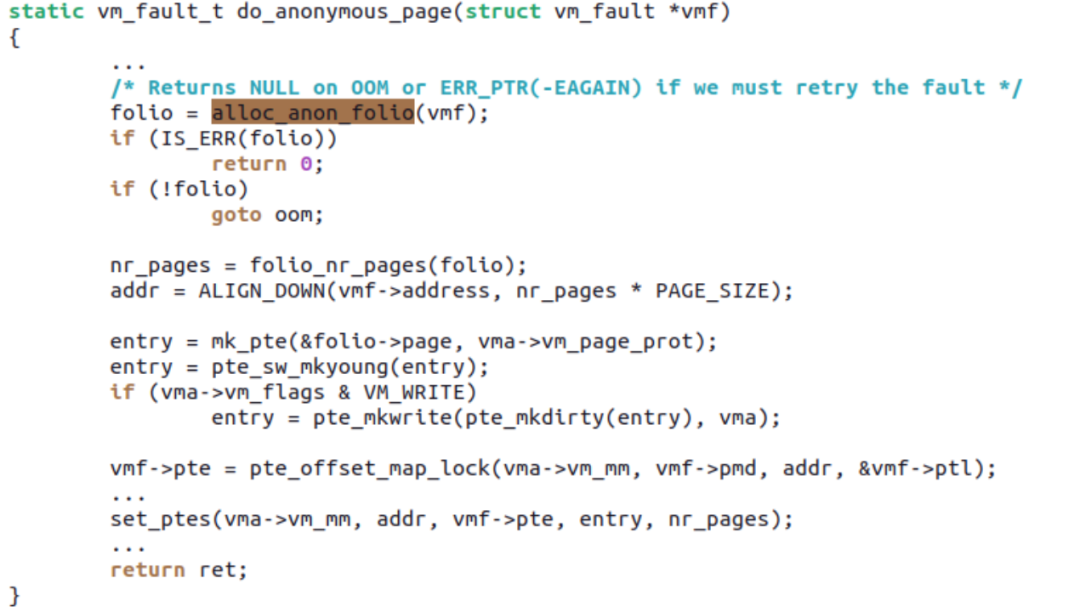
后面 15 个 PTE 就不会再发生 PF 了。Ryan 的 patchset,保持了 mTHP 与之前THP在ABI方面的兼容,比如之前的MADV_HUGEPAGE、MADV_NOHUGEPAGE 针对 mTHP 仍然适用。
2、 Ryan Roberts(ARM)贡献的 Transparent Contiguous PTEs for User Mappings[3]
这个 patchset 主要让 mTHP 可以自动用上 ARM64 的 CONT-PTE,即 16 个 PTE 对应的 PFN 如果物理连续且自然对界,则设 CONT bit 以便让它们只占用一个 TLB entry。Ryan 的这个 patchset 比较精彩的地方在于,mm 的 core 层其实不必意识到 CONT-PTE 的存在(因为不是啥硬件 ARCH 都有这个优化),保持了 PTE 相关 API 向 mm 的完全兼容,而在 ARM64 arch 的实现层面,自动加上或者去掉 CONT bit。
比如原先 16 个 PTE 满足 CONT 的条件,如果有人 unmap 掉了其中 1 个 PTE 或者 mprotect 改变了 16 个 PTE 中一部分 PTE 的属性导致 CONT 不再能满足,set_ptes() 调用的 contpte_try_unfold() 则可将 CONT bit 自动 unfold 掉:
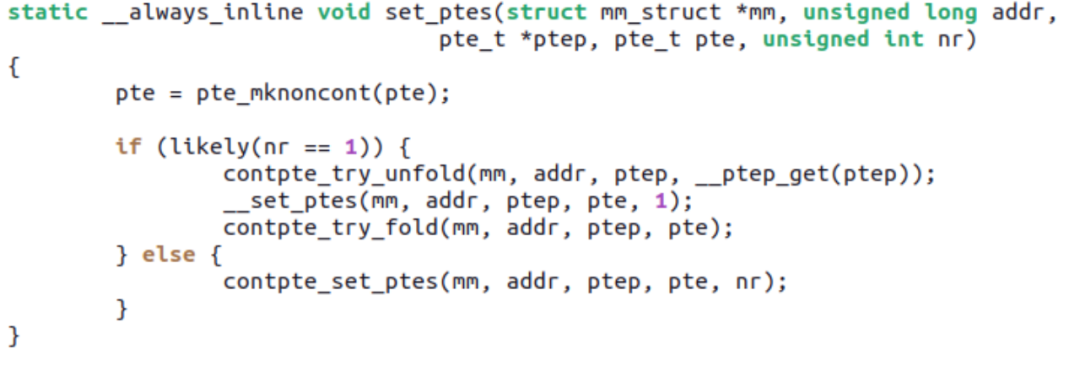
CONT-PTE 的采用有效提升了一些 benchmark 的性能,比如内核编译:

3、Ryan Roberts(ARM)贡献的 Swap-out mTHP without splitting[4]
此 patchset 在 vmscan.c 对内存进行回收的时候,不将 mTHP split 为 small folios(除非 large folio 之前已经被加入了 _deferred_list,证明其很可能已经被 partially unmap 了),而是整体申请多个 swap slots 和写入 swapfile。
不过这里有一个问题,在 add_to_swap() 整体申请 nr_pages 个连续的 swap slots 的时候,swapfile 完全可能已经碎片化导致申请不到,这样它仍然需要回退到 split:

相信 swapfile 的反碎片问题,将是后续社区的一个重要话题,这方面 Chris Li(Google)有一些思考 Swap Abstraction "the pony"[5],更多的讨论可能在 2024 年 5 月盐湖城的 LSF 上进行。
4、Chuanhua Han(OPPO)、Barry Song(OPPO 顾问)贡献的 mm: support large folios swap-in[6]
这个 patchset 瞄准让 do_swap_page() 在 swapin 的时候也能直接以 large folio 形式进行,从而减小 do_swap_page() 路径上的 PF。另外,更重要的一点是,如果 swapin 路径上不支持 mTHP 的话,前述 Ryan Roberts 的工作成果可能就因为 mTHP swapout 出去,swapin 回来就再也不是 mTHP了。
针对 Android、嵌入式等场景,swapout 频繁发生,因为 swapout 而一夜之间失去 mTHP 的优势,变成穷光蛋,实在有点说不过去。理论上 swapin 路径上的 mTHP 支持有 3 条可能路径:
在 swapcache 中直接命中了一个 large folio
在 SWP_SYNCHRONOUS_IO 路径上针对同步设备的 swapin
在 swapin_readahead() 路径上针对非同步设备或者 __swap_count(entry) != 1 的 swapin。
目前 patchset 瞄准 a、b 针对手机和嵌入式等采用 zRAM 的场景进行,相信该 patchset 后续会进一步发展到针对路径 c 的支持。近期可能较早能合入的是路径 a 的部分 large folios swap-in: handle refault cases first[7]。
5、Tangquan Zheng(OPPO)贡献的 mTHP-friendly compression in zsmalloc and zram based on multi-pages[8]
此 patchset 的创意建立在以更大粒度对匿名页在 swapout/swapin 过程中进行压缩和解压的时候,可以极大减小 CPU 利用率和提高压缩率。该 patchset 的 cover letter 呈现了一组数据,对于原始数据,以 4KiB 和 64KiB 为单位进行压缩,时间可以大为减小,压缩后的数据也减小许多:

前述 Ryan、Chuanhua、Barry 等的工作,在 swapout、swapin 的时候能够以 large folios 的粒度进行,这为 Tangquan 的工作提供了实践基础。在 Tangquan 的工作中,如果给 zRAM 的是 64KiB 的 mTHP,它可以直接以 64KiB 为单位压缩;如果给 zRAM 的是 128KiB 的 mTHP,则它可以分解为 2 个 64KiB 来进行压缩(没有 Tangquan 的工作的时候,128KiB 将作为 32 个 4KiB 的 page 进行压缩)。
6、Yu Zhao(Google)贡献的 TAO: THP Allocator Optimizations[9]
这个 patchset(同时也是一个 LSF/MM/eBPF 议题)瞄准解决 large folio 的 metadata 的成本以及分配中经常遇到的碎片化难题。Buddy allocator 在系统运行较长时间的复杂应用后,通常会由于不可移动的内存页导致碎片化,进而无法继续有效的提供连续的物理内存。假如 large folio 的申请 90% 以上 fallback 到 4KB 页,前述的 mTHP 方案基本无法体现其作用。
TAO(同时也是中文“道”的英文翻译)的设计出发点是:4KB 页是几十年之前的遗留产物,并无法适合当代高性能硬件和用户态软件的需求;4KB 的存在只是为了向后兼容。因此操作系统内存管理设计应该是着重于 large folio 做优化,对 4KB 态度应该是不打破 ABI 和其他内核部件(比如SLAB)即可。打个比喻来说,4KB 更像是 DMA zone,DMA zone 的存在是为了保证 80 年代的 ISA 总线设备可以继续工作。基于此理念,内存可被抽象为两种 policy zones:向后兼容的 4KB 页 zone 和更加适合当代软硬件的 large folio zone。前者主要用来负责 4KB 分配需求,但也可提供无保证的 large folio 分配需求;后者只用来负责 large folio 分配需求,并提供整机的最低 THP 覆盖保证(guaranteed THP coverage)。
此设计的优点在于其方便性。具体来说,TAO 可以跟 MGLRU 完美的结合,实现了 4KB 页和 large folios 的有针对行的回收:4KB 页的分配只需要从 4KB 页 zone 做回收;large folio 的分配先从 large folio zone 做回收,如仍无法满足分配需求,可从 4KB 页 zone 做回收并兼而做 compaction。TAO 也将 HVO(HugeTLB Vmemmap Optimization)自然而然的扩展至 THP,从而降低了 2MB THP 的 struct page 的开销(为之前的⅛)。
TAO的结尾篇(见以上链接)还陈述了一个有趣的新概念:以金融学中的可互换性(Fungibility:指可用一物代替他物偿债)来思考THP。以2MB THP为例,如其使用者无法完全发挥此2MB THP的价值,内存管理应将此2MB THP与512个非连续的4KB页互换。此过程称为THP shattering,与现有的THP splitting看似相近,但其精髓是“偷梁换柱”,目的在于为有真正需求的用户保留原始的THP不被split。此概念还可用于未来的1GB THP。如果THP被split,现有的collapse将需分配一个新的THP,并进行数据复制。对与2MB THP来说,分配与复制也许并不是太大的问题。但对于未来的1GB THP,此两项都是无法接受的。所以唯一可行方案是THP recovery,也就是在被split的1GBTHP基础上,保留未被重新分配的页,并将已被重新分配的页的数据复制到额外的4KB页,然后将原有的1GB物理区域“物归原主”成THP。以2MB THP为例,以下2x2矩阵可概括上述的四种组合:

7、Barry Song(OPPO 顾问)贡献的 THP_SWAP support for ARM64 SoC with MTE[10]
此 patchset 解决 large folios 整体 SWPOUT 和 SWPIN 情况下,ARM64 MTE tags 以 folio 为单位 save 和 restore 的问题,从而让支持 MTE 的 ARM64 硬件能享受到 mTHP 整体 swapout、swapin 带来的优势。
8、Barry Song(OPPO顾问)贡献的mm: add per-order mTHP alloc and swpout counters[11]
mTHP发展到今天,计数和调试功能已经成为一个必需品,不然整个mTHP对用户表现为一个难以捉摸的黑盒子。Barry目前贡献的patchset暂时只实现了2组计数:
1) per-order的mTHP分配成功和失败率,从而来反馈mTHP是否真正还在系统里面有效,看看buddy碎片化是否导致mTHP分配容易失败;
2) per-order的mTHP SWPOUT和FALLBACK率,从而来反馈swap分区是否碎片化,导致分配mTHP swapout所需的连续swap slots容易失败。
patchset在每个size的sysfs文件中,增加了一个stats目录,/sys/kernel/mm/transparent_hugepage/hugepages-<size>/stats,来呈现计数:
anon_alloc
anon_alloc_fallback
anon_swpout
anon_swpout_fallback9、Zi Yan(Nvidia)贡献的 Split a folio to any lower order folios[12]
之前 large folio 永远只能 split 成 order-0 的 small folio,Zi Yan 的这个 patchset 让它可以转化为任意 order。这个 patchset 提供了一个 debugfs 接口,可以向 debugfs 接口写入一个 pid,以及虚拟地址范围,然后内核会 split 指定范围的 memory 为指定 order 的 mTHP。
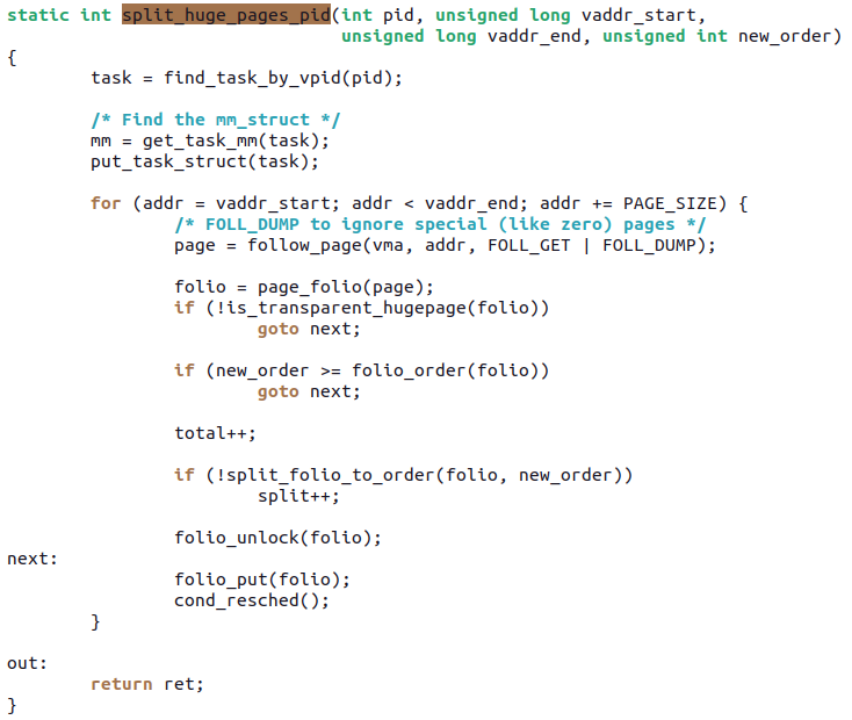
目前 Zi Yan 展示了一个应用场景,在 Pankaj Raghav (Samsung) 的 enable bs > ps in XFS patchset[13]中,truncate 时候,可以有效利用这个 split 到非 order-0 的工作:
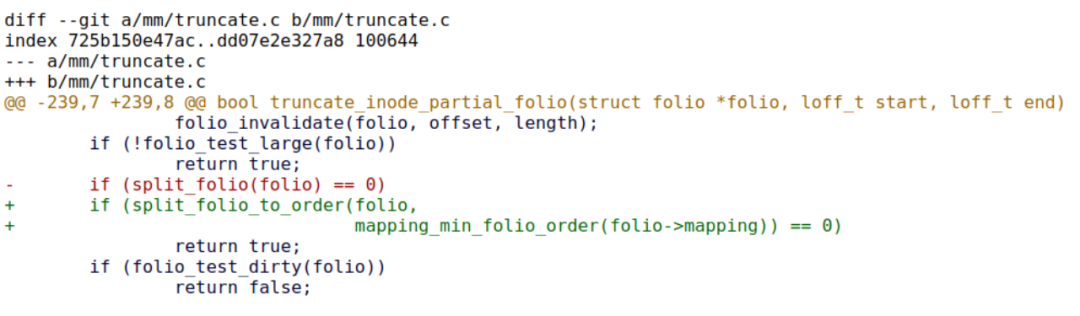
Pankaj Raghav 的工作致力于在 XFS 中提供 block size > page size 的支持,透由 Zi Yan 的工作,在 split了large folios 后,结果依然是 large folios(order 更低,但是满足 mapping_min_folio_order 要求)。
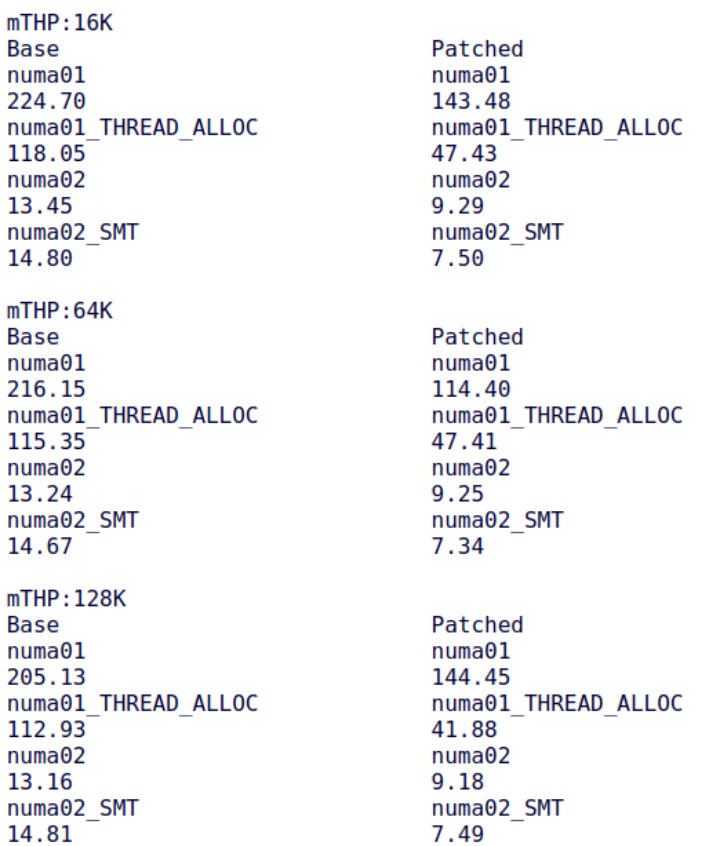
10、Baolin Wang(alibaba)的support multi-size THP numa balancing[14]
Baolin 的这个 patchset 把 NUMA balancing 情况下的内存迁移扩展到 mTHP 领域,它允许 mTHP 被扫描到,也允许它被迁移。由于 mTHP 的 size 大于 4KiB 的 small folios,理论上,它更容易出现 false sharing 的情况,频繁迁移会导致内存跨 NUMA Node 来回 ping-pong,因此,在算法上,mTHP 暂时借用了 PMD-mapped 的 2-stage filter 机制。经由 Baolin 的这个 patchset,autonuma-benchmark 的性能得到了明显提升:
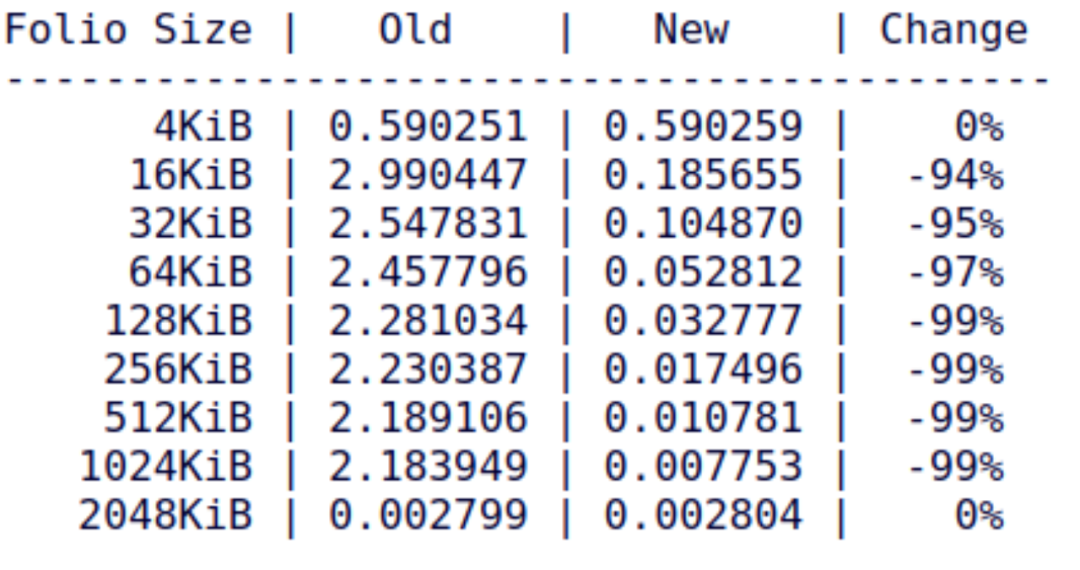
11、内核爱好者 Lance Yang 的 mm/madvise: enhance lazyfreeing with mTHP in madvise_free[15]
这个 patchset 让 mTHP 的 MADV_FREE 即 lazyfree 机制不再需要 split folio。原先的 MADV_FREE 碰到 large folios 是要 split 的,现在不需要了,从而 large folios 的 MADV_FREE 调用速度会急剧提升(笔者也同时相信这会最终提升 lazyfree folio 最后在 LRU 链表被 reclamation 的速度):

Large folios 的真实产品
直至本文成稿的那一刻,社区的 mTHP 还少有成熟商用案例。而 OPPO 手机在社区 mTHP 项目成熟前,先行在 4.19,5.10,5.15,6.1 等内核实现了动态大页, 2023 年并在大量手机部署。
在 2023 年中国 Linux 内核开发者大会上,Chuanhua Han(OPPO)呈现了 OPPO 产品的动态大页项目软件架构和收益成功[16]。
相对于社区项目各种 mTHP size 的支持,OPPO 手机里面部署的动态大页则主要瞄准 64KiB 这一种可利用 CONT-PTE 的 size,下图是一个典型的 do_anonymous_page() PF 处理的流程图。
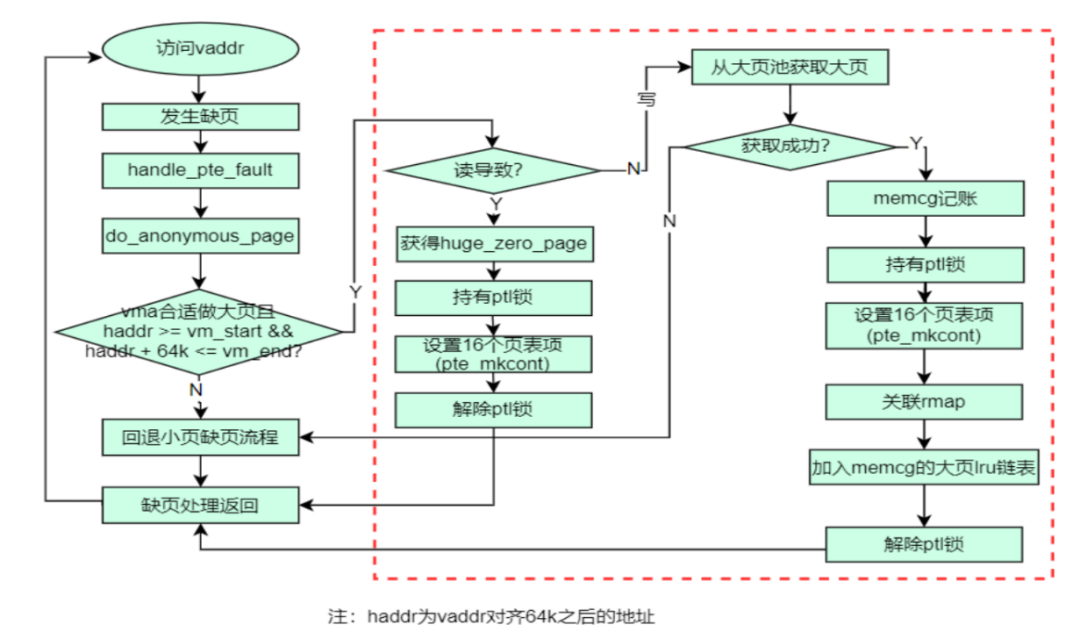
Chuanhua 在 CLK2023 呈现了 OPPO 动态大页的软件架构图:
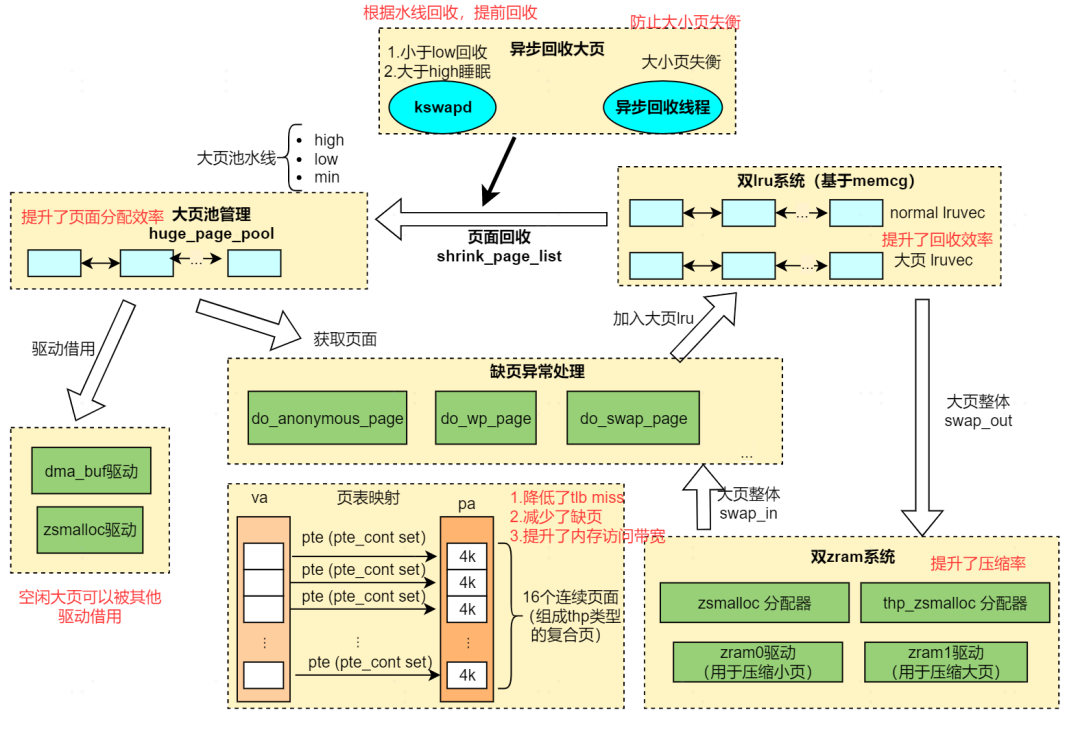
在该架构图中,有几个出彩的地方:
1. 对 do_anonymous_page、do_wp_page、do_swap_page、swapout 进行了全面的修改,这意味着该方案支持 PF 时候的 large folios 申请、CoW 以 large folio 为单位、swapout/swapin 等以 large folios 为单位;
2. 大页池:以池化技术解决 large folios 申请的开销,并提供高的 large folios 申请成功率;
3. 双 LRU:large folio 和 small folio 位于不同的 LRU,而不是混合在一起。这样 large folios 和 small folios 的 reclamation 效率都相对较高,不会出现相互给对方添堵的现象(举个例子,你现在急需 large folios,但是 LRU 的尾部挂了 100 个 small folios,你回收了那 100 个,还是得不到 large folios);
4. zsmalloc、zRAM 支持 large folios 和 small folios 同时支持,享受 large folios 的高压缩比和低 CPU 利用率。
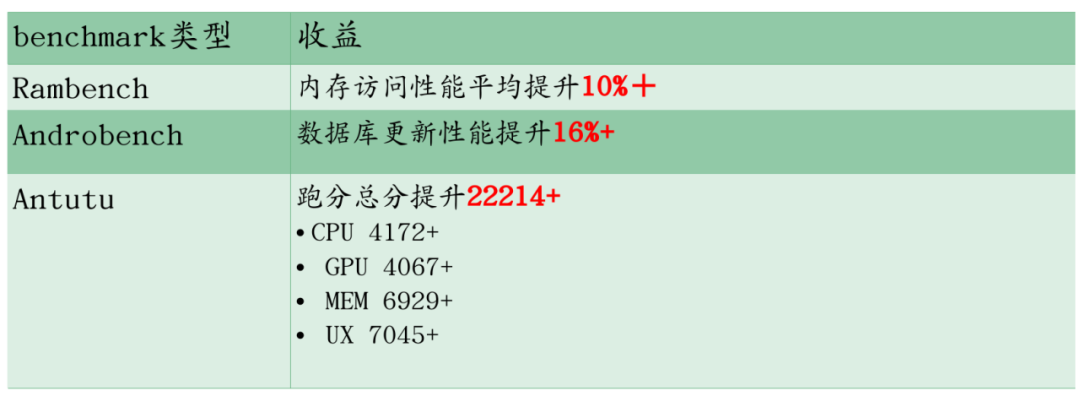
演讲稿也呈现了 OPPO 手机采用动态大页的收益数据:
benchmark 方面:
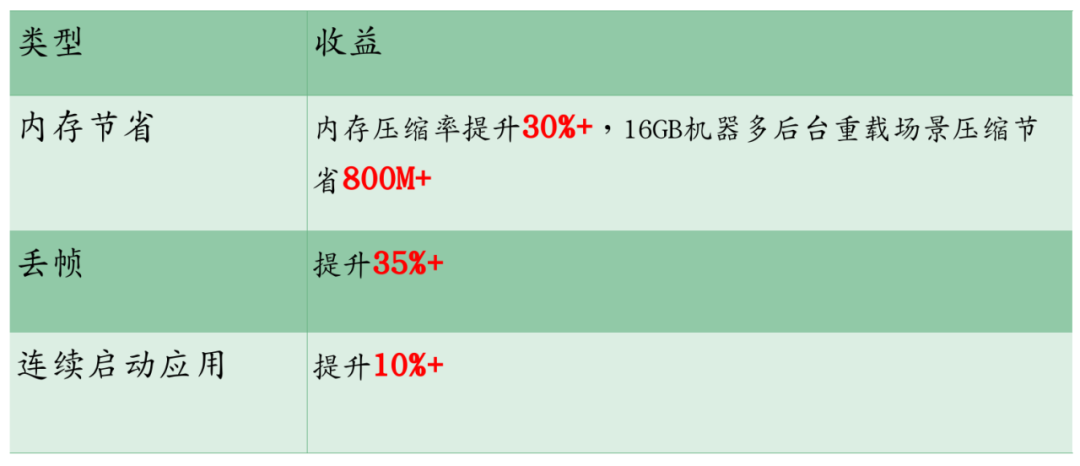
用户体验方面

Large folios 的未来
关于未来的几个预测:
1. 更多文件系统会支持 large folios 的 mapping。
2. 需要一套切实可行的类似 TAO 的保证 large folios 高效率申请成功的机制。
3. large folios 的 swapin 需要被主线支持。
4. large folios 带来更多并行处理的能力,比如结合硬件压缩解压 offload 功能,1 个 large folio 或可被 offload 硬件极快多线程压缩解压。
5. 未来 zswap 可能也需要提供 large folios 支持,目前 zswap 不支持 mTHP。
6. swap 反碎片,或者以不连续的 swap slots 来存放 swap out 出去的mTHP。目前 mTHP 的整体 swapout 必须要求 nr_pages 个 swap slots 是连续且自然对界的。
7. 解决好 mTHP 带来的性能提升,以及潜在增加内存碎片浪费之间的平衡。由于 mTHP 的粒度比 small folios 大,它潜在可能申请一些不需要被访问到的内存。但是,Tangquan 的 zRAM/zsmalloc 工作实际也让我们看到了另外一种可能性,large folios 并不总是浪费之源,它也可能成为省内存之源,这符合万物相生相克的道理。
8. 妥善处理好,用户态 partially unmap 一个 large folio 潜在可能造成的碎片浪费和性能损失。由于用户态通常只理解 base page 的 size,它可能不知道底层已经是一个 large folio,用户态则可能以不与 large folio 对齐的方式来 munmap、mprotect、madvise 等。比如用户态 munmap 一个 64KiB large folio 的 0~60KiB,最后的 4KiB 仍可能较长时间占用整个 64KiB large folio。
作者简介:
Barry Song:长期的一线Linux内核开发者,OPPO顾问,per-numa CMA、SCHED_CLUSTER、ARM64 BATCHED_UNMAP_TLB_FLUSH等项目的作者;
Yu Zhao:Linux内核社区著名开发者,Google Staff Software Engineer, Multi-Gen LRU、POSIX_FADV_NOREUSE等项目的作者。
参考文献
[1] https://lwn.net/Articles/956575/
[2] https://lore.kernel.org/all/20231207161211.2374093-1-ryan.roberts@arm.com/
[3] https://lore.kernel.org/all/20240215103205.2607016-1-ryan.roberts@arm.com/
[4] https://lore.kernel.org/linux-mm/20240403114032.1162100-1-ryan.roberts@arm.com/
[5] https://lore.kernel.org/linux-mm/CAF8kJuMQ7qBZqdHHS52jRyA-ETTfHnPv+V9ChaBsJ_q_G801Lw@mail.gmail.com/
[6] https://lore.kernel.org/linux-mm/20240304081348.197341-1-21cnbao@gmail.com/
[7] https://lore.kernel.org/linux-mm/20240402073237.240995-1-21cnbao@gmail.com/
[8] https://lore.kernel.org/linux-mm/20240327214816.31191-1-21cnbao@gmail.com/
[9] https://lore.kernel.org/all/20240229183436.4110845-1-yuzhao@google.com/
[10] https://lore.kernel.org/linux-mm/20240322114136.61386-1-21cnbao@gmail.com/
[11]https://lore.kernel.org/linux-mm/20240405102704.77559-1-21cnbao@gmail.com/
[12] https://lore.kernel.org/all/20240226205534.1603748-8-zi.yan@sent.com/
[13] https://lore.kernel.org/linux-mm/20240226094936.2677493-1-kernel@pankajraghav.com/
[14] https://lore.kernel.org/all/cover.1712132950.git.baolin.wang@linux.alibaba.com/
[15] https://lore.kernel.org/all/20240402124029.47846-1-ioworker0@gmail.com/
[16] https://github.com/ChinaLinuxKernel/CLK2023/blob/main/%E5%88%86%E8%AE%BA%E5%9D%9B1%EF%BC%88%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86%EF%BC%89/8%20%20%E5%8A%A8%E6%80%81%E5%A4%A7%E9%A1%B5%EF%BC%9A%E5%9F%BA%E4%BA%8EARM64%20contiguous%20PTE%E7%9A%8464KB%20HugePageLarge%20Folios%E2%80%94%E2%80%94%E9%9F%A9%E4%BC%A0%E5%8D%8E.pptx
推荐阅读:
▶“Sora 无法让 AGI 到来,GPT 才是关键”,对话零一万物联合创始人潘欣 | AGI 技术 50 人
▶“退网”两周的前OpenAI大神归来再整活,1000行C代码搞定GPT-2训练,网友:C语言复兴了!
▶苹果曝“内鬼”猛料,索赔 18 万元:五年泄露至少 6 种机密,发送超 10000 条信息!
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。欢迎所有开发者朋友访问官网 http://ml-summit.org、点击「阅读原文」或扫码进一步了解详情。


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 34
34 0
0- 0



 已为社区贡献212条内容
已为社区贡献212条内容

所有评论(0)