
Elasticsearch介绍及其索引库的创建删除和重新绑定
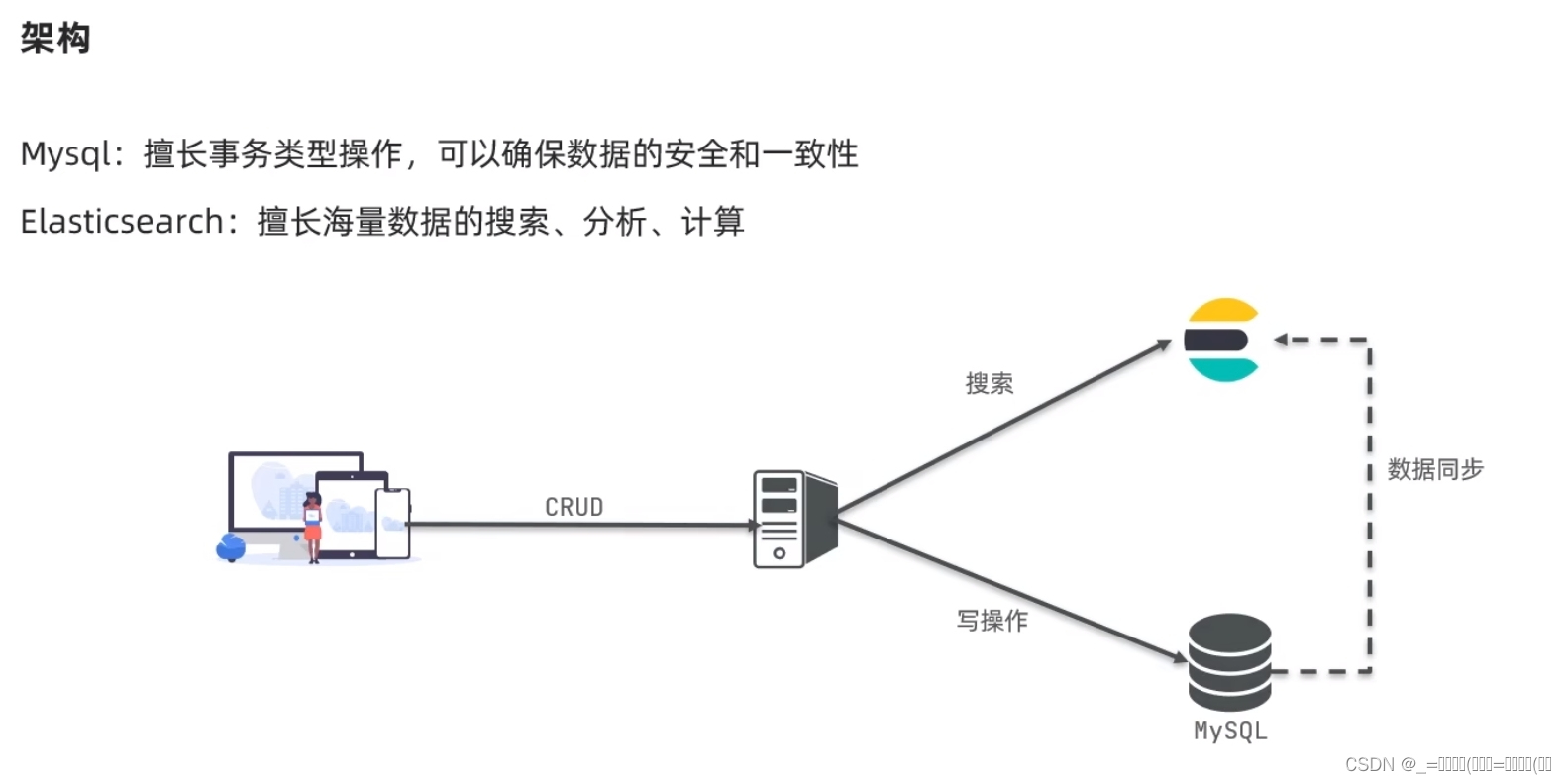
Elasticsearch是一个开源的分布式搜索和分析引擎,基于Apache Lucene构建。它提供了一个快速、实时的搜索和分析功能,适用于各种用例,包括全文搜索、日志和指标分析、安全事件检测等。
1、首先来介绍一下 Elasticsearch:
Elasticsearch是一个开源的分布式搜索和分析引擎,基于Apache Lucene构建。它提供了一个快速、实时的搜索和分析功能,适用于各种用例,包括全文搜索、日志和指标分析、安全事件检测等。
主要特点包括:
-
分布式架构:Elasticsearch采用分布式架构,可以水平扩展以处理大量数据和请求。它将索引划分为多个分片,并将这些分片分布在集群中的多个节点上,从而实现数据的并行处理和高可用性。
-
实时搜索:Elasticsearch提供了实时搜索功能,可以快速地检索和分析大规模数据,并在几乎实时的速度下返回结果。这使得它非常适用于需要快速响应的应用场景,如日志分析和监控系统。
-
多种数据类型支持:Elasticsearch支持多种数据类型的索引和查询,包括文本、数字、日期、地理位置等。这使得它可以用于各种不同类型的数据分析和搜索。
-
丰富的查询功能:Elasticsearch提供了丰富而灵活的查询功能,包括全文搜索、过滤、聚合等。它还支持复杂的查询语法和自定义查询逻辑,使用户可以根据自己的需求进行定制化的搜索和分析。
-
易于集成:Elasticsearch与许多其他流行的开源工具和技术(如Logstash、Kibana、Beats等)集成紧密,可以轻松地与它们一起构建完整的数据处理和分析解决方案。
2、Elasticsearch和MySQL在设计和应用方面有一些显著的区别:
-
数据存储方式:
-
数据模型:
- MySQL使用固定模式(schema),需要在创建表格时定义表格的结构和字段类型。
- Elasticsearch是schema-less的,它允许灵活地索引各种类型的文档,而无需预先定义模式。
-
查询语言:
- MySQL使用结构化查询语言(SQL)来执行各种查询操作,包括插入、更新、删除和查询。
- Elasticsearch使用基于 JSON 的查询语言来执行各种搜索和分析操作,包括全文搜索、过滤、聚合等。
-
搜索和分析功能:
- Elasticsearch专注于搜索和分析,提供了强大的全文搜索、聚合、地理空间搜索等功能。
- MySQL虽然也支持一些基本的搜索和聚合操作,但其功能相对较为有限,主要集中在传统的关系型数据库功能上。
-
实时性和扩展性:
- Elasticsearch具有良好的实时性和可扩展性,可以处理大量的实时数据,并支持水平扩展以应对高负载。
- MySQL在处理大规模数据和高并发访问时可能会遇到性能瓶颈,需要通过垂直或水平扩展来提高性能和容量。
总的来说,Elasticsearch适用于需要实时搜索和分析大规模数据的应用场景,而MySQL适用于传统的关系型数据存储和处理场景。在某些情况下,两者也可以结合使用,例如使用MySQL作为主要数据存储,而使用Elasticsearch作为搜索引擎来提供更快速和灵活的搜索功能。
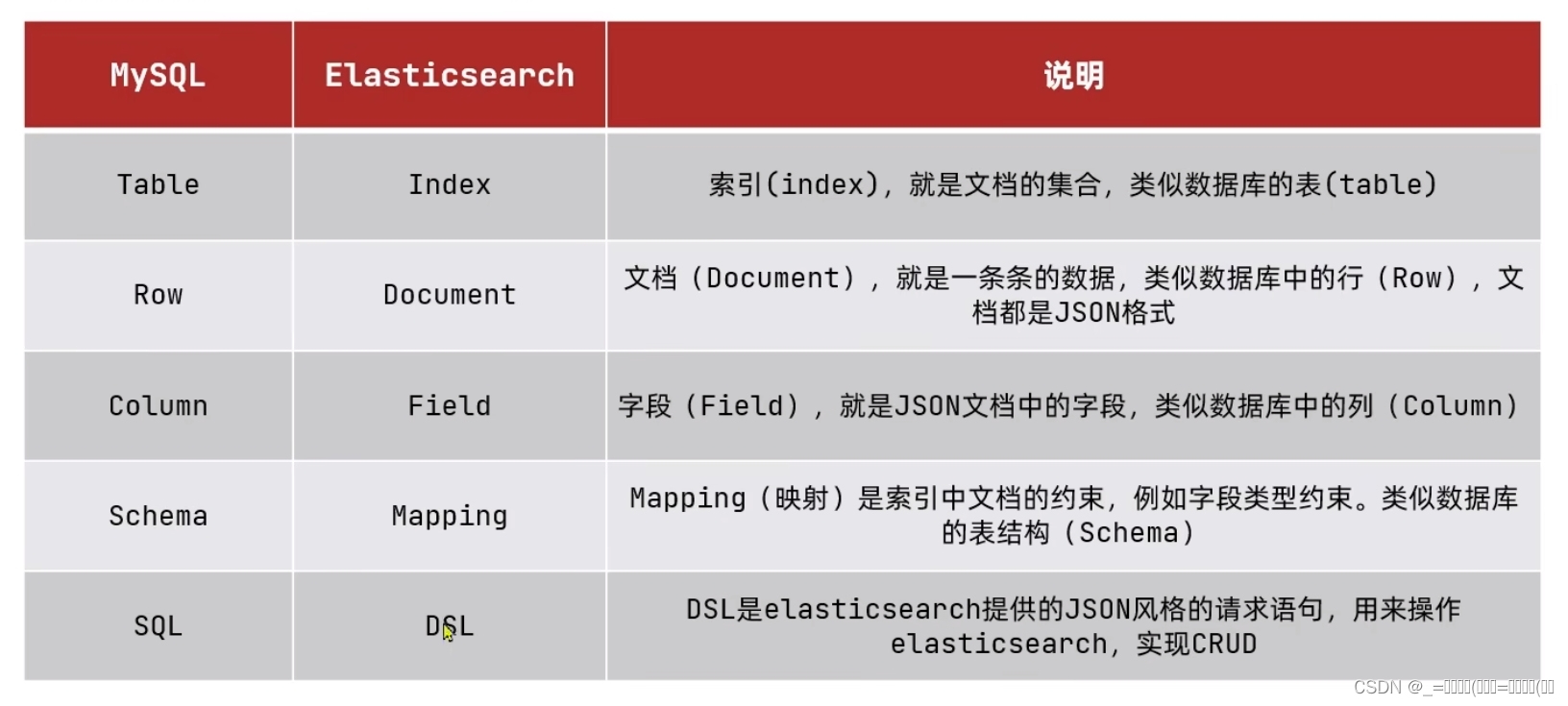
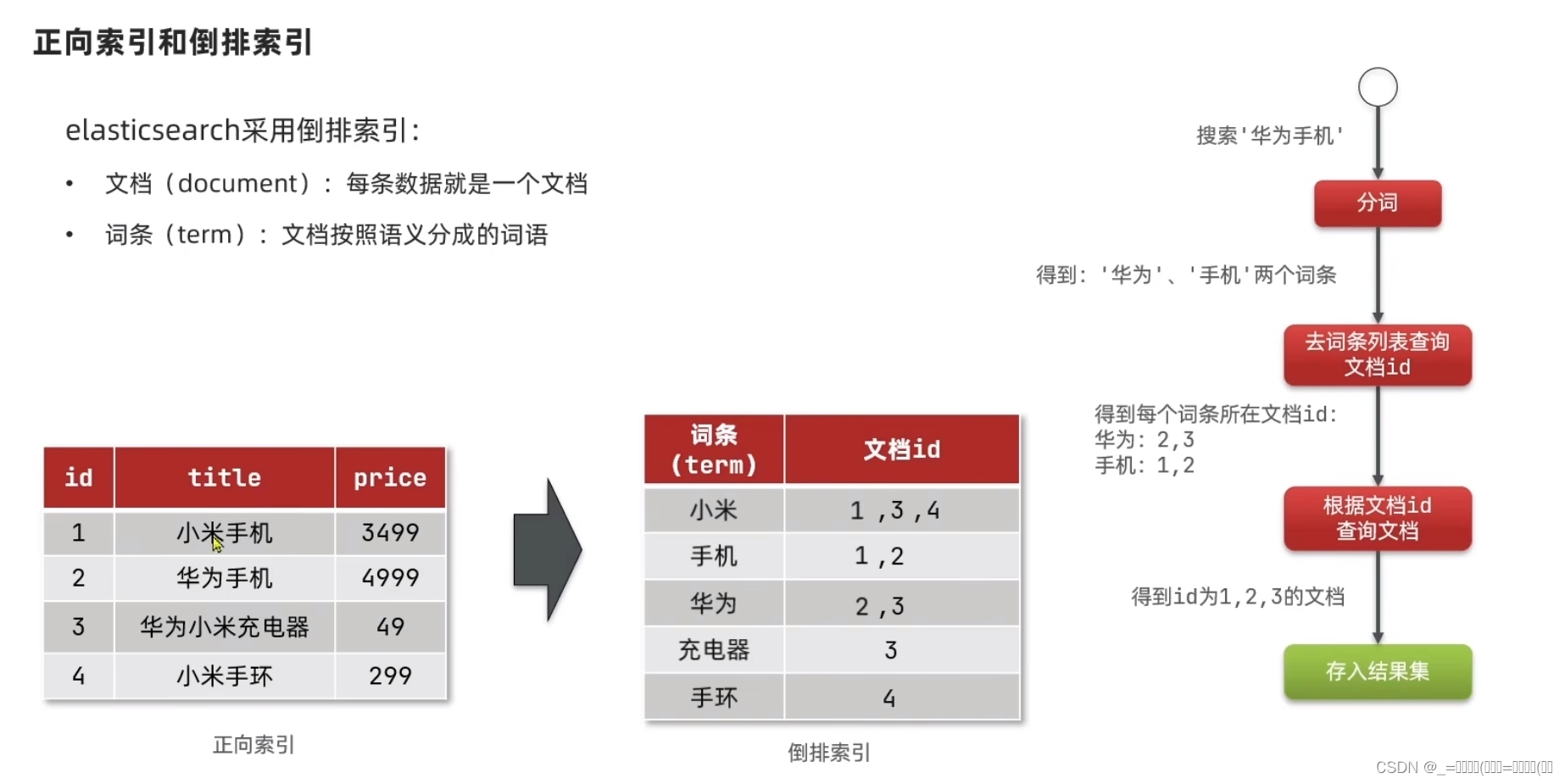
Elasticsearch使用倒排索引(Inverted Index)来支持全文搜索和分析功能。倒排索引将文档中的每个词(或短语)映射到包含该词的文档列表,从而实现了快速的全文搜索。
3、怎么在elastic创建 Elasticsearch索引库:
创建索引库,最关键的是分析mapping映射,而mapping映射要考虑的信息包括:
 为了实现多个属性一起查询会使用all ,代码如下:
为了实现多个属性一起查询会使用all ,代码如下:
PUT /hotel
{
"mappings": { // 定义索引的映射设置
"properties": { // 指定每个字段的属性和数据类型
"id": { // id字段
"type": "keyword" // 数据类型为关键字,不进行分词
},
"name":{ // name字段
"type": "text", // 数据类型为文本
"analyzer": "ik_max_word", // 使用ik_max_word中文分词器进行分词处理
"copy_to": "all" // 将该字段的值复制到名为"all"的字段中
},
"city":{ // city字段
"type": "keyword", // 数据类型为关键字,不进行分词
"copy_to": "all" // 将该字段的值复制到名为"all"的字段中
},
"all":{ // all字段
"type": "text", // 数据类型为文本
"analyzer": "ik_max_word" // 使用ik_max_word中文分词器进行分词处理
}
}
}
}
相关语句:
- 查询Elasticsearch索引库:GET /hotel/_mapping
- 查询Elasticsearch里的数据:GET /hotel/_search
如果觉得当前索引库不满意,可以查询创建一个索引库hotel1,然后使用如下语句,把hotel1绑定到hotel关联的Elasticsearch数据库:
//使用 Reindex API 将现有索引中的数据重新索引到新创建的索引中。例如:
POST _reindex
{
"source": {
"index": "your_old_index" //hotel
},
"dest": {
"index": "your_new_index" //hotel1
}
}
- 删除索引库:DELETE /your_old_index
4、最后对比一下Elasticsearch和Mysql分别使用什么索引:
Elasticsearch和MySQL分别使用不同类型的索引来支持其各自的查询和搜索功能:
Elasticsearch:
- Elasticsearch使用倒排索引(Inverted Index)来支持全文搜索和分析功能。倒排索引将文档中的每个词(或短语)映射到包含该词的文档列表,从而实现了快速的全文搜索。
- 此外,Elasticsearch还支持其他类型的索引,如地理空间索引(Geo Index)、日期索引(Date Index)等,以便于特定类型的搜索和分析。
MySQL:
- MySQL主要使用B树索引(B-tree Index)来加速对表格中数据的查找和访问。B树索引适用于范围查询、等值查询和排序操作,能够有效地加速对表格中的数据行的检索。
- MySQL还支持全文索引(Full-Text Index),它可以用于全文搜索功能,但相较于Elasticsearch的倒排索引,其功能相对较为有限。
总的来说,Elasticsearch的主要索引结构是倒排索引,适用于全文搜索和分析;而MySQL主要使用B树索引来支持关系型数据库的各种查询操作,但也可以使用全文索引来实现一定程度的全文搜索功能。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 13
13 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)