
生物信息学 GO、KEGG
概述了当前生物信息学领域中几个重要的概念和工具,介绍基因本体论(Gene Ontology, GO)、分子通路知识库KEGG(Kyoto Encyclopedia of Genes and Genomes)以及分子通路鉴定和GO注释的过程。首先从北京大学生物信息学团队的研究工作讲起,解释了基因本体论的框架,它是一套用于表示基因产品属性的控制词汇表。然深入探讨了KEGG数据库如何系统地整合了生物化学
b站链接:北大课程
概述了当前生物信息学领域中几个重要的概念和工具,介绍基因本体论(Gene Ontology, GO)、分子通路知识库KEGG(Kyoto Encyclopedia of Genes and Genomes)以及分子通路鉴定和GO注释的过程。
首先从北京大学生物信息学团队的研究工作讲起,解释了基因本体论的框架,它是一套用于表示基因产品属性的控制词汇表。然深入探讨了KEGG数据库如何系统地整合了生物化学通路和分子交互网络的信息。此外,还探讨了GO注释的重要性,它是指将基因本体论的术语分配给基因产品以描述其特性的过程。文章解释了分子通路的鉴定如何帮助科学家理解复杂的生物学过程和疾病机理。
北大
基因本体论

当时不同的生物测序,同源基因对不上,于是大家商讨着确定一套体系

- 在信息科学中,ontology 是对特定领域的概念和概念之间关系的一种规范描述。它通常使用共享词汇来定义领域内的概念类型、属性以及这些概念之间的关系。简单来说,它是一种数据模型,用于组织和整合信息,使其可查询、可分析。
- 在哲学中,ontology 是研究存在本质、变化、实在性以及存在的基本类别及其相互关系的领域。它探讨了现实和存在的基础框架以及如何理解世界的本质。

- 通信(Communication): 本体可以帮助确保不同团队或不同学科领域之间的无歧义沟通。举例来说,在各种基因组项目中,不同研究组对基因功能的注释可能各不相同。使用本体,这些注释可以统一标准化,确保所有人对同一术语有相同理解。
- 计算(Computation): 本体使知识可以以计算机可处理的形式表示,这意味着文献和数据可以结构化,使得计算机程序能够自动执行分析。例如,研究人员可以编写程序来查询和分析基因或蛋白质的功能,这一过程由本体中定义的结构化知识支持。
- 模式发现(Discovery of Patterns): 本体还可以用来发现更大规模的模式和关联。例如,研究人员可以通过本体来识别涉及特定基因集的更广泛的功能分类或代谢途径,从而提供一个从局部到整体的视角。这就像从鸟瞰视角看问题,而不仅仅是从地面水平视角看问题。

- Gene Ontology (GO)
- 从刚开始的三家,到现在有二十多家机构参与

- 三个部分

这张幻灯片介绍了基因本体论(Gene Ontology, GO)中的三个主要类别:
- 分子功能(Molecular Function):指的是基因产品(如蛋白质)的基本活动或任务,比如特定的生化活动。例如,某个蛋白质可能具有碳水化合物结合的功能或ATP酶活性。
- 生物过程(Biological Process):涉及多个分子功能的集合,这些集合合作实现某个宽泛的生物目标或目的,如细胞分裂(有丝分裂)或嘌呤代谢。
- 细胞组分(Cellular Component):特定的细胞位置或复杂体,如亚细胞结构、位置或大分子复合体。这可能包括核、端粒或RNA聚合酶II整体等。
- 使用基因本体论(Gene Ontology, GO)来描述与色素形成(pigmentation)相关的生物过程的一个例子
- GO提供了一个用于描述基因功能和相关生物学特性的标准化词汇。
- 这个系统中,生物过程、分子功能和细胞组分是通过有向无环图(Directed Acyclic Graph, DAG)的形式展现的,其中节点表示GO术语,而边表示这些术语之间的关系。

在这个例子中,每个方框代表一个GO术语,这些术语描述了色素形成的不同方面,例如:
- 色素形成过程
- 发育期间的色素形成调控
- 色素代谢过程
箭头表示的是不同术语之间的关系,比如某个过程是另一个过程的一部分,或者一个过程是另一个过程的调控(正调控或负调控)。GO的这种层级结构和术语间的关系有助于研究人员精确地描述和理解基因产物的功能和它们在生物学中的作用。
-
如何将像上面的图**(有向无环图)**存储进电脑
-
几种存储格式


- 三种relationship
- is a
- part of
- regulates

- 这样的推断规则就让计算机比较方便的处理


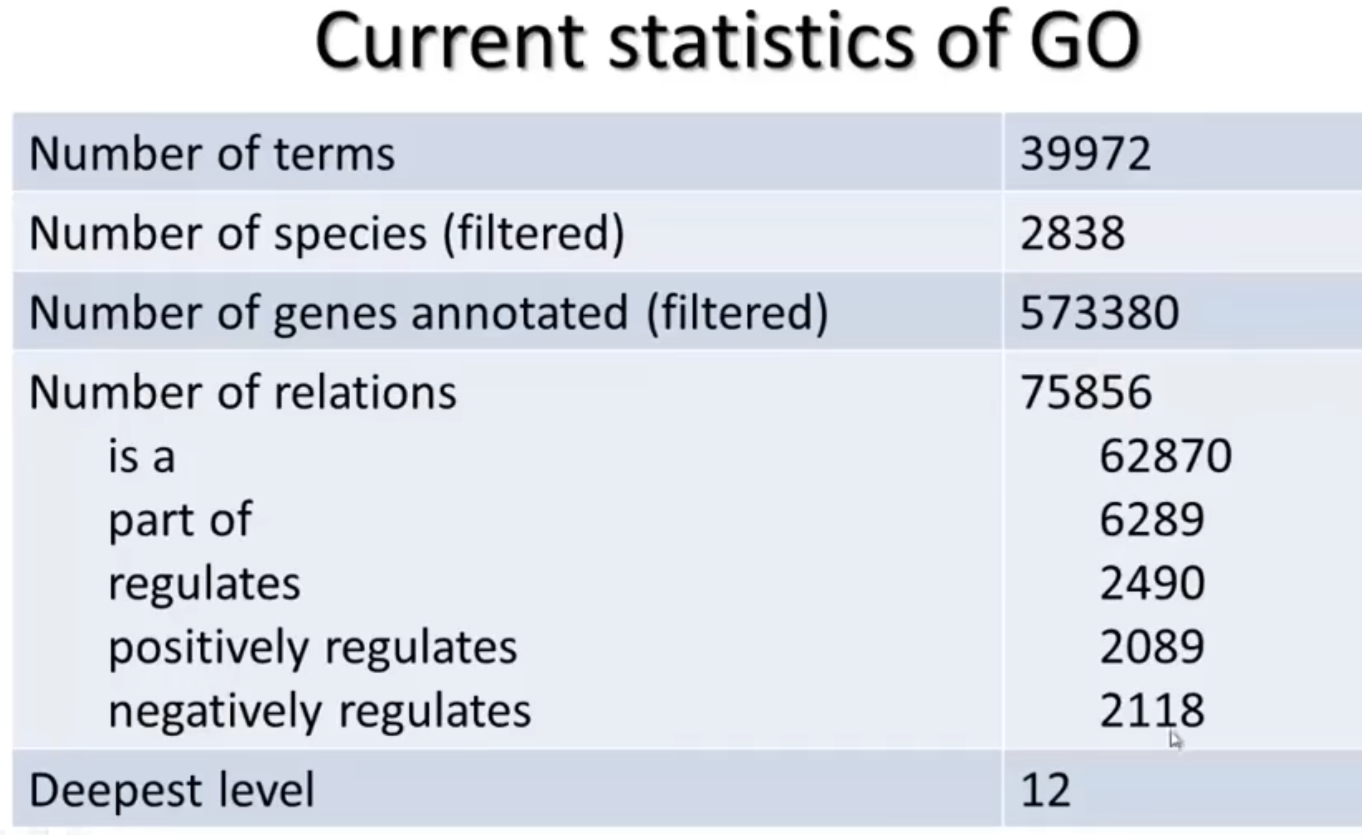
- 目前的GO的规模(2018年)
可以在官网搜索
分子通路KEGG
Main types of biological pathways:
- Metabolic pathways:添加原材料(食物和氧气),转化成产品(能量、生长和维修所需的分子)并分配到身体的各个部分。
- Gene regulation pathways:根据外界/自身的情况,调节哪些基因多表达一些,哪些少表达一些。
- 确定哪些工厂(基因)应当在什么时候开工,生产多少商品(蛋白质和RNA)
- Signal transduction pathways:信号转导
- 帮助城市的各个部分(细胞)根据收到的消息(信号分子)做出反应,调整各自的活动
最完善的是代谢相关的通路

- 每一个pathway也会链到其他的pathway

-
重要的就是interactions
- PPI

- 磷酸化(Phosphorylation):一个蛋白质(酶)向另一个蛋白质添加磷酸基团,通常导致被磷酸化的蛋白质活性的增加或减少。
- 去磷酸化(Dephosphorylation):磷酸基团从蛋白质上移除,这个过程通常是由另一类酶执行的,可以逆转磷酸化的效果。
- 泛素化(Ubiquitination):将泛素(一种小蛋白质)附加到目标蛋白质上,通常标记蛋白质进行降解。
- 糖基化(Glycosylation):添加糖基团到蛋白质上,这可以影响蛋白质的稳定性、位置和功能。
- 甲基化(Methylation):添加甲基团到蛋白质上,这种修改可以影响蛋白质的活性或相互作用。
- 激活(Activation):使蛋白质变得活跃或增强其活性。
- 抑制(Inhibition):降低蛋白质的活性或完全停止其功能。
- 间接效应(Indirect effect):一个蛋白质对另一个蛋白质产生的非直接作用,比如通过影响一个中间分子。
- 状态变化(State change):蛋白质状态的改变,例如从不活跃状态到活跃状态。
- 结合/联合(Binding/Association):两个或多个蛋白质形成稳定的复合物。
- 解离(Dissociation):蛋白质复合物的分离。
- 复合物(Complex):两个或多个蛋白质通过结合形成的稳定结构。
- Gene expression relations
- 酶之间的反应
- PPI
-
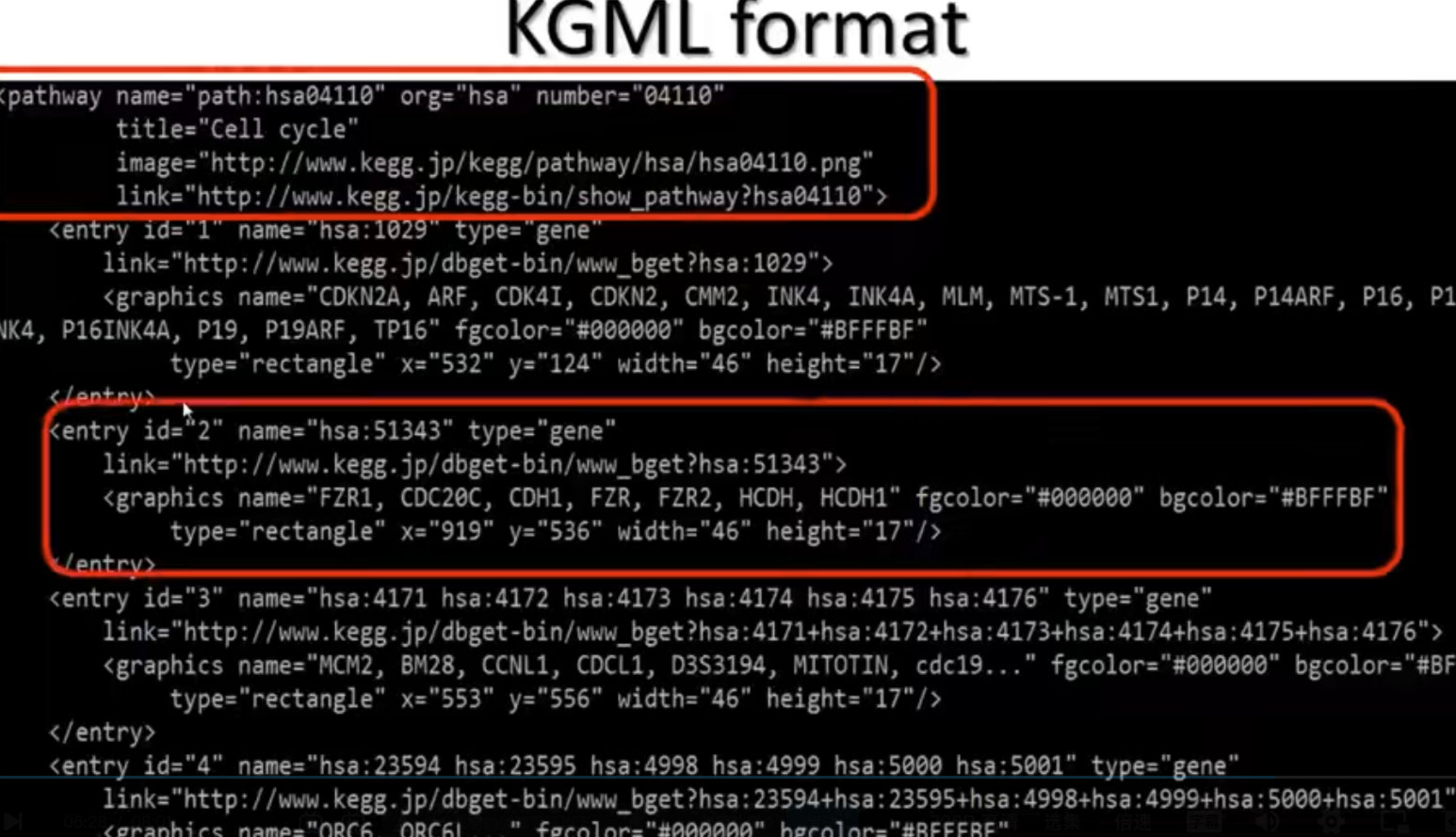
KEGG Pathway File
- KGML格式



- KEGG Orthology (KO):
- KEGG的一个数据库,存储“KO”号
- 主要是对于不同物种中具有相似功能基因的标识符,更多的是针对基因
- KO 提供了一个标准化的方法来标识和分类这些基因和蛋白质,并将它们与 KEGG Pathways 中描述的特定生物化学过程相关联。
- 每个 KO 都是一个编码特定分子功能的基因或蛋白质的集合,在不同物种中,执行相同功能的基因或蛋白质会被分配相同的 KO 编号。
- 在 KEGG Pathways 的上下文中,可以使用 KO 来标识途径中涉及的特定基因或蛋白质,这有助于跨物种比较途径成分。这种关联是双向的:一个特定的 KO 可能参与多个不同的途径,而一个途径可能涉及多个不同的 KO。
KO vs GO
- 基因本体论(Gene Ontology, GO):GO 为基因产品(主要是蛋白质)的功能提供了一个结构化的、动态更新的控制词汇。GO 将基因产品的功能描述为属于三个不同领域的属性:生物过程(biological process)、分子功能(molecular function)和细胞组分(cellular component)。GO 更多关注单个基因产品的特定功能,以及它们在细胞内外的位置。
- KEGG:KEGG 关注的是基因产品参与的整体生物化学途径和网络。KEGG 提供了对这些网络的图形表示,强调了不同基因和蛋白质如何协同工作,影响生物学功能。KO 系统是 KEGG 用来标准化和整合这些信息的方式,侧重于跨物种的功能比较。
GO注释

- 通过实验证据,并且人工review过的

- 通过计算分析,并通过人工review的

- ISO (Inferred from Sequence Orthology): 这是当一个基因产品的功能被推断出与其他已知功能的基因产品有序列同源性时使用的。通常涉及比较进化上相关物种之间的基因。
- ISA (Inferred from Sequence Alignment): 通过序列比对的方法推断功能。如果一个未知功能的蛋白质与已知功能的蛋白质序列对齐,那么未知蛋白质可能具有类似的功能。
- ISM (Inferred from Sequence Model): 通过比对特定的序列模式或序列特征,如保守域或基序,预测功能。
- ISS (Inferred from Sequence or Structural Similarity): 当一个基因产品由于序列或结构相似性被推断具有某种功能时使用。这可以基于序列比对或三维结构的比较。
- IGC (Inferred from Genomic Context): 根据基因在基因组中的位置来推断功能,例如在同一操作单元中的基因,或基因的邻近性,可能参与相同的代谢途径或生物过程。
- IBA (Inferred from Biological aspect of Ancestor): 当一个功能从一个祖先物种中推断出来,并且被认为在当前物种中仍然存在时使用。
- IBD (Inferred from Biological aspect of Descendant): 如果一个功能可以在下游的物种中观察到,并且这种功能被推断在共有的祖先物种中存在,就会使用这种方法。
- RCA (Inferred from Reviewed Computational Analysis): 功能推断是基于经过审查的计算分析,可能涉及多种生物信息学工具和方法。
- IKR (Inferred from Key Residues): 相反的推断,如果序列差不多,但是缺少了关键的残基,那么就排除该序列具有该功能
- IRD (Inferred from Rapid Divergence): 当一个基因或蛋白质与已知的功能相似,但序列发生了快速演变,使其在某些位置有显著差异,可能指示功能上的差异化时使用。
- 通过计算分析但没有人工review
- 其他奇怪的

- 就是说一些没有足够的证据的注释,比如作者在论文中提了一嘴这样
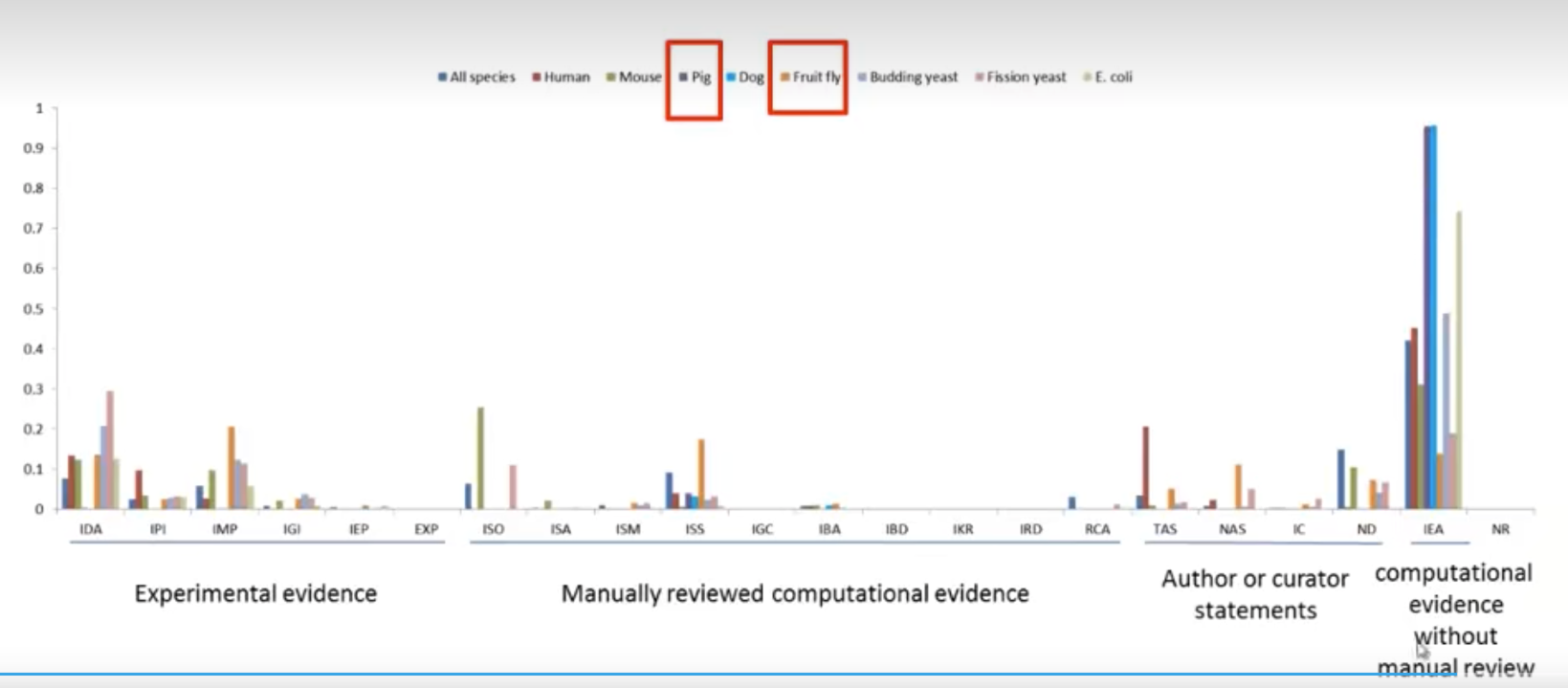
- 这是一个关于不同物种注释类型的数据统计
- 可以看出水果的话,大部分都是实验得到的和经过人工review注释,计算机推测的比较少
- 而对于猪的话,就是计算机推测的还没经过人工review的占比比较大

分子通路鉴定
当时老师课题组的一个工作
- 给基因注释上通路(有时候能注释到8 90% 有时候一半都不到)

- KO
- 存储了KEGG里pathway的表
- 存储了KEGG里KO的表
- 存储了KO对应pathway的表
- Gene
- 存储了gene对应pathway的表 (推理出的)
- 存储了ko对应gene的表(推理出的)
- 存储了genes的信息
大概的思路,是query的gene序列,跟KEGG 里的genes做blast,相似度高的,进行一个mapping。就是query对应到KEGG里的gene的KO,然后再从KO对应到pathway
- 哪些通路是sigificant的
很多时候由于实验,数据是带有噪声的,即数据中存在由测量误差、实验条件或其他非相关生物学过程导致的变异,因此需要统计方法来确定哪些结果是真正具有生物学意义的。
-
Most frequent pathway
-
Most enriched pathway 通路富集
- 对于某一个通路(一个一个看),
- 研究的一个基因组中,所有能注释到的基因称为“background”
- 评估自己实验条件下的这些基因在通路中的概率,跟background中所有基因落在通路中的概率,比较这二者,算p值

-
其实就是一个抽样问题,用超几何分布来算p值



多假设检验矫正 FDR矫正
因为前面是一个一个通路去做检测的,所以每个通路判断的误差累计起来还是不容忽视的,所以这里进行一个多假设检验的矫正

如果这个期望小于0.05,那么认为是比较有生物学意义的

有三类分析方法,这里只介绍了第一种,并且给出了一些分析软件
关于同源 相似性
homology
Ortholog直系同源:不同物种的相同功能序列,来自历史上同个祖先
paralog旁系同源:同个物种,发生复制
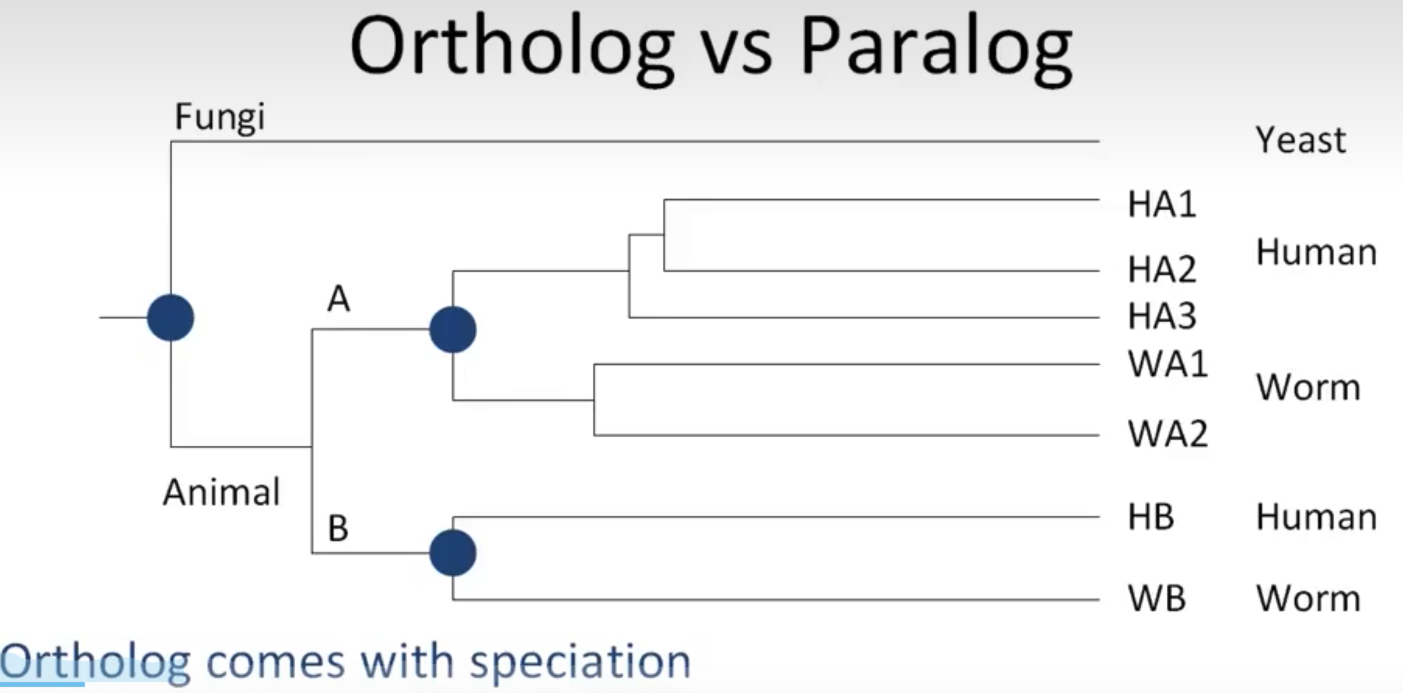
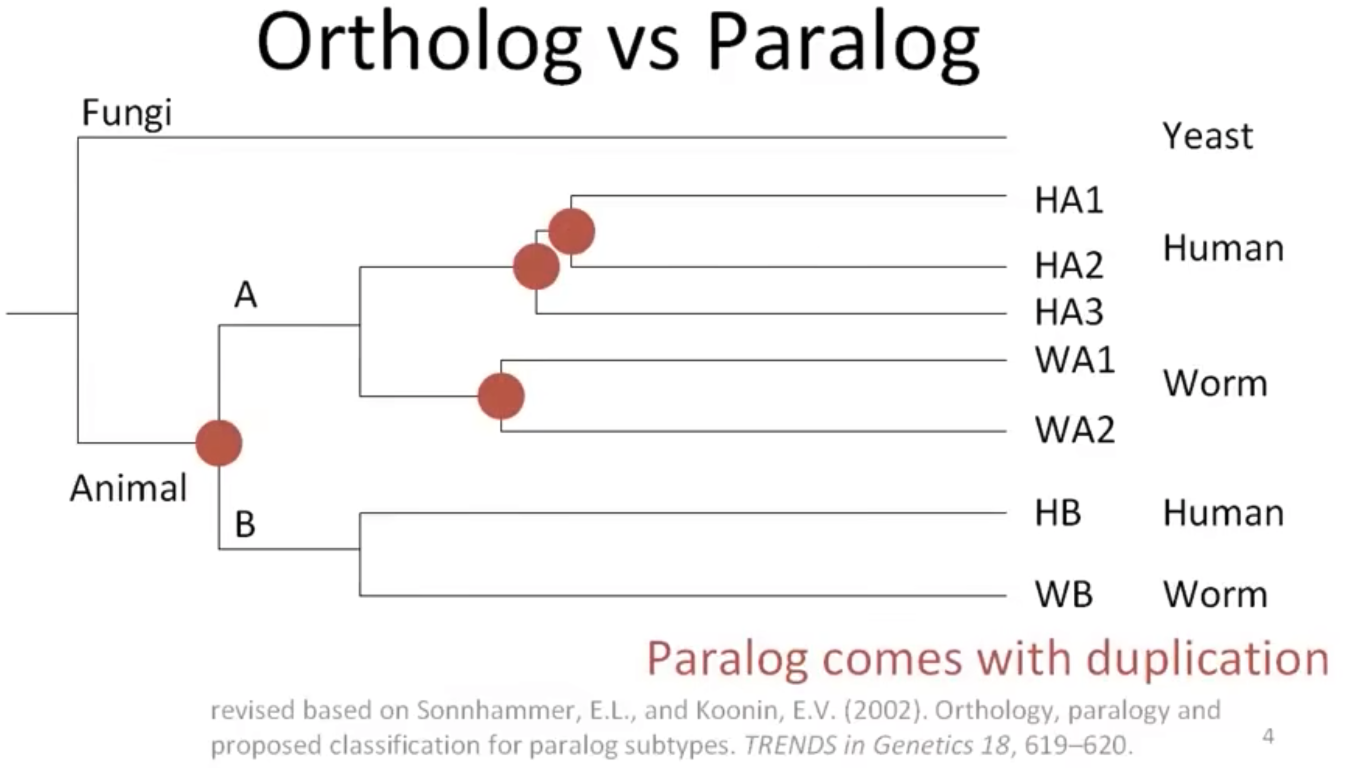
同源性往往具有相似性,所以我们常常会根据相似性去推断同源性
相似性矩阵
- 对于氨基酸
- PAM矩阵
- BLOSUM矩阵

一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐

 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)