

基于Tensorflow库的RNN模型预测实战
Tensorflow是使用较为广泛的一个深度学习框架,通常运用在图像识别、图片分类等领域,它是一个采用数据流图,用于数值计算的开源软件库。从命名来理解的话:Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。在TensorFlow中,数据不是以整数、浮点数或者字符串形式存在的,而是被封装在一个叫做Tensor的对象中。Tensor是张量的意思,张量包含了0到任意维度的量,其
前言
这篇推文主要介绍基于Tensorflow库的RNN模型预测问题。文中首先对Tensorflow库进行简单的介绍,然后以美国二氧化碳数据集为例建立RNN模型进行预测,最后通过实验结果展示了模型的良好表现。
Tensorflow库简介
Tensorflow是使用较为广泛的一个深度学习框架,通常运用在图像识别、图片分类等领域,它是一个采用数据流图,用于数值计算的开源软件库。从命名来理解的话:Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。
在TensorFlow中,数据不是以整数、浮点数或者字符串形式存在的,而是被封装在一个叫做Tensor的对象中。Tensor是张量的意思,张量包含了0到任意维度的量,其中,0维叫做常数,一维叫做向量,二维叫做矩阵,多维度的直接叫做张量。
TensorFlow中的数据流图如图所示。

首先我们要创建一个数据流图,然后将我们的数据放在数据流图中计算。节点(Nodes)在图中表示数学操作,图中的边(edges)表示节点间相互联系的多维数据数组,即张量(tensor)。训练模型时tensor会不断的从数据流图中的一个节点flow到另一个节点。
循环神经网络简介
我们知道对于神经网络模型而言,只要训练数据足够,那么就可以在给定输入层后,通过模型训练得到期望的输出。
那么我们为什么还需要引入RNN呢?我们知道一般的神经网络模型的输入层在时间上没有依赖关系。但是,有时我们需要处理时间序列的问题,比如股票数据、视频数据等,这时就需要RNN模型。RNN是一个具有记忆功能的网络,适合解决连续序列的问题,善于从具有一定顺序意义的样本与样本间学习规律。
一个简单的循环神经网络模型(Recurrent Neural Network, RNN)由输入层、一个隐藏层和一个输出层组成。

我们可以这样来理解,去掉循环层后就是全连接神经网络,代表输入层,代表隐藏层,代表输出层,代表输入层到隐藏层的权重矩阵,代表隐藏层到输出层的权重矩阵。
是上一期的值作为当期的权重矩阵,这里需要注意的是,RNN加入后,隐藏层的值不仅仅取决于当期输入,还取决于上一期的隐藏层的值,我们用公式表示为:
,均为激活函数。
模型实例
首先加载这里需要用到的python库。
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import itertools
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.preprocessing import MinMaxScaler
import statsmodels.api as sm
plt.style.use('fivethirtyeight')
我们以美国1958年3月1日至2001年12月1日的二氧化碳数据集为例,通过建立RNN模型预测未来一期的二氧化碳含量。
data_co2 = sm.datasets.co2.load_pandas()
data_co2 = data_co2.data
data_co2 = data_co2['co2'].resample('MS').mean()
data_co2 = data_co2.fillna(data_co2.bfill())
data_co2.plot(figsize=(15, 6))
plt.show()
#将字符串索引转换成时间索引
data_co2.index = pd.to_datetime(data_co2.index)
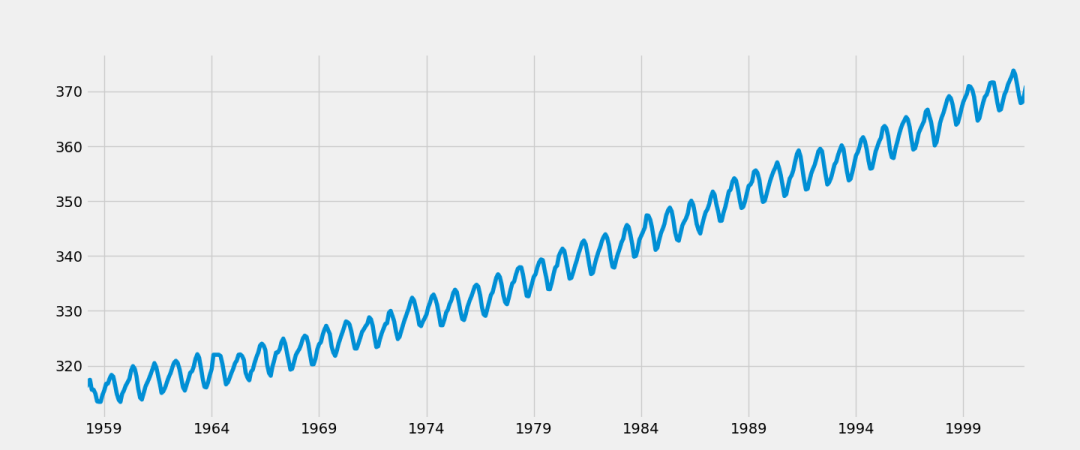
通过绘制原始数据的时序图可看出,二氧化碳含量序列具有季节特征,总体呈上升趋势。
对数据进行归一化处理,并划分训练集和测试集。
data_co2=np.array(data_co2)
data_co2=np.reshape(data_co2,newshape=(-1,1))
co2=MinMaxScaler().fit_transform(data_co2)
co2=np.reshape(co2,newshape=-1)
x=[]
y=[]
day=10
for i in range(len(co2)-day-1):
x.append(co2[i:i+day])
y.append(co2[i+day])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
搭建RNN模型。这里我们采用sigmoid激活函数,均方误差作为损失函数。
model1=tf.keras.models.Sequential([
tf.keras.layers.Reshape((day,1),input_shape=(day,)),
tf.keras.layers.SimpleRNN(units=128),
tf.keras.layers.Dense(units=64,activation='sigmoid'),
tf.keras.layers.Dense(units=1,activation='sigmoid')
])
model1.compile(optimizer=keras.optimizers.Adam(0.01),loss=keras.losses.mean_squared_error)
model1_information=model1.fit(x_train,y_train,epochs=100,verbose=0)
损失函数可视化。
information_loss=model1_information.history['loss']
print(information_loss)
def loss(information_loss):
fig, ax = plt.subplots()
ax.plot(range(len(information_loss)),information_loss,'r', label='loss', lineWidth=0.5)
plt.title("plot of loss")
plt.show()
loss(information_loss)
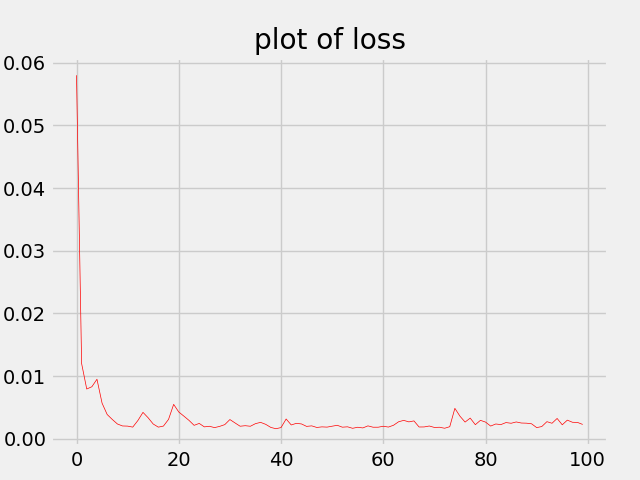
我们可以看到,损失函数逐渐降低,最终稳定在0.002附近。
最后绘制在测试集上的预测值和真实值之间的对比图。
y_pre=model1.predict(x_test)
fig, ax = plt.subplots()
ax.plot(range(len(y_pre)), y_pre, label='prediction', lineWidth=0.8)
ax.plot(range(len(y_test)), y_test, label='practical', lineWidth=0.8)
ax.legend()
plt.title("plot of prediction and practical")
plt.show()

其中蓝色实线表示预测值,红色实线表示真实值。我们可以看到拟合效果还是不错的。
总结和感悟
本文展示了将RNN在序列预测问题上的应用,并通过实例验证了其有效性。但是从它的结构可以看出有三个问题:梯度爆炸、梯度消失、长距离依赖问题。面对一些变化莫测的数据集来说,直接将RNN应用与其中还是有待研究的。针对上述三个问题,使用长短期记忆(Long short-term memory, LSTM)神经网络模型是一个可以考虑改进方向。
参考文献
https://zhuanlan.zhihu.com/p/30844905 https://zhuanlan.zhihu.com/p/52550025 https://blog.csdn.net/qq_29750461/article/details/81701240 https://zhuanlan.zhihu.com/p/55949716

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 36
36 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)