
【ICCV】PointDC,基于深度聚类的无监督3D场景语义分割,FaceChain团队联合出品
针对无监督3D场景的语义分割,提出一套基于深度聚类的自监督学习算法,可以大幅提升3D分割的效果(ScanNet-v2 (+18.4 mIoU)、S3DIS (+11.5 mIoU))。
论文:PointDC:Unsupervised Semantic Segmentation of 3D Point Clouds via Cross-modal Distillation and Super-Voxel Clustering,https://arxiv.org/abs/2304.08965
代码:
一、概览:
针对无监督3D场景的语义分割,提出一套基于深度聚类的自监督学习算法,可以大幅提升3D分割的效果(ScanNet-v2 (+18.4 mIoU)、S3DIS (+11.5 mIoU))。
二、介绍:
基于3D点云的语义分割任务旨在识别一个3D点云中每个点所从属的语义概念,可以广泛应用于各种下游任务,如机器人导航、自动驾驶、具身智能等等。尽管现有的基于全监督范式的3D语义分割方法已经取得了不晓得进展,但是这些方法依然高度依赖于大规模数据集和3D语义标注。最令人感到棘手的是,三维点云的标注成本相比于图像和视频更加麻烦。例如,在ScanNet数据集中要标注一个3D场景需要大约22.3分钟【1】。
为了缓解对于这些数据标注的需求,也有一些工作尝试着从弱监督【2-4】的角度来解决问题,包括2D图像标注映射到3D、3D点云中部分点的稀疏标注等等。然而,很少有工作尝试去探索在不依靠任何标注下进行3D语义分割的任务。在这篇论文中,我们旨在探讨自监督学习在不依靠任何标注下进行3D语义分割的可行性,示意图如下图所示。

图1 无监督3D场景语义分割任务介绍
在开始做之前,一种很自然的想法就是看看基于2D图像的无监督语义分割方法是否有效。IIC【5】和PiCIE【6】是两个经典的基于自监督学习和聚类学习(Learning-by-Clustering)的无监督语义分割框架。通过设计基于数据增强的不变性或等变性对比学习损失,可以让网络学习到丰富的视觉表征;借助聚类过程可以提取出语义空间的有效特征,借助像素级的聚类来挖掘语义概念实现语义分割。STEGO【7】则通过大规模视觉预训练模型的特征来引导聚类过程实现更鲁棒的无监督语义分割。然而,在我们尝试着将这些方法拓展到3D场景时,发现这些方法的性能非常有限,其聚类结果不是很理想。那么,究竟是什么因素导致了这个问题?
我们可以简单地将问题总结为以下两点:
- 聚类过程中的歧义。自监督学习和深度聚类这些方法可行的大前提是我们有足够丰富的大规模数据集。在2D场景,图像数据的采集相对容易,且人类收集的过程保证了这些数据是充分有意义的。然而3D数据的收集受限于其采集成本,较难采集到与2D图像相当规模的数据集,且多样性也很有限。这也导致聚类算法无法在足够丰富的3D视觉特征聚类,无法聚类出有效的3D场景语义特征。
- 点云自身的不规则性。在深度聚类的过程,我们需要在大规模3D点云数据集进行精细到点级别的聚类。在将整个数据集的点云特征聚类的过程中,点云自身的不规则结构,以及不同区域稀疏程度不同的特性,导致常用的基于K-Means等等的深度聚类方法无法有效地获取有用地特征。因为K-Means是基于欧式距离的均衡度量构建的,但却无法有效地处理点云这种非欧式结构数据。例如,如果一块区域非常稠密,那么聚类的中心会更接近稠密区域,而忽视其他稀疏区域。
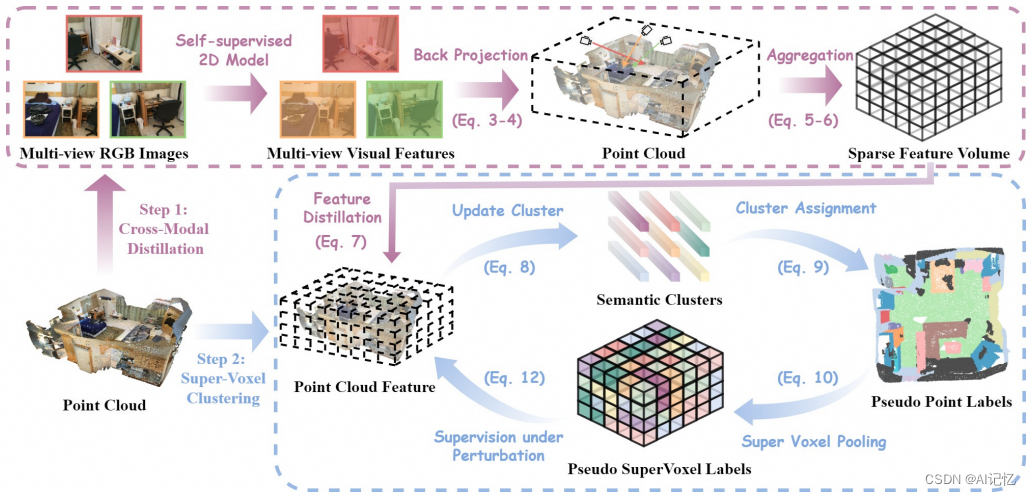
基于以上两点,我们提出了一套完全无监督的3D点云语义分割方法,PointDC。其包含两个核心组件:跨模态蒸馏(Cross-Modal Distillation,CMD)和超体素聚类(Super-Voxel Clustering,SVC)。PointDC的
图2 PointDC示意图,包含两个阶段:跨模态蒸馏和超体素聚类
- 针对第一个问题(聚类过程中的歧义),我们提出跨模态蒸馏(CMD)来借助2D视觉预训练大模型的特征来缓解先验信息的确实。具体来说,我们将点云对应的多视角图像分别送入自监督预训练好的Transformer大模型(如DINO等)提取多视图特征。随后利用单应性投影构建逆投影模块,将多视图的特征投影到3D空间,并通过全局池化进行聚合得到鲁棒的3D特征。
- 针对第二个问题(点云自身的不规则形),我们提出超体素池化(SVC),将原始的点云转换成3D超体素再进行自监督学习和深度聚类训练。在每个局部超体素中对其包含的3D点特征进行聚合,得到一个置换不变的局部表征。再将这些超体素特征在整个数据集层面进行聚类来挖掘出语义概念,转换成伪标签再进行自训练(Self-train)。在自训练的过程中,会像其他对比学习方法一样,引入随机的数据增强,并约束其针对伪标签具有不变性和等变性。
三、实验:
我们分别在ScanNet-v2的验证集和测试集、以及S3DIS上进行了实验验证,均取得了大幅超越此前自监督算法的性能,如下:

表1 在ScanNet-v2验证集上的实验结果

表2 在ScanNet-v2测试集上的实验结果
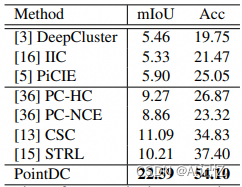
表3 在S3DIS(Area 5)上的实验结果

表4 各个模块的消融实验结果

图3 ScanNet-v2验证集上的可视化结果
四、参考:
- Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017.
- Haiyan Wang, Xuejian Rong, Liang Yang, Jinglun Feng, Jizhong Xiao, and Yingli Tian. Weakly supervised semantic segmentation in 3d graph-structured point clouds of wild scenes. arXiv preprint arXiv:2004.12498, 2020.
- Zhengzhe Liu, Xiaojuan Qi, and Chi-Wing Fu. One thing one click: A self-training approach for weakly supervised 3d semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1726–1736, 2021.
- Yushuang Wu, Zizheng Yan, Shengcai Cai, Guanbin Li, Yizhou Yu, Xiaoguang Han, and Shuguang Cui. Pointmatch: a consistency training framework for weakly supervised semantic segmentation of 3d point clouds. arXiv preprint arXiv:2202.10705, 2022.
- Xu Ji, Joao F Henriques, and Andrea Vedaldi. Invariant information clustering for unsupervised image classification and segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9865–9874, 2019.
- Jang Hyun Cho, Utkarsh Mall, Kavita Bala, and Bharath Hariharan. Picie: Unsupervised semantic segmentation using invariance and equivariance in clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16794–16804, 2021.
- Hamilton M, Zhang Z, Hariharan B, et al. Unsupervised semantic segmentation by distilling feature correspondences[J]. arXiv preprint arXiv:2203.08414, 2022.

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)