
分享一些实用性的大语言模型(GitHub篇)
分享一些实用性的大语言模型(GitHub篇)
1.多模态大模型
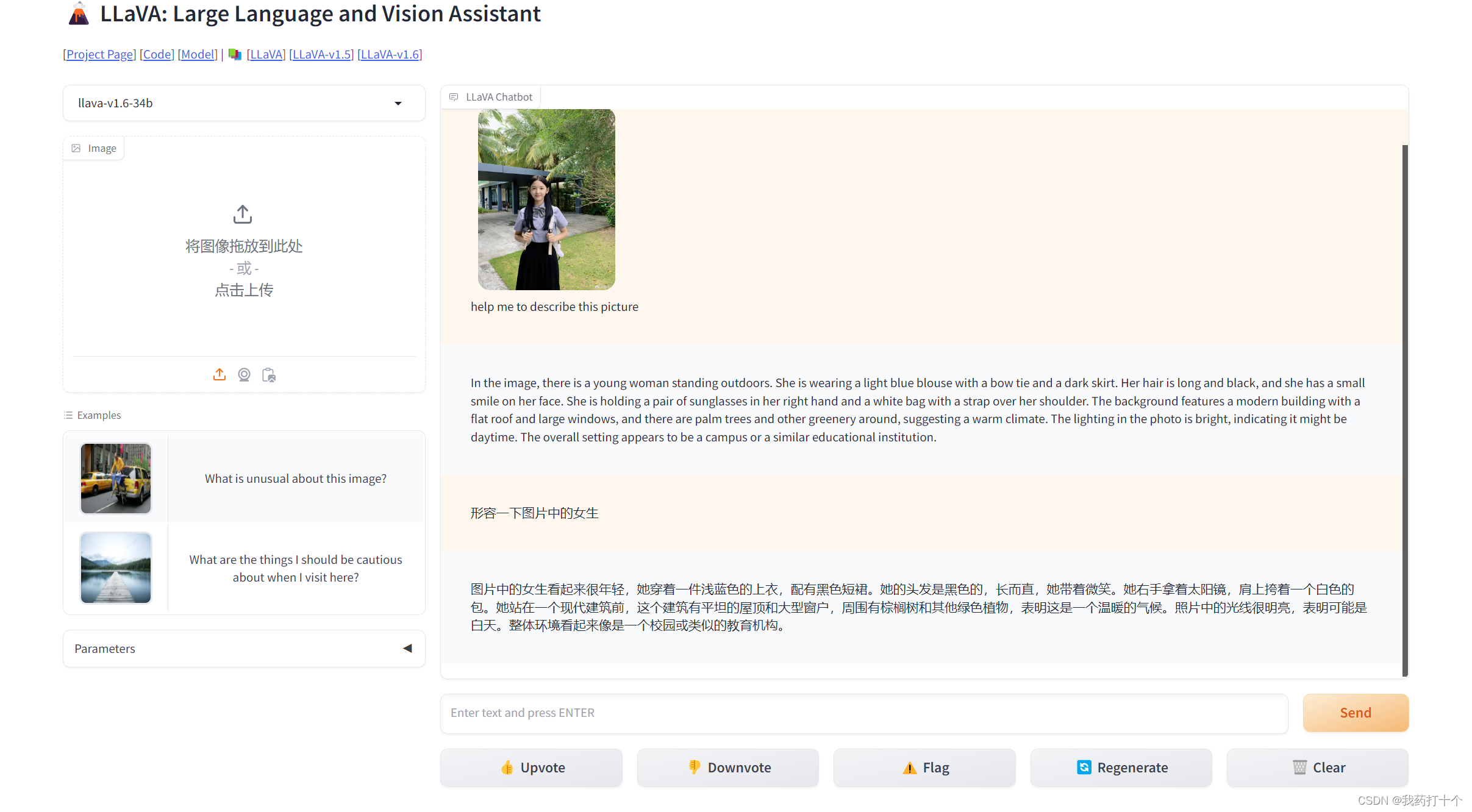
GitHub网址:haotian-liu/LLaVA:[NeurIPS'23 Oral] 视觉指令调优 (LLaVA) 构建,旨在实现 GPT-4V 级别及以上的能力。 (github.com)
下面是LLaVA模型的介绍,作者都有一直维护和更新,主张让大家都能体验部分gpt4的功能,目前1月底已出到1.6版本
LLaVA-NeXT:改进的推理、OCR 和世界知识 |LLaVA(拉瓦) (llava-vl.github.io)
部署网站,可直接使用
2.图像字幕
GitHub网址:
GitHub - rmokady/CLIP_prefix_caption: Simple image captioning model
该模型主要预训练CLIP模型来对图像内容进行说明,也可称为图像翻译
部署网站,可直接使用(有点慢)
rmokady/clip_prefix_caption – 在复制时使用 API 运行 (replicate.com)
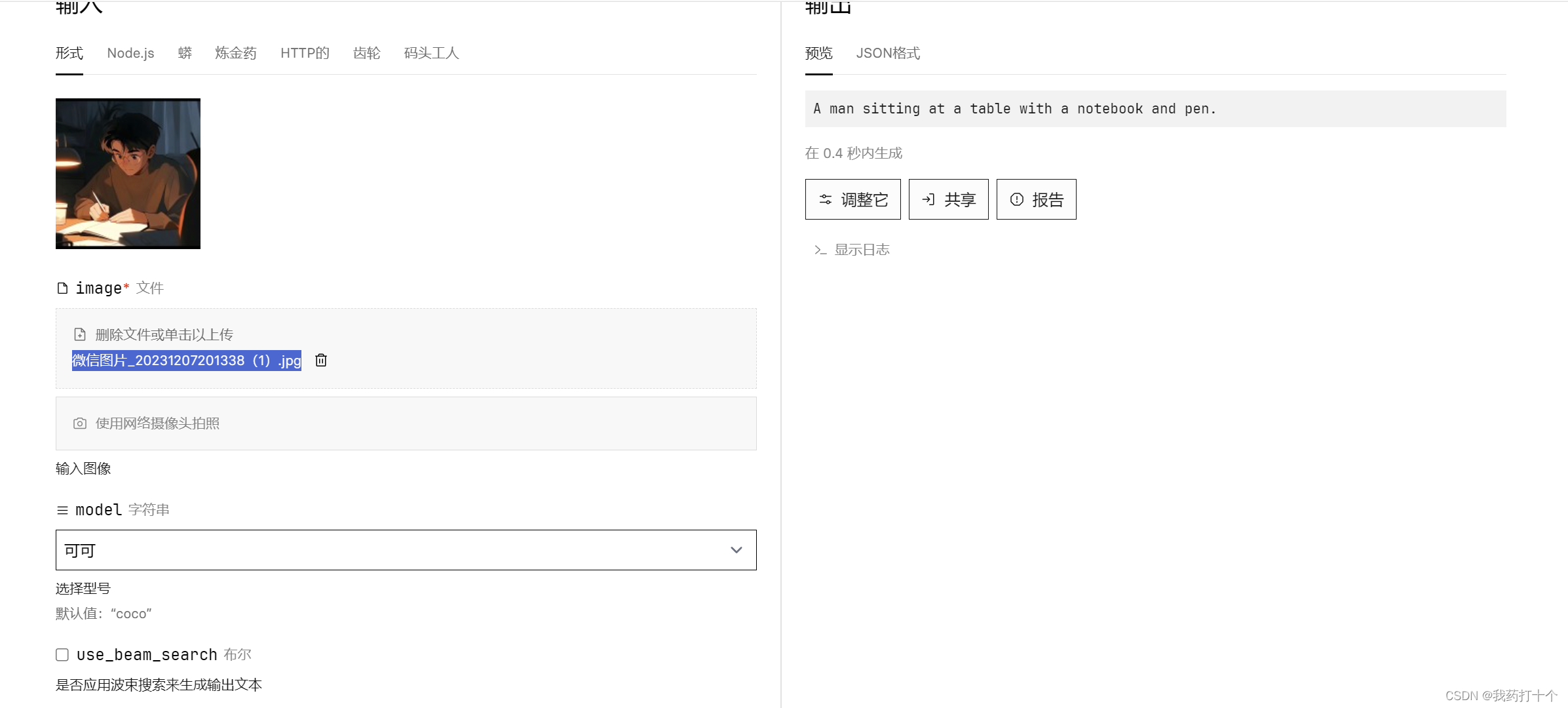
3.通义千问大模型
GitHub地址:
这是阿里云公布的一个大模型,在跑分上超过gpt4的结果,并且对比上面第一个大模型还多了文档输入的功能,试用过,总结得还行
部署网站,可直接使用
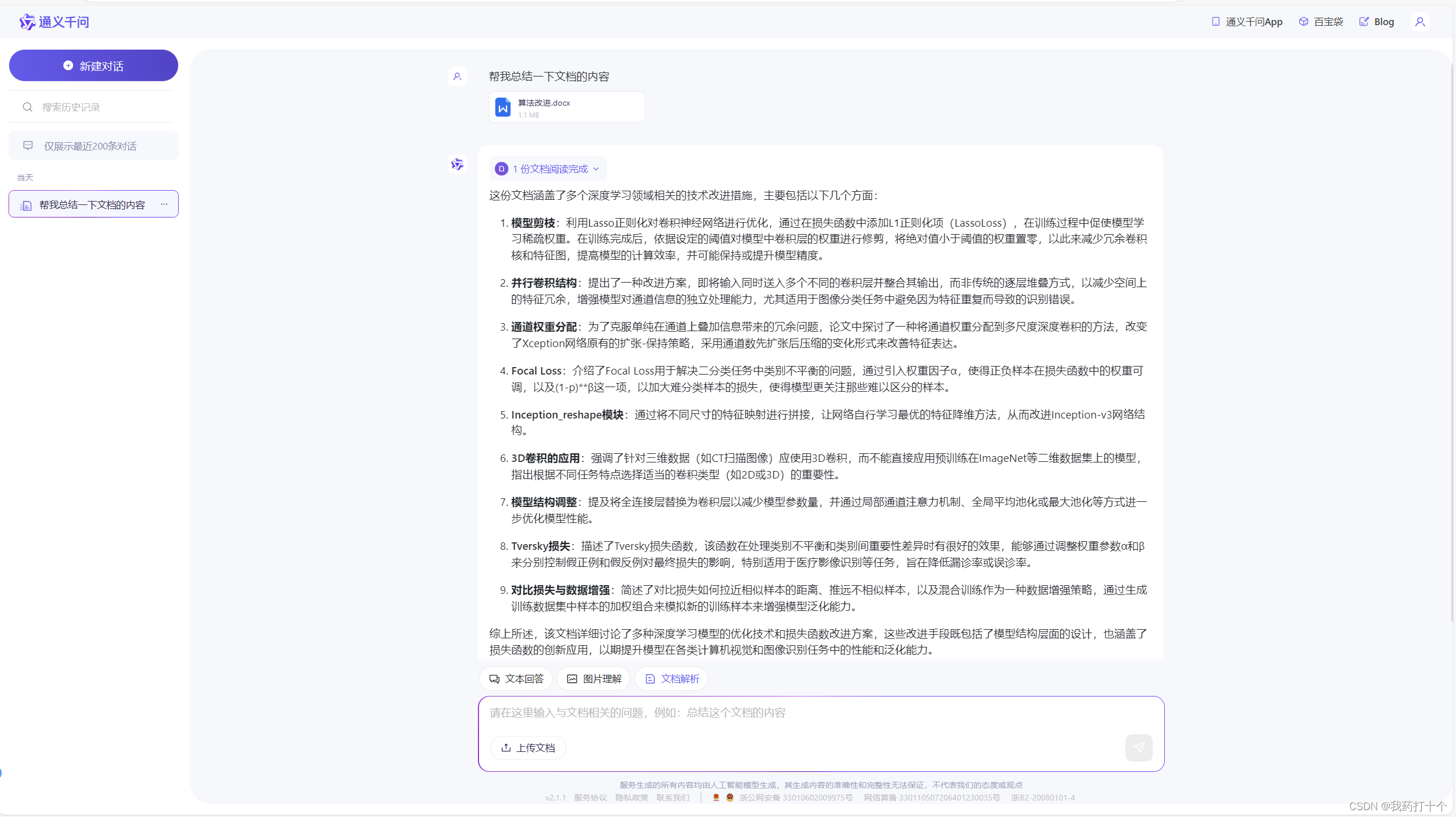
4.中医大语言模型
GitHub地址:
这是针对中医药而训练的大模型,是上海的两所大学联合训练的,因为中医药方向涉及的领域比较难,而且非常耗成本,所以这个模型具有很好的参考价值,可以作为以后中医药领域的预训练模型
模型地址:
Suprit/Zhongjing-LLaMA-base at main (huggingface.co)
目前没有部署网站,但作者在google colab上部署了,可以直接登录使用
上面介绍的模型分享都希望让大家能多多了解AI和使用AI,最重要是大佬们的开源意识,可以根据自己的情况进行预训练和部署, 也可以直接通过GitHub上进行论文的学习和源码查看,由于小弟我功力不够,模型和原理上就没有给大家做过多介绍了,如果有遇到其他好的模型会持续分享
希望这篇博文对你有帮助!!!!

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐

 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)