
3D gaussian splatting 代码阅读(一):Forward
3D gaussian 代码阅读
先学习下cuda的Cooperative Groups
CUDA之Cooperative Groups操作,细粒度并行操作。
CUDA编程入门之Cooperative Groups(1)
submodules/diff-gaussian-rasterization/cuda_rasterizer/rasterizer_impl.cu
forward
- 计算fx、fy
- 根据3D高斯个数初始化几何相关变量内存
- 根据固定block size,计算tile size
dim3 tile_grid((width + BLOCK_X - 1) / BLOCK_X, (height + BLOCK_Y - 1) / BLOCK_Y, 1);
dim3 block(BLOCK_X, BLOCK_Y, 1);
- 根据H,W以及tile size初始化image 相关变量
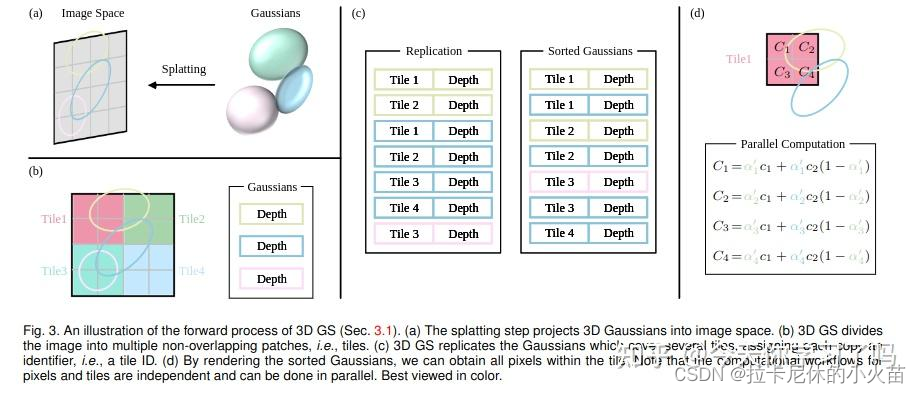
- 预处理:将3D gaussian点集投影到图像
我们先定义一个名词:projected 2d tile,即是3D gaussian投影到tile 网格上的坐标,多个3Dgaussian可能投影到一个2D tile上,这里projected 2d tile只是指一个3D gaussian的投影tile。
预处理由如下步骤构成:
a. 获取3D gaussian point id,由于是在kernel核函数里完成的,这里使用了cuda 9新的Cooperative Groups API,建议在阅读源码前先了解一下。
b. 根据projection matrix,判断3D gaussian 中心点是否在视锥范围内(in_frustum 函数)
c. 计算高斯中心点的2D投影
d. 如果3D 高斯的协方差矩阵没有初始化,那么根据初始scale以及旋转四元数生成初始3D 协方差
e. 计算3D 协方差在2D的投影

f. 计算2D协方差的逆(EWA algorithm)
g. 将投影点转换到像素坐标系,同时根据2D cov计算投影半径
h. 如果3D gaussian的颜色没有初始化,则根据SH球谐计算初始颜色
i. 保存一些有用的信息,用于后续渲染:
// Store some useful helper data for the next steps.
depths[idx] = p_view.z;
radii[idx] = my_radius;
points_xy_image[idx] = point_image;
// Inverse 2D covariance and opacity neatly pack into one float4
conic_opacity[idx] = { conic.x, conic.y, conic.z, opacities[idx] };
tiles_touched[idx] = (rect_max.y - rect_min.y) * (rect_max.x - rect_min.x);
■ 深度
■ 半径
■ 2D投影点
■ 协方差的逆、光度
■ 2D投影矩形的面积
- 利于cub的InclusiveSum,为每个projected 2d tile生成idx
// Compute prefix sum over full list of touched tile counts by Gaussians
// E.g., [2, 3, 0, 2, 1] -> [2, 5, 5, 7, 8]
CHECK_CUDA(cub::DeviceScan::InclusiveSum(geomState.scanning_space, geomState.scan_size, geomState.tiles_touched, geomState.point_offsets, P), debug)
- 为每个projected 2D tile生成key-value:
其中key是 [ tile | depth ],key是一个uint64_t,前32位表示tile id,后32位表示投影深度;value是3D gaussian的id。 - 对上一步生成key-value排序,同样使用的cub库。这样排序的结果是先对tile排序,相同tile id的再按depth排序
如图:

- 为每一个tile分配一个range,因为一个tile会对应多个projected 2D tile,那么需要知道2D projected tile id的起始以及终止。
- 核心的渲染render:
一个tile(即cuda block)包含多个子线程,每个线程对应tile里面的一个pixel。
a. 获取当前kernel对应的block参数
b. 计算当前kernel对应的tile id
c. 计算当前tile对应pixel 左上角的点,以及右下角的点
d. 计算当前kernel对应的pixel id
e. 获取当前tile所对应的range,即为了获取2D projected tile id的起始iD以及终止id。
uint2 range = ranges[block.group_index().y * horizontal_blocks + block.group_index().x];
const int rounds = ((range.y - range.x + BLOCK_SIZE - 1) / BLOCK_SIZE);
int toDo = range.y - range.x;
__shared__ int collected_id[BLOCK_SIZE];
__shared__ float2 collected_xy[BLOCK_SIZE];
__shared__ float4 collected_conic_opacity[BLOCK_SIZE];
代码里toDo代表这个tile共计有多少个projected 2d tile,由于一个tile(即cuda block)包含多个子线程,每个线程对应tile里面的一个pixel,同时代码中采用了cuda中block共享内存操作(一个block共享一段内存),那么针对每个block里的子线程,只需要load 【projected 2d tile】rounds次(为了节省内存读取时间)。
备注:
这里需要好好理解,这里是后续并行渲染的核心
f. 并行渲染
i. 第一个for循环是针对projected 2d tile加载的
for (int i = 0; i < rounds; i++, toDo -= BLOCK_SIZE)
{
// End if entire block votes that it is done rasterizing
int num_done = __syncthreads_count(done);
if (num_done == BLOCK_SIZE)
break;
// Collectively fetch per-Gaussian data from global to shared
int progress = i * BLOCK_SIZE + block.thread_rank();
if (range.x + progress < range.y)
{
int coll_id = point_list[range.x + progress];
collected_id[block.thread_rank()] = coll_id;
collected_xy[block.thread_rank()] = points_xy_image[coll_id];
collected_conic_opacity[block.thread_rank()] = conic_opacity[coll_id];
}
block.sync();
block内所有线程load一次projected 2d tile的信息,包括:id、中心点投影坐标、opacity。等待全部线程读取完成。
ii. 第二个for循环是针对当前在共享内存中的projected 2d tile vector的,计算每个像素所对应的alpha。

如果power和合成的alpha满足条件则退出。
iii. 最后根据两个for循环计算出来的alpha,计算最终的颜色
if (inside)
{
final_T[pix_id] = T;
n_contrib[pix_id] = last_contributor;
for (int ch = 0; ch < CHANNELS; ch++)
out_color[ch * H * W + pix_id] = C[ch] + T * bg_color[ch];
}
备注:
-
__trap

-
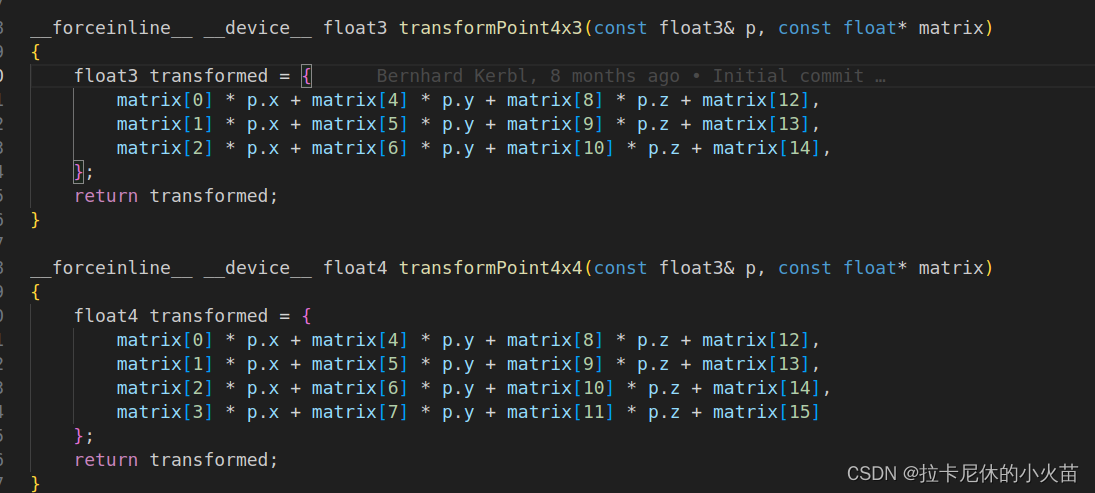
代码投影部分使用的矩阵是col-major
-
computeColorFromSH
根据球谐sh计算颜色的数学部分还没看懂,需要补充 -
alpha颜色混合的数学部分还没仔细看需要补充
参考文献
1. 3D Gaussian Splatting cuda源码解读
2. CUDA之Cooperative Groups操作,细粒度并行操作。
3. CUDA编程入门之Cooperative Groups(1)
4. A survey on 3d gaussian splatting

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)