
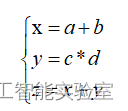
深度学习Pytorch中计算图的概念及理解
深度学习pytorch框架计算图的概念理解
标题0 介绍
0.1 深度学习概览
深度学习是机器学习的一个子领域,旨在模拟人类大脑的神经网络,使机器能够学习并做出明智的决策。神经网络是深度学习的核心,它由相互连接的节点(神经元)层组成,这些节点负责处理和转换输入数据。 层包括输入层、隐藏层和输出层,每个层在信息处理中扮演特定的角色。深度学习模型通过训练过程从数据中学习,在训练过程中,模型根据输入数据和相应的目标结果调整其权重和偏差。反向传播Backpropagation(B-P)是训练神经网络的关键算法。它包括计算损失函数相对于权重的梯度,并调整它们以使误差最小化。激活函数将非线性引入神经网络,使其能够学习复杂的模式。常见的激活函数 sigmoid, tanh, and Rectified Linear Unit (ReLU)。深度学习在计算机视觉(Computer Vision,CV)和自然语言处理(Natural Language Processing,NLP)应用十分广泛。其中卷积神经网络(CNNs)通常用于与图像相关的任务、包括图像分类、目标检测、语义分割等。循环神经网络Recurrent Neural Networks (RNNs)通常用于自然语言处理任务, 包括语言翻译和情感分析等。其中今年较好的大语言模型使用的基于Transformer架构的算法来源于RNN。
0.2 数学表示在深度学习的重要性
数学是深度学习的基础语言,为理解、建模和优化复杂的过程提供了一个精确和结构化的框架。在深度学习领域,人工神经网络模仿人类大脑的工作方式,数学表征在塑造这些复杂模型的结构、训练和解释方面发挥着关键作用。
1.数学建模
深度学习处理数据中复杂的模式和关系。数学表示能够捕获和表达这些复杂关系的模型。方程和函数描述了输入和输出数据之间的转换和交互作用,允许模型从数据样本中学习和推广。
2.神经网络
由层和节点组成的神经网络的体系结构,本质上是基于数学原理的。矩阵乘法、线性变换和激活函数用数学方法表示,以定义通过网络的信息流。图层的排列和激活函数的选择以数学考虑为指导,以提高模型学习层次特征的能力。
3. 优化算法
训练一个深度学习模型包括优化其参数(权重和偏差),以最小化一个预定义的损失函数。这个优化过程依赖于数学优化算法,如梯度下降。微积分和线性代数为计算梯度和迭代更新模型参数提供了数学基础,使误差最小化。
4.损失函数和性能指标
数学表示定义了量化预测结果与实际结果之间差异的损失函数。选择一个适当的损失函数对指导学习过程至关重要。通常用数学方法表示,用来评估模型的性能,以确保它与应用程序的期望目标相一致。
5.Backpropagation(B-P)反向传播
反向传播是训练神经网络的核心算法,它依赖于微积分的链式规则。它便于梯度的计算,允许模型在误差最小的方向上调整其参数。 -反向传播的效率和准确性取决于计算导数的数学原理。
0.3 计算图在深度学习的重要性
在深度学习中,复杂的神经网络解开了数据中的复杂模式,计算图成为理解、优化和实现这些复杂模型的关键抽象。通过神经网络的信息流的视觉和数学表示,提供了一个结构化的框架,以支持训练和推理阶段。计算图在深度学习中的意义在于它能够表达和简化神经网络操作中固有的复杂过程。
1. 计算的图形表示:
计算图提供了在神经网络中执行的操作的直观的可视化表示。图中的节点对应于数学运算,如矩阵乘法和激活,而边表示这些运算之间的数据流。 -这种图形表示有助于概念化和交流深度学习模型中固有的顺序和并行计算。
2. 正向传递、反向传递:
计算图的结构自然地支持神经网络训练过程中的正向和向后传递。正向传递涉及到输入数据通过网络传播以产生预测,而反向传递则使用反向传播等技术来计算梯度。这种双向的信息流被计算图中的有向边优雅地捕获,使模型参数的有效优化。
3. 反向传播和梯度下降:
反向传播,一种训练神经网络的基本算法,它本质上与计算图有关。微积分的链式规则被用来计算相对于模型参数的梯度。计算图提供了一种清晰和系统的方法来组织和计算这些梯度,通过诸如梯度下降等优化算法,促进了权重和偏差的迭代更新。
总之,计算图在深度学习中的重要性是多方面的。它们作为一种计算的表示形式,不仅简化了神经网络的实现,而且增强了对这些模型的理解和优化。从概念到执行,计算图在塑造深度学习的景观中发挥着关键作用,为揭示人工神经网络的复杂性提供了一种结构化和可视化的语言。
1 计算图的概念
计算图是是深度学习模型中数学操作的可视化表示,是计算代数中的一种基础的处理方法,被定义为有向图。该图用于定义和计算神经网络训练过程中的正向和反向传递。在训练过程中,反向传递涉及到使用反向传播等技术计算与参数(权重和偏差)相关的梯度。 计算图是理解和实现深度学习算法的基础,因为它们提供了一种结构化的方法来表示和计算训练神经网络中所涉及的复杂操作。
我们可以通过一个有向图来表示一个给定的数学表达式,并根据图的特点快速方便的对表达式中的变量进行求导。
1.1 计算图实例一
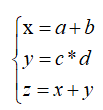
若令a=1,b=2,c=3,d=4 则根据上图的计算过程可以算出 Z

我们或许还会关心:各个输入节点是如何影响输出节点的?影响有多大?也即输出节点对各个输入节点的偏导如何求解的问题。根据链式法则,可以对上面的计算图表示微分:

从图中可以看出各个直接链接的节点之间的偏导

根据链式法则,可以求出。根据链式法则,可以求出
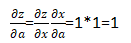
1.2 计算图实例二
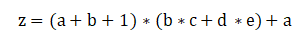
上面表达式的计算过程可以表示成:
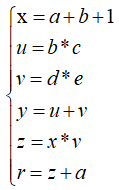
对于上面的计算过程,若令a=1、b=2、c=3、d=4、e=5,则根据上图的计算过程可以算出输出节点r:
可以算出r=105

根据链式法则,可以对上面的计算图表示微分:
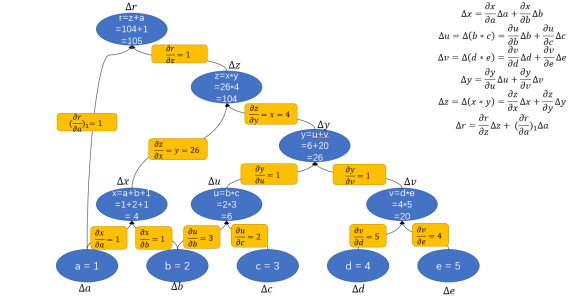
各条边上都注明了偏导。其中a指向r的那条边注明的偏导是是因为a可以通过两种方式影响r,即图中a→r和a→r和a→x→z→r两条边。所以显然r的变化并不仅由a的变化通过a→r这条边影响。
通过链式法则求 :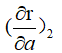
和
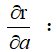
对于a→x→z→r:
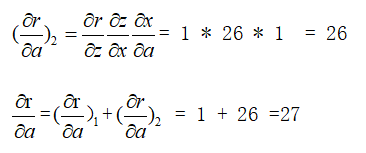
同理,我们也可以求得
2 动态计算图和静态计算图
2.1 静态图
静态图是通过先定义后运行的方式,先搭建图,然后再输入数据进行计算。典型代表是Tensorflow 1.0 版本。其因为张量Tensor在预先定义的图中流动Flow而得名。

2.2 动态计算图
PyTorch 采用的是动态图机制 (Dynamic Computational Graph)。动态图是指计算图的运算和搭建同时运行,也就是可以先计算前面的节点的值,再根据这些值搭建后面的图。

3 pytorch中的动态计算图
3.1 框架使用计算图技术简化网络搭建与计算
在pytorch、caffe、Tensorflow等深度学习出现之前,需要为不同的神经网络编写各自的反向传播算法,这无疑增加了网络实现的难度。目前的深度学习框架都采用了计算图技术(不需要为每一种网络架构实现各自的反向传播算法,只需要关注如何实现神经网络的前馈运算,当前馈运算完成后,深度学习框架自动搭建一个计算图,通过这个图让反向传播算法自动自行计算)。通过计算图来实现反向传播算法的基本思想是将正向的计算过程步骤记录下来。只要这些运算步骤是可微分的,就可以沿着计算图的路径对任意变量进行求导,自动计算每个变量的梯度。
计算图有静态计算图与动态计算图之分,静态计算图是指在程序运行之前就已经确定好了计算图的结构,也就是说在运行时计算图的结构是不会改变的。动态计算图则是在程序运行时动态地生成计算图的结构。在机器学习等领域,使用静态计算图可以帮助优化计算效率,而动态计算图则更加灵活,可以方便地处理变长输入、循环等情况。Tensorflow框架早期的版本实现的是静态计算图,而pytorch实现的是动态计算图。下面我们重点看一下动态计算图。
动态计算图是数值运算和符号运算(微分求导)的一种综合,它是整套深度学习技术和框架中最重要的核心。它实际上是一种描述和记录张量运算过程的抽象网络。一个计算图包括两类节点,分别是变量和运算。计算图上的有向连边表示各个节点之间的因果联系或依赖关系,如下图所示。
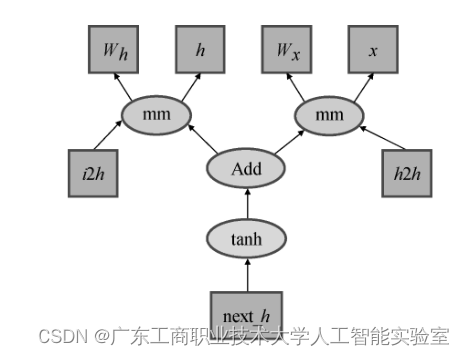
上图中方框节点为变量,椭圆节点为运算操作,它们彼此相连构成了一个有向无环图(一种每条边都有方向且图中并不存在环路的特殊图)。箭头的方向表示该节点计算输入的来源方向,换句话说,沿着箭头的反方向前进就是一个多步计算进行的方向。
3.2 pytorch中的自动微分机制
pytorch是借助自动微分变量(autograd variable)来实现动态计算图的。自动微分变量与普通的张量都可以进行各种运算,但是它的内部数据结构比张量更复杂。在PyTorch1.5中,自动微分变量已经与张量完全合并了,所以,任何一个张量都是一个自动微分变量。在采用自动微分变量以后,无论一个计算过程多么复杂,系统都会自动构造一个计算图来记录所有的运算过程。在构建好动态计算图之后,我们就可以非常方便地利用.backward()函数自动执行反向传播算法,从而计算每一个自动微分变量的梯度信息。
自动微分变量是通过3个重要的属性data、grad以及grad_fn来实现的。data是一个伴随着自动微分变量的张量,专门存储计算结果。这样,PyTorch会将计算的结果张量存储到自动微分变量的data分量里面。此外,当采用自动微分变量进行运算的时候,系统会自动构建计算图,也就是存储计算的路径。因此,我们可以通过访问一个自动微分变量的grad_fn来获得计算图中的上一个节点,从而知道是哪个运算导致现在这个自动微分变量的出现。所以,每个节点的grad_fn其实就是计算图中的箭头。我门完全可以利用grad_fn来回溯每一个箭头,从而重构出整个计算图。最后,当执行反向传播算法的时候,我们需要计算计算图中每一个变量节点的梯度值(即该变量需要调整的增量)。我们只需要调用.backward()这个函数,就可以计算所有变量的梯度信息,并将叶节点的导数值存储在.grad中。
在pytorch中的autograd模块提供了实现任意标量值函数自动求导的类和函数。针对一个张量只需要设置参数requires_grad=True,即可输出其在传播过程中的导数信息。下面通过一个例子来学习pytorch中的自动微分。
x=torch.tensor([[1.0,2.0],[3.0,4.0]],requires_grad=True)
y=torch.sum(x**2+2*x+1)
print(x)
print(x**2+2*x+1)
print(y)
print(x.requires_grad)
print(y.requires_grad)
print("--------")
y.backward()
print(x.grad)
"""
上面的程序首先生成一个矩阵x,并指定其可以求导,
然后根据公司y=x**2+2*x+1计算标量y,因为x可以
求导故y也可以求导。然后通过y.backward()自动
计算y在x上的每个元素上的导数,然后通过x的gard
属性即可获取此时x的梯度信息,并且得到的梯度值为2x+2
"""
4 结语
今天更新的内容,有很多名词大家可能第一次听,阅读完有不懂的疑问可以查阅相关资料尽快搞清,文章如果读不懂,没有关系。让问题就暂时的放在脑子里,占个位置,这次阅读主要把计算图的实例计算理解出来,其余知识可在后面随着学习的深入一点点解开。
作业: 在计算图实例二中,自行求解
参考博文
深度学习入门与Pytorch|2.1 计算图的概念与理解 - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/412542969
Pytorch快速入门系列—(二)动态计算图、自动微分、torch.nn模块_pytorch计算图训练-CSDN博客 https://blog.csdn.net/qq_42681787/article/details/129394170

更多推荐


 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)