
【2024最新】 服务器安装Ubuntu20.04 (安装教程、常用命令、故障排查)持续更新中.....
中的方法二,使用系统自带的 “软件和更新” 程序 - 附加驱动,选择带有recommend的驱动,进行安装。,配置apt-get换国内阿里源。安装过程中可能会出现的问题。
·
安装教程(系统、NVIDIA驱动、CUDA、CUDNN、Pytorch、Timeshift、ToDesk、花生壳)
- 制作U盘启动盘,并安装系统
- 在MSDN i tell you下载Ubuntu20.04 Desktop 版本,并使用Rufus制作UEFI启动盘,参考UEFI安装Ubuntu
- 使用GPT+UEFI模式安装,记得更改主板选项Legacy to EFI support 为 enable
- 出现安装系统重启后黑屏,可能是显卡驱动没有安装,参考重装ubuntu 20.04.1系统完成后遇到黑屏怎么办?
- 安装NVIDIA显卡驱动
-
先参考Ubuntu20.04下深度学习环境配置,配置apt-get换国内阿里源
-
参考Ubuntu18-22.04安装和干净卸载nvidia显卡驱动——超详细、最简单中的方法二,使用系统自带的 “软件和更新” 程序 - 附加驱动,选择带有recommend的驱动,进行安装
-
安装过程中可能会出现的问题
1.The distribution-provided pre-install script failed! Are you sure you want to continue? 选择continue installation 2.Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you install a different kernel later? 选择 No 继续。 3.问题没记住,选项是:install without signing 4.问题大概是:Nvidia's 32-bit compatibility libraries? 选择 No 继续。 5.Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up. 选择 Yes 继续 -
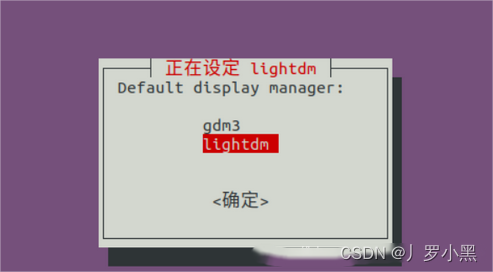
如果出现安装驱动后黑屏,可能是图形管理器gdm3不兼容,可以安装lightdm,代码如下:
sudo apt-get install lightdm
- 安装好后,选择lightedm作为默认图形管理器
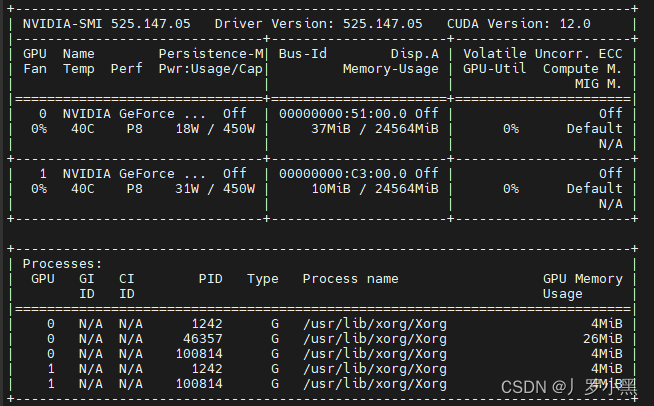
- 验证
//执行此语句,出现显卡信息则证明安装成功。
nvidia-smi
3. 安装Anaconda
-
参考Ubuntu20.04下深度学习环境配置,安装Anaconda
-
可能出现的问题:
1.“Do you accept the license terms” // 是否同意条款,如果拒绝则无法安装 输入“yes” 2.“Do you wish the installer to initialize Anaconda3 by running conda init?” // conda初始化操作,如果拒接可能会遇到接下来的问题 输入“yes” -
在给新用户安装Anaconda后,①没有显示(base),②conda:未找到命令,可采用以下代码:
//先解决 2
sudo vim ~/.bashrc
//打开文件后,按i插入下一行,用户名更改为自己的用户名,之后按esc,输入:wq!,保存并关闭文件
export PATH="/home/用户名/anaconda3/bin:$PATH"
//更新source
source ~/.bashrc
//再解决 1,直接初始化conda
conda init
- pip换清华源
- 在
/home/xx目录下创建.pip文件夹
mkdir ~/.pip
- 创建
pip.config文件
sudo vim ~/.pip/pip.conf
- 写入以下内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn
- 安装Pytorch-cpu
- 参考Ubuntu20.04下深度学习环境配置,安装Pytorch-cpu
- 安装CUDA
- 即使不在新建的conda虚拟环境中安装,如在base中安装CUDA,其他的虚拟环境也能正常使用
- 参考Ubuntu20.04下深度学习环境配置,安装CUDA
- 安装CUDNN
-
所以即使不在新建的conda虚拟环境中安装,如在base中安装CUDNN,其他的虚拟环境也能正常使用
-
cudnn9.0.0版本安装如下:
- 进入官网,cudnn官网
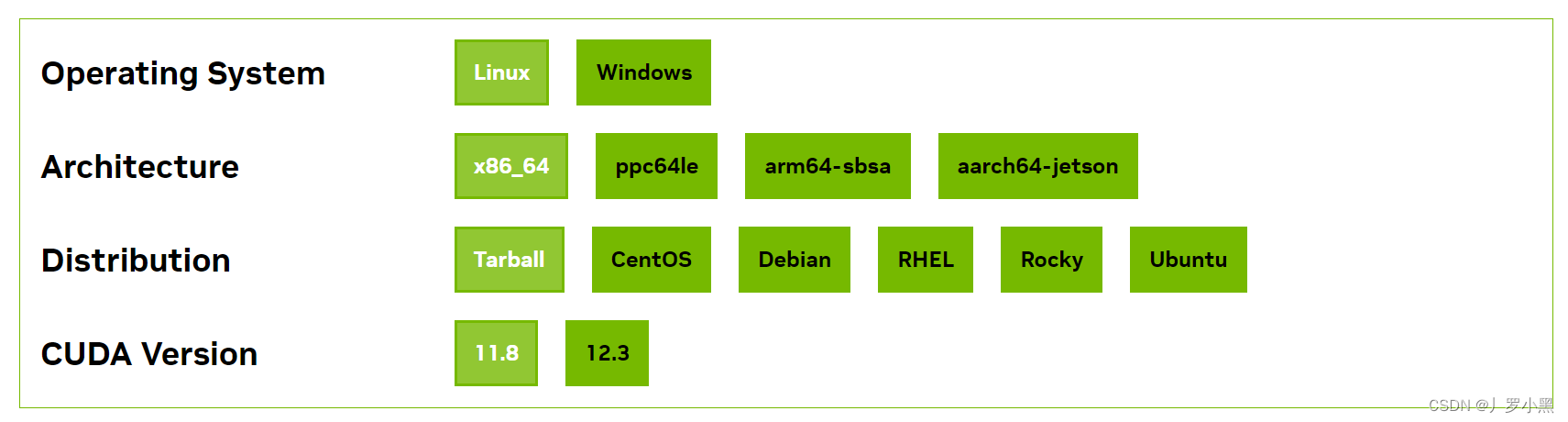
- 选择ubuntu20.04版本,并本地安装,如下图:
-
由于选择Ubuntu时无法验证是否安装成功,所以这里选择第一个Tarball,下载.tar.xz文件进行解压安装
- 安装代码如下:
-
如果上一步选择了Ubuntu,那么这里使用以下代码
wget https://developer.download.nvidia.com/compute/cudnn/9.0.0/local_installers/cudnn-local-repo-ubuntu2004-9.0.0_1.0-1_amd64.deb
sudo dpkg -i cudnn-local-repo-ubuntu2004-9.0.0_1.0-1_amd64.deb
sudo cp /var/cudnn-local-repo-ubuntu2004-9.0.0/cudnn-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cudnn
# 如果当前环境的cuda版本为11.x,那么用这行代码
sudo apt-get -y install cudnn-cuda-11
# 如果当前环境的cuda版本为12.x,那么用这行代码
sudo apt-get -y install cudnn-cuda-12
- Tarball的cudnn安装如下:
- 参考Ubuntu20.04下深度学习环境配置,安装CUDNN
- 在输入以下代码时,前一个cuda是解压CUDNN后的目录,而cuda-xxx表示,将xxx更改为上一步安装cuda的版本号,具体可以打开目录 /user/local 进行查看。
sudo cp cuda/include/cudnn* /usr/local/cuda-xxx/include
sudo cp cuda/lib/libcudnn* /usr/local/cuda-xxx/lib64
sudo chmod a+r /usr/local/cuda-xxx/include/cudnn*
sudo chmod a+r /usr/local/cuda-xxx/lib64/libcudnn*
- 使用以下代码,进行检查:
3. 验证是否安装成功
cat /usr/local/cuda-11.8/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
- 安装Pytorch
- 新建conda虚拟环境,并在虚拟环境中安装Pytorch
- 参考Ubuntu20.04下深度学习环境配置,安装Pytorch
- 注意:pytorch自带cuda和cudnn,所以在安装了pytorch的虚拟环境中,默认使用的是pytorch自带的cuda和cudnn,查看cuda和cudnn版本的命令如下:
# 进入pytorch环境
import torch
# 可以正确输出 cuda 版本号,说明 cuda 安装成功
print(torch.version.cuda)
# 可以正确输出 cuDNN 的 版本号,说明 cuDNN 安装成功
print(torch.backends.cudnn.version())
# 输出是 True,说明 CUDA 和 GPU 驱动的搭配是正确的
print(torch.cuda.is_available())
- 安装Timeshift
- 安装ToDesk
- 由于向日葵在切换Ubuntu账号时会黑屏,暂时找不到解决办法,所以使用ToDesk
- 安装方法,参考ToDesk官网
- 安装花生壳
- 安装花生壳用内网穿透,实现外网访问内网服务器,具体参考花生壳免费实现Linux主机的内网穿透,可通过SSH、SCP远程访问
- 需要注意:由于公开服务器至外网,因此会经常被攻击。所以要么开vip限制访问,要么仅在需要使用的时候开启内网穿透,不需要就及时关闭。
服务器的简化操作(远程Pycharm)
- Pycharm远程连接服务器,参考PyCharm连接远程服务器配置过程
- 注意:连接远程服务器后的Pycharm,相当于可视化修改代码的“记事本”,该项目的所有文件都会自动上传至服务器,因此代码并不在本地运行,但服务器上的文件不能自动同步到本地。
- 实际运行流程为:先由Pycharm发送运行命令,然后服务器开始执行代码,最后代码运行结束,生成的模型也是留在服务器,需要手动下载回本地。
常用命令
- conda命令,参考conda常用命令汇总,随时查询(最全)
- 为普通用户添加sudo权限、删除sudo权限的方法,参考Ubuntu系统上为用户授予和删除sudo权限的方法
- 桌面卡死解决办法,参考Ubuntu桌面卡死解决办法
- 关闭SSH窗口后,使模型继续运行,参考screen命令解决SSH远程服务器训练代码断开连接后运行中断
# 如果-ls输入错误成-l,那么重新输入-ls后会出现以下信息:
(base) pp@slol:~$ screen -ls
There are screens on:
1301732.pts-7.slol (2024年03月18日 21时37分41秒) (Detached)
27515.pp (2024年03月16日 21时07分52秒) (Detached)
26902.pts-0.slol (2024年03月16日 21时00分53秒) (Detached)
3 Sockets in /run/screen/S-pp.
* 这可以使用screen -r命令重新连接到要关闭的会话,例如:
# 第一个和第三个的名称要输全
screen -r 1301732.pts-7.slol
screen -r 26902.pts-0.slol
# 中间一个可以直接这样输入
screen -r pp
# 连接到会话后,可以按下Ctrl + A + K键组合来杀死当前会话,以及杀死对话中的进程。
# 使用Ctrl + A + D键组合来暂时中断当前会话,不会杀死对话中的进程。
- 实时查看CPU、GPU温度,参考Ubuntu 系统实时查看CPU温度和GPU温度
- 实时查看CPU占用率,参考(top命令)如何使用各种工具和命令来检查 Ubuntu 中的 CPU 使用情况?
- 查看磁盘空间占用率,参考【Linux】与磁盘相关的常用命令(自用)
- 更改linux服务器的DNS服务器,禁用IPv6
# 更改DNS服务器,查看DNS服务器设置
systemd-resolve --status
# 1. 修改系统的永久DNS文件,命令如下
sudo vim /etc/systemd/resolved.conf
# 2. 取消DNS行的注释,并更改如下:
DNS=8.8.8.8 114.114.114.114
# 3. 保存并推出永久DNS文件
ESC + :wq!
# 4. 清空本地DNS缓存
sudo systemd-resolve --flush-caches
# 5. 重启systemd-resolved服务
sudo systemctl restart systemd-resolved
# 6. 检查systemd-resolved服务状态
sudo systemctl status systemd-resolved
# 7. 查看接口名称
nmcli con show
# 8. 更改指定连接的DNS,将为IPv4设置Google的公共DNS服务器,并删除IPv6的DNS服务器
# 并告诉NetworkManager忽略由DHCP提供的DNS服务器
nmcli con mod "有线连接 1" ipv4.dns "8.8.8.8"
nmcli con mod "有线连接 1" ipv4.ignore-auto-dns yes
nmcli con mod "有线连接 1" ipv6.dns ""
nmcli con mod "有线连接 1" ipv6.ignore-auto-dns yes
# 9. 重启NetworkManager服务
sudo systemctl restart NetworkManager
# 10. 检查是否修改完成
systemd-resolve --status
# 禁用IPv6
# 1. 进入sysctl.conf文件
sudo vim /etc/sysctl.conf
# 2. 添加以下行
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
# 3. 保存更改后,执行以下命令
sudo sysctl -p
故障排查
- 服务器被陌生IP访问,查看是否被入侵的简单步骤:
# 1. 先lastb 查看登录失败的用户名、ip、时间等信息
sudo lastb
# 2. 若btmp文件过大,被系统的logrotate自动轮转,则旧文件会默认以 btmp.1 btmp.2 btmp.3的形式存储在 /var/log/目录下
# 再用以下命令查看某个btmp文件,如查看btmp.1
sudo lastb -f /var/log/btmp.1
# 3. 使用last命令查看已经登录过的用户名、ip、时间等信息
sudo last
# 4. 使用echo命令清空btmp文件或wtmp文件
sudo echo > /var/log/btmp
sudo echo > /var/log/wtmp
- 根据进程号查看该进程的启动文件以及工作目录
# 1. 先使用top命令查看当前占用cpu的进程号是什么
# 2. 使用nvidia-smi命令查看当前占用gpu的进程叫什么名字
# 3. 拿到进程号,比如3531之后,我们进入root用户
su root
# 4. 执行以下命令,即可查看该进程的目录列表
ll /proc/3531
# 5. 其中 cmd 是进程当前工作目录,exe 是进程的启动路径,cmdline 包含用于启动进程的完整命令行参数
- 防止服务器被暴力破解,给服务器添加脚本:每小时检查是否有登录失败的ip,如果有就封禁该ip
- 可以通过以下命令,查看登陆失败超过4次的ip:
sudo lastb |awk '{print $3}'|sort |uniq -c|awk '{if ($1 > 4) print $2}'
- 服务器被陌生IP访问,查看是否被入侵的排查手册:
- 简单版,参考如何检查linux服务器是否被入侵
- 详细排查手册,参考Linux 应急响应流程及实战演练

瓜分20万奖金 获得内推名额 丰厚实物奖励 易参与易上手
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)