

UUID会不会重复?概率多大?
通用唯一识别码UniversallyUniqueIdUUID)是用于计算机体系中以识别信息的一个128位标识符。UUID按照标准方法生成时,在实际应用中具有唯一性,且不依赖中央机构的注册和分配。UUID重复的概率接近零,可以忽略不计。因此,所有人都可以自行建立和使用UUID,而且几乎可以确定其不会与既有的标识符重复。也因为如此,在不同地方产生的UUID可以使用于同一个数据库或同一个频道中,而且几乎

公众号:疾风追马
前言
有一次面试,面试官问我UUID会不会重复,我当时只知道UUID是通用唯一识别码,既然是唯一,那肯定就不会重复呀。事实证明当前的我还是太年轻了,今天就来一次讲清楚UUID的知识。
正文
什么是UUID?
通用唯一识别码(英语:Universally Unique Identifier,缩写:UUID)是用于计算机体系中以识别信息的一个128位标识符。
UUID按照标准方法生成时,在实际应用中具有唯一性,且不依赖中央机构的注册和分配。UUID重复的概率接近零,可以忽略不计。
因此,所有人都可以自行建立和使用UUID,而且几乎可以确定其不会与既有的标识符重复。也因为如此,在不同地方产生的UUID可以使用于同一个数据库或同一个频道中,而且几乎不可能重复。
UUID的应用相当普遍,许多计算平台都提供了对于生成和解析UUID的支持。
这是百科里关于UUID的描述,大多数人对于UUID的理解可能也就到这里了,但是为什么是重复概率接近零,而不是绝对不会重复呢?
UUID的版本
UUID目前标准版中有5个版本,这里版本的意思,其实就是生成规则,不同版本生成规则不同。
版本1的UUID是根据时间和节点ID(通常是MAC地址)生成;
版本2的UUID是根据标识符(通常是组或用户ID)、时间和节点ID生成;
版本3、版本5透过对命名空间(namespace)标识符和名称进行散列生成确定性的UUID;
版本4的UUID则使用随机性或伪随机性生成。
如何识别UUID的版本
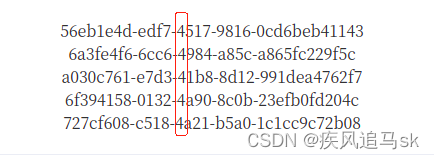
这是版本4的UUID,第二个-后第一位就是他的版本号啦~
Java中的UUID
/**
* Static factory to retrieve a type 4 (pseudo randomly generated) UUID.
*
* The {@code UUID} is generated using a cryptographically strong pseudo
* random number generator.
*
* @return A randomly generated {@code UUID}
*/
public static UUID randomUUID() {
SecureRandom ng = Holder.numberGenerator;
byte[] randomBytes = new byte[16];
ng.nextBytes(randomBytes);
randomBytes[6] &= 0x0f; /* clear version */
randomBytes[6] |= 0x40; /* set to version 4 */
randomBytes[8] &= 0x3f; /* clear variant */
randomBytes[8] |= 0x80; /* set to IETF variant */
return new UUID(randomBytes);
}
/**
* Static factory to retrieve a type 3 (name based) {@code UUID} based on
* the specified byte array.
*
* @param name
* A byte array to be used to construct a {@code UUID}
*
* @return A {@code UUID} generated from the specified array
*/
public static UUID nameUUIDFromBytes(byte[] name) {
MessageDigest md;
try {
md = MessageDigest.getInstance("MD5");
} catch (NoSuchAlgorithmException nsae) {
throw new InternalError("MD5 not supported", nsae);
}
byte[] md5Bytes = md.digest(name);
md5Bytes[6] &= 0x0f; /* clear version */
md5Bytes[6] |= 0x30; /* set to version 3 */
md5Bytes[8] &= 0x3f; /* clear variant */
md5Bytes[8] |= 0x80; /* set to IETF variant */
return new UUID(md5Bytes);
}java中的UUID类位于java.util包下
randomUUID 这个方法是类型4的随机数生成的,也是我们最常用的
nameUUIDFromBytes 这个则是类型3基于名称生成的
我们来通过代码验证一下
UUID uuid1 = UUID.nameUUIDFromBytes(new byte[]{'a', 'b', 'c'});
System.out.println("uuid1 = " + uuid1);
UUID uuid2 = UUID.nameUUIDFromBytes(new byte[]{'a', 'b', 'c'});
System.out.println("uuid2 = " + uuid2);
UUID uuid3 = UUID.randomUUID();
System.out.println("uuid3 = " + uuid3);
UUID uuid4 = UUID.randomUUID();
System.out.println("uuid4 = " + uuid4);uuid1 = 90015098-3cd2-3fb0-9696-3f7d28e17f72
uuid2 = 90015098-3cd2-3fb0-9696-3f7d28e17f72
uuid3 = 2fd31523-bffb-4a7d-8cb9-a8b9c398822e
uuid4 = af06ce71-6da4-4fdc-bc2b-096c99dbaba5用nameUUIDFromBytes这个方法,如果传入的字符数组相同,那么生成UUID也会相同
而用randomUUID这个方法则不会生成相同的UUID
冲突概率
UUID 的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 32 个字符。示例:550e8400-e29b-41d4-a716-446655440000
因为是16进制,每个位置有16种情况,共32个字符,理论上能生成不重复的结果总共有 16^32=2^128种,约等于 3.4 x 10^38。
这是一个非常非常大的数字,想想看,一亿也只是10^8。
我们再来计算冲突的概率,
假设已经生成了1个UUID,那么下一次生成发生冲突的概率是 1/3.4 x 10^38
假设已经生成了2个UUID,那么下一次生成发生冲突的概率是 2/3.4 x 10^38
...
随着我们已经生成的UUID不断变多,下次发生冲突的概率也在不断变大,但是因为总量实在太大,所以尽管概率一直在变大,也可以完全忽略不计
总结
严谨来讲,UUID可能会发生冲突,因为总量大,发生冲突的可能性极小,可以忽略不计
优点:
- 本地生成 ID,不需要进行远程调用,没有网络耗时
- 基本没有性能上限
缺点:
- 可读性差
- 长度过长,16 字节 128 位,生成的 UUID 通常是 36 位 (包含 -),不适合作为数据库主键,如果作为主键,二级索引 (非主键索引) 会占用很大的空间。
- 无法保证趋势递增,在 MySQL 的 InnoDB 引擎下,新插入数据会根据主键来寻找合适位置,会导致频繁的移动、分页增加了很多开销。
在线生成UUID的网站:UUID Online

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 25
25 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)