
从声纹模型到语音合成:音频处理 AI 技术前沿 | 开源专题 No.45
这些开源项目涵盖了音频处理、实时音频转换和语音识别合成等多个领域,利用深度学习技术和开源工具库为音频处理领域提供了先进的工具和模型。它们为语音合成、处理和转换任务提供了丰富的资源,对相关研究和应用具有重要意义。
facebookresearch/audiocraft
Stars: 16.6k License: MIT
AudioCraft 是一个用于音频生成的 PyTorch 库。它包含了两个最先进的 AI 生成模型 (AudioGen 和 MusicGen) 的推理和训练代码,可以产生高质量音频。该项目还提供了其他功能:
- MusicGen:一种最新技术实现的可控文本到音乐模型。
- AudioGen:一种最新技术实现的文本到声音模型。
- EnCodec:一种高保真度神经音频编解码器。
- Multi Band Diffusion:使用扩散算法与 EnCodec 兼容的解码器。
此外,AudioCraft 还包括深度学习研究中使用到的 PyTorch 组件以及开发出来各个模型所需训练流程管道等内容,并提供 API 文档、常见问题 FAQ 等信息。
w-okada/voice-changer
Stars: 12.4k License: NOASSERTION
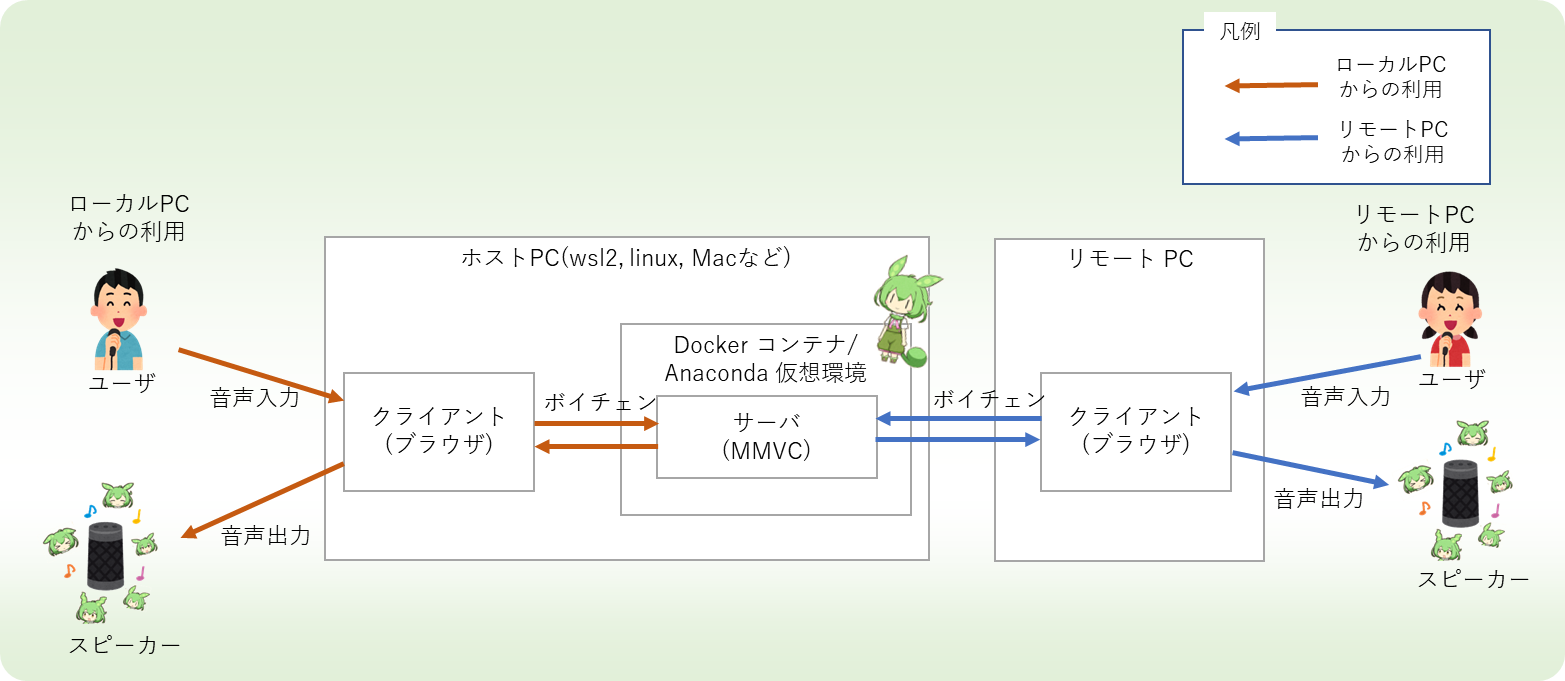
VC Client 是一个用于实时音频转换的客户端软件,使用各种语音转换 AI (VC,Voice Conversion) 进行操作。该项目支持多个平台,并且可以通过网络连接来卸载外部负载以处理音频转换任务。主要功能包括:
- 支持多种声音变化 AI
- MMVC
- so-vits-svc
- RVC(Retrieval-based-Voice-Conversion)
- DDSP-SVC
- Beatrice JVS Corpus Edition (试验性)
- 提供事前构建好的二进制文件和 Docker/Anaconda 环境搭建两种使用方式。
- 可以实现高效率、低延迟的实时语音变化;
- 跨平台兼容性强,适用于 Windows、Mac(M1)、Linux 等系统;
espnet/espnet
Stars: 7.2k License: Apache-2.0

ESPnet 是一个端到端的语音处理工具包,涵盖了端到端语音识别、文本转语音、语音翻译、语音增强、说话人分离等功能。该工具使用 pytorch 作为深度学习引擎,并遵循 Kaldi 风格的数据处理和特征提取/格式以及配方来提供各种不同的实验设置。
- 支持多个 ASR (自动演讲识别) 配方
- 支持类似于 ASR 配方一样的 TTS (文本转声)
- 支持 ST (Speech Translation) 配方
- 提供完整且易用的命令行界面和脚本接口
babysor/MockingBird
Stars: 31.6k License: NOASSERTION
这个项目是一个实时语音克隆的开源项目,主要功能包括支持中文、使用 PyTorch 进行训练和推理、可以在 Windows 和 Linux 系统上运行以及提供 Web 服务器。该项目的核心优势和特点包括:
- 支持多种数据集,并经过测试
- 可与最新版本 (2021年8月) 的 PyTorch 一起工作,并且可以利用 GPU 加速
- 通过重复使用预先训练好的编码器/解码器来轻松生成令人印象深刻的效果
- 提供 Web 服务器,方便远程调用结果
CorentinJ/Real-Time-Voice-Cloning
Stars: 43.3k License: NOASSERTION
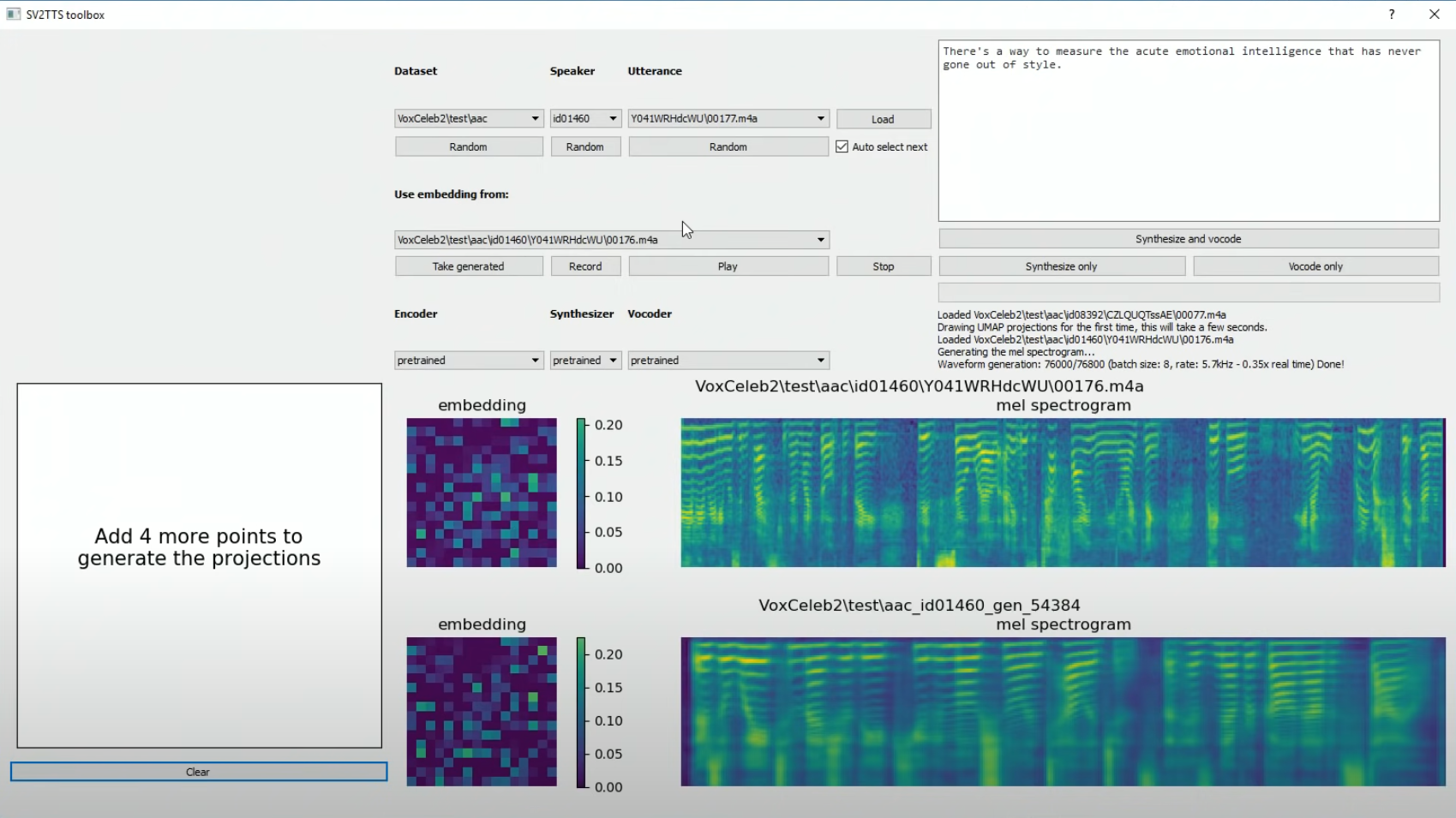
这个开源项目是一个实时语音克隆工具,可以在5秒内复制一种声音,并生成任意文本的语音。
该项目的主要功能包括:
- 从几秒钟的录音中创建声纹模型
- 根据给定文本使用参考声纹模型合成语音
该项目有以下关键特性和核心优势:
- 实时处理:能够快速进行语言克隆并生成对应文字内容。
- 多说话人支持:通过转移学习技术,使得系统能适用于多个不同说话人。
- 简单易用:提供了简洁明了的安装和配置指南以及演示脚本。
neonbjb/tortoise-tts
Stars: 7.2k License: Apache-2.0
TorToiSe 是一个多音色 TTS 系统,其重点在于质量。
它具有以下优势和特点:
- 强大的多声道功能。
- 高度逼真的韵律和语调。
- 可以使用自己预训练的模型。
- 改进了读取工具,并添加了新选项。

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)