

Python爬虫--获取POI
爬虫是一种自动化获取互联网信息的程序。通过模拟人类浏览器行为,自动抓取网页上的数据,并进行处理和分析。他能够获取常规的网页HTML源代码,CSS、JavaScript文件,图片、视频等二进制文件,还有很多API接口类的信息像JSON类信息等。
一、爬虫简介
爬虫是一种自动化获取互联网信息的程序。通过模拟人类浏览器行为,自动抓取网页上的数据,并进行处理和分析。他能够获取常规的网页HTML源代码,CSS、JavaScript文件,图片、视频等二进制文件,还有很多API接口类的信息像JSON类信息等。
二、如何通过python获取POI
POI表示某个地理位置周边的信息。本文使用高德地图api,以获取广东财经大学周边5000米范围内的粤菜馆为例进行阐述。
(声明:本人非计算机相关专业,编程基础也寥寥无几,文章仅是作为选修课学习内容和个人爱好,分享和记录学习过程。)
具体流程主要分为三步:
1.获取所需网页信息
2.将信息进行解析、提取
3.将数据保存为自己想要的格式。
(一)获取所需网页信息。
这里我也将其分为三小步:首先确定广财的具体位置,其次获取地点信息,最后对其进行周边搜索,获取网页信息。
1.确定具体位置
要获得广财大周边信息,首先我们要确认广财大的具体位置,这里有两种方法。
方法一:利用高德地图拾取器确认其坐标位置。
网址如下:
高德地图API![]() https://lbs.amap.com/tools/picker*温馨提示:如果只是作为游客查询,查询地点的坐标精度只有两位数,其实是不够精确的。将”按关键字搜索“获取到的广财大的坐标重新输入”按坐标搜索“,会发现显示出的地址与原来想要查询的有偏差。如图所示:
https://lbs.amap.com/tools/picker*温馨提示:如果只是作为游客查询,查询地点的坐标精度只有两位数,其实是不够精确的。将”按关键字搜索“获取到的广财大的坐标重新输入”按坐标搜索“,会发现显示出的地址与原来想要查询的有偏差。如图所示:
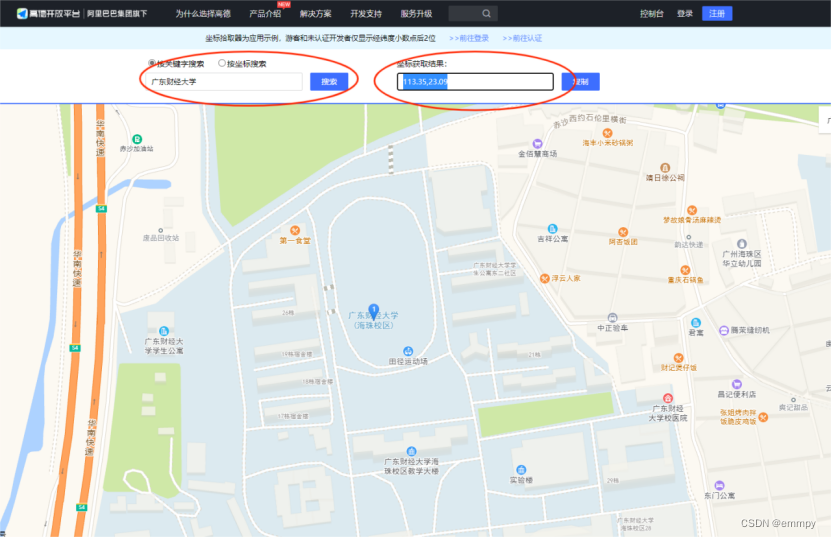
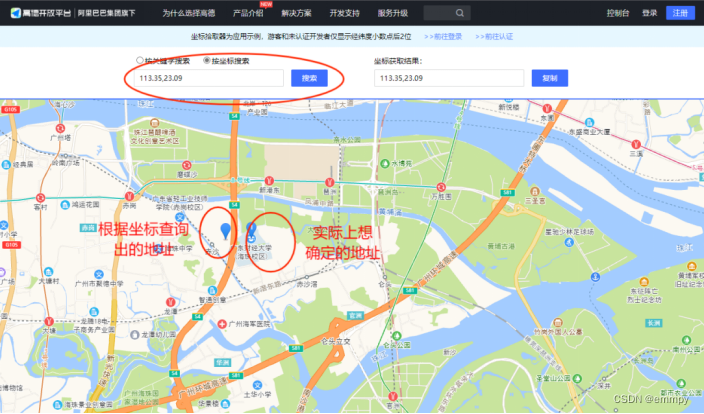
这里只要在高德地图进行登录及认证,就可以获得更精确的坐标了。
结果如图所示,可以精确到小数点后六位:

方法二:关键字搜索POI
高德地图为我们提供了搜索POI功能,能够通过文本关键字搜索想要的地点信息。

具体步骤如下:

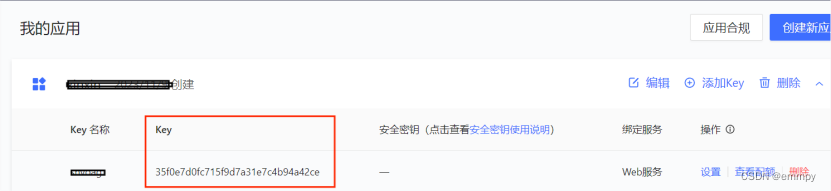
第一步,申请wed服务api类型key。
点击高德地图api控制台—管理应用—我的应用

创建新应用-添加key
这里服务平台选web服务
所需key创建完成
第二步,发起请求。
我们通过高德地图关键字搜索api提供的url访问地点信息,代码如下:
(URL是对互联网上得到的资源的位置和访问方法的一种简洁表示,是互联网上标准资源的地址。)
其中parameters替换为图中所示必填的参数key和keywords(或types)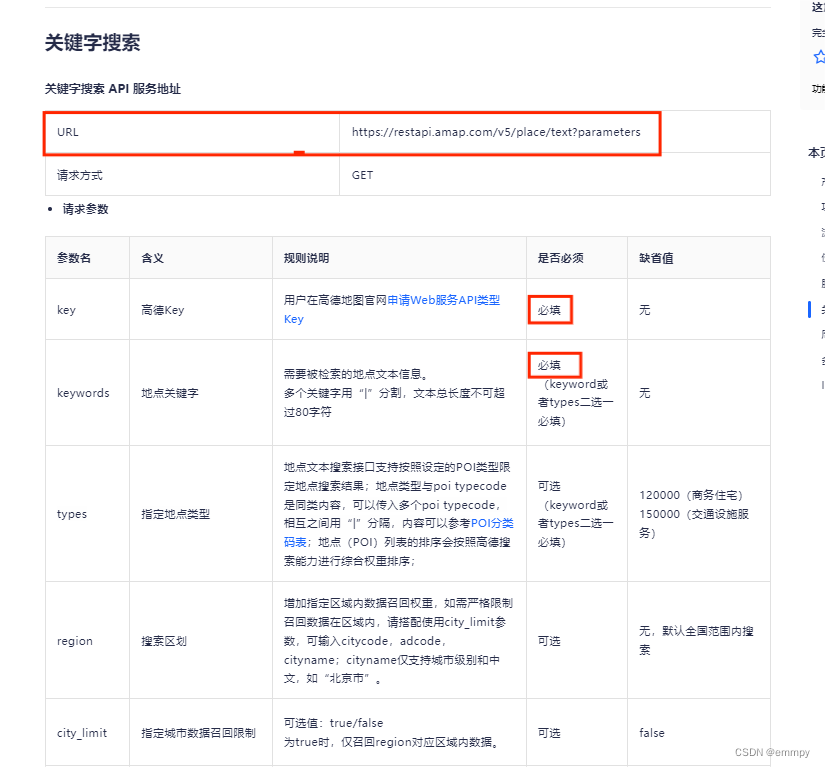
在本文例子下完整代码如下:
(用&连接各个参数)
写好之后可以将url输入浏览器,可以访问一个包含广财大的地址信息的json文件,如下图所示。同时可以通过此检查url是否正确。
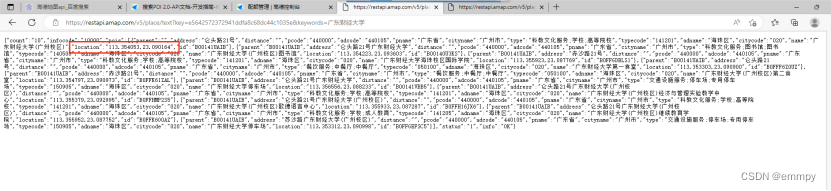
到这里我们获得了广财大的坐标信息就足够了,不用进行第三步,到后面获取我们想要的周边粤菜馆信息时候再进行解析即可。
2.获取周边信息

这里和上一步步骤几乎相同,不过多赘述,这里几个参数进行解释:
types:由于我们要查询的是粤菜馆,所以必须要填写参数types作为制定类型。types的规则说明中有“POI分类码表”excel表。可以查询想要的地点类型。这里types=050103,如果需要查询多个类型,用|将代码隔开。

radius、page_size和page_num:分别表示要搜索的半径范围,每页25条数据,第几页。这些参数也可以不填,则默认为缺省值
此步url为:
https://restapi.amap.com/v5/place/around?key= 48a31ebd6dd0a05b15b97f23393f7895(这里换成自己创建的key)&types=05103&location=113.354053,23.090164&radius=5000&page_size=25&page_num=1
访问结果如图:
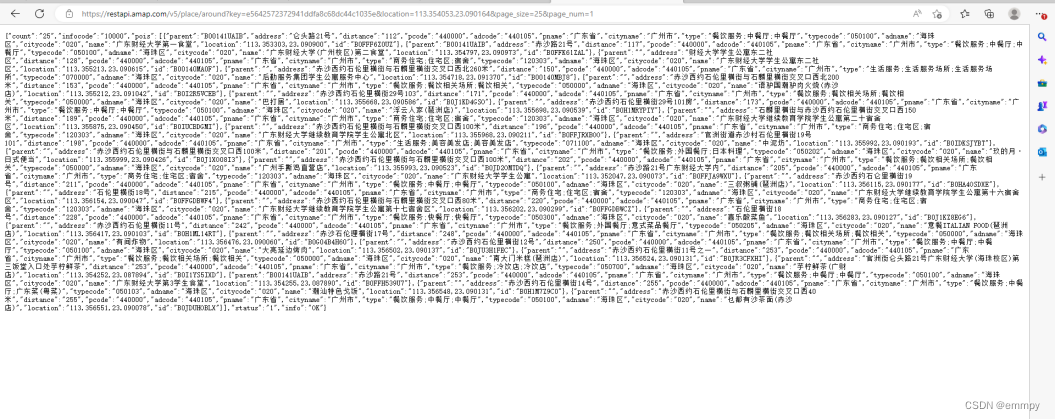
到这里我们已经以json文件的形式获得到我们想要的信息了,但看起来并不整齐直观,接下来我们需要将它解析出来。
(二)将信息进行解析、提取
这里我们用python对所获得的json文件进行解析、提取。
需要用到几个库:
requests,请求访问json文件
pandas,用于存储、处理数据
openpyxl,将数据导入excel
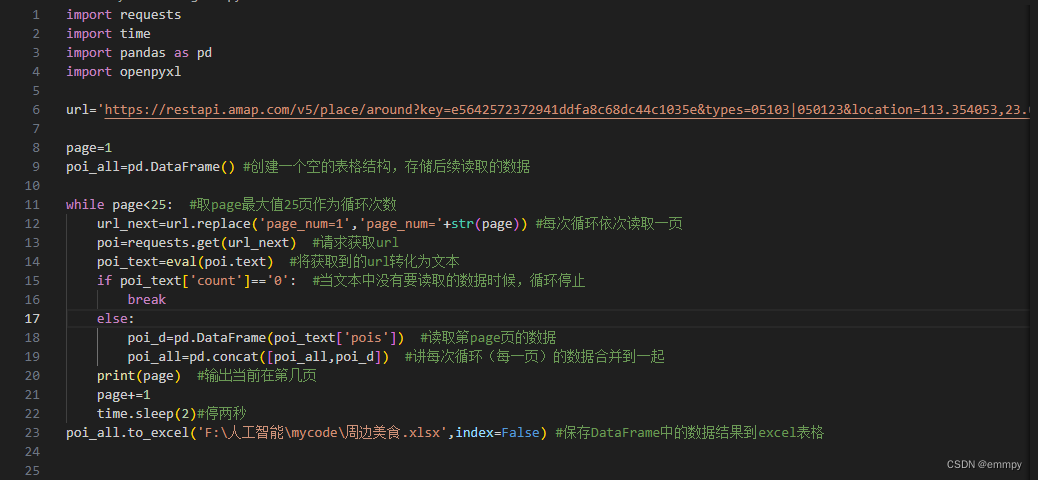
代码如下(按自己理解写的注释,可能解释的不专业):
*最后导入的excel表格需要自己先创建好,再将路径写入代码。
(三)将数据保存为自己想要的格式
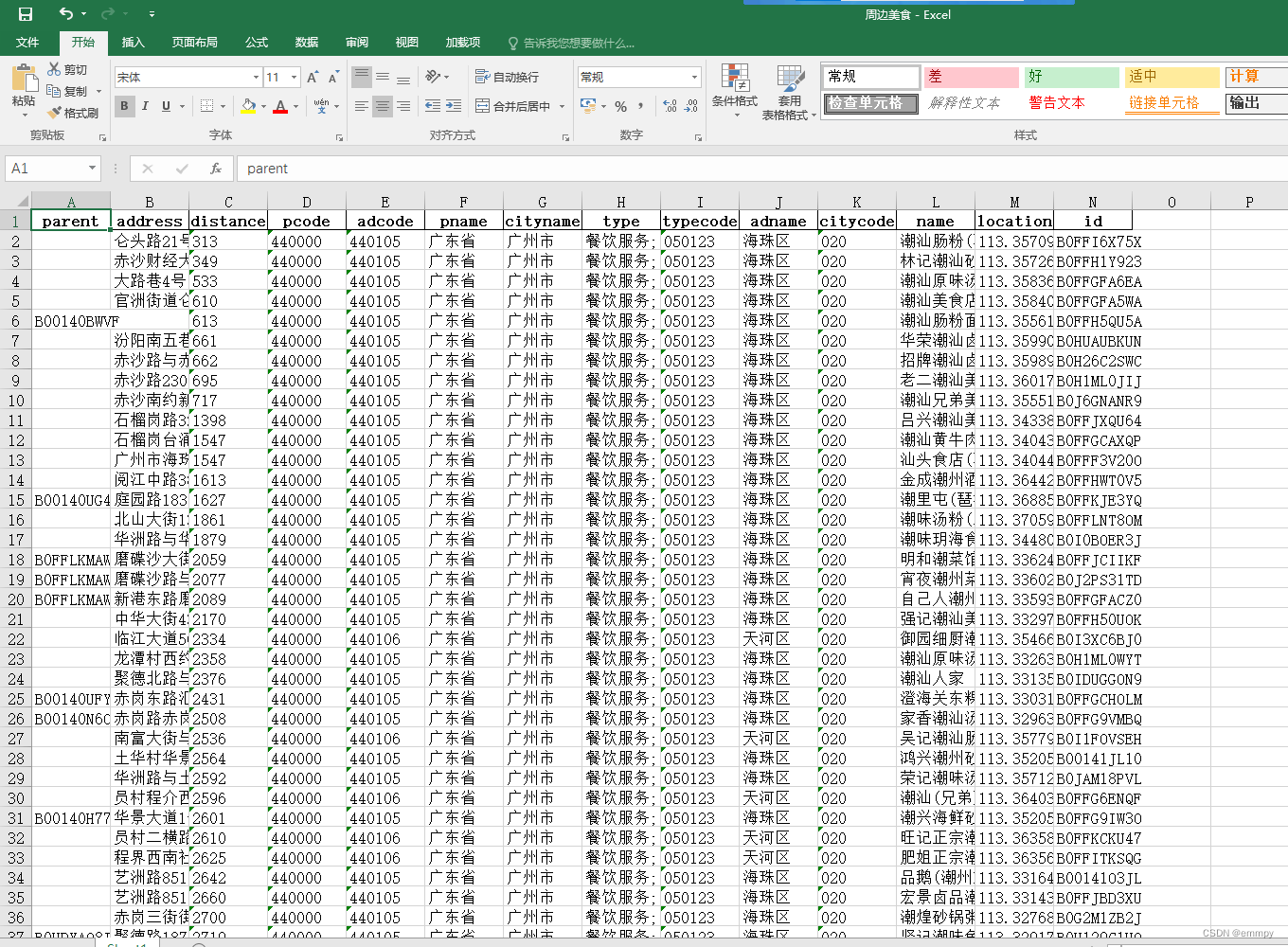
这里我们将数据保存在excel中,结果如图所示:
以上为本案例所有过程,希望大家批评指正。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)