LangChain之CharacterTextSplitter的split_text和split_documents
从说法上,我实在是看不出来有什么关系,然后我就没当回事,就按照字面意思就开整了(OS:当时我就想着,这两个方法应该我用一个就好,处理的是文本,那么就梭哈写出了下面的ChineseTextSplitter类)我本来是用一个csv文件来做demo的,那么就参考别人的代码,开始了照虎画猫的拙劣表演。我心想为啥有两个方法,我就无意中点开了。总结一句话就是,能力不足,基础不牢,只懂梭哈,傻乐吃瓜。至此初步了
前言
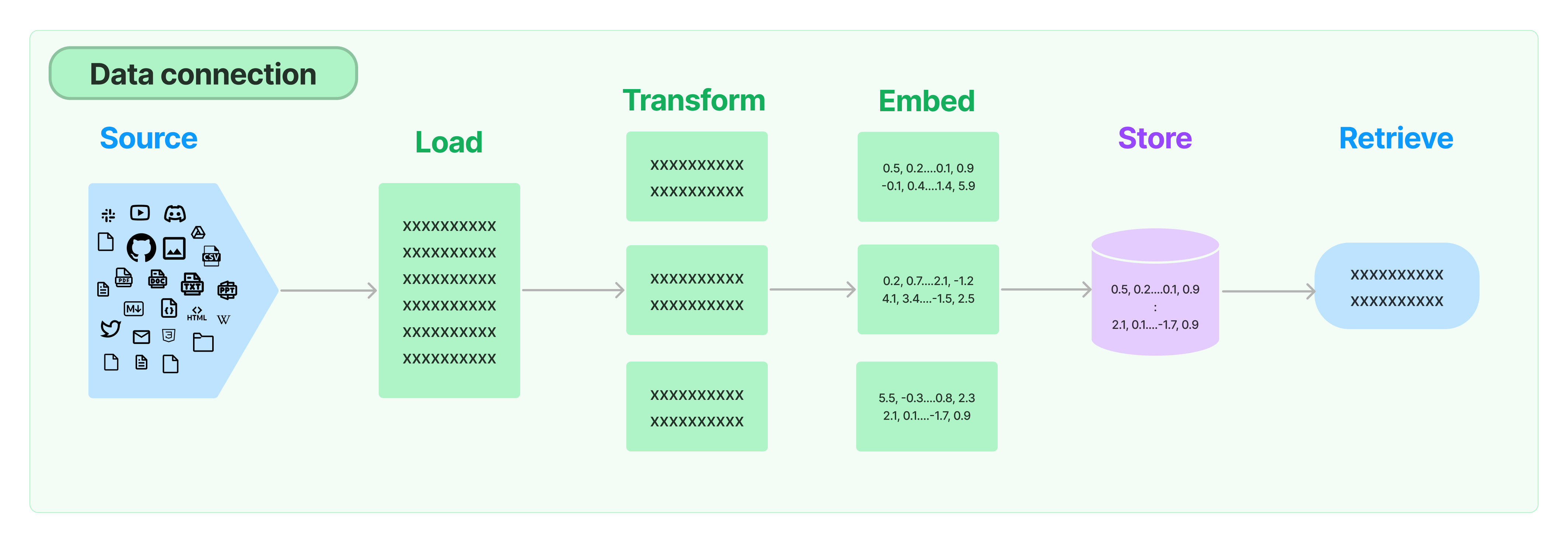
今天第一次尝试深挖LangChain的RAG效果,结果就卡到数据的分割了。
我本来是用一个csv文件来做demo的,那么就参考别人的代码,开始了照虎画猫的拙劣表演。
根据需要,我写出了下面的代码:
def load_file(filepath):
if filepath.endswith('csv'):
loader = CSVLoader(file_path=filepath)
else:
loader = UnstructuredFileLoader(file_path=filepath, mode='elements')
text_splitter = ChineseTextSplitter()# 这个splitter是我继承CharacterTextSplitter定义的类
docs = loader.load_and_split(text_splitter=text_splitter)
return docs
但是在使用的时候,我看到CharacterTextSplitter的API文档,里面有几个方法,大体上感觉问题不大,这把稳了。
但是……,我注意到有split_text和split_documents两个方法。从说法上,我实在是看不出来有什么关系,然后我就没当回事,就按照字面意思就开整了(OS:当时我就想着,这两个方法应该我用一个就好,处理的是文本,那么就梭哈写出了下面的ChineseTextSplitter类)
class ChineseTextSplitter(CharacterTextSplitter):
def __init__(self, pdf: bool = False, **kwargs):
super().__init__(**kwargs)
def split_text(self, text: str) -> List[str]:
print(text)
return text
def split_documents(self, documents: Iterable[object]):
return
结果loader.load_and_split(text_splitter=text_splitter)的结果死活出不来,而且控制台终端上也没有输出。当时我就开始了长达数小时的百度、Bing、Google……。
最后只能说,瞎猫碰上了死耗子。我心想为啥有两个方法,我就无意中点开了CharacterTextSplitter的源码,然后就看到了下面的内容:
[docs]class CharacterTextSplitter(TextSplitter):
"""Splitting text that looks at characters."""
[docs] def __init__(
self, separator: str = "\n\n", is_separator_regex: bool = False, **kwargs: Any
) -> None:
"""Create a new TextSplitter."""
super().__init__(**kwargs)
self._separator = separator
self._is_separator_regex = is_separator_regex
[docs] def split_text(self, text: str) -> List[str]:
"""Split incoming text and return chunks."""
# First we naively split the large input into a bunch of smaller ones.
separator = (
self._separator if self._is_separator_regex else re.escape(self._separator)
)
splits = _split_text_with_regex(text, separator, self._keep_separator)
_separator = "" if self._keep_separator else self._separator
return self._merge_splits(splits, _separator)
我发现,没有实现split_documents,那我自己却给实现了,这不是直接将父类TextSplitter给重写了吗!!!!
然后我又看了看TextSplitter类实现:
[docs] @abstractmethod
def split_text(self, text: str) -> List[str]:
"""Split text into multiple components."""
[docs] def create_documents(
self, texts: List[str], metadatas: Optional[List[dict]] = None
) -> List[Document]:
"""Create documents from a list of texts."""
_metadatas = metadatas or [{}] * len(texts)
documents = []
for i, text in enumerate(texts):
index = -1
for chunk in self.split_text(text):
metadata = copy.deepcopy(_metadatas[i])
if self._add_start_index:
index = text.find(chunk, index + 1)
metadata["start_index"] = index
new_doc = Document(page_content=chunk, metadata=metadata)
documents.append(new_doc)
return documents
[docs] def split_documents(self, documents: Iterable[Document]) -> List[Document]:
"""Split documents."""
texts, metadatas = [], []
for doc in documents:
texts.append(doc.page_content)
metadatas.append(doc.metadata)
return self.create_documents(texts, metadatas=metadatas)
最后终于看到了他们之间的关系,原来是先调用split_documents方法(因为LangChain的处理对象都是以Document为单位);
然后获取数据,调用create_documents;同时在该方法中还调用了split_text的方法对文本继续分词,完成Document对象的封装。
至此初步了解了两个方法之间的关系,以及类之间的继承。
总结一句话就是,能力不足,基础不牢,只懂梭哈,傻乐吃瓜。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)