

LightGBM 的完整解释 - 最快的梯度提升模型
在寻找最佳特征值来分割树节点时,LightGBM使用特征值直方图,并尝试所有直方图bin值,而不是尝试所有可能的特征值,因此可以减少寻找最佳特征吐出值的时间和计算量。例如,给定下面的年龄特征,将直方图离散特征值放入不同的范围箱中,因此我们可以使用像Age⩽30,Age⩽40,,,,Age⩽100这样的吐槽标准,而不是尝试像Age这样的所有可能的年龄值⩽31、年龄⩽32 等。一般来说,GOSS的主要
文章最前: 我是Octopus,这个名字来源于我的中文名--章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
目录
LightGBM是微软于2016年开发的梯度提升决策树模型(GBDT),与其他GBDT模型相比,LightGBM的最大特点是训练效率更快、准确率更高。
LightGBM 与一般的 Gradient Boosting Decision Tree 模型在结构上没有根本的区别,但通过以下特殊技术,LightGBM 使其训练速度更快。
- 基于梯度的一侧采样(GOSS)
- 树节点分裂中基于直方图的最佳值搜索
- 分类特征的最佳分割
- 独家功能捆绑
- 叶向树生长策略
- 并行优化
1. 基于梯度的单侧采样(GOSS)
经典的基于树的梯度提升(GBDT)训练是一个重复过程,用于训练新树以适应所有训练集实例上先前树集的预测误差。(预测误差是所有训练集实例上的损失函数梯度)
因此,默认情况下,GBDT 使用所有训练集实例来训练其集合中的每棵树。
针对这一点,LightGBM引入了GOSS,其中我们只需要使用部分训练集来训练每个集成树。
- 具有大梯度的训练实例意味着该实例具有较大的当前预测误差,并且应该是适合下一个集成树的主要目标
- 小梯度的训练实例意味着该实例当前的预测误差相对较小,不需要下一个集成树过多担心,因此我们可以以某种概率丢弃它。
一般来说,GOSS的主要思想是,在训练下一个集成树之前,我们保留梯度较大的训练实例,并丢弃一些梯度较小的训练实例。
下图为GOSS算法。
所有训练实例均按梯度排序,a表示大梯度实例的采样百分比,b表示小梯度实例的采样百分比。

通过使用 GOSS,我们实际上减少了训练下一个集成树的训练集的大小,这将使训练新树的速度更快。
2. 基于直方图的树节点分裂
在寻找最佳特征值来分割树节点时,LightGBM使用特征值直方图,并尝试所有直方图bin值,而不是尝试所有可能的特征值,因此可以减少寻找最佳特征吐出值的时间和计算量。顺便说一下,LightGBM 的分割标准是减少从父级到子级的梯度方差。
例如,给定下面的年龄特征,将直方图离散特征值放入不同的范围箱中,因此我们可以使用像Age⩽30,Age⩽40,,,,Age⩽100这样的吐槽标准,而不是尝试像Age这样的所有可能的年龄值⩽31、年龄⩽32 等

用bin来替换原始数据相当于增加正则化,bin的数量决定了正则化的程度。bin 越小,惩罚越严重,欠拟合的风险越高。
同样在树分裂场景中,对于给定的特征,直方图是可加的
父节点直方图 = 左子直方图 + 右子直方图
因此,在计算子直方图时,我们只需要计算一个子直方图(选择较小尺寸的子直方图),另一子直方图是父直方图减去计算得到的直方图。
3. 分类特征的最优分割
通常,在处理树节点分裂中的分类特征时,我们总是使用One Vs Rest作为节点分裂规则,例如分裂条件是“Weather = Sunny” vs “All other Weather (Rainy, Cloudy, Snowy etc)”。一般来说,这一“一对一”策略的问题是
- 它往往会在子节点中生成不平衡的数据点分配(例如左子节点比右子节点分配更多的数据点)并且需要增长得很深才能获得良好的准确性
- 由于需要生长很深的树,需要多次节点分裂,所以建树效率很低。
受这些问题的启发,LightGBM 采用了如下多对多策略。
对于给定的分类特征
- 对于特征的每个类别,计算平均值 Sum(y)/Count(y)
- 按平均值对所有类别进行排序(如下图所示)。
- 从最低平均值到最大平均值枚举分割值,以找到最佳分割值。分裂值将所有类别分为两部分(类别均值小于或大于分裂值),这就是节点分裂条件。

4. 独家功能捆绑
EFB旨在通过合并特征来减少特征,具体来说就是合并互斥的特征,这些特征很少同时取非零值。
LightGBM提供了以下两种算法来实现
- 从训练集中识别互斥的特征包
- 合并功能包并为该包分配一个值

下面是一个 EFB 示例,显示了特征合并的结果。
在该示例中,最大冲突计数K=2,表明根据EFB算法,原来的5个特征可以减少到3个特征。

5. Leaf-wise 树生长策略
LightGBM 放弃了大多数 GBDT 工具所使用的 level-wise 决策树生长策略,而使用了具有深度限制的 leaf-wise 算法。
Leaf-wise策略中,每次从所有叶子中,找到分裂增益最高的叶子,然后分裂并循环。

在上面的树生长过程中,绿叶节点是分裂增益最高的节点,因此对其进行分裂,然后重新评估以找到下一个绿叶节点。
leaf-wise的好处是,对于每一次节点分裂,我们总是能为树带来最高的增益,因此它比level-wise更有效地生长树。但我们需要添加树深度和一些其他限制以避免过度拟合。
6. 并行优化
为了处理超大型数据集,LightGBM引入了分布式过程来并行计算特征直方图和最佳分割特征值。
LightGBM支持两种并行策略——特征并行和数据并行
特征并行算法
训练数据被垂直(列或特征)分割并分配到不同的工作计算机,以计算分配的特征的局部直方图和局部最佳分割,然后从所有工作器输出中全局选择最佳分割。

数据并行算法
训练数据被水平(行)分割并分配到不同的工作计算机,根据分配的训练子集计算所有特征的局部直方图,然后合并来自所有工作计算机的局部直方图的所有特征直方图。

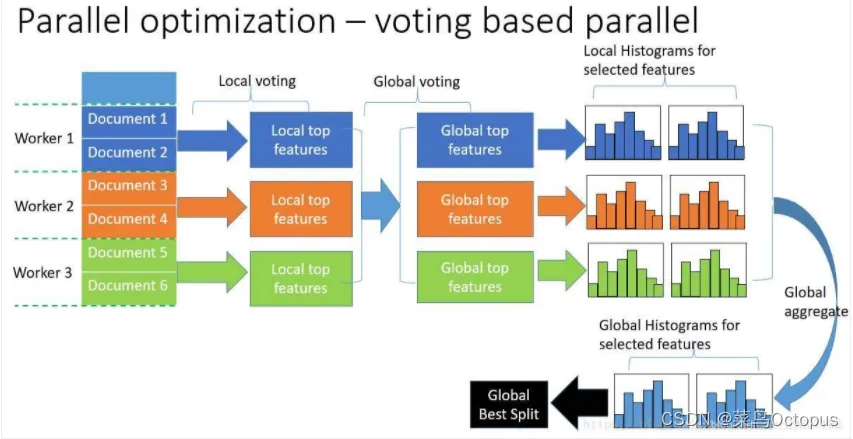
LightGBM还对数据并行算法进行了进一步的优化,其思想是每个worker在本地选择前K个最佳分割特征,然后在全局投票选出顶级特征。
一旦获得顶部特征,我们只需要从所有工人本地直方图中合并顶部特征直方图。
7.总结
上述所有 LightGBM 创新技术的目的都是为了使其训练速度更快,它们使 LightGBM 在以下方面表现出色:
- 训练效率快
- 内存使用率低
- 高精度
- 并行学习
- 处理大规模数据的能力

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)