




- @zy345293721
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
若参与join的表均为分桶表,且关联字段为分桶字段,且分桶字段是有序的,且大表的分桶数量是小表分桶数量的整数倍。此时,就可以以分桶为单位,为每个Map分配任务了,Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶。Map端负责读取参与join的表的数据,并按照关联字段进行分区,将其发送到Reduce端,Reduce端完成最终的关联操作。若参与join的表中,有n-1张表足够小,Map端就

在将NodeManager的总内存平均分配给每个Executor,最后再将单个Executor的内存按照大约10:1的比例分配到spark.executor.memory和spark.executor.memoryOverhead。动态分配可根据一个Spark应用的工作负载,动态的调整其所占用的资源(Executor个数)。此处的Executor个数是指分配给一个Spark应用的Executor个

首先要保证安装了python,并配置好了环境变量;我是利用windows10安装(linux环境下操作更简单)windows安装pip1) 下载安装脚本curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py2) 运行安装脚本python get-pip.py这个就...

利用LSTM对天气温度进行预测
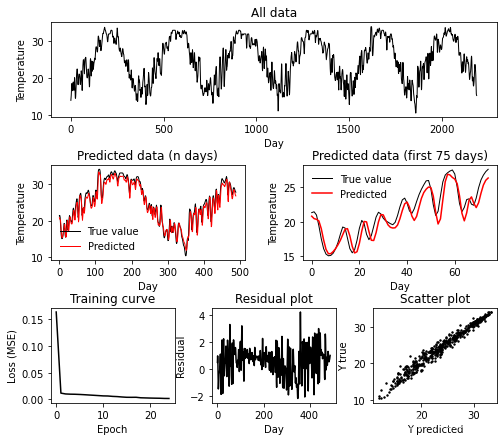
scikit-learn`(或`sklearn`)的数据预处理模块提供了一系列用于处理和准备数据的工具。- `StandardScaler`: 将数据进行标准化,使得每个特征的均值为0,方差为1。- `MinMaxScaler`: 将数据缩放到指定的最小值和最大值之间(通常是0到1)。- `RobustScaler`: 对数据进行缩放,可以抵抗异常值的影响。- `RFE`(递归特征消除):逐步选择
