
浅谈 python 使用speech_recognition 之脱机语音识别
python语音识别
·
常用python识别语音文件的同学,应该对 speech_recognition 并不陌生,对于使用 speech_recognition 联网识别,网上也有很多教程,我们不做多讲解,今天我们来聊一下脱机后,speech_recognition如何识别语音文件。
一、安装依赖库
pip install speech_recognition
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pocketsphinx* pocketsphinx 这依赖库引用的是 清华大学开源软件镜像站
二、准备脱机识别库
目前speech_recognition只有英文(en-US)的脱机识别库,如果需要脱机识别中文(zh-CN),需要手动加入对应的识别库,可参考如下操作

1.通过 pip show numpy,在输出信息中的Location行,可以找到库的安装路径。
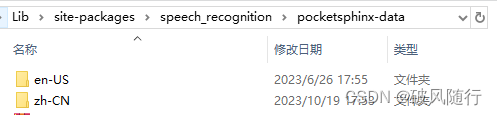
2.逐层找到文件夹 pocketsphinx-data (参考如下路径):
\site-packages\speech_recognition\pocketsphinx-data3.随后将文章的资源 【zh-CN文件】 下载解压到pocketsphinx-data 中,如下图所示
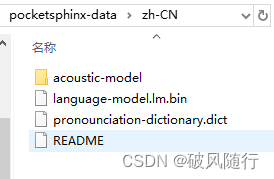
4. 检查文件是否缺失以及命名、存放的位置是否一致
三、语音文件准备
因为 speech_recognition 对脱机识别的文件有要求,目前支持的格式有:
1.WAV
2.AIFF/AIFF-C
3.FLAC四、编写代码识别
import speech_recognition as sr
audio_file = './Sound/1.wav'
r = sr.Recognizer()
with sr.AudioFile(audio_file) as source:
audio = r.record(source)
# 识别音频文件
result = r.recognize_sphinx(audio, language="zh-CN")
print(result)* language参数,可根据情况切换(例: language='zh-CN'、language="en-US"),默认是"en-US"
到这里,基本已经完成了脱机语音识别。目前我试了 [中文普通话]、[英文] 的语音文件可以达到较高的识别准确率,如果想脱机识别 [粤语](即繁体输出)等语种,建议使用 recognize_google 等方法,联网识别会更加的精准

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)