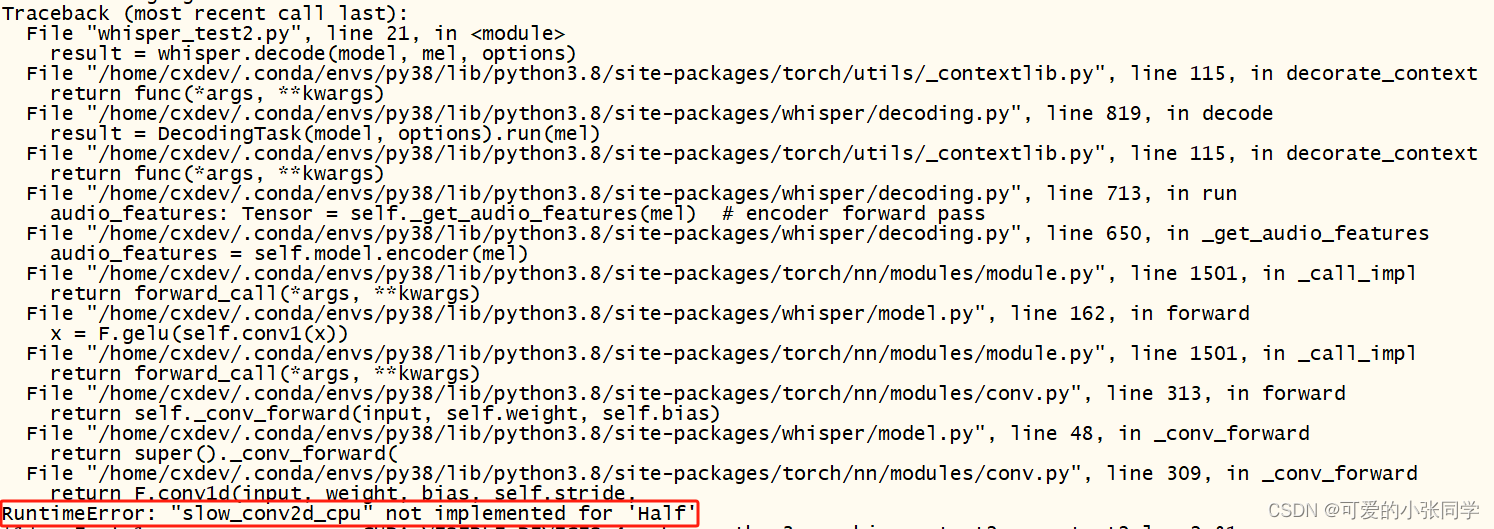
RuntimeError: “slow_conv2d_cpu“ not implemented for ‘Half‘
测试语音识别模型whisper时,出现上述错误!!max。
·
RuntimeError: “slow_conv2d_cpu” not implemented for ‘Half’
背景
测试语音识别模型whisper时,出现上述错误!!
测试代码如下:
import whisper
model = whisper.load_model("base")
# print(model)
# load audio and pad/trim it to fit 30 seconds
mps_path = r"/test/1.mp3"
audio = whisper.load_audio(mps_path)
print("audio:\n", audio)
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions() # fp16=False
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
报错原因
将输入数据的类型设置为Half(半精度浮点数,可以加快计算速度),但是Half只有GPU支持,CPU不支持半(Half)精度训练。
解决方法
通过使用 fp16=False,来指定解码选项,顺利解决了这个错误。
options = whisper.DecodingOptions(fp16=False)
网上给出的参考解决办法如下:
- 执行代码的命令后添加“- -fp32”
- 将use_half=False 或者 将half() 方法 修改为float()
- 搜索代码“half”、“16”等字样,找到代码中涉及半精度的代码,进行修改

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)