
PyTorch 中所有样本对的余弦相似度快速计算
PyTorch 定义了 cosine_similarity 函数来计算向量对之间的余弦相似度。但是,目前还没有方法可以计算列表中每对向量之间的余弦相似度。我们将探索一种非常简单且有效的方法来在 PyTorch 中执行此操作。
PyTorch 定义了 cosine_similarity 函数来计算向量对之间的余弦相似度。但是,目前还没有方法可以计算列表中每对向量之间的余弦相似度。我们将探索一种非常简单且有效的方法来在 PyTorch 中执行此操作。
我们先来看一个公式,这是计算余弦相似度的数学计算公式:
cosine similarity
=
S
C
(
A
,
B
)
:
=
cos
(
θ
)
=
A
⋅
B
∥
A
∥
∥
B
∥
=
∑
i
=
1
n
A
i
B
i
∑
i
=
1
n
A
i
2
∑
i
=
1
n
B
i
2
\text{cosine similarity}=S_C(A,B):=\cos(\theta)=\frac{\mathbf{A}\cdot\mathbf{B}}{\|\mathbf{A}\|\|\mathbf{B}\|}=\frac{\sum_{i=1}^nA_iB_i}{\sqrt{\sum_{i=1}^nA_i^2}\sqrt{\sum_{i=1}^nB_i^2}}
cosine similarity=SC(A,B):=cos(θ)=∥A∥∥B∥A⋅B=∑i=1nAi2∑i=1nBi2∑i=1nAiBi
现在开始系统介绍如何在pytorch中高效计算多对向量之间的余弦相似度(多对向量组成矩阵形式,这在对比学习中经常使用到)
介绍
来自维基百科:
在数据分析中,余弦相似度是在内积空间中定义的两个非零向量之间的相似度的度量。余弦相似度是向量之间角度的余弦;也就是说,它是向量的点积除以向量长度的乘积。由此可见,余弦相似度不取决于向量的大小,而仅取决于它们的角度。余弦相似度始终属于区间 [−1,1]。
用于余弦相似度的 PyTorch API
torch.nn.functional.cosine_similarity(x1, x2, dim=1, eps=1e-8) -> Tensor
这将计算 x1 和 x2 之间沿指定维度的成对余弦相似度。即,如果 x1 和 x2 的形状均为 (10, 4, 5),并且我们希望计算沿最后一个维度的余弦相似度,则结果形状为(10, 4)。
例如:
x, y = torch.randn(10, 4, 5), torch.randn(10, 4, 5)
print(F.cosine_similarity(x, y, dim=2).shape)
#torch.Size([10, 4])
这是因为当我们向 cosine_similarity 提供一个 3d 张量并要求它在第三维(维度索引=2)上运行余弦相似度时,它会将该索引折叠为单个值。
在 PyTorch 中计算所有对的余弦相似度
互联网现有的查询结果表明,人们一直很难找到一种简洁有效的方法来执行全对余弦相似性运算。事实上,这个问题被认为非常复杂,以至于torchmetrics 页面上有一个专门针对该主题的指标。
幸运的是,这个问题有一个可行解决方案(此 PyTorch GitHub 问题中提到了)。让我们一起先看看它长什么样子吧!
cosine_similarity(x[None,:,:], x[:,None,:], dim=-1)
里面发生了很多事情,而且它的真正工作原理可能并不明显,因此本文的其余部分将重点通过从头开始构建解决方案来剖析这个方法的各个子部分到底发生了什么。在下面的小节中,我们将了解以下内容,因为它适用于简洁地计算所有对余弦相似度。
- 用“None”索引张量
- 使用tensor.expand()沿单维展开张量
- 利用 PyTorch 广播语义沿单维隐式扩展张量
用“None”索引张量
我们需要了解的第一件事是,当您使用 None 索引 PyTorch 张量时会发生什么?
与 NumPy 类似,您可以通过使用 None 索引该维度来插入单个维度(“解压缩”维度)。反过来,n[:, None] 将具有在 dim=1 上插入新维度的效果。这相当于 n.unsqueeze(dim=1)
x = torch.randn(3)
# Indexing with None does the same thing as unsqueezing the tensor
# at that dimension. After this indexing operation, the tensors
# x_row_dup and x_col_dup will have 1 additional dimension at
# dimensions 0 and 1 respectively.
x_row_dup, x_col_dup = x[None,:], x[:,None]
print(x, x.shape)
print(x_row_dup, x_row_dup.shape)
print(x_col_dup, x_col_dup.shape)
#tensor([-1.2756, 1.1559, -0.0660]) torch.Size([3])
#tensor([[-1.2756, 1.1559, -0.0660]]) torch.Size([1, 3])
#tensor([[-1.2756],
# [ 1.1559],
# [-0.0660]]) torch.Size([3, 1])
使用 .expand(…) 扩展张量
PyTorch Expand(…) API 用于通过重复某些维度的值来扩展某些维度的值。请注意,只有值为 1 的维度才能扩展。让我们看下面的示例。
x_row_dup, x_col_dup = x_row_dup.expand(3, 3), x_col_dup.expand(3, 3)
print("x stretched across rows")
print(" - - - - - - - - - - - -")
print(x_row_dup, x_row_dup.shape)
print("")
print("x stretched across columns")
print(" - - - - - - - - - - - - - ")
print(x_col_dup, x_col_dup.shape)
# 打印内容
x stretched across rows
- - - - - - - - - - - -
tensor([[-1.2756, 1.1559, -0.0660],
[-1.2756, 1.1559, -0.0660],
[-1.2756, 1.1559, -0.0660]]) torch.Size([3, 3])
x stretched across columns
- - - - - - - - - - - - -
tensor([[-1.2756, -1.2756, -1.2756],
[ 1.1559, 1.1559, 1.1559],
[-0.0660, -0.0660, -0.0660]]) torch.Size([3, 3])
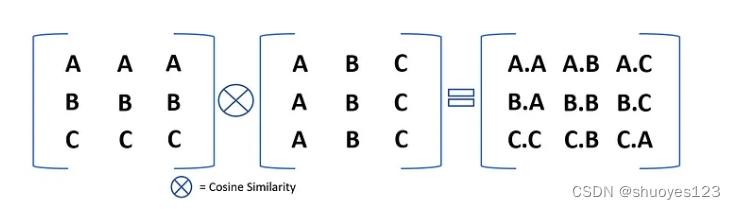
假设我们的输入张量有 3 个元素,即 (A, B, C)。为了计算所有对的余弦相似度,我们首先将这个张量沿 3 行和 3 列展开。具体过程如下:
Unsqueeze:第一步,我们的输入张量 (A, B, C) 大小为3。我们首先沿第0和第1维度将其展开,具体方法就是刚刚介绍过的插入None,使其如下所示:
(A, B, C) 沿维度 0 展开将看起来像 ((A, B, C)) 并具有形状 (1, 3)。
(A, C, C) 沿维度 1 展开将看起来像 ((A), (B), ( C)) 并具有形状 (3, 1)。
Expand:然后,我们将沿着这些张量的单一维度(值为 1 的维度)展开这些张量,使两个张量都成为平方。
((A, B, C)) 扩展为形状 (3, 3) 将如下所示:
((A, B, C),
(A, B, C),
(A, B, C))
((A), (B), ©) 展开为形状 (3, 3) 将如下所示:
((A, A, A),
(B, B ,B),
(C, C, C))
上面这部分如果看不懂的话建议看看numpy的广播操作,这里推荐一篇文章:numpy广播机制,这里面介绍的非常详细。
如果我们执行成对余弦相似度(PyTorch API 已经可以做到),那么我们将得到全对余弦相似度,如下图所示。

就是这样!下面是一个示例,展示了我们迄今为止使用的张量。
# Add a dummy dimension at the end so that we can perform cosine
# similarity on that last dimension.
x_row_dup = x_row_dup.reshape(3, 3, 1)
x_col_dup = x_col_dup.reshape(3, 3, 1)
x_cosine_similarity = F.cosine_similarity(x_row_dup, x_col_dup, dim=-1)
print(x_cosine_similarity)
#tensor([[ 1., -1., 1.],
# [-1., 1., -1.],
# [ 1., -1., 1.]])
可是等等!为什么所有的值都是 1 或 -1?!很容易理解,这是因为单个元素向量的角度为 0 度或 180 度,具体取决于它们指向相同方向还是相反方向。不明白可以看下面的推演过程:

让我们用二维的矩阵而不是 一维 的向量尝试同样的事情。
x = torch.randn(3, 2)
x_row_dup, x_col_dup = x[None,:,:], x[:,None,:]
x_row_dup, x_col_dup = x_row_dup.expand(3, 3, 2), x_col_dup.expand(3, 3, 2)
x_cosine_similarity = F.cosine_similarity(x_row_dup, x_col_dup, dim=-1)
print(x_cosine_similarity)
#tensor([[1.0000, 0.9512, 0.9826],
[0.9512, 1.0000, 0.9920],
[0.9826, 0.9920, 1.0000]])
这看起来就会容易明白了!
最后一招:广播
虽然我们在前面使用了 .expand(…) ,但我们想提一下,这完全没有必要,因为 PyTorch 中定义的大多数操作都支持称为维度广播的概念。从文档来看,如果 PyTorch 操作支持广播,则其 Tensor 参数可以自动扩展为相同大小(无需复制数据)。
因此,当输入形状为 (1, 3) 和 (3, 1) 的 2 个张量时,余弦相似性运算会将它们广播到 (3, 3),并本质上隐式执行我们上面显式执行的张量扩展步骤。
当我们运行下面的代码时。
x_cosine_similarity = F.cosine_similarity(x[None,:,:], x[:,None,:], dim=-1)
# This should print the same matrix as above.
print(x_cosine_similarity)
#tensor([[1.0000, 0.9512, 0.9826],
# [0.9512, 1.0000, 0.9920],
# [0.9826, 0.9920, 1.0000]])
这实际上与我们上面得到的相同。
关于效率的注释
与本讨论中提到的许多解决方案相比,此解决方案不使用任何显式的 for 循环。每次编写显式 for 循环时,都会遇到以下问题:
- 发生了一些重要的 CPU 计算,可能会导致 GPU 饥饿
- 如果您使用 for 循环,则可能会留下一些 GPU 并行执行的机会。这将影响您的整体 GPU 利用率,从而影响运行计算所需的时间
以上文章主要翻译自:All Pairs Cosine Similarity in PyTorch 感兴趣的可以看看原文,绝对精彩!
参考资料:
1.All Pairs Cosine Similarity in PyTorch,https://medium.om/@dhruvbird/all-pairs-cosine-similarity-in-pytorch-867e722c8572
2.numpy广播机制,https://blog.csdn.net/qq_51352578/article/details/125074264

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)