FunASR语音识别GUI界面应用
本文将介绍一个基于FunASR开发的语音识别界面应用,这个应用可以选择本地音频,也可以录音识别。支持多种音频格式和视频格式,可以对识别的结果加上时间戳做成字幕。
·
前言
本文将介绍一个基于FunASR开发的语音识别界面应用,这个应用可以选择本地音频,也可以录音识别。支持多种音频格式和视频格式,可以对识别的结果加上时间戳做成字幕。
安装环境
- 安装Pytorch,根据自己机器的情况可以选择安装CPU版本或者GPU版本的Pytorch。
# 安装CPU版本的Pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch
# 安装GPU版本的Pytorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
- 安装ffmpeg和pyaudio。
conda install ffmpeg pyaudio
- 安装其他依赖库。
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
使用
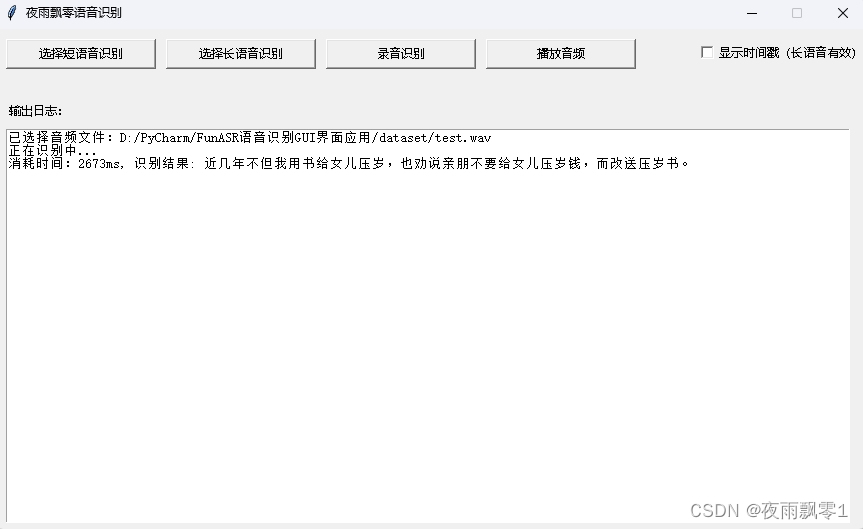
执行main.py即可启动程序,一共有四个功能,分别是短语音识别、长语音识别、录音识别、播放音频。
-
短音频识别,可以选择一个较短的音频或者视频,便可得到结果,这个长度没有固定的限制,一般把小于30秒或者50秒的作为短音频。

-
长音频识别,长音频识别有两种模型,第一种是不添加时间戳的,全部结果拼接起来。长音频识别的方式其实就是使用VAD模型把长音频裁剪成多段的短音频,然后再识别的。

-
长音频识别(时间戳),第二种是显示时间戳,可以知道每句话开始的时间和结束的时间,可以用于制作字幕。

-
录音识别,录音识别是一边说话一边出结果,这种识别方式是流式的。当点击停止录音之后,是使用全部的录音再次执行识别,提高最终的准确率。

-
播放音频,当选择了音频或者录音识别了,可以点击播放音频按钮播放音频,只能播放音频格式,不支持播放视频格式。

扫码入知识星球,搜索【FunASR语音识别GUI界面应用】获取源码

CSDN联合极客时间,共同打造面向开发者的精品内容学习社区,助力成长!
更多推荐



 0
0 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)