
4个详细步骤讲解Python爬取网页数据操作过程!(含实例代码)
今天为大家带来的内容是4个详细步骤讲解Python爬取网页数据操作过程!(含实例代码)本文具有不错的参考意义,希望在此能够帮助到大家!**提示:**由于涉及代码较多,大部分代码用图片的方式呈现出来!
前言:
今天为大家带来的内容是4个详细步骤讲解Python爬取网页数据操作过程!(含实例代码)本文具有不错的参考意义,希望在此能够帮助到大家!
**提示:**由于涉及代码较多,大部分代码用图片的方式呈现出来!
一、利用webbrowser.open()打开一个网站:

实例:使用脚本打开一个网页。
所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序。(我没带这行试了试,也可以,可能这是一种规范吧)
- 1.从sys.argv读取命令行参数:打开一个新的文件编辑器窗口,输入下面的代码,将其保存为map.py。
- 2.读取剪贴板内容:
- 3.调用webbrowser.open()函数打开外部浏览:

注:不清楚sys.argv用法的,请参考这里;不清楚.join()用法的,请参考这里。sys.argv是字符串的列表,所以将它传递给join()方法返回一个字符串。
好了,现在选中’天安门广场’这几个字并复制,然后到桌面双击你的程序。当然你也可以在命令行找到你的程序,然后输入地点。
二、用requests模块从Web下载文件:requests模块不是Python自带的,通过命令行运行pip install request安装。没翻墙是很难安装成功的,手动安装可以参考这里。
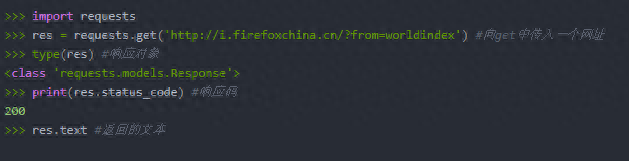
requests中查看网上下载的文件内容的方法还有很多,如果以后的博客用的到,会做说明,在此不再一一介绍。在下载文件的过程中,用raise_for_status()方法可以确保下载确实成功,然后再让程序继续做其他事情。
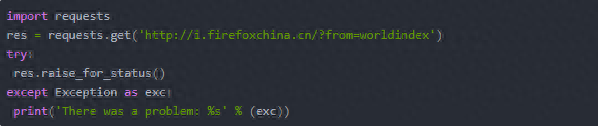
三、将下载的文件保存到本地:
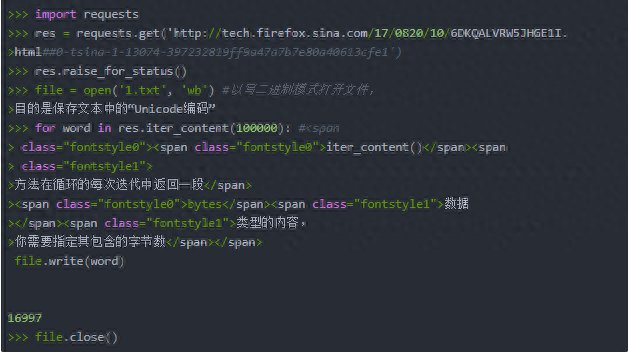
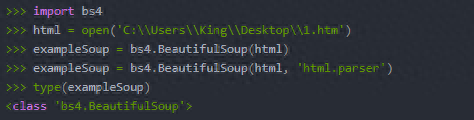
四、用BeautifulSoup模块解析HTML:在命令行中用pip install beautifulsoup4安装它。
1.bs4.BeautifulSoup()函数可以解析HTML网站链接requests.get(),也可以解析本地保存的HTML文件,直接open()一个本地HTML页面。
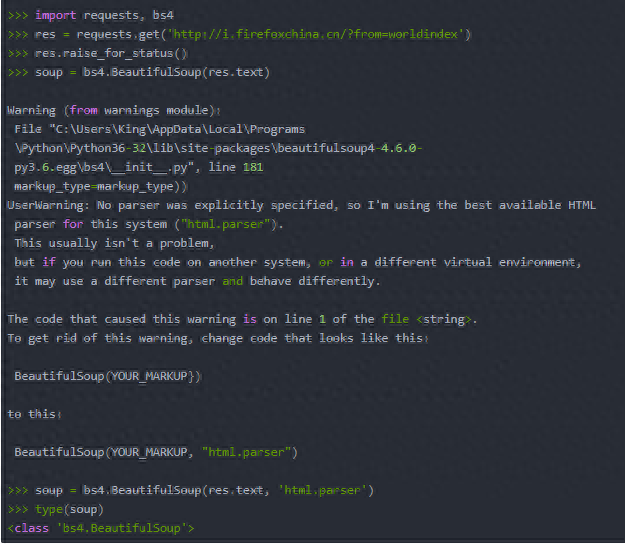
我这里有错误提示,所以加了第二个参数。
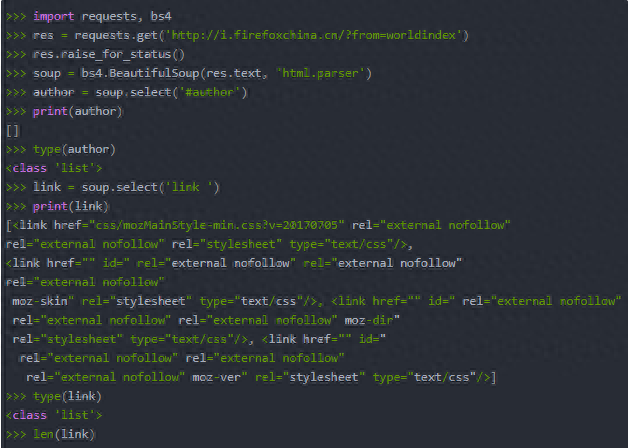
2.用select()方法寻找元素:需传入一个字符串作为CSS“选择器”来取得Web页面相应元素,例如:
- soup.select(‘div’):所有名为
的元素;
- soup.select(‘#author’):带有id属性为author的元素;
- soup.select(‘.notice’):所有使用CSS class属性名为notice的元素;
- soup.select(‘div span’):所有在
元素之内的 元素;
- soup.select(‘input[name]’):所有名为并有一个name属性,其值无所谓的元素;
- soup.select(‘input[type=“button”]’):所有名为并有一个type属性,其值为button的元素。
想查看更多的解析器,请参看这里。
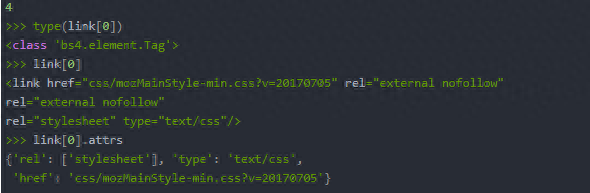
3.通过元素的属性获取数据:接着上面的代码写。
>>> link[0].get('href')
'css/mozMainStyle-min.css?v=20170705
以上就是本文的全部内容啦,同时这些代码实例也算是对“网络爬虫”的一些初探。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析学习等教程。带你从零基础系统性的学好Python!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
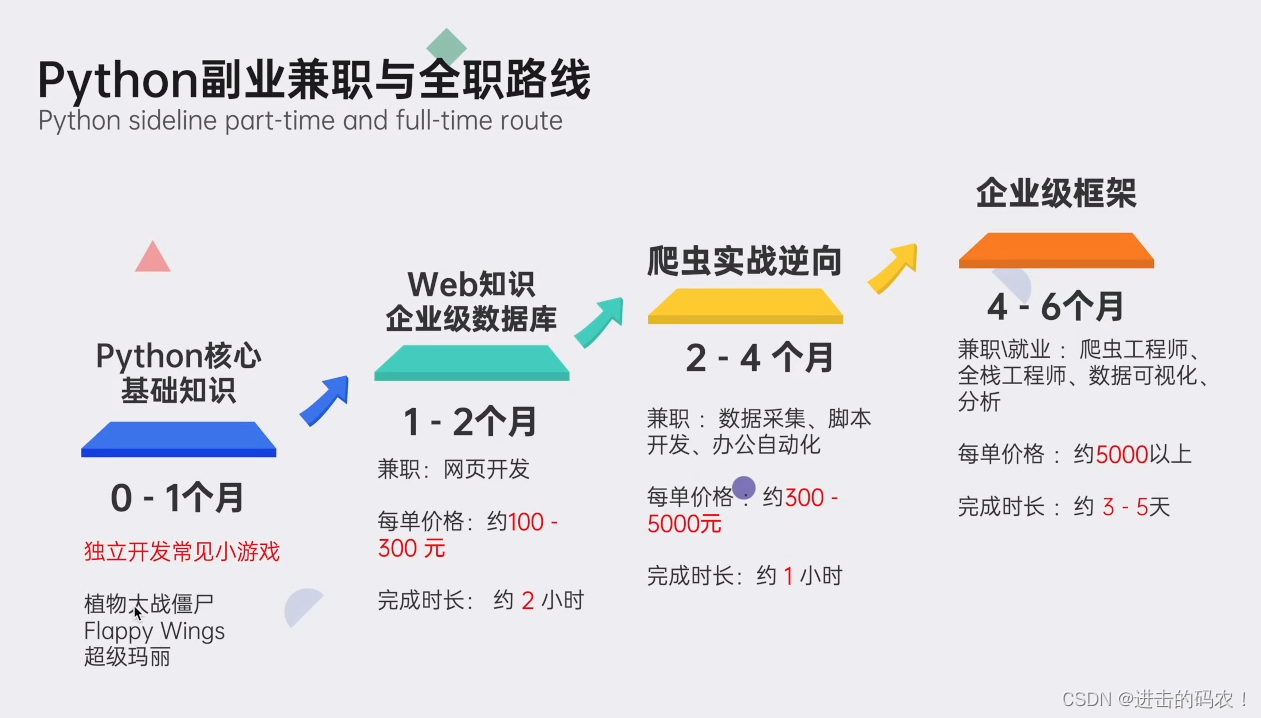
五、python副业兼职与全职路线
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
👉[[CSDN大礼包:《python安装包&全套学习资料》免费分享]](安全链接,放心点击)


旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 1
1 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)