

零基础学习Python|Python高阶学习--Scrapy爬虫框架应用案例
本文主要在前次学习Python爬虫框架的基础上,设计两个案例来爬取豆瓣电影网站数据和新浪新闻数据,并将爬取的数据存储到Mysql数据表中。两个案例参考了CSDN两位博主开源的案例基础上进行改进使用,希望对大家学习爬虫框架Scrpay有所帮助。本次使用的Python3.8的版本,为避免有异常发生,请保持版本一致。如果需要两个案例的源码,请三连后文未咨询免费获取
作者主页:编程指南针
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、腾讯课堂常驻讲师
主要内容:Java项目、Python项目、前端项目、人工智能与大数据、简历模板、学习资料、面试题库、技术互助
收藏点赞不迷路 关注作者有好处
文末获取源码
前言:
本文主要在前次学习Python爬虫框架的基础上,设计两个案例来爬取豆瓣电影网站数据和新浪新闻数据,并将爬取的数据存储到Mysql数据表中。两个案例参考了CSDN两位博主开源的案例基础上进行改进使用,希望对大家学习爬虫框架Scrpay有所帮助。本次使用的Python3.8的版本,为避免有异常发生,请保持版本一致。如果需要两个案例的源码,请三连后文未咨询免费获取。
一,案例一
本案例参考CSDN博主《清风醉雨》写的案例,爬取豆瓣 top250电影数据,在此表示感谢!
案例实现步骤:
1.创建Scrapy项目:进入cmd命令行下执行
scrapy startproject doubanmovie2.定义Item
Item 是保存爬取到的数据的容器;其使用方法和 Python 字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
以豆瓣电影TOP250 豆瓣电影 Top 250 为例,我们需要抓取每一部电影的名字,电影的描述信息(包括导演、主演、电影类型等等),电影的评分,以及电影中最经典或者说脍炙人口的一句话。那么 items.py 文件如下。
import scrapy
class DoubanmovieItem(scrapy.Item):
pic = scrapy.Field() #电影图片
title = scrapy.Field() # 电影名字
movieInfo = scrapy.Field() # 电影的描述信息,包括导演、主演、电影类型等等
star = scrapy.Field() # 电影评分
quote = scrapy.Field() # 电影中最经典或者说脍炙人口的一句话
pass3.编写爬虫文件:在spider目录下创建 doubanspider.py 文件
import scrapy,sys
from scrapy.http import Request
from scrapy.selector import Selector
from doubanmovie.items import DoubanmovieItem
from urllib.parse import urljoin
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
class Douban(scrapy.spiders.Spider):
name = "douban"
allowed_domains = ["douban.com"]
# redis_key = 'douban:start_urls'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
item = DoubanmovieItem()
selector = Selector(response)
Movies = selector.xpath('//div[@class="item"]') #获得所有class="item"的div元素集
for eachMovie in Movies:
pic = eachMovie.xpath('div[@class="pic"]/a/img/@src').extract()
title = eachMovie.xpath('div[@class="info"]/div[@class="hd"]/a/span/text()').extract() # 多个span标签
fullTitle = "".join(title) # 将多个字符串无缝连接起来
movieInfo =eachMovie.xpath('div[@class="info"]/div[@class="bd"]/p/text()').extract()
movieInfo = movieInfo[0].strip("\n ")
#获取评份
star = eachMovie.xpath('div[@class="info"]/div[@class="bd"]/div[@class="star"]/span/text()').extract()[0]
#经典输出
quote = eachMovie.xpath('div[@class="info"]/div[@class="bd"]/p[@class="quote"]/span/text()').extract()
# quote可能为空,因此需要先进行判断
if quote:
quote = quote[0]
else:
quote = ''
item['pic'] = "".join(pic)
item['title'] = fullTitle
item['movieInfo'] = movieInfo
item['star'] = star
item['quote'] = quote
#print("采集数据:",item)
yield item
#翻页读取
nextLink = selector.xpath('//span[@class="next"]/link/@href').extract()
# 第10页是最后一页,没有下一页的链接
if nextLink:
nextLink = nextLink[0]
yield Request(urljoin(response.url, nextLink), callback=self.parse)
#程序入口
if __name__ =="__main__":
#创建CrawlerProcess类对象并传入项目设置信息参数
process = CrawlerProcess(get_project_settings())
#设置需要启的爬虫名称
process.crawl("douban")
#启动爬虫
process.start()name:用于区别 spider,该名字必须是唯一的。 start_urls:包含了 spider 在启动时进行爬取的 URL 列表。因此,第一个被获取到的页面将是其中之一。后续的 URL 则从初始的 URL 获取到的数据中提取。 parse() 是 spider 的一个方法。被调用时,每个初始 URL 完成下载后生成的 response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成 item)以及生成需要进一步处理的 URL 的 Request 对象。
可以对比要爬取的网页的源码来理解解析基本语法:
-
基实做爬虫的基本步骤很简单,主要是掌握XPATH等解析网页的基本语法来获得相关的内容才可以
4.在settings.py文件中设置代理:
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
5.直接运行此爬虫程序即可:看到控制台输出的各个采集的数据即告成功
6.在MySQL中新建数据库doubanmovie,并建表doubantop250,表结构如下:
create table doubantop250(
id int(3) primary key auto_increment,
title varchar(100) not null,
pic varchar(500),
movieInfo varchar(1000) not null,
star float(3,1) not null,
quote varchar(300)
)7.安装pymysql,如果前面学习连接数据库时己安装过则不必安装:
pip install pymysql
8.在settings.py中添加MySQL的连接配置信息:
MYSQL_HOST = 'localhost' # 数据库地址
MYSQL_DBNAME = 'doubanmovie' # 数据库名字
MYSQL_USER = 'root' # 数据库登录名
MYSQL_PASSWD = 'root' # 数据库登录密码
# 数据传输
ITEM_PIPELINES = {
'doubanmovie.pipelines.DoubanmoviePipeline': 301,
}
9.在piplines.py中添加如下代码:
import pymysql
from doubanmovie import settings
class DoubanmoviePipeline(object):
def __init__(self):
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
try:
self.cursor.execute(
"""insert into doubantop250(title,pic,movieInfo,star,quote)
value (%s,%s,%s,%s,%s)""",
(item['title'],
item['pic'],
item['movieInfo'],
item['star'],
item['quote']))
self.connect.commit()
except Exception as err:
print("重复插入了==>错误信息为:" + str(err))
return item
10.运行程序:将采集到的电影数据存入数据库表中
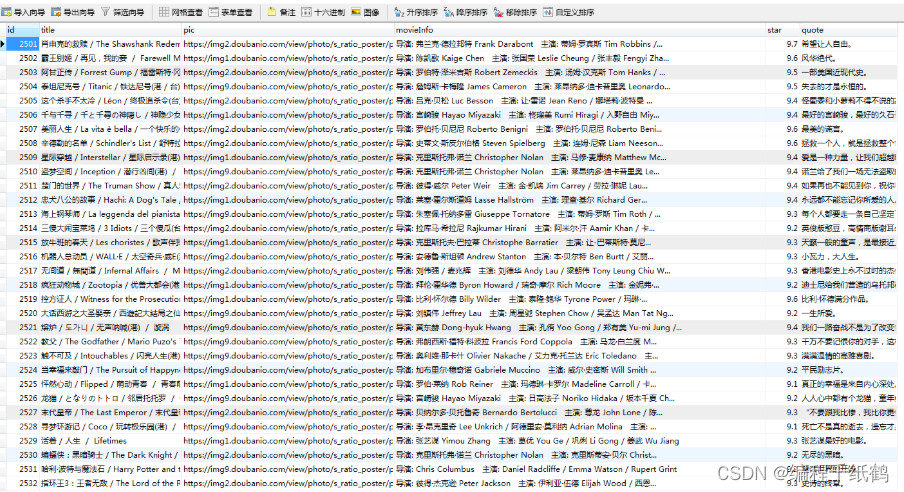
二,案例二
本次案例以爬取新浪新闻简洁版新闻为例:新闻中心滚动新闻_新浪网 ,本案例参考了CSDN博主《[搬运代码打工人》的公开案例,一并致谢!
1.创建一个scrapy的项目
scrapy startproject sinanews2.编写items.py用于存储解析的新闻内容
import scrapy
from scrapy import Item, Field
# 定义新闻数据的字段
class SinanewsItem(scrapy.Item):
"""数据格式化,数据不同字段的定义
"""
title = Field() # 新闻标题
ctime = Field() # 新闻发布时间
url = Field() # 新闻原始url
raw_key_words = Field() # 新闻关键词(爬取的关键词)
content = Field() # 新闻的具体内容
cate = Field() # 新闻类别
3.实现sinaspider.py的爬虫逻辑,解析后的数据存储到mysql中
# -*- coding: utf-8 -*-
import re
import json
import random
import scrapy
from scrapy import Request
from sinanews.items import SinanewsItem
from datetime import datetime
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
class SinaSpider(scrapy.Spider):
# spider的名字
name = 'sina'
def __init__(self, pages=1):
super(SinaSpider).__init__()
self.total_pages = int(pages)
# base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分
self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'
# lid和分类映射字典
self.cate_dict = {
"2510": "国内",
"2511": "国际",
"2669": "社会",
"2512": "体育",
"2513": "娱乐",
"2514": "军事",
"2515": "科技",
"2516": "财经",
"2517": "股市",
"2518": "美股"
}
def start_requests(self):
"""返回一个Request迭代器
"""
# 遍历所有类型的论文
for cate_id in self.cate_dict.keys():
for page in range(1, self.total_pages + 1):
lid = cate_id
# 这里就是一个随机数,具体含义不是很清楚
r = random.random()
# cb_kwargs 是用来往解析函数parse中传递参数的
yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})
def parse(self, response, cate_id):
"""解析网页内容,并提取网页中需要的内容
"""
json_result = json.loads(response.text) # 将请求回来的页面解析成json
# 提取json中我们想要的字段
# json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常
data_list = json_result.get('result').get('data')
for data in data_list:
item = SinanewsItem()
item['cate'] = self.cate_dict[cate_id]
item['title'] = data.get('title')
item['url'] = data.get('url')
item['raw_key_words'] = data.get('keywords')
# ctime = datetime.fromtimestamp(int(data.get('ctime')))
# ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')
# 保留的是一个时间戳
item['ctime'] = data.get('ctime')
# meta参数传入的是一个字典,在下一层可以将当前层的item进行复制
yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})
def parse_content(self, response):
"""解析文章内容
"""
item = response.meta['item']
content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())
content = re.sub(r'\u3000', '', content)
content = re.sub(r'[ \xa0?]+', ' ', content)
content = re.sub(r'\s*\n\s*', '\n', content)
content = re.sub(r'\s*(\s)', r'\1', content)
content = ''.join([x.strip() for x in content])
item['content'] = content
print("item:",item)
yield item
#程序入口
if __name__ =="__main__":
#创建CrawlerProcess类对象并传入项目设置信息参数
process = CrawlerProcess(get_project_settings())
#设置需要启的爬虫名称
process.crawl("sina")
#启动爬虫
process.start()4.修改settings.py配置文件,添加mysql连接配置:创建pythonnews数据库
#MySQL连接
MYSQL_HOST = 'localhost' # 数据库地址
MYSQL_DBNAME = 'pythonnews' # 数据库名字
MYSQL_USER = 'root' # 数据库登录名
MYSQL_PASSWD = 'root' # 数据库登录密码
# 数据传输
ITEM_PIPELINES = {
'sinanews.pipelines.SinanewsPipeline': 301,
}创建表news:
DROP TABLE IF EXISTS `news`;
CREATE TABLE `news` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`url` varchar(500) DEFAULT NULL,
`content` varchar(3000) DEFAULT NULL,
`raw_key_words` varchar(200) DEFAULT NULL,
`cate` varchar(50) DEFAULT NULL,
`ctime` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=430 DEFAULT CHARSET=utf8mb4;5.修改piplines.py,进行数据持久化操作,将解析的items对象数据保存到数据库表news中。
import pymysql
from sinanews import settings
class SinanewsPipeline:
def __init__(self):
self.connect = pymysql.connect(
host=settings.MYSQL_HOST,
db=settings.MYSQL_DBNAME,
user=settings.MYSQL_USER,
passwd=settings.MYSQL_PASSWD,
charset='utf8',
use_unicode=True)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
try:
self.cursor.execute(
"""insert into news(title,url,content,raw_key_words,cate,ctime)
value (%s,%s,%s,%s,%s,%s)""",
(item['title'],
item['url'],
item['content'],
item['raw_key_words'],
item['cate'],
item['ctime']))
self.connect.commit()
except Exception as err:
print("重复插入了==>错误信息为:" + str(err))
return item
6.运行sinaspider.py程序,执行结果如下:

总结:通过以上两个案例来学习Scrapy框架的应用,步骤基本上是固定的,最主要的是找好目标网站,分析网页结构,掌握使用XPATH来解析网页内容,其它的模仿案例步骤来做就可以了。

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)