
Segment Anything论文阅读笔记
Segment Anything 论文笔记
Segment Anything论文阅读笔记
1. Segment Anything论文基本信息
| 论文地址 | https://arxiv.org/abs/2304.02643 |
|---|---|
| 项目地址 | https://github.com/facebookresearch/segment-anything |
| Demo 与数据集SA-1B地址 | https://segment-anything.com/ |
| 论文作者 | Alexander Kirillov1;2;4 Eric Mintun2 Nikhila Ravi1;2 Hanzi Mao2 Chloe Rolland3 Laura Gustafson3Tete Xiao3 Spencer Whitehead Alexander C. Berg Wan-Yen Lo Piotr Dollar ´ 4 Ross Girshick4 |
| 作者单位 | Meta AI Research, FAIR |
2. Segment Anything论文阅读
使用三遍阅读法阅读该论文
2.1 第一遍阅读 Segment Anything
标题:Segment Anything
摘要:我们引入“分割任何事物”项目,一个新的任务、模型和图像分割数据集。在数据收集中循环使用我们的高效模型,我们建立了迄今为止(到目前为止)最大的分割数据集,在1100万张许受可和尊重隐私的图像上拥有超过10亿个掩模。该模型被设计和训练为可提示的,因此它可以将零拍摄转移到新的图像分布和任务。我们评估了它在许多任务中的能力,发现它的零射击性能令人印象深刻-通常可相竞争甚至优于与之前的完全监督结果。我们在https://segment-anything.com上发布了包含1B个掩模和11M张图像的任意图像分割模型(SAM)和相应的数据集(SA-1B),以促进对计算机视觉基础模型的研究。
介绍:在这项工作中,我们的目标是建立一个图像分割的基础模型。也就是说,我们寻求开发一个提示模型,并使用一个能够实现强大泛化的任务在广泛的数据集上对其进行预训练。解决以下三个图像分割问题:
- 什么任务支持零概率泛化?
- 相应的模型结构是怎样的?
- 哪些数据可以为这项任务和模型提供动力?
总结:“任意分割”项目是将图像分割提升到基础模型时代的一次尝试。
我们的主要贡献是一个新的任务(提示分割),模型(SAM)和数据集(SA-1B),使这一飞跃成为可能。
章节标题
摘要
- 简介
- 分割任意事物任务
- 分割任意事物模型
- 分割任意事物数据引擎
- 分割任意事物数据集
- 分割任意事物(RAI)负责任的AI分析
- 零样本迁移实验
- 讨论
参考
附录
A. 分割任意事物模型和任务细节
B. 自动生成掩码细节
C. RAI其他详细信息
D. 实验实现细节
E. 人类学习实验设计
F. 数据集、标注与模型卡
G. 标注指导原则
2.2. 第二遍阅读 Segment Anything
1.仔细看论文中的数字、图表和其他插图。要特别注意图表。坐标轴的标记是否正确?结果是否以误差条显示,以便结论具有统计显著性?像这样的常见错误会将匆忙、粗制滥造的作品与真正优秀的作品区分开来。
2.记住标记相关的未读参考文献以供进一步阅读(这是了解论文背景的好方法)。
第二遍阅读最多需要一个小时。通过这一关后,你应该能够掌握论文的内容。你应该能够向别人总结论文的主旨,并提供支持证据。这种程度的细节适合于你感兴趣的论文,但不属于你的研究专业。
有时你甚至在第二遍结束时也看不懂一篇论文。这可能是因为这个主题对你来说是新的,有不熟悉的术语和缩写。或者作者可能会使用你不理解的证明或实验技术,因此论文的大部分内容都是不可理解的。论文可能写得很差,有未经证实的断言和大量的参考文献。也有可能是深夜你太累了。你现在可以选择:(a)把论文放在一边,希望你不需要理解这些材料就能在你的职业生涯中取得成功,(b)稍后再回到论文中,也许在阅读背景材料之后,或者©坚持下去,继续第三遍。
2.2.1. Segment Anything中相关的图表
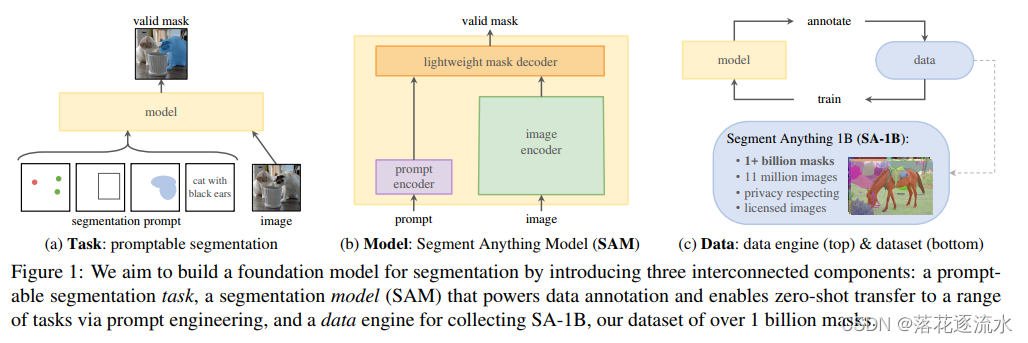
图1列出了本文提到的项目涉及到的三个组成部分,分别是:任务、模型和数据。
其中任务指的是基于提示的分割,如图1中的(a)所示,提示可以是 点、框、Mask或者自由文本,输入图像,输出有效的mask。
模型是指可以分割任意事物的模型,如图1中的(b)所示,该模分割模型(SAM),支持数据注释,并通过提示工程实现零概率转移到一系列任务中。
数据,包含两个方面数据引擎和数据,如图1中的(c)所示,上半部分是数据引擎,通过数据训练模型,通过模型标注数据,循环进行。下半部分是包含十亿mask的数据集SA-1B。
SA-1B含义是SagmentAnything 1B。

图2, 来自我们新引入的数据集SA-1B的带有叠加Mask的示例图像。SA-1B包含11M不同的、高分辨率的、许可的和隐私保护的图像和1.1B高质量的分割Mask。这些Mask是由SAM完全自动标注的,正如我们通过人工评分和大量实验验证的那样,它们具有高质量和多样性。我们根据每个图像的掩模数量对图像进行分组以实现可视化(平均每个图像有~ 100个掩模)。

图3. 每一列展示了3个由SAM通过一个混淆的提示点(绿色圆圈)生成的有效掩码。
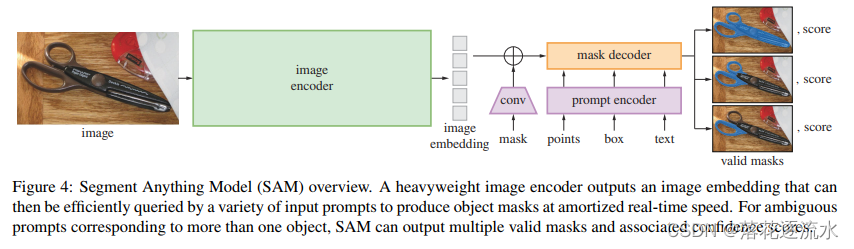
图4. SAM概览。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊实时速度生成对象掩码。对于对应于多个对象的模糊提示,SAM可以输出多个有效掩码和相关的置信度分数。
右侧的预测从上到下依次嵌套掩模通常最多有三层深度:整体、部分和子部分。图3由上到下也是按照整体、部分和子部分这样排列的。
关于模型的细节说明可以看附录中的部分“A. 分割任意事物模型和任务细节”。
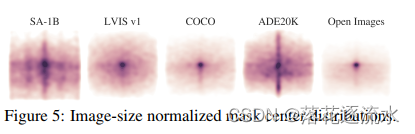
图5 图像大小归一Mask版中心分布。图像归一化后的Mask中心分布图反应了目标在图像中的位置分布,Open Images和COCO数据集分布集中在中心点,ADE20K和SA-1B分布的范围更普遍。通过数据集的对比可以得到使用ADE20K和SA-1B数据集训练的模型泛化性能会更好。
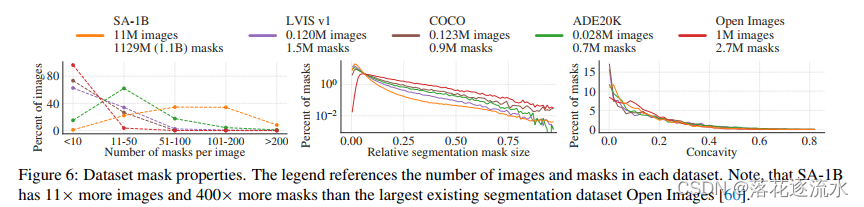
图6. 数据集Mask属性。图例引用了每个数据集中的图像和掩码的数量。注意到,SA-1B比现有最大的分割数据集Open images[60]多11倍的图像和400倍的掩码。
上图对比了几个数据集的属性,在每张图mask个数属性上SA-1B数据集Mask个数较多,在mask相对尺寸属性上五个书籍及相似,在图像凹度属性上五个数据集相似。

图7. SA-1B图像的估计地理分布。世界上大多数国家都有超过1000张图片SA-1B,图片最多的三个国家来自世界各地。
改图说明了图像数据的地理来源分布。











加入「COC·上海城市开发者社区」,成就更好的自己!
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)