k8s服务注册发现
Service 是 将运行在一个或一组pod上的网络应用程序公开为网络服务的方法。定义service前端为service名称、ip、端口等不变的部分,后端为符合标签选择的pod集合。
Service 是 将运行在一个或一组pod上的网络应用程序公开为网络服务的方法。
定义service前端为service名称、ip、端口等不变的部分,后端为符合标签选择的pod集合
注册
- 通过api server提交注册service请求到DNS
- service随后得到clusterIP(虚拟ip地址)
- 在集群内传播service配置
- 集群DNS服务获知该service后,创建必要的DNS记录
service类型
- Headless: 直接采用DNS解析做负载均衡,没有kube-proxy,也没有cluster ip
- ClusterIP: 通过集群ip暴露服务,在域名解析之后会交由kube-proxy进行处理,并分发到pod。
- NodePort: 通过每个节点ip和静态端口暴露服务。这意味着可以暴露服务给外界
- LoadBalancer: 向外暴露服务的外部负载均衡器
- ExternalName: 映射服务和DNS(无代理)
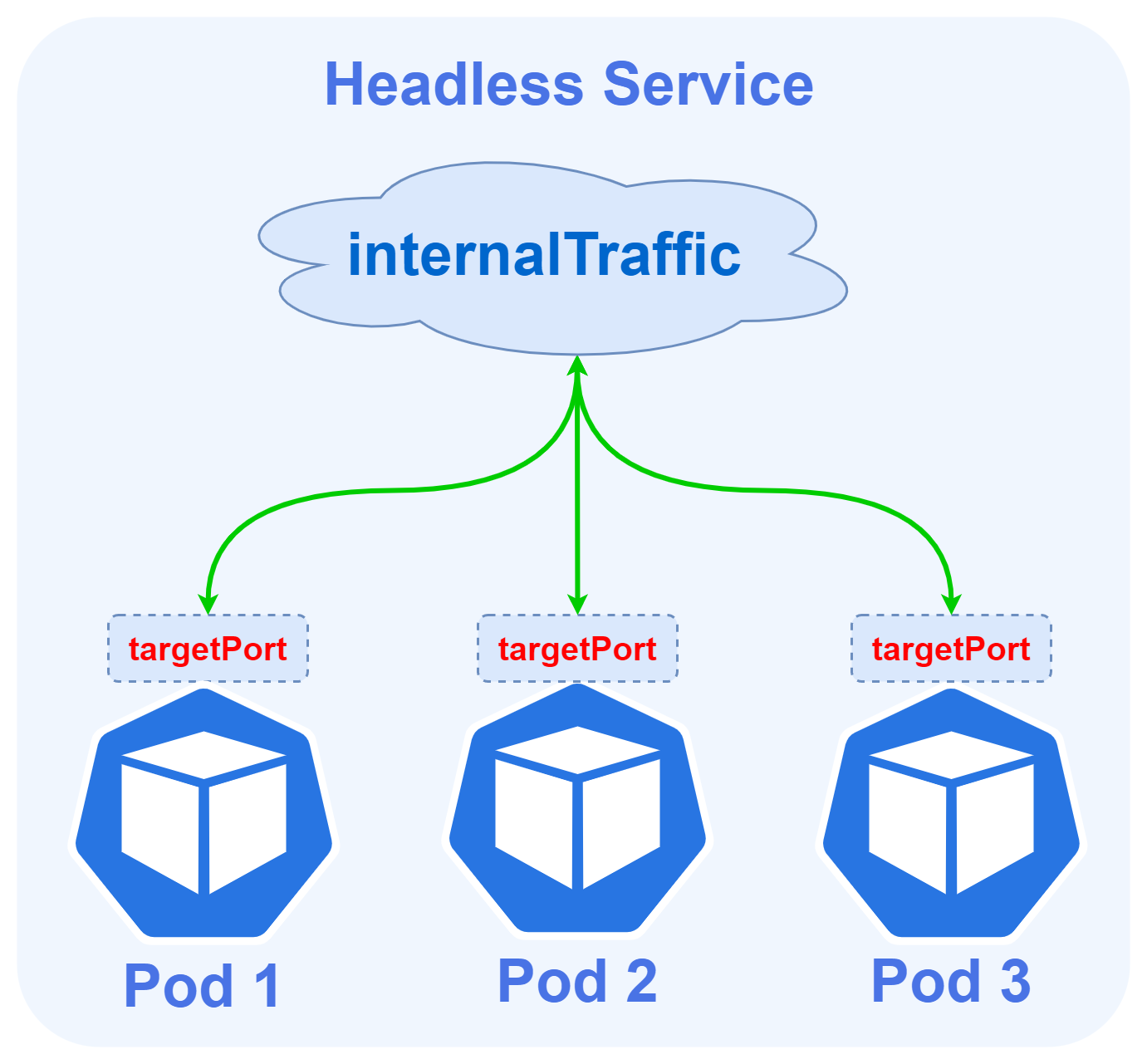
Headless
无负载均衡和clusterIP,可以采用非k8s提供的服务发现机制。此时该服务域名解析结果就是所有关联的pod ip,请求直达pod,此时仅用了DNS解析做负载均衡,而没有利用到k8s内置的kube-proxy

该种方式足够简单,请求链路短。但由于DNS缓存问题,可能会导致DNS服务器压力山大,或者缓存时间过长,导致服务地址没有得到即使更新
clusterIP
通过集群内部IP暴露服务。从集群ip地址池中分配,是默认类型,nodePort、loadBalancer类型也是基于此

相比于headless模式不同之处在于域名解析之后会交由kube-proxy进行处理,并分发到pod。
优势在于避免了直接DNS解析中存在的问题,弊端在于将压力给到了kube-proxy
NodePort
通过每个节点ip和静态端口暴露服务。
从宿主机选择端口分配给某个服务,因此外界也能通过主机和端口进行访问(但仍然要通过kube-proxy进行转发)

优势在于暴露功能到集群外;弊端在于端口数量、选择范围有限以及依然对kube-proxy造成了压力
LoadBalancer
向外暴露的负载均衡。需要第三方支持
以下以openELB为例
拓扑描述如下: 由两个 Pods 支持的服务部署在 Kubernetes 集群中,并为外部访问分配一个 IP 地址172.22.0.2。安装在 Kubernetes 集群中的 OpenELB 与 BGP 路由器建立一个 BGP 连接,并发布指向 BGP 路由器的服务路由。
当外部客户端机器试图访问服务时,BGP 路由器负载根据从 OpenELB 获得的路由平衡master、worker1和worker2节点之间的通信量。在服务流量到达一个节点之后,kube 代理可以进一步将流量转发到其他节点进行负载平衡(Pod 1和 Pod 2都可以通过 kube 代理到达)。

ExternalName
ExternalName映射service到DNS name,而不是诸如my-service、cassandra的典型选择器。
比如在查找my-service.prod.svc.cluster主机时:在本地,集群DNS服务返回一个CNAME记录,值为my.database.example.com。访问my-service的方式与其他服务相同,但有一个关键的区别,重定向发生在DNS级别,而不是通过代理或转发。
service代理模式
- userspace: 最初的模式,将代理交给了用户空间的kube-proxy,但是网络请求的其他处理却仍然在内核空间iptables,效率较低
- iptables: 将代理也交给了内核空间的iptables
- ipvs: 和iptables一样也是基于netfilter,但使用了hash表,这意味着性能将会更高
userspace
- 当客户端请求到达内核空间iptables后,将请求转发给用户空间监听的kube-proxy端口
- kube-proxy处理选择后,转发给pod
由于频繁切换用户空间和内核空间,性能损耗较大,因此已经被废弃
iptables
在这种模式下,kube 代理监视 Kubernetes 控制平面以添加和删除 Service 和 EndpointSlice 对象。
对于每个服务,它安装 iptables 规则,这些规则捕获到服务的集群 IP 和端口的流量,并将该流量重定向到服务的一个后端pod集。对于每个endpoint,它安装 iptables 规则,这些规则选择一个后端 Pod。
默认情况下,iptables 模式下的 kube-proxy 会随机选择一个后端。使用 iptables 处理流量具有较低的系统开销,因为流量由 Linux netfilter 处理,不需要在用户空间和内核空间之间切换。这种方法也可能更可靠。
如果 kube-proxy 在 iptables 模式下运行,并且选择的第一个 Pod 没有响应,则连接失败。这与旧的用户空间模式不同: 在这种情况下,kube-proxy 将检测到与第一个 Pod 的连接失败,并自动使用不同的后端 Pod 重试。您可以使用 Pod 准备状态探测来验证后端 Pods 是否正常工作,这样,iptables 模式下的 kube-proxy 只能看到测试结果为健康的后端。这样做意味着您可以避免通过 kube 代理将流量发送到已知失败的 Pod。
ipvs
在 IPVS 模式下,kube 代理监视 Kubernetes Services 和 EndpointSlices,调用 netlink 接口来创建相应的 IPVS 规则,并定期将 IPVS 规则与 Kubernetes Services 和 EndpointSlices 同步。此控制循环确保 IPVS 状态与所需状态匹配。
当访问一个服务时,IPVS 将流量引导到一个后端 Pods。IPVS 代理模式基于 netfilter 钩子函数,类似于 iptables 模式,但使用哈希表作为底层数据结构,并在内核空间中工作。这意味着在 IPVS 模式下的 kube 代理比在 iptables 模式下的 kube 代理具有更低的延迟重定向流量,在同步代理规则时具有更好的性能。与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
。此外,ipvs为负载均衡算法提供了更多选项,例如:
rr:轮询调度lc:最小连接数dh:目标哈希sh:源哈希sed:最短期望延迟nq:不排队调度
发现
- DNS 发现:支持集群的 DNS 服务器(例如 CoreDNS)监视 Kubernetes API 中的新 Service,并为每个 Service 创建一组 DNS 记录。 如果在整个集群中都启用了 DNS,则所有 Pod 都应该能够通过 DNS 名称自动解析 Service。
- 环境变量:当 Pod 运行在某 Node 上时,kubelet 会为每个活跃的 Service 添加一组环境变量
Ref
- https://kubernetes.io/docs/concepts/services-networking/service/
- https://tinychen.com/20220627-k8s-09-service-discovery-and-traffic-exposure/
- https://openelb.io/docs/concepts/bgp-mode/
- https://kubernetes.io/docs/reference/networking/virtual-ips/

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)