
交叉注意力机制CrossAttention
Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation、Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation、CrossAttention的计算过程、
CrossAttention
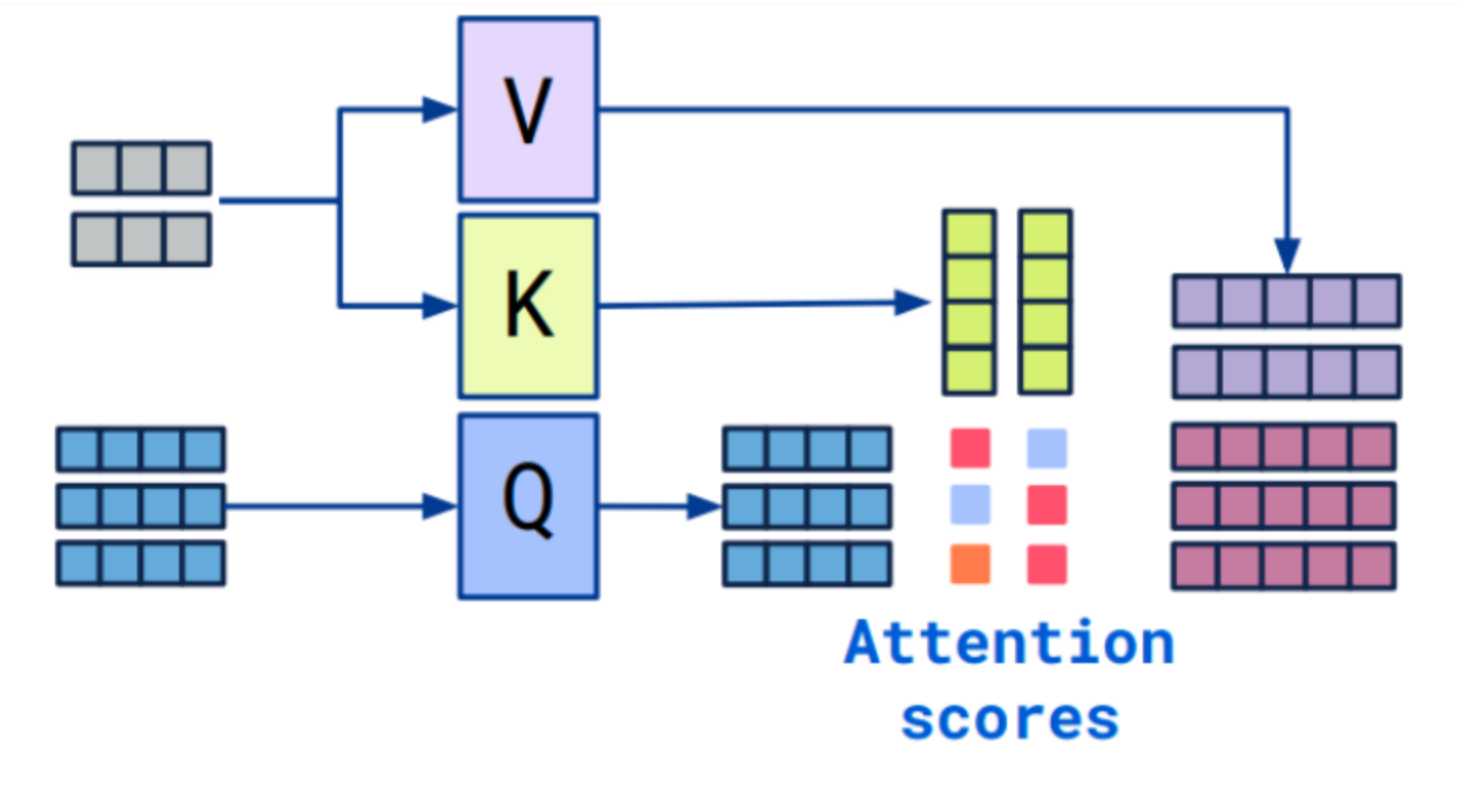
在Transformer中,CrossAttention实际上是指编码器和解码器之间的交叉注意力层。在这一层中,解码器会对编码器的输出进行注意力调整,以获得与当前解码位置相关的编码器信息。在Transformer的编码器-解码器架构中,编码器负责将输入序列编码为一系列特征向量,而解码器则根据这些特征向量逐步生成输出序列。为了使解码器能够对当前生成位置的上下文进行有效的建模,CrossAttention层被引入其中。
CrossAttention的计算过程:
- 编码器输入(通常是来自编码器的输出):它们通常被表示为enc_inputs,大小为(batch_size, seq_len_enc, hidden_dim)。
- 解码器的输入(已生成的部分序列):它们通常被表示为dec_inputs,大小为(batch_size, seq_len_dec, hidden_dim)。
- 解码器的每个位置会生成一个查询向量(query),用来在编码器的所有位置进行注意力权重计算。
- 编码器的所有位置会生成一组键向量(keys)和值向量(values)。
- 使用查询向量(query)和键向量(keys)进行点积操作,并通过softmax函数获得注意力权重。
- 注意力权重与值向量相乘,并对结果进行求和,得到编码器调整的输出。
torch.matmul
参数情况:torch.matmul(input, other, *, out=None) → Tensor
例子:
tensor1 = torch.randn(10, 3, 4)
tensor2 = torch.randn(4, 5)
torch.matmul(tensor1, tensor2).size()
torch.Size([10, 3, 5])代码案例
为了方便理解,此代码只是定义了一个简单的带有线性映射的注意力模型,并没有完整地实现Transformer中的CrossAttention层。如果您想实现Transformer的CrossAttention层,请参考Transformer的详细实现代码或使用现有的Transformer库(如torch.nn.Transformer)来构建模型。
import torch
import torch.nn as nn
class CrossAttention(nn.Module):
def __init__(self, input_dim_a, input_dim_b, hidden_dim):
super(CrossAttention, self).__init__()
self.linear_a = nn.Linear(input_dim_a, hidden_dim)
self.linear_b = nn.Linear(input_dim_b, hidden_dim)
def forward(self, input_a, input_b):
# 线性映射
mapped_a = self.linear_a(input_a) # (batch_size, seq_len_a, hidden_dim)
mapped_b = self.linear_b(input_b) # (batch_size, seq_len_b, hidden_dim)
y = mapped_b.transpose(1, 2)
# 计算注意力权重
scores = torch.matmul(mapped_a, mapped_b.transpose(1, 2)) # (batch_size, seq_len_a, seq_len_b)
attentions_a = torch.softmax(scores, dim=-1) # 在维度2上进行softmax,归一化为注意力权重 (batch_size, seq_len_a, seq_len_b)
attentions_b = torch.softmax(scores.transpose(1, 2), dim=-1) # 在维度1上进行softmax,归一化为注意力权重 (batch_size, seq_len_b, seq_len_a)
# 使用注意力权重来调整输入表示
output_a = torch.matmul(attentions_b, input_b) # (batch_size, seq_len_a, input_dim_b)
output_b = torch.matmul(attentions_a.transpose(1, 2), input_a) # (batch_size, seq_len_b, input_dim_a)
return output_a, output_b
# 准备数据
input_a = torch.randn(16, 36, 192) # 输入序列A,大小为(batch_size, seq_len_a, input_dim_a)
input_b = torch.randn(16, 192, 36) # 输入序列B,大小为(batch_size, seq_len_b, input_dim_b)
# 定义模型
input_dim_a = input_a.shape[-1]
input_dim_b = input_b.shape[-1]
hidden_dim = 64
cross_attention = CrossAttention(input_dim_a, input_dim_b, hidden_dim)
# 前向传播
output_a, output_b = cross_attention(input_a, input_b)
print("Adjusted output A:\n", output_a)
print("Adjusted output B:\n", output_b)CrossAttention模块输入的要求
编码器输入:
- 形状:(batch_size, seq_len_enc, hidden_dim)
- batch_size:批量大小
- seq_len_enc:编码器输入序列的长度
- hidden_dim:编码器的隐藏维度或特征维度
解码器输入:
- 形状:(batch_size, seq_len_dec, hidden_dim)
- batch_size:批量大小
- seq_len_dec:解码器输入序列的长度
- hidden_dim:解码器的隐藏维度或特征维度
对于案例中来说,编码器和解码器的输入维度并不需要完全相同,CrossAttention输入参数是一个三元组(input_a, input_b, hidden_dim),其中input_a表示编码器的输入,input_b表示解码器的输入,hidden_dim表示隐藏维度。
对于input_a和input_b的形状,它们可以有一定的差异,只要满足以下条件之一即可:
1、当input_a和input_b形状不同但维度相同(hidden_dim相同)时,可以通过一些线性变换将它们映射到相同的维度。
2、当input_a和input_b形状不同且维度也不同时,可以通过不同的注意力权重矩阵来分别对它们进行映射和计算注意力。
而Encoder-Decoder架构中CrossAttention的输入要求略有不同。具体而言,Encoder中的输入(input_a)形状通常是(batch_size, seq_len_enc, hidden_dim),而Decoder中的输入(input_b)形状通常是(batch_size, seq_len_dec, hidden_dim),其中seq_len_enc和seq_len_dec可以是不同的。
两篇涉及Cross-Attention的论文
论文链接地址: Cross-Attention is All You Need: Adapting Pretrained Transformers for Machine Translation

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐


 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)