K8s总结
Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的机制。前身为 谷歌的kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化。
K8s 是什么
Kubernetes是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的机制。前身为 谷歌的 Borg
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化。
K8s有什么功能
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
存储编排:可以根据容器自身的需求自动创建存储卷(实现自动虚拟容器和磁盘的映射
K8s解决了什么问题
部署方式的演变
传统部署:互联网早期,会直接将应用程序部署在物理机上
优点:简单,不需要其它技术的参与
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
优点:程序环境不会相互产生影响,提供了一定程度的安全性
缺点:增加了操作系统,浪费了部分资源
容器化部署(docker):与虚拟化类似,但是共享了操作系统
优点:
可以保证每个容器拥有自己的文件系统、CPU、内存、进程空间等
运行应用程序所需要的资源都被容器包装,并和底层基础架构解耦
容器化的应用程序可以跨云服务商、跨Linux操作系统发行版进行部署
缺点:
一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器 当并发访问量变大的时候,怎么样做到横向扩展容器数量
解决方案 :
Swarm (Docker自己的容器编排工具)
Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
Kubernetes:Google开源的的容器编排工具
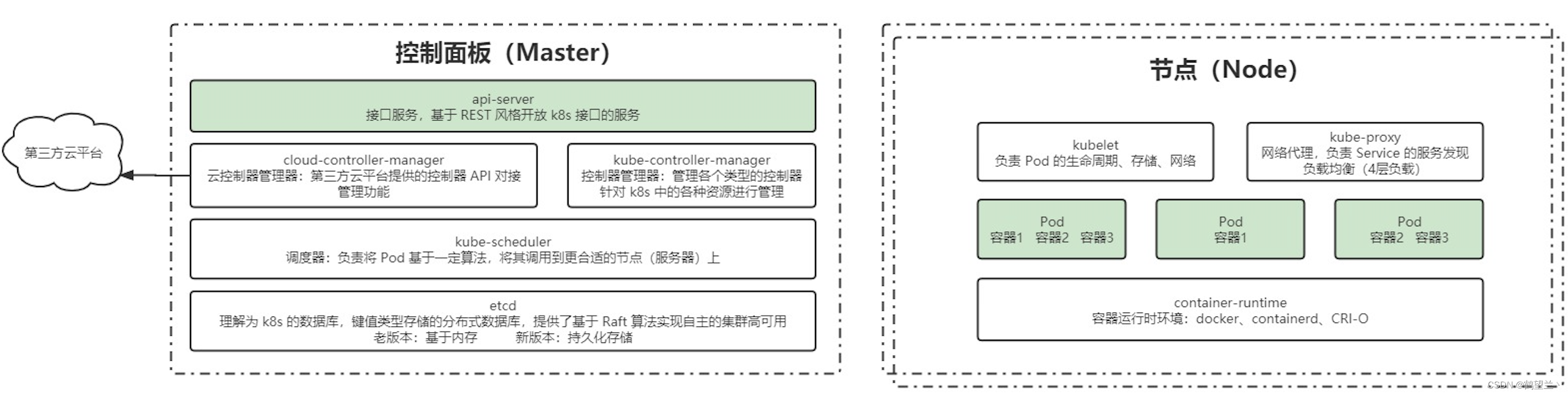
K8s架构与组件
一个kubernetes集群主要是由控制节点(master)、**工作节点(node)**构成,每个节点上都会安装不同的组件。
Master节点
集群控制节点,每个集群需要至少一个master节点负责集群的管控
组成 :
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
ControllerManager : 负责管理Controller 控制器 (Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等)
Etcd :负责存储集群中各种资源对象的信息(持久化存储)
Node节点
工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的docker负责容器的运行
组成 :
Kubelet : 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
KubeProxy : 负责提供集群内部的服务发现和负载均衡(4层)
container-runtime :容器的运行时环境 :docker 、CRI-O
Docker : 负责节点上容器的各种操作
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器

K8s资源和对象
k8s中所有的内容都被抽象为对象,如 pod ,service ,Node 等,对资源的创建,修改删除,都是通过调用 api-server 来实现
对象规约和状态
规约 spec :“规格” 的意思,spec 是必需的,它描述了对象的期望状态
状态status :表示对象的实际状态,该属性由 k8s 自己维护,k8s让对象尽可能的让实际状态与期望状态重合。
资源分类
集群 :集群级别的资源,作用于集群之上,集群内的所有资源都可共享
NameSpace命名空间,用来隔离pod的运行环境,不同namespce之前相互隔离
元数据:元数据级别的资源 ,每个资源都可以访问
元数据级别
- Horizontal Pod Autoscaler(HPA) 自动扩缩容
Pod 自动扩容:可以根据 CPU 使用率或自定义指标(metrics)自动对 Pod 进行扩/缩容。
控制管理器每隔30s(可以通过–horizontal-pod-autoscaler-sync-period修改)查询metrics的资源使用情况
在API Server Aggregator中注册自定义的metrics API
2.PodTemplate pod模板
Pod Template 是关于 Pod 的定义, ,控制器通过 Pod Template 信息来创建 Pod
3.LimitRange
可以对集群内 Request 和 Limits 的配置做一个全局的统一的限制,相当于批量设置了某一个范围内(某个命名空间)的 Pod 的资源使用限制。
集群级别
1.namespace
2.Node
3.ClusterRole
是一组权限的集合,但与 Role 不同的是,ClusterRole 可以在包括所有 Namespace 和集群级别的资源或非资源类型进行鉴权。
4.ClusterRoleBinding
将 Subject 绑定到 ClusterRole,ClusterRoleBinding 将使规则在所有命名空间中生效。
Namespace 命名空间级别
pod
服务发现 (Service Ingress)
存储 (volume CSI)
特殊类型配置 (configMap Secret)
其他(Role RoleBinding)
Pod(k8s最小可部署单元,是一个容器组)
pause容器
每个 Pod 中 会创建一个 pause 容器用来共享网络,文件系统 ,内存 等
pause容器作为您pod中所有容器的父容器。
启用PID(进程ID)名称空间共享后,它将作为每个pod的PID 1进程(根进程),并回收僵尸进程。
Pod探针
容器内应用的监测机制,根据不同的探针来判断容器应用当前的状态
StartupProbe(启动探针)
当配置了 startupProbe 后,会先禁用其他探针,直到 startupProbe 成功后,其他探针才会继续,保证pod真正启动完毕再执行其他探针
ReadinessProbe(就绪探针)
用于探测容器内的程序是否就绪,它的返回值如果返回 success,那么就认为该容器已经完全启动,并且该容器是可以接收外部流量的。
LivenessProbe(存活探针)
用于探测容器中的应用是否运行,如果探测失败,kubelet 会根据配置的重启策略进行重启,若没有配置,默认就认为容器启动成功,不会执行重启策略。
探测方式
ExecAction: 在容器内部执行一个命令,如果返回值为 0,则任务容器时健康的。
TCPSocketAction :通过 tcp 连接监测容器内端口是否开放,如果开放则证明该容器健康
HTTPGetAction :生产环境用的较多的方式,发送 HTTP 请求到容器内的应用程序,如果接口返回的状态码在 200~400 之间,则认为容器健康。
配置参数
initialDelaySeconds: 60 # 初始化持续时间ss
timeoutSeconds: 2 # 超时时间
periodSeconds: 5 # 监测间隔时间
successThreshold: 1 # 检查 1 次成功就表示成功
failureThreshold: 2 # 监测失败 2 次就表示失败
Pod 生命周期
1 pod创建过程
2 运行初始化容器过程(init container)
3 运行主容器过程(main container)
4 容器启动钩子(post start),容器终止前钩子(pre stop)(启动探针、 就绪探针、存活探针)
5 pod终止

资源调度(标签&选择器、控制器、守护进程)
lable 和 selector
Lable(标签) :对pod打上标签 进行分类,可通过 配置文件和命令行(kubectl lable)创建 修改 查看 标签
Selector (选择器):根据 标签 来筛选和匹配对应的 pod,通过 kubectl get 来查询 可根据一个 或多个 标签来进行匹配
Deployment(无状态pod控制器)
Deployment是k8s用来管理部署无状态Pod的控制器
RC :replicationcontroller 动态更新 pod 的副本数量 ,实现扩缩容 (已弃用)
RS :replicaSet 动态更新pod 副本数量,实现扩缩容,可以通过 selector来选择对哪些pod生效
Deployment :针对 RS 更高层次的封装,实现的更丰富的功能。
创建查看
创建: kubectl create deploy xxx
查看: kubectl get deployments ,查看RS :kubectl get rs
滚动更新
修改了deployment 配置文件中的 template 中的属性后,才会触发更新操作
一步步复制容器过来,再将原来容器不可用,而非一步完成
查看滚动更新的过程 kubectl rollout status deploy xxxx
多个滚动更新同步执行:后开始的更新会将先开始的更新删除掉,再执行
回滚
更新失败则需要回滚
通过 kubectl rollout history deployment xxx 获取版本信息 version
确认要回退的版本后,可以通过 kubectl rollout undo deployment 可以回退到上一个版本
也可以回退到指定的 revision
kubectl rollout undo deployment/nginx-deploy --to-revision=2
可以通过设置 .spec.revisonHistoryLimit 来指定 deployment 保留多少 revison,如果设置为 0,则不允许 deployment 回退了。
扩容缩容
扩容缩容可以应对流量激增等情况,修改副本数量,平稳后可缩回来
通过 kube scale 命令可以进行自动扩容/缩容,以及通过 kube edit 编辑 replcas 也可以实现扩容/缩容
扩容与缩容只是直接创建副本数,没有更新 pod template 因此不会创建新的 rs
暂停与恢复
每次对 pod template 中的信息发生修改后,都会触发更新 deployment 操作,那么此时如果频繁修改信息,就会产生多次更新,
而实际上只需要执行最后一次更新即可,当出现此类情况时我们就可以暂停 deployment 的 rollout
通过 kubectl rollout pause deployment 可以暂停 deployment。 kubectl rollout deploy 恢复
StatefulSet (有状态pod控制器)
StatefulSet是k8s用来管理部署有状态Pod的控制器
有状态服务会依赖本地的网络,文件等
创建
扩容缩容
扩容 kubectl scale statefulset web --replicas=5
缩容 kubectl patch statefulset web -p ‘{“spec”:{“replicas”:3}}’
镜像更新
目前还不支持直接更新 image,需要 patch 来间接实现
RollingUpdate滚动更新策略 :StatefulSet 也可以采用滚动更新策略,同样是修改 pod template 属性后会触发更新
在 StatefulSet 中更新时是基于 pod 的顺序倒序更新的
OnDelete更新策略 :只有在 pod 被删除时会进行更新操作
灰度发布
利用滚动更新中的 partition 属性,可以实现简易的灰度发布的效果
例如我们有 5 个 pod,如果当前 partition 设置为 3,那么此时滚动更新时,只会更新那些 序号 >= 3 的 pod
删除
级联删除:删除 statefulset 时会同时删除 pods kubectl delete statefulset web
非级联删除:删除 statefulset 时不会删除 pods,删除 sts 后,pods 就没人管了,此时再删除 pod 不会重建的
删除 pvc
statefulSet删除后PVC还会保留着,数据不再使用的话也需要删除 kubectl delete pvc xxxx
DaemonSet
为每个匹配的Node 设置守护进程,是一个容器副本,
一般用来日志收集,系统监控,es 等
通过 selector 来用 标签匹配 node
NodeSlector :节点选择器 ,会自动监控并对匹配的Node部署守护进程
也支持 滚动更性和Ondelete 一般使用 ondelete
HPA(自动扩容缩容)
通过观察 pod 的 cpu、内存使用率或自定义 metrics 指标进行自动的扩容或缩容 pod 的数量。
通常用于 Deployment,不适用于无法扩/缩容的对象,如 DaemonSet
创建一个 HPA:
先准备一个好一个有做资源限制的 deployment ,Deployment 文件中 会有 cpu 内存指标信息
执行命令 kubectl autoscale deploy nginx-deploy --cpu-percent=20 --min=2 --max=5 (最小2最多5)
通过 kubectl get hpa 可以获取 HPA 信息
测试:
找到对应服务的 service,编写循环测试脚本提升内存与 cpu 负载
while true; do wget -q -O- http://ip:port > /dev/null ; done
查看 pods 资源使用情况
kubectl top pods
服务发现 (Service、Ingress)
Service
Service 实现k8s内部网络调用、负载均衡(4层) (横向流量)
endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址
servie endpoint pod 之间的关系
Master节点维护管理了 service ,service通过 Endpoint 来方位其他的pod
Endpoint 中 维护了pod 的地址信息,通过iptables转发访问 pod 的 kube-proxy来与pod通信
管理人员通过 api-server会访问到servcie,最终实现 k8s内部的网络通信

protocol: TCP 端口绑定的协议,支持 TCP、UDP、SCTP,默认为 TCP
selector: 选中当前 service 匹配哪些 pod,对哪些 pod 的东西流量进行代理
Service代理K8s 外部服务
实现方式:编写 service 配置文件时,不指定 selector 属性 自己创建 Endpoint
Ingress
**lngress 可以提供外网访问 服务 的能力。反向代理,负载均衡(**7层) (纵向流量)
外部的接口 先访问到ingress ,然后访问到 service 最终访问k8s内部服务
Ingress 可以理解为 代替了 nginx,ingress 提供多种控制器方案 :ingress-nginx、 HAproxy 等
rules路由配置规则 :可以基于 路径名、根据域名等 匹配service

配置管理
ConfigMap
创建 :使用 kubectl create configmap -h 查看示例,构建 configmap 对象
原理:基于文件夹、文件、yaml创建,将配置文件连接起来 形成KV形式 的配置
Secret
与 ConfigMap 类似,用于存储配置信息,但是主要用于存储敏感信息、需要加密的信息,Secret 可以提供数据加密、解密功能。
默认使用编码的形式来加密
kubectl create secrte xxx
SubPath
- 同一个pod中多容器挂载同一个卷时提供隔离
- 将configMap和secret作为文件挂载到容器中而不覆盖挂载目录下的文件
配置热更新
更新configMap 的同时更新 pod内的配置
默认方式:会更新,更新周期是更新时间 + 缓存时间
subPath:不会更新
修改configmap : 通过 edit 命令直接修改 configmap 通过replace替换 (–dry-run打印yaml文件)
不可变的配置
对于一些敏感服务的配置文件,在线上有时是不允许修改的,此时在配置 configmap 时可以设置 immutable: true 来禁止修改
持久化存储
Volumes
HostPath
将节点上的文件或目录挂载到 Pod 上,此时该目录会变成持久化存储目录,即使 Pod 被删除后重启,也可以重新加载到该目录,该目录下的文件不会丢失
通过创建yaml文件的形式来创建
EmptyDir
用于一个pod中不同的容器间共享数据, Pod 如果被删除了,那么 emptyDir 也会被删除。
存储介质可以是任意类型,如 SSD、磁盘或网络存储。
创建 :通过创建yaml文件的形式来创建
NFS挂载
nfs 卷能将 NFS (网络文件系统) 挂载到你的 Pod 中。
不像 emptyDir 那样会在删除 Pod 的同时也会被删除,nfs 卷的内容在删除 Pod 时会被保存,卷只是被卸载。
这意味着 nfs 卷可以被预先填充数据,并且这些数据可以在 Pod 之间共享。
安装 nfs
yum install nfs-utils -y
启动 nfs
systemctl start nfs-server
创建设置 共享目录
创建yaml配置文件
PV与PVC
(更高层次的文件存储封装)
持久卷(PersistentVolume,PV) :
是集群中的一块存储,可以由管理员事先制备, 或者使用存储类(Storage Class)来动态制备。 持久卷是集群资源,就像节点也是集群资源一样。
持久卷申领(PersistentVolumeClaim,PVC)
表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存);
!](https://img-blog.csdnimg.cn/d66a141d28d24afbbb37c6a4b6afe324.png)
PV&PVC生命周期
静态构建 :集群管理员创建若干 PV 卷。这些卷对象带有真实存储的细节信息, 并且对集群用户可用(可见)
动态构建:通过 设置StorageClass(存储类) 实现 动态构建PV 有默认的DefaultStorageClass
绑定 :当用户创建一个 PVC 对象后,主节点会监测新的 PVC 对象,并且寻找与之匹配的 PV 卷,找到 PV 卷后将二者绑定在一起。
使用:pod 将 PVC 当作存储卷来使用,集群会通过 PVC 找到绑定的 PV,并为 Pod 挂载该卷。
回收策略 : 保留、删除、回收 。默认为删除
PV状态
Available:空闲,未被绑定
Bound:已经被 PVC 绑定
Released:PVC 被删除,资源已回收,但是 PV 未被重新使用
Failed:自动回收失败
StorageClass (存储类)
StorageClass 可以动态制备PV ,按照PVC的需求来构建合适结构的PV
管理人员可以将存储资源分类,然后使用者就可根据StorageClass的描述申请合适的存储资源
制备器 :每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV
高级调度(污点&容忍、亲和力)
CronJob
在 k8s 中周期性运行计划任务,与 linux 中的 crontab 相同
初始化容器 InitContainer
在真正的容器启动之前,先启动 InitContainer,在初始化容器中完成真实容器所需的初始化操作,完成后再启动真实的容器。
InitController 实际就是一个容器,可以在其他基础容器环境下执行更复杂的初始化功能
使用:在 pod 创建的模板中配置 initContainers
污点和容忍
污点和容忍可以灵活的让pod避开某些节点,也可以根据硬件特点使应用部署到更合适的节点
污点(Taint)
污点:是标注在节点上的,当我们在一个节点上打上污点以后,k8s 会认为尽量不要将 pod 调度到该节点上,除非该 pod 上面表示可以容忍该污点,且一个节点可以打多个污点,此时则需要 pod 容忍所有污点才会被调度该节点。
打上污点 kubectl taint node k8s-master key=value:NoSchedule
移除污点 kubectl taint node k8s-master key=value:NoSchedule-
查看污点 kubectl describe no k8s-master
容忍(Toleration)
容忍:是标注在 pod 上的,当 pod 被调度时,如果没有配置容忍,则该 pod 不会被调度到有污点的节点上,只有该 pod 上标注了满足某个节点的所有污点,则会被调度到这些节点
pod 模板的 spec 下面配置容忍
tolerations:
- key: “污点的 key”
value: “污点的 value”
offect: “NoSchedule” # 污点产生的影响
亲和力(Affinity)
节点亲和力(NodeAffinity)
进行 pod 调度时,优先调度到符合条件的亲和力节点上
硬亲和力:即支持必须部署在指定的节点上,也支持必须不部署在指定的节点上
软亲和力:尽量部署在满足条件的节点上,或尽量不要部署在被匹配的节点上
Pod 亲和力(PodAntiAffinity)
将与指定 pod 亲和力相匹配的 pod 部署在同一节点。
硬亲和力:pod必须部署在同一节点
软亲和力:尽量将pod部署在同一节点
Pod 反亲和力(PodAntiAffinity)
pod 反亲和力:根据策略尽量部署或不部署到一块
硬亲和力:不要将应用与之匹配的部署到一块
软亲和力:尽量不要将应用部署到一块
身份认证和权限
身份认证
所有 Kubernetes 集群有两类用户:由 Kubernetes 管理的Service Accounts (服务账户)和
Users Accounts) 普通账户
(Users Accounts) 普通账户
管理员等账户
普通用户无法通过api创建
Service Accounts (服务账户)
Service Accounts 是针对k8s pod 内跑的服务的 ,用来标记服务和服务的权限
Service Account 自动化
Service Account Admission Controller :
Token Controller :管理 token
Service Account Controller :
授权(RBAC 基于角色的权限)
Role
代表一个角色,会包含一组权限,没有拒绝规则,只是附加允许。它是 Namespace 级别的资源,只能作用与 Namespace 之内。
查看 role :kubectl get role -n
ClusterRole
功能与 Role 一样,区别是资源类型为集群类型
查看:kubectl get clusterrole
RoleBinding
Role 或 ClusterRole 只是用于制定权限集合,具体作用与什么对象上,需要使用 RoleBinding 来进行绑定,作用于 Namespace 内
查看:kubectl get rolebinding --all-namespaces
ClusterRoleBinding
与 RoleBinding 相同,但是作用于集群之上,可以绑定到该集群下的任意 User、Group 或 Service Account

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)