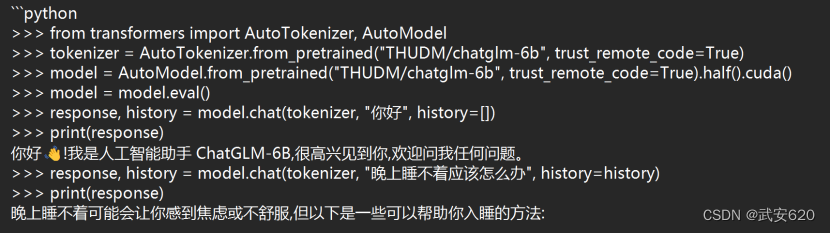
基于langchain-chatglm本地知识库得部署
通过知识图谱可以将各个知识点连接起来,可以增强模型问答的推理能力。我们都是知道文字的信息是通过被数字编码后作为矩阵储存在计算机中的,但是随着文字量的增多,矩阵的容量也是几何倍数增长,但是其中数据的密度会因为数字编码的问题,储存密度极低,这极大地浪费了资源。2.如果使用的是text2vec-base模型,因为警告的存在只可以对词汇向量化,不可以对句子向量化,因此需要分词器来对句子进行分词,因此可以考
- 项目的技术组成
- LLM模型
大型语言模型(LLM,是large language model)是一种人工智能模型,旨在理解和生成人类语言。它们通过在大量文本数据上进行训练,能够执行多种任务,包括文本总结、翻译、情感分析等。LLM的显著特点是其规模庞大,包含数十亿个参数,这使得它们能够学习语言数据中的复杂模式。这些模型通常基于深度学习架构,如转换器,这有助于它们在各种自然语言处理任务上取得令人印象深刻的表现。
比如chatgpt就是目前最典型的llm模型,而在这个项目中我们使用的是清华开源的chatglm-6b模型,是一个最低要求只需要6b完全可以在个人的消费级显卡上部署。
- embedding模型
Embedding翻译过来是“嵌入式”的意思,这一类模型的主要作用是可以把所有物体通过数学换算转换为可以被计算机的识别的数据和信号,这一类模型的主要作用有两个降维和升维。
我们都是知道文字的信息是通过被数字编码后作为矩阵储存在计算机中的,但是随着文字量的增多,矩阵的容量也是几何倍数增长,但是其中数据的密度会因为数字编码的问题,储存密度极低,这极大地浪费了资源。所以,我们可以通过矩阵乘法进行降维,减少资源的浪费,这是降维的用法。
升维的用处主要是在于通过细致观察,我们把眼睛靠近某一处物体,自然可以仔细观察某个物体,这要求我们靠近某一个物体,但是又不可以靠太近,因为靠近这个物体太近会导致我们无法观察到这个物体,embedding模型升维的一个作用是对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。
- 文本向量储存
文本向量储存技术是指将文本数据转换为向量表示,并将这些向量储存起来的技术。通过将文本转换为向量,可以将文本数据表示为数值化的形式,从而方便存储、处理和分析。主流的文本向量储存技术有
1.词袋模型(Bag-of-Words):词袋模型将文本表示为一个向量,其中向量的每个维度表示一个单词,而向量的值表示该单词在文本中的出现频率或权重。可以使用词频(Term Frequency)或词频-逆文档频率(TF-IDF)等方法来计算向量的值。
2.Word2Vec:Word2Vec 是一种基于神经网络的词嵌入模型,它将单词映射为连续向量空间中的向量。通过训练神经网络,Word2Vec 可以学习到单词之间的语义和语法关系,从而产生具有语义相关性的向量表示。
3.GloVe:GloVe(Global Vectors for Word Representation)也是一种词嵌入模型,它通过统计单词在上下文中的共现关系来生成向量表示。GloVe 模型将全局的词语共现统计信息与局部的上下文窗口统计信息相结合,产生更加全面和准确的向量表示。
4.BERT:BERT(Bidirectional Encoder Representations from Transformers)是一种基于 Transformer 模型的预训练语言模型。通过训练大规模的语料库,BERT 能够生成上下文敏感的单词嵌入向量,捕捉到单词的语义和句子之间的关系。
5.Doc2Vec:Doc2Vec 是一种将整个文档(而不仅仅是单词)嵌入为向量的技术。它类似于 Word2Vec,但将文档作为一个整体进行嵌入,从而生成文档级别的向量表示。
而今天我要介绍的的项目使用的是以word2vec为基础生成的embedding模型,适合于通过较少的资源生成精度较高的问答结果。
二.langchain和如何使用langchain
1.什么是langchain
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。它提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
- 如何使用langchain
首先需要安装langchain库(pip install langchain),又因为使用 LangChain 通常需要与一个或多个模型提供程序、数据存储、 API 等集成。如果想要使用openai的话要先安装openai的SDK(pip install openai)
import os
os.environ["OPENAI_API_KEY"] = "..."设置自己的openai的key
然后可以通过langchain的prompt模块快速生成prompt模板
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
然后生成链chain
from langchain.chains import
LLMChainchain = LLMChain(llm=llm, prompt=prompt)
上述是一个langchain的简单应用,总之使用langchain除了可以为我们掉用各个模型提供了方便意外,还为我们设定prompt等模板提供了便利。
三.几个embedding模型的介绍和使用
1.openai的api
第一种使用embedding的方法,通过调用openai的api接口来实现embedding。这里不详细介绍,具体可以参考文章https://zhuanlan.zhihu.com/p/607703047
- text2vec模型
Text2vec模型使用词嵌入(Word Embedding)技术来实现文本向量化。词嵌入是一种将单词映射到连续向量空间的技术,能够捕捉到单词之间的语义和语法关系。通过将文本中的每个单词映射为词嵌入向量,text2vec模型可以将整个文本表示为一个向量序列,从而保留了文本的语义信息。
在文本向量化过程中,text2vec模型可以使用不同的词嵌入算法,如Word2Vec、GloVe、BERT等。这些算法基于不同的原理和训练方法,但都旨在将单词表示为具有语义相关性的向量。目前使用广泛的还是word2vec.
通过使用textvec模型,我们可以将文本数据转换为数值向量,以便应用于各种机器学习和自然语言处理任务,例如文本分类、情感分析、机器翻译等。文本向量化的过程使得计算机能够更好地理解和处理文本数据,从而提高了文本相关任务的性能和效果。但是text2vec也有他自身的局限性,比如比较适合处理短文本,面对长文本容易出现问题数量判断错误,问题的题干理解不清晰等问题。
- m3e模型
M3e模型同样作为一个embedding模型,也是由中文训练集训练出的,对于中文有着高支持度,同时比起text2vec来说,m3e-base还支持英文,比起text2vec更适合多语言场景。同时比较下图中的s2s和s2p能力指数。我们可以观察到m3e的指数明显高于text2vec,因此,在大多数中文场合m3e比起text2vec更适用。

s2s, 即 sentence to sentence ,代表了同质文本之间的嵌入能力,适用任务:文本相似度,重复问题检测,文本分类等
s2p, 即 sentence to passage ,代表了异质文本之间的嵌入能力,适用任务:文本检索,GPT 记忆模块等
- ChatgGLM v1和v2的本地部署
- 通过git命令拉取chatglm模型
想要从git中拉取大型文件首先需要安装git lfs
使用以下命令添加Git LFS软件包源到系统
命令(Curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash)
安装Git LFS软件包:sudo apt-get install git-lfs
启用Git LFS扩展:git lfs install
如果要在本地部署chatglm模型,需要从github中拉取chatglm-6b模型,拉取模型命令git clone https://huggingface.co/THUDM/chatglm-6b,具体参考可以参考(https://github.com/THUDM/ChatGLM-6B)
如果要在本地部署chatglm2-6b模型,需要从github上拉取chatglm2-6b模型,拉取模型的命令(git clone 。具体可以参考https://github.com/THUDM/ChatGLM2-6B。
2.配置模型所需要的环境
使用大语言模型需要gpu,因此我们需要根据自己的显卡型号安装显卡驱动。首先安装好环境
sudo apt-get install g++,
sudo apt-get install gcc,
sudo apt-get install make实验室服务器用的是英伟达显卡这里查看显卡版本的命令是”lspci | grep -i nvidia”,查看好显卡版本后,使用命令行安装英伟达显卡驱动。
安装好英伟达显卡驱动后,我们还需要安装cuda和cudnn。在安装cuda和cudnn之前我们先执行nvidia-smi,执行获得显卡信息,查看显卡支持的最高CUDA的版本,以便下载对应的CUDA安装包。如图是在172.16.17.43的主机上的显卡信息。
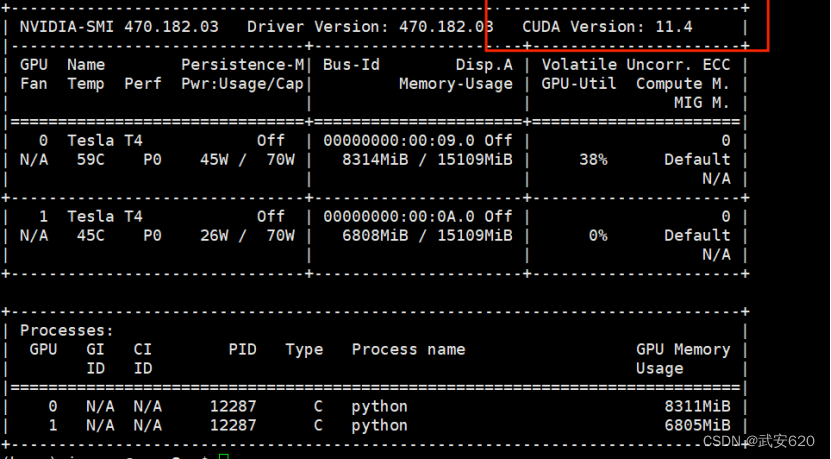
这里我们是可以看到的,实验室的的显卡是由两块t4显卡组成的,这也就说明说明已经安装显卡驱动了。红色框内的cuda版本代表了显卡所支持的最高版本,因此我们可以下载11.4版本的cuda。
下载完cuda
安装必要的依赖项
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install build-essential
安装cuda
sudo sh cuda_11.4.0_<version>_linux.run
按照安装程序的提示进行安装。您需要选择是否安装NVIDIA驱动程序、CUDA Toolkit、cuDNN等组件。建议选择默认选项。
安装完成后,您需要将CUDA的路径添加到环境变量中。在Ubuntu上运行以下命令:
echo 'export PATH=/usr/local/cuda-11.4/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-11.4/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
安装完成后输入nvcc -version
我们会看到cuda输出版本号。
然后我们激活这一个虚拟环境(conda activate chatglm)
当这两个下载完后,我们在ubuntu中创建一个虚拟环境(conda create --name hatglm python=3.10.11)
进入到项目目录中执行pip install -r requirements.txt,安装项目所需要的python包。
安装成功后,我们修改项目中的配置文件cli_demo.py中的路径,将THUDM/chatglm-6b改为本地的模型路径,这样子可以从本地加载模型
3.部署中一些可能出现的bug和解决方案
1.如果出现lib文件软连接错误,可以考虑重装,或者将软连接文件重新下载并建立连接。
2.Python一定要安装3.11以下的版本,某些库(尤其是paddlepaddle)不支持python3.11,最低是3.8以上,但是不建议安装3.8,会出现很多包的版本问题。
3.如果pip install中出现一些包安装错误,一个是建议手动安装尝试,另一个是建议尝试conda安装,如果这两个还不可以,可以个根据报错信息修改。
4.pip如果下载速度慢,可以手动配置清华源进行下载,命令(pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple)
5.部署chatglm2-6b模型大约需要13GB的显存以fp16的精度,在实验室的服务器上部署大约需要125000MIB的显存,自己尝试在电脑上部署的时候要注意自己电脑显存大小。

4.fastllm加速器的使用
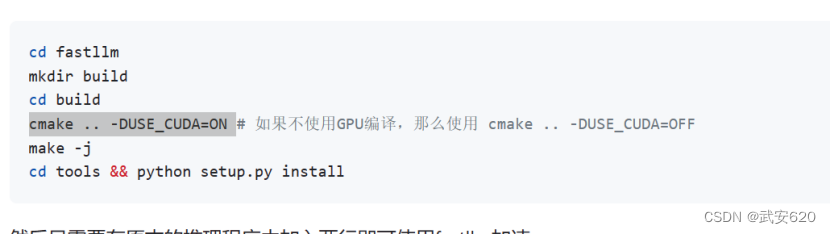
对于加速chatglm和chatglm2模型,我们可以使用fastllm(目前该工具只在ubuntu系统中可以使用),这一个在github上开源的工具。
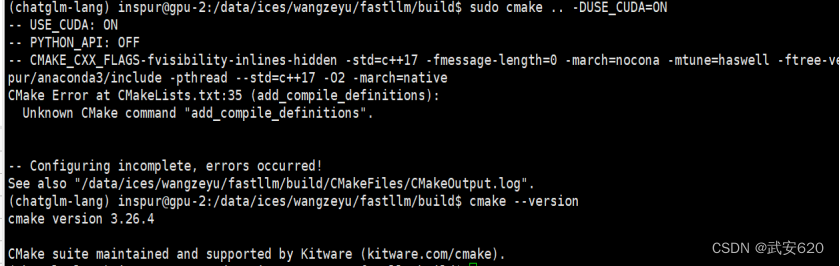
在使用这个加速工具之前我们需要先查看自己的cmake的版本号,要在3.13以上。这里在实验室的服务器上执行cmake ..-DUSE-CUDA=ON的时候存在权限问题.

这个时候要使用管理员权限进行安装sudo cmake .. -DUSE-CUDA=ON,如果sudo 下执行出现以下错误,则需要升级sudo下的cmake版本。
- Chatglm v1和 v2在个人数据库的项目部署
1.项目的拉取和配置
因为该项目是基于langchain(LLM)和清华的chatglm2-6b模型的可以通过必应和本地知识库的问答,本地知识库支持txt,docx,md,pdf 等格式。
从github中拉取项目https://github.com/imClumsyPanda/langchain-ChatGLM
这里使用git命令拉取的时候应该多等待一段时间,模型的第一个权重文件需要下载完成后才会显示下载速度和进程。
对于embedding的处理模型项目使用的是text2vec,可以通过(git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese /your_path/text2vec
)命令下载,我自己下载的时候从项目中的百度网盘下载的,这一个我把他挂在到我的文件夹下,大家可以直接通过xftp下载。
当环境配置好后,我们需要修改模型配置,进入项目以后,我们首先需要进入到config文件夹,找到model_config,修改文件的几处代码,修改代码中的”text2vec”的键值对,将他修改为本地的text2vec模型路径。

如果我们要部署chatglm2-6b模型,因此我们在下面寻找名为chatglm2-6b的字典

将local_model_path变化为本地模型路径。将下面的LLM_MODEL 名称改为chatglm2-6b。
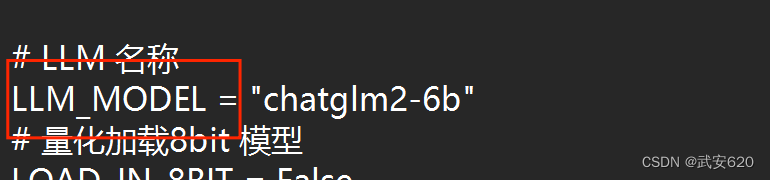
如果要部署chatglm-6b模型,则要寻找名为chatglm的字典。

将local_model_path路径改为本地chatglm模型路径。
如果想要测试其他精度的chatglm2-6b模型或者chatglm模型的性能,按照上述操作,找到对应的模型名称,然后将对应模型下的路径改为本地路径,并且把LLM_MODEL改为模型在llm中的名称。
- 项目的运行
当我们修改完本地配置后,我们可以运行loader的image_loader.py,如果image_loader运行成功,那么可以尝试运行cli_demo.py文件,等到运行成功后,会提示你导入一个文件夹作为数据库,并将把它向量化,这里注意导入的文件中的文档不要有中文命名的文档。
当我们导入本地数据库成功后,可以尝试进行问答了。如果cli_demo可以正常运行,那么webui和api一般都没有问题。
如果我们想要建立属于自己本地数据库我们可以使用webui(api中无法通过文件夹批量上传文件)

图中红色框被框起来的部分便是你的本地数据库,他会被储存在你的langchain-ChatGLM-master/knowledge_base路径下。下面存在传文件和上传文件夹两种上传形式,这两种上传形式同样要遵循文件名不可以含有中文名字。
对于上传数据被向量化的速度,这里我自己稍微做了一个统计
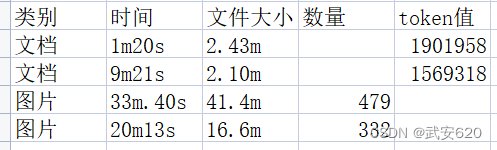
这里的文档后缀名为tex,图片后缀名为jpg。所选择的计算token的库是tiktoken,采用“gpt2”编码进行运算。但是对于文件小,token小的文档上传速度远慢于文件大,token大的文档的原因,我没有找到答案。
3.项目中可能出现的一些bug和解决方法
1.“can’t find configs.model_config.py”,这一个错误意思是找不到configs.model_config文件,这个错误我们可以直接修改image_loader文件,在文件的最上面添加
这两行代码,然后找到from configs.model_config import * 这一行代
 码变为from model_config import * 这个时候就不会再次报错了。
码变为from model_config import * 这个时候就不会再次报错了。
2.当我们把模型修改完成后,在里面找到执行我们执行loader/image_loader.py文件,执行它,如果执行image_loader出现错误,可以根据错误查找一下信息,一般不会出现环境问题,如果image_loader执行成功了,我们可以执行cli_demo.py观察测试是否报错。其中即使执行成功了,会出现一个警告。
WARNING 2023-07-12 09:23:31,619-1d: No sentence-transformers model found with name /data/ices/wangzeyu/text2vec-large-chinese. Creating a new one with MEAN pooling.
这个警告的存在是可以消除的,(根据作者的说法是不影响使用的,但是根据实际使用的交流中发现,因为找不到预训练模型,所以只可以对词汇向量化,不可以对句子向量化,这影响了回答的精确性),具体消除警告的方法可以参考
https://github.com/imClumsyPanda/langchain-ChatGLM/issues/156
- 上传文件的时候出现了在webui页面中出现了无法选择数据库的情况,这个问题主要是因为网页自动翻译的问题,在Edge浏览器中最上侧的导航栏里把页面自动翻译关掉就可以选择数据库了。
4.上传文件的时候,在webui页面中出现某些文档上传成功,但是后台xshell中,在提示这些文档上传成功后,最后出现所有文件上传失败提示 或 提示所有文件上传失败。这种错误有三种原因,
第一种:是因为你的页面自动翻译又打开了,导致上传的时候文件名被翻译过了。
![]()
第二种:你的文件夹种的文档名字存在中文,这里提供一个用python批量修改文档名的方法。

此时会弹出一个提示让你输入你想要导入的数据库,这个数据库可以是txt,jpg等但是注意导入的文件夹或者文件的名字不可以存在中文,如果存在中文会导致文件的导入失败。这里提供一个可以批量修改文件名的代码和一个可以批量删除符合某一条件文件的代码。
第三种:这个文件夹内的内容过多,一次性传输的数据过大,要把这一批数据分为好几个批次分别进行向量化存储。
5.如果要完全部署该项目,chatglm2-6b+m3e-base需要的显存是14000MIB左右,如果进行一次问答,需要的显存会达到147000左右,如果进行多次问答,显存可能会超过15109MIB.也就是实验室中T4显卡的显存,因此不建议单卡部署。
六.未来发展与期望(主要目的是优化模型的问答能力)
1.因为chatglm-6b的模型6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;并且也不擅长逻辑类问题(如数学、编程)的解答。可以使用moss或者chatglm-130b等模型,替代chatglm模型进行问答。在问答效果上可能会比chatglm的问答效果更强。
2.如果使用的是text2vec-base模型,因为警告的存在只可以对词汇向量化,不可以对句子向量化,因此需要分词器来对句子进行分词,因此可以考虑更换分词器,目前使用的分词器当时分词的时候,过短的词语会导致分词器分词不成功,可以更换分词器来增强分词效果。
3.改进embedding模型。可以使用m3e-base模型,根据(三)中的论述,m3e对于中文的支持度,尤其是长文段别的支持远高于text2vec,对于检索问题数量和文段匹配能力强于text2vec模型,对于中文的增强比较明显。(这里观察的到,当如果换用了
4.结合知识图谱。深度学习在一个领域/任务是否成功主要由能否提供的信息量来决定,而信息量则有数据条目和每条数据特征个数两个维度来共同决定。利用了图的结构,将事物背后更高层的背景知识串联在了一起,使得图不光光可以进行直接联系的描述,同时也描述了隐藏在背景知识下的隐藏的联系。通过知识图谱可以将各个知识点连接起来,可以增强模型问答的推理能力。比如encoder-decoder 框架,能够充分利用知识图谱中知识的深度学习问答模型。在深度神经网络中,一个问题的语义往往被表示为一个向量。具有相似向量的问题被认为是具有相似语义。这是联结主义的典型方式。另一方面,知识图谱的知识表示是离散的,即知识与知识之间并没有一个渐变的关系。这是符号主义的典型方式。通过将知识图谱向量化,可以将问题与三元组进行匹配(也即计算其向量相似度),从而为某个特定问题找到来自知识库的最佳三元组匹配。
5.更改prompt模型,使其回答更加人性化。首先,这一个可以使用langchain.prompt来修改回答的模板,呈现总分总或者总分的结构,更容易被使用者抓住重点。其次可以考虑写出多个prompt模板,对其使用后,用相对应的评分规则对每一个prompt模板的答案做出评分,选取最高评分的prompt模板作为答案输出。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 3
3 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)