Hive 中的数据模型分析
Hive 可以说是 Hadoop 生态中比较坚挺的一个组件了,在大数据架构飞速发展的今天,各种组件也是层出不穷,随着k8s 云原生的发展,跟不上云原生脚步的组件也必将被淘汰。Hive 也逃脱不了被 SparkSQL 替代的命运,但是学习掌握 Hive 的数据模型还是很有必要的。技术发展之快,让人不得不感慨一将功成万骨枯!
Hive 架构分析
https://blog.csdn.net/oTengYue/article/details/91129850
Hive 逻辑查询优化
查询重写(Query Rewriting)
- 对查询进行转换,以便更高效地执行。这可能涉及到重写查询的谓词、连接顺序或子查询结构,以减少数据处理和传输的成本。
谓词下推(Predicate Pushdown)
- 将查询的谓词条件尽可能地下推到数据源,以减少从数据源读取的数据量。这可以通过在查询计划中的适当位置应用谓词条件来实现。
列剪裁(Column Pruning)
- 在查询执行过程中仅选择查询所需的列,而不是读取和处理所有列。这可以减少数据的传输和处理开销,并提高查询性能。
表剪裁(Table Pruning)
- 在查询过程中排除不相关的表,从而减少数据的读取和处理。这可以通过分析查询的谓词条件和表之间的关联来实现。
连接重排(Join Reordering)
- 通过重新排列连接操作的顺序来减少查询的成本。优化器可以根据表之间的大小、关联性和其他统计信息来选择最佳的连接顺序。
子查询优化(Subquery Optimization)
- 对查询中的子查询进行优化,以减少计算和数据访问的开销。这可能涉及到将子查询转换为连接、应用连接条件等。
统计信息使用(Statistics Usage)
- Hive 支持收集和存储与表和列相关的统计信息。优化器可以使用这些统计信息来选择最佳的查询计划,例如选择合适的连接算法、选择索引等。
Hive 数据模型
Hive 和传统的数据库一样,才采用关系模型。使用结构化查询语言(SQL)进行数据检索。
支持大多数关系数据库所支持的数据类型,包括基本数据类型和复杂组合数据类型。
基本数据类型
- 数值型

-
字符串类型
String, VARCHAR, CHAR
-
日期时间类型
TIMESTAMP
-
其他
BOOLEAN, BINARY
组合数据类型
- Array/Map/Struct/Union
Hive 数据模型

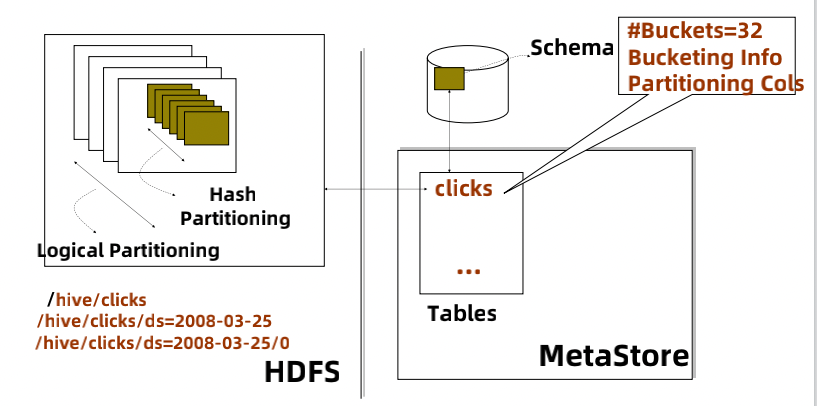
hive 数据模型主要包括Hive 表数据模型和元数据模型,hive 表数据模型存储在 HDFS 上,目录的路径就是表数据的存储路径,目录路径由四部分组成:
- 数据库(Database): 对应上图左边的 /hive
- 表(Table): 对应上图的 clicks
- 分区(Partition): 对应上图的 ds=2008-03-25
- 桶(Bucket): 对应上图的 0
其中分区和桶是可选的,如果没有指定桶,数据对应的文件会以 00000 开头,Hive 元数据模型 MetaStore 存储着表结构、分区信息、表位置、列和数据类型等。默认情况下,Hive 使用关系型数据库(如 MySQL 或 Derby)来存储元数据
表
根据数据是否受 Hive 管理,分为:
- 内部表(Internal Table):内部表是由 Hive 管理的表,数据存储在 Hive 默认的数据存储位置中(通常是 Hadoop 分布式文件系统,如 HDFS)。当删除内部表时,与之关联的数据也会被删除。
- 外部表(External Table):外部表是引用外部数据的表,数据存储在用户指定的位置。当删除外部表时,只会删除 Hive 的元数据,而不会删除实际的数据。
永久表和临时表:
- 默认创建表为永久表,临时表是指仅当前Session 有效的表,数据临时存放在用户的临时目录下,当前session退出后即删除。
- 临时表比较适合于比较复杂的SQL逻辑中拆分逻辑块,或者临时测试
- 如果创建临时表时,存在与之同名的永久表,则临时表的可见性高于永久表,即对表的操作是临时表的,用永久表无效
- 临时表不支持分区
Partition
-
基于用户指定的分区列的值对数据表进行分区(分区字段可以不是已有的列字段)
-
表的每一个分区对应表下的相应目录,所有分区的数据都是存储在对应的目录中
-
分区优点:
分区从物理上分目录划分不同列的数据
用于查询的剪枝,提升查询的效率 -
可以多级分区,指定多个分区字段,但是分区不可无线扩展(多级目录造成HDFS小文件过多影响性能)
Bucket
-
桶作为另一种数据组织方式,弥补Partition的短板(不是所有的列都可以作为 Partition Key)
-
通过Bucket列的值进行Hash散列到相应的文件中,重新组织数据,每一个桶对应一个文件
-
桶的优点:
有利于查询优化
对于抽样非常有效 -
桶的数量一旦定义后,如果更改,只会修改Hive 元数据,实际数据不会重新组织
常用存储格式
常用的存储格式包括行储存和列储存,行存储适合CRUD 事务处理,对列的统计分析需要耗费大量的I/O,对指定列进行统计分析时,需要把整张表读取到内存,然后再逐行对列进行读取分析操作。
列存储不适合事务操作,适合统计查询,尤其是针对列的,只需要把指定列读取到内存进行操作。
Hive 的数据存储在 HDFS 上,支持多种不同文件格式,在创建表时,通过 STORED AS 语句指定存储文件格式。

TextFile
- Hive默认格式(可通过hive.default.fileformat参数定义为默认其他格式)
- 可读性好,肉眼可读
- 磁盘开销大,数据解析开销大,不建议生产系统采用这种格式
- 可以配合压缩来缓解IO压力,比如lzo/gzip/bzip2,但压缩后不可Split
- 对于Schema的变动支持很弱,只能在最后字段新增字段,已存在的字段无法删除
SequenceFile
- 二进制文件,将数据以<key, value> 的形式序列化到文件中
- 相比 Text 更紧凑,支持Split
- 没有Metadata, 只能新增字段
Avro
- 支持数据密集型的二进制文件格式,格式更为紧凑
RCFile

- Hive 推出的一种专门面向列的数据格式,遵循“先按列划分,再垂直划分”的设计理念。
- 针对它并不关心的列时,会在IO 上跳过这些列。
ORC

- 在压缩编码,查询性能方面相比RCFile 做了很多优化
- Metadata 用 protobuf 存储,支持 schema 的变动,如新增或者删除字段
Parquet(目前使用最多的)
-
相比于 ORC 可以将嵌套式数据存储成列式格式,方便对其进行压缩和编码。
可以用更少的IO 操作取出需要的数据。 -
存储 metadata, 支持 schema 变更
总结(感想)
Hive 在笔者的公司已经被 SparkSQL 替代,除了使用 Hive 的 MetaStore 作为存储文件的元数据,已经不在使用 Hive 的 MR计算。
资源调度引擎也从 YARN 切换为 K8S,目前的 Spark 和 Flink 都运行在 k8s 上,Hadoop 的生态也慢慢淡出历史的舞台。储算分离的架构,进一步推进了对象存储的发展,上了 K8s 后, HDFS 也将被 OSS 对象存储替换。
大数据的发展经过这么多年,出现了很多优秀的组件,但是随着历史的潮流,更新换代,让人不得不感慨,一将功成万骨枯。

K8S/Kubernetes社区为您提供最前沿的新闻资讯和知识内容
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)