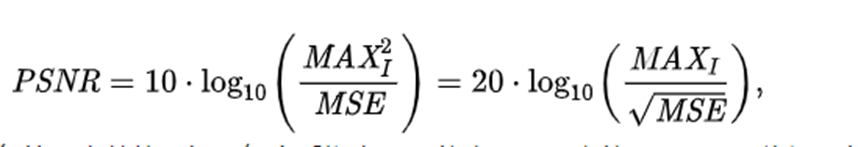
视频编码基础知识及环路滤波
其中,形容结果的两项指标往往联合使用,因为单纯的高质量和单纯的低码率都很难说明编码性能如何,一般公认的是固定单一变量来对比另一个变量,例如相同视频质量下的码率变化率(BD-BR)或相同码率下的 PSNR 变化量(BD-PSNR)。峰值信号的能量与噪声的平均能量之比,通常表示的时候取log变成分贝,由于MSE为真实图像与含噪图像之差的能量均值,而两者的差即为噪声,因此PSNR即峰值信号能量与MSE之
视频编码基础
视频图像的质量评价
采用有损压缩的技术能显著降低码率,但是也会降低视频图像的质量,因此对于有损压缩算法,需要建立一套评价准则,对编码质量进行评价。
可以分为主观质量和客观质量评价
客观质量评价方法
1.均方误差(mean square error,MSE) 原始参考帧和失真帧直接做差取平方求和
2.信噪比(signal noise ratio,SNR)
3.峰值信噪比(peak signal noise ratio,PSNR)
峰值信号的能量与噪声的平均能量之比,通常表示的时候取log变成分贝,由于MSE为真实图像与含噪图像之差的能量均值,而两者的差即为噪声,因此PSNR即峰值信号能量与MSE之比。PSNR是最普遍、最广泛使用的评鉴画质的客观量测法,虽然和人眼看到的视觉品质不完全一致,但目前仍作为对照其他指标的基线。

其中, M A X I MAX_I MAXI是表示图像点颜色的最大数值,如果每个采样点用 8 位表示,那么就是 255。
PSNR的单位为分贝(DB)
PSNR较高时,代表着其客观质量较高,相反,PSNR低代表客观质量低。
最常用的是PNSR
主观质量评价方法
SSIM
- 结构相似性,比PSNR更接近主观
- PSNR使用更广
- 因为1. 复杂度低;
- 2.MPEG官方制定标准时采用PSNR;
- 3.编码器做模式选择时大多使用了均方误差准则
Vmaf
- Netflix制定的主观准则,因阿里云窄带高清2.0的发布广为国内所知
VmafMOS
- 人眼主观评判打分
BDRate
仅靠PSNR质量评价不够!因为我们可以使用无限大码率达到最高质量,所以要将码率和PSNR结合起来评价
考虑以下三种情况,很明显当psnr一样时,码率越低越好。当码率一样时,psnr越大越好。
Case1: A: 700k, 37dB; B: 1000k, 37dB; => A好,省30%码率
Case2: A: 700k, 37dB; B: 700k, 36dB; => A好,高1dB psnr
Case3: A: 700k, 37dB; B: 600k, 36dB; => ?? 因此引入了BDRate
测试4个码率点,拟合曲线,求平均
-
BD-Rate:相同质量下的码率节省(横向截线)
-
BD-PSNR:相同码率下的质量提升(纵向截线)

注意:
- 平时说的gain 30%, 或者谁比谁节省30%码率,一般就是BD-Rate省了30%
- 平时说节省多少码率,都隐含了相同质量下的条件
总结:当您评估编解码器的性能时,您通常会得到一条率失真 (RD) 曲线,该曲线告诉您不同比特率(通常以 kbps 或 Mbps 为单位)的质量(以 dB 为单位的 PSNR)。
BD-Rate 指标使用来自 RD 曲线的信息,告诉您一个编解码器相对于另一个编解码器的改进程度
编码效率\压缩效率
- 压缩比和编码损失综合评价结果或者说码率和质量、
- 码率和失真的折中编码效率越高,
- 可以在相同质量下码率更小
- RD (Rate Distortion)
帧率、分辨率和码率
帧速率也称为FPS(Frames PerSecond)的缩写——帧/秒。是指每秒钟刷新的图片的帧数,也可以理解为图形处理器每秒钟能够刷新几次。每秒钟帧数(FPS)越多,所显示的动作就会越流畅。
分辨率,又称解析度、解像度,可以从显示分辨率与图像分辨率两个方向来分类。大部分时候我们可以简单的将它理解为图片的长度和宽度,即图片的尺寸。分辨率影响图像大小,与图像大小成正比:分辨率越高,图像越大;分辨率越低,图像越小。
码流(Data Rate)是指视频文件在单位时间内使用的数据流量,也叫码率或码流率,通俗一点的理解就是取样率,是视频编码中画面质量控制中最重要的部分,一般我们用的单位是kb/s或者Mb/s。一般来说同样分辨率下,视频文件的码流越大,压缩比就越小,画面质量就越高。在视频领域,码率常被说为比特率。
个人见解:比特率 = 宽 * 高 * 颜色深度 * 帧每秒,所以这样就能理解对码流的定义了。
码流(Data Rate)是指视频文件在单位时间内使用的数据流量
下文中别人的文章也有提到码率
码率**。**即比特流体积与视频时间之比。
三者之间的关系
1、如果码率为变量,帧率越高,每秒钟经过的画面越多,需要的码率也越高,体积也越大。
2、在码率一定的情况下,分辨率与清晰度成反比关系:分辨率越高,图像越不清晰,分辨率越低,图像越清晰
3、在分辨率一定的情况下,码率与清晰度成正比关系,码率越高,图像越清晰;码率越低,图像越不清晰。
个人见解:码率一定,即单位时间内使用的数据流量一定,如果分辨率越大,那说明颜色深度越小,就说明越糊??(这是根据上面比特率的公式来推断的)
但我觉得还可以这样理解:一张图片固定存储大小,如果图像变大,存储空间肯定变大,那还想维持之前的存储大小,那就只好牺牲一下清晰度。
环路滤波
学习资料:基于深度学习的HEVC多帧环路滤波方法-今日头条 (toutiao.com)
我们平时看到的视频,原始数据量往往非常庞大,尤其对高清视频而言,如果直接存储和传输原始信息,需要占用大量的空间和带宽。
为解决这个问题,学术界和工业界制定出了多代视频编码标准,用于将原始视频数据压缩成体积较小的比特流。
压缩关注的性能, 主要在于“多快好省”的后三个字:
- “快”: 编码时间。与视频播放时间无关,此指标是把原始视频编码成比特流所需的时间,即编码器的运行时间。编码时间越短,往往意味着消耗计算资源越少,说明这种编码方法越有希望得到广泛应用。
- “好”: 压缩后的视频质量。最常用的,可以用所有帧平均 PSNR 来表示。或者用其他客观指标如 SSIM 等描述,也可用人的主观打分来衡量。
- “省”: 压缩后的码率。即比特流体积与视频时间之比。
编码时间描述的是过程,视频质量和码率描述的是结果,显然,过程和结果都需要我们关注。
其中,形容结果的两项指标往往联合使用,因为单纯的高质量和单纯的低码率都很难说明编码性能如何,一般公认的是固定单一变量来对比另一个变量,例如相同视频质量下的码率变化率(BD-BR)或相同码率下的 PSNR 变化量(BD-PSNR)。 这种“好”和“省”,更科学地说,称为**“率-失真性能**”,即反映码率和失真两项指标的综合性能。
随着编码标准的发展,例如 H.264/AVC->H.265/HEVC->H.266/VVC,率失真性能在不断地优化,但代价是时间复杂度成倍提高,这主要因为后续的编码标准往往支持更灵活的分块/预测/变换等策略,使得编码器能在更广大的策略空间中搜索最优解,用更多的搜索时间换取率-失真性能。对于一种编码标准,研究者改进的目标也往往基于复杂度或率失真性能,编码领域至少有以下几类研究:
-
保证率-失真性能前提下,节省编码时间:可以理解为减小编码时间的均值(一阶性能);
-
在编码时间可接受的前提下,优化率-失真性能:可以理解为优化BD-BR或BD-PSNR的均值(一阶性能);
-
复杂度控制,减小编码时间复杂度的波动:即减小编码时间的方差(二阶性能);
-
码率控制,减小编码过程中的码率波动:即减小码率的方差(二阶性能)。
可以归结为对复杂度、码率与视频质量的追求
研究背景
作为一种比较先进的视频压缩方法,HEVC 标准相比于上一代 AVC 标准,能够在相同质量下降低约 50% 码率,使编码效率进一步提高。但也需要考虑到,AVC、HEVC 等基于块的编码方法通常用于有损压缩而不是完全无损的,因此不可避免会带来了多种失真(如块失真、模糊和振铃效应等),尤其在低码率情况下,这些失真更为显著。
为了减轻编码过程中的失真,人们提出了多种滤波算法。尽管具体方法不同,这些滤波算法具有一个共同点:都对编码后的每帧视频进行质量增强,并且已经增强过的帧又作为参考帧,为后续帧的编码过程提供帧间预测信息。可见,这类滤波算法既作用于当前帧的输出,又作用于后续帧的输入,逻辑上形成一个闭环,因此统称为环路滤波。合理设计的环路滤波器,使得视频编码的效率可以进一步提高。
首先,HEVC 标准的制定过程涉及到三种环路滤波器,包括去块滤波器(Deblocking filter,DBF)、样本自适应偏移(Sample adaptive offset,SAO)滤波器以及自适应环路滤波器(Adaptive loop filter,ALF)。其中,DBF 首先用于消减压缩视频中的块效应;然后,SAO 滤波器通过对每个采样点叠加自适应的偏移量,来减少压缩失真;最后,ALF 则基于维纳滤波算法,进一步降低失真程度。最终,DBF 和 SAO 被纳入 HEVC 标准。
除了 HEVC 标准环路滤波器,另有 多种启发式的 和 基于深度学习的环路滤波方法 ,也被陆续提出。
启发式方法是根据一些先验特征(如纹理复杂度和相似视频块个数等)对压缩失真构建统计模型,再根据此模型设计滤波器,例如非局域均值(Non-local means,NLM)滤波器 [Matsumura, JCTVC-E206, 2011] 和基于图像块矩阵奇异值分解的滤波器 [Ma, MM 2016][Zhang, TCSVT 2017] 等。启发式方法能在一定程度上提高编码效率,但模型中的先验特征需要手动提取,这高度依赖于研究者的经验,并且难以利用多种特征进行准确建模,因此在一定程度上限制了滤波器的性能。
从 2016 年开始,基于深度学习的方法显著提高了环路滤波性能。此类方法一般通过构建卷积神经网络(convolutional neural network,CNN)来学习视频帧中的空间相关性。例如,文献 [Dai, MMM 2017] 设计了一种可变滤波器尺寸的残差 CNN(Variable-filter-size residue-CNN,VRCNN),以替换帧内模式中的标准 DBF 和 SAO。文献 [Zhang, TIP 2018] 则提出一种带有捷径的残差CNN(Residual highway CNN,RHCNN),用于帧内或帧间模式的标准 SAO 过程之后。
上述基于深度学习的方法有效发掘了单帧内容的空间相关性,然而却没有发掘多帧内容中的时间相关性。实际上,压缩视频一般存在明显的质量波动,而且其中的连续多帧往往包含相似的事物或场景。因此,低质量帧中的视频内容可以由临近的高质量帧推测得到,这即为本文的出发点:基于深度学习的 HEVC 多帧环路滤波。

欢迎加入我们的广州开发者社区,与优秀的开发者共同成长!
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)