
详解大模型微调方法LoRA Adapter(内附实现代码)
以GPT-3 175B参数量为例,过大的参数量在Finetune的时候代价很大,Adapter适配器方法是进行大模型微调的方法之一。本文详细介绍了大模型微调方法LoRA和代码实现
1. 背景介绍
以GPT-3 175B参数量为例,过大的参数量在Finetune的时候代价很大,Adapter适配器方法是进行大模型微调的方法之一。Adapter方法的主要思路是在模型网络结构中加入新定义的Adapter适配器部分,在重训的过程中只更新Adapter部分的网络参数。Adapter-based tuning最早源于19年的【ICML2019: Parameter-Efficient Transfer Learning for NLP adapters】
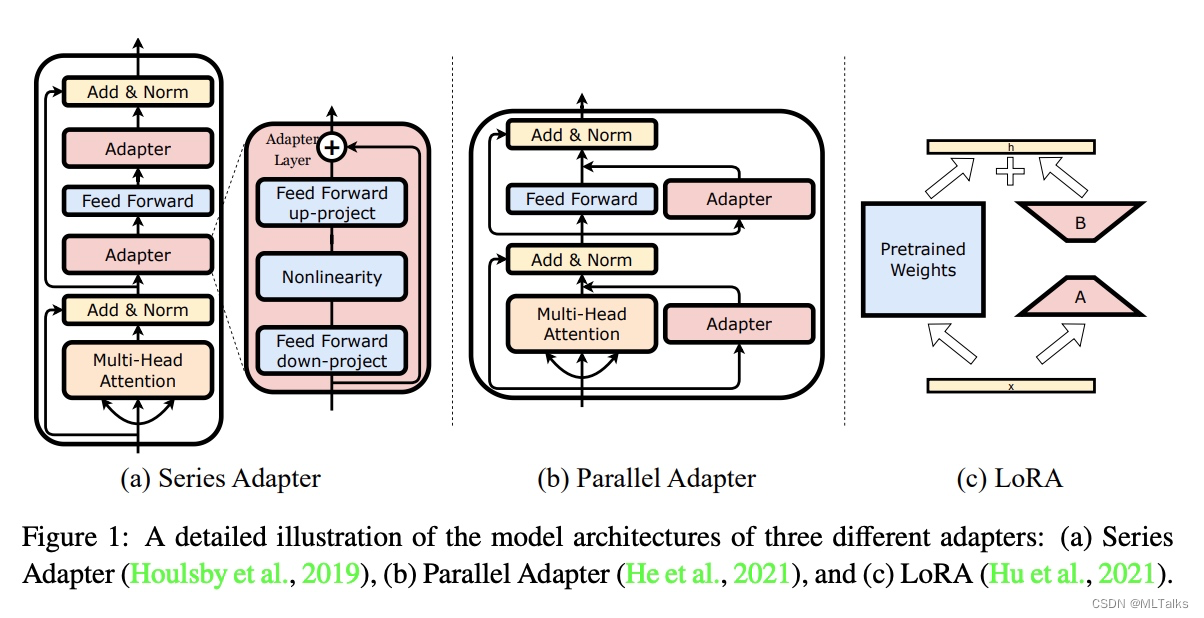
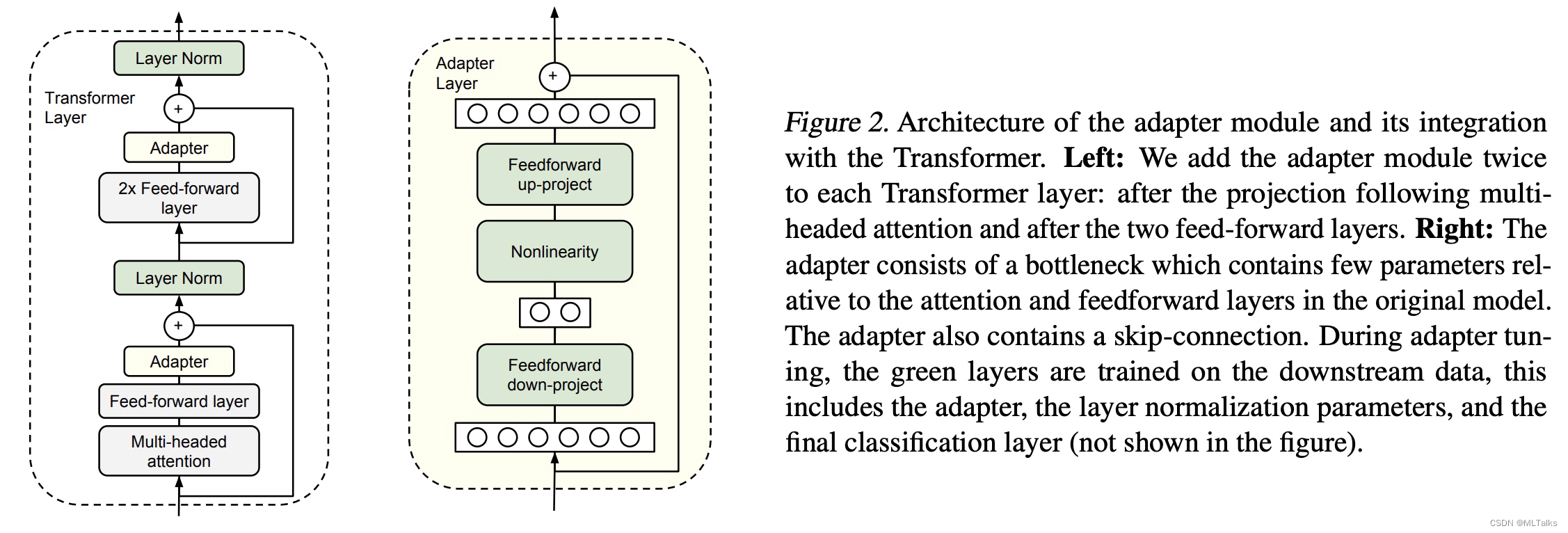
Adapter module会先把输入的d维向量映射为一个小的m维向量,通过非线性层后,再从m维向量映射回d维向量;其中也用到了残差网络,结构如下图(右):
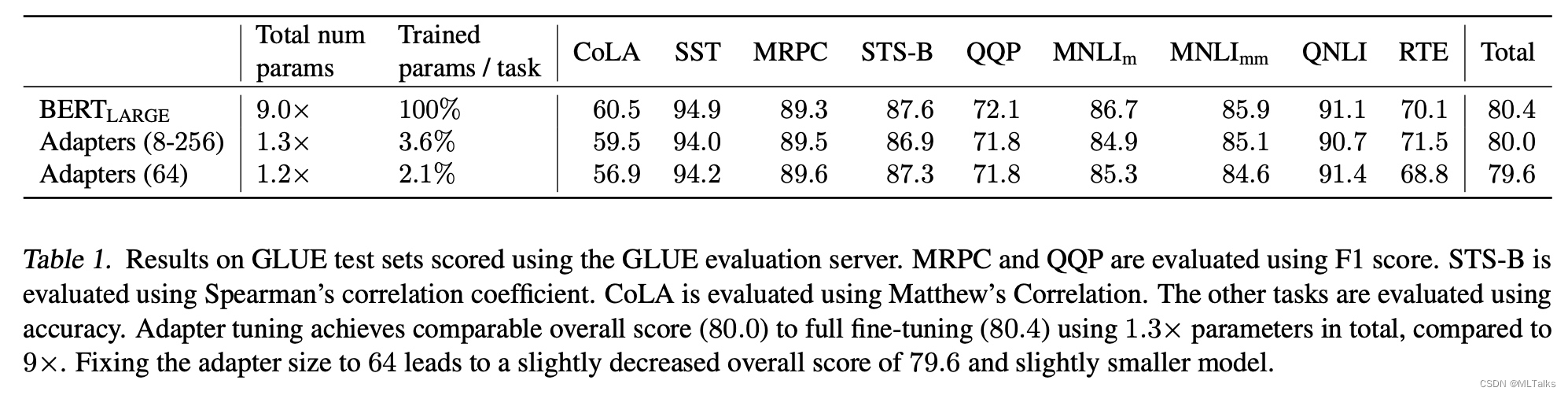
Adapter的效果可以大幅减少微调的参数量:
代码实现可参考:google-research/adapter-bert
def feedforward_adapter(input_tensor, hidden_size=64, init_scale=1e-3):
"""A feedforward adapter layer with a bottleneck.
Implements a bottleneck layer with a user-specified nonlinearity and an
identity residual connection. All variables created are added to the
"adapters" collection.
Args:
input_tensor: input Tensor of shape [batch size, hidden dimension]
hidden_size: dimension of the bottleneck layer.
init_scale: Scale of the initialization distribution used for weights.
Returns:
Tensor of the same shape as x.
"""
with tf.variable_scope("adapters"):
in_size = input_tensor.get_shape().as_list()[1]
w1 = tf.get_variable(
"weights1", [in_size, hidden_size],
initializer=tf.truncated_normal_initializer(stddev=init_scale),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
b1 = tf.get_variable(
"biases1", [1, hidden_size],
initializer=tf.zeros_initializer(),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
net = tf.tensordot(input_tensor, w1, [[1], [0]]) + b1
net = gelu(net)
w2 = tf.get_variable(
"weights2", [hidden_size, in_size],
initializer=tf.truncated_normal_initializer(stddev=init_scale),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
b2 = tf.get_variable(
"biases2", [1, in_size],
initializer=tf.zeros_initializer(),
collections=["adapters", tf.GraphKeys.GLOBAL_VARIABLES])
net = tf.tensordot(net, w2, [[1], [0]]) + b2
return net + input_tensor
Adapter的变种方法有以下几种:
series adapter是19年提出的,主要思路是在Transform的block中加上串联的Adapter的结构;parallel adapter是20年提出的,主要思路是在Transform的block中加上并联的Adapter的结构;lora是21年提出的,主要思路是通过低秩分解的方法减少参数,进行重训。也就是本文的方法。
使用LoRA(Low-Rank Adaptation)方法,通过低秩分解的方法可以减少10000倍的训练参数量,GPU显存占用减少3倍。跟别的adapter方法相比在推理的时候没有额外的延迟。
2. LoRA(Low-Rank Adaptation)实现
2.1 详细说明
已有方案存在的问题
-
推理延迟增加。原有adapter方案会在原有网络中增加新的模块,增加计算量和耗时(+20%)

-
优化prompt的效果不够好。像prefix-tuning在参数量过大的时候效果下降
低秩参数分解
对于一个预训练的矩阵
W
0
∈
R
d
×
k
W_0 \in \Bbb{R}^{d \times k}
W0∈Rd×k ,把对这个矩阵的参数更新通过低秩分解的方式来进行,
W
0
+
Δ
W
=
W
0
+
B
A
W_0 + \Delta W = W_0 + BA
W0+ΔW=W0+BA ,其中
B
∈
R
d
×
r
,
A
∈
R
r
×
k
,
r
≪
m
i
n
(
d
,
k
)
B \in \Bbb{R}^{d \times r}, A \in \Bbb{R}^{r \times k}, r \ll min(d, k)
B∈Rd×r,A∈Rr×k,r≪min(d,k) ,r的维度远小于d和k的维度。当进行微调训练的时候,
W
0
W_0
W0 的参数保存不变,只更新学习
A
A
A 和
B
B
B 的参数。在进行前向计算的时候,
W
0
W_0
W0 和
Δ
W
=
B
A
\Delta W = BA
ΔW=BA 都乘上相同的输入并进行elementwise的求和操作,即
h
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
h = W_0 x + \Delta W x = W_0 x + BAx
h=W0x+ΔWx=W0x+BAx
如下图所示,通过高斯分布初始化 A A A 矩阵, B B B 矩阵初始为0,初始的 Δ W = B A \Delta W = BA ΔW=BA 值为0。在训练的时候使用 α r \dfrac{\alpha}{r} rα 对 Δ W \Delta W ΔW 进行归约, α \alpha α 初始是跟 r r r 值一样的常数,后续训练中会跟学习率一样的方式进行调整。
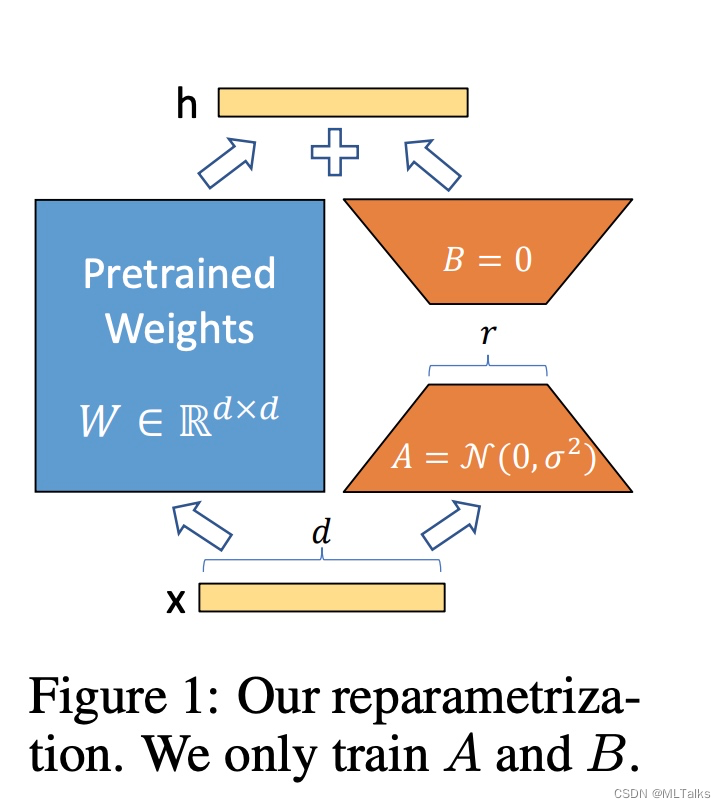
低秩参数分解方法有两个好处:
- 支持广泛意义上的的全量finetuning。如果想做跟之前Finetune方法一样的全量参数重训的话,只用把LoRA中的维度 r r r 改成跟预训练参数矩阵完全一样即可。
- 不会增加额外的推理开销。 W 0 W_0 W0 和 Δ W \Delta W ΔW 的维度都是一样的,并行计算的话跟之前耗时是相当的。
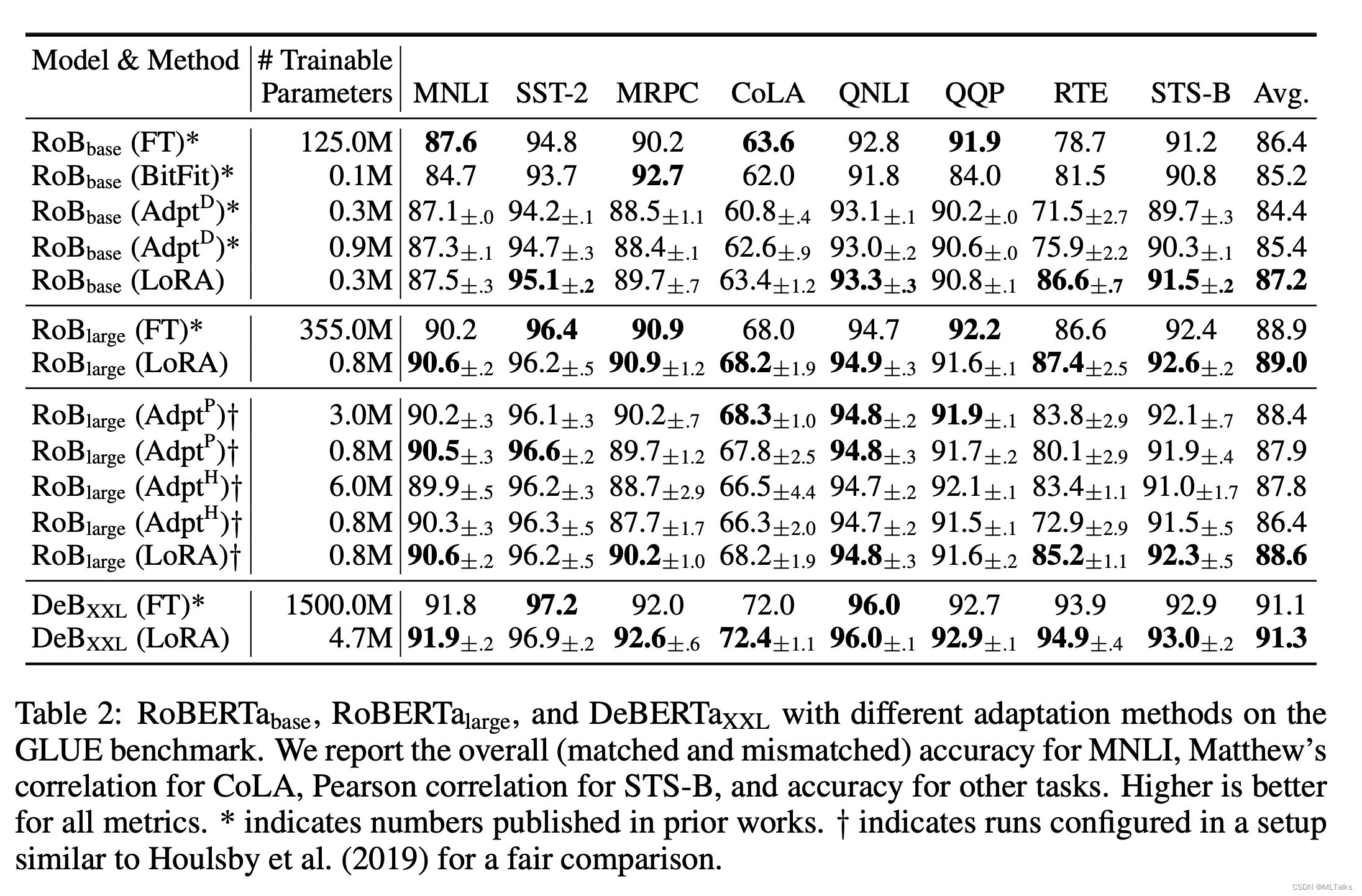
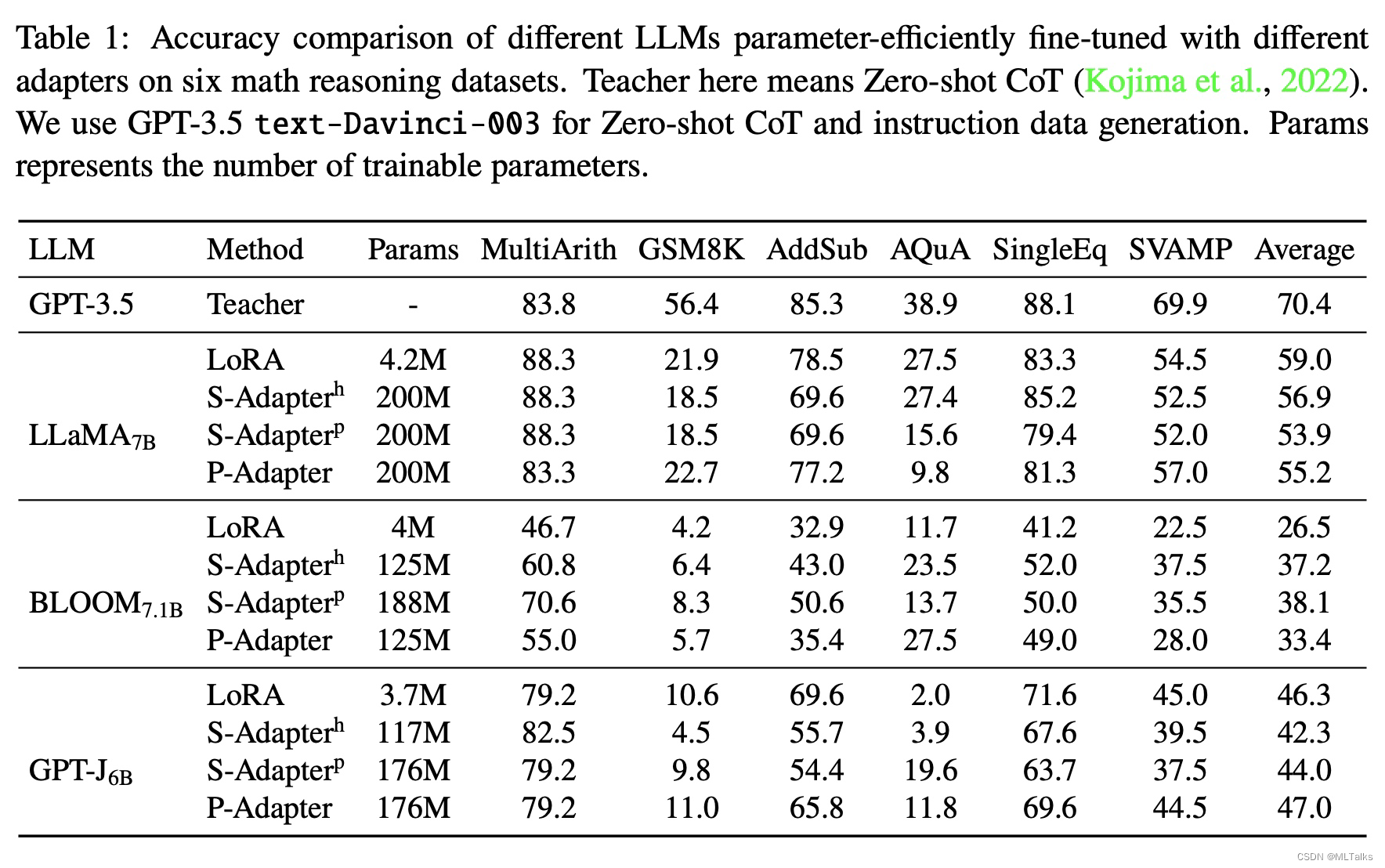
2.2 效果对比
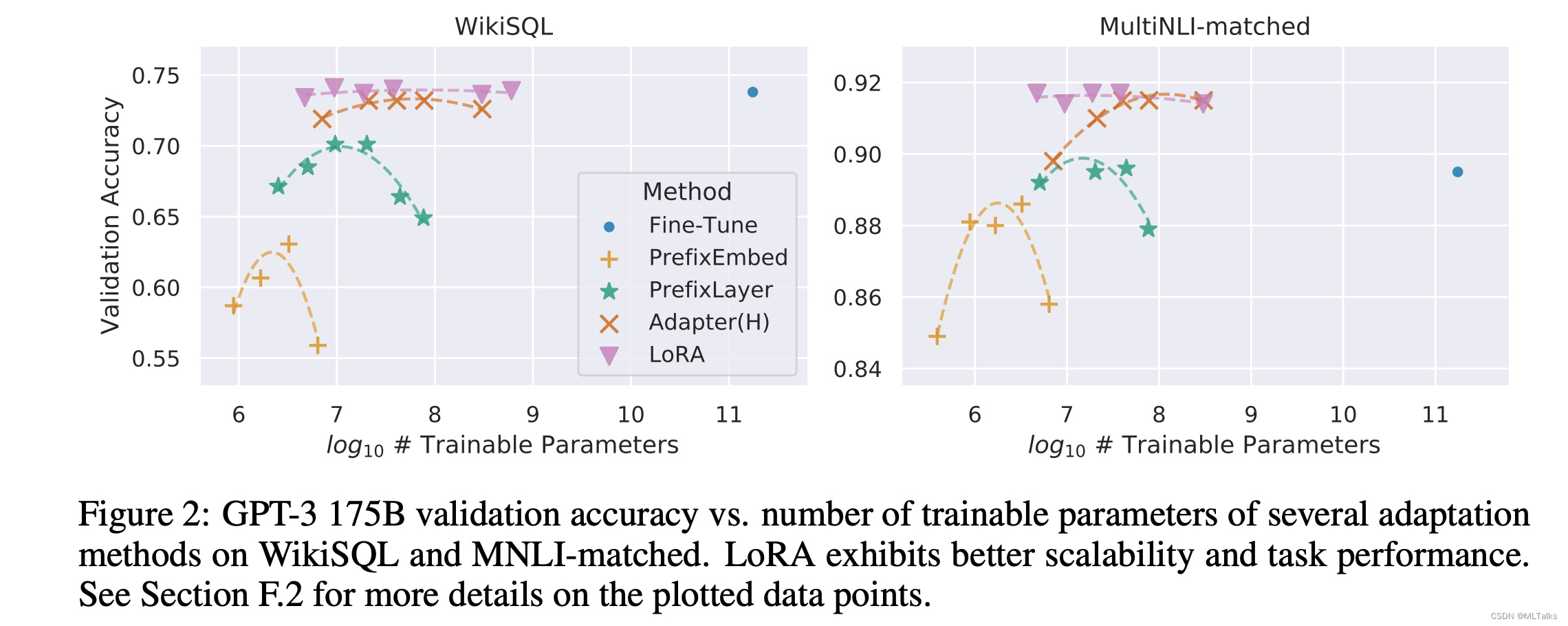
LoRA方法和其他的Adapter方法对比如下,LoRA的参数量明显少了很多, 效果也不错。
2.3 LoRA代码实现
在https://github.com/huggingface/peft/blob/main/src/peft/tuners/lora.py#L542C18-L542C18中实现如下:
class LoraLayer:
def update_layer(self, adapter_name, r, lora_alpha, lora_dropout, init_lora_weights):
self.r[adapter_name] = r
self.lora_alpha[adapter_name] = lora_alpha
if lora_dropout > 0.0:
lora_dropout_layer = nn.Dropout(p=lora_dropout)
else:
lora_dropout_layer = nn.Identity()
self.lora_dropout.update(nn.ModuleDict({adapter_name: lora_dropout_layer}))
# Actual trainable parameters
if r > 0:
self.lora_A.update(nn.ModuleDict({adapter_name: nn.Linear(self.in_features, r, bias=False)}))
self.lora_B.update(nn.ModuleDict({adapter_name: nn.Linear(r, self.out_features, bias=False)}))
self.scaling[adapter_name] = lora_alpha / r
if init_lora_weights:
self.reset_lora_parameters(adapter_name)
self.to(self.weight.device)

旨在为数千万中国开发者提供一个无缝且高效的云端环境,以支持学习、使用和贡献开源项目。
更多推荐



 1
1 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)