昇思MindSpore 2.0,框架全新升级,使能科研创新与产业应用
传统SED(Sub-Entire Domain,子全域基函数)算法计算复杂度是O(𝟗𝑴+𝑵),其中M表示SED中每个阵列单元的参数量,N表示阵列单元的个数,M几乎保持不变,N随阵列规模线性增长。基于昇思MindSpore开发的AI流体仿真工具包MindSpore Flow,提供基于物理驱动、数据驱动和数据机理融合驱动的AI流体仿真技术以及端到端可微分CFD求解器,提供流体领域案例14个,网络
昇思MindSpore1.0版本实现了业界首个全场景AI框架,1.5版本开始原生支持大模型,经过社区开发者们一年多的辛勤努力,我们正式发布昇思MindSpore2.0,实现全新技术升级,使能科研创新与产业应用。
在最新2.0版本,我们支持多维混合自动并行能力,提供大模型套件支持一站式训练,打造大模型最佳训推平台。在提升易用性方面,提供了大量开箱即用的模型套件,且支持灵活高效的动静统一,同时打造AI+科学计算领域套件,突破前沿特性,助力行业技术创新等,下面就带大家详细了解下2.0版本的关键特性。
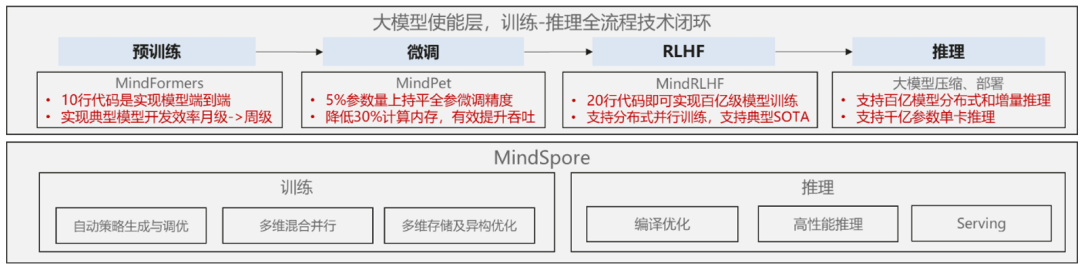
大模型训练与推理
昇思MindSpore 2.0版本提供一站式大模型训练、推理一体化能力,提升训推性能及可跑模型规模,提供套件降低训练成本。
1.原生支持大模型,多维混合并行能力业界领先
昇思MindSpore目前支持数据并行、模型并行、MoE并行、流水线并行、优化器并行、异构训练等多种并行方式,可以原生实现大模型训练,是目前业内大模型训练的最佳框架之一。基于昇思MindSpore,国内外的厂商已经训练22+个大模型,参数规模从百亿~万亿之间,新增支持LLaMA、Bloom、GLM、GPT等百亿大模型。

2.支持全场景统一推理,大幅提高部署效率和推理性能
(1)多后端归一:一个发布包同时支持Ascend/GPU/CPU,简化部署成本,实现极简上线;
(2)MindIR原生支持:MindSpore训练后模型直接使用MindIR无缝推理,缩短模型上线周期;
(3)模型格式统一:支持三方生态(TF、ONNX、Caffe)导出MindIR,实现推理格式归一,减少线上维护工作量;
(4)优化策略多样化:支持算子融合、常量折叠、格式转换、冗余算子消除等推理优化策略以及支持AVX512等高级指令优化算子,提升模型推理性能;
(5)大模型极致优化:针对主流的Transformer大型网络进行深度融合优化,减少模型内存占用,大幅提升推理性能。

MindSpore Lite参考文档:
https://mindspore.cn/lite/docs/zh-CN/r2.0/index.html
3.MindSpore Transformers:大模型训练套件,预置SOTA模型,提供开发流程模块化
MindSpore Transformers的目标是构建一个大模型生命周期内,训练、微调、评估、推理的全流程的开发套件,覆盖CV、NLP、AIGC等热门领域,提供快速开发能力,支持10+ SOTA预训练大模型开箱即用,可一键部署AICC上云。
(1)基于Trainer接口实现2行代码训练,Pipeline接口实现3行代码推理,支持自动模型下载。
(2)提供GPT/GLM/BLOOM/LLAMA等热门领域的模型,支持丰富的下游微调任务,精度与SOTA基本持平,列表如下:

更多信息,请参考套件链接:https://gitee.com/mindspore/mindformers
4.MindSpore RLHF:20行代码即可实现百亿级模型的RLHF训练,助力用户快速实现自己的“ChatGPT”
MindSpore RLHF利用框架具备的大模型并行训练、推理、部署等能力,助力用户快速训练及部署百亿级大模型的RLHF(Reinforcement Learning from Human Feedback,基于人工反馈的强化学习)算法,实现自己的类“ChatGPT”模型。
MindSpore RLHF包含算法所需的三个阶段的学习流程:预训练模型训练、奖励模型训练和强化学习训练。通过集成MindSpore Transformers中丰富的模型库,提供了Pangu-Alpha(2.6B, 13B)、GPT-2、LLAMA、BLOOM等基础模型的微调流程,同时完全继承MindSpore的并行接口,支持一键部署不同规模的大模型到训练集群上。
当前MindSpore RLHF支持的模型如下表所示:
MindSpore Transformers的目标是构建一个大模型生命周期内,训练、微调、评估、推理的全流程的开发套件,覆盖CV、NLP、AIGC等热门领域,提供快速开发能力,支持10+ SOTA预训练大模型开箱即用,可一键部署AICC上云。

表1 :当前MindSpore RLHF支持模型和规模
当前版本支持Pangu-alpha(13B)、GPT2、BLOOM模型进行RLHF训练。未来,我们将提供更多模型,如LLAMA、GLM等。更多信息,请参考套件链接:
https://github.com/mindspore-lab/mindrlhf
5.MindSpore PET:极致低参微调,高效优化大模型,节约计算存储,满足各类任务需求
MindSpore PET(MindSpore Parameter-Efficient Tuning)是基于昇思MindSpore AI融合框架开发的一套大模型低参微调套件,提供了简单易用的API调用接口和使用案例,方便用户轻松快速上手。当前该套件提供6种业界热门的微调算法以及2类共性图操作接口,特别值得一提的是,MindSpore PET还支持用户根据微调算法或模块名冻结网络中指定结构,并针对低参微调算法提供了仅保存可训练参数的接口,从而生成非常小巧的ckpt文件,进一步节约存储空间。
使用MindSpore PET,可以高效地进行大模型的低参微调,显著减少计算和存储内存的消耗,同时缩短微调训练的时间,在资源受限的环境中取得良好的模型性能。微调算法如下表所示,旨在通过微调少量参数来实现低参微调,同时保持全参微调的精度。

参考链接:
https://gitee.com/mindspore-lab/mindpet
6.MindSpore Recommender:支持TB级推荐模型训练,新增在线训练、动态特征能力,支撑模型实时更新上线
MindSpore PET(MindSpore Parameter-Efficient Tuning)是基于昇思MindSpore AI融合框架开发的一套大模型低参微调套件,提供了简单易用的API调用接口和使用案例,方便用户轻松快速上手。当前该套件提供6种业界热门的微调算法以及2类共性图操作接口,特别值得一提的是,MindSpore PET还支持用户根据微调算法或模块名冻结网络中指定结构,并针对低参微调算法提供了仅保存可训练参数的接口,从而生成非常小巧的ckpt文件,进一步节约存储空间。
6.2单卡TB级模型训练
MindSpore Recommender通过分布式特征缓存的方式进行超大规模推荐网络模型训练,该模式建立在自动并行基础上,如下图所示,通过多级特征缓存(Device - Local Host - Remote Host - SSD)实现特征向量逐层级存储分离扩展,实现单张加速卡TB级模型的训练。

使用样例可参考:
https://github.com/mindspore-lab/mindrec/tree/r0.2/models/wide_deep/
6.3在线训练
MindSpore Recommender提供了在线训练和离线训练两种执行模式,提供端到端在线训练解决方案,全Python用户编程表达,支持模型增量导出、导入。
使用样例可参考:
https://github.com/mindspore-lab/mindrec/blob/r0.2/docs/online_learning/online_learning.md

6.4动态特征
在持续训练的过程中,特征通常会随着时间的推移而发生变化,对应系统中需要支持特征的准入和淘汰。MindSpore MapParameter类型支持Hash结构的动态特征表达、特征增删以及增量训练,且所有计算均下沉到Device侧,充分使能硬件加速能力,较异构方案(将动态特征计算层放置在Host侧)更具有性能优势。

详情参考:
https://github.com/mindspore-lab/mindrec
易用性持续提升
7.开发套件集成易用接口和前沿算法模型,助力AI开发与创新
昇思MindSpore联合中科大、西交、西电等高校打造了CV、NLP、Audio、OCR、YOLO等领域的AI套件,集成了大量主流和前沿的算法模型,是加速AI开发和研究的利器。在统一接口模块、降低学习开发成本的同时,用户可以更快地开发和应用不同的深度学习模型以解决不同领域的实际问题。
7.1MindSpore CV套件
MindSpore CV套件是基于昇思MindSpore的开源计算机视觉算法套件,提供了简单易用的模块接口(数据增强/模型构建/优化器等组件),进一步简化模型构建训练流程。利用Ascend+MindSpore混合精度/数据下沉/训练策略等特性,将模型训练时间提速1.x~2.x倍,精度提升1~2%,助力CV领域的应用和创新。
套件代码地址:
https://github.com/mindspore-lab/mindcv
7.2MindSpore NLP套件
MindSpore NLP套件是基于昇思MindSpore的全领域自然语言处理套件,提供了自然语言处理各子领域的经典数据集、经典模型结构、Transformer-based模型等大量实用模块。内置数据集包含机器翻译、问答、序列标注、文本分类、文本生成等NLP常见子领域公开数据集,支持Huggingface权重导入,并支持CPM、GLM等中文预训练模型。简洁的NLP常用模型结构,提供Seq2seqModel、Seq2VecModel、PretrainedModel等结构,可使用数行代码快速构造模型。
套件代码地址:
https://github.com/mindspore-lab/mindnlp
7.3MindSpore Audio套件
MindSpore Audio套件是基于昇思MindSpore的音频处理套件及算法库,通过提供常用音频数据处理接口、快速搭建及训练音频深度学习算法等效果,提升音频算法开发效率,降低音频算法开发的门槛。提供50+常用数据处理API(STFT, Spectrogram, FBank等),5+预训练模型包含ASR任务DeepSpeech2/ Conformer,TTS任务FastSpeech2/WaveGrad,声纹模型ECAPA-TDNN,同时提供常用数据集预处理接口(AISHELL/LibriSpeech/VoxCeleb/LJSpeech)
套件代码地址:
https://github.com/mindspore-lab/mindaudio
7.4MindSpore OCR套件
MindSpore OCR套件是基于昇思MindSpore的OCR算法套件,提供极简易用API,主流SOTA模型dbnet/dbnet++/crnn/svtr等;支持生态三方模型推理(onnx),利用流水线并行加速端到端推理,性能较业界开源工程提升20%。简洁易用的API接口和清晰的模型组件分类,覆盖OCR模型开发全流程。用户可灵活搭建和配置自己的OCR模型,丰富OCR领域的应用。
套件代码地址:
https://github.com/mindspore-lab/mindocr
7.5MindSpore Yolo套件
MindSpore YOLO套件是基于昇思MindSpore的YOLO系列算法套件,统一了各类 YOLO 算法模块的实现,通过提供YOLO系列算法常用的模块接口(数据处理/模型构建/优化器等),简化模型构建和训练流程。当前提供YOLOv3/v4/v5/v7/v8/x 等6+基础模型,可快速复现和迁移;
套件代码地址:
https://github.com/mindspore-lab/mindyolo
8.动态图模式功能/性能全面增强,静态图模式支持返回基础数据类型
2.0版本开始,昇思MindSpore默认为动态图模式。在动态图模式下,框架通过多级流水加速算子下发,提升了动态图模式下的整体网络性能。动态shape场景下优化了自动微分实现,使能CANN的免编译算子能力,大幅度降低了反向图构建和算子编译开销,当前已支持语音类、推荐类、CV类网络等各类型动态shape网络编程,性能基本可用,后续将持续进行优化。
同时,针对静态图模式下无法很好地支持Tensor、tuple类型外的数据类型,导致无法支持返回list,dict,scalar,none等基础数据类型的限制,通过Fallback方式实现语法支持扩展,提供顶层图支持返回list,dict,scalar,none等基础类型的表达能力,从而提升Python语法兼容能力。
详情参考:
https://www.mindspore.cn/docs/zh-CN/r2.0/design/dynamic_graph_and_static_graph.html#jit-fallback
9.全面支持函数式+面向对象融合编程,网络表达能力持续提升
9.1 融合编程新范式,一行代码进行即时编译,降低上手难度
当前业界深度学习框架难以兼顾高效率编码和高性能执行,为此昇思MindSpore提出函数式+面向对象融合编程新范式(Functional Programming+Object-oriented Programming)。
新编程范式提供了更自由的低阶接口,在使代码更加简洁易懂的同时,提高了易用性,降低了上手难度。针对高阶微分和科学计算场景,融合编程范式相较于面向对象范式框架,如Pytorch等,能够更简单的实现数学表达;相较于纯函数式编程框架,如Jax、functorch等,能够提供更简洁的函数式表达。昇思MindSpore在AI和科学计算场景共用同一套自动微分机制,通过融合编程范式的表达,避免了业界框架编程范式的割裂问题。
融合编程新范式保留了MindSpore计算图编译加速的能力。如下图所示,在最外层函数基础上进行JIT即时编译,一行代码进行模块加速,实现易用性和性能的完美结合。

详情参考:
https://www.mindspore.cn/tutorials/zh-CN/r2.0/beginner/quick_start.html
9.2 全面支持函数式算子调用,网络表达能力持续提升
-
新增functional API 100+、Tensor类API 100+、nn计算模块API 30+、算子原语100+,如新增支持了Pooling系列、采样插值系列、线性代数系列、FFT系列等核心功能,进一步提升网络表达能力。
-
多硬件统一功能完善:完善Ascend、GPU及CPU算子支持,Ascend侧满足度82%->90+%;GPU侧满足度75%->90+%;CPU侧满足度78%->90+%;
主要新增算子如下:

详情参考:https://gitee.com/mindspore/docs/blob/r2.0/resource/api_updates/func_api_updates_cn.md
10.MSAdapter:生态接口适配工具,实现第三方生态模型无缝兼容,提升迁移效率
MSAdapter是鹏城启智社区主导开发的一款昇思MindSpore接口适配工具,支持PyTorch的原生态表达代码在昇思MindSpore+昇腾上高效运行。MSAdapter当前发布v0.1 Demo版本,初步兼容torch、torch.nn、torch.nn.function、tensor和torch.utils.data等1000+网络表达和数据处理接口,支持torchvision接口,完成70+主流PyTorch模型迁移验证。用户仅需少量适配即可实现CV/NLP等领域模型的快速迁移,可降低90%以上接口学习和脚本迁移成本。
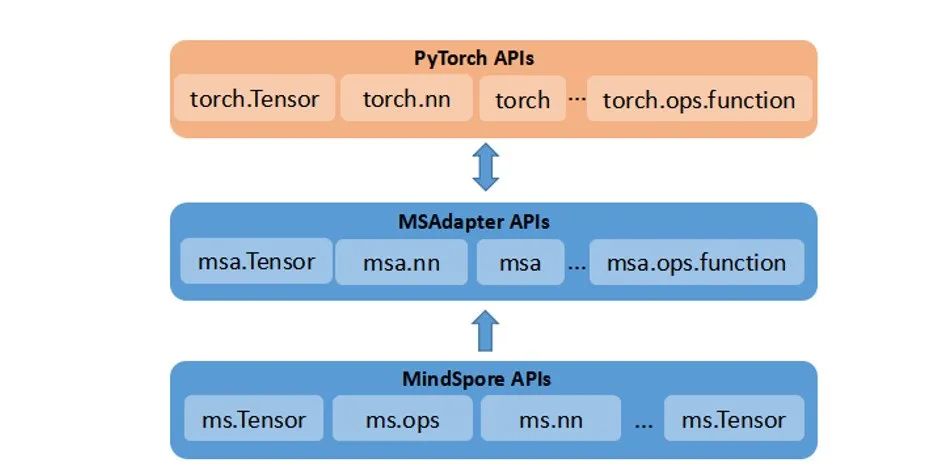
以AlexNet网络为例,通过MSAdapter将PyTorch代码迁移到昇思MindSpore框架流程如下:
1)修改导入包:

2)处理接口完全兼容:

3)模型结构定义接口完全兼容:

4)模型训练代码目前需适配成昇思MindSpore接口:

当前在整体性能上仍有较大的挑战,未来会支持兼容更多的PyTorch接口,持续提升易用性和迁移速度。
参考链接:
https://openi.pcl.ac.cn/OpenI/MSAdapter
11.API文档全面支持中文,教程和文档全新升级
(1)昇思MindSpore共包含20+组件5000+ API接口,除NumPy、SciPy等Python基础库相关接口外,已全面支持中文化,能够帮助国内用户更好地理解功能原理和逻辑。
中文API地址:
https://www.mindspore.cn/docs/zh-CN/master/api_python/mindspore.html
(2)面向初学者,提供全新的初学入门和多领域的应用实践教程,帮助用户快速上手MindSpore。每篇教程可支持一键下载配套的Notebook和样例代码,支持快速部署运行和体验。
教程地址:
https://www.mindspore.cn/tutorials/zh-CN/master/index.html
(3)面向有其他AI框架经验的用户提供迁移指南,涵盖全方位的详细指导,并给出了与其他框架的典型区别和注意事项。
迁移指南地址:
https://www.mindspore.cn/docs/zh-CN/master/migration_guide/overview.html
(4)为了方便用户快速了解官网文档的组成,我们提供了知识地图,包括了从入门到深度开发,再到扩展应用的所有相关信息,可一键直达。
知识地图地址:
https://www.mindspore.cn/resources/knowledgeMap/
12.Dataset流水线支持灵活数据格式,MindRecord易用性/性能全面提升
12.1 数据处理流水线扩展支持任意Python类型
在愈发复杂的数据处理场景中,用户期望使用更强大的数据结构组织和管理数据。因此在昇思MindSpore2.0版本中,Dataset处理流水线对Python原生数据结构dictionary进行了扩展支持,用户可以使用Python的dictionary类型存储数据,并将dictionary直接返回至流水线中被下一个数据处理节点获取和使用。进一步的,用户也可通过dictionary类型管理各种Python对象、数据内容,自由决定在数据处理中的某个环节对dictionary数据进行变更、删除等,使得数据组织和处理更加的流畅和易用。
关于如何使用Dataset处理灵活的数据格式详见:https://www.mindspore.cn/tutorials/zh-CN/r2.0/advanced/dataset/python_objects.html
12.2MindRecord功能/性能全面提升
12.2.1FileReader支持获取MindRecord数据格式的Schema信息和样本条数
FileReader新增schema()接口获取当前MindRecord数据格式Schema,用于辅助查看、分析MindRecord数据格式(数据字段名、数据类型、数据维度等),新增len()接口获取当前MindRecord中包含的样本条数,进一步提升用户易用性。
12.2.2MindRecord创建速度提升10X倍
昇思MindSpore2.0版本对MindRecord的写入API FileWriter进行了大幅度的性能优化,主要通过Python层并发写、Python层 -> C++层数据传递优化、C++层多线程并发转换等操作,实现MindRecord格式数据集写入性能达到10X倍提升。
以ImageNet(1,281,167个样本,140G存储空间)转MindRecord数据格式性能表现如下(运行环境为nvme固态盘,shard_num个数为16):

12.2.3MindRecord超大数据集(>500万样本数)内存加载优化,可减少40%运行内存
大模型训练场景下,训练数据非常庞大,数据预加载时索引的获取是巨大开销,并受到内存限制。昇思MindSpore2.0版本优化了MindRecord的Lazy Load加载模式,实现数据结构精简化加载,只做必要的元数据(样本ID、样本起始偏移、样本结束偏移等)加载,对于大模型训练、多模态数据加载场景更有优势。
13.持续优化报错机制,提供系统化指导,降低用户问题解决门槛
昇思MindSpore2.0版本针对多个报错场景的错误信息结构和内容进行了优化,优化后报错可更为清晰的呈现错误内容,便于用户快速分类和理解错误信息。
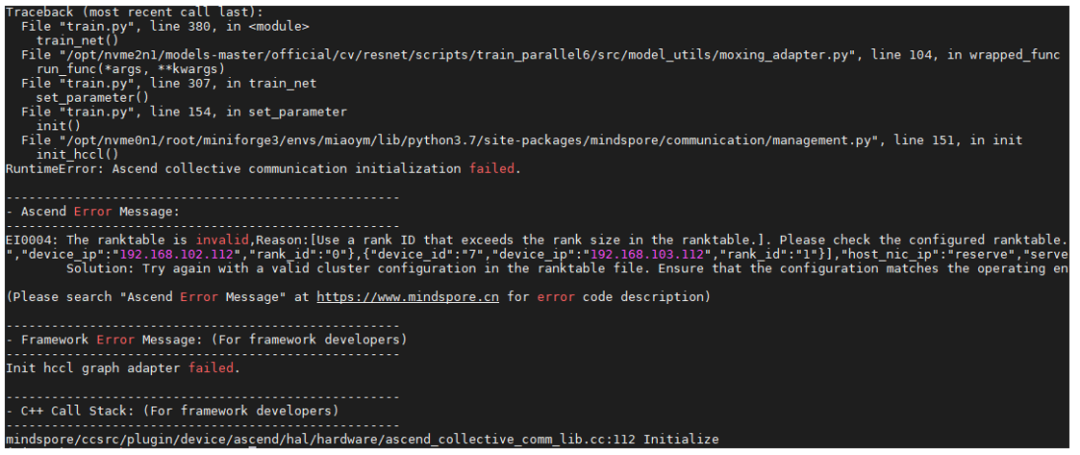
例如:昇腾设备报错优化
优化前:
此例子是使用rank table方案启动并行训练,因为配置文件问题导致训练失败,如下图所示可以看出,Ascend给出的错误信息与MindSpore信息混合呈现,错误和解决方案不清晰。

优化后:
如下图所示,将Ascend设备的错误信息独立呈现,并优化错误描述给出详细的错误原因与解决建议,并提供资料对用户常见的错误码进行说明。
详情参考:
https://www.mindspore.cn/tutorials/experts/zh-CN/r2.0/debug/function_debug.html
14.MindSpore Dev Toolkit:新增API映射扫描功能,智能代码补全功能提供VSCode平台插件
14.1一键扫描全文中可映射API,支持单文件和项目的扫描
MindSpore Dev Toolkit是MindSpore的开发插件,支持在IDE中快速搜索API映射关系基础上,为了进一步提高模型迁移效率,提供了API映射扫描功能,一键获得代码中所有可直接映射成MindSpore API的PyTorch API,并支持API文档浏览,如下图所示。本功能既可以扫描单独的Python文件,也可以扫描整个项目,提供汇总的API映射关系。

14.2 上线VSCode插件,提供智能代码补全功能
MindSpore Dev Toolkit,在已支持PyCharm,本次新增VSCode插件,帮助用户在多平台提升开发效率,可在高达80%的准确性下,提升编码效率30%以上,如下图所示。
在未来,其他Dev Toolkit功能也将陆续接入VSCode,敬请期待
参考链接:
https://gitee.com/mindspore/ide-plugin
科学计算
15.MindSpore Flow:高效易用的AI计算流体仿真工具包
流体力学与航空航天、海洋装备、能源电力的研发息息相关,但发展至今,传统计算流体力学面临着网格剖分复杂、计算依赖度高、精度性能无法兼顾等问题,这些挑战也为AI融合科学计算带来了新的机遇。基于昇思MindSpore开发的AI流体仿真工具包MindSpore Flow,提供基于物理驱动、数据驱动和数据机理融合驱动的AI流体仿真技术以及端到端可微分CFD求解器,提供流体领域案例14个,网络模型8个,充分挖掘神经网络拟合能力,旨在构建高效、高精度的AI流场模拟工具,加速模型开发,满足相关科研工程需求。
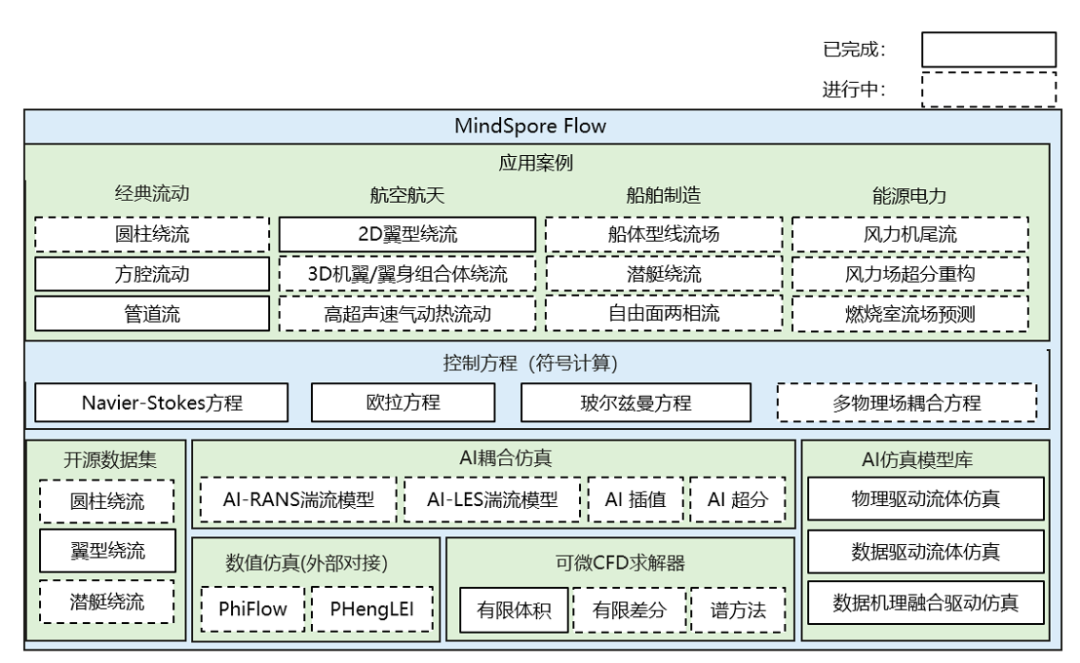
MindSpore Flow的架构图如上图所示,AI仿真模型库提供了物理驱动AI流体仿真、数据驱动AI流体仿真以及数据机理融合驱动的AI流体仿真,并推出可微分CFD求解器,基于开源数据集,支持流体力学相关的控制方程,进而实现经典流动和各个应用领域的流体仿真。
15.1物理驱动AI流体仿真
物理驱动AI流体仿真主要基于物理信息神经网络(PINNs)进行流体仿真,当前,MindSpore Flow为用户提供简单易用的物理驱动AI流体仿真的编程接口,支持sympy定义符号化偏微分方程,支持高效的几何采样、丰富的神经网络架构,便于用户实现流体偏微分方程的快速求解。
15.2数据驱动AI流体仿真
数据驱动AI流体仿真采用AI方法挖掘流场数据的关联,从而实现流场的智能仿真。MindSpore Flow开源了业界首个工业级流体仿真大模型“东方.御风”以及相关数据集,用户可调用相关接口实现模型训练及快速流场仿真。此外,MindSpore Flow也提供了傅里叶神经算子、Koopman神经算子、Vision Transformer等多种神经网络模型库及相关案例数据。
15.3数据机理融合的AI流体仿真
数据机理融合的AI流体仿真将物理驱动与数据驱动相结合,减小数据依赖并获得更强的泛化能力。PDE-Net是一种典型的数据机理融合AI流体仿真模型,MindSpore Flow提供了相关接口,用户可以通过学习卷积核来逼近微分算子,识别被观测的偏微分方程。
15.4端到端可微分求解器
MindSpore Flow在MindSpore框架上实现了传统可压缩流体求解的流程,推出了端到端可微分的求解器MindSpore Flow CFD,求解器支持WENO5重构、Rusanov通量以及龙格-库塔积分,支持多种边界条件,满足激波管、二维黎曼等多种基本流动的求解要求。
详情参考:https://gitee.com/mindspore/mindscience/tree/master/MindFlow
16.MindSpore SPONGE:架构全面升级,新增MEGA-Protein等20+生物计算SOTA模型,正式发布1.0版本
基于昇思MindSpore2.0开发的AI生物领域套件MindSpore SPONGE发布1.0正式版本,架构全面升级,支持业界以及自研的主流模型20+,基本覆盖药物研发全流程,如自研蛋白质结构预测工具MEGA-Protein,开源蛋白质设计工具ESM-IF、分子属性预测模型Pafnucy等;MSA生成增强工具MEGA-EvoGen和蛋白质结构对比评估工具MEGA-Assessement正式开放。MindSpore SPONGE1.0整体构架视图如下:
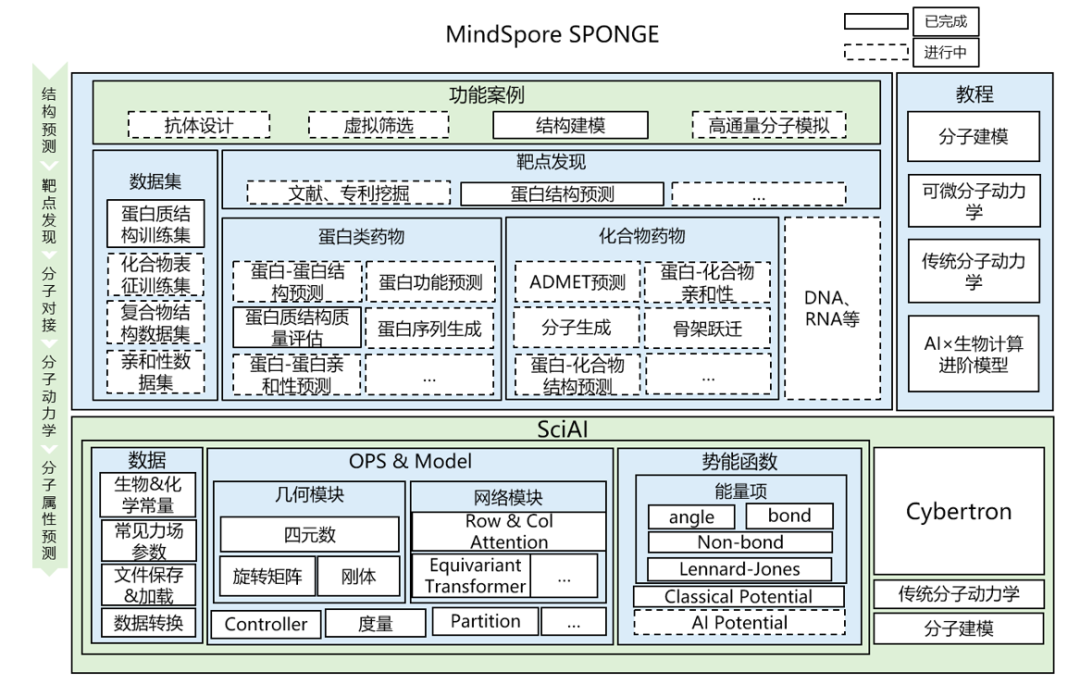
在1.0版本中,MindSpore SPONGE集成了20个自研模型以及业界主流模型,主要涵盖分子表征、结构预测、性质预测、分子设计和基础模型等方向,基本覆盖药物研发全流程。在药物作用靶点及生物标记的选择环节,MindSpore SPONGE提供了用于分子结构预测和分子设计的SOTA模型,例如MEGA-Fold,AlphaFold Multimer等蛋白质结构预测模型, ProteinMPNN,ColabDesign等蛋白质设计模型;在先导化合物确定环节,MindSpore SPONGE提供了用于分子表征和基础模型方向的SOTA模型,例如MolCT,SchNet和PhysNet 深度分子模型,GROVER,MG-BERT 小分子化合物预训练模型;在活性化合物的筛选环节,MindSpore SPONGE提供了用于分子性质预测的SOTA模型,例如GraphDTA, pafnucy等蛋白质-小分子化合物亲和性预测模型。
在旧版本中,MindSpore SPONGE已集成蛋白质结构预测模型MEGA-Fold。在1.0版本中,针对AlphaFold 2在“孤儿序列”、高异变序列和人造蛋白等MSA匮乏场景下无法做出准确预测的限制场景以及缺少蛋白质评估工具的情况,MindSpore SPONGE发布了MSA生成增强工具MEGA-EvoGen和蛋白质结构对比评估工具MEGA-Assessement,极大地突破了AlphaFold 2自身的限制。
为了方便用户快速上手,MindSpore SPONGE新增了PipeLine运行模式,针对上述模型提供统一调用接口,支持一行代码直接执行训练和推理任务,当前已适配大部分模型,模型介绍与调用方法可参考如下链接:https://gitee.com/mindspore/mindscience/tree/master/MindSPONGE/applications
17.MindSpore RLHF:20行代码即可实现百亿级模型的RLHF训练,助力用户快速实现自的“ChatGPT”
MindSpore Elec电磁仿真套件升级至0.2版本,新增了两大特性,分别是联合东南大学实现了“金陵.电磁脑”大规模阵列天线的AI电磁仿真基础模型;联合华为诺亚方舟实验室实现了端到端可微的电磁求解器(AD_FDTD,Automatic Differentiation Finite-Difference Time-Domain)。
(1)“金陵.电磁脑” AI电磁仿真基础模型:大规模阵列天线在国防(相控阵雷达天线)和民用( 5G基站天线,自动驾驶)广泛应用,但阵列天线的阵列规模大、单元构成复杂,亟需快速精确仿真。传统SED(Sub-Entire Domain,子全域基函数)算法计算复杂度是O(𝟗𝑴+𝑵),其中M表示SED中每个阵列单元的参数量,N表示阵列单元的个数,M几乎保持不变,N随阵列规模线性增长。AI代替了其中最为复杂的部分,将计算复杂度降至O(𝟗𝑴+𝟏)。机理融合的“金陵.电磁脑”基础模型精度媲美传统方法,效率提升10X+,而随着目标规模的增大,该提升将会更加显著。

“金陵.电磁脑”AI电磁仿真模型流程图

AI计算方法性能极大提升情况下,精度不降低
(2)端到端可微的电磁求解器AD_FDTD:该求解器可以采用昇思MindSpore的神经网络算子重写FDTD正向求解过程,也可以利用昇思MindSpore的自动微分能力对电磁逆问题中的介质参数进行端到端的优化。AD_FDTD在贴片天线、贴片滤波器以及二维电磁逆散射等场景中得到了验证。在贴片天线、贴片滤波器案例中,S参数仿真精度与传统数值方法相当;在二维电磁逆散射案例中,反演得到的介质参数的结构相似度(SSIM)达96%。

AD_FDTD计算流程图

贴片天线:S参数仿真精度与BenchMark相当

电磁逆散射:反演得到的介质参数的结构相似度(SSIM)达96%
参考链接:
https://gitee.com/mindspore/mindscience/tree/master/MindElec

昇腾万里,让智能无所不及
更多推荐

 1
1 0
0- 0



 已为社区贡献105条内容
已为社区贡献105条内容

所有评论(0)